
Abstract
AI applications in finance including those for the probability of default modeling largely involve using ML classification tools. Oversampling the very minor (very underrepresented) class of defaulted borrowers seems to be a must-be-done step always. However, by crunching more than a thousand of confidence intervals for the classification accuracy metrics, we demonstrate when such oversampling is worth engaging in. Moreover, we argue to what portion of total initial sample size such oversampling should be carried out. Our findings are valuable primarily for the credit risk modeling and Internal Ratings Based (IRB) banks, but are not limited to those and have general applications for the binary classifications in ML domain.
I prefer true but imperfect knowledge,
even if it leaves much indetermined and unpredictable,
to a pretence of exact knowledge that is likely to be false.
Nobel Prize lecture
Introduction
The Basel Committee report BCBS (2017) might be named the first formal recognition of the material artificial intelligence (AI) proliferation in the finance domain. Formally, it even led to the introduction of the new terms like FinTech, RegTech, and SupTech. At the time the committee saw only technological risks posed by the proliferation of AI, machine learning (ML), and advanced data analytics considered jointly. As a result, the committee recommended strengthening the information technologies (IT) with which the bank is equipped, see BCBS (2017, pp. 28).
Since then the AI/ML use made that significant progress that the associated risks stopped being limited solely by IT ones. More conceptual issues arose. Those include the ethical ones whether an algorithm should be allowed or not to discriminate one cohort of customers to the detriment (rarely - to the benefit) of another. This led to the discussion of the ethical probability of default (PD) models in papers like Fuster et al. (2018) and Szepannek and Luebke (2021). The European Parliament extended the discussion by making an unprecedented step and publishing a pan-European AI regulation act, see Europarliament (2023).
So far, it seems that methodologically everything is clear with the development of AI in finance, and it is only the issue of the available (sufficient) computational capacities based on graphical processing unit (GPU). Such thoughts gave rise to the terms of GPU-rich and GPU-poor companies distinguishing companies which have enough access to the needed GPU capacities and those which do not have, see The Economist (2024).
However, today seems to be right the time when we may fall into the fundamental trap created by our obsession with the exact prediction and hence recommendation skills of AI modules driven by the underlying ML solutions. The nature of the trap is as follows. The recent ML trend allows software to elaborate own programming codes and models, in particular (though still far from ideally targeted ones as developed by experienced coders). The AI solution of interest is likely to continue reprogramming the specific model as far as its output performance (accuracy) metrics outpaces that of the previous one. Such a process goes on as in most cases it is the point estimates of the performance metrics which rise, though sometimes at a tiny growth rate. From the outside perspective such an improvement process in addition vastly consumes GPU power making any company GPU-poor in essence.
Nevertheless, the improvement process is not as endless as it seems and as it was in the legend when Achilles failed to outrun the turtle. As a reminder, the legend says that the mighty Achilles is unable to reach the turtle, because every time when he reaches it, the turtle is able to move some distance away. Though the distance might be small, but it is still there and Achilles cannot reach the turtle never.
For a detailed mathematical explanation of this paradox and its original interpretation, please refer to the Feng (2023). In fact, most models become similar when the model performance metrics reach a particular threshold for a combination of classes and features. Such similarity is well captured by the confidence intervals (CI) for the performance metrics, which unfortunately are not that wide-spread though well-known in probability theory. Hence, if the AI algorithm for a credit scoring or fraud detection in finance reached the stage when the upper boundary of the accuracy metrics CI is almost equal to one (to 100%), it is clear that any novel model cannot discriminate poor borrowers from good ones any better (unless there happens a region-wide shock and overall model prediction quality deteriorates). This could mean that AI software may get rise in efficiency by not crunching the code and numbers any longer and by economizing the GPU capacity for other tasks.
The use of confidence intervals for the performance metrics of ML models in finance is not novel. Moreover, the cases when one of the two classes is materially underrepresented is also known (consider the term low-default portfolio (LDP), for instance). Oversampling minor class is a typical industry solution. However, no one, to the best of our knowledge, studied the evolution of confidence intervals for the performance metrics of the models in finance
As a preview of our findings, we show that excessive oversampling (at the extreme when equalizing the proportions of the minor and major classes) leads to the rise in the width of the confidence intervals of the performance metrics making models more indistinguishable from each other, and by overall sacrificing the model performance quality. The practical implication from here is to oversample at a limited degree. Then and only then the model developer (or AI software supposedly in the near future) may be able to evidence the true improvement in the model performance.
To explain how we arrive at our findings, we start with the literature review in Section 2. We describe the methodology in Section 3. The findings follow in Section 4. We conclude in Section 5.
Literature Review
AI applications in finance, though numerous, can be broadly grouped into several groups of which classification tasks continue occupying important place. Those tasks might include distinguishing good and bad borrowers, clients prone to churn and not, online users willing to choose a product or not, fraudsters and general users. Solving classification (properly discriminating) in-between these two groups forms the basis for further recommendation system development.
Hence, it is vitally important to be efficient in solving classification tasks when applying AI and ML in finance. Seems lots has been discussed about it in Mirkin (2016) and Raschka and Mirjalili (2019), for instance. However, gaps still exist. Those relate to situations when one of two classes is materially underrepresented (such a class might be called a very minor one, while the residual class is a major one). A fast, but not always worthy typical solution is to oversample. This is why we intend to study consequences of such a step given often omitted specifics for the confidence intervals when applied to the classification accuracy metrics.
To do so, we first discuss the papers when dealing with minor classes are not a one-off case. Namely, it is the domain of probability of default (PD) modeling and developing PD models for banks specifically. Nevertheless, the findings are of value to other areas, including inter alia cyberfraud detection. Second, we remind approaches to handling a minor class when it might be assumed to be underrepresented in a non-systematic manner. This is where the suggestion to oversample the minor class is being born. Third, we focus on how to choose the best classification model as it is exactly the criteria intended to be improved when oversampling. Fourth, we rehearse the importance of monitoring the confidence intervals for the classification metrics, not limited to their mean values.
PD Modeling
The first formal probability of default (PD) models were proposed in the papers by Beaver (1966), Altman (1968) and Ohlson (1980). Authors of these papers used a countable number of observations driven by the computational capabilities of the first computers. These often equaled a couple of dozen company-year (or just company) observations. Moreover, the samples of defaulted and non-defaulted companies typically equaled in size, giving no rise to the issue of handing a minor class.
Since then software and financial services industries evolved that much that PD models started being considered as part of the financial regulation. Formally, the Basel Committee on Banking Supervision (BCBS) allowed them as a part of the Basel II Internal Ratings-Based (IRB) approach, see BCBS (2006). Prior to formal adoption, the committee published a comprehensive survey of progress in classification models development, and more specifically to that of PD models in BCBS (2000). It was highly likely that the PD model conceptual approval by the international financial regulation standards setter of BCBS triggered the research boom in the area.
As a result, we come across the use of conventional econometric and multivariate statistical analysis tools to develop PD models as discussed by Kumar and Ravi (2007) and Altman (2018). Same time the use of ML tools gains its popularity as can be seen from the following non-exhausting list of papers: Chen et al. (2006), Fantazzini and Figini (2009), Korol and Korodi (2010), Tinoco and Wilson (2014), Geng et al. (2015), Jabeur and Fahmi (2018), Shibitov and Mamedli (2019), Qu et al. (2019), Dendramis et al. (2020), Kim et al. (2020), Moscatelli et al. (2020), Kim et al. (2021), Faraj et al. (2021), Pang et al. (2021), Merćep et al. (2021) and Liu et al. (2022).
PD models were developed for many localities. To name a few, Jabeur and Fahmi (2018) considered France, Chen et al. (2006) and Liu et al. (2022) - China, Altman et al. (2008) - the UK, Tian and Yu (2017) - Japan, Bisogno et al. (2018) - the EU, Kristóf and Virág (2020) - Hungary, Merćep et al. (2021) - Croatia.
Most academic papers present PD models for the retail borrowers because the segment is typically characterized by the enormous number of observations and defaults. PD models for corporate borrowers appear less often, while banks are the rarest research objects. For instance, they are handled in the following relevant works: Bräuning et al. (2020) and Durand et al. (2021) for the EU, Yuksel et al. (2015) for Turkey, Shrivastava et al. (2020) for India, Kočenda and Iwasaki (2022) for Japan, Kocagil et al. (2002), Moody’s Analytics (2016) and Cole et al. (2020) for the USA, Obeid (2021) for the Persian Gulf countries, and Cheong and Ramasamy (2019); Kristóf (2021) for others. Relevant reviews are available at Kumar and Ravi (2007) and Citterio (2020).
The reason for such rarity of the PD model for banks can be vividly seen from the illustrative Table 1. Nowadays, as well as 20 years ago, financial institutions (FI) tend mostly not to default. The proportion of defaulted cases at maximum approaches 2% of the total sample, being as small as less than half of the percentage point (see last column of Table 1). This is why financiers tend to call the FI segment a low default portfolio (LDP). AI/ML practitioners eagerly see the problem (defaulted) cases in the segment as the very minor class with the non-defaulters being a very major one. Despite the widespread regulatory doctrine of “too big to fail,” systemic collapses of major financial institutions still occur, as exemplified by the historical crises of Credit Suisse. The 2008 failure of Lehman Brothers and near-collapses of other large firms critically deepened the recession by destabilizing markets, freezing credit flows, collapsing asset values, and eroding public trust, whereas smaller firm failures have not meaningfully threatened the global financial system’s stability (see Johnson and Mamun (2012)).
Why Dealing with a Tiny Class is Important?
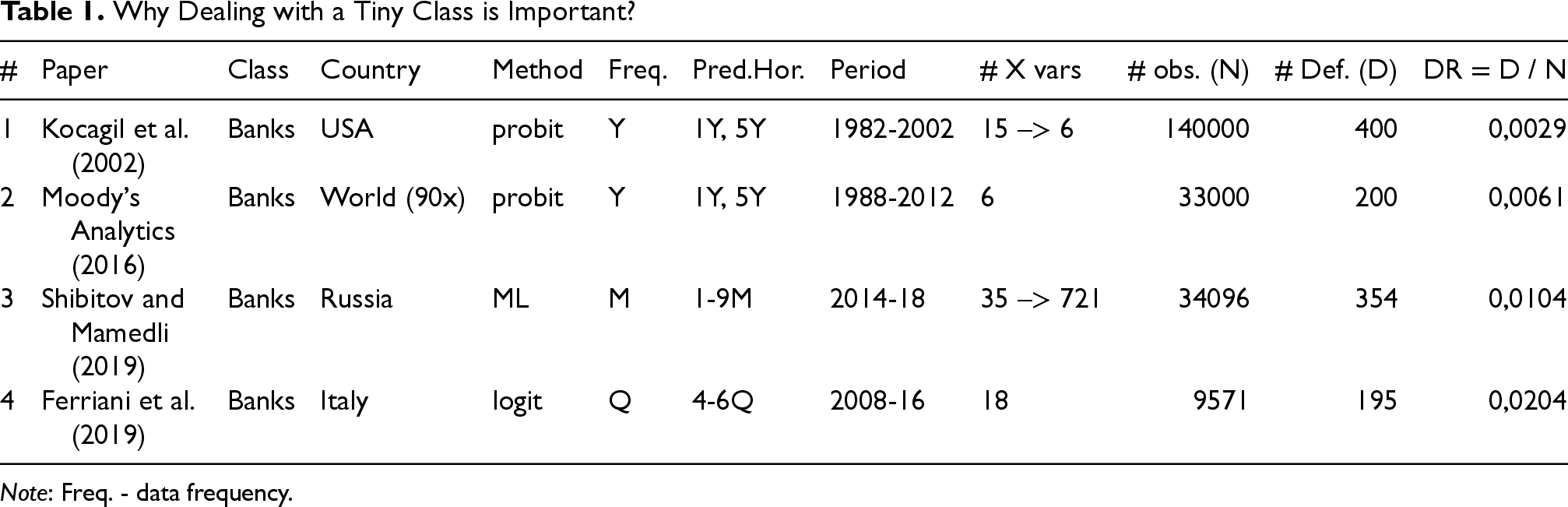
Why Dealing with a Tiny Class is Important?
Note: Freq. - data frequency.
The collapse of Lehman Brothers and other major financial institutions severely exacerbated the crisis and recession by disrupting markets, hindering credit availability, triggering steep asset price declines, and undermining confidence. While the failures of smaller, less interconnected firms remain concerning, they have not meaningfully threatened the broader stability of the financial system.
Though the FI segment is not rich in defaults, the financiers solicited PD models for the segment. There are several solutions on how to act, according to Raschka and Mirjalili (2019, pp. 267–270):
to oversample the minor class, Liu (2021); Nunes et al. (2021); to undersample the major class. to input missings, Audigier et al. (2021);
Koziarski (2021) opts for a combination of over- and undersampling. However, oversampling is grounded on the strong assumptions. According to Rubin (1976) classification, it is assumed that the data (default cases) is missing either completely at random (MCAR), or just at random (MAR). However, Carreras et al. (2021) argues that if the data is of MCAR type, then oversampling is not needed, as one is to add pure noise not-impacting the model of interest.
On the contrary, the possibility of data being missing not at random (MNAR) is rarely checked. To be fair, in the absence of extra defaults, the feasibility of such verification by itself is under question. Pereira et al. (2019) offers arguments to ignore MNAR, as it stems from situations when the data was not collected or was wrongly collected via a survey. Financial default data has a more regular nature, and only extreme force-major events might trigger systematic unaccounting of many default cases. Alternatively, when wishing to handle MNAR cases, one may drift towards Heymans and Twisk (2022) who suggests modeling the missing data. But to do so, one should properly study such MNAR cases, then calibrate the data generating process parameters. One can do the latter step only by using the available limited (LDP) cases. Hence, we also neglect the possibility of MNAR observations here.
Classification Accuracy (Model Performance) Metrics
ML practitioners tend to oversample minor class as rule of thumb. Our objective here is to demonstrate cases when such oversampling is worth undertaking and when it is not. To answer this question, we should first inquire what objective is targeted when oversampling. The ML practitioners seek to improve (increase) the model quality (its performance metrics), i.e., the model developers wish the model to better discriminate (segment, classify, cluster) the incoming data into two classes (in case of PD model into defaulters and non-defaulters). The industry-standard is to look at precision, recall, accuracy and F1 indicators. The respective formulas are available in eqs. (1)–(4).


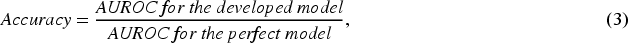
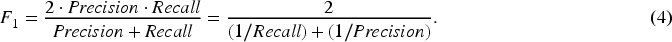
Stylized Default (Success) Prediction Matrix to Analyze Model Accuracy.
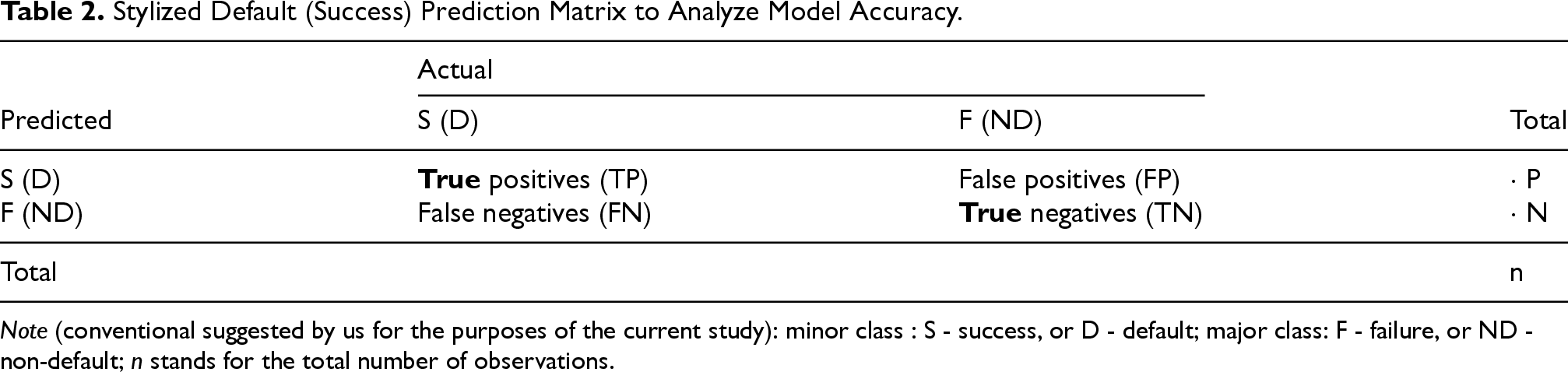
Note (conventional suggested by us for the purposes of the current study): minor class : S - success, or D - default; major class: F - failure, or ND - non-default;
We have evidenced above that PD models are well-studied, accuracy metrics are also commonly known. However, the problem - inter alia with the growing number of papers published and offering the better discriminating PD models - is that authors get obsessed with the improvement solely based on the mean values (point estimates) of the classification metrics of interest, e.g., Faraj et al. (2021, p. 24, Tab. 2), Kim et al. (2021, p. 170, Tab. 4), Pang et al. (2021, p. 10), Merćep et al. (2021, p. 10, Table 1 – p. 12, Table 6), Song et al. (2021, p.1489, Table 1), Liu et al. (2022, p. 10, Tab. 8).
Nevertheless, we should not forget that the performance metrics combine the number of realisations of a random variable, (often a dummy flag taking one in case of default and zero otherwise). They differ from each other in a way of such combination. Disregarding the mode of combination, the accuracy metrics by construction are still random variables in themselves. It means that the mere dominance (excess in arithmetic terms) of one point estimate over another may correspond to probabilistically equal values. To correctly judge upon the superiority of a particular model, when comparing PD models, one has to look at the confidence intervals of performance metrics, not limited to their point estimates. Moreover, as every accuracy metric is a proportion by construction ranging from zero to one, one should specifically look at the confidence intervals for (binomial) proportions.
The development of the confidence intervals (CIs) for proportions has passed through the following stages:
Wald CI, or normal approximation, see formula (5);
Wilson CI, see formulas (6)
Clopper-Pearson (beta) CI, see Dunnigan (2008, p. 3), formulas (7), (8);
Orawo (2021) notes that Clopper-Pearson CI is more conservative, but wider than it is sufficient. Agresti-Coull (AC) CI from Agresti and Coull (1998, p. 120), see formula (9);
Jeffreys CI, see formulas (10), (11);
Brown et al. (2001) above all recommend using Jeffreys interval instead of normal approximation, as well as instead of Wilson’s and Agresti-Coull’s ones.
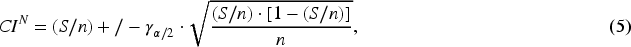
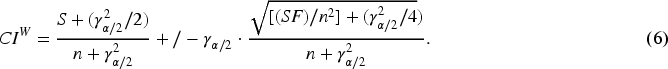


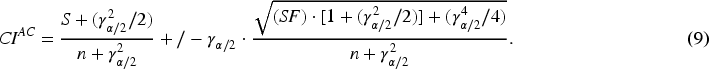
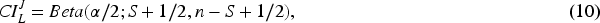
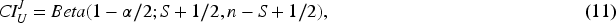
It is worth mentioning that Brown et al. (2001) refer to other types of confidence intervals such as the modified Wilson interval, modified Jeffreys interval, arcsine interval, logit interval, Bayesian interval, and likelihood ratio interval. These confidence intervals were not considered in the present study. The selection of the specific metrics used here is justified by their prevalence in the literature and based on the recommendations provided by the authors themselves in the conclusion of their work.
Hanson and Schuermann (2006) also examined the comparison of confidence intervals for default probability estimates using analytical methods, as well as parametric and nonparametric bootstrap approaches. The key distinction of our study lies in the fact that we analyze confidence intervals not for the default rates in the sample (see Table 2 in the appendix of Hanson and Schuermann (2006)), nor for the default probability (PD) distribution of a classification algorithm, but rather for the performance metrics of a binary classification algorithm. In fact, there is definitely a link between the confidence interval on the model performance metrics and the confidence interval on the model output. Hanson and Schuermann (2006) focused on the latter, we did it for the former, tracing a linkage between the two falls out of our research scope.
Concept
We wish to study how confidence intervals for the classification accuracy metrics evolve under various scenarios. We look at three starting values of the minor class (e.g., default rates, DR): 0.1%, 3.0%, 10.0% of the total number of observations. These portions are the starting (baseline) values. We oversample them to reach up to 50% of the initial number of observations. For instance, take a
We use ten core features (independent factors) to delineate minor class observations from the major ones. We consider four possible factor combinations. Initially, a dataset with 10 core features was generated, where each feature contributes to forming the class label, this is the first dataset. Next, 5 independent columns were added to the original dataset; since these columns do not influence the class label, they are considered redundant, this is the second dataset. Next, 5 significant core features were removed from the original 10-core dataset, this is the third dataset. Finally, 5 redundant features were added to the 5-core dataset, yielding the fourth dataset.
For each model we evaluate four classification metrics as presented in subsection 2.3. For each of the metrics we present five confidence intervals (CIs) discussed in subsection 2.4. Hence, we derive five CI widths as differences between the CI lower boundary (
When the CI width augments, the models become less distinguishable. Hence, it becomes more difficult to offer another model statistically (probabilistically) outpacing the value of the current accuracy metrics value. Thus, we are interested in cases when the CI width shrinks. Then the models are more divisible. Having built a new model, it is more likely to evidence that it is superior to the existing one all else being equal.
Parameter Specification
We use the
We add noise to our classification via a
To oversample, we use an
To build a model, we use
Findings
Here we enlist the key findings which we obtain from our simulation experiment (Table A1 contains the details on the average widths of the five considered CIs for the F1 metrics):
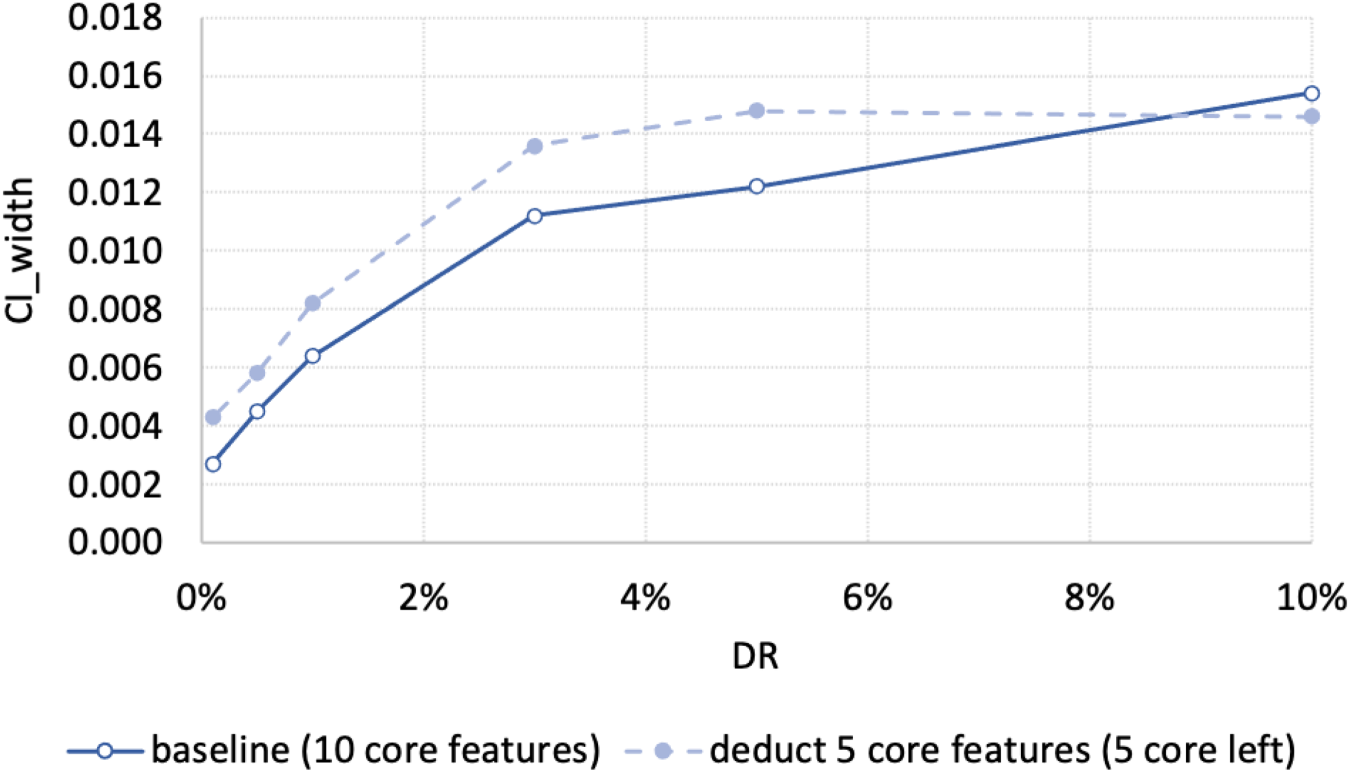
The width of the CI is proportionate to the share of the minor class, e.g., the lower the default rate (DR) is, the narrower the CI is, compare D1 to D7 (1.5% vs 0.3%) in Table A1; see also Figure 1. When the portion of the minor class (DR) is low (below 5%), making some core features unavailable leads to the increase in the CI width (compare D3 to F3 (1.1% vs 1.3%) and D7 to F7 (0.3% vs 0.4%) in Table A1). However, when the portion is larger (e.g., 10%), we may observe reduction of the CI width (compare D1 to F1 (1.54% vs 1.46%) in Table A1). Adding more noise (extra redundant features) widens the CI when oversampling from a very tiny class to equal proportions case (from 0.1% to 50%) (compare D16 to E16 (1.2% vs 1.4%) and F16 to G16 (1.1% vs 1.5%) in Table A1). In other cases, we do not trace neither material deterioration, nor improvement in CI width. Oversampling to equal class shares (50:50%) mostly often leads to deterioration (CI widening) (compare D3 to D6 (1.1% vs 1.3%) and rows 1 to 2 in Table A1). However, in a realistic set-up (column G) when we know part of core drivers and also include several redundant ones, oversampling not a very minor class ( Oversampling the very minor class might be reasonable when considering moderate pace of resampled observations. For instance, oversampling DR of 0.1% enables to slightly reduce the CI width when the portion reaches 3–5%, but above that the CI width starts rising, compare rows 7 to 10 and 11 in Table A1; see also Figure 2. Oversampling often leads not merely to CI widening, but also to overall model performance deterioration. As a result, CI shifts down, see Figure 3.
Higher portion of minor class imply wider CI. Oversampling very minor class improves (narrows) CI, but for mild resampling. Oversampling very minor to equal portions not only widens the CI, but also drastically reduces the mean performance (shifts the CI down).
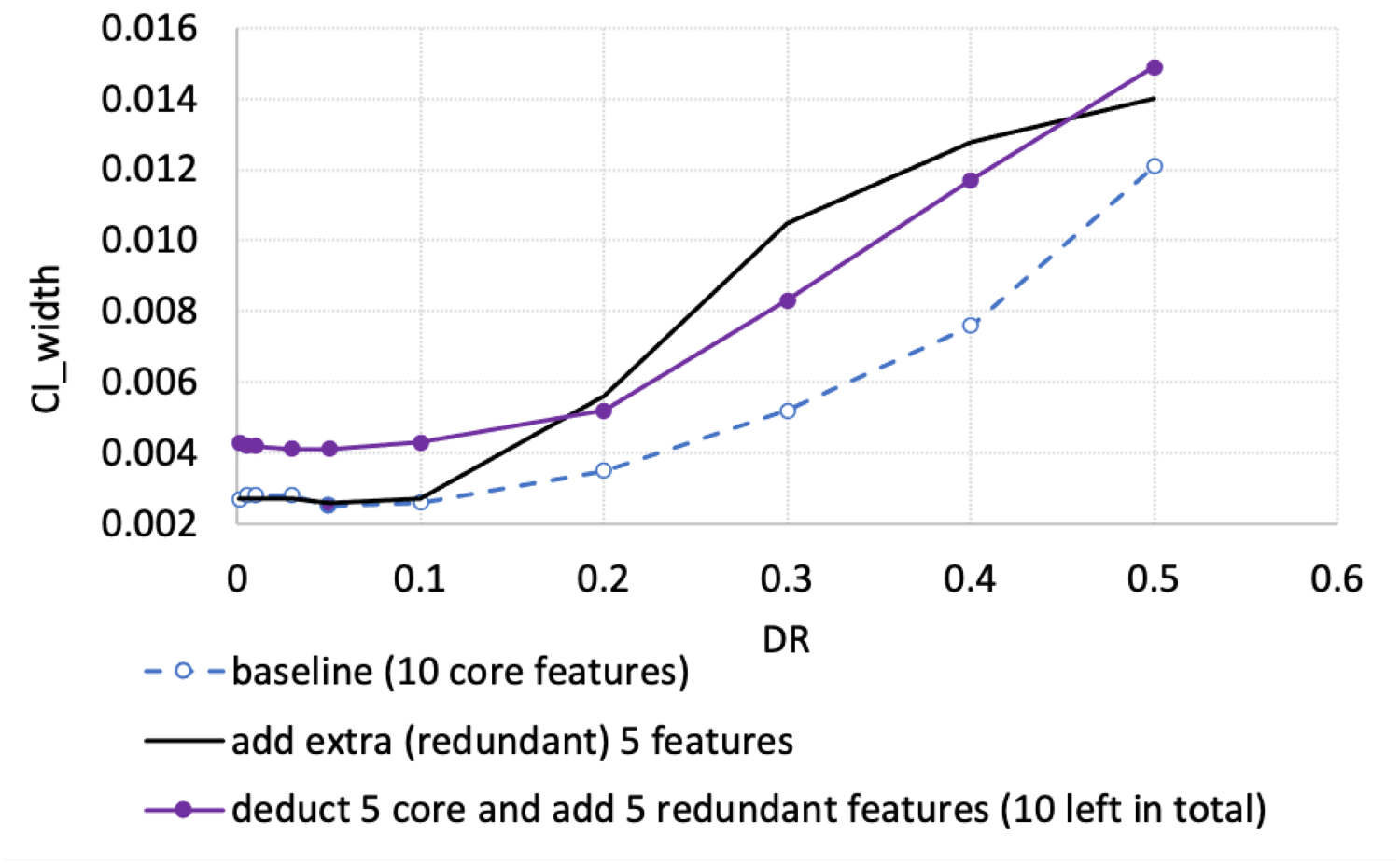
AI, in general, is nowadays thought of being an indispensable element of future progress in finance. Such progress encapsulates the proliferation of the ML models’ use for the numerous classification tasks, including the discrimination of good from bad borrowers, i.e., for the development of the probability of default (PD) models.
We show that PD model developers often face a challenge when coming across an underrepresented (minor) class. As a remedy, they solicit industry-wide practice of oversampling the minor class. This is why we focus on PD models, though our findings spread far beyond PD modeling, and are generally applicable to any binary classification task.
We manage to dig deeper into the properties of models when the underlying data is oversampled. Importantly, we show the thresholds to which it is worth oversampling the minor class given its initial portion. For instance, when the portion is moderately small one (around 3% of the total sample size), one may benefit from oversampling it to 50%. However, when the initial class is very tiny (around 0.1% of total number of observations), it might be worth oversampling only to 3-5% of the total number of entries. Moreover, we argue that such a gain in (narrowing of) confidence intervals for the PD model performance might be achieved with the trade-off by losing the overall model performance (the CI mid-value materially goes down).
We offered a statistical table which might be used by practitioners as a guide when to oversample the data or not. The enclosed programming code in Python allows gathering the equivalent answer for any combination of initial portion of the minor class, number of core and redundant features, the considered oversampling proportions.
Disclaimer
The views expressed herein are solely those of the authors. The content and results of this research should not be considered or referred to in any publications as the Bank of Russia’s official position, official policy, or decisions. Any errors in this document are the responsibility of the authors. All rights reserved. Reproduction is prohibited without the authors’ consent.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Annex
Summary of Simulation Experiments. Note: DR - default rate (proportion, share of the minor class). Underlying confidence interval boundaries are presented in the Technical Annex (available from the authors upon request).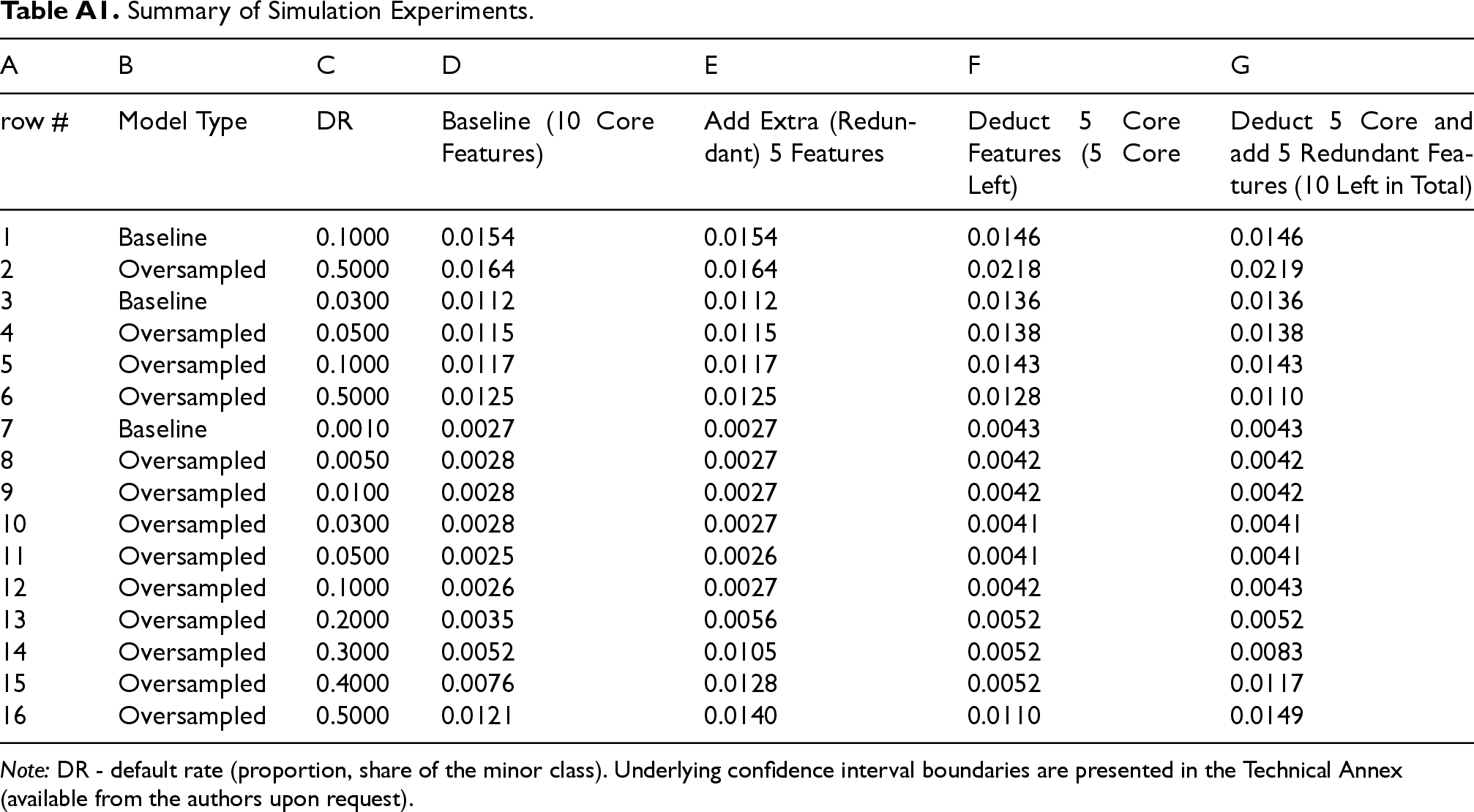
A
B
C
D
E
F
G
row #
Model Type
DR
Baseline (10 Core Features)
Add Extra (Redundant) 5 Features
Deduct 5 Core Features (5 Core Left)
Deduct 5 Core and add 5 Redundant Features (10 Left in Total)
1
Baseline
0.1000
0.0154
0.0154
0.0146
0.0146
2
Oversampled
0.5000
0.0164
0.0164
0.0218
0.0219
3
Baseline
0.0300
0.0112
0.0112
0.0136
0.0136
4
Oversampled
0.0500
0.0115
0.0115
0.0138
0.0138
5
Oversampled
0.1000
0.0117
0.0117
0.0143
0.0143
6
Oversampled
0.5000
0.0125
0.0125
0.0128
0.0110
7
Baseline
0.0010
0.0027
0.0027
0.0043
0.0043
8
Oversampled
0.0050
0.0028
0.0027
0.0042
0.0042
9
Oversampled
0.0100
0.0028
0.0027
0.0042
0.0042
10
Oversampled
0.0300
0.0028
0.0027
0.0041
0.0041
11
Oversampled
0.0500
0.0025
0.0026
0.0041
0.0041
12
Oversampled
0.1000
0.0026
0.0027
0.0042
0.0043
13
Oversampled
0.2000
0.0035
0.0056
0.0052
0.0052
14
Oversampled
0.3000
0.0052
0.0105
0.0052
0.0083
15
Oversampled
0.4000
0.0076
0.0128
0.0052
0.0117
16
Oversampled
0.5000
0.0121
0.0140
0.0110
0.0149