
Abstract
In the human sciences, ability tests or psychological inventories are often repeatedly conducted to measure growth. Standard item response models do not take into account possible autocorrelation in longitudinal data. In this study, the authors propose an item response model to account for autocorrelation. The proposed three-level model consists of multiple facets (e.g., person, item, and rater facets) and slope parameters. Level 1 is an item response (within-occasion) model; Level 2 is a between-occasion and within-person model; and Level 3 is a between-person model. Parameters can be estimated using the computer software WinBUGS, which uses Markov Chain Monte Carlo (MCMC) algorithms. Through a series of simulations, it was found that the parameters in the proposed model can be recovered fairly well. Real data of job performance judged by raters at various time points were analyzed to illustrate the implications and application of the proposed model.
Keywords
In recent years, item response theory (IRT) has been widely applied to the social, behavioral, and health sciences. Most IRT models (e.g., the Rasch model, the two- and three-parameter logistic models and their polytomous extensions) are single-level. Consider a situation where we are interested in a group difference in a latent trait (e.g., gender difference in mathematics proficiency), or in using some background variables (e.g., age) to predict a latent trait. With single-level IRT models, the analysis consists of two stages. In Stage 1, an IRT model is fit to the data to obtain person measures. In Stage 2, an ordinary regression is applied to the person measures. The person measures are thus mistakenly treated as true values without measurement error. If the test was not sufficiently long and the measurement error is not trivial, then the results of the subsequent regression analysis can be seriously misleading. To resolve the problem of measurement error in person measures, one can form a two-level model in which Level 1 consists of an IRT model and Level 2 consists of a regression model. Since the criterion variable in the regression model is latent rather than observed, this approach is also called latent regression (Adams, Wilson, & Wu, 1997; Andersen, 2004; Christensen, Bjorner, Kreiner, & Petersen, 2004; Mislevy, 1985; Zwinderman, 1991).
Higher-level structures are possible. For instance, offspring can be grouped within families, and students can be nested within classes, which can be nested within schools. Offspring from a pair of parents tend to be more alike in their physical and mental characteristics than individuals chosen at random from the population at large. Students in a given class tend to be more homogenous than students who are randomly sampled from the population because the assignment of students to classes is not random but is based on geographic factors; students within a given class may come from a community with similar backgrounds, and they share a teacher, environment, and experiences.
Most IRT models consist of only two facets. That is, item responses are determined by an item facet and a person facet and the other factors are treated as random errors. In some testing situations, more than two facets may be involved; for example, item responses to essay items are often scored by raters and raters may hold different degrees of severity. Rater severity is often (if not always) too influential to be treated as a random noise. To better describe such kinds of data, several facets models have been proposed (Linacre, 1989, 2002; Lunz, Wright, & Linacre, 1990). In facets models, rater severity is often treated as a fixed effect, meaning that the rater holds a constant degree of severity throughout the rating process. This assumption may be too stringent in practice, because a rater may show a varying degree of severity during the rating process. Under such a case, it is more appropriate to treat rater severity as a random effect following a normal distribution. That is, each rater’s severity follows a distinct normal distribution, such that both intrarater and interrater variation in severity can be assessed. The random-effect facets model (Wang & Wilson, 2005) has such strength.
Advantages of multilevel IRT models include better reflection of a multilevel data structure, simultaneous estimation of item parameters and person measures, and accurate inference about higher-level measures (Fox, 2005; Kamata, 1998, 2001; Maier, 2001). Strengths of facets models consist of the simultaneous consideration of more than two facets in item responses so as to yield more accurate and valid measures (Linacre, 1989). Given that data may have a multilevel structure and more than two facets, it is natural to develop a generalized multilevel facets model, such as that recently proposed by Wang and Liu (2007).
Although the generalized multilevel facets model (Wang & Liu, 2007) is very general and includes many existing IRT models as special cases, it does not account for autocorrelation that is commonly found in repeated measures. Longitudinal data are commonly collected in the human sciences. For example, individuals are repeatedly measured on multiple occasions. The temporal ordering of the measurements is important because measurements closer in time within a person are likely to be more similar than observations farther apart in time. Longitudinal data have more statistical problems than cross-sectional data. Repeated observations on a given unit are seldom independent, and thus independence should be tested, not assumed. If the assumption of independence does not hold, the standard likelihood method of breaking up the likelihood of the sample into the product of individual likelihoods can no longer be applied. Stationarity is a basic assumption of longitudinal or time series analysis, which states that the choice of time origin does not affect the statistical properties of the process. When data do not meet this requirement, they can be transformed until they do through some stationary processes.
In the following empirical example, the data set requires complex IRT models to account for the rater effect, dependence in repeated observations, and latent regression. A set of workers from four departments of a company were evaluated by their managers on five criteria along a 5-point rating scale on four occasions. The item responses were ordinal and thus polytomous IRT models were needed. These IRT models should include a rater facet because the ratings were given by managers. The data were longitudinal and repeated observations of a given worker made by a manager may not be independent (e.g., carryover effects). Finally, workers in different departments might follow different growth trajectories, making latent regression necessary.
To meet this demand, we propose a multilevel facets model that can be applied to longitudinal data, show how to estimate its parameters, assess parameter recovery with a series of simulations, and demonstrate its application using an empirical example. This article is organized as follows. First, we introduce the simple Rasch model (1960) and its facets and multilevel extensions. Second, we propose a model which consists of three levels: a within-occasion item response model, a between occasion and within-person model, and a between-person model. Third, we explain how to use the Bayesian method of Markov Chain Monte Carlo (MCMC) to estimate parameters. Fourth, we describe a series of simulations that were conducted to assess parameter recovery and summarize the results. Finally, we provide a real data set of employees' job performances to demonstrate the application of the proposed model.
Facet Modeling
When person n responds to item i, the dichotomous Rasch model can be expressed as:

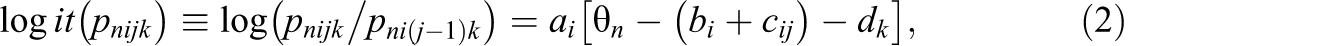
Longitudinal Modeling
Equation (2) does not consider the possible dependence between repeated observations. To account for such dependence, we propose a generalized multilevel facets model for longitudinal data (denoted as GMFM-L), which consists of three levels. The Level 1 model describes item responses at a specific time point. The Level 2 model takes into account variation in the latent traits across measurement occasions within persons, in that a polynomial growth curve is specified to describe how the expected value of a response variable changes over time, and the covariance structure is autoregressive. The Level 3 model specifies the variation in growth trajectories between persons, which can be homoskedastic or heteroskedastic.
Level 1 Model
The Level 1 model describes item response functions, and is referred to as the item (or within-person) level. The log-odds of a response in category j over category j – 1 on item i for person n at time t when judged by rater k are formulated as:
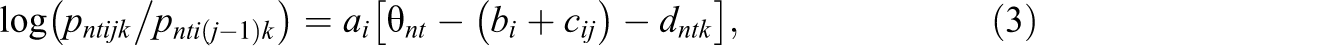
Note that in
If there is only one time point (i.e., t = 1) and the rater holds an identical degree of severity for all persons (i.e., no intrarater variation), then Equation (3) reduces to Equation (2). For ease of estimation, one can specify the following normal priors for item parameters:
Level 2 Model
At Level 2, a latent growth model with an autoregressive residual structure is proposed as:

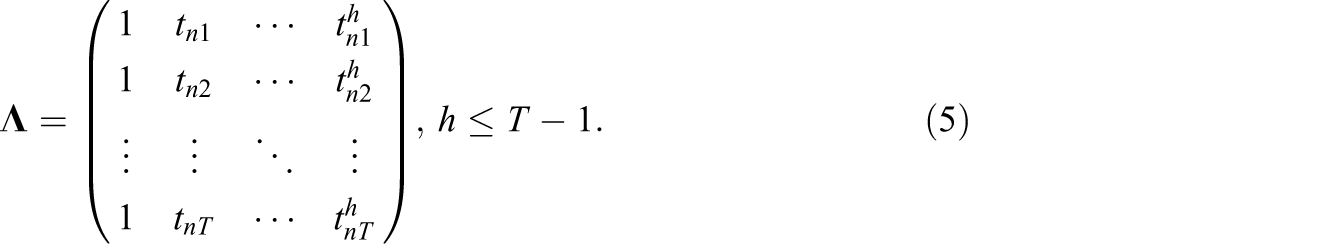

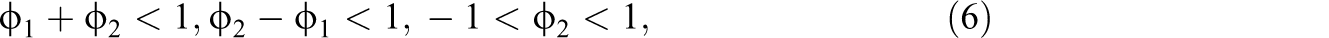

For ease of estimation, one can specify normal priors for ϕ1 and ϕ2 as
Level 3 Model
In order to further describe variations in growth trajectories between persons, the Level 2 regression coefficients are regressed on another set of personal background variables:


It can be shown that the GMFM-L consists of many standard IRT models as special cases. For example, when there is one time point, the GMFM-L reduces to the generalized multilevel facets model (Wang & Liu, 2007). Furthermore, if there are only two facets with a single time point and a single level, the GMFM-L reduces to the generalized partial credit model (GPCM; Muraki, 1992).
Parameter Estimation
The Bayesian approach is used for parameter estimation in the GMFM-L. In recent years, Bayesian methods have been widely applied to estimate parameters in complicated models, such as IRT models (Béguin & Glas, 2001; Patz & Junker, 1999a, 1999b), factor analysis models (Bartholomew, 1981; Lee, 1981), and structural equation models (Scheines, Hoijtink, & Boomsma, 1999). Implementing Bayesian analysis is both computationally intensive and cumbersome to program. Fortunately, the freeware WinBUGS provides users with a simple and user-friendly tool for performing Bayesian MCMC methods. There are various MCMC algorithms, including the Metropolis-Hastings algorithm (Hastings, 1970; Metropolis, Rosenbluth, Rosenbluth, Teller, & Teller, 1953) and the Gibbs sampling algorithm (Baker, 1998; Fox & Glas, 2001; Geman & Geman, 1984; Liu & Sabatti, 2000; Roberts & Smith, 1993).
The most prominent feature of the Gibbs sampling algorithm is that the underlying Markov Chain is constructed by composing a sequence of posterior distributions along a set of directions. In this study, data augmentation and the Gibbs sampling algorithm are used (Albert & Chib, 1993; Geman & Geman, 1984; Tanner, 1993; Tanner & Wong, 1987). Based on the data augmentation proposed by Tanner and Wong (1987), the observed data, 1. Begin with an arbitrary starting point ( 2. Sample each parameter from its posterior distribution, conditioned on the previous values sampled for other parameters: In iteration s, parameters are sampled from their posteriors, conditioned on the parameters from iteration s – 1. 3. Continue this iterative process until a large number of samples are generated.
WinBUGS makes the Gibbs sampling algorithm easily accessible because users do not have to derive the full conditional distributions, and programming MCMC methods in WinBUGS is much easier than that in other computer languages (Segawa, 2005).






Deviance Information Criterion
The deviance information criterion (DIC; Spiegelhalter, Best, Carlin, & Linde, 2002) is defined as a Bayesian measure of model–data fit:




Model Comparison
A common approach for model comparison within the Bayesian framework is to compute a Bayes factor (Gelfand, 1996). When both models have an equal prior likelihood, the Bayes factor is defined as:



The Simulation
Design
A series of simulations were conducted to examine parameter recovery and model–data fit of a two-level GMFM-L with an AR(2) structure and a linear growth curve. The simulated data sets contained four time points, each with the same two 7-point items. There were two groups of test-takers (persons), each with 120 persons. Each person’s item responses were scored by 4 of a total of 16 raters. The rater severity at the four time points was manipulated as follows. At t1 and t2, every rater had a severity generated from the given normal distribution N (0, 0.5); in other words, all raters had the same mean and variance of severity. At t3 and t4, the raters had severities generated from normal distributions with various means and variances.
The data were simulated as follows. First, the white noise series was randomly generated from the normal distribution N (0, 0.78). Second, the series values and the specified parameters (i.e., discrimination, difficulty, step, severity, time covariate, regression, and autocorrelation, shown in Table 2as true values) were used to calculate the corresponding category probability and the cumulative probabilities using Equation (3). Third, these cumulative probabilities were compared to a random number from a uniform (0, 1) distribution. The response was set at the category with the lowest cumulative probability larger than the random number.
Model Comparisons With the DIC and Cross-Validation Log-Likelihoods for Simulated and Real Data

Note: GPCM = generalized partial credit model; AR(1)=first-order autoregressive residual model; AR(2)= second-order autoregressive residual model.
Bias and RMSE in Model 1 for Simulated Data
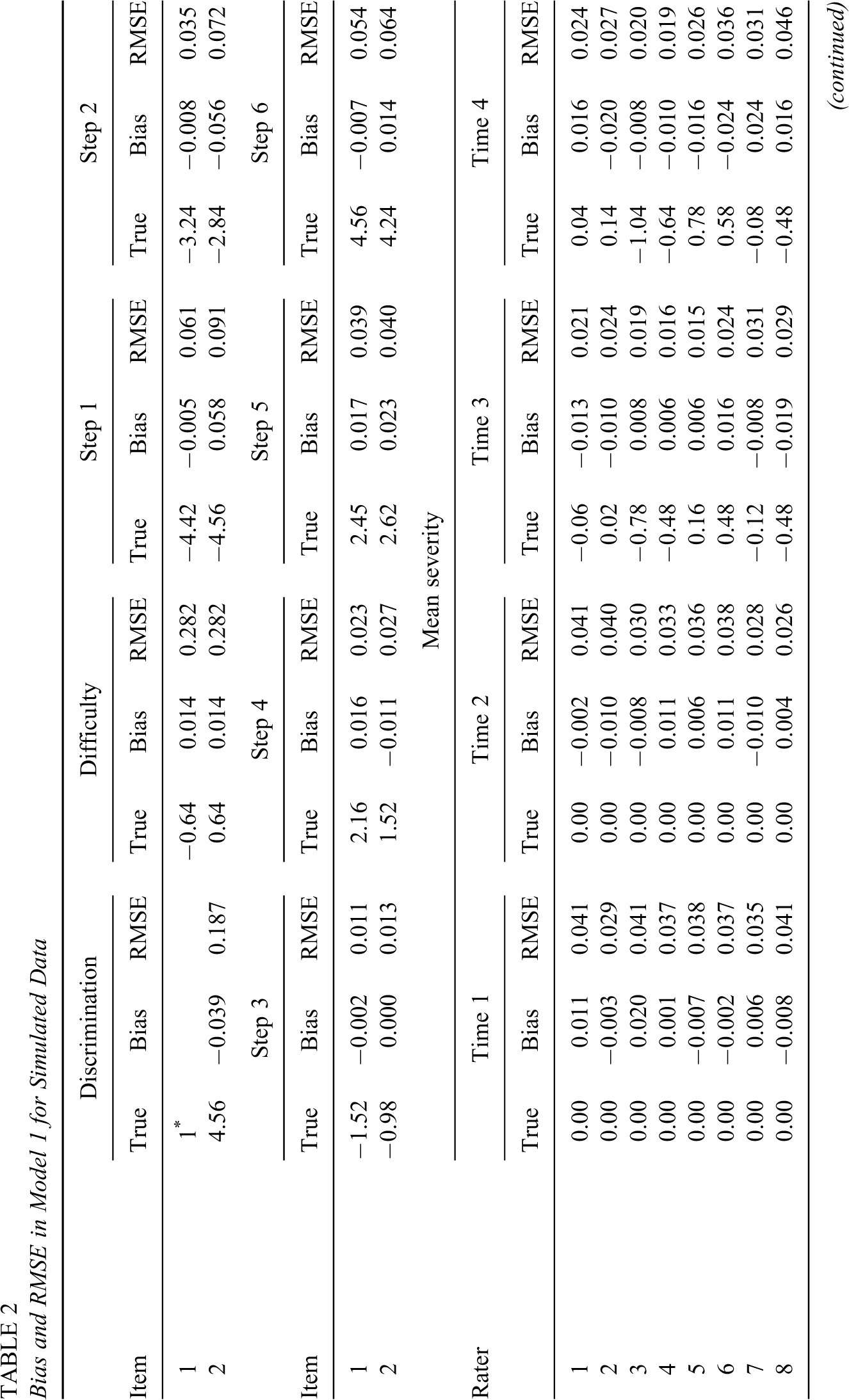
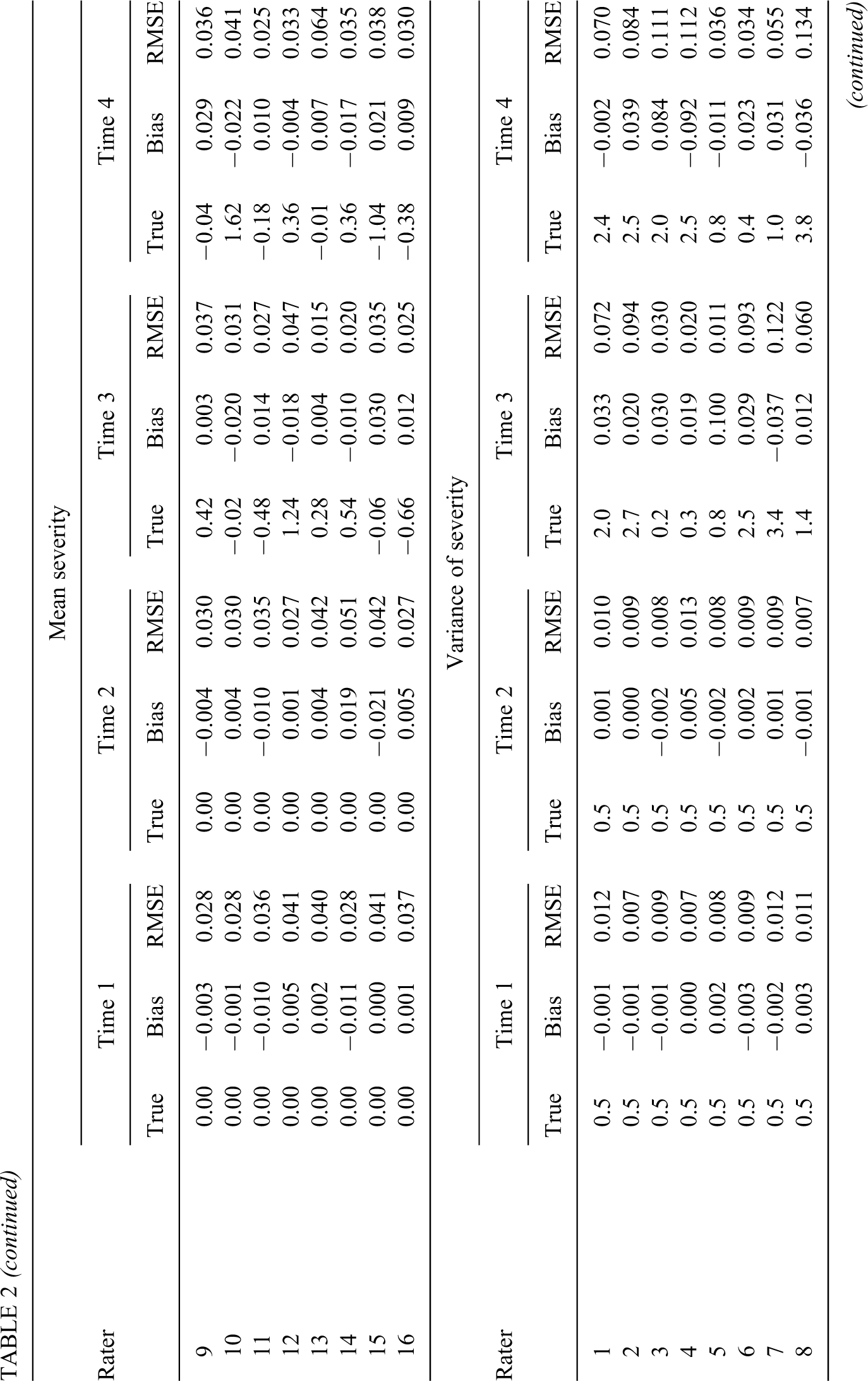
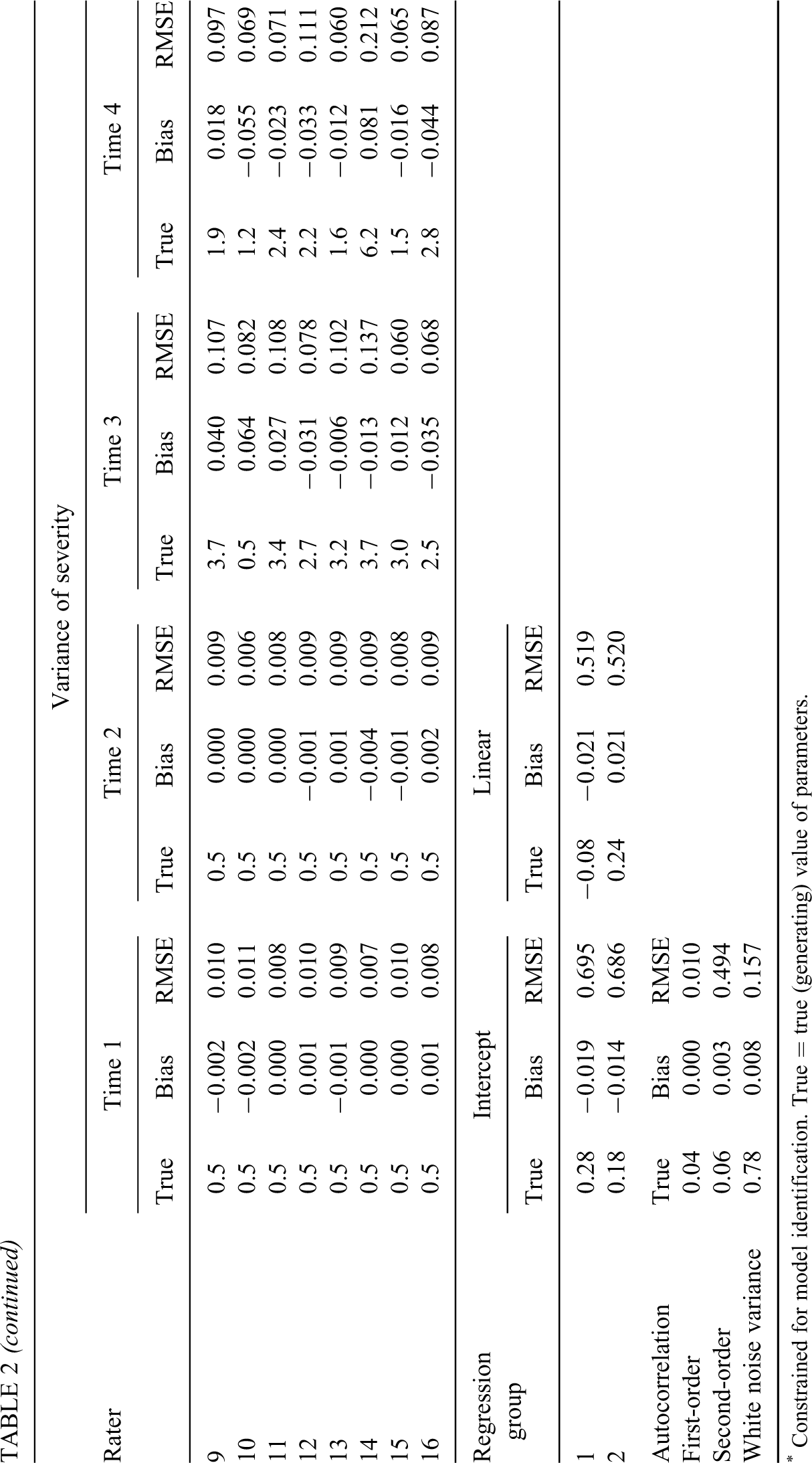
* Constrained for model identification. True = true (generating) value of parameters.
In the analysis, we were interested in the following effects on parameter estimation or model-data fit: (a) intrarater and interrater consistency: at t1 and t2 all raters had identical intrarater consistency and interrater consistency, at t3 and t4 all raters had different intrarater consistency and interrater consistency; (b) rater–time interaction: each rater had varying severity across time points or each rater had an identical severity across time points; (c) autoregressive residuals: white noise or AR(2); and (d) step difficulties over items: each item had a set of step difficulties (i.e., the partial credit modeling; Masters, 1982) or all items shared the same set of step difficulties (i.e., the rating scale modeling; Andrich, 1978).
After the item responses were generated, five models (M1 to M5) were fit using WinBUGS. The upper part of Table 1describes the features of the five models. A total of 30 replications were made. M1 was the generating model. M2 did not consider the time effect; that is, every rater was assumed to hold the same severity distribution across the four time points. M3 was formed by constraining the autocorrelation parameters of M2 to zero; the model became a white noise model. M4 was formed by further constraining the random effect of rater severity in M3 to a fixed effect where the variance of severity for every rater was set to zero. Finally, M5 was formed by constraining the step difficulties of M4 to be the same across items.
In this simulation, the priors were specified as:








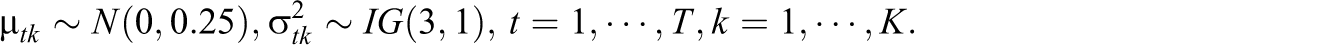
The “eyeball” method, monitoring the convergence by visually inspecting the history plots of the generated sequences, is commonly used. Usually, if there is no change point or trend in the plot, the convergence of the generated sequence is accepted (Zhang, Hamagami, Wang, Grimm, & Nesselroade, 2007, p. 377). To obtain accurate estimates, the Monte Carlo error for each parameter of interest should be smaller than 5% of the standard deviation (Spiegelhalter, Thomas, Best, & Lunn, 2003). Bias and root mean square error (RMSE) were used to assess parameter recovery.
Results
There were 149 parameters in the generating model M1, including 1 discrimination parameter for Item 2 (Item 1’s discrimination was constrained to be unity for model identification), 1 difficulty parameter for Item 2 (Item 1’s difficulty was constrained to be the negative value of Item 2’s difficulty for model identification), 6-step parameters for each item, 3 autocorrelation parameters (ϕ1,ϕ2, and
When the generating model (M1) was fit to the data, as shown in Table 2, it was found that the bias was –0.039 for the discrimination, 0.014 for the difficulty, –0.056 ∼ 0.058 for the step parameters, 0.000 ∼ 0.008 for the autocorrelations, –0.021 ∼ 0.021 for the regressions, –0.021∼ 0.020 for the mean severity of the first two time points, –0.024 ∼ 0.030 for the mean severity of the last two time points, –0.004 ∼ 0.005 for the variance of severity of the first two time points, and –0.092 ∼ 0.100 for the variance of severity of the last two time points. All but the variance of severity of the last two time points had a bias very close to zero. The RMSE was 0.187 for the discrimination, 0.282 for the difficulty, 0.011 ∼ 0.091 for the step parameters, 0.01 ∼ 0.494 for the autocorrelation parameters, 0.519 ∼ 0.695 for the regression parameters, 0.026 ∼ 0.051 for the mean severity of the first two time points, 0.015 ∼ 0.060 for the mean severity of the last two time points, 0.006 ∼ 0.013 for the variance of severity of the first two time points, and 0.011 ∼ 0.212 for the variance of severity of the last two time points. The RMSE for the last two time points (where different raters had different variances of severity) was larger than that for the first two time points (where all raters had a common variance of severity of 0.5), which might be due to the magnitude of the variances for the last time points (0.2 ∼ 6.2, M = 2.2) being larger than that for the first two time points. As also shown in Figure 1, ϕ2 and the four regression parameters had a large RMSE (0.494 ∼ 0.695), which might be due to the small number of time points and insufficient replications.
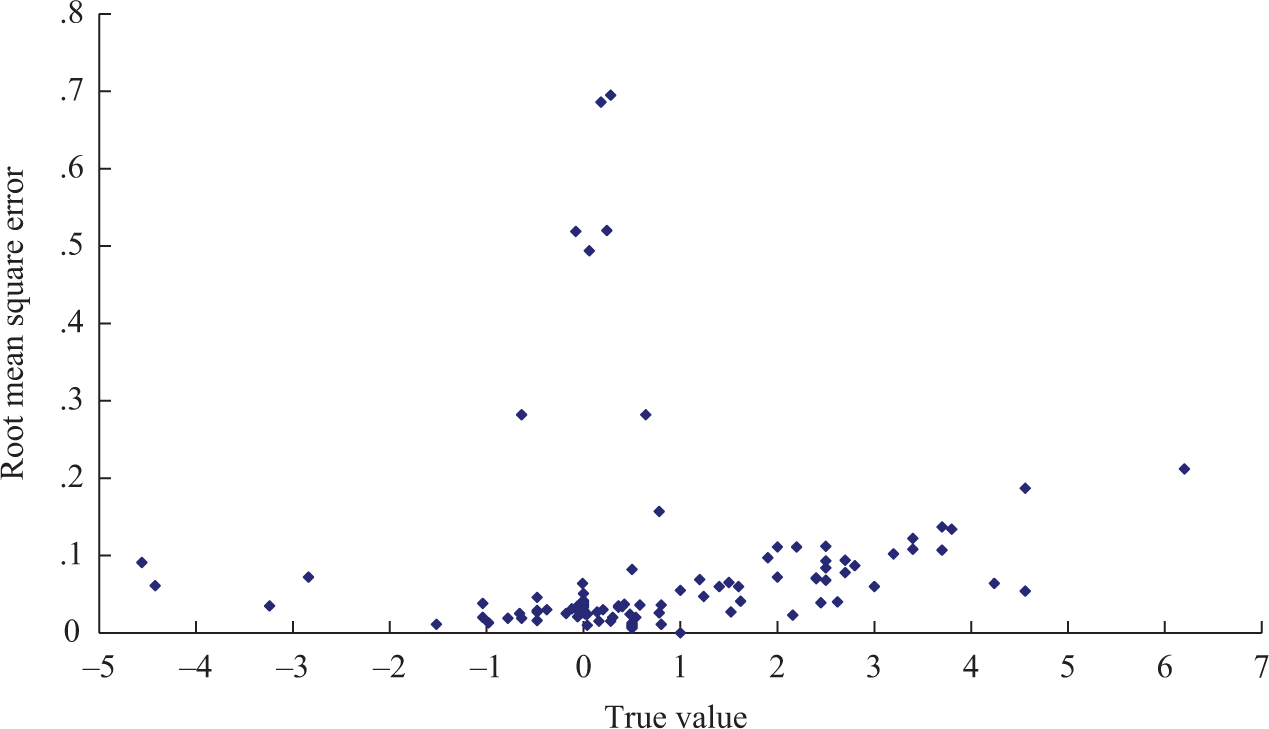
Root mean square error across true values when the generating model is fit.
M2 through M5 were also fit to the data. Since these models were nested and M1 was the most general (and the generating model) and M5 was the least general, it was expected that M1 would have the best fit and M5 would have the worst fit. According to the averaged DIC and the averaged cross-validation log-likelihood across 30 replications (shown in Table 1), as expected, M1 was the best-fitting model and M5 was the worst-fitting model. The difference in the averaged DIC was 372.41 between M1 and M2, 58.94 between M2 and M3, 5535.07 between M3 and M4, and 7226.29 between M4 and M5. The difference in the averaged cross-validation log-likelihood was 175.07 (which is equivalent to the log-BF) between M1 and M2, 114.37 between M2 and M3, 13037.50 between M3 and M4, and 17505.70 between M4 and M5. Relatively speaking, the constraint of a second-order autocorrelation as white noise and the constraint of a constant severity distribution across time were less harmful to model–data fit than the constraint of a common set of step parameters for all items and the constraint of no intrarater variation in severity.
An Empirical Example
A total of 238 workers from four departments of an electronic firm in Taiwan were assessed on four occasions (once per season) by five managers according to five job criteria (thoroughness, creativity, complexity, structure, and accuracy) along a 5-point rating scale. The higher the rating, the better the job performance is. Departments 1 through 4 had 54, 66, 60, and 58 workers, respectively.
We were interested in the following questions: Was multilevel modeling necessary? What kind of modeling for autocorrelation was more appropriate? White noise, AR(1), or AR(2)? Were the growth trajectories homoskedastic or heteroskedastic? What were the intrarater and interrater variations in severity?
To answer these four major questions, a set of six models was formed, denoted as M6 through M11, respectively. M6 was a single-level model, which is equivalent to that proposed by Wang and Liu (2007). M7, M8, and M9 were two-level models (criteria and occasions), with autoregressive residuals constrained as white noise, AR(1), and AR(2), respectively. M10 and M11 were three-level models (criteria, occasions, and workers) with a homoskedastic structure and a heteroskedastic structure, respectively. The larger the code of the model (e.g., M11), the more general the model is.
The lower part of Table 1 lists the DIC statistics and the cross-validation log-likelihoods for the six models. M8 was the best-fitting model (its WinBUGS commands are listed in Appendix B). Thus, two-level modeling was more appropriate than one-level and three-leveling modeling; first-order modeling was better than white noise and second-order modeling for the autoregressive residuals. Table 3lists parameter estimates of M8. The estimates for the item discrimination parameters were between 0.052 (accuracy) and 3.887 (creativity); those for the difficulty parameters were between –4.026 (accuracy) and 2.29 (creativity). Hence, creativity was not only the most important criterion of job performance but also the most difficult to achieve. Different items had very different step difficulties. For example, the step difficulties were –2.44 ∼ 2.525 for creativity but –12.46 ∼ 12.11 for accuracy. The huge variation in step difficulty across items was mainly due to the items having very different discrimination powers (0.052 ∼ 3.887). A quadratic growth curve was applicable to Department 1,
Parameter Estimates and Standard Errors (in Parentheses) in Model 8 for Real Data
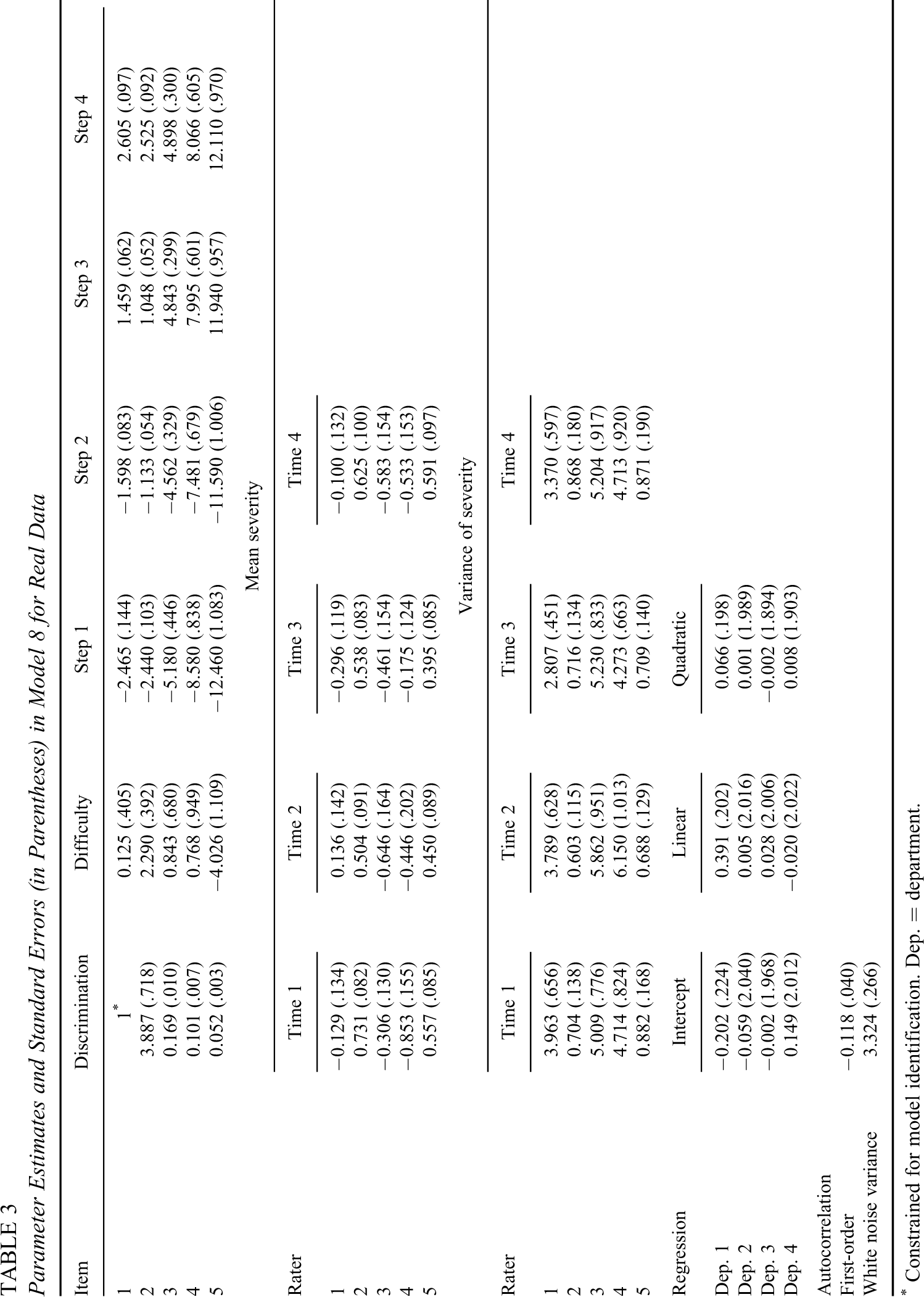
* Constrained for model identification. Dep. = department.
In M8 as well as other models, each rater’s severity was assumed to follow a normal distribution. Figure 2 shows the mean severity of the five raters across time points. Raters 2 and 5 have larger mean severities (i.e., more severe) than those of the other three raters throughout the four time points. As the time point moved forward, the mean severities of the five raters became more similar. Figure 3 shows the variances of severity of the five raters across time points. Raters 2 and 5 have much smaller variances than those of the others, indicating that their intrarater variation in severity was smaller. Figures 2 and 3 reveal that compared to the other raters, Raters 2 and 5 held a more consistent degree of severity and they were more severe across time points.
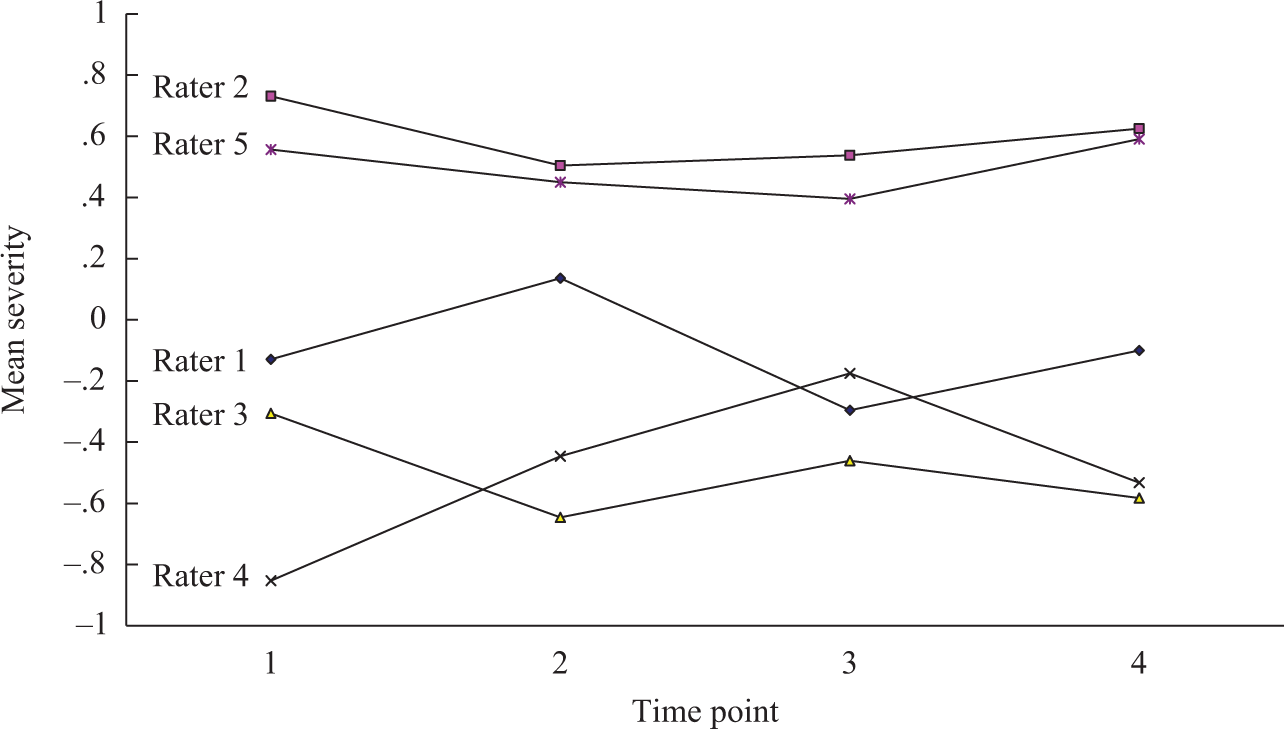
Mean severity for the five raters across time points.
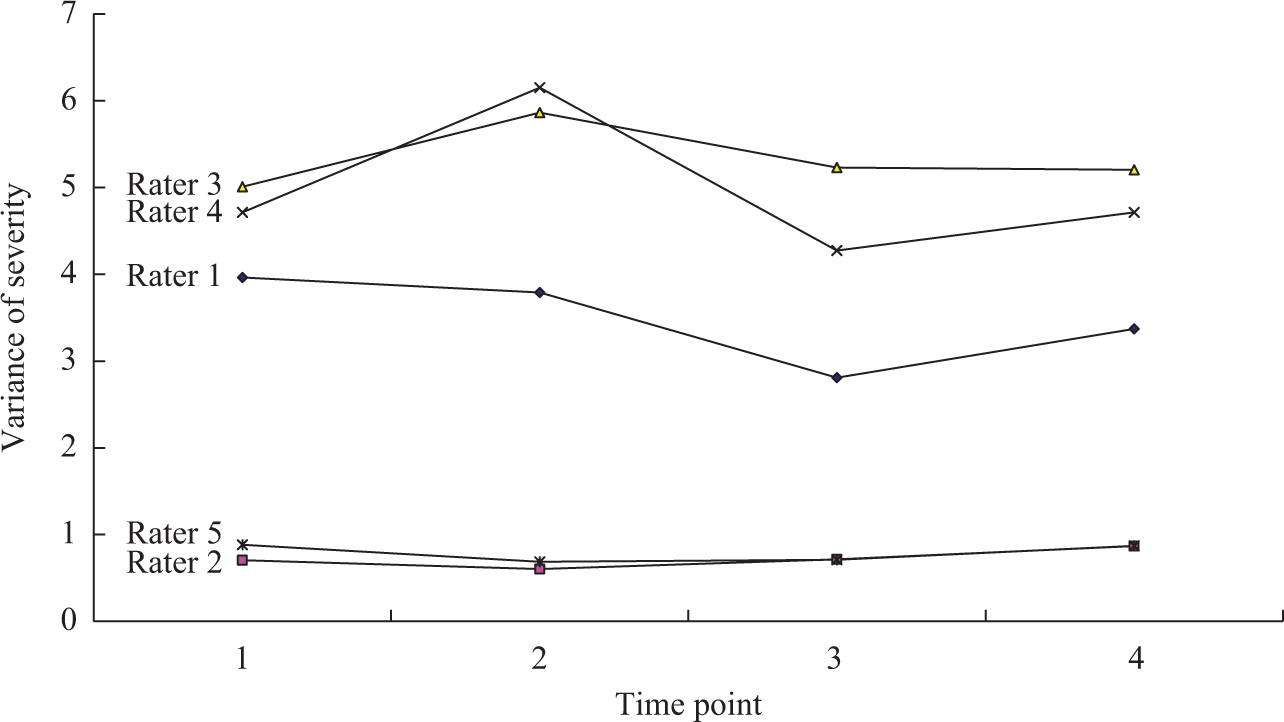
Variance of severity for the five raters across time points.
Conclusion
The generalized multilevel facets model for longitudinal data was developed. The model has three levels. At Level 1, a facets model is specified to describe item responses across time points. At Level 2, a latent trait growth model with an autoregressive residual structure that takes into account variation in the latent traits across measurement occasions within persons is formulated. In the latent trait growth model, a polynomial growth curve is specified to describe how the expected value of a response variable changes over time, and the covariance structure is autoregressive. At Level 3, a regression model is added to consider variation in growth trajectories between persons; it can be homoskedastic or heteroskedastic. The model parameters can be estimated with WinBUGS. The simulations show that WinBUGS yields fairly good parameter recovery, except for regression parameters at Level 2; the DIC and cross-validation log-likelihoods can be used for model comparison. In the empirical example, the data structure was a two-level one; a two-parameter model was more suitable than a one-parameter model; each item had its own step difficulties; each department had its own development trend; and Raters 2 and 5 were the strictest raters.
In this study, we applied a Bayesian hierarchical approach to the GMFM-L and used WinBUGS to analyze longitudinal data. The approach was proven to be efficient. While using a Bayesian approach, the specification of the prior distribution plays a crucial role (Gelman, 2006). This study uses a conjugate distribution, allowing WinBUGS to be used to estimate parameters easily. Multilevel prior specifications can be utilized to define hierarchical models.
The GMFM-L simultaneously considers an individual-based design data structure, missing data in persons and raters, and the interactions among persons, raters, and time points. As sample size is often small in longitudinal studies, the Bayesian hierarchical approach is able to provide more information on parameter estimation than that provided by the traditional non-Bayesian approach through prior information (Wollack, Bolt, Cohen, & Lee, 2002). With respect to repeated measurements, the GMFM-L allows autocorrelations and the Bayesian estimation method works directly on raw data and considers such dependence over time. The GMFM-L can easily deal with complex structures, such as factor analytic structures and multilevel structures. Furthermore, the GMFM-L divides errors into three parts to improve the reliability of analysis results.
Finally, analytical results show that a Bayesian approach can be applied directly in autoregressive residual models. However, because the samples are autocorrelated, WinBUGS converges very slowly. Improving convergence is very crucial for the GMFM-L. Future studies can investigate other programming languages (e.g., C or FORTRAN) or different sampling methods for achieving better convergence.
Footnotes
Appendix A: Second-Order Autoregressive Process
The second-order autoregressive process can be modeled as: