
Abstract
Technological progress has driven the vigorous development of multimedia technology, with massive amounts of multimedia data generated every moment. Efficient sentiment analysis algorithms can help people understand and use multimedia data, reduce production and management costs, and improve the efficiency of human-computer interaction. The extraction of emotional features from multimedia information is a crucial step in capturing semantic information. Accurately extracting emotional states from multimedia content has become one of the important focuses of information processing. Traditional methods for extracting emotional features have limited accuracy in information disclosure due to their singularity, resulting in a significant gap between information content and actual cognition. To address this issue, a multimedia emotion representation method combining graph convolutional adversarial learning and attention mechanism was proposed. This method achieved the final multimedia emotion design model by constructing an emotion representation feature model, adversarial design of multidimensional emotion labels, and attention modules for local and overall emotions. The proposed hybrid model was tested and analyzed, and the results showed that the average loss value of the multimedia emotion fusion algorithm was less than 0.3, and its accurate recognition rate of video data reached 90.47%. The recognition accuracy of neutral, angry, happy, and sad emotional labels exceeded 85%, with the highest value reaching 92.30%, significantly better than other algorithms. In addition, the improved hybrid algorithm performed better in information representation and extraction capabilities, with an increase in emotional information interactivity of over 40% and an overall average time consumption of less than 1.5 s. The study analyzes multimedia emotional data from two dimensions: features and labels, effectively providing important research value and significance for emotional data mining and emotional content capture.
Keywords
Introduction
The development of digital information and data media, as an important carrier of human thinking mode and knowledge reserve, is often full of rich emotional information and content. Strengthening the emotional recognition in multimedia data information is a key step to extract information content and analyze user needs. The traditional method of emotion marking, which is based on a single emotion, has certain limitations due to the diversity and complexity of human emotions. As a result, the multimedia information it presents is often a comprehensive embodiment of a variety of basic emotions. Additionally, its sentence order, emotional words, and logical word connection are expressions of different emotional properties to a certain extent. 1 Positive emotions are more likely to be triggered simultaneously, often with an accompanying relationship, while negative emotions rarely occur simultaneously, and this relationship between emotions can be referred to as the relational model of emotion. The emergence of artificial emotional intelligence technology has changed the field of computer vision, making people pay more attention to the emotional needs behind the expression of information. 2 Lei Y et al. then attempted to improve the mismatch between expected and perceived labels using support vector machines, deep neural networks, and gradient enhanced decision trees. The results showed that all three preference learning models significantly outperformed the traditional classifier baseline, with the combined model based on gradient enhanced decision trees having better accuracy in ranking emotions. 3 A limitation of focusing solely on emotional tags or the distribution of emotional features when analyzing emotional tagging is that it often limits the scope of emotional information expressed and neglects the context of the global data. Therefore, Wang M et al. proposed an image emotion classification method based on multi-graph and multi-label learning, which avoided the loss of graph information by calculating the similarity of emotion features and fusing the node relationships. The results showed that the method could better solve the learning error accumulation situation and had a better performance on the dataset. 4 Wang Q et al. argued that the fusion strategy combining speech and EEG signals could improve the overall accuracy of emotion recognition. 5 Furthermore, the imbalance of the data can also influence the distribution of emotional parts of speech, making it challenging to accurately annotate multimedia emotions. 6 To address this problem, Zhang H et al. proposed to learn local emotion region features using regional multiscale network and encode them using graph attention network. The results showed that the method had a significant improvement on the benchmark dataset. 7 Chen M et al. proposed a feature extraction emotion computation model based on joint mutual information. The results showed that the method achieved an average improvement of 0.85% in the accuracy of emotion classification. 8 The sentiment categories and sentiment labels contained in the information sample data are different, and most of the previous researches have performed sentiment analysis for image or speech data, and it is difficult to represent the complexity of multi-sentiments. The emotional categories and emotional tags contained in the information sample data are different. Based on this, this study studies the correlation analysis of feature tag information based on the emotional relationship mode at the two levels of feature and tag, and combines the graph convolution network (GCN) with excellent topological relationship processing ability and the confrontation network that can shorten the distribution distance, so as to realize the extraction of emotional features. Different from the previous research on the single analysis of emotional characteristics, the research focuses on the multi-dimensional emotional characteristics and the correlation analysis of regional emotions, to better ensure the integrity and accuracy of emotional data information extraction. The research focuses on identifying and analyzing the multimedia emotion representation problem from four aspects. Part I is a literature review and discussion of the current multimedia emotion representation algorithms and related adversarial learning algorithms and so on. Part II is to improve the graph convolutional network and enrich the dimension of feature extraction by introducing the adversarial learning strategy and the theory of attention mechanism, taking into account the characteristics of multimedia information representation. Part III investigates and analyzes the effect of multimedia emotion recognition under this fusion method, and Part IV is an overview summary of the whole study. Figure 1 is a graphical summary of the research, which is used to present the overall idea of the manuscript.
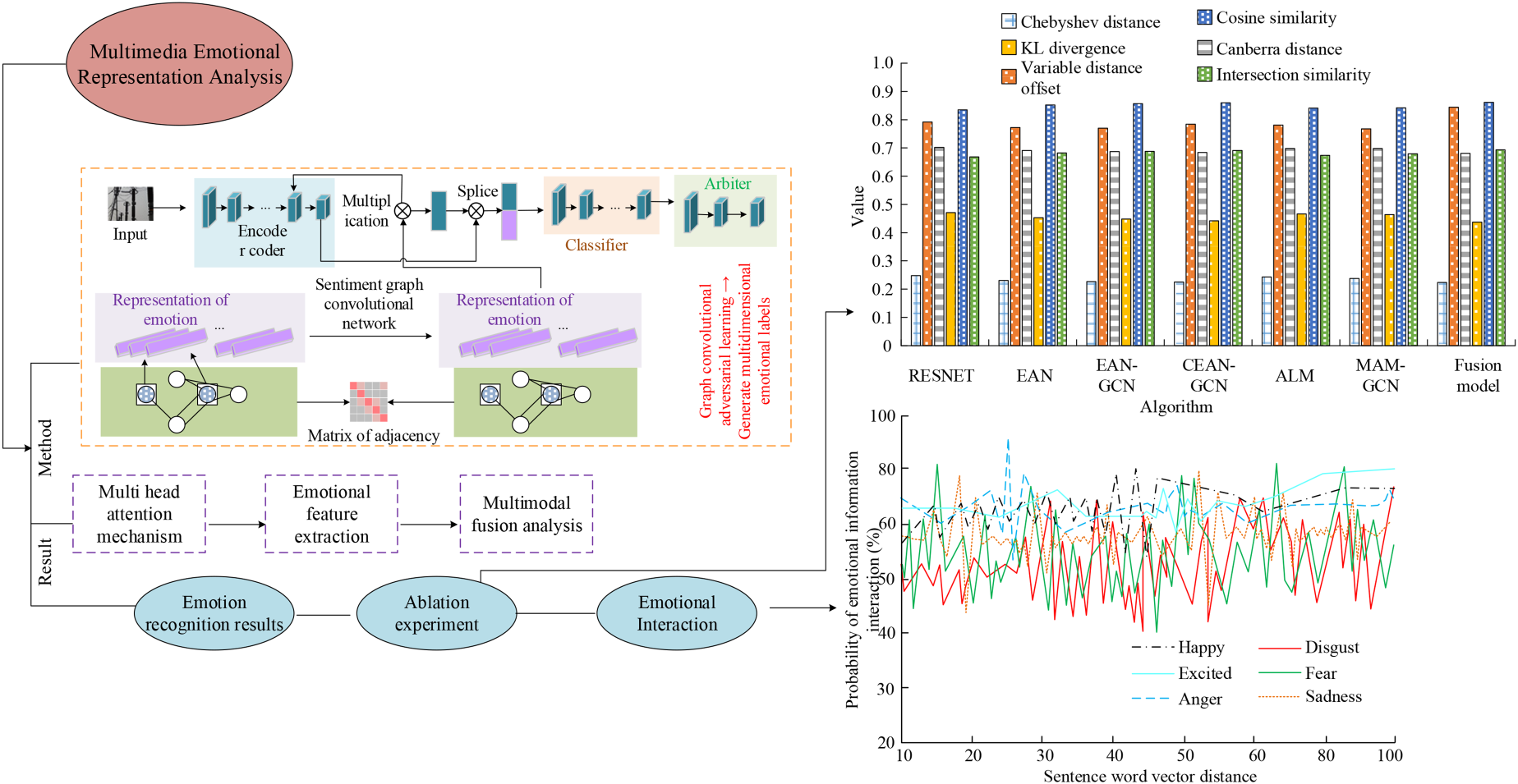
Graphical summary.
At present, there is a surge of multimedia data, and the annual reading volume of Chinese media is calculated in trillion. These data have the characteristics of high dimension, large scale and diversity of types. To analyze emotional tendencies and judge valuable information from massive data, past scholars have proposed a variety of algorithms. Among them, Horvat et al. used unsupervised learning algorithm and nencki emotional picture system data set to verify the Monte Carlo simulation method, and finally developed a software application to identify the characteristics of network emotion. 9 Hao proposed an intelligent model based on deep learning language enhancement, which captured the network emotional state. The research results showed that the method had good detection effect on vector face smile information. 10 Zhao et al. took large-scale heterogeneous multimedia data as the research object, applied the Aho-Corasick (AC) algorithm to compare the effect of emotion analysis of different multimedia types, and the results showed that the algorithm had good application value in emotion analysis. 11 Chattopadhyay et al. took speech in multimedia data as the research object and proposed a hybrid wrapper feature selection algorithm to recognize the emotion represented by speech data from clustering method and atomic optimization search algorithm. The results showed that the recognition accuracy of the hybrid algorithm for various data sets reached more than 70%. 12 Asghar Ma et al. verified the emotion classification method based on EEG in the field of human emotion classification. They used complex continuous wavelet transform for space-time analysis, and extracted features through three deep neural networks. The experimental results showed that the algorithm had lower computational cost, and the algorithm speed and accuracy were guaranteed. 13 Song et al. proposed a robust discriminant sparse regression algorithm, and introduced the regularization constraint of feature selection. Finally, they designed an alternative optimization algorithm and verified the accuracy of the algorithm on multiple data sets. 14 Annadurai et al. proposed an enhanced support vector machine (E-SVM) algorithm to distinguish the true and false emotional information in the research data set. The results showed that the accuracy of the algorithm reached 98%. 15 Marik et al. took multimedia speech as the research object, proposed a two-stage hybrid depth feature selection framework, and combined it with the automatic feature engineering optimization algorithm. They tested it on the data set and found that the algorithm had good application value. 16 Koduru et al. used different feature extraction algorithms to identify emotions, and used Mel frequency cepstrum coefficient to identify emotional features. The results showed that this method had obvious recognition effect in people's general emotions. 17
In multimedia emotion representation analysis, GCN algorithm and attention mechanism are widely used in this field. Among them, the GCN algorithm proposed by Yu et al. expanded the data by encoding complex patterns, and conducted adversarial training based on GCN. The experimental results showed that the framework had good applicability. 18 Aiming at the similarity problem of semantic complementary information, Dong et al. used the sample adjacency relationship and instance construction to realize the feature generator under the GCN and fully connected network, and realized the feature design and representation through the game strategy. The results proved that this method had good applicability and effectiveness in the data set. 19 To solve the end-to-end problem in heterogeneous relational graph, Qin et al. proposed a new heterogeneous graph attention model, which was embedded in entity form and added with adaptive hostile technology. The experimental results showed that the accuracy of this method in image data was improved. 20 Tiwari et al. proposed a shift incremental accelerated linear discriminant analysis method to study multimodal emotion recognition, which extracted the most discriminative and dynamic features from speech and video sequences, and used support vector classifiers to achieve multimodal feature emotion classification. The results showed that the accuracy of this method in emotion classification on the database was above 90%, and the accuracy of emotion recognition was better than other algorithms. 21 Bhattacharya et al. extracted audio file features from a multilingual emotion database and used them as inputs for a convolutional neural network to achieve emotion recognition processing. The results showed that the recognition accuracy of this method in the dataset exceeded 95%, and the multilingual emotion detection model was less affected by language types, with an application accuracy of 97.89%. 22 Le et al. proposed a fusion and representation learning method based on transformers for multimodal emotion recognition in video data. They represented modal information using a unified transformer architecture and classified the information using label level representation methods. The results showed that this method had good emotion recognition accuracy on the benchmark dataset and performed significantly better than other methods. 23 Garcia et al. realized emotion detection by designing heterogeneous emotion result aggregators, and managed different detectors. The results showed that the method had good applicability. 24 Scholar Huang et al. achieved rich task acquisition by multi-view GCN, and realized view fusion by adding attention mechanism, which had efficient application effect. 25 Analyzing individual emotions using social media data has an important role and potential in many fields. For example, Ahmad B and Jun S performed natural language processing and emotions on Twitter data. The results could provide decision support for healthcare professionals to improve the management of cancer patients. 26 Adversarial learning provides a powerful technical support for multimedia sentiment management, which can significantly improve the accuracy, robustness, and practicality of sentiment analysis. Moreover, it has a wide range of applications in affective computing, mental health, and human-computer interaction. Among them, Mao Z et al. proposed weakly supervised target object localization using multi-scale gradient pyramid features for data localization. This method avoided the high cost of manual annotation and had significant localization accuracy. 27 Ahmad B et al. 28 and Ahmad et al. 29 proposed the combination of variational self-encoder and generative adversarial network (GAN) for medical image classification. The results showed that the method had good classification performance. Table 1 summarizes the research contents and ideas of previous media sentiment representation analysis.
Summary of relevant work on media emotion representation analysis.
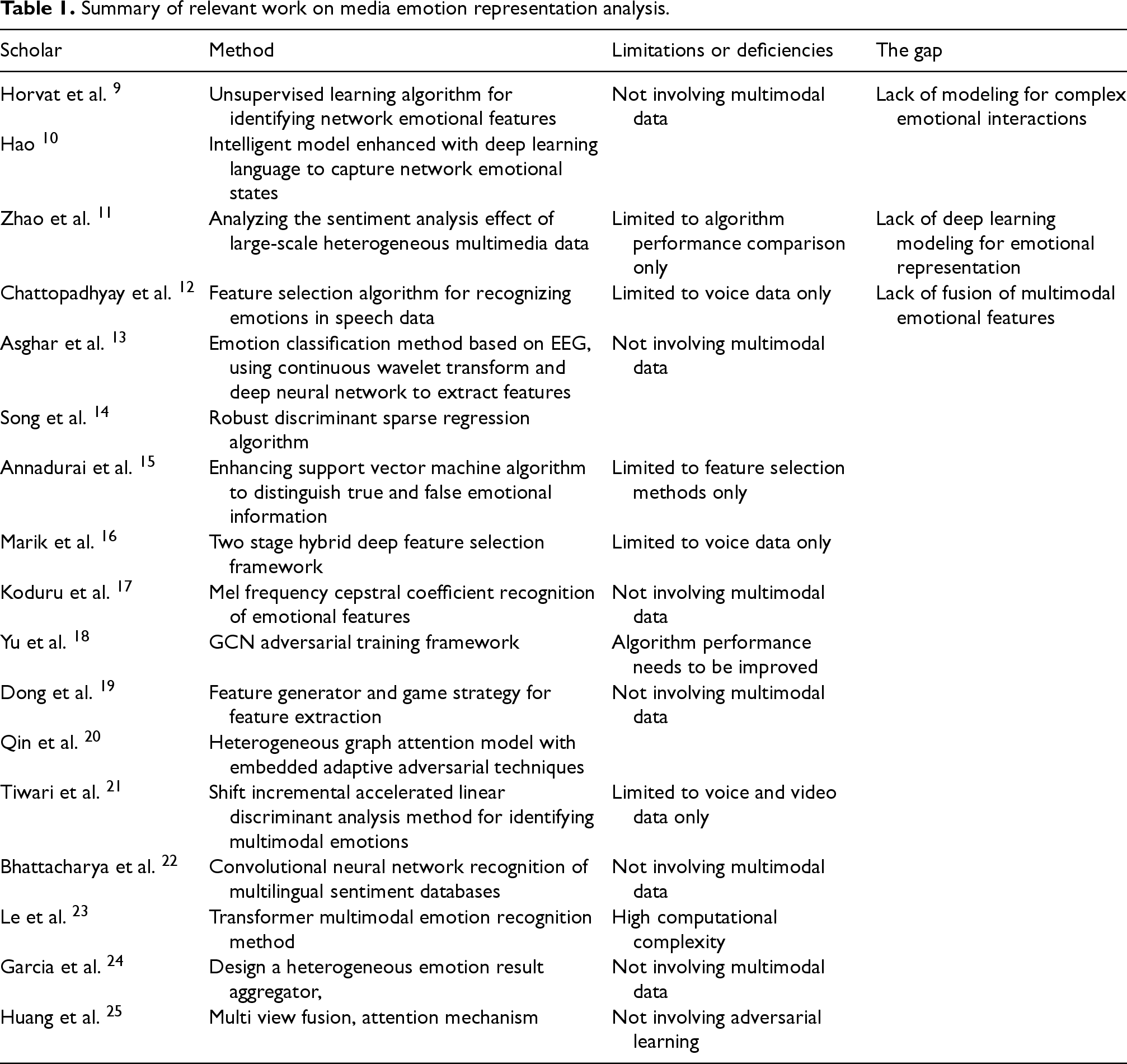
Summary of relevant work on media emotion representation analysis.
To sum up, previous scholars have used ant colony algorithm, mixed wrapper feature selection algorithm, robust discriminant sparse regression algorithm and other algorithms to distinguish multimedia data in the research of multimedia emotion representation algorithms. However, these algorithms have limitations in the application of multimedia picture data, and the recognition of a single emotion can not grasp the relationship between emotion intervals. Therefore, the research combines the improved GCN algorithm with attention mechanism to achieve multimedia emotion representation analysis. It concentrates on emotional region information and dimensional features to construct the representation model, thereby providing a more comprehensive reference for multimedia information analysis. By combining graph convolutional adversarial learning and attention mechanisms, an efficient multimedia sentiment representation analysis method is proposed. Its multimodal fusion approach can also provide important theoretical and technical contributions to improve the accuracy of sentiment analysis and enrich information analysis methods and tools.
Strengthening the representation analysis of multimedia information is the key to extract emotional information. This study studies the advantages of information feature extraction based on GCN, and adds the counter learning strategy to reduce the distance between the two kinds of label information in the global distribution. The loss design of cross entropy function is carried out to grasp the integration characteristics of different emotional information and improve the imbalance of emotional categories. At the same time, the attention mechanism theory is introduced, and the attention map is extracted from the local and overall aspects, so as to better improve the accurate performance and application value of emotion representation combined with GCN.
Multimedia emotion annotation design based on graph convolution adversarial learning network
Unlike convolutional neural network, which is limited to the local structure of the image, GCN mainly realizes the processing of its characterization information through node information interaction, and can represent the learning function on non-Euclidean structure data. To a certain extent, it can better extract the topological spatial features of irregular data.
30
There are connections between samples in the graph data, and the disorganized structure makes it difficult to arrange and combine them. GCN can effectively extract spatial features from topological graphs. It first defines the Fourier transform on the graph, and then transforms the convolution operation from spatial domain to frequency domain. That is, after completing the convolution operation in the frequency domain, it is transformed back to the spatial domain through inverse Fourier transform. The GCN adopts the convolution idea, expanding the size of the convolution kernel to the entire number of samples, and updating each sample with the connection relationship between samples to obtain the trained feature representation. GCN uses mean aggregation in network training to update samples, and the obtained features of each sample not only contain its own information, but also receive other information related to itself. However, GCN is difficult to achieve batch processing of data, so it requires high computing power and cannot determine the strength of the connection relationship between different samples well. GCN is a neural network that processes graph-structured data. Its core idea is to extend convolutional operations from regular grids to graph structures, and its core idea is to use adjacency matrices and node features for information propagation. Its mathematical expression is given in equation (1).
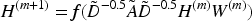
In equation (1), 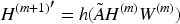
In equation (2), h is nonlinear operation. After interacting with each other, the nodes in the GCN can master the spatial relationship of the characteristic graph. With the help of GCN idea, this study constructs a directed graph based on emotion, and represents the emotional characteristics in the emotional relationship graph. GAN introduce game theory concepts into machine learning. In the case of an optimal or near optimal discriminator, minimizing the loss of the generator is essentially minimizing the Jensen Shannon divergence between the true label distribution and the objective function. This allows the generator to generate data samples that are as realistic as possible.
31
The nodes in the emotion relationship graph can be represented by the representation characteristics of the corresponding emotion word vector, which can be recorded as 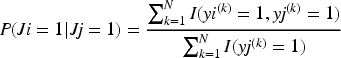
In equation (3), I represents the indicator function, N represents the number of training samples, and 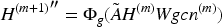
In equation (4), 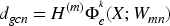
In equation (5), 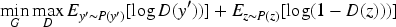
In equation (6), G means generator, D is discriminator,
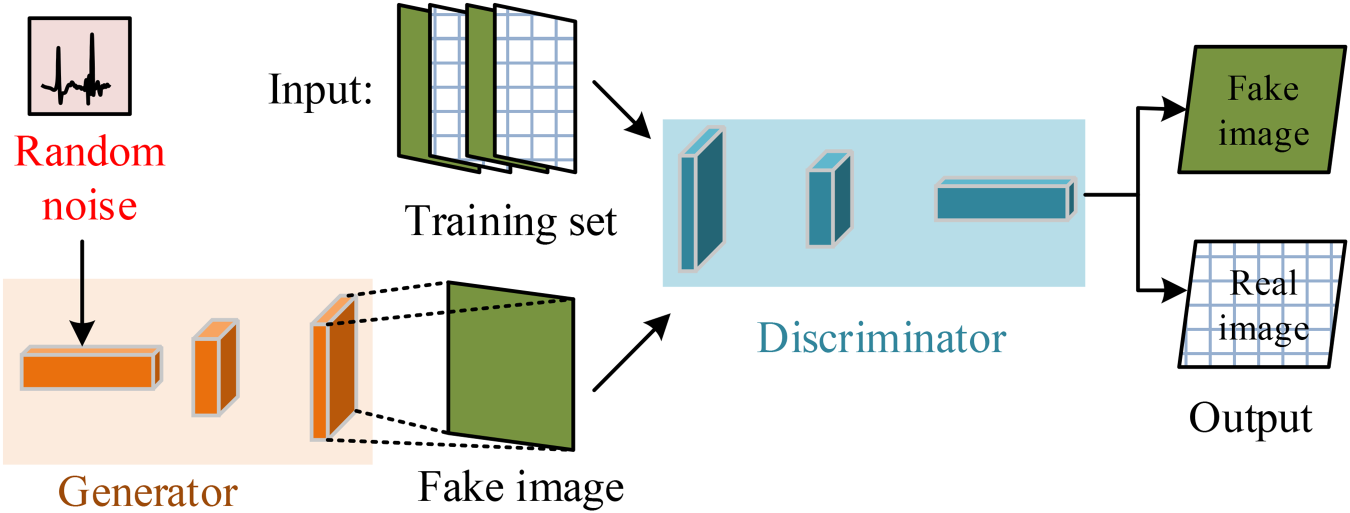
Schematic diagram of model structure of generative adaptive network.
At the same time, considering the collinearity of different emotions, the model should be as close to the real label situation as possible when carrying out label distribution. Therefore, the previous emotion labeling model is used as a label generator, and the neural network with only emotional labels as the input value is introduced as a discriminator to realize the division of different emotional labels. The objective function of confrontation learning is shown in equation (7).
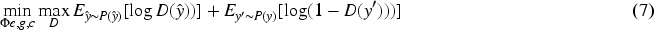
In equation (7), 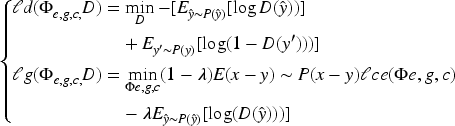
In equation (8), 
In equation (9), c represents the type of occurrence probability,
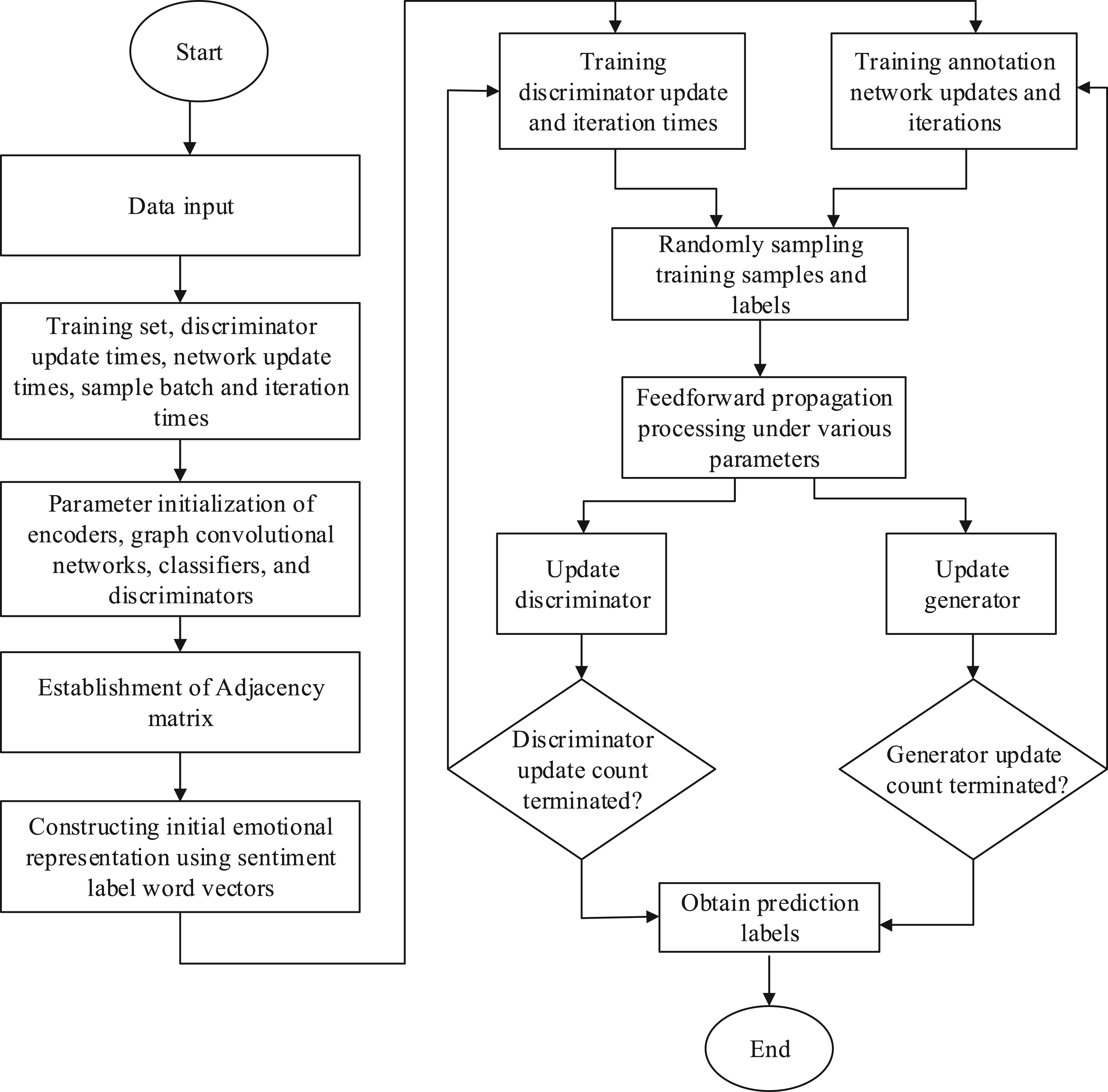
Design process of multimedia emotion annotation algorithm.
The input values (encoder, GCN, classifier, and discriminator) are initialized in the training set, then the matrix is constructed according to the conditional probability of emotional tags, and the matrix is normalized. Second, the emotion representation is constructed according to the word vector of emotional tags, and the conditions of iteration times and network update times are set. Feed forward propagation is carried out for the sampled training samples and training tags under the network and coding processing to obtain the prediction tag and update the discriminator. The above steps are utilized to judge the generator. The overall structure of emotion annotation after implementing the local relationship mode in the GCN and constraining against the learning strategy is shown in Figure 4.
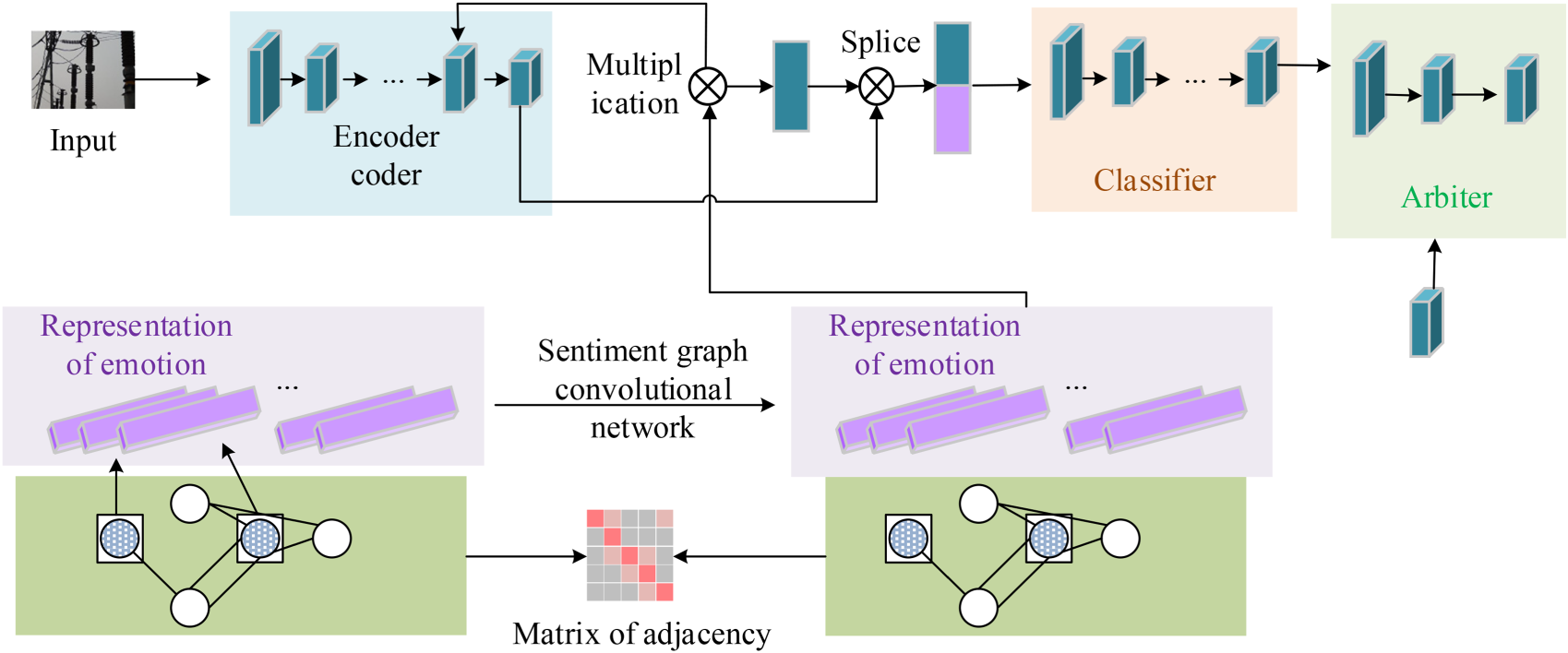
Sentiment labeling with improved graph convolutional network constraints.
In Figure 4, the GCN manages the generated output results and their corresponding emotional representations. The encoder extracts the relevant emotional features from the input value sample data, combines the extracted results with the GCN results, and inputs them into the classifier to obtain the prediction label. Finally, the discriminator is used to distinguish the real tag from the prediction tag, so as to generate a more authentic multi-dimensional emotional tag.
The development of multimedia technology makes image information fill human's lives, and it is important research content to extract and convey emotional information with the help of image visual content. The common key to image emotion analysis is the mining of emotion feature tasks. The limitations and biases of visual cognition make different individuals focus on different aspects of image information content extraction and emotional data mining. Attention mechanism is an important human cognitive ability. 34 In the field of emotional representation, attention mechanism can help people better understand emotion and the multi-level information of emotional experience. Self-attention mechanism can be used to model the relationship between voice, text, and other elements in different time steps in the input sequence, and improve the accuracy of emotion classification. Self-attention mechanism is a kind of attention mechanism, which makes use of the interaction between the elements in the sequence. It can connect the elements in different positions, calculate the correlation degree between them, and give different weights to the elements in different positions, so as to effectively use the information of the elements in the sequence. 35 In multimedia emotion representation analysis, the self-attention mechanism can be used to model the relationship between speech, text, and other elements at different time steps in the input sequence to improve the accuracy of emotion classification. In addition to self-attention mechanism, the introduction of attention mechanism into model training can effectively make the model focus on the extraction of key emotional feature information, and then realize the improvement of its representation ability. Figure 5 is a schematic diagram of the attention mechanism. 36
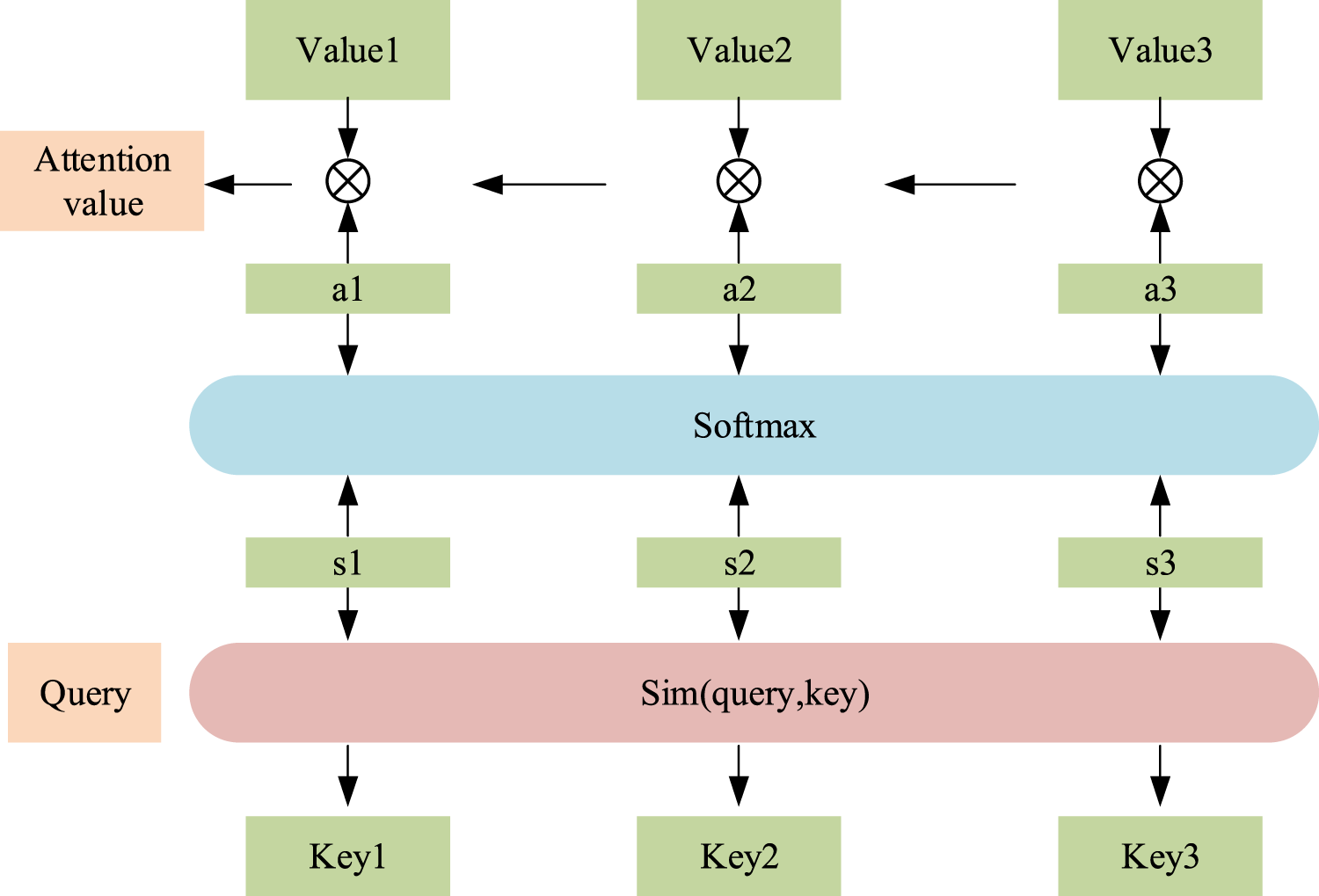
Schematic diagram of attention mechanism.
In the research of multimedia emotion representation analysis based on graph convolutional adversarial learning, the attention mechanism can focus on the key areas and important information of emotion representation. At the same time, compared with the traditional attention mechanism, the multi-head attention mechanism can perform multiple linear transformations on the vector parameters of the input layer, so as to comprehensively extract the emotional information of the samples. Figure 6 shows the combination of attention mechanism and neural network.
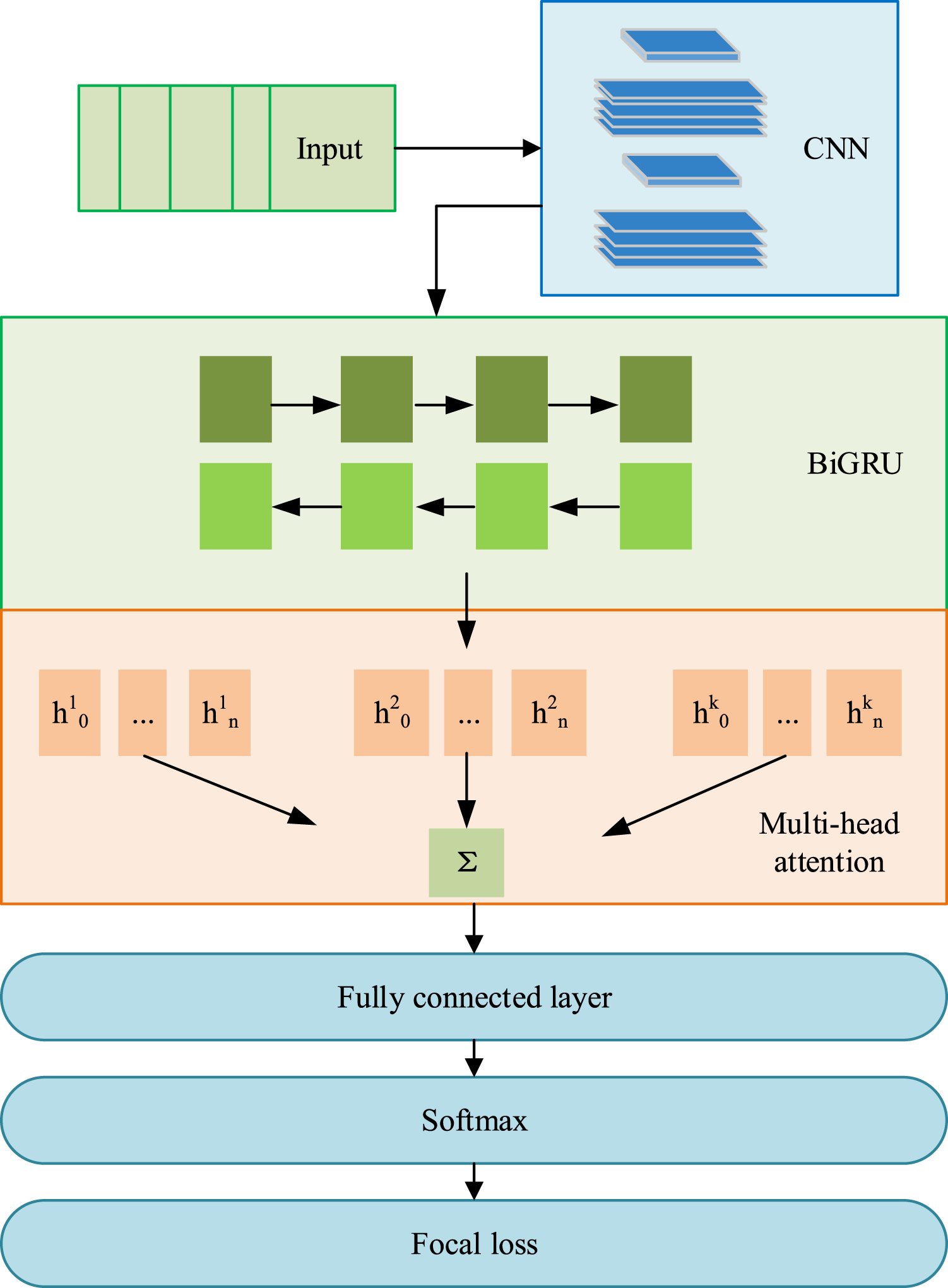
Emotional recognition model combining attention mechanism and neural network.
The multi-head attention mechanism linearly transforms the output processed by the GCN, and the weight value of the attention model can be multiplied by the input value of the network. Multi-head attention captures different feature representations through multiple attention heads, the mathematical expression of which is shown in equation (10).
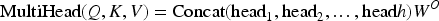
In equation (10), Q, K, and V denote the matrix representation of query, key, and value. 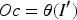
In equation (11), 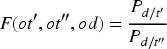
In equation (12), d refers to words, 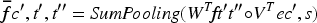
In equation (13), 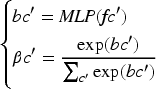
In equation (14), b represents the weight vector, 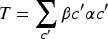
In equation (15), 
In equation (16), 
In equation (17),
Impression distribution algorithm framework based on attention relationship modeling.
Figure 7 shows that the features of the input image are represented, and then it is divided into attention-like graphs with different emotional attributes based on the difference of emotional semantic word vectors. The obtained emotional feature intensities are fed into the GCN to better understand the relationship between emotional features and regions. At the same time, the image propagation thinning under the attention mechanism can better capture the image emotion.
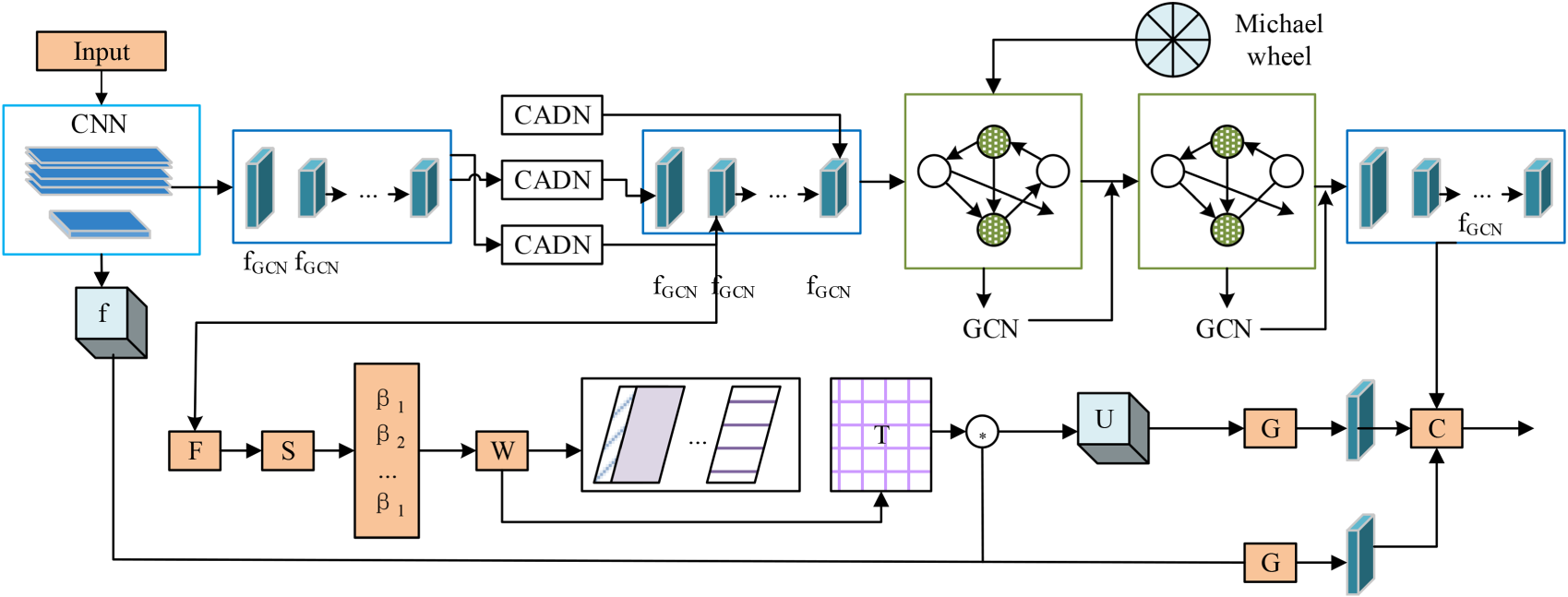
The research selected Music database and NVIE database for experimental analysis. The two databases contained video and music, which involved many emotional categories, including positive emotions and negative emotions. The data were divided into test set and training set according to the ratio of 1:9, and 25% of the data in the training set was selected as the verification set. The experimental analysis was carried out on the windows 10 operating system, and the weight range of combat loss was set to 0.1, the depth of emotion GCN was set to 2, the output emotion representation was 128 and 256, and the word vector dimension trained by glove algorithm was set to 50. The learning rate of GCN network was 0.1, and the number of iterations was 3500. The music database contained 10,000 songs covering various genres such as classical, pop, rock, jazz, and electronic. Audio files were stored in WAV format at a sampling rate of 44.1 kHz, with each song lasting between 30 s and 5 min. The songs had a rich variety of languages (such as English, Chinese, Spanish, etc.) and cultural backgrounds. Emotion labels included happiness, sadness, anger, and serenity, which were manually annotated. The NVIE database contained 10,000 visible light and infrared facial expression images taken by 100 participants under different lighting conditions. Emotion labels covered seven basic emotions (happiness, sadness, anger, surprise, fear, disgust, calm) and were manually annotated by a team of experts. This data included a large number of participants and situations under different lighting conditions. The study considered the visual features of the NVIE database and analyzed them using visual excitability, energy color, average energy, and other factors. The study first removed background noise data from audio and video, and then extracted emotion related feature data, including audio and visual features. Based on the emotion model, the sample data in the database were labeled with emotion tags, and then could be characterized and analyzed using quantitative indicators. In terms of evaluation indicators, the study considered algorithm performance and case analysis, selection loss curves, emotion tag recognition confusion matrices, ablation experimental indicators, information interactivity, error values, etc. to evaluate the performance of the model. The loss curve could be used to reflect the data processing performance of the algorithm, and the confusion matrix could visually display the performance of the model on each emotion category, including common misclassification situations. The ablation experiment could be used to test the effectiveness of the model, and the better the data extraction ability, the better it can achieve emotional representation analysis. The information interaction, feature training time, and error results could reflect the ability of different sentiment part of speech analysis and algorithm processing accuracy. The stronger the emotional interaction, the more helpful it was to analyze the sentiment intensity of information data. The shorter the emotional feature time and error value, the higher the representation accuracy of the algorithm. The loss results of the proposed fusion algorithm were analyzed. The results are shown in Figure 8.
Training loss and testing loss results of the fusion algorithm.
Comparison of training experience results of different models.
The experimental results showed that when using the basic network to analyze the multimedia emotional representation information, the training loss and test loss results showed a significant downward trend with the increase of the number of iterations, and the average training loss and test loss results were 0.28 and 0.26. The slope of the loss curve of the proposed hybrid algorithm was significantly greater than that of the improved algorithm. The curve of the improved algorithm was relatively smooth, and the number of fluctuation nodes was significantly reduced compared with other algorithms. In general, the lower the training loss value, the better the fit of the model to the training data, which usually means that the model can more accurately extract and represent emotional features. Low training loss is often associated with more accurate emotional feature extraction because the model is better able to capture key features and patterns in the data. In the research of multimedia emotional representation, reducing the training loss value could improve the emotional feature extraction ability and overall performance of the model, thereby better achieving accurate expression and understanding of emotional information in multimedia content. Then, the application effect of the multimedia emotion representation model proposed in the study was analyzed and compared with Wasserstein distance guided representation learning algorithm (WDGRL), E-SVM GCN and graph convolutional networks-fully connected networks (GCN-FCN). The results are shown in Table 2.
The results in Table 2 showed that the index evaluation results of the proposed model were better than those of other algorithms on the two databases. The difference between the maximum accuracy feature extraction results of the proposed model and WDGRL algorithm on the Music database was more than 10%, and the difference between the proposed model and GCN-GAN and the algorithm was within 5%. On the video database, in terms of the accurate results of feature extraction, the ranking results of the accurate recognition results of the above algorithm were: research model (90.47)>GCN-FCN (87.12)>E-SVM (83.25) GCN-GAN (80.07)>WDGRL (72.34)>GCN (70.32). The above results indicated that the research method could achieve good extraction accuracy of emotional features in both datasets. However, there were certain differences in the performance of other algorithms on the dataset, and their accuracy values did not exceed 90. The rationale underlying this outcome was that the research model integrated adversarial learning with a multi-head attention mechanism. The former could achieve structured feature learning, while the latter could dynamically capture key emotional features. The attention to different emotional information regions and the extraction of different emotional intensities enhanced their selectivity, which could effectively improve the weight of key emotional clues. Although the WDGRL algorithm used adversarial strategies to reduce cross-domain distribution differences, it was difficult to achieve fine domain alignment for feature extraction, and its generalization performance was limited. GAN enhanced the generation ability of GCN network, so the performance of GCN-GAN was better than GCN network. However, it still had shortcomings in dealing with the sparsity and wide value range problems of weighted dynamic networks, resulting in lower extraction accuracy than the research model and GCN-FCN algorithm. FCN's improvement of GCN could improve its ability to extract edge features. However, it relied heavily on independent modules in series with the E-SVM method. This was not suitable for extracting modal information from video datasets and inevitably led to information loss. To further test and analyze the research model, the vocabulary discrimination under different emotion extraction algorithms was analyzed, and the results are shown in Table 3.
Results of emotional vocabulary extraction under different methods.
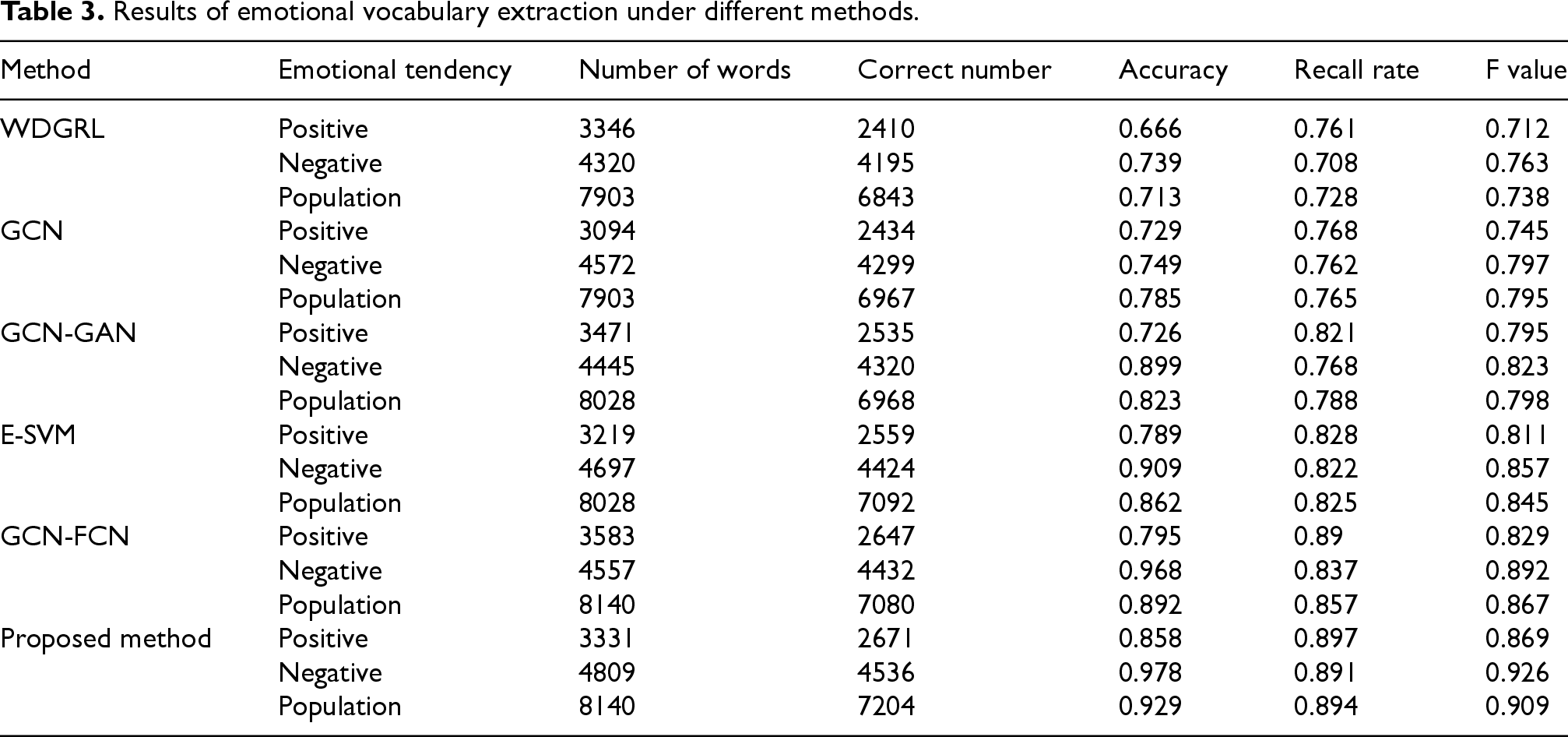
Table 3 shows that the accuracy and recall of WDGRL and GCN methods in extracting sentiment parts of speech were less than 0.8, and the number of correctly extracted sentiment part of speech words accounted for a small proportion. The model proposed in the study achieved an extraction score of 0.85 or higher for goldfish in three different emotional polarities. Compared with the GCN-GAN method, E-SVM method, and GCN-FCN, the proposed algorithm had stable performance and showed high accuracy in emotion discrimination. Then the emotion recognition of different algorithms was analyzed, and the results are shown in Figure 9.
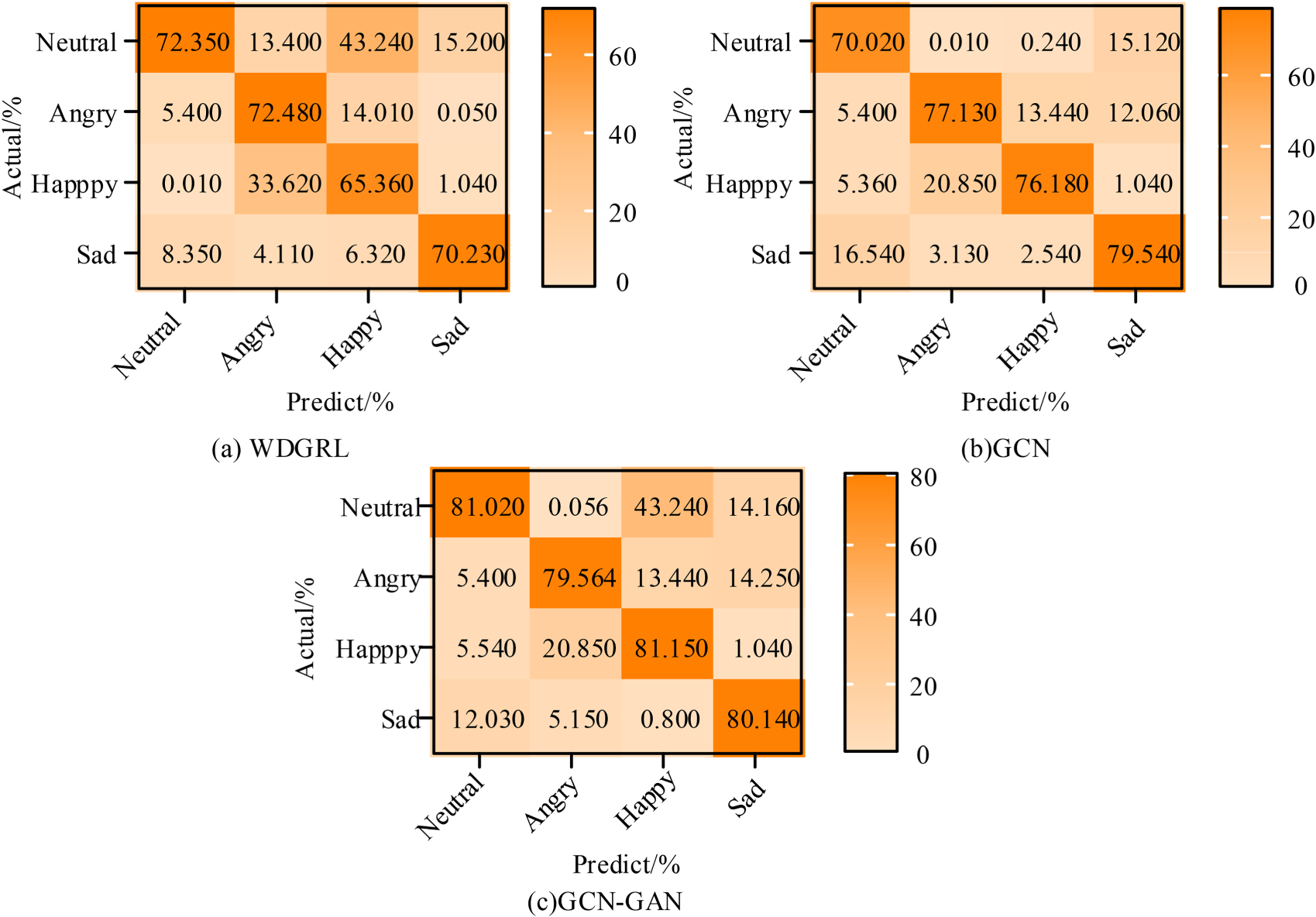
Emotional label recognition results of three algorithms.
Figure 9 shows the emotional tag recognition confusion matrix of the three algorithms, in which the abscissa and ordinate respectively represent the predicted value and the real value. Specifically, there was a big difference between the emotional labels predicted by WDGRL algorithm and the real values, and its accuracy rates in neutral, angry, happy, and sad emotions were 72.35%, 72.48%, 65.36%, and 70.23%, respectively. The accuracy of GCN network's emotional tag prediction results was more than 70%, and the maximum value was 79.54%. The accuracy of GCN-GAN algorithm was 79.564% for angry emotional tags, and the recognition of other emotional tags was 80%. Then, the recognition results of the other three algorithms were analyzed. The results are shown in Figure 10.
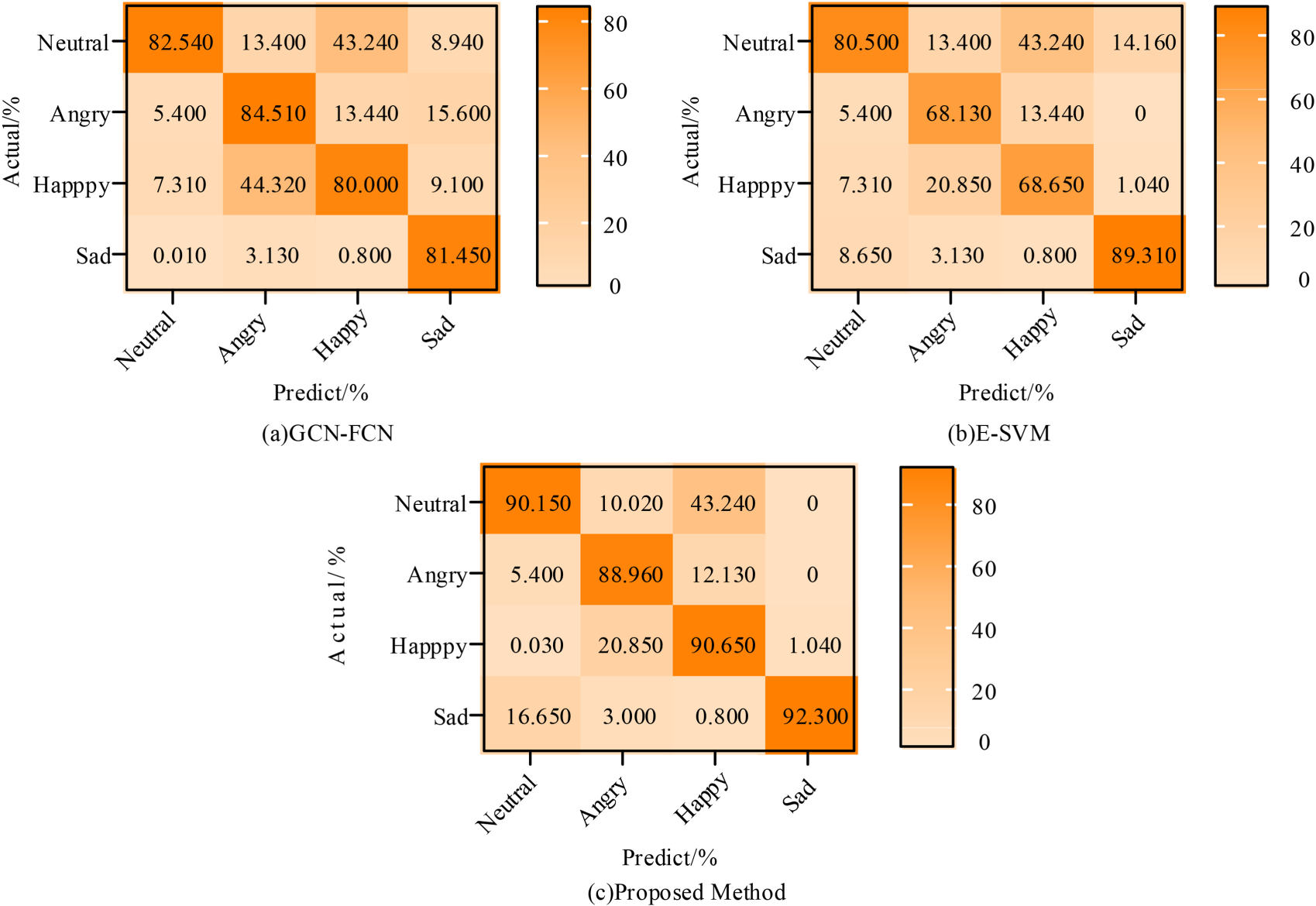
Emotional tag recognition results of three other algorithms.
The results in Figure 10 show the accuracy of the other three algorithms for emotion recognition. The recognition accuracy results of GCN-FCN algorithm and the proposed algorithm under the four kinds of emotional tags were greater than or equal to 80%, which meant that the error between the predicted results of emotional tags and the real value under the corresponding algorithm was small. The accuracy of the proposed method in neutral, angry, happy and sad emotions were 90.15%, 88.96%, 90.65%, and 92.30%, respectively. The recognition results were greater than the other two algorithms, and the maximum recognition accuracy difference was 10.85% and 20.83%. The recognition accuracy of E-SVM algorithm in anger and sadness was 68.13% and 89.31%, respectively. The reason may be that the algorithm is difficult to recognize fuzzy emotional words. The confusion matrix could clearly display the prediction accuracy and misjudgment of the model on each emotional label, which helped evaluate its accuracy on different emotional categories. By analyzing the confusion matrix, the model might have confusion or bias in specific emotional categories. The emotion tags prediction results of the proposed model effectively reflected its information extraction accuracy, and the emotion recognition effect was good. To further test the applicability of the research method, it was analyzed for emotion recognition with deep siamese network (EmoDSN), 39 multi-spatial learning semantic alignment network (SAMS), 40 deep multi instance learning algorithm (EDMIL), 41 multi label multimodal emotion recognition with transformer based (MLM Trans), 42 and multi label multimodal emotion recognition with Transformer based (MLM Trans). 43 The results are shown in Table 4.
Emotion recognition results of different depth algorithms.
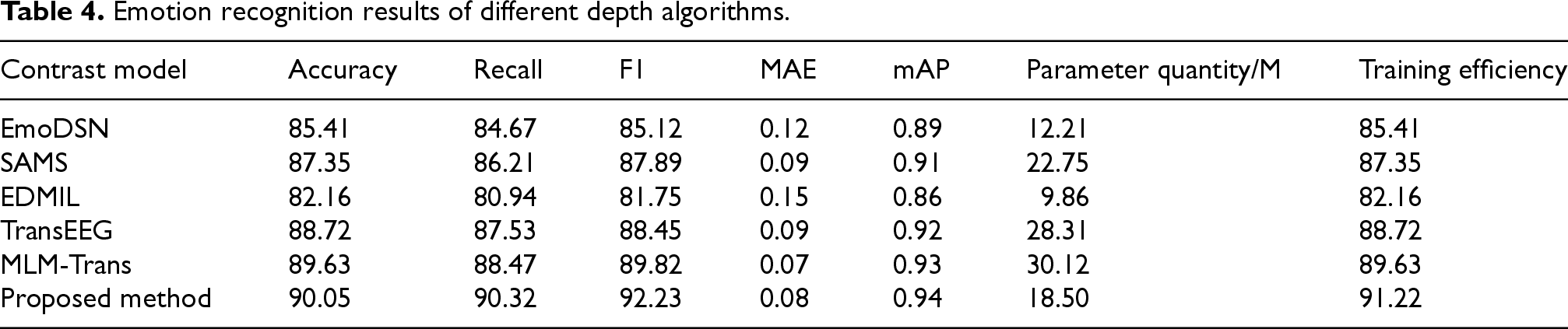
In Table 4, the values of the research model on the four classification indicators of Acc, Recall, F1, and mAP were 90.05, 90.32, 92.23, and 0.94, respectively. Its performance was superior to other comparative algorithms, indicating that it had higher discriminative ability in sentiment classification tasks. Second, the TransEEG model and the MLM-Trans model performed well. The model proposed by the research showed an improvement of over 1.5% in both F1 and mAP compared to MLM-Trans, indicating that graph convolution was better at capturing structured emotional features than Transformer. Compared to SAMS, the Acc improvement of the research model exceeded 3.5%, indicating that multi-head attention was more effective in focusing on key emotional information than traditional attention mechanisms. The performance of the EDMIL method was the weakest, possibly due to its reliance on weakly supervised learning, which made it difficult to handle fine-grained emotions, and its MAE was the highest (0.15). The reason for this may be that it was difficult to handle label features at different levels, resulting in significant prediction bias. Moreover, the research model achieved a good balance between parameter quantity and training efficiency, reducing the parameter quantity by 47.1% and improving the training speed by 38.5% compared to MLM-Trans. EDMIL was the most lightweight and suitable for scenarios with limited resources but low accuracy requirements. MLM-Trans had the highest computational cost, which may be due to the high computational complexity of Transformer's self-attention mechanism. The research model realized the collaborative learning of structured features and dynamic weighting of attention mechanisms, which enabled it to have good multimodal emotion recognition performance, and the design of its loss function could also improve the computational efficiency. At the same time, the AUC curve was used to analyze the emotional feature extraction results of the comparative algorithms mentioned above, as shown in Figure 11.
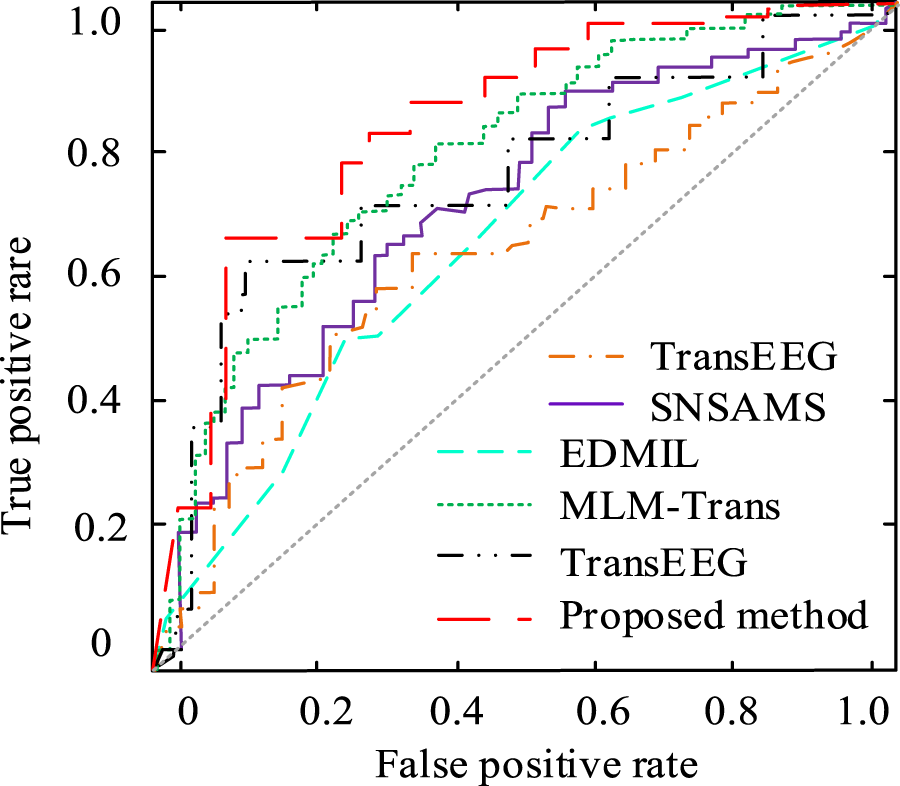
AUC results of sentiment feature classification using different algorithms.
In Figure 11, the overall results showed that the research model had a better AUC value of more than 0.80, followed by the TransEEG algorithm and the MLM-Trans algorithm, which performed better with an AUC value of more than 0.65, and the rest of the comparative algorithms had slightly worse classification accuracy. The above results showed that the research model was able to classify and process emotional features better. Then ablation experiments were carried out on different algorithms, in which algorithms 1–7 respectively represent the basic model (RESNET), emotion-like attention network (EAN), emotion-like attention network + GCN (EAN-GCN), comprehensive emotion attention network + GCN (CEAN-GCN), attention-like mechanism (ALM), multi-attention mechanism + GCN (MAM-GCN) and the fusion model proposed in the article. The results are shown in Figure 12.
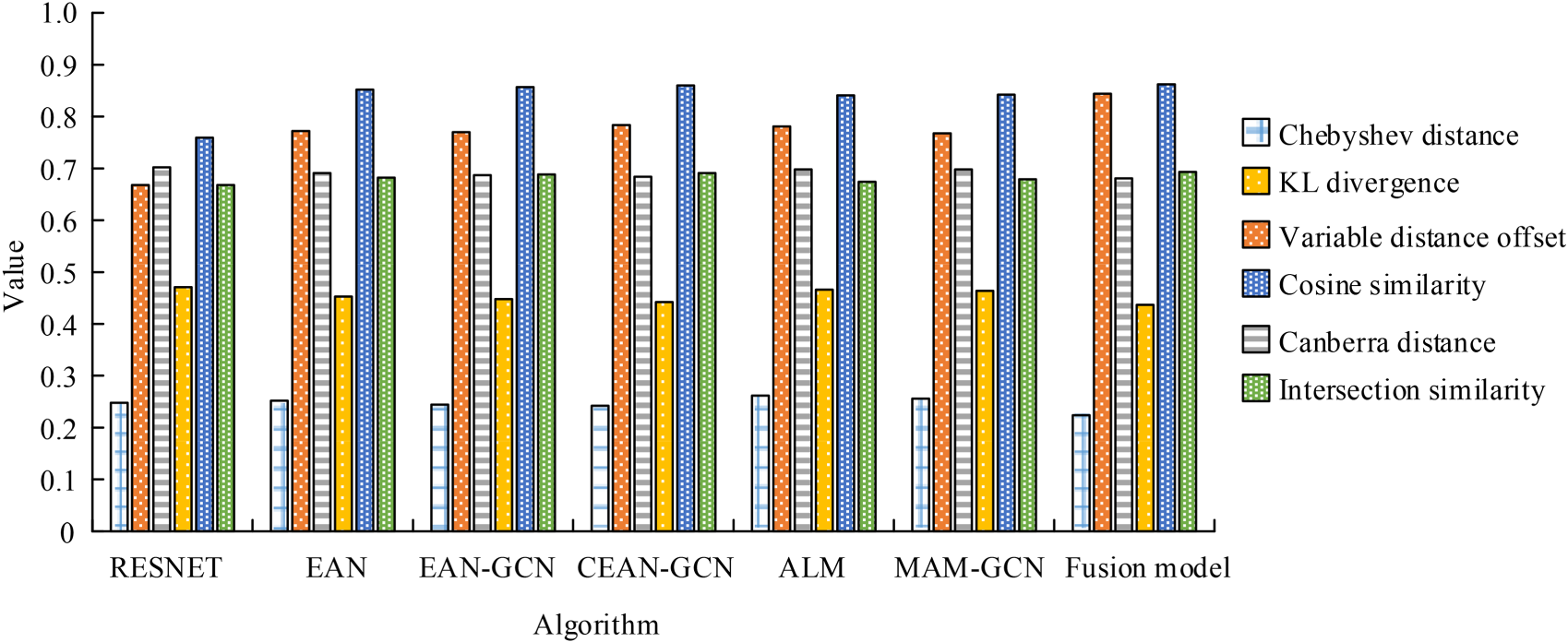
Algorithm attenuation experimental results under a simple dataset.
Figure 12 shows that the ablation results of the algorithms under different selection strategies are different. In the simple data set, the values of various algorithms in the distance measurement (Chebyshev distance, Canberra index, edge distance offset) were above 0.22, 0.75, and 0.65. The Chebyshev distance value of the proposed fusion algorithm was 0.223, which was significantly lower than other algorithms, indicating that the maximum difference of its number was is small. In terms of cosine coefficient and intersection similarity index, the proposed algorithm values were 0.864 and 0.695, respectively. The above results indicated that the performance of the basic model improved in most indicators after adding other components such as attention mechanism, graph convolutional network, etc., indicating that the ResNet model alone might not be sufficient to fully capture the complexity of multimedia emotional representation. The values of the emotional attention network for Chebyshev distance and Canberra distance were 0.25 and 0.68, respectively. This suggested that attention mechanisms helped to better capture emotion-related information. The comprehensive emotional attention network + GCN performed better on multiple indicators compared to the class emotional attention network + GCN, indicating that a more comprehensive attention mechanism might help capture richer emotional information. The class attention mechanism performed worse than the comprehensive emotional attention network + GCN on certain indicators, suggesting that the individual attention mechanism might not be as effective as the combined graph convolutional network. Both emotion-based attention networks and multi-head attention mechanisms showed contributions to performance improvement. The multi-head attention mechanism was particularly effective because it could capture more information, and graph convolutional networks were more helpful in capturing structural information in the data, improving the model's representational ability.
Figure 13 shows that on complex data sets, the results of distance measurement and intersection similarity of the proposed algorithm were 0.876 and 0.698, respectively. The extraction of vector information could better improve its representation ability. The introduction of global attention mechanism and network processing could greatly grasp the relationship between information words, and effectively reduce the loss of data. To further analyze the application performance of the research methodology, the Music and NVIE datasets were expanded to 100 K and 50 K samples, respectively. Moreover, the multiple hardware environments were set up to test the training and inference times. The results are presented in Table 5.
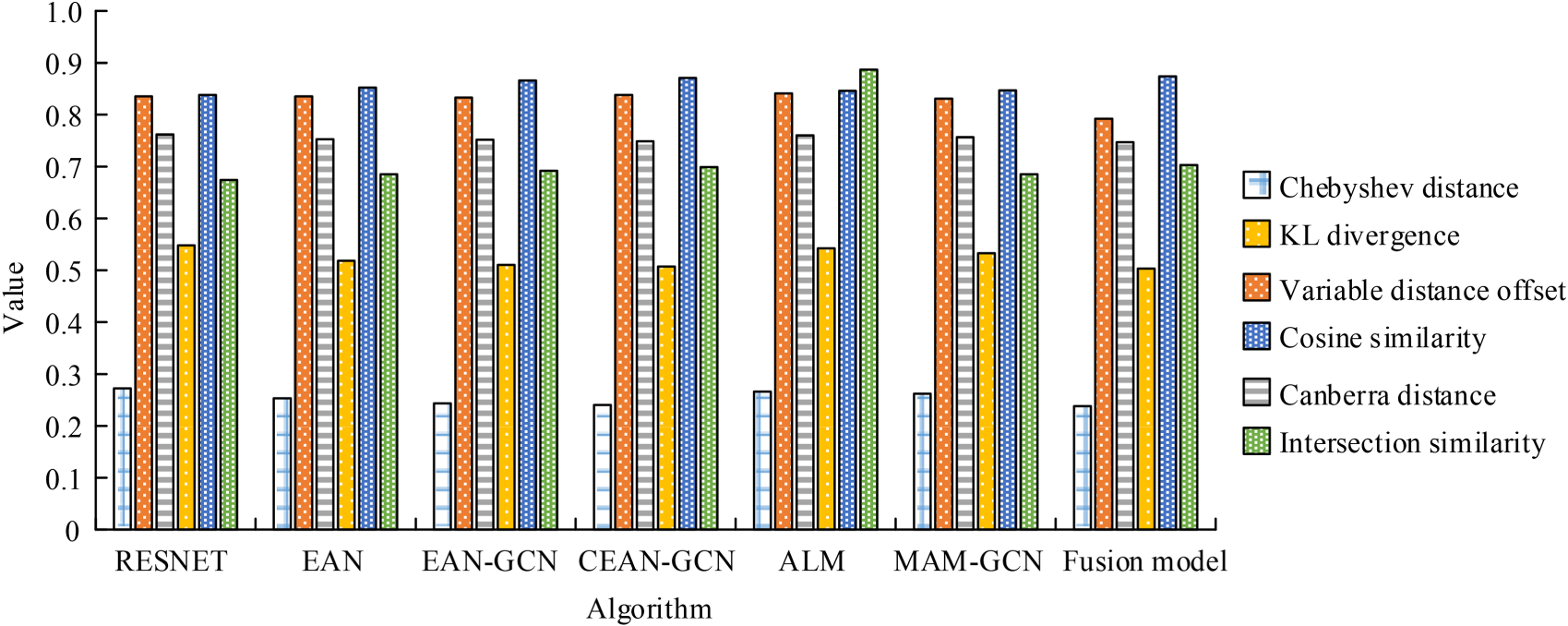
Algorithm iteration experimental results under complex datasets.
Scalability analysis of the proposed model across different computational settings.
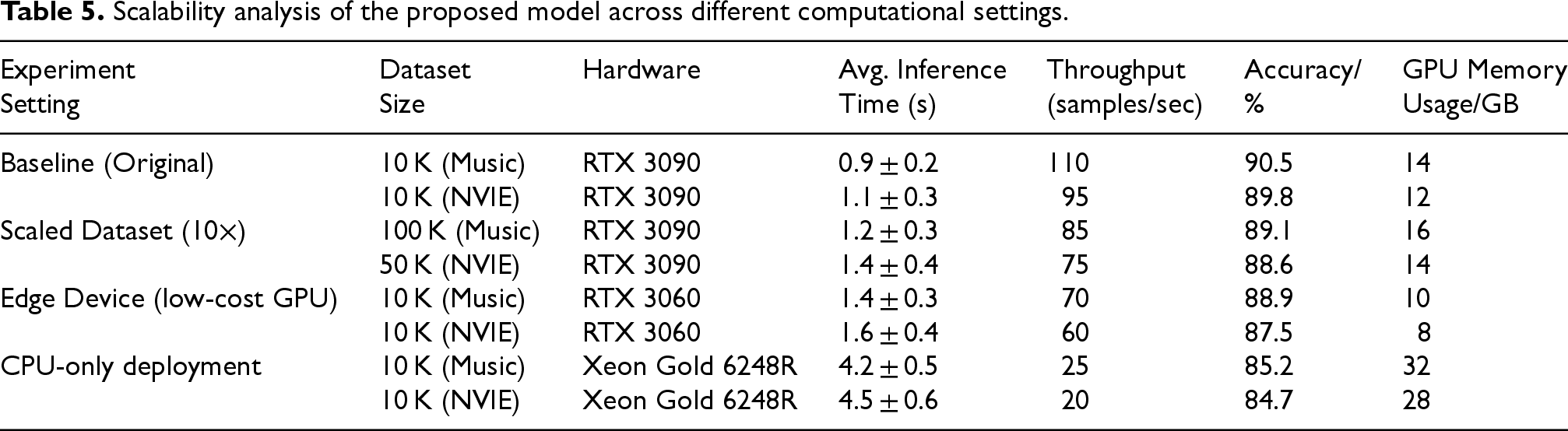
In Table 5, GPU memory consumption referred to the peak memory consumption results during inference. The results in Table 5 showed that even when the dataset size increased by a factor of 10, the model proposed in the study maintained a stable accuracy (decreasing by about 1–2%) and the inference time increased by only 20–30%. On large datasets, the throughput of high-end GPUs was still greater than 75 samples/sec, demonstrating high efficiency, and it had better real-time performance (<1.6 s/sample) on GPUs (RTX 3060) with less than 10% accuracy loss. Subsequently, the proposed algorithm was analyzed for information interactivity to better analyze the representation of information emotion. The results are shown in Figure 14.
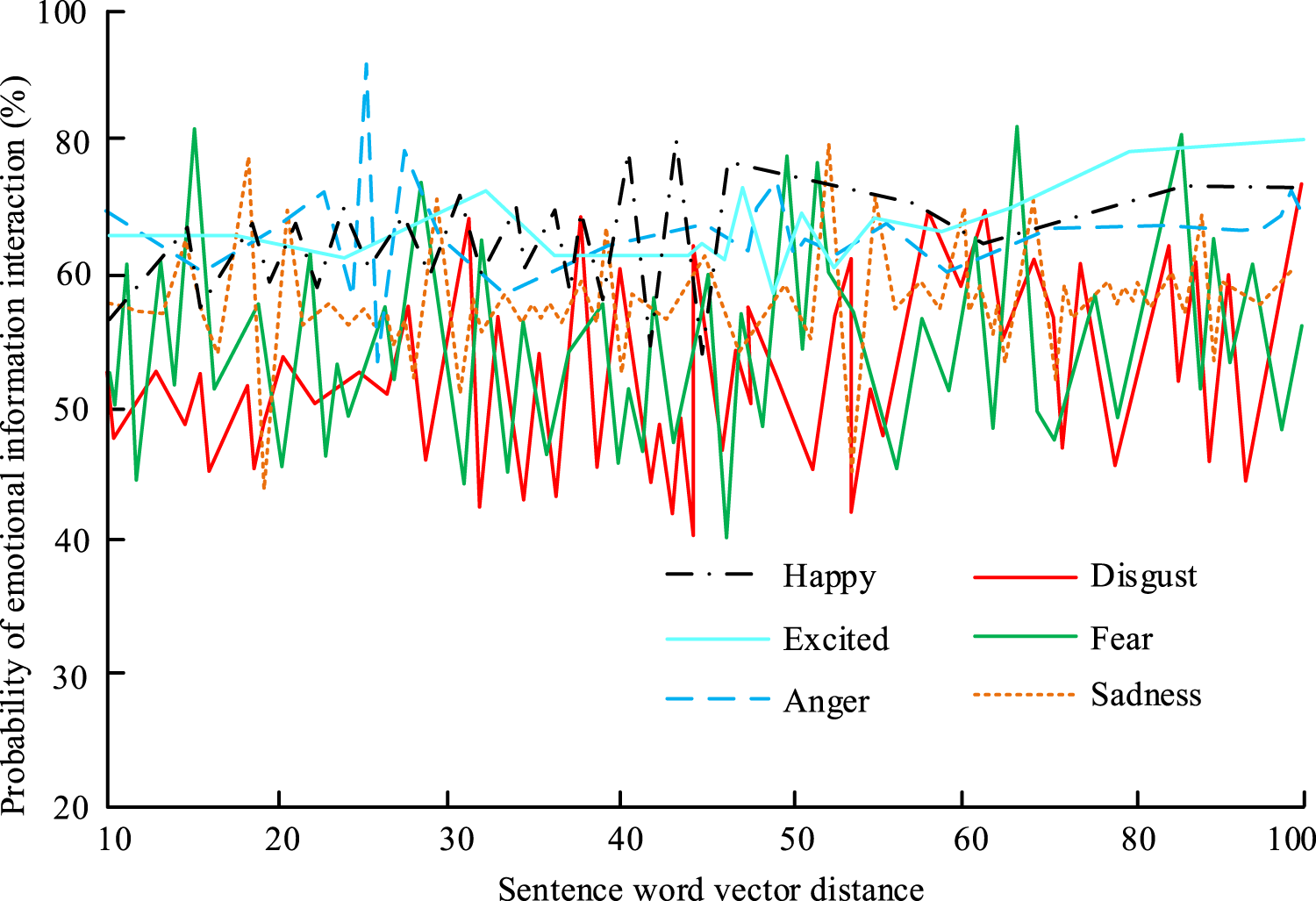
Interaction results of the research algorithm in six emotional parts of speech.
Figure 14 shows that when the hybrid algorithm was used to measure the interactivity of different emotional parts of speech, it was found that the interactivity of these six emotions was more than 40%, and the average emotional interaction results were good. The algorithm could effectively analyze the emotional intensity of sentence information, and effectively extract the interactive representation feature of information. Then, the time-consuming and error results of the emotional feature extraction training of the algorithm were analyzed. The results are shown in Figure 15.
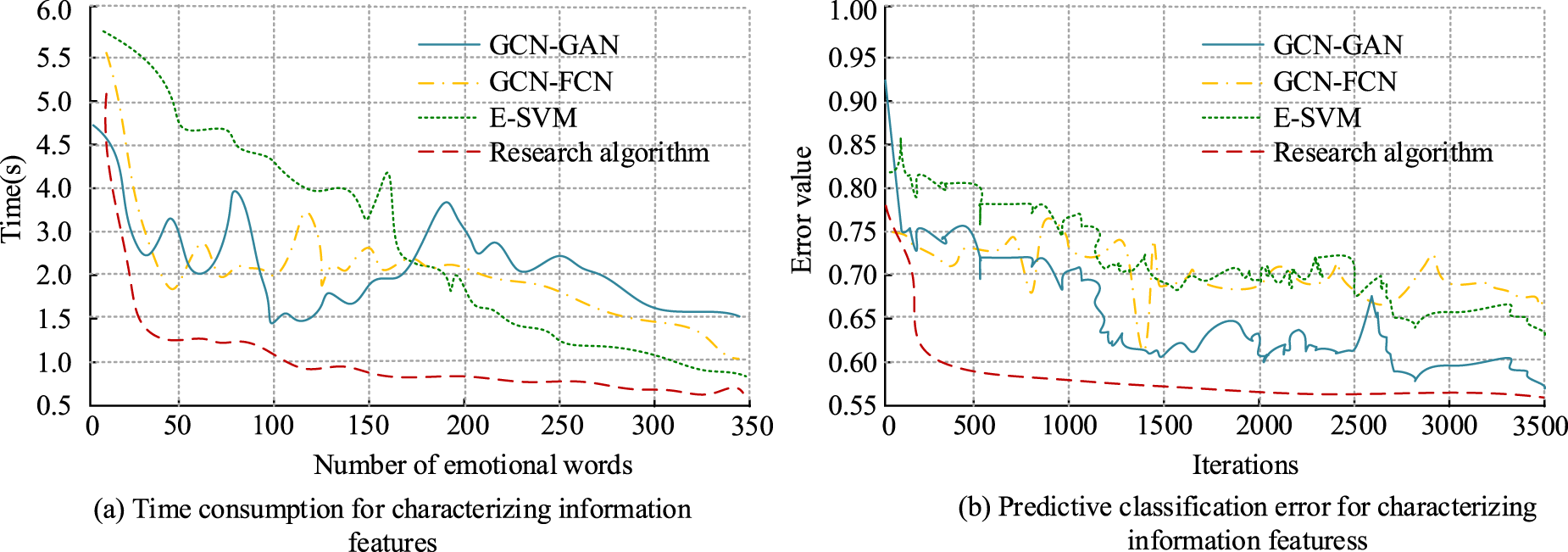
Time consumption and error results of emotional feature extraction training for four algorithms.
The results in Figure 15 (a) show that in terms of emotional feature extraction time, the proposed algorithm had small fluctuation nodes, and the overall average time consumption was less than 1.5 s. Moreover, its curve gradually tended to be stable after the number of emotional words was greater than 100. The average time consumption of GCN-GAN algorithm, GCN-FCN algorithm and E-SVM algorithm was 2.36 s, 1.88 s and 2.97 s. In Figure 15 (b), the emotion classification error curves of the four algorithms showed a downward trend with the increase of the number of iterations, and the loss value of the proposed algorithm tended to 0.56 after more than 1500 iterations. The above results showed that the proposed hybrid algorithm had better emotional feature extraction effect and better algorithm performance.
Emotion analysis is an important part of data mining, and extracting emotional representations rich in emotional content from multimedia data is an important problem that current emotion analysis algorithms need to face. Therefore, this research proposed a representation analysis method based on graph convolutional adversarial learning and attention mechanism. The emotional representation analysis method was tested, and the results showed that the accuracy of the fusion algorithm in video data analysis was 90.47%, far higher than the GCN-FC algorithm's 87.12%, E-SVM algorithm's 83.25%, GCN-GAN algorithm's 80.07%, WDGRL algorithm's 72.34%, and GCN algorithm's 70.32%. Moreover, the fusion method achieved recognition accuracy of over 90% in neutral, angry, happy, and sad emotion labels, and performed well in ablation experiments, which was far superior to other comparative algorithms. The hybrid model measured the interactivity of different emotional parts of speech at over 40%, with an average time consumption of less than 1.5 s, demonstrating good applicability and effectiveness. In summary, the proposed fusion method based on graph convolutional adversarial learning and attention mechanism has significant advantages in emotion representation analysis. It can effectively identify emotion labels and demonstrate good robustness, interactivity and computational efficiency in emotion analysis. It can also effectively provide efficient and accurate solutions for multimedia emotion analysis. Considering that the structure and attributes of different types of multimedia data are different, a universal sentiment annotation algorithm framework was proposed in this study. However, the selected dataset cannot fully represent all possible multimedia emotional contexts. Therefore, in future work, more refined emotional annotation models need to be proposed for multimedia data to strengthen the analysis of emotional data characteristics and the mining of emotional content. At the same time, the representation information analysis algorithm under the fusion of GCN and attention mechanism module is still difficult to comprehensively and accurately grasp the relationship between different emotional regions. The presentation of emotions in different cultures can affect model performance. For example, introverted emotional expression in certain cultures can lead to model recognition bias. If there is an uneven distribution of age, gender, or race in the training data, the model's emotion recognition performance for minority groups may decrease. The experiment is based only on specific databases (such as music and video data from the NVIE) and does not cover a broader cultural background. In the future, it is necessary to introduce cross-cultural and multi-year datasets to verify fairness. Meanwhile, adversarial depolarization techniques and unsupervised domain adaptation methods will be introduced to achieve bias detection, improve the model's cross-domain adaptation ability, and better evaluate different emotional differences. At the same time, in future work, it is necessary to consider the application of personalized systems in image emotion analysis. There is still significant room for improvement in the recognition accuracy of commonly used emotional feature segmentation methods. In future research, network structure optimization, network depth deepening, and the impact of different parameters on model recognition performance can be further considered based on the study of the model. Research should be further conducted on how to efficiently integrate data from different modalities, capture emotional dynamic changes, and improve the accuracy of multimodal emotional representation.
Footnotes
Author contributions
Yanmei Tian and Meng Zhu all participated in the writing of the paper and the review of the final draft.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The data is provided within the manuscript.