
Abstract
The main purpose of this study is to improve estimation efficiency in obtaining maximum marginal likelihood estimates of contextual effects in the framework of nonlinear multilevel latent variable model by adopting the Metropolis–Hastings Robbins–Monro algorithm (MH-RM). Results indicate that the MH-RM algorithm can produce estimates and standard errors efficiently. Simulations, with various sampling and measurement structure conditions, were conducted to obtain information about the performance of nonlinear multilevel latent variable modeling compared to traditional hierarchical linear modeling. Results suggest that nonlinear multilevel latent variable modeling can more properly estimate and detect contextual effects than the traditional approach. As an empirical illustration, data from the Programme for International Student Assessment were analyzed.
Keywords
1 Introduction
In social science research, a contextual effect is traditionally defined as the difference between two coefficients in a hierarchial linear model (HLM) analysis framework (V. Lee & Bryk, 1989; Raudenbush & Bryk, 1986; Raudenbush & Willms, 1995; Willms,1986): one from the individual level and the other coefficient from the group level. A representative application of this kind of contextual effect in education was discussed in Raudenbush and Bryk (2002) using a subset of High School and Beyond data. In this example, individual math achievement is regressed on individual-level socioeconomic status (SES) and school-level math achievement is regressed on aggregated school-level SES using multilevel modeling. The result shows that two coefficient estimates are not the same, indicating two students who have the same SES level are expected to have different levels of math achievement depending on which school a student attends. Statistically significant difference between these two coefficients represents a significant compositional effect. Another kind of contextual effect is a cross-level interaction when random regression slopes are explained by a group-level variable. Cross-level interaction models are not considered in this study. Therefore, a compositional effect and a contextual effect are used interchangeably in this article. Though hierarchical linear modeling opened the door to estimating contextual effects, there have been two unresolved problems. The first one is related to the attenuated coefficient estimates due to measurement error in predictors (Spearman, 1904), and the other is biased parameter estimates due to sampling error associated with aggregating Level 1 variables to form Level 2 variables by simply averaging the values (Raudenbush & Bryk, 2002, Chapter 3).
To handle measurement error and sampling error more properly, multilevel latent variable modeling has been suggested as an alternative to traditional methods (e.g., Lüdtke et al., 2008; Lüdtke, Marsh, Robitzsch, & Trautwein, 2011; Marsh et al., 2009). Multilevel latent variable models were developed in both structural equation modeling (e.g., S. Lee & Poon, 1998; B. Muthén, 1991) and item response modeling frameworks (e.g., Ansari & Jedidi, 2000; Fox & Glas, 2001; Kamata, 2001). Lüdtke et al. (2008) proposed a multilevel latent variable modeling approach particularly for contextual analysis. Lüdtke et al.’s simulation study is noteworthy in that the study examined the relative bias in contextual effect estimates when the traditional HLM is used under different data conditions. The results showed that the relative percentage bias of contextual effect was less than 10% across varying data conditions when a multilevel latent variable model was used. On the other hand, the relative percentage bias of contextual effect was up to 80% when the traditional HLM was used. However, the traditional HLM can yield less than 10% relative bias under favorable data conditions—that is, when Level-1 and Level-2 units exceed 30 and 500, respectively, and when there is substantial intraclass correlation (ICC) in the predictor (e.g., 0.3). However, the type of manifest variables is limited to continuous only in Lüdtke et al.’s study.
Marsh et al. (2009) conducted another noted study using multilevel latent variable modeling for contextual effect analysis. Marsh and colleagues compared several contextual modeling options related to “big-fish-little-pond” effect (BFLPE)” estimation using an empirical data set in which academic achievement (predictor) and academic self-concept (outcome) were measured by, respectively, three and four continuous manifest variables. Among the tested models, a multilevel latent variable model yielded the largest BFLPE estimate. The authors described this model as a doubly latent variable contextual model (see Figure A1 in the Appendix for graphical representation of the model). Such a model is theoretically the most desirable choice for researchers, since the model tries to take both measurement and sampling error into account by utilizing information from all the manifest variables, rather than using summed or averaged scores at both individual and group level. The study also illustrated how the nonlinear multilevel latent variable modeling approach can provide flexibility in modeling by including random slopes, latent (within level or cross level) interactions, and latent quadratic effects. In both Lüdtke et al.’s (2008) and Marsh et al.’s (2009) studies, they utilized continuous manifest variables, while this study considers categorical indicators (item-level data) for all latent variables in the model that introduces need of more efficient computation algorithm for full information maximum likelihood estimation.
While theoretically desirable, nonlinear multilevel latent variable modeling poses significant computational difficulties. Standard approaches such as numerical integration (e.g., adaptive quadrature) based expectation–maximization (EM) or Markov chain Monte Carlo (MCMC; e.g., Gibbs Sampling)–based estimation methods have important limitations that make them less practical for routine use. With respect to numerical integration with a fixed number of quadrature points, its computational burden increases exponentially when the dimensionality of latent variable space is high, as is the case with the current nonlinear multilevel latent variable model. On the other hand, while MCMC is free from the numerical integration problem, it is not immune from issues that include advanced tuning requirements, specification of priors, and convergence analysis for complex models (e.g., Sinharay, 2004). Lüdtke, Marsh, Robitzsch, and Trautwein (2011) also reported the occurrence of unstable estimates. The model has difficulty converging when small sample size is combined with low ICC coefficient in predictors and also when there are substantial amount of missing observations in the manifest variables.
The main objective of this study is to develop a more efficient and stable estimation method for contextual effects in the nonlinear multilevel latent variable modeling framework, by adopting the MH-RM algorithm (Cai, 2008, 2010a, 2010b). This study significantly extends the applications of MH-RM algorithm to the case of multilevel modeling. Prior research using MH-RM is limited to single-level applications, for example, exploratory and confirmatory item factor analysis (Cai, 2010a, 2010b), latent regression modeling (von Davier & Sinharay, 2010), and item response theory (IRT) modeling with nonnormal latent variables (Monroe & Cai, 2014). The extension of the algorithm to multilevel modeling requires construction of proper MH samplers, and tuning of gain constants at multiple levels. These issues have never been explored in single-level applications. Implementation of an alternative approach to approximate observed information matrix by adopting Louis’s (1982) formula is also a unique new feature of this study.
Computational efficiency and parameter recovery were assessed in comparison with an implementation of the EM algorithm using adaptive Gauss–Hermite quadrature (Mplus; L. K. Muthén & Muthén, 2008), which is more widely available to applied researchers. Another objective was to find, through a simulation study, the extent to which measurement error and sampling error can influence contextual effect estimates under different conditions. The results can provide practical rationales for the application of computationally demanding nonlinear multilevel latent variable models. The last objective of this study was to provide an empirical illustration of estimating contextual effects by applying nonlinear multilevel latent variable models to empirical data that contain complex measurement structures and unbalanced data. A subset of data from Programme for International Student Assessment (PISA; Adams & Wu, 2002) was analyzed to illustrate a contextual effect model.
2 Contextual Effects in a Nonlinear Multilevel Latent Variable Model
The particular contextual effect of interest in this study is one that occurs when a group-level characteristic is measured by individual-level variables, and the individual-level variables are in turn measured by categorical manifest variables. This study considers a contextual effect as a compositional effect that captures the influence of contextual variables on individual-level outcomes, controlling for the effect of the individual-level predictor.
2.1 Structural Models
In traditional HLM, a compositional effect β c can be defined as follows:

In Equation 1, Yij
and Xij
denote the outcome and predictor values of individual i in Level-2 unit j, respectively. For the Level-1 equation, the predictor values are centered on the group means
In typical educational research settings, Yij
and Xij
can be constructed by summing or averaging item scores from self-reports or other instruments. The random effects rij
and u
0j
are assumed to be normally distributed with zero means and variances σ2 and τ00, respectively. In this particular definition of a contextual effect as a compositional effect, the slope
In a nonlinear multilevel latent variable model, the predictors and outcomes become latent variables that are denoted as η
ij
and ξ
ij
. Those latent variables are connected to manifest variables through measurement models. For notational simplicity, latent individual deviations from latent group means can be defined as

In Equation 1, η
ij
and δ
ij
denote the latent outcome and group-centered predictor values of individual i in Level-2 unit j, respectively. At the group level, β0j
is regressed on grand-mean-centered latent group mean
For identification purposes, we impose the restriction of
2.2 Measurement Models
The measurement models define the relationship between manifest variables and latent variables. For brevity, only the measurement models of the latent predictor variable ξ ij are described in this section, since the measurement models for the latent outcome η ij can be defined analogously.
When manifest variables are ordinal response variables with multiple categories (including 0 and 1 responses), as is often the case with instruments used in educational research, a logistic version of Samejima’s (1969) classical graded response model can be utilized. Let item l have Kl
-ordered categories and
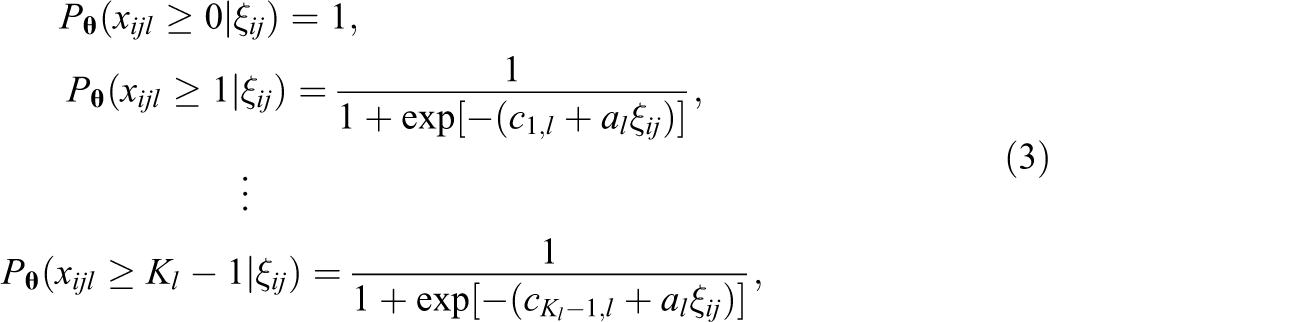
where
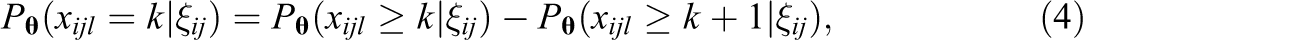
for
Conditional on ξ ij , the distribution of xijl is multinomial with trial size one in Kl categories:

where
The conditional density
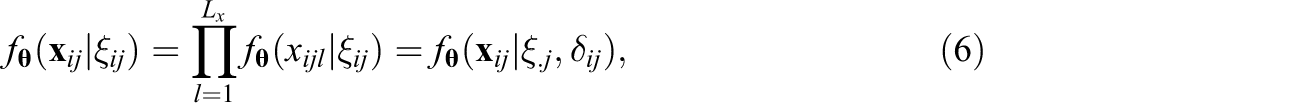
where the last equality follows from the fact that
2.3 Observed and Complete Data Likelihoods
Similar to the case of ξ ij , let us consider the measurement of η ij . Let Ly be the number of manifest variables for η ij . Again under conditional independence, the conditional response probabilities factor into item response probabilities:

where
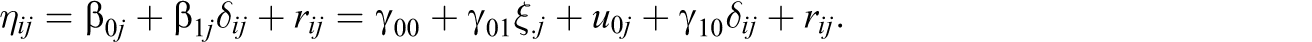
We note that given fixed effects, if we knew the random effect

If we integrate rij out of Equation 8, we have left
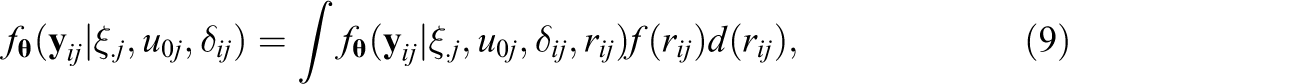
where f(rij ) is the density of a standard normal random variable, given preceding assumptions about the disturbance term. Bringing in results from Equation 6 and integrating out δ ij yields a conditional density that depends only on the Level-2 latent variables and random effects:

where f(δ
ij
) is the density of a standard normal random variable. Equation 10 makes it clear that we assume, under correct model specification, the outcome measures (
Let J and Ij
stand for the number of Level-2 units and number of individuals in Level-2 unit j. Let
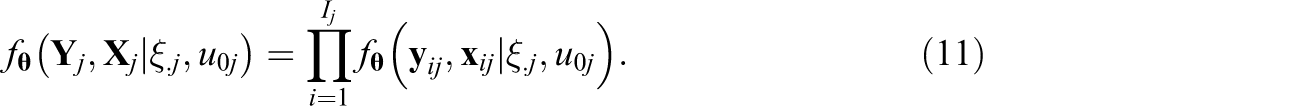
Integrating out the Level 2 latent variables and random effects yields the marginal probability, wherein we have utilized the independence of

By this point, we have integrated all latent variables and random effects out of the joint probabilities. We now make the routine multilevel modeling assumption that the Level-2 units are the independent sampling units. Upon observing

where
An obvious computational limitation to the direct marginal likelihood approach is the integration involved in arriving at the observed data likelihood. All of the integrals must be approximated numerically, which can be computationally challenging. An alternative stance is to treat the random effects and latent variables rij
, δ
ij
,
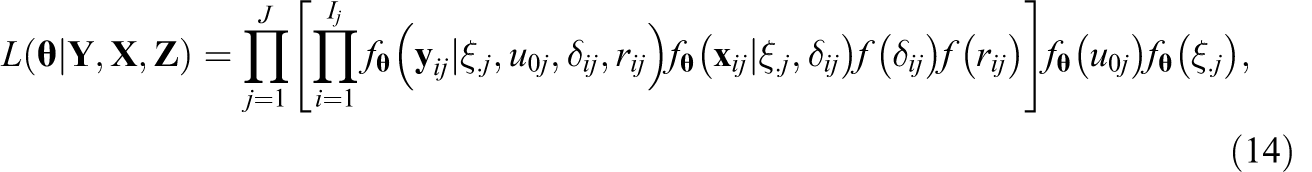
where
This missing data formulation prompts us to consider an alternative estimation approach that eschews numerical integration. In particular, the missing data may be “filled in” by drawing imputations from their posterior predictive distribution
3 MH-RM Algorithm for Contextual Models
3.1 MH-RM Algorithm
The MH-RM algorithm was initially proposed by Cai (2008) for nonlinear latent structure analysis with a comprehensive measurement model, and the application of the algorithm has been expanded to other measurement and statistical models (e.g., Cai, 2010a, 2010b; Monroe & Cai, 2014). The MH-RM algorithm is an extension of the Stochastic Approximation EM algorithm (Celeux, Chauveau, & Diebolt, 1995; Celeux & Diebolt, 1991; Delyon, Lavielle, & Moulines, 1999). The MH-RM algorithm combines the Metropolis–Hastings (MH; Hastings, 1970; Metropolis, Rosenbluth, Rosenbluth, Teller, & Teller, 1953) algorithm and the Robbins–Monro (RM; Robbins & Monro, 1951) stochastic approximation algorithm.
Utilizing the missing data formation of the latent variable model, the random effects and latent variables are treated as missing data (e.g., Gu & Kong, 1998). Once the missing data are “filled in” by the MH sampler, complete data likelihoods can be optimized iteratively. Because imputation noise is introduced in the MH step, the RM algorithm is used to filter out the noise. Let the parameter estimate at iteration t be denoted
Draw Mt
sets of missing data, which are the random effects and the latent variables, from a Markov chain that has the posterior predictive distribution of missing data

Let

denote the gradient vector of the complete data log-likelihood function, evaluated at the current parameter value θ(t) and missing data imputation

By Fisher’s (1925) Identity, the conditional expectation of the complete data gradient vector over the posterior distribution of the missing data is the same as the gradient vector of the observed data log likelihood, under mild regularity conditions; that is,

In other words, though noise corrupted,
To improve stability and speed, we also compute
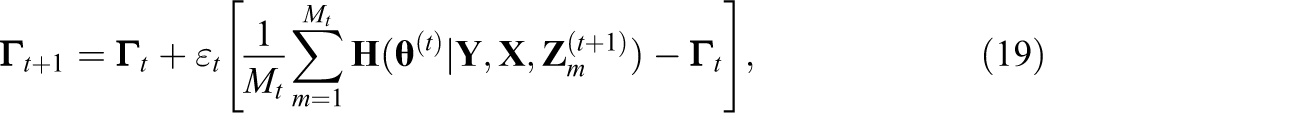
where

is the complete data information matrix, that is, the negative second derivative matrix of the complete data log likelihood. Updated parameters are computed recursively:

where
The gain constant ε
t
is a sequence of decreasing nonnegative real numbers such that
The iterations are started from initial values θ(0) and a positive definite matrix
They can be terminated when the changes in parameter estimates are sufficiently small. As a practical method for convergence check, Cai (2008) proposed to monitor a “window” of the largest absolute differences between two adjacent iterations. Cai suggested three as a reasonable width of the window to be monitored in practice. Cai showed that the MH-RM iterations converge to a local maximum of the observed data likelihood
3.2 Approximating the Observed Information Matrix
One of the benefits of using the MH-RM algorithm is that the observed data information matrix can be approximated as a by-product of the iterations. The inverse of the observed data information matrix becomes the large-sample covariance matrix of parameter estimates. The square root of the diagonal elements are the standard errors (SEs). Utilizing Fisher’s Identity, the gradient vector is approximated recursively,

where
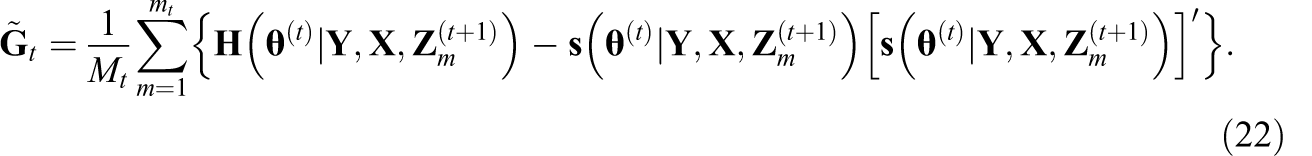
A more stable estimate can be found by further recursive approximation:

Finally, the observed information matrix is approximated as follows:

Gu and Kong (1998) and Cai (2010a) discussed the rationale behind this approximation as a recursive application of Louis’s (1982) formula. The main benefit is that the information matrix becomes a by-product of the MH-RM iterations. Another practical option for approximating the observed information matrix is a direct application of Louis’s (1982) formula, in which additional Monte Carlo samples are used after convergence to directly approximate the gradient vector and the conditional expectations. In this study, SEs obtained by the first method are called recursively approximated standard errors and those from the latter are called post-convergence approximated standard errors. The reader should, however, keep in mind that the likelihood surface of nonlinear multilevel models such as this one may be irregular and inference using curvature information provided by second derivatives should always be taken with a grain of salt.
4 Simulation Studies
4.1 Simulation Study 1: Comparison of Estimation Algorithms
4.1.1 Methods
The first study examined parameter recovery and SEs across two algorithms, an MH-RM algorithm and an existing EM algorithm. The data generating and fitted models followed Equation 2. The simulated data are balanced in that the number of Level-2 units (ng) is 100 and the number of Level-1 units per group (np) is 20. The generating ICC value for the latent predictor was 0.3.
For the measurement model, five dichotomously scored manifest variables were generated for each latent trait (i.e., η and ξ) using the graded response model in Equation 3. For η
ij
, the manifest variables are
We attempted 100 Monte Carlo replications. The first 10 data sets were analyzed using two methods: an MH-RM algorithm implemented in R (R Core Team, 2012) and an adaptive quadrature-based EM approach implemented in Mplus (L. K. Muthén & Muthén, 2010). The MH-RM algorithm’s convergence criterion was 5.0 × 10−5, and the maximum number of iterations for the first two stages of MH-RM with constant gains were M1 = 100 and M2 = 500. To calculate post-convergence approximated SEs, 100 to 500 additional random samples were used. All replications converged within 600 MH-RM iterations with decreasing gains.
4.1.2 Results
The generating values and the corresponding estimates for the compositional effect from different algorithms are summarized in Table 1. The first column contains the true parameters for the measurement and structural parameters. The second set of columns and the third set of columns include the estimates and SEs from EM with different numbers of adaptive quadrature points (qp = 5 and qp = 14). The default number of quadrature points is 15 in Mplus, but the computer cannot handle 15 quadrature points for this four-dimensional model. The maximum possible number of quadrature points was 14 for a compositional effect model. A smaller number of quadrature points, five, was tested to compare point estimates and SEs. The fourth set of columns includes the corresponding point estimates and SEs using the MH-RM algorithm.
Generating values, EM Estimates, and MH-RM Estimates for a Compositional Effect Model
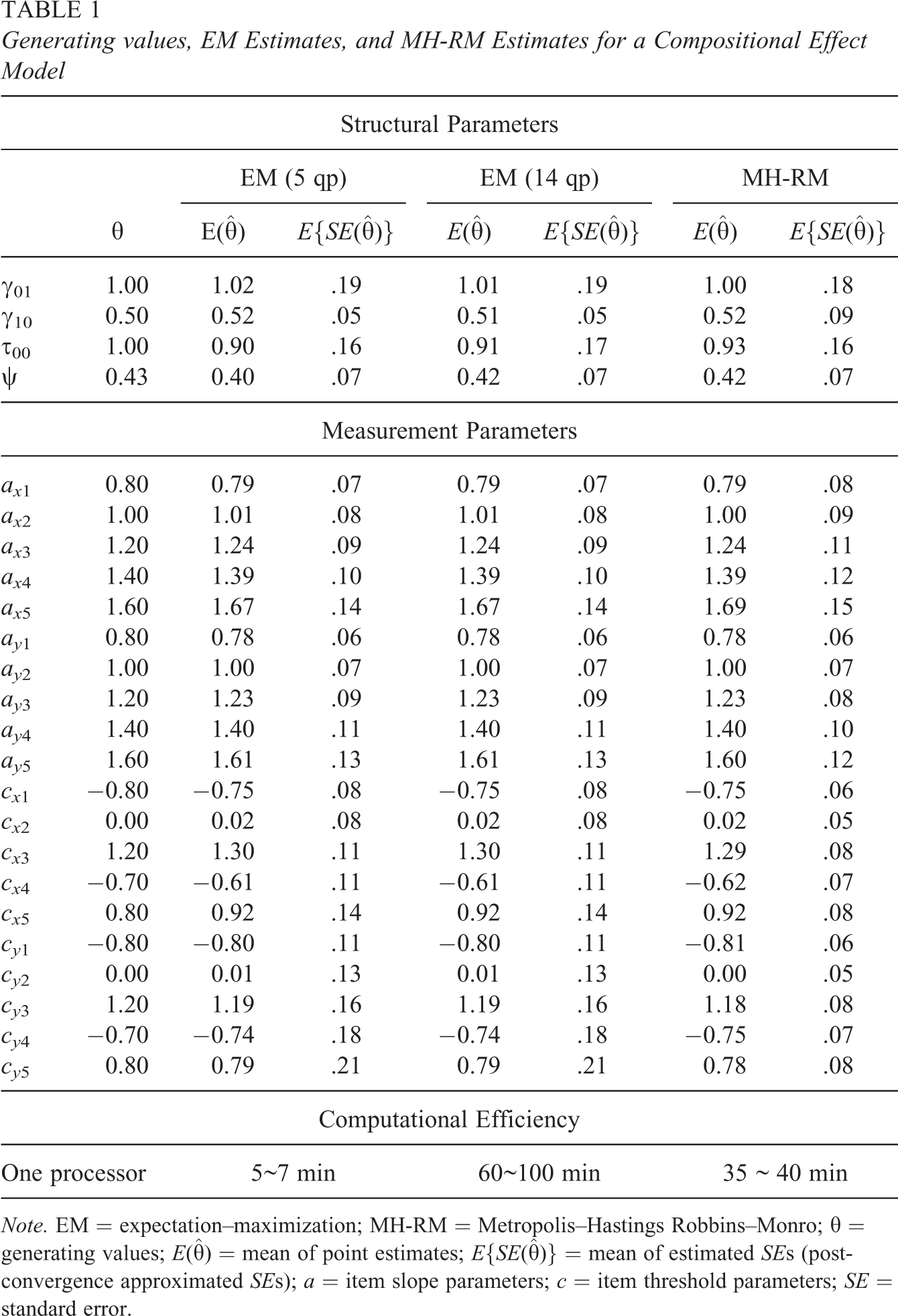
Note. EM = expectation–maximization; MH-RM = Metropolis–Hastings Robbins–Monro; θ = generating values; E(
The means of point estimates from different algorithms are generally very close to one another. For structural parameter estimates, the number of quadrature points does not appear to make a large difference, though 14-quadrature-point estimates are slightly closer to the MH-RM estimates and the generating values in terms of τ00 and ψ. SEs are also very similar.
For measurement parameter estimates, both the means of point estimates and the SEs were the same up to the second decimal place across different numbers of quadrature points. The largest difference in average point estimates between EM and MH-RM was 0.02, indicating that the two approaches yield highly similar estimates. However, mean SE estimates are slightly different between MH-RM and EM results in that the SE estimates from MH-RM algorithm for intercepts are smaller than those from the EM algorithm. The biggest difference in SE estimates for measurement parameters between two algorithms was 0.13.
The natural logarithm of SE estimates from EM algorithm and MH-RM algorithm (post-convergence approximated SEs) are plotted against the natural logarithm of empirical standard deviations of the point estimates across the Monte Carlo replications in Figure 1. The estimates are clustered along the diagonal reference line, indicating that the estimated SEs are generally close to the Monte Carlo standard deviations of the point estimates, except for the intercept parameter SEs, which appear to be underestimated when the post-convergence approximation is used for the MH-RM algorithm.
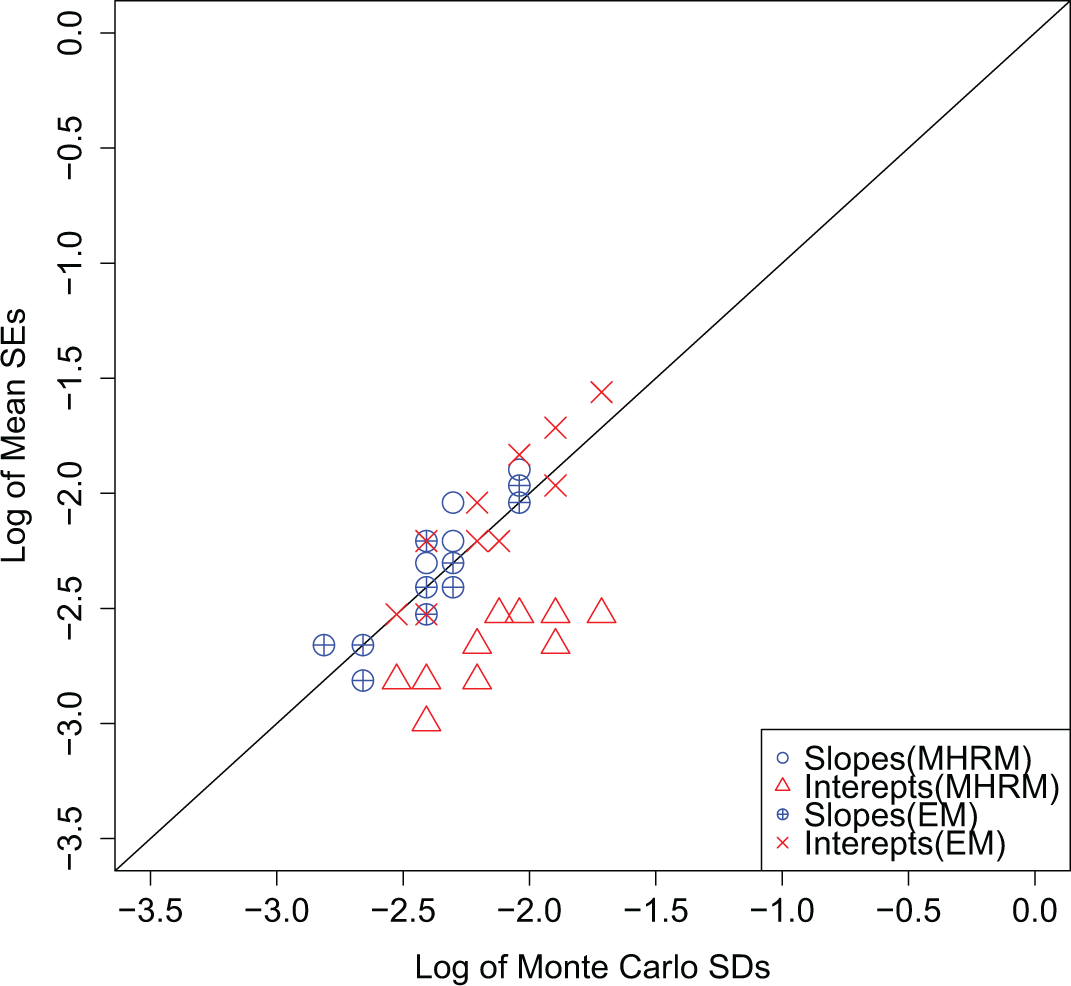
Comparisons of standard errors (SEs) for item parameters.
With regard to computing time, when one processor was used for estimation, EM with 5 quadrature points generally required a small amount of time, while EM with 14 quadrature points generally required over an hour. The MH-RM algorithm required about 40 minutes. Note that MH-RM is implemented in R (an interpreted language) with explicit looping, while Mplus is written in FORTRAN (a compiled language). As an interpreted language is expected to be several orders of magnitude slower compared to a compiled language in terms of looping, a direct comparison is inappropriate. What we can safely conclude is that when ported into a compiled language, MH-RM is poised to be substantially faster.
To examine the performance of the MH-RM algorithm further, all 100 generated data sets were analyzed, and the results are summarized in Table 2. The means of point estimates are reasonably close to generating values in general, with slight underestimation of variance components. The Monte Carlo standard deviations of parameter estimates (column 5) are also similar to SE estimates from both EM and MH-RM (columns 4 and 6); the largest difference is 0.02. With respect to measurement parameters, the average item parameter estimates are very close to generating values.
Generating Values and MH-RM Estimates for a Compositional Effect Model

Note. MH-RM = Metropolis–Hastings Robbins–Monro; CI = confidential interval; θ = generating values; E(
However, we see that recursively approximated SEs are generally closer to the Monte Carlo standard deviations of item parameter estimates than the post-convergence approximated SEs. More specifically, the most prominent differences are found in the SEs of intercept parameters, where post-convergence approximated SEs for item intercept parameters are underestimated. Therefore, we find that recursively approximated SEs perform better than post-convergence approximated SEs. With that said, a drawback of using recursively approximated SEs is the requirement of a relatively larger number of main MH-RM iterations (at least 1,000 in our experience) to reach a positive definite approximate observed information matrix. For this reason, post-convergence approximated SEs are adopted for the remaining simulations in this study since this approach gives proper SE estimates for structural parameters and can be faster.
Finally, 95% confidence intervals for each parameter were calculated. The post-convergence approximated SEs were used to form these two-sided Wald-type confidence intervals. The percentages of intervals that cover the generating values are reported in the last column of Table 2. Based on the 100 replications performed, coverage of structural parameters appears well calibrated in general. For measurement parameters, the coverage rates tend to decrease as the magnitude of parameters becomes larger. Coverage rates are at the lowest for the more extreme intercept parameters due to their underestimated SEs.
4.2 Simulation Study 2: Comparison of Models
The second simulation study was conducted to examine how measurement error and sampling error may influence compositional effect estimation across different conditions with both a traditional HLM and a multilevel latent variable model.
4.2.1 Simulation conditions
A total of 30 data generating conditions were examined: two compositional effect sizes
First, two different sizes of compositional effect were considered in this study. The generating value of
4.2.2 Analysis
Because all simulated data sets have the true generating values of η ij and ξ ij , these values (true scores) can be analyzed using a traditional model. The resulting parameter estimates can be considered gold standard estimates that are influenced only by sampling fluctuations but not by measurement conditions. Therefore, each data set has three sets of parameter estimates: (1) estimates from analyzing the generating values of η ij and ξ ij with a traditional HLM, which is treated as the gold standard, (2) estimates obtained by applying the latent variable model, and (3) the estimates from analyzing the observed summed scores of outcomes and predictors with the standard approach using manifest variables. All of the traditional HLM analyses were conducted using an R package nlme (Pinheiro, Bates, DebRoy, Sarkar, & R Core Team, 2012).
4.2.3 Evaluation statistics
To compare these three sets of estimates, the following three statistics are calculated: (1) the percentage bias of the estimate relative to the magnitude of its generating value, (2) the observed coverage rate of the 95% confident interval, and (3) the observed power to detect the compositional effect of interest as significant.
It should be noted that the regression coefficient estimates from the observed sum score analysis using a traditional multilevel model are not on the same scales as those obtained using the latent variable approach, which yields naturally standardized fixed effects coefficients due to the identification conditions discussed earlier. To make the coefficient estimates more comparable, the estimates from the traditional HLM approach were standardized by multiplying the parameter estimates by the ratio of standard deviation of the predictor to the standard deviation of the outcome.
4.2.4 Results
Convergence rates and mean computing time across generating data conditions are reported in Appendix Table A2. Only converged replications were used to calculate evaluation statistics. In general, the convergence rates at fixed number of iterations (M1 = 100 and M2 = 500) are over 90%. The worst cases of nonconvergence occur when the number of Level-2 units is low and the ICC is small (roughly 80%). The nonconvergence occurs for the approximation of observed information matrix that should be a positive definite. This is particularly true for the second measurement condition when a substantially larger number of item parameters for the multiple-categorical items must be estimated from the data. While more iterations could increase the convergence rates, the nonconvergence rates for the combination of small ICC and small cluster size are informative in that converged solutions might not be available for more extreme conditions.
Let us examine the first measurement condition where all items are dichotomously scored. Because a compositional effect estimate is defined as the difference between
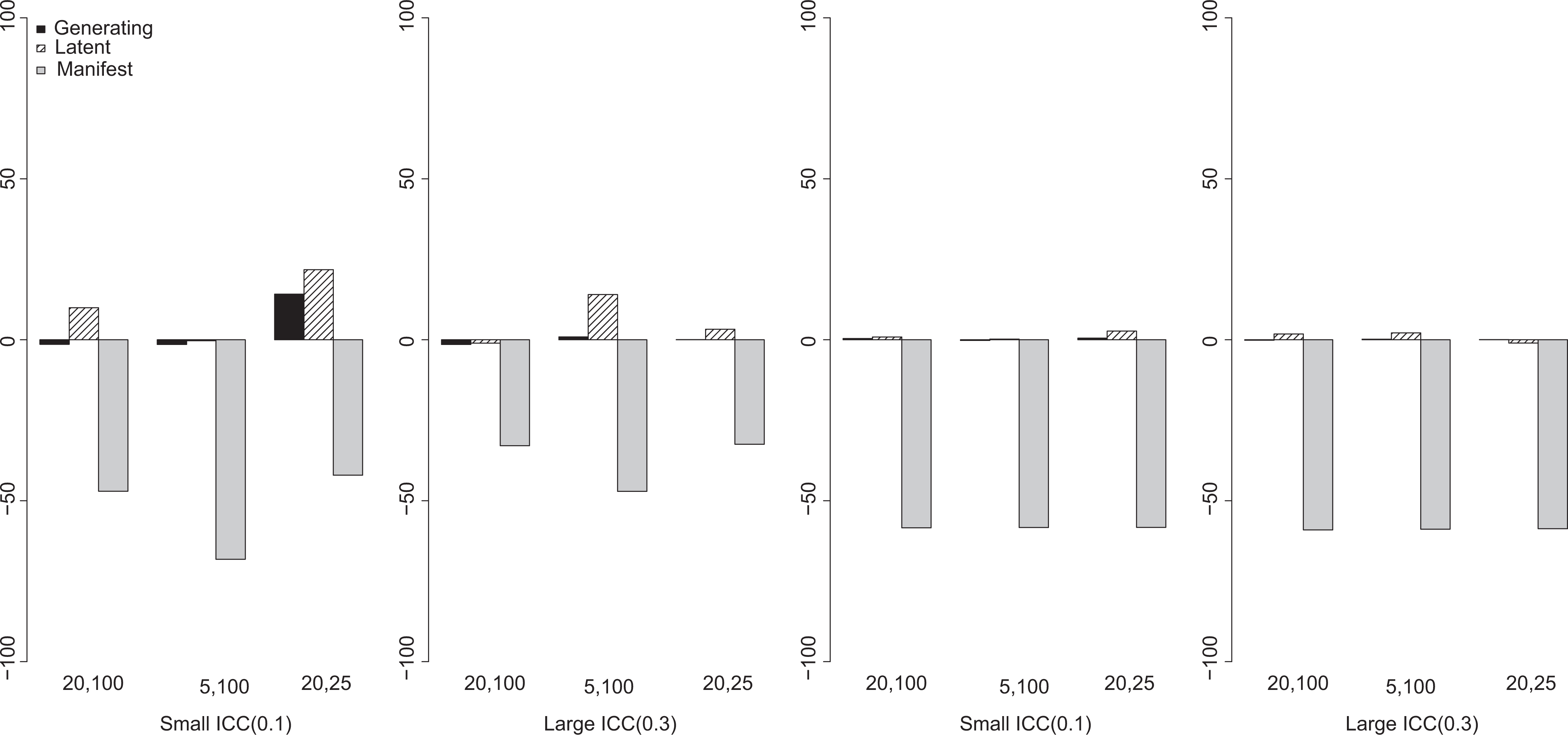
Relative percentage bias in
The biases in the traditional HLM estimates of the regression coefficients lead to an interesting pattern of biases in the compositional effect estimate. The bias can be as small as 8% when the predictor ICC is large and the sampling condition favorable (more individuals in each group), but the bias can be as large as 80% when the ICC is small and the group size is small (see Figure 3). It is also noteworthy that the bias in the compositional effect estimate from the traditional HLM model can also be positive when the ICC is large and the contextual effect size is small (see the last plot of Figure 3).
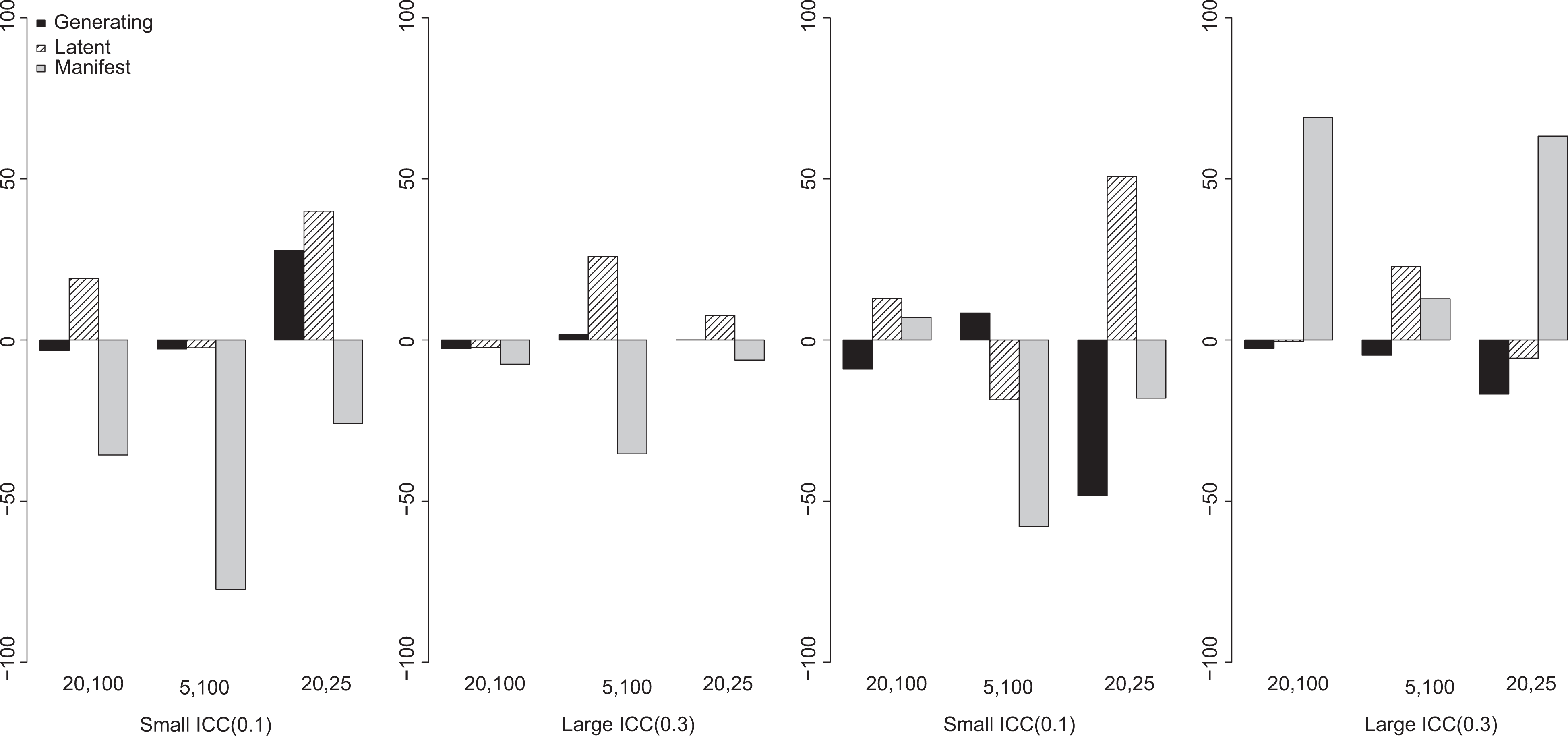
Relative percentage bias in compositional effect estimate
On the other hand, comparing the two plots in Figure 4 with the first two plots in Figure 3 reveals that the performance of the traditional HLM and the latent variable model in terms of estimating
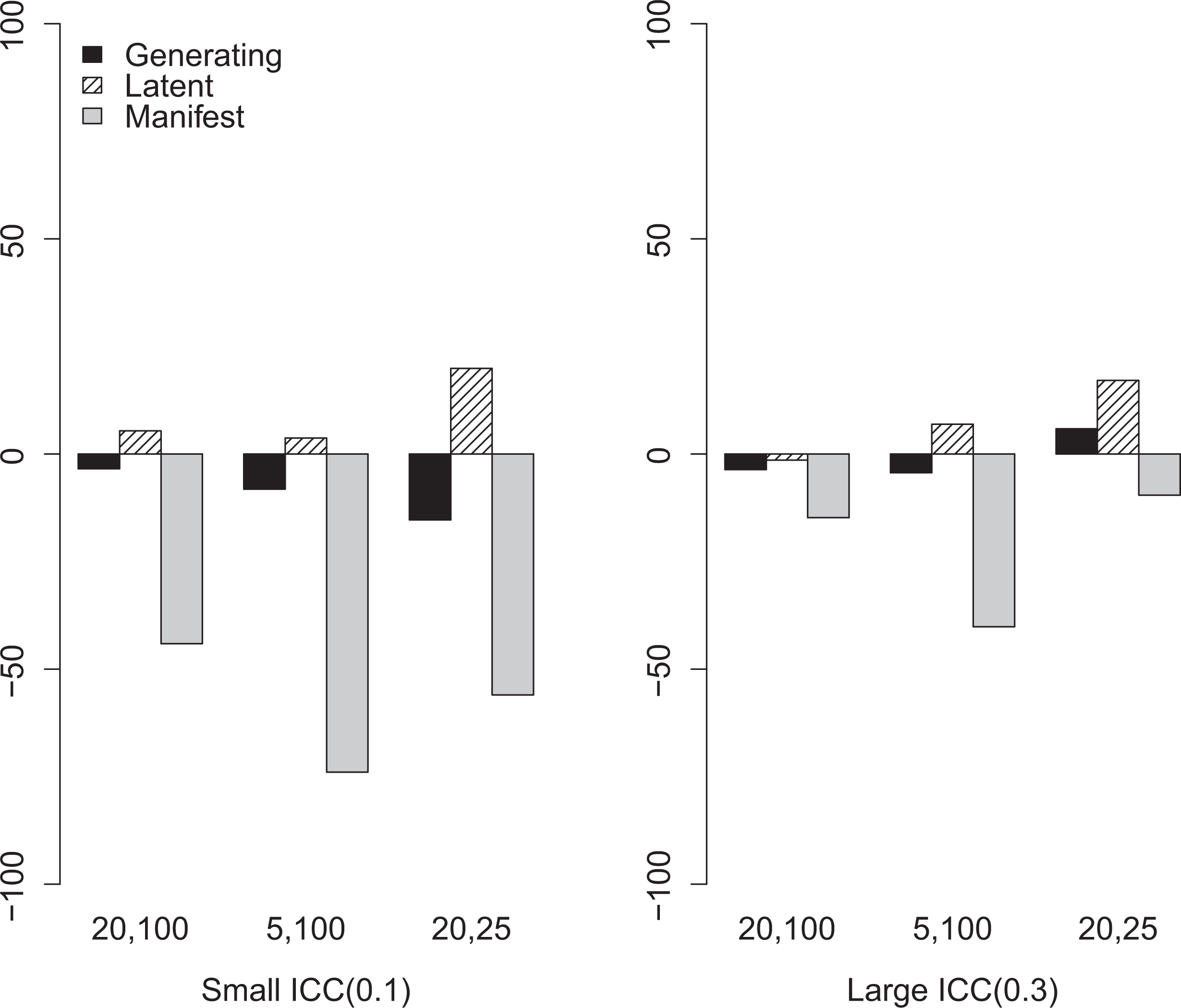
Relative percentage bias in compositional effect estimate
To examine the SE estimates, the coverage rates of the 95% confidence intervals for the true compositional effect were calculated. Results from the condition with large true compositional effect and the first measurement condition are summarized in Figure 5. When generating values are analyzed, the coverage rates across sampling conditions are generally close to 95%, except for the case where the ICC is small and the number of groups is also small. In this case, the coverage rate can be as low as 85%. The coverage rates based on the latent variable model parameter estimates were similar or slightly worse than those from generating value analysis. Coverage rates with traditional HLM estimates can be problematic when both the number of individuals per group and the ICC are low.

Niney-five percent compositional effect estimate confidence interval coverage rates, large true compositional effect, first measurement condition, by the sampling conditions (number of individuals in each group and number of groups).
To examine how researchers can make different inferential decisions when they apply a traditional model and a latent variable model, the empirical Type I error rates are calculated for the conditions where the true data generating model has zero compositional effect. Figure 6 shows empirical Type I error rates across the ICC and sampling conditions for the first measurement condition.
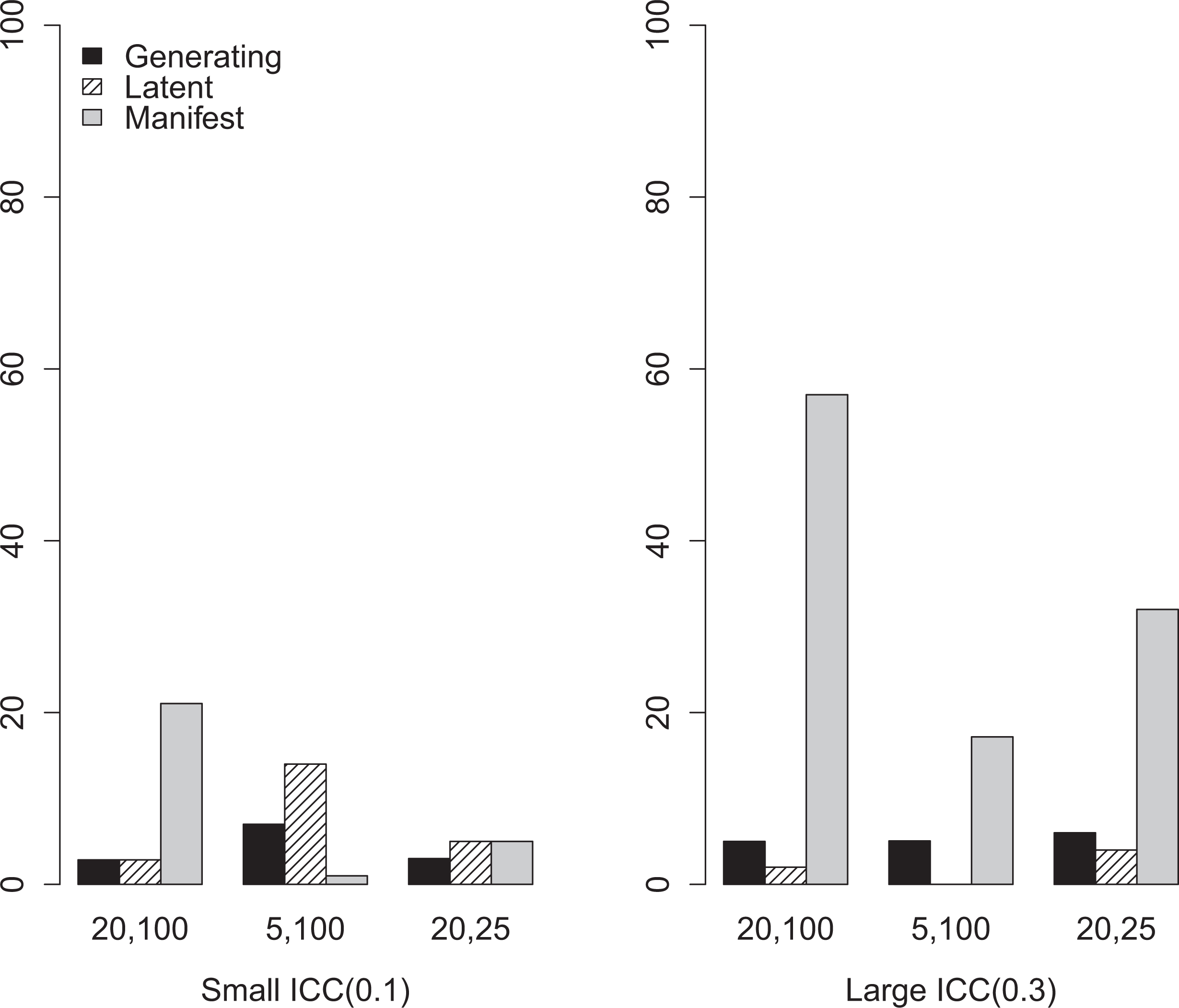
Empirical Type I error rates for the compositional effect estimate, first measurement condition.
Generating value analysis yields Type I error rates of .05 to .07 across sampling conditions. The latent variable model maintains similar Type I error rate calibration, except for the cases when the number of individuals per group is small. For traditional HLM analysis, Type I error rate inflation is dramatic. Only under the conditions when a small predictor ICC is coupled with a small number of group or a small number of individuals per group, does the traditional method maintains proper Type I error rate.
Turning to statistical power, when a compositional effect is large (see Figure 7), generating value analysis yields power of about .85 when the ICC is large and the number of groups is also large. When the ICC is small, power decreases to .35 even with favorable sampling conditions. The lowest statistical power (.15) is found when predictor ICC is small and the number of groups is also small.
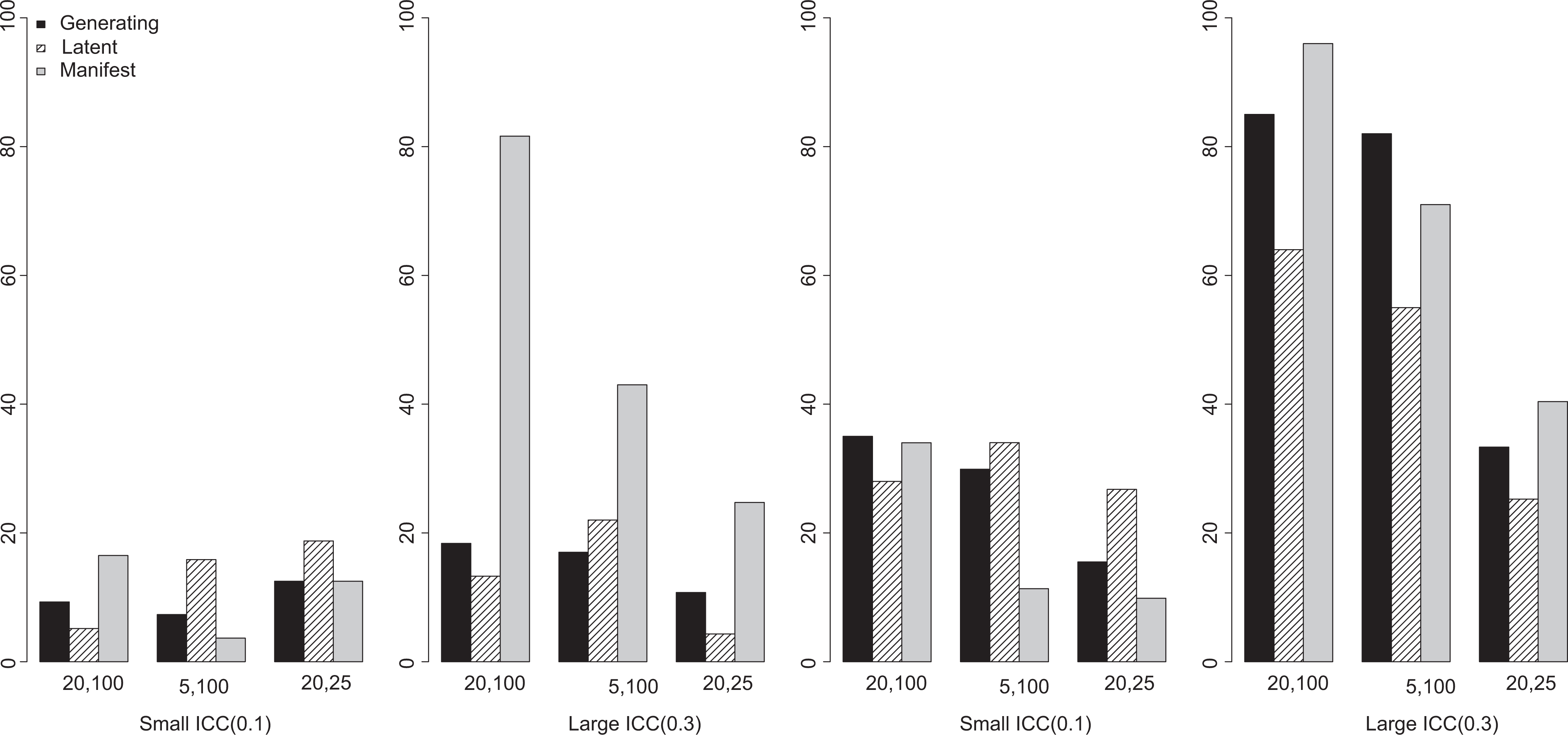
Percentage of significant compositional effect (estimated power), small true compositional effect (first two plots), and large true compositional effect (last two plots), first measurement condition.
The patterns are similar for the latent variable analysis. But when ICC is small, and the number of individuals per group or the number of groups is small, latent variable modeling actually yields a slightly higher percentage of significant compositional effects. While the traditional HLM analysis yields a very high percentage of significant compositional effects when the ICC is large and the number of individuals per group is also large, the power decreases remarkably when the ICC is small and when the sampling condition deteriorates (i.e., when the number of individuals per group or the number of groups is small). Also, the relatively high statistical power associated with the traditional HLM analysis is partially attributable to the inflated Type I error rates observed earlier—the test is liberal overall.
In summary, relative bias of
On the other hand, biases in point estimates seems rather unavoidable when the sampling condition is not favorable (small group sizes and low sample size in general), and especially when ICC is also low. Even with generating true scores the estimates show some biases. However, the latent variable model tends to yield less biased estimates in general. When ICC is small and the number of individuals per group is small, the Type I error rate associated with the latent variable compositional effect estimate increases slightly, but the magnitude of the elevation is still much more preferable compared to the traditional HLM analysis. We also find that the main issue with the latent variable model approach in terms of sampling conditions is related more to small number of groups rather than to the number of individuals per group. This is consistent with what have been found in traditional HLM analysis (e.g., Raudenbush & Liu, 2000). As long as the number of groups sampled is sufficiently large, the performance of the latent variable modeling approach can be satisfactory.
Finally, we find that the measurement structure to be less influential in this study. It can be due to the set of item parameters particularly chosen. The results from the second measurement condition, however, indicate that the estimation of too many item parameters with limited sample size can possibly undermine the performance of the latent variable modeling approach.
5 Empirical Application: “Big-Fish-Little-Pond” Effect
5.1 Data
For this compositional effect demonstration, a subset of publicly available data from 2000 PISA (Adams & Wu, 2002) were extracted and analyzed. PISA is a large international comparative survey. A large amount of student- and school-level information covering cognitive and affective domains was collected with a complex sampling scheme. We use this data set as an illustration only, and more proper analysis should take into account the complex sampling design and weights.
The sample of students from the United States was analyzed in this study. The analysis data set contained responses to 129 reading items (16 ordinal items with three categories, five items with four categories, and 108 dichotomous items) from 3,846 students nested within 153 schools in the United States. The number of students within a school ranged from 1 to 30 in this analysis data set, and the average cluster size was about 25. The outcome variable is the students’ self concept in reading. It was measured by three items (CC02Q05, CC02Q09, and CC02Q23). Each item has a Likert-type scale, ranging from 1 (disagree) to 4 (agree).
5.2 Results
The structural parameter estimates from the multilevel latent variable analysis (the EM algorithm and the MH-RM algorithm) and traditional HLM analysis are summarized in Table 3. In general, a positive and significant within-school coefficient
Structural Parameter Estimates From PISA 2000 USA Data Analysis

Note. BFLPE = big-fish-little-pond effect; HLM = hierarchial linear model; PISA = Programme for International Student Assessment. Reported standard errors (SE) for Metropolis–Hastings Robbins–Monro (MH-RM) algorithm are post-convergence approximated SEs. aThe HLM software program produces a χ2 test for the variance component τ00.
The compositional “big-fish-little-pond” effect is calculated by subtracting
In terms of the statistical significance of the compositional effect, both the traditional HLM analysis and the latent variable model analysis yield a statistically significant compositional effect estimate. This result is consistent with what we found via the simulation study in that the power of the traditional model to detect a compositional effect is not lowered, when the data set is associated with a sufficiently large number of schools and a large number of students per school.
Finally, the item parameter estimates from the MH-RM algorithm are plotted against those from the EM algorithm in Appendix Figure A.2, and the estimates are very close.
6 Conclusion
This study is situated in a current stream of research (e.g., Goldstein, Bonnet & Rocher, 2007; Goldstein & Browne, 2004; Kamata, Bauer, & Miyazaki, 2008) that tries to develop a comprehensive, unified model that benefits from both multilevel modeling and latent variable modeling by combining multidimensional IRT, factor analytic measurement modeling, and the flexibility of nonlinear structural equation modeling in a multilevel setting. Considering that one of the pressing needs in developing a unified model is an efficient estimation method, this study contributes to nonlinear multilevel latent variable modeling by extending an alternative estimation algorithm. The principles of the MH-RM algorithm and previous applications (Cai, 2008) suggest that the algorithm can be more efficient than the existing algorithms when a model contains a large number of latent variables or random effects.
The primary purpose of this study was to improve estimation efficiency in obtaining maximum likelihood estimates of contextual effects by adopting the MH-RM algorithm (Cai, 2008, 2010a, 2010b). R programs implementing the MH-RM algorithm were produced to fit nonlinear multilevel latent variable models. Computation efficiency and parameter recovery were assessed by comparing results with an EM algorithm that uses adaptive Gauss–Hermite quadrature. Results indicate that the MH-RM algorithm can obtain maximum likelihood estimates and their SEs efficiently. Considering the difference between an interpreted language (R) and a compiled language (FORTRAN) in which EM is implemented, substantial improvement in efficiency is expected if the MH-RM estimation code is ported to a compiled language in the future.
The second purpose of this study was to provide information about the performance of the nonlinear multilevel latent variable model in comparison to traditional HLM through a simulation study that covers various sampling and measurement conditions. Results suggest that nonlinear multilevel latent variable modeling can more properly estimate and detect a contextual effect than the traditional approach in most conditions. Type I error rates of the compositional effect estimate from the traditional model can also be substantially elevated whereas latent variable modeling leads to more proper Type I error rate calibration.
The third purpose of this study was to provide an empirical illustration using a subset of data extracted from PISA (Adams & Wu, 2002). A negative compositional effect was found for the relationship between reading literacy and academic self-concept, supporting the results from previous studies, on the “big-fish-little-pond” effect (e.g., Marsh et al., 2009). The compositional effect was statistically significant at the .05 level when the nonlinear multilevel latent variable model was applied. On the other hand, the traditional HLM approach could not detect a statistically significant effect.
This study is limited in several important ways. The latent variable model itself contains a series of strong specification and distributional assumptions. These assumptions require careful checking in empirical settings because the violations of these assumptions can lead to substantial unknown estimation biases. The simulation study only examined a limited set of conditions with fixed item and structural parameters. The data generating and the fitted models in the simulation study also do not contain any model specification error. More complex structural models should also be considered. In future research, an obvious extension of the model discussed here is one that includes cross-level interactions in latent variables. In addition, there are alternative computational approaches (e.g., Haberman, 2013; Rijmen, 2011) that aim at solving the same issue of high dimensionality of latent variables but were not compared in this study. While those alternative approaches have not been fully extended to the same multilevel contextual effect model, they may contribute to computational efficiency, given the logistics and principles of the approaches.
Footnotes
Appendix
Percentage of Converged Solution and Average Time per Replication (in seconds)
| Large Compositional Effect = 0.5 | ||||
|---|---|---|---|---|
| np = 20 | np = 5 | |||
| ng = 100 | MM1 | MM2 | MM1 | MM2 |
| ICC = 0.1 | 100(2,781) | 89(4,911) | 97(972) | 81(1,593) |
| ICC = 0.3 | 100(2,657) | 95(5,301) | 100(955) | 95(1,613) |
| ng = 25 | MM1 | MM2 | MM1 | MM2 |
| ICC = 0.1 | 98(1,046) | 92(1,522) | N/A | |
| ICC = 0.3 | 99(865) | 93(1,524) | ||
| Small Compositional Effect = 0.2 | ||||
| np = 20 | np = 5 | |||
| ng = 100 | MM1 | MM2 | MM1 | MM2 |
| ICC = 0.1 | 97(2,937) | 91(5,165) | 95(1,021) | 92(1,588) |
| ICC = 0.3 | 98(1,785) | 92(4,910) | 100(1,046) | 91(1,593) |
| ng = 25 | MM1 | MM2 | MM1 | MM2 |
| ICC = 0.1 | 95(919) | 78(1,521) | N/A | |
| ICC = 0.3 | 93(915) | 95(1,519) | ||

Note. MM1 = measurement model 1; MM2 = measurement model 2; ng = number of groups; np = number of individuals per group.
Acknowledgments
We thank Drs. Michael Seltzer, Sandra Graham, and Steve Reise for their thoughtful feedback.
Authors’ Note
The views expressed here belong to the authors and do not reflect the views or policies of the funding agencies.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Ji Seung Yang’s dissertation research was supported by a dissertation grant from the Society of Multivariate Experimental Psychology. This project was also partially supported by an IES statistical methodology research grant (R305D100039). Li Cai’s research is additionally supported by IES grant R305D140046 and NIDA grants R01DA026943 and R01DA030466.