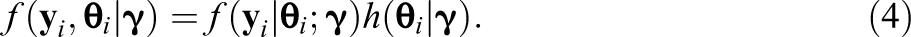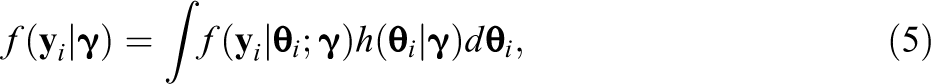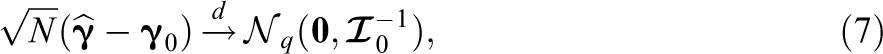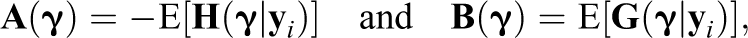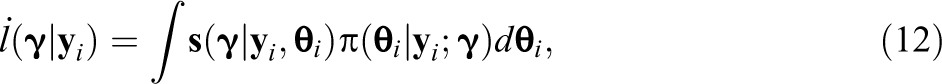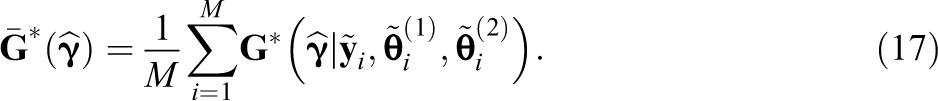In item response theory (IRT) modeling, the Fisher information matrix is used for numerous inferential procedures such as estimating parameter standard errors, constructing test statistics, and facilitating test scoring. In principal, these procedures may be carried out using either the expected information or the observed information. However, in practice, the expected information is not typically used, as it often requires a large amount of computation. In the present research, two methods to approximate the expected information by Monte Carlo are proposed. The first method is suitable for less complex IRT models such as unidimensional models. The second method is generally applicable but is designed for use with more complex models such as high-dimensional IRT models. The proposed methods are compared to existing methods using real data sets and a simulation study. The comparisons are based on simple structure multidimensional IRT models with two-parameter logistic item models.
In item response theory (IRT) modeling in the context of maximum likelihood (ML) estimation, the Fisher information matrix (IM) is used for numerous inferential procedures. These include finding standard errors for the item parameter ML estimates, constructing test statistics (e.g., Glas, 1999; Maydeu-Olivares, 2013), and facilitating test scoring that accounts for uncertainty in the ML estimates (Yang, Hansen, & Cai, 2012). In principal, these procedures may be carried out using either the expected or observed IM. However, depending on aspects of the data and model, calculating either of these matrices can be challenging.
A first challenge involves the number of items. In the context of IRT modeling, the expected IM is a function of all possible response patterns. The total number of patterns, though, is exponential in the number of items, and therefore, direct computation of the expected IM is impractical when there are many items. In contrast, the observed IM is a function of the observed response patterns only and is often easier to compute. Actually, several methods for finding the observed IM have been proposed. These include using the definition of the observed information directly (Tsutakawa, 1984), the Louis (1982) method (e.g., Glas & Verhelst, 1989), the supplemented EM algorithm (Cai, 2008; Meng & Schilling, 1996), and the Oakes (1999) identity (Chalmers, 2018; Pritikin, 2017). An alternative sample-based method, the cross-product approximation (Meilijson, 1989), has also appeared in the literature numerous times (e.g., Maydeu-Olivares, 2013).
A second challenge, which also affects item parameter estimation algorithms, involves the number of latent variable dimensions. For a p-dimensional latent variable, the popular EM algorithm (Bock & Aitkin, 1981) generally requires the evaluation of p-dimensional integrals (cf. Gibbons & Hedeker, 1992) and uses quadrature to perform the integration. The computational demand, however, is exponential in p, and therefore, EM is not a practical option when p is large (e.g., ). This phenomenon is commonly referred to as the “curse of dimensionality.” Alternative estimation algorithms, such as Metropolis–Hastings Robbins–Monro (MH-RM; Cai, 2010), stochastic EM (Diebolt & Ip, 1996; Fox, 2003), and Monte Carlo EM (Meng & Schilling, 1996; Wei & Tanner, 1990), have been designed to overcome this challenge for high-dimensional IRT models. In particular, such algorithms reduce or eliminate the need to precisely evaluate p-dimensional integrals.
Similarly, methods for computation of the IM typically require the evaluation of p-dimensional integrals. When p is small and EM is a practical option for item parameter estimation (e.g., or ), then the integrals needed for the IM may likewise be evaluated by quadrature. However, when p is large, other methods must be adopted. For example, the Louis (1982) method may be used, with Monte Carlo integration instead of quadrature integration (e.g., Cai, 2010). Notably, this approach still depends on sufficiently precise evaluation of the p-dimensional integrals.
Notwithstanding these challenges, estimating the expected IM is clearly desirable. The expected IM at the ML estimates is the ML estimator for the population Fisher IM and has been referred to as the “gold standard” of IM estimates (Paek & Cai, 2014; Tian, Cai, Thissen, & Xin, 2012). Further, research has shown that the expected IM can improve performance for dependent test statistics. For example, in the context of studying a score test designed to detect local dependence, Liu and Maydeu-Olivares (2012) found that the expected IM led to more accurate Type-1 error rates than the cross-product approximation. Other research has also found the choice of IM estimate can impact the performance of inferential procedures (Falk & Monroe, 2018; Yuan, Cheng, & Patton, 2013), but the expected IM is not generally included in such comparisons due to the aforementioned computational challenges.
In the present research, two straightforward methods to approximate the expected IM by Monte Carlo are proposed. Both methods overcome the first computational challenge mentioned above in the same way. Instead of computing the expectation over all possible response patterns, both methods approximate this expectation using data simulated in accordance with the model, as in the parametric bootstrap (Efron & Tibshirani, 1994). This strategy has been used successfully in similar contexts (e.g., Monroe, 2018; Ranger & Kuhn, 2012). The two methods differ, however, with respect to the second computational challenge. The first proposed method precisely evaluates the requisite integrals by quadrature. Therefore, it is best suited to low-dimensional models and complements the EM algorithm. The second proposed method eliminates the need to precisely evaluate any p-dimensional integrals. Thus, it is best suited to high-dimensional models and complements more recently developed parameter estimation algorithms.
2. An Example IRT Model and ML Estimation
The example IRT model is a multidimensional version of the two-parameter logistic (2PL) model. Let there be respondents and items. And, let denote the item score for respondent i to item j. Next, let be a random vector of latent variables. The conditional probability of a correct response by respondent i to item j is
where and are the item discrimination and intercept parameters, respectively, and is a vector of all freely estimated parameters. The conditional probability of an incorrect response is simply .
The sampling model for is a Bernoulli random variable, and the conditional density is
Let be the response pattern for respondent i. Assuming conditional independence of the item responses given (Lord, 1952), the conditional density for is
Next, let be the probability density of the latent variables. The joint probability density of and is
Finally, the marginal density of is obtained from the joint density after integrating out the latent variables,
where the integral is p-dimensional.
To define the marginal log likelihood, let collect the observed data for the entire sample. Then, the marginal log-likelihood is
where is the log-likelihood for the ith respondent.
Maximization of Equation 6 yields , the vector of ML estimates. Under suitable regularity conditions, the asymptotic distribution of the ML estimates is
where is the vector of true parameters and is the inverse of the Fisher IM for one observation. The next section discusses estimation of .
3. Information Matrices
In this section, the IM, in the context of ML estimation, is presented. Then, the two computational challenges discussed in the Introduction section are reviewed. Finally, the two proposed estimators for the expected IM are presented.
3.1. Information Matrices in General
Denote the derivatives of as
Also, let . The expected Fisher IM, for one observation, is
where
and the expectations are with respect to the density . Due to continuous mapping, is a consistent estimator for .
Instead of calculating the expectations over , sample-based estimates of may be used. Define the sample averages
Typically, is referred to as the observed IM, and has been referred to as the cross-product approximation (Meilijson, 1989). Both and are consistent estimators for .
3.2. Proposed Information Matrices for IRT
Before presenting the two proposed estimators for the expected IM, the two computational challenges discussed in the Introduction section are briefly reviewed. The first challenge is that to directly evaluate the expected IM, the expectations in Equation 9 need to be taken over all possible response patterns. Thus, direct computation of the expected IM becomes infeasible as n increases. The second challenge is that like the marginal probability in Equation 5, the derivatives and also involve p-dimensional integration. Consequently, sufficiently precise evaluation of the integral, needed for both expected and observed IM, becomes more difficult as p increases.
Turning to the two proposed strategies, both are based on the cross-product form of the expected IM, . For both strategies, the expectations in Equation 9 are approximated by Monte Carlo integration, using response patterns simulated under the model. The strategies differ in how the derivatives, requiring p-dimensional integration, are computed. The first proposal precisely evaluates the integrals using quadrature, and the second proposal crudely approximates the integrals by Monte Carlo.
3.2.1. First proposal
The first strategy requires random draws from and proceeds as follows:
Sample from the marginal distribution .
Sample from its conditional distribution .
Use to calculate .
Note that the first two steps constitute a draw from the joint distribution . Then, the draw is simply ignored, and may be treated as a draw from the appropriate marginal distribution .
These steps are repeated times, and the first estimator of is the Monte Carlo average
Each cross-product is an unbiased estimate of and due to the law of large numbers, . This approach constitutes a resampling procedure, as in the parametric bootstrap (Efron & Tibshirani, 1994). However, a key distinction is that the Monte Carlo sample size M is selected by the analyst.
The strategy underlying has been used in contexts similar to the current research. Spall (2005) used this approach to estimate for complex models such as state-space models. In an IRT context, Ranger and Kuhn (2012, p. 256) used this approach to calculate a weight matrix for an IM test (White, 1982), a quantity closely related to and . Ranger and Kuhn (2012), however, did not discuss estimation of itself. In addition, in an ordinal data structural equation modeling context, Monroe (2018) used this strategy to calculate the asymptotic covariance matrix of polychoric correlation estimates.
Implementation of is straightforward. In Steps 1 and 2, data are simulated under a specified IRT model, using . Such simulation is often supported by IRT software (e.g., flexMIRT [Version 3.51]; Cai, 2017). Also, is analogous to in Equation 10, except the average is taken over the simulated data instead of the observed data . Thus, the computer code for the empirical cross product may simply be reused.1 Finally, note that although the data for are simulated by Monte Carlo, is still computed using quadrature.
3.2.2. Second proposal
Inspired by more modern parameter estimation algorithms, the second strategy is designed to eliminate the need to accurately evaluate p-dimensional integrals. Recall that requires p-dimensional integration. However, if each individual cross-product is replaced by an unbiased estimate, the average will still converge to . The task, then, is to find such an unbiased estimate that is relatively easy to compute.
The unbiased estimate proposed in this research, defined below, depends on Fisher’s (1925) identity,
where is the posterior distribution of given , and
is the gradient of an individual complete data log-likelihood. With these definitions, the proposal for the unbiased estimate of is
where and are two independent imputations from .
As required, is an unbiased estimate for . To understand why this is so, consider a simple analogous example. Let be a random draw from a standard normal distribution. Then, is an unbiased estimate of , but its square is not an unbiased estimate of . An unbiased estimate of , however, may be obtained for two independent draws and , as .
Analogously, let be a random draw from . Then, by Fisher’s (1925) identity, is an unbiased estimate of , but its cross product is not an unbiased estimate of . An unbiased estimate of , however, may be obtained for two independent draws and , as .
The definition of suggests the following sampling scheme. First, draw from . Then, draw independent , from . The corresponding joint distribution may be written as
A drawback of this scheme is that, depending on the sampling method, it may be difficult to obtain independent draws from . For example, if a Markov chain Monte Carlo method is used, the resulting draws will typically be correlated. Many iterations may be needed to obtain approximately independent draws (Robert & Casella, 2013).
However, an alternative sampling scheme may be developed that avoids this potential difficulty. Using Bayes’s theorem, Equation 15 may be written as
The second proposed strategy is based on Equation 16 and proceeds as follows:
Sample from the marginal distribution .
Sample from its conditional distribution .
Sample from its posterior distribution .
Use to calculate .
Although this scheme samples from the appropriate joint distribution, only is actually sampled from . Thus, the potential difficulty in obtaining multiple independent draws directly from is avoided.
These steps are repeated times to obtain the Monte Carlo average
This matrix is symmetrized to obtain the second estimator of , denoted . Just as with , the second estimator .
Returning to the issue of computational demand, Steps 1 and 2 again constitute simulation under the specified IRT model. This is generally not computationally intensive, even for high-dimensional models. In Step 3, any method for sampling from may be used, such as the Metropolis–Hastings algorithm (M-H; Metropolis, Rosenbluth, Rosenbluth, Teller, & Teller, 1953) or rejection sampling (Robert & Casella, 2013). Finally, calculating in Step 4 will not typically be computationally intensive. Instead of requiring a large number of imputations to precisely evaluate , the proposed strategy requires just two imputations to obtain , an unbiased estimate of , and by extension, .
4. Simulation Study
To evaluate the proposed IM estimates and compare them to existing methods, a small simulation study was conducted. R (R Core Team, 2016) was used for all data generation and to calculate all IM estimates, and flexMIRT (Cai, 2017) was used for all item parameter estimation.
4.1. Data Generation
Three sample size conditions and two model size conditions were studied. The sample sizes were , , and 1,000. The model sizes were and items, using the multidimensional 2PL model in Equation 1. The two models had and latent dimensions, respectively, with all correlations equal to . A simple structure factor pattern was specified, with 6 items loading on each dimension. The sets of item parameters for each dimension were identical and obtained by fully crossing the discrimination parameters with the intercepts . These values were chosen to be representative of parameter estimates from empirical analyses and are similar to values used previously in the literature (Snijders, 2001). For each of the six sets of conditions, 500 data sets were generated.
4.2. Estimation Procedures
For each replication, the data generating model was fit to the data by ML. The two-dimensional model was fit by EM (Bock & Aitkin, 1981), while the four-dimensional model was fit by MH-RM (Cai, 2010). In the sequel, the notation is suppressed to reduce notational clutter.
For the two-dimensional model, the following estimates of were computed: the “gold standard” , the observed IM , the cross-product approximation , and, finally, the two proposed estimates, and . The proposed estimates were each computed twice, with and .
For the four-dimensional model, , , and the second proposed estimate, , were computed. The estimate was excluded because computation would be very burdensome due to the number of items and latent dimensions. The quadrature-based was also excluded. The sample-based estimates and were calculated using Monte Carlo integration, and the Louis (1982) formula was used for . Each estimate was computed twice, with and imputations per response pattern. The proposed estimate was computed with , , and .
For all integration by quadrature (including in the EM algorithm), a set of 49 quadrature points, evenly spaced between and , was used. For all simulation from the latent variable posterior distribution, the M-H algorithm was used. A standardized sum score was used as the initial value for in the Markov Chain. The “burn-in” was set to 25 cycles. Recall that for , for each simulated response pattern, only one sample, , is drawn from the posterior. In contrast, for and , S imputations are drawn, and the thinning interval was set to 10 cycles.
4.3. Collected Statistics
The various estimates were compared to the true Fisher IM . For the two-dimensional model, was computed directly, summing over the possible response patterns. For the four-dimensional model, was approximated by , with . That is, the quadrature-based proposed estimate was used, with the true parameters and a very large sample size. With these specifications, it is expected that . Predictably, this approach was computationally intensive.
To compare the similarity of the estimates to the population benchmark, three statistics were computed to provide a variety of measures of precision. Let be a generic IM estimate. Then, define the matrix of differences and the matrix of relative differences , where is a conforming identity matrix. The first two computed statistics were the Frobenius norms of and , denoted and . The third computed statistic was , where C is the condition number of . All three of these statistics are nonnegative and only equal zero when . Smaller values reflect greater similarity.
Preliminary analyses suggested the various S and M values would be appropriate for the simulation study. However, in practical settings, it is desirable to quantify the Monte Carlo error in the proposed IM estimates. To this end, the relative Monte Carlo standard error (RSE) of the matrix norm was collected. This relative standard error is defined as
where is the Monte Carlo standard error for and is one of the simulation-based IM estimates. The method of batch means, as implemented in Monroe (2018), was used to compute , with 25 batches.
4.4. Results
To evaluate the degree to which the different outcome measures provided distinct information, the correlation between each pair of outcome measures was calculated across replications, for all IM estimates and for all sets of simulation conditions. For example, for the two-dimensional model with , the correlation between and for was . In the current context, a low correlation is desirable as it indicates the outcome measures are not redundant. Across all IM estimates and simulation conditions, the average correlation between and was . For and , the corresponding average correlation was , and for and , it was . Arguably, these average correlations are sufficiently low to justify reporting all of the outcome measures.
4.4.1. Two-dimensional model
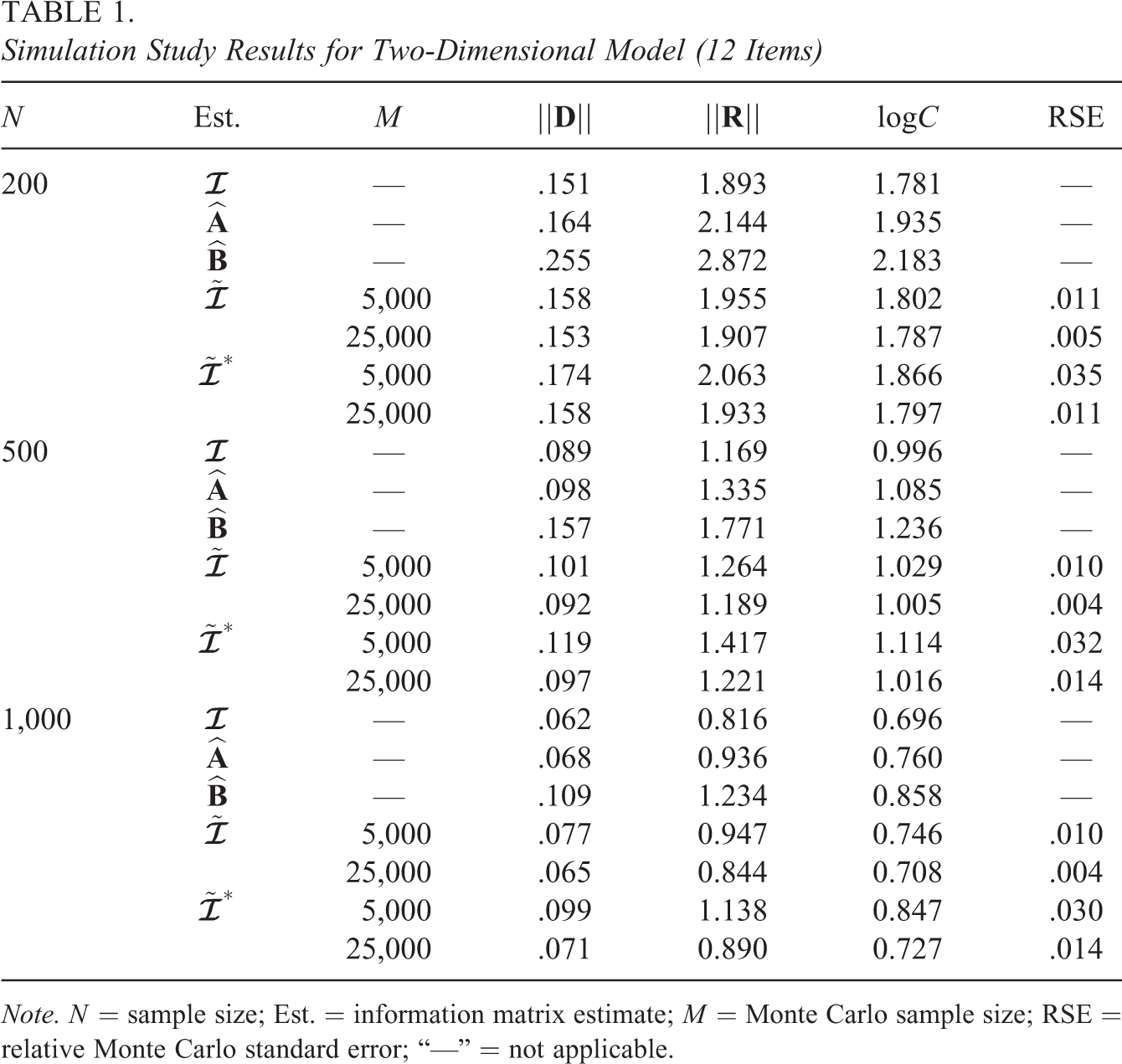
For each IM estimate and sample size, Table 1 presents the means of the outcome measures across the 500 replications. Regarding the accuracy of the estimates, unsurprisingly, the “gold standard” exhibited the best performance, for all outcome measures and sample sizes. Among the established sample-based estimates, the observed information outperformed the cross-product approximation for all outcomes and sample sizes, which is consistent with previous research (Tian et al., 2012).
Simulation Study Results for Two-Dimensional Model (12 Items)
N
Est.
M
RSE
200
—
.151
1.893
1.781
—
—
.164
2.144
1.935
—
—
.255
2.872
2.183
—
5,000
.158
1.955
1.802
.011
25,000
.153
1.907
1.787
.005
5,000
.174
2.063
1.866
.035
25,000
.158
1.933
1.797
.011
500
—
.089
1.169
0.996
—
—
.098
1.335
1.085
—
—
.157
1.771
1.236
—
5,000
.101
1.264
1.029
.010
25,000
.092
1.189
1.005
.004
5,000
.119
1.417
1.114
.032
25,000
.097
1.221
1.016
.014
1,000
—
.062
0.816
0.696
—
—
.068
0.936
0.760
—
—
.109
1.234
0.858
—
5,000
.077
0.947
0.746
.010
25,000
.065
0.844
0.708
.004
5,000
.099
1.138
0.847
.030
25,000
.071
0.890
0.727
.014
Note.N = sample size; Est. = information matrix estimate; M = Monte Carlo sample size; RSE = relative Monte Carlo standard error; “—” = not applicable.
The proposed estimators and may also be compared to , and the differences in the outcomes are attributable to Monte Carlo error. In particular, the differences in results between and are due to the Monte Carlo error when simulated response patterns are used instead of the model-implied marginal probabilities. For a fixed value of M, the differences in results between and are due to the Monte Carlo error when the unbiased estimate is used instead of the actual individual cross product . As expected, for a given M, was more accurate than for all sample sizes and outcome measures. However, with and with yielded similar results. This is notable, as computation for used integration points, while used just two.
Next, the proposed expected IM estimators were compared to the established observed IM . This comparison is informative because is the most accurate of the established methods that is routinely available. To simplify the comparisons, only the condition is used. With one exception, both and were more precise than . The one exception is that for and the statistic, outperformed . More generally, the results show that as sample size increases, the proposed estimators and the observed IM perform more similarly.
Regarding the Monte Carlo error for and , several aspects of the results are noteworthy. First, the pattern of RSE results is consistent with the results for the measures of accuracy. The lowest RSE values correspond to with , the highest values correspond to with , and the values for with and with are comparable. Second, though the RSE results depend on M, they do not appear to depend on N. This is unsurprising, as the RSE statistic quantifies the uncertainty in estimating , not . Finally, the RSE appears proportional to . This is also unsurprising, as it is a basic property of Monte Carlo integration (Robert & Casella, 2013).
4.4.2. Four-dimensional model
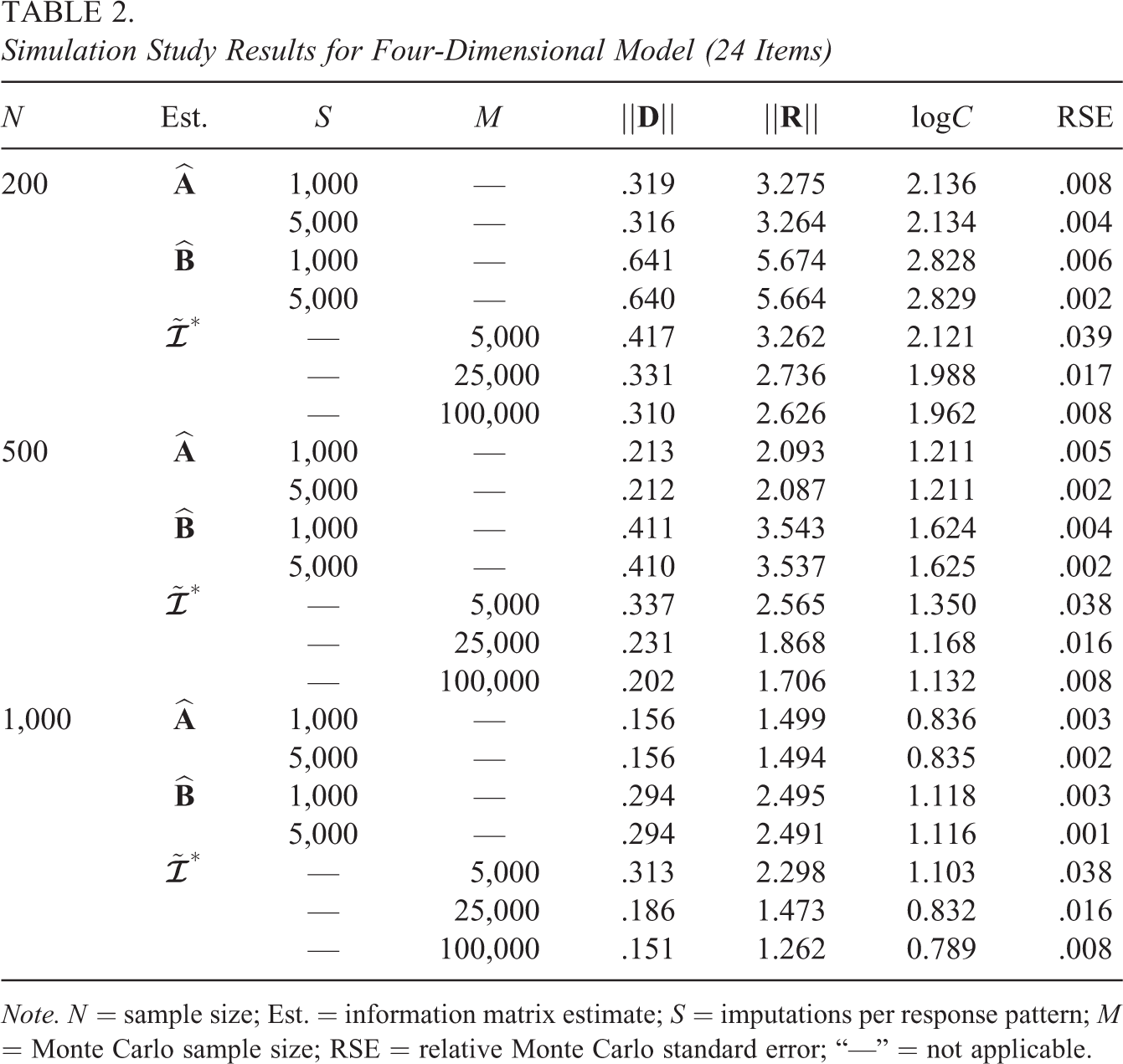
Table 2 presents the means of the outcome measures for , , and the proposed expected IM . Because and are computed by Monte Carlo for the four-dimensional model, the RSE statistic can be computed for these estimates as well. Just as with the results for the two-dimensional model, Table 2 shows that is more accurate than . For both and , the estimates are more accurate for greater sample sizes N or imputations per response pattern S. However, there is little difference in the accuracy for either or as S is increased from to . This suggests there is little Monte Carlo error for the estimates, which is confirmed by the RSE results. For example, for with and , , or .
Turning to the proposed , the estimates are more accurate for greater sample sizes N or number of simulated response patterns M. However, the differences in results for the and estimates are large enough to suggest there is nonnegligible Monte Carlo error for the estimates. Again, this may be confirmed by the RSE results, which show for the conditions. In contrast, for the conditions, .
Comparing and , it should first be noted that S and M are not directly comparable. With that said, the RSE results indicate there is less Monte Carlo error for with than for with . Nevertheless, for all sample sizes and outcome measures, with is the most accurate estimate. These results are also consistent with the results for the two-dimensional model in Table 1, where, for sufficiently large M, outperforms . From another perspective, across studied conditions, for sufficiently small RSE (e.g., ), outperforms . Thus, for the studied conditions, it is reasonable to conclude that can provide more accurate estimation than .
5. Empirical Examples
Two empirical data sets were used to compare the proposed IM estimators to the established observed IM, . The first data set is from a Grade 12 science assessment test and is made available in the TESTFACT manual (Wood et al., 2003). The sample size is , and there are dichotomously scored items. A unidimensional model was fit to the data, using the 2PL model, yielding 64 total parameter estimates. The observed IM and the expected IM estimate with were each computed and used as the basis for a set of standard error estimates. For the estimate, , indicating negligible Monte Carlo error. The two sets of standard error estimates are presented in the left plot of Figure 1. The intercept standard error estimates are, on average, greater for than for , while the slope standard error estimates are, on average, greater.
Standard error estimates for empirical examples.
The second data set is from a PISA 2003 (Organization for Economic Cooperation and Development, 2003) student questionnaire surveying mathematical self-belief. A sample of U.S. students was randomly sampled from the full data set for illustration, and items, each with four response options, were selected. The items belong to three scales theorized to be interrelated. As such, a three-dimensional simple structure model was fit to the data, using a multidimensional version of the graded response model (Samejima, 1969). This yielded 75 total parameter estimates (54 intercepts, 18 slopes, and 3 latent variable correlations). Following the simulation study, and were computed, with and , respectively. For , , and for , . Note that this latter value is slightly larger than the average RSE values reported in Table 2 for . The two sets of standard error estimates are presented in the right plot of Figure 1. There is no difference, on average, for the intercept standard error estimates for the two IM estimates. In contrast, on average, the slope standard error estimates are greater for than for , while the correlation standard error estimates are, on average, greater.
Simulation Study Results for Four-Dimensional Model (24 Items)
N
Est.
S
M
RSE
200
1,000
—
.319
3.275
2.136
.008
5,000
—
.316
3.264
2.134
.004
1,000
—
.641
5.674
2.828
.006
5,000
—
.640
5.664
2.829
.002
—
5,000
.417
3.262
2.121
.039
—
25,000
.331
2.736
1.988
.017
—
100,000
.310
2.626
1.962
.008
500
1,000
—
.213
2.093
1.211
.005
5,000
—
.212
2.087
1.211
.002
1,000
—
.411
3.543
1.624
.004
5,000
—
.410
3.537
1.625
.002
—
5,000
.337
2.565
1.350
.038
—
25,000
.231
1.868
1.168
.016
—
100,000
.202
1.706
1.132
.008
1,000
1,000
—
.156
1.499
0.836
.003
5,000
—
.156
1.494
0.835
.002
1,000
—
.294
2.495
1.118
.003
5,000
—
.294
2.491
1.116
.001
—
5,000
.313
2.298
1.103
.038
—
25,000
.186
1.473
0.832
.016
—
100,000
.151
1.262
0.789
.008
Note.N = sample size; Est. = information matrix estimate; S = imputations per response pattern; M = Monte Carlo sample size; RSE = relative Monte Carlo standard error; “—” = not applicable.
6. Conclusion
The current research proposed two strategies for estimating the expected Fisher IM. Both strategies use simulated data to calculate a Monte Carlo average and avoid direct integration over all possible response patterns. The first strategy is suitable for low-dimensional models, whereas the second strategy is designed for use with high-dimensional or otherwise complex models. The simulation study demonstrated that both strategies are more accurate than the observed IM, given a sufficiently large Monte Carlo sample size. The empirical examples demonstrated that the proposed methods yield slightly different standard error estimates than those obtained using the observed IM. Notwithstanding these examples, arguably, the newly proposed IM estimators will be most useful in settings where the accuracy of the entire IM estimate is important.
The current work can be extended in several ways. First, the simulation study only considered dichotomous items, but, as demonstrated in the second empirical example, the proposed strategies can be applied to models for polytomous data as well. Future simulation work could focus on such polytomous data models. Second, the method for monitoring the Monte Carlo error deserves further study. The simulation study only considered the RSE statistic based on the norm of the IM estimate, but future research could study alternative statistics. Additionally, it should be possible to automate the determination of the Monte Carlo sample size (Booth & Hobert, 1999). For example, a stopping rule such as could be specified. Such a rule would be useful in practice, as the Monte Carlo sample sizes used in the simulation study might not generalize well to applied settings. Third, though the utility of the estimate was explored using multidimensional IRT models, this estimate can also be applied to other relatively complex IRT models such as multilevel or latent regression IRT models. Finally, the proposed estimators can be applied to other modeling frameworks such as diagnostic classification modeling (Rupp, Templin, & Henson, 2010).
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Note
References
1.
BockR. D.AitkinM. (1981). Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika, 46, 443–459.
2.
BoothJ. G.HobertJ. P. (1999). Maximizing generalized linear mixed model likelihoods with an automated Monte Carlo EM algorithm. Journal of the Royal Statistical Society: Series B, 61, 265–285.
3.
CaiL. (2008). SEM of another flavour: Two new applications of the supplemented EM algorithm. British Journal of Mathematical and Statistical Psychology, 61, 309–329.
4.
CaiL. (2010). High-dimensional exploratory item factor analysis by a Metropolis–Hastings Robbins–Monro algorithm. Psychometrika, 75, 33–57.
5.
CaiL. (2017). flexMIRT® (Version 3.51): Flexible multilevel and multidimensional item response theory analysis and test scoring [Computer software]. Chapel Hill, NC: Vector Psychometric Group.
6.
ChalmersR. P. (2018). Numerical approximation of the observed information matrix with Oakes’ identity. British Journal of Mathematical and Statistical Psychology, 71, 415–436.
7.
DieboltJ.IpE. H. S. (1996). Stochastic EM: Method and application. In GilksW.RichardsonS.SpiegelhalterD. (Eds.), Markov chain Monte Carlo in practice (pp. 259–273). London, England: Chapman and Hall.
8.
EfronB.TibshiraniR. J. (1994). An introduction to the bootstrap. New York, NY: Chapman and Hall.
9.
FalkC. F.MonroeS. (2018). On Lagrange multiplier tests in multidimensional item response theory: Information matrices and model misspecification. Educational and Psychological Measurement, 78, 653–678.
10.
FisherR. A. (1925). Theory of statistical estimation. Proceedings of the Cambridge Philosophical Society, 22, 700–725.
11.
FoxJ. P. (2003). Stochastic EM for estimating the parameters of a multilevel IRT model. British Journal of Mathematical and Statistical Psychology, 56, 65–81.
GlasC. A. W. (1999). Modification indices for the 2-PL and the nominal response model. Psychometrika, 64, 273–294.
14.
GlasC. A. W.VerhelstN. (1989). Extensions of the partial credit model. Psychometrika, 54, 635–659.
15.
LiuY.Maydeu-OlivaresA. (2012). Local dependence diagnostics in IRT modeling of binary data. Educational and Psychological Measurement, 73, 254–274.
16.
LordF. M. (1952). A theory of test scores(Monograph No. 7). Chicago, IL: Psychometric Corporation.
17.
LouisT. A. (1982). Finding the observed information matrix when using the EM algorithm. Journal of the Royal Statistical Society: Series B, 44, 226–233.
18.
Maydeu-OlivaresA. (2013). Focus article: Goodness of fit assessment of item response theory models. Measurement: Interdisciplinary Research and Perspectives, 11, 71–101.
19.
MeilijsonI. (1989). A fast improvement to the EM algorithm on its own terms. Journal of the Royal Statistical Society: Series B (Methodological), 51, 127–138.
20.
MengX.-L.SchillingS. (1996). Fitting full-information item factor models and an empirical investigation of bridge sampling. Journal of the American Statistical Association, 91, 1254–1267.
21.
MetropolisN.RosenbluthA. W.RosenbluthM. N.TellerA. H.TellerE. (1953). Equations of state calculations by fast computing machines. Journal of Chemical Physics, 21, 1087–1092.
22.
MonroeS. (2018). Contributions to estimation of polychoric correlations. Multivariate Behavioral Research, 53, 247–266.
23.
OakesD. (1999). Direct calculation of the information matrix via the EM. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61, 479–482.
24.
Organization for Economic Cooperation and Development. (2003). PISA 2003 technical report. Paris: Author.
25.
PaekI.CaiL. (2014). A comparison of item parameter standard error estimation procedures for unidimensional and multidimensional item response theory modeling. Educational and Psychological Measurement, 74, 58–76.
26.
PritikinJ. N. (2017). A comparison of parameter covariance estimation methods for item response models in an expectation-maximization framework. Cogent Psychology, 4, 1279435. doi:10/1080/23311908.2017.1279435
27.
R Core Team. (2016). R: A language and environment for statistical computing[Computer software manual]. Vienna, Austria. Retrieved fromhttps://www.R-project.org/
28.
RangerJ.KuhnJ.-T. (2012). Assessing fit of item response models using the information matrix test. Journal of Educational Measurement, 49, 247–268.
29.
RobertC.CasellaG. (2013). Monte Carlo statistical methods. New York, NY: Springer Science & Business Media.
30.
RuppA. A.TemplinJ.HensonR. A. (2010). Diagnostic measurement: Theory, methods, and applications. New York, NY: Guilford Press.
31.
SamejimaF. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika Monograph Supplement, 34, 100.
32.
SnijdersT. A. B. (2001). Asymptotic null distribution of person fit statistics with estimated person parameter. Psychometrika, 66, 331–342.
33.
SpallJ. C. (2005). Monte Carlo computation of the Fisher information matrix in nonstandard settings. Journal of Computational and Graphical Statistics, 14, 889–909. doi:10.1198/106186005x78800
34.
TianW.CaiL.ThissenD.XinT. (2012). Numerical differentiation methods for computing error covariance matrices in item response theory modeling: An evaluation and a new proposal. Educational and Psychological Measurement, 73, 412–439.
35.
TsutakawaR. K. (1984). Estimation of two-parameter logistic item response curves. Journal of Educational Statistics, 9, 263–276.
36.
WeiG. C. G.TannerM. A. (1990). A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithm. Journal of the American Statistical Association, 85, 699–704.
37.
WhiteH. (1982). Likelihood estimation of misspecified models. Econometrica, 50, 1–25.
38.
WoodR.WilsonD.GibbonsR. D.SchillingS. G.MurakiE.BockR. D. (2003). TESTFACT 3.0: Test scoring, item statistics, and full-information item factor analysis[Computer software]. Lincolnwood, IL: Scientific Software International.
39.
YangJ. S.HansenM.CaiL. (2012). Characterizing sources of uncertainty in item response theory scale scores. Educational and Psychological Measurement, 72, 264–290.
40.
YuanK.-H.ChengY.PattonJ. (2013). Information matrices and standard errors for MLEs of item parameters in IRT. Psychometrika, 79, 232–254. doi:10.1007/S11336-013-9334-4