
Abstract
For mixed-type tests composed of both dichotomous and polytomous items, polytomous items often yield more information than dichotomous ones. To reflect the difference between the two types of items, polytomous items are usually pre-assigned with larger weights. We propose an item-weighted likelihood method to better assess examinees' ability levels. Simulation results show that the estimated ability based on the new procedure is more consistent with examinee’s true ability than the usual maximum likelihood method.
Keywords
Introduction
A scaling process of educational or psychological testing often involves integration of information from multiple sources of items. In general, a well-constructed test can be characterized by a set of carefully sampled items across different subdomains. It is often the case that the scoring process involves assigning different scoring weights to different item types that have different emphases. For example, in a recent large-scale state reading assessment test, each operational multiple-choice item carries a weight of 0.8 while each constructed response item (scored 0–4) carries a weight of 1.2.
The underlying rationale of assigning different weights is easy to understand. In a mixed-type test composed of both dichotomous and polytomous items, polytomous items usually carry more information concerning the level of latent trait than dichotomous items (see, e.g., Donoghue, 1994; Embretson & Reise, 2000, p. 95; Jodoin, 2003; Penfield & Bergeron, 2005). Hence, assigning larger weights to polytomous items shall lead to more accurate estimates of the latent traits than equally weighting all items.
It comes into sight that further progress could accrue in both theoretical and empirical perspectives concerning how to use item weights in ability estimation. More specifically, how to incorporate the weight information into a new estimation procedure so that the accuracy and precision of ability estimation can be improved? The objective of this article is to develop an item weighting scheme according to different item types in mixed-type tests to achieve more accurate latent ability estimation. We propose an item-weighted likelihood estimation (IWLE) procedure that is used in a combination of the three-parameter logistic (3PL) model and the generalized partial credit model (GPCM) under the assumption that item parameters are known. Furthermore, we consider a bias-reduced IWLE (BR-IWLE) method by utilizing Warm’s (1989) technique. The Fisher scoring iteration equations are theoretically derived. Simulation results indicate that the estimated trait levels given by the new IWLE procedure are more consistent with the true trait levels.
Before the IWLE procedure is fully explained, it is important to clarify the essential difference between the weighting rationale of IWLE and those of the existing item weighting methods. For instance, Lord (1980, p. 74) considered the problem of optimal item weights for dichotomously scored items, in which the weights can be different from item to item. The focus of IWLE is different and is on differentiating the information gaining from different item types. Instead of assigning different weights to different items, one only needs to assign different weights to different item types; and items of the same type all have the same weight. Our goal is to rigorously inspect the maximum likelihood equation according to given item-type weights and derive the corresponding Fisher scoring function.
It is worth mentioning that assigning weights to items has always been an important application in item response theory (IRT). For example, Linacre and Wright (1995) described several methods that weights can be implemented with Rasch computer programs (e.g., WINSTEPS/BIGSTEPS). Warm (1989) proposed a weighted likelihood estimation (WLE) method for the dichotomous IRT model that provides a bias correction to the maximum likelihood method by solving a weighted log-likelihood equation. Warm’s method has been implemented by the PARSCALE (Muraki & Bock, 2003) program by specifying the WML method of estimating scale scores. Recently, Penfield and Bergeron (2005) extended Warm’s correction to the case of GPCM. Clearly, IWLE will become a new member of the weights' family.
This paper is organized into two parts. The first part begins with an introduction to the IWLE procedure and then compares the performance of IWLE with that of the usual maximum likelihood estimation (MLE) by a simulation study. The second part is to investigate the possibility of further bias reduction by incorporating Warm’s (1989) WLE method with the IWLE procedure. The performances of the three procedures: MLE, WLE, and the BR-IWLE are compared. Finally, a real data set from a large-scale reading assessment is used to demonstrate the estimation difference between the MLE and the BR-IWLE. The detailed derivations for the components used in the Newton–Raphson equations for the IWLE procedure are given in the Appendix.
Method
In a mixed-type test consisting of dichotomous and polytomous items, a polytomous IRT model may be sufficient for practical fitting needs, in which a dichotomous item is treated as a special case of polytomous item. However, many research works have shown that polytomous items provide more information concerning the level of the latent trait than dichotomous items (see, e.g., Donoghue, 1994; Jodoin, 2003; Penfield & Bergeron, 2005). To reflect the difference between the two types of items and finally to improve latent trait estimation, we will combine dichotomous and polytomous IRT models rather than just fitting a polytomous model.
3PL Model and GPCM
Let us consider a mixed-type test that consists of n items in which m are dichotomous and n − m are polytomous, and we assume that the 3PL (Birnbaum, 1968) and GPCM (Muraki, 1992, 1997) models fit the data well. To simplify the notation, the examinee subscript will not be shown in the following derivations. Then, the probability of the correct response on dichotomously scored item i at ability level θ is defined by


Based on the above 3PL model and GPCM, we consider the problem of likelihood estimation of ability. Note that the likelihood of response can be written as the product of two types of likelihood functions:
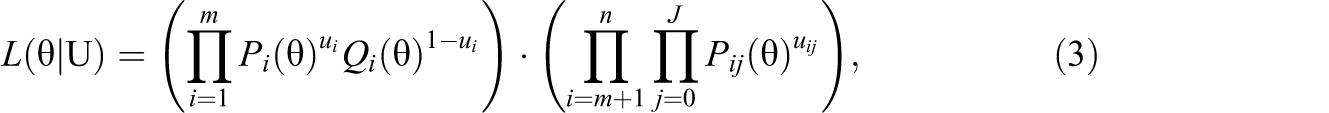
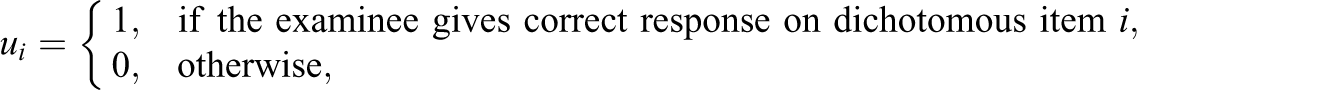
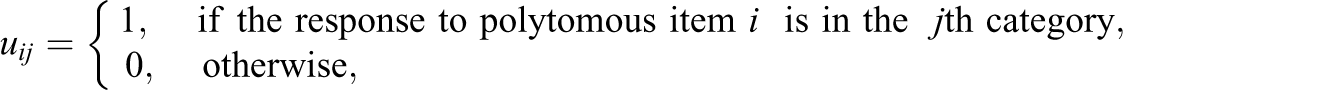
Next, to increase the precision of latent trait estimation, we consider the following item-weighted likelihood:
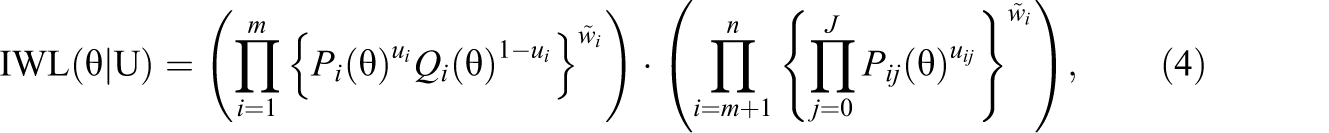
Now, a key issue is to determine how to assign different weights to the items of different types. A general rationale is that high-quality items should carry larger weights whereas low-quality items should carry smaller weights. It seems to be the best strategy to assign weights to the items according to their information. In this article, we investigate a common practice currently endorsed by many state assessments: Polytomous items carry a larger weight whereas dichotomous items carry a smaller weight. Our main objective is to theoretically derive an item weighting scheme for the MLE procedure such that it generates more accurate latent trait estimates.
Taking the natural logarithm on both sides of Equation 4 gives
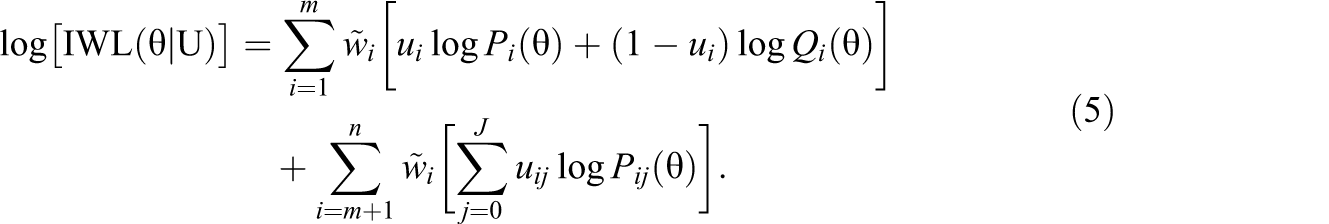
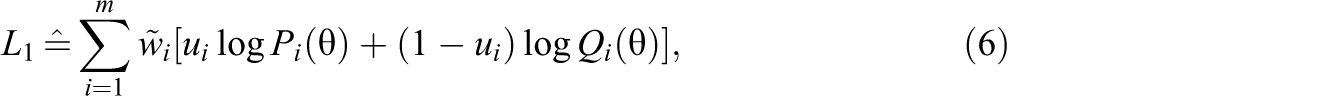


Simulation Study (I)
To evaluate the performance of the proposed IWLE procedure, a simulation study was conducted. We artificially constructed a 30-item test consisting of both dichotomous and polytomous items. Note that tests with mixed item types are commonly used in large-scale assessments in the United States, for instance in the National Assessment of Educational Progress (NAEP). Both theoretical and empirical evidences have shown that polytomous items in general provide more information than that of dichotomous items regarding the precision of trait level estimation (e.g., Donoghue, 1994; Embretson & Reise, 2000, p. 95; Jodoin, 2003; Penfield & Bergeron, 2005). A natural way to allocate weights is to assign higher weights to polytomous items and lower weights to dichotomous items. In practice, the allocation of weights is usually determined by test developers prior to administration of the tests.
Here are some explanations about the assignment of weights in our simulation study. Note that the item-weighted likelihood defined in Equation 4 will reduce to the usual likelihood when all
To explore the effect of the assignment of weights, an intensive simulation study is conducted to cover a wide range of index values, such as the total number of items, the proportion of dichotomous and polytomous items among the whole mixed-type test, and the size of the two types of weights. In general, the simulation results exhibit a similar change trend. Here, due to page limitation, only simulation results based on the following scenario are discussed: the mixed-type test consists of 20 dichotomous items and 10 polytomous items and each dichotomous item has a weight 0.6 and each polytomous item has a weight of 1.8. Here, these two particular weights were assigned just for illustrative purposes.
Item parameters
All the discrimination parameters were randomly generated from the uniform distribution in the range [0.5, 1.5]. The difficulty parameters of the dichotomous items were randomly generated from the standard normal distribution N(0,1), while the guessing parameters were set to 0 in this part of simulation. In the next simulation study (II), we consider the case in which the guessing parameters were randomly generated from the uniform distribution in the range [0.1, 0.3]. The location parameters of each polytomous item were randomly generated from four normal distributions: bi 1 ~ N(−1.5, 1), bi 2 ~ N(−0.5, 1), bi 3 ~ N(0.5, 1), and bi 4 ~ N(1.5, 1), i = 21, . . ., 30.
Ability parameters
In the simulation, 17 equally spaced θ values were considered, ranging from −4.0 to +4.0 within an increment 0.5. At each θ, N = 2,000 replications were performed. At each replication, the dichotomous item responses were simulated according to the 3PL model, and the polytomous item responses were simulated according to the GPCM. The same item responses were used for both MLE and IWLE procedures.
Evaluation criteria
Accuracy, that is, mean bias (Bias), and precision, that is, root mean squared error (RMSE) of the ability estimates, were used to evaluate all the procedures.
Bias and RMSE
Bias was estimated using Equation 9. For Equation 9, we let θ be the true ability value and


Results of simulation
Figure 1 shows the results of bias, absolute bias, and RMSE calculated from a pilot study based on the setting described above.

Comparisons of the bias, absolute bias, and root mean squared error (RMSE) between the maximum likelihood estimation (MLE) and the item-weighted likelihood estimation (IWLE): 20 dichotomous items with common weight 0.6 and 10 polytomous items with common weight 1.8.
The simulation results show that IWLE outperforms MLE regarding reduction in bias especially at extreme levels of the latent trait. However, we note that the effect of bias reduction of IWLE is not as ideal as expected when the levels of latent trait are in the intermediate range (say,
Bias Reduction
Up to the present time, many methods of bias reduction have been proposed, for example, see Lord (1983); Warm (1989); Firth (1993); T. Wang, Hanson, and Lau (1999); and S. Wang and Wang (2001). In this section, we investigate the feasibility of bias reduction of the IWLE procedure using Warm’s (1989) WLE technique.
To simplify the notation, let Pi
(θ) = Pi, Qi
= 1 − Pi, Wi
= PiQi
, and Pij
(θ) = Pij
. Note that





Following the idea of Warm (1989) and Penfield and Bergeron (2005), a class of estimators, θ*, may be defined as the value of θ that maximize the following Equation 14:
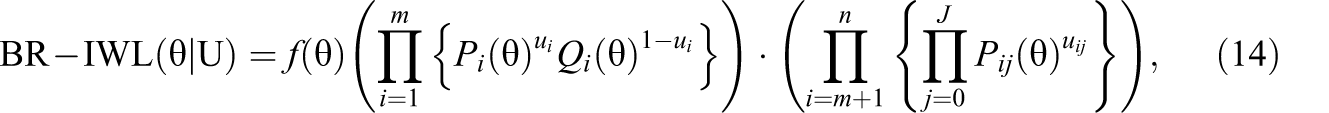
Taking the natural logarithm on both sides of Equation 14 gives
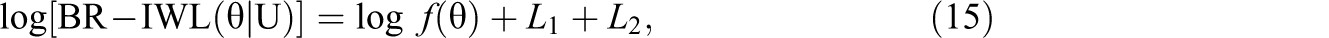
Let

Simulation Study (II)
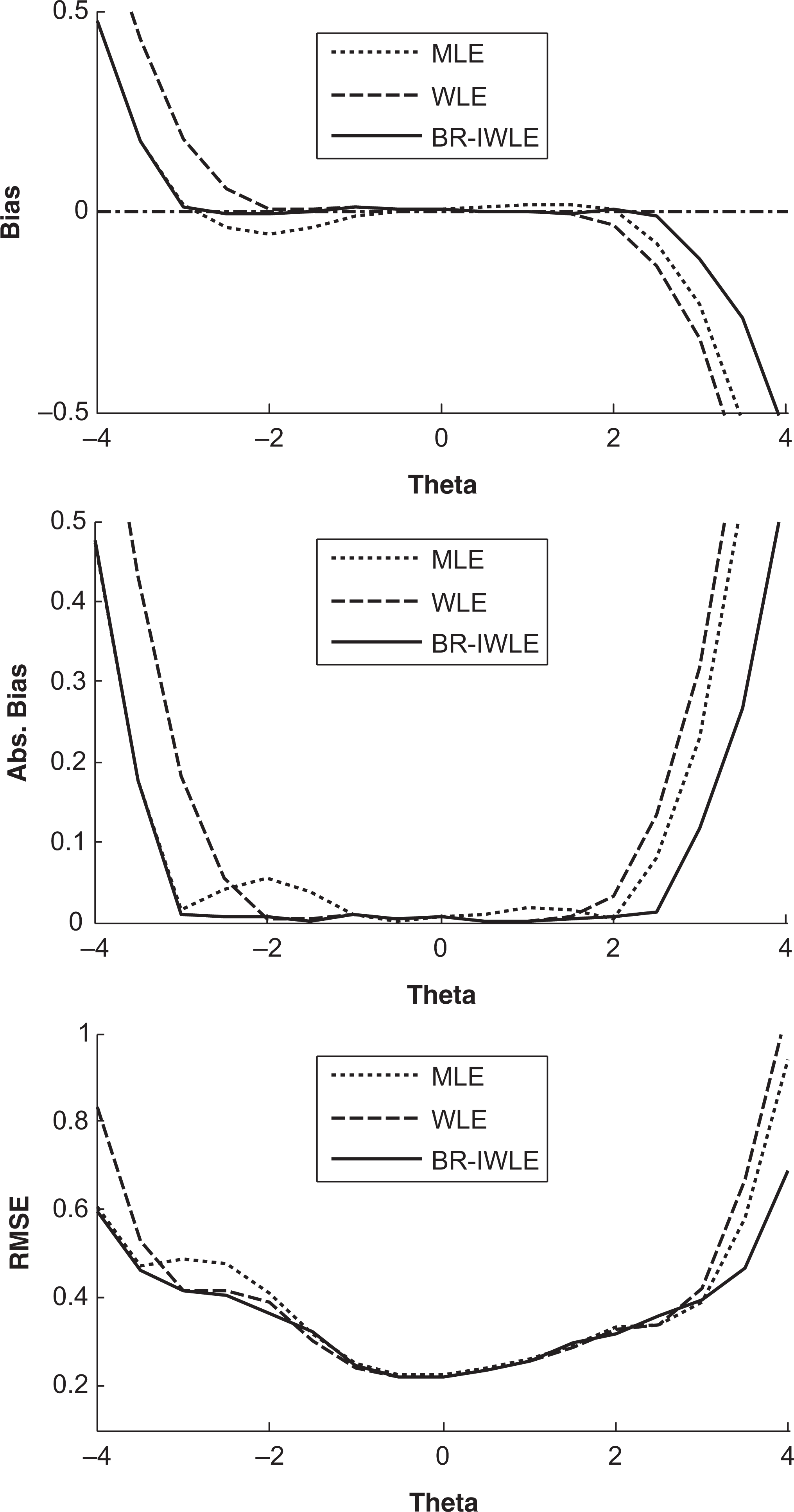
In this section, the performance of the three methods, the usual MLE, the WLE, and the Bias-Reduced IWLE (BR-IWLE), are compared.
Figure 2 shows the bias, absolute bias, and RMSE calculated from a pilot study based on the setting described in the simulation study (I).

Comparisons of the bias, absolute bias, and root mean squared error (RMSE) among the maximum likelihood estimation (MLE), the weighted likelihood estimate (WLE), and the bias-reduced item-weighted likelihood estimation (BR-IWLE): 20 dichotomous items with common weight 0.6 and 10 polytomous items with common weight 1.8. The guessing parameters in the 3PL model were set to 0.
The simulation results show that BR-IWLE outperforms both WLE and MLE regarding reduction in both Bias and RMSE.
True score
Besides the two evaluation criteria (Bias and RMSE), an additional criteria (True Score) was used to evaluate all three procedures. The estimated true scores are computed to account for measurement error. The true score for the mixed-type test is composed of two parts (i.e., dichotomous part and polytomous part) as follows:
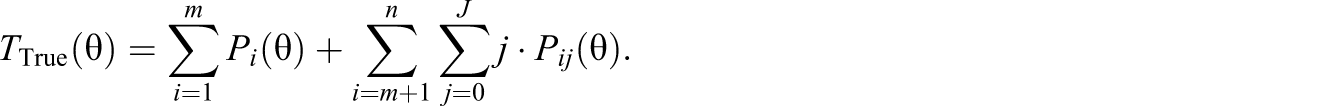
Figure 3 demonstrates that the estimated true scores based on BR-IWLE are always closer to the true scores than those based on MLE and WLE. Furthermore, from Table 1
, we can see that
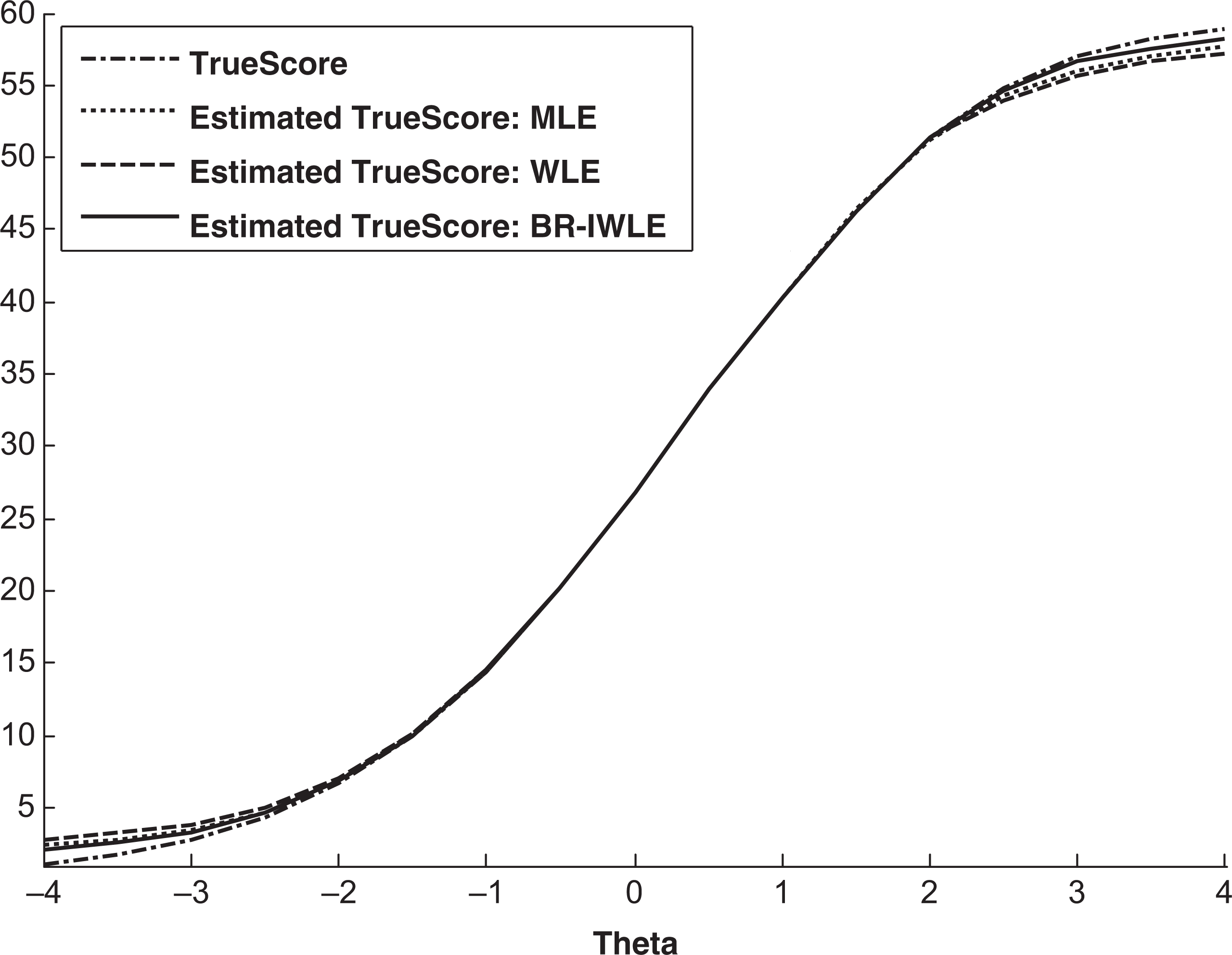
True score vs. estimated true scores: 20 dichotomous items with common weight 0.6 and 10 polytomous items with common weight 1.8. MLE = maximum likelihood estimation; WLE = weighted likelihood estimate; BR-IWLE = bias-reduced item-weighted likelihood estimation.
Differences Between the True TrueScore and the Estimated TrueScores: 20 Dichotomous Items With Common Weight 0.6 and 10 Polytomous Items With Common Weight 1.8
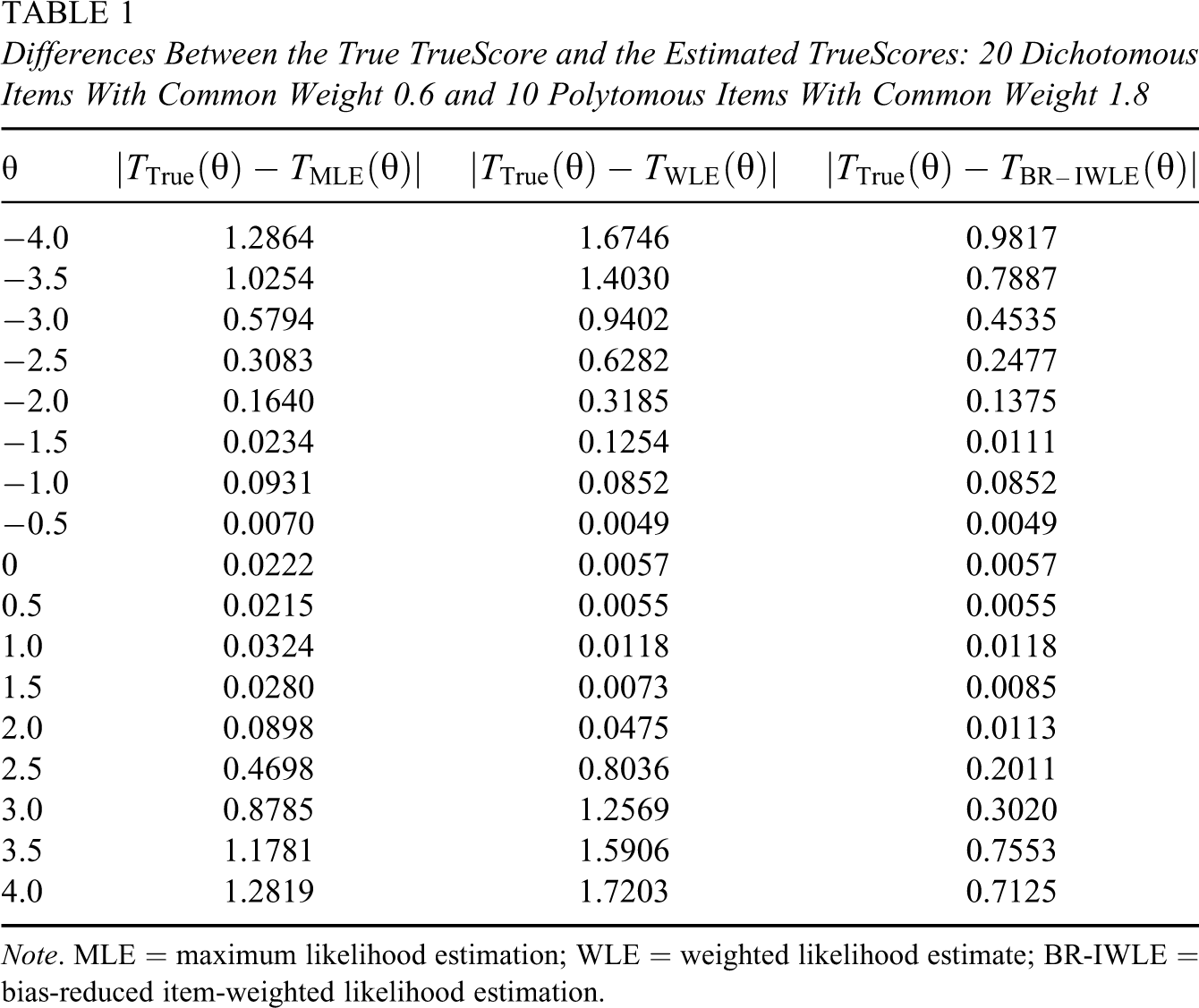
Note. MLE = maximum likelihood estimation; WLE = weighted likelihood estimate; BR-IWLE = bias-reduced item-weighted likelihood estimation.
Finally, to investigate the effect of the guessing parameters, Figure 4 shows the bias, absolute bias, and RMSE when the guessing parameters were randomly generated from the uniform distribution in the range [0.1, 0.3]. From Figure 4, we can see that, at extreme low levels of the latent trait (say, θ < −3.0), the performance of BR-IWLE almost has no difference from MLE. However, BR-IWLE outperforms MLE at higher levels of the latent traits (say, θ > 2.0).
Comparisons of the bias, absolute bias, and root mean squared error (RMSE) among the maximum likelihood estimation (MLE), the weighted likelihood estimate (WLE), and the bias-reduced item-weighted likelihood estimation (BR-IWLE): 20 dichotomous items with common weight 0.6 and 10 polytomous items with common weight 1.8. The guessing parameters in the 3PL model were generated from the uniform distribution U (0.1, 0.3).
Pilot Study Based on Real Data
To study the applicability of the IWLE method in operational large-scale assessments, a pilot study on a sample of 2,000 examinees was conducted. The test studied is from a recent state reading assessment consisting of 50 dichotomous items and 1 polytomous item (5-category). The weights were preassigned by the state testing board: 1.0 for dichotomous items and 1.39 for the 5-category polytomous item. After standardization with respect to the constraint 

Conclusions and Discussion
In many testing programs, it is often the case that different weights are assigned to different items according to certain practical emphases. Therefore, incorporating the weights in θ estimation is important because without considering the scoring weights may not capture all the information and emphases the test provides. In this article, we proposed the IWLE procedure that incorporates item weights into θ estimation. We theoretically derived the formulas for the Newton–Raphson iterations to solve the IWL estimates. According to Equations 8 and 16, the proposed IWLE method can be easily implemented by many practitioners.
A simulation study was conducted under various considerations, such as different settings in item weight, different combinations of dichotomous and polytomous items. The results from the pilot simulation study clearly demonstrate that the proposed IWLE method outperformed the usual MLE in terms of controlling bias and RMSE under the situation where polytomous items carry relatively higher weights and dichotomous items carry lower weights. However, the conclusion may not hold if we assign higher weights to dichotomous items whereas lower weights to polytomous items.
Improving latent trait estimation is always important in assessment and evaluation. Since most state assessments are employing true-score equating and linking, the application of the proposed method may reduce linking error and thus increase assessment reliability. Furthermore, the proposed item-weighted procedure is expected to have a broad range application, particularly in computerized testing. It can be incorporated with item selection procedures to not only lower item exposure rates but also improve ability estimation. Though in the current study the IWLE method is only used in a combination of the three-parameter logistic (3PL) model and the GPCM, the method can be easily generalized to other models such as the Rasch model, Partial Credit Model (PCM), and Graded Response Model.
Footnotes
This research was partially supported by the Fundamental Research Funds for the Central Universities (10JCXK007), the Natural Science Foundation of Jilin Province (201115005), the Training Fund of NENU'S Scientific Innovation Project (NENU-STC07002) and National Natural Science and Social Science Foundations of China (Grant Nos. 10931002, 10828102, 10871037, and 07JZD0031). The authors gratefully acknowledge the helpful comments of the two anonymous reviewers and the Editor.