
Abstract
Quality Assurance and output focused algorithm design is the trend, which is a current day research challenge. Inter- and intra- behavioral changes in the system influence on quality of outputs, this due to class imbalance problem prevailing in the data sets, that read uncertain values causes class imbalance problem (CIP). Predictive models that depend on such states of data sets become highly imbalanced. As the CIP on uncertain data starts from selection of samples and candidates for the algorithms; the selected random samples project high variation of classes, a very smaller class or even larger than expected. EEG image data sets are generated from the electro-encephalogram are always random and often never repeating because they vary coarsely based on subjects, ailments and various levels of voltages generated at various types of montage points. Irrespective of montage points and the voltage generated from the electro-encephalogram, the outcome of the algorithms is to develop a predictive model of the subject’s epileptical state. In this regard, the problem of class imbalance (CIP) shall be addressed and handled with various types of heuristic and sampling methods. We shall work on various types of sampling methods and heuristics that develop a predictive model on the uncertain data and draw comparisons to select based on the uncertain state of the data.
Introduction
Though deep learning has many accolades on EEG data sets, image classification tasks in EEG data sets face severity in class imbalances. The expected image features of EEG data sets appear in very small select portions of the entire EEG data sets. Object classification is a cognitive task which include many dynamic correlations which are temporally related with a particular certainty and state, the EEG data sets differ in patterns and the non-uniformity of the graphs are subject to patients from various reasons. Though it is believed deep learning models analyze as strong as human brain, the anomalies are faced due to the uncertainty in the classes. Certain peculiar symptoms of ictal and pre-ictal categories appear in small amounts in the datasets which are not doubted as outliers, becomes a challenge for the classifier.
In a typical medical classification, images with minor features appear as more similar and different with rare features, mitigation and resolution is the main challenge in CIP. This kind of medical image classification is often handled by two methods, sampling of small sizes and labeling due to cost of labeling issues, identification of prevalent rare classes or common classes, which could only be expected to be handled by the medical experts. The members of rare class appear in small percentages whereas the common class appears in high percentages. So, a large sample with broad features can ignore the rarity and commonality of the features in the positive classes (Kumar et al., 2022).
Classification in Deep Learning faces challenges with real-time data. Classification in deep learning is intended to characterize the data sets towards a problem of decision making. Real-time data consists of various classes of data. The real-time data sets are composed with features often representing attributes that generally will not come into consideration of computations in deep learning. The uncertain presence of some attributes causes imbalances in decision making, as instances of datasets are considered into one target class differently from another class (Kumar et al., 2022; Wu and Li, 2021). Therefore, the CIP is related with dealing of imbalanced datasets in deep learning. Further in the study related to the CIP is the target class with positive presence, that is, positive class which may contain less number of high intensity instances. The instances are lesser but contain high intensities in the positive class; they are also called positive instances or minor instances.
In deep learning most of the classification algorithms focus on maximization of the performance parameters related to accuracy (Jiang et al., 2020; Zhang et al., 2020). On iterative performance of the algorithms in deep learning for classification, the instances appear as of less importance instances and the classes as the less significant classes. In such situations the prediction of positive instances to the positive class becomes less importance of the real objective of the problem of classification in deep learning (Jiang et al., 2020; Li et al., 2020; Zhang et al., 2020). In order to consider such instances for boosting the accuracy of prediction additional exercises have to be considered for maximization of the accuracy of predicting positive classes.
The objective of handling class imbalances is to include uncertain positive instances into the positive class and improve the prediction rates. Many methods are proposed in the literatures for effective and practical prediction rate convergence. Major methods of handling class imbalances work with sampling techniques, transformation of imbalanced datasets to well-balanced and distributed datasets in deep learning using effective classifiers for classification (Jiang et al., 2020; Khan et al., 2019; Li et al., 2020). The sampling methods (Khan et al., 2019; Kim et al., 2018; Peng et al., 2019) are mostly favorable for their portability in various applications, where a researcher is not restricted to a specific category of classifier. One of the simple approaches for handling class imbalances using sampling methods is to repeat the duplication process of positive instances in the positive class, until positive and negative instances are quantified equally. Classifier is forced to learn every specific instance with all the general features which are uncertain causing imbalance, and shall be beware of overfitting. The synthesizing of positive instances with other positive instances in the periphery, by inheriting the features that fit to designate the instance as positive is generally applied (Sun et al., 2006).
Related work
The problem of class imbalances is handled by machine learning and deep learning using three methods, viz., active learning, cost-sensitive learning and sampling methods. Active learning is widely popular in deep learning, which uses small training data sets. With minimum effort and domain knowledge for labeling by using a strategic querying methods unlabeled datasets are extracted and synthesized as labeled datasets. Active learning is again a cognitive and iterative solution (Chawla et al., 2002; Japkowicz and Matwin, 2002). At each iteration, the classifier is enriched with new feature information in order to collect iteratively as many datasets as more possible into the class as members. Different kinds of cost matrices can be used in cost-sensitive learning method, in order to describe cost of unclassified samples of different classes (Kubat and Matwin, 1997). Sampling based methods, effortlessly aim to build the datasets considering the proportions of classes by examples from the real-time training samples, therefore preparing a balanced dataset.
Comparisons of different SMOTE
Comparative study of SMOTE and CIPs.
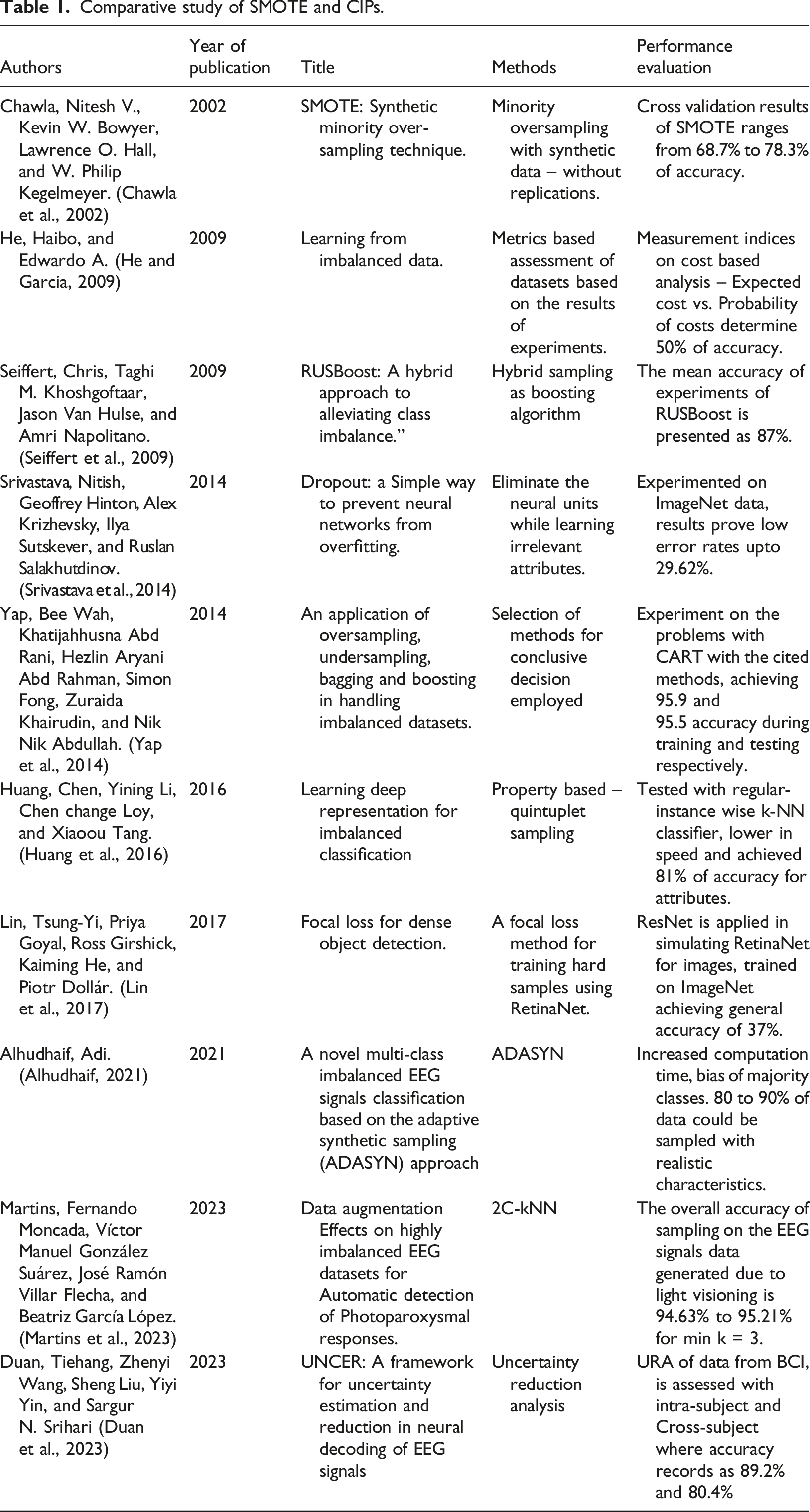
By providing new ‘safe’ approach to over-sampling, SMOTE improves accuracy of classifiers for minority class. It is proved on datasets with variety degrees of imbalances. A normal minority-oversampling technique attempts balancing classes by replicating the instances of minority class, where SMOTE employs synthetic data appending to the datasets which consists of the properties of the minority class, it does not replicate the existing data. A set of standardized practices are essential to evolve a learning model from the imbalanced datasets. He et al. (He and Garcia, 2009) has proposed metrics to mitigate with the imbalances in the data such as singular assessment metrics, receiver operating characteristic curves, precision-recall curves and cost curves. These metrics have been illustrated but still the gap in the work of solving the imbalance data vests with the categories of attributes in the datasets, which is a challenge faced in every new method invented. The reasons for this impossibility have been quoted as lack of uniform benchmark assessment techniques for estimating the quality of data, cost of procuring data with completeness. Various tools are employed in mitigating the said problem, wherefore the problem is domain specific and categories of attributes. Tsung Li et al. (Li et al., 2020) has proposed methods for mitigation of said problem, by altering the shape of the datasets by identifying the entropy loss that causes down-weighing the classifiers. A concept of Focal Loss has been introduced to address the problem of one-stage object detection in extreme conditions of imbalances, while building a learning model. A variant of AdaBoost has been proposed by Chris Seiffert et al. (Seiffert et al., 2009), with a new RUSBoost method. Data sampling and boosting were believed to be methods of alleviating the said problem. The hybrid sampling as boosting algorithm is devised to solve the imbalance in datasets, which is proved best suitable in binary classification problem. As overfitting is observed as problem of misclassification in neural networks, Nitish Srivastava et al. (Srivastava et al., 2014) has proposed a Dropout method. Many irrelevant attributes are considered to be avoided during training, to improve the chances of prediction. This experiment is limited on multi-variate numerical data, averaging predictions during testing and randomly dropping neurons while the network goes into too much adaptations. The classifiers are believed performant for the well distributed data or the data in the known distributions. Imbalanced data is said to be in a asymmetric distribution, which are not possible to estimate the statistical properties of the data. Almost a fundamental approach is applied by Bee Wah Yap et al. (Yap et al., 2014), in their seminal works of applications of oversampling, undersampling, bagging and boosting. Wherefore the sampling methods are the universally proven methods for overcoming the problem of imbalance in datasets. In domains related to vision data, the distribution is highly-skewed and the most important characteristics of the data belong to the minority classes, where they contain scanty number of instances. A cost-sensitive training using a CNN is proposed, the experiment proved to work on constrained vision data.
Observing the properties of the elucidated research works, it is found that a binary classification problem needs large support to determine the classifiers accurately, SMOTE with the safer approach is best suggest approach for the image, vision and numerical data sets (He and Garcia, 2009; Huang et al., 2016; Yap et al., 2014).
The original SMOTE generates synthetic samples by selecting the random minority class instance and nearest neighbors of minority class. The new instance is created by interpolating selected instances. The hazard in this method is that noise might be introduced, if selected instances are not purely belonging to the minority classes. A decision boundary called border-line is constituted to distinguish the classified instances, but this method of Borderline-SMOTE fails if the classes are very less and if they exhibit high intra-class variability. Adaptive Synthetic (ADASYN) (Alhudhaif, 2021) technique adapts with number of synthetic samples for each minority class, in order to balancing the class weights to maintain equivalence. In order to adapt better data distribution, certain minority classes with a smaller number of instances are populated with the synthetic instances. This method is not guaranteed to prove its effectiveness, rather it is very expensive, while incorporating the context sensitive synthetic data generation. As to overcome the said disadvantage in ADASYN, a safe threshold can be constituted to bring the equivalences in the instances to build a rich class, where controlling the size of samples during synthetic generation, is Safe-Level SMOTE. This is an ideal method to reduce / avoid noisy instances accumulated during synthetic generation (He and Garcia, 2009).
The novelty in application of safe-level SMOTE for EEG image datasets is states as follows
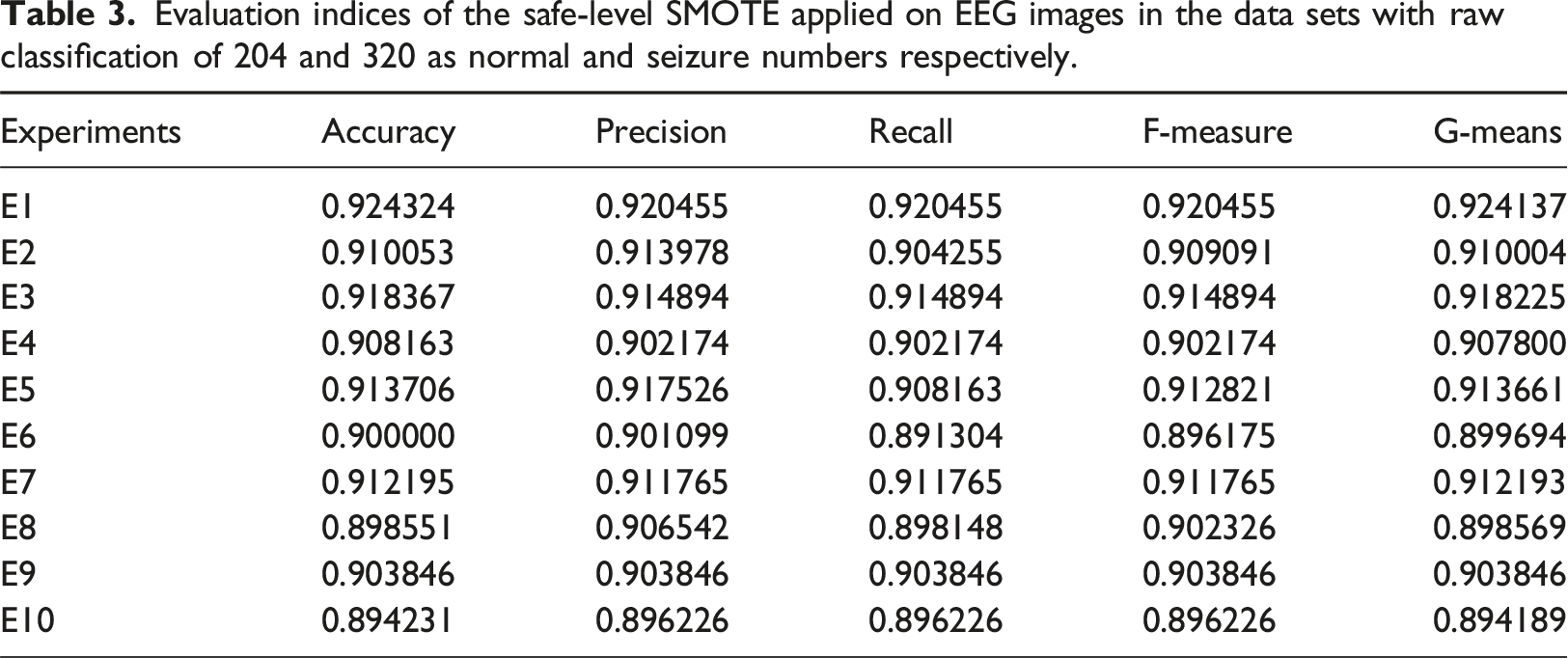
Evaluation indices of the SMOTE applied on EEG images in the data sets with raw classification of 204 and 320 as normal and seizure numbers respectively.

Evaluation indices of the safe-level SMOTE applied on EEG images in the data sets with raw classification of 204 and 320 as normal and seizure numbers respectively.
Proposed method
Safe-Level SMOTE with Ensemble method is introduced to overcome the problem of CIP. As the learning from the imbalanced data sets pose unsatisfying results and over-focused accuracy in identifying the model. However, the samples near the decision boundaries that contain more important information to discriminate and should be taken into consideration for construction of clear boundaries with synthetic samples. Therefore, as an appendix to the proposed framework, to capture the exact boundary decision space an ensemble model is introduced. A novel ensemble method is introduced Safe-Level SMOTE with Bagging.
Ensemble method
Apparently for imbalanced EEG image data sets the presumed classifier model becomes biased. The model’s ensemble strategy is the need of the hour, which overcomes the bias developed from the learned models. Generalization is required to achieve when the model exhibits bias. Therefore, weak classifiers are composed with less number of characteristics whereas a combination of weak classifiers builds into a strong classifier. The ensemble method called bagging technique is applied to develop various models. Bootstrapping is the method of sampling used to generate totally distinct classifiers. Uniform probability shall be taken into consideration for each training sample for replications. The bagging algorithm is mentioned below: (1) Input the Entire Data set | (2) For
a. Generate sample from i. Apply random method to select instances into samples. ii. Develop training data using random methods.
b. Derive the model (3) Ensemble the models { (4) Derive the final model
The goal of application ensemble methods is generalization, which shall enhance the capability of the model. Bagging with SMOTE is applied to deal with imbalanced learning of data. (1) Input the sample (2) Select a random instance (3) Output a new synthetic sample for the minority as xsyn = x
i
+ δ (x∼
Data sets
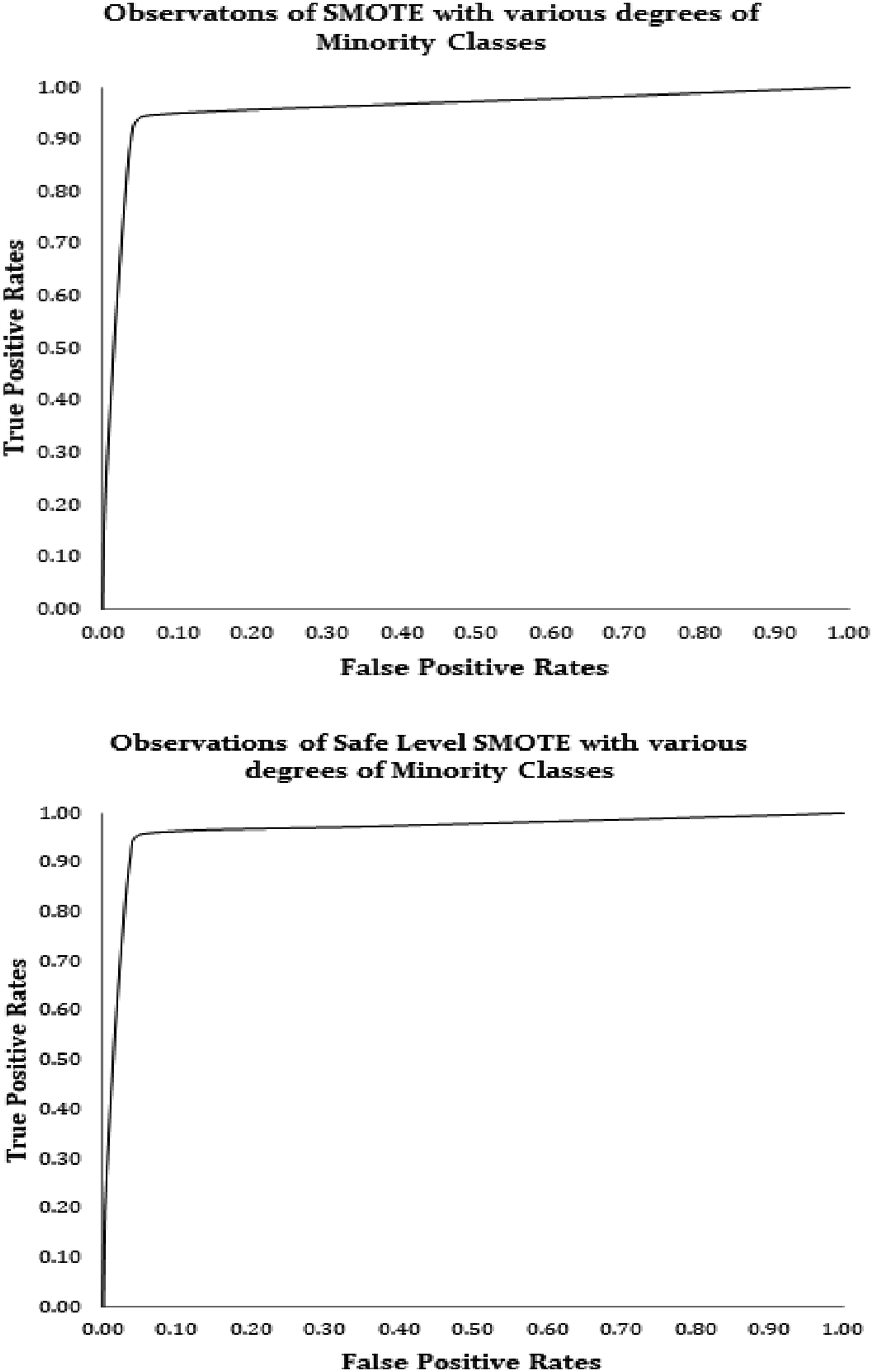
The salient activities in acquiring EEG datasets include signal acquisition, preprocessing, feature extraction and feature classification. The feature signals extracted from the signals acquired are identified with features that discriminate information from different imaginary situations of the electroencephalogram signals. The classification of EEG datasets is greatly influenced by the features that exist in the raw signals, hence the importance of feature extraction in EEG signal data analysis. All the frequencies of samples of the EEG account to 1763.61 Hz, as the ground level benchmark. The maximum and the minimum frequency are 86.81 Hz and 0.05 Hz respectively. The EEG datasets contain images defined by administering the ‘International 10–20 method’ placement of neuro-headset, 24 channels’ data is collected from 24 montage points and the power is traced with 128 samples per second. Most experiments on the EEG consider the benchmark frequency between 0.05 Hz and 64 Hz. The EEG signal data are converted into EEG signal data graph images using EEG signal data generated from matplotlib for the cited data sets from UCI KDD archive. (a), (b): AUC in ROC for SMOTE and Safe Level SMOTE with Bagging.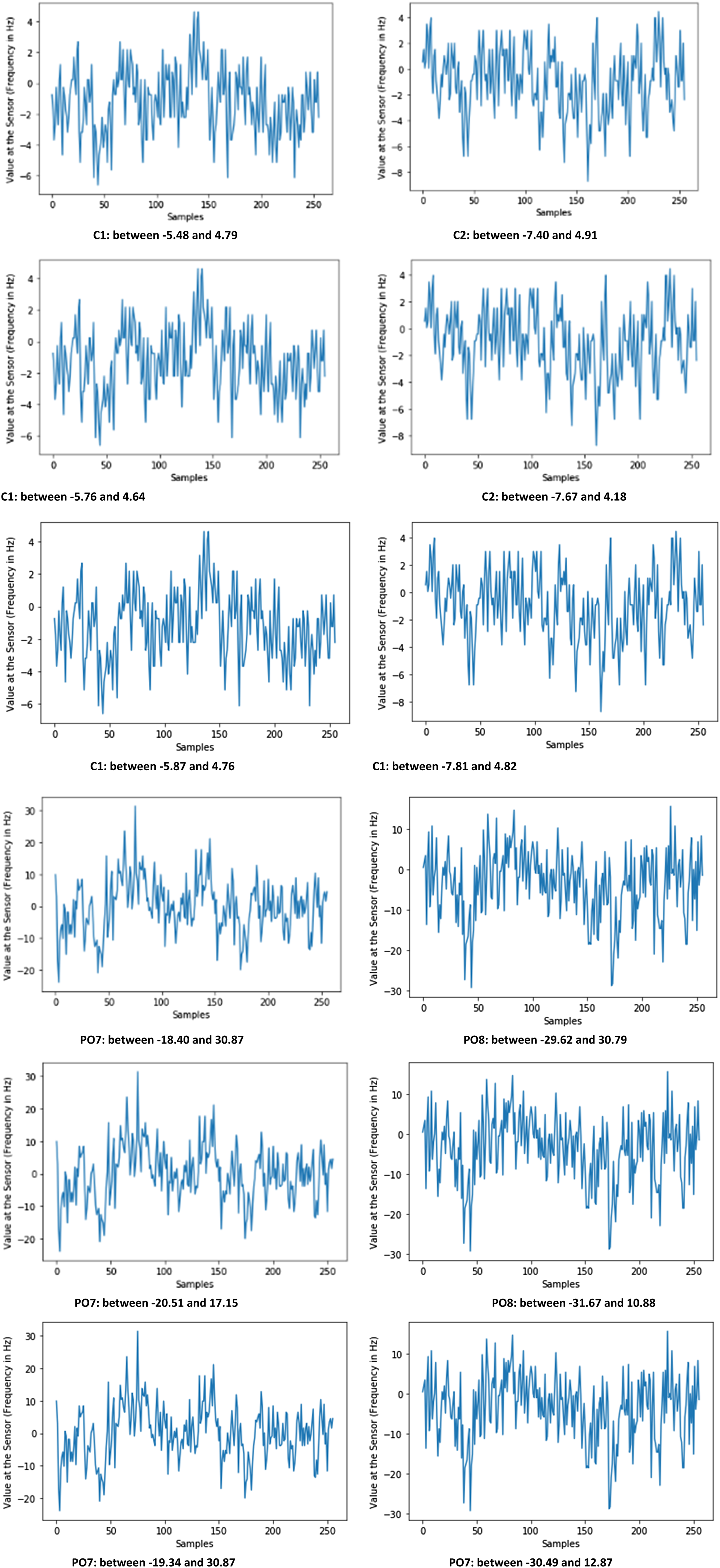
Explanation
The signal images indicated above are category of images selected in the experimentation. As mentioned, 204 normal images and 320 seizure images are selected for the CIP using SMOTE and Safe-Level SMOTE, the images are selected from particular focal points and indicated as per the International System of Electrode Placement of Unipolar channels. Images indicated with prefix ‘PO’ are the points of the Inion, prefix of ‘C’ indicates the cerebral zone between Inion and Nasion, which are at the occipital and central zone of the head. The varying electrical frequencies are indicated for the selected images.
Data augmentation
Data augmentation is a useful task, to improvise performance of deep learning tasks by means of eliminating the irrelevant EEG image datasets (Kim et al., 2018; Siriseriwan and Sinapiromsaran, 2017; Wang and Wang, 2017; Zhang et al., 2020). However, the data augmentation connects with tasks related to cleaning and preparing data suitable for the classification model. The collected data contains 320 seizure and 204 EEG images of various points and frequencies.
The data source is the subset of the collections from the repositories of the UCI KDD Archive of Information and Computer Science of University of California, Irvine, which is allowed, declared free for the experimentation and research. The experiments conducted are related to multiple electrode time series also called as EEG recordings of subjects with normal and alcoholic. The data sets are generated with 64 electrodes placed on scalp which are sample at the frequencies of 256 Hz (3.0 msec epoch) for 1 second.
To make the ease of learning and extracting features in the classification, various sliced samples are generated as image datasets. Instead of creating or generating new EEG image datasets, the UCI KDD (Begleiter, 1999; https://kdd.ics.uci.edu/databases/eeg/eeg.html) archive of 700 Mb is resorted to bring out the features of the EEG data from the healthy and alcoholic subjects. To enable the classifier, learn every possible feature in the EEG image datasets, the datasets with all the general properties are not considered for synthesizing the positive instances of the EEG image datasets. The best approach for synthesizing and augmenting the datasets is
Class imbalance
Handling the CIP is one of the important challenges faced in deep learning while data preprocessing and augmentation (Galar et al., 2014; He and Garcia, 2009; Kim et al., 2018; Zhang et al., 2020). The challenge of ‘dealing with rarity’ starts from identifying the features from the benchmark datasets. The outcome of the solution that is arrived from the CIP is to reduce the majority classifier criterion or to enhance the minority classifier criterion by considering the change of distribution in samples. General method of handling class imbalances is under sampling and oversampling.
The technique of undersampling underlies the principle of selecting a particular set of images randomly that belongs to a class with a number that is more than actual. The greater number of images will deal with the class with the same count of images with other class or classes in the image datasets. This technique is more properly used to balance the uneven datasets of classes by retaining the data that belong to minority class, further by decreasing sizes of majority class instances. However, the complications that arise due to undersampling are loss of potentially relevant information from the majority class as they are reduced (Japkowicz and Matwin, 2002).
The technique of oversampling underlies the principle of duplication of randomly selected images from the minority classes. Synthesizing would help to enhance more images with the like features of the existing minority classes, therefore enhancing the sizes of all classes and making the sizes all similar. The complications that arise due to oversampling is the ‘overfitting of the model’, due to duplicates in the minority classes and making the model learn only specific patterns in the large population of samples, where the model would never learn generalized patterns (Japkowicz and Matwin, 2002).
Various types of class imbalances

The above table shows the degree of imbalance that occurs in the samples based on the percentage of prevalence of the characteristic features (He and Garcia, 2009).
Class imbalances in EEG datasets
As the primary data augmentation phase the images of various sizes are synthesized and scaled down into 380 × 260 pixels’ size. The image slices from the select montage points are generated from the source data with the states of interictal, pre-ictal, seizure and post-ictal. For each experiment 250 samples of EEG image slices with different voltage variations represent the properties of interictal, pre-ictal, seizure and post-ictal. As the said EEG image datasets need multi-class, multi-label classification the class imbalances are managed by sampling.
The signals of various symptoms are found with common signatures in most of the images, which make ambiguous in defining the classes. Therefore, the common solution to overcome the class imbalance in deep learning is possible by using the three methods. 1. Oversampling techniques, 2. Undersampling techniques and 3. Combinations of techniques. By means of data augmentation and sampling the CIP can be solved for most of the cases, particularly in image classification, if the images have common features. For the image data sets which contain differences of features with more granularities, sampling techniques cannot compromise a solution. In the case of EEG signals, as the signals represent similar signatures for various EEG properties, sampling techniques suffices.
Balancing the classes or solution to the CIP in DL using sampling is by means of balancing the class distributions. Changing the compositions in data sets during training the classifier is one of the possible methods for managing class distributions. Statistically, the methods change the class distribution in the EEG image data sets during training are referred to as sampling or resampling. Sampling methods transform the training data sets to the requirements of making the classifier successful. A plethora of machine learning algorithms suitably exists to satisfying the classification problem with unbalanced data when the training data is resampled. The prudence of classification by machine learning algorithms is based on the training data generated by resampling. Testing and training therefore refines the machine learning algorithms, particularly on unbalanced image datasets. Sampling and resampling are advantageous to manage the distributions of data suitable for the classification processes (Zhou et al., 2021).
Method for handling class imbalances
Sampling techniques are also associated closely with the activities similar to data augmentation. Transformation of the training data sets is accomplished by means of tuning the granularities of the data sets. From
Experimental set up
The experimental framework of the CIP in the current work consists of following steps: 1. The data is collected in the form of CSV files from the source mentioned in 2. The images collected are hand-pruned and formatted by eliminating the missing values, outliers and removing irrelevant features which are not in the discussions of the research work, therefore selected images contain normal and seizure features. 3. Binary Classification problem is initially experimented on the datasets with samples using 70% for training and 30% for testing. 4. Using SMOTE API in Python, the classification model introduces overcoming of the class imbalance. 5. Sample generation for the minority classes and synthetic generation are exercised on the selected images after the preliminary classification. 6. Same classification algorithm is again experimented on the resampled datasets and measures are taken for mitigating class imbalances. 7. Model of Class Imbalance is experimented with SMOTE and Safe-Level SMOTE. Both the method achieved considerably 94% - 96% accuracy. 8. Model evaluation indices are computed based on the observations of the experiments and compared for validation.
Synthetic samples are generated as follows: - Consider the difference between the sample of feature vector and the nearest neighbor. - Multiply difference by a random number between 0 and 1. - Upgrade the feature vector with the new product. - Thus select the random point on the line segment. - The random point lies amidst the feature vectors. Observations of SMOTE on the generating synthetic samples.

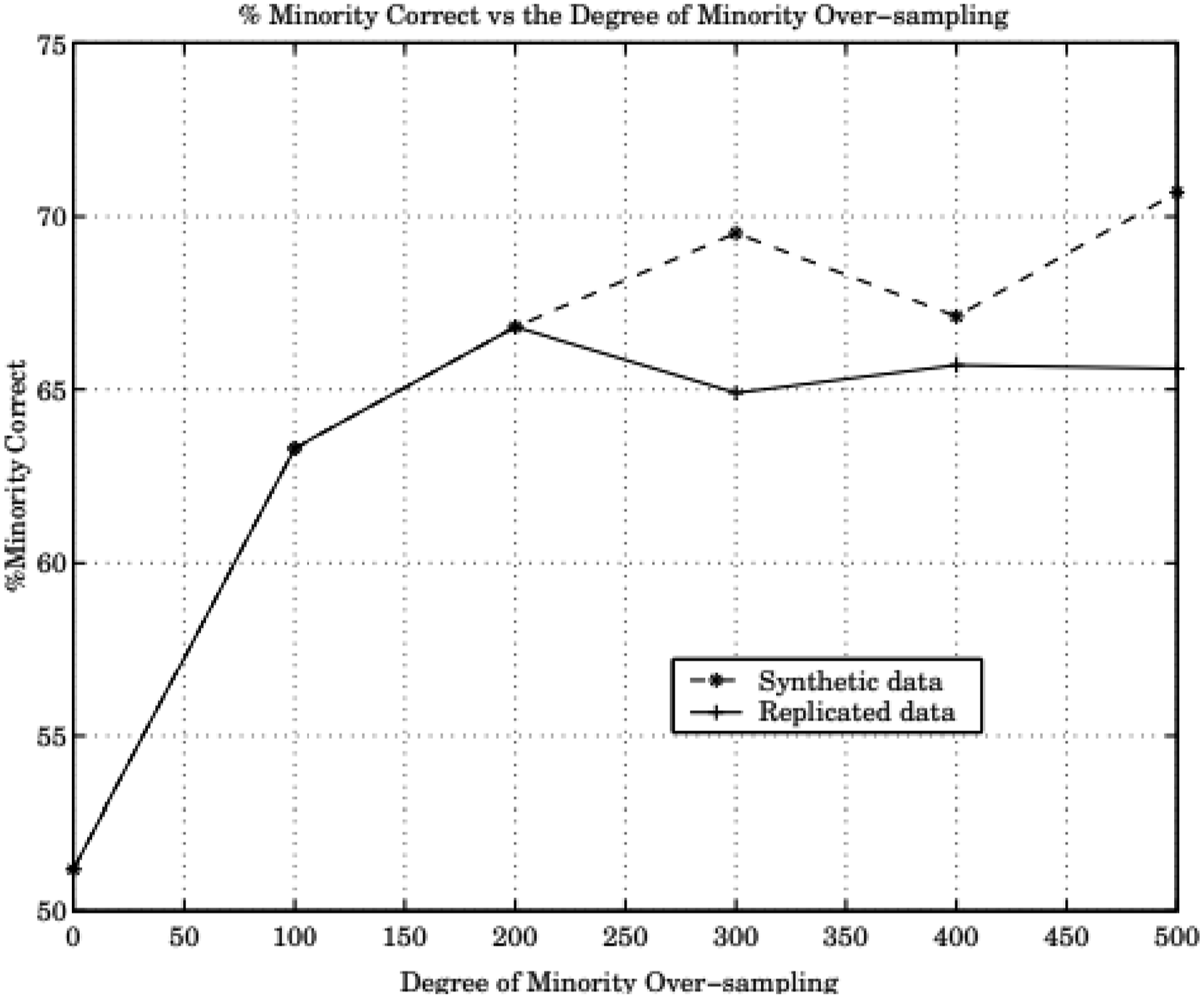
Decision regions created in the process are larger and less specific by the synthetic examples. Decision trees of the samples show more generalization, as more general regions in majority class samples are subsumed for SMOTE experiment than minority classes for the EEG image data sets. The graphs represented in Figures 3 and 4, demonstrate the generalization in SMOTE. The experiment is conducted on EEG image data sets, with 250 samples representing different voltage variations. The data sets in the experiment are generated from the selected montage points of all state’s encephalography. Comparison of expected DT sizes by SMOTE and replicated over-sampling for the EEG image datasets. Percentage of correct minority-samples by SMOTE and replicated over-sampling for the EEG image datasets.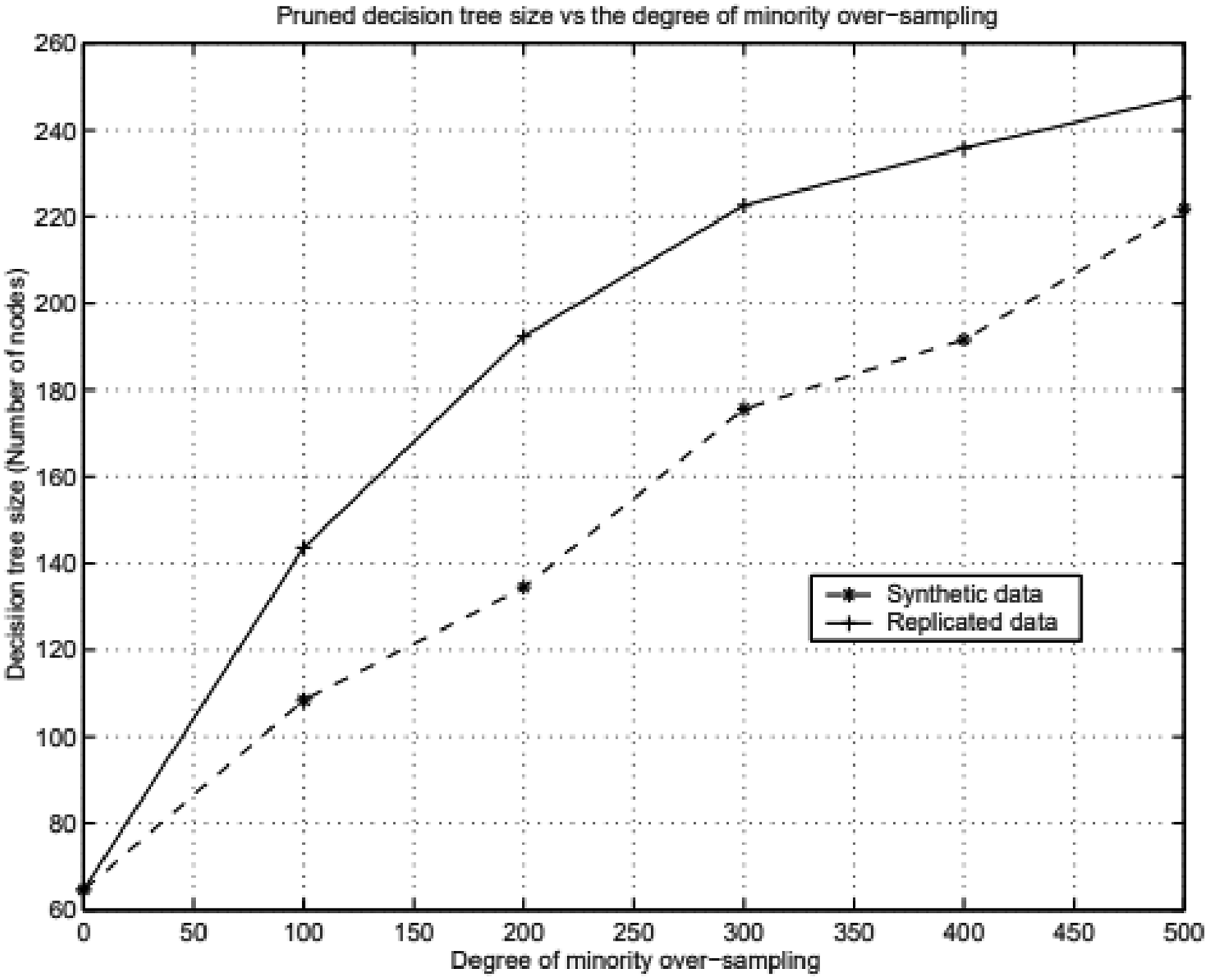

The performance is evaluated by computing the Area Under Curve (AUC). The lower left most points are for the given RoC curve belongs to the performance of the classifier on the raw data and the upper rightmost is (100%, 100%). The curve does not naturally end at the set point, the point at the apex is assumed, which is necessary to compare the AUC’s of various ranges.
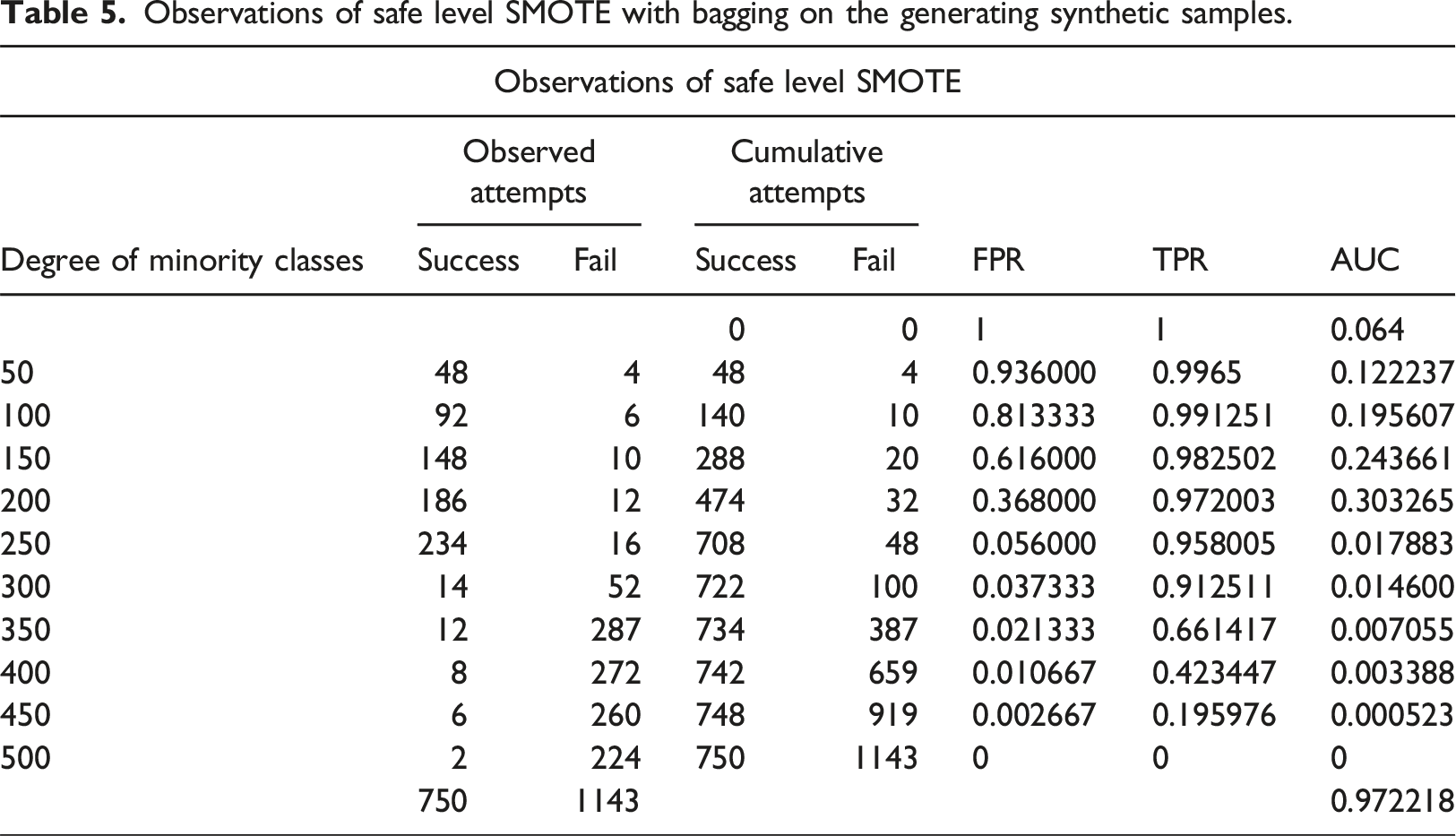
Observations of safe level SMOTE with bagging on the generating synthetic samples.

Conclusions
Several experiments have been conducted on the EEG image data or converging the CIP. The key problem of class imbalances is the variation of voltages at different montage points for each subject. As the uncertainty in EEG signals raise varying from each subject, the sampling and resampling technique is a quite resort for the solution of the problem. As a future work adaptive selection of number of nearest neighbors could be suggested as a valuable parameter, based on which the over-sampling of the minority class can be accomplished. Selection of nearest neighbors focuses on more examples to solve with incorrectly classified data. The performance is not a standard response in the RoC curve, because of the uncertainty in encephalography characteristics. There is a considerable development of accuracy Safe Level SMOTE (95.2456% with AUC 97.22%) on the EEG Image data sets compared to SMOTE (94.3459% with AUC 96.76%). The same level of degree of minority classes are applied for both the experiments and the each minority class can be sampled possibly with respect to the majority class as its nearest neighbor than selecting a pivot of the samples in the minority class. Decision surfaces can be redrawn for various settings of over-sampling of minority classes.
Footnotes
Author contributions
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.