
Abstract
Significance:
Pressure injury is one of the most common health problems among hospitalized patients worldwide, and accurate and timely diagnosis is crucial for its treatment. Research on the application of artificial intelligence in the diagnosis of pressure injury is increasing, but there is currently no comprehensive meta-analysis to evaluate the accuracy of artificial intelligence in diagnosing different pressure injury stages.
Recent Advances:
This study synthesizes evidence on artificial intelligence diagnosis of pressure injury, focusing on evaluating diagnostic performance across different stages using core metrics including sensitivity, specificity, and the area under the summary receiver operating characteristic (SROC) curve.
Critical Issues:
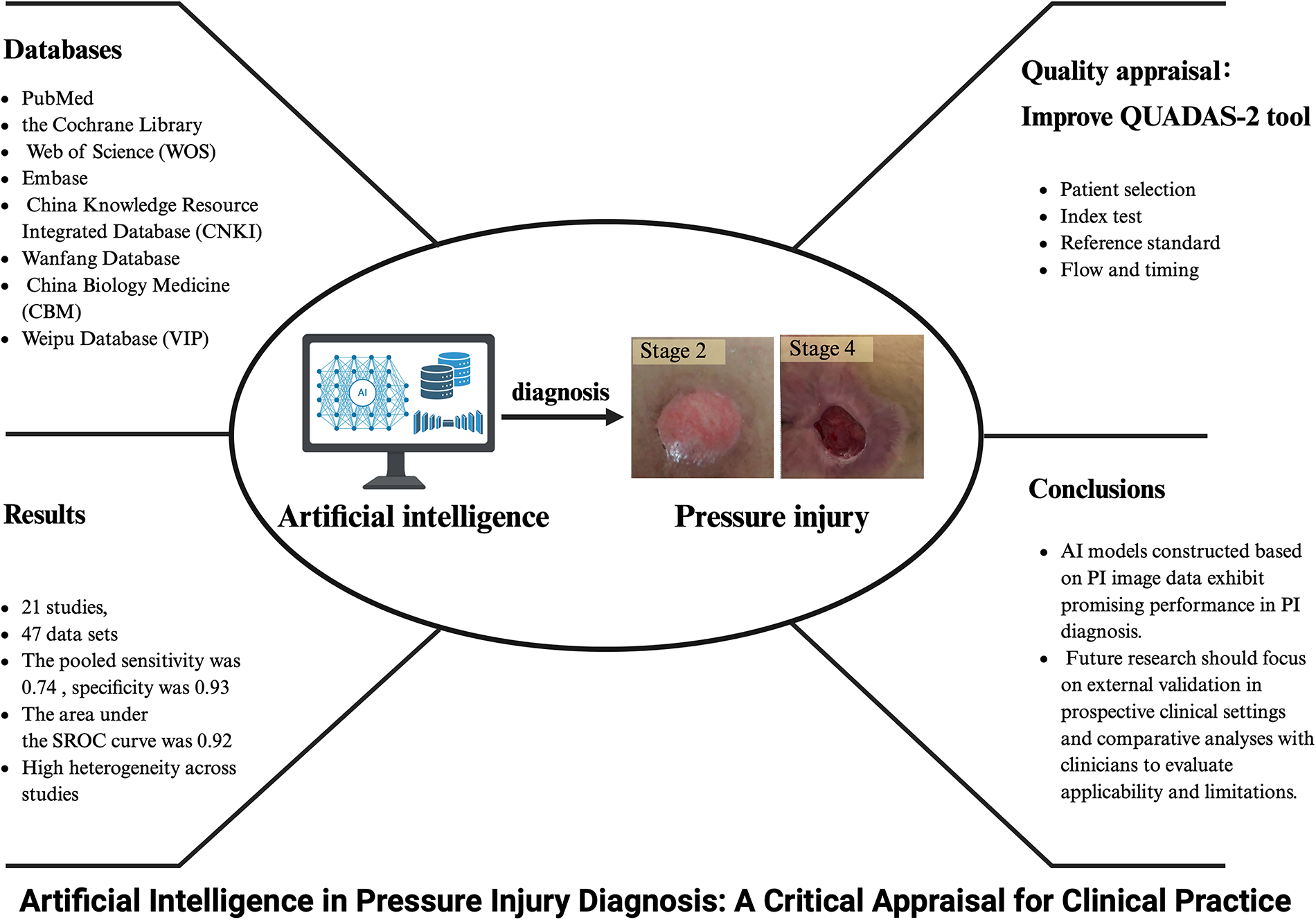
Key findings from 21 included studies (12 contributing 47 eligible datasets) indicate high overall diagnostic accuracy of artificial intelligence for pressure injury, with sensitivity of 0.74 (95% confidence interval [CI]: 0.69–0.78), specificity of 0.93 (95% CI: 0.91–0.94), and area under the SROC curve of 0.92 (95% CI: 0.90–0.94). Moreover, the area under the SROC curve varies across different stages of pressure injury, with area under the curve values for stage 1, stage 2, stage 3, stage 4, unstageable, and deep tissue pressure injury of 0.95 (0.93–0.97), 0.85 (0.82–0.88), 0.88 (0.84–0.90), 0.94 (0.92–0.96), 0.96 (0.94–0.97), and 0.98 (0.96–0.99), respectively.
Future Directions:
Artificial intelligence models based on pressure injury image data show substantial potential for clinical application in pressure injury diagnosis. However, the need for high-quality studies with rigorous reporting and external validation remains critical to address current limitations and advance clinical translation.
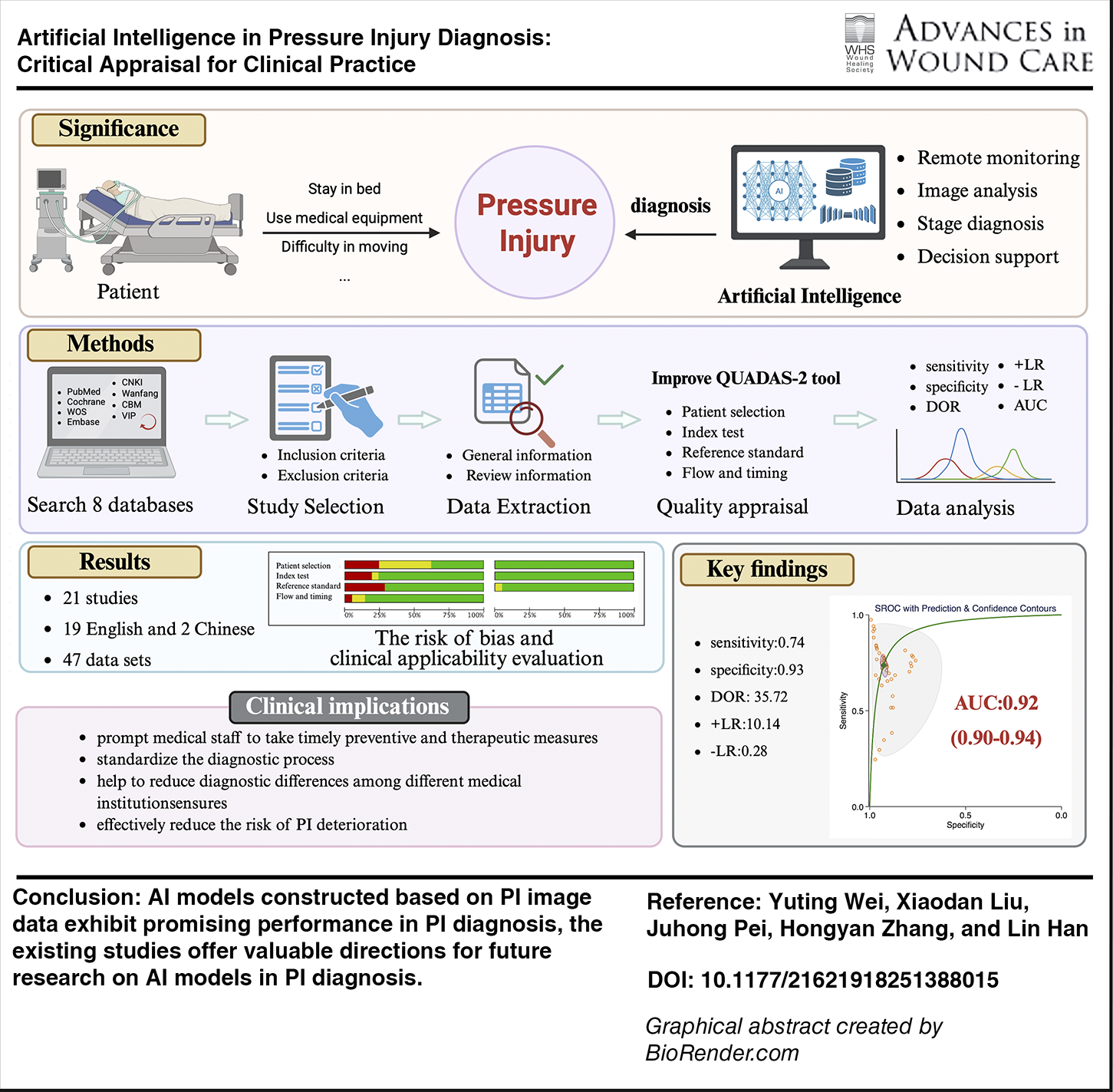
SCOPE AND SIGNIFICANCE
The high incidence and low cure rate of pressure injury (PI) impose a huge burden of disease on patients. More timely and accurate artificial intelligence (AI) diagnostic tools for PI can help to improve patient prognosis, reduce health care costs, and guide clinical practice. However, their performance and quality require careful attention. This review systematically examines and evaluates existing AI for PI diagnosis, identifies critical issues and gaps, and provides constructive recommendations for future model development to enhance their clinical applicability and reliability.
Lin Han, PhD

TRANSLATIONAL RELEVANCE
PI is one of the most common health problems among hospitalized patients worldwide, highlighting the critical need for accurate and early diagnosis. This systematic review and meta-analysis reveal flaws in current AI diagnostic models for PI, including small sample sizes, high risk of bias, lack of adequate external validation, and limited clinical applicability. Overcoming these hurdles may lay the foundation for AI-driven diagnostics from research labs to the bedside. Development of reliable, well-validated, and clinically integrated AI tools for PI diagnosis may facilitate early guidance for interventions, enhance the overall quality of care, and improve patients’ quality of life.
CLINICAL RELEVANCE
Early diagnosis of PI based on AI can prompt medical staff to take timely preventive and therapeutic measures, thereby effectively reducing the risk of PI deterioration. In addition, the use of AI models can standardize the diagnostic process and provide consistent diagnostic results, which helps to reduce diagnostic differences among different medical institutions and ensures that all patients have access to high-quality care. The improvement of this diagnostic level can not only optimize the treatment plan but also significantly improve the quality of life and prognosis of patients.
INTRODUCTION
PI, also known as pressure ulcer, which is defined as localized damage to the skin and/or underlying tissue resulting from pressure alone or in combination with shear, is one of the most common health problems among hospitalized patients worldwide. 1 Surveys have shown that the prevalence of PI in hospitalized patients ranges from 1.1% to 12.8%, 2 and the prevalence in the elderly population is even higher, 3 ranging from 3.3% to 35.7%. 4 Nonetheless, PI has a low healing rate, and the wound healing process is complex and lengthy, 5 resulting in prolonged hospitalization and ongoing treatment, 6 with many physical, emotional, and psychological impacts on the patient, causing a lot of suffering. Studies have shown that PI is associated with an increased risk of death in patients.7,8 In addition, PI poses a significant economic burden to patients and a huge challenge to the health care system. 9 Given that PI is asymptomatic, rapidly progressive, and difficult to treat in its early stages, its early and accurate diagnosis can help to initiate timely interventions and lessen the burden of disease on patients.
PI is caused by continuous pressure on the skin, which thus leads to tissue damage. If not detected and treated in time, microenvironmental changes such as ischemia and hypoxia in local tissues will accelerate tissue necrosis and eventually lead to deep tissue injury. 10 Therefore, early and accurate diagnosis of PI can effectively promote wound healing. 11 The diagnosis of PI requires a comprehensive assessment that takes into account a variety of complex factors. 12 Health care professionals usually diagnose PI by visual inspection and palpation, which include skin color, wound site, PI staging, tissue type, and the presence of underlying infection, 13 and may also use probes or other tools to measure wound depth. 14 However, the current diagnostic approach is highly subjective and may result in diagnostic errors due to inexperience, limited information, and observer bias.15,16 In addition, the patient’s skin color, age, and health status may interfere with visual judgment. 17 Therefore, more timely and accurate diagnostic tools for PI are needed to improve patient prognosis and reduce health care costs.
With AI now widely applied in medicine, its rapid development offers a potential solution to the high subjectivity and low efficiency of current PI diagnostic methods, as well as to the difficulty of detecting PI at an early stage. Jiang et al. synthesized findings from nine studies and revealed that AI facilitates monitoring the progression and healing trajectory of PI through wound images. 18 However, Pelin K et al. assessed the performance of AI in staging PI using real patient images and compared it with manual staging by expert nurses. The results indicated that expert nurses demonstrated superior accuracy and specificity across most PI stages. 19 In addition, due to different sample sizes and fewer large-sample studies on AI diagnosis of PI, most of the image sources are limited to public databases or single organizations. Therefore, despite the non-negligible advantages and room for development of AI methods over traditional diagnostic methods, there is not yet a high degree of consensus on whether they can be applied to actual clinical and health care work.
Recently, Qianwen Chao et al. published a systematic review and meta-analysis evaluating methods for staging PI. 20 Although they analyzed 8 studies involving 24 models, they did not report the accuracy of AI for diagnosing different PI stages. The objective of this study is to provide a comprehensive overview of the existing knowledge regarding the application of AI algorithms in the diagnosis of PI. Furthermore, the study aims to assess whether there are variations in accuracy among different PI stages.
MATERIALS AND METHODS
This systematic review was prospectively registered with PROSPERO (CRD420251029022). Our study was prepared by using guidelines from the Preferred Reporting Items for a Systematic Review and Meta-analysis of Diagnostic Test Accuracy Studies. The comprehensive overview of this study is illustrated in Fig. 1.
The summary graphic illustration of this study.
Terminology definitions
Convolutional neural networks (CNNs) are the most prominent architectures used for image classification tasks. Moreover, CNN architectures offer superior performance in medical image classification. You Only Look Once (YOLO) is the first model to use a one-step object detection approach that simultaneously detects bounding boxes and object classes. Compared with conventional two-step object detectors, YOLO models have shown excellent performance with short object detection time. Area under the curve (AUC): the numerical index represents the area under the summary receiver operating characteristic (SROC) curve. Sensitivity (SEN): the ratio of true positive (TP) to the total number of actual positive samples. Specificity (SPE): the ratio of true negative (TN) to the total number of actual negative samples.
AI functions as a second pair of eyes: trained on thousands of wound images, it can precisely identify specific patterns from a vast number of images and skillfully grasp various wound features. The work of AI in PI diagnosis is shown in Fig. 2. The application of AI in PI diagnosis is illustrated in a video provided in the Supplementary Video.
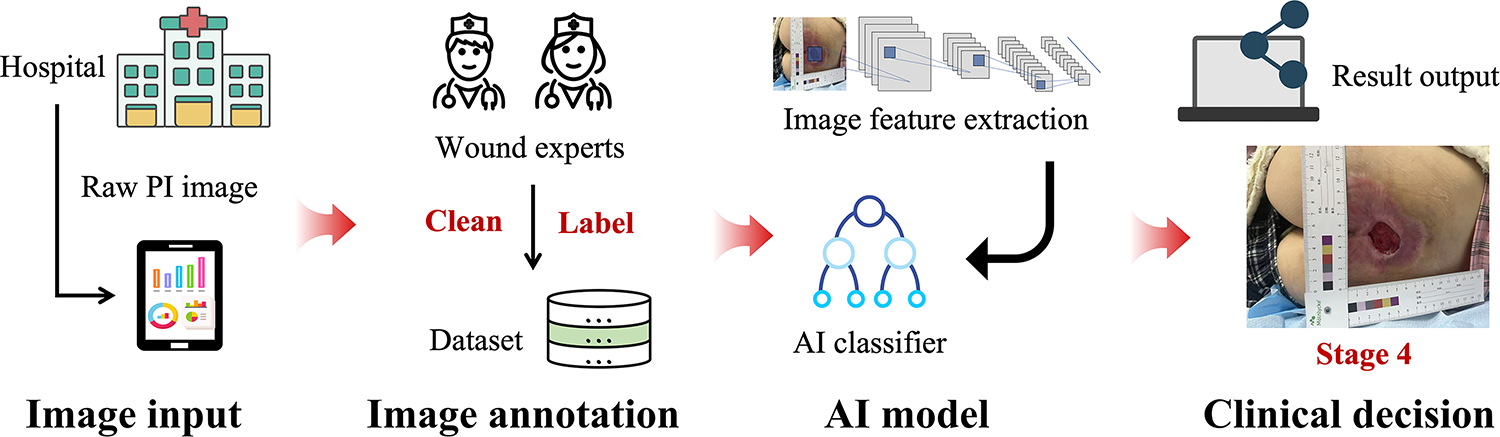
The work of AI in PI diagnosis. AI, artificial intelligence; PI, pressure injury.
Search strategy
A search was performed to identify studies that developed and/or validated an AI algorithm for the purposes of PI diagnosis: a comprehensive search of the literature was performed using eight electronic databases. PubMed, the Cochrane Library, Web of Science, Embase, China Knowledge Resource Integrated Database, Wanfang Database, China Biology Medicine, and Weipu Database were searched from the oldest publications available in each of the databases through May 31, 2025. The search strategies were performed through a combination of Mesh terms and free words. The following Mesh terms and free words were used: “pressure ulcer,” “pressure injury,” “pressure sore,” “pressure damage,” “decubitus ulcer,” “bed ulcer,” “bed sore,” “bedsore,” “skin injury,” “artificial intelligence,” “AI,” “deep learning,” “machine learning,” “computer assisted,” “image analysis,” “image software,” “computer diagnosis,” “diagnostic algorithm.” The precise search strategies for databases are shown in the Supplementary Appendix. Additionally, reference lists included in the identified articles were manually searched to identify additional relevant publications. Gray literature was searched as well. Some authors were contacted via e-mail to obtain further details or help to resolve any uncertainties. The study did not require the approval of an Ethics Committee since it is based entirely on previously published studies.
Study selection
After the removal of duplicate studies, two investigators independently assessed the eligible publications by screening titles and abstracts, using the inclusion and exclusion criteria. Full-text articles were retrieved when at least one reviewer decided that an abstract was eligible for inclusion. Each publication was assessed independently by both investigators for final study inclusion. Disagreements were resolved by discussion.
The criteria for inclusion of a study in the systematic review were as follows: primary research studies that developed and/or validated an AI algorithm for PI diagnosis or classification in PI images, published in English or Chinese, and involving human subjects. Studies with small sample sizes and limited scope were included to ensure the completeness of evidence and the comprehensiveness of research coverage. The exclusion criteria were as follows: conference abstracts, letters to the editor, review articles, studies with poor reporting quality or insufficient validation, and studies containing incomplete data. We excluded duplicates by using Endnote X9. We did not place any limits on the target population, study setting, or comparator group.
Data extraction
Data were extracted from the included studies by two independent investigators. Titles and abstracts were screened before full-text screening. Data were extracted by using a predefined data extraction sheet. A list of excluded studies, including the reason for exclusion, was recorded in a Preferred Reporting Items for Systematic Reviews and Meta-Analyses flow diagram. Any further papers identified through reference lists underwent the same process of screening and data extraction in duplicate.
The following information was recorded: (1) General information of the study: the name of the first author, country, publication year, sample size, sample source, staging criteria for PI, model basis; accuracy, precision, recall, specificity, and F1 index; (2) Information for systematic review and meta-analysis: the number of TP cases, the number of false positive (FP) cases, the number of TN cases, and the number of false negative (FN) cases in each stage. If a study provides multiple TP, FP, TN, and FN columns for the same or different AI algorithms, we will assume that they are independent of each other. If the retrieved literature does not provide the above original data, the data will be transformed through SEN and SPE. Taking stage 1 PI as an example, the specific calculation proceeds as follows: the four contingency-table counts (TP, TN, FP, FN) can be derived from four source variables: SEN, SPE, the reference-standard-positive count for stage 1 PI (TP + FN), and the total study sample size. Furthermore, the TP, FP, TN, and FN of different models in diagnosing PI were calculated, respectively, through TP, FP, TN, and FN at different stages. For example, the TP of each model is equal to the sum of the TP values of different PI stages.
Quality appraisal
The quality of the included studies was evaluated independently by two investigators using the Improved QUADAS-2 tool. In the systematic review of dental caries imaging diagnosis based on deep learning published by Mohammad Rahimi et al., 21 the researchers improved the QUADAS-2 tool in response to the characteristics of the deep learning model studies. The improved QUADAS-2 tool covers four areas. It addresses issues such as data imbalance and insufficient generalization caused by limited dataset diversity; emphasizes data exclusion bias; considers the independence of test set data in validity evaluation; and further accounts for the reproducibility of research results, the robustness of diagnostic models, and measurement errors that may occur during annotation.
Two investigators independently performed quality assessments. If there were discrepancies between the two investigators’ evaluations, a third party adjudicated the results. The quality assessment and graphic production of this study were completed using RevMan 5.3 software. As shown in Fig. 3, the greener the color of each criterion, the lower the risk of bias. To further enhance reporting transparency, we assessed the included studies against the TRIPOD-AL reporting standards. A detailed evaluation checklist is provided in Supplementary Table SA1a.
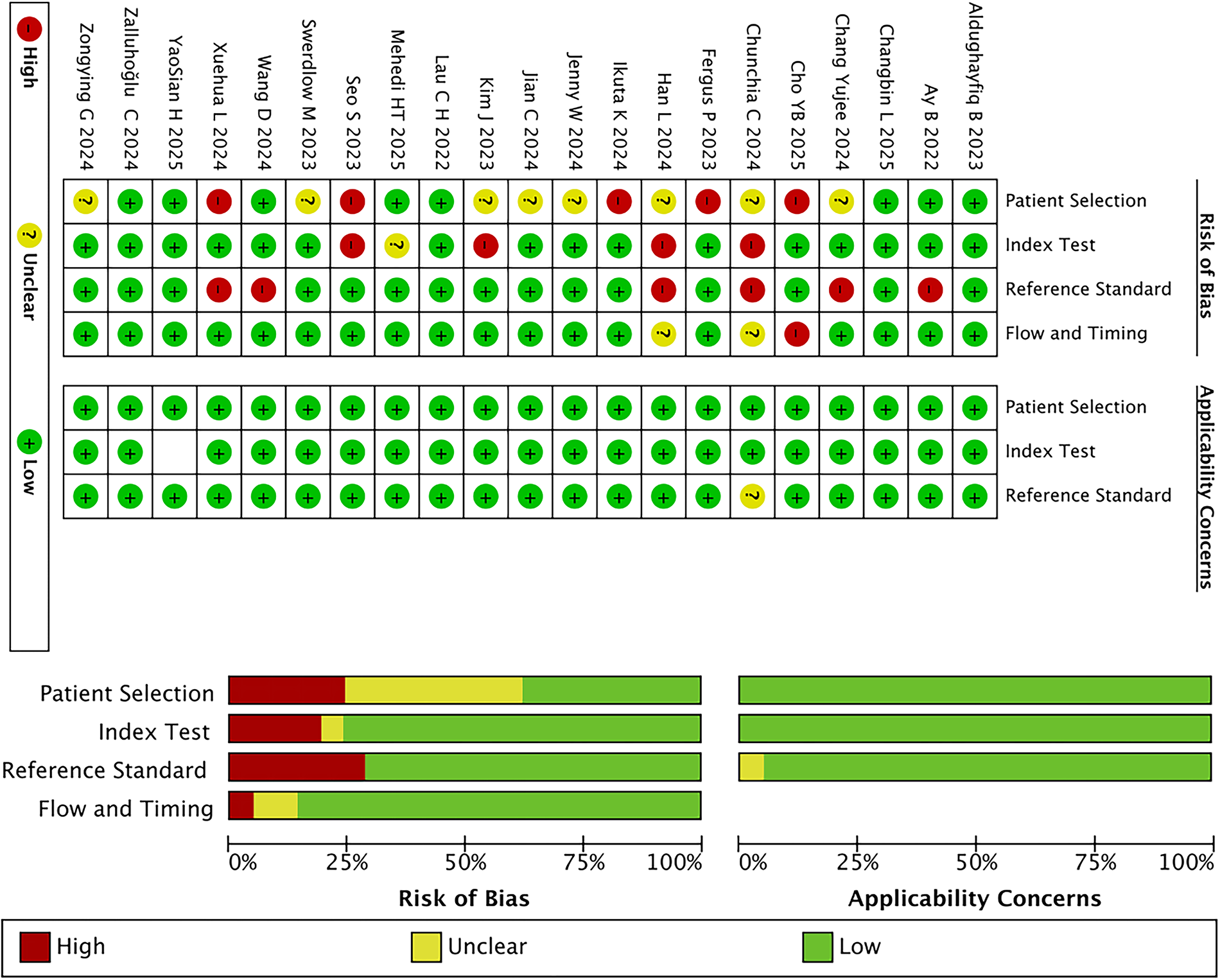
Summary chart of the results of the risk of bias and clinical applicability evaluation of the included studies.
Data analysis
All statistical analyses were performed using Stata 16.0. First, the SROC curve was constructed to examine threshold effects, with a “shoulder-arm” configuration considered indicative of such an effect. Non-threshold heterogeneity was then assessed with the Cochran Q-test for the diagnostic odds ratio (DOR), using a threshold of p < 0.1. Pooled SEN, SPE, DOR, positive likelihood ratio (+LR), negative likelihood ratio (–LR), and their 95% confidence intervals (95% CI) were calculated, and the area under the SROC curve (AUC) was determined. Publication bias was evaluated with Deeks’ funnel plot.
The Bayesian multilevel random-effects model was constructed using R software version 4.5.1 (brms package). Sources of heterogeneity identified by meta-regression were incorporated into the model structure as grouping variables, and the variance characterized by high I2 values was systematically decomposed through random-effect terms. Meanwhile, 95% CI and 95% prediction intervals (95% PI) were reported to comprehensively quantify and provide a quantitative reference for the potential fluctuation range of future research results.
RESULTS
Study process
The initial search retrieved 1,298 articles, of which 835 were duplicates. After screening titles and abstracts, 141 articles were selected on the basis of inclusion criteria. These publications were further evaluated in detail. Ultimately, a total of 21 studies (2 in Chinese and 19 in English) met the inclusion criteria and were utilized for the meta-analysis (Fig. 4).
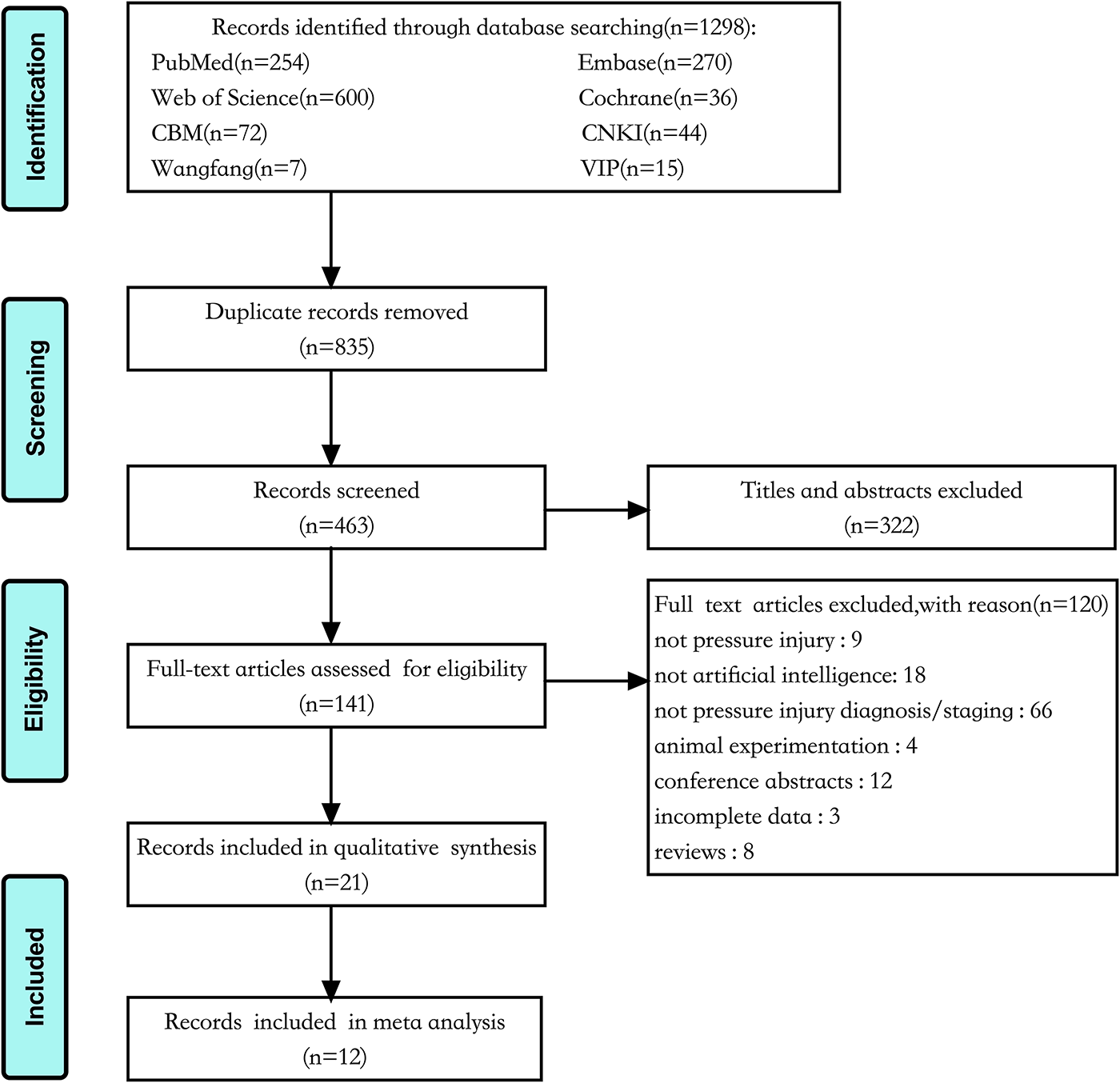
Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram for the study selection process.
Characteristics of the included studies
The characteristics of the 21 studies are summarized in Table 1. The studies included 19 English and 2 Chinese literature studies with publication years from 2022 to 2025. Of the 21 studies included, 14 constructed models based on CNN, and 7 constructed models based on YOLO. The accuracy, precision, recall, sensitivity, specificity, and F1 index of the AI models in the 21 included studies were summarized in Table 2. The top three models in terms of accuracy reported in the included studies are pressure ulcer cluster vision transformer (PUC-ViT), SemiViT, and DenseNet121, with accuracies of 0.9776, 0.9399, and 0.9371, respectively. PUC-ViT and SemiViT enhance the performance of the proposed model by preprocessing image data based on previously acquired images, dividing the original images into smaller patches, and embedding them using a vision transformer architecture commonly used in computer vision. DenseNet121 is a common deep CNN architecture.
Characteristics of included studies
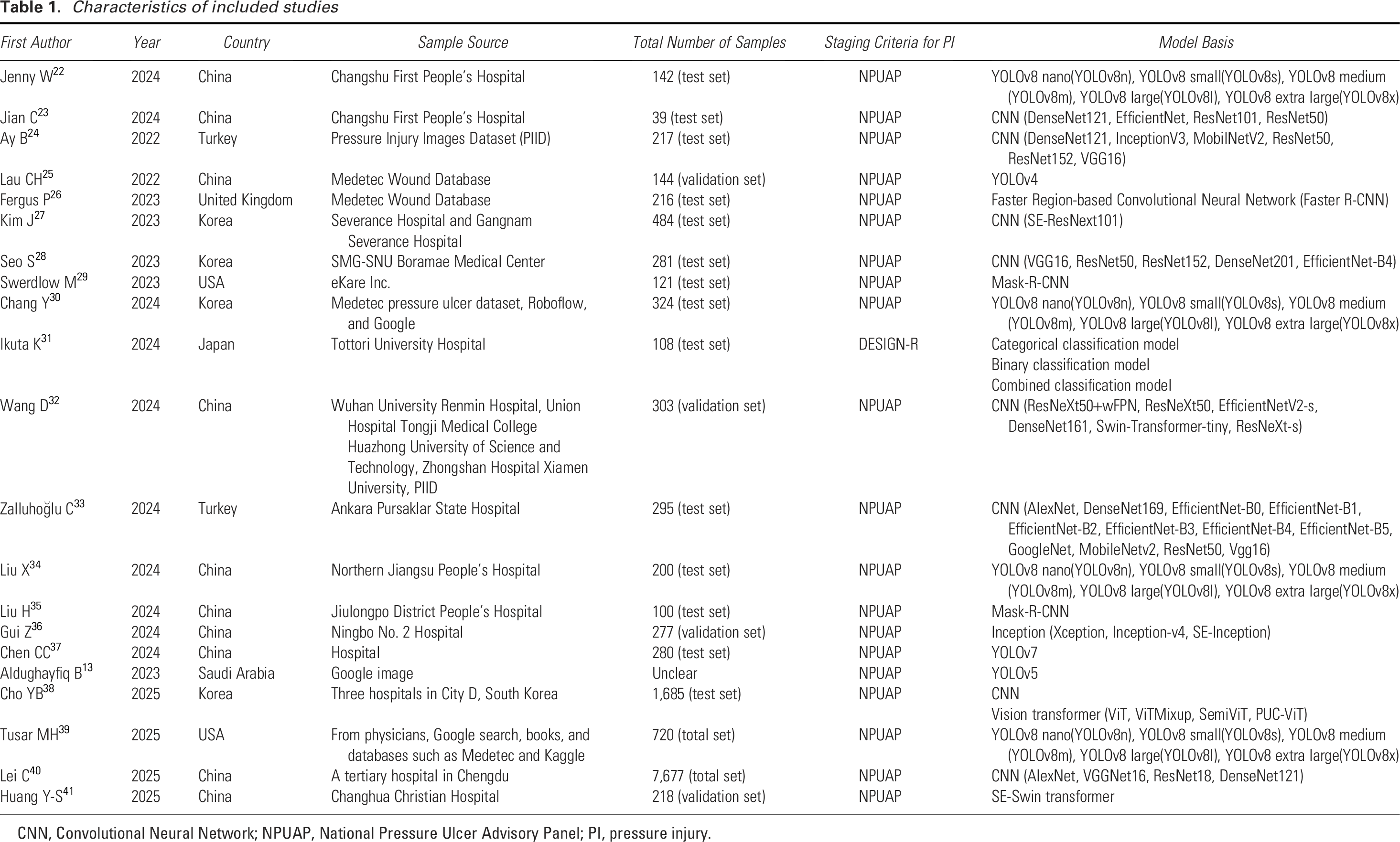
CNN, Convolutional Neural Network; NPUAP, National Pressure Ulcer Advisory Panel; PI, pressure injury.
Characteristics of AI models included studies
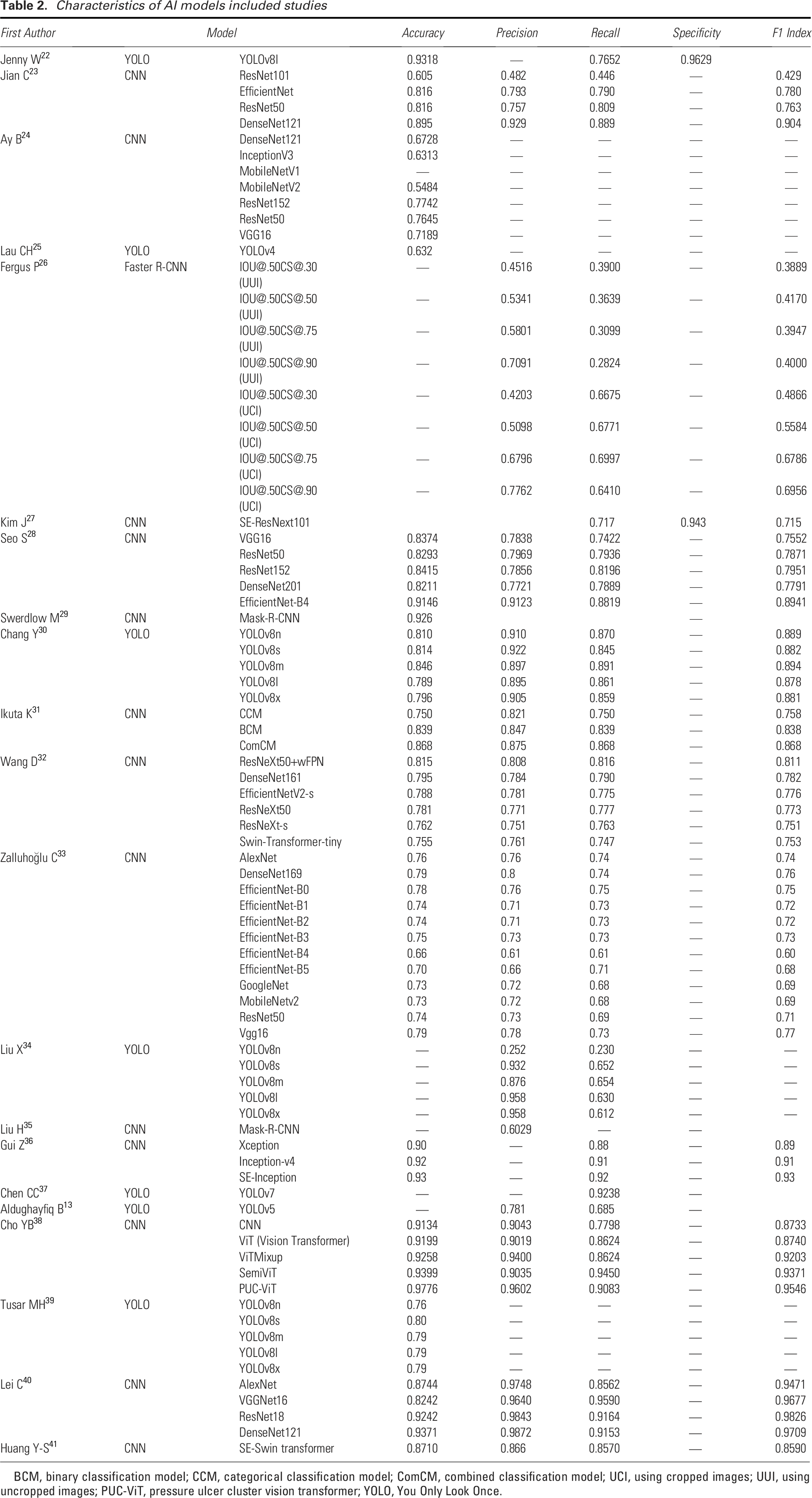
BCM, binary classification model; CCM, categorical classification model; ComCM, combined classification model; UCI, using cropped images; UUI, using uncropped images; PUC-ViT, pressure ulcer cluster vision transformer; YOLO, You Only Look Once.
This review systematically evaluated 21 included studies, from which TP, FP, TN, and FN data could be extracted for 12 studies—all of which met the criteria for meta-analysis. Therefore, meta-analysis was performed on the 12 studies containing 47 datasets. The summary of the datasets included in the meta-analysis is shown in Table 3.
The datasets included in the meta-analysis

Directly reported datasets.
Derived datasets.
DTPI, deep tissue pressure injury; FN, false negative; FP, false positive; TN, true negative; TP, true positive.
Heterogeneity test
To ensure the data quality of the included studies, the included studies were assessed individually using the Improved QUADAS-2 tool. The results showed that the overall study data quality was high. By analyzing the threshold effects of all 47 datasets, the SROC curves constructed for SEN and SPE did not show a “shoulder-arm” distribution, suggesting that there was no threshold effect among the included studies (Fig. 5).
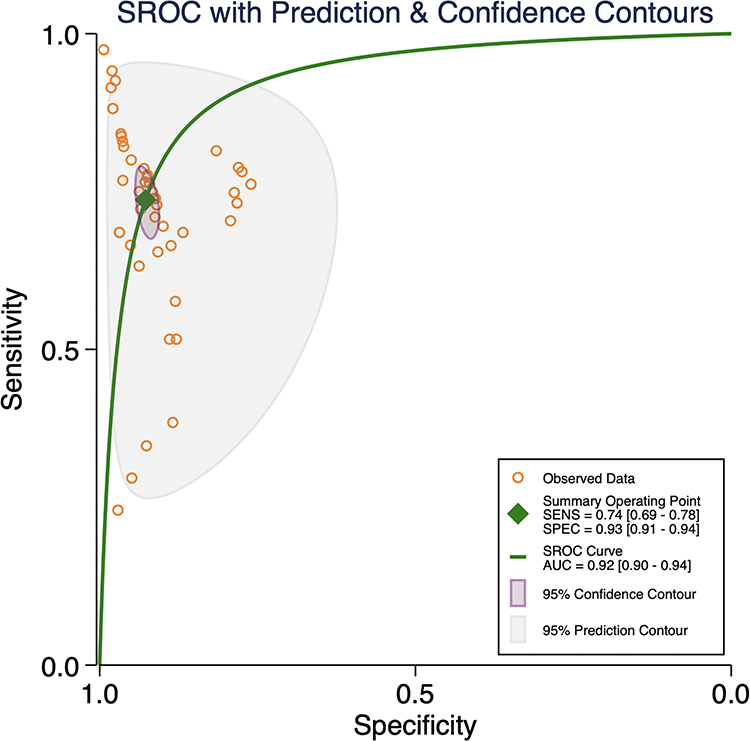
SROC curves of AI in PI diagnosis. SROC, summary receiver operating characteristic.
The data included in the study were analyzed for non-threshold effect heterogeneity, and the Cochran Q-test for DOR resulted in p < 0.1 suggesting the presence of non-threshold effect heterogeneity.
Meta-analysis results
According to Fig. 6, the pooled SEN was 0.74 (95% CI: 0.69–0.78). The Q-test (p < 0.05) indicated that the pooled SEN results of the included studies were statistically significant, and I2 = 96.51% (95% CI: 95.96–97.06) >50%, suggesting significant heterogeneity in SEN. The pooled SPE was 0.93 (95% CI: 0.91–0.94), along with p < 0.05 for the Q-test, indicating that the pooled SPE results of the included studies were statistically significant, and I2 = 98.03% (95% CI: 97.77–98.29) >50%, suggesting that the heterogeneity of SPE was higher. The pooled DOR was 35.72 (95% CI: 24.12–52.88), and the pooled diagnostic score was 3.58 (95% CI: 3.18–3.97); the pooled +LR was 10.14 (95% CI: 7.91–13.00), and the pooled −LR was 0.28 (95% CI: 0.24–0.34). The SROC curve (Fig. 5) was plotted, and the AUC was 0.92 (95% CI: 0.90–0.94), suggesting that the accuracy of AI in identifying the staging of PI was high. Figure 7 presents the likelihood ratio plot of AI for PI diagnosis.
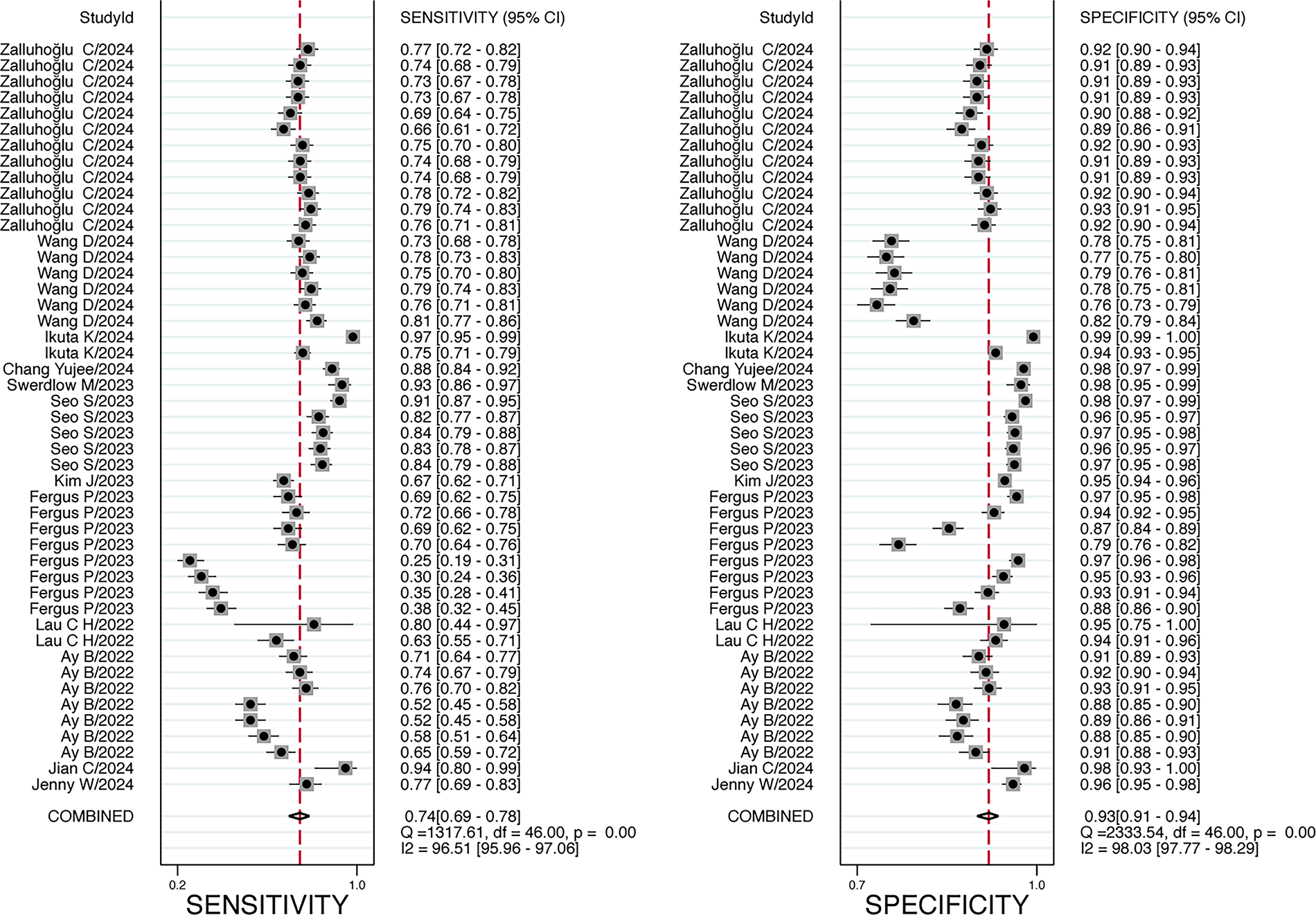
Forest plot of sensitivity and specificity of AI in PI diagnosis.
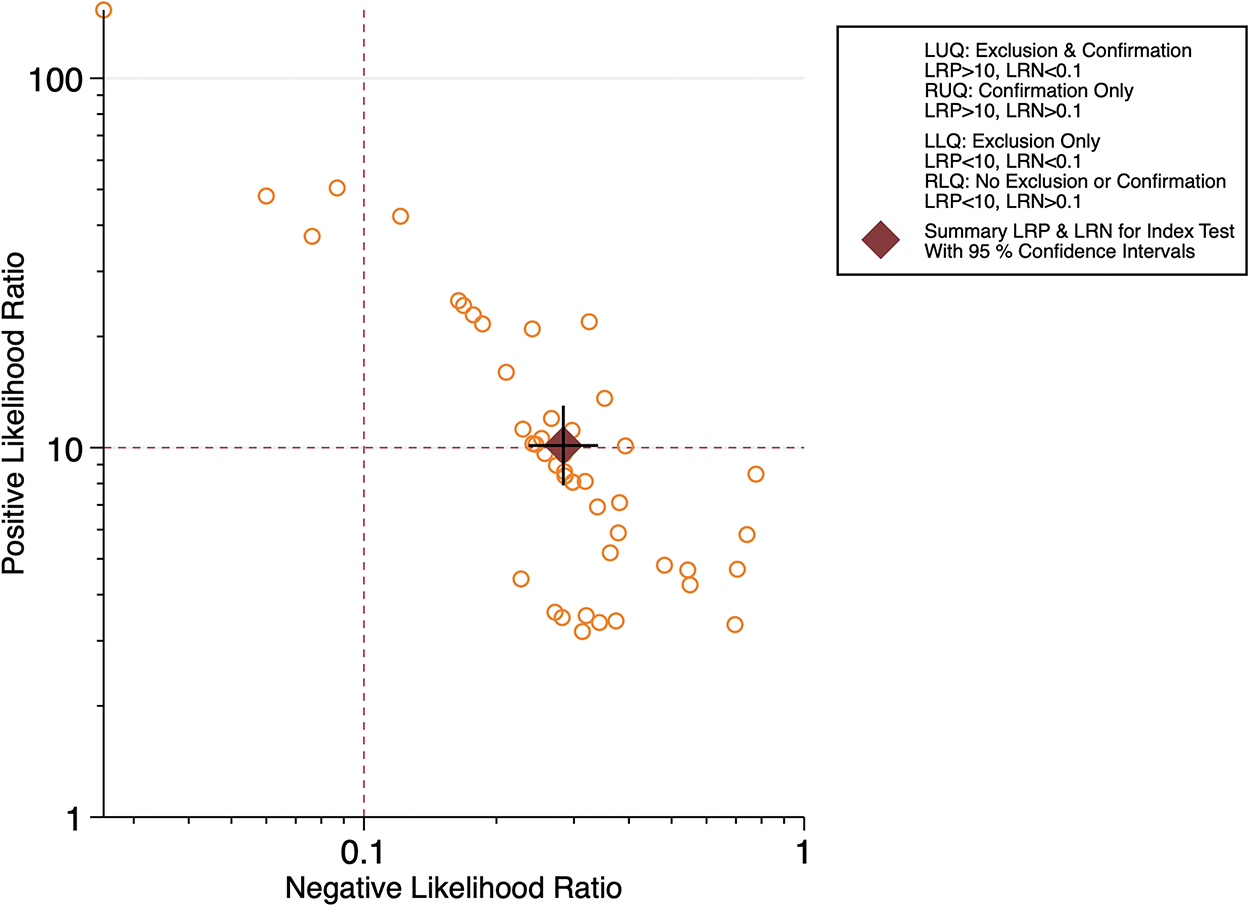
Likelihood ratio plotting of AI in PI diagnosis.
Results of meta-analysis for AI diagnosis of different stages of PI
In this study, a meta-analysis was specifically conducted for each stage of PI diagnosed by AI, and the accuracy of each stage was summarized (Table 4). This study analyzed the data using the revised National Pressure Ulcer Advisory Panel (NPUAP) definitions and staging of PI. 42 The results showed that the best-performing stage for AI diagnosis was deep tissue pressure injury (DTPI), with an AUC of 0.98 (95% CI: 0.96–0.99). Figure 8 shows the Receiver Operating Characteristic (ROC) for each stage of AI diagnosis.
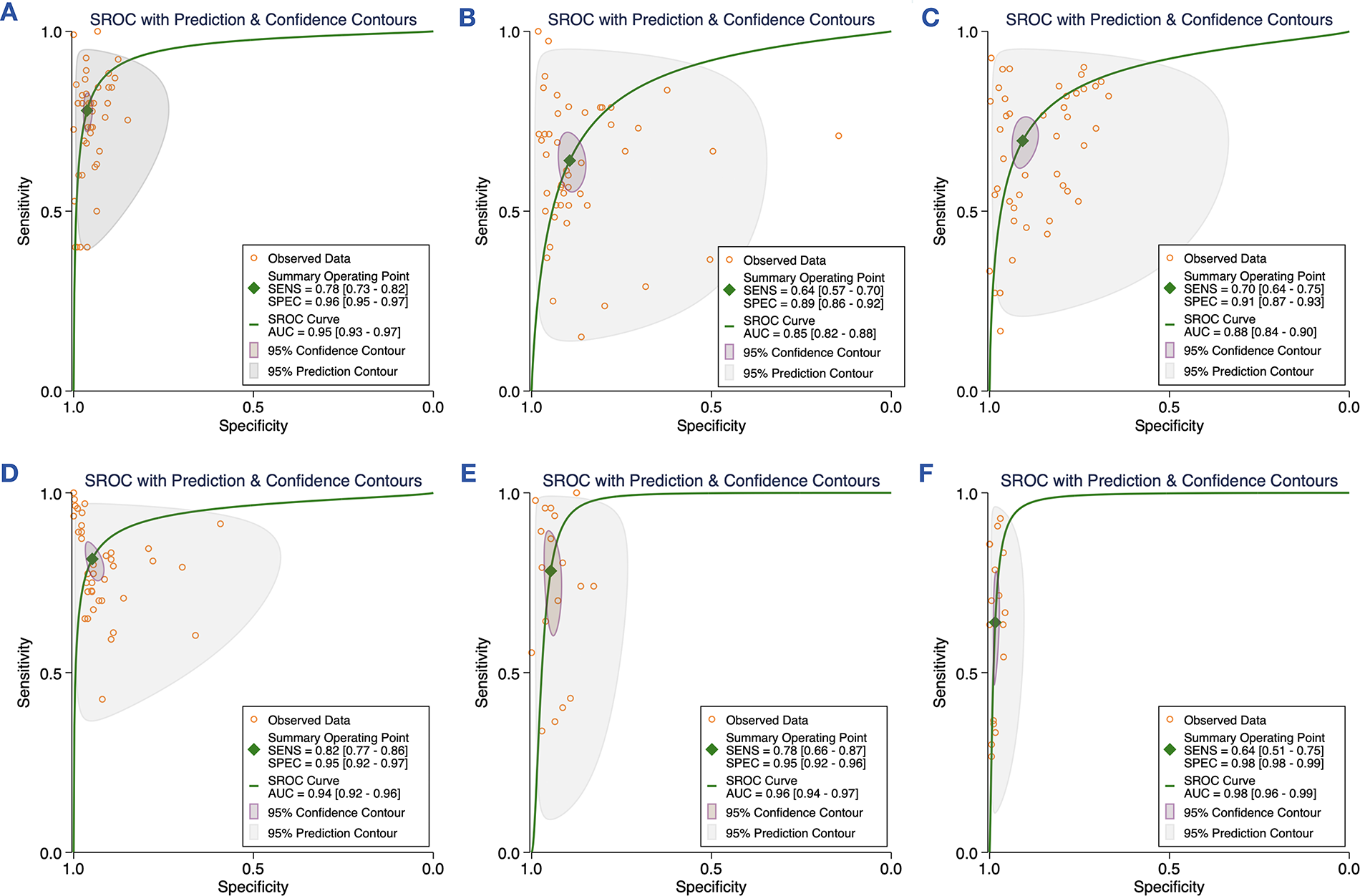
The ROC for each staging of AI in PI diagnosis:
The accuracy of the PI stages
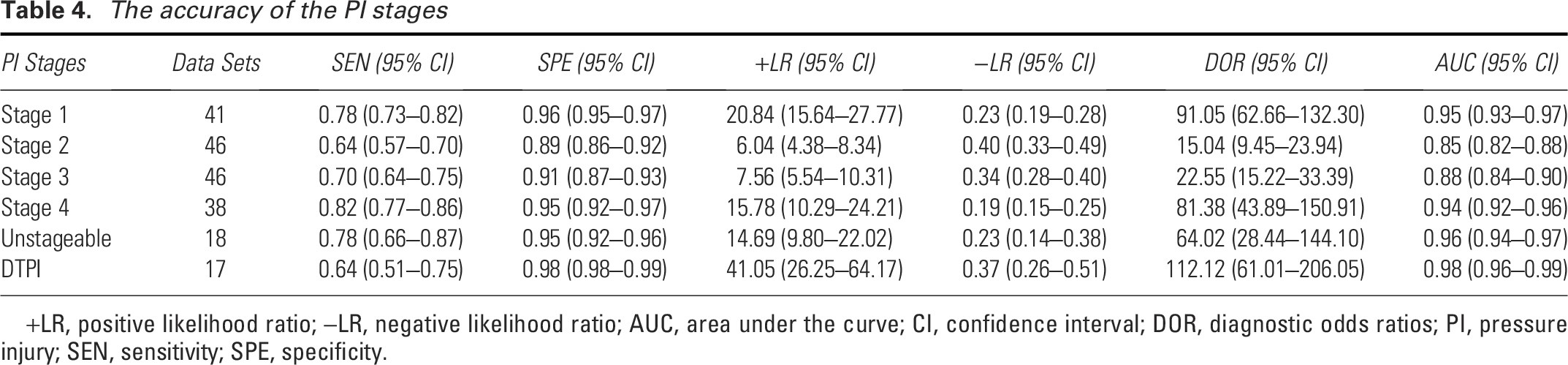
+LR, positive likelihood ratio; −LR, negative likelihood ratio; AUC, area under the curve; CI, confidence interval; DOR, diagnostic odds ratios; PI, pressure injury; SEN, sensitivity; SPE, specificity.
Results of meta-regression and Bayesian multilevel random-effects model
To explore the potential sources of heterogeneity, we conducted meta-regression using Stata 16.0. We included the sources of images, sample size, diagnostic staging criteria, algorithm choice, dataset source, device type, and patient setting in the meta-regression. The meta-regression analysis indicated that the sources of images, sample size, diagnostic staging criteria, algorithm choice, dataset source, and patient setting might be the sources of heterogeneity (Fig. 9).
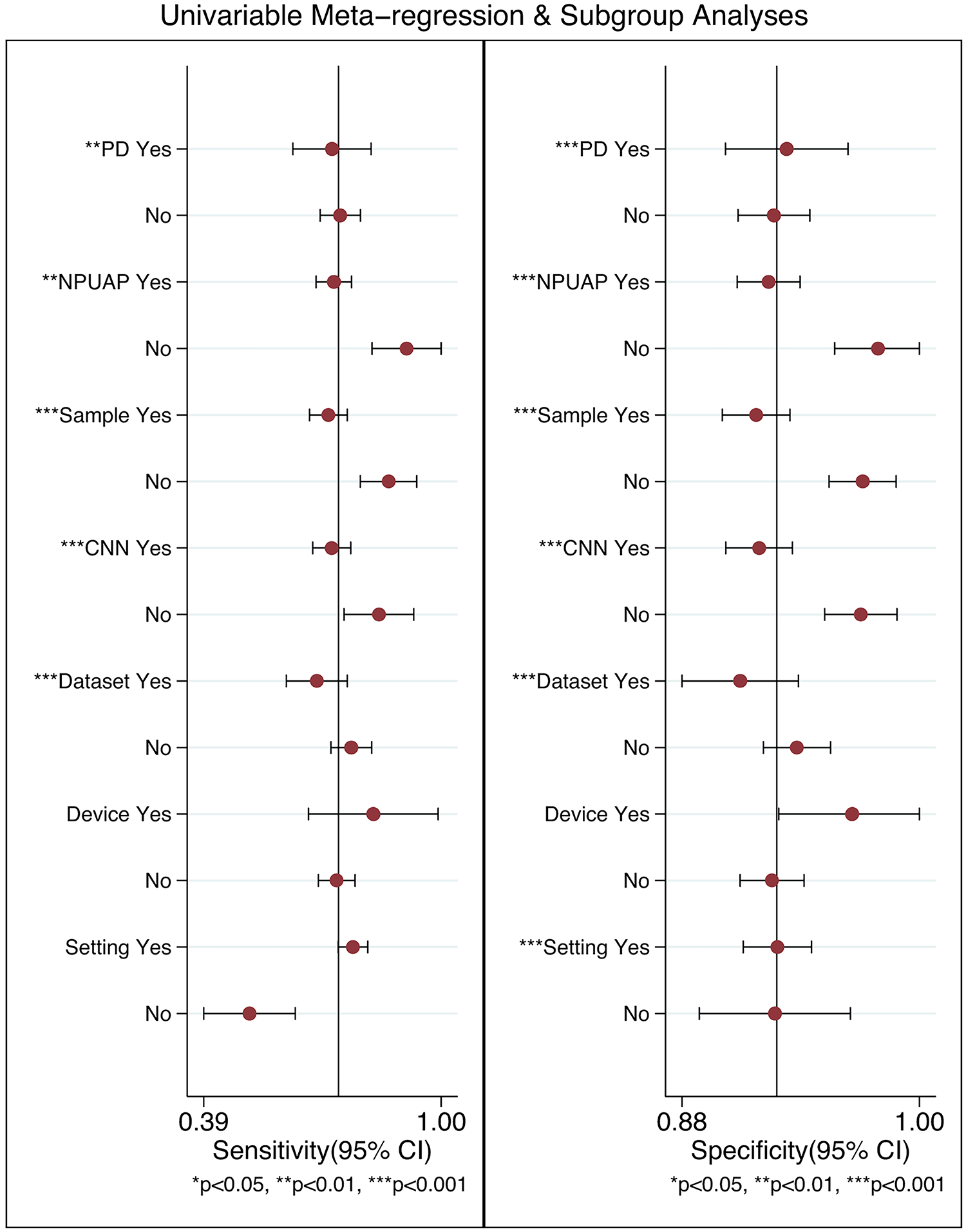
Meta-regression results of AI in PI diagnosis.
In the Bayesian multilevel random-effects model analyses, stratification was conducted across six dimensions based on the meta-regression findings: (1) whether the PI images were sourced from public databases, (2) whether the sample size exceeded 200, (3) whether the PI staging criteria were derived from the NPUAP, (4) whether the CNN algorithm was used, (5) whether the dataset source was multicenter, and (6) whether the patient setting was in-hospital. The results, including SEN and SPE with their respective 95% CI and 95% PI, as well as corresponding heterogeneity indices (I2), are presented in Table 5.
Results of Bayesian multilevel random-effects model analyses for artificial intelligence in pressure injury diagnosis
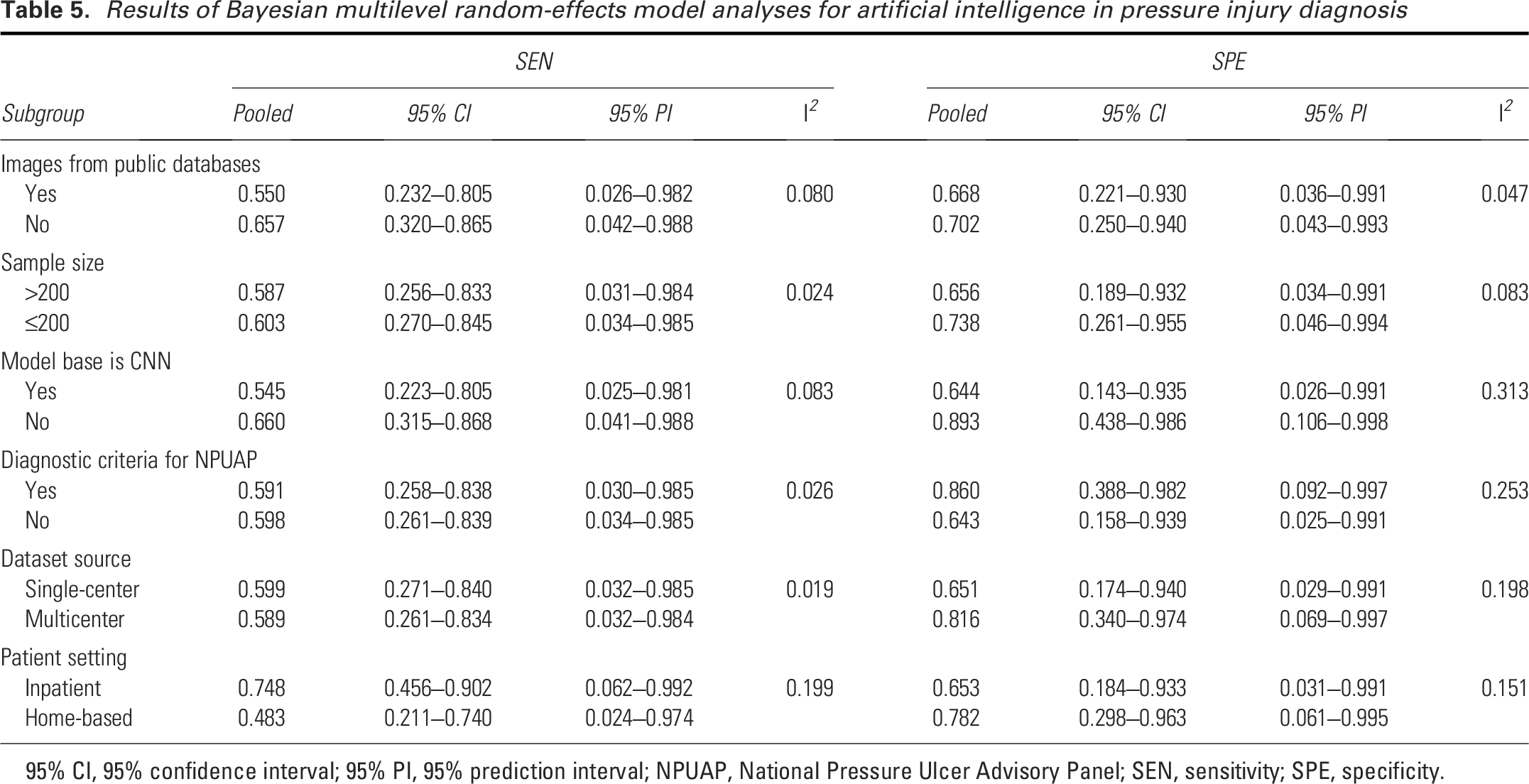
95% CI, 95% confidence interval; 95% PI, 95% prediction interval; NPUAP, National Pressure Ulcer Advisory Panel; SEN, sensitivity; SPE, specificity.
Sensitivity analyses
Sensitivity analyses of the sources of heterogeneity in the included studies using Stata 16.0 software (Fig. 10) revealed that five studies had the potential to generate heterogeneity. Additionally, we conducted sensitivity analyses by excluding studies with small samples, low quality, or indirectly calculated datasets, and then recalculated the pooled effect size. The direction of the core indicators remained consistent compared with the primary analysis, indicating robust and reliable findings (Supplementary Figs. SA1 and SA2).
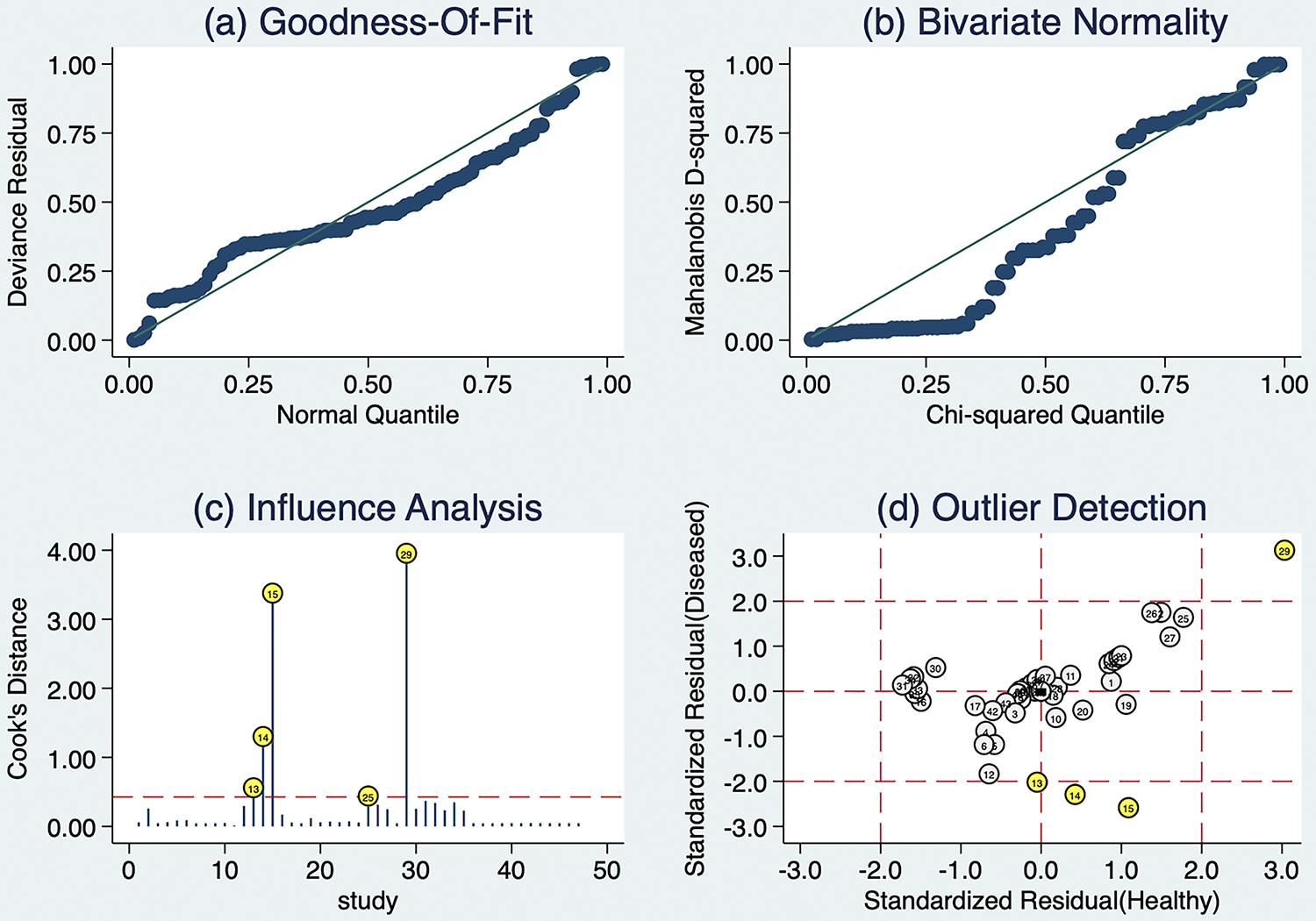
Sensitivity analyses of AI in PI diagnosis.
Publication bias
The included studies were evaluated for publication bias by Deeks’ funnel plot (Fig. 11). The p value was 0.42 (p > 0.05), indicating that there was no publication bias among the included studies.
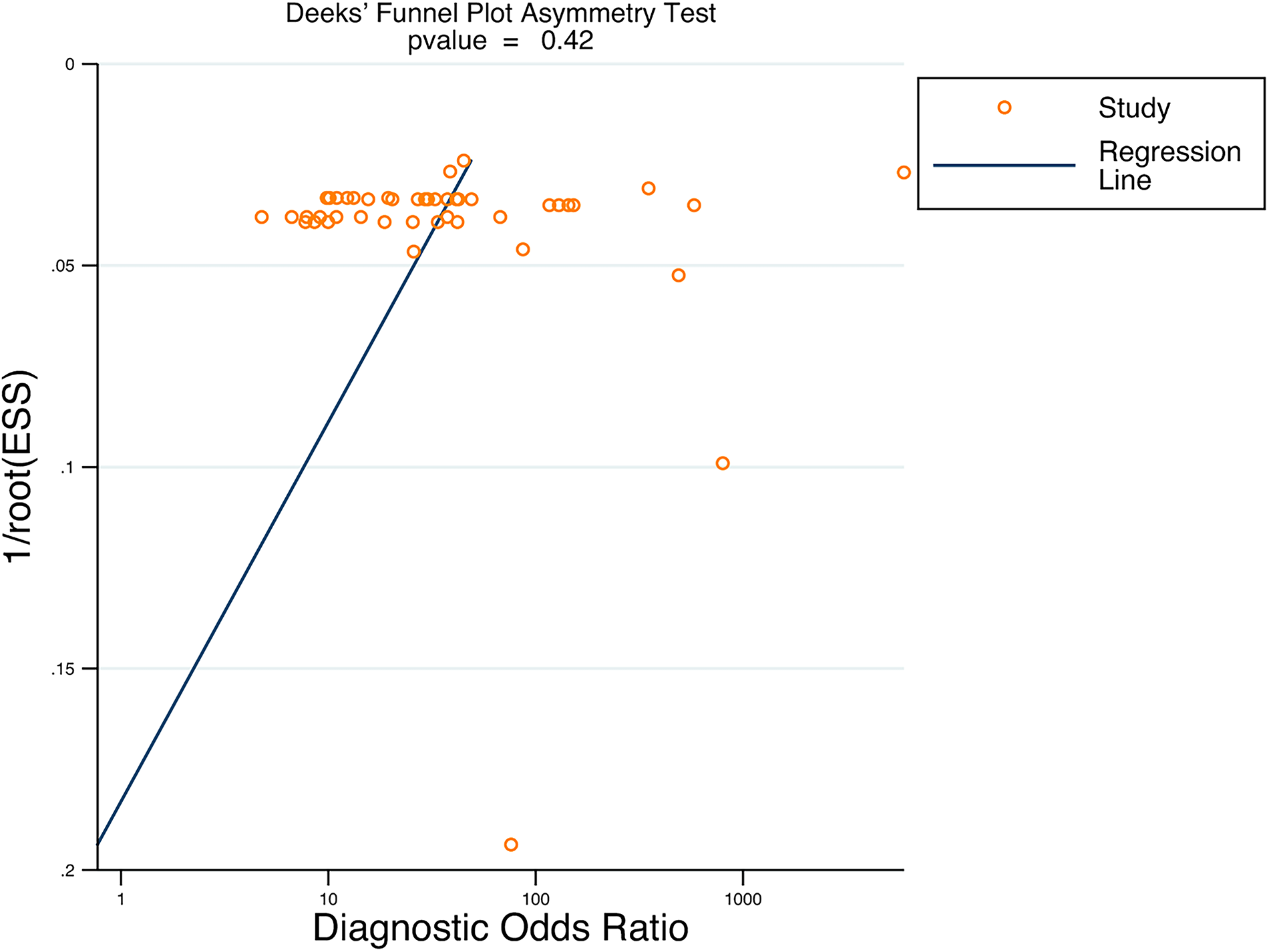
Publication bias of AI in PI diagnosis.
DISCUSSION
An increasing number of studies have been investigating the potential of AI in PI diagnosis. We conducted a systematic review of the methods, results, and quality of studies on AI for PI diagnosis. We not only performed a meta-analysis of the diagnostic results but also analyzed and pooled the diagnostic results for different PI stages. Our review highlighted three principal findings.
First, AI has demonstrated high reported diagnostic accuracy. Studies included in our review had an accuracy range of 60.5 − 97.8%, and meta-analysis showed a pooled SEN of 74% and SPE of 93%. +LR, −LR, DOR, and AUC were 10.14, 0.28, 35.72, and 0.92, respectively. In addition, reviews similarly reported that AI algorithms have significant advantages in PI diagnosis. 43 Therefore, AI has shown potential for the early detection and accurate diagnosis of PI, laying the groundwork for future investigations into its contribution to treatment-strategy formulation and outcome monitoring.
Second, the results of the meta-analysis showed that AI demonstrated significant potential in identifying the different stages of PI. Despite subtle differences between stages, overall, AI demonstrated good diagnostic performance in all stages of PI. Stage 1 presents with intact skin but with redness, pain, and congestion at the site of pressure. 42 When the local pressure is relieved, stage 1 can usually heal on its own without further progression to stage 2. 44 However, in clinical practice, stage 1 deteriorates into more serious stages because it is not easy to detect and is not detected in a timely manner.45,46 In this study, the accuracy of AI in identifying stage 1 was high, with an AUC of 0.95, which shows that AI has a significant advantage in identifying stage 1, and it can make up for the shortcomings of manual observation by virtue of its accurate identification ability, capture the early signs of PI in a timely manner, and provide reliable diagnostic references for the clinical personnel. In addition, in scenarios such as non-large health care facilities, elderly care facilities, and home-based settings, debridement conditions are usually not available for post-debridement staging of patients with the two specific types of PI, unstageable and DTPI.22,47 In this study, meta-analysis of AI recognition of unstageable and DTPI was also performed, and the use of AI enabled early detection of such patients with PI in scenarios where strong PI expertise and debridement conditions are not available, drawing attention to them and transferring them to large hospitals for further treatment when necessary.
Third, there was high heterogeneity across studies, with SEN heterogeneity I2 = 96.51% and SPE heterogeneity I2 = 98.03%, both greater than 50%. We caution that the high pooled accuracy must be interpreted cautiously in light of this heterogeneity. On the one hand, AI models are often regarded as “black boxes,” and the choice of all possible transformations varies widely. 48 Interpretability remains a central challenge for clinical AI models. To secure clinician acceptance, models must supply evidence that is both understandable and trustworthy. We therefore recommend integrating explainable AI techniques such as heatmaps, attention maps, and saliency analysis in future work, enabling clinicians to rapidly verify the diagnostic rationale. Future studies should present explainability results alongside performance metrics. By improving model transparency, explainable models can increase clinician confidence in AI systems, facilitating broader acceptance and integration in clinical workflows. On the other hand, this study used 47 datasets of AI model construction, and the parameters of the PI images acquired varied from one study to another, leading to a large heterogeneity. In this study, the source of heterogeneity was tested for threshold effects, and the SROC curves for sensitivity and specificity did not show a “shoulder-arm” distribution, suggesting that the source of heterogeneity was not a threshold effect but mainly a non-threshold effect.
In this study, a Bayesian multilevel random-effects model was employed for subgroup analysis. Its core advantage lies in its ability to handle complex heterogeneity structures more flexibly and precisely. By incorporating the heterogeneity sources identified by meta-regression—namely, the sources of images, sample size, diagnostic staging criteria, algorithm choice, dataset source, and patient setting—as grouping variables into the model framework, and systematically decomposing the variation characterized by high I2 values with the help of random-effects terms, it provides an analytical framework that is more in line with the data distribution characteristics for explaining the performance differences of AI in PI diagnosis.
Our results revealed that subgroups with images derived from public databases versus nonpublic databases exhibited certain differences in SEN and SPE. The quantity and quality of PI image data directly influence research outcomes. PI images, categorized as optical RGB (red–green–blue) images, are captured using various devices, including mobile phones, digital cameras, and tablet computers. Parameter variations across different devices make it challenging to ensure the homogeneity of PI images. Furthermore, the imaging process is affected by environmental factors, patient positioning, and individual habits of photographers, which further compromise image quality. Currently, most PI images used by researchers are sourced from historical PI images stored in departments and results from web searches, with substantial discrepancies among these images, directly impairing the learning efficacy of AI. 18 It is recommended that future studies develop standardized imaging protocols to ensure the consistency of datasets in terms of illumination, resolution, and device type. Additionally, dataset-sharing initiatives are proposed to improve reproducibility and fairness.
Moreover, subgroup analysis results showed that the CNN model group had a SEN of 0.680 and a SPE of 0.868. However, it should be noted that among the algorithm types included in this study, CNN accounted for an extremely high proportion, while other types had a very low proportion. Such imbalance in subgroup sample sizes may affect the robustness of the results, so it is currently impossible to accurately determine the performance differences between different algorithms. We explicitly acknowledge this imbalance and therefore refrain from claiming that CNNs are intrinsically superior to other architectures. In addition, multiple pieces of research evidence have supported the application potential of other algorithms in PI diagnosis. For example, Bader Aldughayfiq et al. used YOLOv5 to identify four stages of PI lesions and non-PI lesions. 13 Xuehua Liu et al. developed an intelligent machine vision system based on YOLO8, which not only can quickly identify PI stages but also may be extended to the diagnosis of other diseases closely related to color and texture features. 34 Beyond the YOLO series, traditional machine learning models such as Random Forest and Decision Tree have also shown good performance in identifying high-risk patients and classifying wounds based on clinical data. Moreover, emerging methods like transfer learning and explainable AI have demonstrated high performance in wound detection and classification tasks. 49 These diverse classification methods provide strong support for the early diagnosis of PI, the formulation of optimized treatment plans, and the identification of complications. Future studies should prospectively assemble balanced datasets that equally represent CNN, YOLO, transformers, and ensemble models, and conduct strictly matched head-to-head comparisons with systematically delineate the applicable scenarios and performance differences of each AI approach in PI diagnosis.
Several key factors should be considered when evaluating the application of AI tools in the medical field.
First, external validation is an essential step to determine the generalizability of models. This requires researchers to evaluate the model on external datasets different from the training dataset, thereby verifying the stability and reliability of its performance. However, current studies mostly focus on the development and internal validation of AI models, with limited external validation across diverse clinical environments and populations. Consequently, we underscore that without robust multicenter, prospective validation, the clinical translation of these AI tools remains premature. Multicenter external validation is recommended: first assess performance across diverse skin tones and age groups, then test usability in multiple health care settings, followed by a prospective study to confirm clinical value, and finally scale up with iterative refinement to achieve reliable clinical translation.
Second, the consistency of AI tools’ performance across different skin tones and age groups is of great significance. This is because differences in skin tones and ages may reduce the recognition accuracy for certain groups, thereby affecting the fairness and effectiveness of diagnostic results. However, the performance of AI in diagnosing PI across populations with different skin tones and ages is still in the exploratory stage. It is recommended that all future AI wound research mandatorily report demographic information and conduct stratified analysis by skin tone, so as to provide a basis for the generalizability and fairness of AI diagnostic tools.
Finally, with the rise of mobile health, the adaptability of AI tools on smartphones or tablets has become a key factor affecting the accessibility and convenience of their clinical application. The use of these tools on mobile devices enables medical professionals to access and utilize the technology anytime and anywhere, thereby improving the efficiency and scope of health care services. However, in resource-constrained environments, AI diagnostic technology faces multiple challenges, such as difficulty in deployment due to reliance on high-performance devices and stable networks, low operational proficiency of primary medical staff, and lack of technical maintenance support. It is recommended that future efforts focus on developing lightweight, mobile-compatible models that support offline operation, constructing locally adapted datasets to improve diagnostic accuracy, simplifying operational procedures, and strengthening training and remote technical support for medical staff.
At the level of clinical utility, the value of AI extends beyond diagnostic accuracy, with particular prominence in optimizing early detection, reducing misdiagnosis rates, and enhancing the timeliness of interventions. Studies have demonstrated that in outpatient settings, AI enables remote wound monitoring, which effectively improves patient compliance, enhances access to care, and optimizes clinical workflows. 50 Furthermore, compared with clinicians, AI can objectively identify and measure wound tissues, thereby facilitating early detection and reducing misdiagnosis. 51 However, there remains a significant gap in the evaluation of core dimensions of clinical utility in existing research. Most studies included in this analysis focus solely on the consistency between algorithms and PI staging, lacking systematic assessments of integration with clinical workflows, operational convenience, and feedback from health care providers. This constitutes a critical gap that hinders the translation of AI from technical accuracy to practical clinical value. To address this gap, future research is recommended to adopt mixed-methods research (such as surveys, implementation studies, etc.) to evaluate the model’s usability, training needs, and real-world impact.
A fundamental strength of the current analysis is the adoption of robust methodology. The comprehensive literature search was performed in 8 electronic databases and included publications in both English and Chinese. This extensive effort, undertaken by two reviewers, enhanced the ability to accurately catalog the comprehensive information on AI for diagnosing PI and to analyze the accuracy of AI in identifying PI stages 1–4, unstageable, and DTPI, respectively. To the best of our knowledge, the current study is the first to estimate the accuracy of AI in diagnosing different stages of PI. It is expected that the results of this study will be an important reference for clinicians, nurses, medical device developers, health care administrators, and researchers in the field. Clinicians and nurses play a key role in the process of wound assessment, treatment, and ongoing monitoring of patients with diagnostic PI by AI. This application of AI has the potential to promote wound healing and improve patients’ quality of life. Medical device developers can leverage the findings of this study to improve and optimize AI diagnostic tools to increase diagnostic accuracy and efficiency. Health care administrators can use the findings to develop more effective health care policies and rationalize the allocation of resources. Researchers can focus on the pathogenesis, etiology, pathophysiology, and more effective interventions for PI, laying a solid foundation for future clinical practice and care.
LIMITATIONS
Our study had limitations. First, despite subgroup and meta-regression analyses conducted in this study, the high heterogeneity (I2 > 90%) remains a significant concern. Second, the TP/FP/TN/FN data were not directly provided in some of the literature and needed to be calculated indirectly by available methods. As a result, a certain amount of human computational error was included, which may have impacted the results. Third, although CNN dominates in this study, the conclusion remains uncertain due to limitations in model comparison caused by sample imbalance or lack of standardization, making it difficult to draw robust and reliable conclusions regarding performance comparisons between different models.
CONCLUSIONS
In conclusion, the findings of this study indicate that AI models constructed based on PI image data exhibit promising performance in PI diagnosis. Although the included studies extracted PI image data from diverse centers and used various algorithms, our meta-analysis results suggest that these AI models show high diagnostic accuracy. However, the evidence should be interpreted with caution due to the lack of multicenter validation for the algorithms. Nonetheless, the existing studies offer valuable directions for future research on AI models in PI diagnosis. Future research should focus on external validation in prospective clinical settings and comparative analyses with clinicians to evaluate applicability and limitations.
TAKE-HOME MESSAGES
AI diagnosis of PI can identify early PI, which is helpful for timely intervention before the wound worsens. AI can assist clinicians in making more informed decisions. In the absence of wound experts, AI can provide reliable diagnostic support, reducing diagnostic and treatment errors in clinical practice. Clinicians should look for validated models, image quality, user-friendly interfaces, real-time analysis, dynamic monitoring, etc., in AI tools to enhance the accuracy and efficiency of diagnosis and support clinical decision-making.
AUTHORS’ CONTRIBUTIONS
Y.W.: Writing—original draft, methodology, literature screening, quality appraisal data curation, data analysis. X.L.: Writing—methodology, literature screening, quality appraisal data curation. J.P.: Writing—review and editing, methodology. H.Z.: Writing—review and editing, methodology. L.H.: Resources, methodology, writing—review and editing, funding acquisition.
Footnotes
ACKNOWLEDGMENTS AND FUNDING SOURCES
This study was supported by the following three projects: The National Natural Science Foundation of China (grant number 8246140071), The major project of Gansu Province Joint Scientific Research Fund (grant number 23JRRA1538), and The Natural Science Foundation of Gansu Province (grant number 25JRRA320).
AUTHOR DISCLOSURE AND GHOSTWRITING
The authors of this article have no financial conflicts of interest to disclose. No ghostwriters were involved in the writing of this article.
ABOUT THE AUTHORS
Supplemental Material
Supplemental Material
Abbreviations and Acronyms
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.