
Abstract
Measuring teacher effectiveness is challenging since no direct estimate exists; teacher effectiveness can be measured only indirectly through student responses. Traditional value-added assessment (VAA) models generally attempt to estimate the value that an individual teacher adds to students' knowledge as measured by scores on successive administrations of a standardized test. Such responses, however, do not reflect the long-term contribution of a teacher to real-world student outcomes such as graduation, and cannot be used in most university settings where standardized tests are not given. In this paper, the authors develop a multiresponse approach to VAA models that allows responses to be either continuous or categorical. This approach leads to multidimensional estimates of value added by teachers and allows the correlations among those dimensions to be explored. The authors derive sufficient conditions for maximum likelihood estimators to be consistent and asymptotically normally distributed. The authors then demonstrate how to use SAS software to calculate estimates. The models are applied to university data from 2001 to 2008 on calculus instruction and graduation in a science or engineering field.
Keywords
Introduction
On November 23, 2009, President Obama launched an “Educate to Innovate” campaign for excellence in science, technology, engineering, and mathematics (STEM) education. One of the goals of the campaign is to increase the number of students graduating from college in a STEM field, a goal that is shared by many higher education institutions. Numerous government and private organizations have called for strengthening the STEM pipeline (Government Accountability Office, 2006; National Academy of Sciences, 2007; National Science Board, 2007; U.S. Department of Education, 2009) and increasing the number of students majoring in STEM fields.
Value-added assessment (VAA) models are often used to investigate the “value” that individual teachers or schools add to students' knowledge (Resnick, 2004). These models focus on the gains in a student’s achievement that are supposedly attributable to the teacher or school rather than to the background of the student. Some of the VAA models that have been proposed are reviewed in the Spring 2004 issue of the Journal of Educational and Behavioral Statistics and in McCaffrey, Lockwood, Koretz, and Hamilton (2003). Commonly used VAA models employ either a univariate response such as a gain score or repeated measurements on a vertically scaled assessment (Ballou, Sanders, & Wright, 2004; Raudenbush, 2004; Rowan, Correnti, & Miller, 2002; Sanders, Saxton, & Horn, 1997). These models require the student responses to be equated to have the same achievement scale for all time periods. They use information from the test manufacturers for scaling or other item response theory methods (Ballou et al., 2004; Martineau, 2006). Mariano, McCaffrey, and Lockwood (2010) allow longitudinal responses with non-equated responses by using a Bayesian framework to compute estimates. All these VAA models are restricted to continuous responses and do not allow categorical responses. They thus cannot be used to assess value added to real-world long-term outcomes such as graduation with a STEM degree or employment in a STEM field.
In this paper, we study multivariate value-added assessment (MVAA) models for assessing the relative contributions of teachers and institutions toward categorical responses such as graduation with a STEM degree as well as continuous responses such as test scores. The multivariate models allow us to explore the relative variability and correlations of the teacher contributions to different, not necessarily longitudinal, outcomes. They thus present a more comprehensive picture of teacher effects; since teaching is a complex activity, one might expect teachers to have different contributions toward different outcomes. Since the model is not restricted to equated or continuous responses, it can be used in university settings where scores on standardized tests may be considered less relevant than real-world outcomes.
The next section presents multivariate mixed VAA models that explicitly allow non-equated and binary responses. We then derive properties of maximum likelihood estimators and discuss hypothesis tests for the covariance components. These theoretical results are needed so that statistical inferences can be made about the parameters and teacher effects. An important component of this research is making the methodology accessible for use by educational researchers and practitioners, and we provide code in SAS® software for computing estimates from the MVAA models. We then apply the models to estimate calculus teacher effects on calculus grades and on student graduation with a STEM degree and show that the multivariate model provides information that would not be available in a univariate approach. We conclude with a discussion of the uses and limitations of the models.
MVAA Models
We begin by stating the model when all responses are continuous, and then extend the model to allow binary or categorical responses. Let
We use a multivariate mixed model framework to analyze

The


As pointed out by Mariano et al. (2010), a multivariate model that allows a general covariance structure for

The full model for all students

The covariate matrix
Our primary interest in this paper is using MVAA models for situations in which the responses are not necessarily longitudinal, but capture different aspects of teacher contributions. In many university settings, standardized test scores are unavailable. We therefore want to use a more flexible model that still incorporates different teacher effects for different responses, but allows those responses to be quantities other than test scores.
The model in Equation 3 assumes that all responses are continuous and normally distributed. We employ a generalized linear mixed model (GLMM) to allow binary or categorical responses. For binary responses, we adopt the continuous response model (3) for an unobservable latent trait


Under this setup, the likelihood function for a bivariate binary response is
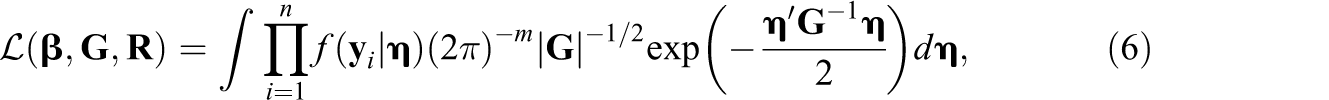
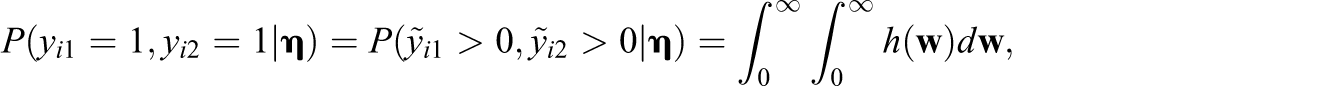
Evaluating the likelihood in Equation 6 requires calculating a
We therefore adopt the penalized quasi-likelihood approach used in SAS PROC GLIMMIX (SAS Institute Inc., 2008) to approximate the maximum likelihood estimates (Breslow & Clayton, 1993; Wolfinger & O’Connell, 1993). The method uses a first order Taylor series expansion of
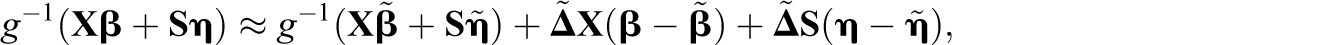


One concern associated with penalized quasi-likelihood methods for fitting models with binary responses is potential bias of the parameter estimates. Rodríguez and Goldman (2001) exhibited substantial bias for penalized quasi-likelihood estimates of variance components in their simulation study of nested binary data with few observations per group. Pinheiro and Chao (2006), however, noted that the bias is minimal in situations with larger group sizes. While the model in Equation 4 is not nested, class sizes are generally larger than the group sizes studied by Rodríguez and Goldman (2001), so we do not expect bias to be a serious problem. We are currently studying other computational methods for the problem including higher order Laplacian approximations and adaptive quadrature methods.
Maximum Likelihood Estimation and Hypothesis Tests in the MVAA Model
Much has been written on properties of maximum likelihood estimators in nested models (Demidenko, 2004; Verbeke & Molenberghs, 2000). Several articles on VAA models claim that the estimators in general mixed models are consistent and asymptotically normal; they cite as their justification a limit theorem that assumes that the response vector
The maximum likelihood estimators for the model in Equation 3 are straightforward to write down from standard theory. The maximum likelihood estimator of Theorem 1: Consider the model in Equation 3, with

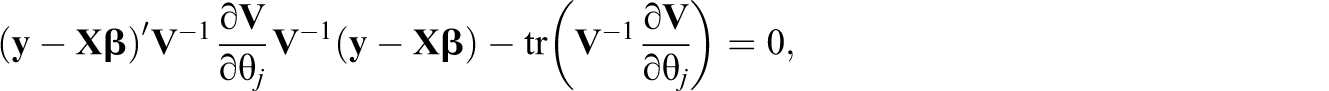




The theorem is proven in Appendix A. The condition that

Since the maximum likelihood estimators are consistent and asymptotically normal, several tests may be used for hypotheses about the parameters in

The Wald test relies on the asymptotic normality of the estimators. Let

The likelihood ratio test statistic for the null hypothesis in Equation 9 is

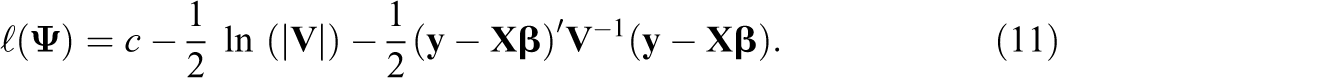
Thus, under the conditions in Theorem 1 for the model in Equation 3, the standard Wald and likelihood ratio tests may be used for hypotheses about
For binary responses and the model in Equation 5, the likelihood ratio test statistics will not be valid since a pseudo-likelihood is used rather than a likelihood. We use a Wald test for binary responses.
Computation in SAS Software
This section discusses computational challenges for multivariate VAA models and gives sample code for computing estimates in SAS software. As stated above, the MVAA models do not have hierarchical structure, so the covariance matrix
Several authors have solved the computational problem by adopting a simpler covariance structure. The models presented in Doran and Lockwood (2006) for VAA models in the R statistical software package allow the student responses to be correlated but do not allow the teacher effects to be correlated. Tekwe et al. (2004) agreed that it would be a “more natural assumption” to allow the teacher effects to be correlated and provided sample code in SAS that allows for this correlation. Their model, however, assumes that each teacher has a different covariance matrix
Mariano et al. (2010) used Bayesian methods to compute estimates of parameters and teacher effects in a multivariate model with continuous responses. The Bayesian computations have the advantage that they will almost always produce parameter estimates and can be implemented in readily available Bayesian modeling software packages. If the primary interest is in the regression parameters
From a practical standpoint, we believe that it is useful to have methods for computing maximum likelihood estimates as an alternative to Bayesian computations: The maximum likelihood estimators have the asymptotic properties shown in Theorem 1, maximum likelihood methods are familiar to persons in a wide variety of fields, they do not rely on a possibly subjective specification of a prior distribution, and they do not require expertise in Markov Chain Monte Carlo methods to fit the models. The methods we present below use SAS software to calculate maximum likelihood estimates, so they are usable by anyone with access to that standard software package. Computations in SAS software have the additional advantage that the SAS procedures have been written to reduce numerical errors. For example, SAS PROC MIXED uses the stable Newton–Raphson algorithm for iterative calculation of variance parameters and a modified sweep-based algorithm to calculate the fixed effects (Wolfinger, Tobias, & Sall, 1994).
Although the estimates can be calculated in SAS software, for large data sets the user may need to increase the amount of memory available to SAS. At present, the computations in SAS do not scale to extremely large data sets. SAS PROC HPMIXED, which uses sparse matrix techniques to solve large mixed model problems, does not currently have the capacity to use the covariance structure we specify, although PROC HPMIXED can be used to obtain initial estimates of the diagonal elements of
There are two levels of random effects in the models, one for teachers and the other for students. To calculate both of these in SAS PROC MIXED, which will be used when all responses are continuous, we use the RANDOM statement for the teachers and the REPEATED statement for the students. In SAS PROC GLIMMIX, used for binary and categorical outcomes, two RANDOM statements are listed. The standard variance structures for the RANDOM statement such as compound symmetry do not allow a correlation among the random teacher effects, so we must define the structure explicitly. Consider the matrix

Value Added in Calculus Instruction
We now apply the models to data from a large public university. The study includes students who entered the university between fall 2000 and fall 2003 and who took at least one of the courses Calculus with Analytic Geometry II or III. These semesters were chosen since entry in those semesters allows at least 5.5 years for degree completion. The study, as with any VAA model, requires the students be linked to a teacher for every class; Broatch (2009) described the steps taken to resolve inconsistencies and link the data sets.
In this section, we present two models: (1) a model with both responses continuous, with
Description of Student-Level Response Variables and Covariates

Description of Instructor-Level Covariates
For the first analysis with responses grade2 and grade3, only 24 instructors who taught both Calculus II and Calculus III were considered because of memory restrictions. The student information from the 2,051 students of those 24 teachers was then retained. Not all students took both classes at the university; many students take Calculus II in high school, while others do not continue on to Calculus III after taking Calculus II; thus, the data set used for the analysis had missing values. The model in Equation 3 may be fit to a data set with incomplete responses, making use of the available data for students with only one response. The model accounts for the missing data in three ways: through the covariance of the response in
Table 3presents the estimates of the fixed effects in the continuous model, omitting covariates that were not significant. No teacher covariates were significant in any of the models we fit. The covariate SATQ was significant, but it was not included since the covariate was missing for a large number of observations. Gender was also not significant in the full model, although it was significant in a model with no other covariates; in the full model, the covariate hsgpa explained the variability that otherwise would be explained by gender because female students have higher high school grade point averages. We also tested the null hypothesis that the slopes are the same for the two responses: Citizen is the only covariate with a significant difference between the grade2 parameter and the grade3 parameter (
Fixed Effects Estimates and Standard Errors in the Continuous Model
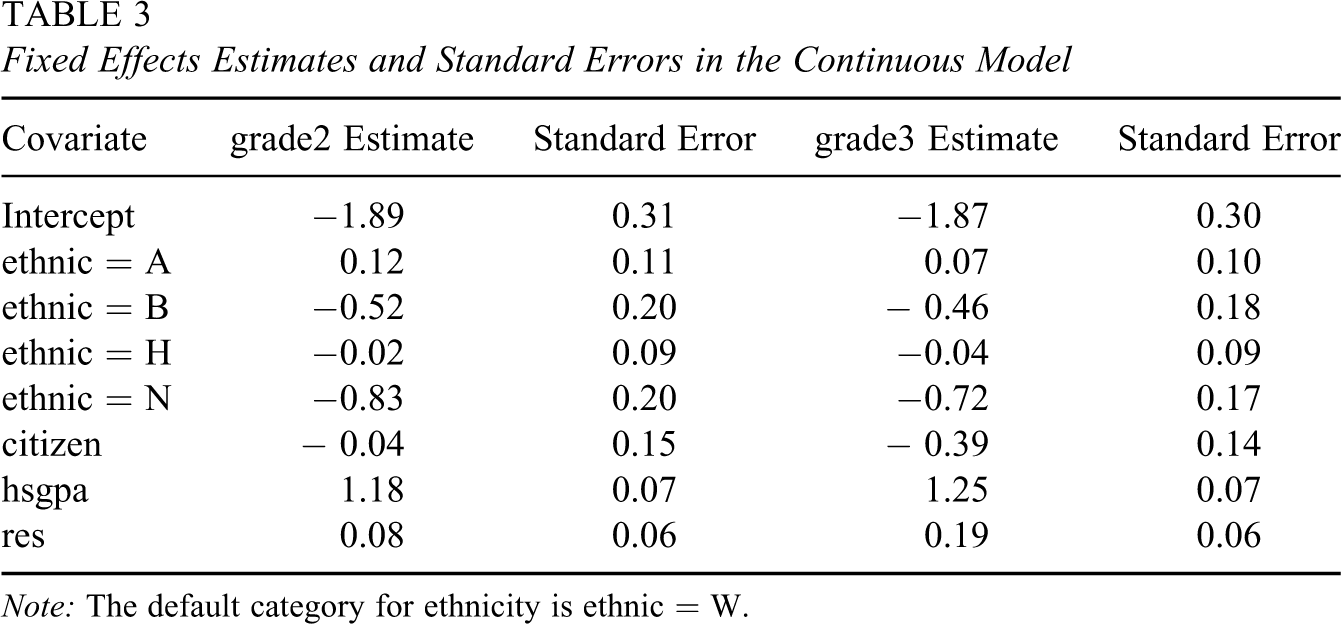
Note: The default category for ethnicity is ethnic = W.
The estimated covariance parameters for the model are
Predicted random teacher effects for responses of grades in Calculus II/III.
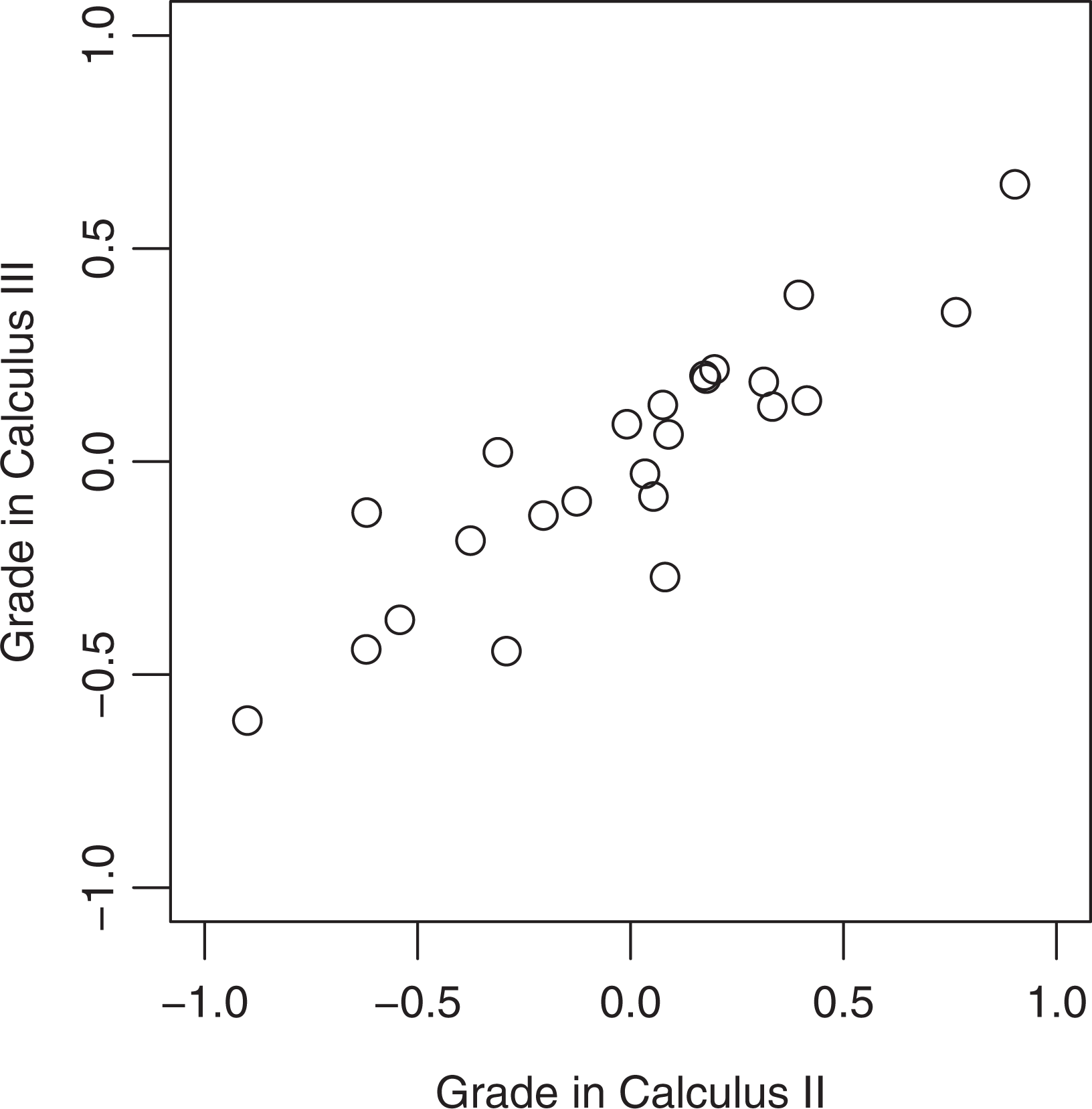
A likelihood ratio test of
The second analysis jointly models a continuous and binary response, with
Fixed Effects Estimates and Standard Errors in the Model With Responses stem and grade3
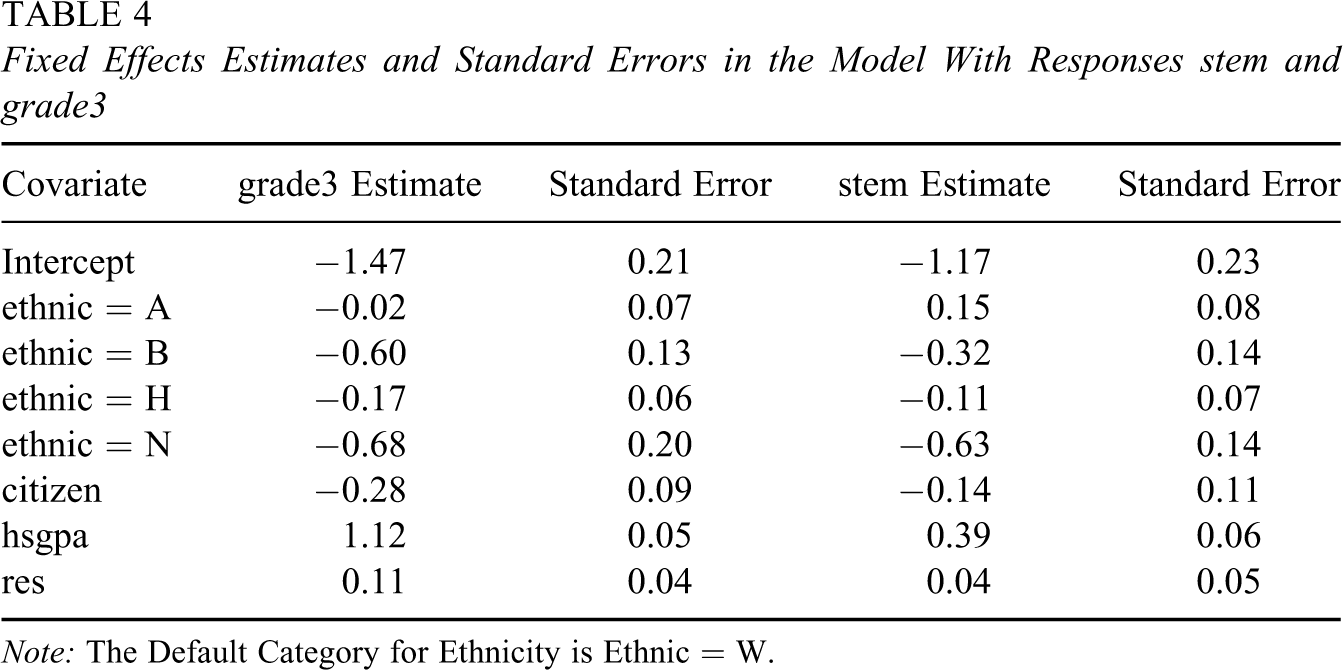
Note: The Default Category for Ethnicity is Ethnic = W.
The estimated covariance parameters for the model with responses grade3 and stem are: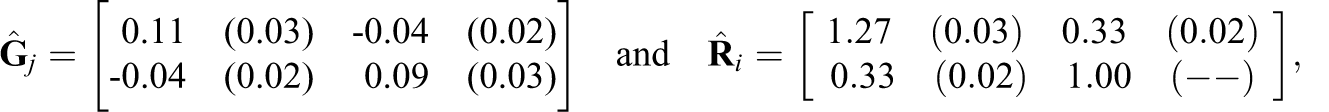
Again, the variance components due to the students are substantially larger than the variance components due to the teachers, and the correlations of the student responses and teacher effects appear to be necessary in the model. The correlation within students for the responses is positive (
Predicted random teacher effects for responses: Grade in Calculus III and graduation with a STEM degree.
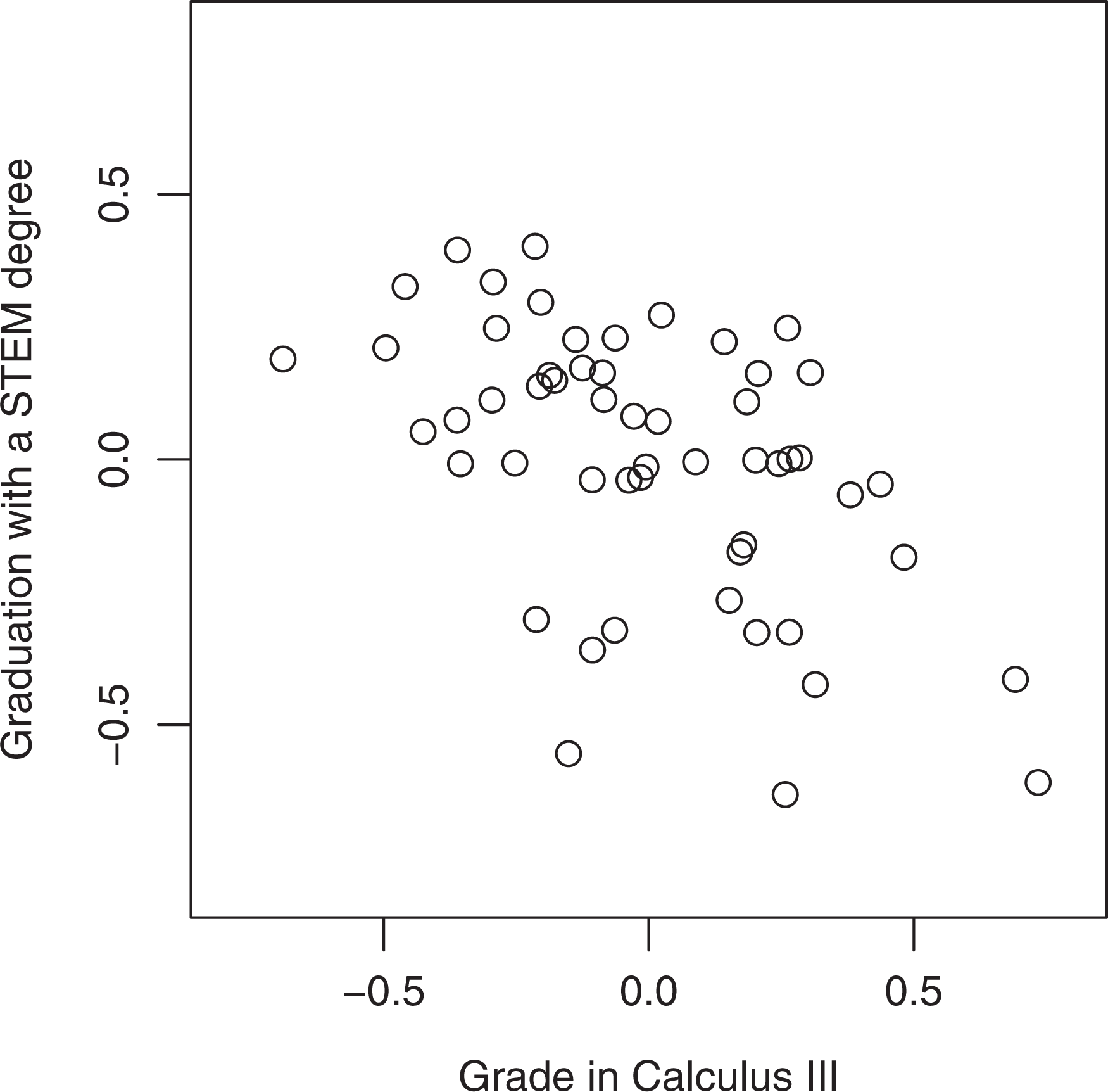
The MVAA models clearly provide more information for these data than a univariate model would have. They allow use of partial information for students who do not have a complete bivariate response, thereby reducing bias in the estimates and giving more precision for parameter estimates. The significance of
Uses and Limitations of the MVAA Models
The model in Equation 3 includes random effects for teachers. If desired, a school level variable (third level of hierarchy) can be included similarly to the teacher effect. Also, a random factor for class nested within teacher can be included. Although the model makes explicit references to students, teachers, and time periods, the model can very easily be generalized to any two- or multilevel analysis with repeated measures. For example, you can model the effect of doctors (teachers) and hospitals (schools) on patients' (students') well-being over time. Regardless of the applied concept, the main goal is to be able to use the MVAA models to estimate the parameters of interest, that is, estimates of individual teacher and school effects and the overall contributions of the teachers to the variability of the student achievement.
When we have discussed this research with colleagues, the first question many people ask is which teachers are the best or worst, and who are the individual teachers appearing in Figures 1 and 2. Many researchers and policymakers argue that VAA models provide more information for teacher evaluation than some other approaches, and therefore should be an important component of official teacher evaluations. Gordon, Kane, and Staiger (2006) are among those who suggest using estimates from VAA models for decisions about hiring or firing teachers.
We believe that our results illustrate potential concerns about using estimates of individual teacher effects for ranking purposes. First, although the models can be used with data from randomized experiments, in most cases, they will be used with observational data. Unmeasured variables may have a large effect on the outcomes. We did not have information, for example, on the number of hours worked per week by the students; it is possible that students who work many hours would be concentrated in certain time slots. Since students choose which teacher they take, and since it is impossible to measure every factor in a student’s background that contributes to success, one cannot say that the estimate for a specific teacher is due to that teacher rather than to the characteristics of students who select that teacher.
Second, the results illustrate that potential rankings depend strongly on the particular outcome studied. Corcoran (2009) argued that if VAA model estimates are to be used for teacher assessment, at the very least they should be precise and consistent across outcomes measured. He also argued that they should admit a causal interpretation, which, given the observational nature of most data sets, does not occur. In our application, neither of Corcoran’s conditions is met. Figure 2 indicates a negative correlation between estimated teacher effects for one of the responses used in the evaluation of instructors at the university, namely, course grades, and a long-term outcome that is one of the stated goals of the university administration, namely, increasing the number of graduates in STEM fields. Thus, a ranking based on one of the responses will ignore contributions to the other response.
The MVAA models in this paper show the relationships among teacher contributions toward different student outcomes and allow consideration of binary real-world outcomes such as graduation or having a career in a STEM field. While they cannot capture the full complexity of student achievement, they can provide a much better picture than relying solely on univariate test scores.
Footnotes
Appendix A: Proof of Theorem 1
We show that the conditions in Theorem 2 of Mardia and Marshall (1984) hold, namely, that (a) the eigenvalues of
We rely on properties of matrix norms to bound the eigenvalues of
Acknowledgments
This research was partially supported by the National Science Foundation under grants SES-0604373 and DRL-0909630. The authors thank the reviewers for their many helpful comments, which led to an improved paper.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation or Arizona State University.