
Abstract
Person-fit assessment may help the researcher to obtain additional information regarding the answering behavior of persons. Although several researchers examined person fit, there is a lack of research on person-fit assessment for mixed-format tests. In this article, the lz statistic and the ζ2 statistic, both of which have been used for tests with only dichotomous items or with only polytomous items, were modified for use with mixed-format tests. In a detailed simulation, the lz and ζ2 statistics are found to be conservative under a (frequentist) asymptotic normal approximation. However, the use of the statistics along with the (Bayesian) posterior predictive model checking method leads to a larger power. The suggested approaches are applied to an operational data set. The approaches appear to be satisfactory tools for assessing person fit for mixed-format tests.
Keywords
Person-fit analysis is concerned with uncovering atypical test performance as reflected in the pattern of scores on individual items in a test (Meijer & Sijtsma, 2001). Person-fit assessment may help the researcher to obtain additional information regarding the answering behavior of persons (Glas & Meijer, 2003).
Several person-fit statistics have been proposed in the context of tests with dichotomous items (see, e.g., Drasgow, Levine, & McLaughlin, 1991; Drasgow, Levine, & Williams, 1985; Klauer & Rettig, 1990; Meijer & Sijtsma, 2001; Smith, 1986; Snijders, 2001; Tatsuoka, 1984; Wright & Stone, 1979). Person-fit statistics for tests with polytomous items are less numerous (e.g., Drasgow et al., 1985; Emons, 2008; Glas & Dagohoy, 2007; van Krimpen-Stoop & Meijer, 2002; Wright & Masters, 1982).
There is a severe lack of research on person-fit assessment for mixed-format tests, which are tests that include both dichotomous and polytomous items, Finkelman and Kim (2007) being the only exception. Several examples of mixed-format tests in educational measurement (e.g., Chon, Lee, & Ansley, 2013; Kolen & Lee, 2011; Sinharay et al., 2014) show that they are quite common in the field. Further, mixed-format tests promise to become more common because of an increasing emphasis on performance tasks in the common core assessments (e.g., Darling-Hammond & Adamson, 2010, p. 1). So, it is important to be able to perform person-fit assessment for mixed-format tests. It is possible to apply the person-fit statistics designed for polytomous item response theory (IRT) models to mixed-format tests in which the Rasch model or the two-parameter logistic (2PL) model is used for the dichotomous items. This is because, as several researchers (e.g., Johnson, 2007) showed, the Rasch model and the 2PL model are special cases of the graded response model (e.g., Samejima, 1973) and also of the generalized partial credit model (GPCM; Muraki, 1992). However, these statistics cannot be applied to mixed-format tests in which the three-parameter logistic (3PL) model (or any IRT model with a guessing parameter) is used for the dichotomous items, because the 3PL model cannot be expressed as a special case of any common polytomous IRT model. The goal of this article is to fill this gap and explore several approaches for person-fit assessment for mixed-format tests.
The lz statistic (Drasgow et al., 1985) is one of the most popular IRT-based person-fit statistics (Armstrong, Stoumbos, Kung, & Shi, 2007). Researchers such as Drasgow, Levine, and McLaughlin (1987) and Li and Olenik (1997) found the statistic to have excellent performance in comparison to other existing person-fit measures. The statistic has been applied to either tests with only dichotomous items (e.g., Drasgow et al., 1985; Glas & Meijer, 2003) or tests with only polytomous items (e.g., Drasgow et al., 1985; van Krimpen-Stoop & Meijer, 2002). The lz statistic for mixed-format tests is defined later in this article by combining the expressions of the statistic for dichotomous items and polytomous items. The null distribution of lz deviates substantially from the standard normal distribution for both tests with dichotomous items and tests with polytomous items—the same phenomenon is expected to occur for mixed-format tests as well. 1 It is possible to simulate data from an IRT model and compute the “empirical” null distribution of lz from these simulated data sets, as suggested by, for example, de la Torre and Deng (2008), Meijer and Nering (1997), and Seo and Weiss (2013). However, the uncertainty in the estimated model parameters is not appropriately accounted for in this approach (e.g., Glas & Meijer, 2003, p. 218). Another possibility is to apply the posterior predictive model checking (PPMC) method (Rubin, 1984), which is a popular Bayesian approach, to find the null distribution. In fact, Magis, Raiche, and Beland (2012, p. 76) called for more research on person fit using Bayesian statistical methods. The PPMC method is applied in this article to find the null distribution of lz .
The ζ2 statistic was suggested by Tatsuoka (1984) for detecting aberrant response patterns that include too many correct answers to difficult items or too many incorrect answers to easy items. The ζ2 statistic, combined with the PPMC method, was found to be the most powerful statistic among the several statistics compared in Glas and Meijer (2003). Both Tatsuoka (1984) and Glas and Meijer (2003) applied ζ2 to tests with only dichotomous items. This article extends the statistic to mixed-format tests and employs the PPMC method to find the null distribution of ζ2.
The next section includes a description of the lz statistic for mixed-format tests and includes a review of the PPMC method. The section then suggests assessing person fit for mixed-format tests using the PPMC method with lz as a test statistic. Then, the ζ2 statistic is described in the section. In the Simulation Study section, the Type I error rate and power of lz and ζ2 are examined under a frequentist approach (using a standard normal null distribution) and the PPMC method in a detailed simulation study. In the Application section, the suggested approaches are applied to data from an operational test. Conclusions and recommendations are provided in the last section.
Method
The lz Statistic for Mixed-Format Tests
Definition
The predecessor of the lz statistic is the l statistic (Levine & Rubin, 1979) that is defined as the log likelihood of the item-level scores of a person. For a test with dichotomous items, l is defined (see, e.g., Drasgow et al., 1985; Glas & Meijer, 2003) as:
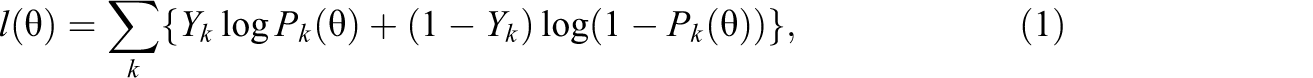
where Yk is the examinee’s score on item k and can be either 0 or 1, and Pk (θ) is the probability of a correct answer on dichotomous item k. The statistic was expressed as a function of θ (unlike in several other articles) to stress the fact that it is a function of θ. For a test with polytomous items, l(θ) is defined (see, e.g., Drasgow et al., 1985; van Krimpen-Stoop & Meijer, 2002) as:

where Yk , the examinee’s score on item k, is any integer between 0 and mk , dj (Yk ) is an indicator function that is 1 if Yk = j and 0 otherwise, and Pkj (θ) is the probability of a score of j on polytomous item k. Note that while both Drasgow, Levine, and Williams (1985) and van Krimpen-Stoop and Meijer (2002) assumed the same number of response categories for all polytomous items, Equation 2 allows the number to vary over the items.
Suppose that an examinee with ability θ was administered a mixed-format test consisting of K 1 dichotomous items and K 2 polytomous items. Combining Equations 1 and 2, the l(θ) statistic for the examinee for the test can be defined as:

where Yk is either 0 or 1 for k = 1, 2,…, K 1 and Yk is any integer between 0 and mk if k > K 1. Note that the application of Equation 3 does not require that the first K 1 items of the test are dichotomous—the notation, denoting the dichotomous items as items 1, 2,…, K 1, holds for a reordering of the items in which the dichotomous items take the first K 1 positions. 2
Equation 3 implies that
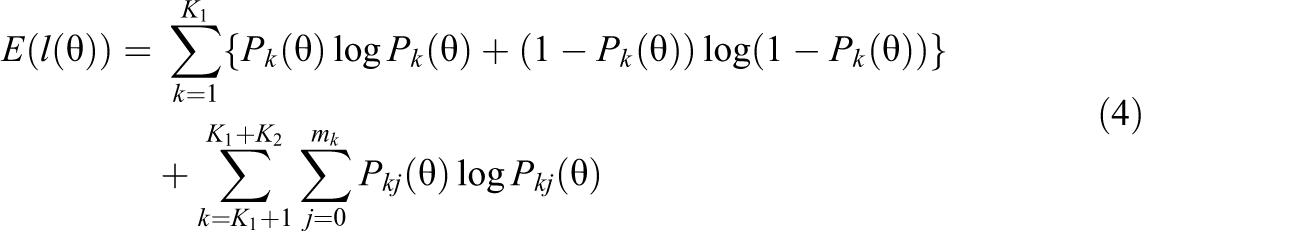
and
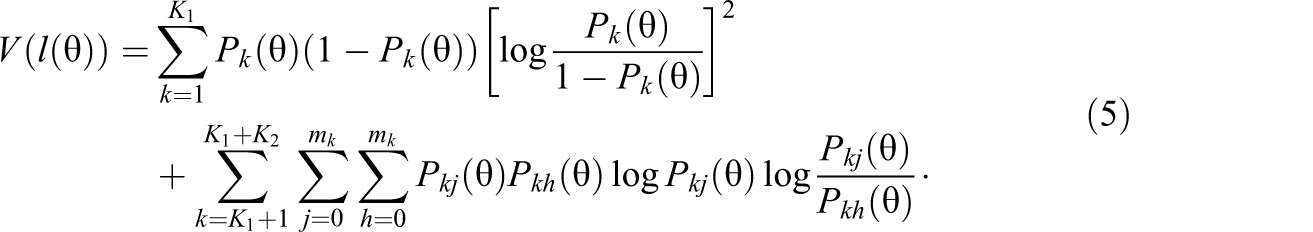
The lz statistic for a mixed-format test can then be defined as:

The value of lz (θ) decreases as the extent of person misfit increases, and a lower one-sided test is conducted to detect person misfit (e.g., Armstrong et al., 2007).
Null distribution of lz(θ) for mixed-format tests
To apply lz
(θ) to assess the fit for a person in practice, one needs to substitute the unknown θ in Equations 3
through 5 by an estimate of θ. Let us denote an estimate of θ by
Researchers such as Molenaar and Hoijtink (1990), Nering (1995), van Krimpen-Stoop and Meijer (1999), and Snijders (2001) proved that the null distribution of
PPMC Method
Description of the method
Let the posterior distribution of the model parameters be:

where

In practice, test quantities or discrepancy measures D(

Because of the difficulty in dealing with Equations 8 and 9 analytically for all but simple problems, Rubin (1984) suggested simulating replicated (or posterior predictive) data sets from the PPD in applications of the PPMC method. One draws N simulations
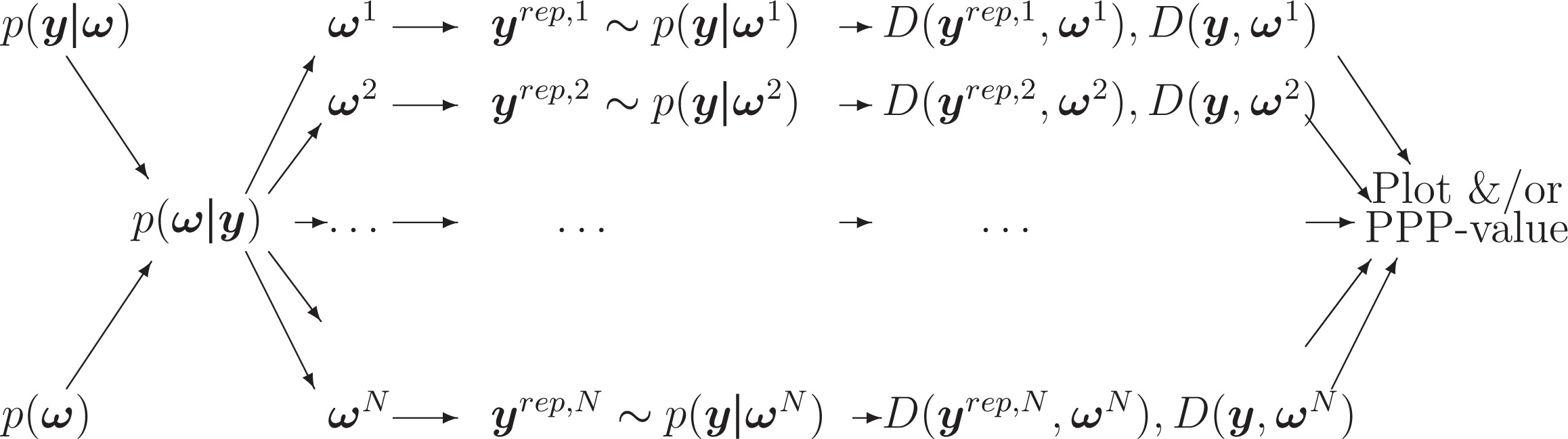
A graph describing the posterior predictive model checking method.
Properties of the method and applications to educational measurement
The PPMC methods have been criticized for being conservative. The PPP-values are not necessarily uniformly distributed when the fitted model is in fact correct, and there is some evidence that PPP-values under the correct model tend to be closer to .5 more often than would be expected under a uniform distribution (Bayarri & Berger, 2000; Sinharay, Johnson, & Stern, 2006). However, researchers such as Beguin and Glas (2001), Fox and Glas (2003), Hoijtink (2001), Li, Bolt, and Fu (2006), Levy (2011), Levy, Mislevy, and Sinharay (2009), Sinharay (2005, 2006), Sinharay, Johnson, and Stern (2006), Toribio and Albert (2011), and Zhu and Stone (2011) successfully applied the PPMC method to assess various aspects of IRT model fit such as item fit, dimensionality, differential item functioning, and overall fit.
Glas and Meijer (2003) used the PPMC method to compute p-values for several person-fit statistics including the l statistic for dichotomous items but found the power of the l statistic to be low. de la Torre and Deng (2008) also applied the PPMC method with lz for dichotomous items but found its power to be low.
Person-fit assessment using lz and the PPMC method
In the application of the PPMC method with
Let us consider the application of the PPMC method to an examinee with scores

The steps in the approach are as follows: Compute Use Repeat the following steps for n = 1, 2, … , N for a large N: Generate a draw of θ from the above posterior distribution using an MCMC algorithm. Let us denote the draw by θ
n
. Generate draws of scores of the examinee on all the items using β and θ
n
. These scores constitute Compute Compute the statistic The above-mentioned steps lead to N replicated values of the test statistic,
Note that one has to ensure that the MCMC algorithm has converged, and a sufficient number of burn-in iterations have already taken place. To perform the method for a sample of examinees, the above-mentioned steps have to be repeated separately for each examinee in the sample.
Steps 3(c) and 3(d) could be replaced by the computation of
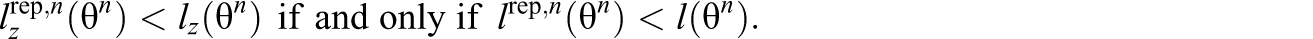
Thus, de la Torre and Deng (2008) effectively used the l statistic with the PPMC method. It was found in initial runs that the use of (the test statistic)
The ζ2 Statistic for Mixed-Format Tests
Glas and Meijer (2003) found the ζ2 statistic (Tatsuoka, 1984) to be the most powerful discrepancy measure with the PPMC method. The ζ2 statistic has been used only for dichotomous items and is defined as:

where Xk
is the score (0/1) on the item, Ak
(θ) is defined as equal to Pk
(θ), T(θ) to the average of the Pk
(θ)’s, and
A Simulation Study
A detailed simulation study was performed to examine the Type I error rate and the power of
Design of the Simulation
The simulation study involved three levels of test length (12 items, 30 items, and 60 items) that represent short, moderate, and long tests. Each generated data set included 2-item clusters: a set of dichotomous items and a set of polytomous items. To make the compositions of mixed-format tests realistic, the proportions for each type of item were set based on the review of existing testing programs (e.g., 71% of multiple choice and 29% of constructed response items for the National Assessment of Educational Progress (NAEP) science assessment for Grades 4, 8, and 12). The number of polytomous items was 4, 10, and 20, respectively (i.e., one third), for the three test lengths. The number of response categories for each polytomous item was fixed at three with a scale ranging from 0 to 2. Because the item parameters are assumed known, the Type I error rate and the power do not depend on the number of examinees in a data set, and the number of examinees was 1,000 in each simulated data set. For each simulation condition, 1,000 data sets were generated.
Data Generation
Scores on dichotomous and polytomous items were generated using the 3PL model and GPCM, respectively. The true item parameters were generated randomly. The true slope parameters of all items were generated, as in Glas and Dagohoy (2007), from a log-normal distribution with, respectively, 0 and .25 as the mean and standard deviation of the logarithm of the variable. The true difficulty and true guessing parameters for the dichotomous items were generated from a standard normal distribution and a Uniform(0.05,0.3) distribution, respectively. The true location parameters of the polytomous items were generated from
The true ability parameters were randomly drawn from the standard normal distribution. For each simulation condition, a new set of true item parameters were simulated and were then used to generate each simulated data set and in the computation of the observed and replicated values of the statistics.
To compute the Type I error of the approaches, score patterns that fit the IRT (3PL + GPCM) model were generated. To compute the power of the approaches, score patterns that are “corrupted” and do not fit the IRT model were generated in several ways. Because the item parameters are assumed known, the power does not depend on the number of examinees whose scores were corrupted—so the scores of all examinees were corrupted under each simulation condition in the “power study.”
As in other simulation studies on person-fit assessment (e.g., de la Torre & Deng, 2008; Glas & Meijer, 2003), such patterns included score patterns that are common under “lack of motivation” or “item disclosure” or “speeding.” When lack of motivation was simulated, the score patterns of all examinees involved lack of motivation to
Computations
Fortran 90 programs written by the author were used for the computation of maximum likelihood estimates (MLEs) of ability
6
and implementing the Metropolis–Hastings algorithm (e.g., Gelman, Carlin, Stern, & Rubin, 2003) that was used to generate draws from the posterior distribution of ability. The proposal/jumping distribution was chosen as a normal distribution with the previous draw as the mean, and the standard deviation of the proposal/jumping distribution was chosen to ensure an acceptance of about 44% of the draws from the proposal distribution.
7
One chain of length 4,000 was run that ensures the convergence of the algorithm and the first 1,000 draws of the chain were discarded as burn-in. The remaining draws were thinned by retaining every third draw to lead to 1,000 draws from the posterior distribution of ability for each examinee. The use of weighted likelihood estimate (WLE; Tao, Shi, & Chang, 2012, discussed the computation of WLEs for mixed-format tests), modal a posteriori (MAP), or expected a posteriori (EAP) of the ability instead of the MLE led to negligible changes in the Type I error rate and power of
Thus, the following steps were repeated 1,000 times for any simulation condition: Simulate a set of true item parameters. Simulate 1,000 true ability parameters. Use the above true item and ability parameters to simulate what would be treated as an “observed” data set. Compute the MLE Compute Use an MCMC algorithm to generate for each examinee 1,000 draws (after the aforementioned burn-in and thinning) from the posterior distribution of the ability. Use the above draws of ability and the true item parameters to generate 1,000 posterior predictive data sets. Compute the MLEs ( Compute Compute the PPP-value for each examinee by comparing the
Type I Error Rate
Table 1 displays the Type I error rates of the
Type I Error Rates From the Simulations
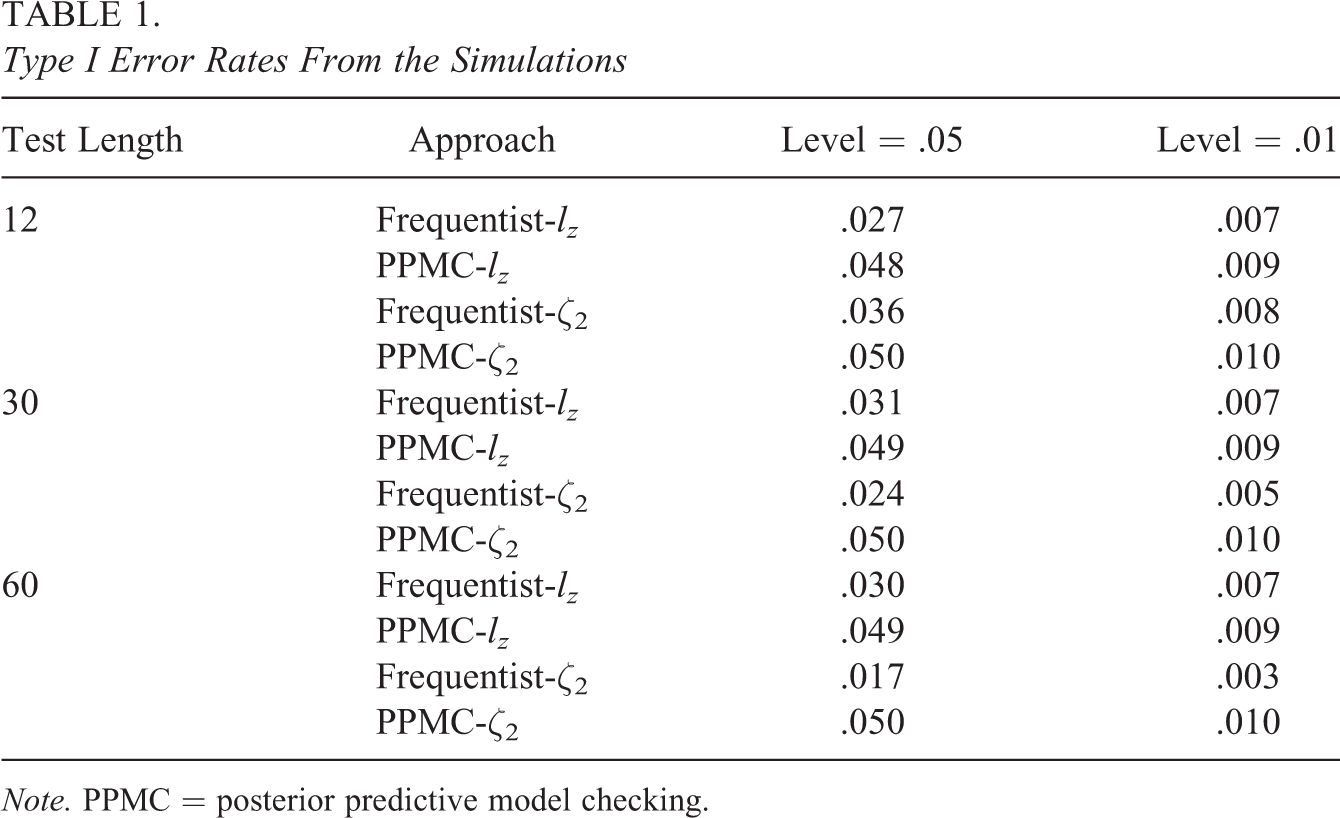
Note. PPMC = posterior predictive model checking.
The short-dashed line in Figure 2 shows the distribution of the observed values of

Distributions of observed and replicated
Figure 3 shows the distributions of p-values from all the examinees from all the 1,000 simulated data sets for the three test lengths from the Type I error rate study. In each panel, the solid line and the dashed line, respectively, denote the distributions of the p-values for the
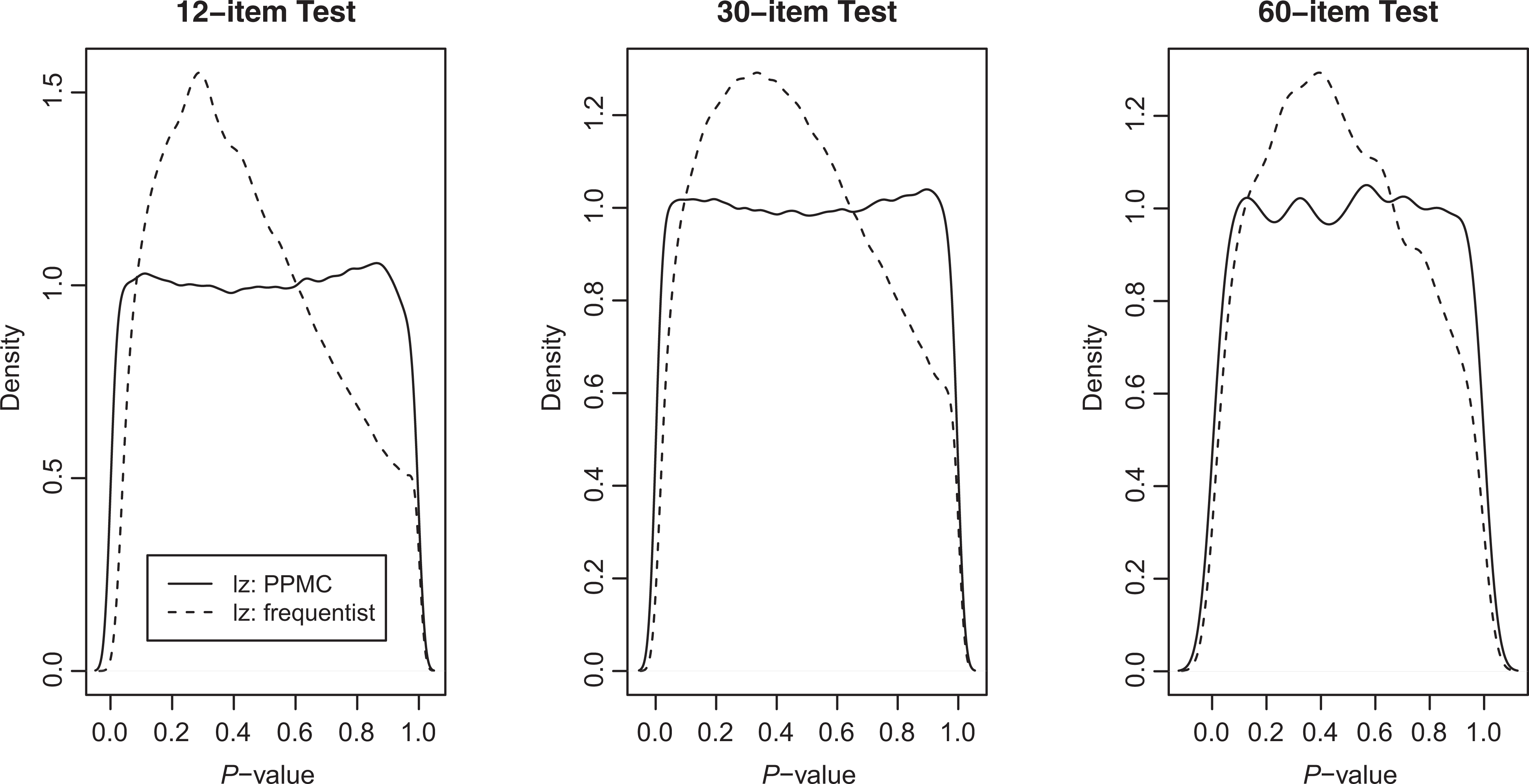
Distributions of the p-values.
Power
Table 2 presents the aggregated power values for level = .05. Columns 3 through 5 show the power of the lack of motivation conditions, Columns 6 through 8 show the power under the item disclosure conditions, Column 9 shows the power under speeding, and Column 10 shows the power when only the polytomous items are disclosed. The first four rows of numbers represent the power, for 12-item tests, for the
Power
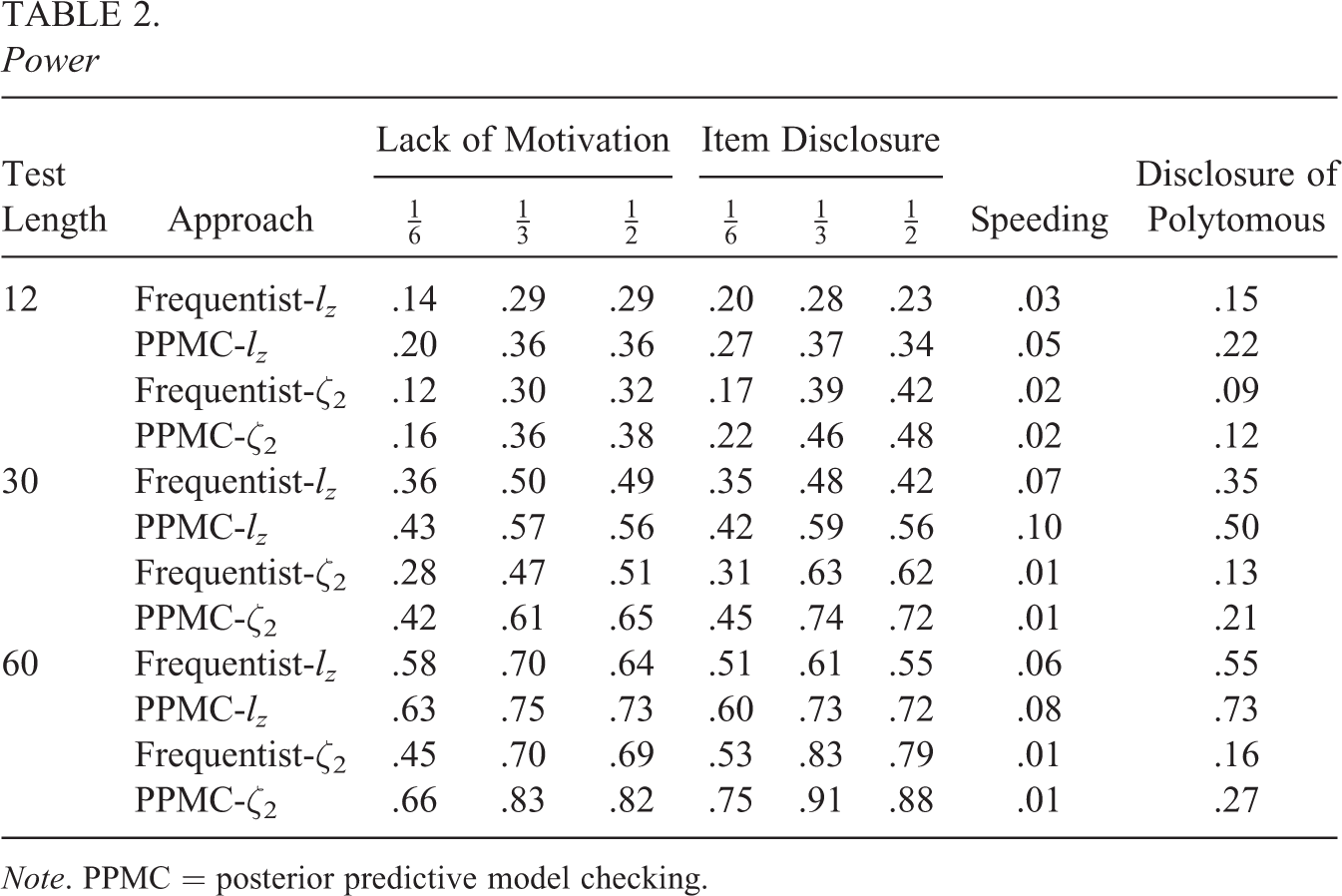
Note. PPMC = posterior predictive model checking.
The power is well below 1.0 for all test conditions. This phenomenon has been observed by several researchers such as Glas and Meijer (2003) and Meijer and Nering (1997) and is a typical feature of person-fit assessment. The power under speeding is extremely low for all the approaches, which agrees with the low power under speeding found in de la Torre and Deng (2008) for dichotomous items.
The power increases as test length increases. This is expected and is in agreement with other simulation studies such as Glas and Meijer (2003) and de la Torre and Deng (2008).
For both
The statistic
For all test lengths, the power for
Application to Real Data
Data and Analysis
Let us consider a test that is used to measure student achievement on several subject areas in a U.S. state. Item-level scores of a random subsample of about 5,000 examinees on one form of a subject area were available. The test form includes 46 multiple-choice (and dichotomous) items and 8 constructed-response (and polytomous) items with 3 to 5 score categories. The 3PL model is used for the multiple-choice items, and the GPCM is used for the constructed-response items to obtain an estimated examinee ability. A linear transformation of the estimated ability is reported to each examinee. It is important to assess person fit for the test to obtain information on answering behavior of the examinees. The item parameters were estimated based on the subsample and used for assessing person fit. The S – χ2 item-fit index (e.g., Chon, Lee, & Dunbar, 2010) were computed for all the items and the value of the statistic was significant only for 3 items. The p-values for
Results
The proportion of extreme p-values at 5% level for the correlation coefficient between the examinee’s fractional scores on the items and the average fractional scores of the items. It is expected that the larger the correlation, the better is the agreement between the scores of the examinee and the scores of other examinees and the less likely it is to detect misfit for the examinee. The items were divided in groups of five with respect to their average fractional scores. The first group included the 5 items with the smallest average fractional scores, the second group included the 5 items with the second smallest average fractional scores, and so on. For each examinee, the average fractional scores on these groups of 5 items were computed. One would expect that the average scores on these groups would increase for each examinee, that is, the average fractional score on the first group would be the smallest, and so on. Any deviation from this increasing pattern would increase the chance of the detection of misfit.
The four panels in Figure 4 show, for four examinees, the average scores for the 11 groups of items, where Groups 1 through 10 include 5 items each and Group 11 includes 4 items. The titles of the panels provide, for each examinee, the above-mentioned correlation coefficient and the p-values (denoted by the symbol “PV”) for

Details of four examinees for the state test data.
For the first examinee, the average score on the item groups increases, and as a result, the correlation is a moderately high .36 and no misfit is detected either by the frequentist or by the PPMC method. The pattern seems to be random for the second examinee. As a result, the correlation is a modest .07 and the p value is 0 for all approaches. The pattern is increasing up to Group 7 for the third examinee, but then it fluctuates for the last four groups. As a result, the correlation is modestly negative (−.05) and the p value is 0 for all the approaches. The pattern for the fourth examinee is fluctuating for the last five groups. The correlation is .07. However, while
Conclusion
This article suggests four approaches for person-fit assessment for mixed-format tests. The approaches are based on the lz statistic (Drasgow et al., 1985) and an extension of the ζ2 statistic (Tatsuoka, 1984). A frequentist large-sample standard normal approximation of the null distribution of lz and ζ2 leads to a conservative assessment of person fit. However, the application of the PPMC method (Rubin, 1984) with these statistics leads to a more powerful assessment of person fit. The ζ2 statistic was more powerful than lz when misfit was introduced by changing the answers to the most difficult items or the easiest items, but less powerful than lz when misfit was introduced in any other manner. In practice, it may be worthwhile to apply both lz and ζ2 because the nature of the aberrant response patterns for a specific data set is usually unknown.
The power of the PPMC method combined with the lz statistic was found to be rather low in de la Torre and Deng (2008) and Glas and Meijer (2003). The better performance of lz with the PPMC method in this article is due to the use of the estimated ability in the computation of lz . Researchers such as Levy et al. (2009) and Sinharay (2006) found in the context of IRT models that some discrepancy measures are more powerful than others using the PPMC method. The results here show, as those in the above-mentioned articles, that although the PPMC method is conceptually straightforward, the chance of success with the method often depends on the choice of the “discrepancy measure” (or “test statistic”). Researchers such as Robins, van der Vaart, and Ventura (2000) have shown that the PPMC method is expected to lack power if the mean of the test statistic depends on the model parameters and vice versa. While the mean of l depends on θ, previous research on lz shows that the mean of the statistic, when computed using an ability estimate such as the MLE or WLE, depends only slightly on θ. 9 Therefore, it is no coincidence that the PPMC with lz , where the latter is computed using the MLE of the examinee ability, was more successful than with l (de la Torre & Deng, 2008; Glas & Suarez-Falcon, 2003).
A statistically significant person-fit statistic does not necessarily mean that the corresponding examinee behaved inappropriately (e.g., cheated) during testing. It is possible, for example, that the unexpected pattern was due to fatigue, lack of motivation, or distraction during the test. Holland (1996, p. 28) stated, in the context of detection of cheating, that one can draw very limited conclusions only from a statistical test regarding the probability of cheating. That is because the test administrators can confidently claim that an examinee cheated only if “the probability that the examinee cheated given other evidence and the value of the test statistic” is very close to 1 and a significant test statistic does not necessarily imply that this probability indeed is very close to 1. Holland (1996) includes an example where, even though the test statistic is statistically significant, one could conclude that the above probability is more than .92 for one set of “the other evidence” and more than .18 for another set of the other evidence. Still, as argued in Holland (1996) in the context of the K-index for cheating detection, while the lz or ζ2 statistic by themselves are unable to lead to definitive statements about “the probability that the individual behaved inappropriately given other evidence and the value of the test statistic,” they can be useful as quality control procedures and can provide some evidence, when evidence from other sources are available, on possible inappropriate examinee behavior. The decision on what steps should be taken for an examinee with an aberrant response pattern will most often be made by policy makers who would most likely use other evidence on the examinees (such as the reports from the test venue) and may request recommendations or statistical evidence from psychometricians. The policy makers may choose to ignore the results regarding the test statistics, request the examinee to take the test again, or invalidate the score of the examinee.
There are several limitations of this article and, consequently, several related topics that can be further investigated. First, this article focused only on the lz
and ζ2 statistic. The statistic
Footnotes
Author’s Note
The research reported in this paper was performed when the author was an employee of McGraw-Hill Education CTB. The author is currently an employee of Pacific Metrics Corporation. Any opinions expressed in this publication are those of the author and not necessarily of McGraw-Hill Education CTB.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.