
Abstract
The Bayesian way of accounting for the effects of error in the ability and item parameters in adaptive testing is through the joint posterior distribution of all parameters. An optimized Markov chain Monte Carlo algorithm for adaptive testing is presented, which samples this distribution in real time to score the examinee’s ability and optimally select the items. Thanks to extremely rapid convergence of the Markov chain and simple posterior calculations, the algorithm is ready for use in real-world adaptive testing with running times fully comparable with algorithms that fix all parameters at point estimates during testing.
Keywords
Adaptive testing programs typically fix all their parameters at point estimates during testing. Use of point estimates of the item parameters rather than their true values ignores the uncertainty about them when estimating the examinee’s ability. Use of point estimates for the examinee’s parameter as well creates additional uncertainty about the values of the criterion of optimality used to select the items. Ignoring both types of uncertainty leads to the report of standard errors (SEs) for the examinees’ final scores that are generally too optimistic. At the same time, with the current increase in the number of security breaches, high-stakes testing programs feel the need to replenish their item pools more rapidly and consequently are under pressure to reduce the size of their calibration samples, which is only possible at the price of larger error in the item parameters. To accommodate this need, it has even been suggested to introduce new items with subjective initial estimates for their parameters only, updating the estimates using subsequently collected operational data (Makransky & Glas, 2010).
Adaptive testing can be formally characterized as a procedure in which we try to optimize a match between the parameters of the items and the examinee’s ability parameter. When the values of these parameters contain error, the optimization may lead to the selection of items because of the size of these errors rather than the true parameter values. The effects of this capitalization on parameter error were studied first for the problem of optimal selection of fixed test forms by Hambleton and Jones (1994) and Hambleton, Jones, and Rogers (1993) and later for adaptive testing by Cheng, Patton, and Shao (2015), Patton, Cheng, Yuan, and Diao (2013), and van der Linden and Glas (2000, 2001). From these studies, three different factors can be identified to have an impact on the effects. The first factor is the size of the errors in the item parameters in the pool from which the items are selected. Items are typically selected using a criterion of optimality based on their Fisher information at the ability estimate. In this case, the selection process tends to favor items with large positive error in the discrimination parameters, whose squared values appear as a factor in the expression of the information measure for the three-parameter logistic (3PL) model (Equation 5). Second, the number of items selected relative to the size of the pool is an important factor. The smaller the item selection ratio, the greater the likelihood of selecting items with positive estimation error. For adaptive testing, the item selection ratio is actually quite unfavorable; only 1 item at a time is selected, each time from a section of the pool supposed to be optimal at a different ability estimate. The third factor is one that actually mitigates the effects of item parameter error. Real-world adaptive testing programs typically impose constraints on their item selection necessary to guarantee satisfaction of an often large variety of content and statistical specifications and/or to serve more practical goals such as control of the exposure of the items for security purposes. These constraints reduce the effective size of the pool from which the items are selected and, in doing so, create a more favorable item selection ratio.
Hambleton and Jones (1994) selected test items for fixed forms of 10 and 20 items from a pool of 80 items calibrated using the responses of
The natural framework for dealing with parameter estimation error is a fully Bayesian approach based on the joint posterior distribution of all model parameters. The approach enables us to integrate all item parameters out of the joint distribution to obtain the marginal posterior distribution of the ability parameter to score the examinee. Unlike the SEs traditionally reported in adaptive testing, the standard deviation (SD) of this marginal posterior distribution is for the actual length of the test, avoiding the need to use any asymptotic approximation. Equally important, the approach allows us to adjust the item selection criterion for the uncertainty about all model parameter, just by taking its average across the complete joint posterior distribution.
The first to offer a Bayesian treatment of the problem of ability estimation in the presence of error in the item parameters were Tsutakawa and Johnson (1990) and Tsutakawa and Soltys (1988) who formulated the problem for fixed test forms scored under the 3PL and two-parameter logistic (2PL) models, respectively. Although their formulation was entirely Bayesian, the mathematical complexity of integrating the joint density over all item parameters to score the examinees, for instance, a total of 90 integrals for each examinee on an 30-item test under the 3PL model was simply beyond the computational means of the late 1980s (and still is). The solution they offered was Lindley’s approximation to the posterior mean and variance of the ability parameters with an adjustment for nonnormality. The empirical examples of their approximations already showed substantial improvement over estimation with the item parameters fixed at point estimates. However, though operational use of the approximations is certainly possible for the case of fixed test forms with delayed score reporting, they still are computationally much too intensive for repeated use in real-time adaptive testing. Besides, they only correct the first two moments of the final marginal posterior distribution of the ability parameter but do not give us the complete joint distribution of all parameters required for Bayesian item selection.
With the advent of modern Markov chain Monte Carlo (MCMC) methods (e.g., Gilks, Richardson, & Spiegelhalter, 1996), the challenge of multiple integrals faced by the earlier Bayesian authors has been overcome. Rather than approximating them analytically, these methods generate a Markov chain that simulates draws from the joint posterior distribution of all parameters once it has reached its stationary state, which is continued until the required degree of accuracy for the posterior computations is realized. However, MCMC methods still have the reputation of being slow, certainly for repeated real-time application in operational adaptive testing.
This article presents an MCMC method optimized for use in adaptive testing, which does produce accurate results in extremely short running times. A key feature of Bayesian adaptive testing is sequential updating of the posterior distribution of ability parameter θ of each individual examinee after each new response (as opposed to scoring all examinees afterward as in large-scale fixed-form testing). As the posterior distributions of the parameters of the items in the pool do not change, the update can easily be performed using a Gibbs sampler with a Metropolis–Hastings (MH) step for the posterior distribution of θ, while resampling vectors of draws from the posterior distribution of the parameters of the administered item saved from its calibration. For the 3PL model, the method effectively requires convergence to one unknown posterior distribution of θ in the presence of distributions for 3 item parameters that have already converged. Convergence is boosted further by the use of prior and proposal distributions for the MH step that automatically follow the posterior distribution of the θ parameter during testing. Besides, the criterion for the selection of each next item can be evaluated simply using averages calculated across the sampled values of the ability and item parameters.
The approach is believed to offer at least three advantages over adaptive testing based on point estimates of all parameters. First, as already indicated, it avoids the necessity to report systematically underestimated SEs for the ability estimates typically arrived at through asymptotic approximation, even though adaptive tests are generally much shorter than their fixed-form predecessors. Second, the approach is robust against the impact of capitalization on item parameter error during item selection in adaptive testing. Rather than capitalizing on this error, the approach accounts for it, resulting in an improved design of the test. Third, the approach illustrates a general sequential Bayesian computational scheme that can be used to manage most aspects of automated testing that require real-time parameter updating such as item selection, item calibration, monitoring of item and test security, time management, item-exposure control, and test norming (van der Linden, 2018). The key feature of the scheme is updating the intentional parameters of each of these processes while resampling the current posterior draws for all nuisance parameters. An empirical example already reported elsewhere is real-time item calibration where the focus is on the parameters of field test items added to the pool as intentional parameters and the examinees’ abilities serve as nuisances parameters (van der Linden & Ren, 2015).
The goal of this study was to find optimal settings for the algorithm with respect to such critical factors as the burn-in length of the Markov chain generated by the Gibbs sampler, the required number of post-burn-in iterations for different calibration sample sizes, the size of the item pool, and the length of the test. The study was also conducted to give us estimates of the expected running times of the algorithm when used in real-world testing programs. A final goal of the study was to empirically evaluate the balance between the increase in the SE of the ability parameter estimates and the simultaneous gain due to the improved design of the test relative to current adaptive testing with point estimates and the maximum information (MI) criterion. Ideally, the latter should compensate for the former.
Adaptive Testing
Let
The 3PL model explains the probability of a correct response as:

where

where
The items in the test are denoted as
The common item selection criterion in adaptive testing is the MI criterion, which selects the items to maximize the Fisher information about the ability parameter in the examinee’s responses. For a fixed response to item i, the observed information about θ is measured as

For a random response, Ui, Fisher’s information is the expected value of Equation 3 across its distribution in Equation 2; that is,

which for the 3PL model takes the convenient closed form of
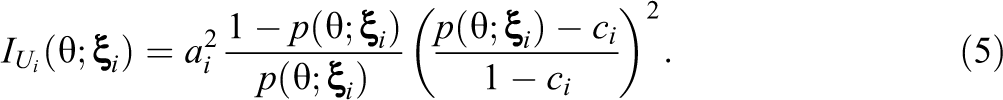
As both the ability and the item parameters are unknown, the typical approach has been to evaluate Equation 5 across all items in
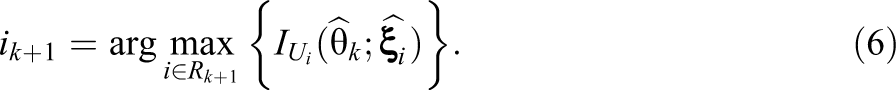
The criterion has been discussed at many places in the literature; for a review of its statistical properties, see van der Linden and Pashley (2010).
In a Bayesian approach, the update of the posterior density of θ upon the examinee’s response to the kth item involves an application of Bayes theorem as

where f(

The calculation of Equations 7 and 8 requires integration across the four unknown parameters that drove the examinee’s response to the last item. However, rather than trying to perform the integration, we evaluate it averaging across a sufficiently large sample from the joint distribution of these parameters obtained by the MCMC algorithm in the next section.
MCMC Algorithm
The proposed algorithm is a Gibbs sampler that capitalizes both on the independence of the posterior distributions of θ and
More specifically, the proposed implementation of the Gibbs sampler is as follows:
Vectors of draws selected from the last update of the posterior distributions of all parameters have been stored in the system for immediate use.
At each next update of θ, the Gibbs sampler iterates between the following two steps:
Random resampling of the vectors of draws for
An MH step to sample the distribution of θ.
Once the iterations are concluded, the vector of draws for θ currently stored in the system is overwritten with new draws collected from the stationary part of the Markov chain.
Let

that is, simply as the average of the Fisher information in Equation 5 across the available posterior draws of its parameters. The choice of the same length for the vectors of the item and ability parameters is not necessary; for vectors of unequal length, the average should be calculated recycling the shorter vector against the longer. The alternative of averaging overall possible combinations of
MH Step
Recall that, under mild conditions always met for operational adaptive testing under the 3PL model, the posterior distribution of θ converges to a normal distribution centered at its true value (Chang & Ying, 2009). An obvious choice of prior and proposal distribution during each MH step is therefore a normal with moments derived from the previous posterior update of θ. Let (

and

the choice of prior density of θ during its update after the kth item is

while as proposal density we use
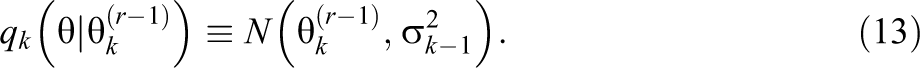
Given the symmetry of Equation 13, the MH step for the rth draw during this update of the posterior distribution of θ simplifies to
draw candidate value
accept
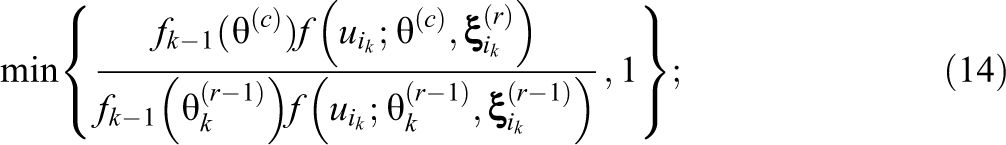
otherwise keep the draw from the previous iterative step,
In most applications of Gibbs samplers with MH steps, tuning of the proposal distribution to create acceptance rates in the optimal range of 30%–40% is a time-consuming task. If its scale parameter is chosen to be too great, the number of rejected draws becomes too large. For scale parameters that are too small, the chain converges more slowly than necessary. The proposal distribution in Equation 13 does not require any tuning though. Its location automatically follows that of the current posterior distribution with a variance that is always somewhat greater, which has been proven to be an efficient choice for samplers for low-dimensional parameters (Gelman et al., 2014, section 12.2).
Computationally, everything is extremely simple. The only quantities that need to be calculated are (1) the averages in Equations 10 and 11 and (2) the product of the prior density and the probability of the kth response in the numerator of the acceptance probability in Equation 14 (its denominator was the numerator in the preceding iteration step and need not be recalculated). Unlike adaptive testing with maximum-likelihood estimation of θ, there is no product likelihood with a number of factors that grow during the test; instead, the entire history of each examinee is captured in the most recent posterior distribution of his or her ability parameter. For the selection of the next item, the only necessary quantity to compute is the simple average in Equation 9.
Observe that Equation 12 involves a normal approximation of the prior distribution of θ only. Although the approximation may seem to be reminiscent of Owen’s (1969, 1975) first attempt at a Bayesian approach to adaptive testing, it differs fundamentally in that Owen’s approach was based on item selection with a normal approximation of the posterior distribution, whereas in our approach, the actual posterior distribution is just sampled (including the final posterior distribution used to report the examinee’s ability estimate). Also, only the shape of the prior distribution is taken to be normal; its mean and variance are still empirical. The impact of the choice of a prior on its posterior distribution is generally known to consist of bias toward the mean of the prior with a size dependent on its variance. However, in adaptive testing, ability estimates invariably are close to the true value after some 5 to 7 items (the rest of the test is basically to reduce the size of the SE to an acceptable level). At this point, possible bias toward the empirical prior mean is already negligible. The larger variance of the prior distribution during the first few items in the test is most welcome; it avoids unwarranted stability of the initial bias. If for some reason a normal shape for the prior distribution of the ability parameter would be undesirable, an alternative is to use smooth estimates of the previous posterior density at
The assumption of a normal proposal distribution in Equation 13 is pretty much standard practice in the world of MH within Gibbs sampling. It does have an impact on the speed of convergence of the algorithm but not on the statistical properties of the converged results. The main concern of choosing a proposal density is adequate coverage of the intended posterior distribution. As just argued, the fact that our choice of prior automatically follows the posterior distributions with a scale somewhat greater than the latter does guarantee this.
Monte Carlo Error
Posterior results obtained from Gibbs samplers have Monte Carlo error. However, the error can be reduced to negligible size just by continuing the iterations after burn-in. In order to calculate the required number of these iterations, the following argument can be applied: Our interest is in reporting the posterior mean of the θ parameter to the examinee. After n items, the mean is estimated with uncertainty equal to the posterior variance
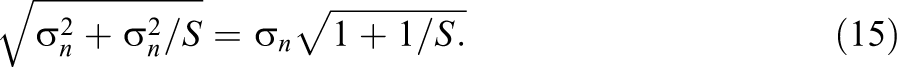
The equation shows that even for small sample sizes, the impact of the Monte Carlo error already becomes negligible. For instance, for

where R now is the total number of post-burn-in iterations of the Markov chain and
In the interest of efficient memory management, an obvious strategy is to find the lag size

and save all iterations.
Empirical Studies
Several simulation studies were conducted to (1) optimize the Gibbs sampler for use in adaptive testing under a variety of possible conditions and (2) evaluate the impact of the proposed Bayesian approach on the statistical properties of the final ability estimates. Specifically, the first set of studies was to find the minimal choice for the burn-in length of the Markov chain and the required number of post-burn-in iterations under various conditions. They were also conducted to give us estimates of the running times of the algorithm required for these choices. The second set of studies was to evaluate the approach using such statistical quantities as the SE and bias functions of the final θ estimates. As already indicated, one consequence of ignoring all parameter uncertainty in current MI adaptive testing is systematic underestimation of the error in these estimates. Another is less than optimal design of the test. The second set was conducted to assess to what extent improved Bayesian design of the test would compensate for a more realistic estimate of the SE.
General Setup
A pool of 210 items was randomly sampled from an inventory of previously used operational items that had been shown to fit the 3PL model in Equation 1. Figure 1 shows the empirical distributions of the values of the item parameters. The ranges were [0.41, 2.08], [−2.44, 2.96], and [0.10, 0.32] for the ai, bi, and ci parameters, respectively, with means (SDs) equal to 1.08 (0.35), 0.16 (1.22), and 0.21 (0.03). All simulations were for adaptive tests with a length of n = 10, 20, and 30 items. The size of the item pool was chosen to be just over 10 times the middle test length of
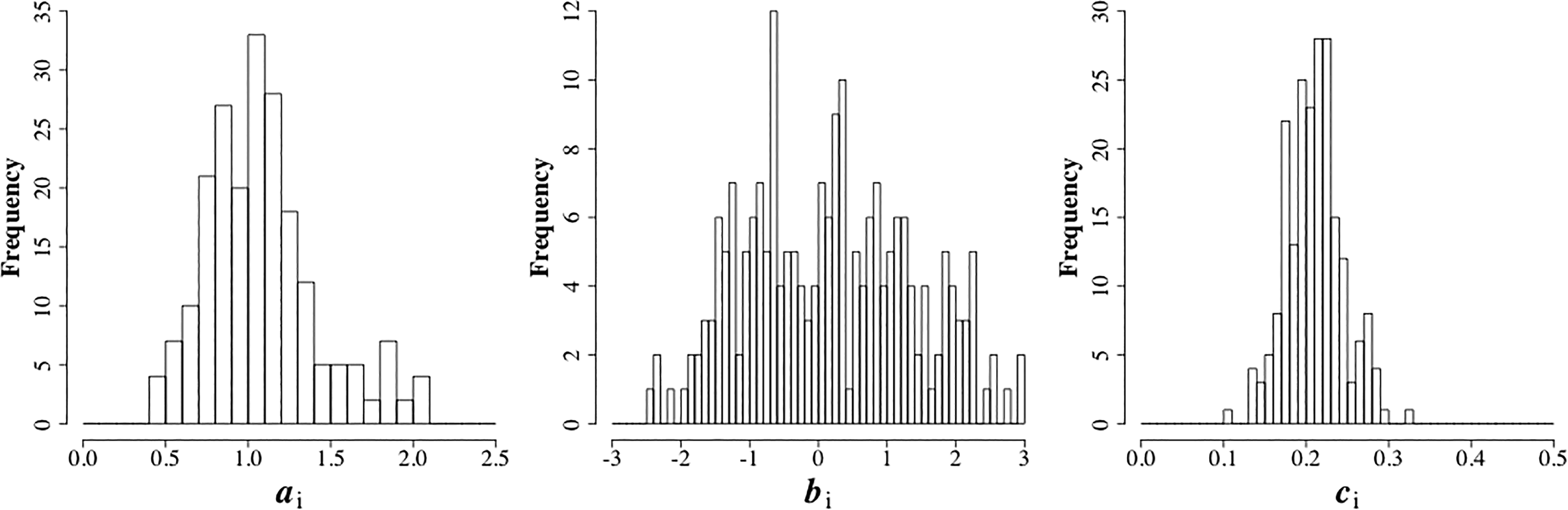
Empirical distributions of parameters ai, bi, and ci in the item pool.
Three different sets of calibration data of size
Figure 2 shows plots of the posterior means of the 3-item parameters versus their true values. Clearly, the best results were obtained for the sample size of N = 1,000. The recovery of the bi parameters was relatively best among the three kinds of parameters, with good results even for the two lower sample sizes. The plots for the critical ai parameters show considerable scatter for each of the three sample sizes, obviously with larger scatter for the smaller sizes. For the largest sample size, most of the scatter was observed at the upper end of the scale. For the ci parameters, the choice of sample size did not have much of an impact. A summary of these results is given in Table 1.
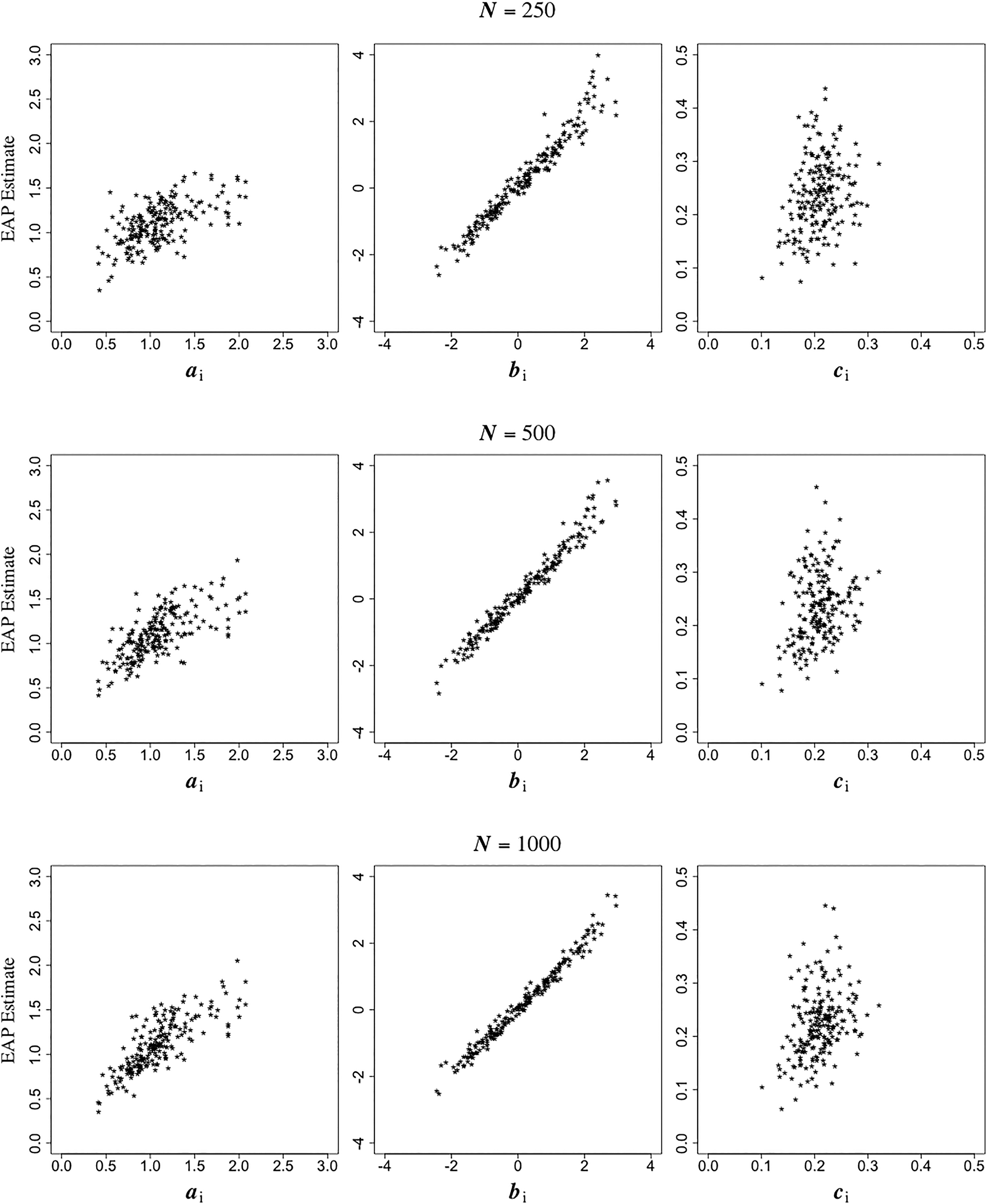
EAP estimates versus true item parameter values after item calibration with sample sizes of N = 250, 500 and 1,000.
Mean, SD, and RMSE of Item Pool Parameter Estimates
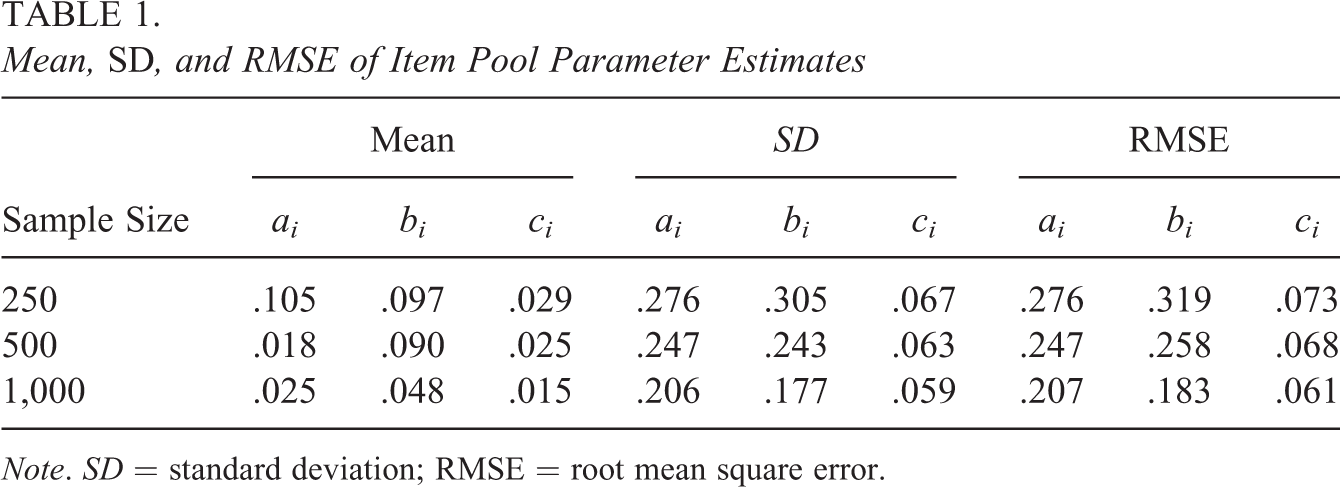
Note. SD = standard deviation; RMSE = root mean square error.
The criterion of effective sample size in Equation 16 was used to determine the length of the vectors of draws from the posterior distributions of the item parameters in the pool to be saved for use in adaptive testing. Figure 3 shows the autocorrelation plots for the posterior draws for the item parameters for each of the three calibration samples produced during the stationary part of the Markov chain as a function of the lag size, l. For a choice of
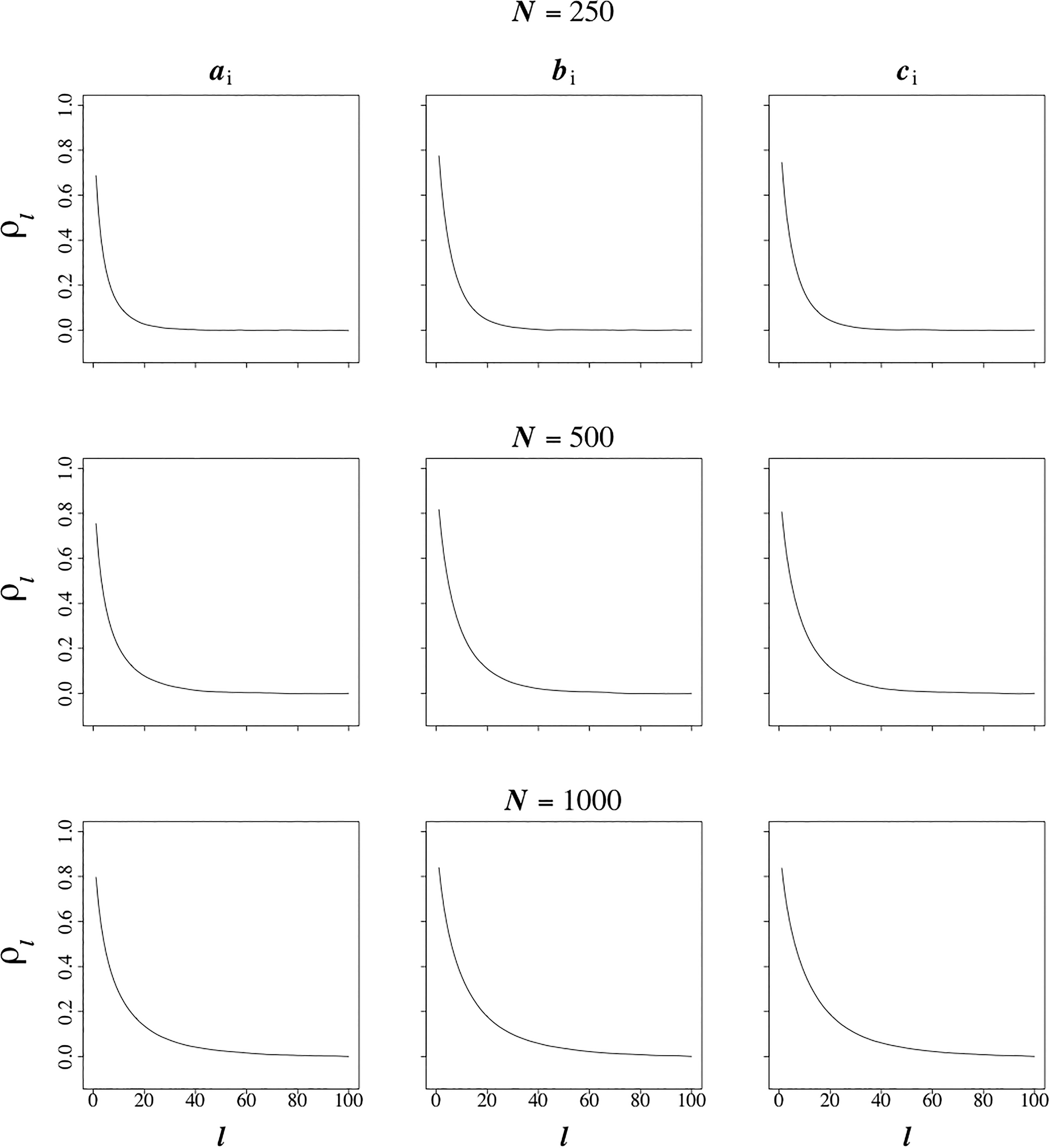
Autocorrelation ρ l in the Markov chains for the items parameters as a function of lag size l for each of the calibration sample sizes of N = 250, 500, and 1,000.
Pre- and Post-Burn-In
The goal of the main part of our study was to find the necessary length for burn-in of the Markov chain for θ during adaptive testing, the required number of additional iterations, and the best size for the vectors of the draws for θ to be saved for the calculation of the item selection criterion in Equation 9. Adaptive tests were simulated using the Bayesian algorithm exactly as introduced above with vectors of draws for the item parameters set at the level of S = 500 used throughout our simulations. All responses were generated for simulated examinees with true ability parameter values of
Our first step was to visually inspect several trace plots for the speed of convergence. Figure 4 shows a few typical examples of the first 2,000 draws of the chain for simulated examinees recorded after k = 1(5)26 items. To be able to present robust results, the chains were initialized choosing starting values with signs opposite to the true value of the ability parameter; for instance, a starting value of
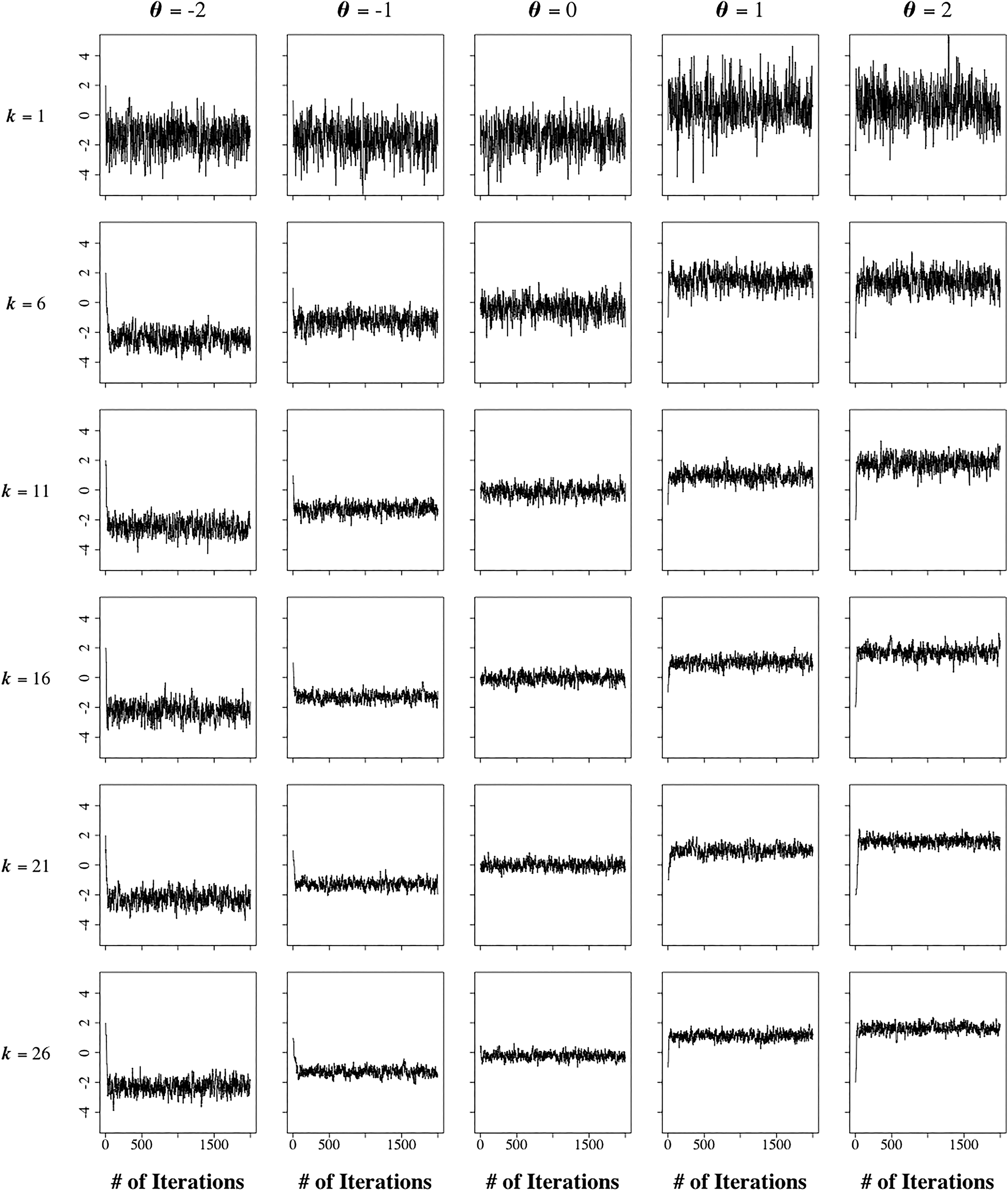
Examples of the first 2,000 iterations of the Markov chain Monte Carlo algorithm during the posterior updates of the ability parameter after k = 1(5)26 items for examinees simulated at θ = −2(1)2.
The minimum length of burn-in was determined using the well-known Gelman and Rubin (1992) statistic for multiple MCMC chains,
Table 2 shows the averages and SDs of the number of iterations required to meet the criterion as a function of k = 1(6)26 for each of the five simulated θ values and three calibration sample sizes. None of these factors did appear to have any systematic impact on the number of iterations required for the chains to mix. Figures 5 and 6 show plots with the proportions of replications failing to meet the criterion of
Number of Burn-In Iterations Required to Meet
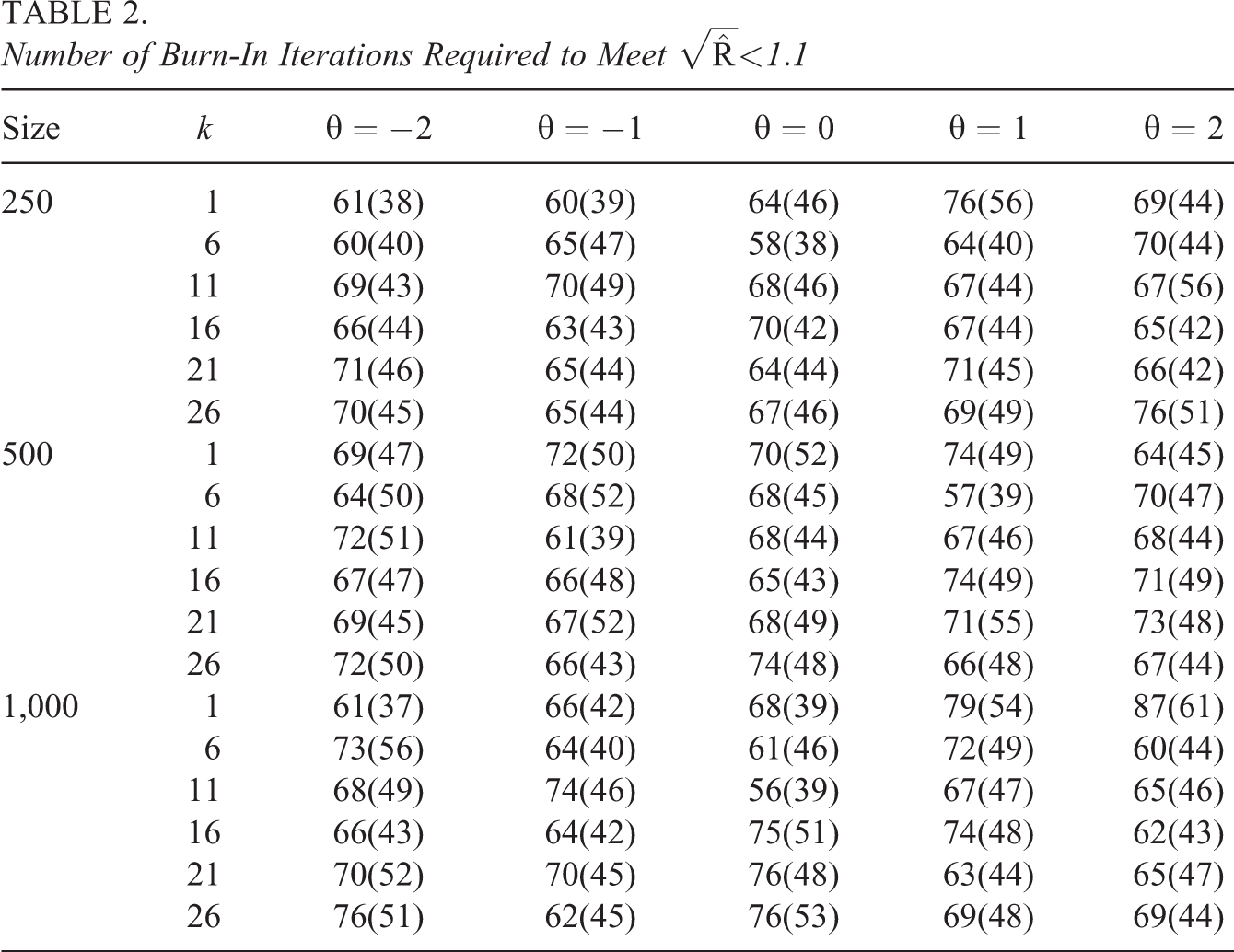

Proportion of replications failing to meet the convergence criterion of
Proportion of replications failing to meet the convergence criterion of
The final decision on the use of the algorithm was with respect to the number of post-burn-in iterations necessary for item selection in adaptive testing. To estimate the autocorrelation of the chain as a function of the time lag, adaptive tests were simulated with 100 replications at each of the true values of

Autocorrelation ρ l in the Markov chains for the ability parameter as a function of lag size l after k = 1(5)2 items for examinees simulated at θ = −2(1)2 and a calibration sample size of N = 250 (solid curves: mean; dashed curves: 5th and 95th percentiles).
Autocorrelation ρ l in the Markov chains for the ability parameter as a function of lag size l after k = 1(5)26 items for examinees simulated at θ = −2(1)2 and a calibration sample size of N = 1,000 (solid curves: mean; dashed curves: 5th and 95th percentiles).
In order to determine the size of the vector of draws of θ to be saved from the thinned chain, adaptive tests of n = 30 items were simulated saving vectors of length of S = 100, 200, and 500 draws from the posterior distribution of θ (implying the necessity of 1,000, 2,000, and 5,000 post-burn-in iterations given the chosen thinning factor, respectively). Figure 9 shows the estimated bias and SE functions calculated from 100 replications at

Bias and standard error of the final ability estimates after n = 30 items for examinees simulated at θ = −2(1)2, vectors of S = 100 (dotted curves), 200 (dashed curves), and 500 draws (solid curves) saved after each posterior update, and calibration sample sizes of N = 250, 500, and 1,000.
Running Times
The average running time across all replications during the simulations with the vector lengths of S = 100, 200, and 500 for the saved draws for θ was 0.009, 0.012, and 0.015 seconds per item, respectively. Based on all these results, it was decided to run all remaining simulations for S = 500 draws for θ from the thinned stationary part of the chain during the test.
Adaptive Testing Results
Our final simulations were to evaluate the performance of the proposed Bayesian algorithm for the choices of 250 burn-in and 500 × 10 = 5,000 post-burn-in iterations, each time saving
and
respectively, where
Figures 10
through 12 report each of these three functions for the calibration samples of N = 250, 500, and 1,000 examinees. The differences between the two algorithms follow the same pattern for all three sample sizes; however, the smaller the size, the more pronounced the pattern. Interestingly, the bias functions for the two algorithms showed an opposite trend with an increase of test length. The Bayesian algorithm began with an inward bias, but as more responses were collected, the bias disappeared and the functions approximated their desired flat shape. Apparently, the prior distribution served as an effective initial buffer against a data-driven outward bias for this algorithm, which became less necessary when more responses were collected. On the other hand, the MI algorithm began with a flat function for n = 10 but produced functions with an outward bias for n = 20 and 30. The SE functions for the Bayesian algorithm ran practically flat across all conditions, but at a lower height for a larger test length, of course. The same was the case for the MI algorithm for

Bias, standard error, and root mean square error of the final ability estimates as a function of θ for adaptive test of n = 10, 20, and 30 items and a calibration sample size of N = 250 (solid curves: Bayesian algorithm; dashed curves: maximum information algorithm).
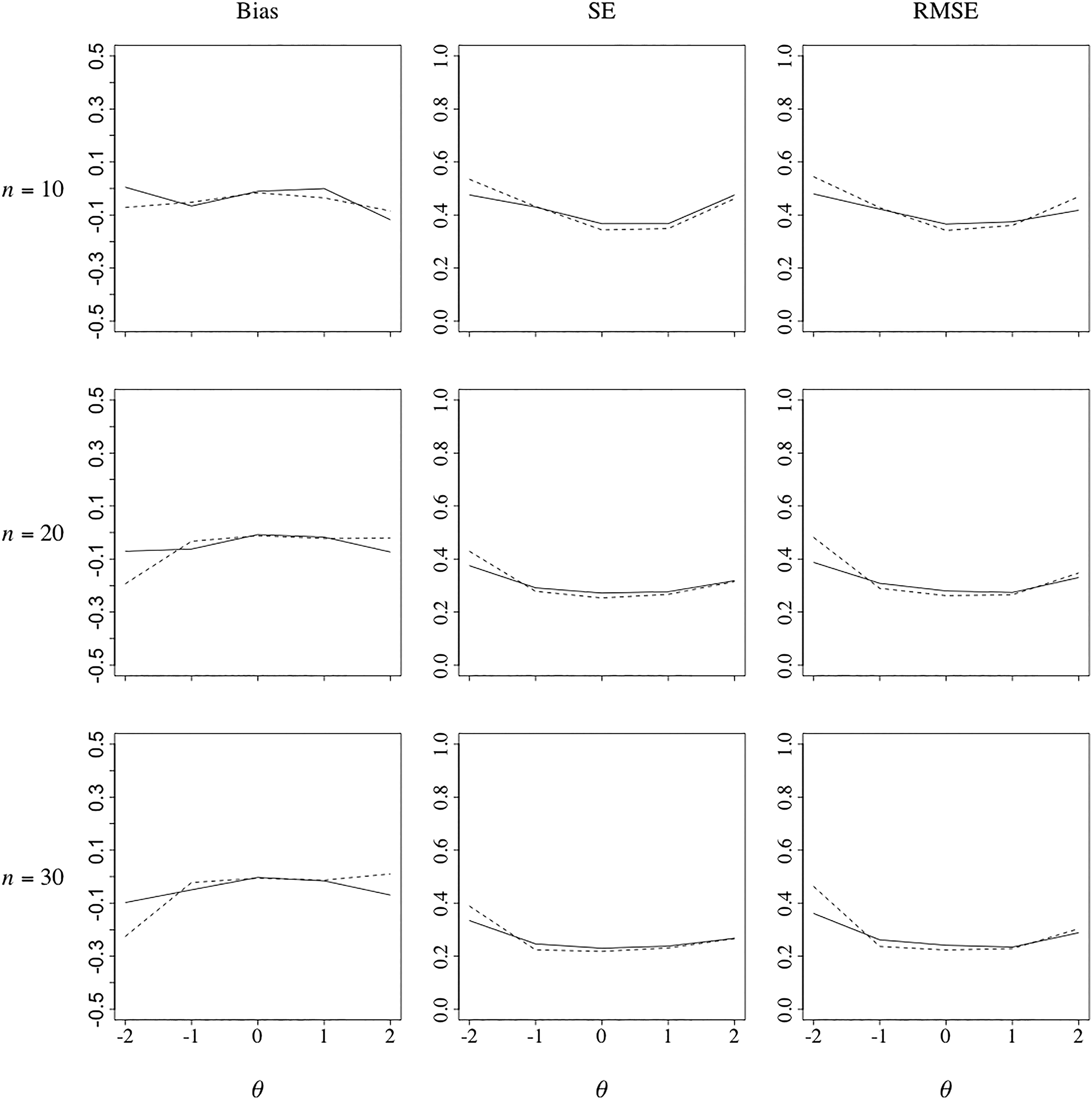
Bias, standard error, and root mean square error of the final ability estimates as a function of θ for adaptive test of n = 10, 20, and 30 items and a calibration sample size of N = 500 (solid curves: Bayesian algorithm; dashed curves: maximum information algorithm).
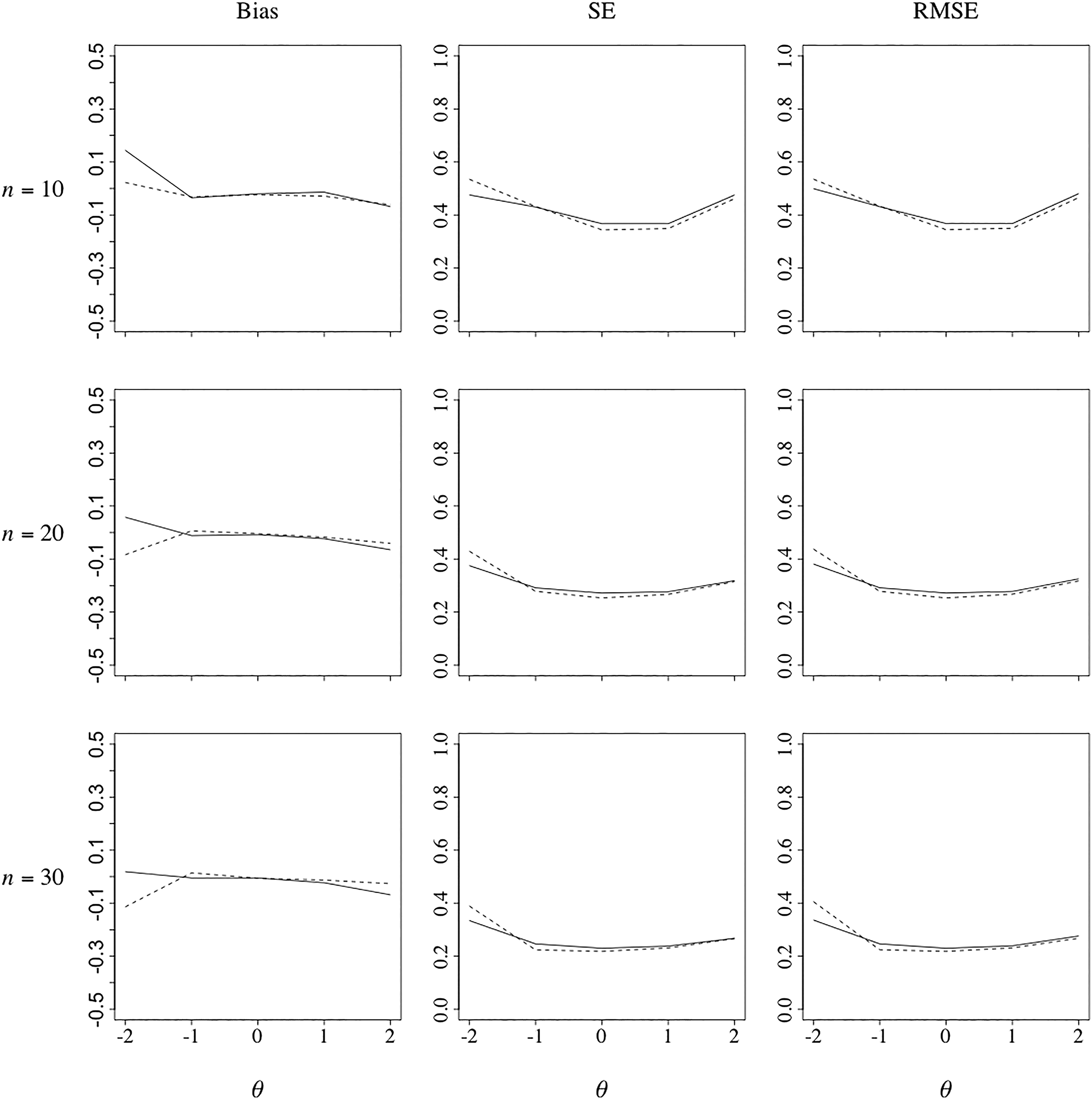
Bias, standard error, and root mean square error of the final ability estimates as a function of θ for adaptive test of n = 10, 20, and 30 items and a calibration sample size of N = 1,000 (solid curves: Bayesian algorithm; dashed curves: maximum information algorithm).
The major lesson the authors learned from this last study was that the reward for the honesty of the Bayesian approach about parameter uncertainty in adaptive testing was not so much direct compensation for the expected increase in the SE of its final ability estimates as a reduction of the bias these estimates might have occurred otherwise. The net effects tended to be positive at the lower end of the scale where estimation error generally tends to be more prominent due to the effects of guessing. We expect these effects to be less prominent under the 2PL model. But adaptive testing does require items that are scorable in real time. Every major adaptive testing program the authors are aware of use multiple-choice items for this reason, a condition under which the 2PL model is unlikely to show satisfactory fit to the response data.
Concluding Remarks
The proposed MCMC algorithm, with its exploiting both of the special structure of the posterior distributions of the item and ability parameters and the sequential nature of adaptive testing, appears to be simple and fast. Running times for a conservative configuration of the algorithm of 0.015 seconds or less per item, as reported above, are low enough for application in real-world adaptive testing.
It is easy to generalize the algorithm to other than the 3PL model used in this article. The change would only involve the substitution of two different expressions, one for the Fisher information in Equation 5 and the other for the probability function
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.