
Abstract
In this article, a proposed Bayesian extension of the generalized beta spatial regression models is applied to the analysis of the quality of education in Colombia. We briefly revise the beta distribution and describe the joint modeling approach for the mean and dispersion parameters in the spatial regression models’ setting. Finally, we motivate the need for the innovative use of the generalized beta spatial regression model to the study of the performance of school children in Mathematics and Language, as well as in the analysis of illiteracy data, and present its results in the context of evaluating the quality of education in Colombia.
1. Introduction
This article studies and motivates the methodology required to analyze a specific real data set situation when the observations are associated with the beta distribution. Observations associated with the beta distribution are commonly found in the quality of education studies, that is, in the evaluation of the school’s performance in Mathematics, Language, Arts, Natural Sciences, or in any other areas of study where a number between
A review of the literature in this area of research indicates that many studies whose focus is to determine the quality of educational systems have been developed in quite different contexts. The Programme for International Student Assessment (PISA) was designed and launched by the Organization for Economic Cooperation and Development (OECD) at the end of the 1990s as an international, comparative, and public way of evaluating the performance of school children so that indicators of the various aspects describing the way educational systems function could be generated. These indicators would enable countries to implement the required policies that can improve the quality of their educational system, with a special focus on the learning results students obtain within the system. The 2009 PISA study involved
In educational studies like the PISA study, the Latin American Laboratory for Assessment of the Quality of Education, or the National Systems Educational Evaluation in countries such as Colombia, Chile, or El Salvador, regional results are also of great interest for researchers in the area. Therefore, the mean performance or the percentage of students (by country or state) having a given reading level are obtained. These results could depend, for example, on variables such as regional policies, income taxes, or the level of regional development, and they cannot be assumed to be independent of variables related to the regional structures. This is one of the reasons that motivates the use of a spatial econometric method that can incorporate spatial interactions and spatial structures into the proposed regression analysis. That is, countries, regions, or departments (departments in Colombia are different regions into which the country is divided, similar to what provinces represent in European countries or states do in the United States) having neighbors with well-developed educational systems would have higher probabilities of educational development than countries having neighbors with not such a developed educational system. Therefore, the application of spatial econometric models can be convenient and justifiable (see, e.g., Anselin, 1999; Anselin & Florax, 1995; Kelley Pace, Barry, & Sirmans, 1998; LeSage, Fischer, & Scherngell, 2007). Moreover, and given that the classical spatial models assume that the variable under study follows a normal distribution, which is clearly not a valid assumption for these studies, we propose to use a Bayesian version of the beta econometric spatial model proposed by Cepeda-Cuervo, Urdinola, and Rodríguez (2011). This model explicitly incorporates spatial structures and it has been mainly applied to study spatial land concentration in the context of generalized econometrics models. More specifically, and in the context of the data under study, in educational data analysis, when data of state or departments are considered, it is necessary to propose statistical models that take into account the spatial structure of the data. If, in addition, the data include bounded outcome variables, such as, for example, proportions or educational indexes of success or failure, a beta spatial regression model, such as the one we motivate and propose in this article, would be appropriate to analyze the real nature of the data under study.
Many applications of the beta regression models have been developed in the last few years, a clear sign of the motivation for its use within the aforementioned context. Some of these recent applications include, for example, Ferrari and Cribari-Neto (2004) and Rocha and Simas (2011) for the study of proportions; Espinheira, Ferrari, and Cribari-Neto (2008) for the analysis of a test of reading accuracy; and Verkuilen and Smithson (2012) for the analysis of the results of cognitive experiments. Therefore, there are many well-motivated reasons to use beta regression models instead of other alternative approaches (Smithson & Verkuilen, 2006). Moreover, these researchers stated in their findings that “one important advantage that beta regression shares with other GLMs over the ladder-of-powers transformations stems from the fact that the transformations transform raw data, whereas the link function in any GLM transforms expected values.”
Besides being used to study the quality of education, many spatial applications of the beta distribution are also possible. For example, to study levels of illiteracy, levels of literacy, unemployment or infant mortality rates by regions, the analysis of the evolution and behavior of poverty and development indexes, study of concentration of wealth or land, and also in the study of risk or corruption indicators by departments, states, or countries. In all of the aforementioned examples, the beta distribution can be assumed as a model. However, and given that the observations of these variables cannot be assumed to be independent, the use of a spatial beta regression model is well justified to model the aforementioned response variables as a function of the socioeconomical political variables that could have an influence on them. Therefore, spatial structures should be considered, so that the proposed model takes into account the existing neighborhood association. Spatial beta regression models can easily measure this association, and their results are very simple to understand from a practical point of view. This issue is addressed by proposing the use of a so-called weights matrix in the model, where its parameter estimates are associated with the corresponding lag variable modeling this neighborhood association. From the above, it is clear that the election of the weights matrix is very important because it should be the result of interpreting and understanding the spatial structure of the variable under study and, although many first-order time structures are considered, other spatial structures can also be assumed. Therefore, this model allows us to assess, in an intuitive and very natural manner, what real influence neighbor departments or states have on the educational system for specific sites in the data we are analyzing. As will be described in detail in Subection 3.2, we will use regression parameters that take into account this site-closeness effect. A brief description of the spatial econometric beta model definition is also given in Subsection 3.2, where it will be shown that this model is also easy to fit and its results simple to interpret in the context of the application.
The rest of the article is organized as follows. In Section 2, we describe the beta distribution. In Section 3, we introduce the general joint mean and dispersion beta regression model and also include a brief description of the econometric beta regression model. Sections 4–6 present the application of the spatial beta econometric model to the data sets under study, which are centered on educational research. Finally, Section 7 includes some conclusions and final recommendations. In addition, the Appendix includes the relevant WinBugs code used to fit some of the models proposed here, as well as a comparison of the fitting for the proposed joint beta regression models and transformation models, where the response variable is transformed. That is, in the Appendix, we have reanalyzed the data on the student’s performance in Mathematics using three different models, the proposed beta regression model with a joint modeling of the mean and dispersion parameters, and two transformation models, a heteroscedastic normal regression model applied to the logit transformation of the response variable, and a heteroscedastic model applied after the logarithm transformation of the response variable.
2. The Beta Distribution
In real data set situations, many random variables can be assumed to have a beta distribution. For example, the income inequality or the land concentration is measured using the Gini index (Atkinson, 1970) or the students’ performance in areas such as Mathematics, Natural Sciences, or Literature. In the latter case, if performance Z takes on values in the real interval
Some reparameterizations of the beta distribution can be appropriate for specific studies. An initial reparameterization makes
The beta distribution can also be reparameterized as a function of the mean and variance parameters, as proposed in Cepeda-Cuervo (2012), where
3. Beta Regression Models
3.1. Joint Modeling in Beta Regression
The aforementioned reparameterization of the beta distribution as a function of μ and φ is interesting and allows us to define double generalized linear models, as originally proposed in Cepeda-Cuervo (2001). In this sense, the joint beta regression modeling approach of the mean and dispersion parameters is defined, and a very flexible Bayesian methodology to fit the parameters of the proposed model is described. In a more general framework, we can assume that we have a random sample

where
An innovative and very useful generalization of the aforementioned joint mean and dispersion beta regression model includes the possibility of having a random error term in the dispersion model. The main purpose of including this random error term would be to be able to incorporate in the model any possible effect that has not been adequately or possibly explained by the independent variables already included in the dispersion model. Therefore, we have that, for this new joint mean and dispersion beta random effects models, the mean can be defined by Equation 1, whereas the dispersion model is now given by

where
3.2. Double Generalized Spatial Beta Regression
It is of great interest for states or regions within a given country, or for countries themselves, to investigate and find out if the implemented educational policies or particular sociocultural conditions have an influence over the students’ performance in specific areas, such as, for example, Mathematics, Language, or Science. In order to further investigate this research question, a particular test (of Mathematics, Language, or Science) is given to a sample (or to the whole population) of students in a particular level within the formal educational process that is being evaluated. This specific test will be used to assess the students’ performance in each subject, assigning a real number (i.e., a score) in the interval
Our initial interest will be focused on trying to explain how, within the settings of beta regression models, the students’ average performance is influenced by a function of the available explanatory variables associated with each of the observational units (i.e., states or municipalities) in the study. However, and given that there is a cultural interaction and that sociocultural conditions do not change from one observational unit to another, it may not be reasonable or justified to assume independence between the different observational units’ performances. That is, it does make perfect sense to assume that there will be a “contagious” or “border” effect in the quality of education among geographical neighbors within the same country. This effect is clearly expected in the Colombian case for several reasons. The main and most important reason can be motivated by the obvious relation neighbors sharing borders have, given that they share similar socioeconomic and cultural characteristics. For example, a poverty or economic boom can clearly be shared across neighbors’ borders, as well as their similarity in the reasons that may have caused such poverty or temporary economic shock.
Modeling proposals that may be used to include such effects are the so-called spatial econometric models (Anselin, 1988), where a spatial lag specification introduced as explanatory variable in the regression model can be used to be able to capture the spatial neighbors’ interaction effect. This new lag-specification variable is defined as the product of the
Therefore, for this specific type of application, we propose the analysis using a spatial beta regression model assuming that the spatial variable under study
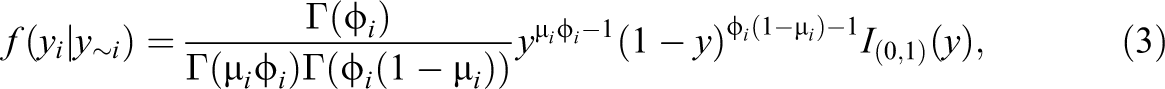
where


where
In the previously proposed model, the lag spatial variable
Finally, in order to apply Bayesian methodology, very flexible and general independent normal prior distributions
4. Application: Quality of Education in Colombia
In this section, we use the aforementioned double generalized beta regression model to analyze a real data set obtained from the evaluation of the quality of education in Colombia, disaggregated by department. Although the average performance score in Mathematics takes on values in the closed real interval
In this application, the response variable under study is the average development in Mathematics (for each one of the
4.1. Analysis of the Performance in Mathematics of Colombian School Children: The Colombian Border Plan
The Colombian border plan was a program of the Colombian government whose main objective was to strengthen and visualize the National Government Relations, as well as those relations between neighboring communities, by strengthening governance in

where
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for Parameters in the Initial Beta Regression Model in Equation 6
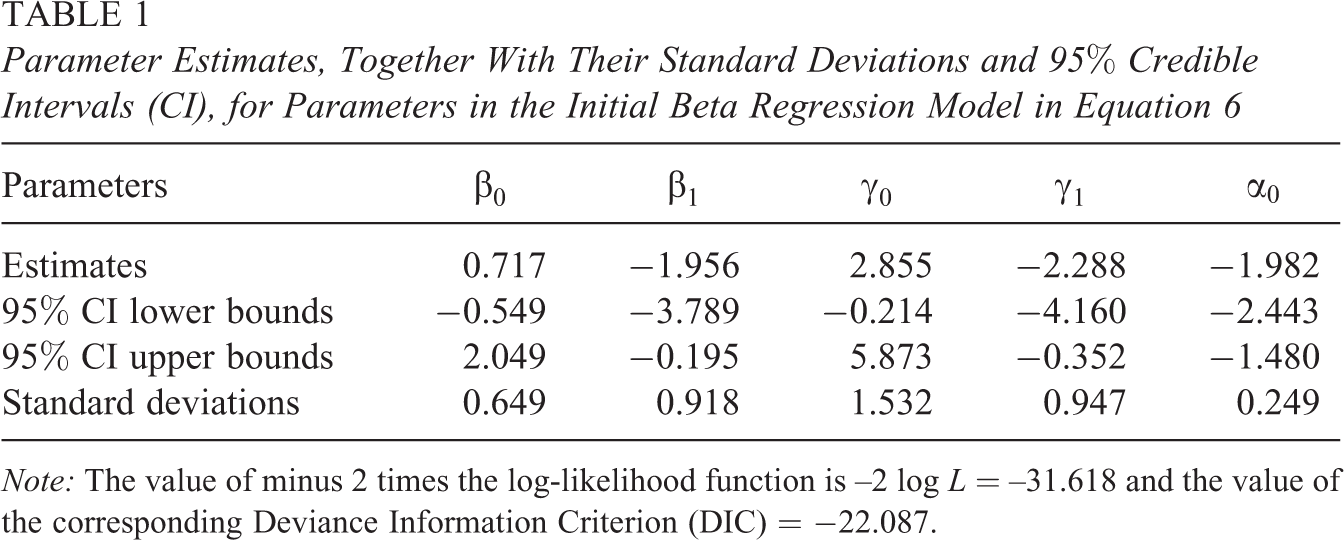
Note: The value of minus 2 times the log-likelihood function is –2 log L = –31.618 and the value of the corresponding Deviance Information Criterion (DIC) = −22.087.
We should mention that, given that the mean model in Equation 6 does include the indicator variable
As a result of fitting model (Equation 6) and from the estimated parameters reported in Table 1, we can conclude that the mean model for departments in the Colombian border (i.e.,
Some of the alternative models that were considered in this study included NBI, PORC, as well as the lag
5. Spatial Analysis of the Performance in Language of Colombian School Children
In this second application, the response variable under study is the average development in Language (by department) for students in their fourth year of secondary school studies. As in the previous example, data were provided by the ICFES and the DANE. The average performance in Language for each department is denoted by P and it takes on values in the closed real interval between 0 and 100 (i.e.,
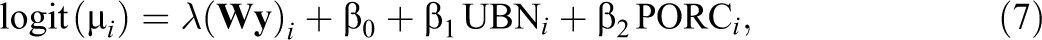

where
As in previous sections, independent normal
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 7 and Dispersion Parameters in Equation 8, With

Note: The value of minus 2 times the log-likelihood function is –2 log L = –50.140 and the corresponding Deviance Information Criterion = −33.271.
In addition and given the results reported in Table 2, we have considered the model that does not include the spatial effect in the mean model. That is, we also consider the beta regression model with mean given by

and dispersion model given by Equation 8. Table 3 includes the parameter estimates, together with their corresponding standard deviations and 95% credible intervals for the parameters in the spatial models for the mean and dispersion parameters given by Equations 9 and 8, and the value of minus 2 times the log-likelihood function as well as their corresponding DIC value, which is a smaller value than that associated with the more general model in Equations 7 and 8. Based on the results obtained from the fitting of the aforementioned models and on their DIC values, the latter model will be the best one to study students’ Language performance. It is important to mention that these fitted models clearly motivate and justify the usefulness of including the spatial effect structure in the model. In our view, and given that language development is expected to be associated with socioeconomic factors, this is a natural fact. In the results reported in Tables 2 and 3, the resulting estimate for the coefficient associated with the variable UBN is negative and statistically significant, implying that larger values of the variable UNB are associated with poorer students’ Language performance scores. Along the same lines and given that the estimated coefficient associated with the variable PORC (i.e., the percentage of teachers having a PORC) is positive and statistically significant, this implies that larger values of the variable PORC are associated with better students’ Language performance scores. Finally, in order to better justify the need and usefulness of the proposed spatial beta regression model, we have also fitted the model in Equations 7 and 8 (detailed results not reported for brevity), but without including its spatial terms (i.e., with
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 9 and Dispersion Parameters in Equation 8, With

Note: The value of minus 2 times the log-likelihood function is –2 log L = –50.619 and the corresponding Deviance Information Criterion = −35.251.
6. Spatial Analysis of Illiteracy in Colombia
In this application, we study the illiteracy proportion for a population aged 15 and over in Colombia. Data were collected by DANE. Illiteracy proportions are lower than


Table 4 includes the parameter estimates, together with their corresponding standard deviations and 95% credible intervals, as well as the value of minus 2 times the log-likelihood function and the corresponding DIC value.
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 10 and Dispersion Parameters in Equation 11

Note: The value of minus 2 times the log-likelihood function is –2 log L = −131.190 and the corresponding Deviance Information Criterion = –121.409.
The second spatial beta regression model we have considered is similar to the previous one in the specification of the dispersion model, but with a mean model now given by
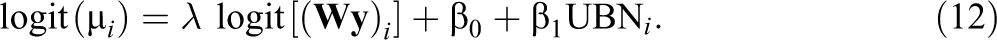
We should mention that the latter model includes the lag variable having the same structure than that in the link function. Table 5 includes the parameter estimates, together with their corresponding standard deviations and 95% credible intervals, as well as the value of minus 2 times the log-likelihood function and the corresponding DIC value. Parameter estimates reported in Table 5 suggest several very interesting issues to be carefully analyzed: There is a clear agreement between the regression parameter estimates obtained for the explanatory variable and also in their DIC values. Moreover, the credible intervals obtained for the regression model parameter λ in both models do not include the value zero. Therefore, we can conclude that in both models the lag variable has a significant contribution in explaining the illiteracy proportion variable under study.
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 12 and Dispersion Parameters in Equation 11
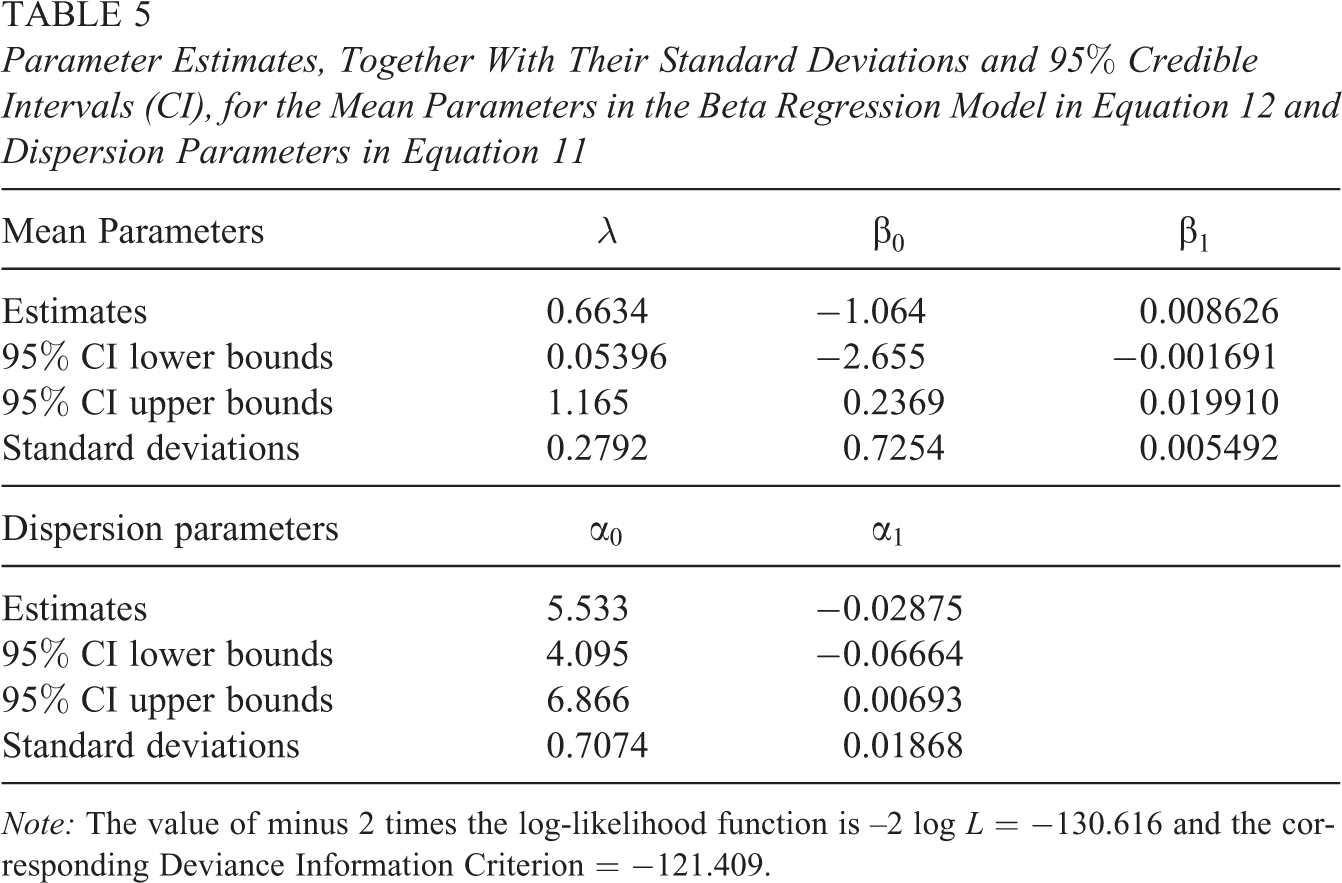
Note: The value of minus 2 times the log-likelihood function is –2 log L = −130.616 and the corresponding Deviance Information Criterion = −121.409.
In addition, to further illustrate the contribution made by the aforementioned lag variable in the spatial beta regression model, a third model was fitted. This model does not include any spatial component in the mean model, and it only includes the UBN variable as explanatory variable. The dispersion model is given by Equation 11. Thus, the mean model is now given by

Table 6 includes the parameter estimates, together with their corresponding standard deviations and
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 13 and Dispersion Parameters in Equation 11
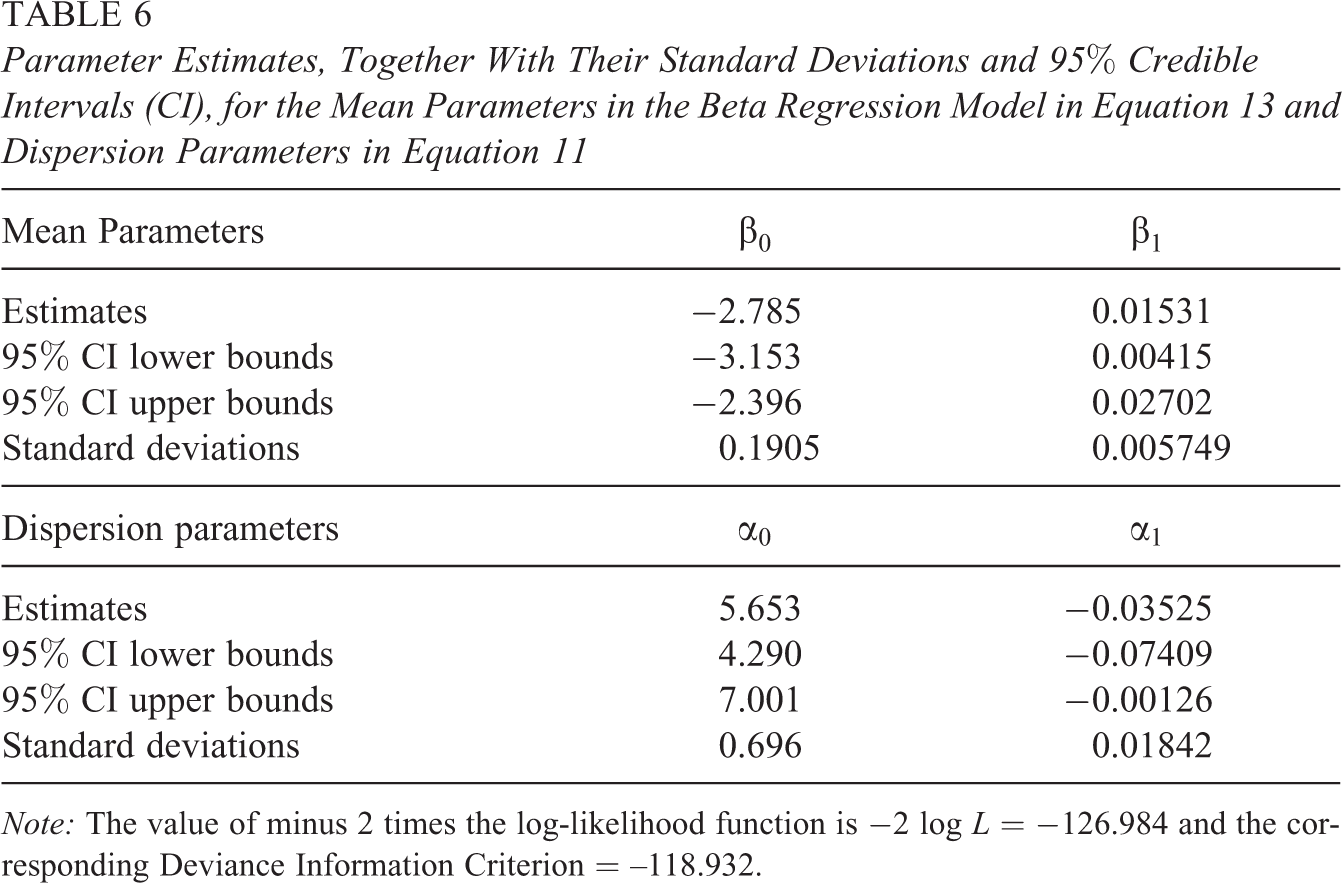
Note: The value of minus 2 times the log-likelihood function is −2 log L = −126.984 and the corresponding Deviance Information Criterion = –118.932.
From the results of the aforementioned models, we can conclude that the variable UBN may not be significant in the mean and dispersion models, and that the lag variable is clearly significant in the mean model. There still remains the question about the need to include or not the lag variable in the dispersion model. Therefore, as a final model for the illiteracy data, we fit mean and dispersion models that do not include the UBN explanatory variable, but that include the corresponding lag variables. That is,


Table 7 includes the parameter estimates, together with their corresponding standard deviations and 95% credible intervals, as well as the value of minus 2 times the log-likelihood function and the corresponding DIC value. The DIC value for this model (i.e.,
Parameter Estimates, Together With Their Standard Deviations and 95% Credible Intervals (CI), for the Mean Parameters in the Beta Regression Model in Equation 14 and Dispersion Parameters in Equation 15
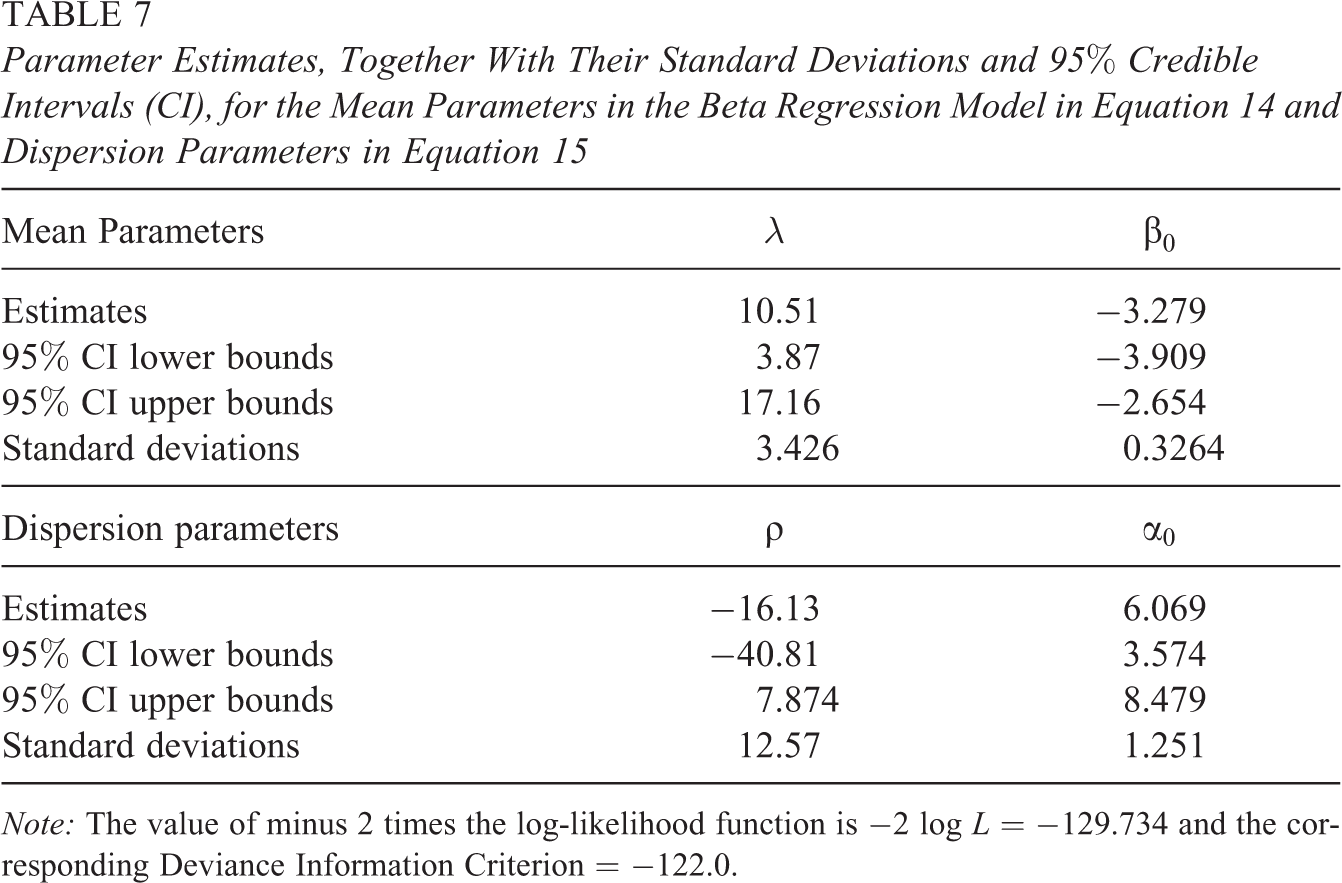
Note: The value of minus 2 times the log-likelihood function is −2 log L = −129.734 and the corresponding Deviance Information Criterion = −122.0.
7. Conclusion
We have motivated an innovative application of the generalized beta spatial regression models to the analysis of the quality of education in Colombia. In order to do so, the beta distribution was briefly described and the joint modeling approach for the mean and dispersion parameters in the spatial regression models’ setting was introduced. Our proposed methodology suggests the use of a Bayesian version of the beta econometric spatial model recently proposed by Cepeda-Cuervo et al. (2011), especially of those models that consider the inclusion of a random effect term in the dispersion model. Results obtained from the analysis of the generalized beta spatial regression model to the study of school children performance in Mathematics have suggested that factors such as the UBN and the teachers’ training are significant factors to be taken into account by the government in order to improve the quality of education in Colombia.
Finally, when the model takes into account the information about departments belonging or not to the border of Colombia, we could see that, when the explanatory variable measuring the teacher’s training, PORC, increases, the mean increases more rapidly for departments that are not in the Colombian border than for those that are in the Colombian border. Proposed models have shown their usefulness and applicability within this area of research.
Even though the models associated with the performance in Mathematics did not include the spatial factor
In the applications used in this article to illustrate the proposed methodology, inferences from the posterior distribution samples were obtained using the well-known WinBugs software. However, the generalized beta distribution models can be fitted by applying different methodologies. A classic approximation can be applied by maximizing the logarithm of the likelihood function with the use of the Newton Raphson algorithm. A Bayesian approach can be applied as well by appropriately adapting and using the Bayesian methodology proposed in Cepeda-Cuervo (2001).
Footnotes
Appendix
In this section, we include the WinBugs code that can be used by interested readers to fit the joint mean and dispersion beta regression models. In this specific WinBugs code, it is assumed that
Acknowledgments
The authors wish to thank the editor and two anonymous referees for providing thoughtful comments and suggestions which have led to substantial improvement of the presentation of the material in this article.
Declaration of Conflicting Interests
The author(s) declared no conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work of the first author was supported by the Department of Statistics of Universidad Nacional de Colombia and by Ministerio de Ciencia e Innovación and FEDER under research grant MTM2010-14913. The work of the second autor was supported by Ministerio de Ciencia e Innovación, FEDER, the Department of Education of the Basque Government (UPV/EHU Econometrics Research Group), and Universidad del País Vasco UPV/EHU under research grants MTM2010-14913, IT-334-07, UFI11/03, US12/09, and IT-642-13.