
Abstract
The distributed, heterogeneous, and shared security risks of power equipment data across its entire lifecycle limit the facilitation and integrated sharing of data across the entire lifecycle. This paper proposes a machine-learning-based secure data-sharing model for power equipment data during its lifecycle. The development of the proposed model includes multi-source data merging from the operation, inspection, and maintenance process into one data format through semantic mapping, in the unified structure of the data so that machine-learning is used for feature extraction and risk-prediction for dynamic access control and the adaptive encryption and de-sensitization balance between risk mitigation and data sharing is still maintained. The full-process monitoring and feedback monitoring to detect anomalous behavior can also optimize the polices in real-time. The experimentation provides an assigned data penetration rate of 96.3% for the disconnector. The leakage rate of sensitive information was reduced to 1.8% once the risk level was increased to extremely high. This separation alleviates the conflict of data security and data sharing by providing original research efforts for intelligent information and database systems.
Keywords
Introduction
The intelligent transformation of the critical national infrastructure power system relies on deploying data efficiently and managing it all along the equipment life cycle. With smart grid developments and operationalization, equipment, including substations; transmission and distribution networks; and other new power-sector equipment, are capable of producing substantial quantities of heterogeneous data while in operation, during testing, and maintenance. Data contains essential information regarding the equipment state, operational behaviors, and risk factors, and may be useful in strengthening the reliability of the power system, as well as for operational and maintenance optimization studies.1–2 The power system, at present, has acute data silos and interoperability problems across systems. Equipment operational data and maintenance records are recorded in history, operations, and maintenance sections of disparate departments and systems and do not have unified data standards or semantic understanding frameworks.3–4 Incompatible data formats and inconsistent metadata definitions lead to fragmentation of information and greatly limit the analysis of integrated equipment data in the lifecycle of the equipment.5–6 At the same time, power data sharing presents drastic security issues. Sensitive information, such as equipment parameters and behavior related to user electricity use, carries leakage risk when transferred between departments. Static traditional security protection mechanisms are unable to adequately defend against increasingly sophisticated network threat vectors.7–8 Current data-sharing methods are often challenged to balance security strength with sharing efficiency. Generally, when security is made more stringent, data access latency is increased or data sharing is made more complicated; to ease data sharing, the necessary security will be lessened.9–10 The duality of power equipment data's sensitivity - requiring requisite security protections - while still needing to share data will be further accentuated. The call for novel solutions that can both maintain data security and allow for efficient connectively are critical to enabling digital transformation for power systems.11–12
This article provides an outline for a data security sharing framework applicable to the life cycle of power equipment. The framework uses an ontology-based method to accommodate multi-source of heterogeneous data, creating instead a common data model to account for equipment condition from operation, testing, to maintenance. The risk assessment module combines deep neural networks and graph convolutional networks to facilitate deep features extraction from accessing logs and real-time behaviors, providing a dynamic risk indicator system that mitigates the limitations of conventional rule-driven risk assessment. The access control mechanism implements a reinforcement learning algorithm that employs risk assessment as state inputs to perform real-time optimal and refine permission allocation management. The data protection layer suggests a parameter-adaptation mechanism that offers the possibility of altering encryption strength and desensitization schemes to risk levels in order to introduce a balance between data availabilities against risks. The anomaly detection module monitors potential threats based on behavioral patterns and collectively realizes the optimization of risk assessment, policy enforcement and resulting feedback. The framework offered solves the challenges caused by both unifying security and efficiency in power data sharing in a systematic manner. The true system of combining semantic unification with dynamic risk is a step towards intelligent, secure data lifecycle management. The structured approach of the framework both address significant issues in data governance in the power industry while also providing a transferable technical route for secure data sharing across other critical infrastructure, enabling the feasible use of data in safe operation of the power system.
Related work
The study of data connectivity and sharing procedures in the whole life cycle of power equipment is dedicated to multi-technical synergy to enhance efficiency of the overall system. The field of renewable energy power development is studied from the perspective of big data technology. Hong et al. 13 presented an analysis of the current state of power generation, the power grid, and the user side data processing, built a cloud platform energy storage system architecture, and explained the core value of data fusion for improving coordination efficiency and optimizing energy configuration. This achievement provided a practical foundation for power equipment data integrated management. In industrial Internet of Things, Huo et al. 14 reviewed blockchain technology based on a layered architecture design enabling framework, reviewed and revealed technical adaptation operational rules in equipment security, shared trust data, and process automation that support the trusted operation of intelligent manufacturing systems. The innovative exploration of data transfer mechanisms has drawn boundaries further out with communication performance optimization.15–16 In the study of synchronous wireless charging and data transmission systems, Yao et al. 17 analyzed key links, including crosstalk suppression, signal-to-noise ratio improvement, and modulation strategies, by classifying and comparing architectural solutions, and clarified the inherent trade-offs among efficiency, speed, and reliability. The above research is still insufficient in terms of the deep integration of data throughout the life cycle of power equipment and in the systematic construction of a secure sharing model.
Research on data security-sharing models based on machine learning in intelligent information systems is continuously deepening its technical depth and breadth of application. Gupta et al. 18 used artificial intelligence technology to ensure the confidentiality, integrity, and authenticity of data in response to security threats in the dynamic topology of mobile networks. Machine learning and deep learning methods have demonstrated technical potential for addressing unauthorized access and fraudulent links, providing theoretical support for a high-trust mobile data protection system. This research direction has successfully strengthened practical applications, and promoted the adaptability of network security detection techniques. Asif et al. 19 created a machine-learning intruder detection model on the MapReduce framework that discovered efficient anomaly prediction based on multi-source and near real time network data. This model produced detection accuracies of 97.7% during the training phase and 95.7% during the validation phase. Their results demonstrated efficiency improvements by leveraging distributed computing and intelligent analysis to target large-scale security threats. The maturity of this detection mechanism has improved the design capabilities of information management system security designs.20–21 Lv et al. 22 optimized the optical gradient enhancement algorithm. Using an Android-based intelligent support information management system they classified and managed a large-scale information file into specific classes rapidly. This system produced an accuracy of 89.24%, where the training time was about 100 s, and the testing time about 0.68 s, establishing a technical benchmark for timely information management. However, the adaptability of the above results to secure sharing mechanisms in the data integration for the entire life cycle of power equipment is yet to be fully verified.
Power equipment data secure sharing method
Unified modeling of full life cycle data
Data from the whole lifecycles of power equipment is the result of operating, inspecting, and maintaining those devices, and each of the three phases will display different heterogeneous characteristics. Operations data is collected from SCADA (Supervisory Control and Data Acquisition) and smart meter systems, presented as high frequency time series data. Inspection data is collected from periodic status inspection systems, presented as structured inspection reports. Maintenance data is collected from ERP (Enterprise Resource Planning) systems reporting on the device maintenance, presented as unstructured maintenance records. These three types of data have fundamental differences in terms of data structure, time granularity, and semantic expression.23–24
In this study, an ontology for power equipment has been developed as a unified semantic framework, built using OWL (Web Ontology Language) for formal description. The ontology classes are organized into core classes such as power equipment, operational state, detection indicators, and maintenance activities, forming a hierarchy of conceptual classes to encompass comprehensively.25–26 The process of developing ontology construction includes the industry standard data dictionary in the power industry standard IEC 61970/61968 CIM standards actual system data dictionary to ensure the unified semantic framework is industry compliance and business relevance.
The process of semantic mapping uses multi-faceted similarity calculations to accurately relate the heterogeneous data to the unified ontology:
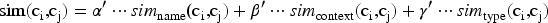
The architecture of the power equipment complete lifecycle data model is shown in Figure 1, and is a pathway of transformation from raw, heterogeneous data to a semantic representation in a unified way. The heterogeneous data flows through preprocessing, format standardization, to semantic mapping to create a unified RDF (Resource Description Framework) representation.
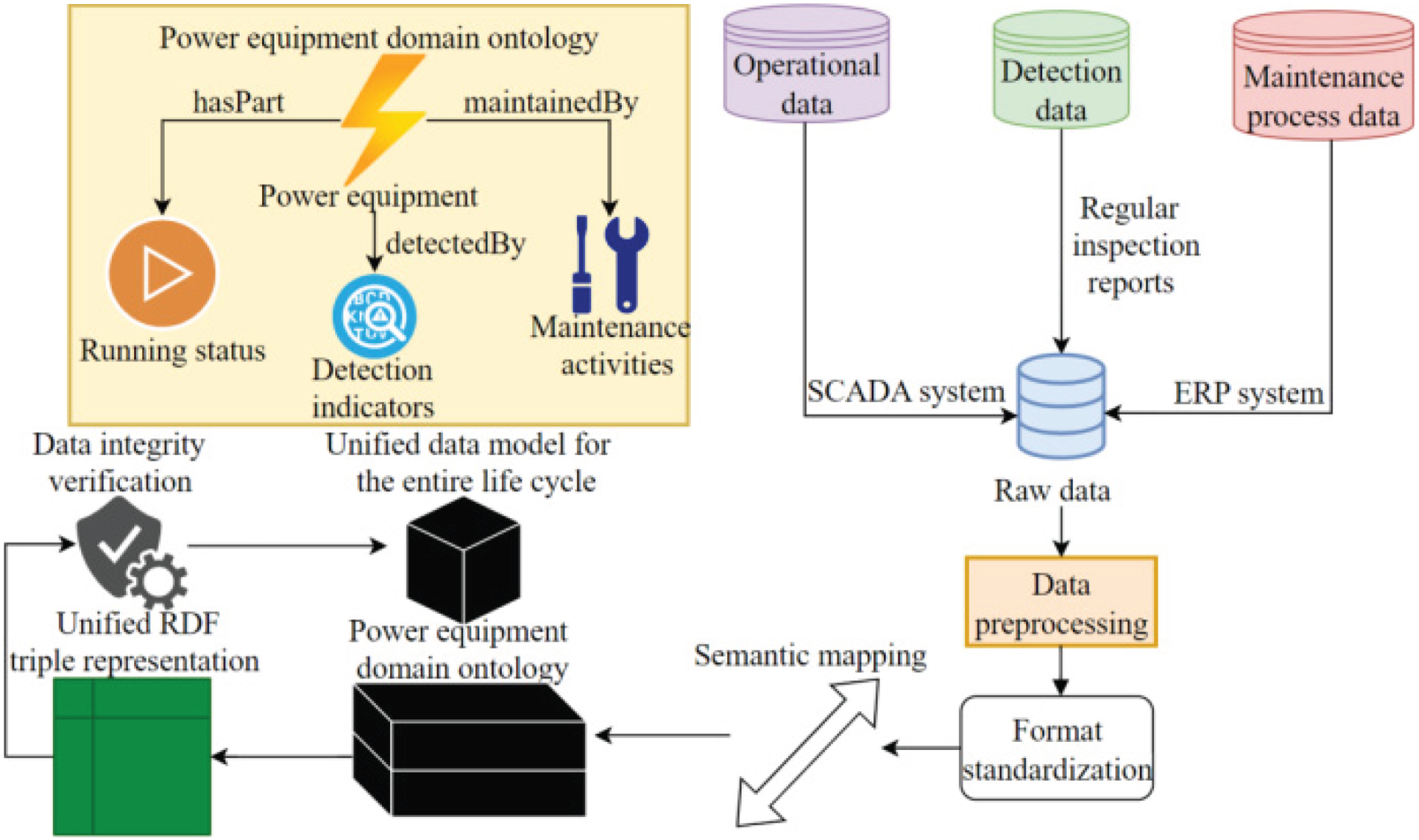
Power equipment full lifecycle data model architecture.
Table 1 illustrates the differences in representation and the unified mapping results for key data fields of power equipment across heterogeneous systems. This demonstrates the various naming conventions for the physical quantities utilized in the operation and maintenance systems, as well as establishing a relationship between the fields by means of semantic mapping. A unified representation combines representation and eliminates any semantic gaps between the systems in their entirety, thus enabling a standardized foundation for introducing data to be integrated across a complete lifespan. The rules of mapping rely on semantic similarity calculations, along with industry standard constraints, to validate the accuracy and consistency of data conversion.
Mapping relationships between key data fields for power equipment.

The data conversion will utilize a bidirectional traceability mechanism to build an accurate mapping chain between the source data fields and target ontology concepts. The traceability index is organized as a B + tree for fast reverse queries based on either the source data or the target ontology. The data integrity constraints are established to be:
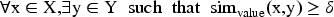
The risk perception and feature extraction module works on the standardized data stream resulting from the unified data model, for the entire lifecycle of power equipment.The data preprocessing step removes outliers, and performs missing value imputation. Missing values are imputed interpol blindly using an algorithm based on similarity between equipment type and time series. The outliers are identified, and corrected using the Three Sigma principle.27–28 Feature engineering proposes a security feature set distilled from access behavior, data sensitivity, and context. This set consists of 24 feature variables, organized as a time series using a 15-min sliding window.
The feature vector is fed into a hybrid architecture combining an LSTM (Long Short-Term Memory) and a GCN (Graph Convolutional Network). LSTM processes the temporal feature sequence.29–30 Its unit structure is mathematically expressed as:
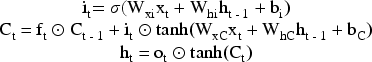
The LSTM output is passed to the GCN layer to construct the power data access graph. The adjacency matrix 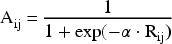
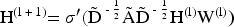
The dynamic access control policy generation module constructs an adaptive permission management protocol that is based on the outputs from the risk perception and feature extraction modules. The state space is expressed as:
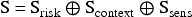
The action space is defined as:
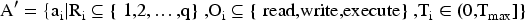
The policy optimization process uses a weighted security utility function:
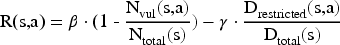
Policy parameter updates follow the temporal difference learning rule:
Figure 2 shows the risk-aware access control decision making process, with three stages: state establishment, policy decision making, and permission output. Conducted in a dual-buffer system, the overall response time is at a millimeter level, with a closed-loop feedback mechanism designed to optimize policies.
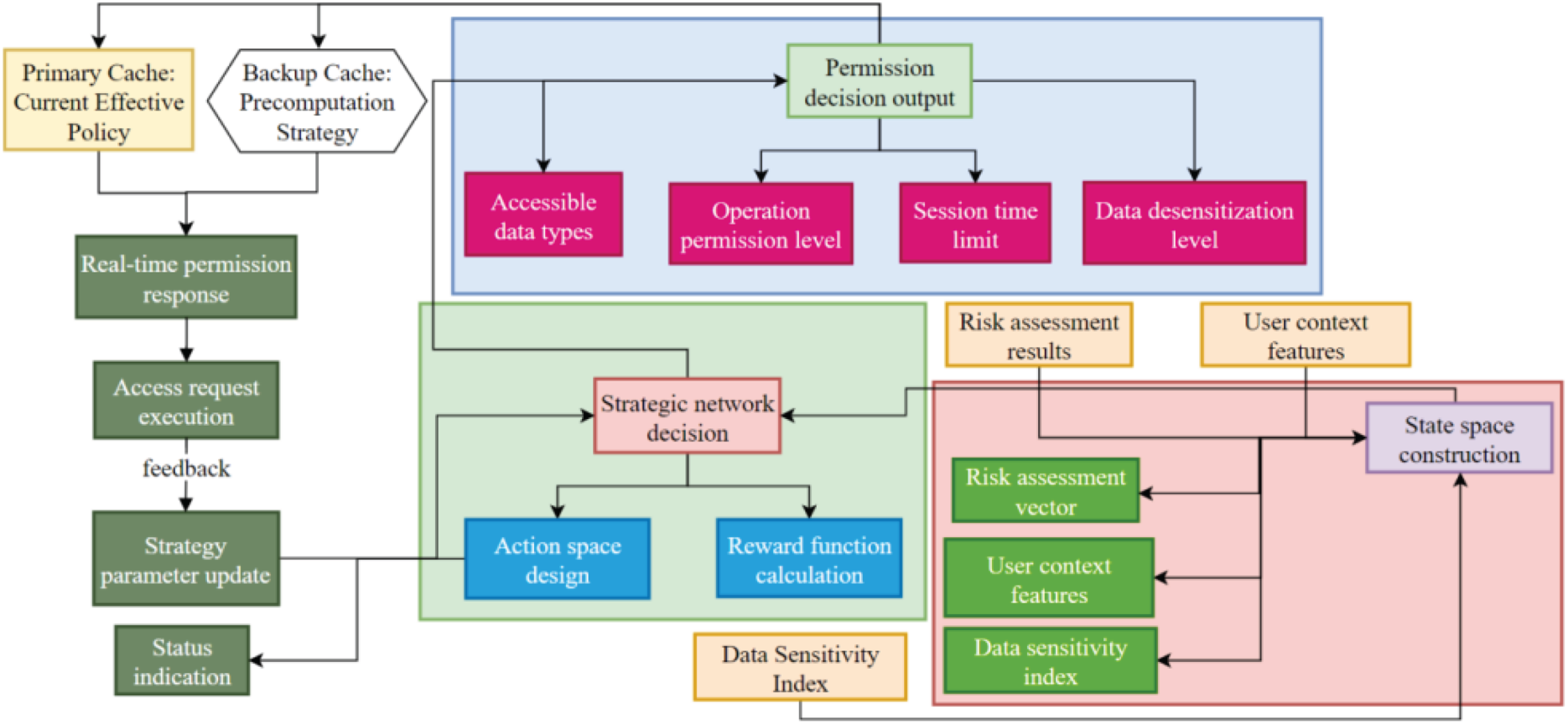
Dynamic access control decisions.
Table 2 presents a quantitative relationship among risk scores and permission parameters, which govern access scope, the scope of allowed activity, time allowed to operate in the session, and level of redaction for each risk zone, all of which allow for risk-adaptive, nuanced permission management.
Risk-Permission mapping rules.

The risk-permission mapping mechanism dynamically adjusts access rights based on the real-time assessment results, balancing the strength of security protection and efficiency of shared use of data. In order to enable real-time risk assessment, the system employs a two-level caching mechanism. The primary cache contains the currently valid policies. The backup cache allows to pre-calculate state responses.
The adaptive encryption and desensitization mechanism designs a dynamic security protection system based on the risk score output by the risk perception module and aim to balance data protection strength and business availability. This mechanism takes the risk score as the core input parameter and applies a nonlinear mapping function to determine the encryption strength and desensitization level.
A hierarchical strategy is used in the adjustment of encryption parameters.When the risk score is lower than the threshold 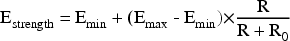
The process of data desensitization applies multidimensional adaptive control that includes, but is not limited to, interval generalization for numerical data, hierarchical aggregation for categorical data, and key information masking for text data. Desensitization levels are computed by using a power law function:
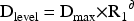
The security-availability trade-off model quantitatively evaluates redaction effectiveness using data retention rate:

To create a closed-loop security system for the entire power data-sharing process, monitoring unusual behaviors and improving the feedback are developed. In the end, the process involves developing a Gaussian Mixture Model (GMM) to create a “time-sliding-window” model baseline, where the window equals 24 h (the period corresponding to the lifecycle of the business). The behavioral feature vector consists of indicators established in 12 dimensions. Model parameters are iteratively solved through the EM (Expectation Maximization) algorithm for estimating the model. Anomaly detection has a multidimensional, multi-dimensional score:

The feedback optimization process implements a balancing mechanism between parameter updates and system stability:

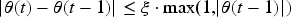
Experimental environment and dataset construction
The experimental platform is built on a high-performance computing cluster composed of multi-core CPUs (Central Processing Units), GPUs (Graphics Processing Units) and distributed storage connected using a high-speed network.
The experimental data are obtained from equipment operation, inspection, and maintenance records from a provincial power grid company from 2019 to 2022. Operational data come from SCADA systems, inspection data is obtained from status-monitoring terminals, and maintenance data originates from an enterprise resource management system. The raw data types are heterogeneous, ranging from time series data to structured reports and text records. In the preprocessing phase, all the data were consolidated and coded in the same format. Missing values were filled in using an interpolation algorithm, and outlier values were filtered out using a statistical threshold method to establish consistency and validity of data.
Table 3 presents summary statistics on the dataset characteristics including the number of data points or records, the number of fields, mean and variance for the numeric fields.
Statistical characteristics of the power equipment dataset.

Statistical characteristics of the power equipment dataset.
The data in Table 3 illustrates the differences in dimension and statistical properties of the operation, inspection, and maintenance data, which creates a aligned data base for model training and evaluation for future experiments.
The evaluation framework of the current study includes an assessment of three areas: data integration efficiency, security protection capabilities, and operational performance of the system. Data integration efficiency is assessed based on the accuracy of field-mapping, semantic well-formedness, and cross-system query latency as indicators of how well unified modeling and semantic mapping can support data processing. Assessments of security protection capability consider rates of sensitive information leaks, abnormal access detection, and incident response latency. These measures describe the effectiveness of the system in identifying risks and responding to them. Assessment of performance largely focuses on CPU utilization, memory usage, throughput, and the latencies incurred to process individual data points, which reflect the resource consumption and scalability of the method in application scenarios with large amounts of data.
To maintain fairness in the comparative experiments, a number of standard data-sharing solutions were included as benchmarks. The benchmark system includes fixed-rule access control, single-strength encryption, statistical feature anomaly detection, blockchain data-sharing, and knowledge graph data-sharing methods. All five of these methods capture standard implementations with power data-sharing applications and were configured to run in the same environment and time as the methods provided in this paper for reproducibility of comparison.
Results analysis
Data integration efficiency analysis
In this research, the results corresponding to the data connectivity performance for each device type in the proposed full-process data security sharing model were reported. More specifically, it referred to the data processing performance pertaining specifically to six typical power equipment types: transformers, circuit breakers, cables, capacitors, disconnectors, and current transformers. The data penetration rate measures the completeness of cross process data integration, while the format conversion success rate measures the compatible formats between heterogeneous types of systems. The semantic consistency metric represents the consistency of data meaning across different business processes, whereas the cross-system query response time shows the real-time processing capability of the system. Penetration performance of the ontology standardized data model across the different power equipment types is compared in Figure 3.

Comparison of data transmission quality and system performance for power equipment throughout the entire process.
The disconnector had the highest data transmission rate of 96.3% and a query response time of 85.6 ms (see Figure 3) because the data structure is relatively simple with fewer business-related dimensions. Transformers serve as major core equipment in the power grid and because of the complexity of the data model and multidimensional business connections, the transformer response time was 183.7, while still indicating good transmission rate of 94.2%. Cables had an extremely high rate of semantic consistency, reaching 91.8% of consistency which speaks to the standardized description of physical properties. Current transformers had only 86.3% consistency, and the conversion of formats only had a performance rate of 89.7%, which indicates that the multi-source heterogeneous nature of the measurement data increases the complexity of semantic mapping. The relationship between the device type and the complexity of the data complexity directly influences the efficiency of data integration which validates the ontology approach adaptability to heterogeneous informational data coming from the power equipment and demonstrates that the model proposed in this research can effectively integrate data based on device characteristics and configurations.
In order to comprehend the dynamic protection capabilities of the power equipment full-process data security sharing model for each of these threat environments, this study expanded to a five-level risk assessment framework based on Table 2. This risk assessment framework systematically examined the five core indicators of interest: (1) abnormal access detection rate; (2) attack success rate: (3) sensitive information leakage rate; (4) false alarm rate; and (5) security incident response time. The five levels are strictly classified as follows: *Very Low (0.0–0.15);* *Low (0.15–0.3);* *Medium (0.3–0.6);* *High (0.6–0.8); and* *Very High (0.8–1.0)*. The abnormal access detection rate reflects how accurately the system detected illegal behavior. The attack success rate reflects the chances of an attacker successfully breaching defenses, the sensitive information leakage rate reflects the capacity for data protection, the false alarm rate reflects the accuracy of security policy, and the security incident response time reflects the timeliness for the system to handle security incidents, attack, etc. A dynamic representation of this relationship between time and risk level for the various indicators is shown in Figure 4.
Protection performance evaluation of the power equipment full-process data security sharing model at different risk levels.
Figure 4 shows that as the risk level rises from very low to very high, the abnormal access detection rate rises from 96.2% to 98.9%, while the attack success rate decreases from 8.7% to 1.5%. This displays that the risk perception mechanism can dynamically increase protection strength to match the threat level. The rate of sensitive information leakage fell to 1.8%, confirming the influence of the adaptive encryption and desensitization mechanism. However, the increase in the false alarm rate from 3.8% to 6.1% illustrates the compromises commonly associated with tightened security policies. Security incident response time fell from 382 ms to 143 ms, representing that the system can prioritize response time in high-risk situations. This dynamic balancing mechanism successfully mitigates the tension between security and efficiency in power data sharing. This shows good, reliable support for the innovative grid data security service design.
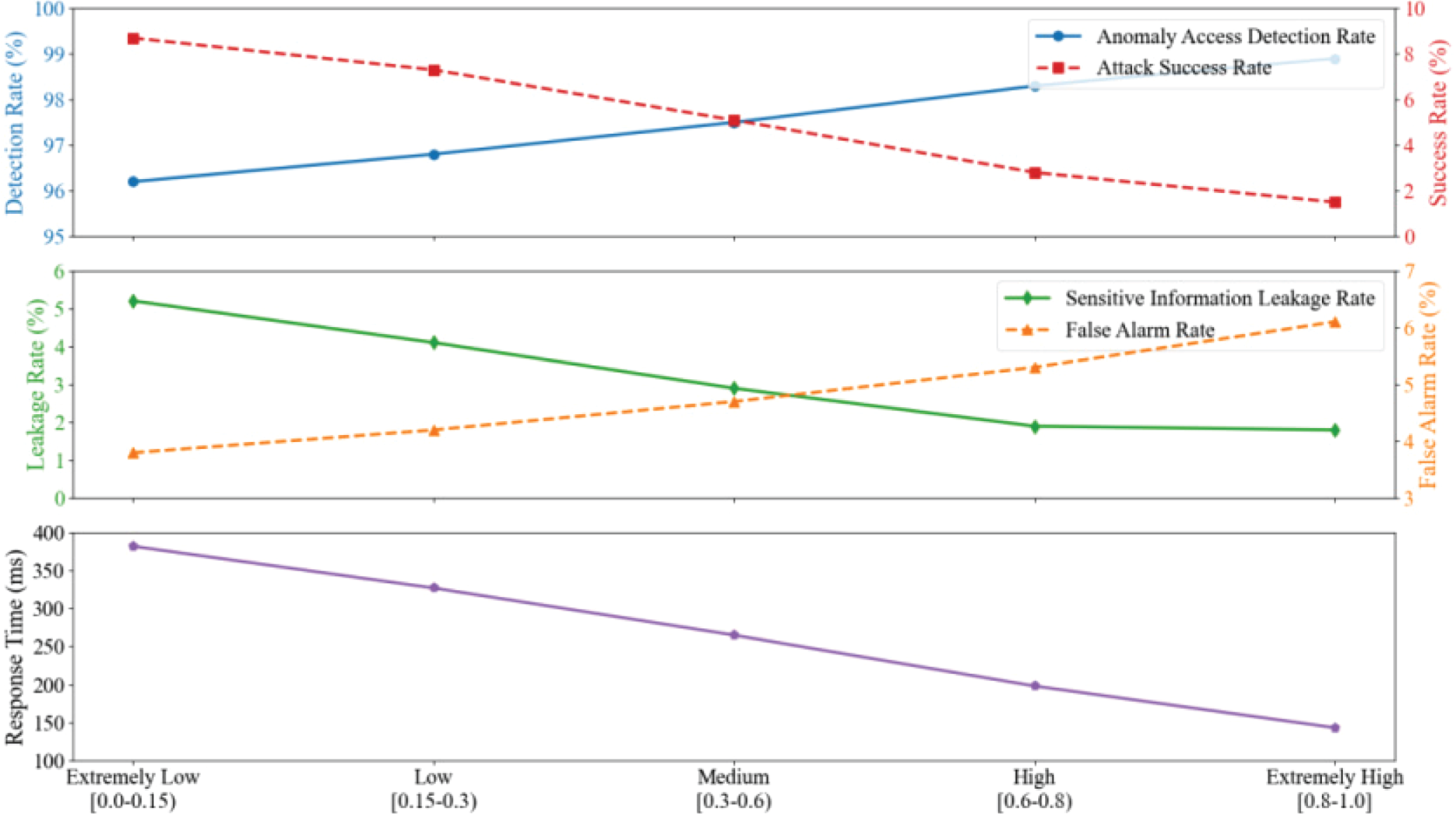
In order to assess the dynamic adaptability of the full-process data security sharing model for power equipment across risk scenarios, the research investigated four indicators: risk prediction accuracy, policy adjustment frequency, policy adaptation delay, and scenario switching response time. Risk prediction accuracy indicates the system's ability to anticipate likely threat types; policy adjustment frequency indicates the dynamic responsiveness of the access control policy approach to changes in the provisioning of data; policy adaptation delay indicates the efficiency of the timeframe of creating and accomplishing policy parameter changes; and scenario switching response time describes the system's responsiveness to changes in business scenario factors. Using a five-level risk assessment framework as the horizontal axis the study systematically outlines the known relationships among indicators across risk levels as illustrated in Figure 5.
Dynamic policy adaptability evaluation of the power equipment full-process data security sharing model.
The risk prediction accuracy rises systematically from 88.7% to 98.4% as the risk escalates in Figure 5. The frequency of policy adjustment ranges from 2.9 to 24.1 times per hour, revealing that the system enhances its risk perception and the policy update mechanism in high risk contexts. At the same time, the policy adaptation latency decreases from 291.5 ms to 102.6 ms, then the associated scenario-switching response time decreases from 325.8 ms to 118.3 ms, and these show that the system optimizes the strategy of prioritizing response time in high-risk contexts. Such nonlinearity arises from the risk perception module's hybrid architecture that combines deep neural networks with graph convolutional networks that supports richer feature extraction. Moreover, the reinforcement-learning based access-control policy network dynamically updates its parameter space based on risk assessment results to ensure faster convergence to the optimal policy with an increase in the risk level. The closed-loop feedback mechanism demonstrates efficacy in balancing the inherent contradiction between the strength of protection against risk of loss (security) and efficiency of shared data dissemination through real-time surveillance and parameter tuning. This provides an engineering consideration for a pragmatic dynamic policy-adaptability design for secure data sharing for the entire life cycle of power equipment.
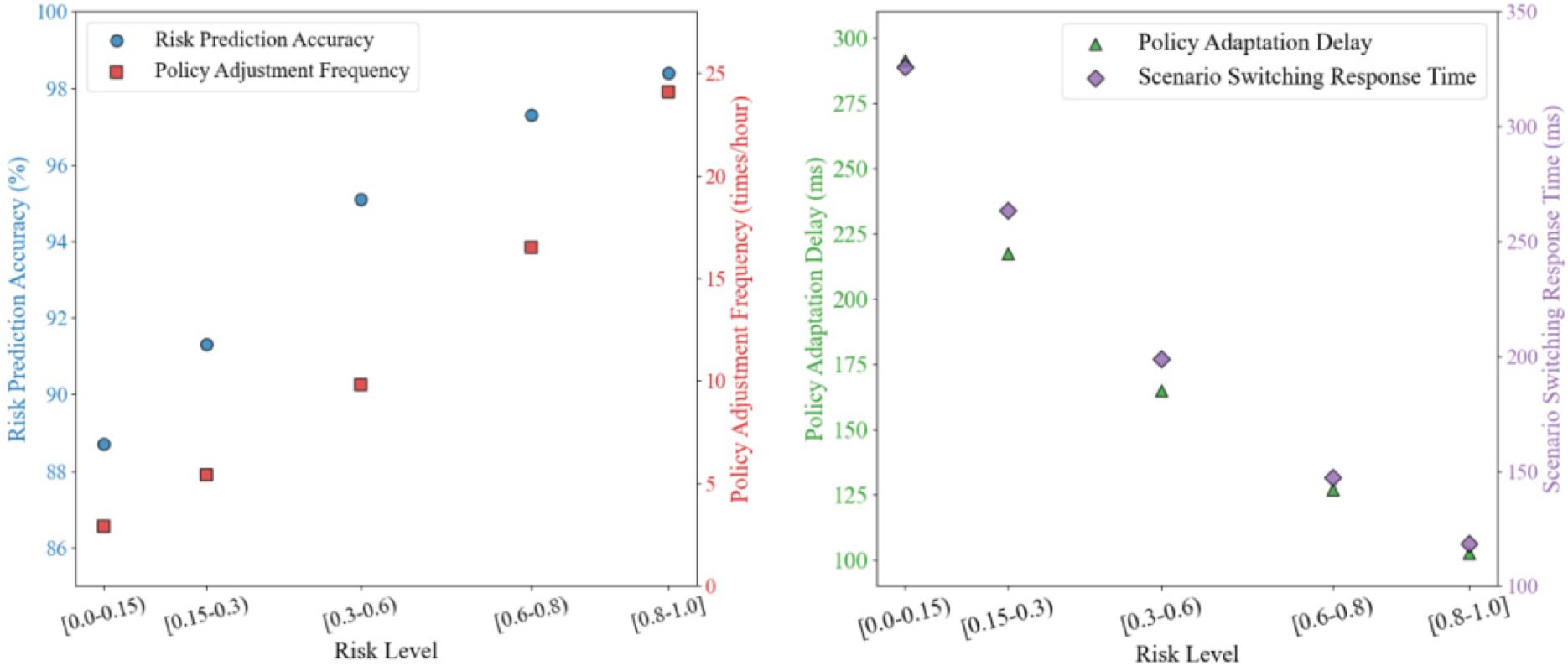
The analysis of the system resource consumption focuses on the effectiveness of computing and the resource use characteristics of the secure data-sharing model across the lifecycle of the electrical power equipment process and under different risk conditions. The analysis reflects computing resource requirements by monitoring CPU and memory use, characterizes the efficiency of data flows by monitoring network bandwidth use and latency, and captures economic viability by monitoring system throughput and the cost of processing individual pieces of data. Five distinct risk conditions are the critical variables in this analysis, and show the trade-off between strength of security and system resource consumption (Figure 6).
Resource overhead variation with risk level in the power equipment full-process data security sharing model.
In Figure 6, CPU utilization rises from a level of 14.3% to 71.2%, memory utilization rises from a level of 17.8% to 49.3%, and processing cost per 1000 records rises from 0.072 yuan to 0.518 yuan as the risk level increases. The CPU utilization for AES-256 strong encryption mode is enhanced with an ECC to provide doubly-protective methodology. Network bandwidth utilization rises and falls and rises and falls with a downward trend initially of 12.4 MB/s to 9.3 MB/s, with a rebound to 13.5 MB/s. This change in bandwidth utilization was due to both the efficiency of data compression at the lower and medium level of risk, and the increased size of the data from the ECC signing protocol at the very high level of risk. In addition, data transmission latency rises from 43 ms to 254 ms and system throughput declines from 4780 messages/s to 1260 messages/s and demonstrates nonlinear trading off of effective security strength and processing performance. This model implies that it can be assured a high level of data security is guarantee that retains an acceptable compromise of resource overhead.
To ensure secure data sharing across the entire process of power equipment, a trade-off between functional completeness and implementation cost is necessary. Study conducted a multidimensional assessment of six common methods: the machine learning method assessed in this paper, static rule-based access control, single-strength encryption, statistical feature anomaly detection, distributed ledger technology data sharing, and knowledge graph sharing. In the functional completeness dimension, we examine full lifecycle coverage which assesses the ability to combine data from the equipment operating, testing, and maintenance stages; and dynamic policy adaptability, which assesses how quickly the process can respond to changes in risk. The multi-device compatibility dimension assesses the ability to adapt to data shared across six categories of devices (e.g., transformers, circuit breakers). The implementation cost dimension includes (1) deployment complexity, (2) cost of routine maintenance (3) difficulty of system upgrades, respectively considered the difficulty of integrating systems, operational resource overhead, and flexibility in upgrading technologies. Figure 7 depicts the functional completeness and implementation cost across various methods.

Comparison of functional completeness and implementation cost of the full-process data security sharing method for power equipment.
As evidenced in Figure 7, the suggested approach is highly effective for providing functional completeness, achieving scores of 92.5 for full lifecycle accessibility, 95.3 for dynamic policy adaptivity, and 93.7 for multi-device adaptability. This is a result of the risk aware mechanism that integrates an LSTM and a GCN to reliably capture the time-based and correlation patterns of power data. Knowledge graph sharing provides scores of 86.4 for multi-device compatibility that is not far off from the score of the method proposed in this paper, since it provides ontological modeling advantages for working with multi-source heterogeneous data. Blockchain data sharing, as expected, performed the worst with implementation cost, with deployment complexity (84.3), maintenance cost (78.2), and upgrade difficulty (82.6), showing the challenge in adapting its distributed architecture to meet the power system environment. Fixed-rule access control achieves the lowest implementation cost but lacks functional completeness, in which complete lifecycle coverage scored only 68.3, and therefore is not a good fit to meet the needs of secure data sharing in the power industry. As such, this approach provides an optimal balance between functional completeness and implementation cost, ultimately providing an achievable method to securely share data throughout the lifecycle of power equipment.
This paper constructs a machine learning-based secure data sharing model for the entire process of power equipment. This model uses a domain ontology to unify semantics and standardize the format of multi-source heterogeneous data across operations, inspections, and maintenance. Furthermore, it employs a hybrid LSTM and GCN architecture for risk feature extraction and prediction. A risk-driven dynamic access control mechanism was then established, along with encryption and desensitization strategies that adjust to risk scores, forming a closed-loop optimization system of “risk assessment – strategy execution – effect feedback.” Results showed that this model improved data connectivity and security protection for power equipment, achieving a 96.3% data connectivity rate for disconnector data and reducing the sensitive information leakage rate to 1.8% under extremely high-risk conditions. The model achieves consistency in data transformations with semantic mapping backed by bidirectional traceability, while risk-permission mapping facilitates the trust management process by providing an integrated view. To balance security with availability, we manage the trade-off with adaptive encryption and desensitization. The enduring management of the user-permission model and anomaly monitoring, indexed by historical user policy feedback, contribute to stable operation. The research outlines technical measures to address the challenge of balancing security and efficiency in operated data sharing of power systems - and provides technical safeguards for the life-cycle development and intelligent transformation of power process equipment.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.