
Abstract
In longitudinal multilevel studies, especially in educational settings, it is fairly common that participants change their group memberships over time (e.g., students switch to different schools). Participant’s mobility changes the multilevel data structure from a purely hierarchical structure with repeated measures nested within individuals and individuals nested within clusters to a cross-classified structure with repeated measures cross-classified by both individuals and clusters. If researchers fail to consider the cross-classified data structure and simply use the hierarchical linear models (HLMs) instead of the more appropriate cross-classified random-effects models (CCREMs) to analyze the data, there will be biases in the estimates of variance components and inaccurate statistical inference regarding the fixed effects. In addition, the impact of such model misspecification depends on factors including the rate of mobility and the pattern of mobility.
In social science research disciplines, longitudinal multilevel data are commonly encountered. There are two common features of longitudinal multilevel data: Individuals are generally clustered in some higher level groups, and individuals are measured repeatedly over time. For example, in educational settings, students are clustered within schools, and their academic achievements are measured repeatedly over time. Longitudinal multilevel data are very useful for investigating development-related issues because they allow researchers to examine the average trend of the development of an outcome (e.g., achievement) over a period of time, the variability of individual developmental trajectories, and the influences of individual-related factors (e.g., gender and ethnicity) and contextual factors (e.g., school type and school climate) on the development.
Multilevel models are commonly used to analyze longitudinal multilevel data. The outcome variable is typically modeled as a function of the time variable (i.e., the variable that indicates the assessment occasions), the time-varying covariates (e.g., credit hours taken by a student at each occasion), and the time-invariant covariates (e.g., students' gender). In multilevel models, hierarchical linear models (HLMs) are frequently used to model growth. Such models usually have repeated measures at Level 1 nested within individuals (e.g., students) at Level 2 that are further nested within clusters (e.g., schools) at Level 3 (see Figure 1a for an example of such data structure).

Hierarchical versus cross-classified data structure. A. Repeated measures nested within individuals and individuals nested within clusters. B. Repeated measures cross-classified by individuals and clusters. Note: The numbers in the cells indicate the number of repeated measures.
HLM is based on the strictly hierarchical data structure in which individuals remain in the same cluster over time. However, in reality multilevel data may not always have strict hierarchies, especially in educational settings where students often switch schools. Due to student mobility, the multilevel data structure is no longer strictly hierarchical because repeated measures are only nested within students but not nested within the same schools over time. Such data are called cross-classified multilevel data because repeated measures are now cross-classified by both students and schools. In contrast with the strictly hierarchical structure as shown in Figure 1a, Figure 1b shows an example of the cross-classified data structure. For example, Student 1 had three repeated measures when he was in School 1 and one repeated measure when he was in School 3. Student 4 had three repeated measures when he was in School 2 and one repeated measure when he was in School 10.
As an extension of the HLMs, cross-classified random effects models (CCREMs) were developed to investigate the relationships among variables within a given level and across levels when random factors are not nested (Goldstein, 1986, 1995; Hill & Goldstein, 1998; Rasbash & Goldstein, 1994; Raudenbush, 1993). During the last decade, CCREMs have been introduced in many major multilevel modeling textbooks (e.g., Goldstein, 1995; Hox, 2002; Raudenbush & Bryk, 2002; Snijders & Bosker, 1999), and many multilevel modeling computer programs have included routines for estimating CCREMs, such as HLM 6.08 (Raudenbush, Bryk, Cheong, & Congdon, 2004), MLwiN 2.17 (Rasbash, Steele, Browne, & Goldstein, 2009), SAS PROC MIXED (SAS Institute Inc., 2004), and R package lme4 (Bates & Sarkar, 2007).
The use of CCREMs has also become more frequent in empirical research. For example, Fielding (2002) examined educational effectiveness using cross-classified data in which students' exam scores on different subjects were cross-classified by students and teaching groups. Jayasinghe, Marsh, and Bond (2003) investigated the effect of assessor and researcher attributes on assessor ratings using CCREMs in which assessor ratings at Level 1 were cross-classified by assessors and proposals. However, most of the applications of CCREMs were restricted to cross-sectional data. The application of CCREMs for modeling growth was rare due to the complexity of model specification and missing information on individuals’ cluster membership. For example, students may change classrooms or schools over time, but researchers may only be able to retrieve the identifications of the original classrooms or schools but not the identifications of the new classrooms or schools that the students move to. Researchers generally tend to exclude participants who move to different classrooms or schools from their sample of analysis to keep the hierarchical structure of their data (e.g., De Fraine, Van Landeghem, Van Damme, & Onghena, 2005; McCoach, O’Connel, Reis, & Levitt, 2006) or simply ignore the cross-classified structure of the data and use HLMs (e.g., George & Thomas, 2000; Ma & Ma, 2004).
A few methodological investigations have been conducted to examine the impact of misspecifying CCREMs (Berkhof, 2000; Luo & Kwok, 2009; Meyers & Beretvas, 2006). Those studies examined the type of misspecification in which a crossed random factor was completely omitted. For example, if students are cross-classified by schools and neighborhoods, the correct model with both crossed random factors is specified as


This study focuses on a different type of misspecifications of CCREMs that is more common in growth models. Consider the example of students switching schools over time. The correct model should treat repeated measures as cross-classified by students and schools, thereby should have the form as Equation 1, with

The purpose of this study is to investigate the impacts of such misspecifications in cross-classified growth models on parameter estimates and the corresponding statistical inferences. We first used the data from the Early Childhood Longitudinal Study—Kindergarten Class of 1998–1999 to compare the parameter estimates resulting from the cross-classified random effects model and the HLM. Simulation studies were then conducted to further investigate the research question. Although analytical approach to investigating consequences of model misspecifications is always preferable, the nature of this type of model misspecification (i.e., the incorrectly specified design matrix
We conducted two simulation studies. Simulation I focused on the case in which a subsample of students switch schools once simultaneously and used a full factorial design to investigate the influences of the manipulated design factors. Simulation II further investigated the case in which students can switch schools at any time points and for multiple times. Before presenting the real data and the simulation studies, we briefly introduced the specification of cross-classified multilevel growth models.
Cross-Classified Multilevel Growth Models
Consider an example of students' math achievement being measured annually for 3 years. During the course of the study, students move to different schools over time. Suppose J is the total number of students and K is the total number of schools. Let students be indexed by j = 1, …, J; let schools be indexed by k = 1, …, K; and let occasions be indexed by t = 1, 2, 3. Assuming a linear growth trajectory of math scores for each student, the Level 1 (repeated measure level) model is specified as follows:
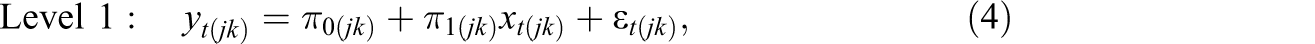
Level 2 is the level at which students and schools are crossed with each other. An unconditional model is specified as

It is assumed that
Substituting Equation 5 to Equation 4 yields the combined model
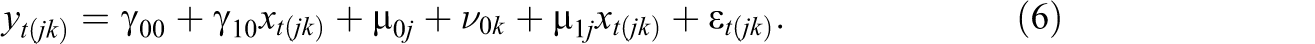
If the three schools have the same random effect (i.e.,

Growth trajectory of student j. A. Trajectory of student j when schools have equal random effects. B. Trajectory of student j when the three schools have unequal random effects.
Equation 6 can be rewritten in a matrix form for student j who attended School 1 at Occasion 1, School 2 at Occasion 2, and School 3 at Occasion 3 as follows:

If a researcher ignores the cross-classified structure caused by students' mobility and treat the data as strictly hierarchical by assuming students stay in the same school at all occasions, the design matrix for the school random effects (i.e., the
Real Data Study
Data
The Early Childhood Longitudinal Study–Kindergarten Class of 1998–1999 (ECLS–K) is a longitudinal study that aims to advance the understanding of children’s development and experiences in elementary and middle schools. The multistage probability sampling design of the study gave rise to the multilevel structure of the data. To date, seven waves of data have been collected. For demonstration purposes, we used three waves of repeated measures (i.e., the springs of kindergarten, first grade, and third grade) to examine the growth of students' math achievement and the effects of gender and school type on the growth. The sample of analysis contained 4,301 students with full information on school identifications at each wave and complete data on the dependent variable (i.e., math scores) as well as the independent variables (i.e., gender and school type).
Because students switched schools overtime, the data structure was not strictly hierarchical but cross-classified. In the sample of analysis, 1.7% of the students switched schools between Waves 1 and 2 (i.e., kindergarten and first grade) and 3.7% switched schools between Waves 2 and 3 (i.e., first grade and third grade).
Analyses
We first analyzed the data using the cross-classified random effects model to accommodate the cross-classified structure of the data. An HLM was then fitted to the same data, ignoring students' mobility. Parameter estimates from the two models were compared.
CCREM Analysis
The Level 1 model was the same as in Equation 4, where

HLM Analysis
In this analysis, students' mobility was ignored and their school identifications at Wave 1 were used for all three waves. This yielded a strictly hierarchical data structure with repeated measures at Level 1 nested within students at Level 2 nested within schools at Level 3. The Level 1 model was the same as that in the CCREM analysis. At Level 2 (i.e., the student level), the random initial status and growth rate were predicted by gender such that


Comparison of HLM and CCREM Results Using Real Data
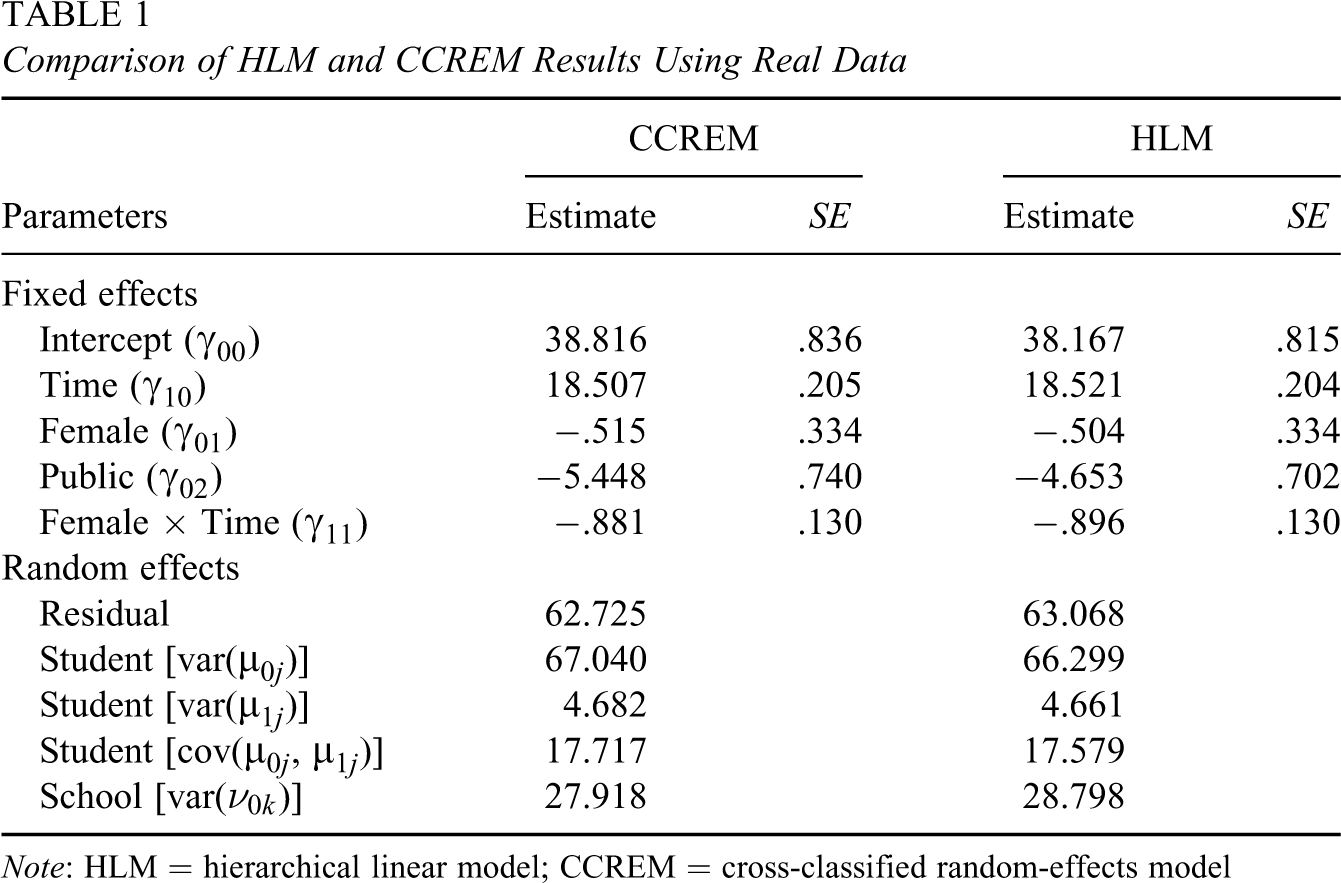
Note: HLM = hierarchical linear model; CCREM = cross-classified random-effects model
With real data analysis, we do not know the true population parameters. Therefore, it is unknown whether the differences we observed between the results from the CCREM and the HLM analyses were simply due to sampling error. In addition, because we cannot manipulate the mobility rate in real data analysis, it is unknown how different the results would be if the mobility rate is higher. Therefore, we conducted the following simulation studies to further investigate the impacts of ignoring students' mobility, considering a number of design factors such as the number of schools and students per school, mobility rate, and the magnitude of the variances of different random effects.
Simulation I
There are many factors affecting students’ school switching. Students may move due to completion of an academic program, such as graduating from middle schools and entering high schools. In this case, it is likely that a subsample of students switches schools simultaneously at a certain time point. In the first simulation study, we examined the mobility pattern in which students only switch schools once between the first and the second assessment occasions. We presented the procedures for data generation and analyses, followed by results.
Method
Data generation
The data were generated using SAS 9.1 (SAS Institute Inc., 2004). The model used for data generation was a two-level cross-classified growth model:

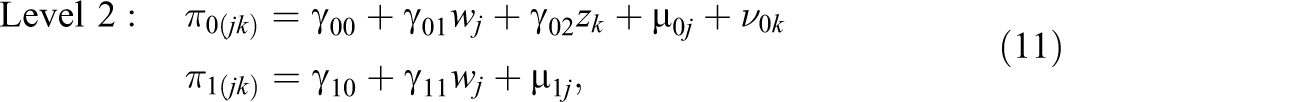
Design Factors
Five design factors were considered in the study, including (a) the number of schools, (b) the number of students per school at Occasion 1, (c) mobility rate, (d) variances and covariance of the student random effects (
The number of schools
A recent systematic review of 27 studies using multilevel models conducted by Graves and Frohwerk (2009) in School Psychology Quarterly showed that the average number of schools used in those studies was 28 with the 25th and 75th percentiles of 3 and 36, respectively. Thus, we used 25 and 50 schools as the two levels in this design factor.
The number of students per school at occasion 1
Based on Graves and Frohwerk’s review, the average number of students per school was 44 with a standard deviation of 43. Hence we selected 50 versus 100 students per school as the two levels in this design factor. The overall number of students, based on these simulation conditions, ranged from 1,250 (50 × 25) to 5,000 (100 × 50), which covered a reasonable range of sample sizes for multilevel growth models in educational studies.
Mobility rate
Despite the requirement of the No Child Left Behind Act (NCLB) that mandates student mobility be taken into account when rating schools, there is surprisingly little standardization in the definition and computation of mobility rate (Demie, 2002). In this study, the term student mobility was defined as a student switching school between two assessment occasions. The mobility rate of a school was calculated as the ratio between the number of students leaving the school and the total number of students in the school. According to the 1998 National Assessment of Educational Progress (NEAP), one third of 4th graders, 19% of 8th graders, and 10% of 12th graders changed schools at least once in the previous 2 years. Hence, we selected three levels of mobility rate, 5%, 20%, and 35%, to represent low, medium, and high mobility rate, respectively.
Variance and covariance of student random effects ()
Based on the criteria provided by Raudenbush and Liu (2001), we used
Variance of school random effects (τ)
Following previous simulation studies (Meyers & Beretvas, 2006; Moerbeek, 2004), two levels were chosen for this factor: (a) a small size with τ = .1 and (b) a medium size with τ = .2. The intraclass correlation (ICC) for schools, computed by
Combining these five factors, this study involved 48 conditions. For each condition, 200 data sets were generated. A total of 9,600 data sets were generated for the analyses. Using the lmer function in the R package lme4 (Bates & Sarkar, 2007), each data set was analyzed with two models: (a) the correct model, that is, the cross-classified model used to generate the data; and (b) the misspecified model, in which students' mobility was ignored. More specifically, the misspecified model was a three-level strictly HLM assuming that repeated measures were nested within students and students were nested within their Time 1 schools, as follows:
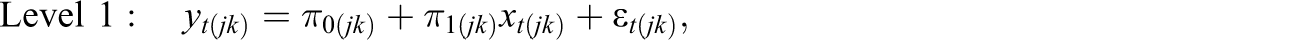


Analysis
Following the recommendations by Burton, Altman, Royston, and Holder (2006) on designing simulation studies, we examined the relative bias, accuracy, and coverage of the parameter estimates.
Relative bias
For both the fixed effects and the variance components, we computed the relative bias of the estimates by


Analysis of variance (ANOVA) was used to partition the total variation of the observed relative biases to determine the effects of the five design factors. Given that the purpose of using ANOVA in the present study was descriptive rather than inferential, the p value of the F test was not reported. Instead, the eta-squared (η2) effect size 2 was computed and reported as a measure of practical significance. Only effects with η2 greater than .01 were reported.
Accuracy
The square root of mean square error (SRMSE) was used as a measure of the overall accuracy of a parameter estimate. It was computed by

Coverage
The coverage of a confidence interval is the proportion of obtained confidence intervals that include the specified true parameter value. The 95% confidence interval for a fixed effect was computed as
Results
Variance Components
In both the correct and the misspecified model, there were five variance components, including variance of the school random effects (τ), variance of the student random effects associated with the intercept (
Estimated variance of the school random effects (τˆ)
In general, the variance of school random effects was underestimated. When the mobility rate was 5%, the relative bias was small and acceptable. As the mobility rate increased to 20% and 35%, the relative bias became larger, ranging from −.149 to −345. 4 The accuracy of the estimate also decreased in the misspecified model compared to that in the true model when mobility rate was high. The average SRMSE at the high mobility rate (35%) was .037 in the true model and .054 in the misspecified model. ANOVA results showed that mobility rate accounted for about 20% of the total variation in the observed relative bias (η2 = .19).
Estimated variance of the student random effects associated with the growth rate (ψˆ11)
When the mobility rate was 5%, the relative bias in
The ANOVA results indicated that mobility rate was the most important factor influencing the observed relative bias (η2 = .14). The increase in the mobility rate caused larger relative bias in
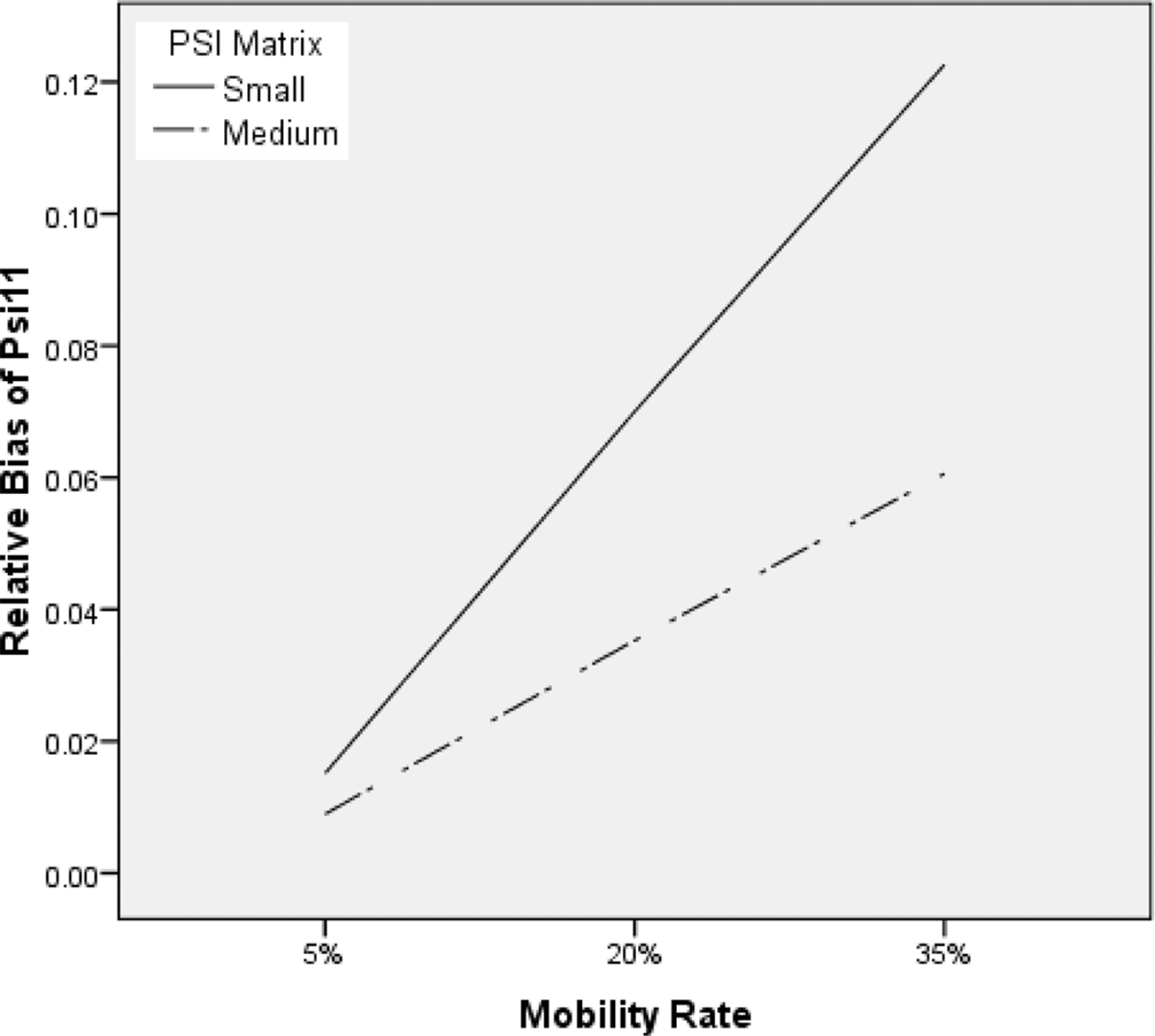
Effects of the mobility rate and ψ on the relative bias of
Estimated covariance of the student random effects (ψˆ01)
In general, there was a positive relative bias in
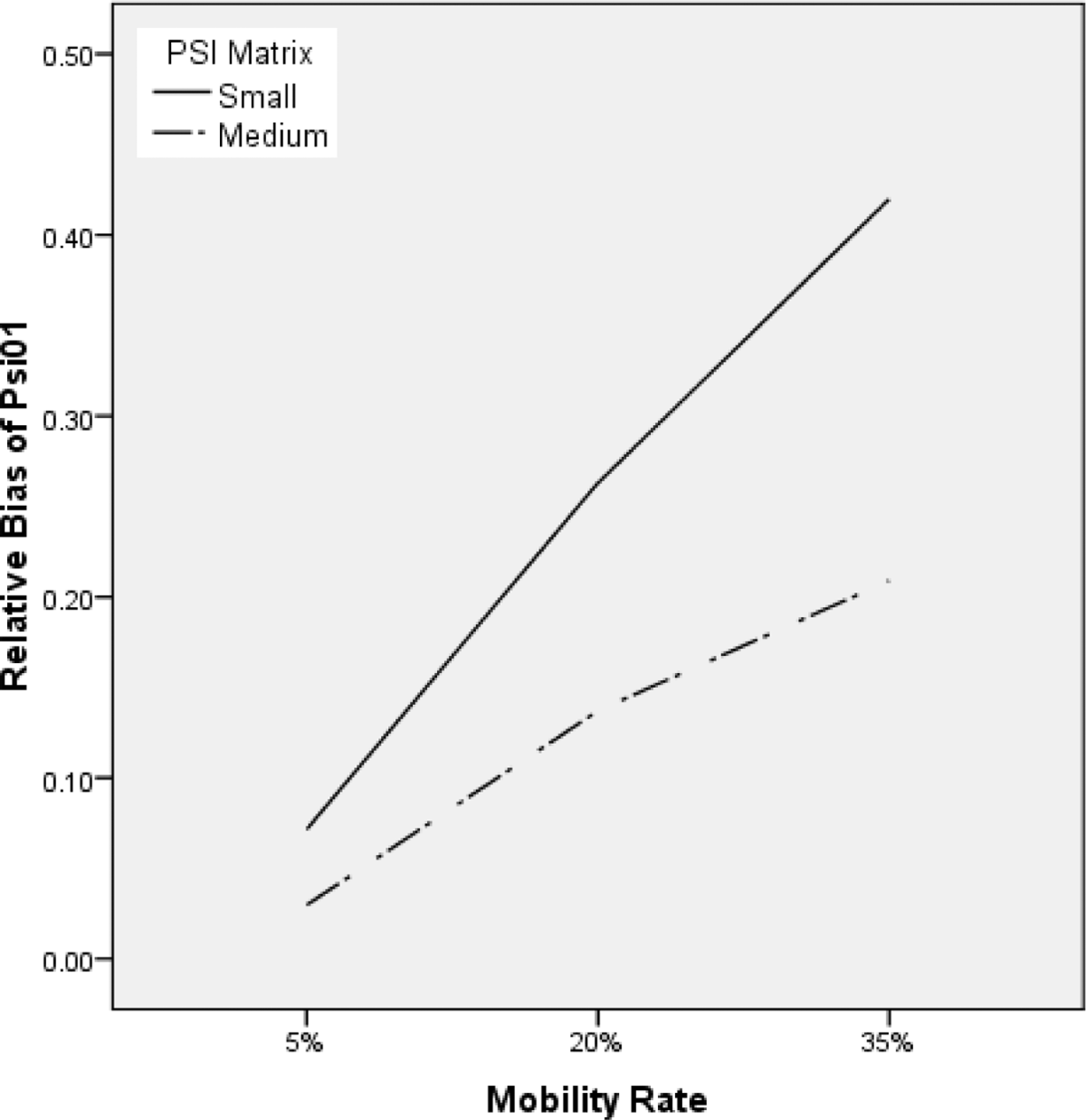
Effects of the mobility rate and ψ on the relative bias of
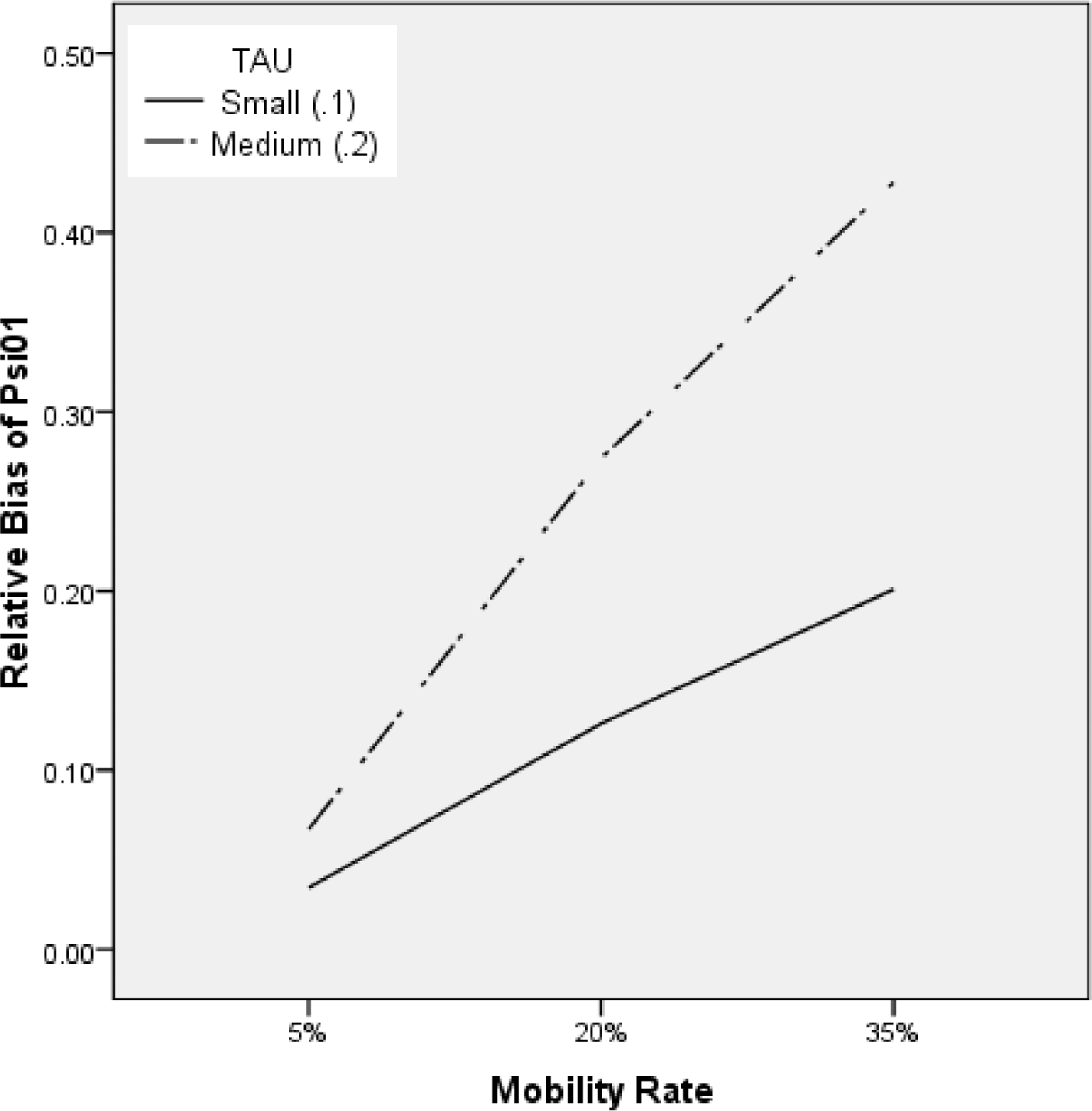
Effects of the mobility rate and τ on the relative bias of
Fixed Effects
The estimates of the fixed effects themselves remained consistent under the misspecified model because the consistency of generalized least squares (GLS) estimator does not depend on the specification of the random effects of the model (Kreft & de Leeuw, 1998). However, the standard error of the intercept (
Estimated intercept (γˆ00) and the corresponding standard error
In general, the standard error of the intercept (
Estimated regression coefficient of the school-specific predictor (γˆ02) and the corresponding standard error
The standard error associated with the school-specific covariate had a moderate to large negative relative bias (or underestimation) under all conditions, ranging from −.197 to −.813. The mobility rate had the largest effect (η2 = .61). As expected, the larger the mobility rate, the greater the relative bias in
Simulation II
Method
The first simulation study mimicked the type of students' mobility that was prompted by program design. Students also move for all kinds of other reasons, such as temporary housing, change of parents' occupation, family breakdown, and poverty. In those cases, students may switch schools at any time point, and a student can switch schools for multiple times. In the second simulation study, we generated data to mimic the more complicated situation. At each assessment occasion, a group of students was randomly selected to switch schools. In the generated data, some students move only once and some move more than once. Based on the findings from the first simulation study, the high mobility rate and the magnitude of τ and the
Results
The results had some similarities with those in the first simulation study. More specifically, τ was underestimated [B(
There were also important differences in the results. First, the variance of the student random effects associated with the intercept was underestimated [
Discussion and Conclusions
Multilevel models are widely used in educational research to model growth. If students stay in the same school overtime, the data structure is strictly hierarchical with repeated measures nested within students and students nested within schools. On the other hand, if students switch schools, the structure of the data becomes cross-classified with repeated measures cross-classified by students and schools. This study showed that treating the multilevel cross-classified data structure as strictly hierarchical led to the misspecification in the design matrix of the school random effects, and such misspecification could cause biases in the variance components estimates and the standard error estimates of the fixed effects. It was found that depending on the pattern of student mobility, the direction and magnitude of observed relative biases changed dramatically.
Pattern of Student Mobility
Students move in different patterns. In the first simulation, students switch schools altogether at a particular time point simultaneously (pattern I), whereas in the second simulation, students switch schools at any time point, and some students switch schools more than once (pattern II).
The pattern of student mobility is related to the degree of cross-classification. According to Luo and Kwok (2009), there were complete versus partial cross-classification. In completely cross-classified data, units in a cluster of one crossed factor could affiliate with any clusters of the other crossed factor and vice versa. On the other hand, in partial cross-classified data, units in a cluster of one crossed factor can only affiliate with part of the clusters of the other crossed factor. Most cross-classified longitudinal data are partially cross-classified because (a) only some of the students change schools and (b) students do not switch schools at every time point. Only in a very rare scenario in which all students are shuffled to different schools at all time points can the data be deemed as completely cross-classified.
Both patterns of mobility (I and II) investigated in this study produced partially cross-classified data. Pattern I produced a partially cross-classified data structure that was closer to the hierarchical structure, whereas pattern II produced structure that was closer to the completely cross-classified structure. The difference can be seen from the design matrix for school random effects. In pattern I, the correct design matrix takes such form as 5
Redistribution of Variance Components
Knowing the relationship between mobility pattern and degree of cross-classification helps us to understand the mechanism of the redistribution of the variance components and to link the findings of this study to previous research findings. In both patterns I and II, model misspecification causes part of the school variance to redistribute to the other levels, leading to underestimation of the school-level variance component. In pattern I, the redistributed school variance is added to the student level, causing overestimation of the variance of students random effects associated with the growth rate (
These findings have some similarities with those of previous studies in which a crossed factor was completely omitted in the misspecified model (i.e., the design matrix for school random effects was misspecified as a zero matrix). It has been shown that when the remaining crossed factor is almost nested within the omitted crossed factor, a situation similar to pattern I, almost all of the variance component of the omitted factor is added to the variance component of the remaining crossed factor, and little is added to the level below (Luo & Kwok, 2009). On the other hand, when the remaining crossed factor is more cross-classified with the omitted crossed factor, a situation similar to pattern II, all the variance component of the omitted factor is added to the level below, and some variance of the remaining crossed factor is also redistributed to the level below.
Standard Error Estimates of the Fixed Effects
The covariance matrix of the maximum likelihood estimator of the fixed effects γ as in Equation 1 is given by cov(
Under pattern I (i.e., students move once simultaneously), no substantial relative biases have been found in the standard error estimates of the regression coefficients of the time variable x, the student-level predictor w, and the cross-level interaction xw. However, under pattern II (i.e., students move multiple times), positive relative biases have been found in those standard error estimates. We drew upon mixed model theories to explain these differences. According to Berkhof and Kampen (2004), the standard error of the regression coefficient of the student-level predictor is a weighted sum of the Level 1 residual variance (σ2) and the variance of the student random effects associated with the intercept (
For the regression coefficients of the time variable x and the cross-level interaction xw, their standard errors are the weighted sums of the Level-1 residual variance (σ2) and the variance of the student random effects associated with the slope (
The Use of School Switching as a Student-Level Predictor
Previous research has demonstrated that children whose families live in poverty are more likely to move and that student mobility has a negative impact on academic achievement at all levels (e.g., Demie, 2002; Kerbow, 1996). Given that switchers and non-switchers may not come from the same population, it is important to take the school-switching status (i.e., “having switched schools or not”) into consideration. However, some researchers have the misconception that including a covariate of school-switching status would be a remedy for not considering the cross-classified structure of the data. In a supplementary simulation, 7 we examined the effect of ignoring cross-classification but including the school-switching status covariate. Similar biases were found in parameter estimates. In addition, because school-switching status is a student-level predictor, its standard error is overestimated in the misspecified model, causing a reduced statistical power in detecting the effect of the variable. Therefore, simply including the covariate of school-switching status does not help to reduce biases.
Implications
In longitudinal multilevel studies, it is common that participants change group membership or move to different clusters over time. In some circumstances, researchers may not have participants' cluster identifications at every time point; therefore, they may not be able to adequately analyze their data with CCREMs. To assess the potential impact of ignoring student mobility, researchers should consider three factors: the target of the analysis, the rate of mobility, and the pattern of mobility. If the target of the analysis is on testing the overall intercept and the effect of a school-level predictor, it is likely to have spurious significant results (i.e., inflated Type I error rates) under the misspecified model even when the mobility rate is relatively low. If the target of the analysis is on testing the overall growth rate and the effect of a student-level predictor on the intercept and growth rate, it is likely to have reduced power (i.e., inflated Type II error rates) when the mobility pattern is more spread out (i.e., students switch schools at any time and multiple times) and the mobility rate is relatively high. In addition, model misspecification will have a larger impact when there is a large variance at the school level and a relatively small variance at the student level.
Limitations
The present study only provided a preliminary investigation of the impact of misspecifying CCREMs in cross-classified longitudinal data. A major limitation is that the CCREM used in the study assumed that the effect of a particular school disappears when students move out of the school. In other words, it was assumed that there was no cumulative school effect. It should be noted that there are less restrictive CCREMs that allow for cumulative school effects (Grady & Beretvas, 2010; McCaffrey, Lockwood, Koretz, & Hamilton, 2004; Raudenbush & Bryk, 2002). Additionally, we only considered a simple linear growth model for the repeated measures that may not be applicable especially for multiwave longitudinal studies (Kwok, Luo, & West, 2010). Similarly, in the simulation studies, we assumed a very simple error structure (i.e., identity structure: V(ϵ t(jk)) = σ2I) for the within-subject repeated measures, which may not be always suitable for longitudinal data (Kwok et al., 2008; Kwok, West, & Green, 2007). Future research could investigate the impacts of ignoring the cross-classified structure in longitudinal multilevel data with less restrictive assumptions.