
Abstract
Lortie-Forgues and Inglis (2019) convincingly demonstrate that 40% of rigorous, large-scale education trials are uninformative about impact. However, they and others dismiss the value of larger trials for solving this problem, based on a miscalculation. Contrary to this, I argue that making trials larger is a feasible and affordable way of making them more informative.
Randomized controlled trials (RCTs) balance both the observable and unobservable characteristics of treatment and control groups while employing minimal assumptions. They are therefore well placed to determine impact. Despite this, Lortie-Forgues and Inglis (2019; henceforth LF&I) reach the startling conclusion that 40% of education RCTs are uninformative. The Education Endowment Foundation (EFF)—a large trial commissioner—has responded with a defense of their approach (EEF, 2019). In this note, I argue that both LF&I and EEF have missed a feasible, affordable way of improving the informativeness of trials: making them larger.
LF&I review 141 RCTs commissioned by EEF and the National Centre for Educational Evaluation (NCEE). They define a trial as uninformative if the findings are consistent with the intervention being both effective and ineffective. This is operationalized with a Bayes factor, which is the ratio of how well the alternative and null hypotheses predict the data. Following convention, LF&I deem a trial informative if the data are predicted by one hypothesis 3 times better than the other and find 40% are uninformative on this basis. Put another way, LF&I find that 93% of trials estimated effect sizes below their minimum detectable effect size (MDES).
LF&I make two recommendations for trial design. First, target interventions at specific groups likely to be most responsive. Second, use proximal outcome measures likely to show a stronger response. Importantly, LF&I are skeptical that trials can be made more informative by increasing sample size, calculating that for an independent-samples t test to detect an effect size of 0.04 (their weighted mean effect size), an individually randomized trial would require 20,000 participants!
EEF does not dispute the data or analysis used by LF&I—both of which, to the authors’ credit, are publicly available. Instead, it emphasizes that its trials do now include proximal, nonachievement outcomes. While pointing out that its trials have been increasing in size, EEF also doubts that larger trials are the solution. It calculates that a cluster RCT capable of detecting an effect size of 0.05 would require 800 schools (assuming intraclass correlation = .1 and R2 = .5). EEF argues that this would drastically reduce the number of trials it could run, rendering its overall output less informative.
LF&I and EEF base their sample size calculations on the expected effect size. This is reasonable, given their aim is to determine whether larger trials could detect the effects typically found in the literature. The contention of this article, however, is that they miscalculate the expected effect size. Education is an applied field, which aims to identify both effective practices for practitioners to adopt and ineffective practices, which practitioners should avoid. It follows that the relevant benchmark is actually the expected absolute effect size. Using the LF&I data, I calculate this to be 0.08, twice the mean weighted effect size. 1 This has substantial implications for trial design. Indeed, reproducing the EEF sample size calculation using the 0.08 benchmark shows that such a trial would require only 280 schools (140 in treatment).
To quantify the trade-offs, I model the cost of achieving a given MDES. Cost is partly determined by the level of randomization and type of intervention. I therefore augment the LF&I data with information from EEF: the type of intervention, as coded by EEF (e.g., behavior) and additional indicators for texting interventions as well as individual versus cluster randomization. I drop NCEE trials, due to lack of comparable data. Figure 1 plots MDES against cost, overlaid with a regression line showing the predicted relationship, conditional on the additional EEF covariates. The line reaches the target MDES of 0.08 at around $3,136,750 (£2,500,000)—4–5 times the current average cost ($640,001 or £510,083). This finding relies on extrapolation along the x-axis, but this is by design—we need future trials to be different from past trials.
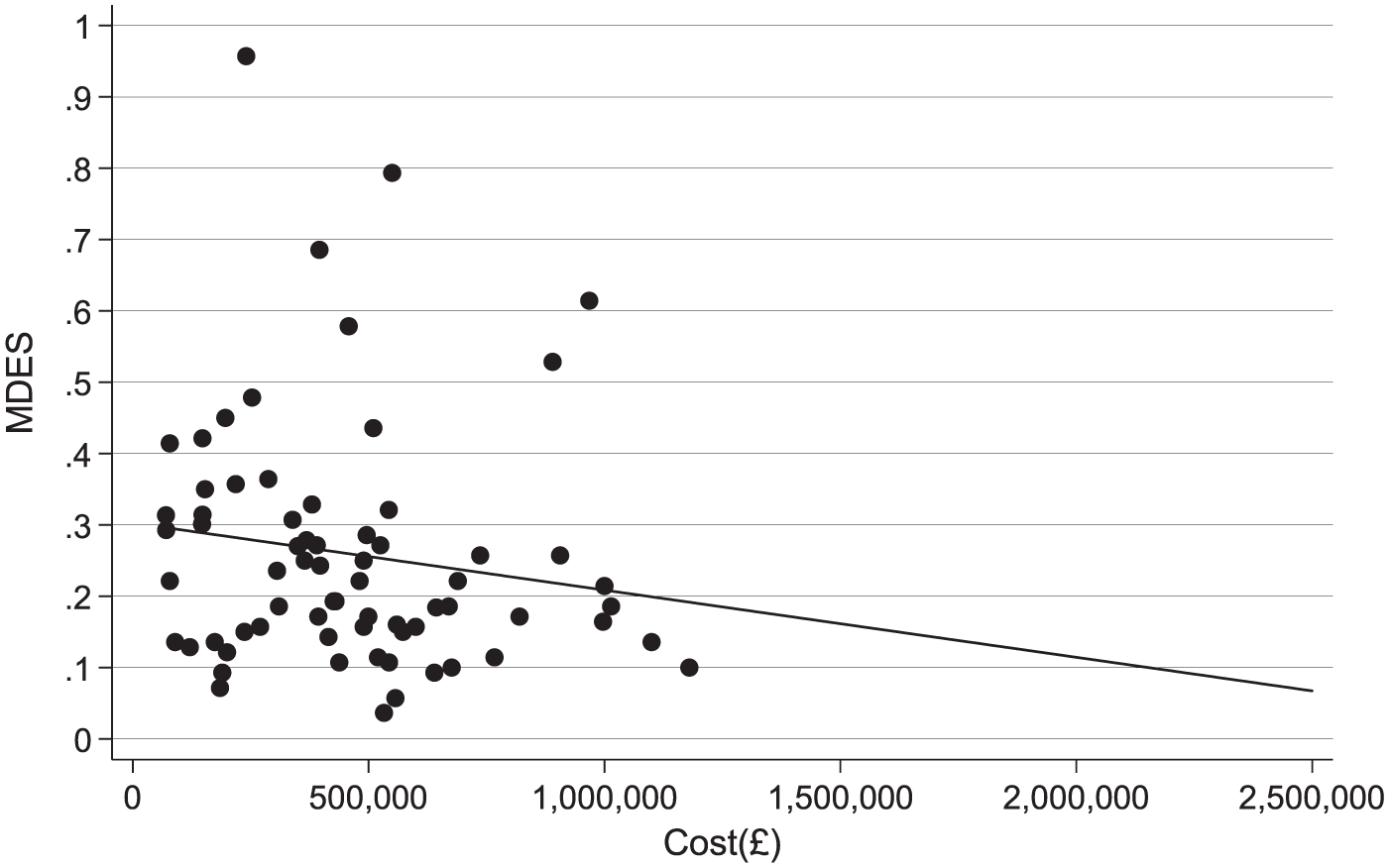
Scatterplot of minimum detectable effect size (MDES) and intervention cost.
LF&I demonstrate convincingly that trials are often uninformative with regard to impact. Their findings are important and deserve to prompt a rethink of trial design. However, both LF&I and EEF have been too quick to dismiss the value of making trials larger, due to miscalculating the expected effect size. Trials with MDES of 0.08 are feasible, requiring cluster RCTs with around 140 intervention schools. Large-enough trials will of course be more expensive, reducing by around 75–80% the number of EEF trials. This sounds costly, but it must be kept in mind that 93% of such trials have estimated effect sizes below their MDES and/or 40% were uninformative. Conducting fewer, larger trials is therefore likely to increase, not decrease, the number of informative findings.
One potential objection to this line of reasoning is that effect sizes of 0.08 are not worth detecting, because they imply a poor cost-benefit ratio and would therefore provide no useful information anyway. For some interventions, this will be true. For others, however, such as text messaging interventions, costs can be as low as $1 per pupil, implying that even interventions with small effects would be economically worthwhile implementing (Kraft, 2018). That larger RCTs can detect quite small effects therefore only strengthens the argument that they are a feasible and affordable way of making trials more informative, across a wide range of interventions.