
Abstract
We meta-analytically investigated relations between the four-branch model of ability emotional intelligence (EI) with fluid (Gf) and crystallized intelligence (Gc; 352 effect sizes; ntotal = 15,333). We found that for each branch, the strength of relations with Gf and Gc were equivalent. Understanding emotions has the strongest relation with Gf/Gc combined (ρ = .43, k = 81, n = 11,524), relative to facilitating thought using emotion (ρ = .19, k = 51, n = 7,254), managing emotions (ρ = .20, k = 74, n = 11,359), and perceiving emotion (ρ = .20, k = 79, n = 9,636); for the latter, relations were also moderated by stimulus type. We conclude with implications and recommendations for the study of ability EI.
While some individual studies find ability emotional intelligence (EI) is moderately to strongly correlated with measures of intelligence (e.g., MacCann, Joseph, Newman, & Roberts, 2014), recent meta-analyses show that for some branches, disattenuated correlations with general intelligence are only weak on average (Joseph & Newman, 2010; Pietschnig & Gittler, 2017; Roberts, Schulze, & MacCann, 2008). These meta-analyses, however, ignore general expectations that the magnitude of relations should differ depending on whether the EI branches are related to fluid or crystallized intelligence (e.g., Roberts et al., 2008), suggesting relations should be higher when related to just one intelligence type. We address this limitation through a new meta-analysis, examining relations of each ability EI branch with fluid and crystallized intelligence. In addition, we extend previous meta-analyses by sampling tests beyond the popular Mayer–Salovey–Caruso Emotional Intelligence Test (MSCEIT; Mayer, Salovey, & Caruso, 2002; Mayer, Salovey, Caruso, & Sitarenios, 2003), because of its many identified psychometric limitations (e.g., Maul, 2012; Roberts, Zeidner, & Matthews, 2001).
We begin with a brief historical background on the study of ability EI, followed by a summary of current theory, and expectations regarding relations with fluid and crystallized intelligence based on a review of the cognitive literature. Then, we meta-analyze relations of ability EI and its branches with measures of fluid and crystallized intelligence, concluding with recommendations for the study of ability EI.
Ability EI
Emotional intelligence, despite its name, was (e.g., Davies, Stankov, & Roberts, 1998) and still is (e.g., Locke, 2005; Murphy, 2006) controversial as a new type of intelligence. Since the initial critiques, researchers of EI have embraced a distinction in measurement approach, with an accompanying distinction in terminology, leading to the identification of trait and ability EI. This distinction allowed the field to assess EI as typical behavior (i.e., general everyday behavior), referred to as trait EI, and maximal effort (i.e., best performance under optimal circumstances; Cronbach, 1949), referred to as ability EI, with expectations that only the latter, but not the former, would operate as a distinct cognitive ability (e.g., Mayer, Caruso, & Salovey, 2000). Trait EI, using self-report questionnaires, assesses “people’s perceptions of their emotional world” (Petrides et al., 2016, p. 335). Ability EI, using cognitive tasks, is “the ability to reason validly with emotions and with emotion related information, and to use emotions to enhance thought” (Mayer, Caruso, & Salovey, 2016, p. 296). Early tests of convergent and discriminant validity suggested that, while trait EI is relatively synonymous with the Big Five personality factors, implying the construct has limited incremental validity, ability EI is distinct from known personality constructs and is positively related with other cognitive abilities (e.g., Davies et al., 1998), suggesting even initial measures of ability EI assessed a unique construct.
The most commonly embraced theoretical model of ability EI is the four-branch model (Mayer & Salovey, 1997; Mayer et al., 2016; Salovey & Mayer, 1990). This model proposes four branches of ability EI, each representing one problem solving area. From the most cognitively basic to the most complex, they are: (a) perceiving emotion, (b) facilitating thought using emotion, (c) understanding emotions, and (d) managing emotions (Mayer et al., 2016). Mayer and colleagues identify between five and eight types of reasoning or skills nested within each branch, which we briefly summarize here. Perceiving emotion involves identifying emotions in oneself, emotions expressed by others, and emotional content in the environment, including when expressed emotions are accurate or inaccurate, and honest or dishonest. Facilitating thought using emotion involves consciously using felt emotion to facilitate thinking, such as judgment, memory, and attention, as well as selecting problems based on one’s currently felt emotion. Understanding emotions refers to knowledge about the nature and relation between emotions, including which situations will lead to certain emotions, and how cultures may differ in their evaluation of emotions. Managing emotions involves managing emotions within oneself and others to achieve a desired outcome, evaluating strategies to control felt emotion, and engaging or disengaging with felt emotions as needed.
Relations With Fluid and Crystallized Intelligence
Within the Cattell–Horn–Carroll theory (CHC; Sternberg & Kaufman, 1998), fluid intelligence (Gf) is the ability to solve unfamiliar problems, and includes lower order abilities such as abstract reasoning, concept formation, and the generalization of solutions to new problems. Crystallized intelligence (Gc) is the breadth and depth of skills and knowledge appreciated by one’s culture and the use of this knowledge (McGrew, 2009). While it is sometimes argued that ability EI is more related to Gc than Gf because, for example, ability EI is more of an “acculturated” intelligence (Roberts et al., 2006, p. 664), recent theoretical descriptions of each branch, which frequently involve terms regarding memory, attention, managing, and evaluating (Mayer et al., 2016), suggest ability EI is instead mostly conceptualized as a fluid ability.
It is important to acknowledge, however, that ability EI branches are conceptualized more broadly than is matched by current measurement. At the time of this writing, the most recent description of the four-branch ability EI model identifies 26 separate types of reasoning, many of which can be further divided into more types (Mayer et al., 2016). In practice, however, we lack assessment tools for many of the individual types of reasoning and it is not clear that the assessment tools available sufficiently elicit and assess the type of reasoning of interest. Given this distinction between conceptualization and measurement, our discussion will focus on expected relations at both levels.
Perceiving Emotion
Mayer et al. (2016) describe seven types of reasoning for this branch, the majority of which are about perceiving and reasoning about expressions of emotion (e.g., “Discriminate accurate vs. inaccurate emotional expressions”; Mayer et al., 2016, p. 294). These cognitive abilities presumably rely on basic attentional and visual processing skills, which are constructs strongly related to Gf (MacCann et al., 2014; Redick et al., 2016). In particular, the ability to perceive aspects of a neutral face, which is strongly related with the ability to perceive emotions in the face (Hildebrandt, Sommer, Schacht, & Wilhelm, 2015), is strongly related with Gf (Wilhelm et al., 2010). Also, auditory perceptual capacities, which would be needed for perceiving emotion in the voice, are moderately related with Gf and Gc (Morrill, McAuley, Dilley, & Hambrick, 2015). A majority of types of reasoning also imply some knowledge about emotions and how they are typically displayed, as well as variations in those displays. Knowledge about objects, like figures (Beauducel, Brocke, & Liepmann, 2001), as well as knowledge about one’s culture, within which emotions are nested, are abilities strongly related with Gc (Beier & Ackerman, 2001). This branch also includes the ability to express emotion and the ability to identify emotion within oneself. Given verbal expression abilities are weakly to moderately related to Gc and Gf (Tirre & Field, 2002), we would assume the ability to express emotion is comparably related to Gf and Gc. The ability to identify emotion within oneself, however, describes a cognitive process that is somewhat interoceptive in nature, which is unrelated to Gf and Gc combined (Mash, Schauder, Cochran, Park, & Cascio, 2017). Overall, based on the full theoretical description of this branch, we would expect perceiving emotions to be equally related to Gf and Gc, with relations strong in magnitude (see Figure 1 for an illustration), according to Cohen’s (1992) guidelines for weak (r = .10), moderate (r = .30), and strong (r = .50).
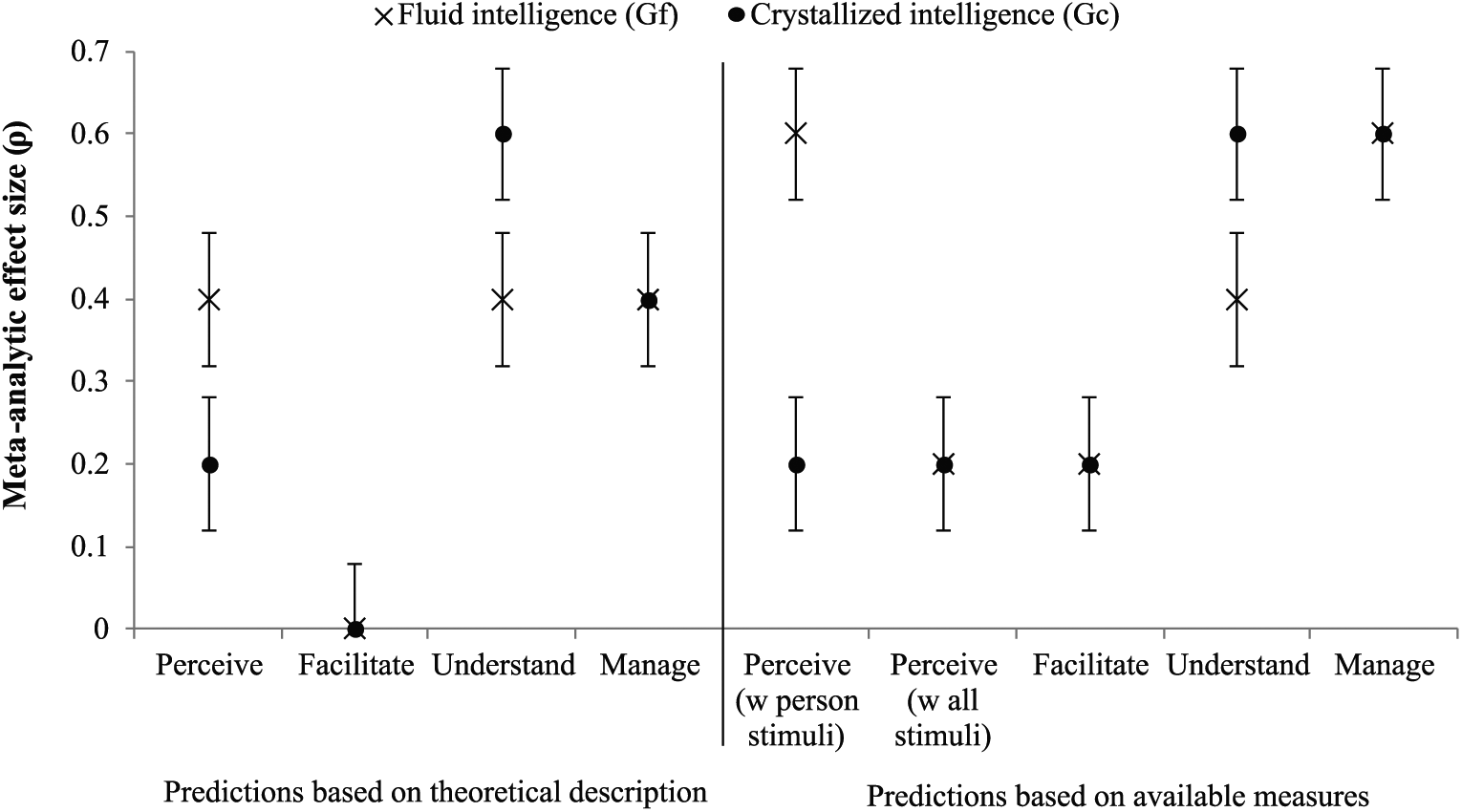
Predicted meta-analytic relations of ability EI branches with Gf and Gc.
In practice, however, assessment is typically limited to just two of the seven proposed types of reasoning—perceiving emotions in other people through their (a) voice, face, language, and behavior or through (b) the environment, visual arts, and music. An example of the former is participants being presented with an emotional face and asked to select the correct label for the emotion expressed in that face (e.g., DANVA Version 2; Nowicki & Duke, 1994) or asked the extent to which several emotions are present in that face (e.g., MSCEIT). An example of the latter is participants being presented with a picture of scenery, and asked to what extent certain emotions are viewed in that picture (MSCEIT). A majority of tests focus exclusively on the first type of reasoning, most often with facial stimuli, for which there is a large body of theoretical and empirical support (e.g., Ekman et al., 1987; Ekman, Rosenburg, & Hager, 1998), suggesting it is possible to identify a veridical response. In addition, person stimuli are likely to be more ecologically valid, relative to nonperson stimuli. In contrast, nonperson stimuli have little empirical support for a veridical response. We would argue the testing method is somewhat anthropometric and most likely involves participants perceiving what they feel when they view the picture, and inferring that is the emotion presented in the picture. Thus, this test type more likely assesses individual differences in typical behavior and not in abilities. As such, we expect that the particular type of reasoning assessed will moderate relations with Gf and Gc, specifically with relations higher for tests using person stimuli, and weaker for tests using nonperson stimuli.
Because perceiving emotions tests that use person stimuli material are similar to measures of Gf, placing a large emphasis on visual processing and reasoning about new information, we expect that relations of performance on these tests with Gf will be strong (Hypothesis 1). However, because they have a limited assessment focus on knowledge of emotion expressions and how they differ depending on context and culture, we would expect weak relations with Gc (Hypothesis 2). In contrast, tests that use nonperson stimuli material, because they most likely assess a personality trait and not an ability, should be weakly related with Gf (Hypothesis 3) and Gc (Hypothesis 4). This is because, as was stated earlier, they are somewhat anthropometric and most likely involve participants perceiving what they feel when they view the picture, and inferring that is the emotion presented in the picture. However, because these tests still use a multiple-choice format, which require basic Gf and Gc abilities to complete (Hartung, Weiss, & Wilhelm, 2017), we expect at least some relation (and not no relation at all).
Facilitating Thought Using Emotion
This branch describes two general categories of types of reasoning: (a) generating emotions to facilitate thought, (b) tailoring thinking, or one’s choice of tasks, to match one’s felt emotion (Mayer et al., 2016). Research regarding the relation of Gf and Gc with the generation of emotion is inconclusive (Ochsner & Gross, 2005), so it is difficult to develop hypotheses for these types of reasoning based on a review of the literature; however, they could each be thought of as involving some capacity for reasoning, suggesting weak relations with Gf, as well as a basic knowledge about emotions and one’s own experiences, implying weak relations with Gc. The second category of types of reasoning implies some problem solving or decision making capacities, which describe Gf, as well as attentional processes, which are strongly related with Gf (Redick et al., 2016). However, these types of reasoning also generally assume an awareness of one’s emotions, which is interoceptive in nature and unrelated with Gf and Gc (Mash et al., 2017). Overall, based on the theoretical description of this branch, we would assume weak relations with Gf and Gc.
In practice, however, this branch is assessed with participants presented with a scenario and asked to rate the appropriate mood to facilitate that scenario (e.g., MSCEIT). This test format does not directly test any of the types of reasoning described for this branch; for example, a more appropriate test design would be asking participants which set of problems should be tackled, given a specific mood. However, the testing format requires basic reasoning skills and knowledge about emotions. Hence, we would expect at least weak relations with Gf (Hypothesis 5) and Gc (Hypothesis 6).
Understanding Emotions
Mayer, Salovey, Caruso, and Sitarenios (2001) proposed that the understanding emotions branch is the “most cognitively saturated” (p. 235) of the four branches, with this branch strongly related to abstract reasoning. Likewise, Austin (2010) suggested that only understanding emotions qualifies as an intelligence because, in her data, it was the only branch significantly related to measures of Gf and Gc. This is supported by theoretical descriptions of the types of reasoning involved in this branch, almost all of which suggest relations with Gf and Gc. A majority of the types of reasoning for this branch require knowledge about emotions, including their relations, antecedents and consequences, and the influence of culture, suggesting the branch is strongly related with Gc. Indeed, knowledge about one’s culture (Beier & Ackerman, 2001) and everyday knowledge are strongly related with Gc as well as Gf (Weatherbee & Allaire, 2008). In fact, generally domain-specific knowledge is moderately related with Gc (Rolfhus & Ackerman, 1999). In addition, this branch includes some reasoning about emotions, such as the ability to “determine the antecedents, meanings, and consequences of emotions” (Mayer et al., 2016, p. 294), implying moderate relations with Gf. However, the “affective forecasting” type of reasoning is conceptually similar to empathic accuracy, which is unrelated to Gf (Hülür et al., 2016). Based on the full theoretical description of this branch, we would expect understanding emotions to have a strong relation with Gc and a moderate relation with Gf.
In practice, this branch is often assessed with multiple-choice items where persons are presented with a situation and asked what someone should feel in that situation, or presented with a feeling and asked what situation should lead to that feeling (e.g., MSCEIT, STEU; MacCann & Roberts, 2008). While culture is not included in the described situations, this design otherwise requires participants to use most of the other types of reasoning listed for this branch. Because of our expectations regarding relations with Gf and Gc based on the theoretical description of this branch, we hypothesize a moderate relation with Gf (Hypothesis 7) and a strong relation with Gc (Hypothesis 8).
Managing Emotions
This branch is considered the most cognitively complex of the four branches because the types of reasoning entailed are expected to build on the abilities described in the other branches. Indeed, the description of many of the types of reasoning for this branch (e.g., “Effectively manage others’ emotions to achieve a desired outcome”; Mayer et al., 2016, p. 294) imply a heavy reliance on reasoning abilities, as well as knowledge about emotions. The management of emotions in others suggests complex problem solving skills would be needed, which are moderately to strongly related with Gf and moderately related with Gc (Kretzschmar, Neubert, Wüstenberg, & Greiff, 2016). Persons who are better at self-regulation in general have higher working memory capacity (Hofmann, Gschwendner, Friese, Wiers, & Schmitt, 2008), which is strongly related with Gf (e.g., Schmitz & Wilhelm, 2016). Persons who self-reported a weaker negative emotional reaction to certain negative stimuli (e.g., disgust) had higher working memory capacity, and persons who were better at regulating their emotions in social situations, as indicated by their emotion expressions, performed better on executive function tasks (Schmeichel & Tang, 2014), which is also related with Gf (Blair, 2006). Based on the full theoretical description of this branch, we would expect strong relations with Gf and Gc.
In practice, this branch is assessed with situational judgment items, with participants presented with a scenario and asked to identify the appropriate action (e.g., STEM; MacCann & Roberts, 2008) or to rate the effectiveness of several actions (e.g., MSCEIT) to manage the emotions elicited in that situation. However, it could be argued that this type of testing misses the types of abilities theoretically described under this branch (i.e., it has insufficient ecological validity) because participants do not have to actually try to manage emotions, which would require strong Gf, but instead report on what they think is best, which instead has a focus on Gc (Fiori, 2009; Ortony, Revelle, & Zinbarg, 2007). Thus, we expect that performance on managing emotion tests is moderately related to Gf (Hypothesis 9) and strongly related to Gc (Hypothesis 10).
Current Study
This meta-analysis conceptually extends published meta-analyses (Joseph & Newman, 2010; Pietschnig & Gittler, 2017; Roberts et al., 2008) on relations of the ability EI branches with cognitive abilities in several ways. First, we examine relations separately for Gf and Gc and include relations with facilitating thought using emotion. While the meta-analysis by Roberts et al. (2008) also distinguished between Gf and Gc, this meta-analysis examines a much larger number of articles, providing more confidence in the final estimates. In addition, we expanded the list of ability EI measures used beyond the traditionally employed MSCEIT and its predecessor, the MEIS (Mayer et al., 2000), with a prescreened list of ability EI measures. This was especially beneficial given the many critiques of the MSCEIT and MEIS (e.g., Maul, 2012). Likewise, by using a variety of measures of ability EI, in addition to a variety of measures of Gf and Gc, we restricted the extent to which estimated relations represent shared method variance, a concern raised by Roberts et al. (2008). Finally, for perceiving emotions we examine test characteristics as moderators of the strength of relations, lending more insight into how measurement affects relations with established measures of Gf and Gc.
Methods
Literature Search
The keyword-based literature search was conducted between March and May 2016 (see Figure 2). We searched for articles written in English and in German, but the German literature search did not reveal any additional studies not already identified with the English search terms, thus, henceforth we only describe the results of the English literature search. The major part of the search was performed using Ovid, an aggregator we used to simultaneously search PsycARTICLES, Medline, Embase, PsycINFO, PSYNDEX, and the Cochrane libraries. To assist in our literature search, we generated a list of ability EI tests through consultation with ability EI experts. Search terms included the full name or acronym of the ability EI tests, which were then combined with the general cognitive ability search terms, specifically valid*, cognit* test, psychometric, psychometric propert*, IQ test, ability test, ability measure*, mental ability, cognitive abilit*, SAT, cognitive abilit*. This process was then repeated for ProQuest to identify grey literature, specifically dissertations and theses. Finally, we conducted a more exploratory search to identify any remaining studies that could have been missing in the previous search. To this end, we used search terms for the EI branches, as well as emotion* percept*, emotion* understand*, emotion* facilitation, emotion* manag*, and emotion* intelligence, combined with fluid intelligence, crystal* intelligence, general intelligence, vocabulary, knowledge, lexical, matri*, reasoning, verbal intelligence, nonverbal intelligence. The exploratory search led to 3000+ articles that were screened by checking titles and abstracts. Finally, we wrote to authors of studies in instances where the study matched our inclusion criteria, but lacked important statistical information (this was limited to manuscripts published 2000 or later, to increase the chance of a response).
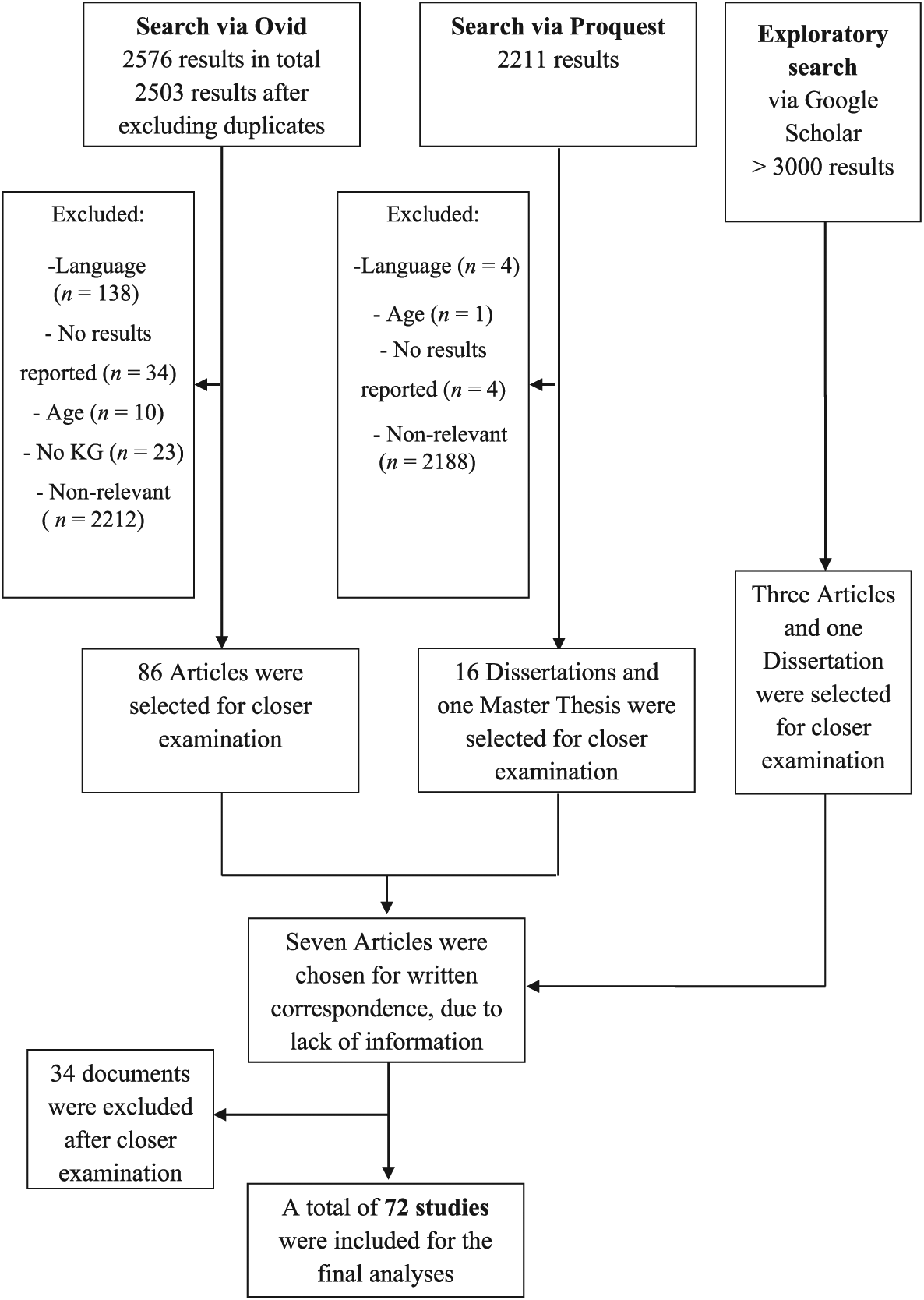
Flowchart displaying the literature search process.
Inclusion and Exclusion Criteria
Studies needed to meet the following inclusion criteria: (a) report a correlation between one of the ability EI branches and a measure of Gf or Gc, (b) report exact sample sizes, (c) mean age of the sample was between 18 and 60 years, without a known clinical diagnosis, and (d) the full text was available in English. We then excluded studies that did not include the relevant information and the authors could not be reached, or were based on a previously included sample. We had no a priori restrictions concerning Gf or Gc instruments, however, we made an a priori decision against including coefficients associated with grade point average, which we considered a rather broad variable and not a clear indicator of Gf or Gc.
Recorded Variables
We coded 44 variables; those essential to testing our hypotheses are listed next.
Correlations with Gc/Gf
We coded the names of the tests, the test version, the EI branch measured, the effect size, type of correlation, reliability of both tests, the type of the reliability estimate, as well as the ratio of female participants and the mean age of the sample in years. To reduce dependencies between effect sizes, we only coded the relation of the EI branches with one measure of Gf and one measure of Gc. However, not all measures of Gf and Gc are considered pure measures of their respective construct, so we coded the construct saturation of these measures according to the extent to which the test qualified as a pure (i.e., closely measures Gf or Gc according to CHC theory), proxy (i.e., essentially measures Gf or Gc), or tendency towards measure (i.e., somewhere in between Gf and Gc, but leaned towards one direction or the other; see Table 1 for ratings). Coders were instructed to select effect sizes associated with pure measures of Gf and Gc. When this was not possible, in order to maximize the effects coded, coders were instructed to code effects associated with the proxy tests, followed by those classified as tendency towards.
Basic characteristics of the included studies.
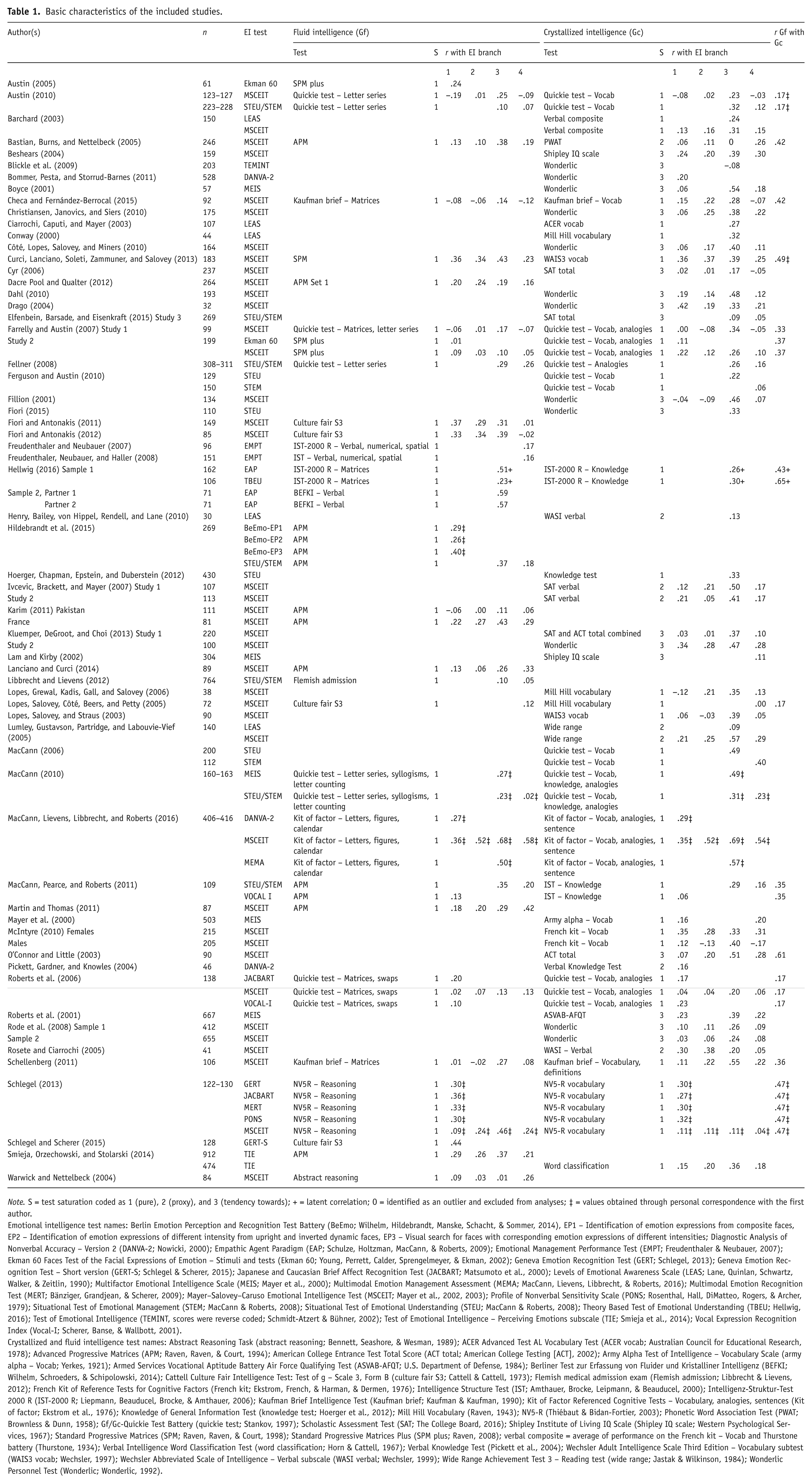
Note. S = test saturation coded as 1 (pure), 2 (proxy), and 3 (tendency towards); + = latent correlation; O = identified as an outlier and excluded from analyses; ‡ = values obtained through personal correspondence with the first author.
Emotional intelligence test names: Berlin Emotion Perception and Recognition Test Battery (BeEmo; Wilhelm, Hildebrandt, Manske, Schacht, & Sommer, 2014), EP1 – Identification of emotion expressions from composite faces, EP2 – Identification of emotion expressions of different intensity from upright and inverted dynamic faces, EP3 – Visual search for faces with corresponding emotion expressions of different intensities; Diagnostic Analysis of Nonverbal Accuracy – Version 2 (DANVA-2; Nowicki, 2000); Empathic Agent Paradigm (EAP; Schulze, Holtzman, MacCann, & Roberts, 2009); Emotional Management Performance Test (EMPT; Freudenthaler & Neubauer, 2007); Ekman 60 Faces Test of the Facial Expressions of Emotion – Stimuli and tests (Ekman 60; Young, Perrett, Calder, Sprengelmeyer, & Ekman, 2002); Geneva Emotion Recognition Test (GERT; Schlegel, 2013); Geneva Emotion Recognition Test – Short version (GERT-S; Schlegel & Scherer, 2015); Japanese and Caucasian Brief Affect Recognition Test (JACBART; Matsumoto et al., 2000); Levels of Emotional Awareness Scale (LEAS; Lane, Quinlan, Schwartz, Walker, & Zeitlin, 1990); Multifactor Emotional Intelligence Scale (MEIS; Mayer et al., 2000); Multimodal Emotion Management Assessment (MEMA; MacCann, Lievens, Libbrecht, & Roberts, 2016); Multimodal Emotion Recognition Test (MERT; Bänziger, Grandjean, & Scherer, 2009); Mayer–Salovey–Caruso Emotional Intelligence Test (MSCEIT; Mayer et al., 2002, 2003); Profile of Nonverbal Sensitivity Scale (PONS; Rosenthal, Hall, DiMatteo, Rogers, & Archer, 1979); Situational Test of Emotional Management (STEM; MacCann & Roberts, 2008); Situational Test of Emotional Understanding (STEU; MacCann & Roberts, 2008); Theory Based Test of Emotional Understanding (TBEU; Hellwig, 2016); Test of Emotional Intelligence (TEMINT, scores were reverse coded; Schmidt-Atzert & Bühner, 2002); Test of Emotional Intelligence – Perceiving Emotions subscale (TIE; Smieja et al., 2014); Vocal Expression Recognition Index (Vocal-I; Scherer, Banse, & Wallbott, 2001).
Crystallized and fluid intelligence test names: Abstract Reasoning Task (abstract reasoning; Bennett, Seashore, & Wesman, 1989); ACER Advanced Test AL Vocabulary Test (ACER vocab; Australian Council for Educational Research, 1978); Advanced Progressive Matrices (APM; Raven, Raven, & Court, 1994); American College Entrance Test Total Score (ACT total; American College Testing [ACT], 2002); Army Alpha Test of Intelligence – Vocabulary Scale (army alpha – Vocab; Yerkes, 1921); Armed Services Vocational Aptitude Battery Air Force Qualifying Test (ASVAB-AFQT; U.S. Department of Defense, 1984); Berliner Test zur Erfassung von Fluider und Kristalliner Intelligenz (BEFKI; Wilhelm, Schroeders, & Schipolowski, 2014); Cattell Culture Fair Intelligence Test: Test of g – Scale 3, Form B (culture fair S3; Cattell & Cattell, 1973); Flemish medical admission exam (Flemish admission; Libbrecht & Lievens, 2012); French Kit of Reference Tests for Cognitive Factors (French kit; Ekstrom, French, & Harman, & Dermen, 1976); Intelligence Structure Test (IST; Amthauer, Brocke, Leipmann, & Beauducel, 2000); Intelligenz-Struktur-Test 2000 R (IST-2000 R; Liepmann, Beauducel, Brocke, & Amthauer, 2006); Kaufman Brief Intelligence Test (Kaufman brief; Kaufman & Kaufman, 1990); Kit of Factor Referenced Cognitive Tests – Vocabulary, analogies, sentences (Kit of factor; Ekstrom et al., 1976); Knowledge of General Information Test (knowledge test; Hoerger et al., 2012); Mill Hill Vocabulary (Raven, 1943); NV5-R (Thiébaut & Bidan-Fortier, 2003); Phonetic Word Association Test (PWAT; Brownless & Dunn, 1958); Gf/Gc-Quickie Test Battery (quickie test; Stankov, 1997); Scholastic Assessment Test (SAT; The College Board, 2016); Shipley Institute of Living IQ Scale (Shipley IQ scale; Western Psychological Services, 1967); Standard Progressive Matrices (SPM; Raven, Raven, & Court, 1998); Standard Progressive Matrices Plus (SPM plus; Raven, 2008); verbal composite = average of performance on the French kit – Vocab and Thurstone battery (Thurstone, 1934); Verbal Intelligence Word Classification Test (word classification; Horn & Cattell, 1967); Verbal Knowledge Test (Pickett et al., 2004); Wechsler Adult Intelligence Scale Third Edition – Vocabulary subtest (WAIS3 vocab; Wechsler, 1997); Wechsler Abbreviated Scale of Intelligence – Verbal subscale (WASI verbal; Wechsler, 1999); Wide Range Achievement Test 3 – Reading test (wide range; Jastak & Wilkinson, 1984); Wonderlic Personnel Test (Wonderlic; Wonderlic, 1992).
Test design variables
We coded the channel of stimulus presentation: (a) person stimuli, including presentation of a face, voice, and/or body, (b) nonperson stimuli, including text and nonperson pictures.
Double coding and interrater agreement
All studies were double coded; coding was done by three psychology students completing their master degree. In order to reduce the coding burden, only those variables deemed essential to testing the study hypotheses (listed before) were double coded. The proportion agreement was on average .89, ranging from .46 to 1.00 for the individual variables. The lowest proportion agreement was for the continuous variables and was found to be due to differences in rounding or decimal placement. Discrepancies were then resolved through discussion between coders.
Data Analytic Strategy
All analyses were conducted within R Version 3.2.0 (R Development Core Team, 2016) with the package psych for the estimation of basic psychometric statistics, metafor for the meta-analysis of data with independent effect sizes, and robumeta for the meta-analysis of data with dependent effect sizes (Fisher & Tipton, 2014; Revelle, 2016; Viechtbauer, 2016). To account for measurement error, all correlation coefficients were first corrected for attenuation (Hunter & Schmidt, 2004) using published estimates of internal consistency (Cronbach’s α, test–retest, or split-half). When reliability coefficients were not reported (42% of EI tests, 60% of Gf tests, and 55% of Gc tests), we used the median value for that test based on our data, or, when it was the only time that test was included in our data, estimates published in the relevant test manual. When correlations were between latent variables, the coefficients were considered to be corrected for unreliability (Card, 2012).
Disattenuated correlation coefficients were then transformed to Fisher’s z values to stabilize variances, and we estimated the variances of the z scores (Schulze, 2004), which is recommended to account for greater imprecision of the adjusted effect size estimates. Variances of the z scores were also corrected for unreliability (Hunter & Schmidt, 2004). All meta-analyses were conducted on the z scores and we assumed a random effects model throughout. For interpretation, final estimates were transformed back into ρ coefficients (Borenstein, Hedges, Higgins, & Rothstein, 2011). Because some studies provided multiple effect sizes, we used robust variance estimation (RVE), an innovative approach for handling nonindependent effect sizes without knowing the within-study correlations (Hedges, Tipton, & Johnson, 2010). Specifically, RVE results in correct standard errors for pooled effects and metaregression coefficients in the presence of dependent endpoints. A small sample size adjustment was used (Tipton, 2015). Finally, we imputed the default within-study correlation value of .8 needed for RVE computations, which was checked later through sensitivity analyses, as is recommended by Fisher and Tipton (2014).
Since this meta-analysis employs a between-study strategy to study the difference of ρgc,b and ρgf,b, where b is one of the four EI branches, the difference could be confounded by reporting biases at the between-study level. To check how sensitive our results are to this strategy, differences of z-transformed correlations were calculated for those studies reporting estimates of both ρgc,b and ρgf,b, yielding a meta-analysis of within-study differences. The asymptotic standard error provided in Equation 10 of Dunn and Clark (1969) was used for the within-study differences, since the two estimates are dependent. The correlation between Gf and Gc was coded in the subset of studies reporting both correlations so that this asymptotic standard error could be computed, and then an RVE meta-analysis was conducted for each of the four branches.
We estimated the variance of the true effect sizes (i.e., the dispersion between studies; τ²) and heterogeneity of the effects with Higgin’s I² (Borenstein et al., 2011). Publication bias was examined with funnel plots complemented by an RVE metaregression of effect size on sample size, an analogue of Egger’s regression test (Sterne & Egger, 2005). A regression coefficient significantly different from zero indicates that, on average, smaller studies report smaller or larger effect sizes and hence hints at publication bias. For all of the statistical analyses, an alpha value of .05 was used, and we followed the suggestion of 10 studies for every level of a categorical predictor variable included in the between-study metaregressions (Borenstein et al., 2011).
Results
We identified 352 effect sizes from 80 unique studies presented in 70 separate documents (57 peer reviewed empirical articles, and 13 dissertations or unpublished theses) with a total sample size of 15,333 participants. Most of the samples were exclusively students (n = 54 samples; 12 nonstudent samples, 15 mixed samples), and most samples were collected in North America or Australia (n = 54 samples, 22 European samples, three other samples). The average age of the samples ranged from 18.5 to 51.3 years (weighted M = 23.4 years). Samples ranged from all males to all females (weighted M = 57.1% female). Based on a visual inspection of the effect size histograms, plotting relations of all EI branches with Gc, one outlier was identified (6 standard deviations from the mean) and was removed. No outliers were found for relations of the EI branches with Gf.
Gf and Gc Test Saturation
First, we checked whether the extent to which the Gf and Gc instruments measured their respective constructs inappropriately reduced relations with ability EI and the individual branches. Gf and Gc test saturation was dummy coded and, in a series of regressions, tested as a predictor of relations of Gf and Gc with ability EI and the individual EI branches. There was no significant effect for Gc, suggesting that for these relations, Gc test saturation had no effect on the meta-analyzed relations of Gc with EI and the EI branches. However, there was a significant decrease in the estimated relation between (a) Gf measures coded as pure versus those coded as tendency towards for the relation between Gf and general EI, (b) Gf measures coded as pure versus those coded as proxy for the relation between Gf and perceiving emotions, and (c) GF measures coded as pure versus those coded as tendency towards for the relation between Gf and managing emotions. Given the proxy and tendency towards tests were also related to the other three EI branches, effects involving these tests (k = 66) were excluded across all branches for the remainder of the analyses, resulting in a final sample of 285 effect sizes (68 studies; n = 13,445; see Table 1 for the final list of included studies).
Emotional Intelligence With Gf and Gc
To account for dependencies between studies, we estimated an intercept-only robust variance estimation (RVE) metaregression model, through robumeta, to estimate separate pooled correlations between ability EI and Gf and Gc (Model 1: τ² = .04, I² = 86.7). Ability EI was positively related to both Gf and Gc (see Table 2 for effect sizes). In a second model, we again estimated an intercept-only RVE metaregression to estimate separate pooled correlations for the relations between the four ability EI branches and Gf and Gc. As is illustrated in Table 2, there was some variety in the magnitude of effect sizes between the four branches. Perceiving emotion, facilitating thought using emotion, and managing emotions were weakly related to Gf and Gc, while understanding emotions was moderately related (Model 2: τ² = .04, I² = 83.9).
Intercept-only models presenting pooled correlations.
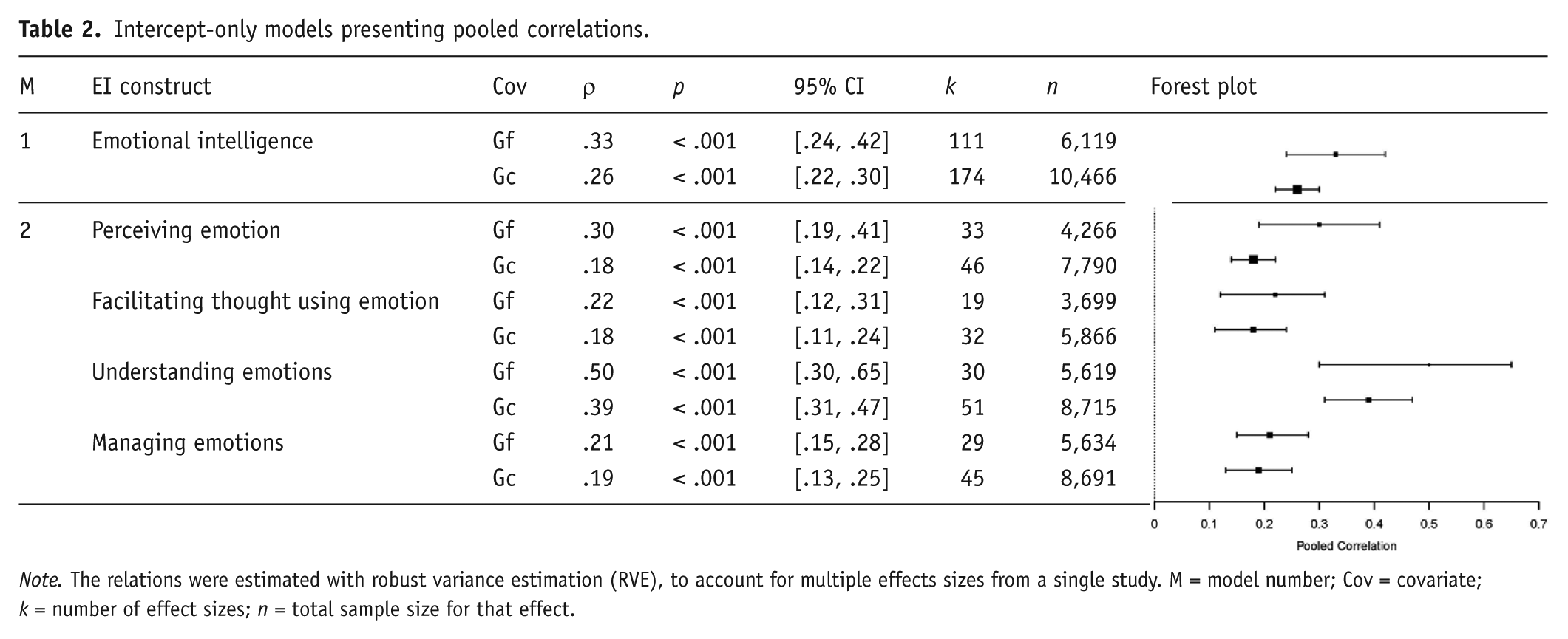
Note. The relations were estimated with robust variance estimation (RVE), to account for multiple effects sizes from a single study. M = model number; Cov = covariate; k = number of effect sizes; n = total sample size for that effect.
Hypothesis testing
Next, we tested whether the relations of ability EI and the four branches with Gf were comparable with Gc. The first RVE metaregression compared relations for overall ability EI with intelligence type dummy coded, with Gf as the reference category (Model 3). Then, four additional metaregressions were estimated, one for each EI branch (Models 4–7). In contradiction to expectations regarding perceiving emotions, understanding emotions, and managing emotions, the relations of ability EI and the four branches with Gf were equivalent in magnitude to relations with Gc (ρs from −.08 to .01, ps from .11 to .89). Several post hoc analyses revealed results did not change if we focused on specific popular tests (MSCEIT – Understanding Emotions, MSCEIT – Managing Emotions, STEU, STEM) and/or included only Gc tests rated pure.
Within-study differences between relations of an EI branch with Gf and Gc (z-transformed differences between relations of an EI branch with Gf and Gc) from 13 studies were additionally meta-analyzed with RVE, though not all studies reported all branches, resulting in 10 to 18 different studies reporting up to five sets of estimates for each relation (Models 8–11). None of the coefficients were significantly different from zero (ρs from .01 to .05, ps from .23 to .67). While these models are based on a substantially reduced pool of studies, the within-study results are in line with the between-study results, so it seems reasonable to assume that there is no significant difference in the relations of the individual EI branches with Gf and Gc. Pooled correlations of ability EI and the four branches with Gf and Gc combined are presented in Table 3 (Models 12–16).
Pooled correlations of ability EI and its branches with Gf and Gc.

Note. The relations were estimated with robust variance estimation (RVE) to account for multiple effects sizes from a single study. M = Model number; k = number of effect sizes; n = total sample size for that effect.
Next, we tested whether perceiving emotion tests that exclusively used person stimuli (BeEmo, DANVA, Facial Expressions of Emotion – Stimuli and Tests [FEEST], GERT/GERT-S, JACBART, MERT, PONS, VOCAL-I) were more strongly related to Gf and Gc, relative to other test designs (MSCEIT, MEIS, TIE). The effect was statistically significant for Gf (Model 17: pooled correlation: ρ = .17, p < .01, 95% CI [.06, .29]; moderator: ρ = .18, p = .04, 95% CI [.01, .35], k = 33, n = 4,266, τ² = .04, I² = 82.6), and for Gc, with a one-tailed p value with the effect in the predicted direction (Model 18: pooled correlation: ρ = .16, p < .001, 95% CI [.11, .21]; moderator: ρ = .010, two-tailed p = .07, one-tailed p = .04, 95% CI [−.01, .22], k = 46, n = 7,790, τ² = .01, I² = 66.7). To illustrate the final effect sizes for relations of perceiving emotion with Gf and Gc, further categorized by the type of stimuli, we estimated four intercept-only models (Models 19–22; Table 4). To facilitate an interpretation of these effects, we estimated two random effects meta-analyses, with test dummy coded, and present pooled correlations of the individual perceiving emotions tests with Gf (Model 23; τ² = .03, I² = 78.3) and Gc organized by test (Model 24; τ² = .02, I² = 70.4; Figure 3).
Intercept-only models presenting pooled correlations between perceiving emotion with Gf and Gc, organized by type of perceiving emotion stimuli.
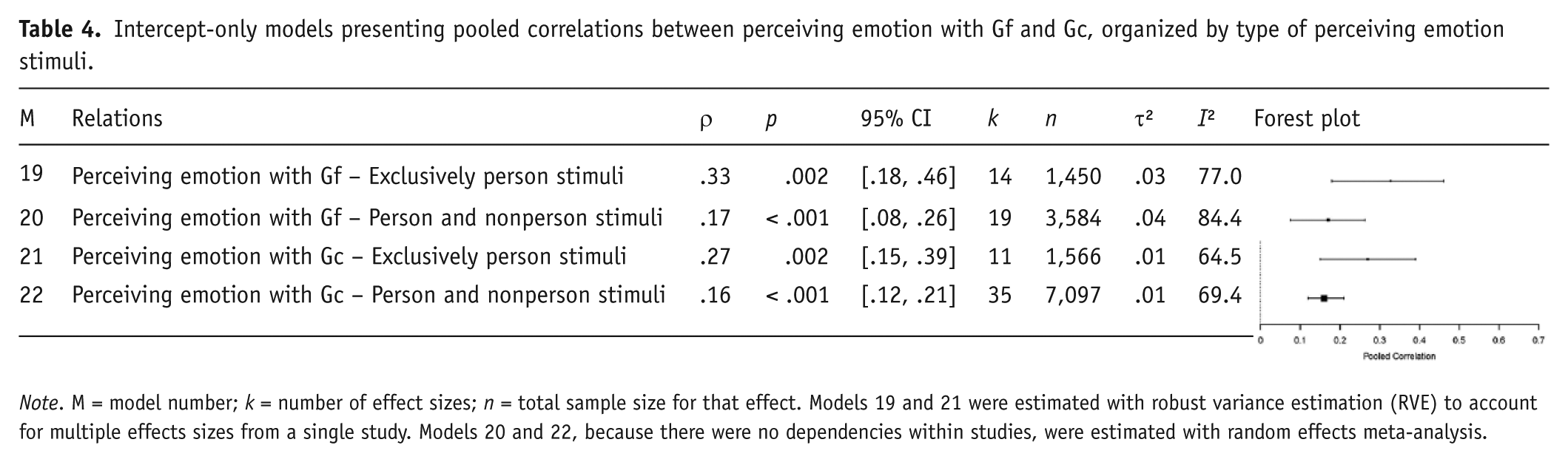
Note. M = model number; k = number of effect sizes; n = total sample size for that effect. Models 19 and 21 were estimated with robust variance estimation (RVE) to account for multiple effects sizes from a single study. Models 20 and 22, because there were no dependencies within studies, were estimated with random effects meta-analysis.
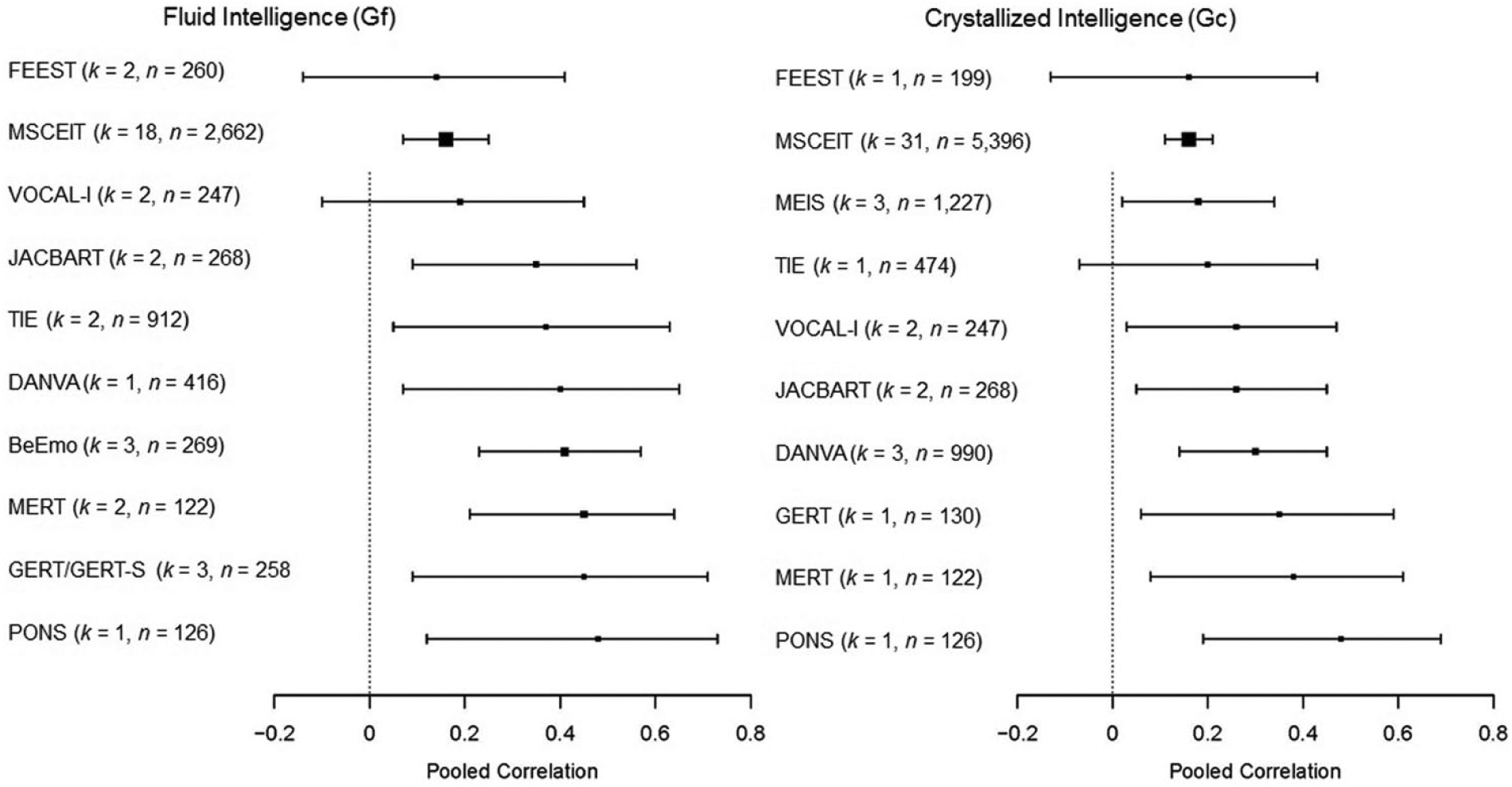
Relations of Gf (Model 23) and Gc (Model 24) with individual perceiving emotions tests, ordered by magnitude of relations. Full test names are in the note of Table 1.
Sensitivity Analyses and Publication Bias
For all of the estimated models, sensitivity analyses were conducted; effect sizes and standard errors are robust at different levels of sample heterogeneity. Funnel plots of Fisher’s z transformed correlation coefficients against estimates of standard error for ability EI with Gf and Gc are inconclusive as to whether or not there is a publication bias (see Figure 4). Thus we estimated two RVE metaregressions, predicting Fisher’s z-transformed correlation coefficients’ effect sizes by sample size. For both ability EI with Gf (Model 25: pooled correlation: ρ = .30, p < .001, 95% CI [.18, .41]; moderator: ρ = .00001, p = .96, 95% CI [−.001, .001], k = 121, n = 6,498, τ² = .06, I² = 88.4) and ability EI with Gc (Model 26: pooled correlation: ρ = .27, p = .03, 95% CI [.21, .33]; moderator: ρ = −.000002, p = .91, 95% CI [−.0003, .0003], k = 174, n = 10,466, τ² = .04, I² = 86.7), sample size did not moderate the strength of relations, suggesting lack of publication bias on our results.
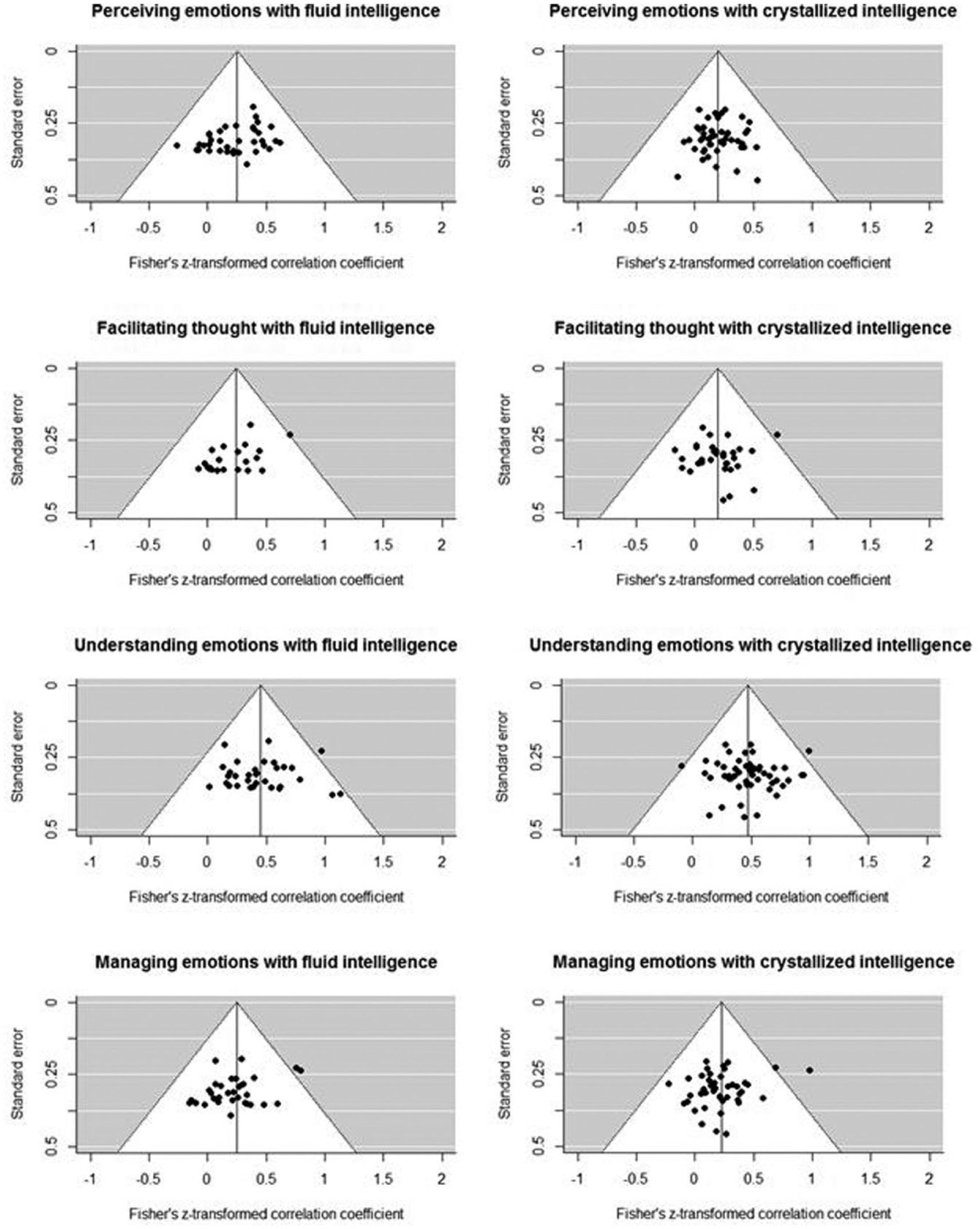
Funnel plots.
Discussion
Our meta-analysis revealed that current measures of the ability EI branches do not differentially relate to Gf and Gc. In addition, despite looking at relations separately for Gf and Gc, relations for facilitating thought using emotion, managing emotion, and perceiving emotion tests with nonperson stimuli were still only weak in magnitude. The magnitude of these relations also fall below the lower bound of 95% confidence intervals of other meta-analyses on the relations between cognitive abilities (e.g., average working memory with general reasoning: ρ = .43, 95% CI [.36, .49]; perceptual speed: ρ = .27, 95% CI [.26, .32]; and knowledge: ρ = .25, 95% CI [.22, .28]; Ackerman, Beier, & Boyle, 2005). The implications of these findings, as well as recommendations for the field, are discussed next.
Implications and Recommendations
We found that emotion perception tests that exclusively used person stimuli were more strongly related to Gf and Gc, and a review of the relations of individual tests (see Figure 3) suggests many tests actually have a much stronger relation, moderate to strong in magnitude. However, because all of the effect sizes in the category of tests without an exclusive use of person stimuli are based on the MEIS or the MSCEIT (with the exception of one effect size for the TIE), there are other possible explanations for this effect. In particular, the unique response method used in these tests (instructions: “Indicate the emotions expressed by this face”; response options: 1 = not at all present, 5 = present to a great extent) and the fact that participants routinely select Option 1 (Fiori et al., 2014) could mean that the difference may be because both tests assessed the ability to detect the presence of a neutral expression, instead of the presence of an emotional expression. 1 This confound should be further examined in future research. Measures of perceiving emotion with facial stimuli could be expanded to use nonprototypical facial expressions, given critiques of the prototypical nature of facial expressions of emotion (e.g., Barrett, 2011; Jack, Garrod, Yu, Caldara, & Schyns, 2012). Also, many of the types of reasoning identified within the perceiving emotions branch, which could be effectively assessed externally with a veridical response, are not assessed (e.g., “Discriminate accurate vs. inaccurate emotional expressions”; Mayer et al., 2016, p. 294).
The use of a rating scale has been linked to weaker relations with Gc, relative to the use of a multiple-choice format (MacCann & Roberts, 2008), which is a characteristic of tests of facilitating thought using emotion and the MSCEIT measure of managing emotion, which were weakly related to Gc and Gf. However, the STEM, which uses a multiple-choice format, was also weakly related to Gf and Gc, implying a multiple-choice format is not sufficient for qualifying the assessed construct as an intelligence. Likewise, given Gc is needed simply to complete multiple-choice tests (Hartung et al., 2017), it may be that this testing method artificially inflates correlations larger than they would be otherwise. Other testing methods should be used to help identify what is unique about these constructs and what is due to method variance (MacCann et al., 2014).
The weak correlations with managing emotions suggest the use of situational judgment items is also not sufficient to achieve moderate relations with Gf or Gc, and recent studies suggest situational judgment tests are not dramatically improved with the use of media (MacCann et al., 2016). There is also always the risk that situations and correct responses are culturally specific, preventing the test’s universality, and in order to necessarily decrease the burden on the participant, may be insufficient to explain all relevant variables of interest (e.g., personal or relational history of the characters). Instead, as an alternative direction, researchers could directly test the emotion knowledge presumably underlying the skills described in the four-branch model (Orchard et al., 2009), for example, through a Gc test based on empirical literature on emotions. This would involve removing the situational aspect of many ability EI tests, and avoid the necessity of consensus scores that limit tests to only easy items and include the risk of different veridical responses per culture (Zeidner, Roberts, & Matthews, 2004; although see recent advances in consensus scoring by Anders, Alario, & Batchelder, 2017).
There is still a significant amount of heterogeneity unexplained by our predictors. One possible explanation, which is difficult to test in the present meta-analysis, is that studies differ in the basic ability level of the sample, with Spearman’s Law of Diminishing Returns leading to weaker correlations in the higher ability samples (Legree, Mullins, LaPort, & Roberts, 2016). Alternatively, relations may increase with increasing age, in line with the dedifferentiation hypothesis (e.g., Baltes, Cornelius, Spiro, Nesselroade, & Willis, 1980).
Conclusion
Contrary to expectations, the four branches of ability EI are not differentially related to Gf or Gc. We also found that, when looking at relations for Gf and Gc separately, some branches are still only weakly related to intelligence. The four-branch model has allowed the field to make significant strides in the study of emotional abilities, outlining new constructs and inspiring many lines of research. However, as our meta-analysis and those of others illustrate, we still do not consistently find moderate or strong relations between most branches and Gf or Gc. Given the relevance of ability EI to many applied and clinical contexts, it is important to have a clear measure of this construct and a clear understanding of its nature, in order to maximize its predictive utility. Many concerns regarding the assessment of ability EI have already been raised (e.g., Maul, 2012; Roberts et al., 2001; Wilhelm, 2005), which have been partially addressed (e.g., Mayer et al., 2001, 2003). We presented further recommendations for research on ability EI.
Supplemental Material
Supplemental_Material – Supplemental material for Four-Branch Model of Ability Emotional Intelligence With Fluid and Crystallized Intelligence: A Meta-Analysis of Relations
Supplemental material, Supplemental_Material for Four-Branch Model of Ability Emotional Intelligence With Fluid and Crystallized Intelligence: A Meta-Analysis of Relations by Sally Olderbak, Martin Semmler and Philipp Doebler in Emotion Review
Footnotes
Author note:
We would like to thank Olesia Kukin, Daniela Gühne, Johanna Ohnmacht, Florian Schmitz, and Oliver Wilhelm for their help with the study design, coding, and comments to the manuscript. In addition, we would like to thank Elizabeth Austin, Antonietta Curci, Andrea Hildebrandt, Carolyn MacCann, and Katja Schlegel for providing additional effect sizes not included in the original publication, as well as the anonymous reviewers for their helpful suggestions.
The full list of search terms; coding manual; coding sheet; imputed reliability estimates; list of excluded fluid intelligence effect sizes; list of included ability emotion intelligence, fluid intelligence, and crystallized intelligence tests; and interrater agreement estimates per coded variable are available in the supplementary material.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.