
Abstract
This article discusses estimation of multilevel/hierarchical linear models that include cluster-level random intercepts and random slopes. Viewing the models as structural, the random intercepts and slopes represent the effects of omitted cluster-level covariates that may be correlated with included covariates. The resulting correlations between random effects (intercepts and slopes) and included covariates, which we refer to as “cluster-level endogeneity,” lead to bias when using standard random effects (RE) estimators such as (restricted) maximum likelihood. While the problem of correlations between unit-level covariates and random intercepts is well known and can be handled by fixed-effects (FE) estimators, the problem of correlations between unit-level covariates and random slopes is rarely considered. When applied to models with random slopes, the standard FE estimator does not rely on standard cluster-level exogeneity assumptions, but requires an “uncorrelated variance assumption” that the variances of unit-level covariates are uncorrelated with their random slopes. We propose a “per-cluster regression” (PC) estimator that is straightforward to implement in standard software, and we show analytically that it is unbiased for all regression coefficients under cluster-level endogeneity and violation of the uncorrelated variance assumption. The PC, RE, and an augmented FE estimator are applied to a real data set and evaluated in a simulation study that demonstrates that our PC estimator performs well in practice.
1 Introduction
We consider linear regression models for clustered data that include cluster-specific random intercepts and slopes. Such models are called multilevel models, mixed models, random-coefficient models, or hierarchical linear models. If the models are viewed as “structural models,” the perspective taken in this article, the regression coefficients represent structural or causal parameters, and the error terms represent the effects of omitted covariates. If there are omitted confounders that are correlated with included covariates, then the error terms are correlated with the included covariates. These correlations lead to omitted variable bias. This article focuses on estimation methods that avoid bias due to omitted cluster-level confounders, also referred to as “cluster-level endogeneity.” An alternative view of models, not taken here, is that regression coefficients merely represent associations between included variables, or linear projections in the case of linear models, in which case the error terms are orthogonal to the covariates by construction (see Spanos, 2006, for a discussion of “structural” vs. “statistical” models).
Research on addressing cluster-level endogeneity in multilevel models has traditionally been confined to correlations between unit-level covariates (i.e., covariates that vary over units) and random intercepts that vary over clusters in which units are nested. This constitutes a type of “cluster-level” endogeneity, as it involves correlation with a cluster-level random error term. For instance, in estimating the effect of Catholic schooling on student achievement controlling for student socioeconomic status (SES), one may worry that school-level omitted variables, such as school resources, may be correlated with SES. Left unaddressed, this endogenity may lead us to misattribute the impacts of these omitted variables to the effect of SES. This bias may in turn spill over to other coefficients. To address this type of endogeneity, Mundlak (1978) shows that consistent estimators of the coefficients of unit-level covariates can be obtained by a fixed-effects (FE) approach. However, with standard FE estimators, coefficients of cluster-level covariates (i.e., covariates that only vary over clusters) cannot be estimated. The Hausman and Taylor (1981) instrumental variable estimator resolves this limitation and is consistent for the coefficients of both unit- and cluster-level covariates under appropriate assumptions (see Castellano, Rabe-Hesketh, & Skrondal, 2014).
Endogeneity in the form of correlations between unit-level covariates and random slopes varying over clusters may also arise. Referring back to the Catholic schooling example, when controlling for students’ SES, the slope of SES (or SES achievement gradient) may vary between schools, due to interactions between SES and omitted school-level covariates, such as school resources. If the omitted variables are negatively correlated with the SES achievement gradient, then the random slopes will be negatively correlated with SES.
Remarkably, such endogeneity is rarely considered. One exception is Frees (2004) who extends the Mundlak approach to handle random slopes. Another is Wooldridge (2005) who shows under seemingly benign conditions that traditional FE estimation of random-intercept models is robust against correlations between unit-level covariates and random slopes. However, neither of these approaches permits estimation of the coefficients of cluster-level covariates even if the covariates are exogenous (i.e., not endogenous). This limitation is overcome by Kim and Frees (2007) who use generalized method of moments estimation to extend the Hausman–Taylor approach to multilevel models with random slopes. However, their method is difficult to implement, making the FE approach more feasible in practice.
Unfortunately, a key assumption required for the FE approach may be violated in important applications. Specifically, the within-cluster variance of a unit-level covariate must be uncorrelated with the random slope of that covariate, which we refer to as the “uncorrelated variance assumption” throughout this article. Turning back to the Catholic schooling example, it is possible that more diverse schools (schools with high variance of SES) may be better equipped to mitigate the effects of SES (lower the SES achievement gradient) than schools that are more homogeneous (schools with low variance of SES). Such a situation would directly violate the uncorrelated variance assumption.
In this article, we investigate estimation of the coefficients of unit-level and cluster-level covariates in multilevel models in the presence of two sources of endogeneity; (nonzero) correlations between unit-level covariates and both the random intercept and random slopes. Throughout, we assume that covariates are uncorrelated with the unit-level error term and that cluster-level covariates are uncorrelated with the random intercepts and random slopes. We propose a simple “per-cluster regression” (PC) approach that is unbiased and consistent for coefficients of both unit-level and cluster-level covariates under both forms of cluster-level endogeneity and violation of the uncorrelated variance assumption. We contrast its performance to the “standard” random-effects (RE) estimator and what we call the “augmented FE” (FE+) approach, which extends the FE approach to provide estimates of the coefficients of cluster-level covariates. In Section 2, we first introduce our motivating empirical example and specific model of interest and then present our general model. In Section 3, we discuss the traditional RE and FE estimators and their conditions for unbiasedness. In Section 4, we introduce new estimators, namely, the FE+ estimator and the PC estimator, and show under what assumptions they are unbiased. We provide conditions for consistency for all four estimators in Online Appendix A. All estimators are applied to a data set in Section 5, and Section 6 investigates performance of the estimators using a simulation study.
2 Motivation and Multilevel Model
2.1 Motivating Example and Specific Model
As a motivating example, we consider the effect of private schooling on student achievement. We use the Raudenbush and Bryk (2002) data from the 1982 High School and Beyond (HSB) Survey because it is familiar in education and it is in the public domain, allowing us to provide data and commands for all estimators in Online Appendix B.
This two-level data set provides us with an estimation sample of 7,185 students (units) nested in 160 schools (clusters), 70 of which are Catholic (private) and the remaining of which are public. The number of observations per school ranges from 14 to 67 students (mean = 45, SD = 12). We use a mathematics standardized test score for student i in school j as our response variable, yij , which has a mean of 12.75 and a standard deviation of 6.88. Our primary variables of interest are wj , a binary indicator for whether school j is Catholic, and xij , a continuous index of students’ SES, composed of parental education, parental occupation, and parental income. This index has a mean of 0 and a standard deviation of 0.78.
We write the model using a two-stage formulation, similar to that used in Raudenbush and Bryk (2002). The first stage is the Level-1 model:

This is a simple regression of the student mathematics test scores yij on their SES xij , where the intercept η0j and slope η1j can vary between schools, as indicated by the j subscript. Each student’s test score can deviate from the school-specific regression line by a random error term ε ij .
The school-specific intercepts and slopes become (unobservable) outcomes in the Level-2 models:

The mean intercept and slope of SES, for the population of schools, depend on whether the schools are Catholic or public (wj ). The intercepts γ0 and β1 in these models therefore represent the population means of the intercepts and slopes of SES for public schools, whereas the slopes γ1 and β2 represent the differences in population means of the intercepts and slopes between Catholic and private schools, respectively. The Level-2 models have errors u 0j and u 1j to allow the schools' intercepts and slopes to vary within the subpopulations of Catholic and private schools. Assumptions regarding the error terms are discussed in Sections 3 and 4.
Substituting the Level-2 models into the Level-1 model, we obtain the reduced form of the model:

We see that β2 is the coefficient of a cross-level interaction between the student-level covariate xij and the school-level covariate wj .
In this setting, it is likely that there are omitted school-level variables that affect student achievement, and hence enter the random intercept u 0j , and are correlated with student SES. If these omitted school-level variables also interact with student SES, then they enter the random slope u 1j , and the slope is then correlated with SES. Ignoring such endogeneity may lead to bias when estimating the coefficients of this model.
2.2 General Multilevel Model
The general model we consider in this article is for two-level data, such as the HSB data described previously. In the cross-sectional case, units (Level 1) are typically individuals nested within clusters (Level 2), such as schools, hospitals, or neighborhoods. In the longitudinal case, units refer to measurement occasions nested within individuals who constitute the “clusters.” Clusters are indexed j, with j = 1,…, J, and units are indexed ij, with i = 1,…, nj . The general model includes unit-level covariates that vary between units within clusters (and between clusters) as well as cluster-level covariates that vary between clusters but are constant across units within the same cluster. Same-level and cross-level interactions may also be included, where cross-level interactions are unit-level covariates. Some unit-level covariates may have random slopes.
The general model can be written as:

Here
For the specific model of the HSB data in Equation 3, P = 1, so that
The model in Equation 4 can be expressed more compactly by combining all covariates (i.e.,

It will often be convenient to stack the covariates for all J clusters in the matrix
Writing this general model using a two-stage formulation, analogous to Equations 1 and 2, requires additional notation, so we defer this until Section 4.2 where this formulation is useful for explaining the PC approach.
3 Standard Estimators and Conditions for Unbiasedness
3.1 Exogeneity and Endogeneity
Throughout this article, we assume unit-level exogeneity or strict exogeneity, given the random effects,

It follows that
The assumption of cluster-level exogeneity can be expressed as:

When this assumption is violated, there is cluster-level endogeneity.
We assume that cluster-level exogeneity holds for the cluster-level covariates

and discuss the problem that unit-level covariates may be cluster-level endogenous,

Cluster-level endogeneity occurs if, for example,
In this article, we consider RE, FE+, and (our proposed) PC approaches for estimating the model in Equation 3 when
3.2 RE estimators
For RE estimators, the random effects,
It follows from these assumptions that the mean and covariance structure of

and

Under the exogeneity assumptions in Equations 6 and 7, consistent estimators for the parameters of the model in Equation 5 can be obtained using maximum likelihood (ML), restricted ML (REML), or feasible generalized least squares (FGLS). The FGLS estimator can be expressed in closed form as

where
The conditional expectation of the GLS estimator

Note that
Unfortunately, due to the nonlinear nature of the FGLS estimator, this unbiasedness result does not automatically apply when estimates
3.3 FE Estimators
In econometrics, the term fixed-effects (FE) estimator refers to an estimator that does not rely on cluster-level exogeneity, and we adopt this terminology here. Some of the estimators can be derived by treating the random effects as fixed and others by eliminating the random effects, but in either case, the effects are typically viewed as random. The traditional FE approaches have been developed for random-intercept models, with
We define the FE estimator in terms of the de-meaning (or group-mean centering) transformation

Note that

where
To derive the conditions for unbiasedness, stack the

Keep in mind that
Wooldridge (2005, 2010, section 11.7.3) considers FE estimation for a special case of Equation 4 without cluster-level covariates

As pointed out by Wooldridge (2010, p. 382), this assumption allows

because
We now look at the assumption in Equation 12, which is required for consistency and unbiasedness, in more detail for our specific model for the empirical example in Equation 3 to understand how it can be violated. In that model,

Concentrating on the first equation, we obtain

where
4 New Estimators and Conditions for Unbiasedness
4.1 FE+ Estimator
The FE approach does not permit estimation of the coefficients, γ, of any cluster-level covariates, but it can be “augmented” so that it does. The FE+ estimator we use is similar to the estimator proposed by Hausman and Taylor (1981) to estimate effects of cluster-level covariates for two-level models with only random intercepts—and no random slopes. As pointed out by Castellano, Rabe-Hesketh, and Skrondal (2014), the estimator discussed here has been invented and reinvented several times (e.g., Ballou, Sanders, & Wright, 2004; Raudenbush & Willms, 1995; Wiley, 1975). However, the conditions for unbiasedness for random-coefficient models have not previously been considered. Step 1: Estimation of
In the first step, Step 2: Estimation of
In the second step, we obtain quasi-residuals r j ,

and estimate

The POLS estimator of

where
The conditional expectation of the POLS estimator

Conditional unbiasedness,
To implement the FE+ approach for the empirical example, the two steps are as follows: (1) estimate β1 and β2 by FE and (2) regress quasi-residuals,
4.2 PC estimator
In this section, we define our proposed PC estimator. This estimator is best understood by using the two-stage formulation (see Section 2.1) of the general model in Equation 4, which requires some new notation.
The columns of the matrix


where
Equations 15 and 16 are a generalization of the two-stage formulation of the model for the HSB example in Equations 1 and 2. In that model, there are R
1 = 1 covariates Step 1: Estimation of β3
Wooldridge (2005, 2010, section 11.7.2) considers the special case of this model without cluster-level covariates, that is, with

Defining

The POLS estimator of β3, denoted
where
The conditional expectation of
Unit-level exogeneity, which implies that Step 2: Estimation of
Next, form quasi-residuals as

and then obtain OLS estimates
where
The estimator in Equation 17 can alternatively be expressed as
and the conditional expectation of

where Step 3: Estimation of γ, β1, and β2
The remaining regression coefficients γ (for cluster-level covariates), β1 (for unit-level covariates with random slopes), and β2 (for cross-level interactions involving unit-level covariates with random slopes) are now estimated. These coefficients are contained in the vectors α
r
,

Denoting the vector of estimates

We estimate
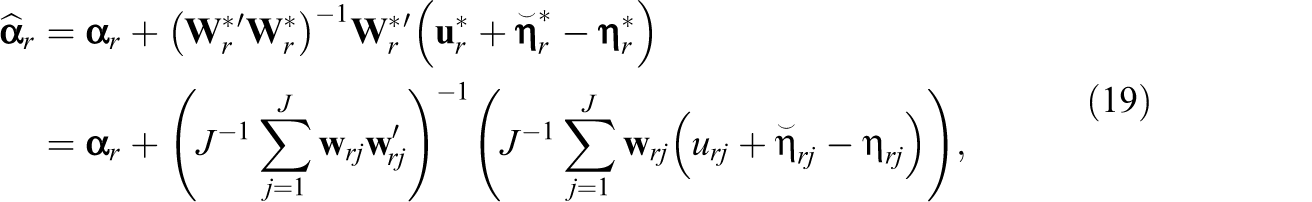
where, for each r,
The conditional expectation of

It follows from cluster-level exogeneity that
For the special case of our model with
5 Empirical Example
To ground comparisons of our estimators of interest, we apply each to the HSB data introduced in Section 2.1. Table 1 provides estimates of the regression coefficients for Equation 3. All estimates were obtained using standard commands in Stata 13 (StataCorp, 2013), such as mixed and xtreg (see Online Appendix B). Note that the RE estimate of the correlation between the random intercept and slope is 1, a relatively frequent occurrence in random-coefficient models (Chung, Gelman, Rabe-Hesketh, Liu, & Dorie, In press).
Estimates of Regression Coefficients From Different Methods For HSB Data

Note. All estimates are significantly different from 0 at the 0.05 level. HSB = high school and beyond.
Castellano et al. (2014) show that positive correlation between a random intercept and a student-level covariate leads to overestimation of the coefficient of the covariate. Indeed, from the HSB data results presented in Table 1, we see that RE produces the largest estimate of the coefficient of SES, 2.958, approximately 6% higher than the closest estimate (FE+). The indicator variable wj for Catholic schools is positively correlated with SES and therefore overestimation of the coefficient of SES is accompanied by underestimation of the coefficient of wj , with RE producing the smallest estimate of γ1, at 2.130.
While the differences in the FE+ and RE estimates of γ1 may be practically significant, they are close in magnitude to the estimated standard errors (SEs) of the coefficient estimates. FE+ produces estimates of both β1 and γ1 that lie between the estimates produced by RE and PC, which is intuitive, given that FE+ relies only on the uncorrelated variance assumption, whereas RE additionally requires exogeneity, and PC requires neither assumption. PC gives the smallest estimated effect of SES on math achievement scores (
The small difference between estimates of β1 from FE+ and PC suggests that the within-school variance in SES is not strongly correlated with the random slope. In fact, the within-school standard deviation of SES has a correlation of only 0.04 with the estimated residuals from the regression of
6 Simulation Study
We now conduct a simulation study to investigate the performance of the RE, FE+, and PC estimators. In particular, we are interested in the amount of bias for RE and FE+ when the respective assumptions of cluster-level exogeneity and uncorrelated variance are violated. We also evaluate all three estimators, RE, FE+, and PC, by their root mean square errors (RMSEs) and consider performance of the estimated SEs. We use Stata 13 (StataCorp, 2013) throughout.
6.1 Data Generation Process
We generate the data using our model of interest in Equation 3. We first draw the school-level variables for each of J = 100 clusters. The random intercepts u
0j
and random slopes u
1j
are drawn from a bivariate normal distribution with zero means and variance–covariance matrix defined by variances ψ0 = 0.42 and ψ1 = 0.252 and correlation ρ = 0.5, giving the covariance ψ10 = 0.05. We specify these variances to reflect those found in our empirical example. The exogenous school-level covariate wj
is drawn independently from a normal distribution with mean 1.7 and variance
We then generate the student-level covariate xij as

where
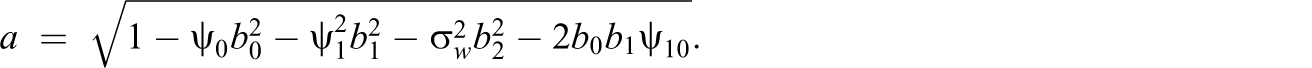
Here, b
0 = 1.33, b
1 = 2.13, and b
2 = 0.20, so that
The key assumption under which we want to assess the performance of the competing estimators is that the sample within-cluster variance
Although our empirical example involves schools that tend to have large numbers of students, both RE and FE are commonly used with classrooms serving as clusters. Furthermore, there are numerous relevant applications with longitudinal data where we often find even smaller cluster sizes. Thus, we also vary cluster size, primarily considering cluster sizes of 4 and 20. For simplicity, we set cluster sizes equal across clusters, nj = n. We fully cross the cluster size and uncorrelated variance assumption factors, yielding four primary simulation conditions defined by (large/small n) × (uncorrelated variance assumption holds/violated). To further determine the effect of cluster size when the uncorrelated variance assumption is violated, we also consider a range of cluster sizes from 4 to 50: n = 4, 8, 14, 20, 50.
All conditions are replicated 500 times. Due to occasional lack of variation of xij within some small clusters, the PC approach fails for some replications. The lowest number of successful replications is 489, which occurs when the variance of xij is correlated with the random slopes, and we have only four observations in each cluster. For all simulation conditions with a cluster size of 20, all 500 replications are successful.
6.2 Results
We evaluate the performance of each of our three estimators (RE, FE+, and PC) of the fixed regression coefficients in our model of interest (Equation 3) across our four simulation conditions. The estimated bias and RMSE are given in Table 2. Online Appendix C provides supplemental tables for each coefficient that also include the mean SEs, standard deviations of the estimates, and the ratios of these values.
Comparing Methods for Estimating the Coefficients Using Simulated Data

Note. RMSE = root mean square error; RE = random effects; FE+ = augmented fixed effects; PC = per-cluster regression; small clusters: nj
= n = 4, large clusters: nj
= n = 20; uncorrelated variance:
*Estimated bias differs significantly from 0 at the 0.05 level.
6.2.1 Bias
For β1, the coefficient of the endogenous student-level covariate xij , there are three main results. First, the PC estimator is unbiased across all conditions even when the uncorrelated variance assumption is violated. Figure 1 clearly illustrates this finding as the empirical distributions of the errors (i.e., estimate − parameter) of the PC estimator (the solid curves) are centered on 0 in all four panels, where each panel represents one of the four simulation conditions.
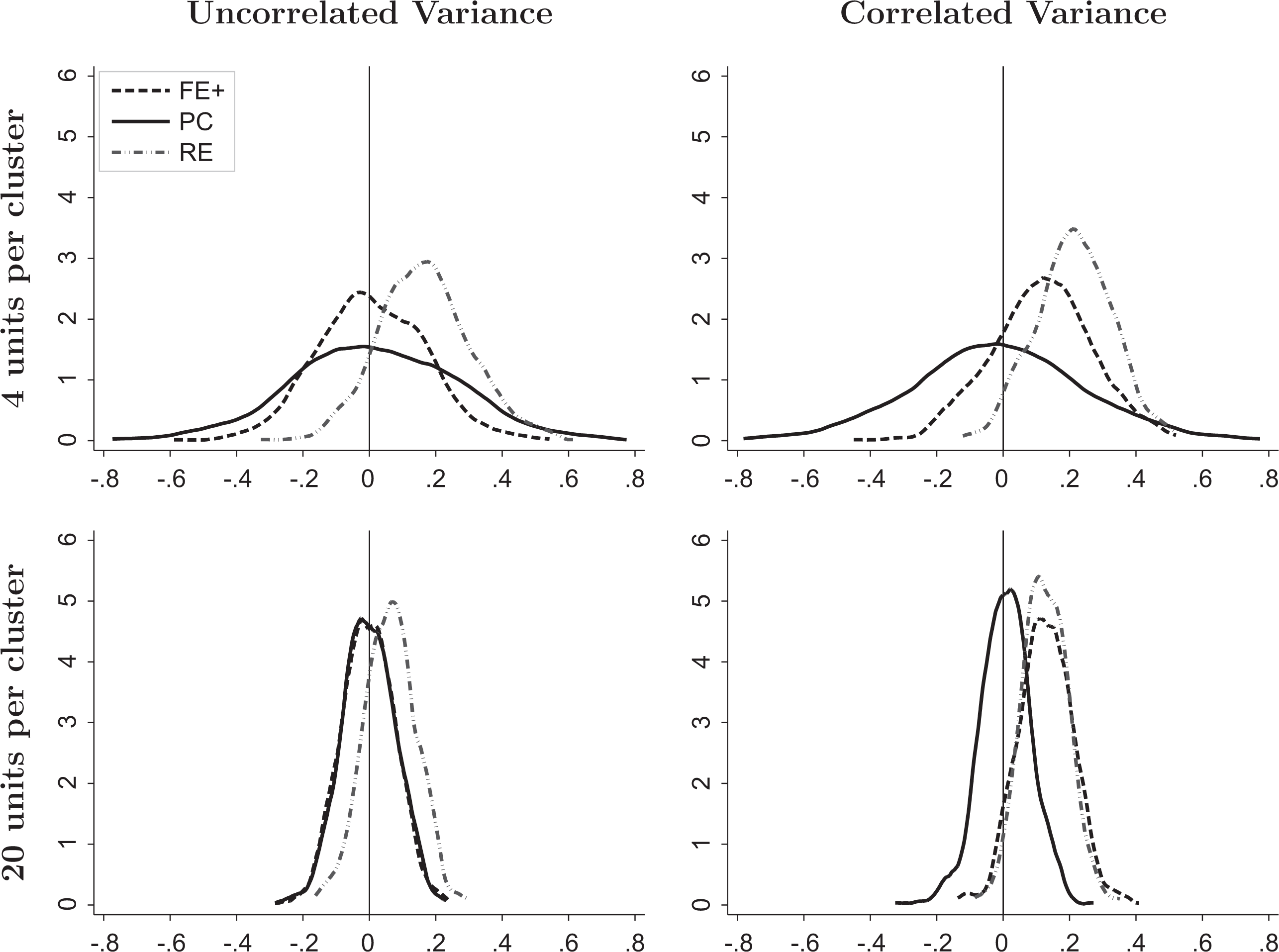
Kernel density plots of estimation errors,
Second, the RE estimator is biased regardless of whether the uncorrelated variance assumption holds, whereas the FE+ estimator is biased only when this assumption is violated. This result for RE is expected, given that the RE estimator relies on the assumption of both unit- and cluster-level exogeneity (see Section 3.2), and cluster-level exogeneity is violated in all four conditions, with the nonzero correlation between xij and both the random intercept and its random slope. We do note, however, that violation of the uncorrelated variance assumption exacerbates the magnitude of the RE estimator’s bias: For the small cluster size condition (n = 4), the estimated bias is 1.28 times as large; and for the larger cluster size (n = 20), the estimated bias more than doubles as shown in the first column of results in Table 2. In contrast, the FE+ approach only requires unit-level exogeneity assumptions and thus produces unbiased estimates under cluster-level endogeneity as long as there is no correlation between the random slopes and within-cluster variance of xij . This is evident in Figure 1 by observing that the curves for FE+ (dashed) are more similar to those for PC (solid) in the left-hand plots (for uncorrelated variance simulation conditions) and more similar to the curves for RE (dot-dashed) in the right-hand plots (for correlated variance simulation conditions).
Third, the estimated bias for β1 is larger than that for the other two regression coefficients, which is not surprising, given that xij
is the source of the endogeneity. For instance, as shown in Table 2, the estimated bias of
The coefficient of the interaction term, β2, is the least affected by the simulation conditions. We only find statistically significant bias (at the 5% level) for
The estimated biases of the estimators for the coefficient γ1 of the exogenous school-level covariate wj follow similar patterns as for the coefficient β1 of the endogenous student-level covariate xij . Just as for β1, the PC estimator is unbiased across all conditions, the FE+ estimator is biased only when the variance of xij is correlated with the random slope u 1j (i.e., uncorrelated variance assumption violated), and the RE estimator is biased regardless of whether the uncorrelated variance assumption is violated. These findings are clearly illustrated in Figure 2 by comparing the centers of the empirical distributions of errors for all estimators across all conditions: the PC curve (solid) is always centered on 0, whereas the RE curve (dot-dashed) is always centered below 0, and the FE+ curve (dashed) is centered below 0 only for the correlated variance conditions in the right-hand panels. Just as with β1, the FE+ estimator’s bias for γ1 does not vary with cluster size—its estimate is about 0.8% of the true parameter value for both n = 4 and n = 20 as seen in Table 2. Cluster size affects the RE estimator’s bias for γ1, as it did for β1: As cluster size increases, the bias decreases. When the uncorrelated variance assumption holds, this bias decreases by about 63% going from n = 4 to n = 20, and by about 45% when the assumption is violated (see Table 2).
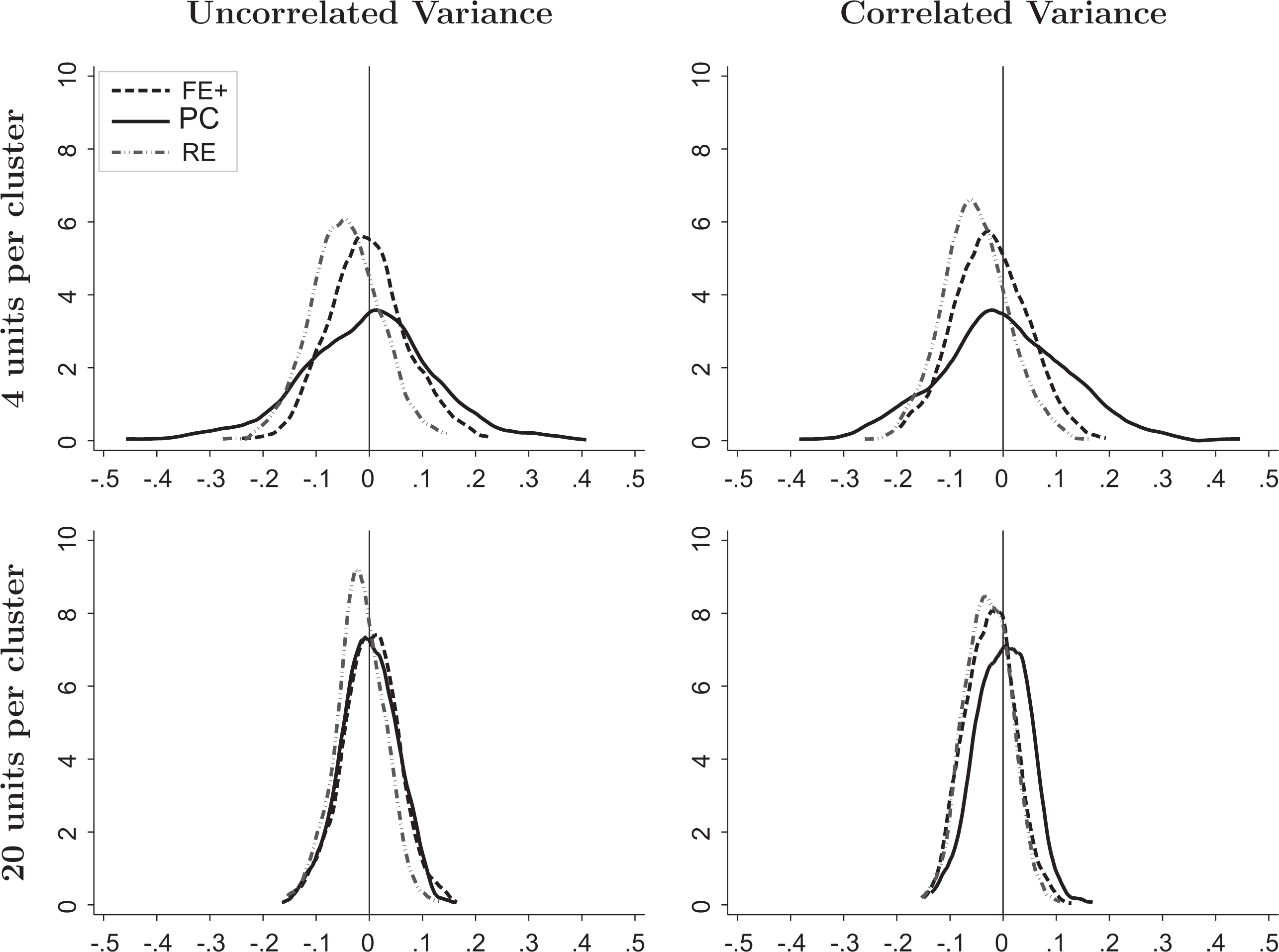
Kernel density plots of estimation errors,
Given that β1 was most affected by the violation of the uncorrelated variance assumption, we further investigated the effect of cluster size on the estimates of this regression coefficient. Figure 3 gives the estimated bias for each estimator across cluster sizes of 4, 8, 14, 20, and 50. The PC (solid) curve hugs the y = 0 line. The FE+ and RE curves cross at n = 20: As cluster size increases, the RE estimator’s bias decreases (dot-dashed curve), whereas the FE+ estimator’s bias is not as affected by cluster size, shown by its dashed curve staying relatively constant across the range of cluster sizes. Thus, cluster size has a differential effect on the bias of the estimators. When using bias to evaluate the estimators, our simulation study provides strong evidence that our proposed PC estimator outperforms the other estimators.
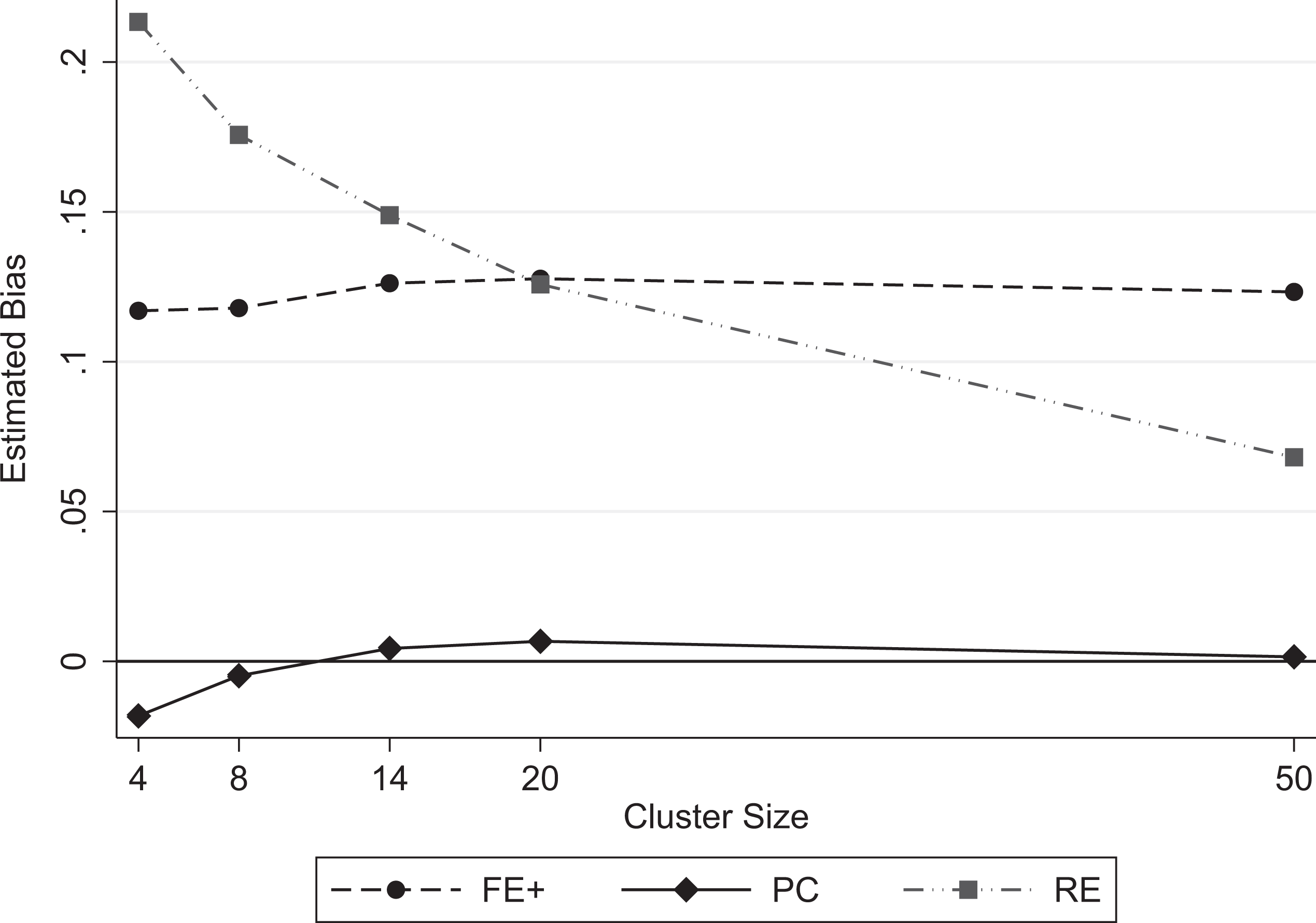
Estimated bias for coefficient β1 of xij versus cluster size. Note. FE+ = augmented fixed effects; PC = per-cluster regression; RE = random effects.
6.2.2 Precision and RMSE
As is often the case, there is a trade-off between bias and precision, which depends in part on the size of the clusters. The rank ordering of the estimators by their standard deviation (SD) is approximately the same for the three regression coefficients with slight differences between the smaller and larger cluster size conditions. Accordingly, we discuss how the precision of the estimators depends on cluster size, without distinguishing among the coefficients.
For the smaller cluster sizes of n = 4, RE produces the estimates with the smallest variances, followed by FE+, and PC produces the most variable estimates. This is clearly illustrated by comparing the widths of the empirical distributions of errors in Figure 1 or 2 for each estimator: The RE curves are the narrowest and the PC curves are the widest. For instance, for n = 4 and when the uncorrelated variance assumption is violated, the SD of
For the larger cluster size of n = 20, RE always yields the smallest variances, but the variances are not much smaller than those for FE+ and PC, which tend to have about equal variances. For instance, for β1, for the large clusters and uncorrelated variance condition shown in the lower, left-hand panel of Figure 1, it is difficult to discern any differences in the widths of the distributions. Indeed, the SD for RE, in this case, is about 0.078 and the SDs for both FE+ and PC are 0.080.
With regard to precision, RE consistently outperforms FE+ and PC for all the regression coefficients and across all the simulation conditions. However, given the trade-off between bias and precision, it is useful to evaluate the estimators with regard to their RMSEs, which take both bias and imprecision into account. Given that the estimates of β1 are the most affected by the simulation conditions and that precision depends on cluster size, we consider the RMSEs as a function of the extended range of cluster sizes for β1 in Figure 4. Just as with bias in Figure 3, Figure 4 shows that the FE+ and RE curves cross with RE outperforming FE+ as cluster size increases. This figure also shows that, for the smallest cluster size of 4, the RMSE for PC is large and similar to that of RE. However, with clusters of at least 8, the PC estimator outperforms both RE and FE+ with regard to RMSE, providing strong evidence in favor of the PC estimator.
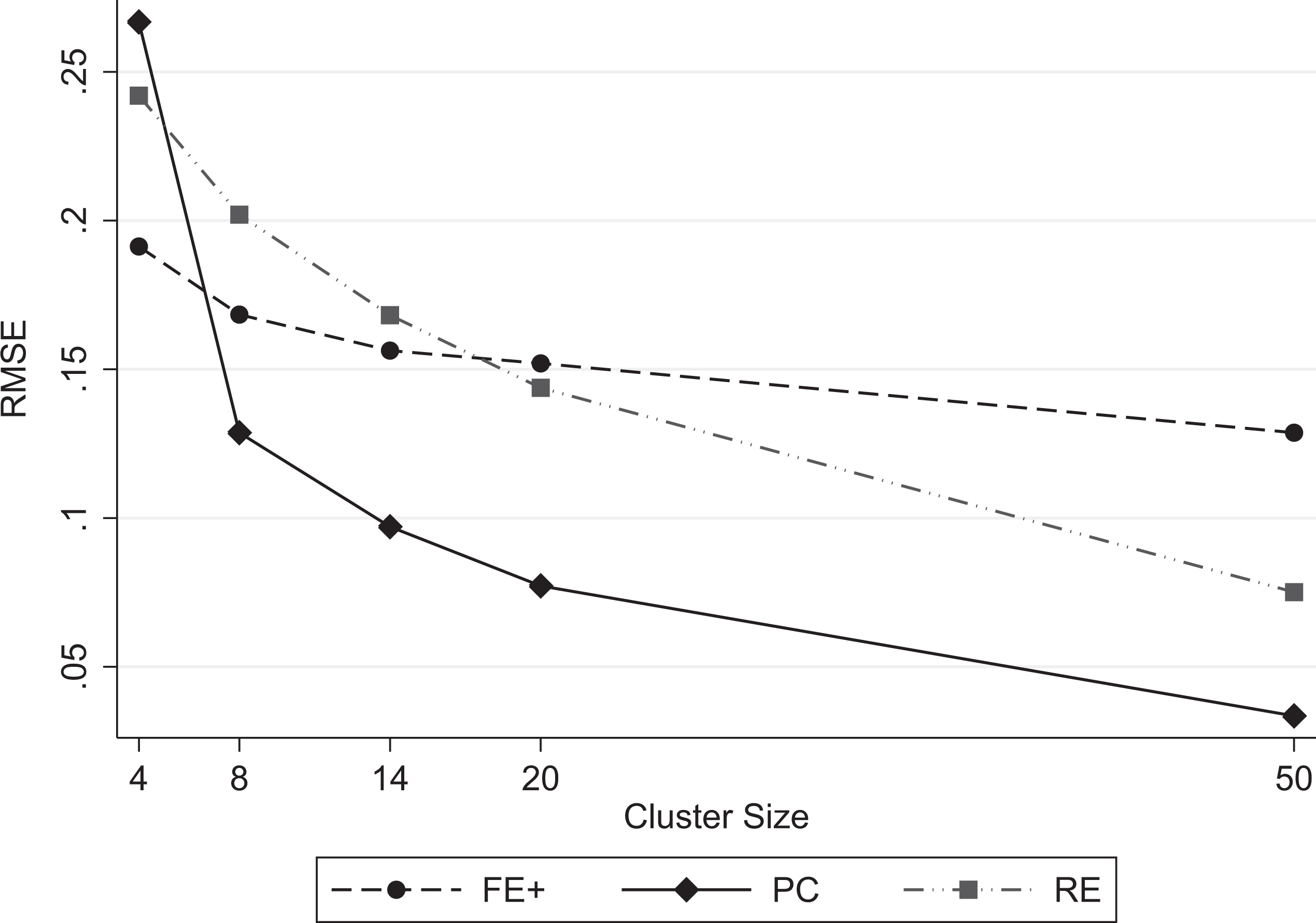
Estimated root mean square error (RMSE) for coefficient β 1 of xij versus cluster size. Note. FE+ = augmented fixed effects; PC = per-cluster regression; RE = random effects.
6.2.3 SE Estimation
As a final point, we evaluate the estimators in terms of how well their estimated SEs approximate the sampling SDs. We again focus on the most affected regression coefficient β1. Figure 5 displays this ratio of mean SE to SD over the extended range of cluster sizes—similar to Figures 3 and 4. If the SE estimation works well, this ratio should equal 1. We see that both the PC (solid curve) and RE (dot-dashed curve) approaches provide good SE estimates. In contrast, for the FE+ approach, the SEs are increasingly underestimated as the cluster size increases. Although both the FE+ and PC approaches treat estimated coefficients from previous steps as known in the subsequent steps, it appears that underestimation of the SE is a larger problem for the FE+ approach. Accordingly, we recommend using either analytically derived or bootstrapped SEs for the FE+ approach. These could also be used for the PC approach and may be necessary if Step 1 is required.
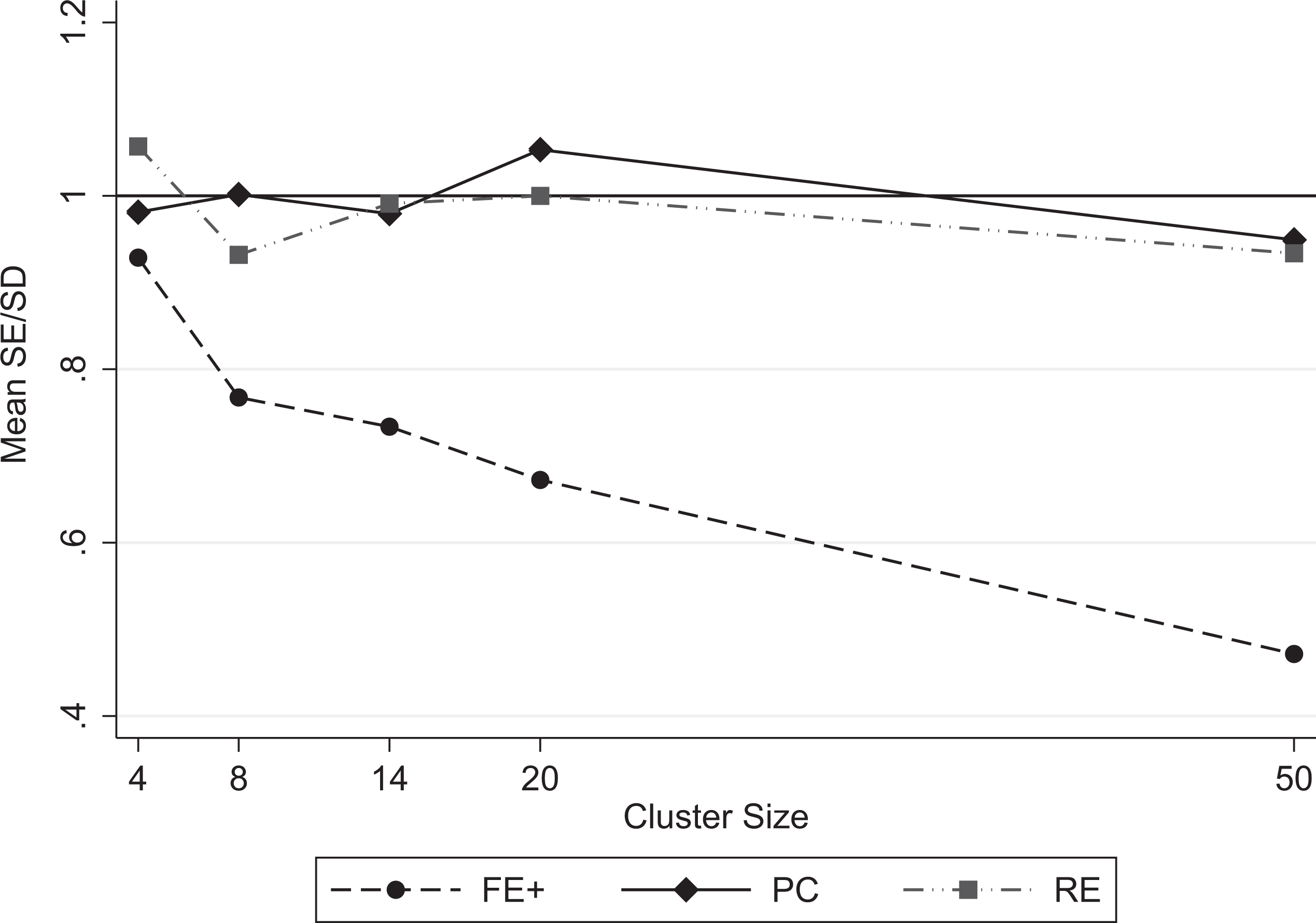
Ratio of mean standard errors (mean SEs) divided by standard deviations (SDs) of estimates versus cluster size. Note. FE+ = augmented fixed effects; PC = per-cluster regression; RE = random effects.
7 Conclusion
Given the popularity of multilevel models, studies that investigate potential biases for key parameters and provide simple solutions are clearly important. We have shown that commonly used random effects and FE estimators are biased in the presence of correlation between random effects and the within-cluster variance of unit-level covariates. Further, such bias can spill over to the estimation of coefficients of other covariates. We have proposed a new PC estimator that avoids such bias, produces good estimates of SEs, and generally has low RMSE. Consequently, we recommend broad use of PC when working with longitudinal or nested cross-sectional data when the clusters are sufficiently large. Stata code for applying this method to the HSB data is provided in Online Appendix B. In instances where the cluster sizes are small relative to the number of random effects, or where estimates for the random part of the model are of interest, we recommend using PC as part of a sensitivity analysis for alternative estimators.
Per-cluster methods have been used in the past for linear multilevel models (Burstein, Linn, & Capell, 1978, p. 369) and multilevel structural equation models (Chou, Bentler, & Pentz, 2000). Per-cluster methods can also be used for nonlinear multilevel models, such as probit models with random intercepts (Borjas & Sueyoshi, 1994) and logit models with random intercepts and slopes (Korn & Whittemore, 1979). However, the purpose of that work was to develop simple estimators and not to address endogeneity concerns. For our proposed PC estimator for linear models, it might appear to be inefficient to use OLS in the final step, not taking into account that the intercepts and slopes are estimated with different precision for different clusters. However, FGLS approaches, such as those discussed by Berkey, Hoaglin, Antczak-Bouckoms, Mosteller, and Golditz (1998), suffer from similar biases as RE estimators, as we confirmed in simulations (not shown).
An alternative approach for handling endogeneity, proposed for random-intercept models by Allison and Bollen (1997) and Teachman, Duncan, Yeung, and Levy (2001), is to model the unit-level covariates jointly with the responses using structural equation modeling and allow them to be correlated with the random intercept. This approach can be generalized to random-coefficient models but becomes infeasible for large cluster sizes.
In summary, we have demonstrated that our proposed, simple-to-implement PC approach outperforms standard estimators when estimating regression coefficients in multilevel models under violations of both the cluster-level exogeneity and uncorrelated variance assumptions. We recommend that researchers consider the validity of the uncorrelated variance assumption and add the PC method to their toolbox when investigating effects of covariates in cross-sectional and longitudinal analyses.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported here was supported by the Institute of Education Sciences, U.S. Department of Education, through grants R305B090011 to Michigan State University and R305B110017 to University of California, Berkeley. The opinions expressed are those of the authors and do not represent the views of the Institute or of the U.S. Department of Education.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.