
Abstract
Cognitive diagnostic computerized adaptive testing (CD-CAT) is a cutting-edge technology in educational measurement that targets at providing feedback on examinees’ strengths and weaknesses while increasing test accuracy and efficiency. To date, most CD-CAT studies have made methodological progress under simulated conditions, but little has applied CD-CAT to real educational assessment. The present study developed a Chinese reading comprehension item bank tapping into six validated reading attributes, with 195 items calibrated using data of 28,485 second to sixth graders and the item-level cognitive diagnostic models (CDMs). The measurement precision and efficiency of the reading CD-CAT system were compared and optimized in terms of crucial CD-CAT settings, including the CDMs for calibration, item selection methods, and termination rules. The study identified seven dominant reading attribute mastery profiles that stably exist across grades. These major clusters of readers and their variety with grade indicated some sort of reading developmental mechanisms that advance and deepen step by step at the primary school level. Results also suggested that compared to traditional linear tests, CD-CAT significantly improved the classification accuracy without imposing much testing burden. These findings may elucidate the multifaceted nature and possible learning paths of reading and raise the question of whether CD-CAT is applicable to other educational domains where there is a need to provide formative and fine-grained feedback but where there is a limited amount of test time.
Keywords
1. Introduction
What knowledge, content, and skills have students mastered as time passes by? This is a question that always haunts teachers and students. Regarding reading, one of the most commonly evaluated literacies (Kim & Wagner, 2015), several large-scale reading assessments (e.g., the Programme for International Student Assessment (PISA), the Progress in International Reading Literacy Study (PIRLS), the Test of English as a Foreign Language (TOEFL), and so on) have been retrofitted under the cognitive diagnostic models (CDMs) framework to extract diagnostic information of individuals’ reading development (e.g., Chen & Chen, 2016; George & Robitzsch, 2021; Javidanmehr & Sarab, 2019; Ravand & Robitzsch, 2018). This research identified several common reading attributes crucial for successful reading and supported the use of CDMs as a promising approach that pinpoints students’ weaknesses and strengths in mastering these reading attributes (Li et al., 2021). However, the application of such fine-grained feedback is scarce as it requires students to answer a static, time-consuming, or less accurate test paper (Chang et al., 2021). Formative assessment of children’s reading ability and subskills is essential and ongoing throughout their primary school years (Carlson et al., 2014), and therefore, it is worthy of exploring a more accurate and efficient way.
Conventional ways of measuring reading progression are often based on independent fixed linear tests as they are easy to administer (Pfost et al., 2014). However, comparability and efficiency issues related to these assessment have not been appropriately addressed (Bennett, 2011; Higgins et al., 2010; McCallum & Milner, 2021). For example, primary students’ reading ability develops so much throughout their education that the linear testing design across all grades could be time-consuming and burdensome thus limiting its applications in the classroom (Brennan, 2006; Wang et al., 2021). Therefore, studies adopted the unidimensional or multidimensional item response theory (IRT) to equate reading ability across multiple grade levels (Lee, 2003; Wang et al., 2013) or investigated the structural stability of reading processes across grades using factor analysis (Wang & Jiao, 2009). However, these methods fit the reading data in a way of neglecting the within-item multidimensionality (Adams et al., 2016), that is, neglecting the fact that multiple cognitive processes and skills could be concurrently recruited in real reading activities (Pearson & Hamm, 2005). Besides, although researchers adopted the multilevel booklet design to calibrate the item bank and test takers ability into a common scale, the subtle learning progressions of reading subskills remain unclear (Zhan et al., 2019).
CDMs assume test takers’ performance as functions of attribute mastery states (Leighton & Gierl, 2007). Therefore, CDMs aggregate students into similar profiles according to their mastery (denoted by 1) and nonmastery (denoted by 0) of the attributes. Thus, the diagnostic reporting could provide fine-grained information on student’s learning status and directions and make up for the shortcomings of total scoring and ranking generated by traditional classical test theory or IRT (von Davier & Lee, 2019). Besides, researchers have proposed a family of confirmatory CDMs regarding different interactive mechanisms among attributes. Within these CDMs, the general models, especially the generalized deterministic inputs, noisy, “and” gate (GDINA) model, fitted various reading data better than reduced CDMs (Javidanmehr & Sarab, 2019; Ravand & Robitzsch, 2018). This is probably because the general CDMs could capture the flexible interactions among reading skills and reveal its multifaceted nature. However, most CDM studies are applied to a specific grade and a specific short test (Chen & de la Torre, 2014; George & Robitzsch, 2021; Javidanmehr & Sarab, 2019; Ravand & Robitzsch, 2018) and are not applicable to formative assessment situations.
Cognitive diagnostic computerized adaptive testing (CD-CAT) is a cutting-edge approach that unifies major characteristics of both CDMs and computerized adaptive testing (Yu et al., 2019). During a CD-CAT session, an examinee’s sequential responses are utilized to establish a provisional estimate of the attribute mastery profile, which is then used to select the next item from a calibrated item bank adaptively. The CD-CAT session would stop automatically if either the prespecified number of items (fixed-length) has been administered or if a certain level of test precision (fixed-precision) is achieved. By maximizing the information that the next item contains to specify the examinee, CD-CAT could account for the multidimensionality of an individual’s latent profile and maintain the high test efficiency that CAT produces (Zhu & Chang, 2021). These advantages are especially desirable for formative educational assessments, since the domains of interest (e.g., reading, math, etc.) are often complex, multifaceted, and progressive, while testing time is limited.
Over the past decades, researchers have made significant methodological progress to improve the major components of CD-CAT, including the calibrated item bank, the item selection methods, and the termination rules (Chang, 2015). A sufficient amount of parameter-calibrated items are vital foundations before implementing a CD-CAT system; otherwise, the test precision and security levels of the adaptive system might be constrained significantly (Stocking, 1994; Thissen et al., 2007). However, the calibration of item parameters via the GDINA model relied more on testing situations (e.g., sample size, item quality), and thus, the test-level GDINA model showed a higher risk of capitalization of chance (Sorrel et al., 2017). Therefore, researchers introduced the item-level CDMs, which adopt a two-step likelihood ratio test or the Wald test to each item to choose the most appropriate CDM. After comparing the general and reduced CDMs for an optimal model-data fit, the item-level CDMs showed increased parameter accuracy in multiple simulated experiments (Sorrel et al., 2021a).
Besides, considering the discreteness of the attribute profiles generated by CDMs, researchers proposed several item selection methods for CD-CAT, including the Shannon entropy approach (SHE; Xu et al., 2003), the mutual information (MI; Wang, 2013), the posterior-weighted Kullback–Leibler information (PWKL; Cheng, 2009), the modified PWKL (MPWKL), the GDINA model discrimination index (GDI; Kaplan et al., 2015), and the Jensen–Shannon divergence strategy (JSD; Kang et al., 2017). Yigit et al. (2019) and Wang et al. (2020) compared these abovementioned methods and found that the SHE, MPWKL, and GDI are closely interrelated, whereas PWKL performed consistently worse in all simulations. JSD efficiently resolved the noncomparability problem and outperformed the SHE and MI method in pattern recovery, computation, and item pool usage (Kang et al., 2017; Wang et al., 2020). However, the empirical application value of the abovementioned item selection strategies remains unclear.
Despite these methodological advancements, only two studies have investigated the practical use of CD-CAT implementations yet. Liu and colleagues (2013) developed an item bank of English competency and constructed an online fixed-length CD-CAT system using a general CDM and the content-constrained SHE procedure. Its field test reported a high level of convergence between the test takers’ English attribute profiles from CD-CAT and their English achievement. Another study recently collected 136 items assessing 10 depression attributes based on the International (International Classification of Diseases, Tenth Revision) and American (Diagnostic and Statistical Manual of Mental Disorders (Fifth Edition)) diagnostic criteria and constructed a fixed-precision CD-CAT tool using the item-level CDMs and the PWKL item selection method. The study found that the termination rule of posteriori probability > .75 performed the optimal, showing ideal evidence of diagnostic reliability and validity (Wang & Tu, 2021). Both studies provided positive evidence of test efficiency and validity, indicating that CD-CAT has a good prospect for large-scale applications. However, because of the high complexity of algorithms and system development, both studies adopted relatively fixed settings in CD-CAT key components, especially in terms of calibration models, item selection methods, and termination rules. Therefore, the landscape of today’s teaching and learning is still far from integrating these cutting-edge progression into real testing and instructions (Ravand & Baghaei, 2020; Sessoms & Henson, 2018).
The purpose of the study is to explore and optimize the effectiveness of CD-CAT to a Chinese reading comprehension assessment, so as to obtain a vertically comparable, accurate, and efficient tool of assessing reading development. Specifically, we developed and vertically calibrated a real item bank of reading comprehension via data of 28,485 primary students in Grades 2 through 6. After obtaining the real distribution of students’ reading profiles and item parameters, we investigated the feasibility and performance of its CD-CAT implementations in two simulation experiments, with respective focuses on optimizing the test accuracy or the test efficiency. Further, we compared the overall performance of various combinations of key CD-CAT components, including calibrating CDMs, item selection methods, and termination rules. An optimal CD-CAT system setting and several dominant student clusters in reading were proposed for future reference. These processes can shed light on the limited real applications in CD-CAT and provide practical tools of assessing reading development.
2. Methods
As prior research has validated the reading attributes and the instrument from a multitude of perspectives (Li et al., 2021), the present study focuses on the foundation and optimization of the reading CD-CAT system. Figure 1 outlines the two research phases, including item bank development and the simulated CD-CAT experiments.

Workflow of the cognitive diagnostic computerized adaptive testing research processes.
2.1. Instruments
2.1.1. Diagnostic Chinese reading comprehension assessment (DCRCA)
The DCRCA is a Web-based reading comprehension assessment for pupils in Grades 2 through 6 (Li et al., 2021). The DCRCA was developed and validated under the CDM framework, targeting six stable reading attributes, namely, α1 retrieving information, α2 making inferences, α3 integration and summation, α4 reflective evaluation, α5 literary text, and α6 practical text. Items are questions on students’ comprehension of short literacy or practical texts, in a multiple choice and dichotomously scored format. The majority of items assess one cognitive processing attribute (i.e., α1–α4) and one text-related attribute (i.e., α5–α6) of reading comprehension. Corresponding to the three key stages in the national Chinese curriculum criterion, the initial DCRCA contains three short expert-assembled linear booklets, each containing 16 items. The Cronbach’s α of the DCRCA was from .72 to .82. The average diagnostic reliability of the DCRCA was above acceptable levels, namely, .83 at the attribute level and.61 at the pattern level, according to the classification accuracy indices in Wang et al. (2015).
2.1.2. Item bank development
In order to align the new item bank with the DCRCA and reading instruction, the attributes and item development procedures were borrowed heavily from previous work (Li et al., 2021), while the item coverage of text-related attributes was adjusted for the Chinese curriculum criterion (Ministry of education, 2011). Specifically, six experts in reading assessment and/or education compiled 232 new items using previous item compiling procedures. After two rounds of expert review and a small-scale pilot, 160 new items were retained and included in formal data collection. The proportions of each attribute were 25.5%, 26.0%, 26.4%, 24.0%, 81.3%, and 18.8%, respectively.
2.2. Data Collection
The present research was conducted during a regional reading educational program in three provinces of China, so the sample was collected using stratified cluster sampling design (reading classes as clusters). The final sample for item bank calibration included 28,485 Grades 2 through 6 students from 45 primary schools. Participants were basically balanced among Grades 2 through 6, ranging from 5,588 to 5,989. The total sample included 13,627 (47.84%) girls, 14,586 (51.21%) boys, and 272 (0.95%) students who did not report gender. The assessments were administered collectively in school computer classrooms under the guidance of Chinese and computer teachers. Written informed consents were collected from students’ legal guardians or next of kin. There are no missing values in the test papers because the assessment system sets all given items as compulsory.
From a statistical perspective, the optimal way of calibration is to jointly calibrate the old items with the new items (Thissen et al., 2007). So, data collection for calibration was conducted using a combination of the common-item nonequivalent design, vertical scaling design, and random groups design (see also Kolen & Brennan, 2014) in three batches. As shown in Table 1, all participants answered their corresponding booklet of the expert-assembled DCRCA. Therefore, reliable assessment results could be generated for instructions. Then, 244 students in Batch 1 answered another initial booklet, and 6,812 students in Batch 2 answered another four linking items, which were intentionally selected to cover the six attributes. In this way, the initial booklets could be vertically equated. Finally, 21,449 students in Batch 3 were randomly assigned two to six new items after they finished their corresponding booklet. In summary, students answered 20.59 items on average, and an average of 551 students answered each new item, which is considered adequate in producing reliable estimates of parameter calibration (Chen et al., 2011).
Illustration of the Final Sample and Item Calibration Design
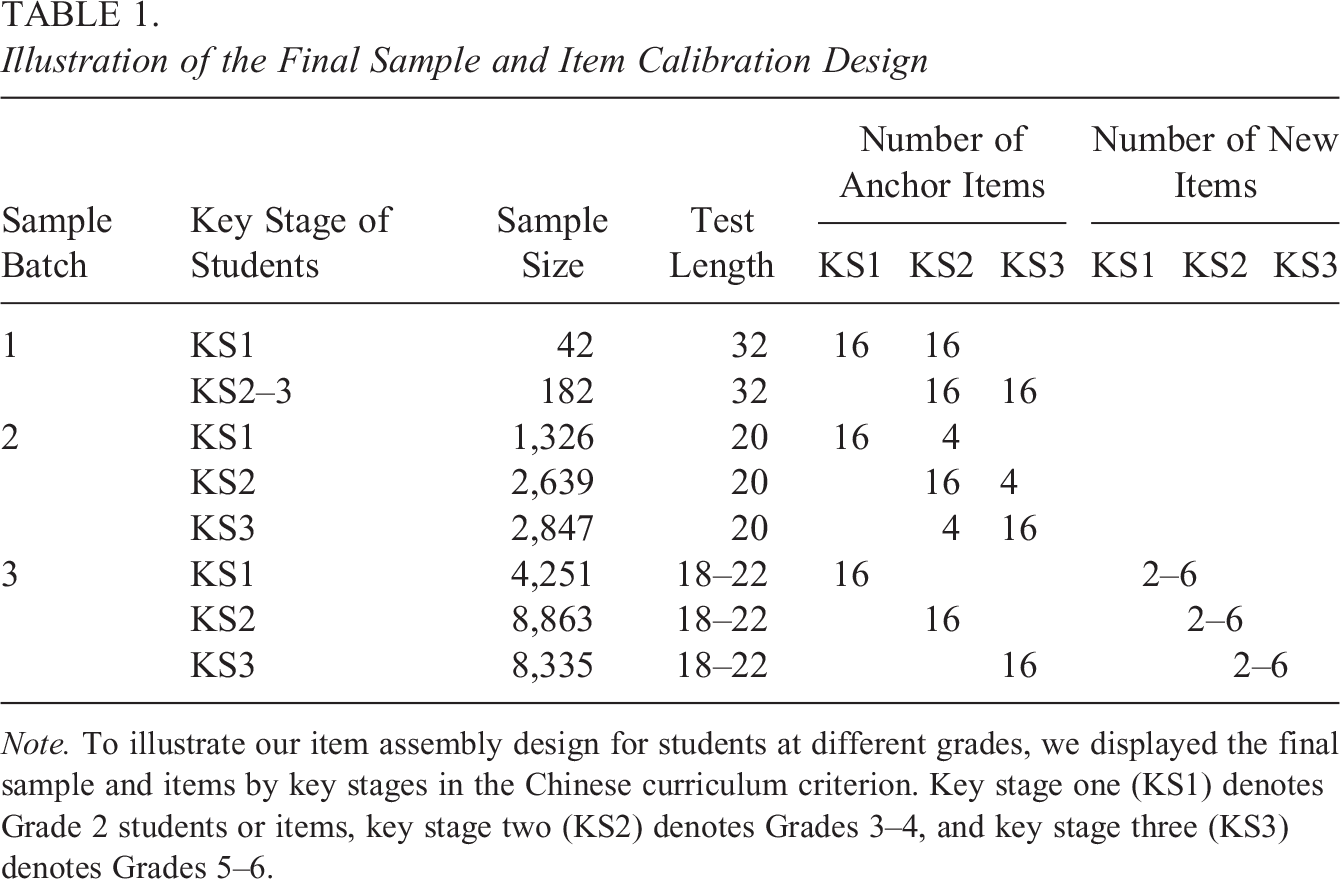
Note. To illustrate our item assembly design for students at different grades, we displayed the final sample and items by key stages in the Chinese curriculum criterion. Key stage one (KS1) denotes Grade 2 students or items, key stage two (KS2) denotes Grades 3–4, and key stage three (KS3) denotes Grades 5–6.
2.3. CD-CAT Simulation Designs
To investigate how different CD-CAT conditions influence the test accuracy and efficiency of the empirical CD-CAT reading system, data generation was based on the empirical reading item bank and real student profiles. More specifically, we applied the targeting calibration CDMs (i.e., the GDINA model or the item-level CDMs) to compute the true student mastery profiles and item parameters, using the empirical response data of 28,485 students on the 195 items. Then, 10,000 examinees were randomly selected from the real profile patterns of our sample. Their complete response matrix on all items was generated using the Monte Carlo simulation method, the real item parameters, and the prespecified CDMs. Therefore, the distributions of the reading attribute profiles generated by the simulated and the real response patterns were consistent.
Besides, two simulation experiments were carried out to compare the performance of the key CD-CAT components. Factors and levels were chosen according to the literature review of the latest advances in CDM (Ravand & Baghaei, 2020) and CD-CAT (Yigit et al., 2019; Yu et al., 2019). Experiment 1 focused on two key components that might increase test accuracy. The first factor is the CDM fitted in the item bank calibration and data generation, including the bank-level GDINA model and the item-level CDMs. The second factor is the item selection method, including the PWKL, MPWKL, GDI, JSD, and random method. The test length was set to 30 items in Experiment 1. This study did not take the SHE and MI methods into account, as JSD was proven to be a superior alternative (Kang et al., 2017; Wang et al., 2020). Accordingly, Experiment 2 explored the test efficiency of fixed-precision CD-CATs, with all item parameters calibrated by the item-level CDMs. Two factors were varied. The item selection rules were limited to the JSD and GDI methods. Following the suggestions of Hsu and colleagues (2013), Experiment 2 compared three levels of termination criterion that the test would terminate whenever the current posteriori probability of a given pattern reaches .7, .8, or .9. Considering the testing burden shall not be excessive, the CD-CATs would also stop when the examinee have answered a maximum of 30 items. In both simulation experiments, an item was randomly administered to each examinee at the beginning of the CD-CAT, and the maximum a posteriori method was used to obtain interim latent mastery profiles.
For practical considerations in low-risk scenarios, this study aims to achieve the optimization of both the testing accuracy and burden. The key evaluation criteria were the pattern-wise agreement rate (PAR), the attribute-wise agreement rate (AAR), and the average test length. Higher PAR and AAR values indicate better accuracy levels. According to Johnson and Sinharay (2019), who compared a list of the existing reliability-like measures, the AAR/PAR of the CD-CAT approximated the attribute-level and test-level diagnostic reliability (Wang et al., 2015) of the cognitive diagnostic assessment. Thus, this study used diagnostic reliability as a reference baseline for comparing the improvement of the CD-CAT to linear assessments. The formulas are as follows:

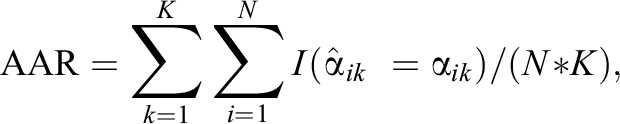
where N is the number of examinees, K is the number of attributes, and I
The item usage and computational efficiency of CD-CATs were calculated as references. Item usage uniformity was evaluated by the asymmetry of ideal and real item exposure distribution (
2.4. Data Analysis
R studio was used to analyze the data (R Core Team, 2021). As the correct specification of Q-matrix is necessary for valid diagnostic classifications (Kunina-Habenicht et al., 2012), an empirical validation procedure was used to achieve the best item-attribute relationships iteratively (Ma & de la Torre, 2020). For item bank calibration, researchers used a two-step likelihood ratio test statistic for model comparison at the item level (see also Sorrel et al., 2017). This study considers the GDINA model as the default and several reduced models as the comparison, including the DINA, DINO, ACDM, RRUM, and LLM models. Please see Supplementary Table 1 for the detailed proportion of the item-level CDMs in the item bank. The “GDINA” package was applied for most CDM analysis, including diagnostic reliability, item bank calibration, and individual mastery profiles. The mastery profiles in the first experiment were generated by either the bank-level GDINA or the item-level CDMs. On all the other occasions, we used the item-level CDMs, which outperformed the counterparts in the experiment. As the monotonicity and the local dependency assumptions for the DCRCA and for the item bank were not violated, the three-parameter logistic IRT (3PL-IRT) statistics were computed using the “ltm” package. We did not test the unidimensionality assumption, as we intentionally designed the DCRCA to incorporate the within-item multidimensionality by tapping two attributes at one item. Differential item functioning was conducted by the Wald statistic calculation using the “CDM” package (George et al., 2016; Hou et al., 2014). All CD-CAT simulation experiments and analyses in this study were performed using the “cdcatR” package (Sorrel et al., 2021b) and self-programming in R. Each experimental design was repeated 10 times and the results were averaged.
3. Results
3.1. Item Bank Calibration
The Q-matrix of the 208 items were validated through the data-driven empirical procedure (de la Torre & Chiu, 2016), which compared the proportion of variance accounted for (PVAF) of all credible q-vectors of the given item. This procedure suggested accepting the q-vectors of 198 items, as they were the simplest with a PVAF above 0.95. Only 10 items were screened out and iteratively modified by experts. So, results showed high consistency between the empirical and data-driven Q-matrix of the item bank (Deonovic et al., 2019). Item analysis was then conducted using the item-level CDMs, a 3PL-IRT model, and the differential item functioning by gender. A total of 13 new items were excluded for psychometrical considerations, including poor discrimination (CDM item discrimination index < 0.20 or IRT discrimination < 0.45) or having above moderate differential item functioning issues (significant χ2 and effect size > 0.88).
Table 2 summarizes the final 195 items for the item bank calibration. The CDM item discrimination index varied from 0.21 to 0.85 with an average of 0.52, showing clearly that the remaining 195 items could differentiate the masters from the nonmasters of reading effectively. IRT discrimination parameters were also acceptable, ranging from 0.46 to 4.02. The average item difficulty in Key Stages 1–3 steadily increased from −0.55, 0.55, to 0.83, providing satisfactory evidence of the rising item complexity. The 195-item bank covered the six reading attributes in a balanced way, and the proportions of each attribute were 28.21%, 24.62%, 25.13%, 22.05%, 81.03%, and 19.49%, respectively (see Supplementary Table 1 for the distribution of Q-matrix and the item-level CDMs). The test information function (Supplementary Figure 1) was over 9.70 for the total sample of 28,485 students, whose reading ability θ ranged from [−2.10, 2.43]. According to Embretson and Reise (2000), the reliability of the full item bank is greater than 0.90.
Descriptive of the Item Parameters in the Item Bank
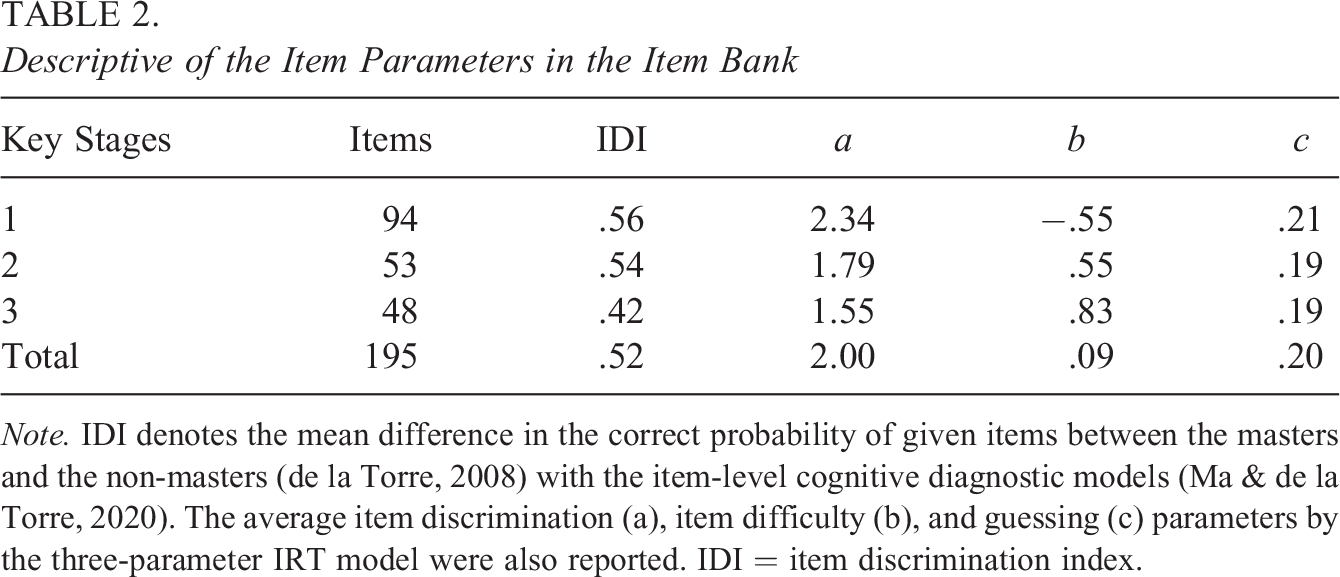
Note. IDI denotes the mean difference in the correct probability of given items between the masters and the non-masters (de la Torre, 2008) with the item-level cognitive diagnostic models (Ma & de la Torre, 2020). The average item discrimination (a), item difficulty (b), and guessing (c) parameters by the three-parameter IRT model were also reported. IDI = item discrimination index.
3.2. Distribution of Reading Mastery Patterns of Primary Students
Items were designed to measure six previously validated reading attributes and thus could theoretically identify 26 = 64 mastery profiles, denoted as nonmasters [000000] to all-masters [111111]. So, we estimated the mastery profiles of 284,85 primary students according to their responses on the final item bank. However, to facilitate understanding and intervention, we excluded a total of 597 students with 45 profiles (the rest four profiles were not identified), as these students only accumulated 2.10% of the total sample. So, only 15 profiles with proportions greater than 0.3% (over 80 students) were considered meaningful in the current sample.
Figure 2 presents the distribution of these meaningful reading mastery profiles across grade levels, in descending order of their average latent reading ability. Among the 15 meaningful profiles, seven profiles showed a clear cluster effect, as their proportions were consistently greater than 2.0% (over one student in each class) in the total sample and all five grades. We defined these seven profiles, namely, [000000], [100000], [110000], [111000], [111100], [000011], and [111111], as dominant and instructively noteworthy. These dominant profiles accumulated 91.9% of the total sample, ranging from 89.0% to 93.1% of students in each grade. From the perspective of reading development, the proportion of the [111111], master of all attributes, clearly showed a stable rising trend with grade level, increasing from 12.2% to 25.0%; while the proportions of the nonmasters [000000] and the masters of the four attributes [111100] decreased with grade level. The proportions of the rest dominant patterns were largely stable.

The proportion of meaningful reading profiles in Grades 2–6. Note. The attribute mastery profile represents student’s mastery (denoted by 1) and nonmastery (denoted by 0) state of the six reading attributes. For simplicity reasons, only the proportions of the dominant categories are presented.
3.3. Fixed-Length CD-CAT Simulation Results
Figure 3 shows the trajectories of the classification accuracy as a function of test length in the fixed-length CD-CATs. The accuracy rates of CD-CAT implementations calibrated by the item-level CDMs (Figure 3a and c) consistently outperformed those of the GDINA model (Figure 3b and d). Regarding pattern recovery, the differences between these two calibration models (Figure 3a and 3b) increased as more items were applied, reaching approximately 0.26 at the end of the 30-item CD-CAT. Besides, the AARs and PARs of all adaptive conditions outperformed those using the random selection method. The performance of three item selection methods (the JSD, GDI, and MPWKL) tended to be similar regardless of the calibration model used, with the JSD index being slightly better than the GDI and MPWKL methods. Among all adaptive item selection rules, the PWKL method performed the worst, which is in line with previous studies (Chang et al., 2019; Chiu & Chang, 2021).
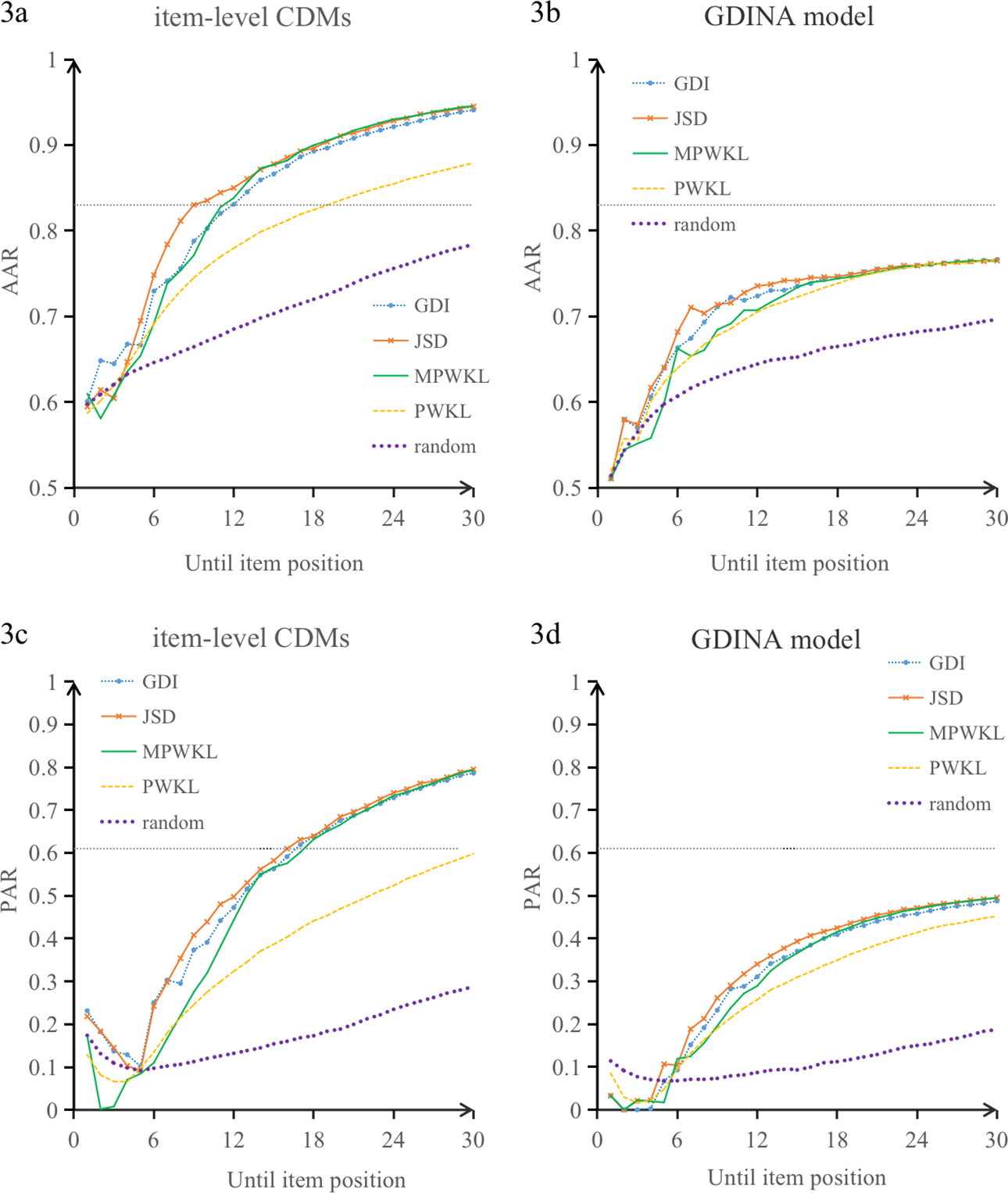
Test accuracy comparison of fitted methods and test length. Note. The pattern and attribute accuracy of the linear-version DCRCA are represented by gray dotted lines. AAR = attribute-wise agreement rate; PAR = pattern-wise agreement rate; GDINA = generalized deterministic inputs, noisy, “and” gate; GDI = GDINA model discrimination index; JSD = Jensen–Shannon divergence; PWKL = posterior-weighted Kullback–Leibler; MPWKL = modified PWKL; random = random item selection; DCRCA = diagnostic Chinese reading comprehension assessment.
Furthermore, in several conditions, when the item-level CDMs and the JSD, GDI, or MPWKL were applied, the AARs surpassed those of the linear DCRCA (i.e., average attribute accuracy = 0.83) after 9 to 12 items were administered, and the PARs surpassed the linear DCRCA (i.e., average pattern accuracy = 0.61) after 16 to 17 items. When the above CD-CATs terminated with a fixed length of 30 items, the AARs and the PARs reached 0.94–0.95 and 0.79–0.80, respectively, suggesting the potential for improving accuracy as a function of test length.
Table 3 summarizes the item usage and computational intensity of the fixed-length CD-CAT implementations. Results indicated that item selection methods had a significant impact on the item usage uniformity and the TOR, while little differences were produced by different calibration models. The JSD, GDI, and MPWKL methods performed comparably on the item usage criteria. However, the PWKL index had larger TOR and the
Comparison of Item Usage for the Fixed-Length CD-CATs
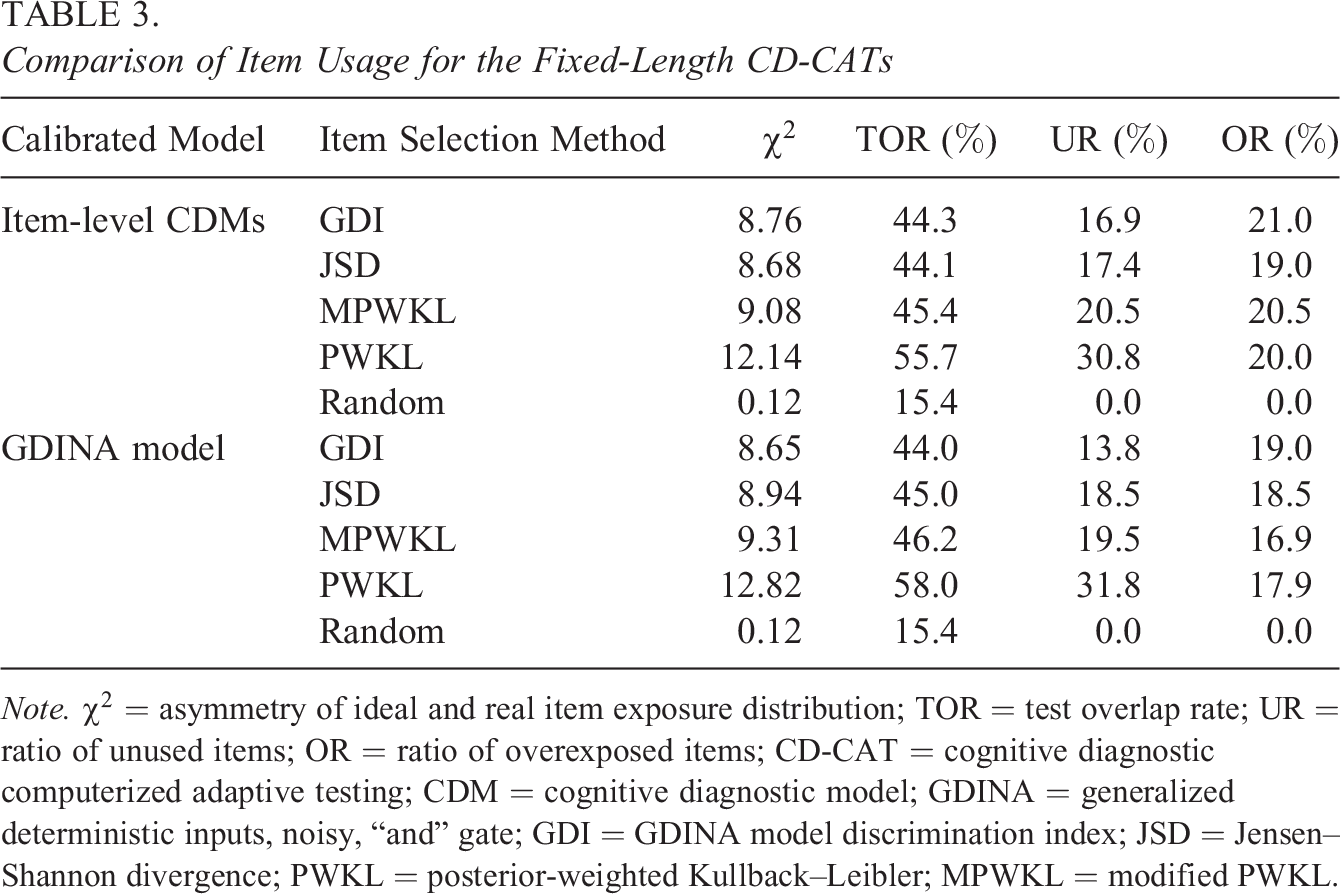
Note.
3.4. Fixed-Precision CD-CAT Simulation Results
Table 4 presents the results of Experiment 2, comparing the effects of item selection and termination rules under the fixed-precision CD-CAT implementations. The classification accuracies of all fixed-precision CD-CATs exceeded that of the experts-assembled linear DCRCA (PAR = 0.61 and AAR = 0.83). However, the trade-off effect of test length and test accuracy was illustrated clearly, as stricter termination threshold criteria steadily increased both test accuracy and test length. That is, for every 0.1 increase in the posterior probability of mastery (ppm) in the termination rule, the average value of AARs increased by 0.011, the average value of PARs increased by 0.053, the test length increased by 2.36 items, and the proportion of examinees who answered the maximum of 30 items increased by 15.72%. It was also found that the JSD index slightly but consistently outperformed the GDI index in almost all values, including slightly improved classification accuracy, decreased item usage uniformity, and shorter test length.
Comparison of Evaluation Criteria for the Fixed-Precision CD-CATs

Note. The fixed-precision CD-CATs terminated when the posterior probability of mastery (ppm) of a latent profile was higher than the threshold criterion or the number of administered items was 30. Full response denotes the proportion of examinees who answered the maximum of 30 items. GDI = GDINA model discrimination index; JSD = Jensen–Shannon divergence; CD-CAT = cognitive diagnostic computerized adaptive testing; AAR = attribute-wise agreement rate; PAR = pattern-wise agreement rate.
Considering that the DCRCA is mainly applied to low-stakes situations where accuracy and efficiency are the most crucial considerations, the adaptive DCRCA in practice shall set its key components as follows: item calibration model as the item-level CDMs, item selection method as the JSD index, and termination rule as posterior probability of mastery > 0.8 or answering up to 30 items. The average test accuracies of this proposed adaptive DCRCA are expected to be 0.93 at the attribute level and 0.72 at the pattern level. The item bank usage is expected to be relatively balanced with an average test length of 20.48 items.
3.5. Group Analysis of CD-CAT Application
Table 5 compares the conditional performance of the proposed CD-CAT system for each dominant reading profile. The AARs were above 0.88, and the PARs ranged from 0.60 to 0.85. Of note, the dominant profiles with lower reading ability [000000], [100000], [110000], and [111000] had higher accuracies and shorter test lengths than the profiles with higher ability [000011], [111100], and [111111]. Thus, this CD-CAT system performed better in diagnosing students with lower reading ability and less mastered attributes than students with the higher reading ability.
The CD-CAT Accuracy and Test Length for Each Dominant Profile

Note. Dominant profile is defined as the student’s reading mastery profile with an overall percentage greater than 2%. CD-CAT = cognitive diagnostic computerized adaptive testing; AAR = attribute-wise agreement rate; PAR = pattern-wise agreement rate.
4. Discussion
The present study has explored and optimized the effects of the CD-CAT system for an empirical reading assessment for Chinese primary students. The study developed a Chinese reading comprehension item bank tapping into six well-defined reading attributes, with 195 items jointly calibrated using data of 28,485 second to sixth graders and the item-level CDMs. A total of seven dominant reading profiles are identified and exist stably in second to sixth graders, showing a clear cluster effect that calls for future attention. Besides, the measurement precision and efficiency of the reading CD-CAT system were compared and optimized. Results suggest that the CD-CAT implementations have significantly improved the classification accuracy of the Chinese reading comprehension assessment assembled by domain experts, as CD-CAT techniques enable the assessment to be tailored to each test taker’s latent profile. Results also suggest that the combination of item-level CDMs, the JSD item selection method, and the fixed-precision termination rule of ppm > 0.80 performs ideally. These processes can shed light on the real applications in CD-CAT and provide practical tools of assessing reading development.
In contrast to previous reading assessments that focused on discriminating between good and bad readers (Sabatini et al., 2015), the adaptive DCRCA provides fine-grained feedback on two to six graders’ reading development. As the meta-analytical research revealed, individuals could be slackened by the knowledge chasm, but motivated by a knowledge gap (Hattie & Yates, 2013). Therefore, the ladder-like feedback of the adaptive DCRCA may be useful for children, especially those with less mastered attributes, as it may help them to identify their next step, rather than daunt students by results of how far behind they are on a continuous scale. Besides, direct feedback on learning progressions could improve students’ meta-cognitive awareness of approaches to mastery (Pérez-Segura et al., 2022) and the necessity for remediation (Howard et al., 2021), resulting in real individual improvement.
The seven dominant reading profiles, namely, [000000], [100000], [110000], [111000], [111100], [000011], and [111111], exist stably across grades and deserve further concern. These major clusters of readers and their variety with grade indicate some reading developmental mechanisms that primary students may progress and deepen step by step. According to the learning path hypothesis, students’ learning trajectories could reflect the cognitive structure and the learning sequence formed in the learning process of group consciousness (Wang & Lu, 2021; Wu et al., 2021). Inspired by this hypothesis, the optimal learning trajectories for reading profiles might be [000000] → [100000] → [110000] → [111000] → [111100] → [111111] or [000011] → [111111] at the primary level. Apart from knowing what students know, knowing how they become knowers could be beneficial to a broad range of researchers and practitioners. Therefore, future research is needed to learn the attribute hierarchical pattern from reading data (Wang & Lu, 2021) and to explore the corresponding modeling in the CD-CAT design. Besides, given the increasing demand for strategy-oriented instruction in reading, studies of the longitudinal remedial effects of incorporating the adaptive DCRCA would also be pertinent.
This study clearly demonstrated the benefits of CD-CAT by applying its recent methodological advances to an empirical reading assessment, the DCRCA. The CD-CAT implementations significantly improved the measurement accuracy than the linear counterparts without imposing much test burden. Results could serve future studies in several ways. Specifically, we found that the calibration model for the item bank is critical in maximizing the accuracy of CD-CAT. The item level model, that is, selecting the most appropriate CDM for each item, performed significantly better. Despite that the GDINA model fitted better than another four reduced CDMs in the linear DCRCA (Li et al., 2021), this was not the case when calibrating the item bank. This is probably because the parameter estimation of a general CDM (the GDINA model) typically requires a pretty large sample size. Otherwise, the classification accuracy might be compromised when the number of parameters to be estimated is large, the Q-matrix is complex, and the sample size is not large (Sorrel et al., 2017; Sorrel et al., 2021a). Besides, the calibration of an item bank often involves a scarce dataset, as real participants are unlikely to finish all items. Both may explain why the GDINA model failed in providing more reliable pattern recovery than the item-level CDMs. Second, although the JSD method was slightly better in test accuracies than other item selection methods, it performed similarly to the GDI and the MPWKL methods in detailed and statistical comparisons. Currently, methodological research regarding item selection methods has been critical concerns among researchers. Our findings, however, suggested that item selection methods differed little in the test efficiency and accuracy, as previous studies have also reported a close theoretical relationship among these items selection methods (Kaplan et al., 2015; Xu et al., 2016). Future research shall put more emphasis on calibration models, content balancing, and so on, which are of greater practical use. The adaptive DCRCA system may also benefit from better initial item selection strategies, such as administering a short pretest as initial information (Riley et al., 2007) or incorporating auxiliary background information (von Davier & Cheng, 2014). Third, the fixed-precision termination rule achieves the full potential of CD-CAT better than the fixed-length rule. The termination rule with posterior probabilities > 0.80 is the most balanced for the CD-CAT system, which is consistent with previous suggestions for low-stake tests (Hsu et al., 2013). However, the high ratio of 30.46% of examinees hitting the maximum test length merits further investigation. Promising directions include modifying the termination rule, adding more high-quality items, or using the attribute hierarchical structure (Leighton & Gierl, 2007) to reduce the number of candidate latent classes and thus speed up the CD-CAT system (Guo & Zheng, 2019).
The present study showed that the proposed CD-CAT system was faster and more accurate in diagnosing students with lower reading ability and less mastered attributes, but its performance on students with higher reading ability still needs optimization. This might be because the initial mastery status of the CD-CAT is [000000], which may facilitate the recommendation of appropriate items to lower ability participants. To enhance the efficiency of the adaptive DCRCA, future research should include more items, especially those examining more attributes. As an early exploratory study of CD-CAT applications on reading assessment, there are two directions to further improve the adaptive DCRCA. First, because of the excessive complexity of the CD-CAT system development, this study has not yet completed the online system and the field testing of the proposed adaptive DCRCA. So, future studies are needed to verify its empirical reliability (Johnson & Sinharay, 2019) and to provide convergent and ecological validity evidence for its real adaptive effects (Riley et al., 2007). Besides, although the test efficiency of the proposed adaptive DCRCA was satisfactory, future studies should continuously improve its psychometric and invariance properties by supplementing and assembling more balanced items, especially those targeting dominant profiles and students with higher levels.
Given the need and scope of such a large-scale CD-CAT application, more research is needed to determine the extent to which our findings can be generalized beyond the experiment designs. For example, Kang and colleagues (2017) proposed that the JSD method also has a high potential for dual-objective CD-CAT applications that simultaneously generate test takers’ discrete learning statuses and continuous overall performance. Therefore, assessments that cost a sizable amount of resources in development can provide more valuable information to students. Additionally, our suggestive findings on learning paths of reading need further investigation. A deeper understanding of CD-CAT application can be further demonstrated through interviews, tailored remedial instructions, and other longitudinal designs. For example, future research could explore the longitudinal effects of the targeted remedial instruction and the scaffolding reading materials that integrated the ladder-like feedback of the adaptive DCRCA. This type of research will be particularly relevant, given the growing need for strategy-oriented reading instruction.
5. Conclusion
This study proposed and demonstrated how the CD-CAT can be employed to provide valid and useful diagnostic information on reading progression in a more accurate and effective way, which is one of the principal challenges in current formative reading assessment (Chang et al., 2021; Sabatini et al., 2015). Results showed that CD-CAT could provide a greater wealth of information, accuracy, and efficiency in evaluating the innate structure and developments of reading than the traditional linear assessments. These findings contribute to our understanding of the CD-CAT and the reading progression of Chinese primary students. The adaptive DCRCA, if integrated into the remedial instructions for reading courses and programs as a routinized formative assessment, has the potential to accurately inform primary students of their reading progressions and next focuses during their key stages of reading development.
Supplemental Material
Supplemental Material, sj-docx-1-jeb-10.3102_10769986231160668 - Diagnosing Primary Students’ Reading Progression: Is Cognitive Diagnostic Computerized Adaptive Testing the Way Forward?
Supplemental Material, sj-docx-1-jeb-10.3102_10769986231160668 for Diagnosing Primary Students’ Reading Progression: Is Cognitive Diagnostic Computerized Adaptive Testing the Way Forward? by Yan Li, Chao Huang and Jia Liu in Journal of Educational and Behavioral Statistics
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research and/or authorship of this article: This work was supported by the National Key R&D Program of China (2019YFA0709503) and National Natural Science Foundation of China (31861143039).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.