
Abstract
Evaluating blocked randomized experiments from a potential outcomes perspective has two primary branches of work. The first focuses on larger blocks, with multiple treatment and control units in each block. The second focuses on matched pairs, with a single treatment and control unit in each block. These literatures not only provide different estimators for the standard errors of the estimated average impact, but they are also built on different sets of assumptions. Neither literature handles cases with blocks of varying size that contain singleton treatment or control units, a case which can occur in a variety of contexts, such as with different forms of matching or poststratification. In this article, we reconcile the literatures by carefully examining the performance of variance estimators under several different frameworks. We then use these insights to derive novel variance estimators for experiments containing blocks of different sizes.
Keywords
1. Introduction
Beginning with Neyman and Fisher, there is a long literature of analyzing randomized experiments by focusing on the assignment mechanism rather than some generative model of the data. One major family of experimental designs in this literature is the blocked randomized experiment, where units are grouped to hopefully create homogenous collections, and then treatment assignment is randomized within each group (see Fisher, 1926). Ideally, this process gives a higher precision estimate of the overall average treatment effect as compared to a completely randomized design.
In the potential outcome causal literature (as in Imbens & Rubin, 2015; Rosenbaum, 2010), 1 much of the prior work on randomized experiments has focused on two forms of blocking: blocking where there are several treated and control units in each block and blocking where there is exactly one treated and one control unit in each block (matched pairs). See, for example, Imai et al. (2008) or Imbens (2011) for treatments of large blocks and Abadie and Imbens (2008) or Imai (2008) for treatments of matched pairs. This literature, for the most part, has a gap: It has not extensively treated the cases where researchers have generated groups of varying size but where there is still only one treated and/or one control in some of the blocks, which we call the “hybrid design.” Recent textbooks such as Field Experiments: Design, Analysis and Interpretation (Gerber & Green, 2012) and Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction (Imbens & Rubin, 2015) do not propose a clear answer for Neyman-style variance estimation in this case. While obtaining a point estimate for the overall average treatment effect is straightforward in this context, assessing the uncertainty of such an estimate is not. Currently one would instead have to turn to Fisher-style permutation tests, which typically rely on constant treatment effect assumptions, or regression-based approaches, which can be biased and usually require assumptions as to the residual error structure. We build on prior work to fill this gap by providing novel methods for conducting Neyman-style analyses for this more general hybrid design. The approach to causal inference used in this work also has strong connections to the survey sampling literature, as treated in, for example, Särndal et al. (2003) or Cochran (1977).
This gap is important as hybrid experiments with blocks of different sizes, and different numbers of treated and control units within the blocks, can easily arise in many modern social science experiments. For example, multisite trials in education often have several sites (e.g., districts) with only a few schools in each site. Many matching methods used in observational studies generate hybrid designs as well. For instance, coarsened exact matching (CEM; Iacus et al., 2012) can lead to many variable-sized blocks, some of which have singleton treatment or control units. “Full matching,” which identifies collections of units that are similar on some baseline covariates (Hansen, 2004; Rosenbaum, 1991), creates variable-sized blocks, each with exactly one treated or one control unit. Our approach allows for a Neyman-style analysis in these contexts. See Section 6 for more on these applications.
There are several different models used for Neyman-style causal inference. The first, the finite sample model, takes the sample of units in the experiment as fixed, using the assignment mechanism as the sole source of randomness. Other so-called super-population or population models assume that the units in the experimental sample come from some larger population; this can induce additional uncertainty that needs to be accounted for. With blocking, there is the further complication of how the blocks in the final experimental sample are formed. There can be fixed blocks in which every unit inherently belongs to one of a finite number of blocks; flexible blocks made by the experimenter once a sample is obtained; and structural blocks that capture natural groupings of units. There are also several possible sampling mechanisms beyond the classic simple random sampling of units typically presumed, such as sampling from strata corresponding to the blocks or sampling entire blocks rather than individual units. We believe these variants in how blocks are formed and sampled has caused the gap of the hybrid design: Because much of the current literature uses different frameworks tailored to the specific special cases of either large blocks or matched pairs, it is not easily extended as the variance and variance estimators differ across these variants. As part of our work we carefully outline the common frameworks used and discuss how they are different from each other and how they connect to different types of blocks. We also analyze the performance of uncertainty estimation for all cases.
Recent work by Fogarty (2018) has also addressed some of these issues. In particular, Fogarty presents a method for estimating variance with small blocks of variable size, not just matched pairs. His estimators share some similarities with ours, though they are distinct and we note the difference in bias in Section 3.4. He also makes explicit the issue of differing results under different population and sampling frameworks by comparing multiple settings. In our article, we tackle the issue of creating a cohesive hybrid estimator for experiments with large and small blocks and do not focus on the use of covariates to model treatment effect heterogeneity.
In Section 2, we set out our notation and discuss blocked randomization. We begin with the finite sample framework because it is a building block for the infinite population frameworks. Section 3 provides methods for estimating uncertainty in the case of large blocks, small blocks, and the hybrid of the two and gives their bias under the finite sample framework. We then, in Section 4, provide true variance formula and the performance characteristics of the variance estimators for several infinite population frameworks. Section 5 contains finite sample simulation studies to illustrate estimator performance, and Section 6 illustrates estimation in two data examples. For clarity in presentation, we have moved the derivations of provided formulae to the Supplementary Material, available in the online version of the journal. To use these methods in practice, we refer readers to our R package,
2. Overall Setup and Notation
We use the Neyman–Rubin model of potential outcomes (Rubin, 1974; Splawa-Neyman et al., 1923/1990). We assume the Stable Unit Treatment Value Assumption of no differential forms of treatment and no interference between units (Rubin, 1980). Consider an experimental sample of n units. In a completely randomized experiment, the entire collection of the units is divided into a treatment group and a control group by taking a simple random sample of
The sample average treatment effect (SATE) is the typical estimand in so-called finite sample inference, which takes our sample as fixed, leaving the assignment mechanism as the only source of randomness. Under blocking, the SATE within block k, for

where

In this work, we consider two estimators for the SATE (and later the population average treatment effect [PATE]), one typically used for complete randomization and one for blocked randomization. Define the variable Zi as
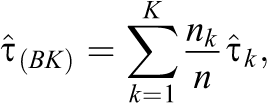
with the
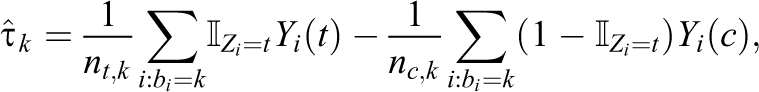
In general,
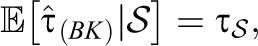
with
An important aspect of blocking is how the blocks are formed. Explicit articulation of block formation will be useful when we discuss asymptotic properties of our estimators and will also be used to differentiate the various population frameworks in Section 4. We identify three primary ways that blocks are formed: Fixed blocks: It occurs when the total number of blocks and the covariate distribution of blocks is fixed before looking at the sample. For example, blocking that occurs on a single categorical covariate. Flexible blocks: It occurs when the covariate distribution and total number of blocks may not be known before looking at the sample’s covariates. For example, if there are many covariates or continuous covariates and matching or discretizing is used to form blocks. Structural blocks: It occurs when units have some natural grouping such that the blocks are self-contained. The members of each block are fixed, and if a block is represented in the sample, typically all members of that block are in the sample. For example, twins or classrooms.
Note that structural blocks are often thought of as clusters. With clusters, however, treatment assignment is commonly assigned at the cluster level, whereas we are focusing on treatment assigned within cluster. We use “structural block” to clarify this difference.
3. Variance Estimation
We next discuss how to estimate a blocked estimator’s variance, an integral part of obtaining standard errors and confidence intervals. We discuss from a Neyman–Rubin randomization perspective. See online Supplementary Material A for a discussion of alternative variance estimators (such as from linear models) that make additional assumptions on the data structure. We first investigate bias under a finite sample framework and extend to other frameworks in Section 4.
We start by giving the true variance in the finite sample. To do so, we need some additional notation. The mean of the potential outcomes for the units in the sample under treatment z for block k is
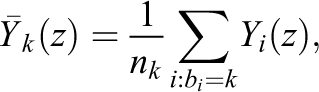
the sample variance is
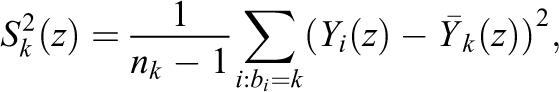
and the sample variance of the individual-level treatment effects is
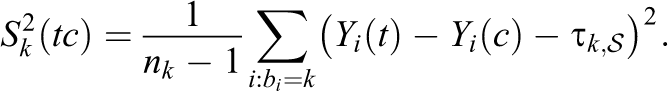
For the finite sample, the variance of
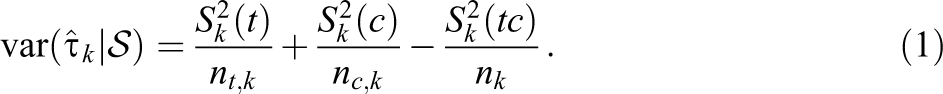
Summing these across the independent blocks, with the weights for block sizes, gives an overall variance of

For blocked experiments, the type of variance estimator one would use in the finite sample depends on the sizes of blocks one has. In cases where we have at least two treated and two control units in each block, we can directly extend classic results for completely randomized experiments by using them within each block and weighting (see, e.g., Imbens, 2011; Miratrix et al., 2013; Mukerjee et al., 2018). In particular, we can estimate each variance component of Equation 2 as
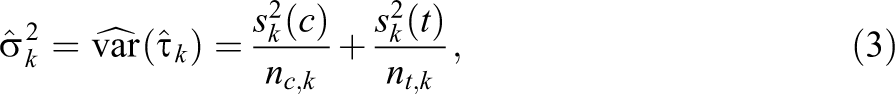
with

This gives a conservative estimate due to the dropping of the
For the “small blocks” case, where our blocks have only one treated unit or one control unit, we need to use an alternative approach as we cannot estimate the variance for a treatment arm with a single unit. Our approach is presented below. To give some background, the analytical problems that arise when estimating the variance in matched pairs experiments, especially when working in the finite sample framework, have been lamented by many statisticians (see, e.g., Imbens, 2011). The issues arise from the fact that there is no way to estimate the within pair variance with only one unit assigned to treatment and one unit assigned to control in each pair. Previous work has found conservative estimators, however, which we build on. For instance, Imai (2008) showed that the standard matched pairs estimator is biased in the finite sample setting and put bounds on the true variance. The RCT-YES R package and documentation (Schochet, 2016) also provides a conservative variance estimator for the matched pairs design (as well as estimators for blocked designs); this is discussed more in online Supplementary Material A.3. For a hybrid experiment with both big and small blocks, we combine results to create an overall variance estimator.
3.1. Small Block Experiments With Equal-Size Blocks
When we have small blocks of the same size, we can directly use the usual variance estimator in the matched pairs literature (e.g., Imai, 2008) as a variance estimator for

This estimator directly estimates the variance of the overall block treatment effect estimator rather than estimating the variance for each individual block and then weighting. We will see that, depending on the framework used, this estimator can give positively biased estimates if the true
3.2. Small Block Experiments With Varying Size Blocks
For experiments with small blocks of varying sizes, we offer two variance estimators. The first directly extends the standard matched pairs estimator by grouping the blocks by size into J groups and using Equation 5 for each group. We then weight and combine to get an overall variance estimator.

where Kj is the number of blocks of size mj and
with
The second approach allows the variance of all of the small blocks to be estimated at the same time, without requiring multiple blocks of the same size.

For
3.3. Hybrid Experiments
When doing variance estimation in a hybrid blocked design, we can split the blocks up into small blocks and big blocks. Grouping the big and small blocks together allows us to write the causal effect estimand as a combination of two estimands for our two different types of block sizes. Let there be

where

The estimator for the overall treatment effect can also be written as

For finite sample inference, we can similarly break down the variance, and estimator of the variance, of

Here, we would use
3.4. Finite Sample Bias of the Variance Estimators
In the finite setting, all of the above estimators are conservative and are only unbiased in specific circumstances. Each block is a miniature complete randomized experiment. For such experiments,

If all of the blocks have at least two treated and two control units, we can extend this result to
This extends readily to the big block component of the hybrid estimator by only including in the sum those blocks that are big, changing the n2 in the denominator by
For the small blocks of varying sizes, we have two main results. In presenting these, we assume that the whole sample is made up of small blocks, though, as with the bias of

The above extends prior results for
For

assuming no blocks have
If the average treatment effect is the same across all small blocks then this estimator is unbiased, and if there is heterogeneity, it is conservative. This is a distinction from the behavior of the variance estimator suggested in section 4.2 of Fogarty (2018) for use with variable size small blocks without covariates, in which even with the average treatment effect being the same across all small blocks, the bias is strictly greater than zero.
The improved potential performance of
Mukerjee et al. (2018) create a general framework for a class of conservative Neyman variance estimators that extends to a variety of causal estimands and estimators in the finite sample context. Of our estimators,
For our estimators, how conservative the estimators are may vary with blocks sizes. In the case where all blocks are the same size, when we have blocks with m control units and one treated unit, as m increases the variance of the treatment effect estimator will decrease, as we are getting a more precise estimate for the control units. However, the form of the bias of
The type of blocks also impacts whether the bias of these estimators go to zero as sample size increases. For instance, one might argue for the use of
In the hybrid setting, the overall bias will be a weighted sum of the biases for the big and small block components. Therefore, because the overall weighting depends on the block sizes, having a poor estimator for the small blocks may not have a large effect on the overall bias if small blocks make up only a small proportion of the sample.
There is no way to unbiasedly estimate variance within small blocks without additional structure or covariates. If we think that the treatment effects of different strata are not too far apart, then we suggest using one of the previous estimators. We at least know that the bias incurred is positive. However, if we have reason to believe that the treatment effects of different strata will be very far apart, a plug-in estimator, as discussed in online Supplementary Material A, may be more appropriate.
4. Infinite Population Frameworks
Up to this point, we have examined blocking in a finite sample framework, conditioning on the units in the experiment in question. In the literature, however, blocking has often been examined under a variety of infinite population frameworks. In particular, the matched pairs literature uses a framework where the blocks themselves are sampled from an infinite population of blocks, whereas the big block literature typically assumes stratified random sampling from a finite number of infinite size strata. Using different population frameworks will give different answers to important questions of what the true variance of the treatment effect estimate is and what the bias of our variance estimators are. In this section, we first discuss the literature related to variance estimation for infinite populations, identifying the apparent tensions that exist. We then systematically discuss different frameworks, deriving the true variance of the treatment effect estimators under each of them. We also evaluate the bias of the variance estimators introduced in Section 3. We focus on infinite superpopulations; finite superpopulations substantially larger than the sample would give similar results. We explore work pertaining to the use of linear models, such as Cochran (1953) and Lin (2013), in online Supplementary Material A.1. An important note is that in some cases, these sampling schemes are chosen for convenience and that the generalizability of the experiment to the population will depend upon the assumptions made in them being true. The sampling model may also be considered to serve as a conservative approach to finite sample inference (see Ding et al., 2017).
Related Work
For matched pairs experiments, Imai (2008) showed that with a superpopulation of an infinite number of structural blocks, specifically matched pairs, from which pairs are randomly sampled, the standard matched pairs variance estimator (Equation 5) is unbiased for the PATE. On the other hand, Imbens (2011) showed that the standard matched pairs variance estimator is biased in the setting where we have fixed blocks and units are drawn using stratified random sampling (see Section 4.3 for more on this setting). This is a clear example of how the population framework being used matters. We therefore advise practitioners to carefully consider what population and sampling structure they are assuming and to not simply assume a framework for convenience.
The general blocked design has been previously discussed in various forms. Imbens (2011) discussed blocking in the context of a superpopulation with a fixed number of strata from which units are sampled using a stratified sampling method. He formed unbiased estimators for the variance in this context, assuming that the blocks each have at least two units assigned to treatment and control. These results are similar to finite sample results discussed in Section 3 and will be discussed more in Section 4.3. Imai et al. (2008) analyzed estimation error and variance with the blocked design. Scosyrev (2014) also analyzed the blocked experiment in the finite sample and under two sampling frameworks, recognizing that the different settings resulted in different outcomes. Sävje (2015) analyzed flexible “threshold” blocking and made critical points about the importance of block structure and sampling design when analyzing blocked experiments, which we will echo and expand on.
4.1. Infinite Populations in General
Inference for the PATE typically takes the sample as a random sample from some larger population, as opposed to inference for the SATE discussed earlier that held the sample of potential outcomes as fixed. This makes estimation an implicit two-step process, estimating the treatment effect for the sample and extrapolating this estimate to the population. Frequently, in fact, the estimators themselves are the same as for finite sample inference even though the estimands are different.
Define the PATE as

where
Under blocking, the PATE within block k is

where, again, bi indicates the block that unit i belongs to. It is possible that k indexes a (countably) infinite set of blocks in the case of some infinite population models.
Overall, using the law of total expectation and variance decompositions, we can generally obtain the properties of our estimators with respect to population estimands by first obtaining expressions for a finite sample and then averaging these expressions across the sampling distributions. In other words, we heavily exploit

There are several different frameworks that one might assume. These can generally be characterized by two primary features: the block types, which also dictates the population strata structure, and the sampling scheme. Note that the term strata is used for the population here analogously to blocks in the sample. We may obtain a sample using simple random sampling and then form blocks based on covariates postsampling and prerandomization, that is, flexible blocks. Or we may have fixed blocks (e.g., blood types) and use stratified sampling where we sample units from each population stratum. Finally, we may have structural blocks and conceptualize a population of an infinite number of these blocks (e.g., schools in an “infinite” population of schools) from which we randomly select a fixed number of blocks. As we show next, the bias of the variance estimators can differ depending on the framework assumed. We refer to frameworks using their sampling method as a shorthand, leaving the block type and population structure implicit.
4.2. Simple Random Sampling, Flexible Blocks
In this framework, denoted
The variance in this framework, using the basic variance decomposition, is

The expectation is across the sampling and blocking process. SRS denotes the simple random sample and subsequent blocking of sampled units.
In this context, we have an unbiased variance estimator if we have all big blocks:

is an unbiased estimator for
See online Supplementary Materials G for a derivation. The first term in the estimator looks similar to our usual big block estimator and captures part of the first term in our variance decomposition. The second term looks similar to our proposed small block estimator and accounts for the rest of the variation. While very similar to the estimator found in Scosyrev (2014), we have made adjustments to achieve unbiasedness of the estimator whereas Scosyrev focuses on consistency. Scosyrev also works with fixed blocks where the number of blocks is assumed known before sampling and weights are used to match the sample to the population proportions, as opposed to flexible blocks which allow random numbers of blocks that are created postsampling.

where
Similarly, if we use either of the small block variance estimators, the bias will be the difference between the expected finite sample bias for those estimators (which depends on treatment effect heterogeneity between blocks) and
4.3. Stratified Sampling, Fixed Blocks
In the “stratified sampling” framework, denoted
As in the finite sample, overall variance is a weighted sum of within block variances:

with
As noted in Imbens (2011), the variance estimator of big blocks,
First, as with the finite sample, we can extend results for
As with finite sample inference, this shows that
Second, for our new variance estimator we have the following result:
assuming no blocks have
This shows that
4.4. Random Sampling of Strata, Structural Blocks
In the “random sampling of strata” framework, denoted
Within this framework, which blocks are included in the sample is itself random. Therefore, the variance estimator needs to capture not only the within strata variance but also the variance due to which strata are chosen to be in the sample. Furthermore, if the block sizes vary, the total number of units is random which introduces additional complexities.
For the more general variable-size version of this framework, the variance of

where Bk is the indicator that stratum k is included in the sample, with
When blocks are of the same size, we can simplify the expression with

and this is an unbiased estimator for
Variance estimators when the strata vary in size are more complicated. In particular, under this framework, there is a chance that there is only a single block of a given size, making the first variance estimator infeasible. If we condition on the number of strata drawn of each possible strata size, assuming that there are multiple strata of the each size in the sample, we obtain the following Corollary:
This result can be seen directly from the results in online Supplementary Material E.3.
Alternatively, if we are willing to assume that block size is independent of treatment effect, then we have the following more general result:

It is straightforward to extend the results of Corollary 4.4.1 and Theorem 4.4.1 to this case.
4.5. Discussion
While the variance formulas that we presented above share a similar structure with each other and the finite sample forms, there are important differences. In the finite sample framework (Equation 2), there is a term regarding treatment effect variation that reduces the variance due to the correlation of potential outcomes. This term is retained in the random sampling of strata framework of Section 4.4 but not in the stratified sampling framework of Section 4.3. This difference in the true variance implies that different variance estimators may be more appropriate in different settings. It also suggests comparisons of blocking to complete randomization under these different assumptions will also diverge; for further discussion on this, see Pashley and Miratrix (2020). In fact, this difference explains much of the apparent discrepancy between the matched pairs literature and the blocking literature.
Relatedly, different variance estimators can have different amounts of bias depending on the framework being used. The small blocks estimators (
The big blocks estimator (
Overall, only the framework of Section 4.4 of sampling structural blocks, with the additional assumption of independence of impact and block size given there, has unbiased variance estimators for a mixture of big and small blocks. This means that, without additional assumptions allowing for plug-in approaches, the hybrid estimators, where possible, will always be conservative.
5. Simulations
We compare different estimators of the variance for hybrid blocked experiments where there are a few big blocks and many small blocks in a finite sample context. We explore a context where 50% of our units are in small blocks, each with only one treated unit, and the remainder are in big blocks with at least two treated units. None of our blocks have many treated units due to only having approximately 20% of the units treated overall. (The 20% was approximate in order to create varying size small blocks to see the different performance of the hybrid estimators.) We have 15 blocks with sizes ranging from 3 to 20.
The simulations presented here are for the finite sample framework, as it is both a common mode of inference and a core building block to the population frameworks. These results, however, are largely applicable to the other settings. For instance, the biases for the small blocks variance estimators have the same form for the finite sample and the stratified sampling frameworks.
We considered our two hybrid estimators, which correspond to estimating the variance of the small blocks two different ways. We also considered two regression estimators: the HC1 sandwich estimate (Hinkley, 1977) from a linear model with fixed effects and no interaction between treatment indicator and blocking factor, and the standard variance estimate (inverse Fisher information) from a weighted regression, weighting each unit by the inverse probability of being assigned to its given treatment status in its block, multiplied by the overall proportion of units in its treatment group (this is a variant of the approach in Gerber and Green, 2012; see also Miratrix et al., 2020). 2 Note that the HC1 estimator is the “robust” estimator used in Stata (StataCorp, 2017) for estimating standard deviations.
In our simulations, we varied both to what extent blocking successfully separated units based on their potential outcomes under control and also on their treatment effects. The average potential outcome under control and the average treatment effect for each block were both negatively correlated with block size, so that smaller blocks had larger control potential outcomes and larger treatment effects. The correlation of potential outcomes within blocks was also varied between
We compared all of the variance estimators to the actual variance of the corresponding blocking treatment estimator in Figure 1 by looking at the percent relative bias (
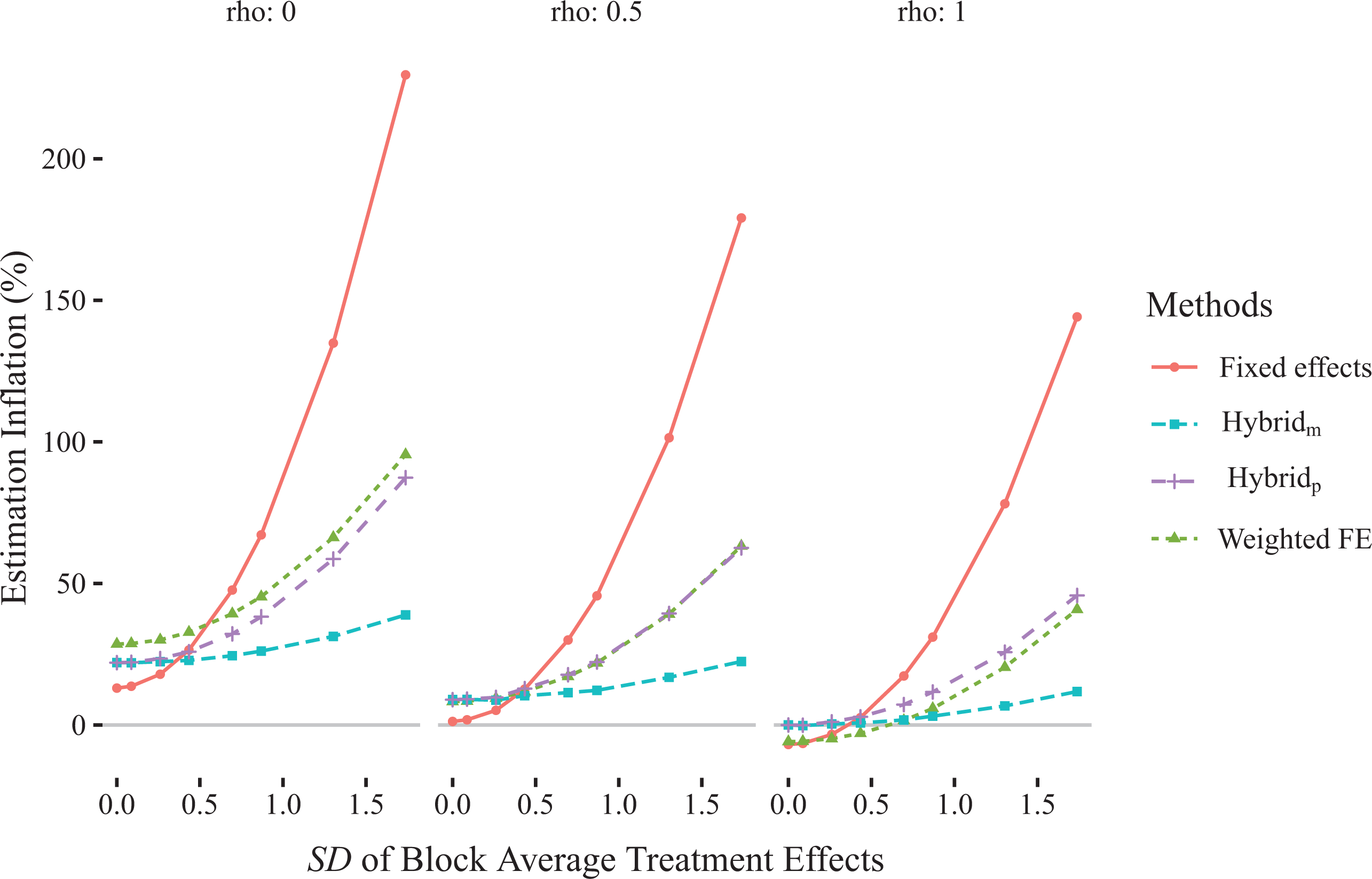
Simulations to assess variance estimators’ relative bias as a function of treatment variation across blocks. Each column represents a different value of
For discussion of the variance of the variance estimators, see online Supplementary Material D. The variance estimators’ variances were found to be comparable, with weighted regression generally the most stable.
When comparing the performance of estimators, there is an important note about the linear model estimator: The sandwich estimate for a linear model is associated with a different treatment effect estimator than the others. In particular, a linear model with fixed effects is estimating a precision weighted estimate of the treatment effect across the blocks. It is well-known that as treatment heterogeneity increases, this estimator can become increasingly biased. See Raudenbush and Schwartz (2020) for a longer discussion on this and related estimators. This is not an issue for the weighted regression which, similar to adding interactions between treatment and block dummy variables, will recover
6. Data Example
One area where analysts are often faced with many small blocks of varying sizes is found in the matching literature. In particular, full matching (see Hansen, 2004; Rosenbaum, 1991) finds sets of similar units, with either one treated and several control or vice versa, that could be considered as-if randomized. After matching, a researcher could then analyze these data using permutation tests and associated sensitivity checks (see, e.g., Rosenbaum, 2010), but in this context, generating confidence intervals or standard errors using permutation inference would typically rely on a constant treatment effect assumption across the blocks. One might alternatively wish for a Neyman-style randomization analysis such as would be typically done for large block experiments to obtain inference for the average effect in the presence of treatment variation. The average treatment effect estimate is easy to obtain; it is the uncertainty estimation that causes the trouble. Our small block variance estimators fill this gap. To illustrate, we analyze a data set from the National Health and Nutrition Examination Survey (NHANES) 2013–2014 (Centers for Disease Control and Prevention [CDC] National Center for Health Statistics [NCHS], 2013–2014) given in the
Although Zhao et al. (2018) analyzed numerous outcomes, we focus on a measure of mercury (LBXGM), converted to the
There were some block sizes that were unique, so the hybrid estimator with
Results of National Health and Nutrition Examination Survey (NHANES) (Full Matching), and Lalonde (CEM) for Different Estimation Strategies

A second method for analyzing observational datasets where our variance estimators could be useful is CEM. CEM coarsens covariates used to match and then exactly matches to these coarsened variables (Iacus et al., 2012). We follow the example from the vignette of the
7. Discussion
Blocking can be viewed under a wide variety of population frameworks ranging from a fixed, finite sample model to one where we envision the units as being sampled from a larger population in pre-set groups. Because different types of blocking tend to use different frameworks, there has not been good guidance on how to proceed when faced with some singleton units in some blocks and not in others.
We have worked to bring the different frameworks together in order to compare them systematically. We identified and compared the true variance of a blocking-based estimator under multiple settings, and created corresponding estimators of the impact estimator’s variance. We also provide simple, model-free variance estimators for two types of experiments that have not received much attention: blocked experiments with variable-sized blocks containing singleton treatment or control units and hybrid blocked experiments with large and small blocks combined. These contexts are quite common, frequently appearing in, for example, the matching literature. We analyzed the performance of both our new variance estimators and the classic variance estimators under different frameworks, identifying when they are unbiased or conservative. This investigation again illustrates how different sampling frameworks and block types can impact assessments of an estimator’s performance.
Future work includes extending these results to other population settings and sampling methods, in particular finding small block estimators for the setting of constructing blocks postsampling and prerandomization. Variance estimation is also a missing and needed piece in poststratification research, as noted in Miratrix et al. (2013). Although conditional answers for poststratification would correspond to the estimators presented in this work, the unconditional case remains an open extension.
Supplemental Material
Supplemental Material, blocking_variance_appendices - Insights on Variance Estimation for Blocked and Matched Pairs Designs
Supplemental Material, blocking_variance_appendices for Insights on Variance Estimation for Blocked and Matched Pairs Designs by Nicole E. Pashley and Luke W. Miratrix in Journal of Educational and Behavioral Statistics
Footnotes
Authors’ Note
Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation, the Institute of Education Sciences or the U.S. Department of Education.
Acknowledgments
The authors would like to thank Guillaume Basse, Avi Feller, Colin Fogarty, Michael Higgins, Luke Keele, and Lo-Hua Yuan for their comments and edits. We would also like to thank members of The Miratrix C.A.R.E.S. Lab and Donald B. Rubin’s research lab for their useful feedback on the project and Peter Schochet and Kosuke Imai for insightful discussion of this material. Finally, we thank anonymous reviewers for their helpful feedback.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research and/or authorship of this article: The research reported here was partially supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305D150040. This material is also based upon work supported by the National Science Foundation Graduate Research Fellowship under Grant No. DGE1745303.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.