
Abstract
Causal mediation analysis is the study of mechanisms—variables measured between a treatment and an outcome that partially explain their causal relationship. The past decade has seen an explosion of research in causal mediation analysis, resulting in both conceptual and methodological advancements. However, many of these methods have been out of reach for applied quantitative researchers, due to their complexity and the difficulty of implementing them in standard statistical software distributions. The
1. Introduction
The primary role of statistical causal inference in policy studies is to estimate the effects of interventions, treatments, and general causes. But estimating cause and effect does not satisfy the scientific mind and should not satisfy policy studies either. For both scientific and practical reasons, researchers need to know how a treatment caused its effect. This is the realm of statistical mediation analysis.
The past decade has seen an explosion into research in methods for statistical mediation analysis based on solid conceptual and statistical footing. In particular, methodologists such as VanderWeele (2008, 2014, 2015), Hong (2010, 2015), and a group of scholars including Imai, Keele, Tingley, and Yamamoto (2009) have adapted the Neyman–Rubin Causal Model (Rubin, 1978) to studies of mediation, and the result has included advances in conceptual clarity, a suite of new statistical methods, and a better understanding of what causal mediation analysis can and cannot do. The latter group has written
In this article, I will summarize some of the recent advances in mediation analysis and review the
The structure of the article is as follows: The following section defines the causal mediation effects, Section 3 demonstrates how the
1.1 Example Data Analysis
To demonstrate the functionality of the
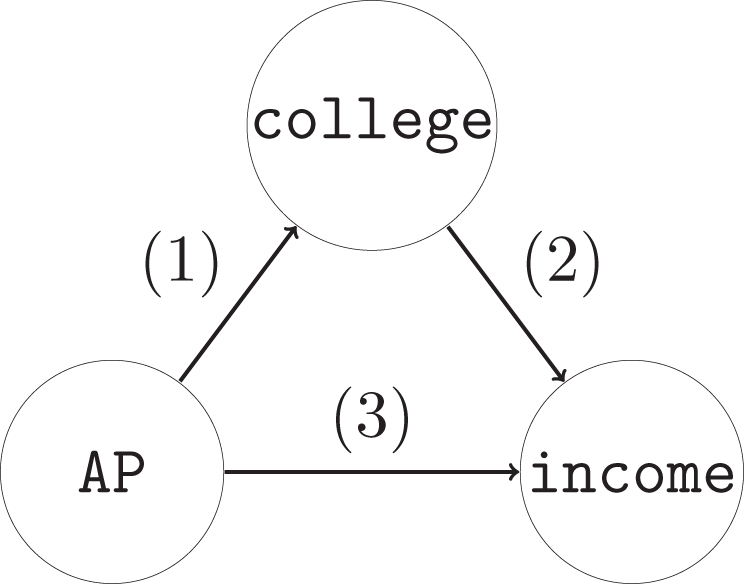
A schematic representation of mediation analysis, in which the treatment variable Z, in this case the variable
2. The Goals of Mediation Analysis: Defining Direct and Indirect Effects
Let Z denote a treatment of interest, and let Y denote an outcome. In a traditional causal inference study, each subject has a set of “potential outcomes”: Y(Z = z), for each z in the support of Z (Holland, 1986; Rubin, 1978; Splawa-Neyman, Dabrowska, & Speed, 1990). These record the outcome that a subject would present were she assigned to treatment z. Notably, Y(Z = z) is well defined for all subjects in the study but only observed for subjects whose treatment assignment was z.
In our AP program example, Z equals 1 for students who participated and 0 for others; so every student, in the treatment or the control arm, has two potential outcomes of this sort, Y(Z = 1) and Y(Z = 0). However, Y(Z = 1) is only observed for subjects in the intervention group, and Y(Z = 0) is only observed for subjects in the control group. Then subject i’s observed value is Yi = ZiYi(Z = 1) + (1 − Zi) Yi (Z = 0). Each subject i’s treatment effect is Yi (Z = 1) − Yi (Z = 0); since we only observe one of Y(Z = 0) or Y(Z = 1), an individual’s treatment effect is typically unidentified. However, aggregate treatment effects, such as the average treatment effect (ATE) E[Y(Z = 1) − Y(Z = 0)], may be identified under certain conditions. Specifically, the ATE is identified when there is no interference between units—that is, a subject’s potential outcomes are functions of his or her treatment status Zi and not the treatment status of other subjects—and no unobserved confounding—an unobserved variable that predicts both Z and Y(Z = 1), Y(Z = 0), or both, after conditioning on observed variables.
In the presence of a mediator M, for instance, college attendance, the potential outcomes framework needs to be expanded. Specifically, since M itself is a function of the treatment, M also has potential values M(Z = z). Furthermore, Y’s potential values may be written as a function of both Z and M, as Y(Z = z, M = m) or, more compactly, as Y(z, m). In fact, Y’s potential values can reflect M’s dependence on Z. So, for instance, Yi(Z = 1, M = M(1)) = Y(Z = 1) is subject i’s log income if i participates in the AP encouragement program and exhibits resulting amount of schooling. Alternatively, Yi(Z = 0, M = M(0)) = Y(Z = 0) is i’s log income if he does not participate in the program and receives the resulting amount of schooling. Adding M = M(z) to the potential outcomes for Y may seem redundant; however, it allows for strictly counterfactual outcomes—those that could never be observed but could still be rigorously defined. Specifically, Yi(Z = 1, M = M(0)) represents subject i’s log income if i participates in the program but goes on to complete the amount of schooling he would have completed without the program, and Yi(Z = 0, M = M(1)) is i’s log income if i does not participate in the program but attains the education he would have completed if he had participated.
The
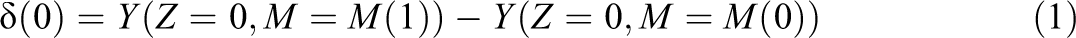
or
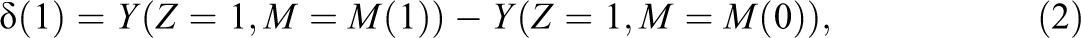
in which we imagine that Z is held fixed at either 0, as in δ(0), or 1, as in δ(1), but M is allowed to vary from what it would be under treatment M(1) to what it would be under control M(0). For instance, in the AP example, δ(0) is the effect, for subjects who do not participate in the program, of educational attainment varying as if they had attended the program. Say the AP program affects her income in several different ways, including causing her to attend college—having participated, she did attend, so M(1) = 1, but had she not participated, she would not have attended college, so M(0) = 0. Without participating in the AP program, she would not have been motivated to attend college, so M(0) = 0. But say the program also, by causing her to take an AP class, increased her confidence and analytical abilities, which improve her income regardless of her educational attainment. δ(0) is the effect in her income of attending college, if she has the confidence and analytical ability she would have without the AP program. δ(1) is the effect in her income of attending college, if she has confidence and analytical ability she would have if she does participate in the AP program. A difference between δ(0) and δ(1) is referred to as a “treatment-mediator interaction” and captures the difference of the effect of M in treatment or control conditions.
Direct effects, on the other hand, capture the effect of the treatment that does not depend on M. Analogous to δ(0) and δ(1), there are two types:
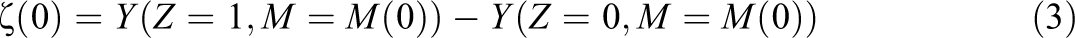
or

These hold the mediator value fixed at what it would have been under control (ζ(0)) or treatment (ζ(1)). For instance, in the AP example, ζ(0) is difference in our example subject’s log income if she gains the confidence and analytical ability from the AP program versus if she does not, assuming she does not attend college. ζ(1) is the same difference, if she does.
The mediation and direct effects add up to the total effect of the treatment:
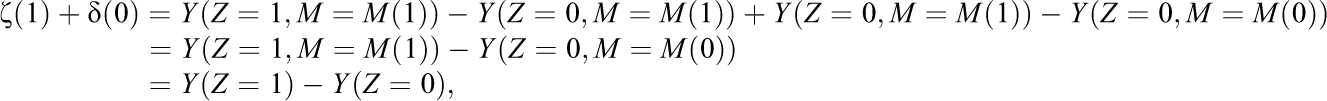
with an analogous result for ζ(0) + δ(1). Mediation analysis, then, decomposes the effect of the treatment Z on the outcome Y into a portion dependent on M and one dependent on other mechanisms.
Just as individual treatment effects Yi(1) − Yi(0) are not typically identified, individual causal mediation effects and direct effects are not identified either. The
3. Estimating ACME and ADE in the mediation Package
Estimating average direct and indirect effects is a three-step procedure (Imai, Keele, Tingley, & Yamamoto, 2011). The first step is to estimate a distribution for M(z) for each treatment z, using a model of the mediator as a function of the treatment or fM|Z. For the AP example, with college attendance
I included
The next step fits a model for Y(Z, M), fY|M,Z, yielding a distribution for Y’s potential outcomes for each possible treatment z and mediator value m. In the AP example, I used ordinary least squares (OLS) regression, regressing
This model also contains
Jointly, fM|Z and fY|M,Z can estimate the quantities Y(1, M(1)), Y(1, M(0)), Y(0, M(1)), and Y(0, M(0)) for each subject—each subject’s potential log income if she participates or does not participate in the AP program and attends college as if she had attended, or not attended, college. These are the four quantities necessary for estimating δ and ζ. The final step estimates these quantities, and with them, δ and ζ.
Generally, the procedure is as follows: first, estimate fM|Z and fY|M,Z from the data and then combine the fitted models with the
Use the
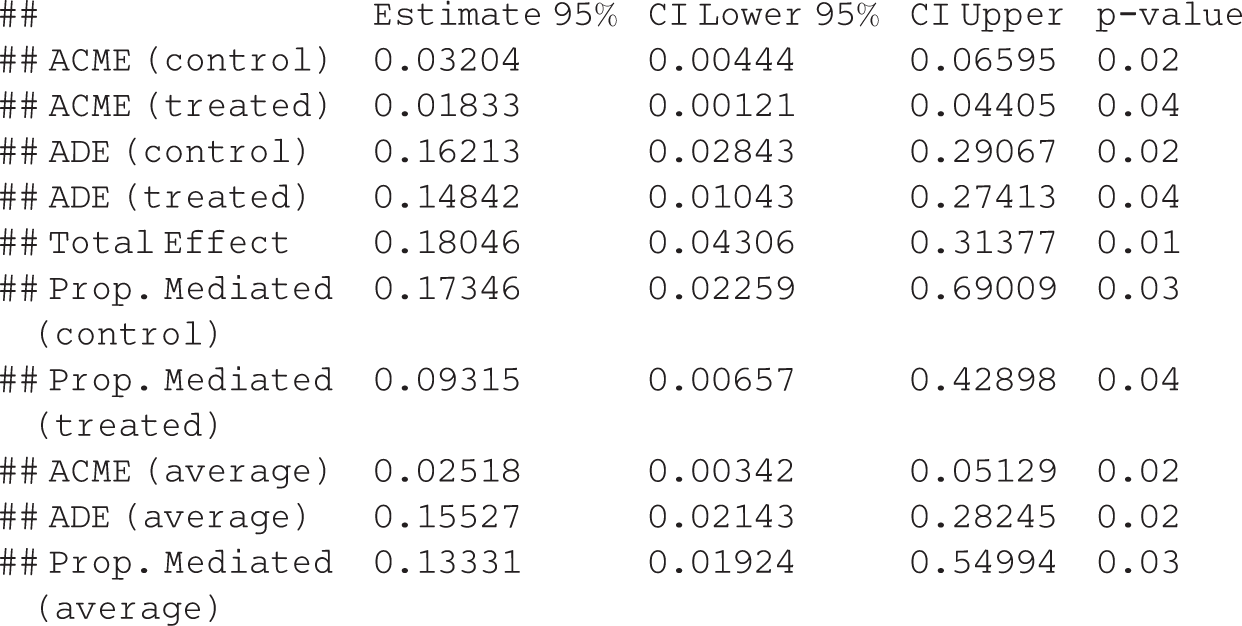
The model detected both natural direct and indirect effects. Since the outcome model I specified, fY|M,Z, included an interaction between
The summary function also displays results for the ADE, estimated as [0.028, 0.291] or [0.01, 0.274] in the control and intervention groups, respectively, and the total effect, estimated as [0.043, 0.314]. Finally, perhaps the most interpretable measure of mediation is the “proportion mediated,” which is the proportion of the total effect explained by the mediator, or δ(0)/(δ(0) + ζ(1)) or δ(1)/(δ(0) + ζ(1)). For control subjects, this proportion is between 0.023 and 0.69, and for treated students, the proportion is between 0.007 and 0.429.
It is also possible to plot 95% confidence intervals for the ACME, ADE, and total effect, as in Figure 2.

Estimates (points) and 95% confidence intervals for the average causal mediation effect (ACME), average direct effect (ADE), and total effect. The solid points and lines represent ACME and ADE for the treatment group, and the dotted lines and empty points represent estimates for the control group.
In principle, any models that yield estimates of M or Y as a function of Z or Z and M, respectively, would be compatible with potential outcomes framework for mediation analysis. In practice, the
Options in the
4. Identification Assumptions and Sensitivity to Hidden Bias
Causal mediation analysis requires stronger assumptions than traditional causal inference, one of which is untestable even in conventional randomized controlled trials. 2 In addition to assuming no interference between units, as discussed in Section 2, analysts must also assume that there is no unmeasured confounding. Specifically, mediation analysis requires sequential ignorability (Imai, Keele, & Yamamoto, 2010):



The first two ignorability assumptions, Equations 5 and 6, are familiar from conventional causal inference—in order to infer the effect of Z on M or Y, Z must be independent of M and Y’s potential outcomes, conditional on observed covariates X. Equations 5 and 6 are satisfied in randomized trials, where the researcher controls distribution of Z.
The third part of the assumption, Equation 7, is necessary to infer the effect of M on Y. It posits that, conditional on realized treatment Z = z and covariates, M is independent of Y’s potential outcomes. Randomizing Z, as in conventional randomized trials, does not guarantee that Equation 7 is satisfied. Indeed, since the effect of Z on M is a crucial piece of mediation analysis, directly manipulating M would be undesirable.
Figure 3 gives an interpretation of sequential ignorability in terms of unmeasured confounders U1, U2, and U3 which would violate it. If an unmeasured variable predicts both Z and M, such as U1, both M and Y, such as U2, or both Z and Y, such as U3, sequential ignorability does not hold. Importantly, U2 may be pre- or posttreatment—in either case, it will violate sequential ignorability and bias the mediation analysis. The three omitted variables in Figure 3 map on to the three equations that comprise sequential ignorability: U1 violates Equation 5, U2 violates Equation 7, and U3 violates Equation 6. As above, then, randomization of Z implies that there are no variables such as U1 and U3 that could confound the analysis; however, a confounder such as U2 is harder to control. The fact that U2 may be posttreatment is especially troubling, since even if it were measured, adjusting the analysis for a posttreatment U2 is nontrivial and requires further untestable assumptions.
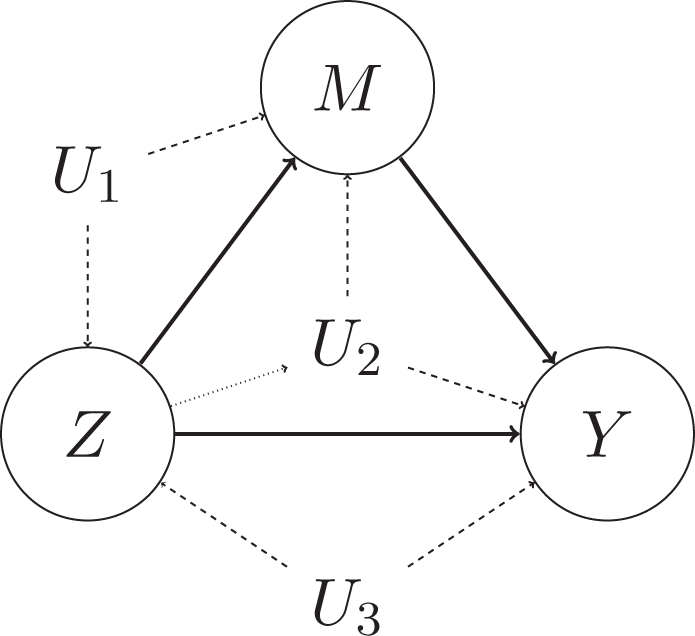
A graph of three different types of confounding variables, which may violate sequential ignorability. U1 confounds the relationship between Z and M, U2 confounds the relationship between M and Y, and U3 confounds the relationship between Z and Y. The dotted line from Z to U2 indicates that the confounder U2 may be posttreatment.
The
Choosing plausible values for ρ is a difficult task, since it depends wholly on substantive theory and prior research—the data themselves are not informative. Moreover, ρ is a difficult parameter to interpret. However, Imai, Keele, and Yamamoto (2010), along with the output from
With a fitted mediation model in hand, such as med, above, conducting such a sensitivity analysis in

Users can also plot the sensitivity as in Figure 4. Figure 4 shows how the point estimates (solid line) and confidence intervals for δ(0) and δ(1) vary as a function of ρ. The dotted line indicates estimates and confidence intervals for δ when sequential ignorability holds and ρ = 0.

Sensitivity analysis for causal mediation.
Alternatively, users can directly access the sensitivity results to compute sensitivity intervals or other analysis summaries. For instance, an education researcher may hypothesize a particularly problematic unmeasured covariate (ambition, say) and argue that it is implausible that it accounts for more than 25% of the unexplained variation in either college attendance or log income. Then, she may use the following code to compute a sensitivity interval assuming
The sensitivity analysis of the toy AP data suggests that its estimates are rather sensitive to hidden bias; unless theoretical or background knowledge rules out mediator-exposure confounders of all but minimal importance, the interpretation of the mediation analysis must be conservative.
The focus of
5. Moderated Mediation
It is possible for direct and indirect effects to depend on a pretreatment covariate X. For instance, in our AP example, the AP intervention may have a larger effect on college attendance for low-SES students than for high-SES students. Then the natural indirect effect δ would depend on X, as δ(z, X). This is referred to as “moderated mediation.” The

Estimating mediational effects at high and low SES: Moderated mediation.
6. Limitations
The
Another valuable addition would be options for sensitivity analysis for data from observational studies, as described above. Although randomized experiments are becoming more common in the social sciences, they are still not the norm, so accessible sensitivity analysis methods for observational studies could prove very useful.
Finally, the
7. Conclusion
The past decade of research has made mediation analysis rigorous, flexible, and conceptually sound. However, many of the newer mediation methods can be difficult to implement, especially when either M or Y is nonnormal, or relationships are nonlinear. Additionally, the strong untestable assumptions in mediation analysis make sensitivity analysis indispensable; this adds even further to the difficulty of implementing a careful mediation study. All that being the case, the
Mediation analysis is one of the more exciting new developments in statistical causal inference. The
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.