
Abstract
Fine-grained visual classification (FGVC) is challenged by subtle interclass differences, which lead to both out-of-group and in-group errors, particularly when label hierarchies are only partially available. To leverage hierarchical labels for enhanced feature discriminability, this paper introduces two novel loss functions. First, a hierarchically discriminative loss (
Keywords
Introduction
Fine-grained visual classification (FGVC) aims to distinguish between subordinate categories within a domain, a task that is significantly more challenging than general object recognition due to subtle interclass variations and large intraclass variations. While a general object recognition system might be tasked with distinguishing a “car” from a “bicycle,” an FGVC system must differentiate between a “2012 Honda Civic” and a “2012 Toyota Camry,” which share a vast number of visual features. This demand for high precision has driven the adoption of FGVC in a wide range of applications where nuanced understanding is critical. These domains include automated biodiversity monitoring (Wah et al., 2011), where it aids in tracking and conserving species; fashion analysis (Chang et al., 2017), for powering recommendation engines and trend analysis; facial expression analysis (Lo et al., 2023), for more sophisticated human–computer interaction; intelligent transportation (Chen et al., 2021), for autonomous driving and traffic management; and medical analysis (Han et al., 2017), where it assists in the diagnosis and grading of diseases from medical imagery.
The precision of FGVC enables a deeper understanding and more detailed categorization of objects, which is crucial in fields where detailed information is vital for making important decisions. For example, in medical applications, the accurate and timely diagnosis of breast cancer is paramount. A fine-grained classification of breast cancer is more meaningful than a simple benign/malignant classification, as identifying subtypes of malignant tumors can help doctors select more appropriate treatment options and formulate targeted therapeutic plans. However, achieving this level of precision is a significant challenge, as it requires a model to learn highly discriminative features that can capture the subtle, localized differences that define subordinate classes. This difficulty has spurred the development of various advanced FGVC methods (Chang et al., 2020; Chen et al., 2022; Hu et al., 2025; Liu et al., 2022).
Many fine-grained classification datasets contain hierarchical labels from coarse to fine (Chen et al., 2018; Wah et al., 2011) (e.g., breast cancer-malignant-ductal carcinoma), which can be represented by a tree-like hierarchy. This structure is not merely an organizational convenience; it encodes crucial semantic relationships between categories. Based on this hierarchy, two primary semantic relationships exist between fine-grained categories: in-group and out-of-group. An “in-group” relationship exists between two fine-grained categories if they belong to the same coarse-grained category; otherwise, an “out-of-group” relationship exists. Figure 1 provides a schematic illustration of these relationships defined by the label hierarchy.
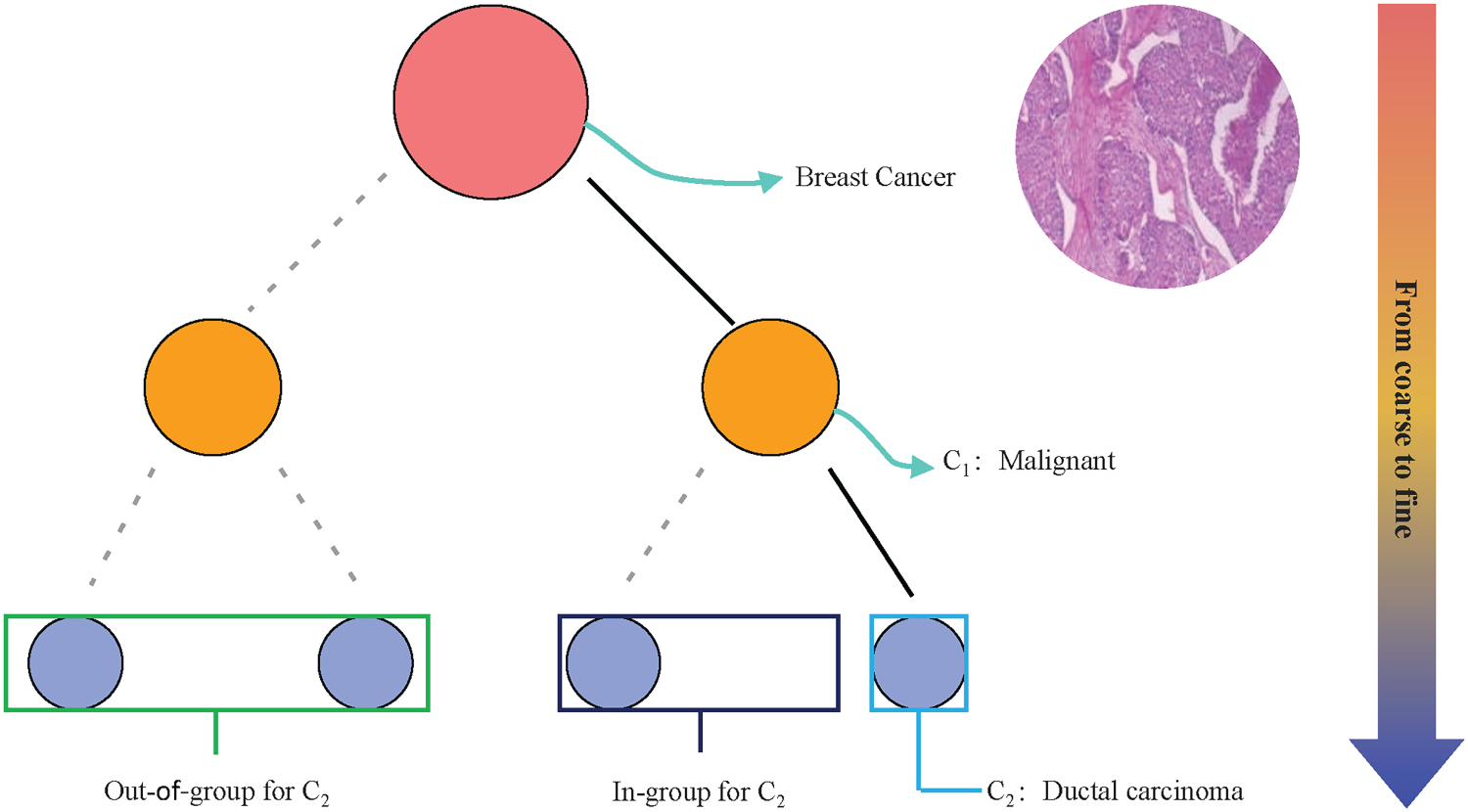
Each object can be annotated at multiple levels in the label hierarchy. The coarse-to-fine labels can be used to define two semantic relationships between the same-level labels: out-of-group and in-group.
Figure 2(a) illustrates this relationship with image examples: the “Red-winged Blackbird” in the first column and the “Rusty Blackbird” in the second column have an in-group relationship, as both are types of blackbirds. In contrast, the “Blue-throated Goldentail” in the third column has an out-of-group relationship with the first two, as they belong to different coarse-grained superclasses (blackbirds vs. hummingbirds). In the BreakHis dataset shown in Figure 2(b), both adenosis and fibroadenoma are benign tumors, whereas ductal carcinoma is a malignant tumor. It is evident that subclasses under the same superclass are often visually very similar, making them difficult to distinguish. This high visual similarity among in-group categories is a primary source of classification errors, while distinguishing between out-of-group categories, though generally easier, still requires a model to learn robust parent-class features.

Images selected from (a) the CUB-200-2011 dataset and (b) the BreakHis dataset, respectively.
This study aims to leverage hierarchical labels to learn more discriminative feature embeddings to reduce prediction errors. To this end, we propose two novel loss functions that target out-of-group and in-group prediction errors, respectively, by explicitly modeling the hierarchical relationships in the feature space.
First, to address out-of-group errors, we propose a hierarchically discriminative loss. This loss promotes the inheritance of parent superclass attributes in fine-grained categories by linearly combining their features with those of their coarse-grained ancestors. This feature fusion helps constrain fine-grained predictions within the correct group and effectively distinguishes them from categories with an out-of-group relationship, thereby reducing out-of-group errors.
Second, for in-group errors, we propose an in-group regularization loss. Since in-group categories have only subtle differences in appearance, this loss treats other in-group categories as distractors. By linearly combining the target category’s features with randomly selected in-group category features, it increases the difficulty of extracting discriminative features. This regularization strategy helps the network discover more unique features and reduces in-group misclassifications.
By effectively reducing misclassifications and enhancing the identification of subtle differences, our proposed loss functions are particularly valuable for improving the reliability of applications such as medical image analysis.
The main contributions of this paper can be summarized as follows: We propose a hierarchically discriminative loss, We propose an in-group regularization loss, Extensive experiments on a medical dataset and several FGVC benchmark datasets demonstrate that the proposed loss functions can effectively improve the performance of existing multigranularity methods, especially in scenarios with limited fine-grained annotations.
The remainder of this paper is organized as follows. Section 2 reviews related work in FGVC and hierarchical classification. Section 3 details our proposed methodology, including the architecture and the formulation of the two novel loss functions. Section 4 presents the experimental setup, datasets, evaluation metrics, and a comprehensive analysis of the results, including ablation studies and comparisons with state-of-the-art (SOTA) methods. Finally, Section 5 discusses the limitations and future directions, and Section 6 concludes the paper.
Fine-Grained Visual Classification
FGVC is a specialized form of image classification that distinguishes between closely related categories by identifying subtle interclass differences. Traditional fine-grained problems, such as distinguishing between the species of birds or flowers, have attracted considerable research attention. Early works (Wei et al., 2018; Zhang et al., 2014) often relied on a localization-classification pipeline, attempting to address these problems using extra annotations, such as object bounding boxes or part-level labels. For example, Part Region-based Convolutional Neural Network (Zhang et al., 2014) learned detectors and part models, imposing geometric constraints between parts and between parts and the object. Subsequently, a fine-grained category was predicted from a pose-normalized representation.
However, acquiring supervisory information for parts or bounding boxes is time-consuming and expensive. To overcome this issue, subsequent methods have focused on weakly supervised approaches that can localize discriminative parts using only image-level labels (Chang et al., 2020; Yang et al., 2018; Zheng et al., 2017). These approaches often leverage attention mechanisms to guide feature extraction, focusing on subtle yet informative parts of the image. For instance, Zheng et al. (2017) proposed the Multiattention Convolutional Neural Network, which can simultaneously learn discriminative parts and fine-grained feature representations across all feature channels. Another popular line of work involves orderless feature encoding, such as Bilinear Convolutional Neural Networks (CNNs) (Liu et al., 2020), which capture second-order statistics of feature interactions to create highly discriminative representations.
Despite their success in localizing key regions, a common limitation of these traditional FGVC methods is that they treat all categories as a flat list. They typically do not explicitly model the semantic relationships that exist between categories, such as the hierarchical structure. Chang et al. (2020) introduced Mutual-Channel Loss (MC-Loss), which consists of a discriminative loss and a diversity loss. The discriminative loss ensures that each feature channel is discriminative for a specific category, while the diversity loss encourages feature channels to be mutually exclusive in the spatial dimension. However, by ignoring the label hierarchy, MC-Loss and similar methods are limited in their ability to transfer knowledge from coarse to fine levels, a gap that our proposed method aims to fill.
Hierarchical FGVC
Recent research has focused on applying multigranularity labels to FGVC (Chang et al., 2021; Chen et al., 2018, 2022). Chen et al. (2018) proposed the hierarchical semantic embedding framework, which predicts category score vectors in a coarse-to-fine hierarchical order. The predicted score vectors at each coarse-grained level are used as prior knowledge to learn more fine-grained feature representations. Chang et al. (2021) divided the classification head into hierarchy-specific heads and fused fine-grained features into coarse-grained features for coarse-level classification.
To further explore the semantic relationships within the label hierarchy, Chen et al. (2022) proposed a combined loss function that integrates a tree-like hierarchical probability classification loss, encoding parent–child relationships, with a multiclass entropy loss for the leaf categories. Liu et al. (2022) designed a cross-hierarchy orthogonal fusion module to simulate the human attention process, which shifts from coarse to fine details.
Transformer-Based FGVC
In recent years, the Transformer architecture, which has achieved tremendous success in natural language processing, has been adapted for computer vision tasks. The introduction of the Vision Transformer (ViT) (Han et al., 2022) marked a significant shift, demonstrating that a pure Transformer-based model can achieve SOTA performance on image classification benchmarks. Unlike traditional CNNs that process images through convolutional filters, ViT treats an image as a sequence of flattened patches, using self-attention mechanisms to capture global dependencies between them.
This new paradigm has been quickly adopted and extended for FGVC, leading to a new class of powerful models. For instance, TransFG (He et al., 2022) progressively selects discriminative image patches at different layers using an attention-guided mechanism, effectively filtering out background noise. RAMS-Trans (Hu et al., 2021) introduces a recurrent attention multiscale Transformer to iteratively locate and magnify subtle regions. Feature Fusion Vision Transformer (FFVT) (Wang et al., 2021) focuses on fusing features from different Transformer blocks to obtain a more comprehensive representation. Dual Cross-Attention Learning (DCAL) (Zhu et al., 2022) proposes a DCAL mechanism to enhance feature discrimination by modeling interpart and interimage relationships. These Transformer-based approaches have shown great promise, often outperforming their CNN-based counterparts by leveraging the ability of self-attention to model long-range dependencies and focus on subtle, discriminative regions without explicit part annotations.
Pathological Image Classification
Early methods for pathological image classification (Doyle et al., 2008) primarily relied on hand-crafted features, such as morphological, texture, and nuclear features. With the excellent performance of deep neural networks in computer vision tasks, recent studies (Han et al., 2017; Hou, 2020; Li et al., 2023) have increasingly adopted deep learning for pathological image classification, achieving remarkable results. Furthermore, some models (Tian et al., 2023) have borrowed ideas from fine-grained classification on natural image datasets to tackle pathological image classification tasks. Beyond pathology, deep learning architectures like ResNet have also demonstrated robust performance in broader health classification tasks, such as fetal health monitoring via sensor fusion (Selvan et al., 2025), highlighting the versatility of these backbones as benchmarks for medical applications.
Methods
Overview
Our network architecture, illustrated in Figure 3, is designed to explicitly leverage label hierarchies for improved fine-grained classification. It integrates our two proposed loss functions, the hierarchically discriminative loss (
Given an input image, a foundational feature map
Hierarchically Discriminative Loss
As shown in Figure 3, each image is annotated with a three-level label chain,
The backbone feature map
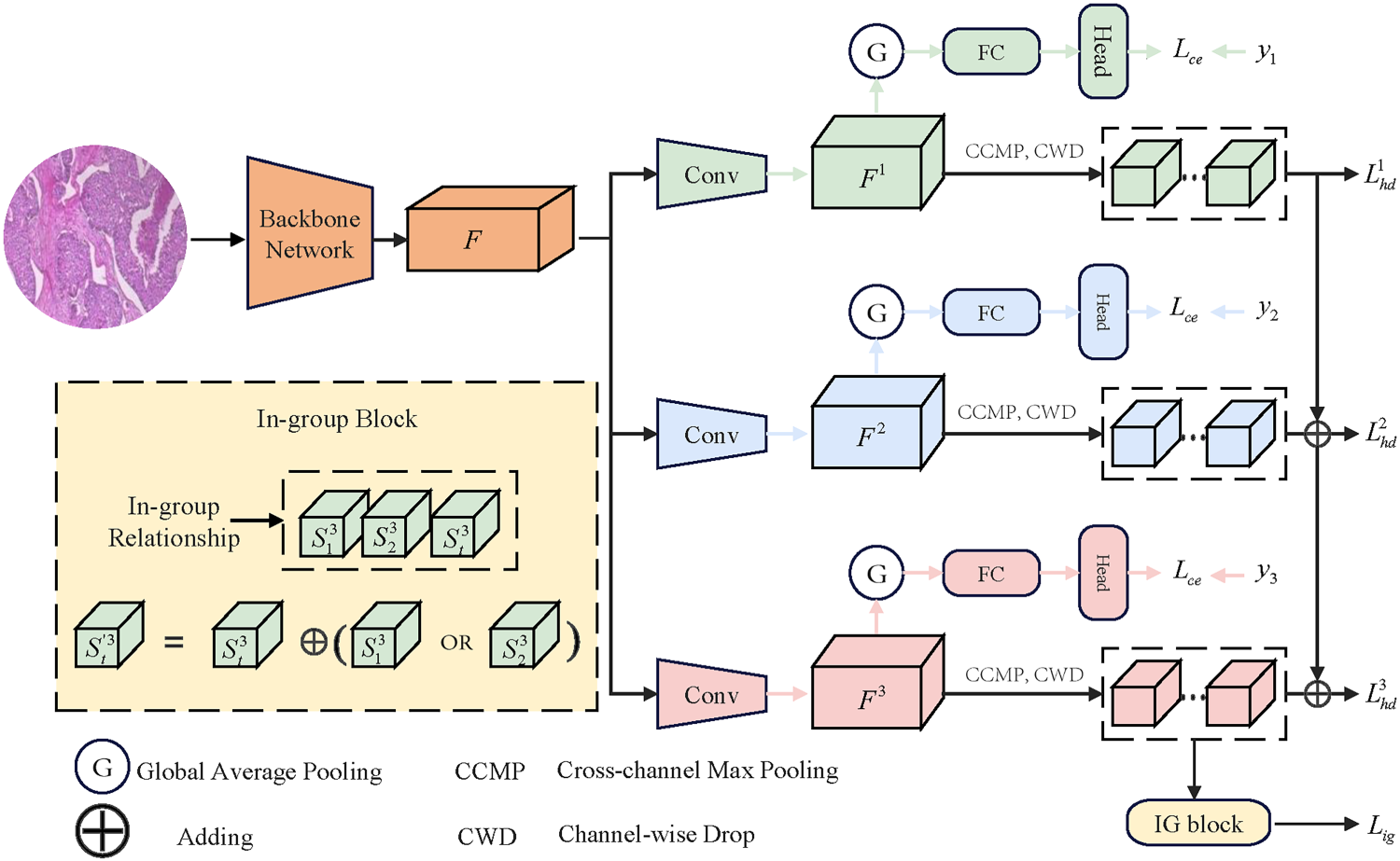
The framework of the multigranularity fine-grained classification network using
To leverage the semantic hierarchy, we propose a hierarchically discriminative loss that encourages subclass features to inherit the properties of their parent classes. This helps to distinguish them from out-of-group categories. We first compute a hierarchically fused feature, denoted as

CWD is designed to ensure that the network captures discriminative information from all
Specifically, to compute the correlation matrix



CCMP computes the maximum response across the
The summation in equation (1) linearly combines the features from the current fine-grained level with those from all its ancestral coarse-grained levels. This ensures that fine-grained categories not only learn their unique attributes but also inherit the defining properties of their superclasses. This hierarchical fusion strengthens the model’s ability to learn discriminative features that respect the label hierarchy.
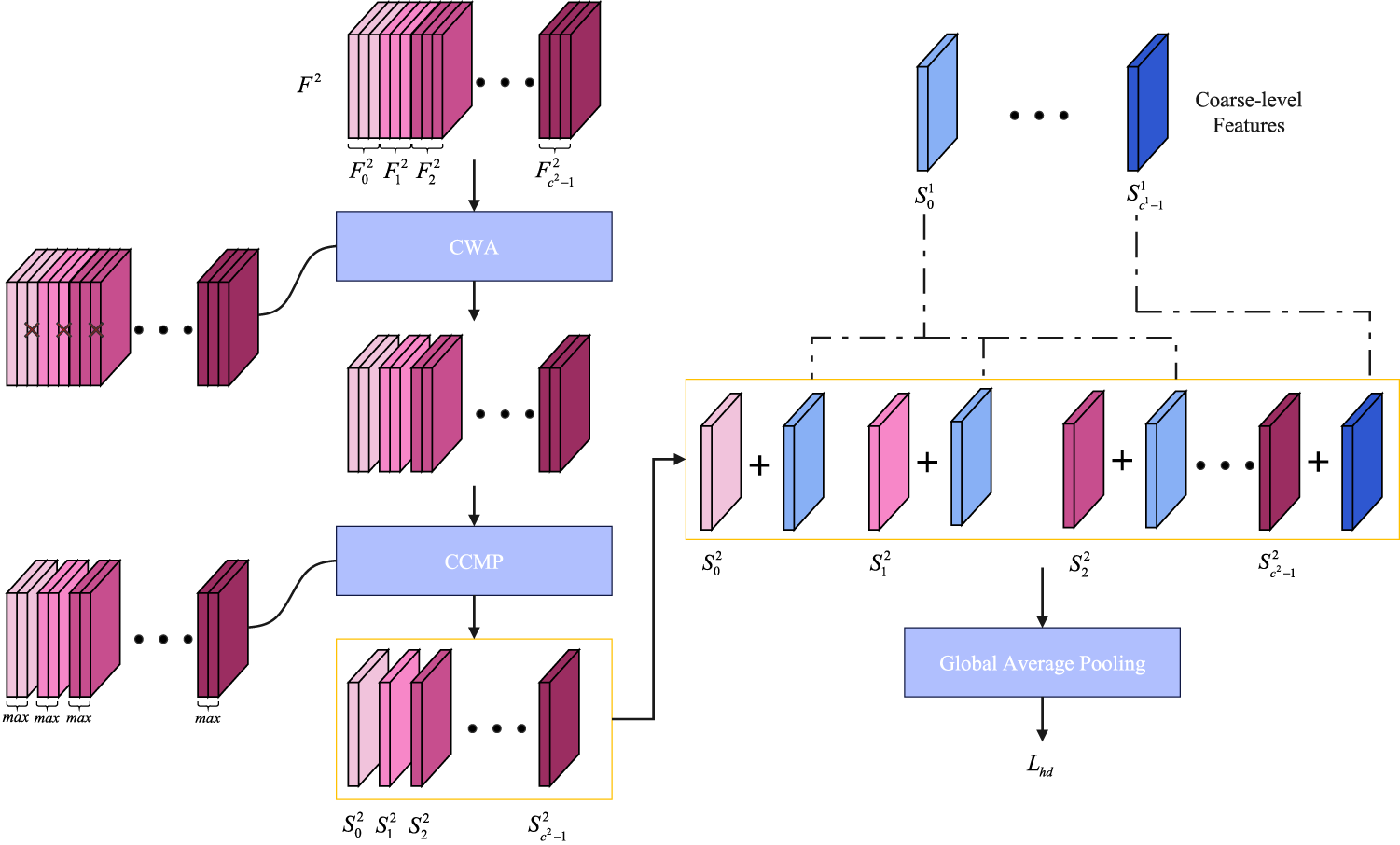
The proposed hierarchically discriminative loss
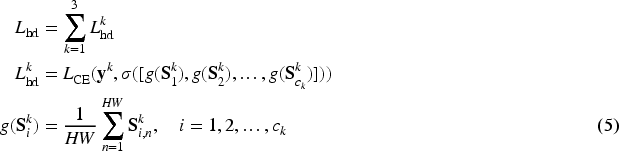
Figure 4 illustrates this process for a two-level hierarchy. The fine-grained features
Overview of the hierarchically discriminative loss.
In FGVC, visual differences between categories are often subtle, particularly for categories sharing an in-group relationship. This high intragroup similarity, combined with the often limited size of fine-grained datasets (e.g., CUB-200-2011; Wah et al., 2011), has only 5,994 training images for 200 classes, whereas ImageNet (Deng et al., 2009) has over a million images for 1,000 classes), increases the risk of overfitting. The network may learn to rely on sample-specific artifacts rather than generalizable, discriminative features to distinguish between visually similar categories, leading to in-group errors. Traditional regularization techniques like weight decay or standard dropout may not be sufficient to address this specific challenge, as they do not explicitly account for the semantic similarity between in-group classes.
To address this, we propose an in-group regularization loss,

It is important to note that unlike standard data augmentation techniques such as MixUp (Zhang et al., 2018), which interpolate both input images and their corresponding labels (using soft labels), our approach mixes features while retaining the original hard label of the target class. We deliberately chose this design over label smoothing or label mixing for two key reasons. First, our goal with
The in-group regularization loss
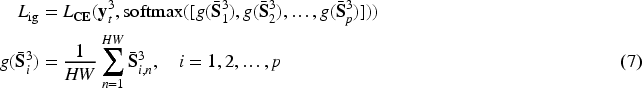
By introducing controlled interference from confusing classes,

Attention map visualizations for HRN, HRN +
For multigranularity classification, we use a standard cross-entropy loss at each of the three hierarchical levels, summed as

Datasets
We evaluated our method on five challenging benchmark datasets, including four standard FGVC datasets and one medical imaging dataset. For datasets without a predefined label hierarchy, we followed the procedure from Chang et al. (2021) and constructed hierarchies by tracing parent nodes on Wikipedia. For all datasets, we used the official training and testing splits.
Implementation Details
Image Preprocessing and Augmentation. For a fair comparison, we adopted a standard preprocessing pipeline. All images were first resized to
Network Architecture and Training. We used a ResNet-50 model (He et al., 2016), pretrained on the ImageNet dataset, as our feature extraction backbone. We utilized the backbone without any structural modifications, keeping the original layer configurations intact. The weights of the backbone were fine-tuned during training. The three hierarchy-specific convolutional blocks following the backbone each consist of a
Optimization and Hyperparameters. For optimization, we used Stochastic Gradient Descent (SGD) with a momentum of 0.9 and a weight decay of 0.0005. The use of momentum helps accelerate SGD in the relevant direction and dampens oscillations. A differential learning rate strategy was employed: the learning rate for the pretrained backbone network was set to a smaller value of 0.0002, while the learning rate for all other newly added components (convolutional blocks, FC layers) was set to 0.002. This strategy is common in transfer learning to ensure that the pretrained weights are not drastically altered early in the training process. We employed a cosine annealing strategy to schedule the learning rate, which starts with a relatively high rate and gradually decreases it, allowing for better convergence. The model was trained for a total of 200 epochs with a batch size of 8. The loss hyperparameters were set to
Inference Phase. During the inference phase, the auxiliary branches and the proposed loss calculations (
Experimental Design and Evaluation Metrics
Following Chen et al. (2022), our experimental setup simulates scenarios with partially available fine-grained labels. We created training sets where 10%, 30%, 50%, 70%, and 100% of the samples have complete, fine-grained labels, while the remaining samples are annotated with only coarse-grained labels. During inference, all models were evaluated on the test set using the complete label hierarchy.
We use four metrics for performance evaluation, among which the first metric consists of top-1 accuracy evaluated at three different semantic granularity levels, namely the finest-grained, intermediate-grained, and coarse-grained levels. To assess performance across the entire label hierarchy, we use the mean Average Precision (


For a representative medical application, we evaluated our method on the BreakHis dataset (Spanhol et al., 2015) for breast cancer classification, using a 100% complete label hierarchy.
The baseline methods were divided into three groups: (1) traditional CNNs, such as ResNet-50 (He et al., 2016) and Inception V3 (Szegedy et al., 2016); (2) fine-grained methods designed for natural images, such as NTS-Net (Yang et al., 2018) and WS-DAN; and (3) fine-grained methods specifically developed for medical images, such as DLD-Net (Tian et al., 2023), EFML (Li et al., 2023), and MagNet (Iqbal et al., 2024). We also include comparisons with the recent SOTA methods SFME (Yu et al., 2025) and MCG (Yang et al., 2024).
As shown in Table 1, our method achieves the highest accuracy across all image magnifications. We attribute this consistent improvement to our two proposed loss functions, which leverage the label hierarchy to guide the model toward learning more discriminative features while mitigating overfitting to sample-specific artifacts. The task of classifying breast cancer subtypes is a natural fit for our approach. For instance, distinguishing between benign subtypes like adenosis and fibroadenoma represents a classic in-group challenge due to their high visual similarity. Our in-group regularization loss (
Results on the BreakHis Dataset.
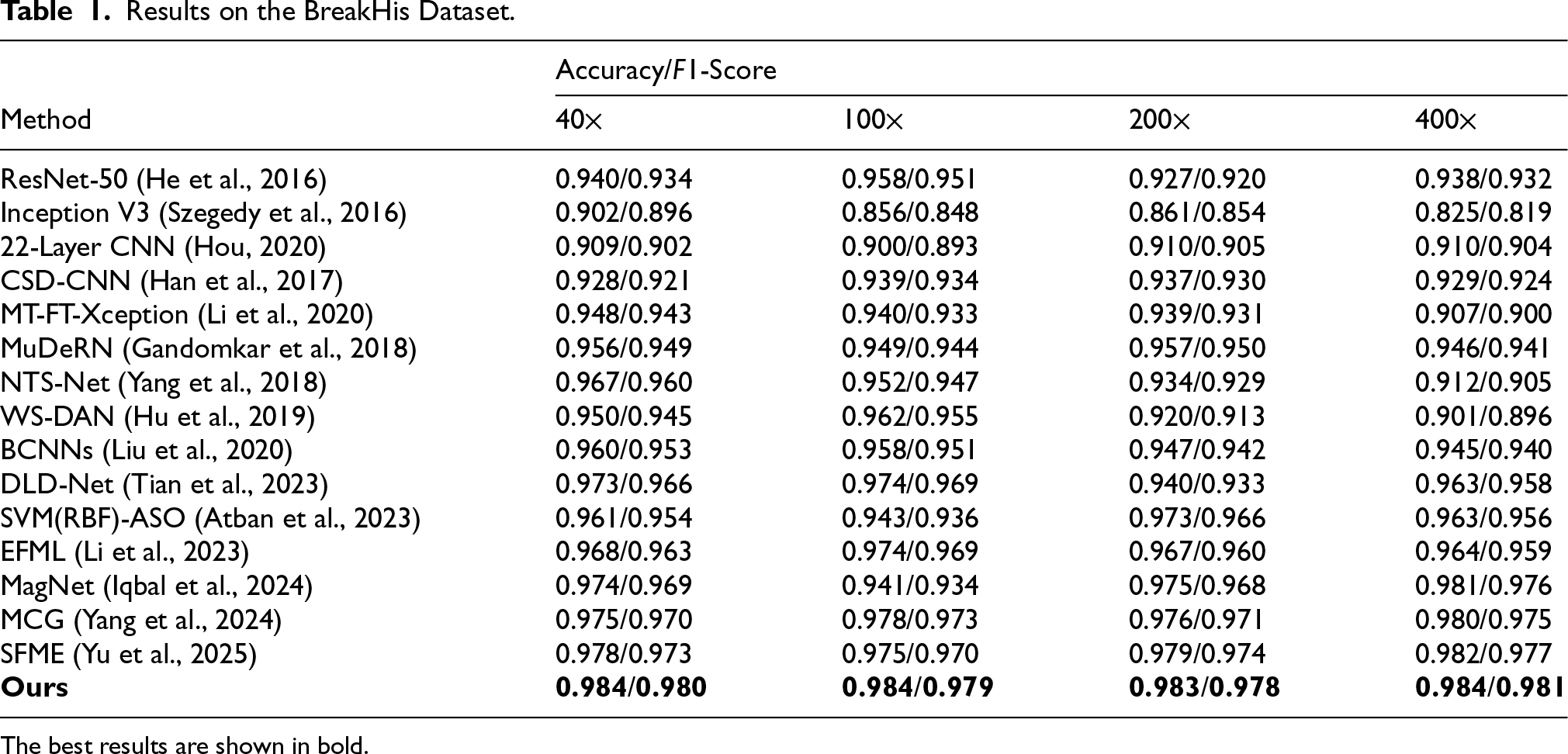
Results on the BreakHis Dataset.
The best results are shown in bold.
We conducted a comprehensive evaluation on four standard FGVC benchmarks—CUB-200-2011, Butterfly-200, FGVC-Aircraft, and Stanford Cars—following the hierarchical setup from Chen et al. (2022). This involved training all methods with varying ratios of fine-grained labels.
For comparison, we selected SOTA techniques in both hierarchical multilabel classification (HMC-LMLP, Cerri et al., 2016; HMCN, Wehrmann et al., 2018; C-HMCNN, Giunchiglia & Lukasiewicz, 2020), hierarchical fine-grained classification (Chang et al., 2021; HRN, Chen et al., 2022), and recent general FGVC methods (MCG, Yang et al., 2024; SFME, Yu et al., 2025).
As shown in Tables 2 through 6, our method consistently outperforms all baselines in both top-1 accuracy at each hierarchical level and overall performance as measured by both
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
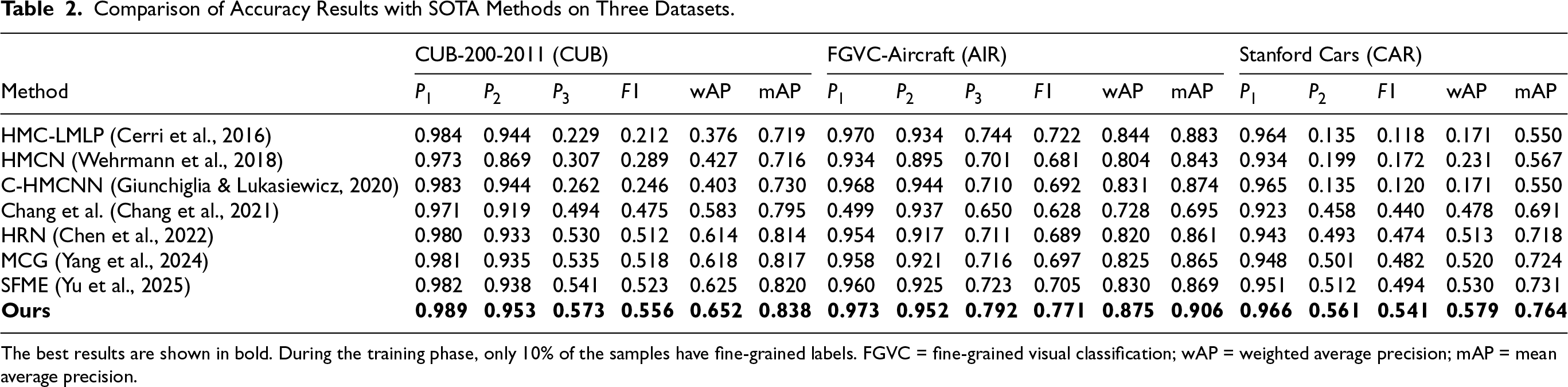
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
The best results are shown in bold. During the training phase, only 10% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
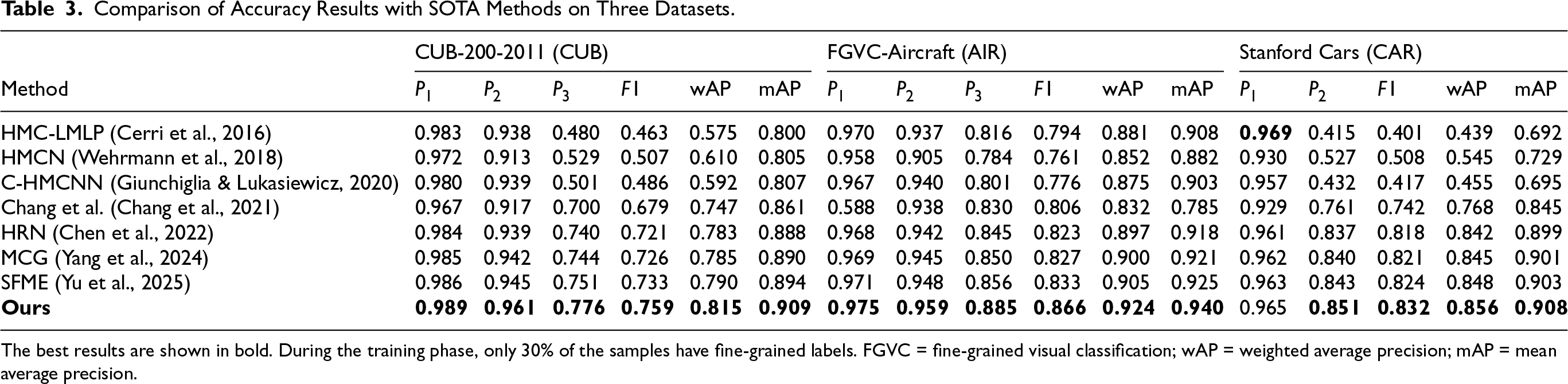
The best results are shown in bold. During the training phase, only 30% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
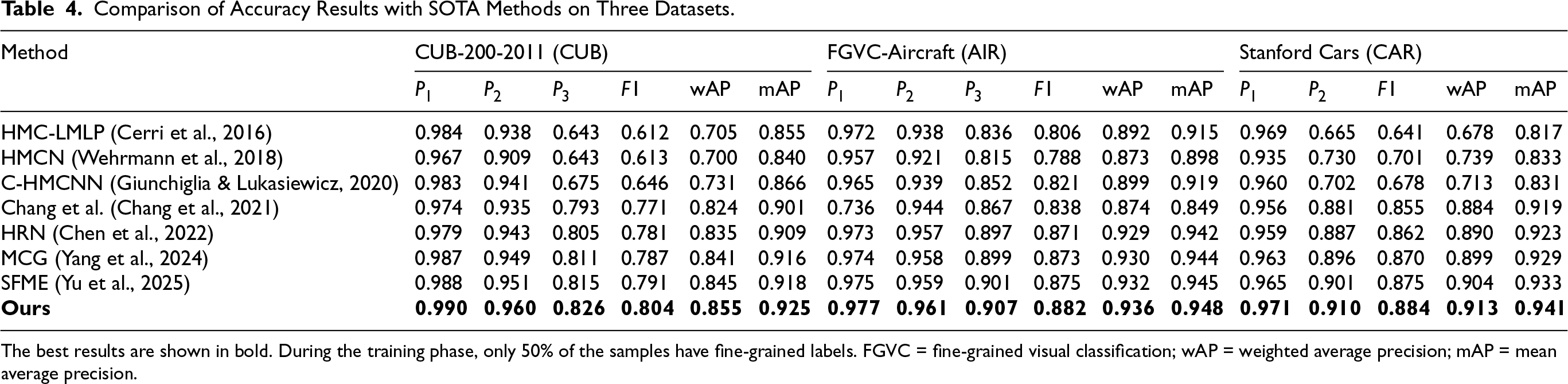
The best results are shown in bold. During the training phase, only 50% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
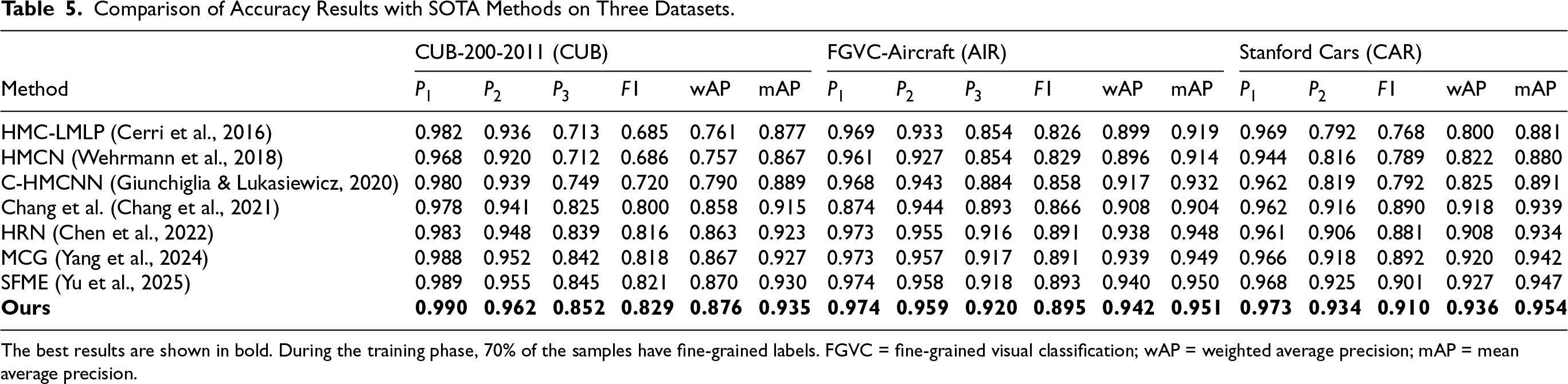
The best results are shown in bold. During the training phase, 70% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
Comparison of Accuracy Results with SOTA Methods on Three Datasets.
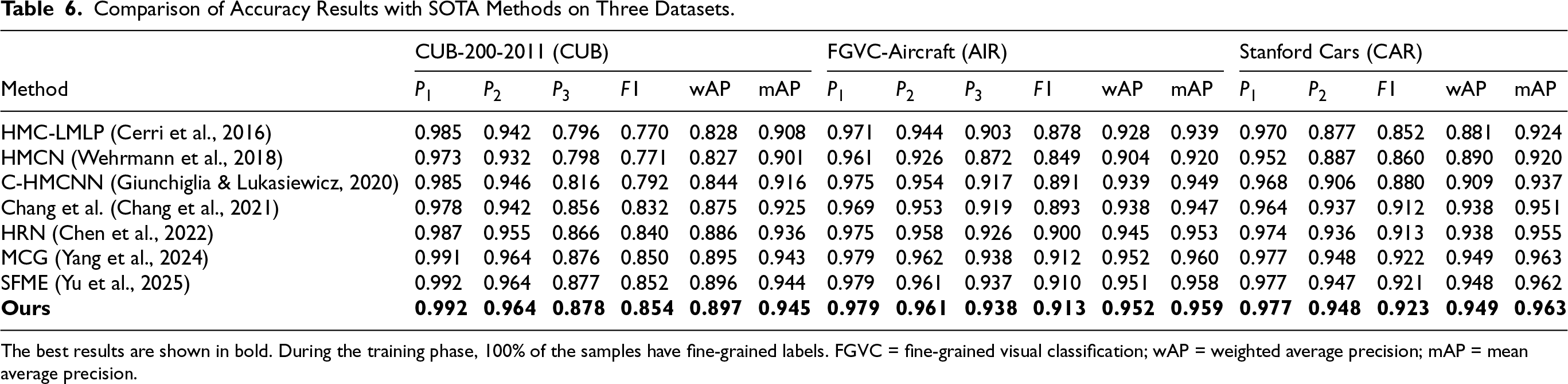
The best results are shown in bold. During the training phase, 100% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
Accuracy Results on Three Datasets Compared with SOTA Methods.
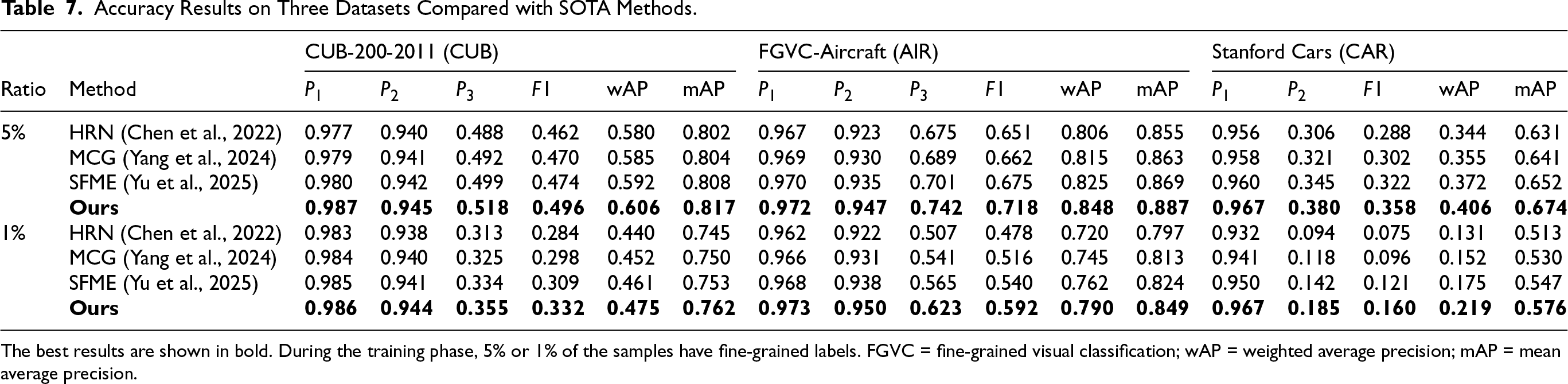
The best results are shown in bold. During the training phase, 5% or 1% of the samples have fine-grained labels. FGVC = fine-grained visual classification; wAP = weighted average precision; mAP = mean average precision.
As the proportion of fine-grained labels increases (Tables 4 to 6), all methods show improved performance, yet our approach maintains a consistent advantage. For example, even when all training samples have complete fine-grained labels (Table 6), we still achieve a clear, albeit smaller, margin of improvement in the
To further stress-test our method, we conducted experiments with extremely few fine-grained labels (5% and 1%), with the results shown in Table 7. In these challenging settings, the advantage of our approach becomes even clearer. With only 1% of fine-grained labels, our method improves the
Finally, to demonstrate scalability to deeper hierarchies, we experimented on the four-level Butterfly-200 dataset (Table 8). Our method again significantly outperforms the recent baselines across all seven annotation ratios. The improvements are most dramatic in the low-data regime, with
Accuracy Results on the Butterfly-200 Dataset Compared with SOTA Methods.
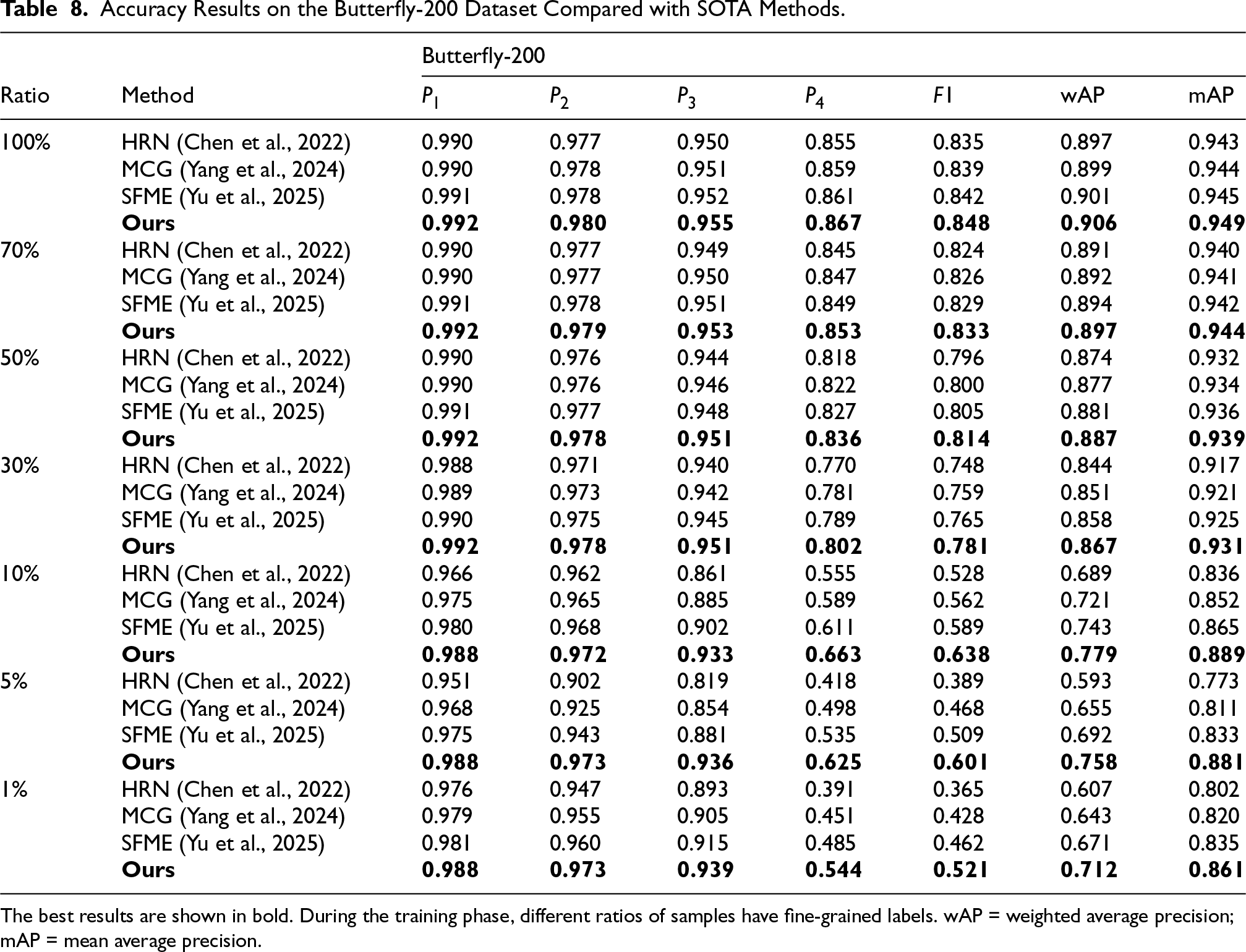
The best results are shown in bold. During the training phase, different ratios of samples have fine-grained labels. wAP = weighted average precision; mAP = mean average precision.
Contribution of
and
To isolate the contribution of each proposed loss function, we conducted an ablation study using the strong HRN (Chen et al., 2022) model as our baseline. We sequentially added
The Effect of the Two Proposed Loss Functions on Three Datasets.
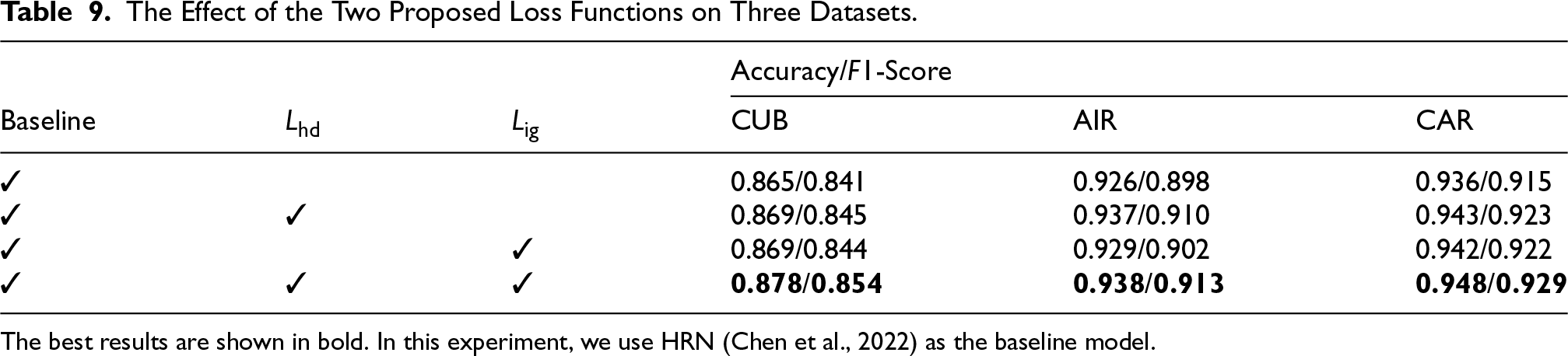
The Effect of the Two Proposed Loss Functions on Three Datasets.
The best results are shown in bold. In this experiment, we use HRN (Chen et al., 2022) as the baseline model.
To further validate that each loss function addresses its intended problem, we performed a targeted error analysis. We define an “out-of-group error” as a misclassification where the predicted category and the ground-truth category belong to different superclasses, and an “in-group error” as one where they share the same superclass. As hypothesized,
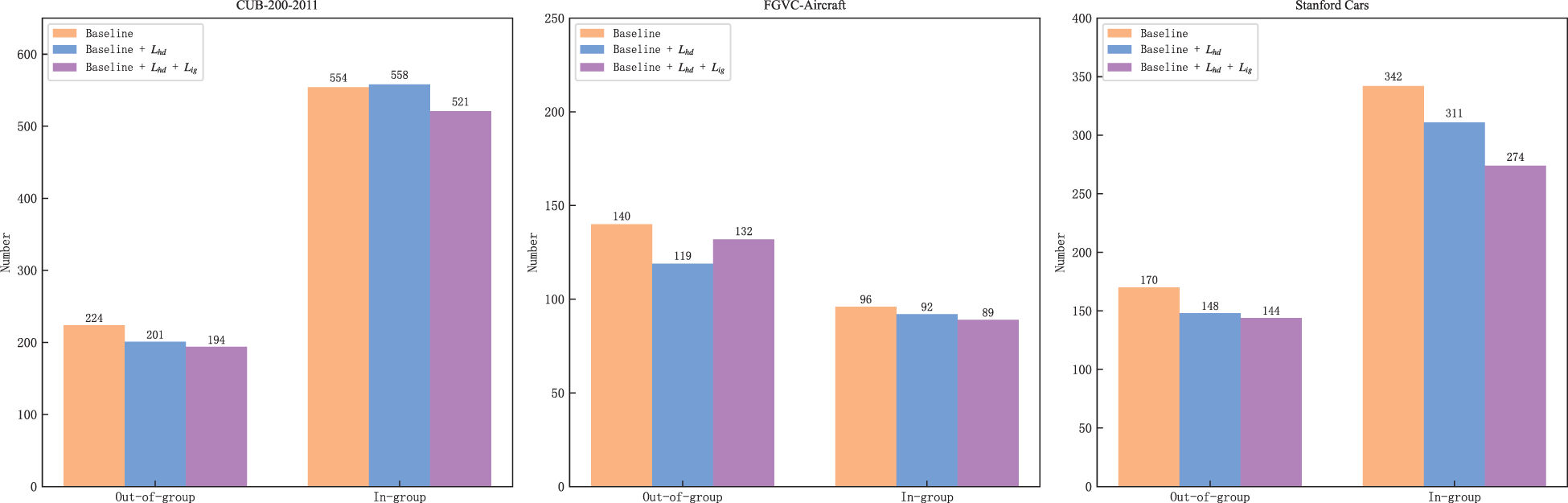
The number of out-of-group and in-group errors for the baseline model on three datasets, with and without our proposed loss functions.
We investigated several strategies for selecting the distractor feature in
Comparison of Different Regularization Methods.
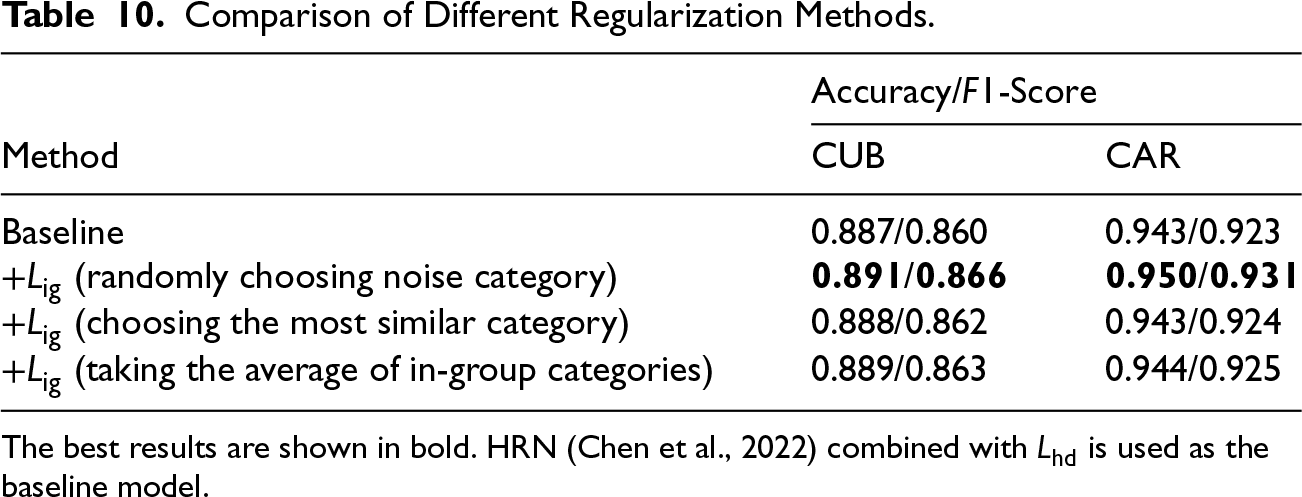
Comparison of Different Regularization Methods.
The best results are shown in bold. HRN (Chen et al., 2022) combined with
We analyzed the model’s sensitivity to its key hyperparameters: the noise weight
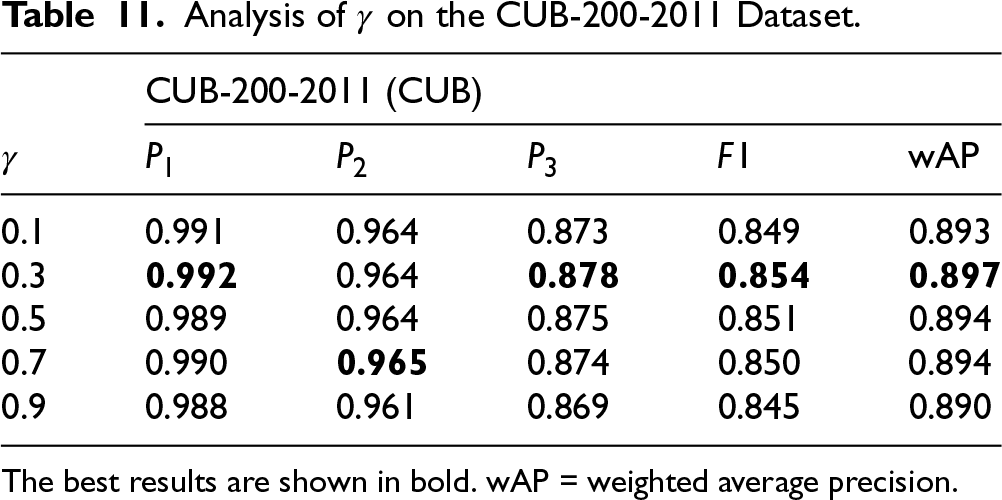
Analysis of
We also acknowledge the sensitivity of the hyperparameter
Analysis of
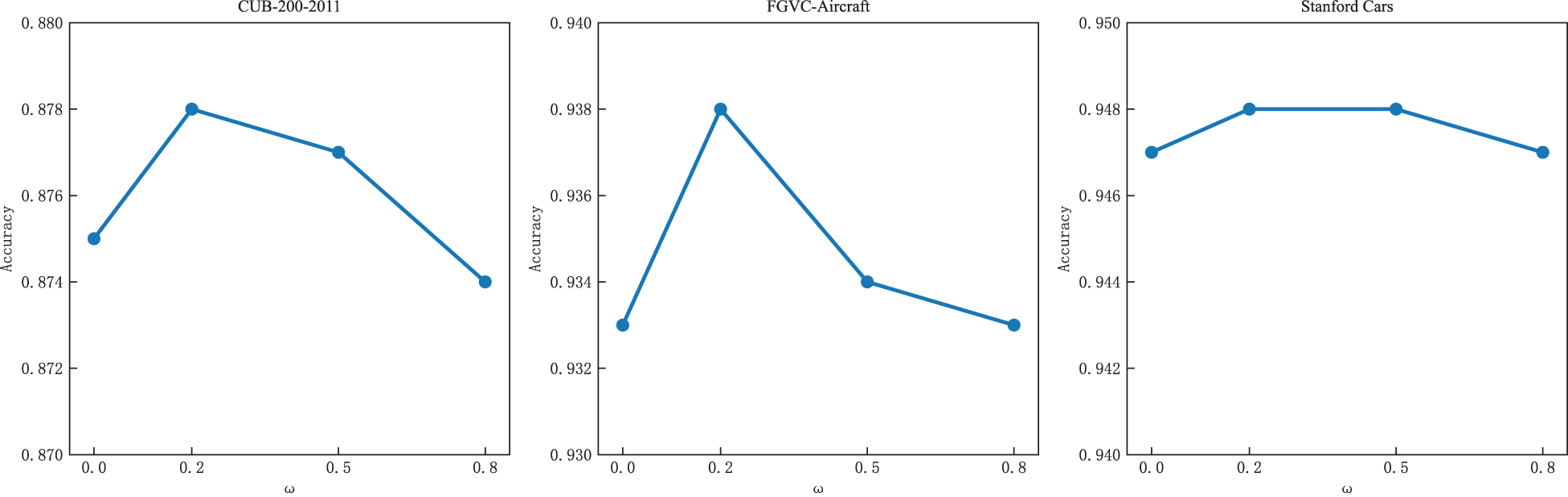
Sensitivity test for
Analysis of
The best results are shown in bold. wAP = weighted average precision.
Analysis of Loss Weights: We also analyzed the weights for the three loss components. The results on the CUB dataset are shown in Table 12. The baseline model corresponds to
Analysis of
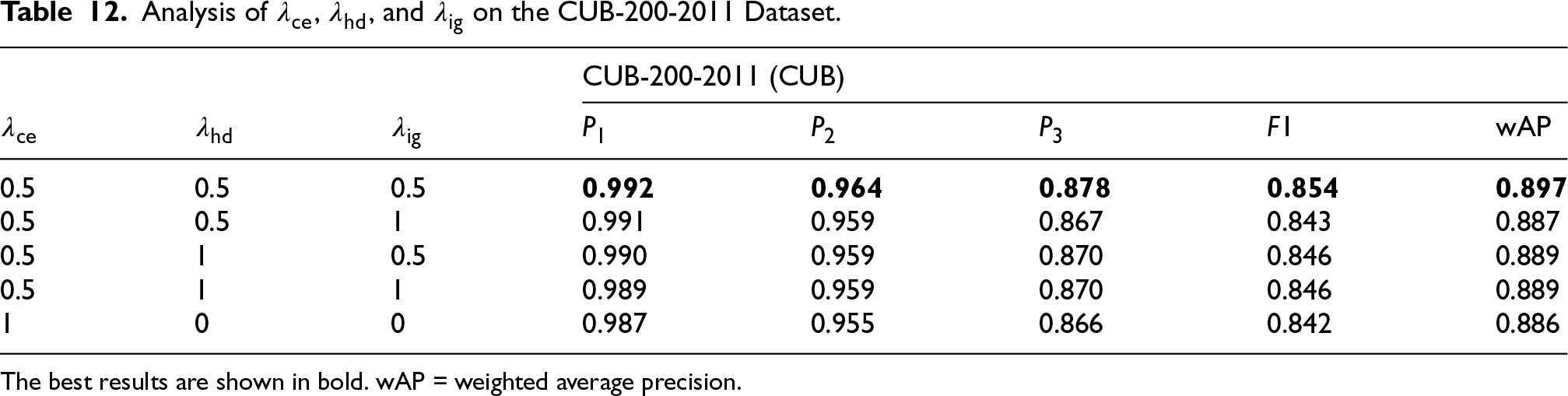
The best results are shown in bold. wAP = weighted average precision.
To evaluate the computational cost of our method, we analyzed the increase in the number of parameters and the training time per epoch compared to the HRN baseline. Our proposed loss functions,
The primary computational overhead stems from the calculation of the loss terms during the forward and backward passes. For
Regarding inference efficiency, as detailed in Section 4.2, all auxiliary branches and loss modules are removed during the testing phase. Thus, the inference latency and FLOPs are identical to the baseline backbone, incurring no additional computational cost for deployment.
Qualitative Results
To gain a more intuitive understanding of how our proposed loss functions affect the model’s decision-making process, we supplement the quantitative results with a qualitative analysis of the attention maps. As shown in Figure 5, we can observe distinct changes in the model’s focus as each component is added. The baseline HRN model, while generally focusing on the object, often produces diffuse attention maps that cover broad, less discriminative regions. This suggests that without explicit hierarchical guidance, the model may struggle to pinpoint the most informative parts for fine-grained distinction.
Upon introducing the hierarchically discriminative loss (
Finally, with the addition of the in-group regularization loss (
Comparison with Traditional FGVC Methods
To demonstrate the versatility of our proposed loss functions, we evaluated their effectiveness in a traditional (nonhierarchical) FGVC setting. For this, we treated the label hierarchy as having a single level (the finest granularity) and integrated our losses into two strong backbone architectures: ResNet-50 (He et al., 2016), representing traditional CNNs, and the more recent CSWin Transformer (Dong et al., 2022), representing hierarchical Vision Transformers. We then compared their performance against a range of SOTA methods on three standard benchmarks.
It is worth noting that while ViT-B (Han et al., 2022) is a popular Transformer baseline, we chose CSWin-L for our Transformer experiments because its hierarchical design is naturally aligned with our method’s objective of leveraging multiscale features. Standard ViT architectures process images as a flat sequence of patches with a constant resolution, lacking the inherent hierarchical feature maps that our
As shown in Table 13, simply adding our loss functions significantly boosts the performance of both backbones, achieving results that are competitive with or superior to recent, more complex models. For instance, when applied to ResNet-50, our method achieves SOTA accuracy on the AIR and CAR datasets, outperforming even the latest Transformer-based methods like MCG (Yang et al., 2024). This is particularly notable because our approach achieves these results without requiring complex network modifications or extra annotations (such as the human gaze data used by CHRF; Liu et al., 2022), highlighting the power of leveraging the inherent (even if simple) label hierarchy. The performance gains are also evident on the stronger CSWin-L backbone, where our method improves the baseline on all three datasets, demonstrating that our approach is not limited to CNNs and can effectively enhance Transformer-based models as well. This underscores the model-agnostic nature and broad applicability of our proposed hierarchical losses.
Performance Comparison on Three Fine-Grained Visual Classification Benchmarks.
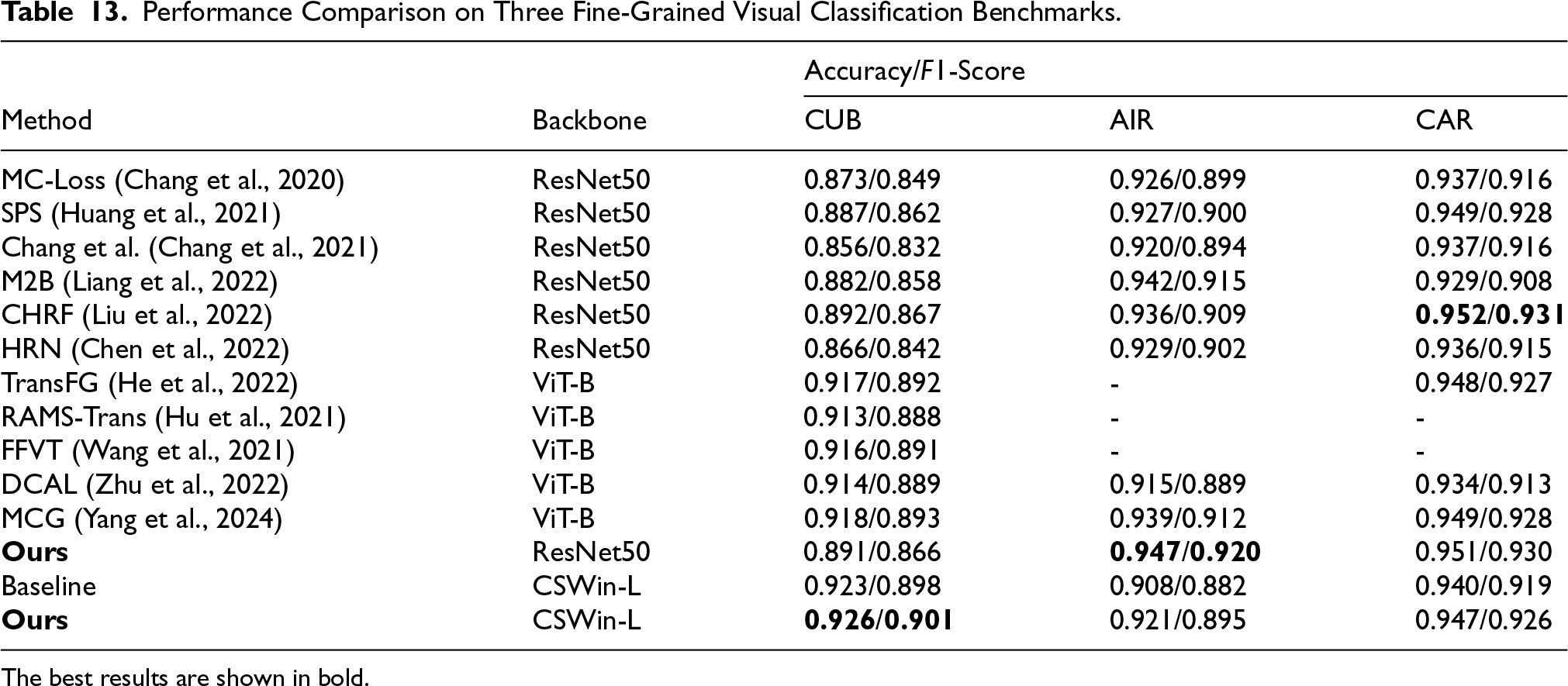
Performance Comparison on Three Fine-Grained Visual Classification Benchmarks.
The best results are shown in bold.
To visually interpret the effects of our loss functions, we used Grad-CAM (Selvaraju et al., 2017) to generate attention map visualizations, shown in Figure 5. The baseline HRN model often focuses on broad, common features. The addition of our hierarchically discriminative loss (
Discussion
While our proposed method has demonstrated strong performance, it is important to acknowledge its limitations and consider avenues for future research. One potential limitation is the reliance on a predefined, clean label hierarchy. In real-world scenarios, such hierarchies may be noisy, incomplete, or not available at all. The performance of our method could be affected by the quality of the hierarchy, and future work could explore methods to automatically learn or refine hierarchies from data.
Another aspect to consider is the scalability of the approach to datasets with extremely deep or large-scale hierarchies. While our experiments on the four-level Butterfly-200 dataset show promising results, the computational complexity, especially for the in-group regularization, might increase with the number of classes at each level. Investigating more efficient sampling strategies or alternative regularization techniques for large-scale hierarchies would be a valuable direction.
Furthermore, our current framework is built upon a CNN-based architecture. While we have shown its effectiveness, exploring the integration of our loss functions with Transformer-based backbones could be a promising future direction. The global attention mechanism in Transformers may interact with our hierarchical losses in interesting ways, potentially leading to further performance gains.
Finally, the core ideas of hierarchical feature discrimination and in-group regularization could be extended beyond classification. Future work could explore their application in other fine-grained tasks, such as retrieval or zero-shot learning, where leveraging label hierarchies can provide crucial semantic constraints. We believe that explicitly modeling hierarchical relationships is a key direction for advancing fine-grained visual understanding.
Future work will focus on extending this approach to deeper label hierarchies and a wider range of application domains. We will also explore its integration with semisupervised and active learning paradigms, its generalization to Transformer and multimodal architectures, and the development of a stronger theoretical foundation for hierarchical fine-grained learning.
Conclusion
In this paper, we introduced a dual-pronged approach to address the key challenges of out-of-group and in-group errors in FGVC, particularly in scenarios involving label hierarchies. Our primary contribution is the proposal of two novel, complementary loss functions: the hierarchically discriminative loss (
A key advantage of our method is its simplicity and ease of integration. The proposed loss functions can be readily incorporated into existing multilevel classification frameworks for end-to-end training without requiring any complex architectural modifications or additional data annotations, such as bounding boxes or part labels. Our extensive experiments, conducted on five diverse and challenging benchmark datasets, demonstrated that this approach consistently improves classification accuracy across various metrics. The performance gains were particularly significant in challenging low-data regimes, where only a small fraction of training samples had complete fine-grained labels, highlighting the strong regularization effect and data efficiency of our method. The ablation studies and attention map visualizations further validated our design, confirming that the two loss functions work synergistically to guide the model toward a more accurate and robust understanding of fine-grained categories. We believe this work provides a valuable and effective strategy for leveraging label hierarchies in FGVC.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions, which have helped to improve the quality of this manuscript.
Ethical Considerations
This article does not contain any studies with human or animal participants.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The datasets used in this study are publicly available at CUB-200-2011 (CUB), Butterfly-200, FGVC-Aircraft (AIR), StanfordCars (CAR), and ![]() . The specific hierarchical label mappings generated for this work are available from the corresponding author upon reasonable request.
. The specific hierarchical label mappings generated for this work are available from the corresponding author upon reasonable request.