
Abstract
The modern web-based technology greatly popularizes computer-administered testing, also known as online testing. When these online tests are administered continuously within a certain “testing window,” many items are likely to be exposed and compromised, posing a type of test security concern. In addition, if the testing time is limited, another recognized aberrant behavior is rapid guessing, which refers to quickly answering an item without processing its meaning. Both cheating behavior and rapid guessing result in extremely short response times. This article introduces a mixture hierarchical item response theory model, using both response accuracy and response time information, to help differentiate aberrant behavior from normal behavior. The model-based approach is compared to the Bayesian residual-based fit statistic in both simulation study and two real data examples. Results show that the mixture model approach consistently outperforms the residual method in terms of correct detection rate and false positive error rate, in particular when the proportion of aberrance is high. Moreover, the model-based approach is also able to correctly identify compromised items better than residual method.
1. Introduction
Modern web-based technology has greatly popularized computer-administered testing, which is also known as online testing. For instance, in educational assessment, 44 states currently have operational or pilot versions of online tests for their statewide or end-of-course assessment (Dean & Martineau, 2012). In employment settings, many organizations have provided Internet-based assessment for job applicants in personnel selection and recruitment (Lievens & Chapman, 2009; Sackett & Lievens, 2008). To ensure test scores are reliable and valid, statistical procedures for detecting aberrances are essential to identify flaws in the design of a test or irregular behavior of the test takers. Aberrances usually come in different forms such as bad test items, ambiguous instructions, special accommodated examinees, speededness of the test, answer coping, and test cheating. The focus of this article is particularly on the identification of aberrances in online testing that exemplifies as extremely short response times, which usually imply cheating or rapid guessing behaviors.
Taking cheating as a form of aberrant behavior, it is defined as any activity that violates the established rules governing the administration of a test (Cizek, 1999). Different from the answer-copying or answer-changing behavior that is normally seen with paper-and-pencil test, the security breach of online and/or adaptive testing is often due to the item overexposure. This is because online testing is usually administered to small groups of examinees at frequent adjacent time intervals within a certain “testing window,” known as “continuous administration.” As a result, examinees who take the test earlier may share information with those who take it later, imposing the risk that items may become known to many examinees before they take the test (Wang, Zheng, & Chang, 2014). When some items become less difficult over a defined life span, it is reasonable to believe that the performance changes are because of its content having been distributed outside valid usage boundaries (such as published in unauthorized testing review guides), and these items are usually called compromised items. Compromised items should be duly detected, removed, and replenished by new items to ensure test security and validity.
Another commonly observed type of aberrant behavior is rapid guessing (Wang & Xu, 2015; Wise, 2017; Yang, 2007), which is defined as quickly obtaining an answer without carefully processing the meaning of the item (Wise & Kong, 2005). It occurs either due to test speededness or lack of motivation. In the former situation, rapid guessing often happens toward the end of the tests, whereas in the latter situation, rapid guessing can happen on any item. Compared to cheating behavior, rapid guessing also results in extremely short response times, but with a much lower correct response probability. The main objective of this article is not to differentiate cheating behavior from rapid guessing but rather to differentiate aberrant behavior from normal solution behavior. As the article unfolds below, two methods will be compared in terms of their power of detecting aberrant behavior, namely, the mixture hierarchical modeling approach and the Bayesian residual method. The two methods will also be evaluated with respect to their power of detecting item compromise when cheating is a concern.
In what follows, we will briefly review the existing methods for aberrance detection within the framework of residual analysis. We will then review the mixture modeling approach relevant for detection of aberrant behavior and introduce van der Linden’s (2007) hierarchal model that forms the basis of the mixture model.
1.1. Residual Analysis
Detecting test takers’ aberrant behavior and item compromise (we also use item preknowledge exchangeably hereafter) are pivotal to correctly interpret test scores. The traditional approach of detecting aberrant behavior at the person level is to analyze the response vectors for patterns of unexpected responses. This type of analysis is known as person-misfit analysis (McLeod & Lewis, 1999; Meijer & Sijtsma, 1995; van Krimpen-Stoop & Meijer, 2000) and belongs to the broader class of problems of outlier detection (or residual analysis) in statistics. In a review paper by Meijer and Sijtsma (2001), they showed that there are over 40 available statistics to evaluate person-fit. Key to this approach is the availability of a psychometric model that adequately represents regular behavior. Karabatsos (2003) evaluated the performance of 36 person-fit indices side by side, and one main finding in Karabatsos (2003) is that when the proportion of aberrant behavior increases, the power of correct detection drops. This is unsurprising because the reference formed by the “remaining examinees” is contaminated. This is in fact the limitation shared by almost all person-fit indices because when the proportion of aberrancy increases, the separation between normal and aberrant observations is blurred, making the outlier detection harder.
While all person-fit indices reviewed in Meijer and Sijtsma (2001) and Karabatsos (2003) are constructed from response patterns, it was soon realized by researchers that response time (RT) provides additional information to help detect aberrant behavior (e.g., Marianti, Fox, Avetisyan, & Veldkamp, 2014; van der Linden & Guo, 2008; van der Linden & van Krimpen-Stoop, 2003). When assessments are delivered via computer-based devices, collecting response times for each item and person combination becomes straightforward. The benefit of RT usually comes in two different forms including (1) improving the precision of both item (van der Linden, Klein Entink, & Fox, 2010) and person parameter estimation (e.g., Wang, Fan, Chang, & Douglas, 2013b), such that the discrepancy between observation and model prediction from aberrant responses becomes more prominent due to more precise “model prediction” and (2) constructing residuals based on RT (van der Linden & van Krimpen-Stoop, 2003) because aberrant behavior usually manifests itself by irrationally shorter RT.
Several person-misfit indices using RTs were proposed. For example, Marianti, Fox, Avetisyan, and Veldkamp (2014) proposed a Bayesian standardized person-fit index based solely on RT and it worked well in both simulation and real data analysis. On the other hand, van der Linden and van Krimpen-Stoop (2003) proposed to construct residuals based on both responses and RTs and seek for a combination of undesirably negative residual for RTs and positive residual for responses as indicators of item preknowledge. They considered both classical and Bayesian checks when constructing the residuals. For classical checks, the detection rate is .30 and the false-alarm rate is .05. For Bayesian checks, the detection rate doubled relative to the classical checks, but at the cost of a considerable increase in the false-alarm rate. Later, van der Linden and Guo (2008) proposed a fully Bayesian procedure based on the hierarchical model of van der Linden (2007). The primary idea is to form a posterior predictive distribution of RTs as a reference distribution to which the actual RT is compared. This distribution of RTs is constructed based on information accrued through RTs and responses on all other administered items. If the actual RT is too small relative to the posterior predictive distribution, this implies the potential aberrant behavior. Note that because this index is computed for each person-by-item encounter, it can be aggregated at either person level or item level to flag aberrant examinees or to detect item compromise (Qian, Staniewska, Reckase, & Woo, 2016). In this regard, no separate item-misfit index is needed. Their index will be used as a reference to which the mixture modeling approach is compared.
1.2. Mixture Modeling Approach
Different from detecting aberrance via residuals, another commonly seen approach is to directly model the aberrant behavior (rapid guessing behavior mostly) using mixture models. Earlier, only response information enters into the mixture model (e.g., Bolt, Cohen, & Wollack, 2002; Boughton & Yamamoto, 2007; Chang, Tsai, & Hsu, 2014; Goegebeur, De Boeck, Wollack, & Cohen, 2008). For instance, Bolt, Cohen, and Wollack (2002) classify examinees into one of the two classes: speeded or nonspeeded, and all examinees who belong to the speeded class tend to engage in solution behavior at first but switch to rapid guessing behavior at the same fixed switching point. Boughton and Yamamoto’s (2007) HYBRID model allows individual change-point locations for different examinees, and thus, it is more flexible. Goegebeur, De Boeck, Wollack, and Cohen (2008) further propose a speeded item response theory (IRT) model, and their model includes an examinee-specific change-rate parameter, such that it models a smooth, gradual switch from solution behavior to rapid guessing. Of note, a common assumption shared among all these models is that just one change point appears in the entire test-taking process.
In parallel, various mixture models have been proposed to represent divergent RT distributions from solution behavior and rapid guessing such as the two-state model by Schnipke and Scrams (1997) and the effort-moderated IRT model by Wise and DeMars (2006). In particular, when the two types of behaviors coexist, the resulting RT distribution is likely bimodal, and the two-state model intends to curve fit the bimodal shape of RT distribution (Schnipke & Scrams, 1997). Each item therefore has two sets of parameters quantifying the lognormal RT distributions from the two behaviors. However, person parameters are not included in the model, and hence, the model is suitable for evaluating speededness of a test but not suitable for detecting rapid guessing behavior at person level.
Very recently, a few mixture models have been proposed that take into account both RT and response information. For instance, Meyer’s (2010) model assigns examinees to either a speeded or a nonspeeded latent class with each latent class having separate item and population mean/variance parameters. However, the classification is at person level that provides no clue on which item rapid guessing actually happens. Wang and Xu (2015) propose a mixture hierarchical model that can differentiate rapid guessing from solution behavior for each item by person encounter. Their model includes a latent indicator variable that implies the underlying behavior of the test taker on a specific item, whether it be normal (solution based) behavior or rapid guessing behavior. Our model bears close resemblance to Wang and Xu’s model, but the main difference is we replace their person-level guessing propensity parameter (πi ) by an item-level parameter πj . The justification is, in case of cheating, items that are overexposed are more likely to be compromised, yielding higher πj . In case of rapid guessing, items that are placed toward the end of the tests are more likely to be rapidly guessed on, also leading to higher πj . In addition, different from Wang and Xu (2015), another main objective of this article is to compare the performance of mixture modeling approach versus the Bayesian residual method side by side.
As emphasized earlier, residual analysis is theoretically underpowered if a certain, nonignorable proportion of examinees exhibit aberrant behavior. Therefore, it will be important to check the conditions under which the Bayesian residual method will perform equally, better, or worse than the mixture modeling approach in terms of detecting aberrant behavior at person level, as well as identifying item preknowledge at item level.
2. Method
2.1. A Mixture Hierarchical Model
When modeling responses and RTs jointly (e.g., van der Linden, 2007; Wang, Chang, & Douglas, 2013a; Wang et al., 2013b), the hierarchical model of van der Linden (2007) is by far one of the most popular models for responses and RTs, and this model has become the standard approach to model responses and RTs in standardized testing (Ranger, 2013).
As the name entails, the core of van der Linden’s (2007) model is a hierarchical structure that integrates the responses and RTs through a second-level covariance structure. In particular, the two levels are (1) a measurement model level, wherein RT follows a lognormal model and response accuracy comes from a three-parameter logistic (3PL) model and (2) a subject model that specifies correlation between speed and ability at a population level.
In adhering to the conventional notation, let aj , bj , and cj denote the item discrimination, difficulty, and pseudoguessing 1 parameters for item j, and let θi denote the ability for person i, then the probability that person i answers item j correctly using “solution-based” behavior is summarized by the 3PL model as follows:

Other IRT models, such as the 2PL model, 1PL model, partial credit model, or graded response model, can be supplied in this framework depending upon the nature of the assessment and the type of responses collected (i.e., either dichotomous or polytomous responses).
In parallel with the parameterization in Equation 1, let αj
and
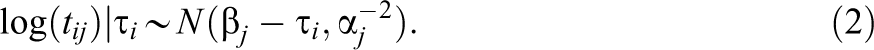
As seen from Equation
2, items with higher time intensity (i.e., larger
At the second level, it is assumed that the latent ability and speed parameters,
The mixture model is a natural extension of van der Linden’s (2007) hierarchical model. Let


In Equation 4, when the person engages in solution behavior, the correct response probability follows the typical 3PL model in Equation 1; otherwise, the correct response probability is quantified by dj . For compromised items, dj might be close to 1 because the chance of answering a compromised item correctly should be high, regardless of the item difficulty or person’s ability level. If a person engages in rapid guessing, dj will be close to the chance level of one over the number of options for a multiple-choice item.
Imitating van der Linden’s
(2007) hierarchical structure, the latent ability and speed parameters,
Please note that in our mixture model, we used item level parameter,
πj
, to indicate the propensity of item being problematic, whereas Wang and Xu (2015) used a
person-level parameter, πi
. The decision between two model parameterizations should be made with caution.
If a test contains items with different features, such as old and new items, then a model
with πj
makes more sense. On the other hand, if the test is given to a heterogeneous
sample in which the examinees’ test-taking behaviors may differ dramatically (i.e.,
students with different backgrounds or motivations), then a model with
πi
is more appropriate. Depending upon the type of mixing proportion parameter
included in the model, item-level or person-level covariates can be included in the future
to predict the severity of aberrance. With our model set up, the estimated
In sum, the parameters that need to be estimated in model calibration include item
parameters,
2.2. Bayesian Residual Analysis
As a comparison to the mixture modeling approach, the Bayesian residual method (van der Linden & Guo, 2008) is
introduced in this subsection. To be specific, let
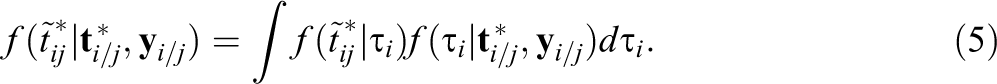
In Equation 5,
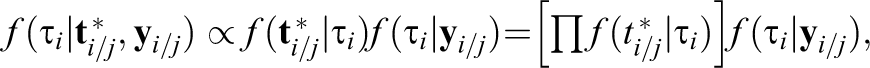
where

and a variance of
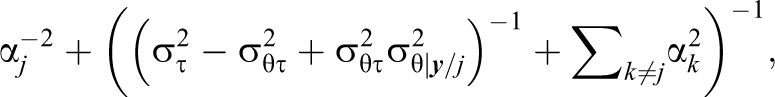
which are essentially Equations 36 and 37 in van der Linden and Guo (2008). According to their
suggestions,
The fully Bayesian posterior predictive p value is computed by comparing
3. Simulation Study
3.1. Design
The simulation study was designed to evaluate (1) if the proposed MCMC algorithm can
successfully recover model parameters as a sanity check, (2) whether the indicator
variable
Two factors were manipulated in the simulation study, aberrance size and aberrance severity. Aberrance size is defined as the proportion of problematic items and aberrance severity is determined by the magnitude of πj , implying the proportion of aberrance exhibiting on the problematic items. Examinee sample size was fixed at N = 1,000; test length was fixed at J = 30. Neither sample size nor test length was manipulated to keep the scope of the study manageable. Two levels of aberrance size were considered, they are 10% (low) and 20% (medium), yielding the number of compromised items as either 3 or 6. The aberrance severity varied between two levels, low (i.e., simulate πj from uniform (0, 0.5)) and high (i.e., simulate πj from uniform (0.25, 0.75)). A null condition with no aberrance was added as well. To facilitate the fair comparison between the mixture model approach and residual approach, the “true” data were generated from either mixture model or residual approach (with details given below). Table 1 summarizes the manipulated conditions in this study. It is expected that the proposed method outperforms the Bayesian residual method especially when the proportion of cheating behavior is high.
Simulation Design Conditions

Note. The “proportion of aberrant behavior” (i.e., 2.5% in the table) is defined as the proportion of all item–person encounters that are resulted from aberrant behavior.
3.2. Data Generation
For solution-based behavior, the response pattern was simulated from the 3PL model
according to Equation
1, with
3.3. Model Calibration
Both the new mixture hierarchical model and van der Linden’s (2007) hierarchical model were calibrated using the Bayesian MCMC algorithm written in R. Prior specification and initial values are briefly mentioned for the mixture model in this section.
The priors we chose for the item parameters are:
The conjugate priors are preferred to invoke direct Gibbs sampling, making the chain more
efficient. Otherwise, if no conjugate prior exists, we adopted widely used priors (i.e.,
normal, beta, or uniform) depending upon the property of the parameter (whether it is
bounded or unbounded). The specification of the hyperparameter values of the prior also
requires careful delineation. We chose the specific hyperparameter values through trial
and error to ensure fast mixing and convergence of the Markov chain. Of note, during the
MCMC update, to ensure that the covariance matrix is positive definite, we first freely
update the variance term,
The initial values of the parameters were set up as follows. Regarding solution behavior,
aj
= 1, cj
= 0.1 for j = 1,…, J; b
parameters were initialized to using normal percentiles with the percentage equal to the
proportion correct for that item (see Wang et al., 2013a). Person parameter θ was initialized using maximum likelihood
estimator (MLE) given the initial values of item 3PL parameters; τ was initialized again
using the normal percentiles by ranking the examinees with respect to their total RTs. The
covariance of θ and τ was initialized as 0.1. α and β were initialized using MLE that has
closed form expressions, namely,
Both dynamic trace lines and time-series lines indicate the chains converge before 1,000 iterations. Thus, the length of each Markov chain is 10,000, with the first 1,000 as burn-in. The final parameter estimates are the average of the post burn-in iterations. The Monte Carlo standard error is the standard deviation of the post burn-in iterations.
4. Results
4.1. Parameter Recovery
Parameter recovery is evaluated by average bias and mean squared error (MSE) computed on
each type of parameter. For instance, for item-level parameter including
aj
, bj
, cj
, αj
, βj
, and πj
, average bias was computed as the mean difference between true and estimated
parameters over all items in a test, that is, Bias(a) =
We considered results from Table 2 as a quality control check to evaluate whether the proposed MCMC algorithm performed well with the mixture model. It can be seen from Table 2 that the parameters for both mixture and nonmixture models are recovered precisely in Condition 0 (no cheating). Starting from Condition 1, the mixture model produces more accurate parameter recovery as compared to the nonmixture model. The improvement in estimation precision is more profound regarding parameters a, α, and β because mistakenly treating responses/RTs generated from aberrant behavior as if they are from solution behavior result in biased parameter estimates. In particular, the item difficulty, discrimination, time intensity, and time discrimination are all underestimated with the nonmixture model. A further exploration of the results reveals that the large negative bias of item parameters from nonmixture model is predominantly caused by compromised items. The estimation bias for noncompromised items is mostly negligible from the nonmixture model and hence comparable to the results from the mixture model.
Parameter Recovery of Both Mixture Model and Nonmixture Model in Simulation Study I
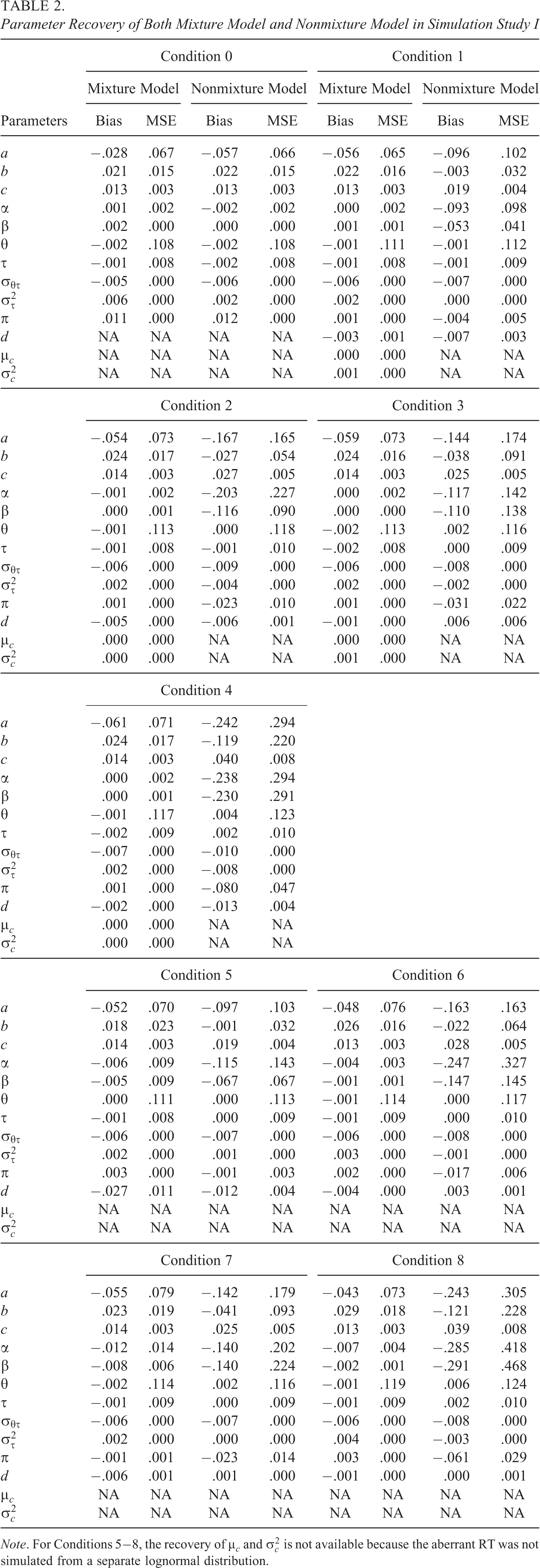
Note. For Conditions 5−8, the recovery of μc
and
4.2. Classification of Aberrant/Normal Behavior
Table 3 summarizes the average
true positive rate (TPR) and false discovery error (FDR) rate of both the mixture model
approach and the Bayesian residual method. TPR is defined as the proportion of cheating
behavior that is correctly flagged, and false discovery error rate is defined as the ratio
between incorrectly flagged behavior and the total flagged behavior. Both indices are
computed based on all person-by-item encounters and averaged over 25 replications. For the
mixture model approach, we fixed
Summary of the True and False Detection Rates of Both Methods Under Different Manipulated Conditions in Simulation Study I
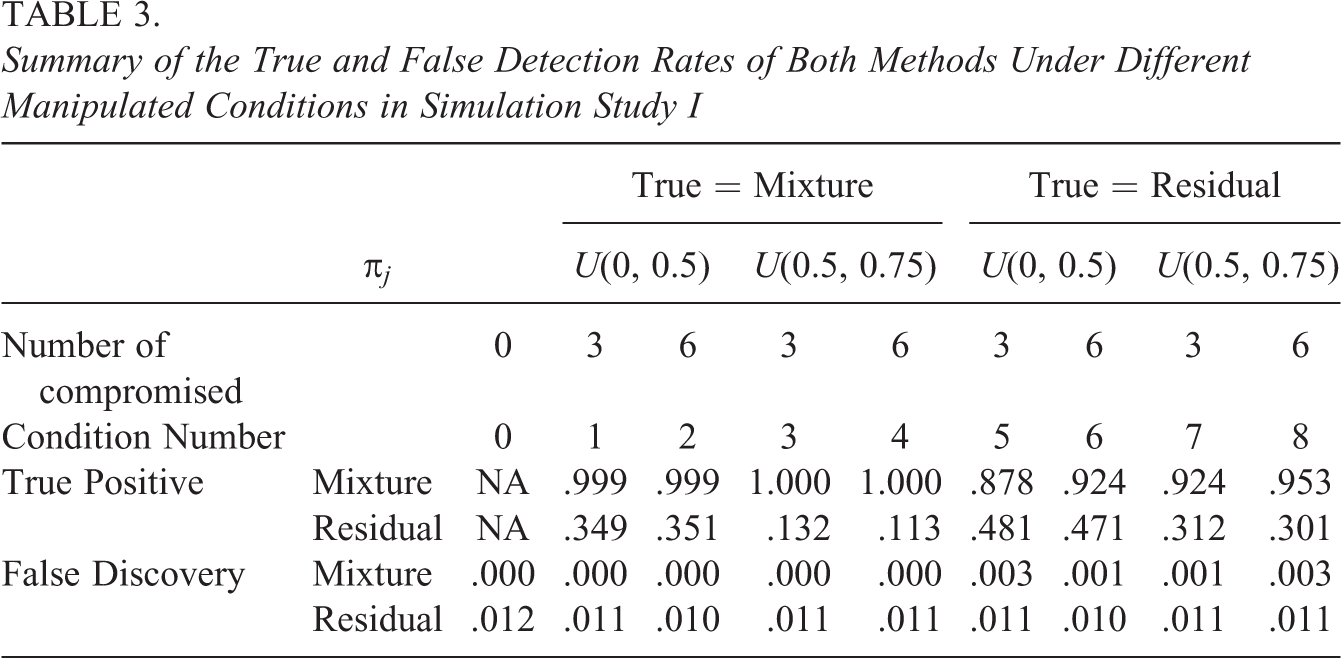
As clearly shown in Table 3, the mixture model approach demonstrates excellent TPR in virtually all manipulated conditions (except Condition 5, which is slightly low), whereas the residual method shows visibly worse TPR, especially when the cheating proportion is high. In Conditions 3 and 4, the TPR of the residual method is even lower than 0.15. This observation is consistent with the power study in van der Linden and Guo (2008; Tables 3 and 4). An interesting observation from Table 3 is that the aberrance severity is more devastating than the aberrance size to the TPR of the residual method. One possible explanation is that in the residual method, for each individual, the RT on a certain item is compared against the responses/RTs from the remaining items—high aberrance severity distorts the posterior predictive distribution (see Equation 3) formed by the remaining items and, thus, adversely affects the TPR. The results presented in Table 4 are consistent with the findings in Table 3. That is, the lower TPR of the residual method is because this method misclassifies many aberrant behaviors as normal behavior. In terms of the false detection rate (FDR), the mixture approach still yields low error rate, whereas the residual method generates slightly higher, yet still acceptable FDR. The classification results reported in Table 4 can further shed light on the classification behavior of both approaches.
Classification Contingency Table for Nine Manipulated Conditions

Note. Results are averaged over 25 replications, so the numbers in each cell are no longer integers.
Table 4 presents the direct comparison between the mixture approach and the residual-based approach in terms of a 2 × 2 contingency table for each simulation condition. It appears from Table 4 that the mixture modeling approach generates much fewer misclassified cases than the residual method. As mentioned earlier, the large misclassification error of the residual method is due to incorrectly classifying an aberrant behavior as a normal behavior, yielding drastically low correct detection rate.
If one computes the false positive rate as the proportion of normal behavior that is
misflagged as aberrant behavior (analogy to Type I error), then the false positive error
rate for both methods does not adhere to a typical nominal .05 rate. This is because the
decision is not made from a hypothesis testing perspective but rather it is made by simply
comparing
4.3. Selection of Threshold
In the proposed mixture modeling approach, choosing an appropriate threshold value to
which the estimated probability,

The false detection rate (a.k.a. false discovery rate) and true positive rate (a.k.a. power) as a function of threshold in the mixture modeling approach.
4.4. Compromised Item Detection
As alluded to earlier in Section 3.1, the correct detection of compromised items hinges
on the proper recovery of πj
. From Table 2, the
bias of

The detection of compromised items. “M” stands for mixture approach, and “R” stands
for residual approach. Each point represents the estimated proportion of cheating
behavior on the respective item, and the arrow marks the true compromised items in the
simulation design. The values beneath the arrows are the true
Figure 2 presents the item detection for the eight manipulated conditions from one replication. The plots are compelling and reveal an eminently good detection of the proposed mixture model approach. The arrows indicate the manipulated compromised items, and the numbers beneath the arrow indicate the true aberrance size.
Specifically, when the aberrance size is generated from U(0, 0.5) (i.e.,
Conditions 1 and 5), the estimated proportion of aberrance for these 3 items shows
excellent adherence to the true value. On the contrary, the estimated
In contrast, the residual method starts out working fine, with acceptable detection when
the aberrance size is low, irrespective of the number of the compromised items. In this
case, the estimated
Therefore, in sum, the results show favoritism to the mixture model approach because it not only successfully flags compromised items but also precisely recovers the severity of compromise (by showing how much percentage of sample engage in cheating behavior on each compromised item). This piece of information will be invaluable for test administrators to decide whether to replace those items.
5. Real Data Examples
5.1. A Low-Stakes Computerized Testing Example
In this subsection, we illustrate the proposed mixture model approach using a real data set from Acuity Indiana English/Language Arts Test grade 10, 2012–2013 administration. The purpose of the test is to provide diagnostic measures and standards-aligned performance data, which support an educator’s ability to inform instruction at the student, class, school, and corporation level. The data set contains 1,776 students, each has responses and RTs recorded on 35 items. For data preprocessing, we deleted all records with 0 RT and deleted all records with total RTs shorter than a cutoff value of 4.736 minutes (resulting in log-RT of −2) because those examinees might not respond to any items via solution behavior probably due to lack of motivation. The resulting sample size that enters into final analysis is 1,682. Figure 3 presents the histogram of item response time for all persons and all items in the sample. It is clear the RT follows a bimodal distribution (Meyer, 2010; Wise & Kong, 2005), implying that there might be two underlying behaviors, normal behavior and aberrant behavior.
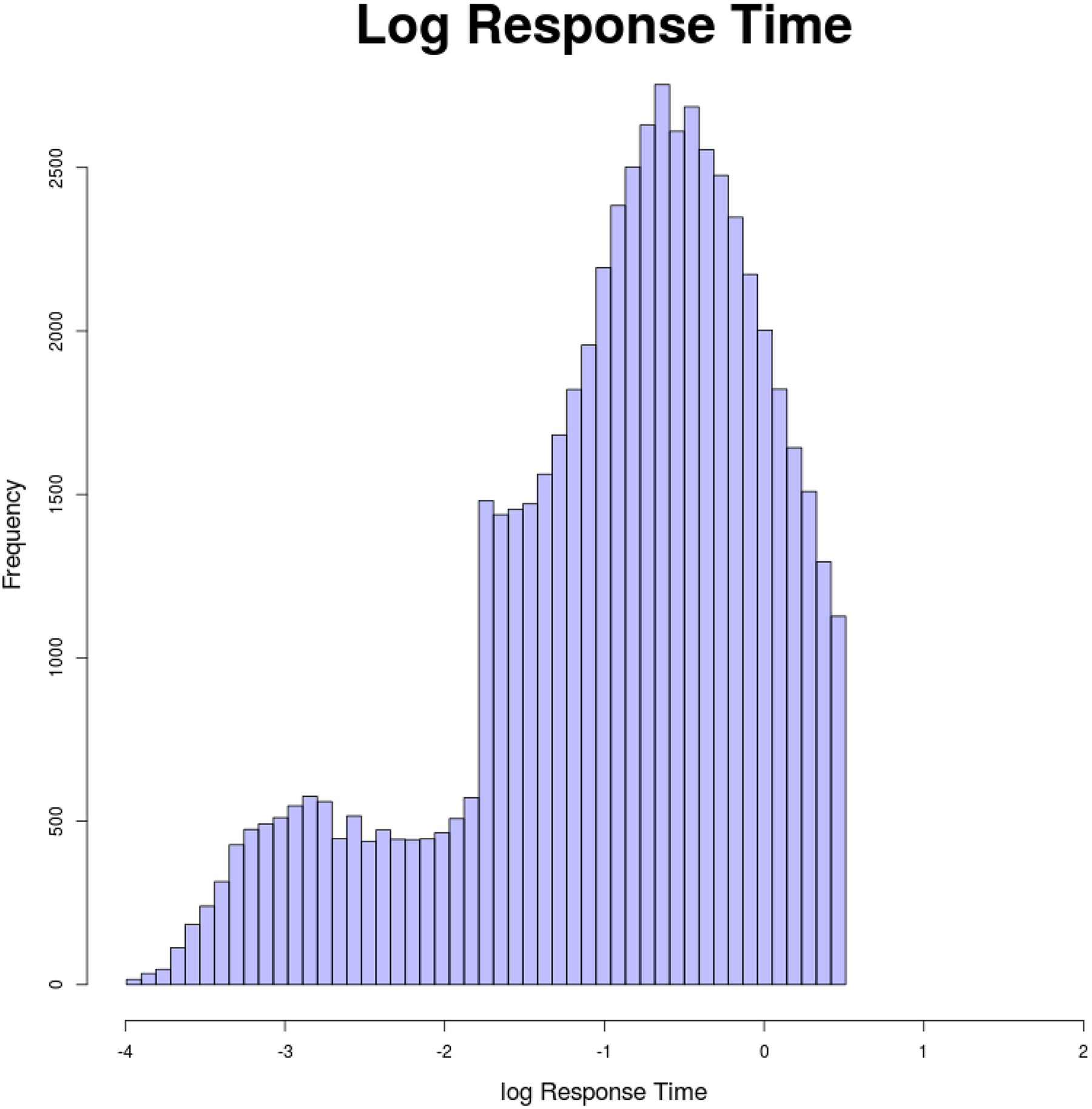
Log-response time of the 1,682 examinees and 35 items.
Because this test is relatively low stakes, we intended to (and actually are more likely
to) find aberrance due to rapid guessing because of lack of time toward the end of the
test. Cheating might not be a problem for this data set. Both the proposed mixture model
and the nonmixture model were fit to the data set. The same priors are used as in the
simulation study, except the prior for βj
becomes
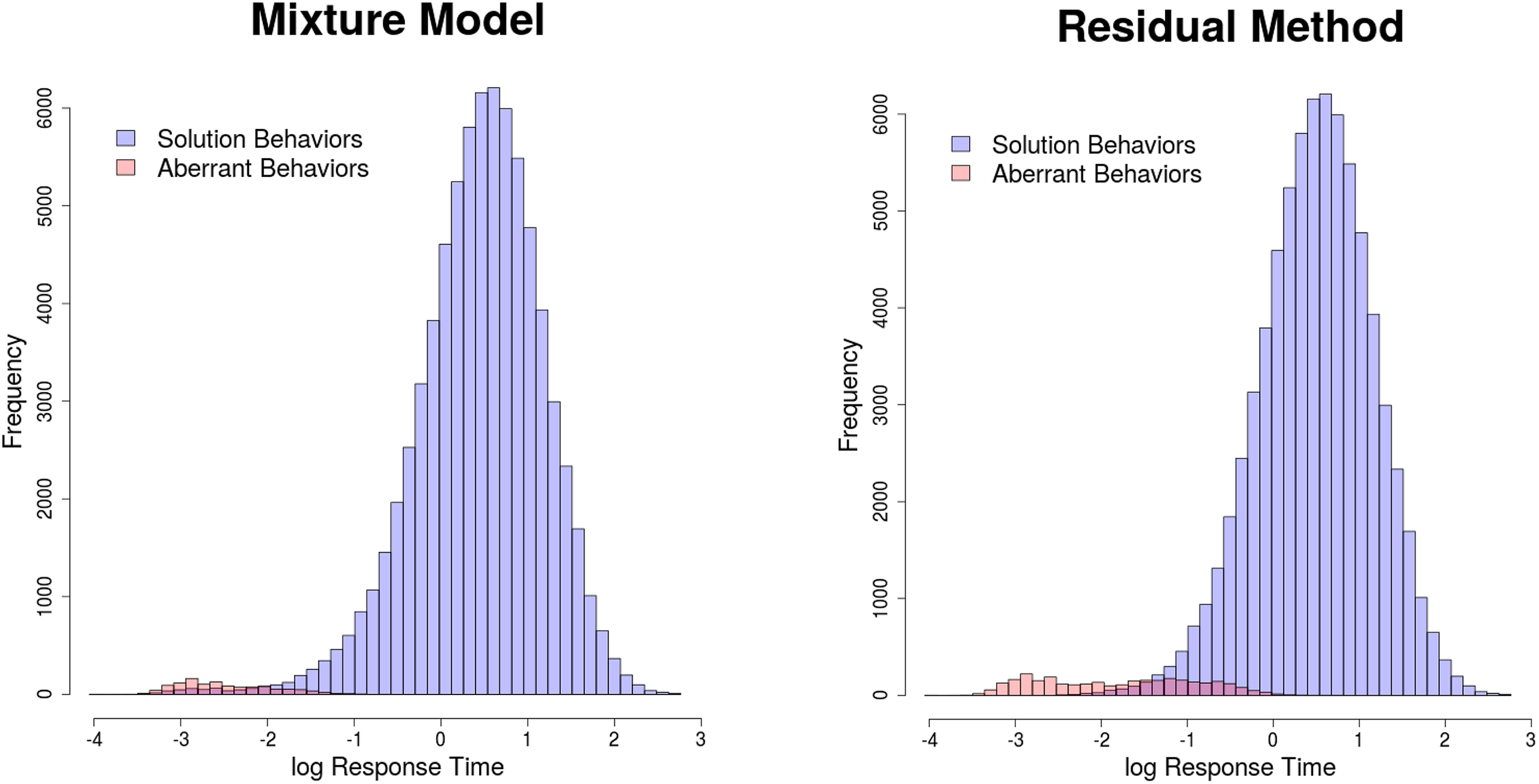
Figure 4 further presents the histogram of log RTs classified as from solution and aberrant behaviors, marked by blue and red colors separately. Not surprisingly, the mixture model approach gracefully classifies the RTs constituting the first mode as from the aberrant behavior and the RTs constituting the second mode as from the normal behavior. On the other hand, residual method seems not to have enough power to flag aberrance, yielding a huge overlap between RTs from aberrant behavior and RTs from normal behavior. This outperformance of the mixture approach continues to be true even when looking at the item level RT distribution, as shown in Figure 5, for Items 2 and 26, as an example.
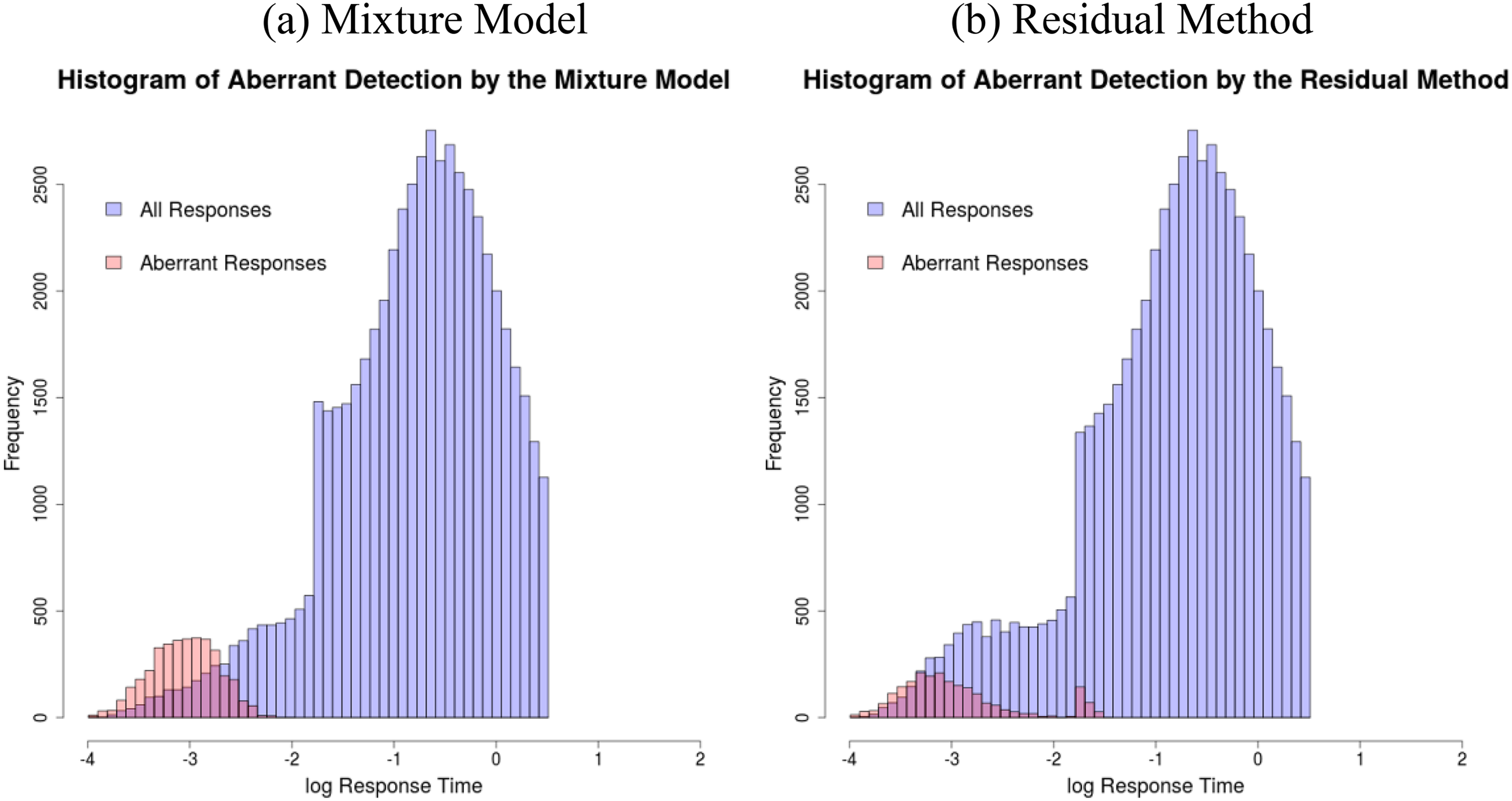
Histogram of log-response time classified by two behaviors (Real Data Example 1).
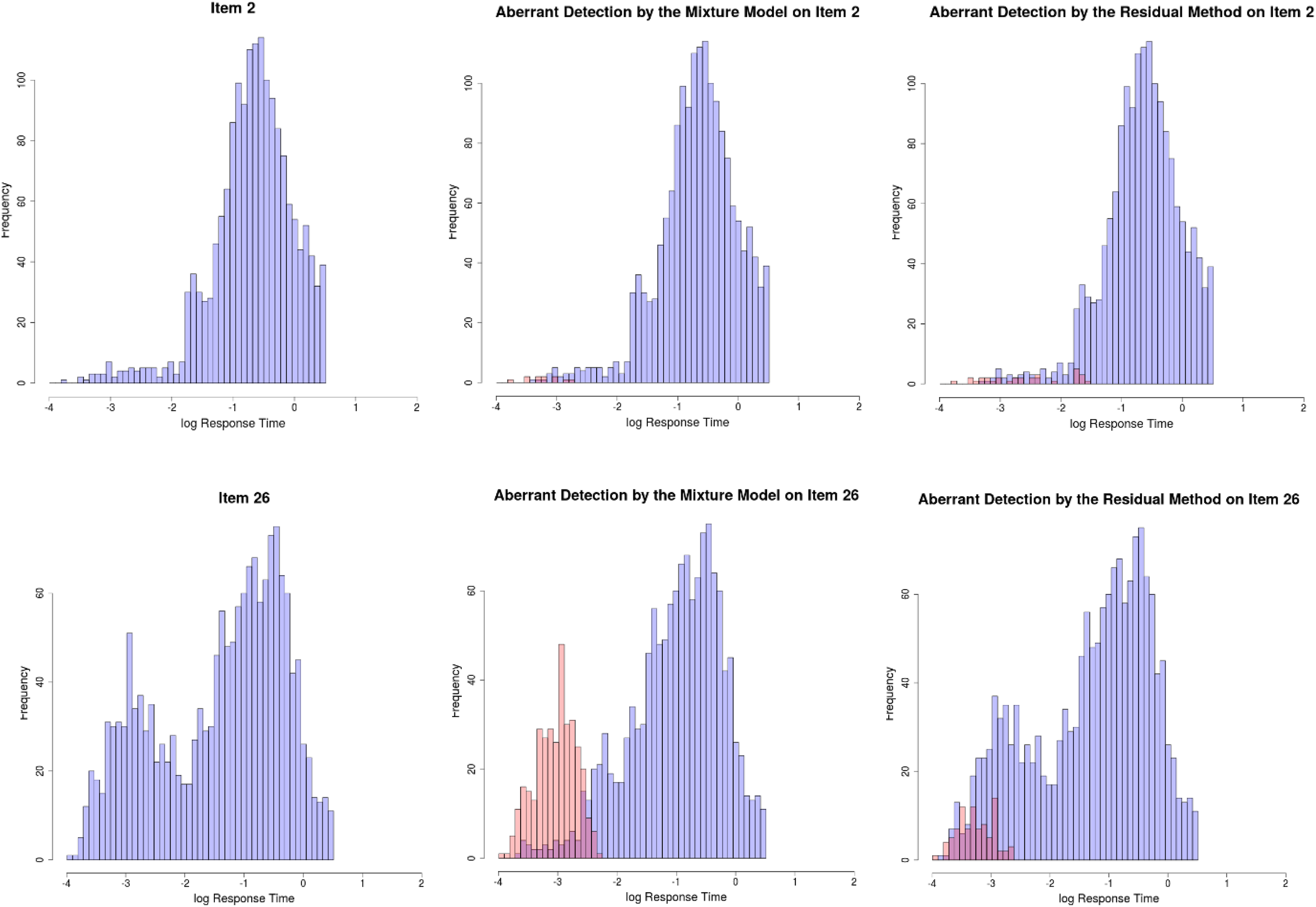
Histogram of item-level log-response time classified by two behaviors (Real Data Example 1).
To further identify the specific type of aberrant behavior, Figure 6 presents the estimated
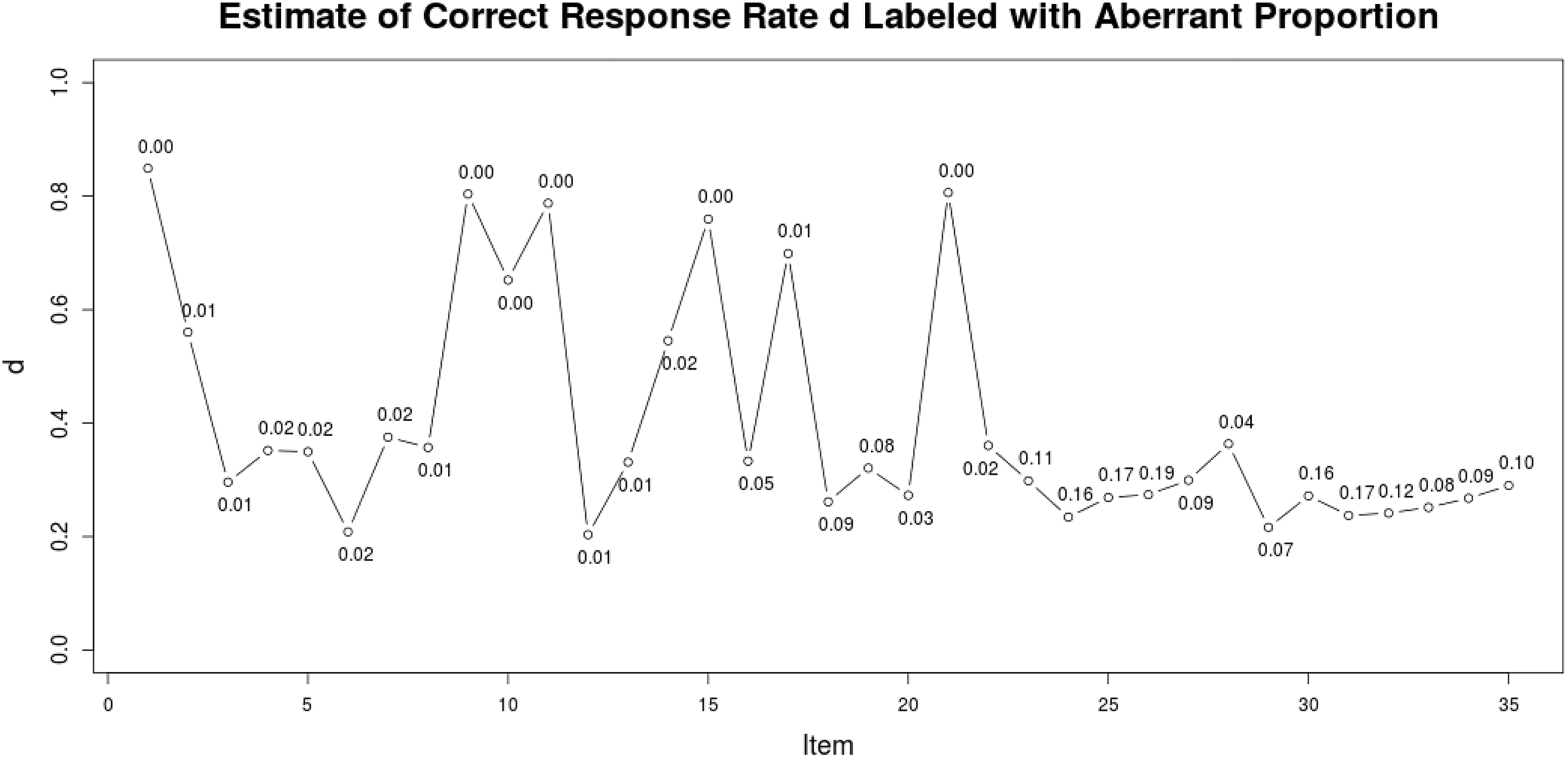
Estimated correct response rate for the aberrant behavior for each item, labeled by the proportion of aberrant behavior on the respective item (Real Data Example 1).
5.2. A High-Stakes Computerized Adaptive Testing Example
This data set comes from a large-scale, high-stakes, computerized adaptive test. The item
bank consists of 620 multiple choice items, and examinees’ responses are recorded as
either right or wrong. Examinee sample size is 2,106. Test length is 37 and testing time
is 75 minutes. Due to the adaptive design, every item is answered by a different set of
examinees, and the examinee sample size per item varies between 5 and 364. RT distribution
of all item-by-person encounters again reveals a bimodal structure, which implies that the
examinees are from a mixture of two populations with potentially different behaviors. Even
though this is a high-stakes test, the data come from well-protected testing sites, and
the items used for this data collection are secure items. Hence, we expect the aberrant
behavior mainly takes the form of rapid guessing rather than cheating. Similar to the
previous example, both mixture hierarchical model and nonmixture model were fitted to this
data set, and the Markov chain length is 50,000 with the first 10,000 as burn-in. The DIC
from mixture model is 281,399, whereas the DIC from nonmixture model is 616,367. Again,
mixture model exhibits better fit. For the mixture model,
Figure 7 presents the histogram of log RTs classified as from solution and aberrant behaviors. Mixture model method flagged 1,194 aberrant behaviors (i.e., 1.52% of aberrance) from 336 examinees, whereas residual method flagged 10,118 behaviors (i.e., 13.1% of aberrance) from 1,967 examinees. As shown in Figure 7, many of the cases flagged by the residual method do not have extremely short RTs; in fact, those observed log-RTs are between −1 and 0 (i.e., 22–60 seconds), which can hardly be considered as “rapid” guessing. In this regard, we suspect that those behaviors flagged solely by residual method are false detection. One possible explanation is that in the residual method, the cutoff of the Bayesian posterior predictive p value determines the number of false alarms in case there is no irregular responding. Hence, a more stringent cutoff (i.e., lower than typical .05) might help lower the false alarm rate.
Histogram of log-response time classified by two behaviors (Real Data Example 2).
To further verify our conjecture, we plotted the box plot of the estimated

Boxplot of estimated
6. Discussion
Online testing or web-based assessment is becoming a mainstream form of modern testing due to the internet’s flexibility, accessibility, and potential capacities for faster data analysis and reporting. In web-based standardized testing, RT can be recorded conjointly with the corresponding responses. This broadens the scope of potential modeling approaches because RTs can be analyzed in addition to analyzing the responses themselves. One appealing application of RT is to help distinguish aberrant behavior from normal behavior and to help diagnose problematic items. From psychometrics perspective, failing to recognize the existence of different behaviors can be detrimental to the validity of inferences based on the test scores. Moreover, the existence of compromised items in the test may also inflate the test score and result in invalid inferences.
Looking into the literature, most statistical analysis to identify aberrant behavior or item compromise belongs to the broader class of residual analysis or outlier detection (e.g., van der Linden & Guo, 2008; van der Linden & van Krimpen-Stoop, 2003; Wang, Shu, Shang, & Xu, 2015; Wise, 2017). This class of methods is flexible as they make no assumptions concerning the form of irregular behavior. However, it has low power if a large proportion of examinees exhibit aberrant behavior, as demonstrated in both the simulation studies. The performance of this class of methods could potentially be improved by employing an iterative purifying approach. That is, one refits the model repetitively using a “cleansed” data set after removing the aberrant responses/RTs. This approach is worth exploring in future studies. In this article, we introduce a mixture hierarchical model to account for the dependency between item responses and item RTs with a special focus on differentiating between normal and aberrant behavior. The mixture model also offers an indicator showing the severity of item compromise (i.e., πj ). This indicator effectively distinguishes compromised items from secure items in virtually all manipulated conditions, whereas the Bayesian residual method has heavy reliance on the severity of aberrance. The latter leads to low power and sometimes high false detection rate when the aberrance severity is high. While previous papers either focus on person-fit analysis or item fit analysis and those focus on item fit analysis have either rarely considered item misfit due to item compromise or have not included RT information, our article combines both objectives together to demonstrate that the mixture model approach offers checks on both items and persons.
The successful execution of the proposed mixture model approach requires using sophisticated model calibration algorithm. Different from the Monte Carlo expectation-maximization (MCEM) algorithm used in Wang and Xu (2015), we used the fully Bayesian MCMC algorithm. There are several reasons for making this choice. First, MCMC allows natural incorporation of certain prior information about the model parameters into the estimation processes. Second, it is relatively more straightforward than MCEM for complex models. Third, we can obtain the entire posterior distribution of each parameter from MCMC rather than just the point estimate. Therefore, statistical inference on certain parameters can be carried out easily if necessary. The details of the algorithm are provided in the Online Appendix, and the R code is available from the authors. Alternatively, the comprehensive prior information and initial values presented in the previous sections enable readers to try out this model using other available Bayesian packages.
We acknowledge that this article is limited in a few aspects. First, the response time is assumed to follow lognormal distributions throughout this article, and a wrongly specified RT distribution will greatly deteriorate the performance of any model-based approach. However, one flexibility of the hierarchical model, as well as its mixture extension, is that any model can be plugged in to model RT distribution. It does not have to be lognormal model, but it can be exponential, gamma, or even semiparametric models. Second, the current approach cannot differentiate rapid guessing and cheating for each item and person encounter, unless these two aberrant behaviors result in different RT distributions. In this case, a three-class mixture model would be ideal. However, from our real data example (see, e.g., Figure 4 or Figure 5 for item-level RT distributions), the majority of the item-level RT distributions exhibit a two-mode shape rather than a three-mode shape, implying that based on RT, only a two-class mixture model will be identified. At the very least, the objective of this article is to differentiate aberrant behavior from normal behavior, instead of differentiating cheating behavior from rapid guessing behavior. This latter objective is hard to achieve at person-by-item level without separation of RT information. At the item level, in practice, if we know certain items are likely to be compromised (e.g., being active for a long period), then we can restrain the prior of dj to a certain range accordingly to speed up its convergence. Even so, using dj alone is not sufficient to identify the specific type of aberrant behavior, future research needs to delve into this challenge further. Third, a well-recognized issue with mixture modeling approach is that if the difference between regular and irregular behavior is small, mixture model might not perform well (e.g., Depaoli, 2013; Tolvanen, 2008). Fourth, in the case of rapid guessing, the mixture model can be further extended to include the dependency of the type of behavior on elapsed testing time.
In closing, the aforementioned limitations need to be weighed against the potential advantages of the proposed mixture model approach, as exemplified in the simulation studies. Even though preventing aberrant behavior by carefully proctoring exams, enlarging item bank, increasing testing time, and increasing the number of parallel forms are commendable—prevention is better than cure—given that writing and calibrating new items are extremely expensive, routinely analyzing responses/RTs to diagnose any possible aberrant behavior and item compromise still has profound practical value. Last but not least, detection of aberrant behavior (especially cheating behavior) is sensitive in reality, so instead of merely relying on statistical evidence, careful qualitative analyses of the entire RT pattern for flagged test takers and items and corroborating evidence such as reported irregularities during the testing session should also be taken into consideration. Overall, we present an improved and efficient method for detecting aberrant behavior during testing that would also permit precise identification of compromised items.
Supplemental Material
Supplemental Material, DS_10.3102_1076998618767123 - Detecting Aberrant Behavior and Item Preknowledge: A Comparison of Mixture Modeling Method and Residual Method
Supplemental Material, DS_10.3102_1076998618767123 for Detecting Aberrant Behavior and Item Preknowledge: A Comparison of Mixture Modeling Method and Residual Method by Chun Wang, Gongjun Xu, Zhuoran Shang, and Nathan Kuncel in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is partially supported by 2014 CTB/McGraw-Hill R&D research grant and Institute of Education Sciences grant R305D160010.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.