
Abstract
Objective
This study aims to develop an efficient and stable medical image classification framework that enhances feature extraction in high-dimensional spaces and improves training stability in traditional neural network models. The ultimate goal is to improve the accuracy and generalization capability of medical image classification
Keywords
Introduction
With the advent of the big data era, various complex high-dimensional datasets have gradually become the focus of research in the field of machine learning. How to effectively process and analyze these large-scale datasets to extract useful features is the key to improve the performance of models. Traditional feature extraction approaches, such as Principal Component Analysis (PCA), are able to reduce the dimensionality of the data and extract the main features of the data to a certain extent, but PCA often fails to adequately capture the complex structure of the data when confronted with nonlinear, high-dimensional data (Greenacre et al., 2022). In order to solve this problem, Fractional Principal Component Analysis, FPCA, as an improved dimensionality reduction approaches, has received widespread attention in recent years. Different from traditional PCA, FPCA does not introduce nonlinearity in the transformation itself. Instead, it redefines the covariance structure through fractional-order statistics, which modify the contribution of different signal amplitudes in the variance estimation (Abdi & Williams, 2010). This property enables FPCA to emphasize weak but discriminative structural variations while reducing the dominance of noise-sensitive components, leading to improved feature representation for complex medical images.
Although FPCA shows excellent performance in some specific applications, its parameter selection problem is still a challenge. For this reason, Particle Swarm Optimization, PSO is added to the FPCA algorithm to further improve its feature extraction capability and generalization performance by optimizing the key parameters in FPCA (Gewers et al., 2021). The particle swarm optimization algorithm can quickly find the optimal solution in the search space by simulating the process of bird flock foraging, so it is widely used in parameter optimization and model selection (Hasan & Abdulazeez, 2021). Combining PSO with FPCA can not only address the sensitivity of FPCA to fractional-order selection, but also improve its robustness by adaptively identifying the variance structure that best preserves discriminative information in a given dataset..
In this paper, a particle swarm optimization based fractional order principal component analysis algorithm (Particle Swarm Optimization Fractional Principal Component Analysis, PFPCA) is proposed, and the generalization ability of the algorithm on multiple standard datasets is verified. Through experiments on MRI brain tumor, COVID-19, and ocular ultrasound vascular image datasets created by lab members, this paper demonstrates the advantages of PFPCA in high-dimensional data processing, especially its potential to enhance feature extraction accuracy, reduce computational complexity, and improve classification accuracy, and validates the algorithm's ability to generalize across different datasets.
Materials and Methods
Improved PCA Algorithm Design
Traditional PCA Algorithm
PCA is a commonly used technique for dimensionality reduction, the core idea of which is to transform the data into a new column of mutually orthogonal axes using linear transformations on the axes, these new axes are referred to as the principal components (Uddin et al., 2021). The main purpose of PCA is to simplify the complexity and redundancy of the data while retaining the maximum amount of information (Biwasaka et al., 2024). The steps for its realization are as follows: The data set is combined into a matrix X of size Data standardization. The raw data were standardized to ensure that each feature had the same scale (mean of 0 and variance of 1). It is shown in Eq. (2).
Calculate the covariance matrix. The covariance matrix is used to measure the linear relationship between different features in the data. It is shown in Eq. (3).
The eigenvalues The first k principal components are selected based on the size of the eigenvalues, where k is the dimension after dimensionality reduction. Principal components with larger eigenvalues have higher variance in the data and represent important information in the data. The eigenvectors The dataset is transformed into a new feature space consisting of k feature vectors to obtain new data
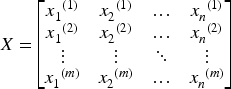
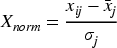
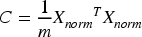
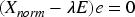
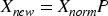
FPCA is an extension of traditional PCA, which finds the main features of the data by calculating the covariance matrix (Pahnehkolaei et al., 2022), but this approaches may not be able to capture the weak feature information well on some complex datasets (e.g., images and signals) (Wang et al., 2019). FPCA, by utilizing the fractional order covariance matrix, is able to better deal with the complex, non-smooth, and long-range dependent signal or image data (Sahlol et al., 2020).
Let
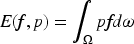
Eq. (6) can also be viewed as the weighted average of function f with respect to weighting function p. Therefore, the variance formula can also be expressed as follows:
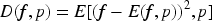
Based on the definition of fractional order moments, we can obtain a new formula for the definition of fractional order variance of a function
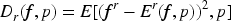
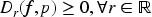
In statistical applications, for any function
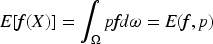
The variance expression is Eq. (11).
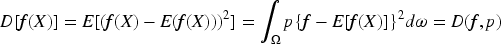
In summary, the expression for the fractional order variance of the random variable
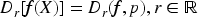
Therefore, the following relationship between fractional order variance and general variance can be introduced:
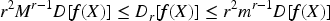
Applying the fractional order variance matrix in Eqs. (13) to PCA, a new technique will be obtained, which we call fractional order principal component analysis FPCA, due to the uncertainty of the fractional order variance results, for this purpose a normal distribution solver for solving the fractional order variance is used. The mean value Eqs. (14) is utilized on the basis of Eqs. (13).
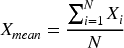
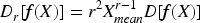
After FPCA, the number of retained principal components was determined based on the cumulative variance contribution rate. In this study, the smallest number of components preserving at least 95% of the total variance was selected, resulting in a reduced feature dimension that balances information retention and computational efficiency.
From a statistical and spectral perspective, the introduction of fractional-order variance changes the relative contribution of different eigenmodes by applying a power-law weighting to signal amplitudes. Compared with conventional second-order variance, fractional-order statistics are less dominated by large-amplitude variations and therefore more sensitive to weak structural patterns that are often overwhelmed by noise in medical images.
As a result, FPCA improves robustness to noise and illumination variations while preserving the linear interpretability of PCA-based feature representations. Similar advantages of fractional-order statistics for image analysis and medical imaging tasks have been reported in previous studies.
Particle Swarm Optimization (PSO) is an optimization algorithm that simulates group intelligence (Xie et al., 2021). Originally proposed by Knnedy and Eberhart in 1995, the algorithm was inspired by the social behavior of birds foraging and fish swimming in flocks (Lu et al., 2022). In the PSO algorithm, each particle represents a potential solution in the solution space, has a position and velocity, and searches for the optimal solution based on its current position and velocity as it moves through the search space. Each particle adjusts its position during the search process based on its own experience and the experience of its neighbors to achieve the global optimal solution search (Gad, 2022).
For any particle i in the particle swarm, the position and velocity at the k th update can be denoted as

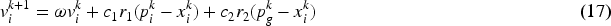
Where
According to the inertia weighting approaches, the inertia coefficient ω varies decreasingly during the search process according to Eq. (18).
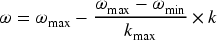
In each iteration, each particle trains the PCA model based on the current
The model framework proposed in this paper is shown in Figure 1. An improved Particle Swarm Optimization Fractional Principal Component Analysis, PFPCA, which combines the particle swarm algorithm with the mean fractional order covariance calculation, not only improves the local sensitivity and nonlinear feature extraction ability of the algorithm in the image feature extraction process, but also effectively searches for the global optimal solution through the advantages of the particle swarm algorithm. The algorithm combines the particle swarm algorithm with the mean fractional order covariance computation, which not only improves the algorithm's ability to extract local sensitivity and nonlinear features in the process of image feature extraction, but also effectively searches for the globally optimal solution through the advantage of particle swarm algorithms (2020). And the BP neural network with improved Sigmoid activation function is utilized to classify the dimensionality reduced ocular vascular ultrasound image, which effectively improves the classification performance and restores the main features of the image through the linear property of PCA (Li et al., 2021)
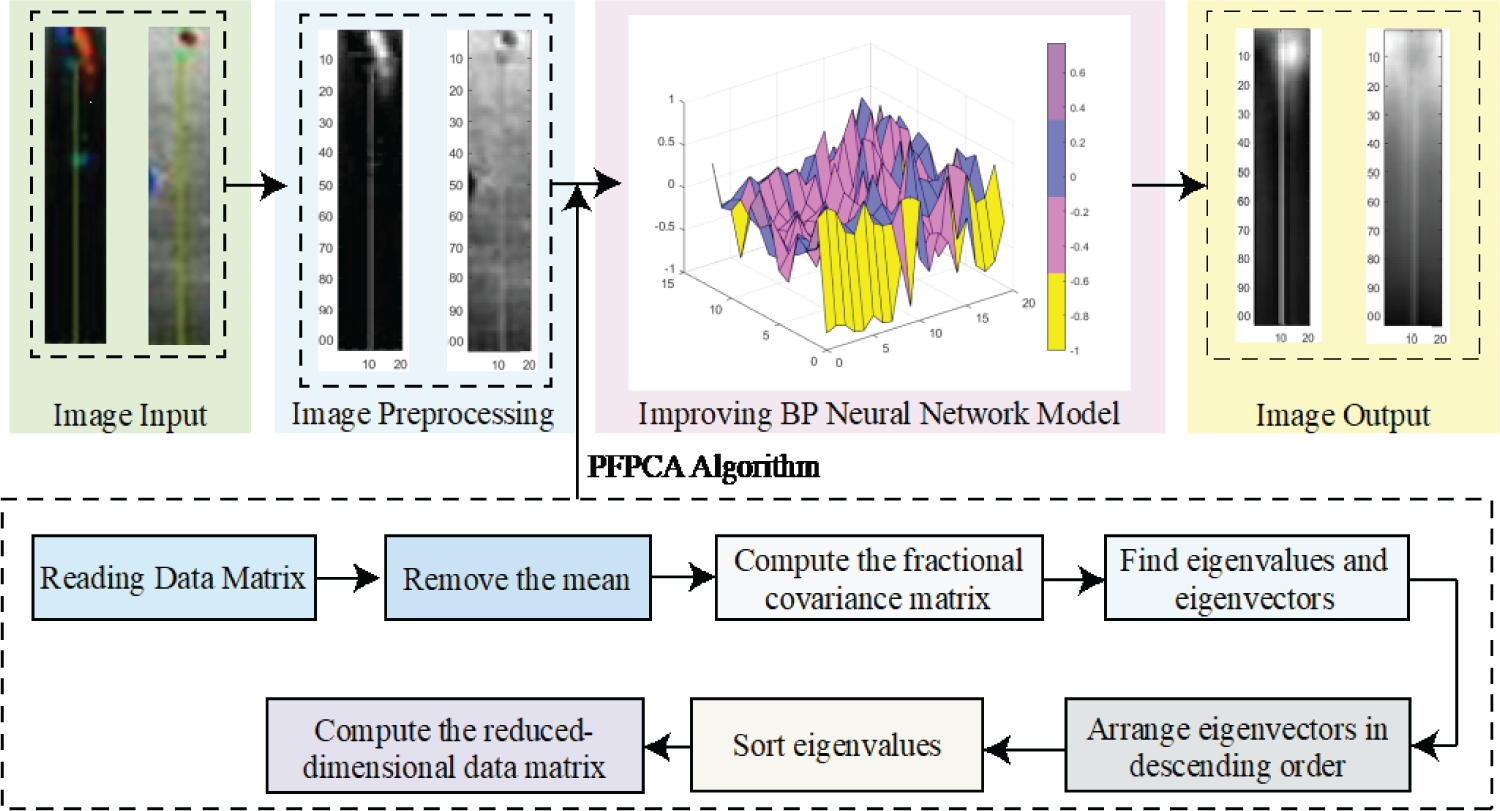
Model framework.
In neural networks, the activation function plays a crucial role, especially during backpropagation (Aswathy & Hareendran A, 2021). The classical Sigmoid function is widely used to activate neurons, but its output is bounded within the range [0, 1], which may lead to output saturation when the input values are extremely large or small, potentially affecting training dynamics and convergence behavior.To improve numerical stability during training, this paper adopts a modified Sigmoid activation function by applying an output shift to the original Sigmoid function (Tang & Yu, 2021). This modification adjusts the output range of the activation function and is intended as a practical stabilization strategy within the conventional BP neural network framework, rather than a theoretical alteration of gradient behavior.
The expression of the improved Sigmoid function is:
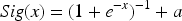
BP neural network is a commonly used multilayer feed-forward neural network, which is widely used in various pattern recognition and classification tasks (Hosseinzadeh et al., 2021). Its basic principle is to achieve the goal of minimizing the network error by continuously adjusting the network weights through the error backpropagation algorithm (Backpropagation Algorithm, BA). The algorithm was first proposed by Rumelhart and McClelland, and effectively overcame the problem of adjusting the weights of the hidden layer, laying the foundation of BP neural networks (Annamalai & Muthiah, 2022).
The structure of BP neural network is shown in Figure 2, which usually consists of input, hidden and output layers, and the layers are connected to each other by weights. Assuming that the input layer of the network is The inputs to the hidden layer neurons are:
The output of the hidden layer neuron is:
the input to the output layer neuron is:
The output of the output layer neuron is:
Bp neural network structure diagram.
where 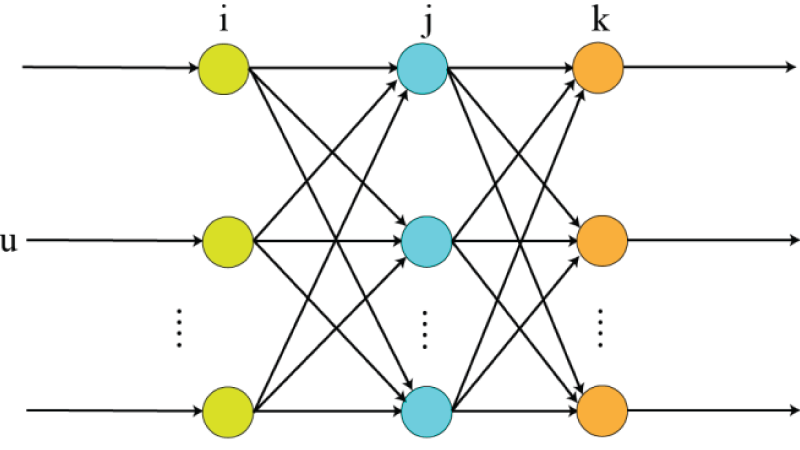
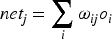
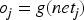
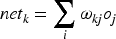
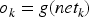
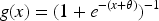
In the training process of BP neural network, the error of the network is calculated by back propagation algorithm and the weights are updated according to the gradient descent approaches. Assuming that the actual output of the network is
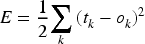
In the weight update phase, backpropagation calculates the gradient of the error to the weights and obtains an update formula for each weight by the chain rule. Specifically, the error gradient of the output layer is:
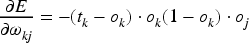
The error gradient of the hidden layer is:
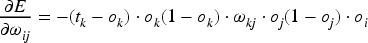
In this paper, the improved sigmoid activation function is used, whose formula is shown in Eq. (19), and the range of values is set to [0,10], and its recognition rate is shown in Figure 3:
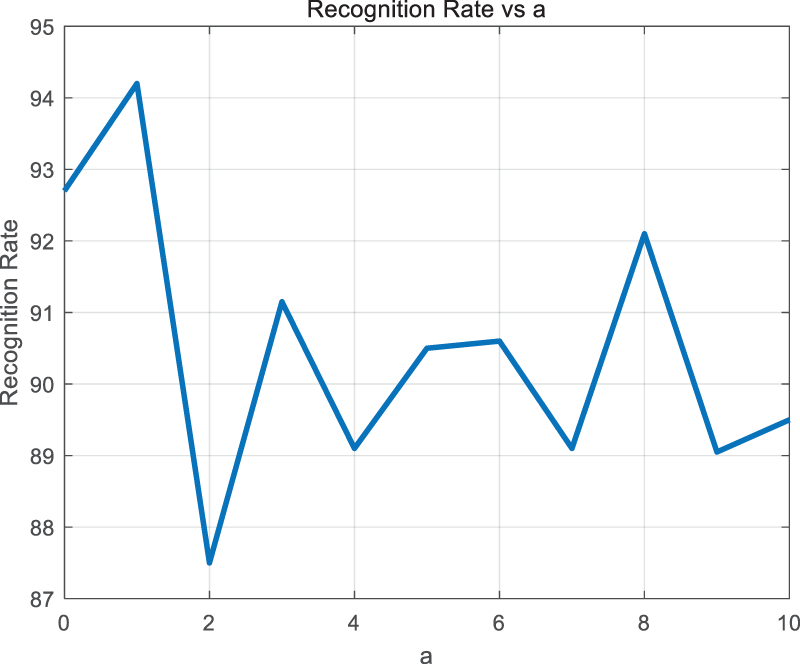
Model recognition rate at different a.
In summary, the value of a is determined to be 1. The improved sigmoid activation function formula is shown in Eq. (28).
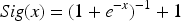
Through this adjustment, the activation function maintains a larger gradient during backpropagation, which enhances the stability and convergence speed of the network during the training process. Compared with the traditional Sigmoid function, the improved function can effectively avoid the training stagnation phenomenon caused by the small gradient, especially in the face of complex medical image data, which can accelerate the training process of the network and improve the classification accuracy.
It should be noted that the proposed modification is not intended to replace modern activation functions such as ReLU or its variants, but rather to provide a simple and stable adjustment within the BP neural network framework adopted in this study, allowing controlled comparison with conventional BP-based classifiers.
After using the improved Sigmoid activation function during the training process, the formula for the output layer becomes:
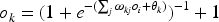
The formula for the hidden layer becomes:
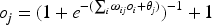
For the gradient computation of the weight update, the gradient formula for the error to-weight after using the improved Sigmoid activation function is as follows:
This improvement enhances the nonlinear transformation capability of the network, which helps to accelerate the training process of the network and improve the classification accuracy, especially in the complex medical image classification task to better adapt to the characteristics of the data.
Experimental Platform and Parameter Setting
Experimental platform: the operating system is Windows 11, the processor is Intel i7, and the memory is 16 GB. experiments were conducted using MATLAB R2023a. the three datasets used in this paper are the public dataset MRI brain tumors on the web, the COVID-19 dataset, and the ophthalmologist of a medical school accumulates, and the laboratory members carry out the processed ocular vascular images.
The COVID-19 chest X-ray image dataset used in this study was downloaded from the Kaggle repository “Radiography Dataset COVID” (available at https://www.kaggle.com/datasets/raunakgola/radiography-dataset-covid). This dataset contains chest radiographs from four classes (COVID-19, Lung Opacity, Viral Pneumonia, and Normal) and was curated from publicly available medical imaging repositories under the guidance of radiology experts.The COVID-19 dataset consists of four categories, of which the training set includes COVID (3616 images), Lung Opacity (6012 images), Normal (10192 images) and Viral Pneumonia (1345 images). And 1300 images from each of the four diseases were sorted out as the data for this experiment; MRI brain tumor dataset includes four categories, of which the training set includes glioma tumor (826 images), meningioma tumor (822 images), nontumor (395 images) and pituitary tumor (827 images). The images were processed and the resolution was changed to 244*244. some of the experimental samples are shown in Figure 4.For the COVID-19 dataset, an equal number of images (1300 per class) were selected to construct a balanced experimental dataset. The samples were randomly drawn from the original dataset without replacement to avoid duplication. This strategy was adopted to reduce class imbalance and to ensure fair comparison across categories, rather than to preferentially select simpler or cleaner samples.
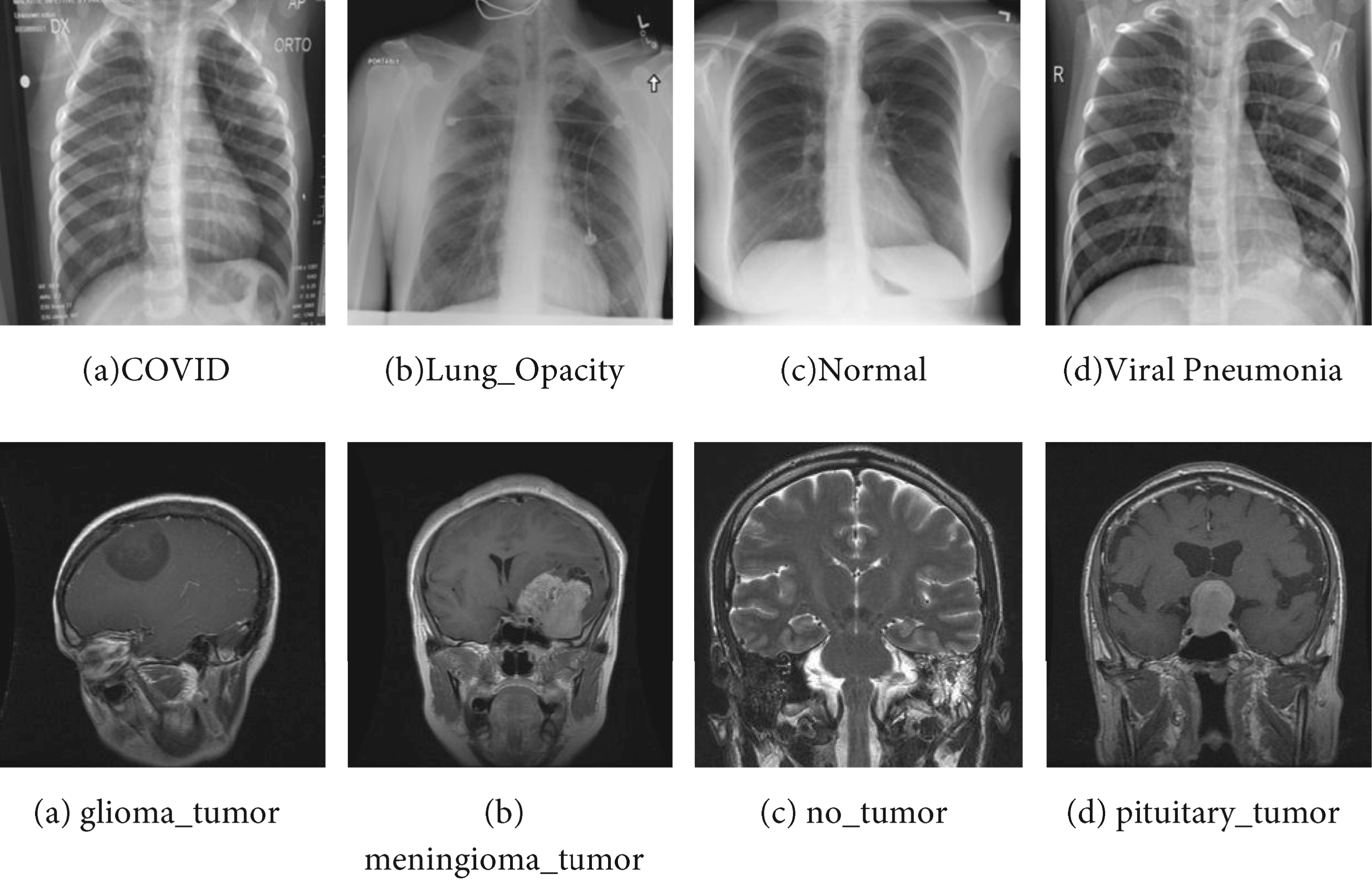
Diagram of experimental samples.
The ocular vascular image dataset contains two main categories, the central retinal artery (CRA) and the posterior ciliary artery (PCA). This dataset contains 2 directories, each directory represents a different category, there are 1296 images under each directory, and its resolution is 640*480. the acquired images are processed, the left side of Figure. 5 is the original image, the red box position in the figure is the part we need, and the right side is the processed image.
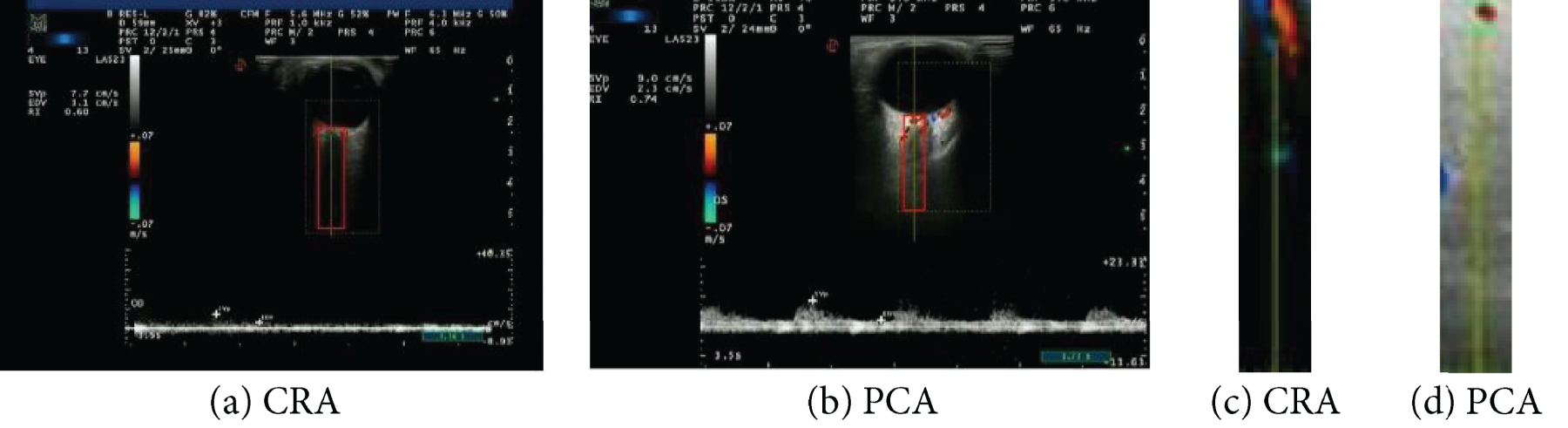
CRA, PCA image.
For all experiments, each dataset was randomly split into training and test sets, with 70% of the samples used for model learning and PSO-based parameter optimization, and the remaining 30% strictly reserved for final performance evaluation and not accessed during the optimization process.
In the PSO implementation, the swarm size was set to 20 particles, and the maximum number of iterations was 30. The inertia weight decreased linearly during optimization, and the acceleration coefficients were set to commonly used values. The optimization process terminated when the maximum number of iterations was reached.
Validation of Different Algorithms on Three Datasets.

Results of Ablation Experiments.

The following figure Figure 6: Recognition rate for different rshows the line graph of recognition rate for different datasets with different r-values in the PFPCA + Improved BP model.
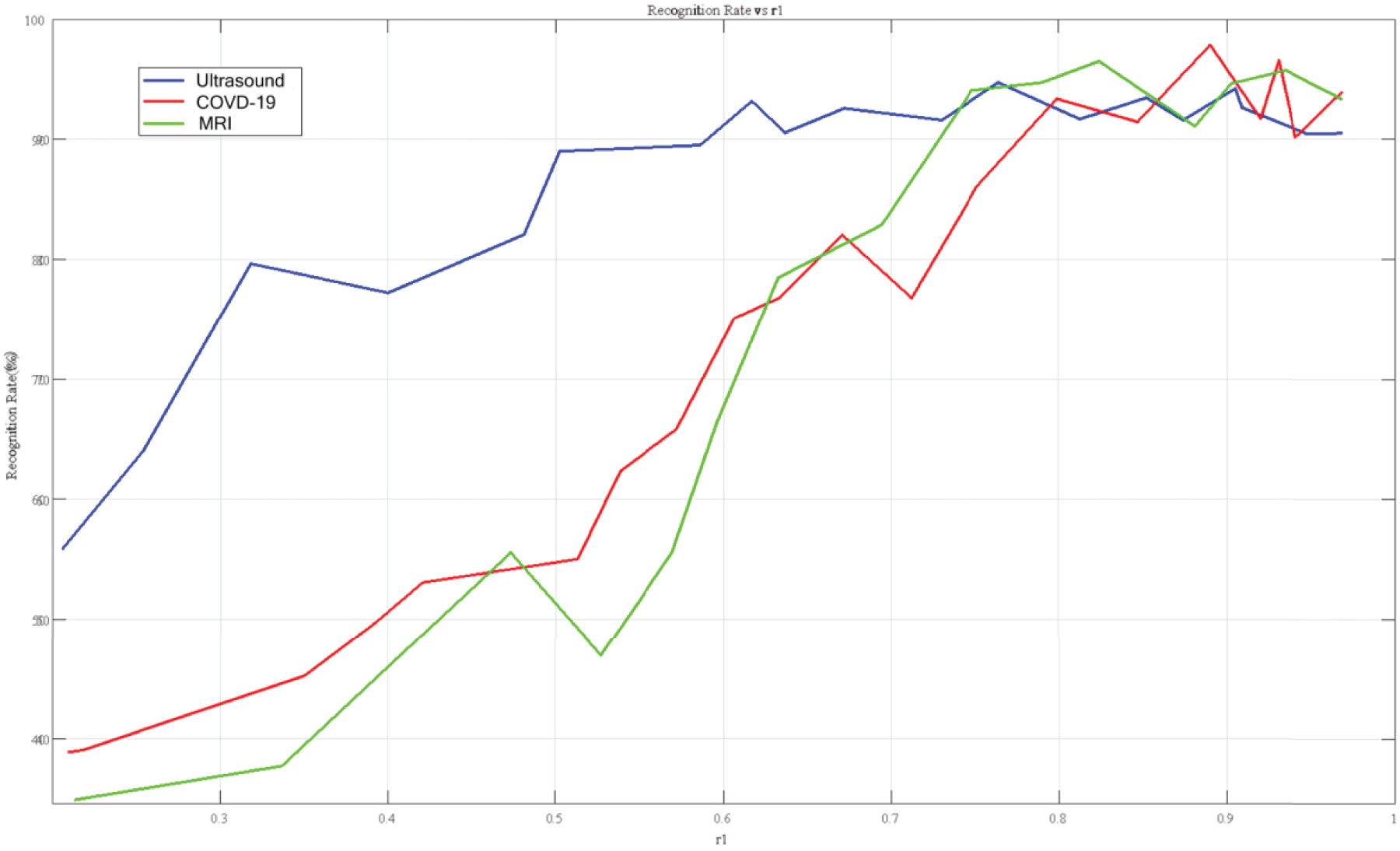
Recognition rate for different r.
To provide a more comprehensive evaluation beyond overall accuracy, we report additional performance metrics including macro-averaged precision, recall, F1-score, and specificity. These metrics are particularly important for multi-class medical image classification tasks, as they better reflect per-class performance and potential misclassification patterns.The confusion matrix for the MRI brain tumor dataset is shown in Figure. 7. The model achieves high correct classification rates across all four classes, with minimal inter-class confusion. Most misclassifications occur between glioma and meningioma tumors, which is consistent with their visual similarity in certain cases.These results demonstrate balanced performance across all categories.Additional performance evaluation results are illustrated in Figure 8. The high macro recall (0.958) indicates strong sensitivity in detecting different tumor types, while the high macro specificity (0.987) reflects a low false positive rate. The macro F1-score (0.951) further confirms the robustness and stability of the proposed classification framework.
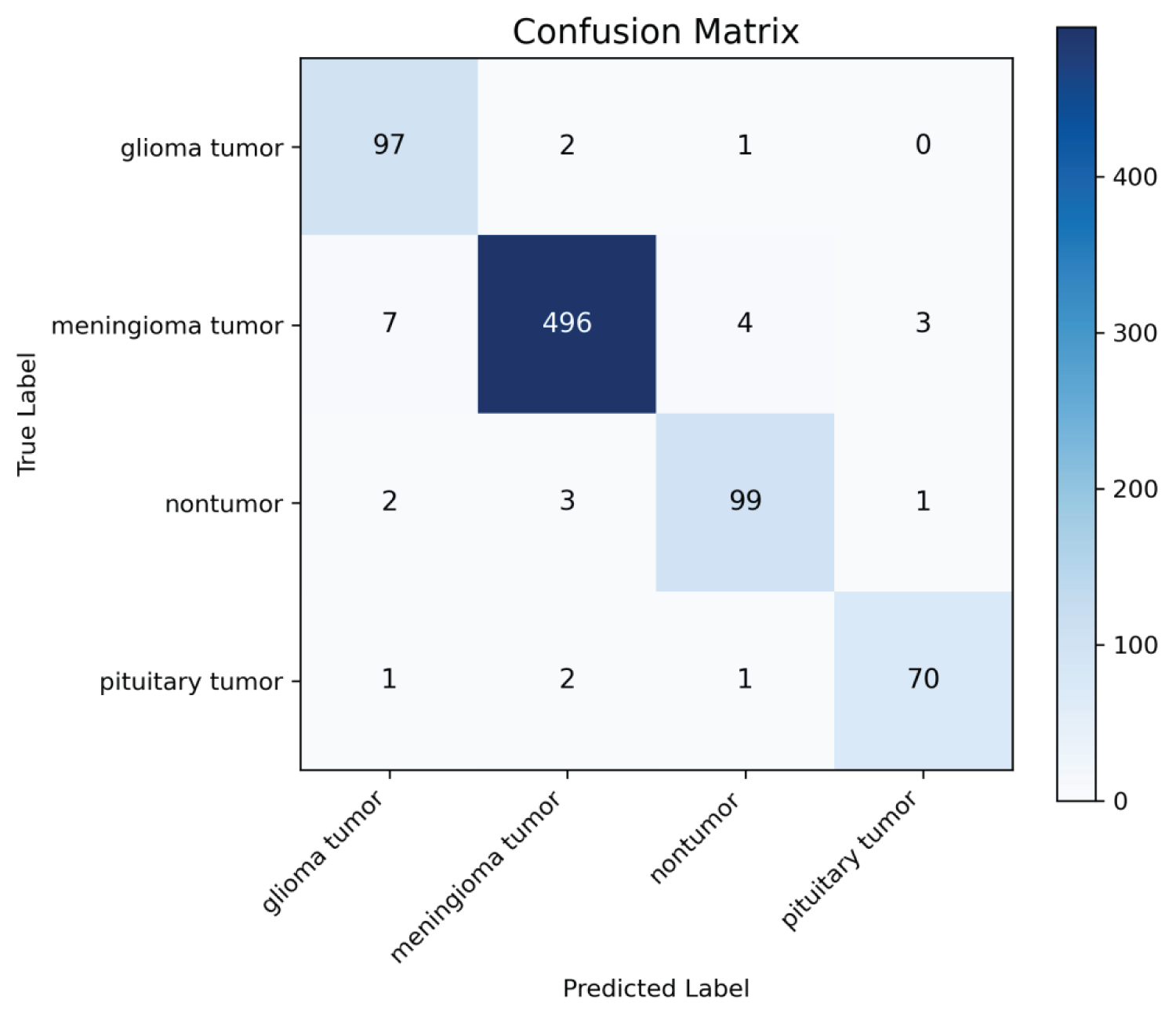
Confusion matrix of the proposed model on the four-class MRI brain tumor dataset.
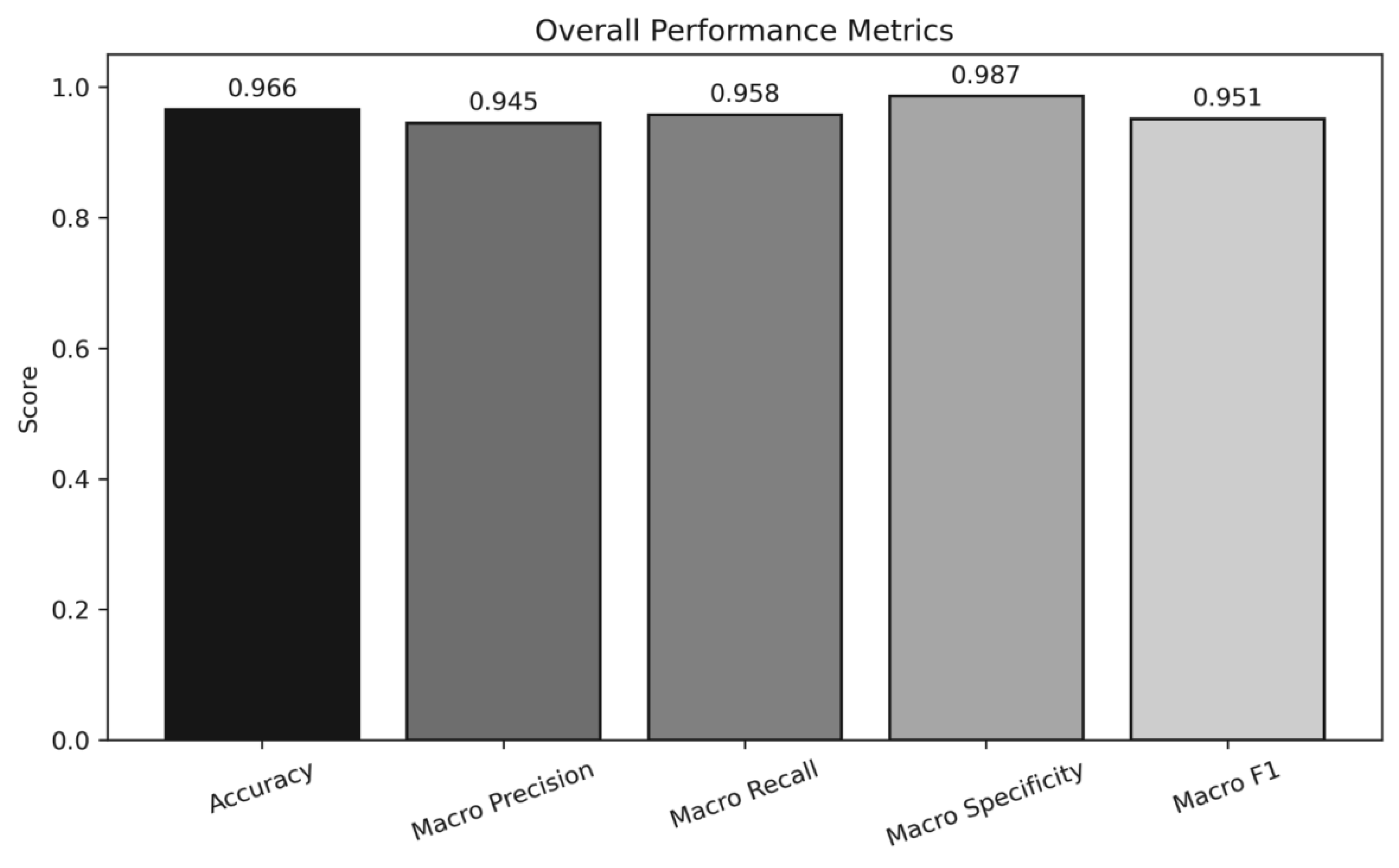
Overall performance metrics of the proposed model on the MRI brain tumor dataset.
In the MRI brain tumor dataset, the recognition rate reaches the maximum value of 96.53% when the fractional order is 0.824; in the COVID-19 dataset, the recognition rate reaches the maximum value of 97.89% when the fractional order is 0.89; in the ocular vascular image dataset, the recognition rate reaches the maximum value of 94.75% when the fractional order is 0.764. It can be seen that for different datasets, the order of fractional order is different when the maximum recognition rate is reached, so the fractional order principal component analysis algorithm with the addition of PSO can better deal with this problem.
For all experiments, the datasets were randomly split into training and test sets, with the test set used exclusively for final performance evaluation. During the PSO optimization process, the fitness of each particle was evaluated only on the training data, and the test set was not accessed or used in any stage of parameter tuning. The fractional-order parameter optimized by PSO was fixed after training and then applied to the test set for reporting the final results.
In order to verify the contribution of each of the innovations proposed in this paper to the ophthalmic image classification performance, we designed a series of ablation experiments. The specific experimental setup is as follows: Complete model: Includes improved Sigmoid function, fractional order principal component analysis (PCA), and particle swarm optimization (PSO) algorithm. Remove PSO: Instead of using PSO optimization in fractional order PCA, fixed fractional order parameters are used. In conducting the lab, r1 is chosen to be 0.9. Remove fractional order PCA: Instead of fractional order PCA, traditional PCA is used for feature extraction. Remove the improved Sigmoid function: the standard Sigmoid function is used instead of the improved Sigmoid function.
All experiments are performed on the same training set and test set.
As can be seen from Table 2, the complete model outperforms the other models in all evaluation indexes, which are analyzed as follows: Contribution of PSO optimization: after removing PSO, the classification accuracy of the model decreased by 2.04%. This indicates that PSO plays an important role in automatically finding the optimal fractional order parameters, which can effectively improve the classification performance of the model. Contribution of fractional-order PCA: After removing fractional-order PCA, the classification accuracy of the model decreases by 3.6%. This indicates that fractional-order PCA is better than traditional PCA in feature extraction and can better retain the key feature information of the image. Contribution of the improved Sigmoid function: after removing the improved Sigmoid function, the model has the highest classification accuracy when r1 is 0.8, but the classification accuracy decreases by 1.79% compared with the full model. This indicates that the improved Sigmoid function has an advantage in nonlinear mapping and can improve the expressive ability of the model.
According to the results, it can be seen that the addition of the fractional order PCA has the greatest impact on the experiment, which reaches 3.6%, and the PSO can help to find the r1 value at the optimal accuracy, but it does not have an impact on the classification results.
Based on the above analysis, in the image classification problem, this paper further improves the performance of image classification by introducing the particle swarm algorithm to optimize the fractional order parameter in the FPCA algorithm. The particle swarm optimization algorithm improves the classification accuracy and robustness by globally searching for the optimal fractional order r1, which enables FPCA to extract the features in the image more effectively. The experimental results show that the particle swarm optimization optimized FPCA algorithm is improved in terms of recognition rate. Although PSO introduces additional computational overhead due to iterative parameter evaluation, the optimization is performed only once during training, and the resulting fractional-order
parameter is fixed for inference. In practice, the additional training time was moderate compared with the overall classification pipeline.The generalization ability of the proposed algorithm is also demonstrated by validating it on different datasets.
By comparing with PFPCA + BP and FPCA + Improved BP algorithms, the particle swarm optimization algorithm is able to provide accurate parameter tuning for FPCA, which helps to improve the accuracy and efficiency of image classification. It should be noted that the experimental evaluation in this study is limited to a small number of benchmark datasets. Although the proposed method demonstrates consistent performance improvements across these datasets, further validation on larger-scale clinical data, cross-institutional datasets, or under domain shift conditions would be necessary to fully establish its generalization capability.In future research, this paper plans to further optimize the algorithm and explore more preprocessing approachs, such as denoising and contrast enhancement, to further improve the classification effect. In addition, combining deep learning models such as convolutional neural networks and other improved algorithms will be the focus of future work to further improve the efficiency and robustness of image classification.
Footnotes
Ethical Approval and Informed Consent Statements
This paper utilized publicly available datasets and were used in accordance with their respective license agreements.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was supported by the Liaoning Provincial Department of Education Basic Research Project for Higher Schools (LJKZ0245) and the Equipment Preliminary Research Key Laboratory Fund Project (2021JCJQLB055006).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of Data and Materials
The data that support the findings of this study are available from the corresponding author upon reasonable request.