
Abstract
Nonresponse bias is a widely prevalent problem for data on education. We develop a ten-step exemplar to guide nonresponse bias analysis (NRBA) in cross-sectional studies and apply these steps to the Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. A key step is the construction of indices of nonresponse bias based on proxy pattern-mixture models for survey variables of interest. A novel feature is to characterize the strength of evidence about nonresponse bias contained in these indices, based on the strength of the relationship between the characteristics in the nonresponse adjustment and the key survey variables. Our NRBA improves the existing methods by incorporating both missing at random and missing not at random mechanisms, and all analyses can be done straightforwardly with standard statistical software.
Keywords
1. Introduction
Surveys of educational assessment, such as the National Assessment of Educational Progress survey, the Program for International Student Assessment, and the Early Childhood Longitudinal Study (ECLS), have provided important data to inform policymakers and improve educational experiences. Such large-scale studies often implement complex probability sample designs to collect educational measurements on a sample representative of the target population. Survey variables are only collected for respondents to the study. However, statistical analyses of the collected data are subject to nonresponse bias, especially given rapidly declining response rates. A variety of indicators of potential bias have been proposed, generally functions of the response rate and the difference between respondents and nonrespondents on variables measured for both respondents and nonrespondents, such as auxiliary variables available in the sampling frame or from external data sources (Andridge and Little, 2011, 2020; Brick and Tourangeau, 2017; Groves, 2006; Hedlin, 2020; Montaquila and Brick, 2009; Särndal and Lundquist, 2014; Schouten et al., 2009; Wagner, 2010). Results may vary depending on the choice of adjustment approaches for nonresponse.
Responding to a solicitation from the U.S. National Center for Education Statistics, we develop exemplars to help guide practices of the nonresponse bias analysis (NRBA) for educational assessment surveys. This article describes an exemplar developed on the ECLS, Kindergarten Class of 2010–2011 (ECLS-K:2011; National Center for Education Statistics, 2013). The ECLS-K:2011 study collects national data on children as they progress from kindergarten through the 2015–2016 school year, when most of them will be in fifth grade. The ECLS-K:2011 program is unprecedented in its scope and coverage of child development, early learning, and school progress, drawing together information from multiple sources, including school administrators, parents, teachers, early care and education providers, and children.
We focus here on a cross-sectional NRBA based on the first wave, 2010 fall data collection. Nonresponse in the ECLS-K occurs when schools in the sample are missing due to lack of cooperation and when children, parents, and teachers are nonrespondents within schools. We summarize the current NRBA implementation in the ECLS-K study, which has the limitation of the strong reliance on the missing at random (MAR) assumption (Rubin, 1976) and is described formally in Section 5. A major objective of our exemplar is the systematic formulation of NRBA steps to guide practice. These steps include a sensitivity analysis based on proxy pattern-mixture models (Andridge and Little, 2011, 2020), which allows for missing not at random (MNAR) missingness mechanisms. We present the NRBA measures and evaluate the quality of such measures based on the predictive performances of auxiliary variables in multivariate models.
This article is organized as follows. Section 2 discusses the background of missing data and NRBA. Section 3 describes the sensitivity analysis framework. The systematic NRBA with 10 detailed steps is summarized in Section 4. We demonstrate the NRBA steps with the ECLS-K:2011 study in Section 5. Section 6 concludes with challenges and future extensions.
2. Background
The pattern and mechanism of missing data play an important role informing the potential bias from unit or item nonresponse. The pattern refers to which values in the data set are observed and which are missing. Specifically, let
Unit nonresponse occurs when the survey variables Y are missing for units subject to nonresponse and leads to a special case of the monotone missing data, where the variables can be ordered, so that
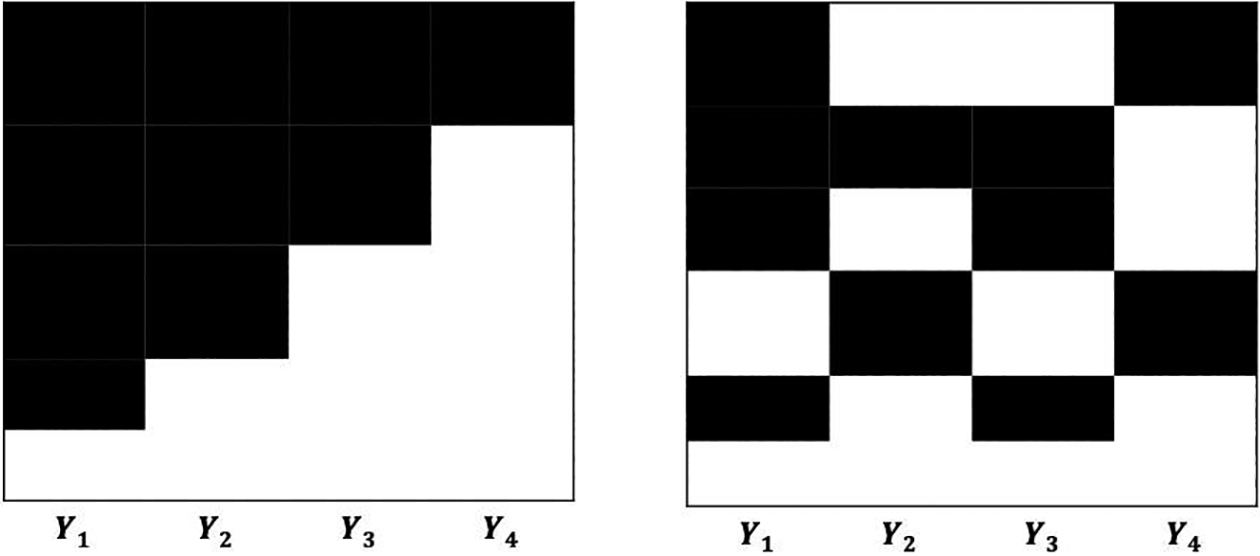
Illustration of missing patterns and the implied response indicator matrices with four variables (black areas indicate response with
The missingness mechanism addresses why values are missing and whether these reasons relate to values in the data set. For example, schools or pupils with schools that refuse to participate in the ECLS-K may differ in academic performances from schools or pupils that participate. Rubin (1976) treats R as a random matrix and characterizes the missingness mechanism by the conditional distribution of R given Y, say
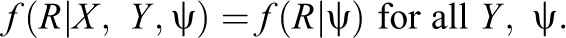
The missingness is called missing completely at random (MCAR), and MCAR missing data lead to an increase in the variance of estimates but do not lead to bias. However, MCAR is a strong and unrealistic assumption in most survey settings, including the ECLS-K.
A less restrictive assumption is that missingness depends only on X and the values
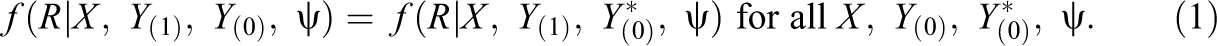
The missingness is called MAR at the observed values of R and
Most existing analyses, either by nonresponse weighting or imputation, make the MAR assumption, in part because MNAR analyses are often strongly reliant on untestable assumptions. The inclusion of variables predictive of survey variables strengthens the NRBA, providing more confidence that the MAR assumption is justified. In contrast, an NRBA based on variables that are weakly related to key survey variables provides weak evidence pro or con nonresponse bias; in other words, lack of evidence of bias from such an analysis does not imply lack of bias.
A simple expression of nonresponse bias for the mean of respondents

where N is the population size, NR
is the number of respondents, and
If variables are measured for respondents and nonrespondents, either survey variables measured on other levels in the sample (e.g., collected school characteristics for nonresponding students) or auxiliary variables from the sampling frame and a census or large survey of the population, they can be used to attempt to reduce bias. The main approaches to bias adjustment are nonresponse weighting, where responding units are weighted by the inverse of an estimate of the probability of response, and imputation, where missing values are imputed by predictions based on observed variables. Weighting is commonly used to adjust for unit nonresponse, and imputation is usually applied to handle item nonresponse because it is more effective than weighting for handling general patterns of missing data (Little and Rubin, 2019).
To construct response propensity weights for unit nonresponse, let Rj be the indicator for response to Yj , for j = 1, 2. With a monotone pattern of data with Y 2 less observed than Y 1, the MAR condition for missingness of Y 2 can be weakened to
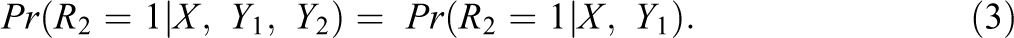
That is, the propensity to respond to the survey variable Y
2 can depend on the values of survey variables Y
1. Assuming MAR with the monotone pattern,
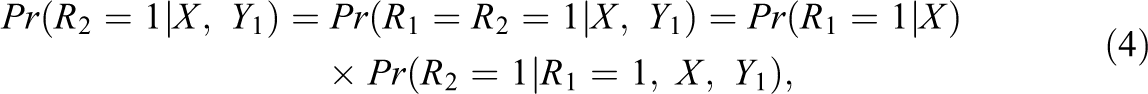
and the conditional probability of R
2 given R
1 can depend on the values of Y
1 as well as X. The response weight for variable Yj
is then the product up to variable Yj
of the inverse of these estimated conditional propensities (Little and David, 1983). In the ECLS-K study, the unit refers to a student. When the school refuses to participate in the study, all students in that school will be missing; and in participating schools, only a subset of students respond. Therefore, the school-level and child-level missing-data patterns are monotonic, where R
1 denotes the school-level response indicator and R
2 denotes the child-level response indicator. Applying this factorization in (4) to the ECLS-K study, we model the conditional response propensity of children given the observed variables X and school characteristics
To handle item nonresponse, a drawback of single imputation is that it overestimates the precision of survey estimates. A recommended solution to this problem is multiple imputation (MI), where missing values are drawn from their predictive distributions, and multiple data sets are created with different draws of the missing data imputed. Although the theories are rooted in Bayesian statistics, MI can be applied with replication sampling methods, such as bootstrap and jackknife algorithms, to take into account imputation uncertainty. Estimates of the resulting data sets are then combined using Rubin’s MI combining rules (see, e.g., Rubin, 1987 or Little and Rubin, 2019). A useful feature of MI for practitioners is that a wide variety of software for MI is now available, as summarized by Yucel (2011) and Si et al. (2022).
To reduce bias, auxiliary variables in the nonresponse adjustment must be predictive of both the survey variable of interest and nonresponse indicator (Little and Vartivarian, 2005). Table 1 presents the bias and variance of MI and inverse propensity weighting for estimates of means, compared to unadjusted analyses based on the complete cases. The variances are calculated based on large-sample approximations. Taken from Little et al. (2022), this table is a refinement of the simpler table in Little and Vartivarian (2005). Weighting is only effective when the auxiliary variables are related to the survey variables; otherwise, it increases the variance with no reduction in bias (Little et al., 2022; Little and Vartivarian, 2005).
Bias and Variance of MI and IPW Relative to CC Analysis for Estimating a Mean by Strength of Association of the Auxiliary Variables With Response (R) and Outcome (Y; Little, Carpenter, and Lee, 2022)
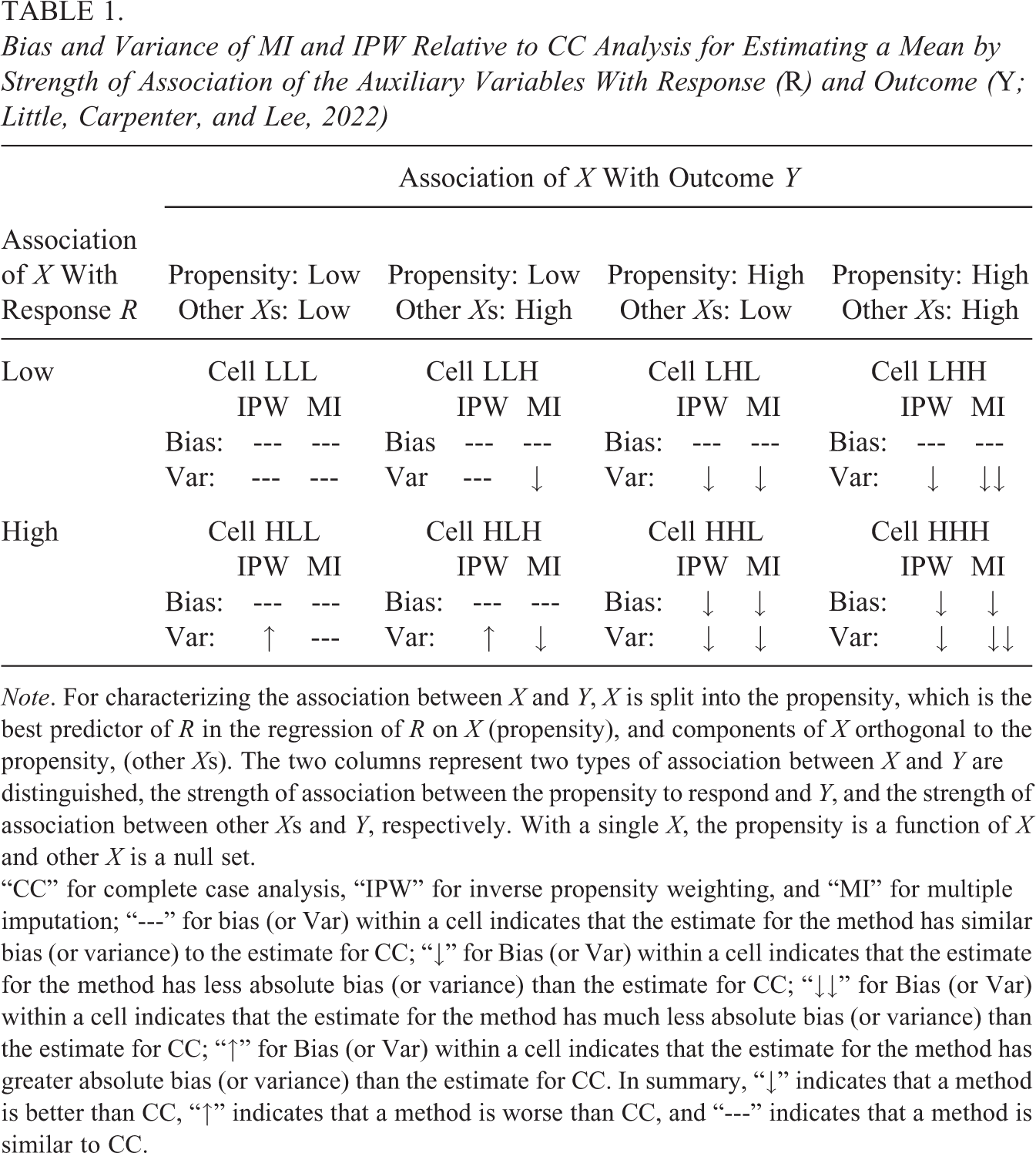
Note. For characterizing the association between X and Y, X is split into the propensity, which is the best predictor of R in the regression of R on X (propensity), and components of X orthogonal to the propensity, (other Xs). The two columns represent two types of association between X and Y are distinguished, the strength of association between the propensity to respond and Y, and the strength of association between other Xs and Y, respectively. With a single X, the propensity is a function of X and other X is a null set.
“CC” for complete case analysis, “IPW” for inverse propensity weighting, and “MI” for multiple imputation; “---” for bias (or Var) within a cell indicates that the estimate for the method has similar bias (or variance) to the estimate for CC; “↓” for Bias (or Var) within a cell indicates that the estimate for the method has less absolute bias (or variance) than the estimate for CC; “↓↓” for Bias (or Var) within a cell indicates that the estimate for the method has much less absolute bias (or variance) than the estimate for CC; “↑” for Bias (or Var) within a cell indicates that the estimate for the method has greater absolute bias (or variance) than the estimate for CC. In summary, “↓” indicates that a method is better than CC, “↑” indicates that a method is worse than CC, and “---” indicates that a method is similar to CC.
3. Methods for NRBA and Sensitivity Analysis
A substantial difference between unadjusted estimates and estimates adjusted by weighting or imputation suggests that nonresponse adjustment is important and, hence, is often a component of NRBA. The key to a useful NRBA is to identify a rich set of auxiliary variables X that are highly predictive for the survey variables Y. These might include variables in the sampling frame for bias adjustments, from external data sources that are not included in the analysis of the data, and also available via data linkage.
We fit multivariate models for the survey variable
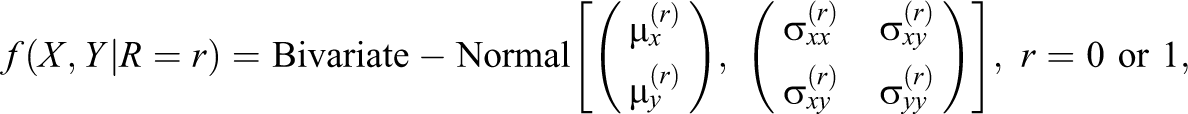
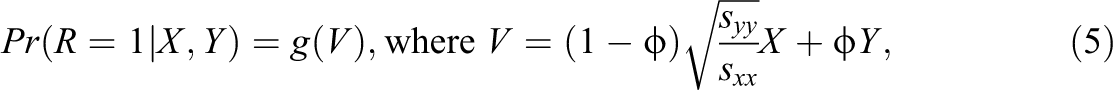
which is a bivariate-normal distribution with mean
We can estimate the mean
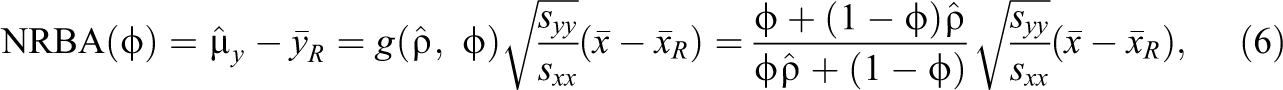
where
When the inferential interest is subgroup analysis, for example, educational assessments across different race/ethnicity groups, we modify the expression (6) for each subgroup k, for
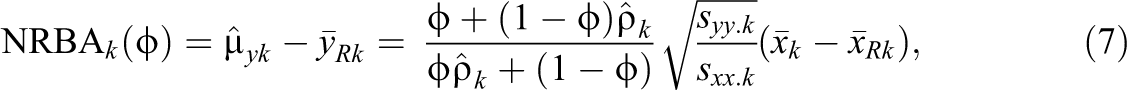
where
4. Main Steps of the NRBA
Figure 2 summarizes the steps of our proposed systematic NRBA.
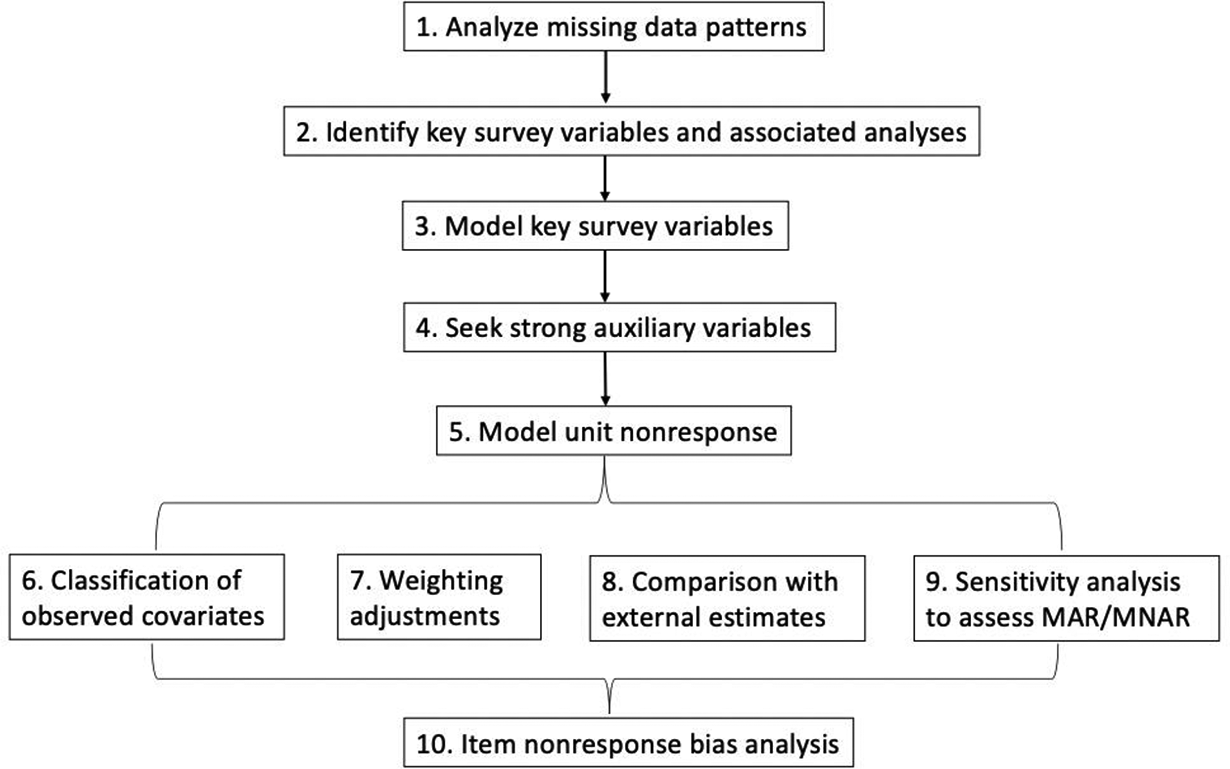
Nonresponse bias analysis process.
5. ECLS-K Analysis: Background and Application
We demonstrate the ten steps of our proposed NRBA in the ECLS-K:2011 study with 15,830 responding students out of 18,170 total eligible units. An NRBA needs to account for the design of the survey. We briefly introduce the ECLS-K:2011 sampling design, weighting adjustment, and current NRBA procedures.
The ECLS-K:2011 adopts a three-stage sample design, with geographic areas as primary sampling units (PSUs), schools sampled within PSUs, and children sampled within schools. A stratified sample of PSUs is selected with probability proportional to size (PPS), where the measure of size is the estimated number of 5-year-old children in the PSU, with oversampling of Asians, Native Hawaiians, and other Pacific Islanders (APIs). All PSUs are grouped into 40 strata defined by metropolitan statistical area status, census geographic region, size class (defined using the measure of size), per capita income, and the race/ethnicity of 5-year-old children residing in the PSU. The sources for the school frames are the most recent Common Core of Data (2006–2007 CCD) and the Private School Survey (2007–2008 PSS). Schools are selected with PPS. The measure of size for schools is kindergarten enrollment adjusted to account for the desired oversampling of APIs. Schools are also sampled from the supplemental frame of newly opened schools and added kindergarten programs that are not in the original frames, and the selection probability for a new school in an existing PSU is conditional on the within-stratum probability of selecting that PSU. Public school substitution is conducted in nonparticipating districts assigned with the base weight of the original school, adjusted for school size differences. In the third stage of sampling, children enrolled in kindergarten of graded schools and 5-year-old children in ungraded schools are selected within each sampled school. Two independent sampling strata are formed within each school, one containing API children with a higher sampling rate than the second containing all other children. Within each stratum, children are selected using equal probability systematic sampling and the target number of 23 at any one school. Once the children are sampled from the school lists of enrolled kindergartners, parent contact information for each child is obtained from the school. The information is used to locate a parent or guardian, conduct the parent interview, and gain parental consent for the child to be assessed. Teachers who teach the sampled children and before- and after-care providers are also included in the study and asked to complete questionnaires.
For the base year of ECLS-K, weights are provided at the child and school levels as the inverse of the probability of the multistage selection. The ECLS-K applies raking to external control margins (Deming and Stephan, 1940). The base-year coverage-adjusted child base weight is raked to external control totals from the number of kindergartners enrolled in public schools in the 2009–2010 CCD and in private schools in the 2009–2010 PSS, the two most up-to-date school frames available at the time of weight computations that are also the closest to the time frame of the kindergarten year of the ECLS-K:2011. Raking cells are created using census region (Northeast, Midwest, South, and West), locale (city, suburb, town, and rural), school type (public, Catholic, non-Catholic private, and nonreligious private), and kindergarten size (fewer than 85 and 85 or more). After raking, the extremely large weights are trimmed.
The response status is used to adjust the base weight for nonresponse to arrive at the final full sample weight. Nonresponse classes are formed separately for each school type (public/Catholic/non-Catholic private). Within school type, the analysis of child response propensity is conducted using child characteristics, such as date of birth and race/ethnicity to form nonresponse classes. The child-level nonresponse adjustment factor is computed as the sum of the weights for all the eligible (responding and nonresponding) children in a nonresponse class divided by the sum of the weights of the eligible responding children in that nonresponse class.
An NRBA of ECLS-K:2011 by Westat (Tourangeau et al., 2013) examines unit nonresponse with four approaches. The first approach reports school-level and student-level response rates for subgroups—an analysis related to Steps 1 and 5 above. The response rates show variation across school types, census regions, locale, kindergarten enrollment, percent minority, race/ethnicity, and years of birth, and large variation increases the potential for nonresponse bias. With a similar role, the R indicator (Schouten et al., 2009) measures the variability in the probability of responding to a survey as a function of auxiliary variables. Response rates and R indicators are agnostic with regard to specific survey variables of interest, failing to reflect the fact that selection bias depends on the strength of the relationship of selection with the survey variable. We recommend in Step 2 to select a few key variables of interest, which are child assessment outcomes in the ECLS-K:2011 study. The second and third approaches compare sample estimates to estimates computed from the sampling frame, the Census data, and other sources, similar to our recommendation in Step 8. The fourth approach compares ECLS-K:2011 estimates weighted with and without nonresponse adjustments, as recommended in Step 7. Larger differences could be indicative of substantial nonresponse bias; however, the strength of this evidence depends on whether the characteristics used in the nonresponse adjustment are strongly related to survey variables of interest.
Our proposed NRBA process distinguishes from the current practice (Tourangeau et al., 2013) with three aspects: (1) We explicitly conduct an outcome-specific NRBA and examine multiple key survey variables, (2) we calculate the NRBA measures and evaluate the quality of such measures based on the predictive performances of auxiliary variables in multivariate models, and (3) we conduct sensitivity analyses to assess the impact of deviations from MAR. The multistage sampling of PSUs, schools, and children results in nonresponse for schools and children, and there are school substitutes to replace the nonresponding schools. As an illustration, we focus on the child-level NRBA with interest in estimating the mean values of child assessment outcomes overall and across subgroups of interest.
5.1. Step 1: Analyze Missing-Data Patterns
The school-level and child-level missing-data patterns are monotonic, shown in the left plot of Figure 1, so school characteristics can be used in the child-level NRBA. In Figure 3, we present the unit nonresponse patterns of the child, parent, teacher, and teacher–student assessment surveys both for the fall and spring collection. The goal is to check response rates and whether nonrespondents in one variable could have information available from other variables that can be used in the NRBA. Conditional response propensities can be computed based on the factorization given in Equation 4.
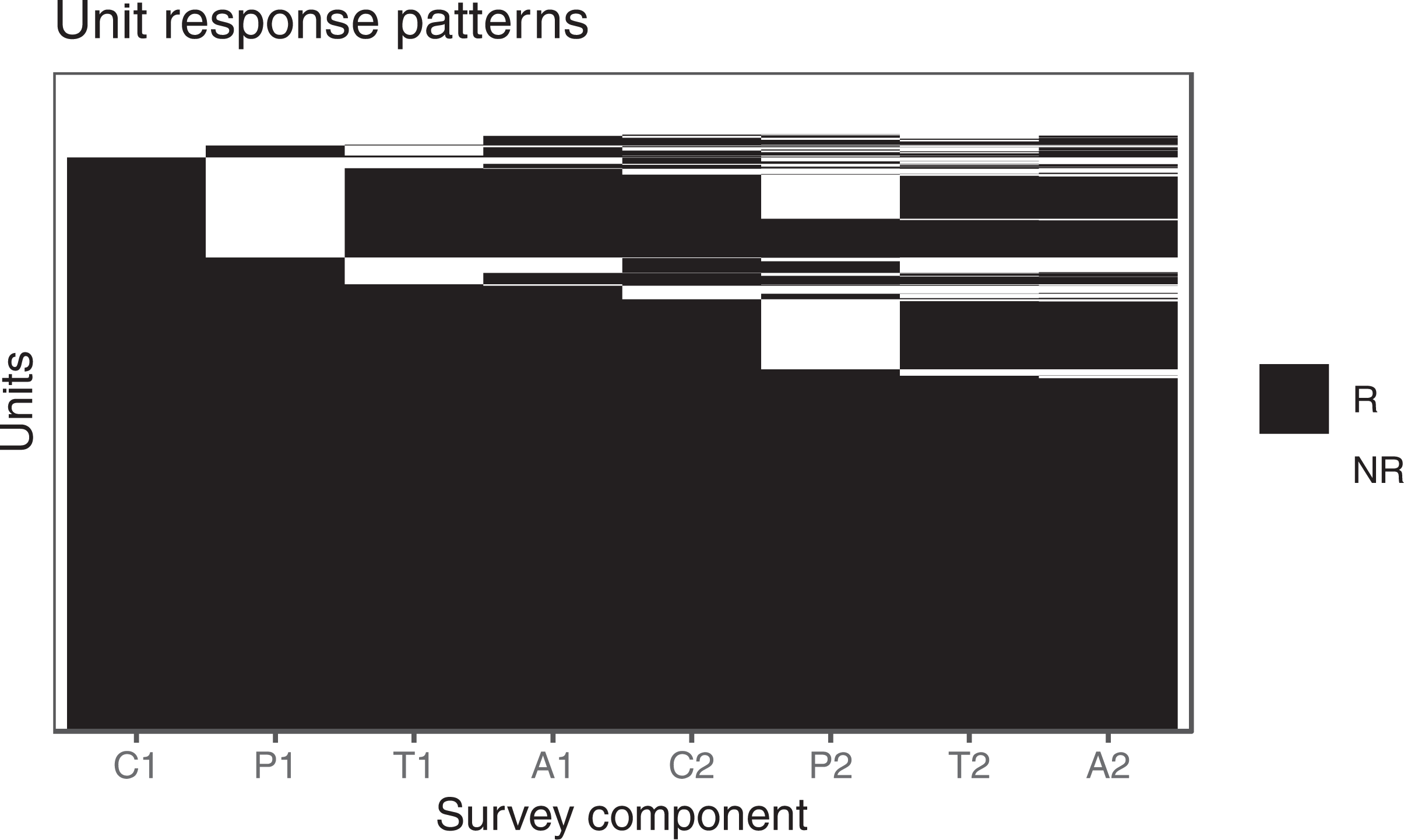
Unit response (R marked by black areas) and nonresponse (NR marked by white areas) patterns of child (C), parent (P), teacher (T), and teacher student-level assessment (A) survey instruments for fall 2010 (1) and spring 2011 (2) data collection. C1: child survey in fall 2010, P1: parent survey in fall 2010, T1: teacher survey in fall 2010, A1: teacher–student assessment survey in fall 2010, C2: child survey in spring 2011, P2: parent survey in spring 2011, T2: teacher survey in spring 2011, and A2: teacher–student assessment survey in spring 2011. Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011, 2010 Fall and 2011 Spring.
Detailed response rates by school/child characteristics are reported in the User Manual of the ECLS-K:2011 Kindergarten Study (Tourangeau et al., 2013) and generally high during the base year, with an overall rate of 69% for schools, 87% for children, 74% for parents, and 82% for teachers. Looking into the missing data patterns of Figure 3, we do not have information on parents or teachers for most of the nonresponding children and for a small proportion of responding children. Characteristics of child respondents could be useful to inform the NRBA of parent and teacher interviews.
5.2. Step 2: Identify Key Survey Variables and Associated Analyses
Since the ECLS-K study focuses on child development, we have identified a few key survey variables on child assessment outcomes: reading scores estimated by the item response theory (IRT; Hambleton et al., 1991), mathematics IRT scores, child body mass index (BMI), scores on being impulsive/overactive and self-control based on parent interviews, and scores on externalizing and internalizing problems based on teacher interviews.
We are interested in estimates of means in the population and in mutually exclusive subgroups defined by race/ethnicity (non-Hispanic White, non-Hispanic Black, Hispanic, API, and Other) and school type (public and private).
5.3. Step 3: Model Key Survey Variables as a Function of Fully Observed Predictors
For the cross-sectional NRBA at the baseline, we have frame variables from the 2006–2007 CCD for public schools and the 2007–2008 PSS for private schools. We include the public and private schools and exclude schools selected from the supplemental frames. Because the sample size of private schools is smaller than that of public schools, we conduct the NRBA by combining the two sampling frames. That is, we identify overlapping variables between the CCD and PSS data and select one set of frame variables that are available for both respondents and nonrespondents in the sample.
The auxiliary variables include sex, year of birth, race/ethnicity, school type, census region, locale, the number of students, number of full-time-equivalent teachers, student to teacher ratio, lowest and highest grades offered, percentages of kindergarteners, American Indians, Asians, Hispanics, and Black in schools.
Given the auxiliary variables available for both respondents and nonrespondents, the survey variable is conditionally independent of the response indicator. Because the survey variables are continuous, we fit a linear regression model for Y given the auxiliary variables. As alternatives to regression models, tree-based models, random forests, and gradient boosting algorithms can be used to model the survey variable, as well as the response propensity. Machine learning algorithms automatically detect interactions and nonlinear relationships and could yield good predictive performances. The nodes determined by a tree structure can be used as weighting classes for nonresponse adjustments. As an illustration, we use tree-based models for variable selection and regression models for prediction. We fit a tree model to select high-order interaction terms. Then, we include all main effects and the identified interactions into the linear regression for Y and perform a stepwise variable selection based on the Akaike information criterion to determine the final models.
Using the reading IRT score as an example, the selected predictors in the final outcome model include race/ethnicity, year of birth, sex, school locale, region, lowest and highest grades offered, school type, the number of enrolled students, the number of full-time-equivalent teachers, percentages of Hispanics, Asian, and Black in school, the two-way interactions between locale and school type, between locale and the percentage of Asian, between race/ethnicity and region, between race/ethnicity and the percentage of Hispanics, between race/ethnicity and the percentage of Black, between race/ethnicity and the lowest grades offered, and between locale and the number of full-time-equivalent teachers.
We predict the outcome values for both respondents and nonrespondents and obtain the proxy variable X. The correlation between the outcome Y and the proxy variable
5.4. Step 4: Seek Strong Observed Predictors in Auxiliary Data
The analysis in Step 3 indicates that strong variables are absent in the data set, and efforts should be made to add more predictors in the model for Y and improve the prediction.
For the child assessment outcomes, the highly predictive variables include poverty level, socioeconomic status, the type of language use at home, parental education, parental marital status at the time of birth, and nonparental care arrangements during the year prior to kindergarten. The correlation
5.5. Step 5: Model Unit Nonresponse as a Function of Observed Predictors
First, we model the school-level response propensities with logistic regression and find that the predictive variables include school type and percentages of kindergarteners and Asians in schools. The model for the school-level response propensities has a value of .60 for the area under the receiver-operating characteristic curve (AUC), an assessment of discriminatory ability. The small AUC value shows that the auxiliary variables are weakly predictive of the school-level response.
Next, we use a response indicator with
Figure 4 depicts the frequency distribution of the predicted child-level response propensities
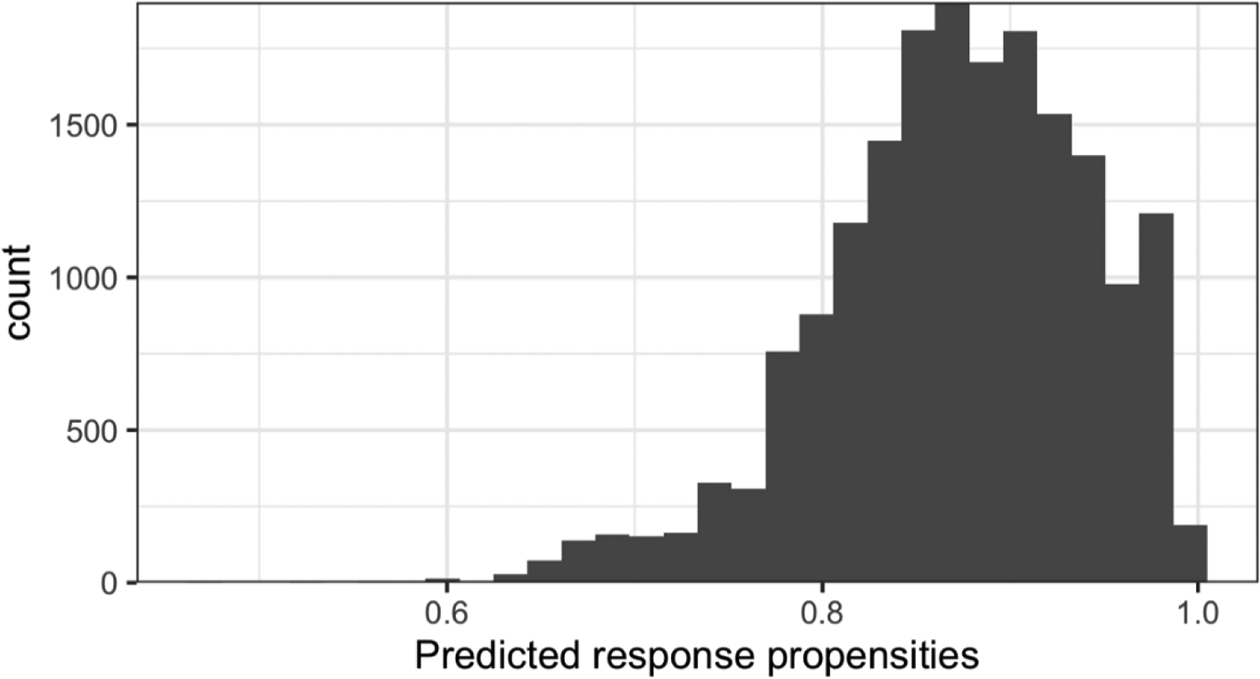
Frequency distribution of the predicted response propensities by the logistic regression. Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. 2010 Fall.

Reading score distributions of respondents stratified by the quintiles of predicted response propensities. Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. 2010 Fall.
5.6. Step 6: Assess Observed Predictors for the Potential for Bias Adjustment
Results from Steps 2 to 5 provide the basis for the classification of observed predictors according to Table 1. Steps 2 and 3 show that the observed predictors are generally weakly related to the survey variables, and Step 5 finds that the response propensities are weakly related to the survey outcome. Referring to the first column in Table 1, weighting adjustment based on the observed predictors and the response propensities will not substantially affect nonresponse bias.
The resulting measure of deviation for the proxy variable is small with
5.7. Step 7: Assess Effects of Nonresponse Weighting Adjustments on Key Survey Estimates
We compare ECLS-K:2011 estimates of average reading IRT scores in Table 2 between unweighted and weighted estimates and between estimates using coverage-adjusted base weights and estimates using nonresponse adjusted weights.
Comparison of Unweighted, Nonresponse-Unadjusted Weighted Estimates and Weighted Estimates

Note. SE = standard error; Deff = design effect.
Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. 2010 Fall.
Sampling variance estimation has to account for design features, such as clustering and survey weights. We use the Taylor series linearization approximation to obtain the standard errors with the PSU clustering effects and weights in the estimation (Binder, 1983). Table 2 also includes the design effects, calculated as the ratio of estimate variances under the complex design with PSUs and final weights, and the simple random sampling selection with the same sample sizes. For subgroup analyses, in addition to subgroups defined by race/ethnicity and school type, we add the estimates of subgroups defined by the quartiles of socioeconomic status. The estimates are significantly different across subgroups. API students tend to have better reading performances than those in different race/ethnicity groups. Students in private schools have higher scores than those in public schools. The reading scores are highly correlated with socioeconomic status.
The existing nonresponse adjustment of ECLS-K:2011 uses weighting classes defined by the cross-tabulation of date of birth, race/ethnicity, and school type (Tourangeau et al., 2013). This shows that the nonresponse weighting factors will be equal for subjects that fall in each subgroup defined by race/ethnicity or school type. This is not the case for the subgroups defined by socioeconomic status. The unweighted, unadjusted, and adjusted estimates are not substantially different. The findings on nonresponse adjustment effects are consistent for overall and subgroup mean estimates. The complex sample design is considerably less efficient than simple random sampling. Because the weighted and unweighted estimates and standard errors are similar, the large design effects are mainly due to the PSU clustering effects, not due to weighting adjustments, which is confirmed by the large values when only accounting for clustering in the complex design.
5.8. Step 8: Compare the Survey With External Data Using Summary Estimates of Key Survey Variables
Current NRBA by Westat compare estimates of selected items from the base year ECLS-K:2011 parent interviews and the parent interviews in the 2007 National Household Education Survey, subset to parents of kindergartners. The differences in the estimates between the two studies could be due to various sources of heterogeneity in data collection, such as time discrepancies, coverage, and sample design. These comparisons inform potential nonresponse bias but are not direct assessments. External data of high quality are crucial to validate the NRBA.
5.9. Step 9: Sensitivity Analysis
We set the sensitivity parameter
Nonresponse Bias Analysis for Mean Estimates (With Standard Errors in Parenthesis) Under Different Missingness Mechanisms for Different Survey Variables
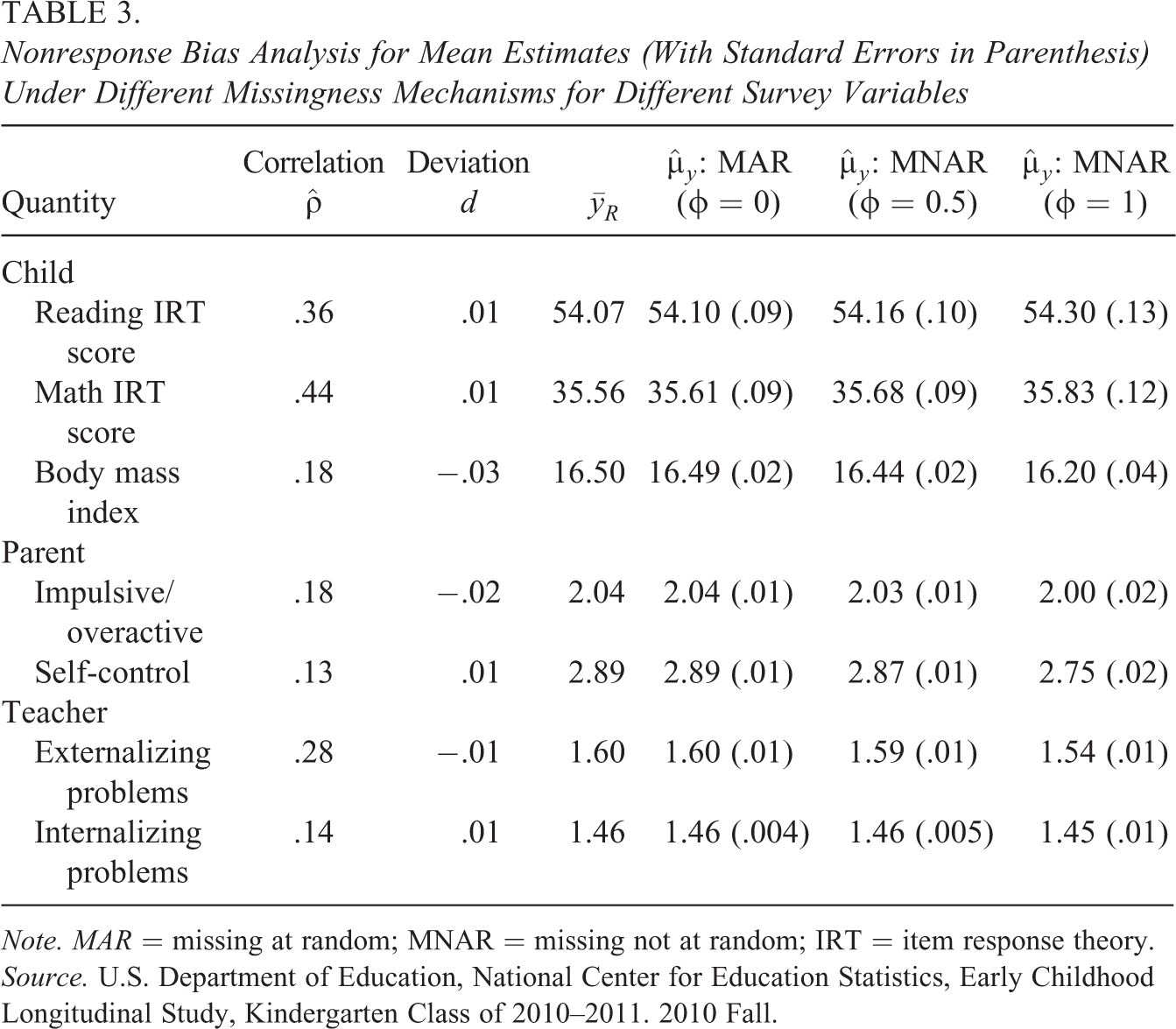
Note. MAR = missing at random; MNAR = missing not at random; IRT = item response theory.
Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. 2010 Fall.
For the reading IRT scores, the mean estimates in Table 3 slightly increase as
Table 3 also presents the NRBA results for other outcomes of interest. The correlations between the outcome and the proxy variables are generally low, ranging from .13 to .44, showing modest evidence for the NRBA. The sensitivity analyses find that the mean estimates for BMI, scores for self-control, and externalizing problems are significantly different under different missing data mechanisms, where the nonrespondents have substantially lower average scores than respondents. This indicates the potential for nonresponse bias for these outcomes, but the evidence is modest.
We estimate average reading IRT scores across subgroups defined by race/ethnicity and school type in Table 4. Similar to those overall estimates, subgroup estimates are not substantially different under different missing data mechanisms. Even with subtle differences, we observe different adjustment effects across subgroups as the missing data mechanisms change in the sensitivity analysis.
Nonresponse Bias Analysis of Reading IRT Scores for Subgroups

Source. U.S. Department of Education, National Center for Education Statistics, Early Childhood Longitudinal Study, Kindergarten Class of 2010–2011. 2010 Fall.
5.10. Step 10: Item NRBA
Continuing the example with the reading IRT score, the outcome has 50 more null values than the number of unit nonresponses and 120 values of −9 indicating item nonresponse. Since the proportion of nonresponse mismatch is very small, we treat the 15,670 observed cases of the outcome variable as respondents. However, item nonresponse could also lead to substantial bias. Future extensions of this work will perform MI and assess the effects on inferences.
6. Discussion
We present a 10-step exemplar of the NRBA for cross-sectional studies. Our NRBA assesses the pattern of missing data, fits regressions of key survey outcomes and indicators of nonresponse on variables observed for both respondents and nonrespondents, compares estimates with and without nonresponse weighting adjustments, and implements sensitivity analyses based on proxy pattern-mixture models to assess the impact of deviations from MAR missingness. All analyses can be carried out straightforwardly with standard statistical software. We provide our example R codes in the Supplemental Appendix.
Overall, we do not find substantial evidence of nonresponse bias in the ECLS-K:2011 study, though modest differences present for several estimates, perhaps reflecting the high response rates at baseline. However, lack of evidence of bias in the NRBA does not necessarily mean lack of bias; the key to a strong NRBA is the existence of a rich set of auxiliary variables that are highly predictive of the survey variables. The strength of the evidence is generally weak in this application because the observed predictors are not strongly related to the survey outcomes. The auxiliary variables are collected from the frame, available for both respondents and nonrespondents, but a time lag exists between the frame (around 2007) and the actual data collection (around 2010), leading to weak correlations with the survey variables. The ECLS-K:2011 dataset has the children’s zip codes and geographic information that can be linked to the census data for the neighborhood characteristics. Obtaining auxiliary information via geospatial linking will be future work.
As regard future work, data integration with multiple sources greatly enhances many ongoing survey research activities (National Academies of Sciences, Engineering, and Medicine, 2017). The NRBA requires information that is available for both respondents and nonrespondents. Combining multiple data sources and record linkage can provide auxiliary information for nonresponse adjustment and benchmark information for external validation. The proxy pattern-mixture models assume that the response mechanism depends on an additive effect of the survey variable and the proxy variable, and the assumption cannot be verified without external data. The mean estimates with large sample sizes are robust against the normality misspecification (Andridge and Thompson, 2015), but the effect on other estimands with small samples is unclear and needs future work. Linking ECLS-K:2011 studies to other data could have great potential for the NRBA. Second, the NRBA of analytic inferences could have different findings from that of descriptive summaries.
We focus here on mean estimates for the population and population subgroups. The NRBA in regression models is important, and many of the steps outlined above can also be applied in the regression setting. Extensions of the proxy pattern-mixture approach to sensitivity analysis for regression are discussed in West et al. (2021). In the regression setting, the key to a strong analysis is the availability of strong auxiliary variables that are not predictors in the regression model of interest. Third, we mainly demonstrate the assessment and adjustment of estimates for unit nonresponse, which is the main concern in ECLS-K; assessment of item nonresponse may be important in surveys where the level of item nonresponse is greater. Si et al. (2022) have demonstrated the applicability of MI in handling various challenges on item nonresponse with massive data sets. MI has been used to simultaneously handle unit nonresponse and item nonresponse (Si et al., 2015, 2016). Combining weighting adjustment and imputation into one systematic process would be helpful for practical survey operation. Future work will also develop an NRBA exemplar for longitudinal studies.
Supplemental Material
Supplemental Material, sj-docx-1-jeb-10.3102_10769986221141074 - A Case Study of Nonresponse Bias Analysis in Educational Assessment Surveys
Supplemental Material, sj-docx-1-jeb-10.3102_10769986221141074 for A Case Study of Nonresponse Bias Analysis in Educational Assessment Surveys by Yajuan Si, Roderick J. A. Little, Ya Mo and Nell Sedransk in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research and/or authorship of this article: This work was supported by National Center for Education Statistics.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.