
Abstract
Named Entity Recognition (NER) is a challenging learning task of identifying and classifying entity mentions in texts into predefined categories. In recent years, deep learning (DL) methods empowered by distributed representations, such as word- and character-level embeddings, have been employed in NER systems. However, for information extraction in Police narrative reports, the performance of a DL-based NER approach is limited due to the presence of fine-grained ambiguous entities. For example, given the narrative report “Anna stole Ada’s car”, imagine that we intend to identify the VICTIM and the ROBBER, two sub-labels of PERSON. Traditional NER systems have limited performance in categorizing entity labels arranged in a hierarchical structure. Furthermore, it is unfeasible to obtain information from knowledge bases to give a disambiguated meaning between the entity mentions and the actual labels. This information must be extracted directly from the context dependencies. In this paper, we deal with the Hierarchical Entity-Label Disambiguation problem in Police reports without the use of knowledge bases. To tackle such a problem, we present HELD, an ensemble model that combines two components for NER: a BLSTM-CRF architecture and a NER tool. Experiments conducted on a real Police reports dataset show that HELD significantly outperforms baseline approaches.
Keywords
Introduction
Named Entity Recognition (NER) is a challenging learning task of identifying named-entity mentions in texts and classifying them into predefined categories, such as person, location, and organization. NER is an essential task for a variety of Natural Language Processing (NLP) applications, such as topic detection and speech recognition. Early NER systems often require significant human effort in carefully designing rules or features. This trend has motivated the use of deep learning (DL) in NER over the past few years due to requiring minimum feature engineering. Besides, DL-based NER approaches have been empowered by distributed representations, which consider word- and character-level embeddings as well as the incorporation of additional features like orthographic features and language-specific knowledge resources, such as gazetteers [30]. However, language-specific resources and features are costly to develop, especially for new languages and new domains, making NER a challenge to adapt [38].
Furthermore, traditional NER tasks focus on a specific set of entity labels and one label per named entity. For relation extraction in domain-specific applications, it is more useful to work with an authentic set of fine-grained labels for the domain [33, 58]. Typically, fine-grained NER tasks focus on a larger number of entity labels arranged in a hierarchical structure, where an entity mention can be assigned to multiple labels. In the attempt for finer granularity, complex knowledge bases have been used to leveraged NER models [27]. Existing systems first extract the entity mentions and then link the mentions to one or more referent entities in a knowledge base [5, 11, 43]. Such ability can be performed by Named Entity Disambiguation (NED) methods. For example, given the sentence “Paris is the capital of France”, NER would pass the mentions of Paris and France to the NED stage, which would identify Paris as the capital city of France and not as something else as a building or even a person (e.g., the businesswoman Paris Hilton). Within this context, Paris is a CAPITAL_CITY, a sub-label of CITY, which, in turn, is a sub-label of LOCATION. If a knowledge base has these three matching labels, all of them must be assigned to Paris. The knowledge bases for NED are commonly derived from Wikipedia, YAGO, or a complex combination of several resources, including, among others, WordNet and Wiktionary [5, 11, 43], or by using linked datasets [20].
However, not all domains have well-defined knowledge bases that provide a background repository to fine-grained named entity disambiguation. For instance, in the Police reports domain, it is impractical to have a knowledge base that describes previously some details about all incidents, such as knowing from the persons involved who is the victim, witness, robber, etc. Besides, each case must be analyzed individually. Consider a part of a real Police narrative report: “The above-qualified declarant stated that her sister Augusta Dias was beaten and had her car stolen on the day, place, and time mentioned above. The declarant informs that the author was a person known as Augus. Augusta was seriously injured at the incident location. With nothing else to declare.”1
For reasons of confidentiality and preservation of those involved, the names mentioned in the narrative are fictitious.
In this work, we deal with the Hierarchical Entity-Label Disambiguation problem in Police reports. Our proposed solution, called HELD, enhances a state-of-the-art NER tool by using an ensemble architecture and is a domain-independent approach (i.e., it can be used by various real-world applications or even by NER systems in general domain). We build HELD to be free from knowledge bases, language-specific resources (e.g., gazetteers, word clusters id, and part-of-speech tags), or hand-crafted features (e.g., word spelling and capitalization patterns). HELD is an ensemble model that combines two sequence labeling components for NER: a bidirectional Long-Short Term Memory neural network with a subsequent Conditional Random Field decoding layer (BLSTM-CRF) and an off-the-shelf NER tool from the spaCy library, to learn from the context how to disambiguate fine-grained entity labels.
As stated in [30], there are some strengths of why using DL architectures for the NER task, which explain the considerable number of studies that applied DL-based NER systems and successively advanced the state-of-the-art performance. The same motivations are considered for this work. First, compared to feature-based approaches, deep learning is beneficial in discovering hidden features automatically. DL-based models use non-linear activation functions to learn complex features from raw data. In fact, the Hierarchical Entity-Label Disambiguation problem corresponds to a non-linear transformation between the input and output. Second, DL-based models can learn useful representations and underlying patterns from Police reports, saving significant effort in designing features to perform fine-grained label disambiguation.
Several approaches propose NER models derived from LSTM [28, 21, 24], by combining BLSTM with CNNs [7] or by solving the problem of word disambiguation [46]. None of these works solves the label disambiguation problem given an input text without the use of knowledge bases. Current fine-grained NER systems also leveraged their models and automatically annotate training corpora with over a hundred labels via knowledge base lookup [33, 48, 1, 16, 18]. In [59], the HYENA model performs a top-down hierarchical fine-grained label classification based on an extrinsic study with a NED tool, however, the authors build a set of classifiers that mark entity mentions connected to a knowledge base. Recently, BERT [17] is becoming a new paradigm for NER task as proposed in [31, 32, 34, 4]. While in practice, BERT and other contextualized language-model embeddings [44, 45, 3] have a prohibitively large number of parameters, require a massive amount of training data and powerful computing resources to ensure promising results for a specific language or domain. Due to the limitation of an available huge dataset of annotated Police reports, we will investigate language models to our problem as future work. The contributions of this paper are as follows:
We introduce a formalization of the Hierarchical Entity-Label Disambiguation problem in Police reports. The formalization defines the hierarchical structure present in the fine-grained named entities of Police reports. We propose and developed HELD, an ensemble and domain-independent approach that extends a pre-trained NER tool from the spaCy library and a BLSTM-CRF model to solve the Hierarchical Entity-Label Disambiguation problem in Police reports without the use of knowledge bases. We explore some different approaches for coping with the data imbalance problem present in a real-world manually annotated dataset for the Police domain. An in-depth study to provide the best word-level representation (pre-trained or domain-specific), that most effectively represent the Police report’s vocabulary, for one of the main components in HELD. An extensive experimental evaluation over a real-world dataset, where we assess the validity of HELD in terms of quality of results. Our proposal can surpass F
The remainder of this paper is organized as follows. Section 2 reviews related works. Section 3 provides the problem definition. Section 4 presents the methodological details of HELD. Section 5 presents the experiments and discusses the experimental evaluation. Finally, Section 6 summarizes this work and discusses future directions.
Several works have presented models that use well-formatted documents heavily depend on a phrase’s local linguistic features, such as capitalization, part-of-speech (POS) tags of previous words, external resources, such as gazetteers, or large dictionaries of entities gathered from Freebase, Wikipedia, and YAGO, to perform NER and NED tasks [47, 5, 11, 43, 49, 42, 36]. Other examples include current works that deal with a hundred fine-grained entities that also use knowledge bases to leverage their models, such as automatically annotate training corpora [33, 48, 1, 16, 18]. In recent years, deep learning models have attracted attention to solving NER tasks due to require minimal feature engineering, as stated in [30] that reviews the literature based on varying deep learning models for NER.
Apart from the English language, there are many studies on the classification of named entities in documents written in other languages or cross-lingual setting. For example, [54] investigated a deep learning method to recognize clinical entities in Chinese clinical documents using the minimal feature engineering approach. In [52], the authors incorporated dictionaries into deep neural networks for the Chinese named entity recognition task. In addition to Chinese, there also exist studies that have been conducted for named entity detection in documents in other languages. Examples include Portuguese [19], and Japanese [57]. Each language has its characteristics for understanding the fundamentals of the NER task for that language, which makes NER models very challenging to adapt.
Many studies as [6, 55] use a self-attention mechanism to the neural architecture to solve the NER problem in a cross-lingual setting by transferring knowledge from a source language to a target language with few or no labels. Another interesting work is [56], which examines the effects of transfer learning for deep hierarchical recurrent networks across domains, applications, and languages, showing that significant improvements can often be achieved in several tasks, including NER. There has also been a long history of research involving neural networks for entity recognition in documents, even with fine-grained entities. [21] attempted NER with a single direction LSTM network. The work [28] proposes two neural architectures for sequence labeling: one based on bidirectional LSTMs and a CRF model, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers.
Similarly, [7, 37] combine bidirectional LSTM with CNNs, while [39] re-implemented the NER model described by [37], adjusting it to work with fine-grained labels for the English language. For Japanese, [39] removed the CNN layer, which previously learns character-level embeddings, to use dictionary (gazetteer feature) and category embeddings. [1] use an LSTM to encode the fine-grained entity mentions representations and a bidirectional LSTM as context encoder, and perform a feature and model level transfer learning. [18] combining token embeddings from the ELMo contextualized language model [44], which are fed into a residual LSTM module, to finally pass the detected entities into the Wikidata knowledge base. [10] uses a CNN over a sequence of word embedding with a CRF on the top. [19] is based on the CharWNN deep neural network, which uses word and character embeddings to perform sequential classification. [46] addresses an orthogonal problem called word sense disambiguation problem. Its contribution consists of models from a traditional LSTM-based model, a variant that incorporates an attention mechanism and an encoder-decoder architecture.
Recently, the contextualized language models, such as BERT, GPT [45], ELMo, and Flair Embeddings [3], are becoming a new paradigm of NER. BERT, which uses the Transformer architecture [51], among with its derived models, such as RoBERTa [35] and Albert [29], is one of the most adopted models. Some works have achieved promising performance via leveraging the combination of traditional embeddings (e.g., Google Word2Vec, Stanford GloVe, etc.) and BERT or by fine-tuning BERT with one additional output layer for the NER task as [31, 32, 34, 4]. However, BERT has a prohibitively large number of parameters and require substantial computational resources [2]. Besides, even though the Transformer encoder is more effective than LSTM, it fails the NER task if they are not pre-trained, and when training data is limited [30]. The pre-trained contextualized embeddings are data-hungry and require a massive amount of training data to be fine-tuning for a domain-specific NER task. Due to this limitation, we will jointly investigate our approach with the pre-trained language models in future works.
It is worth mentioning that none of the previously mentioned related works address our problem. The problem addressed by [59] solved by the HYENA model is adjacent to the Hierarchical Entity-Label Disambiguation problem. Different from HELD in practice, HYENA is a representative supervised method that uses a top-down hierarchical classifier. Its features include the words in the named entity mention, in sentence and paragraph, and POS tags. It performs basic co-reference resolution and marks entity mentions connected to the fine-grained labels present in the YAGO knowledge base.
In our previous work [13], we also tackle a quite similar problem, i.e., the label or class disambiguation in Police reports documents. We proposed a Char-BLSTM-CRF model that concatenates char and word embeddings to combine word- and character-level representations to feed them into BLSTM to model context information of each word. On the top of BLSTM, there is a sequential CRF to decode labels for the whole sentence jointly. In this paper, we propose HELD, an ensemble model that combines a variation of Char-BLSTM-CRF to enhance an off-the-shelf NER tool to solve the Hierarchical Entity-Label Disambiguation problem in Police reports. Compared to existing works in the literature, we highlight that our approach does not rely on knowledge bases to disambiguate the entities present in the text. This brings advantages to HELD in several domains where it is unfeasible to create knowledge bases to support NER tasks, such as in the Police domain.
Problem definition
In this section, we introduce the formulation of our Hierarchical Entity-Label Disambiguation problem in Police reports, and some basic concepts and notations used throughout the paper. A Police narrative report is a document that describes all of the raised facts, circumstances, and timeline events surrounding an incident. The process of writing and the protocols applied to the Police reports might vary from one agency to another, however, the general information and function are relatively the same.
A challenge to automate the information extraction from such a document is the correct interpretation of the domain-specific named entities according to their roles in the narrative. In literature, NER is the task to identify entity mentions from text belonging to predefined categories, such as person, location, and organization, which define the well-known generic category of entity labels. In order to intelligently understand different texts and extract a wide range of information, it is useful to precisely determine the labels of entity mentions for domain-specific NER systems. Thus, for our Police reports domain, the entity labels may reflect the victim, robber, witness, etc.
Specifically, the entity recognizer for our Police domain must categorize the entities into fine-grained labels. This kind of NER task is called as fine-grained NER, which allows one entity mention to have multiple labels. Together, these labels constitute a path in a given label hierarchy, depending on the local context (i.e., the sentence context). The formal definitions of named entities and fine-grained entity labels in Police reports are as follows:
.
(Named Entities): The named entities are the real-world objects written in the narrative reports, represented by words or phrases that serve as a name for something or someone.
.
(Fine-Grained Entity Labels): The fine-grained entity labels are the roles or specialization of the named entities present in the narrative reports (e.g., victim, witness, incident location, etc.), organized in a hierarchy (e.g., victim is a sub-label of person and incident location is a sub-label of location).
In particular, when dealing with Police reports, it is crucial to avoid misunderstandings between the fine-grained entities. Most of them are proper nouns or terms often ambiguous. For example, the actual victim can not be recognized as the robber, and vice-versa. The same is also true for entities concerning the locations of the events present in the reports: the location of the incident should not be classified as the victim’s residence location. The lack of a knowledge base to give a disambiguated meaning to entity mentions in the narratives increases the complexity of the problem. Consequently, it requires to perform the disambiguation of these named entities based on the context.
Recognize and disambiguate named entities is still a limitation to a NER-based approach, especially for the categorization of fine-grained entity labels. Thus, the problem that we want to solve here is to classify the named entities present in the Police reports according to their entity labels, arranged in a hierarchical structure. For this task, the classifier needs to solve the label disambiguation problem when assigning the proper role of the existing entities. Therefore, we define our Hierarchical Entity-Label Disambiguation problem:
.
(Hierarchical Entity-Label Disambiguation using Context): We consider a variable-length sequence of input symbols
In practice, to solve the Hierarchical Entity-Label Disambiguation problem, we consider for the experimental procedures that our fine-grained entity labels are arranged in a two-level label hierarchy. The first level corresponds to generic super-labels, whereas, the second level contains fine-grained entity labels for the Police domain. For instance, named entities such as the victim’s name and the robber’s name should be assigned labels of type VICTIM and ROBBER, respectively. Also, both VICTIM and ROBBER entity labels correspond to only one super-label, in this case, PERSON. We will present and discuss further below in the next sections on this hierarchical structure present in the fine-grained labels of our domain.
HELD: A method for hierarchical entity-label disambiguation in police reports
In this section, we present HELD from bottom to top, characterizing the layers of the architecture. HELD is an ensemble approach designed to solve the Hierarchical Entity-Label Disambiguation problem in Police reports. Although the problem definition and our method were developed within the context of narrative reports, HELD is a domain-independent approach that can be applied to texts from different domains. As defined in the previous section, these texts must have ambiguous fine-grained entity labels organized in a hierarchy.
Refer to Fig. 1 for an example illustration that provides an overview of HELD. Overall, given an input sentence
The overall architecture of HELD. An illustrative sentence is provided as input to the two main components of HELD: the NER component and the BLSTM-CRF component. For this example, the named entities we are interested in are: Anna, Ada, and Paris. All entities preserve the same orthographic features but observe that Paris is mentioned twice in different contexts. At first, it indicates Anna’s residence, and, finally, the place where the incident occurred. The NER component recognizes the entities with the two super-labels PER (PERSON) and LOC (LOCATION). From the BLSTM-CRF component, we obtain the Probability Distribution of the Fine-Grained Labels. The output of the two components is used to feed into the Disambiguation Mask, which is the ensemble method that disambiguates the meaning. The final model output contains each sentence token assigned with its label: (i) Anna is the person involved in the incident; (ii) the first occurrence of Paris indicates that it is a residence location; (iii) Ada is the victim; and (iv) the second occurrence of Paris is the incident location.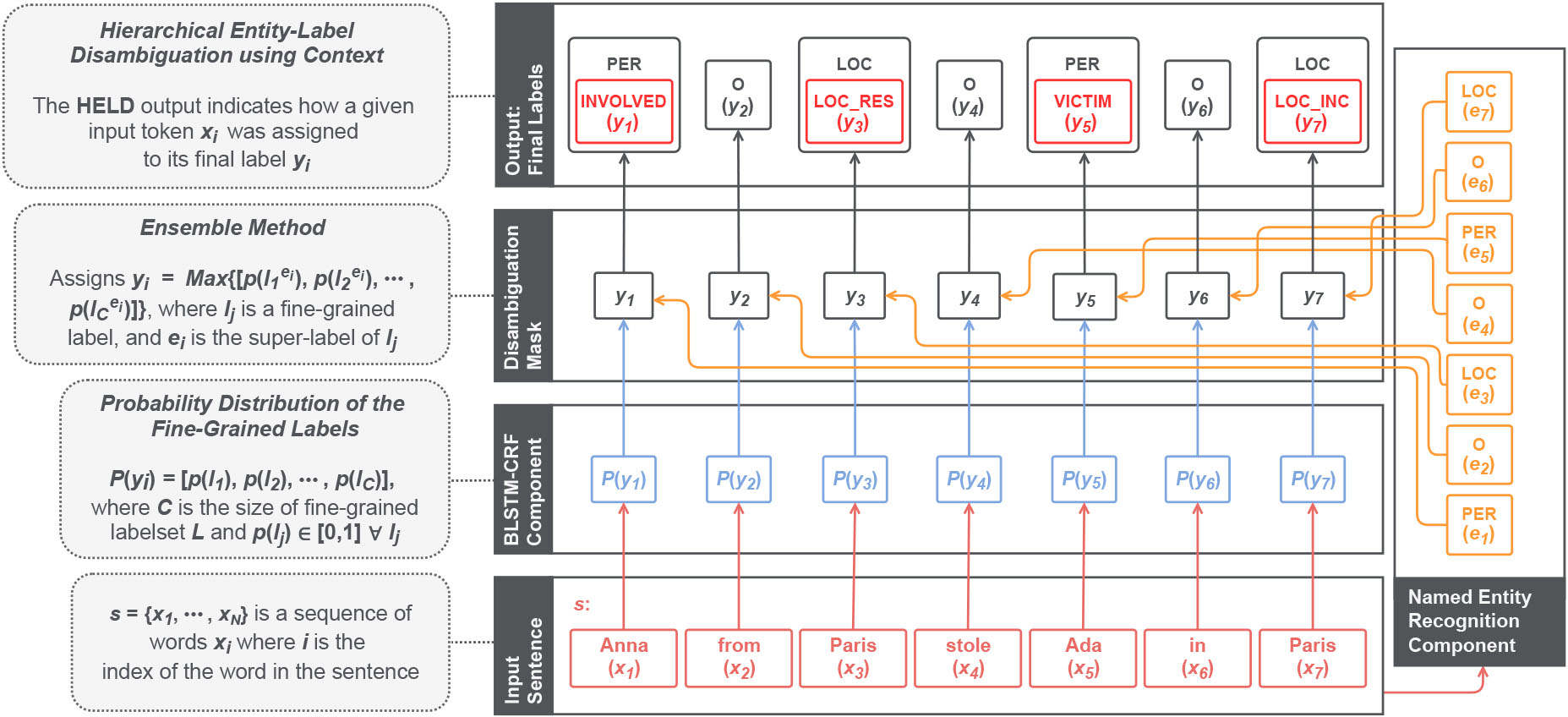
As illustrated in Fig. 1, HELD must intrinsically extract information from the context. One may think HELD could use OSM2
In our proposed ensemble model, the NER component is the one in charge of recognizing the named entities in Police reports into the top-level labels of the hierarchical structure present in our fine-grained entity labels. This component does not disambiguate the fine-grained entities. Instead, it identifies and classifies the entities belonging to the super-labels by performing a traditional sequence labeling NER task. Particularly in our context, we are interested in the recognition of two main types: LOCATION and PERSON. Afterward, the output of this component, jointly with the BLSTM-CRF output, will feed into the Disambiguation Mask.
We use spaCy NER4
The spaCy NLP models, especially NER, follow a simple four-step formula: embed, encode, attend, and predict. First, the model receives the text and transforms the words into unique numerical values. In the embedding stage, features such as the prefix, suffix, shape, and lowercase are used to extract the similarities between the words. To encode the context-independent embeddings, the values pass through a CNN network, producing a context-sensitive sentence matrix. Before the prediction, the matrix has to pass through the CNN Attention layer to be converted into a single vector. Then, a standard Multi-layer Perceptron (MLP) with a Softmax layer is used as a tag decoder layer for class prediction. After the training process, the spaCy model is ready for several NLP tasks.
The BLSTM-CRF component in HELD is the one in charge of learning how to disambiguate the fine-grained entities present in the Police reports. In other words, while the NER component only recognizes the entities to the super-labels in the two-level hierarchy (i.e., PERSON and LOCATION), the BLSTM-CRF must recognize and disambiguate them accordingly to their actual fine-grained labels (i.e., the PERSON and LOCATION sub-labels). As previously mentioned, the input for the Disambiguation Mask is the combined output of these two main components.
In the setting of sequence labeling for NER, our BLSTM-CRF component first feeds word-level representations into a BLSTM layer to encode context information of each word. On top of the BLSTM, a sequential CRF layer takes context into account to decode labels for the whole sentence jointly. In the following sections, we describe in detail the architecture of this deep learning model.
Word-level representation
Using as the input, traditional word embeddings can capture semantic and syntactic properties of words, which do not explicitly present in the input text. We consider two types of non-contextualized word-level representations in this research: (a) domain-specific or (b) pre-trained word embeddings. We call domain-specific word embeddings the word vectors that have their weights randomly initialized in the word embedding layer by using a vocabulary to map the integer indices from the training set data to dense vectors. Iteratively, during training, these word vectors are gradually adjusted via back-propagation, structuring the space into something the model can exploit. Once fully trained, the domain-specific embedding space will show a structure specialized for the problem.
For the pre-trained word embeddings, we consider those available in online repositories, typically trained over large collections of text reflecting a wider domain, such as FastText, GloVe, Wang2Vec, and Word2Vec. By using a domain-specific dataset, we can face an out-of-vocabulary (OOV) problem, which happens when some words from our data do not exist in the pre-trained word embeddings vocabulary. To handle this, we use the Levenshtein Edit Distance metric, since we do not have a vector representation for these words (i.e., domain-specific or misspelled words). Also, we want to ensure that the position of similar words in the high-dimensional space can remain the same or improve during training, in order to achieve a consistent domain-specific representation.
Specifically, the word embedding layer of the BLSTM-CRF component converts each word
BLSTM for context encoder with a CRF decoder
The BLSTM-CRF component must capture the context dependencies, taking into account the local context of each embedded word to predict labels for the tokens in the input sequence. For many sequence labeling tasks, it is beneficial to have access to both past (left) and future (right) contexts. However, LSTM’s hidden state takes information only from the past, knowing nothing about the future. An elegant solution is bidirectional LSTM (BLSTM), which consists of using two regular LSTM layers. Each LSTM layer processes the input sequence in one direction (chronologically and anti-chronologically) and then merging their representations. By treating a sequence in both ways, a BLSTM can catch patterns that may be missed by the chronological-order version alone. To capture such contextual information, we use a stacked BLSTM layer.
For prediction, it is beneficial to consider the correlations between labels in neighborhoods and jointly decode the best chain labels for a given input sequence [37]. For example, consider a category of generic entity labels, such as PERSON, LOCATION, and ORGANIZATION. It is known that a token that identifies an ORGANIZATION cannot follow a PERSON token. Having this in mind, we use a Conditional Random Fields (CRF) statistical model as the tag decoder. The output vectors of the BLSTM layer are fed into a CRF layer to jointly decode the best sequence of labels, focus on sentence-level instead of individual positions. CRFs takes context into account, and it is powerful to capture label transition dependencies when adopting word embeddings, producing a higher accuracy performance in general [24, 30].
Equation (1) formalizes the combination of a BLSTM neural network with a CRF model. Let
The Disambiguation Mask component is in charge of assigning the final fine-grained labels to the input tokens. For this task, the Disambiguation Mask combines the outputs of the NER and BLSTM-CRF components by performing a pairwise decision. Both main components in HELD identify approximately the same-named entities, dealing with them in different ways. Within this context, review Fig. 1 which illustrates HELD. Given an input token
In this section, we discuss the experimental evaluation. The main research questions that guide this study are:
For this research question, we explore the two possible usage versions of the spaCy NER. One version has the available pre-trained entity recognizer model trained on a large corpus, while the other version concerns the update (fine-tuning) of the pre-trained spaCy NER with our data. We aim at evaluating how these versions perform for the Police domain in the super-labels recognition.
This research question investigates the best input word representation for the BLSTM-CRF component. We present the performance of the BLSTM-CRF model on different pre-trained word embeddings: FastText, GloVe, Wang2Vec, and Word2Vec. We also generate domain-specific word embeddings using the training set data, mapped through a domain-specific vocabulary with almost 400,000 tokens.
With this research question, we want to compare the performance of our proposed model against some baselines. Through the experimental results, it will be possible to have a better clue of the importance of each proposed component in the architecture.
Note that these three research questions, previously defined by domain experts, are complementary to each other and follow the architecture of Fig. 1. In the following sections, we discuss the schemes designed to answer them. We first introduce the dataset used in the experiments, report the experiment setups, and finally discuss the results.
To evaluate our proposed method, we use a real dataset with texts from Police reports. In contrast to other domain-specific datasets, to our best knowledge, there is no available annotated dataset for the Police domain.
Data annotation remains time-consuming and expensive. It requires domain experts to perform intensive annotation tasks. A total of nine domain experts were responsible for hand-labeling the data with HNERD. The manually annotated dataset was based on a less fine-grained annotation scheme with five labels:
VICTIM, a named victim; PARENTS, the names of the victim’s parents; INVOLVED, the names of any other person mentioned in the narrative, other than VICTIM or PARENTS; LOC_DEATH, the name of victim’s death location; and, LOC_RES, the name of victim’s residence location.
The two corresponding super-labels in the two-level hierarchy present in the fine-grained labels are: PERSON, which covers the labels VICTIM, PARENTS, and INVOLVED, and recognizes a named person or family; and LOCATION, the names of politically or geographically defined location (i.e., names or addresses of public or private spaces, cities, provinces, countries, bodies of water, mountains), covering the labels LOC_DEATH and LOC_RES. Also, we use the O (OTHER) label to indicate non-entity tokens.
We follow the iterative stratification technique proposed by [50] to provide the official training (60%), development (20%), and test (20%) sets, using the same seed for the split of our multi-label corpus, which has several target labels per text. Since we are dealing with a sequence labeling task, the iterative stratification manages to output a proportional sample of labels in the three sets to prevent measurement errors for the data imbalance issue. After the split, the training set remained with a total of 1,833 texts, while the development and test sets both with 625 instances each. The per-token named entities distribution for each subset is reported in Table 1.
Fine-grained label distributions per token
For the NER component training process, we replace the annotated fine-grained labels in our dataset with only the super-labels. This experimental procedure is explained in Section 5.3.
The CB loss can be applied as a generic loss to a wide range of deep learning models and loss functions. This version considers exactly one label per sample [12], so we had to adapt it to deal with multi-label data. Our adaptation assigns each sentence token to one of the mutually exclusive classes, which corresponds to the Categorical Cross-Entropy (CCE) loss [8]. We replace the loss function
This work focuses on the token-level method evaluation for all the tested models in this experimental procedure. The metrics P, R, and F
spaCy NER (spaCy): We use the pre-trained spaCy NER model [23] available for Portuguese fine-tuned on our training set annotated with the fine-grained labels. The idea here is to compare how a NER solver performs on our Hierarchical Entity-Label Disambiguation problem.
BLSTM-CRF: In [13], we developed a deep learning model called Char-BLSTM-CRF, which achieved high performance on tackle the label or class disambiguation problem in Police reports documents. In the present work, we designed the BLSTM-CRF component of HELD based on the Char-BLSTM-CRF model. Char-BLSTM-CRF incorporates character-based word representations extracted by an LSTM neural network, so we removed the character-level layer since we deal with OOV words differently. Therefore, we only use word-level embeddings as input for the BLSTM-CRF recognition baseline model. This model was implemented using the Keras library [9] with TensorFlow in the backend.
Our experimental results for the RQ1 over the test set are summarized in Table 2.
The performances of spaCy NER pre-trained and fine-tuned models for the super-labels
The performances of spaCy NER pre-trained and fine-tuned models for the super-labels
We observed by addressing RQ1 that the spaCy
With the most effective spaCy NER model setup identified for the NER component, following the architecture of HELD, we focus here on the RQ2 to investigate the best word-level representation for the BLSTM-CRF component. We make the following observations before discussing the results of Table 3:
Specifically, we evaluate three different input setups for the word embedding layer: domain-specific, pre-trained, and concat. The domain-specific version learns word embeddings for our Police domain jointly with the BLSTM-CRF model training, while the pre-trained version uses the original pre-trained vectors (from FastText, GloVe, Wang2Vec, and Word2Vec) fixed during training. Lastly, the concat (i.e., a concatenation layer) concatenates both the domain-specific and the pre-trained vectors.
The general performances of the BLSTM-CRF variations
The BLSTM-CRF
Two main observations are obtained from this experiment. First, the performance of the BLSTM-CRF model does not necessarily have just one specific best word embedding representation for all the loss functions. In fact, even though that BLSTM-CRF
A closer examination of the BLSTM-CRF
The performance of BLSTM-CRF
In conclusion, the pre-trained word-level representation generated by the Wang2Vec Skip-Gram model most effectively captures the semantic properties of the Police report’s vocabulary. We also observe that the use of domain-specific embeddings from our training data has not improved consistently the performance of the models. It may suggest the need of a larger corpus for the domain. By addressing the RQ2, the best setup for the BLSTM-CRF component in HELD is the BLSTM-CRF
We continue our experiments focusing on the last research question. To address RQ3, we finally investigate the performance of our proposed ensemble architecture: HELD. Our experimental results are reported in Table 5.
The performances of HELD and the baseline models
The performances of HELD and the baseline models
In summary, in RQ3, we have assessed that by combining the BLSTM-CRF and spaCy NER models in an ensemble architecture, it allows HELD to exploit the best of each model to improve the fine-grained classification in Police reports of the named entities recognized as the super-labels of our two-level hierarchical structure. The important conclusion here is that our approach can leverage the NER component (i.e., spaCy
This paper has presented HELD, an ensemble model for the Hierarchical Entity-Label Disambiguation problem in Police reports. This problem is very challenging since the fine-grained entities must be recognized and disambiguated in the narrative reports based on the sentence context. To the best of our knowledge, we believe that our work is the first to tackle such a problem. Our ensemble approach is domain-independent, which ensures that it can be applied in various domains as long as it has texts with ambiguous entities arranged in a hierarchical structure. HELD is free from knowledge bases, language-specific resources, and hand-crafted features, and includes two main components for sequence labeling in NER: a NER component represented by the spaCy NER tool and a BLSTM-CRF component. Each component has a specific task: spaCy NER identifies and classifies only super-labels from a two-level label hierarchy, and the BLSTM-CRF model recognizes and disambiguates fine-grained entity labels. HELD combines the predictions of the spaCy NER and BLSTM-CRF models via Disambiguation Mask to assign the final fine-grained labels for the input texts.
We train HELD and the baseline models using a real corpus of Police reports human-annotated in the HNERD framework. To guide our experimental evaluation, we address three research questions. The first research question explored the most effective spaCy NER model setup for the NER component. The spaCy
Several directions could be pursued to expand this research. First, a research direction would be to explore active learning techniques to reduce the effort of the data annotation process. Second, we can further enhance the performance of HELD by testing other state-of-the-art approaches. Our main interest is in the recent language models, such as BERT, GPT, ELMo, and Flair Embeddings, to improve the BLSTM-CRF component. We can attach the BLSTM-CRF model on top of the pre-trained language model to predict the labels of each token independently by fine-tuning the model for our domain. Thus, for the NER task, the contextualized language model will have the role of context encoder, besides given contextualized word-level representations. However, to do this, we have to generate a larger annotated Police reports corpus. Also, with more data available, we can increase the number of labels for our fine-grained annotation scheme. Third, another future direction is to explore different loss functions, such as the variations of the Dice Loss [32], or data level strategies for our data-imbalanced dataset. Further, we can explore data-augmentation techniques, such as word-embeddings substitution [25, 53] and masked language model applied by Transformer models, to generate additional synthetic data using the Police reports corpus. Augmentation methods are widely used approaches in computer vision applications, and they are just as powerful for NLP. For our context, they can help generate more labeled data and deal with the data imbalance problem.
Footnotes
Acknowledgments
We would like to thank the anonymous reviewers for their helpful comments. This work has been partially supported by FUNCAP, under project 04772551/2020, and by UFC-FASTEF, under project 31/2019.