
Abstract
In causal matching designs, some control subjects are often left unmatched, and some covariates are often left unmodeled. This article introduces “rebar,” a method using high-dimensional modeling to incorporate these commonly discarded data without sacrificing the integrity of the matching design. After constructing a match, a researcher uses the unmatched control subjects—the remnant—to fit a machine learning model predicting control potential outcomes as a function of the full covariate matrix. The resulting predictions in the matched set are used to adjust the causal estimate to reduce confounding bias. We present theoretical results to justify the method’s bias-reducing properties as well as a simulation study that demonstrates them. Additionally, we illustrate the method in an evaluation of a school-level comprehensive educational reform program in Arizona.
1. Introduction: Two Types of Neglected Data
Matching-based observational studies in education sciences often neglect data from the “remnant” of a match: untreated and unmatched subjects. That is, researchers will select a set of matched controls that most closely resemble the treated subjects and discard data from the remnant, the unmatched controls.
Similarly, due to sample size and other modeling limitations, researchers will typically condition their experimental and observational studies on a small set of pretreatment covariates that are deemed most relevant to the study—the variables thought most likely to pose a confounding threat. In many cases, reams of less relevant data are available, perhaps from state longitudinal data systems or from other sources. These less relevant covariates are often discarded.
Conducting a causal analysis using only the matched sample and using only relevant covariates makes good statistical sense. The data from subjects that are not part of a match are likely to be distributed differently than data from the match. The process of matching encourages researchers to focus their analysis on the region of common support; the remnant is typically outside this region by construction. Including irrelevant variables into an analysis can swamp the sample, introduce overfitting or extreme imprecision, and make impossible common statistical techniques such as ordinary least squares (OLS) and logistic regression.
But these excluded data—the remnant and ostensibly irrelevant covariates—may also contain valuable information. Perhaps the distribution of the outcome conditional on covariates could be estimated with more precision by vastly increasing the sample size using discarded subjects. Perhaps discarded covariates are not so irrelevant and capture important baseline differences between treated and untreated subjects.
This article is an attempt to thread this needle with a new method that we call “remnant-based residualization” or “rebar.” The idea of rebar is to, on the one hand, extract as much useful information as possible from the remnant and all available covariates and, on the other hand, to preserve the most attractive properties of a good matching design. To implement rebar, we fit a machine learning prediction model to the unmatched controls—the remnant—predicting their outcomes in the control condition as a function of the entire set of covariates. Using this fitted model, we then generate predicted outcomes for the matched sample. Finally, instead of calculating the effect of the treatment on participants’ outcomes themselves, we estimate the intervention’s effect on the difference between participants’ predicted outcomes under the control condition and their actual outcomes, that is, their prediction residuals—this is “residualization.” The predictive model need not be correct in any sense or consistent or unbiased for any particular parameter. It must only yield predictions that are closer, on average, to control potential outcomes than their mean.
Rebar builds thematically on prior work combining matching with outcome modeling, such as Rubin (1973) and Ho, Imai, King, and Stuart (2007a), among others, alongside “doubly robust” estimation (e.g., Kang & Schafer, 2007). Its most direct antecedents are Rosenbaum (2002a) and Abadie and Imbens (2012), which suggest forms of residualization for matching estimators, and Middleton and Aronow (2015), which does the same for weighting estimators. Our contribution to that literature is twofold: First, rebar is remnant-based. We argue here that residualization is well suited to recovering otherwise lost information from the remnant. Second, we demonstrate by simulation and example how rebar can exploit machine learning methods and high-dimensional covariates without compromising the classical statistical properties of the match.
Rebar can supplement a wide range of matching analyses and may be used alongside other outcome models and covariate adjustments.
The following section will review causal matching studies, and Section 3 will formally introduce rebar. There, we will discuss a possible threat to the validity of a matching design that rebar can introduce: If the distribution of outcomes, conditional on covariates, differs widely enough between the remnant and the matched set, rebar might increase, rather than decrease bias. We will introduce a diagnostic called “proximal validation” that should detect such pathological cases and suggest ways to tweak the algorithm if a researcher was to confront one.
Rebar can potentially reduce both the bias and the variance of causal estimates, by modeling otherwise unmodeled variation. That said, this article will focus its attention on rebar’s bias reducing properties. We will argue with analytical results (Section 4), a simulation study (Section 5), and an empirical example (Section 6) that rebar is an effective method for reducing confounding bias from measured, but unmodeled, confounders in a high-dimensional data set, without compromising the key advantages of matching.
2. Matching in Observational Studies: Review
In an observational study, let i = 1, …, n index n subjects, and let Zi denote subject i’s binary treatment assignment, and Yi subject i’s observed outcome of interest. Assuming noninterference (Cox, 1958) and following Neyman (1990) and Rubin (1974), let yTi and yCi denote subject i’s (perhaps counterfactual) responses were subject i treated and untreated, respectively. Then,
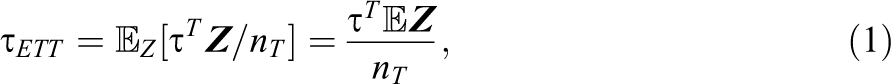
the expected average effect of the treatment on the treated. The expectation in Equation 1 is taken conditional on the posited sampling scheme.
In a matching-based observational study, a researcher will create a new categorical variable,
Ideally, within any matched set, no subject’s a priori probability of making its way into the treatment group was larger or smaller than any other’s:
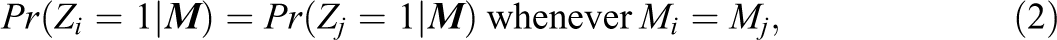
this is perfect matching. Under perfect matching in the sense of Equation 2, matched comparisons are statistically equivalent to contrasts of treatment and control conditions in block- or paired-randomized designs (e.g., Braitman & Rosenbaum, 2002; Hansen, 2011; Rubin, 2008).
A simple matching-based estimator compares average treated and untreated outcomes within each match. The average difference between treated and untreated subjects in matched set m is:
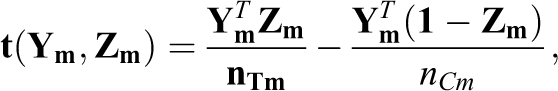
where

where weight wm = nTm/nT. Estimator
Frequently, subjects who are not sufficiently similar in x to other units are left unmatched. We will refer to the set of unmatched untreated subjects as the remnant from a match. Typically, the remnant is discarded. While discarding data might seem unwise, there is good reason to discard the remnant. Since no suitable comparisons may be found between subjects in the remnant and treated subjects, any causal comparisons using the remnant necessarily involve modeling yC as a function of
An extensive, occasionally contentious literature discusses variable selection for propensity score models. This literature begins with Rubin and Thomas, who advised erring on the side of inclusiveness, striving to exclude only those covariates that a consensus of researchers believe to be unrelated to each outcome variable (1996, §2.3); Rosenbaum’s (2002b, p. 76) view is similar. Later contributions argued that including variables only weakly related to outcomes may increase the mean-squared error (MSE) of effect estimation (Austin, 2011; Brookhart et al., 2006). These additional losses can in principle take the form of bias, not only variance, even if the MSE-increasing variable was determined in advance of treatment assignment (Greenland, 2003; Pearl, 2009; Sjölander, 2009). Most recently, Steiner, Cook, Li, and Clark (2015) argued via case study for including all available covariates, unless “strong substantive theory” (p. 573) suggests the presence of bias-amplifying covariates covariates (they write that bias amplification “seems less likely as the size of the covariate set increases”); ideally, researchers should include covariates from multiple domains, with each domain including as many covariates as possible. Pimentel, Small, and Rosenbaum (2016) suggested conducting two analyses, each matching on a different set of covariates. Methods attempting to limit the MSE penalty by limiting propensity modeling variables to those that correlate with observed outcomes have been met with criticism of a different nature: In Rubin’s view, in order to maximize objectivity, during matching researchers should keep outcome measurements in a virtual locked box, only to emerge once the matching structure and other study design elements have been determined (Rubin, 2008).
Rebar, the method of this article, is compatible with either attitude to selection of propensity score variables; our illustration (§6) emphasizes this compatibility by adhering to the more restrictive of the two schools. Without reference to outcome associations, we select for inclusion in the propensity model those variables we felt that a consensus of scholars would be most likely to deem potential confounders. In this example as in many others, the number of potential confounders that could be addressed in this way was limited: When p ≥ nT or p ≥ nC, then the treatment and control samples can ordinarily be separated by a hyperplane, in the space spanned by
3. Rebar: Using an Outcome Model to Reduce Bias in a Matching Design
The procedure we recommend is the following: Using the full data set, construct a match
Using units in the remnant, construct an algorithm Assess the performance of For all subjects i in the matched sample, use Construct prediction errors Estimate treatment effects in the matched sample, substituting e for Y in the outcome analysis.
As in Rosenbaum (2002a), the model
The predictions
Now, as above, define residuals,
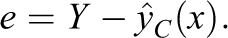
Then, we may define “potential residuals”:

where τi as above is subject i’s treatment effect, yTi − yCi. To see this, note that
The prediction errors e, then, may replace Y in an outcome analysis. In particular, replace matched-set-specific treatment-control differences in Y, tm(Y,Z) with differences in e: tm(e,Z). That is, let
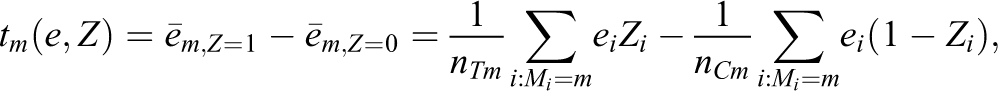
then define

Residualization, then, means revising a matching estimator by replacing outcomes y with observed value/
3.1. Cross-Validation and Proximal Validation: Assessing
Using the remnant to model outcomes as a function of covariates affords the researcher a great deal of flexibility. Researchers may use data from the remnant—both covariates and outcomes—to attempt a variety of prediction techniques and choose the one which performs best. This is particularly important when the dimension of
Cross-validation estimates an algorithm’s predictive performance when applied to new cases drawn from the same population as the training set. Of course, this is manifestly not the case for rebar. Subjects in the matched sample are likely to be different from those in the remnant; a model fit and cross-validated in the remnant may not perform as well in the matched sample as that validation would suggest. Write SM to denote the matched sample, that is,
One does not expect MSEM to exceed
Fortunately, simple diagnostic tools can identify such pathological cases. Further, in many of those cases, there are simple modifications to rebar that will improve its performance. To illustrate a diagnostic that we call proximal validation, consider full matching within calipers of width c0 in terms of a continuous variable or index, such as the propensity score. All control subjects within c0 of a treated subject are matched, with remaining controls constituting the remnant. How well does an algorithm
As compared to estimating MSEM with rebar’s MSE on the control group, proximal validation permits the analyst to keep matched subjects’ outcomes in Rubin’s (2008) virtual locked box, even as the rebar model is being validated and improved. Proximal validation is not limited to propensity-score full-matching designs with calipers; it may be used with any matching design that involves a quantitative restriction on allowable matches. The procedure, in general, will be to slightly relax that restriction, choose a second, more expansive match, and use the results to divide the remnant into proximal and distal portions.
If
Another useful diagnostic test is to check covariate balance on the predictions
4. Rebar’s Effects on Bias
To see the potential of rebar to reduce the bias of a matching estimator, note that the rebar estimator

the matching estimator of the effect of the treatment on Y, minus an estimate of the effect of the treatment on
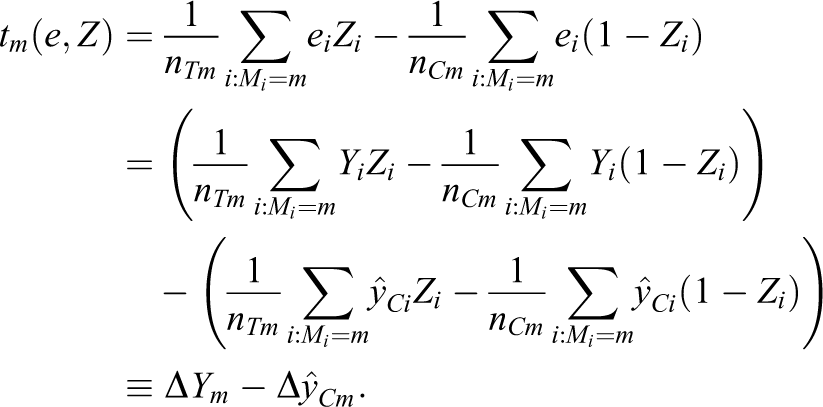
The expression in Equation 6 follows by taking weighted averages of ΔYm and
Two properties of the rebar estimate follow immediately. First,

Viewing
Next,
This follows since, when treatment is essentially randomized within matches,
4.1. An Upper Bound on the Bias of the Rebar Estimator
The closer, on average, predictions
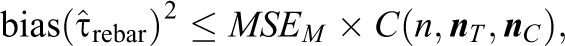
where

Equivalently,
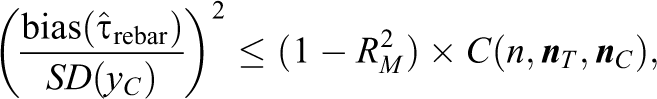
where SD(yC) is the sample standard deviation of yC in the matched set and
Therefore, the bias of
In practice, the bounds in Proposition 3 are unobservable, since they involve control potential outcomes in the matched set, which are only observable for the matched controls. Further, since the prediction algorithm
Proposition 3 assumed nothing about subjects’ respective probabilities of treatment assignment within matches. In particular, it allowed for a situation in which some subjects may be assigned to treatment with probability 1—this is a rather extreme violation of the stratified randomization assumption (Equation 2). Under weak assumptions about the distribution of treatment assignments, the bound in Proposition 3 may be considerably tightened. For instance, Rosenbaum (2002b) suggests a general model for sensitivity analysis for observational studies: the assumption that for some Γ ≥ 1, if Mi = Mj—that is, i and j are in the same matched set—and Pi = Pr(Zi = 1) and Pj = Pr(Zj = 1), then

That is, for matched subjects i and j, the ratio of the odds that i is selected for treatment to the odds that j is selected is bounded by 1/Γ and Γ. Proposition 4 uses the framework in Equation 7 to tighten the bound in Proposition 3 in the simple case of a matched-pair design; an analogous result may hold for more complex designs, but we leave such an extension for future work.
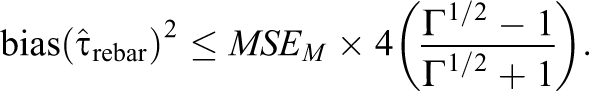
Equivalently,
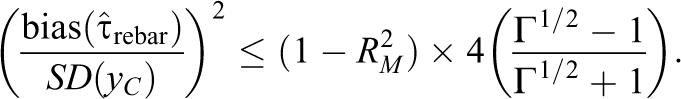
(The proof may be found in the Appendix.)
Propositions 3 and 4 show that by using data from the remnant and covariate matrix
5. A Simulation Study
This section presents a simulation study with two principal goals: to demonstrate rebar’s potential to improve upon matching estimators under a variety of circumstances, and rebar’s ability to interact with, and improve upon, a variety of matching designs and estimators. A second, smaller study examines rebar’s performance under pathological circumstances.
5.1. Data-Generating Models
The study imagined a researcher estimating the effect of a treatment Z on an outcome Y, using a sample of n = 400 subjects, in the presence of p = 600 covariates. While all of the covariates are potential confounders, the simulated researcher knows that five of the covariates—the first five columns of covariate matrix
The outcomes yC were generated as a linear function of a multivariate normal vector
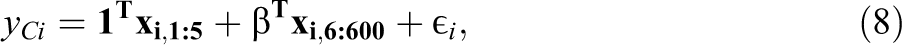
where the coefficients β were drawn from an exponential distribution with a rate of λ = 5 and ϵ is drawn from a standard normal distribution. A “treated” group was selected according to probabilities
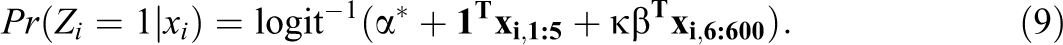
That is, the log odds of treatment assignment were linear in covariates. We chose the parameter α* in such a way that, on average, nT = 50 were treated. As in Equation 8, the coefficients for the first five columns of
The factor κ controlled the amount of confounding after matching. When κ = 0, only the first five columns of
A second parameter, ρ, controlled the covariance structure of
Covariates
5.2. Treatment-Effect Estimators
In each round of the simulation, we constructed four matches. Each of these matches, in turn, gave rise to two or three treatment-effect estimates; all in all, we compared 10 different estimators. These are summarized in Table 1.
Summary of the Matching and Estimation Methods in the Simulation Study

Note.
Optimal pair matching with propensity scores from logistic regression
We estimated propensity scores using logistic regression, with
Next, we computed rebar-adjusted estimates. With the remnant from the pair match as a training set, we used a combination of lasso (Tibshirani, 1996) and random forests (Breiman, 2001) to construct
Nearest-neighbor match with propensity scores from logistic regression
Using the same propensity scores as in the optimal pair match, we constructed a “nearest-neighbor” match, as proposed by Abadie and Imbens (2006), and implemented by the
Coarsened exact matching
We constructed a coarsened exact match, as described in Iacus, King, and Porro (2011) and implemented in R with the cem package (Iacus, King, & Porro, 2015). We coarsened each of the first five columns of
Optimal pair matching with propensity scores from SuperLearner
The first three matching designs, optimal pair matching, nearest-neighbor matching, and coarsened exact matching, used only the first five columns of
5.3. Simulation Results
Figure 1 shows the results of the simulation, after 1,000 simulation runs. Each row of Figure 1 corresponds to a value of κ; in the first row, κ = 0, corresponding to approximately no confounding from the covariates not used in the match, in the second row κ = .1, corresponding to moderate confounding from the left-out covariates, and in the third row κ = .5, corresponding to a high degree of confounding. Each column of Figure 1 corresponds to a different value of ρ: 0, .004, and .05. These correspond to data sets increasingly amenable to prediction algorithms; the top of the figure lists the average cross-validation
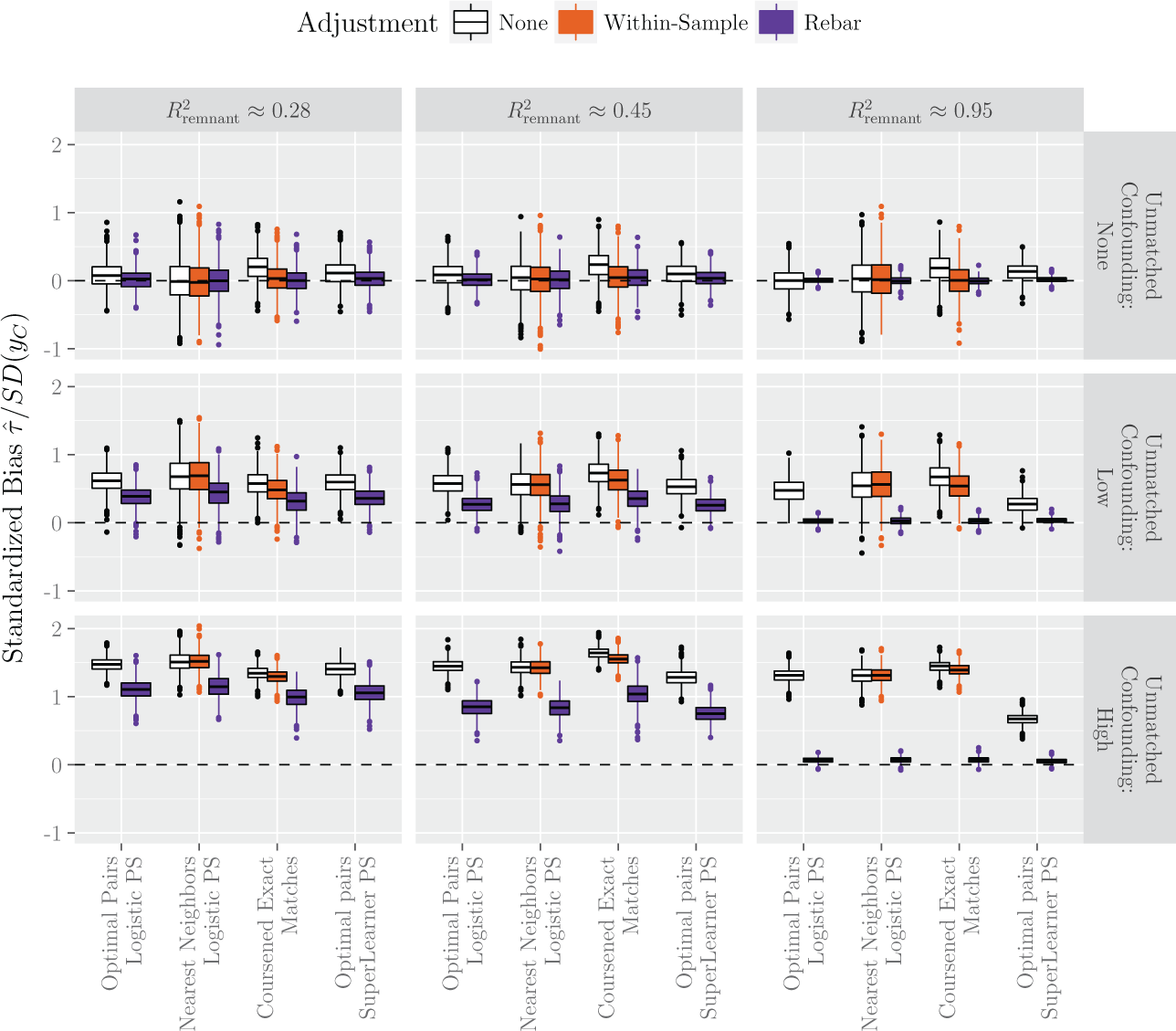
Boxplots of treatment effect estimates from 1,000 simulation runs under the data-generating models in Section 5.1. The true treatment effect of zero is indicated by a horizontal dotted line. The estimated treatment effects were divided by the standard deviation of yC. The matching and outcome adjustment methods are described in Section 5.2 and Table 1. The nine simulation scenarios, described in Section 5.1, are arranged in a matrix, with rows for κ = 0, .1, and .5, and columns for ρ = 0, .004, and .05. The
A number of patterns are apparent. When κ = 0, the covariates not used in the match do not pose a confounding threat, and all the estimators are unbiased. Both within-sample bias reduction and rebar reduce the variance of the effect estimates, subtly for the first two columns and dramatically in the third. As κ, or confounding from the nonmatching covariates, increases, all effect estimates become increasingly biased. However, rebar substantially reduces the bias. Rebar is similarly effective when used on its own and when used in conjunction with within-sample outcome model adjustments—that is, rebar has quite a bit to add even after other adjustments. Unsurprisingly, rebar’s performance, both in terms of bias and variance reduction, improves with higher
The high-dimensional propensity score match demonstrates that rebar can improve upon designs that incorporate all of
This simulation study showed rebar’s potential: Rebar can substantially reduce both the bias and the variance of a matching estimator, especially in the presence of high-dimensional confounding and with an accurate prediction algorithm.
5.4. Rebar’s Performance Under Nonlinearity
We conducted a parallel simulation study to investigate rebar’s performance when the distribution of yC, conditional on X, differs greatly between the remnant and the matched set. Since it is the match that determines which subjects are in the matched set and which are in the remnant, and the data generation occurs prior to the match, we could not set the distribution of yC in the remnant exactly. Instead, we let the data-generating model for yC vary with Pr(Z = 1), subjects’ probabilities of being treated. To do so, we modified both the outcome model (Equation 8) and the treatment model (Equation 9). To select treated subjects, we chose those 2nT with the highest linear predictors, as defined in Equation 9 and assigned half to treatment. That left an “untreatable” group of subjects with Pr(Z = 1) = 0. For the untreatable subjects, yC was generated as in Equation 8. For the 2nT subjects with Pr(Z = 1) = 0.5, the outcomes were generated as
The simulation results suggest that this is, indeed, a concern—in some cases. Figure 2 shows the results of rebar adjustment to optimal pair matching using two different rebar algorithms

Boxplots of standardized treatment effect estimates from 500 simulation runs under the data-generating models in Section 5.4. The true treatment effect, indicated by a horizontal dotted line, is zero. The methods are optimal pair matching (propensity-score matching) and rebar-adjusted optimal pair matching, with yC predicted using lasso or random forests. The four simulation scenarios are arranged in a matrix, with rows for κ = 0 and .5 and columns for ρ = 0 and .05. covariates. The
In summary, under data-generating models combining nonlinear responses with limited propensity score overlap, rebar’s performance depended on the prediction algorithm. In this particular case, rebar adjustment via lasso increased the MSE of the matching estimator, while rebar adjustment via random forest caused little to no harm; general recommendations for the choice of
6. Example Data Analysis: Evaluating Board Exam Systems (BES)
BES comprise a class of similar comprehensive educational reforms. BES are packages that a school can adopt: sets of rigorous curricula for all academic courses, corresponding sets of end-of-course exams, professional development and instructional guidance for teachers, and systems of assistance for struggling students. Though uncommon in the United States, BES are common around the world, and several research studies have suggested that they improve student achievement (Bishop, 1997, 2000; Collier & Millimet, 2009).
Seven Arizona High Schools began implementing BES programs in the 2012–2013 school year: either the ACT Quality Core program or the Cambridge program. A pilot study sought to evaluate the results after 1 year, in part by estimating the effects of the BES programs on 10th-graders’ end-of-year standardized test scores—specifically, the Arizona Instrument to Measure Standards or AIMS. Here, we present a simplified version of the study’s estimate of the effect of BES on school-average 10th-grade AIMS Reading scores. The analysis we present here is intended to illustrate the rebar method, not to evaluate the effectiveness of BES programs in Arizona.
For Arizona high schools in our sample, we had 4 years of pretreatment data. That is, data from four cohorts of students who preceded the adoption of BES—students set to graduate in 2011 through 2014. For each cohort, we have the total enrollment, the percents of students who are male, White, Black, Hispanic, other race, or ethnicity, receiving free or reduced-price lunches (FRL), special education (SPED), and English language learners, in addition to average 8th-grade and 10th-grade AIMS scores on writing, reading, math, and science. We also have the percentage of students in each cohort with missing AIMS English and Math scores. From these data, we computed composite scores by averaging the four components, and school “trends” for 10th-grade math and reading scores: OLS slope estimates from the school-level regressions of school mean AIMS scores on a linear time variable. From the U.S. Center for Education Statistics Common Core of Data (2013), we have a categorization of each school into one of 10 categories of urbanicity, ranging from urban to remote rural. All in all, there are 90 covariates, for a total of 509 high schools.
6.1. A Propensity Score Match
To estimate effects, then, we began with a propensity score match. Since there are only nT = 7 intervention schools, logistic regression with all 90 predictors was not feasible. Instead, our propensity score model incorporated only a small subset of the covariates, those that we believed would be most recognizable as potential confounders to the end audience of the research. Specifically, we regressed schools’ BES status on the percent FRL, White, SPED, Hispanic, and average and percent missing 8th- and 10th-grade AIMS scores for students in the cohort immediately prior to BES implementation (those set to graduate in 2014) along with estimated school trends in English and Math AIMS scores. Since this still gave more predictors than there were observations in the treatment group, we expected that classical logistic regression would fail to fit, so we instead used the Bayesian variant implemented in the
We constructed optimal propensity-score matches, using the
Table 2 displays covariate balance for the variables in the propensity score model—standardized differences in covariate means and Z-scores—before and after matching. Covariate balance was assessed with the
Standardized Differences Testing Balance on Covariates From the Propensity Score Model and Predictions

Note. FRLs = free or reduced-price lunches; AIMS = Arizona Instrument to Measure Standards.
6.2. Rebar to Adjust the Match
6.2.1. Estimating
After setting aside the treated schools and their untreated matches, there were 483 schools in the remnant. We considered four different predictive modeling strategies to construct
Cross-Validation RMSE, R2, and Ensemble Learner Weight From the SuperLearner. The Seven Models Displayed Are the Lasso, Random Forest, a Linear Model With Weak Priors on the Coefficients (“BayesLM”), Ridge Regression, and a Grand Mean Model
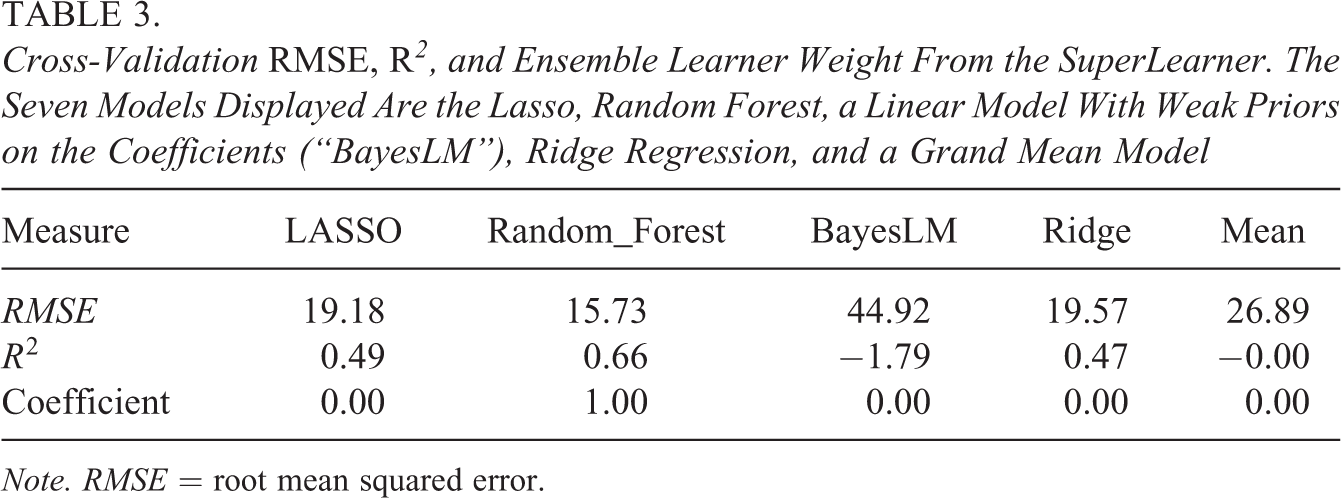
Note. RMSE = root mean squared error.
6.2.2. Proximal validation
To gauge how model trained on the remnant might perform on the matched sample, we conducted proximal validation, described in Section 3.1. First, we constructed a second match, mbig, identical to the first, but allowing each treated subject to match at most 10 control subjects. This resulted in
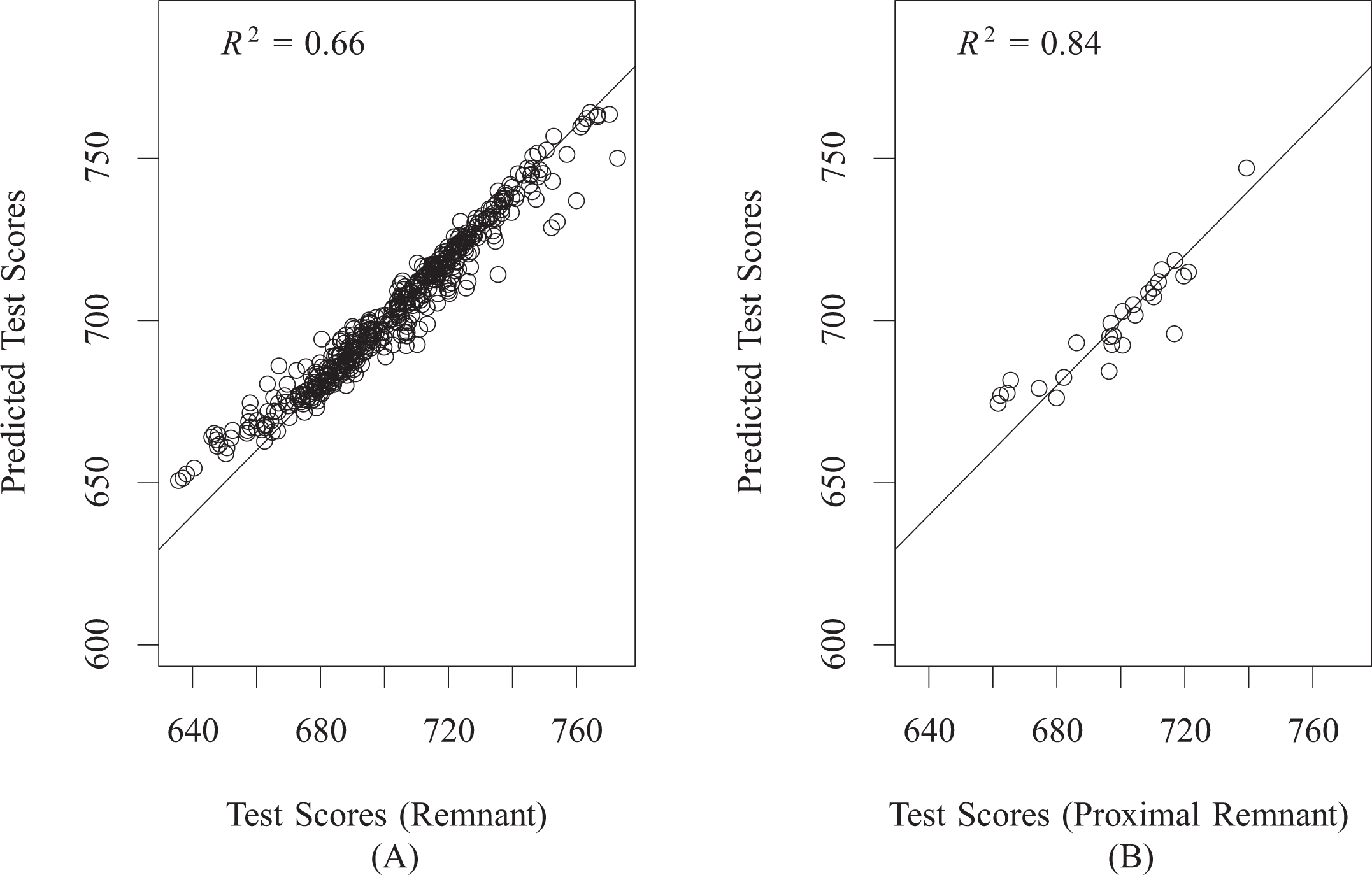
SuperLearner prediction accuracy: predictions (
As an additional check of the identification assumption (Equation 2) for match m, we tested balance on
6.2.3. Estimating treatment effects
Finally, we calculated both τM, the matching estimator using Y, and
The Average Treatment Effect on the Treated τETT, Along With Regression Standard Errors and Permutational p Values and 95% CIs, Estimated With Conventional Propensity-Score Matching, as Described in Section 6.1, and With Rebar
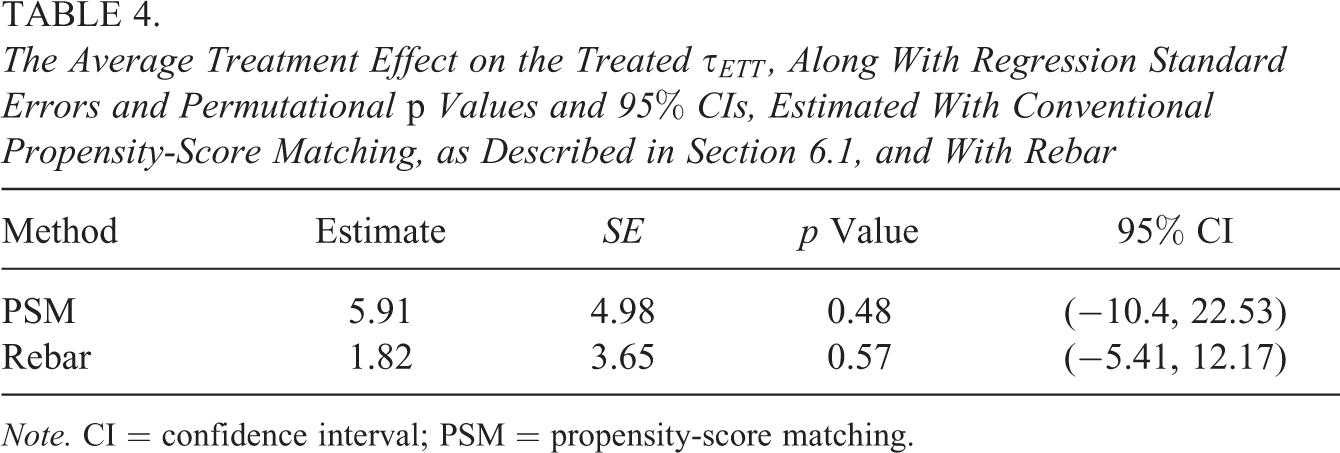
Note. CI = confidence interval; PSM = propensity-score matching.
An anonymous reviewer suggested a post hoc assessment of
7. Conclusion
In structural engineering, rebar abbreviates “reinforcement bar,” a metal beam that is embedded in concrete. Concrete is resistant to compression, whereas rebar is resistant to tension; the combination of the two materials, rebar and concrete, is robust to a variety of threats. Similarly, the rebar method of this article complements the use of matching for confounder control. Whereas matching typically focuses primarily on possible confounders’ associations with the treatment variable and typically leaves some subjects unmatched, rebar addresses bias by using the the remnant from matching, the unmatched controls, to model possible confounders’ associations with outcomes. The predictions that result,
Residualizing using the remnant confers these benefits without compromising the statistical rationale for matching. Indeed, matching supplemented with rebar inherits a number of central attractions of the matching estimator. For instance, researchers with any level of statistical training can assess the success of the matching procedure by examining matched units’ comparability on substantively meaningful baseline variables. Although it typically makes use of data from outside the range of common support—the set of subjects i for which 0 < Pr(Zi = 1|xi) < 1—its final estimate
Generating predictions
We have focused on the capacity of rebar to reduce bias, but the method may have other benefits as well. For instance, the confidence interval from a rebar analysis of the BES data had less than half the width of the confidence interval from the corresponding matching analysis. Indeed, confidence interval widths and standard errors generally vary inversely with the variance of the outcome. Unless the rebar extrapolation is sufficiently unstable as to worsen MSE—within the matched sample, the mean-square difference between rebar’s out-of-sample prediction and Y exceeds the variance of Y—confidence intervals based on e are bound to be tighter than those based on Y alone. In addition, studies with more stable outcomes tend to have lower design sensitivity (Rosenbaum, 2010; Zubizarreta, Cerdá, & Rosenbaum, 2013). Barring instability, the rebar analysis will be less sensitive to confounding from unmeasured or unmodeled variables. The relative stability of e and Y is reflected in the prediction R2 of the rebar
Footnotes
8. Appendix Proofs of Propositions 3 and 4
Authors’ Note
The authors gratefully acknowledge support and helpful comments from Brian Junker, Kerby Shedden, Walter Mebane, Sue Dynarski, and three anonymous reviewers.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Work on this paper was partially supported by a contract with the National Center on Education and the Economy to evaluate the implementation and efficacy of its Excellence for All Initiative and by IES Grant R305B1000012.