
Abstract
Credit scoring, which forecasts the probability of loan default based on borrower attributes and credit history, is still a crucial task in the financial industry. Finding the most important characteristics to improve credit scoring accuracy has become more difficult due to the complexity of borrower profiles. This paper presents a systematic and multidimensional evaluation of the impact of different feature selection techniques, namely wrapper-based, filter-based, and embedded methods, on the performance of various machine learning classifiers such as Random Forest (RF) and Extreme Gradient Boosting (XGBoost). The influence of data resampling techniques to address class imbalance is also explored. The study evaluates all combinations under three settings: original, oversampled, and undersampled data, using three publicly available datasets: German, Taiwan, and Australian credit scoring datasets. Experimental results show that ensemble classifiers, especially XGBoost and RF, consistently outperform single classifier models. Additionally, feature selection methods, especially embedded and wrapper techniques, enhance model performance and reduce false positive and false negative rates across the three datasets.
Introduction
Credit scoring remains a crucial function in the financial sector. The objective of this function is to evaluate borrower credit history and other characteristics to anticipate the possibility of loan default. The importance of robust credit scoring models has increased dramatically due to increasingly complex economic environment (Ala’raj & Abbod, 2016). Using these models, financial institutions are able to make more accurate lending decisions. These models provide a reliable framework for assessing creditworthiness, which help reduce financial risks and support more inclusive lending practices. Financial organizations have historically depended on expert guidelines and basic statistical analysis. These traditional methods use variables such as credit history and income. However, due to the rapid growth of data that is now available and advancements in the financial industry, several challenges have emerged in the field of credit scoring. One of the primary challenges is feature selection. As data availability increases and borrower profiles become more complex, identifying the most relevant features to enhance the accuracy of credit scoring models has become increasingly difficult. With so many potential factors to consider, it can be difficult to determine which ones are truly significant in predicting credit risk. Another significant challenge is the issue of high dimensionality. The high dimensionality of data can cause overfitting and reduce model performance (Leiva et al., 2019). Models may become very complex as the number of characteristics rises. Such complex models can capture noise in the data instead of learning significant patterns. A third challenge is data imbalance. Imbalanced datasets, where defaulters are usually a minority class, can lead to performance degradation. Since detecting high-risk borrowers is often the main objective of credit scoring, this imbalance may result in models that perform badly in this regard.
The ability to handle these difficulties has improved significantly due to the development of computational powers. Credit score datasets are now of higher quality thanks to sophisticated methods for managing outliers, missing data, and data validation. In traditional banking settings, where data quality can range greatly between systems and time periods, this development is very important. Furthermore, the accuracy of model performance predictions has been enhanced by specific validation methods that take into consideration temporal dependencies in credit data, where past borrower behavior or evolving economic conditions influence future credit risk. For example, a borrower who has maintained timely payments for years but recently missed several payments might present a different risk profile than someone with consistent payment delays. The issues of feature selection, excessive dimensionality, and data imbalance in credit scoring are discussed in this study. This study addresses these challenges by offering a systematic and comprehensive evaluation of how different types of feature selection techniques (wrapper, embedded, and filter-based) interact with different machine learning models under multiple dataset conditions (original, oversampled, and undersampled) using three publicly available datasets. Unlike previous studies that typically examine individual aspects in isolation, this study has the following main contributions: A three-dimensional evaluation that simultaneously considers feature selection methods, classifiers, and resampling approaches. This integrated approach offers a more holistic analysis of model behavior. An extensive experimental setup that evaluates different combinations of feature selection methods, classifiers, and resampling techniques, which provides a detailed performance analysis and ensures robustness and practical relevance of the findings. Applicable recommendations on the best combinations of feature selection, resampling methods, and classifiers under different conditions. This can serve as a practical guide for industry experts and data scientists working on credit scoring applications. An emphasis on how feature selection enhances model interpretability, especially for complex ensemble models, to provide a trade-off between accuracy and interpretability, which is crucial in regulated financial settings. Comprehensive performance comparison of different models across various metrics such as accuracy, precision, recall, and area under the receiver operating characteristic (AUC-ROC) curve, to provide a thorough evaluation of their effectiveness in credit scoring tasks. The development of a clearly structured and reproducible framework that can be replicated or extended by other researchers who may wish to test new frameworks or hybrid models of credit scorings.
Three publicly accessible datasets are used in this work to analyze credit scores. These datasets are the German credit scoring dataset, the customers default payments in Taiwan dataset, and the Australian credit approval dataset. These datasets offer a wide variety of borrower attributes and credit histories, enabling a thorough assessment of the suggested methods. Correlation-based and mutual information-based feature selection strategies are investigated; these strategies are combined with machine learning algorithms. The remainder of this paper is organized as follows: A thorough survey of the literature on credit scoring models is provided in Section 2. This section sets the scene for the current investigation and identifies the research gaps that this paper seeks to fill. The methods used in this paper are described in Section 3. This section explains the feature selection techniques and machine learning algorithms employed. The data resampling methods used to address the issue of imbalanced datasets are also explained in this section. The employed datasets and the experimental results are explained in Section 4. This section provides information on the efficacy of various models and feature selection strategies in credit scoring tasks by comparing their performance. Section 5 concludes the paper.
Many studies have focused on using advanced machine learning and ensemble techniques to improve credit scoring accuracy. A novel ensemble method that adapts to different imbalance ratios in credit rating information was introduced by He et al. (2018). Their approach, which combined multiple classifiers, such as decision trees (DT), RF, and support vector machines (SVMs), demonstrated improved performance in controlling class imbalance, and considerable adaptability to various situations. The researchers did observe a number of significant drawbacks, though, including reduced interpretability due to the combination of multiple models and higher computational complexity and resource intensity when executing multiple classifiers. Despite these limitations, the ensemble method’s ability to improve the overall accuracy and robustness of credit scoring models is a noteworthy advancement in the field. Zhang and Chi (2021) proposed a heterogeneous ensemble model using adaptive classifier selection to address the issue of imbalanced data. This model made use of base learners such as linear SVM, multivariate discriminant analysis (MDA), k-nearest neighbors (KNN), logistic regression (LR), and DT. The ensemble model resulted in better performance compared to base classifiers. However, the ensemble model is more complicated to implement and interpret than simpler models. Moreover, selecting the optimal base classifier can require a lot of resources when dealing with large datasets. Laborda and Ryoo (2021) focused their investigation on the critical element of feature selection in credit scoring. They compared filtering-based, wrapper-based, and embedded methods across LR, DT, RF, SVMs, and naive Bayes (NB) algorithms. Their study demonstrated how important it is to choose features carefully in order to increase the accuracy and efficacy of models. Tripathi et al. (2022) compared the performance of multiple credit scoring models that included nine ensemble learning techniques and five classification techniques. Examples of the ensemble techniques included bagging, adaboost, multiboost, and dagging while the classification techniques included LR, radial basis function neural network (RBFN), and sequential minimal optimization (SMO) (Ellis et al., 2022). These models were trained and evaluated on six benchmark credit scoring datasets such as Taiwan, bank marketing, and German datasets. The best ensemble models were multiboost and bagging. Mokheleli and Museba (2023) addressed the issues of concept drift, verification latency, and class inequality through developing a model that combined SVM with XGBoost. Liao et al. (2024) investigated data augmentation techniques in order to address the issue of data representativeness. They suggested two techniques that pseudo-label denied loan applications according to confidence levels. The proposed model was compared with a supervised model and a conventional reject inference method with fuzzy augmentation. The results demonstrated that a self-training model with calibrated probabilities increased loan approval rates by
A Comparison of Related Studies on Credit Scoring Models.
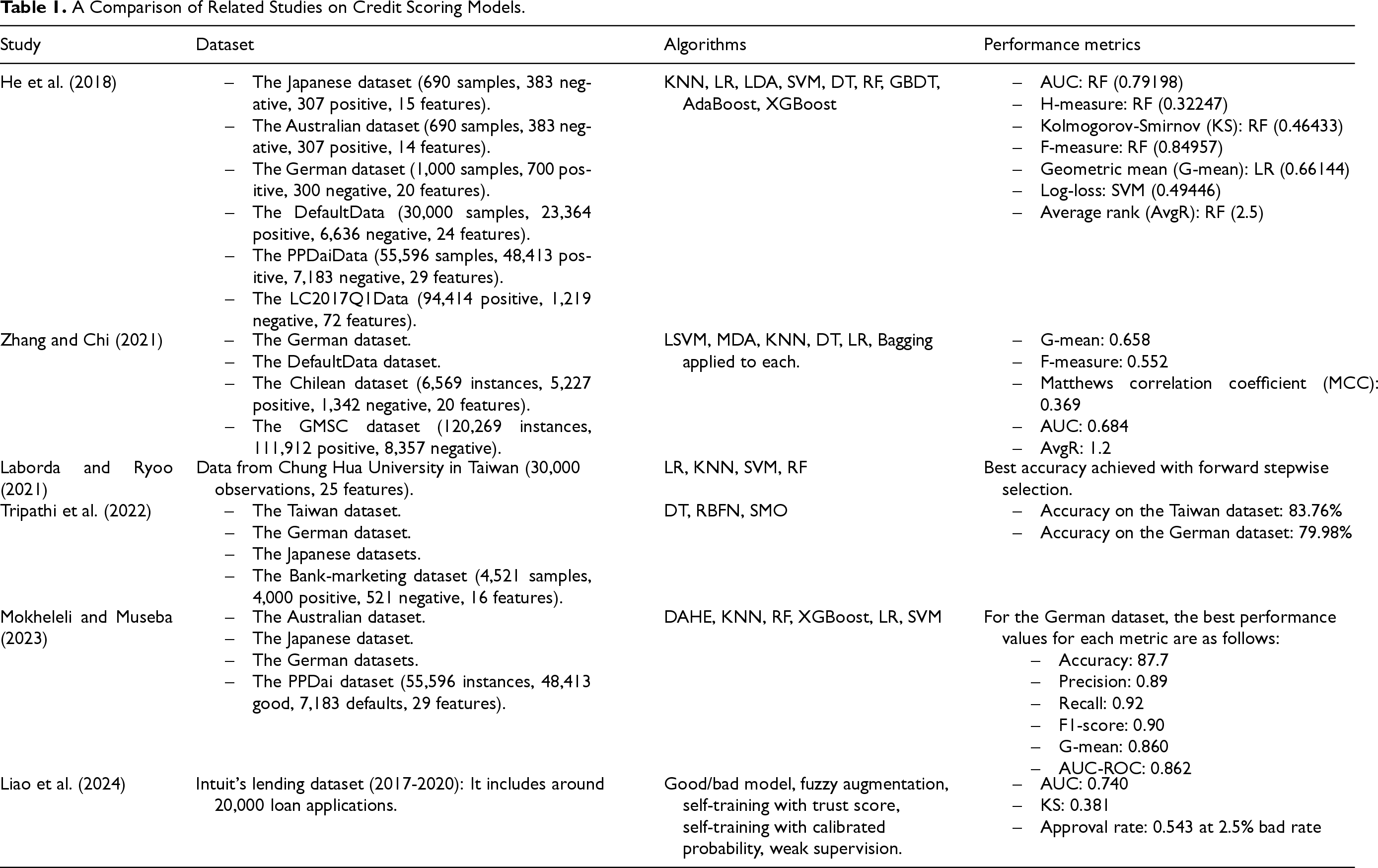
A Comparison of Related Studies on Credit Scoring Models.
Recent studies showed that credit scoring techniques have advanced significantly, especially in resolving issues with feature selection, model performance, and data imbalance. Advanced machine learning techniques and ensemble approaches have demonstrated encouraging outcomes in handling complicated data interactions and increasing accuracy. Nevertheless, these developments frequently result in higher processing requirements and possible difficulties with interpretability. In a recent study, Tu and Wu (2025) proposed a model that balances interpretability and predictive performance. Their model, based on the optimal classification tree with hyperplane splits (OCT-H), combines the simplicity of decision trees with the expressive power of hyperplane-based splits. Esenogho et al. (2022) proposed a model that combines a long short-term memory (LSTM) network with adaptive boosting (AdaBoost). The authors employed a hybrid data resampling method using the synthetic minority oversampling technique and edited nearest neighbors (SMOTE-ENN) to handle data imbalance. The proposed LSTM-AdaBoost ensemble demonstrated superior performance compared to traditional algorithms like SVM, DT, and standalone LSTM. Rofik et al. (2024) proposed a model that employs SMOTE for handling data imbalance and ensemble classification techniques to improve credit scoring performance. A federated learning approach was proposed by Wang et al. (2024) In this model, knowledge distillation and fine-tuning were employed to extract both generic and specific knowledge for improved performance. Koc et al. (2023) investigated the impact of feature selection, data scaling, and hyperparameter optimization on performance of credit scoring models. Results showed that combining appropriate feature selection and scaling methods with advanced ML algorithms significantly improves accuracy and reduces error rates compared to traditional approaches. Emmanuel et al. (2024) proposed a model that combines ensemble classifier with a filter-based feature selection method based on information gain. Evaluation on three datasets showed that the stacked model outperforms traditional classifiers such as DT and KNN. Talaat et al. (2024) proposed a model that combines deep learning with explainable artificial intelligence (XAI) techniques to improve model interpretability. The models identifies the features of payment delays and outstanding bill amounts as having a high impact on default risk. Kwon et al. (2025) proposed a multitask learning technique based on Siamese neural networks to improve both predictive power and stability in credit scoring models. The results demonstrated that the proposed model outperforms both classical machine learning and deep learning models in accuracy and stability.
This study employs a comprehensive approach to evaluate and improve credit scoring models using various techniques. The methodology encompasses several stages that include data preprocessing, feature selection, model development, and performance evaluation. The basic processing steps of the proposed methodology are illustrated in Figure 1.

The Proposed Methodology for Crediting Scoring: Multiple Classification Models are Combined with Different Feature Selection Techniques and Different Data Resampling Methods and Evaluated Using Three Different Datasets.
Data preprocessing is typically a crucial step in many data science projects, transforming raw data into a format suitable for analysis. In general, preprocessing may involve: Cleaning: Removing missing values and noisy data. Integration: Combining data from multiple sources. Discretization: Converting continuous variables into categorical ones. Standardization: Scaling numerical features to a standard range.
These steps are often necessary to ensure data quality and prepare datasets for effective modeling. While the datasets selected for analysis in this paper were pre-processed and structured, additional preprocessing steps were implemented to further enhance data quality. These steps included removing outliers with values exceeding 40% of the interquartile range (IQR), imputing missing values using median for numeric data and constant values for categorical data. Furthermore, feature scaling, standardization, and categorical variable encoding were applied to prepare the data for optimal model performance.
The use of feature selection strategies to determine which features are most pertinent to credit scoring is examined in this study. Three distinct strategies are used: Filtering-based methods. Wrapper-based methods. Embedded methods.
One technique for choosing a subset of pertinent features from a big candidate pool is filtering-based feature selection. By concentrating on the most informative features, it seeks to increase the predictive model’s accuracy (Akogul, 2023). The procedure entails:
Among the many benefits of filtering-based feature selection techniques are their ease of use, computational effectiveness, and ability to manage high-dimensional data. However, they might overlook complex relationships between features and the target variable. The chi-square statistical test is used to evaluate the dependence between each feature and the target variable. This method offers several key advantages:
Larger chi-square scores denote strong dependence between the features and the target variable. It is noteworthy that chi-square testing works best with non-negative feature values and categorical data. Our model was improved by the chi-square feature selection, which found and chose the most pertinent features while preserving statistical reliability and computational efficiency.
The “wrapper feature selection” technique utilizes a feature selection algorithm to “wrap” around the machine learning model. It assesses various feature subsets according to how they affect the model’s performance. The objective is to find the smallest optimal subset that maximizes the model’s accuracy (Belete & Manjaiah, 2020).
Embedded methods offer an intermediate solution between filter and wrapper methods, combining the qualities of both approaches. Like filter methods, embedded methods are computationally efficient while still allowing interaction with the classifier to incorporate its bias into feature selection, which tends to produce better classifier performance. In this study, RF was implemented as the embedded method for feature selection. RF is a predictive clustering method that uses multiple interconnected decision trees, where feature selection is integrated directly into the classifier algorithm. As the classifier trains, it automatically adjusts its internal parameters to determine the importance of each feature, performing feature selection and model construction in a single step. RF was specifically chosen for its: Ability to handle noisy features effectively. High accuracy and robustness in feature selection. Built-in feature importance metrics. Ability to manage high-dimensional data. Seamless handling of both numerical and categorical features.
This approach enabled efficient feature selection while maintaining model interpretability and performance.
The employed datasets are split into training and testing sets, with 85% allocated for training and 15% for testing. A fixed random seed was applied to maintain reproducibility of the results. This split was chosen due to the relatively small size of the dataset, ensuring sufficient data for robust model development while preserving a meaningful portion for unbiased performance evaluation (Gholamy et al., 2018). For smaller datasets, a higher training percentage is necessary to avoid overfitting and ensure the model captures relevant patterns.
Data Resampling
The imbalanced data can affect the accuracy and the performance of the model, and this requires using data resampling techniques. The methods listed below can be applied to deal with an unbalanced dataset. Only classification issues employ these methods (Song et al., 2021). Two data resampling techniques are examined in this work:
Each data resampling technique has advantages and disadvantages; thus, the choice should be dependent on the particulars of the dataset and the issue the study is attempting to address. To make sure that the oversampling technique doesn’t result in overfitting or other problems, it’s also critical to assess how well the machine learning models trained on the oversampled dataset perform.
For this paper, seven classification algorithms were chosen because of their extensive use and demonstrated efficacy in credit scoring. These algorithms include DT, RF, XGBoost, categorical boosting (CatBoost), Voting Classifier, light gradient-boosting machine (LightGBM), and bootstrap aggregating (Bagging). Previous studies have shown how good these models are in predicting credit risk, which validated this choice. Every algorithm was selected due to its distinct method of ensemble learning: RF uses random feature sampling RF, XGBoost and CatBoost use gradient boosting with various optimization techniques, LightGBM uses gradient-based one-side sampling, and Bagging and Voting classifier use diverse strategies for integrating multiple models (Tripathi et al., 2022). This variety of approaches makes it possible to thoroughly assess which ones work best for credit scoring applications.
DT
DT are supervised learning models that split data into branches based on feature values, forming a tree-like structure. At each node, the algorithm selects the feature that best separates the data according to a criterion like Gini impurity or information gain. They are easy to interpret and visualize but can overfit, especially with complex datasets.
RF
The RF algorithm employs a group of decision trees to build a classification model. The trees cooperate, and the addition of randomness from the tree-based component is what distinguishes this ensemble classifier. RF is made up of multiple random decision trees.
XGBoost
XGBoost is an extremely effective gradient boosting technique that is optimized for scalability and performance. It expands on the idea of boosting, in which several weak learners—typically decision trees—are trained one after the other, with each new tree fixing mistakes committed by the ones before it (Chen & Guestrin, 2016). XGBoost’s salient characteristics include:
CatBoost is a powerful gradient boosting technique that can handle categorical data natively, therefore, it does not require one-hot encoding or other intensive preprocessing. It is known for its accuracy, scalability, and fast performance in both classification and regression tasks. To reduce overfitting and stop target leakage, CatBoost employs a special ordered boosting technique that enhances the model’s reliability. In addition to supporting GPU acceleration for even quicker training on big datasets, it works well right out of the box and requires little hyperparameter tweaking (Prokhorenkova et al., 2018).
CatBoost
The Voting Classifier is an ensemble learning method that combines the predictions of several separate classifiers to enhance model performance. To improve overall accuracy, this technique makes use of the variety of models, including DT, LR, and SVM. The two ways to aggregate predictions are soft voting and hard voting. Soft voting averages the projected probabilities and typically produces superior results. In hard voting, each classifier votes for its anticipated class. Voting classifiers can perform better on unseen data and are resistant to overfitting. They have broad applications in several fields, such as natural language processing, healthcare, and finance (Re & Valentini, 2012).
LightGBM
LightGBM is an efficient and scalable gradient boosting technique designed for large-scale machine learning applications. By classifying continuous data into discrete bins using a histogram-based learning technique, it drastically lowers computing complexity and speeds up training. LightGBM uses a leaf-wise tree growth technique by choosing the leaf with the highest delta loss for growth in order to frequently produces a more accurate and ideal tree structure. There is no need for intensive preprocessing because the system can handle categorical features directly. Furthermore, LightGBM facilitates GPU and parallel learning, increasing its speed and scalability and making it appropriate for a range of uses, such as marketing and financial prediction modeling (Ke et al., 2017).
Bagging
Bagging is an ensemble learning technique that generates numerous copies of a base model by training each version on a distinct bootstrap sample of the original dataset. These samples are produced by selecting observations at random with replacement, which means that some observations might show up more than once and others might not show up at all. Usually, the final prediction is determined by obtaining a majority vote (for classification) or averaging the predictions (for regression) across all base models.
Experimental Results and Discussion
Multiple experiments were conducted to explore the performance of the proposed models on three publicly available datasets (The German (Asuncion & Newman, 2007a), Taiwan (Yeh & Lien, 2009), and Australian (Asuncion & Newman, 2007b) credit scoring datasets) across three different scenarios: the original dataset, an oversampled dataset, and an undersampled dataset. In each scenario, the various proposed feature selection methods combined with different classification algorithms were evaluated using multiple performance metrics: accuracy, AUC, false positive rate (FPR), false negative rate (FNR), recall, precision, and F1-score. In the first scenario, the proposed models were evaluated using the original samples from the three employed datasets. In the second scenario, the proposed models were evaluated using an oversampled dataset. In oversampling, new samples are generated for the minority class. However, this technique can lead to overfitting, as the model may memorize duplicated samples rather than generalizing well. In the third scenario, the proposed models were evaluated using an undersampled dataset. In undersampling, a similar number of samples from the majority class is selected to match the number of samples in the minority class. Since this technique removes samples from the majority class, it could negatively affect the performance due to the loss of valuable information from the majority class.
Dataset Description
This study makes use of three popular, preprocessed credit rating datasets:
These datasets are publicly available and often utilized in related studies, offering a solid foundation for comparing and evaluating models. Since these datasets provide a variety of attributes pertaining to consumer demographics, financial data, and credit behaviors, they were selected for their applicability to credit scoring and their ease of use.
The performance of each model is assessed using the test dataset. The following metrics are used for evaluation:
Accuracy
Accuracy in credit scoring is a straightforward metric that measures the overall proportion of borrowers correctly classified as either low-risk or high-risk. It is calculated by summing the true positives (TP) and true negatives (TN) and dividing them by the total number of borrowers. A higher accuracy score indicates better overall classification performance (Labatut & Cherifi, 2012). It is defined by equation (1):

The percentage of low-risk borrowers who are mistakenly classified as high-risk is known as the FPR in credit scoring. A high FPR causes losses for business due to the rejection of creditworthy borrowers. FPR is computed mathematically by equation (2). Minimizing the FPR improves business decision-making by balancing between identifying high-risk borrowers and avoiding rejecting low-risk borrowers (Galdi & Tagliaferri, 2019).

The percentage of high-risk borrowers that are mistakenly classified as low-risk is known as the FNR in credit scoring. FNR is defined by equation (3). Minimizing the FNR is essential to accurately identify high-risk borrowers (Galdi & Tagliaferri, 2019).

The AUC-ROC assesses how well the model distinguishes between positive and negative examples (Carter et al., 2016). The ROC curve shows the true positive rate (TPR) versus the FPR. The closer the AUC-ROC value is to 1, the higher the model’s performance.
Precision
Precision is a performance metric that is especially crucial for binary classification such as credit scoring. By figuring out the percentage of real positive predictions among all of the model’s positive predictions, precision assesses how accurate the forecasts are. It is defined by equation (4):

Recall (also known as sensitivity or TPR) is an important performance metric in the context of credit scoring, particularly for detecting high-risk borrowers. It calculates the percentage of real positive examples that the model accurately detects. It is computed mathematically by equation (5):

When assessing credit scoring models on unbalanced datasets, the F1-score is very helpful because it integrates precision and recall into a single value. Precision and recall are given equal weight in the F1-score, which is the harmonic mean of the two measures. A higher F1-score shows that the model properly classifies high-risk borrowers while striking a solid balance between recall and precision. In contrast to accuracy alone, the F1-score takes into consideration the class imbalance that is frequently present in credit scoring datasets, where there are generally more low-risk borrowers than high-risk borrowers. Consequently, the F1-score offers a more reliable assessment of the model’s performance, particularly when it comes to precisely identifying the comparatively uncommon high-risk cases (Galdi & Tagliaferri, 2019). It is defined by equation (6):

The performance of the proposed models is first explored on the German credit scoring dataset across three different scenarios: the original dataset, an oversampled dataset, and an undersampled dataset. Table 2 lists the results of the various feature selection strategies and classification models on the original German credit scoring dataset, without applying any data resampling techniques. In the analysis of the results on the original German credit dataset, RF consistently demonstrates superior and balanced performance, particularly when combined with the backward selection method. This combination achieves the highest accuracy (82.66%), the highest recall (94.23%), the highest F1-score (88.28%), and maintains strong performance across other metrics, including a balanced FPR (43.48%) and one of the lowest FNR rates (5.77%) in handling the imbalanced credit risk assessment scenario. Although XGBoost with the embedded method shows competitive performance with the highest AUC-ROC (76%) and strong precision (84.07%), RF with filtering demonstrates exceptional recall (94.23%). The Voting classifier performs notably well in precision metrics, particularly with the filtering method (84.54%), showcasing its effectiveness in reducing false positives in credit risk assessment. LightGBM, while showing promising results in FPR minimization, struggles with higher FNR rates and lower F1-scores, suggesting that it may not be the optimal choice for achieving balanced performance in credit risk prediction.
Evaluation Metrics of the Models Using Original Dataset (The German Dataset).

Evaluation Metrics of the Models Using Original Dataset (The German Dataset).
Table 3 lists the results of the various feature selection strategies and classification models on the oversampled German credit scoring dataset. The evaluation of classification models on an oversampled German credit scoring dataset shows that oversampling improves performance, particularly when combined with feature selection. Chi-squared filtering with RF achieves the highest accuracy (81.33%) and the highest F1-score (87.15%), which means that balancing the dataset enhances RF’s performance. on the other hand, forward selection results in lower accuracy (around 71%), lower recall, and the lowest F1-scores, which means that removing too many features harms model performance. In general, oversampling, combined with Chi-squared filtering or backward selection, improves model performance, while forward selection leads to poor results.
Evaluation Metrics of the Models Using Oversampled Dataset (The German Dataset).
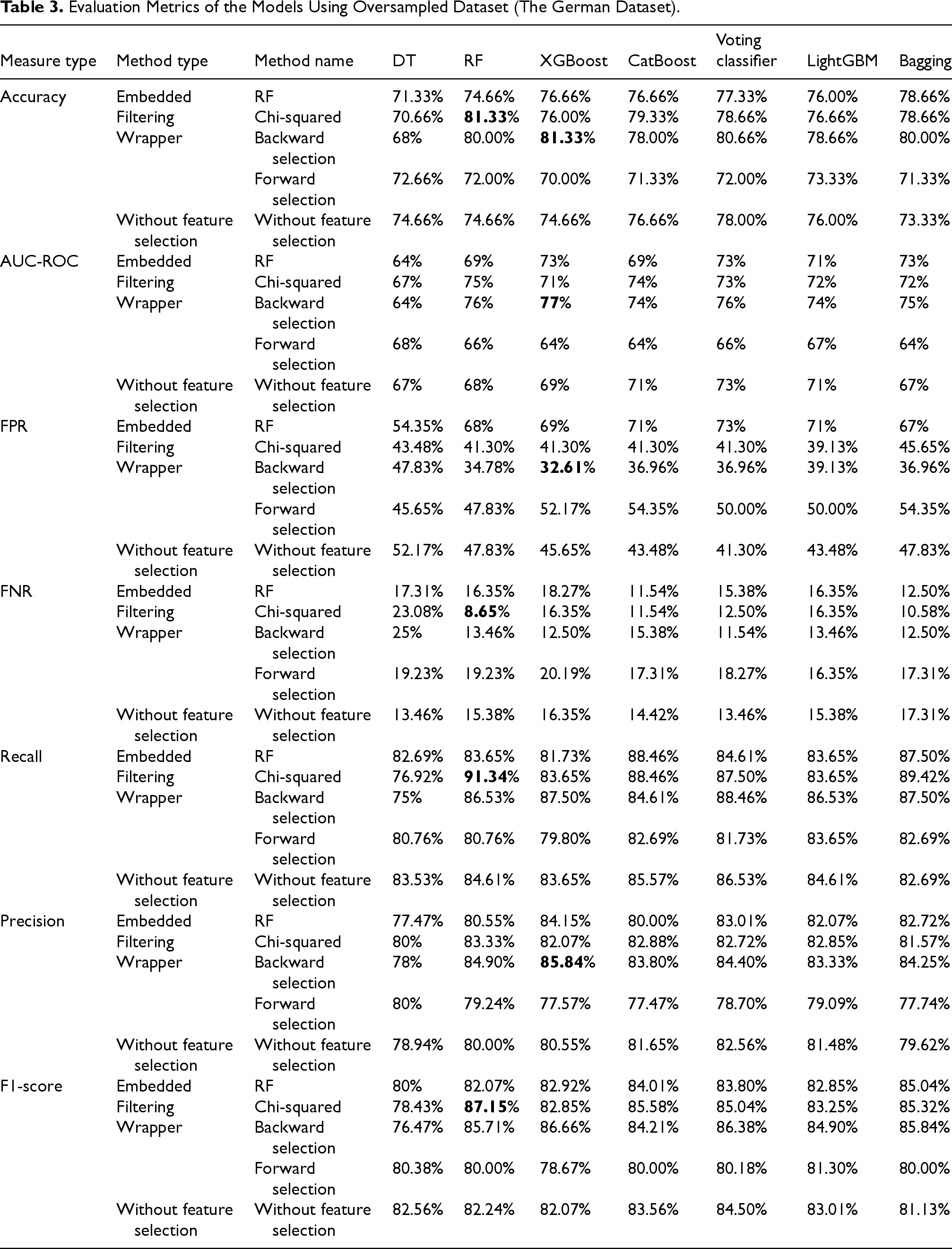
Table 4 lists the results of the various feature selection strategies and classification models on the undersampled German credit scoring dataset.
Evaluation Metrics of the Models Using Undersampled Dataset (The German Dataset).

The evaluation of classification models on the undersampled German credit scoring dataset shows that backward selection with XGBoost achieves the best accuracy, AUC-ROC, and precision. It also results in the lowest FPR. On the other hand, forward selection leads to poor results across all metrics, which means that excessive feature elimination negatively affects model performance when working with undersampled data.
The evaluation of the different models on the German credit scoring dataset under the three scenarios (original, oversampled, and undersampled) shows that the original dataset provides a baseline performance. Oversampling improves model accuracy and recall, while undersampling reduces FPR. Backward selection combined with RF and XGBoost leads the best performance, while forward selection leads to poor results.
In this section, the performance of the proposed models is explored on the Taiwan credit scoring dataset across the three scenarios: the original dataset, an oversampled dataset, and an undersampled dataset. Table 5 lists the results of the various feature selection strategies and classification models on the original Taiwan credit scoring dataset, without applying any data resampling techniques.
Evaluation Metrics for the Models Using Original Dataset (The Taiwan Dataset).
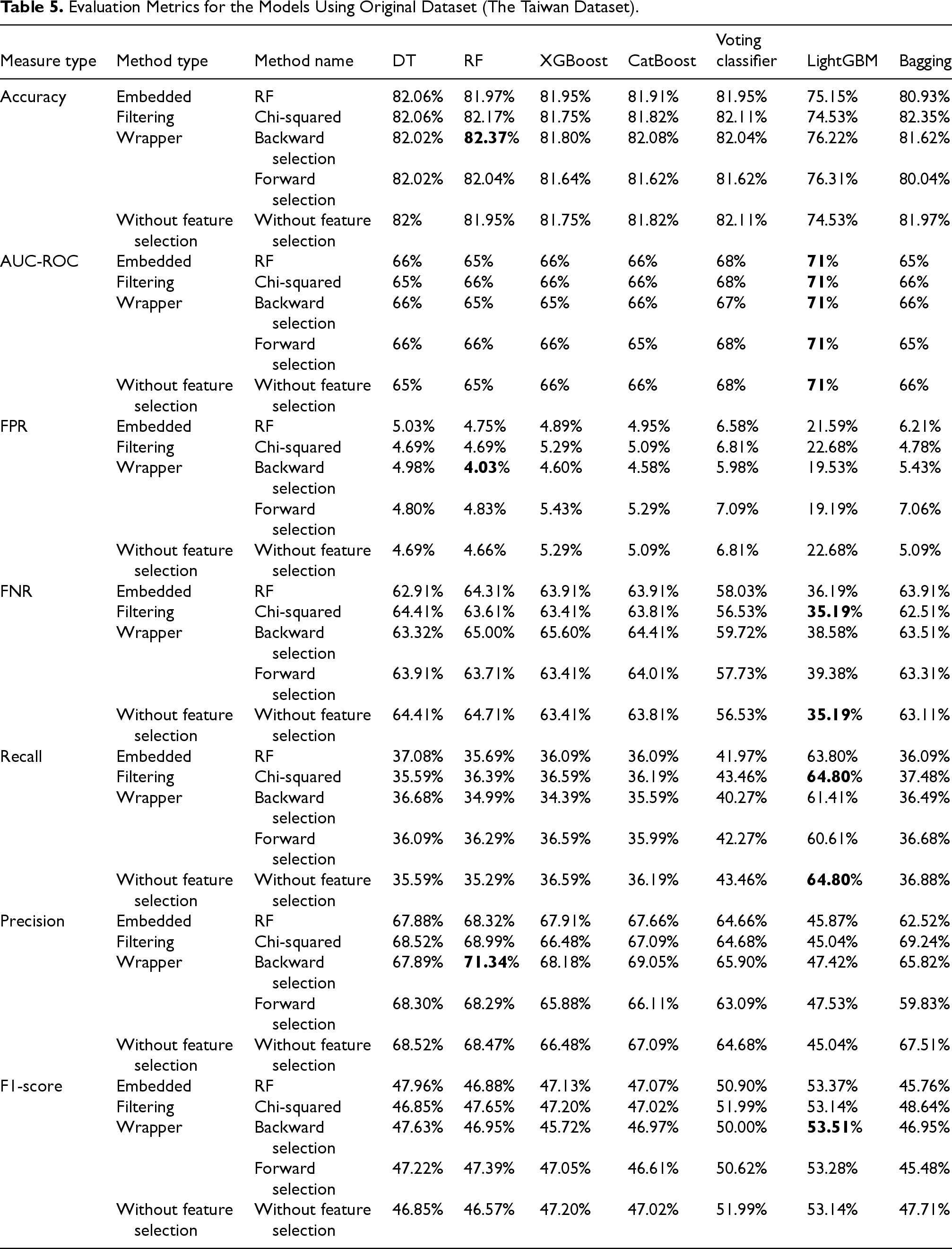
Evaluation Metrics for the Models Using Original Dataset (The Taiwan Dataset).
Table 6 lists the results of the various feature selection strategies and classification models on the oversampled Taiwan credit scoring dataset. The results in Table 6 show that accuracy of all models remains high but slightly lower than the accuracy on the original dataset. The highest accuracy is achieved when chi-squared filtering and backward selection are employed. This indicates that feature selection methods help improve performance when dealing with an oversampled dataset. In contrast, the FPR decreases for most models compared to the original dataset. Therefore, oversampling can be effective in minimizing false alarms.
Evaluation Metrics of the Models Using Oversampled Dataset (The Taiwan Dataset).

Table 7 lists the results of the various feature selection strategies and classification models on the undersampled Taiwan credit scoring dataset. The results in Table 7 show that accuracy on the undersampled dataset is lower than the accuracy on the oversampled dataset. However, RF and XGBoost models that integrate feature selection methods, especially forward selection, achieved high accuray. The results of these models indicate that feature selection method effectively compensates for data reduction due to undersampling. Another important note regarding the results in Table 7 is that the FNR is significantly lower than the FNR in case of the oversampled dataset, which means the models are better at detecting defaulters. This was proven by applying the paired t-test to the FNR values across all model-feature selection combinations. The results showed a statistically significant difference between the two sampling methods. The paired t-test resulted in a p-value of
Evaluation Metrics of the Models Using Undersampled Dataset (The Taiwan Dataset).
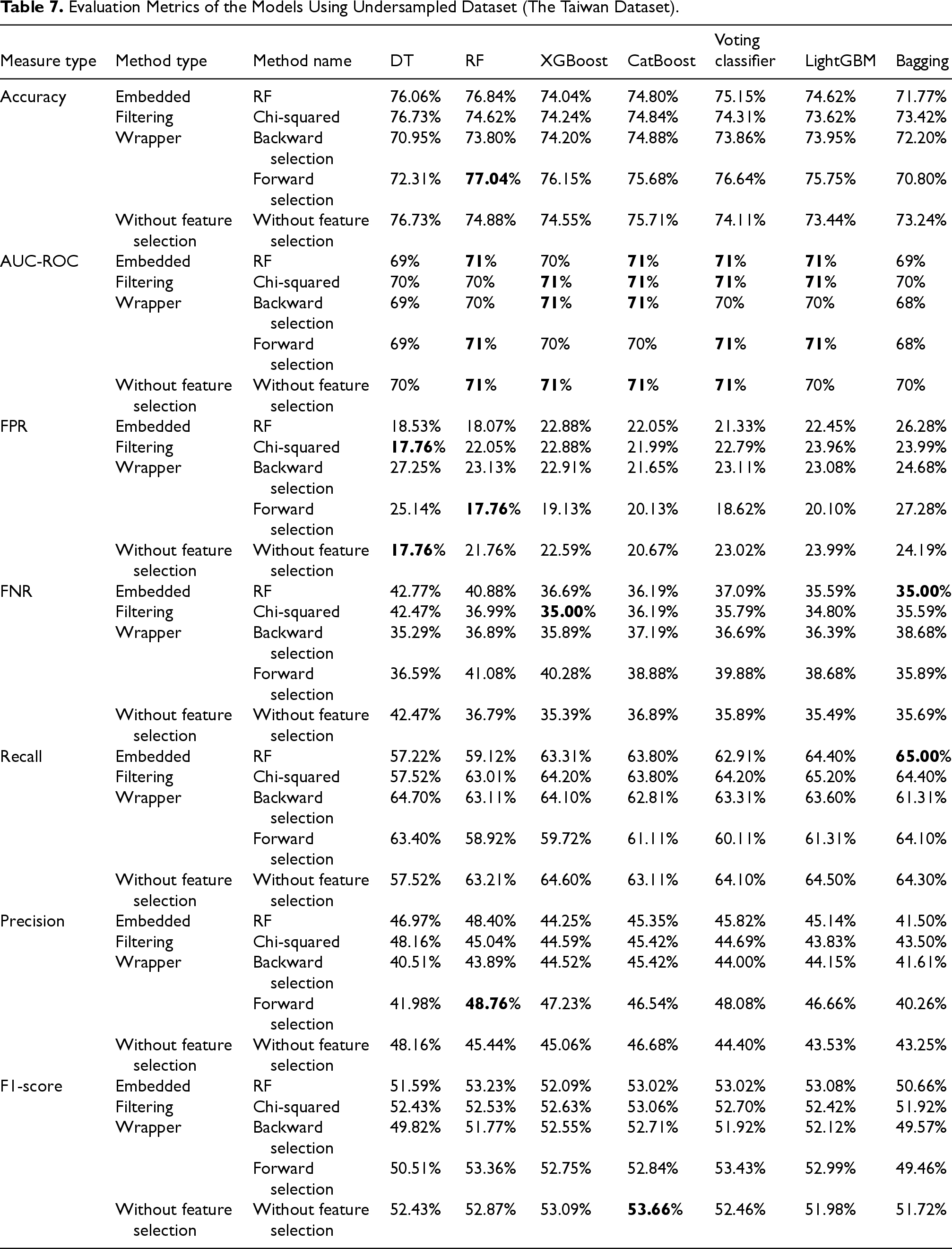
The evaluation of the different models on the Taiwan credit scoring dataset under the three scenarios (original, oversampled, and undersampled) shows that oversampling improves model accuracy and recall but increases FPR. Undersampling improves recall significantly but reduces accuracy and precision. Feature selection methods, especially forward selection, improve accuracy in case of the undersampling scenario.
In this section, the performance of the proposed models is explored on the Australian credit scoring dataset across the three scenarios: the original dataset, an oversampled dataset, and an undersampled dataset. Table 8 lists the results of the various feature selection strategies and classification models on the original Australian credit scoring dataset without applying any data resampling techniques. The results in Table 8 show that RF is the most balanced model. It achieves high accuracy and reasonable FPR and FNR. In contrast, models like XGBoost and CatBoost offer slightly less stable results.
Evaluation Metrics for the Models Using Original Dataset (The Australian Dataset).

Evaluation Metrics for the Models Using Original Dataset (The Australian Dataset).
Table 9 lists the results of the various feature selection strategies and classification models on the oversampled Australian credit scoring dataset. The results show notable improvements in certain metrics. For example, the FNR is reduced to 18.92%, while recall reaches 86.48% for RF. These results indicate that oversampling enables the model to identify defaulting customers more effectively. On the other hand, oversampling has a slight impact on accuracy and precision.
Evaluation Metrics of the Models Using Oversampled Dataset (The Australian Dataset).

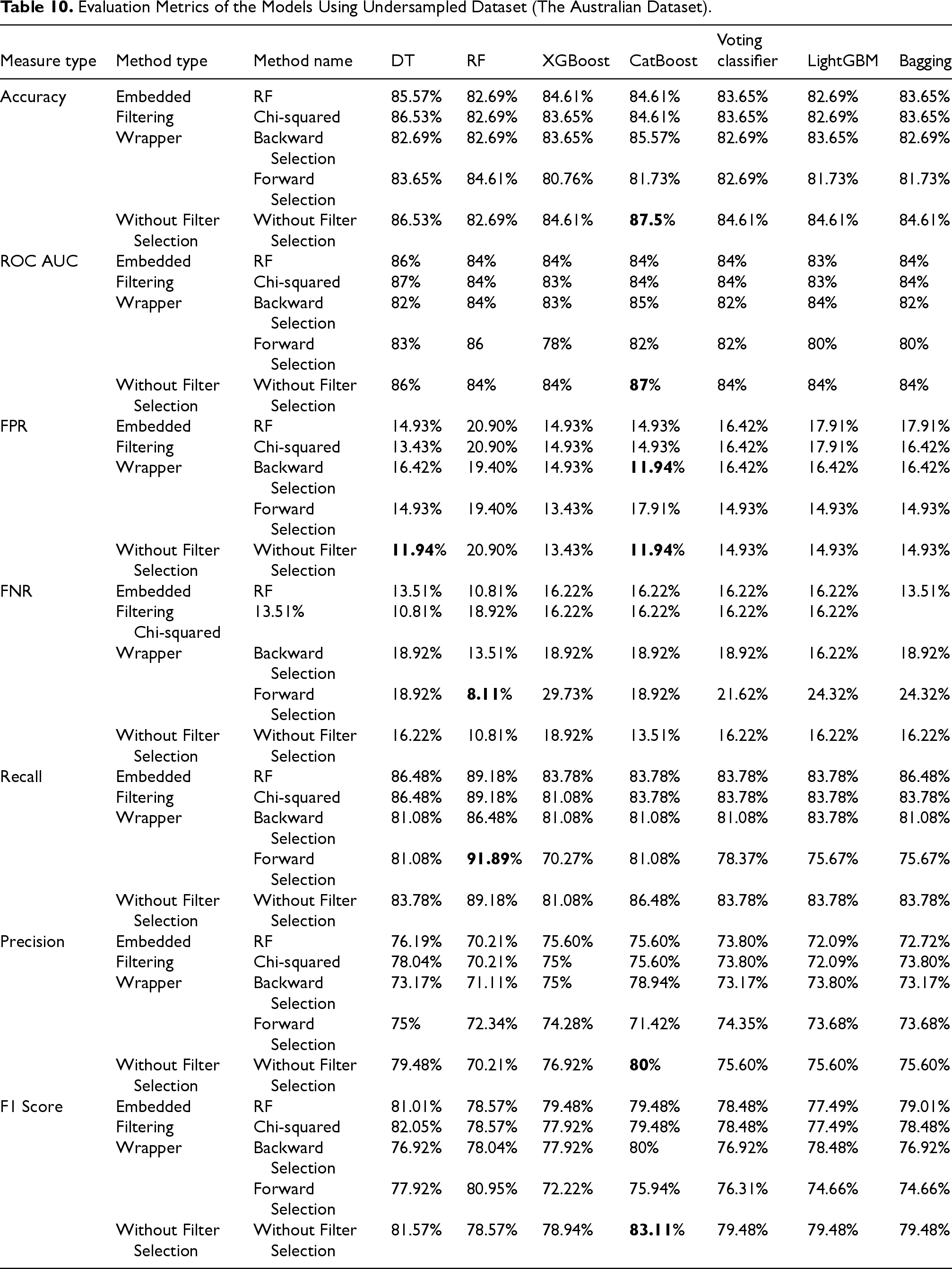
Table 10 lists the results of the various feature selection strategies and classification models on the undersampled Australian credit scoring dataset. The results show a decrease in accuracy and precision for many models. Additionally, the FPR for RF is slightly higher compared to the oversampled data. However, recall remains high, which indicates that the models are able to identify defaulting customers using undersampled data. Overall, overampling offers a better balance between recall, FNR, and accuracy when compared to undersampling.
Evaluation Metrics of the Models Using Undersampled Dataset (The Australian Dataset).
The experiments conducted using different models show that feature selection not only improves credit scoring performance but also enhances the interpretability of such models. By reducing the number of input features, feature selection methods can simplify the structure of complex classifiers, which makes their decisions easier to understand. For example, applying feature selection to simple models such as DT can result in more concise and interpretable decision rules. Even for ensemble models such as XGBoost and RF, which are typically less interpretable, reducing the feature space may lead to more explainable models. Therefore, it is recommended to employ feature selection not only as a performance enhancement tool but also as a mechanism for improving the interpretability of machine learning models in credit scoring applications.
In this paper, a framework for credit scoring is proposed. This framework consists of three main steps. It starts with data preprocessing. Then, multiple feature selection techniques such as, filtering-based methods and embedded methods are examined. Finally, seven different classifiers such as, RF, XGboost, and the voting classifiers are evaluated using the German, Taiwan, and Australian credit scoring datasets across three different scenarios: the original dataset, an oversampled dataset, and an undersampled dataset. For the original datasets, the model that led to the best performance is RF with backward selection. In the scenario of oversampled datasets, XGBoost with backward selection performed best. This paper highlights that feature selection methods, particularly backward selection, improve models’ performance. RF and XGBoost are the most effective models and oversampling is the best approach for handling imbalanced datasets. For future research, investigating the potential of deep learning models and advanced data enhancement techniques could be promising avenues for further improving credit scoring models. Furthermore, validating the proposed models using proprietary datasets to evaluate the model’s applicability and robustness in real-world contexts. Additionally, exploring the integration of nontraditional data sources, such as social media activity, consumer reviews, or loan application transcripts, could potentially offer additional insights into an individual’s creditworthiness and enable more personalized credit scoring approaches.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.