
Abstract
As any empirical method used for causal analysis, social experiments are prone to attrition which may flaw the validity of the results. This article considers the problem of partially missing outcomes in experiments. First, it systematically reveals under which forms of attrition—in terms of its relation to observable and/or unobservable factors—experiments do (not) yield causal parameters. Second, it shows how the various forms of attrition can be controlled for by different methods of inverse probability weighting (IPW) that are tailored to the specific missing data problem at hand. In particular, it discusses IPW methods that incorporate instrumental variables (IVs) when attrition is related to unobservables, which has been widely ignored in the experimental literature before.
1. Introduction
Causal inference based on experiments, which dates at least back to Neyman (1923) and Fisher (1925, 1935), is a cornerstone of the evaluation of policy interventions. It has been used in many different fields of research such as medicine, welfare policies, labor economics, education, and development economics; see for instance, the literature surveys in Duflo (2006), Harrison and List (2004), and Imbens and Wooldridge (2009). If well conducted and appropriate to the research question, experiments are widely regarded to be the most reliable source of causal inference; see for instance, Cochran and Chambers (1965), Freedman (2006), Rubin (2008), and Imbens (2009), as they invoke a minimum of identifying assumptions. They neither impose functional form assumptions as regression models nor particular correlations between observables and unobservables, which have to be assumed in observational studies. However, as any empirical method, experiments are prone to attrition which may flaw the validity of the results, see the discussion in Hausman and Wise (1979).
In this article, we consider the problem that the outcome of interest is only partially observed due to attrition, whereas the treatment and several socioeconomic characteristics, which are typically measured in baseline surveys prior to the intervention, are fully observed. Thus, attrition here refers to the censoring problem due to missing outcomes, but not to truncation, that is, the absence of information on the outcome, the treatment, and further variables for some subpopulation. The missing outcome problem arises, for instance, when individuals with known pretreatment characteristics are randomly assigned to an active labor market policy (such as a training), but some of them do not participate in a follow-up survey that measures labor market success (e.g., employment or income) several months or years later due to reluctance or relocation. Similar problems are inherent in clinical trials when some of the participants randomly assigned to medical treatments pass away before the health outcome is measured. Finally, suppose that high school students are randomly provided with private school vouchers and that we are interested in their scores obtained in college entrance examinations several years later. Attrition in the outcome arises if a subsample of students decides not to take the exam.
Various remedies have been proposed to deal with attrition in outcome data. Multiple imputation of missing values goes back to Rubin (1977, 1978); see also Rubin (1996) for a more recent review. Based on Bayesian techniques, the idea is to use multiple attrition models to impute multiple sets of plausible values for the missing data. This allows computing a probability interval for the parameter of interest. Several studies use single imputation methods such as regression adjustments to correct for attrition. For example, Hausman and Wise (1979) use a probability model of attrition in conjunction with a random effects model of individual response in their evaluation of the Gary Income Maintenance experiment. Angrist, Bettinger, and Kremer (2006) analyze the effects of school vouchers on test scores in college entrance examinations in Columbia and apply tobit regression to control for the fact that voucher winners are more likely to take the tests than voucher losers. Another approach is based on weighting observations according to their likelihood to respond, that is, by the inverse of their conditional response probability; see for instance, Scharfstein, Rotnitzky, and Robins (1999). The idea of inverse probability weighting (IPW) goes back to Horvitz and Thompson (1952), who first proposed an estimator of the population mean in the presence of nonrandomly missing data.
Barnard, Frangakis, Hill, and Rubin (2003) use a principal stratification framework (see Frangakis & Rubin, 2002) to estimate treatment effects under attrition (and further missing data and noncompliance problems) by means of a parametric mixture model. Still based on principal stratification, Mealli and Pacini (2008) exploit discrete instruments to identify effects for particular subgroups under various assumptions. Finally, the estimation of nonparametric bounds (see Horowitz & Manski, 1998, 2000) does not require a model for attrition at the cost of sacrificing point identification even for particular subpopulations. Empirical studies estimating bounds include Angrist et al. (2006), Lee (2009), and Grogger (2009), who assesses the effectiveness of Connecticut's Jobs First experiment. See also Zhang and Rubin (2003) and Zhang, Rubin, and Mealli (2008) who discuss the identification of bounds in a principal stratification framework.
This article makes two contributions to the literature on attrition in social experiments. First, it reveals systematically under which forms of attrition—in terms of its relation to observable or unobservable factors—experiments do (not) yield causal parameters, as a comprehensive discussion on attrition in experiments and its implications for identification is still lacking. Starting from a general treatment effect model, it makes explicit and formally discusses under which conditions experiments identify average treatment effects (ATEs) on the entire population and/or on the subpopulation of respondents.
Second, the article shows how the alternative forms of attrition can be controlled for by IPW methods, that is, by reweighting observations by the inverse of their conditional response and/or treatment probabilities. Depending on whether attrition is related to all or subsets of observable and unobservable variables, we will apply different weighting approaches, each of which is tailored to the specific attrition problem at hand. This provides practitioners with straightforward solutions depending on the suspected missing data problem. Simulation results presented further below suggest that assuming the wrong attrition process (e.g., by neglecting attrition related to unobservables) may do worse than not controlling for attrition at all. This underlines the importance of carefully thinking about the nature of attrition in order to choose an attrition model that is appropriate for the empirical application considered.
The use of IPW to control for attrition related to observables, that is, when outcomes are missing at random (MAR, see Rubin, 1976), is well established in the literature; see for instance, Robins and Rotnitzky (1995), Robins, Rotnitzky, and Zhao (1995), Rotnitzky and Robins (1995), Scharfstein et al. (1999), and Wooldridge (2002, 2007). In contrast, the case when attrition is related to unobservables such that identification requires an instrument for attrition (which does not directly affect the outcome variable) has been widely ignored in experiments. One of the very rare examples is DiNardo, McCrary, and Sanbonmatsu (2006) who use conventional sample selection correction techniques based on regression (see Heckman, 1976). The present work is the first that discusses the usefulness and application of IPW under attrition on unobservables in an experimental context. This approach is closely related to Huber (2009), who uses IPW to control for sample selection and attrition in observational studies.
Attrition related to unobservables is a problem likely to be found in many empirical problems. For example, suppose that motivation is not observed in a labor market policy or education experiment where the outcomes of interest are employment and earnings or test scores and educational achievement, respectively. While there is little doubt that motivation is correlated with these outcomes, there are also good reasons to believe that it affects the response behavior. For example, the least motivated individuals in a labor market policy experiment might be most reluctant to respond to the follow-up survey and unmotivated students are likely to be less inclined to participate in an exam than others. These and similar examples motivate the use of novel IPW methods based on continuous instruments for attrition. Unfortunately, such instruments, which are ideally randomly assigned in a similar way as the treatment, are rare in experiments conducted to date. Therefore, we argue that the creation of randomized instruments should be considered in the design of future experiments. Two potential instruments are the number of phone calls in follow-up surveys or financial incentives to respond to a survey.
Even though this study covers a range of attrition problems that are relevant in many empirical applications, the exposition is not exhaustive, as one can think of many different ways of modeling response behavior. For an alternative set of restrictions, see Imai (2009) who assumes that attrition is related to the outcome but is independent of the treatment conditional on the outcome and other observable variables. As the author argues, this is plausible when response behavior is strongly driven by the outcome variable (e.g., when considering the outcome “voting,” voters may be more willing to participate in postelection surveys than nonvoters), whereas the treatment represents only a mild intervention that is unlikely to affect attrition (e.g., a psychological voting stimulus). In contrast, we focus on scenarios where the treatment drives attrition even conditional on other variables (with the exception of the introductory case in which outcomes are missing completely at random [MCAR]). Whereas identification in Imai (2009) relies on controlling for the dependence between attrition and the treatment, we impose different assumptions that allow us to control for the dependence between attrition and the outcome.
The remainder of this article is organized as follows. The next section introduces a general treatment effect model along with attrition. Section 3 discusses identification under random attrition and attrition related to observables. Identification under attrition related to unobservables is treated in Section 4. Section 5 presents simulation studies based on both generated and empirical data. An application to a U.S. labor market policy experiment is provided in Section 6. Section 7 concludes.
2. Model
Let D denote a treatment indicator, either 1 (treatment) or 0 (nontreatment), which is randomly assigned to an independent and identically distributed (i.i.d.) sample of n units, indexed by
However, under particular assumptions a randomized experiment allows identifying treatment effects by the fact that the potential outcomes are independent of the treatment assignment. Throughout this article we will therefore rule out any interaction effects between the individuals participating in the experiment such as spill over, peer, or general equilibrium effects. This implies the validity of the Stable Unit Treatment Valuation Assumption (SUTVA); see, for instance, Rubin (1990). Furthermore, we will assume that treatment compliance is perfect, that is, everybody being assigned takes the treatment and everybody not assigned does not. If noncompliance occurred, identification would be further complicated. In this case, one might at best recover the effect on the subpopulation of the compliers (those behaving according to the assignment), given that the treatment assignment is a valid instrument for the realized treatment state. Even though we are fully aware that interaction effects and noncompliance in experiments (see, for instance, Robins & Tsiatis, 1991) may occur in practice, they are beyond the scope of this article. In the subsequent discussion, we will exclusively focus on the identification problems related to attrition in the outcome variable.
Under random treatment assignment, the expected potential outcomes are equal to the expected conditional outcomes given the treatment. Formally,
To formally discuss the various forms of attrition, we consider a general treatment effect model. Assume that the outcome Y is an unknown function of the treatment, a vector of observed covariates X, and an unobserved term U. Assumption 1:


This model provides us with a useful framework for the evaluation of policy interventions. Consider for instance the identification of the effect of vouchers for private schooling (D) to which high school students are randomly assigned on test scores in college entrance examinations (Y) several years later. Empirical evidence suggests that private schooling has an effect on test scores (see Angrist et al., 2006). Thus, we suspect the test scores to be a function of the treatment, but also of observed baseline characteristics (X) such as age and gender, which are usually provided in surveys accompanying randomized trials. Furthermore, also unobserved factors U such as motivation most likely influence the test scores. As a second example, consider labor market experiments where individuals are randomly assigned into a training; see, for instance, Bloom et al. (1997). The labor market outcomes (Y), for example, employment, unemployment, or income, are a function of training (D); socioeconomic characteristics like age, education, and gender (X); and unobservables (U) such as innate ability.
To introduce attrition into our framework, let R denote a binary response variable which is
While there is little doubt that Δ is an interesting policy parameter (even more so in experiments, where the ATE on the entire population is equal to the ATE on the treated population), the policy relevance of
However, under most forms of attrition, the identification of Δ requires somewhat stronger assumptions than the identification of
3. Identification Under Random Attrition and Attrition Related to Observables
The most innocuous form of attrition is the case when outcomes are MCAR; see, for instance, Rubin (1976) and Heitjan and Basu (1996). MCAR says that attrition is not related with any observed or unobserved parameter in the treatment effect model. After considering this benchmark case, we will systematically investigate more severe attrition problems. Assumption 2: Assumption 3:

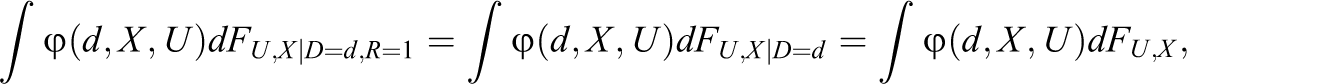
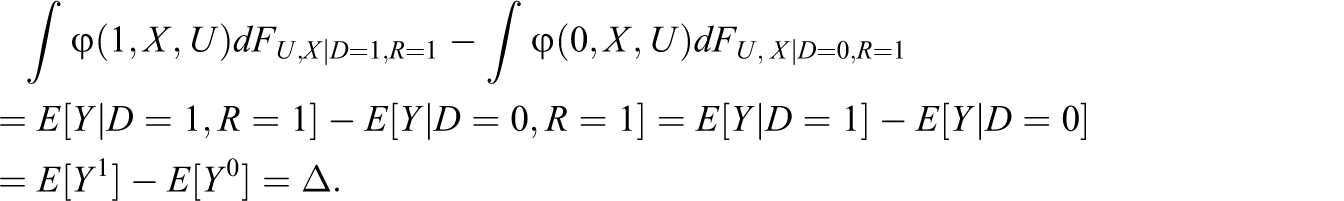
(3a)
(3b)
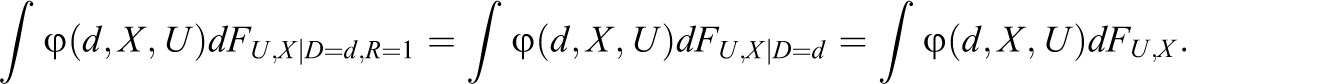
The forms of attrition considered under Assumptions 2 and 3 are unlikely to hold in many, if not most, social experiments. Empirical evidence suggests that response behavior is often related to the treatment and other observed characteristics; see, for instance, Hausman and Wise (1979), Fitzgerald, Gottschalk, and Moffitt (1998), and Grilo et al. (1998). These characteristics, X, are typically measured in baseline surveys prior to the intervention and commonly include gender, age, education, and other socioeconomic variables.
In the remainder of this section, we will assume that response is a function of the treatment and the covariates. In a first step, we impose a very particular relationship between X and D, namely, independence conditional on response. This case is primarily chosen for illustrative reasons rather than practical relevance. Interestingly, it entails internal validity of the experiment while external validity no longer holds without controlling for attrition. Assumption 4:
(4a)
(4b)
(4c)
By Assumption 4, attrition affects the distributions of D and X, which are, however, not related to each other even conditional on response (4c). This implies that the distributional change in X is equal across treatment states. For example, assume that X represents age in our school voucher experiment and that it is positively related with response (i.e., older students are more likely to take the test). Then, the age composition must change in the same manner for voucher winners and losers when conditioning on test participation. As U does not affect the response, the joint distribution of (X, U) conditional on R = 1 is independent of D. Thus,
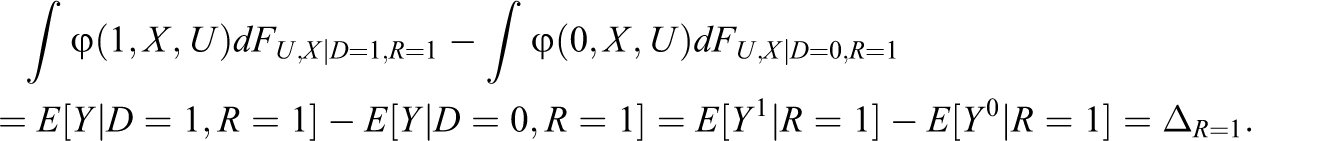
However, it is not externally valid, which would require that
Under certain conditions, the ATE on the entire population is identified by weighting respondents according to the likelihood that their observed characteristics appear in the entire population. To this end, we define the response propensity score (see Rosenbaum & Rubin, 1983), that is, the conditional response probability given (D, X), as Assumption 4’: Proposition 1:
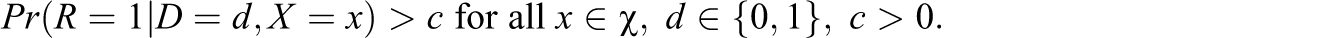
Under Assumptions 1, 4, and 4’, the ATE is identified by Proof: See Appendix A, available online at http://jeb.sagepub.com/supplemental.
Thus, weighting observations by the inverse of their respective response propensity score identifies the ATE. The idea of using IPW to control for attrition or similar selection problems goes back to Horvitz and Thompson (1952), who proposed an estimator of the population mean when data are missing nonrandomly. IPW has been frequently applied when the attrition process is assumed to depend only on observables, that is, when outcomes are MAR in the notation of Rubin (1976). Formally, the MAR requires that

To make our framework more general, we relax Assumption 4 somewhat by omitting Assumption (4c). This allows the gradient of X on the response process to differ across treatment states. For example, one could imagine that in the school voucher experiment, private schools (D = 1) are equally successful in sending younger and older students ( Assumption 5:
(5a)
(5b)
Without further assumptions,
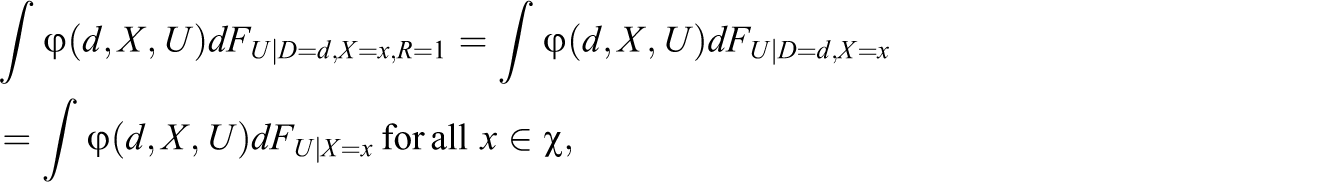
It follows that the mean potential outcome among respondents is Assumption 5’: Proposition 2:

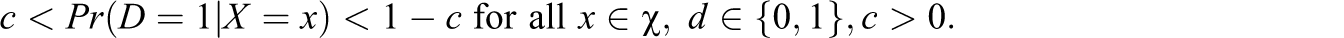
Under Assumptions 1, 5, and 5’, the ATE on respondents is identified by Proof: See Appendix B, available online at http://jeb.sagepub.com/supplemental
By reweighting the outcomes of respondents by the inverse of the (non)treatment propensity score, we control for differences in the distributions of X across treatment states conditional on response to identify

However, under somewhat stronger common support conditions, we can even identify the ATE on the entire population and reestablish external validity. To this end, note that the mean potential in the entire population is Proposition 3:

Under Assumptions 1, 4’, 5, and 5’, the ATE is identified by Proof: See Appendix C, available online at http://jeb.sagepub.com/supplemental.
Δ is identified by using

4. Identification Under Attrition Related to Unobservables
In the last section we considered various forms of attrition related to observables. In our treatment effect model, MAR requires that U and V, the unobserved terms in the outcome and response equations, are independent, at least conditional on observed characteristics. This assumption will be no longer maintained in this section. Instead, we will assume attrition on unobservables by allowing for a nonzero correlation between U and V even conditional on D, X. Analogous to sample selection models (see Heckman 1974, 1976, 1979)—at least when identification is nonparametric (e.g., Das, Newey, & Vella, 2003; Huber, 2009; Newey, 2007)—point identification hinges on the availability of an instrument that affects response but has no direct effect on the outcome.
Reconsider the school voucher experiment in which only a subpopulation takes the test. Assume that the probability to take the test is a function of unobserved motivation and ability which are correlated with tests scores even conditional on the treatment and observed characteristics (e.g., age and gender). Then, identification requires an instrument that shifts test participation but has no direct effect on the test scores. Assumption 6:
(6a)
(6b) Cov
By Assumption 6, R is a function of at least one element that is excluded in Assumption 6’:
(6’a) Cov
(6’b)
(6’c)
(6’d)
Assumption (6’a) states that Z shifts R but is not directly related with Y. Assumption (6’b) rules out that being treated or nontreated predicts attrition perfectly. For example, not winning a school voucher must not rule out test participation. To see the usefulness of this assumption, assume the opposite such that units with D = 0 never respond independent of the values of (X, Z). Obviously, the treatment effect cannot be evaluated as no comparisons with D = 0 are available in the subpopulation of respondents.
By (6’c), we impose that (D, Z) are jointly independent of the unobservables (U, V). Independence between (U, V) and D is satisfied by the randomization of the treatment if V is not a posttreatment variable. Still, it needs to be plausibly argued that
As argued by DiNardo et al. (2006), the instrument should ideally be randomly assigned in a similar way as the treatment. This would plausibly justify Assumption (6’c). For example, in a follow-up telephone survey, Z may be the number of phone calls per experimental unit which is randomized prior to the treatment assignment. A higher number of attempted calls should increase the response probability while being unrelated with other factors under random assignment. Also financial incentives are likely to affect response behavior (see Castiglioni, Pforr, and Krieger, 2008). In the school voucher example, students could be randomly offered different levels of cash payments or refunding of travel expenses in the case that they take the test. Of course, one would need to unambiguously communicate that the payment is conditional on participation alone, not on the test score (otherwise the motivation to prepare oneself for the test is likely to be affected). A further example would be the randomization of the distance to the test center, given that the choice of various test locations is feasible in the experimental design. Note that (6’c) could be relaxed to
Concerning Assumption (6’d), first note that
However, conditioning on the response propensity score alone does not suffice for causal inference. A first reason is that, similar to Assumptions 4 and 5, response is a function of X and D. Therefore, random treatment assignment does not necessarily entail independence of D and X among respondents, as the distribution of X might differ across treatment states conditional on R = 1. Second, this is even more likely to be the case conditional on the response propensity score. To see this, note that individuals in different treatment states D but with equal values of X and Z must have distinct response propensity scores. That is,
We will now formally discuss identification. For notational ease, let
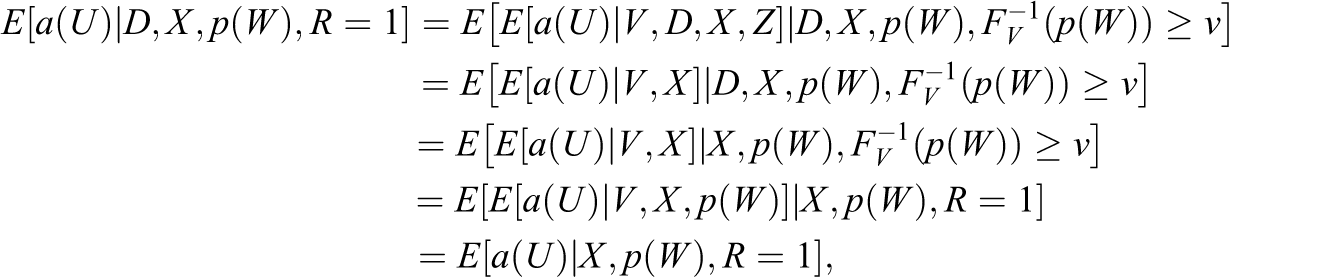
Thus, treatment effects are identified by conditioning on the response propensity score and the covariates. To see this, note that the conditional ATE given X and p(W) conditional on response is defined as Assumption 6”:
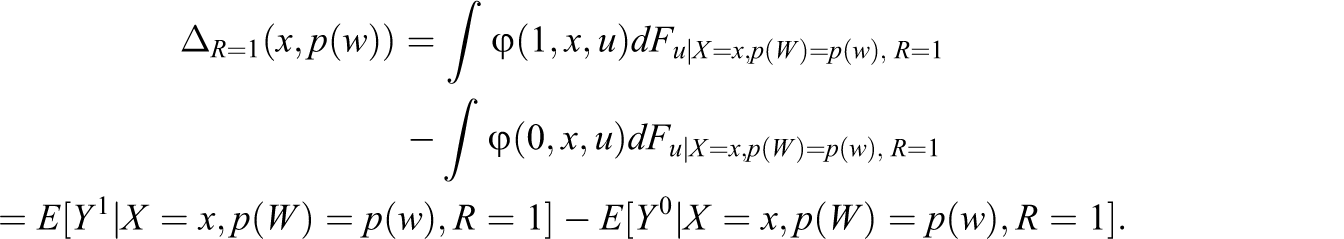

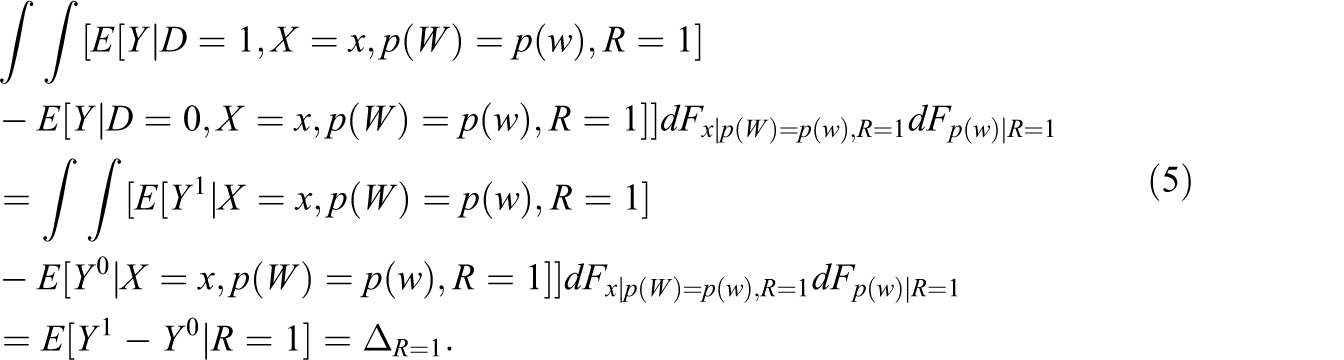
(6”a)
(6”b)
(6”c)
Proposition 4: Proof: See Appendix D, available online at http://jeb.sagepub.com/supplemental.
Under Assumptions 1, 6, 6’, and (6”b), the ATE on the respondents is identified by
By weighting observations by the inverse of the (non-)treatment propensity score, we adjust for differences in the distributions of X and p(W) between treated and nontreated respondents. Proposition 4 is similar to Proposition 3, with the exception that we have to additionally condition on the response propensity score in the treatment propensity score to control for attrition on unobservables.
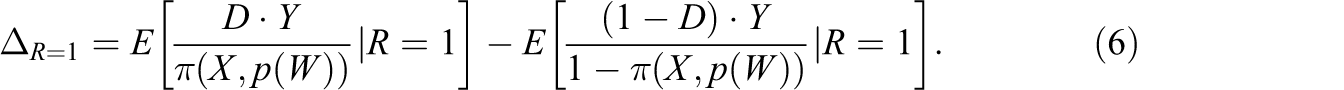
It seems useful to compare our approach based on the propensity score and a continuous instrument to Mealli and Pacini (2008) who control for attrition by conditioning on a binary instrument (
This example illustrates that conditioning on the propensity score is equivalent to conditioning on the response behavior, which can be easily shown in a principal stratification framework. For this reason and as already discussed before, effects are identified if particular combinations of D and Z yield the same response propensity scores across treatment states (which need not necessarily be equal to one) for a given X, for example, if Proposition 5: Proof: See Appendix E, available online at http://jeb.sagepub.com/supplemental.
Under Assumptions 1, 6, 6’, and 6”, the ATE is identified by
The ATE on the entire population is identified based on reweighting observations (in addition to the inverse treatment propensity score) by the inverse of the response propensity score, that is, by using the relative likelihood of a particular triple (D, X, Z) to appear in the entire population, as weighting function.
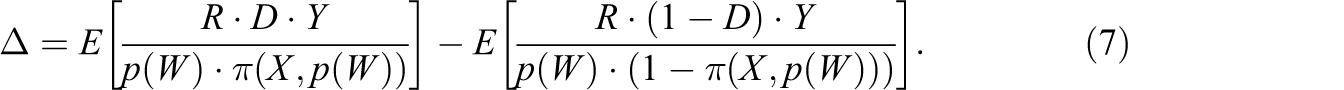
This result may seem surprising, given the fact that outcomes are only partially observed and observed outcomes do not allow inferring on the unobserved outcomes. That is,
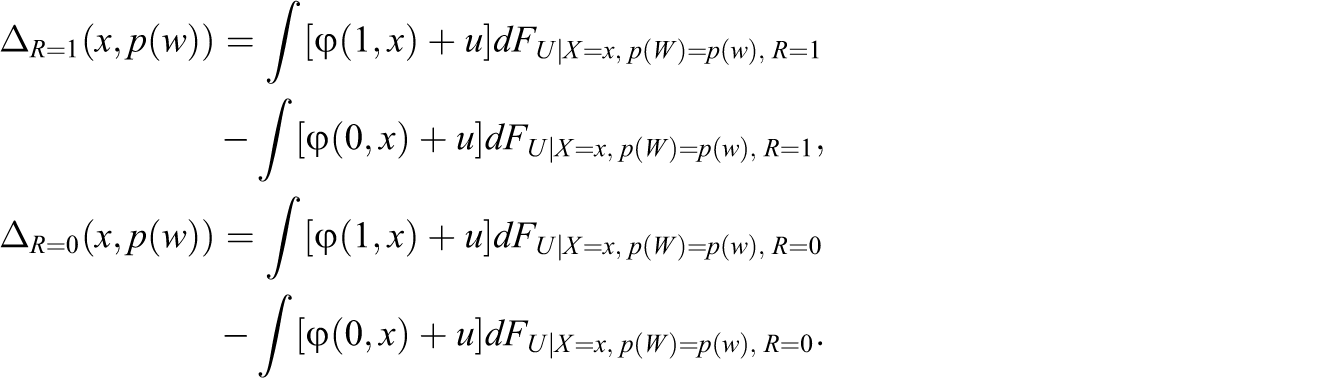
For completeness, we will briefly discuss identification under a particular deviation from the previous model, assuming that response is a function of D, Z, and V, but is not related with the covariates X. Assumption 7:
(7a)
(7b) Cov
Under this particular form of attrition, the response behavior is merely a function of the treatment and unobservables but unrelated to the observed covariates. Whether Assumption 7 is plausible depends on the evaluation problem at hand and may even be tested (by testing the explanatory power of X on R). The response propensity score is now Assumption 7’:
(7’a) Cov
(7’b)
(7’c)
(7’d) Assumption 7”:
(7”a)
(7”b)
(7”c)
Assumptions 7’ and 7” are straightforward modifications of 7’ and 7”, with the exception of (7’c), which assumes independence of the (D, Z) also with respect to X. Again, the treatment is independent by randomization, whereas the independence of Z and X may or may not be plausible and might be tested. By Assumptions 1, 7, and (7’c) it holds that X is independent of D conditional on p(D, Z) and R = 1, because Proposition 6:
Under Assumptions 1, 7, 7’, and (7”b), the ATE on the respondents is identified by Proof: See Appendix F, available online at http://jeb.sagepub.com/supplemental. Proposition 7: Proof: See Appendix G, available online at http://jeb.sagepub.com/supplemental.
Under Assumptions 1, 7, 7’, and 7”, the ATE is identified by
In the last two sections, we have covered several forms of attrition and provided a guideline on which weighting methods are appropriate under specific assumptions. In particular, the use of IPW incorporating IVs when attrition is on unobservables has been discussed, a case widely ignored in the experimental literature. The subsequent sections will present simulation results and an empirical application to a U.S. labor market policy experiment.
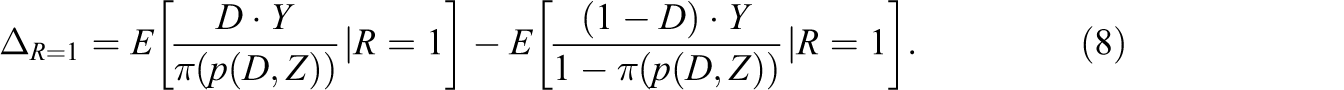
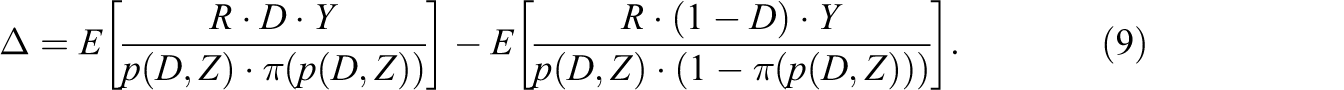
5. Simulation Studies
In this section, we run a horse race between the experimental mean difference estimator not controlling for attrition and IPW estimators assuming that attrition is related to observables and unobservables as treated under Assumptions 5 and 6, respectively. For this reason, we conduct simulation studies based on both generated and empirical data. Starting with the former scenario, we consider the following data generating process (DGP):

We use normalized versions (such that weights add up to unity, see Imbens, 2004; Busso, DiNardo, & McCrary, 2009b) of the sample analogs of Propositions 2, 3, 4, and 5 as estimators of the ATE on the entire population (denoted as
Table 1
displays the estimates, bias, standard errors (SE) and mean squared errors (MSEs) for the different methods when attrition is related to observables. Note that the ATEs on the entire population and on the respondents are normalized to unity. The IPW estimators following from Propositions 2 and 3 are effective in controlling for attrition bias.
Attrition on Observables, Simulated Data
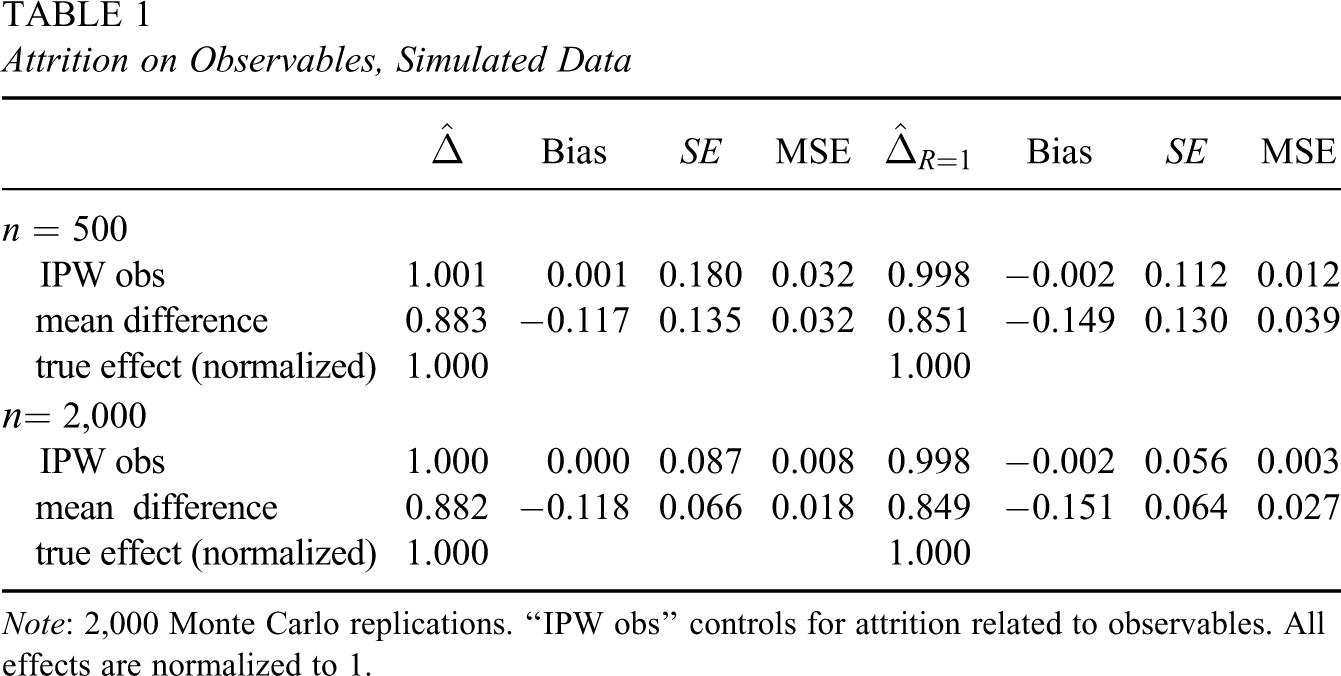
Note: 2,000 Monte Carlo replications. “IPW obs” controls for attrition related to observables. All effects are normalized to 1.
Table 2 shows the results for IPW estimators (a) controlling for attrition on unobservables (“IPW unobs,” following from Propositions 4 and 5) and (b) observables alone (“IPW obs,” following from Propositions 2 and 3) when response depends on unobservables, too. The former methods exploiting the instrument entail only moderate biases and MSEs, whereas the accuracy of IPW only controlling for attrition on observables is considerably lower. When estimating the ATE on the entire population, “IPW obs” performs even worse than the mean difference estimator. That is, omitting the unobserved factor in the attrition model entails poorer results than not controlling for response bias at all. This finding bears great relevance for empirical applications. It implies that using the wrong attrition model and/or accounting for an incomplete set of variables may even be worse than completely ignoring the problem. This underlines the importance of carefully thinking about the attrition process in order to choose a model that is appropriate for the empirical problem at hand.
Attrition on Unobservables, Simulated Data
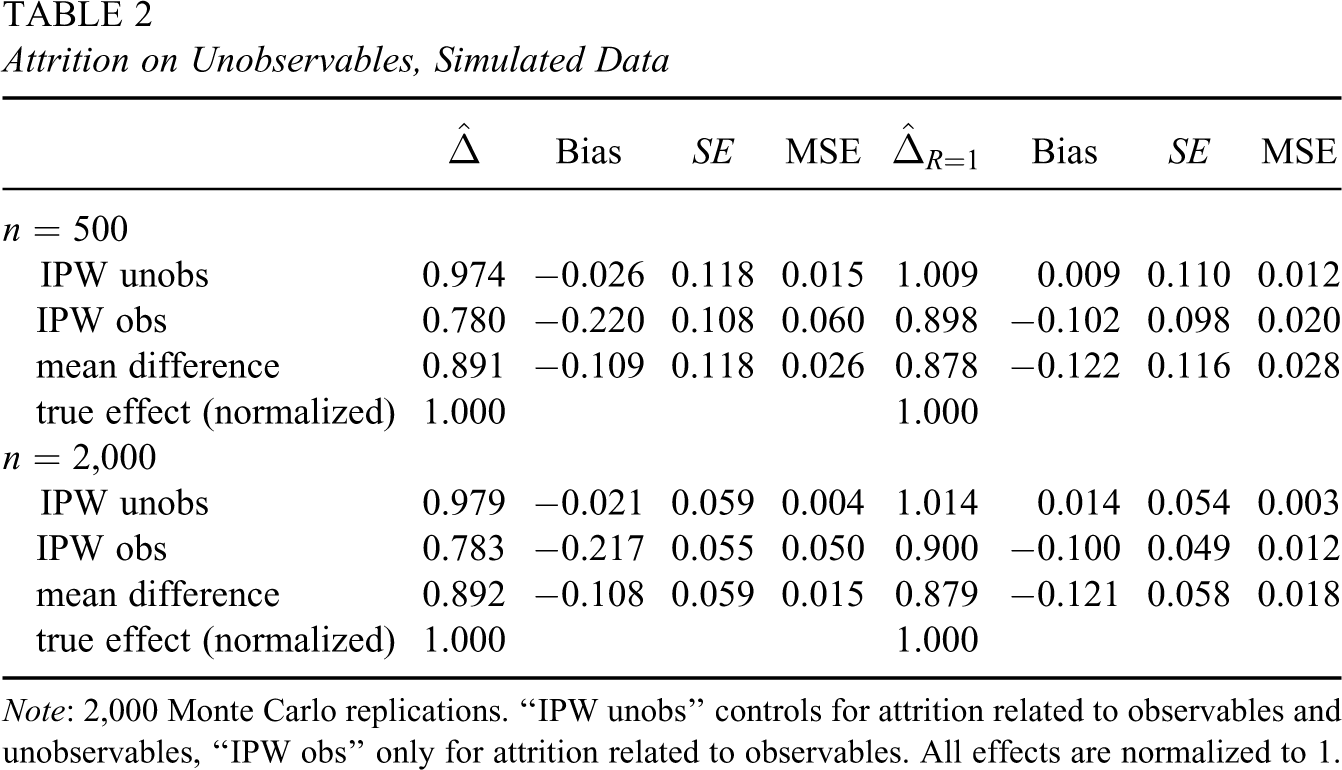
Note: 2,000 Monte Carlo replications. “IPW unobs” controls for attrition related to observables and unobservables, “IPW obs” only for attrition related to observables. All effects are normalized to 1.
Finally, we use a publicly available subsample of Tennessee’s Project STAR Experiment for a simulation study based on empirical data to illustrate the potential gains of IPW when attrition is related to unobservables. The motivation for the use of empirical data is to conduct simulations that are more closely linked to real-world problems with the hope that they are more realistic than studies merely based on generated data. For further examples of simulations that rely on empirical data, see, for instance, Bertrand, Duflo, and Mullainathan (2004), Diamond and Sekhon (2006), Huber, Lechner, and Wunsch (2010), and Lee and Whang (2010).
Project STAR was conducted in the mid-1980s to evaluate the effects of small class sizes (target 13–17 students instead of 22–25 students in regular classes) in kindergartens and schools on student achievement; see, for example, Finn and Achilles (1990, 1999) and Krueger (1999). A major issue for the applicability of the proposed IPW methods under attrition related to unobservables is the requirement of a continuous instrument. Therefore, future experimental designs might consider the inclusion of (close to) continuous instruments that should ideally be randomly assigned in a similar way as the treatment. As mentioned before, the number of phone calls or financial incentives could be used to instrument the response rate to posttreatment surveys. Up to date, however, such variables are typically not available in social experiments and this is also the case for Project STAR. For this reason, we will pursue a somewhat unorthodox simulation approach to investigate the performance of IPW when estimating the ATE on the entire population under attrition related to unobservables.
The original data set that our simulations are based upon contains 6,325 children in kindergarten. We only use those 5,852 observations for which we observe our outcome of interest (Y), namely, the Stanford Achievement Test (SAT) in maths at the end of the kindergarten year (average test score: 485.377, standard deviation: 47.698). From the sample, 1,757 children were randomly assigned to a small class in kindergarten. We discard all treated observations and only keep the sample of controls (n = 4,095), which will serve as the population of interest in the simulations. Moreover, a binary placebo treatment D is randomly assigned among the controls with a “treatment” probability of 0.5. Thus, the true treatment effect is equal to zero as none of the observations was assigned to a small class. Therefore, we know the correct ATE and can determine the bias and MSE in our simulations, despite the use of empirical data.
In a next step, the experiment is artificially broken by the introduction of the following response process, which is designed such that roughly two thirds of the outcomes are observed: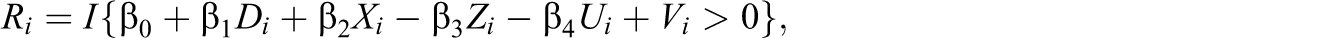
In each of the 2,000 Monte Carlo replications, (Y, X, U) are randomly drawn from the “population” without replacement and (D, Z, V) from their respective distributions in order to compute R. Then, we estimate the response propensity score by regressing R on (1, D, X, Z) and the treatment propensity score, which is unknown in our simulation due to the use of empirical data, by regressing D on
Table 3 presents the results which are in line with the previous simulations. The bias of the IPW estimator is moderate irrespective of the sample size and the trimming level, whereas it amounts to roughly 1.8 SAT scores when taking mean differences. Yet, when considering the smaller sample size, the mean difference estimator is superior with respect to the MSE as it is more precise than IPW. However, as the sample size gets larger IPW increasingly outperforms mean differences. We therefore conclude that weighting based on instruments is effective in reestablishing the validity of experiments under attrition on unobservables, at least when the sample size is not too small such that the gain in bias reduction outweighs the loss in precision due to the estimation of the propensity scores and weighting. Of course, a precondition for this result is the availability of a continuous instrument that is both relevant (sufficiently correlated with response behavior) and valid (no direct effect on the outcome). Table 3 also reports the average numbers of trimmed response and treatment propensity scores in the simulations, which are acceptable even under the 10% trimming level.
Attrition on Unobservables, Empirical Data, Zero Treatment Effect

Note: 2,000 Monte Carlo replications. “IPW unobs” controls for attrition related to observables and unobservables.
In summary, both studies based on simulated and empirical data suggest that IPW becomes increasingly accurate in terms of the MSE and relatively superior to taking mean differences, as the sample size gets larger and given that the correct attrition process is assumed. This is an interesting finding because there exists, as already briefly mentioned, an important difference between the two designs: Parts of the model, for example, the outcome equation, remain unknown when using empirical data. Therefore, it may not be taken for granted that IPW performs equally well in the latter case, because the threat of incorrectly specifying the treatment propensity score remains even when assuming the correct form of attrition. This advocates a flexible specification of the propensity scores and motivates the use of specification tests in the empirical application presented below.
6. Empirical Application
We present an application of Propositions 4 and 5 (attrition related to observables and unobservables) to a labor market policy experiment which was conducted in the United States in the mid-1990s in order to assess the publicly funded Job Corps program. This program (D), which is currently administered by 124 local Job Corps centers throughout the United States, targets young individuals (aged 16–24 years) who have a legal residence in the United States and come from a low-income household (see Schochet, Burghardt, and Glazerman, 2001) for further details. It provides participants with approximately 1,100 hours of vocational training and education as well as with housing, board, and health services over an average duration of roughly 8 months. Here, we use a subset of the experimental data analyzed by Lee (2009), namely, the female sample that includes 4,044 observations.
Suppose that we would like to learn about the ATE on women’s potential log wages (Y) 1 year after program assignment (mean: 1.661; standard deviation: .415). However, we face the problem that wages are only observed for the nonrandom subsample of the 1,454 employed females (R = 1). Economic theory suggests that the latter are likely to differ from the nonworking with respect to unobservables such as motivation and ability. From an econometric perspective, this sample selection problem is equivalent to the attrition problem discussed in Section 4. Furthermore, empirical results (see, for instance, Mulligan & Rubinstein, 2008, among many others) provide strong evidence that socioeconomic characteristics as education, age, race, and labor market experience are important confounders related to both the employment probability and the potential wages. Fortunately, the data set contains information on all of these factors (X) that were measured in the baseline survey at the program assignment. Finally, we require one or more instruments (Z) that plausibly affect the labor supply decision, but have no direct affect on wages. Following the literature (see, for instance, Das et al., 2003), we assume the number of children and parents' education to be valid instruments for employment, at least given the other information in the data.
We use a probit specification (see Appendix H, available online at http://jeb.sagepub.com/supplemental) to estimate the labor supply equation required for the computation of the response propensity score. Interestingly, the treatment coefficient is significantly negative, which points to the prevalence of so-called lock-in effects due to reduced job search effort during program participation. This phenomenon is well documented in the literature (see, for instance, Sianesi, 2004). As expected, education, age, and a favorable labor market history all increase the employment probability. This implies that the working females have better labor market preconditions than the entire sample. Also mother’s education has a positive impact, supposedly through role models, while the coefficient on number of children is negative, albeit not significant. As a model check, we conducted the nonparametric specification test for propensity scores suggested by Shaikh, Simonsen, Vytlacil, and Yildiz (2009). The test yields a p value of .81 and, therefore, does not reject the null hypothesis of a correct specification. In the second step, we regress the treatment on the observed variables X and the response propensity score in order to estimate the treatment propensity score. Again, the specification test does not reject the null at any conventional level.
We estimate the ATEs on the respondents (
Table 4 shows the results on estimation and inference. The estimates suggest that the program increases the wages of working women on average by 5.5% (which is only borderline significant) and those of the entire population by 6%, irrespective of the trimming level. These effects are up to one third higher than the mean difference of 4.5%. Therefore, the results, which are robust under alternative propensity score specifications not reported here, suggest that the mean difference may be downward biased, albeit the differences in the effects are not statistically significant. In conclusion, the ATEs on the working and on all women are within the range (but rather at the lower end) of those commonly found for an additional year of schooling (see, for instance, Card, 1999). This appears reasonable, given that the scale of the Job Corps program roughly corresponds to a full year in high school, as argued by Lee (2009).
ATE of Training Participation on Log Wage 1 Year Later
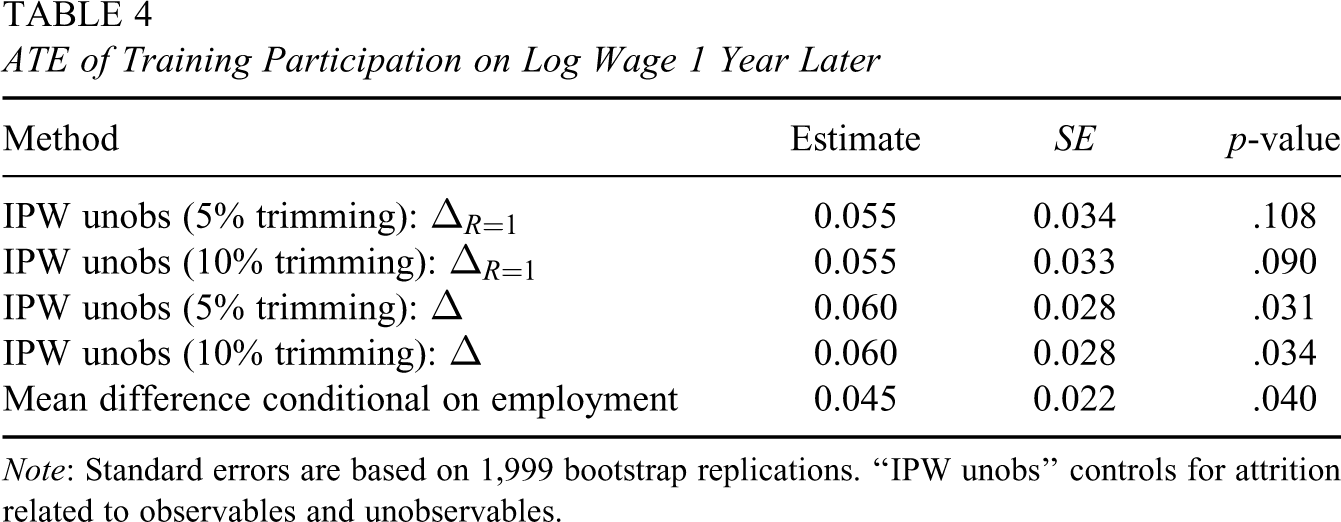
Note: Standard errors are based on 1,999 bootstrap replications. “IPW unobs” controls for attrition related to observables and unobservables.
7. Conclusion
This article discusses the identification of treatment effects in randomized experiments when outcomes are only partially observed due to attrition and nonresponse in follow-up surveys. Its first contribution is the systematic coverage of various forms of attrition, that is, when outcomes are MCAR and when attrition is related to observables (MAR) and unobservables. We treat these various forms by imposing different assumptions on the relation between the response behavior and the treatment, the observed covariates, and the unobserved characteristics in a fairly general treatment effect model.
The second contribution is to show point identification of ATEs on the respondents and on the entire population based on different implementations of IPW. Each IPW method is tailored to the specific nature of attrition considered, which provides practitioners with straightforward solutions depending on the suspected missing data problem. In particular, we introduce an IPW approach based on an IV strategy to tackle attrition on unobservables, which was not considered in the experimental literature before. Our simulation results suggest that an incorrect model for attrition, which, for instance, omits attrition on unobservables, may do worse in terms of bias and MSE than not controlling for the missing outcome problem at all. This highlights the importance of a thorough analysis and correct specification of the response behavior.
Despite its technical ease of implementation, the IV-based IPW approach appears to be rarely applicable in social experiments conducted up to date, due to the lack of credible continuous instruments for attrition. This is unfortunate, as attrition on unobservables seems to be a potential threat in many fields of research where randomized trials are conducted (such as education and labor economics), in particular when the number of observed baseline characteristics is low. For example, in an education experiment, unobserved motivation is likely to be correlated both with the outcome (such as the grade or the test score) and the likelihood to respond (e.g., to participate in a test or exam). Therefore, we argue that future experimental research should seriously consider the creation and random assignment of instruments in order to increase the credibility of experimental inference in the presence of attrition. The number of phone calls in follow-up surveys or financial incentives for responding are just two examples for potentially interesting instruments.
Footnotes
Acknowledgments
The author has benefited from comments by Eva Deuchert, Bernd Fitzenberger, Michael Lechner, Blaise Melly, conference/seminar participants in Freiburg i. B. (research seminar), London (EALE 2010), and Fribourg (SSES 2010), and two anonymous referees.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.