
Abstract
Artificial Intelligence (AI) is increasingly infiltrating the field of medicine, particularly in the area of assisted diagnosis. Traditional AI models, limited to single data types, struggle to accurately diagnose skin conditions. Incorporating diverse data sources, such as patient narratives, lab. results, and various skin images, can significantly improve diagnostic capabilities. Large-scale multimodal models, trained on extensive clinical data, can effectively integrate diverse data types to improve diagnostic accuracy. This paper investigates the methodologies, applications, and limitations of unimodal models, while also exploring how multimodal models can amplify precision and reliability. Moreover, amalgamating advanced technologies such as Federated learning and multi-party privacy computing, when integrated with AI, can significantly alleviate privacy risks associated with dermatological data while enabling highly accurate self-diagnosis. Diagnostic systems supported by large-scale pre-trained multimodal models can aid dermatologists in formulating effective diagnostic and treatment roadmaps, ushering in a new frontier in healthcare. Machine learning can transform dermatology by enabling more accurate diagnoses and customized treatment plans. The convergence of vast datasets, including electronic health records, image repositories, and genomic data, coupled with accelerated computing power and affordable storage, has fueled the evolution of sophisticated Machine Learning algorithms capable of replicating acumen resembling dermatological diagnosis and treatment. This paper provides a comprehensive overview of machine learning, encompassing its foundational principles, current applications in dermatology, and potential challenges that may hinder its further development.
Introduction
Human skin is considered the most uncertain and troublesome terrains due to numerous mitigating characteristics like tone, density of hair if present, level of melanin, etc. Dermatological disorders are one of the most extensively spread disorders and are increasing because of many environmental, geographical and genetic distinctions among the people. Diseases of the skin are infectious and need to be treated at earliest stages to avoid escalation and can cause immeasurable non fatal burdens on day to day life. Conventional AI diagnostic models typically utilize a single data type, leveraging specific textual or image attributes to identify potential diagnostic outcomes through feature correlation within trained algorithms. Computer-aided diagnosis (CAD) systems typically rely on either text or image data to classify diseases or provide diagnostic insights. However, these systems are often limited by factors such as data scarcity, model complexity, and reliance on single data sources, hindering their ability to offer comprehensive diagnostic support: (a) Text-based disease classification - based on text information and (b) image-based diagnostic feedback - based on image information. Despite their potential, these AI-aided diagnostic methods are limited by factors such as insufficient training data, model complexity, and reliance on single data types, hindering their ability to provide comprehensive diagnostic assistance.
Numerous websites on the Internet generate a wide range of textual data, including news, research articles, ebooks, personal blogs, and user reviews. The sheer volume of this textual data often makes it challenging for users to find relevant information efficiently. This overwhelming volume of information often makes it challenging for users to locate relevant content efficiently. To address this problem, Text-based Recommendation Systems are created to efficiently extract relevant information from textual data. These systems utilize sophisticated algorithms to effectively sift through large volumes of textual content, such as online articles, reviews, or social media posts, and identify and suggest content that matches a user’s interests or preferences. Despite the proliferation of techniques for building and evaluating recommendation systems, a comprehensive understanding of text-based systems remains elusive, as existing surveys primarily focus on general recommendation methods. Our research primarily addresses four key aspects of text-based recommendation systems discussed in the reviewed literature: datasets, feature extraction techniques, computational methods, and evaluation metrics. Validated datasets are crucial for research, and this paper provides a comprehensive review of publicly accessible options. However, it’s important to note that many proprietary datasets, unavailable to the public, can be utilized in text-based recommendation systems. To facilitate research, we have compiled a comprehensive overview of attributes from both publicly accessible and proprietary datasets. Additionally, the feature extraction methods from text are outlined, and their application in the deployment of text-based recommendation systems is discussed. Subsequently, different strategies that utilize these features are examined based on statistics and machine learning. To assess these systems, certain evaluation metrics are employed. Additionally, it provides a comprehensive overview of evaluation metrics used to assess system performance, visualized based on popularity. The survey uses the approach that combining text features with other data types improves recommendation accuracy, according to the survey. Our research predominantly focuses on textual data, with news recommendation being the dominant application area within the field (Figure 1). AI Areas and respective techniques.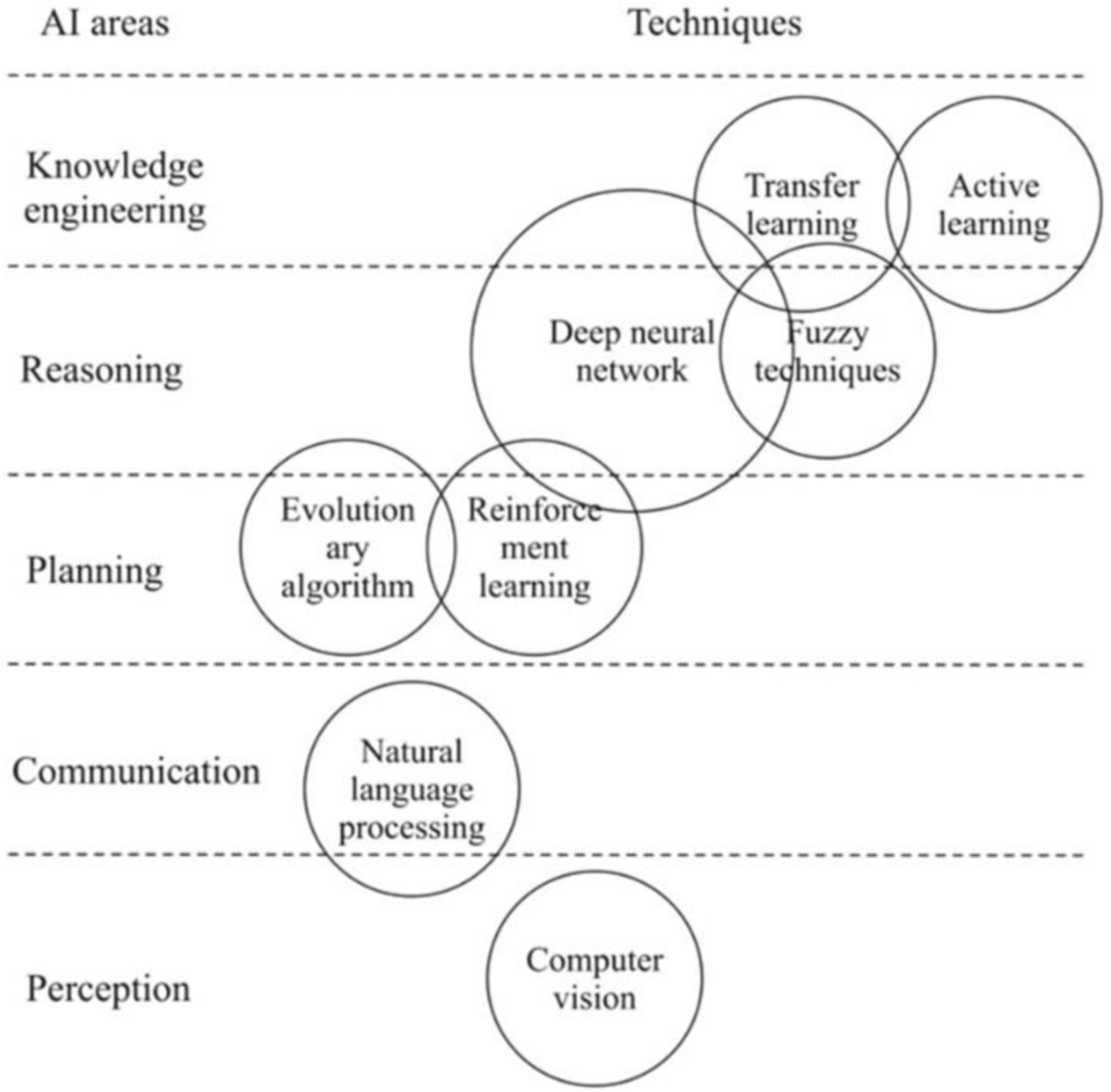
Recommender systems are a subfield of computer science that leverages computational statistics, information retrieval, and machine learning to empower users to make informed decisions. The primary goal of recommender systems is to aid users in their decision-making process. They accomplish this by recommending new items that may interest users or by narrowing down options according to their preferences. In essence, recommender systems help manage information overload by enabling users to distinguish relevant content from irrelevant content when properly implemented. Recommender systems are tools that help handle information overload. When used effectively, they assist users in separating useful information from what isn’t relevant (Kim and Lee, 2005; Lam and Riedl, 2004).
Literature review
Collaborative filtering is a popular recommendation method commonly used in many e-commerce platforms (Linden et al., 2004; Resnick et al., 1997; Sarwar et al., 2001). This filtering works by predicting a user’s preferences based on similarities with other users and recommending items that have been selected by people with similar preferences and demographics. By identifying similar users, collaborative filtering can recommend items that these like-minded individuals have enjoyed. (Breese et al., 2013; Herlocker et al., 2000; Resnick et al., 1994).
The efficacy of collaborative filtering has led to its widespread adoption in online communities, where personalized recommendations based on user similarities are increasingly common. Collaborative filtering struggles to provide accurate recommendations for infrequently rated items. This limitation arises due to insufficient data points for accurately calculating user similarity when recommending infrequently rated items. Also, collaborative filtering often struggles to capture the nuances of user preferences, as individuals with diverse backgrounds and interests can share similar tastes. Even without shared ratings, individuals may exhibit similar preferences. Additionally, user preferences are not static and can change over time due to factors like age, life experiences, and social influences.
To address the limitations of traditional rating scales, sentiment scores were utilized as an alternative rating mechanism (Matsunami et al., 2016). This approach enabled a more nuanced representation of product quality, as sentiment analysis of user reviews provided richer information than simple numerical ratings, ultimately enhancing the classifier’s performance.
Jalili et al (2018) designed a skincare recommender system that incorporates content-based filtering and utilizes existing knowledge. This system was developed through an expert system framework, incorporating multiple criteria and existing knowledge. The recommendation process involves calculating similarity scores between product content and corresponding ratings, as well as applying association rule mining to identify item combinations based on support and confidence values. This approach effectively identifies products with similar characteristics and usage patterns. This model, based on content-based filtering, was tested on a dataset of 40 skincare products, and attained a maximum similarity score of 0.447. Additionally, association rule mining identified a rule with 40% support and 40% confidence, resulting in an overall confidence of 88.8%.
A deep neural network architecture was proposed to analyze the sequential arrangement of cosmetic ingredients and predict product effects based on skin analysis from frontal face images. This model enables personalized cosmetic recommendations by considering both product composition and individual skin characteristics (Lee et al., 2024). The ingredient analyzer, evaluated using four-fold cross-validation, demonstrated strong generalization capabilities, with an accuracy of 81.7%, precision of 44.6%, recall of 47.3%, and an F1-score of 43.6%. The ingredient analyzer exhibited relatively low precision, recall, and F1-scores, primarily due to class imbalance within the dataset. This imbalance hindered the model’s ability to accurately predict underrepresented ingredient classes. This imbalance is a common challenge in classification problems and highlights the need for techniques like oversampling or under sampling to address class distribution issues.
Nakajima et al (2019) A system was developed to identify ingredients linked to high cosmetic efficacy and recommend products containing these ingredients based on user reviews from a cosmetic review Web site. TF-IDF was employed to identify key ingredient terms associated with highly effective products by analyzing product descriptions and user reviews. A novel metric, “invalidated product number (IPN),” was introduced to assess recommendation effectiveness. IPN measures the frequency of products recommended by the system but not subsequently rated by users, providing insights into the system’s ability to recommend relevant and engaging products. The recommender system demonstrated a consistent 5% invalidated product rate, indicating reliable performance. Incorporating additional attributes could potentially further reduce this metric.
A metric named “recommended product satisfaction level” was defined to evaluate the system’s performance after applying the IF-IPF method to identify key ingredients associated with high-efficacy product groups. The system effectively recommended products with unexpected yet relevant qualities, often surprising users. Nakajima et al (2019) This was achieved by utilizing Inverse Product Frequency (IPF), which calculates the rarity of an ingredient across the product dataset. The frequency, IF value, and IF-IPF value were calculated for each ingredient and compared across user groups. The two ingredients with the highest IF-IPF values within each group were selected for further analysis. This analysis revealed that ingredients with higher IF-IPF values were frequently associated with positive user feedback, suggesting their potential as key indicators of product effectiveness. Products containing at least one ingredient with a high IF-IPF value were consistently associated with positive user feedback, indicating the effectiveness of the recommendation system in identifying products with desired cosmetic effects. Leveraging additional user attributes beyond age and skin quality can substantially improve the precision and relevance of recommendations, resulting in a more personalized user experience.
A recommendation system was developed to streamline the skincare selection process by efficiently filtering product options based on specific skin characteristics, empowering users to make informed choices. A content-based filtering approach using K-means clustering with five clusters was employed to generate product recommendations, which after optimizing the number of clusters based on ingredient profiles could potentially enhance recommendation accuracy Putriany et al (2019).
Rubasri et al (2022) had a content-based filtering approach utilizing K-means clustering with five clusters employed to generate product recommendations. Optimizing the number of clusters based on ingredient profiles is a potential avenue for improving recommendation accuracy. NLP techniques were applied to analyze chemical compounds, resulting in the generation of a Document Term Matrix (DTM). The DTM demonstrated effective performance, achieving an overall accuracy of 85%. To enhance the system’s precision, incorporating additional product attributes such as product price, brand name, and customer ratings can refine recommendations to better align with user preferences and expectations.
Rajegowda et al (2023) used a convolutional neural network (CNN) to analyze skin type from facial images and offer tailored skincare recommendations within an immersive user experience. The model achieved a 93% accuracy rate, with potential for further improvement through the integration of additional skin attributes.
Hansanie et al (2024) designed a convolutional neural network (CNN) that was utilized to assess a person’s skin type from facial images and deliver customized skincare recommendations within an immersive interactive platform creating an engaging experience for the user. The model demonstrated 93% accuracy in skin type classification and has the potential for further enhancement by incorporating additional skin attributes, ultimately providing a more tailored and effective user experience.
Liew (2021) A factorization machine learning algorithm was employed to design a recommendation engine that proposes skincare products specific to a person’s skin conditions. A DistilBERT-based sentiment analyzer was built to assess product sentiment from reviews, and a CNN model was trained to classify skin types into dry, oily, combination, and normal categories. Other neural networks can be used in combination with the sentiment analyzer to compare the results.
A deep learning model was developed to predict the skin concerns addressed by each skincare product. The model compared the performance of LSTM and Bi-LSTM architectures in accurately identifying skin conditions based on product descriptions. Bi-LSTM outperformed LSTM, achieving a significantly higher accuracy of 98.04% and a considerably diminished loss of 19.19% compared to LSTM’s 94.12% accuracy and 19.91% loss, indicating its effectiveness in predicting skin concerns from product descriptions compared to LSTM (Fitrianah et al., 2022).
The study demonstrates the prospect of Deep Learning, particularly CNNs, in accurately classifying skin types from facial images. The CNN model achieved an accuracy of approximately 85% for classification, albeit with a particular emphasis on identifying oily skin. This indicates that the Deep Learning algorithm holds promise for improving the efficiency and accuracy of skin type classification, offering a more reliable alternative to traditional methods. Moreover, the results suggest that with a larger dataset, the model could yield even more optimal and less error-prone outcomes, underscoring the scalability and potential for further advancements in this field (Hanchinal et al., 2024)
Balush et al (2021) focused on proposing cosmetic items based on skincare datasets utilizing neural networks algorithms like CNNs and RNNs, and their variations of deep learning techniques. Although validation loss was low, their algorithm faced larger training loss which can be dealt with by increasing the dataset
Research gaps
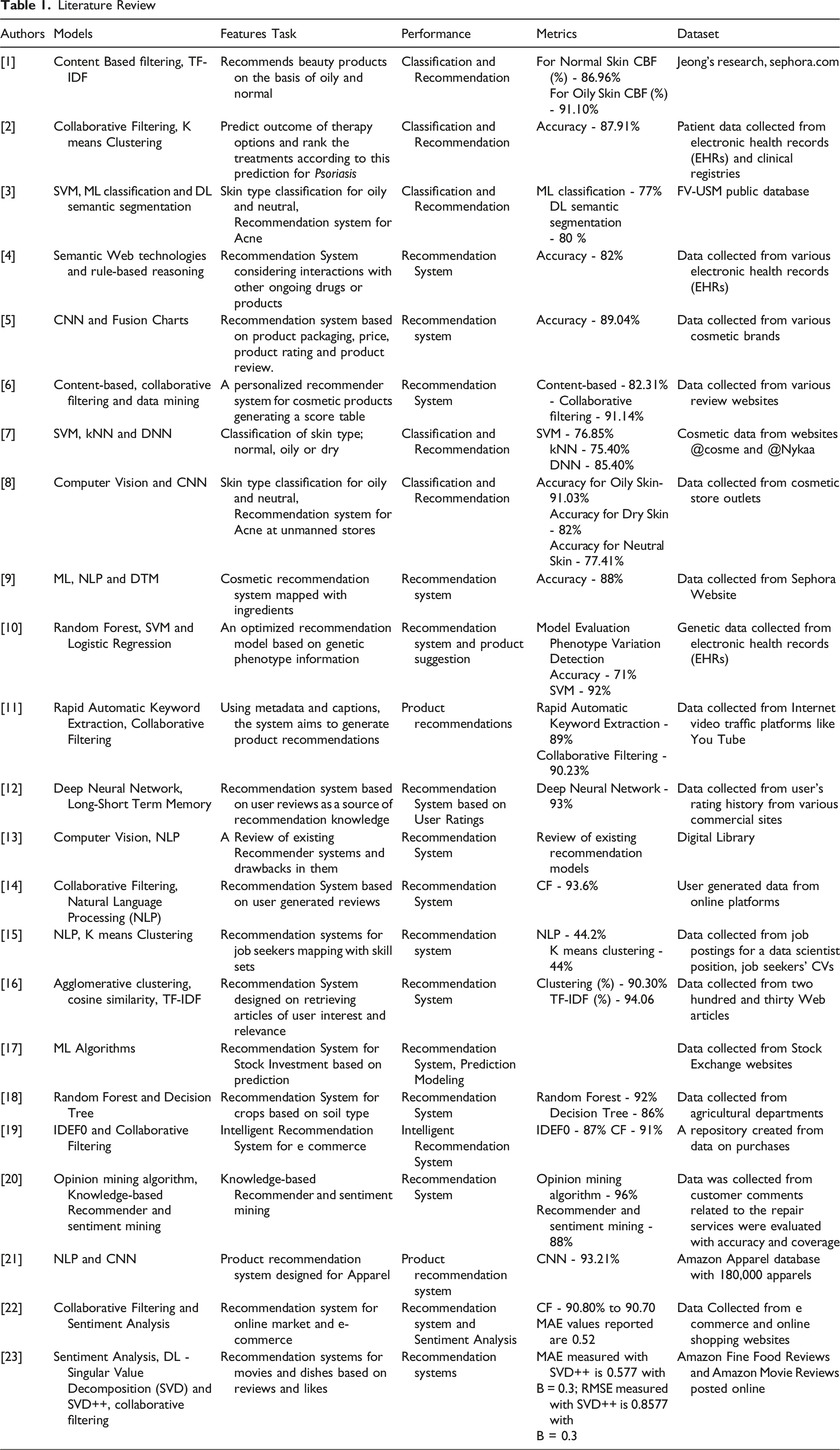
Literature Review
The following are the gaps observed: (1) Current research deals with skin care recommendation systems for personalized beauty and make up options. (2) Recommendation systems are limited to type of the skin; oily, dry or neutral and corresponding products. (3) The AI-based systems are designed by researchers to identify skin diseases and recommend products, but NLP is not integrated which can personalize the products based on ingredients. (4) Products recommended need to be locally available and the system should work in their native language to common people. (5) There is no significant research work found for AI-based systems on mapping the product availability locally.
Research methodology
Figure 2 shows the overall model for our proposed system. The data set for skin diseases and their corresponding treatment or products are obtained from dermatologists, pharmacies and online resources as well as from field surveys at various places in Maharashtra. These are then fed to the NLP module to map them accurately. After that, a disease is provided to the Recommendation system for testing, and results are displayed as location, availability and price of the product required to treat the skin disease. Proposed methodology for AI enabled NLP approach for skin care product recommendation system.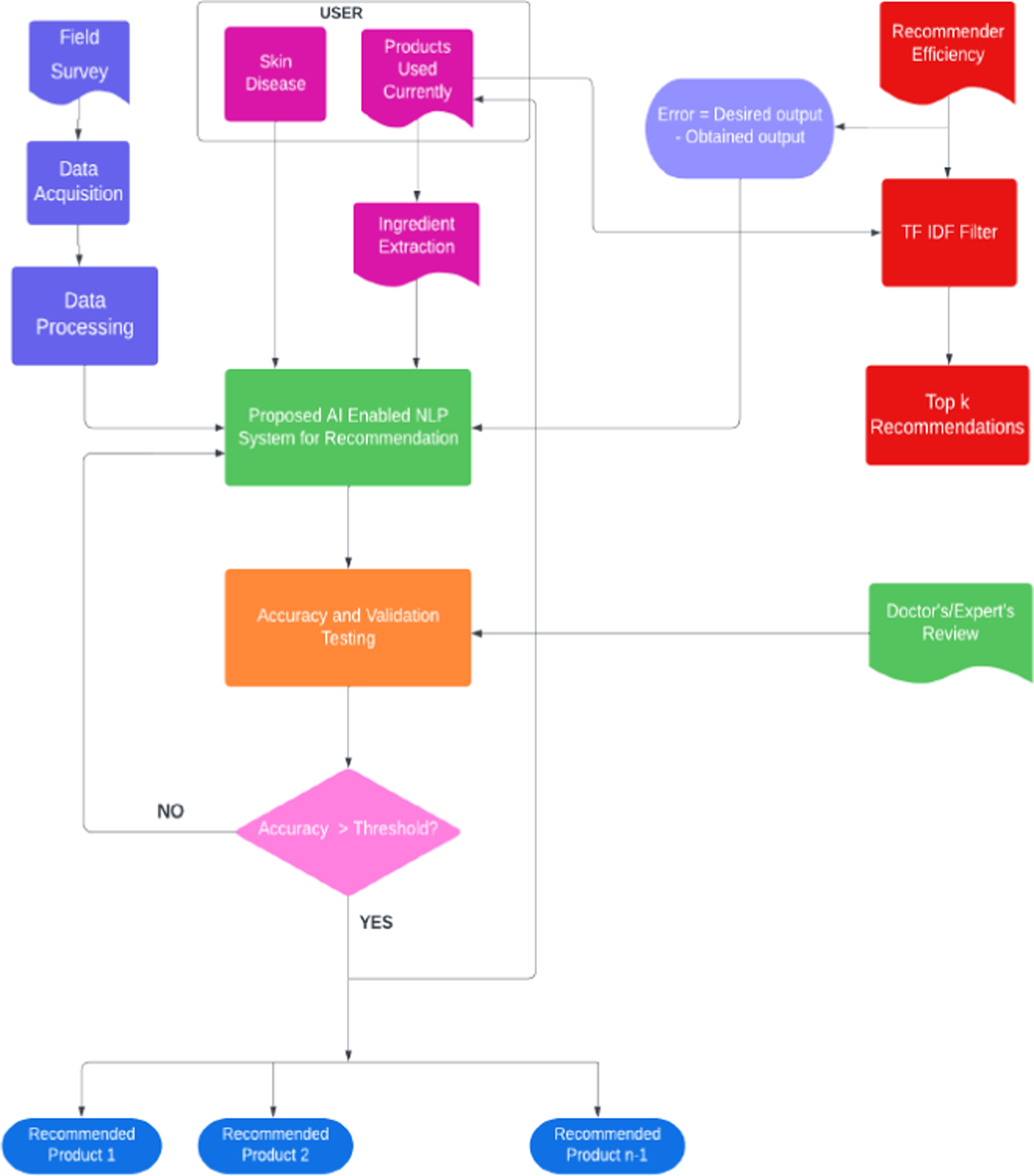
The proposed user interface serves as the entry point for a system designed to recommend skin care products. Initially, users input their skin condition and any existing product usage. If no product is currently used, the system gathers additional details about the skin issue.
Subsequently, the interface collects comprehensive user demographics like age, gender, skin type, lifestyle factors, and potential allergies. This collected information is then processed to match user profiles with suitable ingredients and products. Leveraging the data collected, the system generates a list of recommended skin care products. To enhance user satisfaction, the interface incorporates visual elements, customization options, and clear explanations for product suggestions. Finally, the system presents product recommendations to the user in a textual format.
The initial phase involves data preparation and model training. Processed user and product data is fed into a Natural Language Processing (NLP) model to establish connections between skin diseases and corresponding treatments or products. Simultaneously, a preprocessed template is constructed using existing database information. Backend data is collected and carefully verified to ensure accuracy. This curated dataset is then divided into training and testing sets. The training set is used to refine the NLP model built for product recommendations based on ingredients, while the testing data evaluates the model’s accuracy in predicting treatments for specific skin diseases.
Model evaluation
To elevate the user experience, visual elements such as product images and ingredient breakdowns can be integrated. Additionally, offering customization options like price range, brand, or product type filters can tailor recommendations to individual preferences. Providing explanations for recommended products can increase user understanding and trust. Furthermore, incorporating image analysis capabilities could lead to more accurate recommendations based on visual skin assessments.
The system’s effectiveness hinges on a robust and up-to-date database of products and ingredients. Data privacy is paramount and requires adherence to relevant regulations. The algorithm employed for data mapping and recommendation generation must be capable of handling diverse skin conditions and user profiles.
The model’s performance is assessed through rigorous testing. The reliability of the NLP algorithm in recommending products derived based on their ingredients and its competence to identify relevant treatments for skin diseases are evaluated. Performance metrics such as accuracy percentages are calculated to gauge the model’s effectiveness. Insights derived from the evaluation process are utilized to refine the model, optimize algorithms, and streamline the performance of the system. Iterative improvements are made to the built model to ensure it consistently delivers accurate and reliable recommendations.
Building upon the foundational user interface, future enhancements could involve refining data collection methods, expanding the product database, and exploring advanced recommendation algorithms. Integrating artificial intelligence for personalized suggestions and real-time feedback mechanisms can further enhance the system’s capabilities.
By addressing these areas, the system can evolve into a comprehensive and reliable solution for personalized skin care recommendations.
Data verification and expansion
The process begins with stringent security measures, verifying stakeholder identities through login credentials. To enhance data comprehensiveness, additional datasets encompassing an expanded range of medicines, pharmacies, and their locations are incorporated. The system’s flexibility is ensured through customizable attributes for generating diverse reports. To maintain data integrity, expert review is conducted on datasets and derived results.
Data analysis and preparation
A thorough analysis of the enriched dataset, including medicines, ingredients, and their geographical distribution, is undertaken. This exploration serves as a foundational step for data preprocessing, which is essential for transforming raw data into a suitable format for subsequent analysis. The objective is to extract meaningful insights and patterns from the data, facilitating informed decision-making and accurate reporting.
Conclusion
Our research aims to develop an AI-powered NLP search engine capable of providing accurate dermatological product recommendations based on skin diseases. The system will assist users in taking prompt action by suggesting suitable products and referencing relevant medications and ingredients. Additionally, our project will integrate location-based services to map nearby pharmacies offering recommended products, while also this system will integrate user feedback to iteratively enhance recommendation precision and relevance. To ensure accessibility, the platform will be designed with user-friendly interfaces for individuals with varying technological proficiency.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.