
Abstract
Semantic segmentation was performed on 177 large histological images of re-endothelialized mouse lung vasculatures. Specifically, patch-based semantic segmentation algorithms were used to classify pixels corresponding to two classes: organ tissue, which includes lung and heart tissue; and ruptured and/or dilated vessels, which are abnormal vessels formed during re-endothelialization. Semantic segmentation is a potential means to automate the end-to-end analysis of these images, circumventing denoising and enhancement operations to visualize tissue and bypassing the manual diagnosis of ruptured and/or dilated vessels. To increase data quantity, images were compressed to sizes 1024 × 1024, 768 × 768, and 512 × 512 and then divided into nonoverlapping 256 × 256 patches. To benchmark the performance of the patch-based models, a vanilla model trained on complete images compressed to size 256 × 256 was also evaluated. The U-Net and LinkNet architectures were used to train and test each model using a data augmentation and transfer learning approach, and their results were ensembled. The loss of image context in the 3 × 3 and 4 × 4 patch-based models negatively impacted performance, generating many false positive predictions for target classes, whereas the low-image quantity of the vanilla model hindered performance. The 2 × 2 ensemble patch-based model returned the best performance, classifying organ tissue with a precision, recall, and intersection over union (IOU) of 88.0% ± 5.7%, 84.7% ± 9.2%, and 76.3% ± 10.9%, respectively, and classifying ruptured/dilated vessels with a precision, recall, and IOU of 78.4% ± 5.2%, 60.2% ± 11.4%, and 51.0% ± 8.4%, respectively.
Impact Statement
To evaluate re-endothelization quality, the absence of ruptured and dilated vessels must be confirmed in the resultant re-endothelialized lung scaffold through subjective, work-intensive, and time-consuming per-image manual analysis. In this study, we apply computer vision to detect the ruptured and/or dilated vessels from re-endothelialized histology images via end-to-end semantic segmentation. We also investigate the viability of a patch-based semantic segmentation approach to detect ruptured and/or dilated vessels and generate high-resolution masks. Through this work, the potential of computer vision to automate and standardize the characterization of recellularized lung histology is demonstrated.
Introduction
Lung disease remains a leading cause of death across the world. 1 Lung transplantation is the sole treatment for end-stage lung disease, which was estimated in 2019 to affect up to 392 million people worldwide. 1 Despite the necessity of transplants in improving and/or prolonging the life of the recipient, the median survival postprocedure is only 5.9 years, 2 mainly due to high rates of graft rejection post transplantation. 3 Although survival has improved over recent years due to advances in the use of immunosuppressants, lung transplant survival still lags in comparison to other organ transplants. 4 Thus, alternate treatments, such as the use of nonimmunogenic bioengineered lungs that have the potential to ameliorate immune rejection, are necessary. 5
Of particular interest is the use of decellularization and recellularization to generate bioengineered lungs.6–8 This involved repopulating a decellularized donor lung scaffold with cells that have been isolated from the recipient (or nonimmunogenic universal cell lines 9 ), thus reducing the likelihood of a posttransplant rejection.10,11 Decellularization typically involves treatment with a detergent to lyse and remove the donor cells from the organ, leaving behind a structurally intact scaffold. Recellularization is then performed on the resultant scaffold, repopulating it via delivery and culture of cells. Although the generation of bioengineered lungs via recellularization is a promising and captivating approach, there are challenges that need to be overcome to enable eventual clinical application. The majority of these challenges pertain to the repopulation of scaffolds, which requires reconstitution of both the epithelium and the endothelium. Hindrances impeding successful endothelialization include uneven distribution of seeded cells in the lung, in particular to the distal vessels, and the formation of ruptured and dilated vessels in the scaffold.
During the re-endothelialization process, ruptured and dilated vessels can form in the lung vasculature, both of which are noted in the literature as undesirable results.12–15 A rupture and a dilated vessel in the lung vasculature can not only impede the functionality of a lung but also compromise its viability for transplantation. Although a high accumulation of pressure during re-endothelialization can cause a rupture, their formation cannot necessarily be predicted. 13 Hence, detecting ruptures and dilated vessels in images of re-endothelialized lungs is an important step in evaluating the quality of the re-endothelialization process.
The detection of ruptures and dilated vessels in histology also has relevance outside of re-endothelialization. For instance, detecting ruptures in histological images aids in the characterization of blast lung injury 16 or pneumothoraxes. 17 Moreover, the presence of dilated vessels in histological images contributes to the diagnosis of conditions such as acute respiratory distress syndrome 18 and bronchopulmonary dysplasia. 19 In essence, the detection of ruptures and dilated vessels in histological images is not exclusive to re-endothelialization, which is the focus of the work herein.
Histological imaging is an important tool in diagnosing ruptures and dilated vessels, but the process can be subjective when distinguishing them from ordinary vessels. In addition, the analysis of many histological images can be time consuming, especially when considering the varying quality of these images, which can leave them difficult to interpret. Image operations can reduce noise, remove artifacts, and improve readability, but the appropriate operations can differ across images, making image enhancement another lengthy and work-intensive process. The automation of tissue segmentation to visualize the vasculature and the detection of ruptures and dilated vessels to highlight regions of interest could provide a consistent and scalable means of analyzing images of re-endothelialized lungs. This can be accomplished through semantic segmentation.
Semantic segmentation refers to the pixel-wise classification of an image, typically through the application of machine learning methods. Specifically, semantic segmentation makes use of deep learning, where inputs are mapped to outputs using a network of complex mathematical functions called neurons (i.e., an artificial neural network). 20 A convolutional neural network (CNN) is a deep learning neural network often applied to image analysis, where a series of maximum pooling, convolutional, and other mathematical operations are used to extract and make predictions based on features such as edges and colors from image data. 20 The most common semantic segmentation models are inspired by or based on the CNN, with an example being the popular U-Net model.
Data scarcity is a frequent hindrance in biomedical imaging research for deep learning applications,21–23 which typically require thousands of instances of training data to optimize the many model parameters. To overcome this scarcity, Ronneberger et al. 24 designed the U-Net model, a semantic segmentation algorithm that can accurately and efficiently perform segmentation on a limited quantity of images. The promising performance of the U-Net model has led to its high popularity within the literature and inspired many variants based on its architecture, such as the LinkNet model by Chaurasia et al. 25 The U-Net has remained a key benchmark to measure the performance of semantic segmentation. 26 However, data scarcity can be further remedied via data augmentation techniques, which include operations such as rotations to increase variety in the data or to create new data by taking patches of the available images. More details of how the U-Net functions and the aforementioned data augmentation techniques are given in the “Methodology” section.
There are several instances of a U-Net or a variant model being applied to medical image segmentation to automate diagnosis. In Maji et al., 27 an Attention Res-UNet model was used to perform semantic segmentation on brain tumors in magnetic resonance imaging (MRI) images. Another instance is in Soulami et al., 28 where breast cancer masses were detected from mammograms using a U-Net model. The detection and diagnosis of pulmonary nodules via deep learning methods is also becoming common in lung imaging, as is observed in the literature review by Zhang et al., 29 with an example being found in Teramoto et al., 30 where pulmonary nodules in positron emission tomography and computed tomography (CT) images were detected using CNNs. Furthermore, the segmentation of organ tissues can also improve the analysis of and diagnosis from medical images. Examples of this in the literature include Anthimopoulos et al., 31 where the semantic segmentation of pathological lung tissue in CT images was performed via CNNs; and Wieslander et al., 32 where deep learning was used to perform semantic segmentation on whole slide images of lungs to extract and quantify regions of interest while minimizing noise. Whether semantic segmentation is applied to detect abnormalities or segment tissues for analysis, the results are typically satisfactory.
Common classification metrics applied to assess model performance may include accuracy, the percentage of true predictions to the total predictions made; and intersection over union (IOU), the percentage of overlap of the predicted class to the ground truth class. Examples of satisfactory results from the aforementioned literature can be found in Maji et al., where a mean IOU of 83.8%, 78.1%, and 66.8% was reported across differing brain tumor classes, and in Soulami et al., where a mean IOU of 90.04% for breast cancer masses with an overall accuracy of over 99% was observed. Other performance metrics can be found in Anthimopoulos et al., where model performance was favorably compared to other state-of-the-art methods, and in Wieslander et al., where noise reduction was observed. The encouraging results of the aforementioned works suggest that, when applying semantic segmentation to analyze the vasculature of a re-endothelialized lung, promising results can be expected.
In this study, 177 raw histological images of re-endothelialized mouse lungs were obtained to investigate the ability of a U-Net, LinkNet, and ensemble model to segment tissue and instances of ruptured/dilated vessels as proof of concept for semantic segmentation applied to regenerated lungs. To address the data scarcity, patch-based models were implemented with a transfer learning and data augmentation approach, in addition to a vanilla model that uses full images compressed to size 256 × 256. The performance of patch-based and vanilla model implementations was compared to observe the effect of patch-based learning on model performance. To the best of our knowledge, this is the first attempt to distinguish ordinary vessels from ruptured and dilated vessels in a re-endothelialized lung vasculature via semantic segmentation. Hence, the results presented in this article will provide a significant and tangible contribution to medical image research, particularly the analysis of re-endothelialized lungs.
Methodology
In this study, 177 raw images of re-endothelialized mouse lungs were obtained for analysis. To annotate the tissue and rupture/dilated vessel classes, Otsu-thresholded and manually annotated masks were made from each image and combined to create an encoded ground truth mask. U-Net and LinkNet models were then implemented to perform pixel-wise classification on the raw images, generating a mask in an end-to-end setting to be compared against the ground truth. The U-Net and LinkNet models were trained and tested via k-folds cross-validation on multiple patch-based implementations of the raw images and ground truth masks. The performance of the vanilla and patch-based models was evaluated and compared against one another.
Acquiring histological images
The histological images used in this study were obtained from the work by Chan et al.,33,34 Ahmadipour et al., 35 conference papers, 36 and other unpublished work by our group. In these works, samples were taken from 12- to 16-week-old C57BL/6J strain male mice (Jackson Laboratory, ME). After euthanizing the mice, ex vivo cell seeding was performed via an injection of phosphate-buffered saline (Thermo Fisher Scientific, CA) through the right ventricle. Then, the pulmonary artery and trachea were cannulated, and the heart-lung block was removed and stored in a solution of phosphate-buffered saline and 1% antibiotic-antimycotic (Thermo Fisher Scientific) at a temperature of 4°C. The decellularization procedure was completed as per the process outlined in Daly et al. 37 For sample re-endothelialization, five million mouse C166 endothelial cells (CRL2581; ATCC, Canada) with a cell concentration of 250,000 cells/mL after suspension in 20 mL of cell culture were used.
The raw histological images were obtained after performing re-endothelialization by cell seeding on decellularized mouse lung scaffolds. These images were obtained from scaffolds repopulated with endothelial cells using different seeding methods, described herein: (1) direct injection into the pulmonary artery, (2) negative gauge pressure seeding, and (3) the dual pressure method, a novel combination of direct injection and negative gauge pressure seeding methods. For the direct injection method, a constant flow rate (4–10 mL/min) was used to pump the cell media via the artery directly into the lung. For the negative pressure method, a pressure gradient was created to draw the seeded cells into the lung by keeping the artery inlet at atmospheric pressure and applying negative pressure to the vein and parenchyma of the lung. Examples of these direct injection 6 and negative pressure 35 methods can be found in existing literature. For the novel dual pressure scenario, 34 the seeding was performed with the same inlet conditions of the direct injection scenario, but additional conditions, including a surrounding negative parenchyma pressure outlet condition and keeping the pulmonary vein at atmospheric pressure, were applied.
The re-endothelialized samples were imaged via staining by hematoxylin and eosin, as per the procedure outlined in Wallis et al. 38 Water content was removed by transferring the samples into a 70% ethanol solution. The sample images taken were of 5-µm thick whole lung sections from the re-endothelialized lungs, and they were processed using Excelsior ES Tissue Processor (Thermo Fisher Scientific) to remove fat from the tissue and allow for wax infiltration. In total, 177 histological images of re-endothelialized mouse lungs were obtained for this study.
Image annotation process
The raw histological images obtained for this study were converted to ground truth masks through an annotation process that involved the segmentation of tissue by Otsu thresholding and the manual annotation of ruptured and dilated vessels; a process that began with the raw image observed in Figure 1a and ultimately generated the ground truth mask observed in Figure 1e. The steps taken to obtain the ground truth mask are described herein.
The conversion of raw histological images into ground truth masks is visualized. Each subfigure shows different stages of the annotation process:
The annotation of tissues was performed using Otsu thresholding 39 and subsequent postprocessing techniques on a raw histological image, an example of which is observable in Figure 1a. The Otsu thresholding algorithm, which implements the method proposed by Nobuyuki Otsu, separates the foreground and the background pixels in an image into distinct classes, with an Otsu-thresholded image observable in Figure 1b.
Due to the heterogeneous nature of the imaged lungs and the varying intensities of the tissue pixels, noise, and artifacts present across the raw images, the number of classes used for the Otsu algorithm was tailored on a per-image basis to maximize the foreground detail segmented. In cases where noise and artifacts were found to significantly hinder the accuracy of Otsu thresholding, color segmentation was applied to remove any noise and/or artifacts interfering with thresholding accuracy. In other cases, contrast-limited adaptive histogram equalization (CLAHE)40,41 was used to enhance the local contrast of the tissue pixels and reduce noise before applying Otsu thresholding. In spite of these methods, postprocessing was necessary in many thresholded images, as some superfluous data remained after preprocessing.
Remnant artifacts and noise were occasionally mistaken for tissue by the applied Otsu thresholding algorithm due to similar color, intensity, and so on. Multiple instances of this can be observed within the red boxes of Figure 1b, where dark spots, gray lines, and other noise are segmented as tissue. Postprocessing was performed to remove this noise, with operations that included but were not limited to: Gaussian blurring, small object removal, and manually zeroing regions of pixels. Note that to implement the Otsu thresholding and remove small objects algorithms, the scikit-image library 42 was used, whereas the Gaussian blurring, color segmentation, and CLAHE algorithms were implemented using the OpenCV library. 43 In rare instances, an area of analysis mask was manually drawn and multiplied to the tissue mask to remove irrelevant areas. The result of these operations, performed as needed to remove the noise specific to each image, can be observed in Figure 1c, where only tissue pixels remain.
To annotate the ruptured/dilated vessels class, the APEER™ software by ZEISS was used to generate an image mask, as seen in Figure 1d. These masks were drawn with and approved by a thoracic surgeon, using a consistent criterion for what constituted a dilated and/or ruptured vessel. An abnormal vessel was expected to appear as larger than other vessels in the same relative area, with proximal regions and distal regions being expected to have larger and smaller vessels, respectively. Relative to these regions, if a vessel appeared significantly larger in addition to other factors such as a deformation of shape, it was considered a dilated vessel. If a vessel presented these characteristics and had a breakage of the vessel wall, it was considered a rupture. Since ruptured and dilated vessels could appear to be very similar, no distinction was made between these two in order to limit the subjectivity of the annotation process.
The annotated tissue and ruptured/dilated vessel masks were combined to generate a ground truth mask with both pixel classes, as shown in Figure 1e. The image annotation process, for both the tissue and ruptured/dilated vessel masks, was exhaustive, time consuming, and work intensive, which further emphasizes the potential benefits of an automated end-to-end segmentation algorithm. In total, 124 raw images were determined to contain at least one ruptured or dilated vessel, whereas 53 images were found to have none. Overall, there were 541 annotations of ruptured and dilated vessels made in the images available, leaving this class dwarfed by the significantly larger tissue and background classes. In the 177 total images, the ruptured/dilated vessel class made up 1.5% of the total labeled pixels, with 13.3% and 85.2% belonging to the tissue and background classes, respectively, possibly biasing the model toward the other classes.
The number of ruptured and dilated vessels varied per image, ranging from 0 to 23 instances in this data set. Side-by-side comparisons of raw images and their corresponding ground truth masks are visualized in Figure 2. An instance of an image with few ruptured and/or dilated vessels can be found in the raw image and corresponding mask in Figure 2a and b, respectively. Many ruptured and/or dilated vessels can be observed in Figure 2c and d, with one large vessel not considered to be ruptured or dilated due to its proximal location. An instance of no ruptured or dilated vessels is seen in Figure 2e and f.
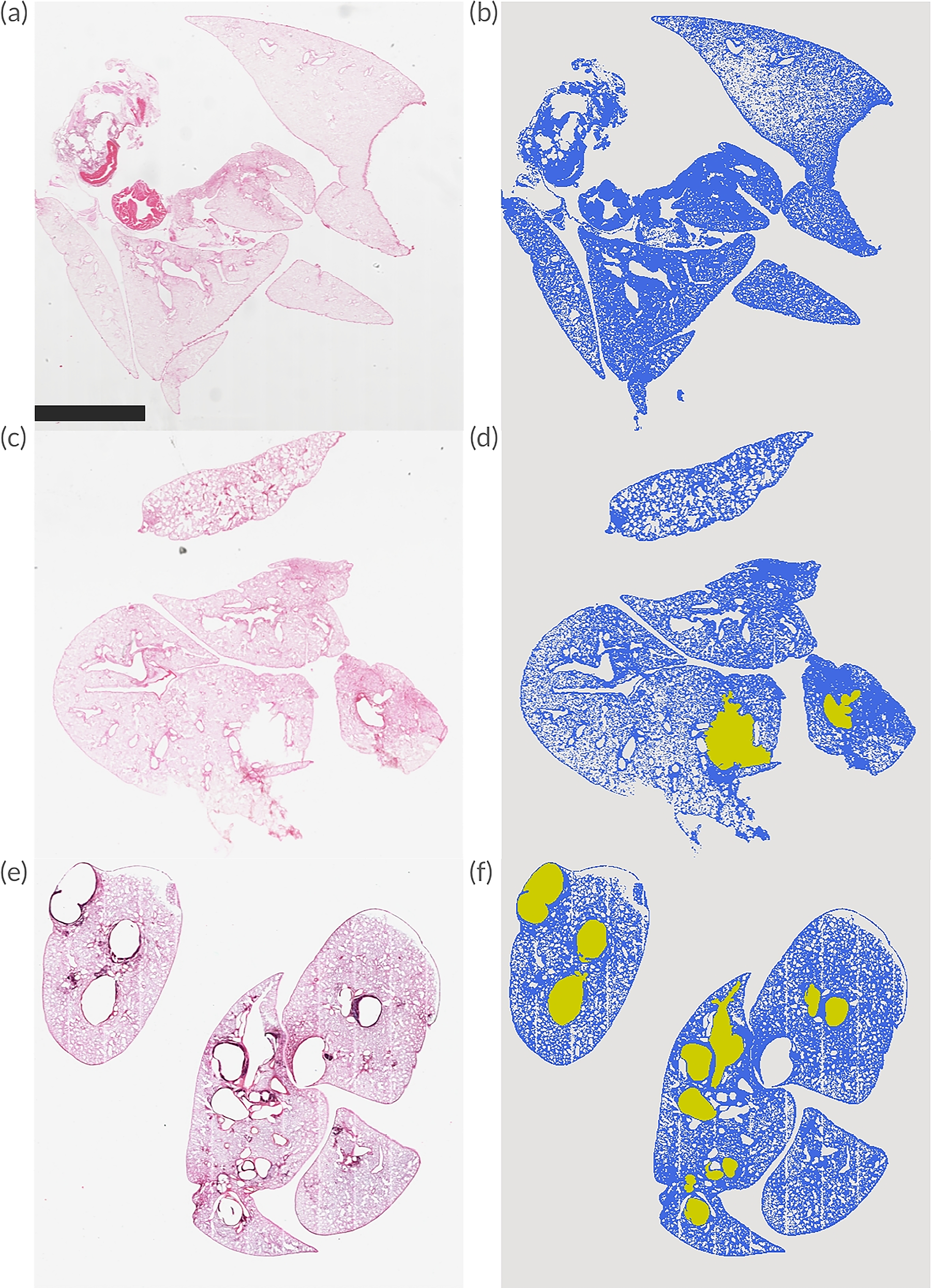
The raw images and their corresponding masks are shown in each row, with the raw image and mask in the left and right columns, respectively.
Model architectures
In this study, raw histological images of re-endothelialized lungs and ground truth masks were utilized to train and test a CNN-based deep learning semantic segmentation algorithm: the U-Net model. The U-Net model was specifically designed to efficiently and accurately segment medical images with a low sample size. 24 This study made use of the publicly available segmentation_models library 44 to access the U-Net model architecture. The functionality of U-Net is described herein.
The U-Net model is composed of two interacting paths: a contracting (encoder) path and an expansive (decoder) path, both of which are visualized in Figure 3. The contracting path extracts the contextual features of image pixels, and the expansive path analyzes regional image data.
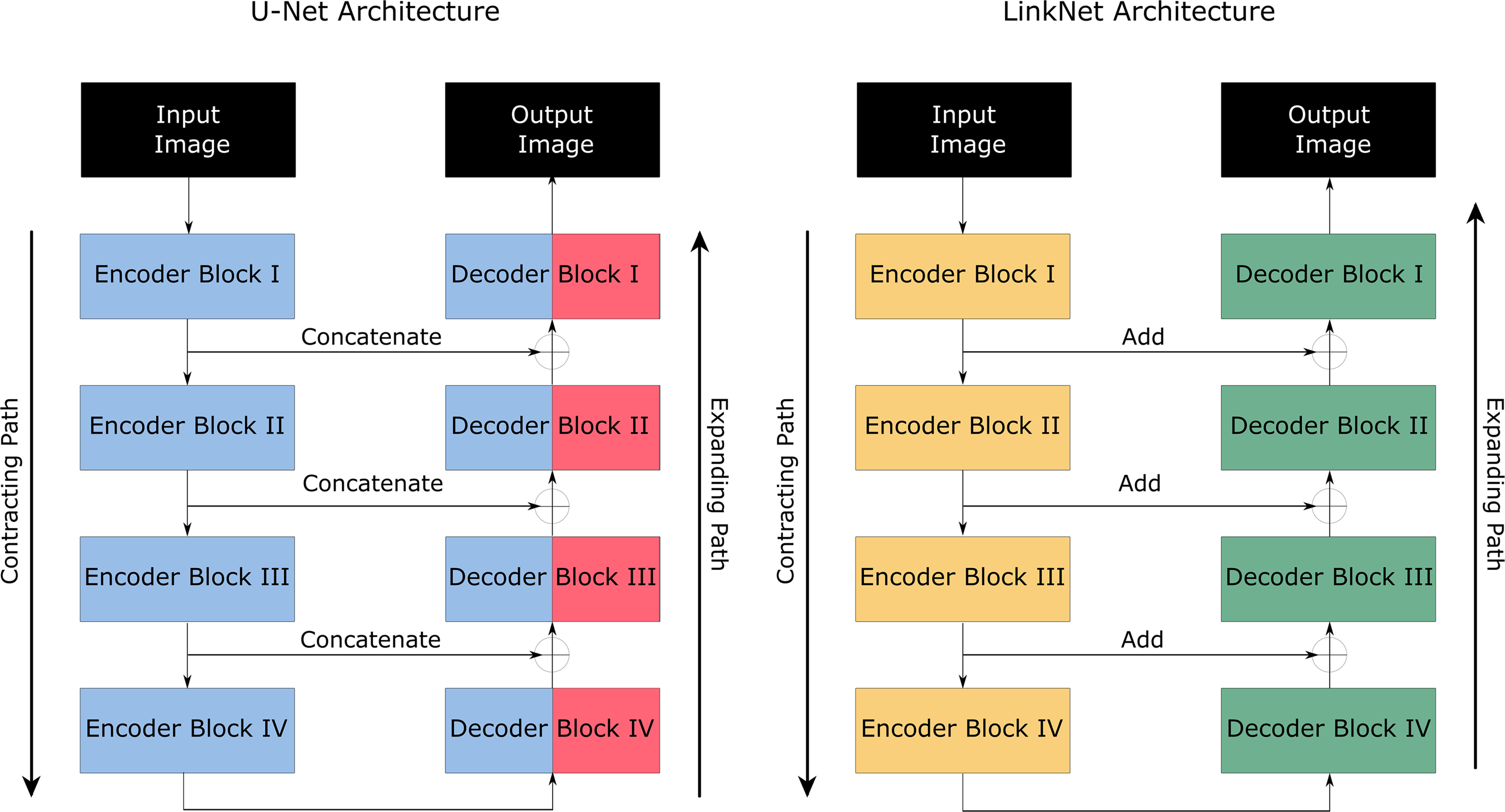
A block diagram visualization of the U-Net and LinkNet model architecture. The contracting path uses encoder blocks that downsample the image, and the expanding path uses decoder blocks that upsample the image by concatenating and adding the output of the corresponding encoder blocks for the U-Net and LinkNet models, respectively.
Each contracting block consists of two convolutional filters of size 3 × 3, further processing via a rectified linear unit function, and maximum pooling operation of size 2 × 2 to downsample the image, extracting only the most relevant features (i.e., shape, color, etc.). Each expansive block consists of 2 × 2 convolution that halves the feature channels (upsampling), a concatenation operation that combines the halved features in the decoder with the features in the corresponding encoder, followed by a pair of 3 × 3 convolutions and respective rectified linear unit functions. Through downsampling, the feature channels are doubled in each step, increasing the amount of data for analysis, whereas upsampling allows for key features to be localized. The architecture of the U-Net model is integral to its potential for accurate and efficient semantic segmentation and was a significant reason for its application in this work.
The LinkNet model is an adaptation of the U-Net model, also with an encoder and decoder path, but with several significant differences. For instance, LinkNet requires fewer parameters and less training time than U-Net, yet is able to produce a comparable, if not superior, accuracy. Another significant deviation from U-Net is that LinkNet bypasses the input of each encoder block to the output of each corresponding decoder block. The information that would be lost during downsampling in the encoder of the U-Net is instead added to the decoder of the LinkNet, maintaining the spatial information that would need to be relearned during training.
In order to train the ensemble model, the predictions of the U-Net and LinkNet models were equally weighted and combined into an image mask. It was found that giving both model predictions equal weighting resulted in the best performance for the ensemble model.
Vanilla and patch-based model training
To offset the relatively low number of images available, patch-based learning was implemented to provide more training examples to the U-Net model while observing the effects of lost context on model performance. The patchify library 45 was utilized to convert images to patches. Nonoverlapping patches of size 256 × 256 were taken from the raw and ground truth masks and used to train and test the model. All image patches with <1% of their pixels belonging to tissue or ruptured/dilated vessel classes were filtered out of the training data, as they contained little relevant information and would unnecessarily increase model runtime.
The size of the raw images varied from ∼700 to 10,000 pixels, providing a high variety of image resolutions. To minimize the RAM consumed by model training, the images and masks used for training and testing were resized to 256 × 256 pixels, for both the vanilla and patch-based models. Four types of images were input to four corresponding model types: the full image resized to 256 × 256, patches of an image resized to 512 × 512, patches of an image resized to 768 × 768, and patches of an image resized to 1024 × 1024. These image types are the vanilla, 2 × 2 patches, 3 × 3 patches, and 4 × 4 patches, respectively, visualized in Figure 4.
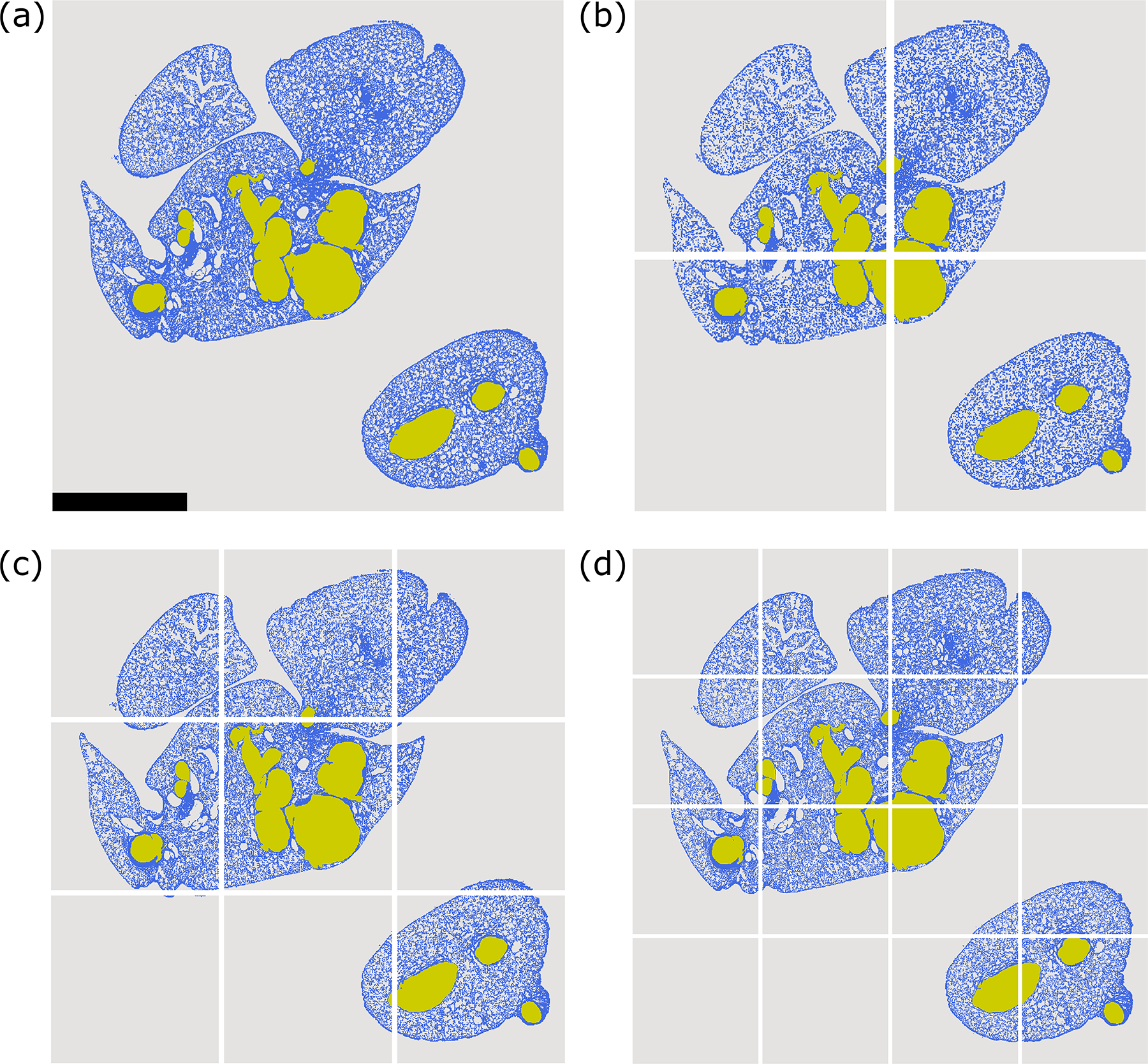
The four raw image types input to the respective vanilla and patch-based U-Net models are shown:
The varying image resolutions were used to extract different numbers of patches to compare model performance and to produce higher resolution output masks. Though the vanilla model uses the lowest number of images, it has the most context, whereas the 4 × 4 patch-based model has the most images but the least context, also shown in Figure 4. Recalling that the location and size of a vessel can determine if it is ruptured or dilated, it was expected that model performance may be hindered rather than improved when trained on patches.
The vanilla and patch-based models were trained and tested using k-folds cross-validation where k = 10. This value of k was chosen to maximize the training data available to the model while maintaining variance in the testing data. To avoid biasing this diagnostic model, 46 the data were organized into 10 folds manually since some images were taken of different regions of the same lung. The lungs imaged were distinct across the 10 folds, each of which comprised 9.6% or 10.7% of the total data. A visualization of this cross-validation approach is observed in Figure 5.
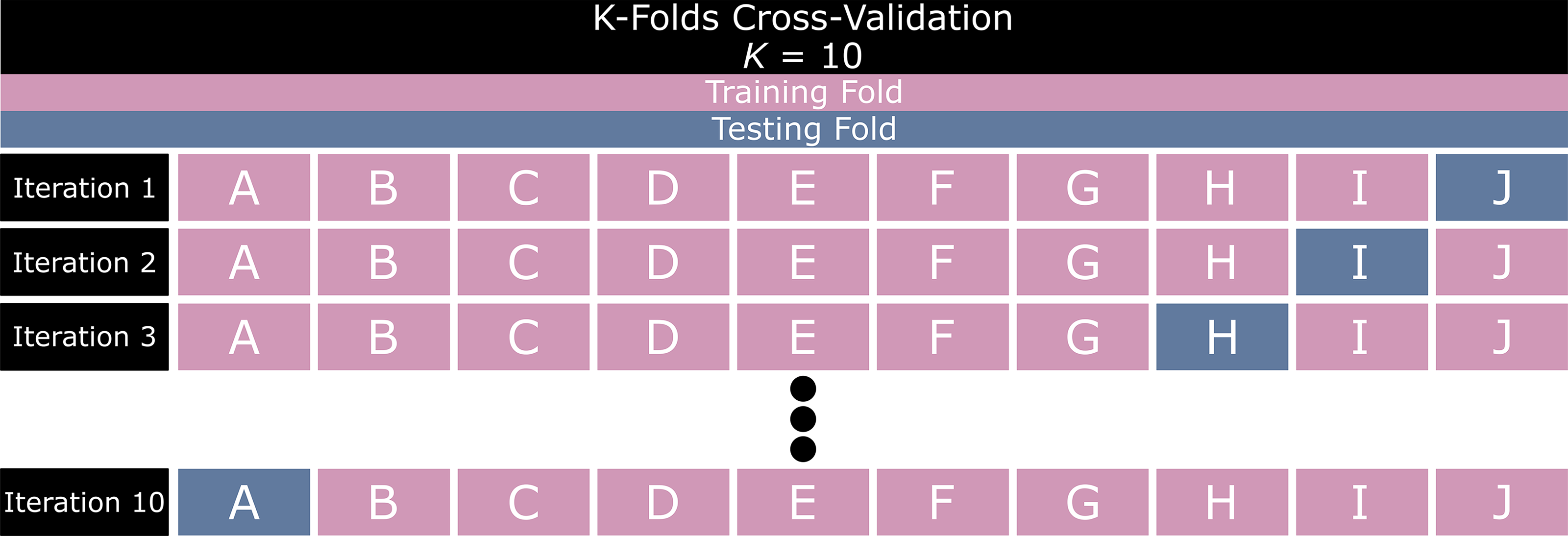
K-folds cross-validation visualization where k = 10 and folds are assigned a letter from A to J.
Transfer learning and other data augmentation operations were implemented in the training data of the vanilla and patch-based models. Transfer learning is the adoption of a machine learning model pretrained on a large set of data to another, typically smaller set of data. This technique has been shown to significantly improve performance in deep learning models over models trained from scratch, specifically when applied to image analysis. 47 In this work, the pretrained weights from the famous ImageNet dataset 48 for the ResNet-38 model 49 were applied to our U-Net. Data augmentation methods of rotating and/or mirroring images were applied to all model training data via the TensorFlow Keras Image Generator. 50 These augmentations were performed to introduce more variety and more quantity in the training data, generating artificially created images to offset the limited amount of available data and improve performance. 51
During model training, the predictions were minimized using the categorical focal Jaccard loss function, which is the sum of the categorical focal and Jaccard losses. The categorical focal loss (FL) is a metric that prioritizes pixels more often mislabeled by the semantic segmentation model over easily classifiable pixels. As the ruptured/dilated vessel class comprises 1.5% of the total data, in addition to being context sensitive, it was anticipated that this loss would help avoid biasing the model against this class. The categorical FL can be expressed by the following equation:
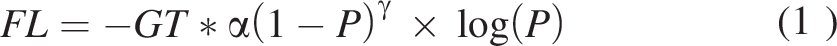
The Jaccard index, also called the IOU, is a key evaluation metric for semantic segmentation defined as the area of overlap of the predicted class and the ground truth class divided by the area of union between the predicted and the ground truth classes. During model training, the aim is to minimize the Jaccard loss function to maximize the IOU. The Jaccard loss function can be expressed as follows:

Evaluating model performance
To evaluate the performance of the vanilla and patch-based models, key performance indicators including precision, recall, and IOU were used to compare the predicted classes to the ground truth. Precision is the ratio of the correct predictions to the sum of true and false positive predictions made by the model. Recall is the percentage of the correct positive predictions to the total positive predictions. The IOU, as defined above, is the ratio of the overlapping area between the predicted and the ground truth class to the area of the union between the predicted and ground truth class. These parameters are expressed via the following equations:
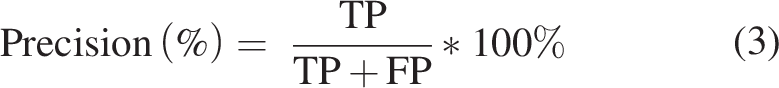
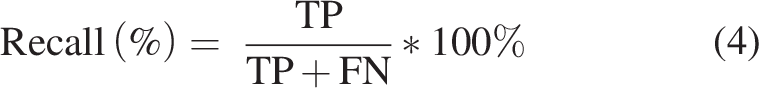
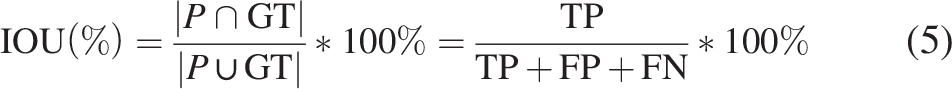
The aforementioned parameters were calculated for each cross-validation iteration, and the mean was taken, along with the standard deviation (SD) across predictions, to quantify the consistency of model performance. SD was determined as per the following formula:
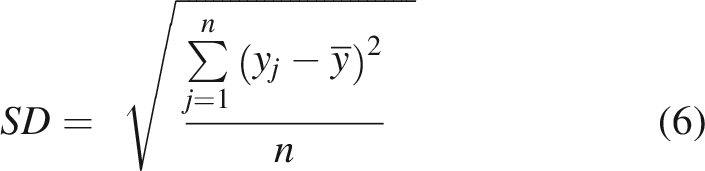
Experiment
The precision, recall, and IOU for each vanilla and patch-based semantic segmentation U-Net, LinkNet, and ensemble model, averaged across the cross-validation iterations, are visualized in Figure 6.
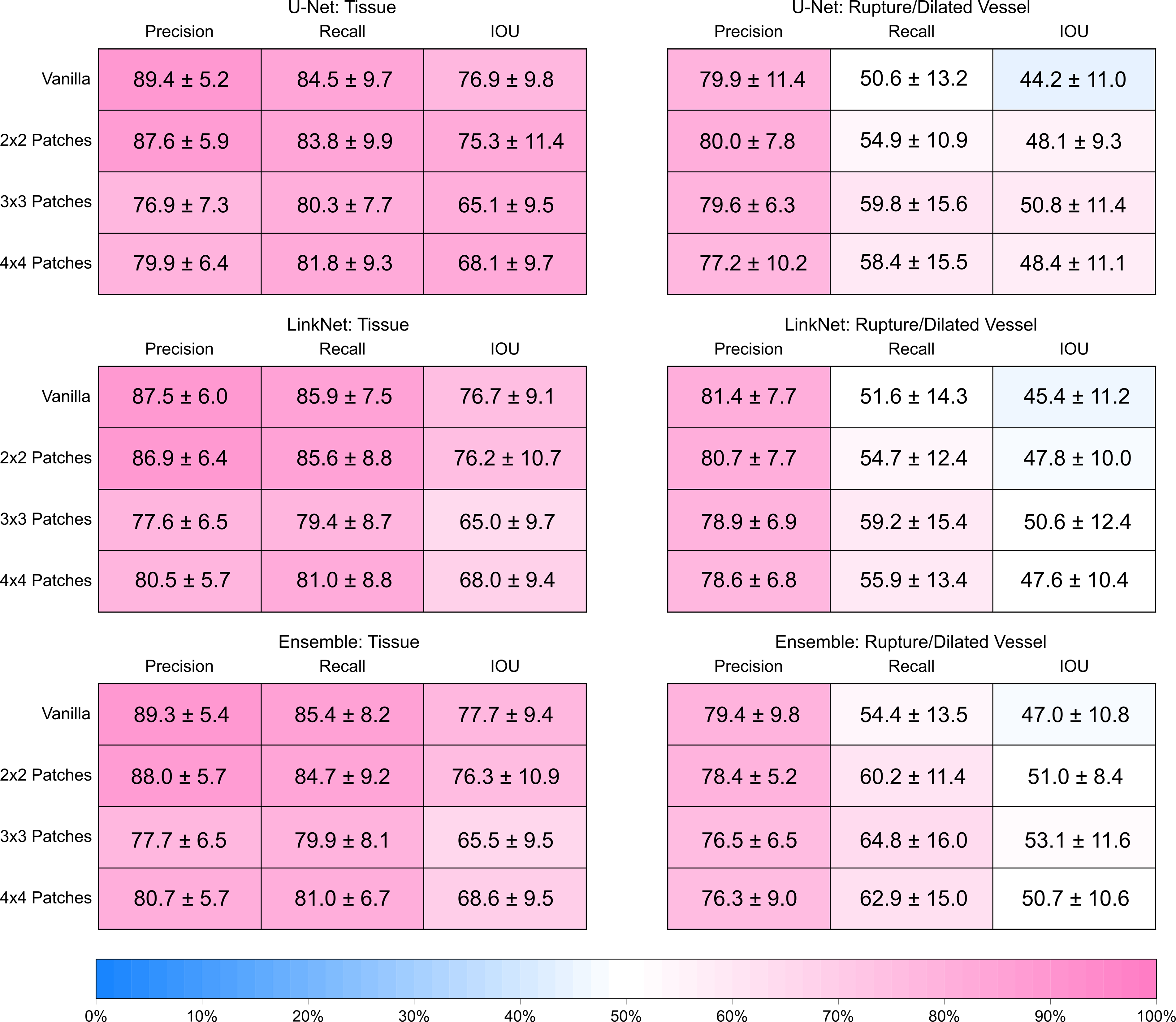
The heat map tables comparing the performance of vanilla and patch-based U-Net, LinkNet, and ensemble models for both the tissue and ruptured/dilated vessel class. The precision, recall, and IOU are the metrics used to compare performance, calculated by taking the mean across the 10 cross-validation iterations, with standard deviation also reported.
In each of the vanilla and patch-based models, the ability of the model to classify the tissue is satisfactory, although it is observed that performance degrades as the number of patches increases beyond 2 × 2 patches. The vanilla models generate the highest precision, recall, and IOU values across the board for the tissue class, whereas the 3 × 3 or 4 × 4 models generate the lowest. For instance, the vanilla U-Net model reports a precision, recall, and IOU of 89.4% ± 5.2%, 84.5% ± 9.7%, and 76.9% ± 9.8%, respectively, whereas the 3 × 3 and 4 × 4 patch-based models report precision, recall, and IOU values that are at least 9.5%, 2.5%, and 8.8% lower, respectively. This suggests that the lost context in the patch-based models negatively affects the ability to classify tissue pixels, and the lower precision and IOU imply that a higher false positive classification rate is a significant cause of this degradation.
The prediction of ruptured and dilated vessels produced mixed results across the models, with the 3 × 3 patch-based ensemble model returning the highest performance metrics for this class, with a precision, recall, and IOU of 76.5% ± 6.5%, 64.8% ± 16.0%, and 53.1% ± 11.6%, respectively. The precision across the patch-based models remained in the range of 76–82%, whereas the recall and IOU were significantly lower. Due to the false negatives for the ruptured and dilated vessel class, the recall ranged from 50% to 55% in the vanilla models to ∼59% to 65% in the patch-based models. Due to the false negatives and false positives, the IOU was lower than the reported recall, ranging from 44–47% to 50–53% in the patch-based models. Note that the 4 × 4 patch-based models return an inferior performance, with metrics 1–3% lower than the results of the 3 × 3 patch-based models across the board, likely due to these false positives and false negatives caused by the loss of full image context. For a visualization of the false positive and false negative classifications, please refer to Figure 7. We observed the false positives and false negatives in the 3 × 3 and 4 × 4 patch-based ensembles (Fig. 7d and e, respectively), which were absent in the vanilla and 2 × 2 ensembles (Fig. 7b and c, respectively).
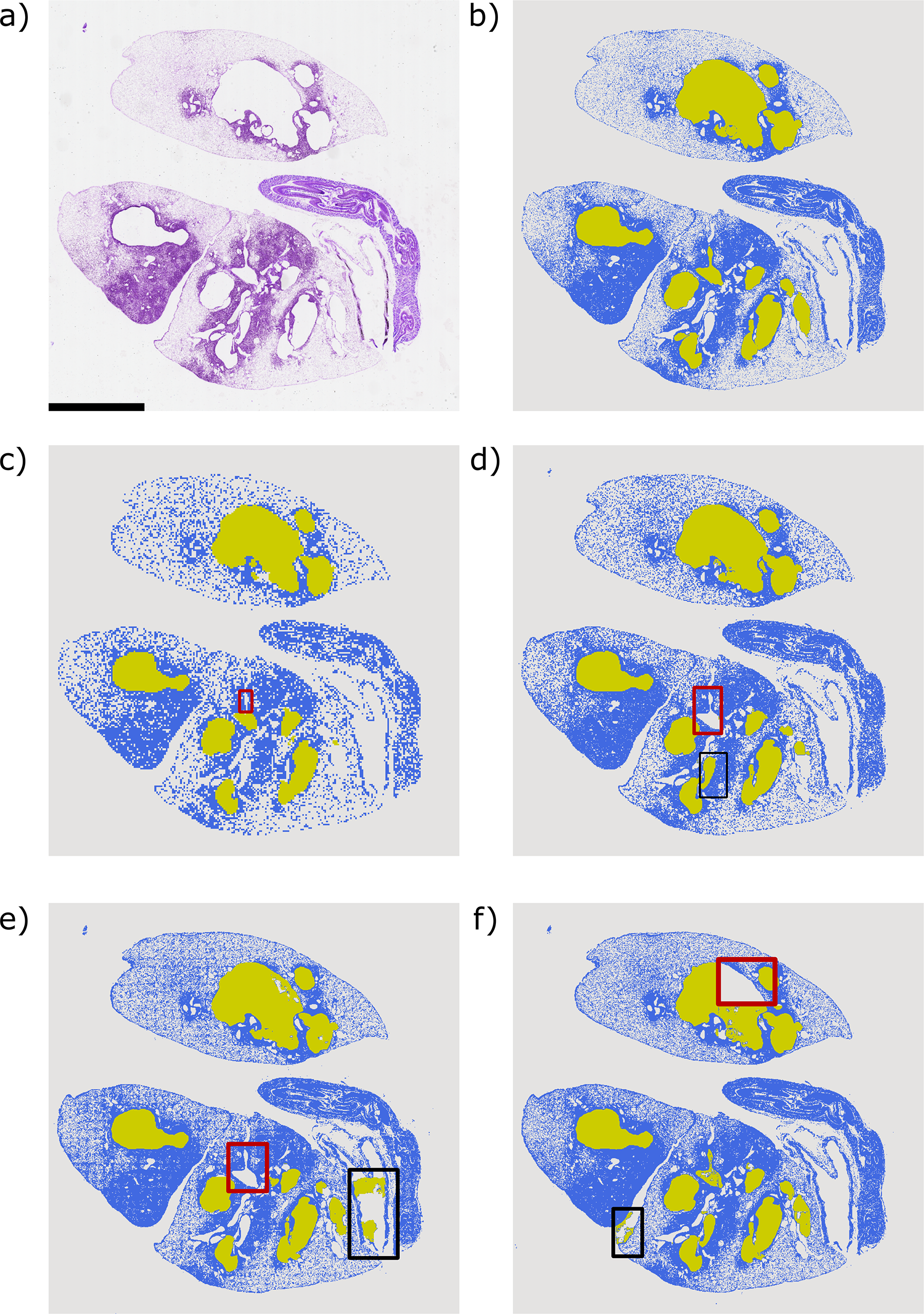
A visualization of model predictions on a selected image.
Overall, the 2 × 2 patch-based ensemble model returned the best performance. Although the 3 × 3 patch-based ensemble model returned higher metrics for the ruptured/dilated vessel class, the corresponding tissue class predictions generated an IOU >10% lower than the 2 × 2 model, suggesting significantly more false negatives/positives for the tissue class. However, the 2 × 2 and 3 × 3 patch-based ensembles returned similar metrics for the ruptured/dilated vessel class, although the recall and IOU of the 2 × 2 model were 4.6% and 2.1% lower, respectively. The high precision of the models investigated for the ruptured/dilated vessel class suggests that the pixel-wise classifications made are generally correct, although a considerable number of ruptured/dilated vessels are missed, causing the lower recall and IOU values.
Discussion
It is apparent from the results that the low quantity of distinct full images limited the performance of the semantic segmentation models when predicting the ruptured/dilated vessels class. Although improvements in the classification metrics for the ruptured/dilated vessel class were observed in the 2 × 2 patch-based model implementation, the models still returned a significant number of false positive and false negative predictions in this class. Moreover, the 3 × 3 and 4 × 4 patch-based models showed a degradation in performance. This was observed in spite of the substantial increase in training image quantity offered by the patch-based models, as shown in Table 1.
Vanilla and Patch-Based Training Image Counts
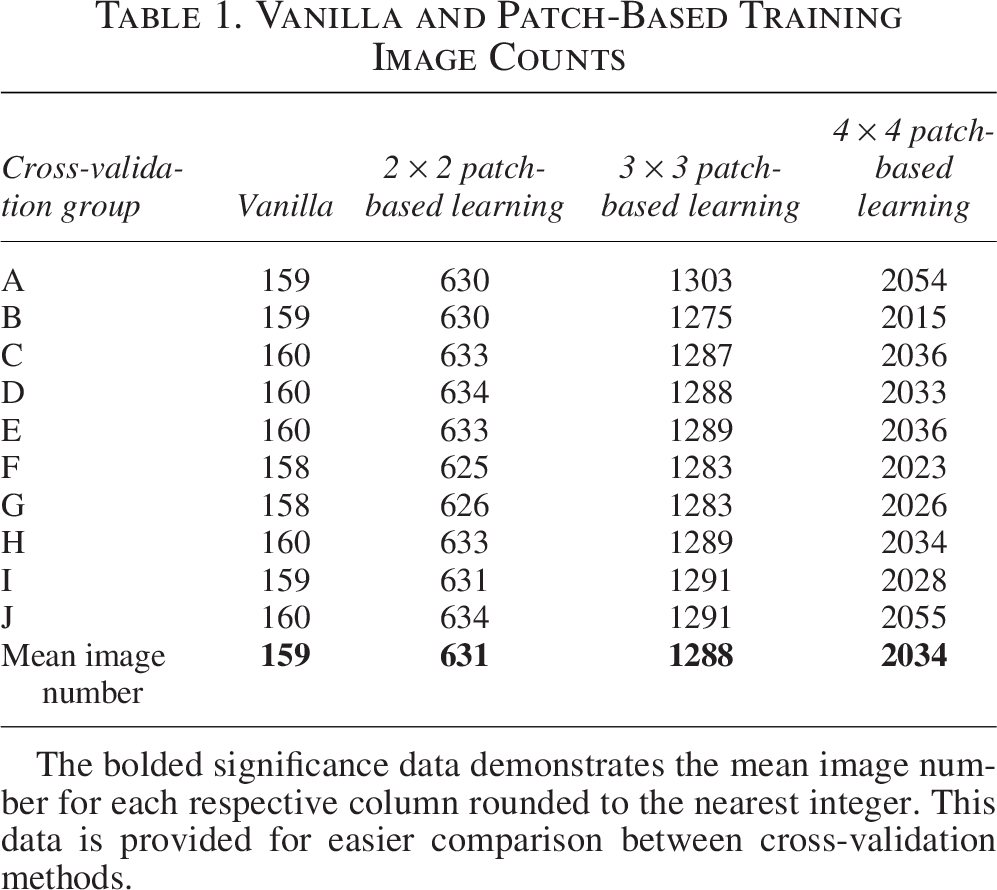
The bolded significance data demonstrates the mean image number for each respective column rounded to the nearest integer. This data is provided for easier comparison between cross-validation methods.
The diagnosis of ruptured/dilated vessels is sensitive to the size, shape, and location of the vessel in the lung, and this context-sensitive analysis would likely have been improved had there been more distinct full images used for training. The patch-based models increased the number of images available for training, but the lost context of vessel location, size, and shape when divided into patches limited the benefits of patch-based learning for model performance.
Conclusions
In this work, we demonstrated the potential of a patch-based ensemble model to perform semantic segmentation on raw histological images of re-endothelialized mouse lungs, generating pixel-wise predictions of the tissue and ruptured/dilated vessel classes in an end-to-end process superior to that of a singular U-Net or LinkNet model. We compared vanilla and patch-based U-Net, LinkNet, and ensemble models and found that the 2 × 2 patch-based ensemble model returned the most desirable performance, classifying tissue pixels with a precision, recall, and IOU of 88.0% ± 5.7%, 84.7% ± 9.2%, and 76.3% ± 10.9%, respectively, and classifying ruptured/dilated vessel pixels with a precision, recall, and IOU of 78.4% ± 5.2%, 60.2% ± 11.4%, and 51.0% ± 8.4%, respectively.
We observe that the 2 × 2 patch-based ensemble model improves the recall and IOU with respect to the ruptured/dilated vessel class substantially over a singular vanilla model, increasing both of these parameters by over 6.5%. Furthermore, the 2 × 2 ensemble does not experience significant degradation for the tissue class, unlike the 3 × 3 and 4 × 4 ensembles. The 2 × 2 ensemble produces performance metrics ∼1–1.5% lower than the vanilla ensemble, whereas the latter two produce metrics up to 12.2% lower. It is clear that an image can be divided into, at most, 2 × 2 patches until the loss of full image context can significantly impede performance. For future work, the potential of patch-based learning to grow the quantity of the training data should be balanced against the context lost by taking image patches.
These results demonstrate our proof of concept for patch-based ensemble semantic segmentation models to generate a superior performance to singular, vanilla models when segmenting tissue and ruptured/dilated vessels in raw histological images. Although the tissue segmentation produced accurate results that demonstrate the ability of semantic segmentation to provide an end-to-end method of denoising histological images, the prediction of the ruptured/dilated vessels class remains in need of improvement, particularly in lowering the number of false negatives. It is impressive that the under-represented and context-sensitive class could be predicted adequately with a patch-based ensemble; however, further improvement is required before standard use is recommended.
Authors’ Contributions
J.P.: Investigation, writing—original draft, and writing—review and editing. A.H.: Writing—review and editing. J.C., D.T., and S.K.: Investigation and writing—review and editing. C.A.: Supervision. G.K. and A.B.: Supervision and writing—review and editing.
Footnotes
Acknowledgments
Joshua Paciocco is a grateful recipient of Mechanical and Industrial Engineering Endowed Fellowships for graduate students, including the Mart Liinve Graduate Scholarship and the University of Toronto Fellowship.
Data Availability Statement
The raw image data and annotated mask data used to train the semantic segmentation models in this article will be made available by the authors upon request.
Ethics Statement
The animal study was reviewed and approved by the Institutional Animal Care and Use Committee of the Toronto General Hospital Research Institute at the University Health Network and the University of Toronto.
Disclosure Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding Information
This work was supported by the