
Abstract
Abstract
Spatial unit roots can lead to spurious regression results. We present an overview of the methods developed in Müller and Watson (2024, Econometrica 92: 1661-1695) to test and correct for spatial unit roots and introduce a suite of commands (
Introduction: Spatial unit roots
Spatial data present challenges for statistical analysis: observations that are close to each other geographically tend to be correlated, violating the assumption of independent and identically distributed (i.i.d.) errors. In such settings, heteroskedasticity- and autocorrelation-consistent (HAC) corrections or clustered standard errors at broader geographic levels (like states) are often used.
However, these correction methods fail when spatial dependence is too strong (“spatial unit roots”). Even with clustering or HAC corrections, spuriously significant regression coefficients can arise. Müller and Watson (2024) developed new statistical tests to detect such strong dependence and procedures to correct for it, extending techniques from time-series analysis. We present a Stata implementation of their original MATLAB code, along with practical guidelines for applied researchers.
In the time-series context, weak serial correlation in the regressors and regression errors [the I(0) case] can be dealt with by HAC corrections. However, when the serial correlation is strong [the I(1) case], inference fails and ordinary least-squares (OLS) produces “spurious regressions” (Granger and Newbold 1974). Furthermore, test statistics behave in nonstandard ways (Phillips 1986).
The spatial context is similar (Fingleton 1999), but as Müller and Watson (2022) discuss, there are also important differences: First, time-series operate in a one-dimensional space, whereas in the spatial context, we are dealing with two (or three) dimensions. Second, in the time-series context, observations are usually equally spaced (…, t — 1, t, t + 1,…), whereas in the spatial context, the location of observations on a map can be substantially different from a uniform distribution on a grid. Third, while there is a directionality in the time-series context (…, t — 1, t, t + 1,…), in the spatial context, going east is as natural as going west or north or south. Müller and Watson (2022) propose a method for constructing confidence intervals that accounts for many forms of spatial correlation. It uses a projection-type variance estimator, where the projection weights are spatial correlation principal components (SCPC) from a given “worst case” benchmark correlation matrix.
Müller and Watson (2022) require stationarity of both regressors and dependent variables for the large-sample validity of their SCPC method. In Müller and Watson (2023), they present a robust version that can deal with some nonstationarities relevant to applied research. The methods developed in these two articles have been implemented in Stata by the authors in their
In this article, we provide a community-contributed version of the programs developed by Müller and Watson (2024) to test for and correct for spatial unit roots. These methods can be used in conjunction with the
We also provide practical guidelines for applied researchers dealing with potential spatial unit roots in regression analysis: how to test for nonstationarity or the presence of spatial unit roots and what to do in case nonstationarity is detected or when the presence of spatial unit roots cannot be rejected. To illustrate this algorithm and the use of our community-contributed commands, we present a simulated example and a Monte Carlo simulation.
The rest of the article proceeds as follows: Section 2 summarizes and illustrates the tests developed by Müller and Watson (2024) to diagnose spatial unit roots, as well as our Stata implementation of their MATLAB code in the commands

Spurious correlations with unit roots
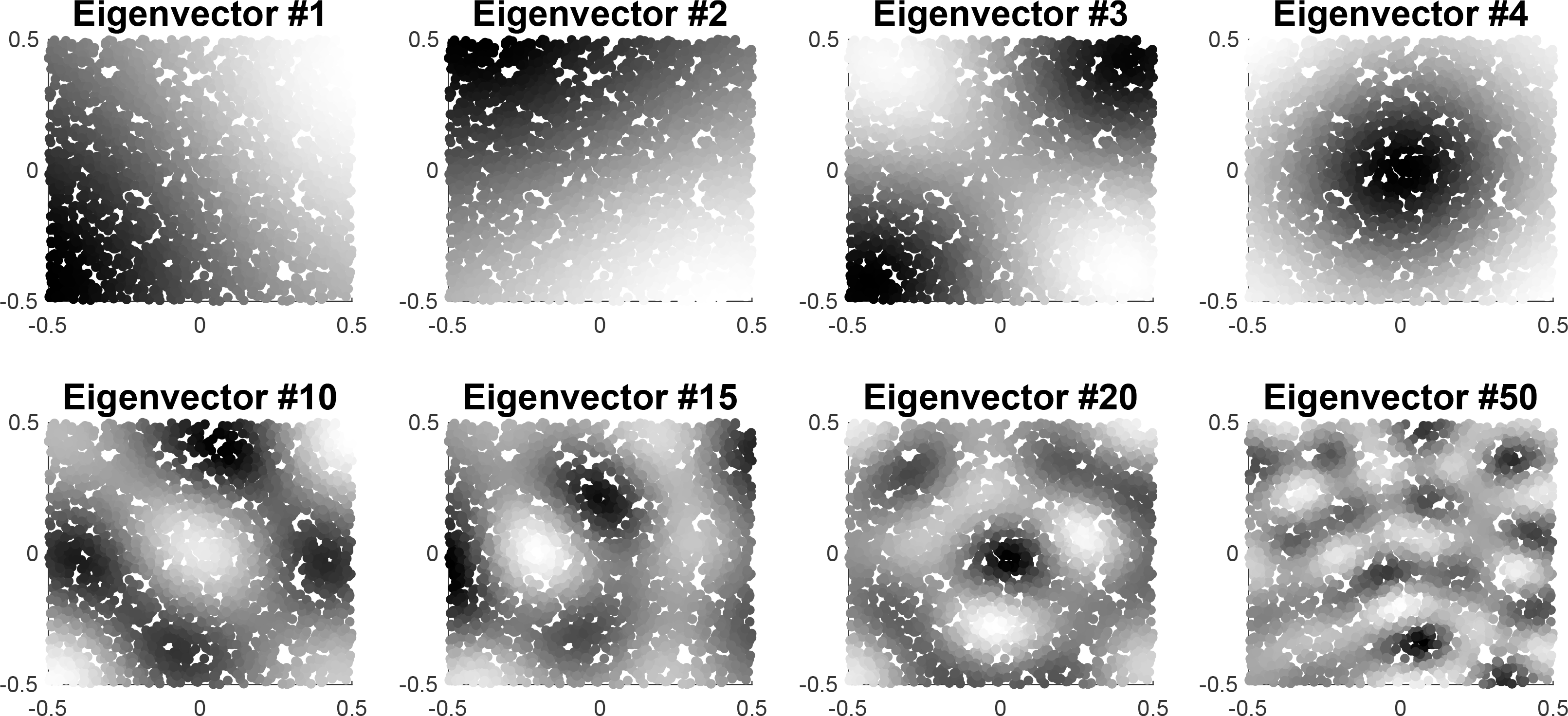
Illustration of the weights

Simulated data and weighted averages
Differencing transformations
This section discusses the approaches to inference about the degree of spatial dependence developed by Müller and Watson (2024). They motivate their analysis of spatial unit roots by starting from the time-series analogue: in time series, the canonical I(1) process is a Wiener process (also called Brownian motion). Its extension to the (two-dimensional) spatial case is via a so-called Lévy-Brownian motion (LBM). Figure 1 illustrates the similarity between spurious regressions in the time-series context and spatial context: Panel (a) shows realizations of two independent Gaussian random walks, and (b) shows independent simulated spatial unit-root processes over n = 722 US commuting zones. In each case, we report the R2 and t statistics from the linear regression (with HAC correction) of the first on the second process, which show spuriously significant correlation in both cases. Panel (c) shows two variables from Chetty et al. (2014): their outcome variable (mobility index) and one regressor (teen labor force participation). These resemble the unit-root processes in panel (b). This highlights the potential relevance of strong spatial autocorrelation, which needs to be detected and addressed in empirical work.
Specifically, Müller and Watson (2024) develop four diagnostic tests, examining the following null hypotheses, respectively:
H0: Scalar variable y is I(1). H0: Scalar variable y is I(0). H0: Linear regression residuals u are I(1). H0: Linear regression residuals u are I(0).
They also developed a method to construct confidence intervals for the spatial halflife of a scalar variable. All of these tests exploit the different variance-covariance structures implied by the canonical spatial I(1) and local-to-unity (LTU) models (Müller and Watson 2024).
The canonical spatial I(1) model is LBM, a spatial generalization of the Wiener process (Brownian motion) common in time-series analysis. This can be thought of as a continuous-time analogue of a random walk. Conversely, LTU models describe stationary processes with weak mean reversion governed by a parameter c > 0. They are a generalization of the pure unit-root model, in which the autoregressive root approaches unity as the sample size increases at a rate determined by c. This allows them to behave similarly to I(1) processes for small c and similarly to weakly dependent I(0) processes for large c. Thus, they span a continuum of dependence between the dichotomous I(0) and I(1) cases. Their canonical form is the Ornstein-Uhlenbeck process, which can be thought of as a continuous-time analogue of a first-order autoregressive process in the time-series context. The variance-covariance structure of these two canonical models in the spatial case is given by
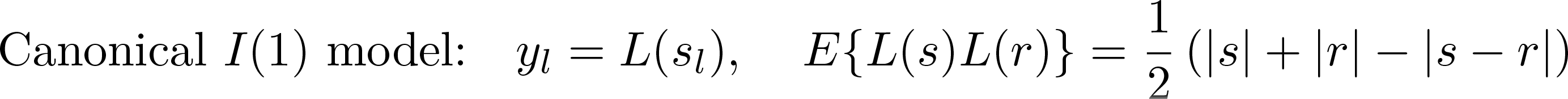

Low-frequency weighted averages
The fundamental idea is to compare the performance of these two models in rationalizing the data. Rather than performing tests on the raw data, Müller and Watson (2024) build on Müller and Watson (2008) and compute the test statistics from a fixed number q of weighted averages of the data. Specifically, given a data vector
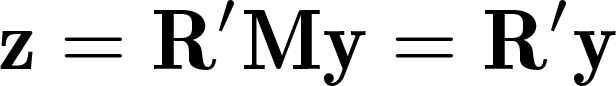
Basing the tests on these weighted averages is useful in two broad ways: First, summarizing the data in a fixed number of averages yields an asymptotically multivariate (q-dimensional) normal distribution (following from a central limit theorem), which enables the use of standard inference methods. The covariance matrix of this limiting distribution is simply
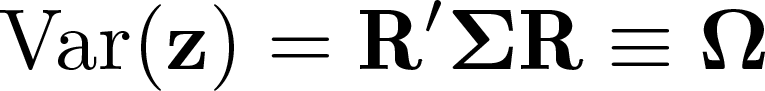
The “frequency” of the variation clearly increases with the order of the eigenvectors. To see how
This is further illustrated by the subplots of figure 3: The first two subplots show simulated data for an LBM process,
Generic testing procedure
Given the weighted averages drawing Nrep random q x 1 vectors computing the test statistic setting

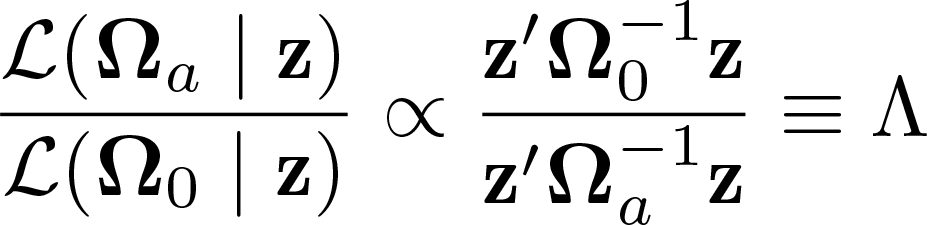
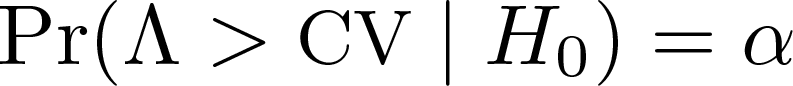
The test then rejects H0 if Λ > CV.
4
All test commands in our package include the option
I(1) test
The I(1) test examines the presence of a unit root in a scalar variable y, that is, the I(1) model versus the LTU model. The hypotheses are therefore
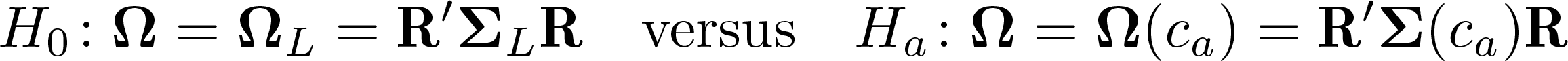
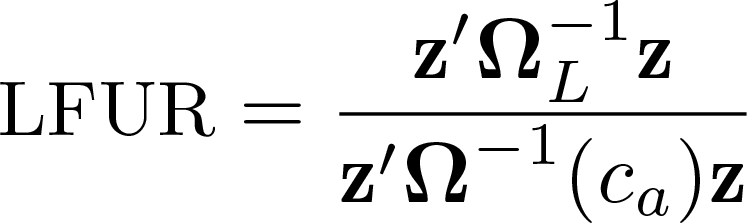
I(0) test
Testing the I(0) null hypothesis, that is, spatial stationarity, is not as straightforward: the LTU model, as discussed in section 1, is similar to both an I(1) process for small c and an I(0) process for large c. Therefore, to specify an I(0) null hypothesis, one must take a stance on the value of c that separates the two. Müller and Watson (2024) propose setting this value to c0 03, defined as the value of c such that the average pairwise correlation induced by Σ(c) is 0.03.
7
They then propose the hypotheses

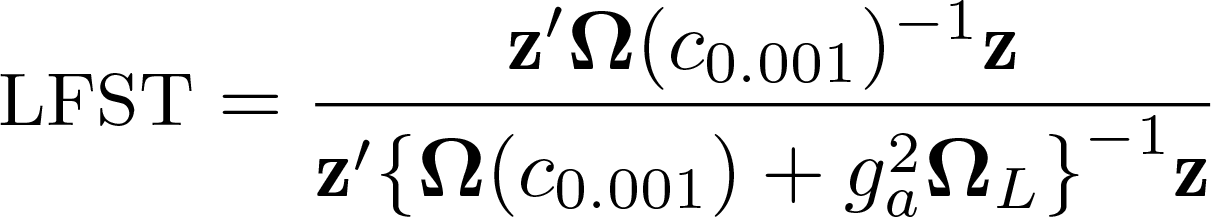
yields a test that works well for a wide range of c ≥ c0 03. The test rejects H0 if LFST is larger than the CV (computed as described in section 2.2, with the modification that first the CV is computed for a range of values c ≥ c0 03, and then the highest of those values is used to compare with the test statistic).
I(1) and I(0) tests for regression residuals
In many practical applications, the econometrician wants to test the persistence of the errors of a regression model

The spurtest command
All four tests described in the previous sections are implemented in the command spurtest, which has four versions for the four different tests.
Syntax

In each case,
All our commands require that the variables containing the spatial coordinates be named
Most of the code underlying this and the other commands in our package is written in Mata. We provide an
Options
Stored results

Confidence sets for spatial half-life and the spurhalflife command
For completeness, we also implement a method proposed in Müller and Watson (2024) to construct confidence sets for the spatial half-life of a process, that is, the spatial distance at which the correlation in the process is equal to 1/2. In the LTU framework, this is directly connected to the parameter c. Specifically, the half-life h is equal to ln 2/c. Confidence intervals can then be constructed as the sets of values of h for which the null hypothesis H0 : h0 = h cannot be rejected. The test statistic suggested by Müller and Watson (2024),
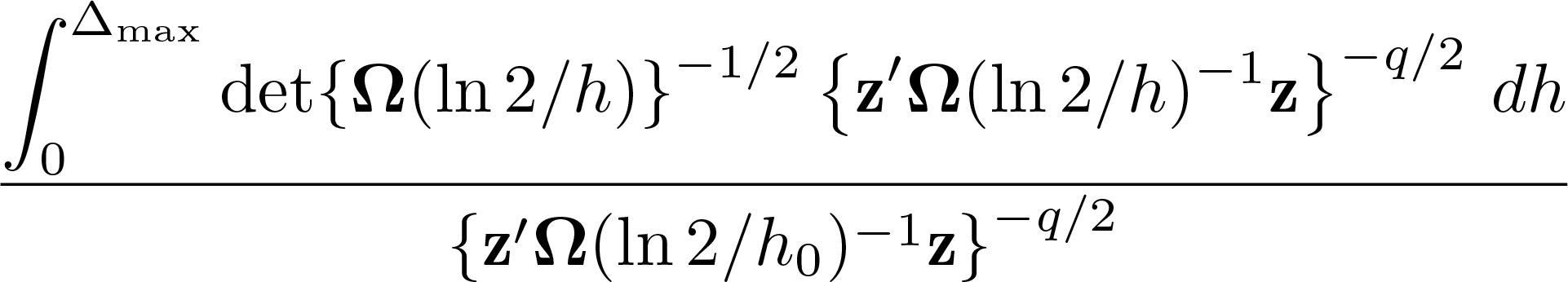
Syntax
The variables containing the spatial coordinates must be named
Options
Stored results

Correction through spatial differencing and the spur- transform command
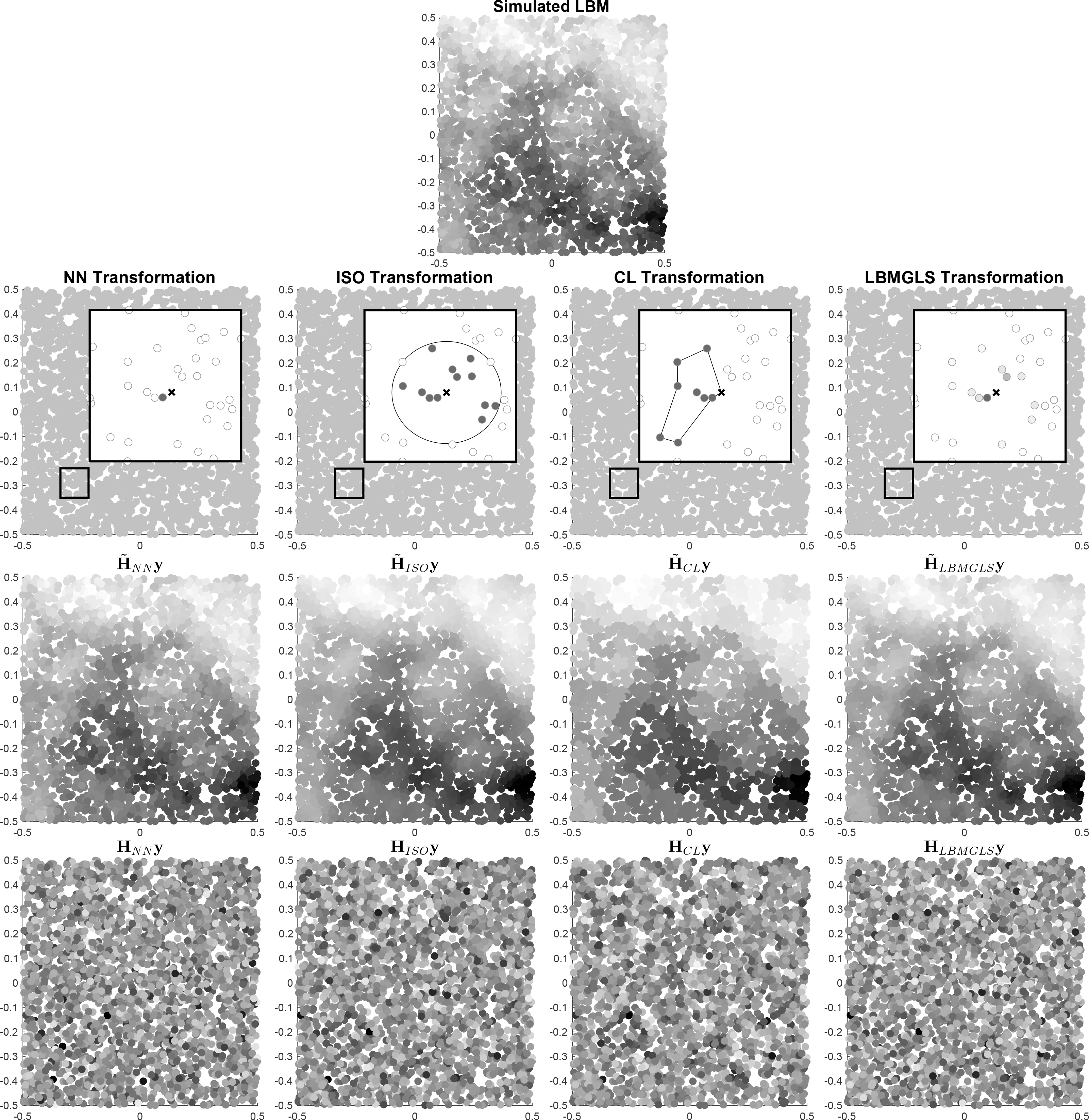
Having tested for and found evidence of the presence of spatial unit roots, the econometrician needs a way to correct for them to be able to estimate regression coefficients consistently. The standard approach in the time-series literature is to take first differences of the data:
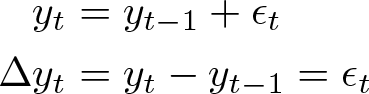
Nearest-neighbor differences
One obvious differencing procedure would be

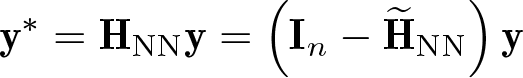
Isotropic differences
Instead of taking differences only with respect to the nearest neighbor (NN), another option would be to subtract the mean of all observations in a neighborhood of radius b:
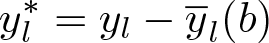
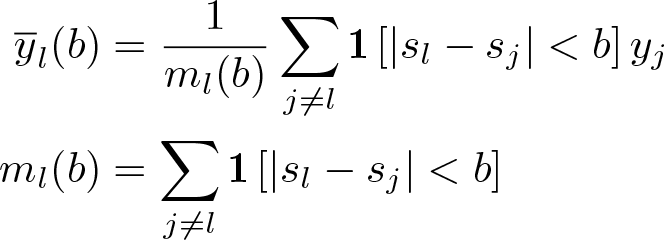
This is equivalent to

where
Clustered demeaning
A third option is to partition the data into K clusters and subtract the mean within its cluster from each observation (or, equivalently, including cluster fixed effects in the regressions). These clusters could be based on knowledge of the structure of the data (for example, states) or constructed through techniques like k-means clustering. The transformed data are then
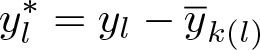
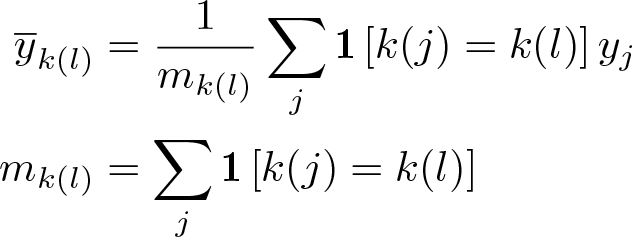

LBM generalized least-squares transformation
The previous three transformations are ad hoc ways of correcting strong spatial dependence. Following their characterization of spatial unit-root processes as approximated by LBM, Müller and Watson (2024) propose a generalized least-squares (GLS) transformation based on the covariance matrix induced by LBM. Recall that under LBM, the demeaned data are distributed as
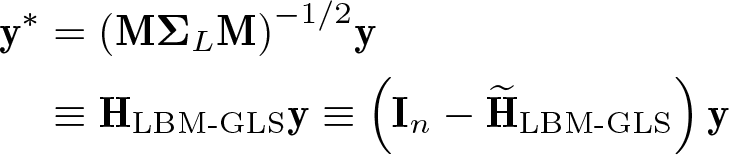
Figure 4 illustrates all four transformations. The single plot at the top is the “raw” data used for this illustration, which is the simulated LBM process from figure 3. The four columns below show the four described transformations. Within each column, the top panel illustrates the transformation for one focal data point (marked with x): the shaded dots are the data points whose weighted values are subtracted from the focal point, with a darker shade indicating a larger weight. In the NN transformation, only the closest neighbor is subtracted. In the isotropic and cluster transformations, an unweighted mean of surrounding observations is subtracted. The LBM-GLS transformation subtracts a weighted mean of all surrounding observations, with weights quickly decaying with distance. The middle panel shows the values that are subtracted from the raw data
Syntax
The variables containing the spatial coordinates must be named
Options
Regression analysis using the M^ler-Watson approach
Proposed procedure
Having outlined the methods presented in Müller and Watson (2024) as well as our implementation thereof, we now turn to their practical application in regression analyses of spatial data. We propose a simple algorithm, summarized in figure 5:
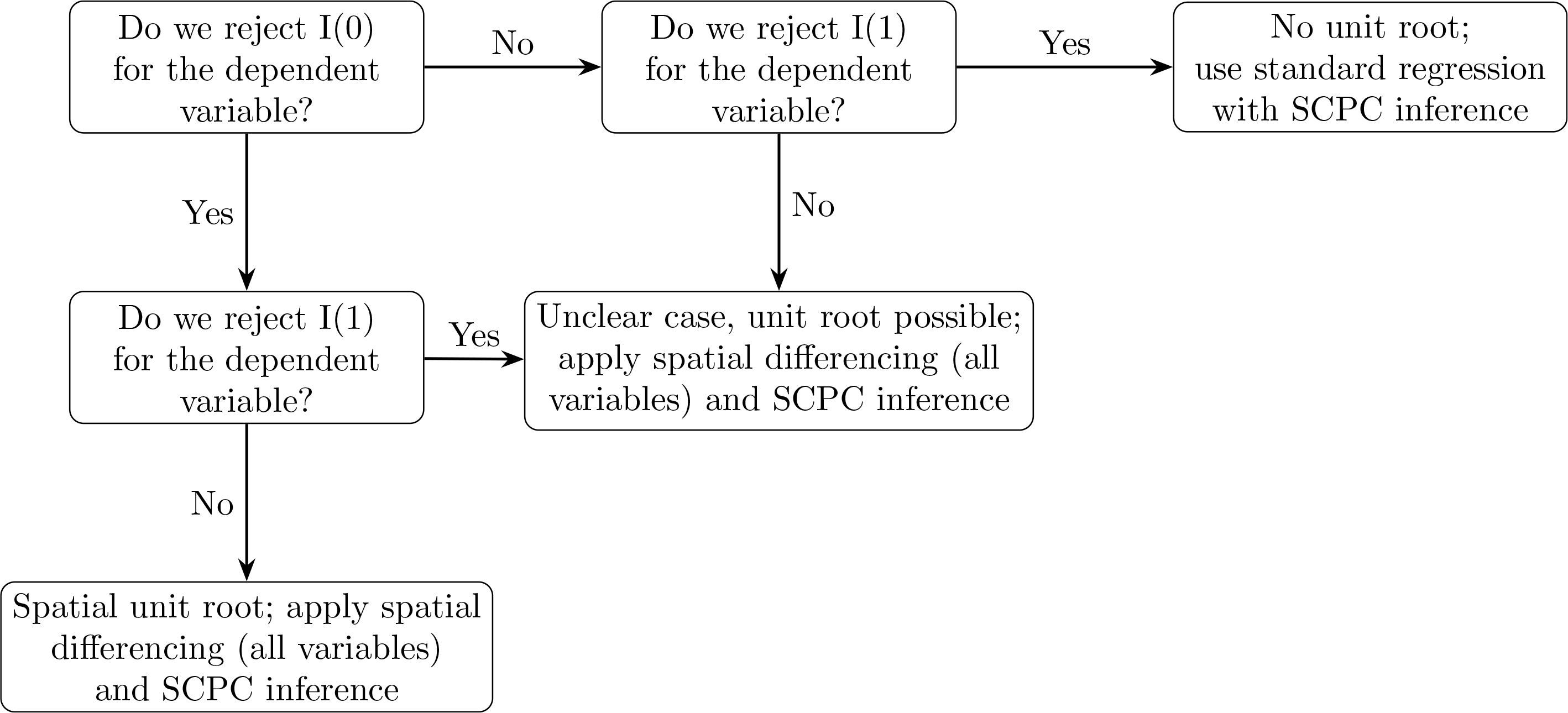
Flow diagram showing how to apply the Müller–Watson approach
We first test whether the dependent variable contains a unit root. To this end, we examine whether we can reject that it is I(0). If so, we test whether we can reject that it is I(1). If we cannot reject, a unit root is most likely present, and we need to apply one of the transformation methods discussed above to remove it. In this case, we propose differencing both the dependent and the independent variables for ease of interpretation of the regression coefficients. If we reject I(0) but also I(1), or neither, the case is indeterminate; it is arguably wise to difference and report results using transformed variables. If we do not reject the dependent variable being I(0) but can reject that it is I(1), we can confidently proceed without differencing. In all cases, regression inference still needs to account for any remaining (weak) spatial correlation; we suggest using the SCPC approach in Müller and Watson (2022, 2023).
Multivariate cases and instrumental variables can be handled analogously. Because the hypothesized relationship involves x and y, we should proceed with differencing all independent variables. Also, because instrumental-variables estimation represents a rescaling of the relationship between y and z via x, we can proceed analogously in this case. 10
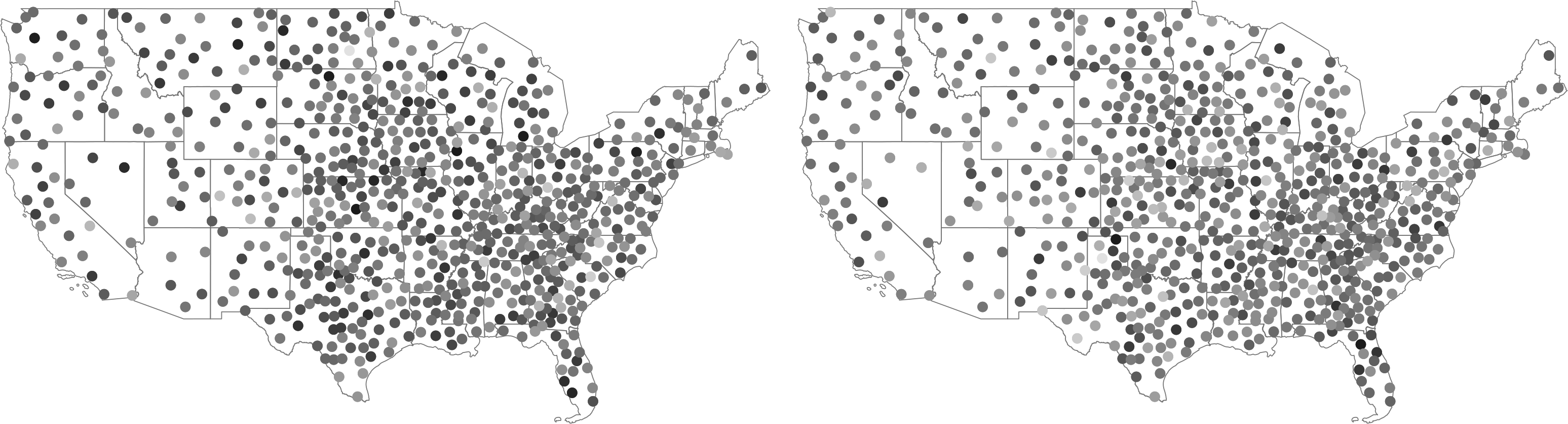
To illustrate this procedure and the use of our community-contributed commands, we simulate two independent LTU processes x and y with very high persistence (c = 0.01), using 722 US commuting zone centroids as locations. We take the location data from the replication package of Müller and Watson (2024), who obtained them from Chetty et al. (2014), and provide them in a supplementary file,

Figure 6 plots the simulated variables using the
Running a simple regression of


Simulated dependent variable y (left) and independent variable x (right)
We now follow the procedure outlined above by applying the I(0) and I(1) tests to

Therefore, we use
Transformed dependent variable

Finally, we run the regression of
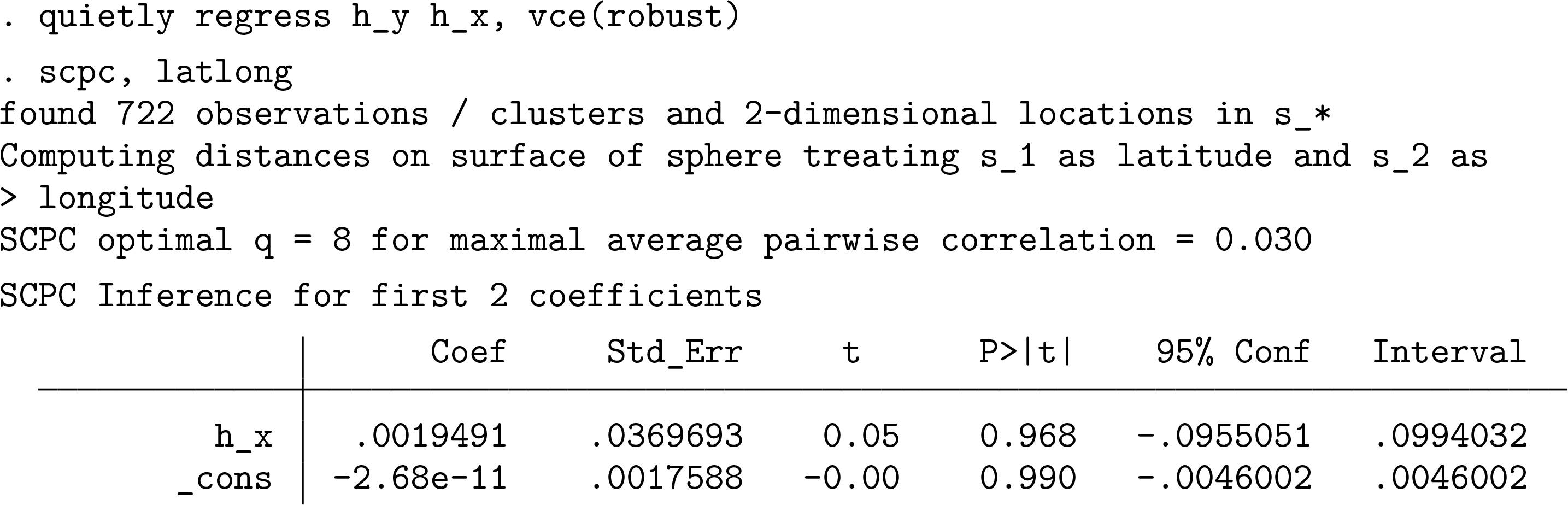
We repeat the above exercise 200 times, each time simulating independent x and y processes as above. We omit the simulation code here for brevity but provide it in the supplementary materials as
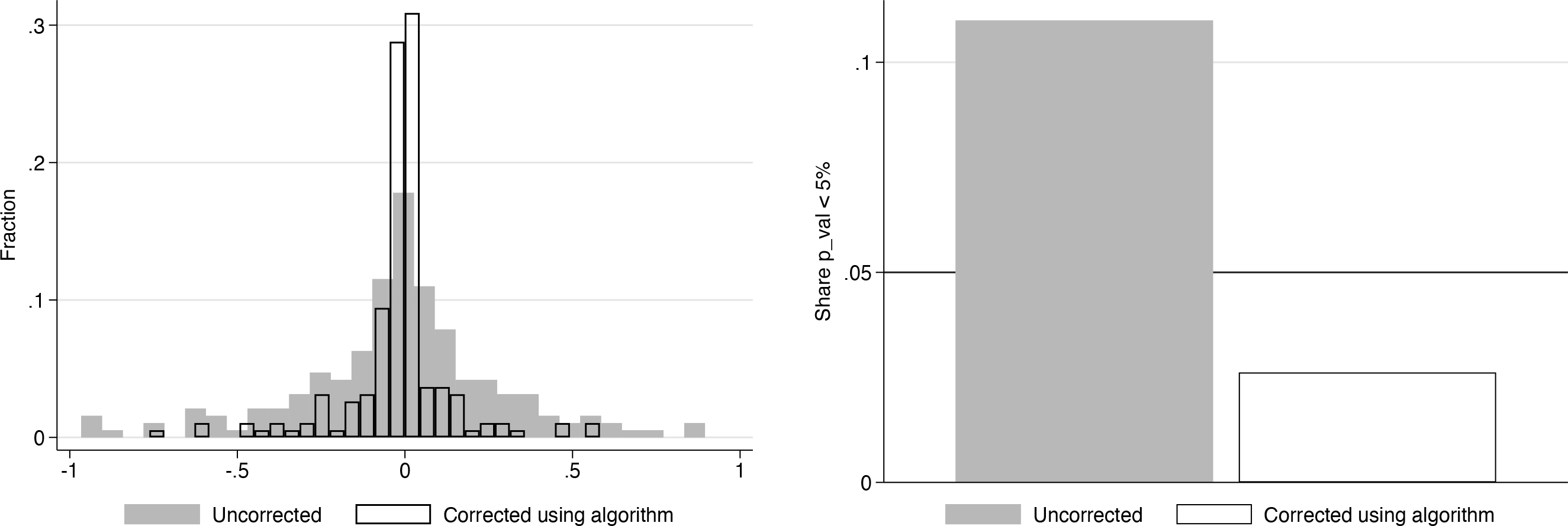
Simulation results: Estimated coefficients (left) and rejection shares at 5% level (right)
Conclusions
We presented spur, an implementation of newly developed econometric methods that help to diagnose and correct spatial unit roots (Müller and Watson 2024), and we discussed its use in regression analysis. How these new methods perform compared with alternative methods to correct for strong spatial dependence is an open question. In follow-up work, we plan to apply this approach as well as several alternatives to both simulated and observational data, examining their power and size properties. This will clarify when each method is best applied, given a particular setting.
Supplemental Material
sj-txt-1-stj-10.1177_1536867X261449932 - Supplemental material for Testing and correcting for spatial unit roots in regression analysis
Supplemental material, sj-txt-1-stj-10.1177_1536867X261449932 for Testing and correcting for spatial unit roots in regression analysis by Sascha O. Becker, P. David Boll and Hans-Joachim Voth in The Stata Journal
Supplemental Material
sj-pdf-1-stj-10.1177_1536867X261449932 - Supplemental material for Testing and correcting for spatial unit roots in regression analysis
Supplemental material, sj-pdf-1-stj-10.1177_1536867X261449932 for Testing and correcting for spatial unit roots in regression analysis by Sascha O. Becker, P. David Boll and Hans-Joachim Voth in The Stata Journal
Supplemental Material
sj-dta-2-stj-10.1177_1536867X261449932 - Supplemental material for Testing and correcting for spatial unit roots in regression analysis
Supplemental material, sj-dta-2-stj-10.1177_1536867X261449932 for Testing and correcting for spatial unit roots in regression analysis by Sascha O. Becker, P. David Boll and Hans-Joachim Voth in The Stata Journal
Supplemental Material
sj-dta-1-stj-10.1177_1536867X261449932 - Supplemental material for Testing and correcting for spatial unit roots in regression analysis
Supplemental material, sj-dta-1-stj-10.1177_1536867X261449932 for Testing and correcting for spatial unit roots in regression analysis by Sascha O. Becker, P. David Boll and Hans-Joachim Voth in The Stata Journal
Footnotes
Acknowledgments
The community-contributed code is based on the MATLAB code provided by Ulrich Muller and Mark Watson (![]() ). Our community- contributed code replicates the results in Müller and Watson (2024) based on their MATLAB code 1:1. Any errors in the community-contributed code remain our own. We are obliged to Ulrich Muller and Mark Watson for useful conversations and suggestions. We thank Daniel Gottlich and Elie Malhaire for excellent research assistance.
). Our community- contributed code replicates the results in Müller and Watson (2024) based on their MATLAB code 1:1. Any errors in the community-contributed code remain our own. We are obliged to Ulrich Muller and Mark Watson for useful conversations and suggestions. We thank Daniel Gottlich and Elie Malhaire for excellent research assistance.
8 Programs and supplemental materials
To install the software files as they existed at the time of publication of this article, type
The latest version of the programs can be installed using
and (
Revised and improved versions of the programs may become available in the future at
https://github.com/pdavidboll/SPUR or on our webpages (![]()
We provide example do-files and data to replicate the results in section 4 and appendix A. Please refer to the provided
Notes
About the authors
Sascha O. Becker is professor of economics at the University of Warwick, UK, and Xiaokai Yang Chair of Business and Economics at Monash University, Australia. He is also affiliated with CAGE, CEH@ANU, CEPH, CESifo, CReAM, CEPR, Ifo, IZA, ROA, RF Berlin, and SoDa Labs.
P. David Boll is a PhD candidate at the University of Warwick, UK.
Hans-Joachim Voth is UBS Foundation Professor of Economics, University of Zurich, Switzerland, and Scientific Director of the UBS Center for Economics in Society. He is also affiliated with CEPR and CAGE.
A Appendix: Reproducing the Chetty et al. (2014) results in Müller and Watson (2024)
To demonstrate that our community-contributed code works as expected, we reproduce table 1 in Müller and Watson (2024), which uses data from Chetty et al. (2014). These data are originally in
After this, we call the commands in the
We follow the exact same ordering of columns as Müller and Watson (2024) to allow for comparison of results of their original MATLAB code and our community-contributed code. Our results are shown in table A1. Apart from minor differences in the second decimal place, which are explained by the fact that the methods use simulations based on random numbers, our code reproduces the results in Müller and Watson (2024) exactly.
Note that in most cases, applying the LBM-GLS transformation does not turn significant results in levels into insignificant ones. While there are occasional cases like the effect of the manufacturing share or Chinese import growth (significant in levels but not after the transformation), where the new 95% confidence interval includes zero, these are rare. This is true despite the fact that the overwhelming majority of dependent variables appear to be I(1), exhibiting a strong form of spatial dependence.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.