
Abstract
A review of the software Just Another Gibbs Sampler (JAGS) is provided. We cover aspects related to history and development and the elements a user needs to know to get started with the program, including (a) definition of the data, (b) definition of the model, (c) compilation of the model, and (d) initialization of the model. An example using a latent class model with large-scale education data is provided to illustrate how easily JAGS can be implemented in R. We also cover details surrounding the many programs implementing JAGS. We conclude with a discussion of the newest features and upcoming developments. JAGS is constantly evolving and is developing into a flexible, user-friendly program with many benefits for Bayesian inference.
Just Another Gibbs Sampler (JAGS) was developed by Martyn Plummer as an open-source program for analysis and statistical inference of Bayesian hierarchical models. JAGS was first released in 2003, and at the time of writing this article, JAGS was in version 4.3.0. Since 2006, JAGS and its related materials have been downloaded over 200,000 times around the world. JAGS and other relevant resources (e.g., examples and manuals) can be downloaded from https://sourceforge.net/projects/mcmc-jags/files/.
Development of JAGS
JAGS was developed using the dialect of Bayesian inference Using Gibbs Sampling (BUGS) language, which uses the Markov chain Monte Carlo (MCMC) estimation algorithm for Bayesian inference. The BUGS project was initially designed in 1989, based on developments from artificial intelligence (Lunn, Spiegelhalter, Thomas, & Best, 2009). Conceptually, the BUGS language uses directed acyclic graphs (DAGs) as the basis for model specification. In short, DAGs capture relationships among objects by using declarative statements that allow for uncertainty to be represented with probability distributions. DAGs are subsequently converted into model code and run via the MCMC estimation algorithm through an inference engine.
WinBUGS (Lunn et al., 2009) became the first widely popular BUGS program to implement Bayesian estimation via MCMC methods. In 2004, the BUGS team released OpenBUGS (Thomas, O’Hara, Ligges, & Sturz, 2006), which has greater extensibility and flexibility than its predecessor. The last patch for WinBUGS was released in 2007, when the development team decided to focus exclusively on the OpenBUGS project.
JAGS was created to be compatible with the BUGS software but is arguably more extendible, flexible, and user-friendly than the BUGS software. Differences between WinBUGS, OpenBUGS, and JAGS are explained below in the section titled “JAGS Compared to Other Bayesian Software.”
What the User Needs to Know About JAGS
JAGS uses MCMC algorithms to sample from probability distributions. JAGS was initially developed to be a clone of WinBUGS and OpenBUGS, while allowing its users additional flexibility to directly modify the program. JAGS uses the BUGS language; however, unlike WinBUGS, it is able to run on platforms other than Windows (e.g., Unix, Linux, or OS X). Additionally, JAGS users are able to create their own modules to extend the program’s capabilities. A JAGS module is a general term that can encompass various functions, distributions, and samplers—the latter of which refers to specific sampling algorithms (e.g., the Gibbs sampler) used with the MCMC estimation algorithm. Several JAGS modules have been created for use with the R software (R Core Team, 2016). For instance, the
JAGS does not have a built-in graphical user interface (GUI). 1 Instead, it can be run directly from the command line. However, since the base program uses C++ language, existing software written in C or Fortran (e.g., R, MATLAB, Python, or Stata) can be easily used in conjunction with JAGS. JAGS is most commonly called from the R programming environment, and it is designed to work closely with the R language (Plummer, 2013). We describe how JAGS interfaces with R in a subsequent section.
JAGS Implementation
In this section, we focus on important details related to model specification and the implementation process. The key elements for running JAGS include (a) definition of the data, (b) definition of the model, (c) compilation of the model, and (d) initialization of the model. To help solidify these concepts, we reference code, as it relates to an applied example of latent class analysis (LCA) throughout. LCA is a statistical model used to identify latent (or unobserved) groups of individuals based on patterns of responses to observed indicators (or items). The application of LCA is fully explained in a subsequent section, where we present an example using large-scale education data.
Definition of the Data
Users may define the data in several different ways depending on how JAGS is being used (e.g., calls from R can be more flexible than command line invocations). The data and the model are typically specified in different files, but JAGS allows users to flexibly incorporate them simultaneously. For instance, the same script can be used to define the data and model in adjacent blocks, using functions that call data being generated in the same model for concomitant use (e.g., with the “cut” function), or by passing data created from a previous model run to a subsequent run; the latter of which is particularly useful when conducting simulation studies. Data may also be defined using calls to a function, with a character string, or by placing it in a separate text file using the format created by the
Definition of the Model
The model is defined using variations of the BUGS language. Models can be called with script files, text files, model strings, or through function calls. In a later section, we demonstrate an applied example, where the model is specified within R and saved as a text file. The model file is initiated by calling the
Unfortunately, the use of JAGS’ model notation in conjunction with the array-style definitions for data can make it cumbersome and challenging to correctly specify certain types of models. In most instances, specifying
Model definitions in JAGS must adhere to a certain set of restrictions imposed by the BUGS language. Reliance on the BUGS language can therefore be a major barrier when developing complex models. However, a plethora of accessible modeling examples (see, e.g., Kruschke, 2015) and Internet resources are available to JAGS users, which can serve as a foundation for model building. At the same time, JAGS is becoming quite user-friendly by allowing for the use of R-style formatting inside model code. Likewise, a major benefit of JAGS is the ability to omit data from the model, allowing for independent sampling from the prior distributions. Direct sampling from the prior distributions is a useful tool for ensuring that priors are being specified as intended. The data and model can often be set up relative to a user’s preferences. We therefore refer the reader to the JAGS User’s Guide (Plummer, 2015c) for specific details about the data and model setup.
Compilation of the Model
The model compilation process involves the conversion of model syntax into a graphical representation of the model in the format of a DAG, which is stored in the computer’s memory. At this stage, JAGS checks the model syntax for errors. If the model syntax is appropriately specified, then JAGS may subsequently require an adaptation phase, during which time the software decides upon the most appropriate samplers for each parameter. The length of the adaptation phase (i.e., the number of iterations specified before burn-in) can be manually requested by the user and may require longer periods depending on model complexity or unusual specifications (e.g., latent variable models can often be specified using data stacked in long format with indexical indicators pointing to different “groups” of variables or units, in wide format using multidimensional arrays, or a combination of both).
Initialization of the Model
In order to initialize a model, the user may specify starting values for the model parameters, along with a random number generator (RNG) and samplers for each parameter. Users can choose the initial values and which parameters to supply initial values for. For instance, the following illustrates how starting values can be set for parameters p and pi by defining initial values in an R object:
Parameters often do not require that the user specify initial values. For simple models (e.g., a basic regression model), for example, the specific choice of initial values may not have an impact on the posterior inference. Conversely, more complex models consisting of many unobserved (i.e., latent) variables often benefit from the careful selection of initial values (e.g., structural equation models). When initial values are not supplied for a given parameter, JAGS generates them by sampling from the specified prior distribution. Supplying appropriate initial values can improve chain mixing, reduce computation time, and aid model convergence. For complex models (e.g., multilevel finite mixture models [FMMs]), the burn-in period can be shortened and chain mixing can improve by running the model twice, where estimates from the first run are used to inform initial values for model parameters in the second run (see, e.g., Almond, 2014).
The recent major update in JAGS has made it possible to ensure that results from an analysis are completely reproducible. In particular, specifying the same pseudo-RNG name and RNG seed (i.e., a specific number) for each chain in an analysis will result in identical findings upon replication. Note, however, that without specifying an RNG name and corresponding seed explicitly, JAGS will set an RNG name from the base module at random and select a seed using the current timestamp. Thus, the RNG name and seed are important if users are concerned with reproducibility. Accounting for the RNG state can also be useful; for instance, to extend a user-specified model when convergence has not been obtained. 2
Another aspect of JAGS that has undergone recent updates concerns a larger selection of samplers and modules than were previously available. In brief, different types of samplers are associated with different JAGS modules. The base module includes a variety of useful arithmetic operators that are synonymous with those used in R. With the base module, four RNG names are available, each of which can be used to specify a different RNG name for each chain in a given analysis. The BUGS module is loaded in JAGS by default and includes a long list of distributions and functions that can be called by the user. Modules that can be loaded manually include (a) the generalized linear model (GLM; which is recommended for most analyses and can improve performance for even very simple GLMs such as a basic logistic regression), (b) the mix module (for identifying finite mixtures of normal distributions), and (c) the multistate model module or merge module (which incorporates the matrix exponential function and the multistate distribution). Each of these modules allows users to call various functions and samplers that serve to enhance the extensibility of JAGS and maximize modeling efficiency. However, it is important to note that one should become familiar with the samplers associated with these modules before making manual adjustments. For instance, turning off the tempered transitions sampler in the mix module can result in considerable speed improvements, but between-chain label switching (defined in the next section) must be monitored closely under these conditions (Almond, 2014). Finally, the deviance information criterion (DIC) module has several monitors that can be useful for evaluating model fit. The DIC module calculates the deviance of the model (i.e., −2× the log likelihood), which can be used to compute a variety of model fit measures; for example, the pD, which is used as an indicator of the effective number of free parameters, and the Popt fit measure, which is used to compute the penalized expected deviance.
Like other Bayesian software programs that rely on MCMC for estimation, JAGS models can be slow to converge to a target distribution, particularly in the presence of models with highly correlated parameters, models that are weakly identified, or models that are highly complex. The implementation of alternative or redundant parameterizations and the use of hyperpriors can be used to overcome some of these potential limitations (see, e.g., Almond, 2014; Gelman & Hill, 2007; Ghosh & Dunson, 2009; Kruschke, 2015). Additionally, computation time and chain mixing can often be improved by manually selecting modules associated with the most appropriate samplers for specific sets of model parameters. Users should check regularly for version updates, as JAGS continually adds new samplers and builds upon the samplers that are readily available. The variety of samplers currently available in JAGS can be considered a key benefit of the program, especially when complex models are under investigation. Specifying multiple chains and allocating them to different computer cores or creating computer clusters can also reduce computation time. In such cases, it is common practice for users to specify disparate initial values for each chain as evidence that each chain is independently converging upon the same target distribution during the post-burn-in period.
Once the model has been initialized, users can manually set monitors on specific model parameters to record the simulated values (e.g., a trace monitor saves the sampled values for each iteration in a given chain). The monitored values are stored in the form of coda files. The
An important consideration when saving samples for variables pertains to the amount of computer memory available. When files are run in R, the amount of computer memory can accumulate quickly depending on the number of monitored parameters. For complex models with a large number of variables, it is often useful to consider whether a monitor needs to be set for a given parameter.
An Example of LCA in JAGS Using a Large-Scale Database
In this section, we demonstrate an empirical application in JAGS utilizing the Program for International Student Association (PISA; Organization for Economic Co-operation and Development, 2014) database. PISA is an international survey administered triennially since 2000. Fifteen-year-old students from randomly selected schools worldwide are administered tests aimed at evaluating educational systems by assessing a student’s ability to apply knowledge obtained in school to real-life situations (e.g., balancing a checkbook). Tests include a mixture of open-ended and multiple-choice questions in key subjects: reading, mathematics, and science, with a focus on one subject in each year of assessment. For the purposes of this example, we use data from the 2012 PISA cycle, which evaluated students’ performance as well as their attitudes and self-reported aptitude in mathematics.
Approximately 510,000 students from 65 participating countries and economies completed the assessment in 2012. Here we concentrate only on data from the U.S. sample. This includes over 6,000 randomly selected students from 161 randomly selected schools. Because this example is intended solely for pedagogical purposes, we ignore the nesting of students within schools as well as cases with missing data. Eight mathematic self-efficacy items are used in this analysis (N = 3,196, after removing all cases with missing data). These items asked students to indicate their confidence level in performing a variety of mathematical tasks such as “Using a train timetable” or “Solving an equation: 3x + 5 = 17.” Student scores for these items were modified to represent whether students had confidence in their ability to solve the item (coded as 1) or did not have confidence (coded as 0). This coding scheme was used to highlight the ability for JAGS to handle dichotomous outcome variables. In this example, we demonstrate the implementation of an LCA with two latent subgroups and dichotomous outcome variables in JAGS. The model is displayed in Figure 1, with a categorical latent variable that defines the latent classes. There are eight observed indicators for the latent class variable, and conditional response probabilities are computed for each indicator. Typically, patterns of response probabilities will substantively differ across latent classes. We implemented analyses using the
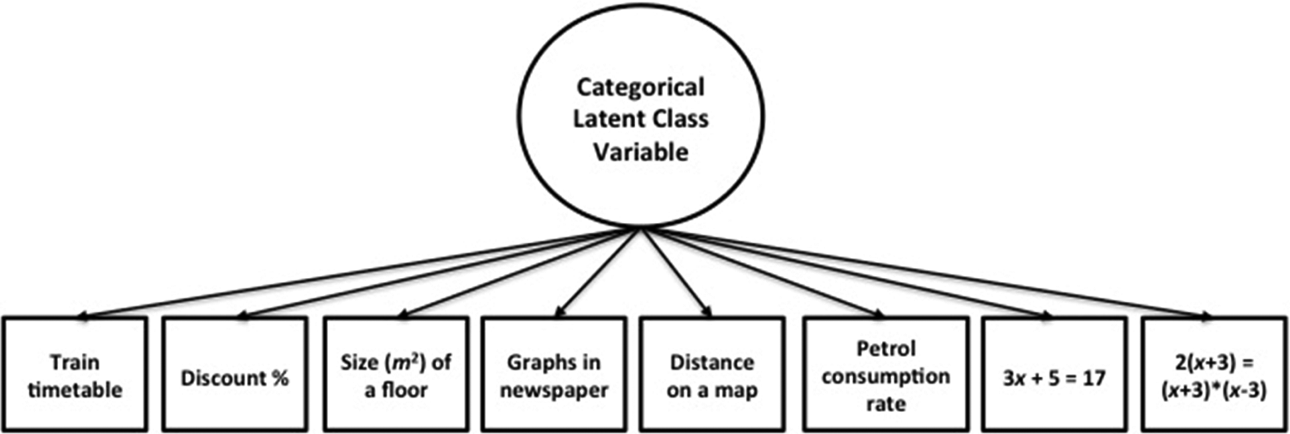
Latent class model with eight categorical indicators.
To perform MCMC sampling of a posterior distribution in JAGS, we first define the prior, the likelihood, and the observed data. The user is not required to specify information about the posterior or the sampling mechanism used. Here, we allowed JAGS to determine the most appropriate sampler(s) to implement for each parameter. In JAGS, the likelihood and prior distribution are specified in the model statement. The basic model code is written in the BUGS language and read as follows (text following the # symbol is a note describing the preceding line of code): # Begin model definition
# Data likelihood # Prior distributions
The first
Once an object containing the PISA data is created, we define all of the observed variables within the model. Here we use N and items. Using the
A single Markov chain was used in the analysis. A total of 70,000 iterations were performed, with the first 20,000 iterations specified as burn-in. Markov chains for each variable were monitored for convergence, first by visual inspection using trace plots (available from the first author, along with full data set). Plots were examined for each parameter, including the class proportions and conditional item probabilities. Additionally, chains were monitored for convergence using the Gelman and Rubin (1992) convergence diagnostic.
The R output includes information regarding which iterations were used in the posterior estimation, the thinning interval (set at 1 for no thinning), and the number of chains used (a single chain was used to avoid between-chain label switching for the latent classes). 4 The first 20,000 iterations were specified as burn-in, so each chain consisted of the last 50,000 iterations. Next, the posterior mean and standard deviation estimates for each parameter are produced. Each estimate represents the probability of answering confident to each question for each latent class. Looking at the pattern of responses across classes can provide an overall picture regarding the substantive meaning of the latent classes (Table 1 shows these patterns).
Latent Class Analysis Response Probabilities for 8 PISA Items

Note. Values in the table represent conditional response probabilities. For example, Item 1 (Using a train timetable) has a 0.939 probability of endorsement, given membership in Class 1. PISA = Program for International Student Association.
Each row in Table 1 represents a different item in the questionnaire. The two columns of numbers are the probabilities of answering confident to the item, given that a person belongs to that latent class. That is, a person belonging to Class 1 has a 93.9% chance of saying that they were confident in “Using a train table.” By plotting these responses (see Figure 2), we can more easily ascertain the difference in response patterns across the two latent classes. The x-axis represents the item and the y-axis represents the probability of reporting being confident about completing a given item, given that one belongs to a particular latent class. Class 1 is comprised of individuals responding with confidence across all observed indicators, and Class 2 shows much more variability and lower confidence in certain items (e.g., Distance to scale). Overall, this example shows the relative ease to which models can be implemented in JAGS as well as the extreme overlap with the BUGS language.
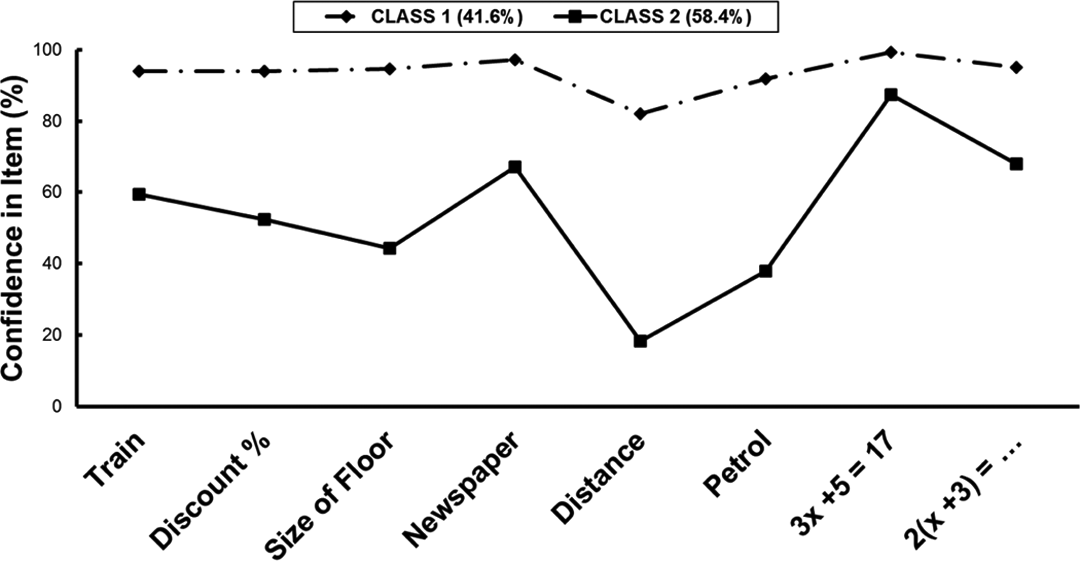
Latent class response probabilities. Notice that Class 1 shows high endorsement of confidence in all items and Class 2 is much more variable.
JAGS Interfacing With Other Software
We highlight some of the notable instances where other software programs or packages utilize JAGS—overtly or behind the scenes.
Interfacing With Packages in R
Rjags
The R programming environment has many packages that now implement JAGS for Bayesian inference. The package
Runjags
The
R2jags
Another popular package in R that interfaces with JAGS is called
R Packages Using JAGS Behind the Scenes
There has been a recent growth in other R packages implementing JAGS behind the scenes, where JAGS is used as the base for Bayesian inference within these packages. There are many packages using JAGS in this manner, and we provide a few examples here. First, the
In addition to the more popular, general-purpose packages listed above, several have been created for more specific modeling purposes. For instance, an extension of the
Several R packages have also been designed to expand the JAGS tool kit in ways that serve to enhance the functionality of the base software. For instance, the
Finally, a newly introduced flexible package called
Other Programs: MATLAB, Python, and Stata
The flexibility of JAGS has allowed the program to be implemented in a variety of ways beyond implementation in R. There are additional programs that have packages or modules allowing for interfacing with JAGS. MATLAB (MATLAB 6.1, 2000) has an interface called
JAGS Compared to Other Bayesian Software
In this section, we briefly compare JAGS to other popular Bayesian software programs. A full comparison of available Bayesian software is beyond the scope of this article. The number of Bayesian software programs has grown considerably in recent years, and many of them were developed to solve unique problems that arise in specific scientific fields (e.g., ecology, physics, etc.). By comparison, general-purpose Bayesian softwares such as JAGS and BUGS offer extensive modeling flexibility and are applicable in a wide variety of research contexts.
One common complaint about MCMC-based programs such as JAGS concerns the computation time and amount of computer memory that can accrue when estimating complex models. However, JAGS continues to be updated regularly, offering new samplers, modules, and other modeling features. Some of these developments are designed to reduce the computational cost associated with implementing MCMC.
At the same time, a variety of approaches that use alternative sampling methods for Bayesian inference are growing in popularity due to their ability to improve computational speed and accuracy. For instance, several software programs now offer variational Bayes (VB) methods (see, e.g., Fox & Roberts, 2012, for a tutorial on VB) and related approaches to approximate Bayesian inference. These techniques incorporate various optimization algorithms (e.g., iterative procedures akin to the expectation–maximization algorithm) or other numerical methods (e.g., the Laplace approximation; Kass & Raftery, 1995; Lindgren & Rue, 2015), which can reduce the computational burden of MCMC. For brevity, we do not review these techniques here. Instead, we limit our comparison of JAGS to well-established MCMC-based software programs that are most frequently used in applied settings, namely, Stan, WinBUGS, and OpenBUGS. 5
Stan
Unlike the MCMC-based methods currently available in JAGS, Stan uses a Hybrid Monte Carlo approach (see, e.g., Neal, 2011) based on Hamiltonian Monte Carlo (HMC) estimation (Carpenter et al., in press), using a no-U-turn sampling algorithm (Homan & Gelman, 2014). Stan has become a popular software program for Bayesian applications in the social, behavioral, and educational sciences (Kruschke, 2015). At present, Stan’s largest limitation is that it cannot handle discrete parameters. 6 The JAGS software has had a longer history of development and is capable of flexibly modeling a variety of discrete parameters with univariate and multivariate distributions (see, e.g., the applied example above). Users of R who have little background in C++ programming may find Stan to have a steeper learning curve than JAGS, because only the latter program is coded in a manner akin to R. A recent review of the Stan software (Gelman, Lee, & Guo, 2015) provides an in-depth comparison to JAGS. We briefly describe some of the software differences here; however, for more information about how JAGS compares to Stan, we refer the reader to Gelman, Lee, and Guo (2015).
It can be difficult to make direct comparisons between Stan and JAGS, as the potential scale reduction factor (Gelman et al., 2013; Gelman & Rubin, 1992) and effective sample size (Gelman et al., 2015) are computed differently across both programs. However, Gelman et al. (2015) present a small comparison showing differences in mixing time. A fundamental difference between Stan and JAGS pertains to the former program’s capacity to use built-in optimizers for computing penalized ML, as well as log densities, along with their gradients and Hessians—features that allow for direct modal inference. In addition, Stan now offers VB methods as an alternative to HMC estimation.
WinBUGS and OpenBUGS
Being based on the BUGS language, JAGS is most similar to WinBUGS and OpenBUGS. However, the latter two programs were developed using Component Pascal—an obscure programming language that only runs on Windows machines. Most software developers use Unix or Linux platforms to modify source code, thereby limiting the ability of independent software engineers to make improvements to WinBUGS or OpenBUGS. In contrast, JAGS was developed in C++, a cross-platform programming language that allows developers and entry-level programmers to manipulate the source code more easily.
WinBUGS was initially designed as a closed-source program that could only be run on a Windows platform, unless using the Wine program to emulate the Windows operating system on other machines. By comparison, OpenBUGS is an open-source program that allows users to access source code. However, the source code for Component Pascal can only be read through the BlackBox Component Builder from Aberon Microsystems. Users consequently have limited access to source code with OpenBUGS when compared to JAGS. Being built in C++ allows software developers to easily access JAGS source code and manipulate it for their own needs.
WinBUGS, OpenBUGS, and JAGS are very similar programs. We therefore refer the reader to the JAGS User’s Guide (Plummer, 2015c), which lists some fundamental differences between the programs. There are a few points worth noting, however. First, JAGS distinguishes between censoring and truncation, whereas OpenBUGS does not, and defines prior ordering in an arguably more intuitive manner. Second, JAGS continues to be updated at a faster pace than OpenBUGS, regularly adding new functionality to the existing software. Finally, WinBUGS and OpenBUGS were designed for 32-bit software; only JAGS runs on a 64-bit system. Varying results were obtained in a comparison of speed for estimating models across the BUGS and JAGS programs, with results being highly dependent on the type of model being estimated (Plummer, 2010). All three programs are very flexible and are among the most popular software engines for Bayesian estimation.
New Features and Future Developments for JAGS
In October 2015, the latest major revision (Version 4.0) of JAGS was officially released. There were many new features introduced in this latest version, and we highlight some of the main changes here. For more information on these changes, we refer the reader to Plummer (2015b, October 15, n.d.). We will also discuss some of the planned additions and changes that have been announced for future versions of the program.
New Features
There are many new features to the newest version of JAGS. One current drawback is that the official documentation for JAGS has not been updated to reflect these changes. The program’s creator, Martyn Plummer, has cited that the overhaul of the documentation will be quite time-consuming and officially documenting these changes was delayed because the priority was to get the changes done and the new version published. However, Plummer does keep a detailed blog on many of the new features of JAGS (see www.martynplummer.wordpress.com).
As mentioned above, there is an increased focus on making results from JAGS reproducible. Previous versions of the program would not produce the same results across identical runs, even when the same seed value was specified. In the release of new features, Plummer (2015b, October 15) acknowledges the importance of exact replication of results within the same version of a program when using the same seed value. Therefore, major changes were made to ensure that results were reproducible under JAGS 4.0. In addition, this version includes unit tests that can be implemented to confirm functions and distributions are working properly within JAGS.
JAGS now also has the capability to monitor a node array that has undefined values. For example, if the definition does not include the first element of the array because it is set to zero, then the code may look like:
The normalized log density can be computed for all distributions using the code
There were many changes specifically made to JAGS to make it more consistent with the R programming language; this is especially helpful, given that there are so many packages in R that allow for an interface with JAGS. JAGS 4.0 now includes vector indexing and the
On his website, Plummer has mentioned plans to continue updating the GLM module and having it loaded by default (along with the basic BUGS module). In addition, Plummer has noted that he is working on procedures for optimization—but it is still too soon to be sure what this will look like. This latter improvement would be a substantial enhancement (e.g., by allowing for direct modal estimation) to the program. In addition, a new Outcome class within the GLM module now offers an abstract normal approximation to the GLM engine, due to a refactorization of the samplers. Finally, there is a new distribution available for latent Dirichlet allocation models.
We hope that the trend continues toward building optimization procedures within JAGS, as the scalar representation of the BUGS dialect can be quite verbose and allows limited capabilities for vector or matrix manipulations. If future versions of the program continue a trend toward refining vectorization characteristics, allow for matrix operations on model parameters, and include optimization procedures, then the entire BUGS dialect as we know it would be completely altered for the better.
Concluding Remarks
The JAGS software has provided great flexibility and advantages for implementing Bayesian inference. As a result, the field of statistical computing has seen a rise in the number of R packages and other software that use JAGS. Further, the program has undergone many iterations of updates since its release, making it a continually evolving tool for Bayesian estimation. The new features of JAGS Version 4.0 have considerably improved the versatility, simplicity, and readability of model specification procedures through the addition of R-style declarations added to the BUGS language, and a reconfiguration in the way nodes are defined. With continued developments and the focus on replicability, JAGS could eventually make WinBUGS (a program that is no longer under development; Lunn et al., 2009) and OpenBUGS obsolete. The pattern of developments seems to suggest that JAGS is headed in a promising direction with respect to its accessibility and flexibility for both beginner and advanced programmers alike.
Footnotes
Appendix
There have been announcements of additional updates documented on harder-to-find webpages, detailing changes that recently occurred in the program (https://sourceforge.net/p/mcmc-jags/code-0/ci/tip/tree/NEWS). Some of these updates are as follows: The addition of a new distribution, called The Weibull distribution has been reparameterized to be consistent with OpenBUGS, whereas in previous versions it followed the same parameterization used in R. Within the BUGS module, users can now draw samples from a continuous distribution by using the censoring function. This feature was only available for discrete distributions prior to Version 4.1. In addition to constraints provided by the
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.