
Abstract
Generative Artificial Intelligence methods using large language models can rapidly generate and process text, fuelling interest in qualitative research applications. To explore these possibilities, we developed a chatbot to interview social scientists at a Swedish university (n = 74) and then conducted follow-up email exchanges about their experiences (n = 23). This article presents an empirical example of a Gen AI–mediated qualitative interviewing setup, in which a chatbot conducts simultaneous, adaptive interviews to elicit in-depth engagement. We also show that around half of the social scientists in our sample are already experimenting with Gen AI in their academic work, primarily for writing support, literature engagement, transcription and, to a lesser extent, data analysis. We argue that chatbots can be powerful tools for qualitative research, but caution that they require careful oversight, critical reflexivity, and ongoing methodological development. This knowledge adds a nuanced, empirically grounded example of Gen AI–mediated interviewing, relevant for social scientists seeking to integrate Generative AI into their research practice.
Keywords
Introduction
Social scientists have used artificial intelligence techniques since at least the 1980s, for a wide range of tasks, such as natural language processing and theory evaluation (Carley, 1996; Woolgar, 1985). However recent developments show that Large Language Models (LLMs) and other Generative Artificial Intelligence (Gen AI) systems are rapidly becoming part of the everyday toolkit of social science researchers. Recent studies show that qualitative researchers are already experimenting with Gen AI across the research pipeline—for brainstorming, drafting, translating, summarising and coding assistance, while simultaneously expressing concern about data protection, loss of autonomy, and alignment with qualitative values (Anis and French, 2023; Bail 2024; Bolanos et al., 2024; Chatzichristos, 2025; Davidson, 2024; Grossmann et al., 2023; Kirsten et al., 2025; Schroeder et al., 2025; Van Noorden and Perkel, 2023: 674). This fast uptake is fundamentally changing the nature of qualitative inquiry (Bail, 2024; Davidson and Karell, 2025; Eryaman, 2025; Ibrahim and Voyer, 2025; Joyce and Cruz, 2024; Kozlowski and Evans, 2025; Pilati et al., 2024) and has led to calls for a rejection of Gen AI in reflexive qualitative research (Jowsey et al., 2025; Nguyen and Welch, 2025).
In parallel, a growing body of work evaluates Gen AI administered chatbots as interviewers and conversational survey instruments (“multi-turn dialogue systems,” see, e.g. Yi et al., 2025). Across political opinion studies, web surveys, telephone systems, classroom feedback, and public consultation, LLM-based agents have been shown to be capable of administering complex questionnaires, handling branching logic, and eliciting substantial open-ended data at scale, often matching or surpassing conventional online surveys on metrics such as informativeness, clarity, and reduced satisficing (Barari et al., 2025; Chopra and Haaland, 2023; Geicke and Jaravel, 2024; Lang and Eskenazi, 2025; Yu et al., 2024; Wuttke et al., 2024). In some cases, Gen AI interviewers outperform human interviewers in eliciting responses (Liu et al., 2025; Sun et al., 2025; Wuttke et al., 2024). At the same time, LLM-based chatbots have systematic limitations: they lack a full understanding of participants’ specific motives, or context-sensitive nuance, resulting in lower richness and narrower thematic diversity compared to human-led interviews (Beltoft et al., 2025; Cuevas et al., 2025; Dortheimer et al., 2024; Geicke and Jaravel, 2024; Nardon et al., 2025; Zarouali et al., 2024).
These developments sharpen a longstanding tension in qualitative social science between scalability (both of thematic coverage and sample size) and interpretive depth. On one hand, Gen AI interviewers promise to extend qualitative-style data collection to much larger samples and hard-to-reach populations, potentially democratising participation and enabling new kinds of large-n, text-rich studies (Chopra and Haaland, 2023; Geicke and Jaravel, 2024). On the other hand, scholars warn that extensive automation in interviewing and analysis may incentivise a reorientation towards pattern–seeking epistemologies (Chatzichristos, 2025). This may allow the goals of speed, coverage, and apparent coherence to subordinate reflexivity, contextual richness, and the co-constructed nature of qualitative data (Brailas, 2025; Ibrahim and Voyer, 2025; Ornelas et al., 2025; Sanaei and Rajabzadeh, 2025; Schroeder et al, 2025). Frameworks such as “depth and autonomy” (Sanaei and Rajabzadeh, 2025) and “technological reflexivity” (Ibrahim and Voyer, 2025) have started grappling with the how of using Gen AI in qualitative research.
Advances in automated interviewing, for better or worse, raise questions about the production of knowledge. Traditional qualitative interview methods emphasise the dynamic interplay between interviewer and interviewee, where meaning emerges through dialogic exchange (e.g. Brinkman, 2013; Holstein and Gubrium, 1995; Knott et al, 2022). LLM-driven interviews fundamentally alter this dynamic by introducing non-human agents to facilitate data collection. In this article, we take these tensions as a starting point and empirically examine how a Gen AI–mediated qualitative interviewing can operate in practice by asking: How do LLMs perform as qualitative interviewers? How are social scientists using Gen AI? And how can LLMs support qualitative analysis?
To address these questions, we use an LLM-based chatbot to interview social scientists about their own use of Gen AI tools. Our contribution is threefold. First, we demonstrate how LLM-driven interviews can play out. Second, we report on our data and describe how respondents in our sample use Gen AI tools. Finally, we explore the use of LLMs in qualitative inquiry. In the following sections we: describe our methods and present and discuss our results, before concluding. Our work contributes to current debates on how Gen AI is reconfiguring qualitative research methods and the production of social scientific knowledge.
Methods
Chatbot design and participant recruitment
To interview social scientists, we developed a web-based chatbot driven by an LLM. We wanted our chatbot to adhere to several qualitative research principles (Small and Calarco, 2022). We wanted it to pose broad, open-ended questions that were neutral and non-leading. It should probe adaptively, adjusting its line of questioning based on interviewee responses, including recalling previous points, identifying recurring themes, and guiding the discussion towards new topics without disrupting its natural flow. We aimed to balance thematic and stylistic consistency with adaptability: that is, the chatbot should behave consistently across multiple interviews and extended conversations, while adapting to interviewees’ style and avoiding sensitive topics. By incorporating these principles, we aimed to balance the methodological demands of qualitative research with the practical benefits of automation.
To conduct the interviews, we used a web-based chatbot based on Google’s Gemini Flash 1.5 model (Gemini Team, 2024). We accessed the AI model using the Gemini application programming interface (API) to preserve the respondents’ privacy and the confidentiality of their responses, since Google does not reuse data from API calls—that is, interviewees’ responses—as future training data. The chat interface was built as a web application, developed in the Python and JavaScript programming languages, which accessed the Gemini model API using web service calls. We prompted the model to conduct a semi-structured interview using a social science interview style (Brinkmann, 2013; Knott et al., 2022) following a topic guide that included several overarching themes (Supplemental Appendix A). The prompt directed the model to introduce each theme to guide the interview by asking a sequence of expansive, open-ended questions like “Can you describe your experiences with. . .?” followed by targeted probes such as “Can you tell me more about. . .?”. This approach allowed the chatbot to steer the conversation to subsequent topics using fresh open-ended inquiries, while keeping track of the conversation and earlier responses (see Figure 1, chatbot interface). The prompt forbade any discussion of sensitive topics (motivated by European Commission, 2024), and to move on if an interviewee declined to answer a particular question.
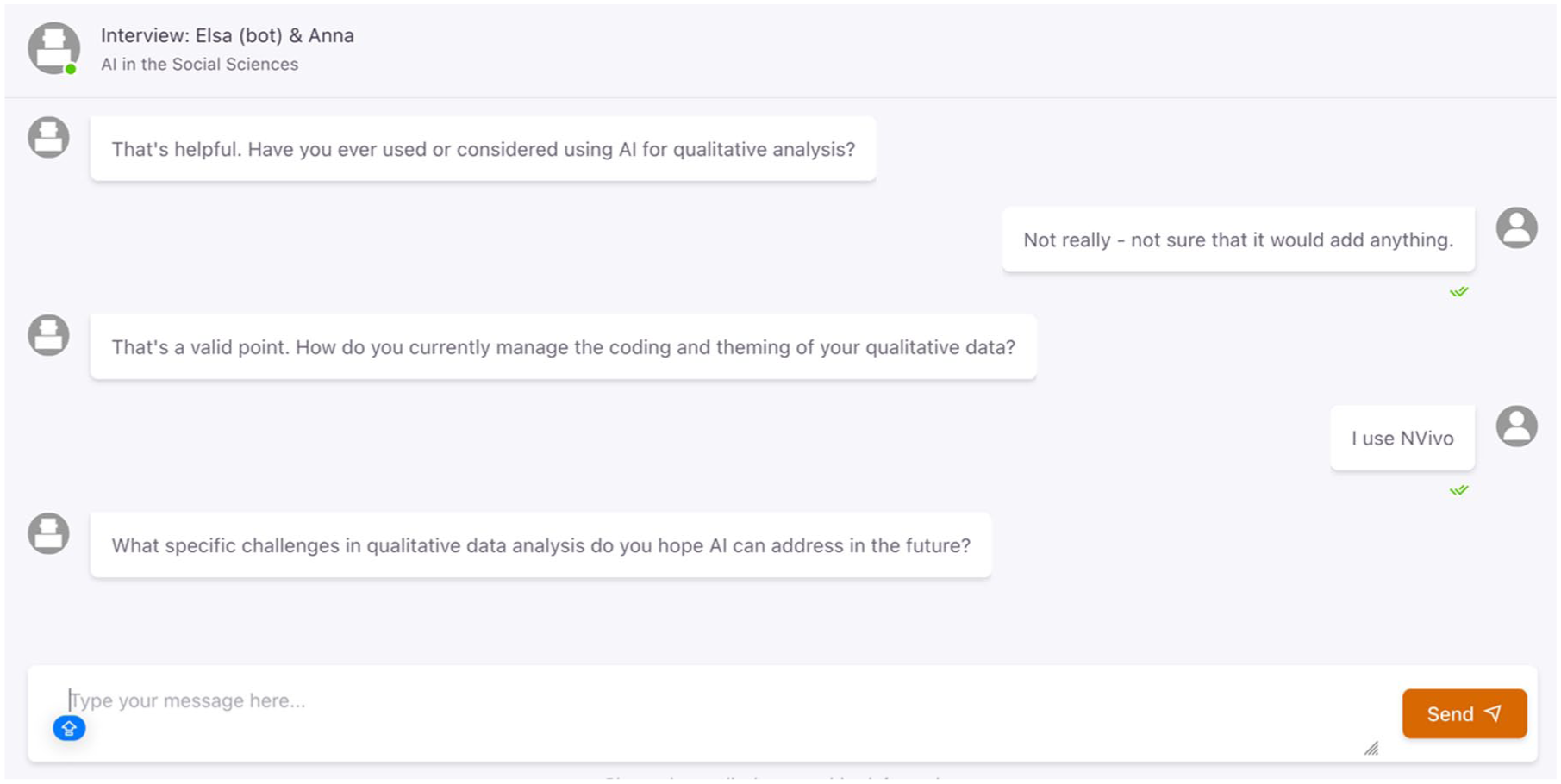
Screenshot of chatbot interface. Respondents type answers and press “send” and the chatbot processes the reply and generates either a probing question or moves on to the next topic until all themes have been covered.
Recruitment and application
Before starting the interview, interviewees were informed that the chat would take around 10 minutes and asked to complete a web form that captured consent to participate, consent for follow-up, acknowledgement that participation is voluntary and may be discontinued at any time, and a disclosure that we intended to publish anonymised responses. We thought that the shorter time would lower the barrier to accepting to do interviews, but acknowledge the limited depth available in 10 minutes. We also asked for name, follow up email, academic role, discipline, and age (defined as number of years since PhD completion). These details were not mandatory for participation, but when provided were available to the LLM as context, which allowed it to tailor the conversation, such as by addressing the respondent by name. To avoid capturing spam from automated agents on the internet, access to the system was gated by a “humanness” test provided by reCAPTCHA.
Our interview guide explored four key themes related to the integration of Gen AI methods in qualitative research within the social sciences. The first theme investigates the current adoption and application of Gen AI techniques in the respondent’s research practices. The second theme delves into the respondent’s existing methodologies for coding and organising qualitative data. The third theme explores the respondent’s aspirations and ideal scenarios for Gen AI driven qualitative data analysis, focussing on the types of phenomena they aim to investigate and the capabilities they imagine. Finally, the fourth theme addresses the ethical considerations surrounding Gen AI use in research. Throughout the interviews, the chatbot mostly followed these four themes, while adjusting to match the interviewees’ interests.
Data was collected in three rounds. Our two chatbots were iteratively refined using versions identified by nicknames. First, we collected pilot responses with “Percival,” completed by attendees at a Qualitative Analysis using Gen AI workshop (23 responses). We incorporated feedback to make the chatbot less overly positive and include a final catch all question. We then proceeded with the full-scale data collection using “Elsa,” the link for which was circulated via email (Supplemental Appendix B) to Heads of Department at the Faculty of Social Sciences at a Swedish University and forwarded to researchers in their departments (51 responses). Of the 51 responses, 39 consented to follow up contact and received a personal email from the first author asking for reflections on their experience (Supplemental Appendix C), to which 23 responded. All material was collated in a secure server hosted in Sweden. For analysis, respondents were assigned pseudonyms. Our dataset includes 74 chats with Percival and Elsa and 23 follow up email responses. All responses were pseudonymised and we include respondent pseudonyms in our analysis so that the interested reader can locate additional context in the transcripts.
Sample
In our sample, academic age varies, from PhD researchers with an academic age of 0 (n = 10) to academics of over 20 years (n = 12) with an average academic age of 13 years. Disciplines included Sociology, Human Geography, Psychology, Social Work, and Political Science. We remain cognisant that, due to our sampling strategy of asking social science researchers to complete a chatbot interview about using Gen AI, many of the respondents may have an affinity for and may be early adopters of Gen AI which, in turn, may shape the responses we gathered.
A strength of our study is the expertise of our interviewees, all of whom are active social science researchers with experience in research design, data collection, and analysis. This high level of methodological literacy means that participants are particularly well-equipped to critically evaluate the quality of interviews, including the effectiveness of prompts, the appropriateness of follow-up questions, and the overall conversational flow. Our data thus offers a critically informed perspective on the capabilities and limitations of AI-driven interviewing, grounded in the experience and expectations of the social science research community. We remain aware that the respondents with an interest in Gen AI self-selected to take part in this study and therefore suggest that the findings of this study reflect a snapshot of researchers with an interest in Gen AI.
Analysis
To analyse our data, all authors read and re-read the interview transcripts and email responses (added as notes in our data library). The first author made notes, identified interesting concepts and trends and summarised hunches using our platform (https://monklet.com/), a PDF print out and word document in tandem. She was interested in more than identifying themes and focussed rather on describing, comparing, and relating (Bazeley, 2009). Once the results were drafted, all authors discussed and added depth, continually referring back to our data library and PDF print out. We are also active social scientists curious and a little bit sceptical about using Gen AI in research and our personal experiences also informed the analysis. Although we flirted with using our model to identify themes that emerged in the transcripts (see section 3.3), humans analysed the data.
Results
We organise the results into three subsections aligned with our research questions. Section 3.1 explores how LLMs perform as qualitative interviewers, including interviewees’ experiences of the chatbot. Section 3.2 turns to what social scientists use Gen AI for, how they currently conduct analysis, what they would like Gen AI to do, and the ethical concerns they raise. Section 3.3 then examines how LLMs can support qualitative analysis, drawing on our own attempts with integrating the model into the analytic process. These three strands provide the basis for our final reflections in Section 3.4, where we consider what Gen AI–mediated interviewing can and cannot yet offer qualitative social science. Instead of waiting until the limitations section to discuss shortcomings of this study, we critically reflect throughout so that the reader isn’t left thinking, “yes, but. . .”.
LLMs as qualitative interviewers
In our study, LLMs demonstrated potential as semi-structured qualitative interviewers. The chatbot proved to be a cost effective (0.04€ for the entire project not including our salaries) method for data collection, allowing for simultaneous interviews and eliminating the need for complex scheduling. Without too much effort, we collected 149 pages of text, including the chatbot interviews and follow-up email correspondence with participants.
The interviews varied in length and depth, with most conversations lasting 8–12 minutes. Over four-fifths of participants finished the interview (continuing until the chatbot reached the end of its script and terminated the conversation). No reasons were given for not finishing the interview, however there were some bugs leading the chatbot to freeze which may account for some of these. We assume other non-finishers grew fed up or had had enough. The shortest completed interview, with Aisha, lasted 1 minute and 49 seconds, while the longest–Dimitri’s – lasted 33 minutes and 20 seconds. Elin chatted for 51 minutes and 16 seconds but since her responses were quite sporadic, we assume she was multitasking. Most interviews maintained a constant level of engagement with answers increasing in detail and length as the interviews progressed, perhaps due to the chatbot homing in and asking expert questions on the interviewees’ topics.
The Gen AI interviewer demonstrated both breadth and depth in conducting the interviews. It posed open-ended questions, followed up on responses, summarised key points for confirmation (Figure 2, interview with Carl), and suggested alternatives when respondents seemed stuck (Figure 3, Dimitri). It could summarise key points for clarification, even when they were briefly mentioned (see for example Figure 4, interview with Felix). This proficiency in understanding and reiterating complex concepts often prompted respondents to delve deeper into their explanations, resulting in more comprehensive and nuanced discussions of the research topics. In six instances when probed by the interviewees, the chatbot gave impromptu lessons on Gen AI in qualitative analysis (see for example Figure 5, interview with Alex). The chatbot showed capability in probing expert topics, recognising and understanding field-specific acronyms, which encouraged participants to engage more deeply, although it was not always clear when and why the chatbot probed and when it moved on. Many of the respondents were impressed by the chatbot. After chatting with it, Mei wrote “You’re a great chatbot interviewer but at the beginning you said ‘a few minutes’ and that was over a quarter of an hour ago. I should probably get back to work!” Field specific knowledge, ability to probe and go deeper into respondents’ research across a broad range of topics surpasses what any human interviewer would typically be capable of, and the data collected was deeper and broader than we anticipated.

Interview with Carl, model summarises a point for confirmation.

Interview with Dimitri, model suggests ways forward.

Interview with Felix, model is familiar with field specific acronyms.

Interview with Alex, model gives impromptu Gen AI analysis lesson.
There is a risk that our chatbot’s active interviewing style may, at times, shift from priming and prompting respondents, to over-interpretating or misinterpreting responses which may be the case in the interview with Carl (Figure 2) and Dimitri (Figure 3). In contrast, the interview with Felix (Figure 4) actively engages in his response and asks pertinent follow-up questions in a non-leading manner. In several instances, our chatbot followed its interview guide and persisted in asking about qualitative methods, even after respondents repeatedly stated they primarily used quantitative approaches, for example, Carlos who appeared to become irritated, although when Greta said she used quantitative methods the chatbot probed further into her quantitative analysis. The chatbot stayed on topic while adjusting to different interviewees, tailoring questions to dig more deeply into topics outside of our interview guide like sarcasm or bias when broached by interviewees (e.g. Clara). The chatbot did steer clear of sensitive topics as instructed, and we did not see evidence of any hallucinations in any of the chats. Our model posed follow-up questions as soon as respondents hit enter and occasionally interrupted respondents, cutting off potential information. Additionally, it sometimes posed multiple questions simultaneously, and when participants answered one question and pressed enter, the chatbot did not follow up the other line/s of questioning. The chatbot missed many opportunities to probe or ask follow-up questions (e.g. Figure 1, Anna). It also had an apparent “hunch” regarding the time-consuming nature of traditional qualitative analysis, possibly from its training data, which lead some respondents (e.g. Tomas, Priya, Birgitta, Sven, Darius, Alex, and Elin) to discussing time saving potential of Gen AI analysis – a finding that we may not have arrived at without the chatbot’s leading questions. These limitations highlight the need for further refinement to ensure the chatbot’s responsiveness, conversational pacing, and contextual sensitivity more closely mirror best practices in qualitative interviewing, all issues that can be addressed in future iterations.
The Gen AI interview experience
According to our 23 follow-up emails, four interviewees felt disengaged, or that the interview was less thorough, or they became mildly annoyed at the chatbot. Frida for example found it “a bit ‘weird’ to know that it’s an AI tool collecting the data and not a real human.” The chatbot’s overly friendly tone annoyed Carlos who wrote “I do not appreciate the extreme friendliness (like thanking profusely after every answer).” Layla said “Elsa was a bit repetitive and kept using the same language/phrase. It felt like it was going round in circles and I did not think it as very helpful.” And Klaus felt he could not elaborate on points as he would with a human interviewer “I usually think while I speak/write. This means that I often have not thought through my reply in detail before I present it . . . The thing with Elsa was that I would write one thing and send it off and I would want to write a second point but then I had already gotten a reply from “her” with a follow up question and the conversation would then derail a bit because I was intellectually still at the previous question.” These chatbot glitches could perhaps be resolved by adjusting the prompt to more closely mirror interviewees’ chat style, however these examples do clearly illustrate mistakes that a skilled human interviewer would not make. The benefits of automated data collection should be weighed against the risk of lower quality data, which we consider to be a considerable disadvantage to this method.
On the other hand, many of our follow-up interviewees quite enjoyed the chatbot. Some found it thought-provoking, raising questions they had not considered before and allowing for more direct and blunt responses. For example, Thomas wrote “It was good. I was impressed. I found it really interesting as a data collection tool. To some degree it made it almost easier to give honest answers to what I knew was a chatbot, so no real human on the other side.” Bjorn also enjoyed chatting to Elsa: “It was a very interesting and positive experience. This was the first time, and I was quite impressed by the clarity and accuracy of the comments and questions generated, not to mention the speed with which they were delivered. I am still completely new to this technology but must say that I think it worked much above my expectations. Almost a bit scary. . .”. While eleven responses were generally positive, eight were neutral or mixed. Siri for example wrote “Aha, the chat thing. Actually, I just filled it in in a haste and then forgot about it. No lasting impressions at all, I’m afraid!”.
A further consideration of the Gen AI interview experience is that it was conducted via screens where respondents’ attention is pulled in a multitude of directions. Elin’s nearly hour-long interview with sporadic answers, is a case on point. When interviews are slotted in between emails, messaging apps, and other onscreen tasks, the attention economy becomes a threat to data quality rather than a backdrop. In an onscreen context, participants may skim questions, offer shorter or more generic responses, and invest less effort in reflection, producing accounts that are thinner, more fragmented, and less dialogically co-constructed than in dedicated, face-to-face or even focussed online interviews. Multitasking also makes it harder for researchers to interpret silence, hesitation, or brevity: these may signal distraction or divided attention rather than discomfort, uncertainty, or lack of experience. Gains in data collection efficiency are potentially being made at the expense of participant engagement or ethnographic observations in the interview situation which serve to capture vital interactional and contextual information.
In summary, the chatbot enabled efficient, cost-effective interviewing at scale, generating a dataset of 149 pages (a little less than half of the words from respondents and a little more than half from the chatbot) from 74 participants, with most interviews lasting 8–12 minutes and a high completion rate. That chatbot mostly behaved themself and stuck to the themes from our prompt while adjusting to interviewee interest and avoided discussing sensitive topics. Respondents generally enjoyed chatting with the chatbot and appreciated the field-specific knowledge, probing ability, and adaptability, with many noting that it prompted them to reflect on their research practices. Some participants felt disengaged because the conversational pacing and tone detracted from the experience, while others valued the directness and found it easier to be candid with the chatbot. We suspect that some respondents completed the interview while distracted by other tabs, tasks, or media. To answer our first research question: How do LLMs perform as qualitative interviewers? We can say that we gathered plenty of data without too much expense or effort, that the chatbot generally stayed on topic and did not breach sensitive topics, and that, not insignificantly, the interviewees had fun even if potentially not paying full attention. However, data quantity should not be the defining marker of a successful interview, rather the aim of a qualitative interview is often to attain a level of depth and nuance to answers which we do not believe we achieved in this study.
Using Gen AI in social science research
We then move on to our second research question: How are social scientists using Gen AI? In this section we report on how the participants in our study who were experimenting with Gen AI (n = 37) are using Gen AI, see table 1 for an overview of the use functions. We also discuss how they conduct qualitative analysis, their hopes, and some ethical concerns for Gen AI. This section gives unique insights into how social scientists are using Gen AI in everyday research practice.
Respondent uses of Gen AI.
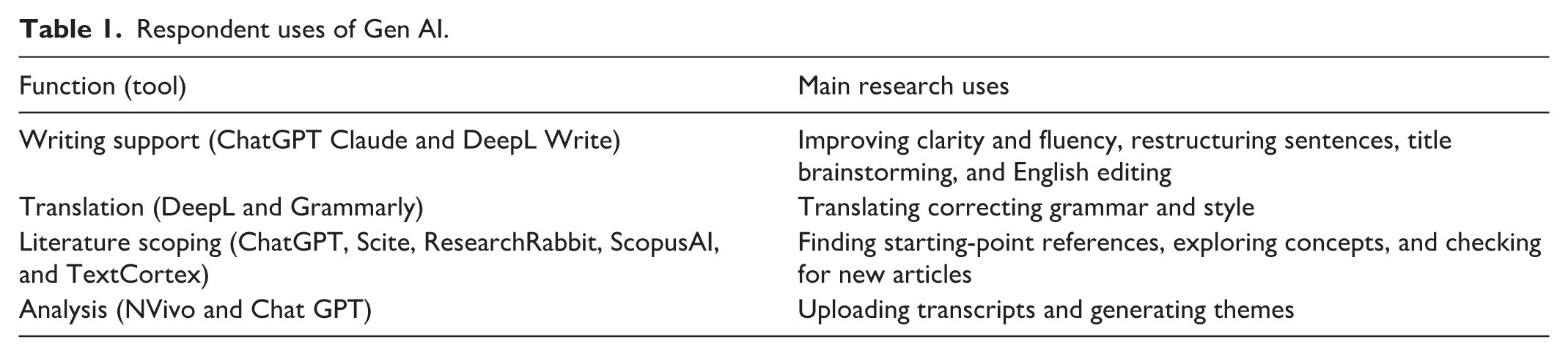
For most, the use of Gen AI tools remains exploratory: participants describe testing Gen AI to undertake various research tasks, but few participants fully integrate these tools into everyday research practice. Most respondents report using Gen AI to improve the clarity and fluency of academic writing and a few use it for generating catchy titles, writing abstracts, and structuring popular science articles. Several participants regularly use automated transcription and translation tools such as ChatGPT and DeepL. Seven respondents tested tools such as ScopusAI, TextCortex, and ResearchRabbit to conduct literature reviews and identify novel literature. While nearly all participants remain cautious about the limitations of Gen AI and the blackbox nature of LLMs, there is a clear sense of curiosity about its potential to enhance research.
To analyse data, most respondents use traditional, manual approaches, such as close reading, coding by hand, and thematic analysis using NVivo, Atlas.ti, or MaxQDA (current versions of these tools incorporate Gen AI features, however few researchers report using these features). Respondents prefer traditional methods for their interpretive depth, transparency, and the opportunity for deep engagement with data—a process nearly all describe as essential for generating reproducible insights and maintaining research integrity. The level and extent of Gen AI use varied among this subset of respondents: many reported more experimental use, while a few described more comprehensive, regular applications of Gen AI in their work. Additionally, several researchers expressed interest in using Gen AI tools in the future, even if they had not yet incorporated them into their research processes. Six of the respondents even asked our chatbot to give them a lesson in Gen AI during the interview.
Respondents report high hopes that Gen AI could support their research. Many anticipate that Gen AI could “save time and nerves” (Clara), automatically “categorise material” and “find patterns in a large amount of text” (Birgitta) and help with “summarising content automatically and also coming up with codes I wouldn’t have thought of myself” (Johan). Several interviewees imagine Gen AI as a tool for managing and organising large, complex datasets: “The human brain cannot comprehend that large amount of data. The patterns are an area where AI could help” (Leif). Others want Gen AI to assist with “data exploration and creating themes or categories” (Fiona), or to “help identify themes and codes, that first step of the analysis, so that we the researchers can go even deeper than what maybe time allows us to do today” (Solveig). There is also interest in using Gen AI to identify researcher bias or blind spots: “I think AI could help discover bias in analysing material. For instance how we in our interpretation of material can see some aspects but not others” (Ester). At the same time, respondents emphasise the importance of keeping the “researcher’s own thoughts, critical thinking” at the centre of the analytic process (Ellen), and many see Gen AI as a complement rather than a replacement: “Support from AI is definitely good, but I like doing it myself!” (Ebba). Overall, social scientists want Gen AI to enhance the speed, scale, and creativity of research, especially for repetitive tasks, as long as they can preserve the critical and interpretive depth in knowledge production.
Social scientists in our sample express a range of ethical concerns regarding the use of Gen AI in research, with many highlighting the risks associated with black box analyses, replicability, and the erosion of researcher responsibility. Several participants worry that Gen AI’s opaque algorithms make it difficult to stand behind results, as the underlying processes are often inaccessible: Johan says there is a problem if “researchers don’t use the tools reflectively but accept AI coding as a black box,” while Thomas is concerned about giving up his “academic agency to the AI.” The issue of replicability is also present, for example Marco says, “it is probably going to lead to a lot more information pollution as researchers use AI to write their stuff without proper checks, then have peer reviewers use AI to review the papers, leading to even more and more sub-par output.” Concerns about the ethics of delegating critical analysis to AI were also common: Birgitta states that “Outsourcing analytical work to a machine would be unethical . . . It would be like cheating,” while Ebba emphasises that “working with AI is fine as long as you also put in work. Otherwise it is like plagiarizing.” Both Bengt and Astrid also describe LLMs as plagiarism tools. Data security and control over sensitive information are further concerns, with worries about data being leaked or used to train Gen AI models, and the challenge of ensuring participant confidentiality in cloud-based environments. Many anticipate that science will change dramatically in the next 5 years, but voice apprehension that, if not used critically, Gen AI could foster echo chambers and limit creativity. Ellen warns, “If not used critically, I think research will end up in echo chambers,” and Aaliyah noted that Gen AI risks “mirroring our own biases, limiting creativity by echoing the broader literature and taking it at face value.” Loss of control over the analysis, loss of academic integrity, plagiarism and data security are the most common ethical concerns.
In summary, the social scientists in our sample are experimenting with Gen AI as a complement to more traditional, manual approaches to research. There are high hopes for streamlining repetitive and large-scale tasks, allowing researchers more time to engage with core research and analysis. There are also significant concerns about the adoption of Gen AI unverifiable and irreproducible analysis, plagiarism, and data security. These results should be understood in the exploratory context of our study – the experience of 74 social scientists in Sweden (of which 37 currently use Gen AI in their research) is not generalisable to every context – however our results do provide new insights into how some social scientists are engaging with Gen AI in everyday research practice.
LLMs in qualitative data analysis
The discussion in this section is motivated by respondents in our data that report using, and being curious about using LLMs to aid qualitative analysis. Here we address the question of whether LLMs can assist with qualitative analysis, our third research question. The LLM queries in this section use in-context learning (Dong et al., 2022), a simple way to provide models with post-training data alongside the prompt. This approach is conceptually similar to uploading a file to a web-based LLM chat. Gemini LLMs are particularly well-suited to this task, because their context window is large enough to fit our entire dataset, avoiding the need for cumbersome retrieval augmented generation approaches (Lewis et al., 2020).
To explore the analytic task of grouping respondents by their attitude to AI. We prompted our model as follows: Using data from all 74 interviews please develop ideal types (Weber) of what social scientists are using AI for, their attitudes around AI. Please ask some clarifying questions first. After some refining back and forth, the model suggested five ideal types. We then compared these five types to our own reading of the material and noticed overlap between some of the categories (e.g. two types that both described cautious, instrumental users, differing mainly in intensity rather than in kind). Through an iterative process of combining overlapping types and simplifying labels, we collapsed the five into three broader types: Enthusiasts, Pragmatic Adopters, and Gen AI Agnostics. See Supplemental Appendix D for a full description of the resulting typologies. We double-checked all quotes against the data library and the broad claims against our reading of the data and found them to be generally reasonable. This was possible since our entire dataset was only 149 pages. In hindsight, the ease with which the model generated semi-plausible “ideal types” in response to small changes in our prompts made it tempting to keep iterating without fully pausing to reflect.
This attempt at using a chatbot to conduct analysis, while superficially exciting at the quickness and plausibility of outputs, speaks to the black box nature of LLM output. The quotes were accurate about 80% of the time and the typologies seemed plausable, however, this exercise illustrates some of the concerns of our participants and wider literature (Davidson and Karell, 2025). One example is hallucination: our model suggested that younger researchers were more enthusiastic about Gen AI, for which we did not find evidence for in our reading of the data. This exposes one of the risks of naively trusting outputs generated by an LLM.
Our study raises further questions about transparency and reproducibility. While the model generated plausible archetypes, its black-box nature offers little visibility into the reasons the model generated this output. We can infer from the architecture of our model that it did not take the same iterative approach to coding, developing themes, and allocating respondents to groups that a human researcher would have taken. This complicates efforts to replicate the analysis. Furthermore, delegating analytic tasks to an LLM risks eroding researcher reflexivity, which we experienced ourselves.
Our experience underscores the need to exercise caution when using Gen AI tools as part of research workflows, and the need to clearly understand tools’ capabilities and limitations. Naturally, the use of these tools should be documented alongside research methods. LLMs proved useful for tasks like generating pseudonyms and suggesting possible themes. The tendency of LLMs to “hallucinate” content remains an open problem, which presents serious risks to the AI-assisted researcher (Farquhar et al., 2024; Huang et al., 2025).
These findings echo warnings that uncritical reliance on model output may prioritise convenience over depth, producing superficial insights that lack the interpretive rigor central to qualitative inquiry (Jowsey et al., 2025; Lu, 2024; Nguyen and Welch, 2025). Removing the active role of the researcher who reflects on and engages with unexpected and unusual codes and themes risks compromising the quality of the analysis. Ultimately, our study illustrates LLMs’ potential for supportive tasks such as ideation and initial theme extraction, but our model we used is not designed to be—and indeed failed to perform as—an automated analysis system.
Reflections on using Gen AI interviewers
A key limitation of our approach is that the interview was entirely textbased, which likely shaped who felt able to participate fully and how they expressed themselves. Text chat requires respondents to formulate and type answers, which may disadvantage those who are slower typists, less confident writing in English, or more comfortable thinking aloud than composing written responses. This may narrow the range and nuance of accounts compared to spoken interviews, where hesitation, tone, and co-constructed phrasing can be negotiated in real time. It also aligns the interaction more closely with familiar digital formats such as email and surveys, which may encourage brevity and multitasking rather than the sustained, situated engagement of a face-to-face or video interview. Future work should therefore explore multimodal Gen AI-mediated interviewing (e.g. hologram interviewers) and examine how different modalities redistribute whose voices are heard and with what depth.
Beyond these modality issues, our study also underlines that this type of social science research requires a new skillset, albeit one that is changing rapidly as the technology itself evolves. To develop the chatbot we used in this study involved conceptual work on interview design, and we also deployed our technical competencies in web development, including API integration, data security, and iterative prompt engineering. This gave us fine-grained control over the interface, user experience, and data storage and protection. Researchers contemplating similar methods therefore need to consider whether to invest in bespoke development (as we did), collaborate with technically skilled colleagues, or adopt alternative open-source options (e.g. Geiecke and Jaravel’s, 2024 customisable chatbot). However, emerging technologies may greatly reduce the required skillset. For instance, the open-source agent software OpenClaw (Steinberger, 2026) can conduct conversations via messenger apps and email.
Our implementation, based on Google’s Gemini 1.5 flash model, is just one specific example of Gen AI-assisted research. Results will inevitably differ with other models, tools, and as the technology evolves to be more capable (just as a different roster of human respondents, or even the same people on a different day, would generate different interview transcripts). The stochastic nature of LLMs, and humans, means that they produce different outputs even when given the same input, posing challenges for research reproducibility. Additionally, the rapid pace of technological advancement in Gen AI means that models and tools are constantly being updated or replaced, which can quickly render specific methodologies or analyses obsolete. As LLMs become better at enhancing empirical research, we argue that social scientists should continue to critically engage with how these models shape qualitative inquiry. By sharing our particular experience with our particular setup, we hope to encourage others reflect critically on the unique affordances and limitations of similar Gen AI assisted research.
Discussion and Conclusion
The pervasive integration of Gen AI into research pipelines is reshaping every aspect of research and academic life. AI is now present in email systems that summarise communication, reference managers that suggest and map citations, writing assistants, and data augmentation and analysis tools. These developments fundamentally alter the way researchers read, listen, ask questions, interpret data, and think. For those of us working with interviews, observations and other forms of qualitative inquiry, this moment is therefore not only technologically but also methodologically charged: if Gen AI can be used to write literature reviews (Bolanos et al., 2024) ethics proposals (e.g. Godwin et al., 2024), generate interview guides, recruit respondents, conduct text-based conversations (e.g. Wong et al., 2025), or propose thematic patterns in transcripts (e.g. Bowden et al., 2026), then debates about depth, rapport, reflexivity, bias, and the status of talk itself acquire a new urgency. We are no longer confronted with the question of whether, but rather how and to what extent, Gen AI can and should support interview-based research.
To this end, our study set out to answer three research questions: How do LLMs perform as qualitative interviewers? How are social scientists using Gen AI? And how can LLMs support qualitative analysis? Our research shows that Gen AI chatbots can be highly efficient and cost-effective tools for data collection, capable of conducting simultaneous, in-depth interviews that adapted to respondents’ expertise and encouraged detailed engagement. About half the social scientists in our sample are largely experimenting with Gen AI, using it for tasks such as writing support, literature reviews, transcription, and translation, and, to a lesser extent, analytical work. When we asked Gen AI to generate typologies based on our interview data, it quickly generated plausible ideal types of researcher adoption of Gen AI but required human refinement. Superficially, our findings suggest that Gen AI chatbots can be powerful tools for assisting qualitative research, and Gen AI is already being used in the social sciences.
Our findings also raise fundamental questions about the production of knowledge. One observation was our chatbot’s ability to foster engagement and elicit detailed responses—sometimes surpassing what experienced human interviewers typically achieve. This reality check 1 suggests that, regardless of interviewer identity (human or non-human), participants are eager to share insights when they encounter an attentive, knowledgeable, and empathetic conversational partner. The chatbot’s simulated empathy, capacity to recall field-specific details, and ability to probe deeply into respondents’ expertise encouraged rich, reflective answers. This aligns with recent findings that LLMs, are rated as highly empathetic conversationalists, sometimes preferred over human professionals in certain contexts (e.g. Chopra and Haaland, 2023; Sorin et al., 2024).
Respondents in our study appreciated the chatbot’s impartiality and lack of judgment, which may reduce social desirability bias and foster candour. However, our model was far from perfect: we had many instances where the chatbot persisted with irrelevant lines of questioning, cut off respondents, didn’t follow up or probe, got side-tracked, failed to adapt pacing and tone and disconnected from a few of our respondents mid interview due to a technical error, issues also experienced by Wong et al. (2025) in their LLM chatbot study. Unlike human interviewers, who draw on professional training and experience, models like Gemini flash 1.5 have likely been trained on conversational patterns from millions of interviews across countless domains and languages, most of which are drawn from non-research contexts. This enables LLMs to mirror and adapt to diverse respondent styles, but it also may inadvertently lead respondents (as it did many times in our study), miss nuanced cues, or default to generic patterns learned from non-research interviews (like suggesting that senior researchers were averse to incorporating Gen AI). After all, instruct-tuned LLMs are explicitly trained to provide information (see, e.g., Zhang et al., 2025).
Moreover, concerns regarding what is lost in the human-to-human interactional setting of a traditional qualitative interview lie at the forefront. Although we were easily able to gather a high quantity of data, size does not always matter. Moving forwards, we suggest that chatbots may be a suitable tool for gathering data in order to address specific types of research question, perhaps as a compliment to questionnaires, but are currently not appropriate for gathering thick data. Moreover, the ability of a chatbot to create an empathic interview setting needs to be examined in more detail before its integration into a wider range of research studies (see, e.g. Concannon and Tomalin, 2024).
Despite rapid growth, the Gen AI literature on interviewing and conversational agents remains largely decoupled from wider debates about qualitative inquiry. Most studies treat LLM-mediated interviews as technical or methodological innovations to be benchmarked on response quality, engagement, guideline adherence, or user satisfaction (c.f. Barari et al., 2025; Chopra and Haaland, 2023; Geiecke and Jaravel, 2024; Lang and Eskenazi, 2025; Liu et al., 2025; Sun et al., 2025; Yu et al., 2024; Wuttke et al., 2024), rather than as socially situated encounters implicated in long-standing concerns about participants’ life-worlds, the epistemic status of talk-as-data, and the logics of sampling and case selection. Social scientists need to engage with qualitative inquiry’s core questions about how interviews relate to everyday life, how moral and strategic accounts are shaped by interviewer identity and institutional context, and how cases and field sites are constituted in Gen AI mediated settings.
In this paper, we aim to re-centre questions of Gen AI assisted research as qualitatively unfolding in time, space, and place. Drawing on 74 chatbot‑led interviews and follow‑up reflections with 23 social scientists, we show how Gen AI surfaces emerging concerns about sampling, exposure, and attentiveness in a fast paced, financially incentivised research landscape. We also use participants’ accounts of their own Gen AI research practices and their experiences of being interviewed by a chatbot to probe how interviewer identity, perceived agency, and platform infrastructures configure what can be said, and how efficiency, replicability, or neutrality are valued or problematised.
By holding these empirical materials against discussions of talk‑as‑data, sampling logics, and the ethics and politics of digitally mediated fieldwork, our findings show that the Gen AI models we tested are not a seamless solution for qualitative research. Instead, our contribution is to clarify where these systems intersect with qualitative inquiry, how they introduce new opacity and bias, and how they expose existing methodological tensions. Although these tools can streamline research, effective use requires a strong human-in-the-loop approach (Mosqueira-Rey et al., 2023). A hybrid future for qualitative research is likely, but ensuring Gen AI supports rather than distorts inquiry will demand sustained effort.
Supplemental Material
sj-docx-1-mio-10.1177_20597991261448157 – Supplemental material for Automating the qualitative interview? Using Gen AI chatbots in social science research
Supplemental material, sj-docx-1-mio-10.1177_20597991261448157 for Automating the qualitative interview? Using Gen AI chatbots in social science research by Tullia Jack, Alex Cooper and Lisa Flower in Methodological Innovations
Footnotes
Acknowledgements
Kind thanks to colleagues for feedback on earlier versions of this text, Matthias Lehner, Elin Bommenel, and Mahesh Menon.
Ethical considerations
Institutional Review Board waived the requirement for approval for this study on the 21/08/2024.
Consent to participate
Informed consent to participate in this study was provided after reading the plain language statement by checking a box before the chat started.
Author contributions
TJ author conceived the study, led the writing, coordinated data collection, and conducted the primary analysis. AC author developed the chatbot platform and contributed to the manuscript writing and analysis. LF author assisted with data collection and provided critical feedback on all sections of the text. All authors reviewed and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Material used for this study is available in supplemental material.
Declaration of generative AI use
During the preparation of this manuscript the authors used Google Gemini in order to build our chatbot, store data, run queries on the data and generate catchy titles. The authors reviewed and edited the content and take full responsibility for the content of the publication.
Preregistration statements and disclosures
This study was not preregistered. The analyses and findings reported in this manuscript are based on exploratory, inductive research conducted to investigate the integration and use of generative AI in social science research. As such, the research questions, data collection, and analytic approach were developed and refined iteratively throughout the study, rather than being specified in advance. The empirical results are intended to provide novel, qualitative insights into current practices and perceptions of generative AI among social scientists, and to inform ongoing methodological discussions in the field.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.