
Abstract
In a randomized trial that collects text as an outcome, traditional approaches for assessing treatment impact require that each document first be manually coded for constructs of interest by human raters. An impact analysis can then be conducted to compare treatment and control groups, using the hand-coded scores as a measured outcome. This process is both time and labor-intensive, which creates a persistent barrier for large-scale assessments of text. Furthermore, enriching one’s understanding of a found impact on text outcomes via secondary analyses can be difficult without additional scoring efforts. The purpose of this article is to provide a pipeline for using machine-based text analytic and data mining tools to augment traditional text-based impact analysis by analyzing impacts across an array of automatically generated text features. In this way, we can explore what an overall impact signifies in terms of how the text has evolved due to treatment. Through a case study based on a recent field trial in education, we show that machine learning can indeed enrich experimental evaluations of text by providing a more comprehensive and fine-grained picture of the mechanisms that lead to stronger argumentative writing in a first- and second-grade content literacy intervention. Relying exclusively on human scoring, by contrast, is a lost opportunity. Overall, the workflow and analytical strategy we describe can serve as a template for researchers interested in performing their own experimental evaluations of text.
Experimental research in education routinely relies on text collected from survey responses, written compositions, interviews, and other forms of discourse as a means to test psychological theories and to evaluate instructional practices. For example, recent studies have used written assessments, reflective journals, and dialogue transcribed from video recordings to investigate the influences of different learning interventions on students’ scientific conceptions (Hsu et al., 2011; Tsai & Chang, 2005), critical thinking skills (Sharadgah, 2014), and writing competencies (Fu et al., 2019). In order to make inferences about these types of cognitive and psychosocial abilities, the text produced in these settings must first be reduced to sets of statistical features that represent qualitative constructs relevant to the theory and/or intervention being assessed. This is typically done through a process of human coding, whereby trained human raters apply a set of scoring rubrics to hand-code each document for the constructs of interest. Once all documents have been scored, an analyst can then estimate the average treatment effect (ATE) of an intervention by calculating the difference in average scores between the treatment and control groups (possibly adjusting for demographic variables, other observed covariates, etc.).
This process, the current standard, is both time-consuming and limiting: Even the largest human coding efforts are typically constrained to measure only a small set of dimensions. Such efforts also represent a massive simplification of the data; written language encodes a rich set of information that captures far more than what can feasibly be extracted by a human rater. In general, the inference that an intervention has led to meaningful changes in holistic judgments of text (e.g., essay quality) may reasonably be the result of changes along a number of different dimensions (e.g., grammar, vocabulary, organizational structure). Thus, while we believe human coding for specific constructs of direct interest is critical for assessing overall impact, we also believe this distillation of the rich mechanism of a treatment into an average shift along a few high-level summary measures of text leaves a lot on the table.
Machine-based text analytic and data mining tools offer one potential avenue to help facilitate research in this domain: We could, for example, supplement our “top-line” results with secondary analyses of a suite of automatically generated auxiliary outcomes. To this end, modern methods based on natural language processing (NLP) allow for the automatic evaluation of an array of linguistic properties including the measures of grammatical and mechanical accuracy, discourse structure, and lexical diversity. In addition to simple “surface features” of language, modern methods can compute the measures of construct-relevant characteristics, such as semantic meaning, coherence, and variations in prosody (i.e., patterns of rhythm and tone in language; Yan et al., 2020). These features characterize a rich set of abilities reflected in student writing, many of which are “invisible” to a human rater coding for higher level constructs (Pennebaker et al., 2014). By examining the patterns of impacts across a wide array of such outcomes, we can explore how different microfeatures of text (e.g., specific linguistic properties and/or psychological characteristics reflected in writing) may be driving the top-line impacts.
Aim of the Current Article
This article presents an illustrative tutorial on an analytic approach for using automated scoring techniques (i.e., NLP, machine learning [ML], and text analysis) for experimental assessments of text. We present our tutorial as a case study, using data from a recent evaluation by Kim et al. (2021b). We show how to leverage automated methods to expand the scope of what researchers might measure, in terms of a treatment impact, when using text as an outcome. We then demonstrate how this approach can be used to supplement an existing analysis by unpacking what may be driving an overall impact on a hand-coded outcome. We also explore how, for those without the necessary resources for a full human coding effort, automated methods can be used to conduct an impact analysis in their own right.
While the methods we present are not themselves new, we believe the workflow and analytical strategy we describe is novel and also likely to be useful in other education evaluations. In particular, we keep our proposed tools general and also provide the technical details necessary, so that researchers can try them out on their own experiments. To this end, we provide an accompanying R package,
In summary, our goal is to help evaluation researchers capitalize on the synergies between human and machine scoring in large-scale assessments of text. We do this by (1) presenting a comprehensive analytical workflow grounded in a case study based on real data and (2) providing a unified collection of computational tools, along with advice and practical guidelines, for implementing the techniques described.
Motivating Example
Our case study is to extend the analysis of a randomized controlled trial (RCT) recently conducted by Kim et al. (2021b) that evaluated the effectiveness of a model of reading engagement (MORE), a content literacy intervention designed to improve elementary grade students’ background, and vocabulary knowledge in science and social studies. The theory behind MORE is that thematic lessons that focus on a single topic over consecutive weeks provides an intellectual structure for helping young children connect new content learning and vocabulary to a general schema (Anderson & Pearson, 1984; Kintsch, 2009; Perfetti, 2007). The core components of the MORE lessons included 20 thematic lessons (10 life science and 10 social studies). For example, Grade 1 teachers taught a 10-day life science lesson on the topic of Arctic animal survival, read aloud and discussed conceptually related nonfiction texts on a variety of Arctic animals to further deepen students’ knowledge of semantically related vocabulary, and provided opportunities for argumentative writing to promote students’ mental instantiations of topic knowledge while accessing argument discourse structures and target vocabulary in working memory. In theory, the MORE lessons were designed to help students learn how to use argument structure while writing about science and social studies topics, to retrieve relevant background and vocabulary knowledge, and to develop greater confidence in their writing skills.
In the study by Kim et al. (2021b), the researchers collected over 5,000 student-generated essays, which were then hand-coded by trained research assistants as a preliminary step to assessing treatment impact. Once all essays had been scored on a measure of holistic writing quality, the research team estimated an average impact as the difference in these scores between students who received the content literacy intervention (i.e., treatment) and students who received the typical instruction (i.e., control). They found the estimated impacts of
The main results provide clear evidence that the content literacy intervention substantially improved the quality of students’ argumentative writing essays. However, complex and nuanced questions remain. For example, through what mechanisms did these benefits occur? Did treated students use more sophisticated vocabulary or more refined argument structures in their essays? Did they write with more confidence or sense of authority?
In this article, we demonstrate how to use ML tools to enrich the initial top-line analysis by examining impacts on other aspects of the text as measured using automated methods. In particular, we show how to answer the following research questions (RQs): Do students exposed to the intervention exhibit different underlying psychological states in their writing than those of the control group? Do students use different words or phrases to convey their ideas in writing as a result of treatment? Which words? Which phrases? With respect to both structure and content, are essays in the treatment group systematically more similar to “gold-standard” source texts than essays in the control group?
We also explore to what extent automated scoring methods—specifically, an ML model trained to predict essay quality on prior data—can recover the estimated impacts of the intervention on human-coded writing quality scores for this example.
Traditional Approaches for Evaluating Writing in Education and Psychology
Our case study, which examines a corpus of student-generated essays collected during a large-scale randomized trial, is a fairly classic example of an experimental study that relies on text as a basis for evaluating treatment impacts. In this standard (human-coded) approach, researchers first develop a scoring rubric for the construct of interest that lists the criteria for coding a given document and outlines the characteristics of different score levels. This instrument would then be applied to a representative sample (or an entire collection) of texts by at least one human rater to generate a numerical outcome value for each document. Once all essays have been scored, an analyst could then estimate the average impact by calculating the difference in average scores between the treatment and control groups (possibly adjusting for demographic covariates, etc.). This approach could, in principle, be augmented or simply repeated to evaluate treatment impacts for any additional constructs (e.g., strength of argument, creativity, etc.), but the time and resources required for human scoring could quickly make this untenable. As a result, human scoring efforts are more often limited to coding only one or a small set of outcomes.
In general, there are many factors that contribute to overall changes in writing, or more broadly, overall changes in the expression of ideas through language (Shermis & Burstein, 2003). Indeed, there is a long history of empirical research linking different, directly calculable measures of text to pertinent aspects of language acquisition, reading and writing proficiency, and content knowledge (Boyd & Pennebaker, 2015). Previous research in education has established connections between the linguistic properties of text and students’ cognitive engagement (Joksimovic et al., 2014) as well as various learning outcomes (Crossley et al., 2016b). Other studies have found that more frequent use of specialized or specific terms (McNamara et al., 2010), longer words (Crossley et al., 2011), and more academic words (Douglas, 2013) are all indicative of higher quality writing.
The expression of language also offers a window writers’ social, cognitive, and affective states (Dowell & Graesser, 2014). For instance, high rates of pronoun use have been associated with greater focus on one’s self or one’s social world, auxiliary verb use has been associated with a narrative language style, and the use of conjunctions has been associated with higher levels of cognitive complexity (Crossley, 2020). Similarly, Pennebaker and King (1999) found that a person’s “linguistic style” (i.e., their habitual use of specific function words including pronouns, prepositions, articles, conjunctions, and auxiliary verbs in writing) serves as a reliable measure of individual differences. Function word use has also been identified as an important predictor of social status, culture, truthfulness, and depression (Chung & Pennebaker, 2007). In sum, there is clear evidence from the literature that suggests that the words writers use provide information about how they are thinking in addition to what they are thinking about (Pennebaker et al., 2014). Incorporating these measures as outcomes in an impact analysis may therefore reveal systematic differences between treatment and control groups on psychologically meaningful aspects of writing that would have otherwise been overlooked.
In the extreme, one might even imagine that we could use fully automated methods for impact assessments with text, using machine scored outcomes as our primary outcome of interest. In fact, a number of automated scoring systems have been successfully developed and deployed to address the cost of essay grading, particularly in the context of standardized assessments (e.g., Attali & Burstein, 2006; Foltz et al., 1999; Page, 1994). While these approaches have serious risks, most particularly, the risk of automatically coding constructs that do not have the depth of meaning or nuance that one might achieve by human coding, automated methods also have a number of advantages. In addition to scalability, automated scoring tools offer more objectivity, consistency, and reproducibility than what can reasonably be achieved by human raters. Hand-scoring complex constructs requires complex and nuanced judgment, which is subject to biases and inconsistencies that can quickly complicate large-scale assessments of text (Shermis & Burstein, 2003). By applying the same scoring algorithm across all text documents, automated methods therefore have the potential to reduce measurement error introduced by human raters (Correnti et al., 2020). These tools also present an opportunity to reduce the scale of human coding in assessments that aggregate scores across multiple human raters. Previous studies in the automated essay scoring literature have found that the level of agreement between human and machine generated scores is comparable to that achieved between two human raters (Shermis & Hamner, 2013). For these reasons, there has been increasing debate in the research community about moving away from the exclusive reliance on human coding as the gold standard, particularly in the context of educational assessments of writing (Correnti et al., 2020). Even if these scores are biased or misaligned with human judgment, the consequent estimated impacts are valid due to the randomization of the experiment, in that they show there was an impact of the applied intervention on the machine-coded outcome; the key is that the interpretation of what a found impact means is what is potentially undermined by a lack of human oversight. To engage with this question, we show two approaches for conducting a proxy impact analysis and compare these analyses to the human-coded gold standard, in our empirical application.
A Workflow for Impact Analysis
Given an experimental (or quasi-experimental) sample where text data constitute the outcome of interest, researchers might ask either of two general questions. The first question, typically based in substantive theory and initial interest that motivated the intervention itself, is confirmatory: “did the intervention change a specific aspect of the text?” The second question is more exploratory in nature: “which aspects of the text, if any, did the intervention change?”
To make these questions explicit, consider a randomized trial with N subjects, indexed by
We can similarly use this approach to estimate the causal impacts of treatment on a set of secondary text-based outcomes measured using automated scoring methods. Consider, for instance, an arbitrary procedure or calculation f that returns a numerical feature
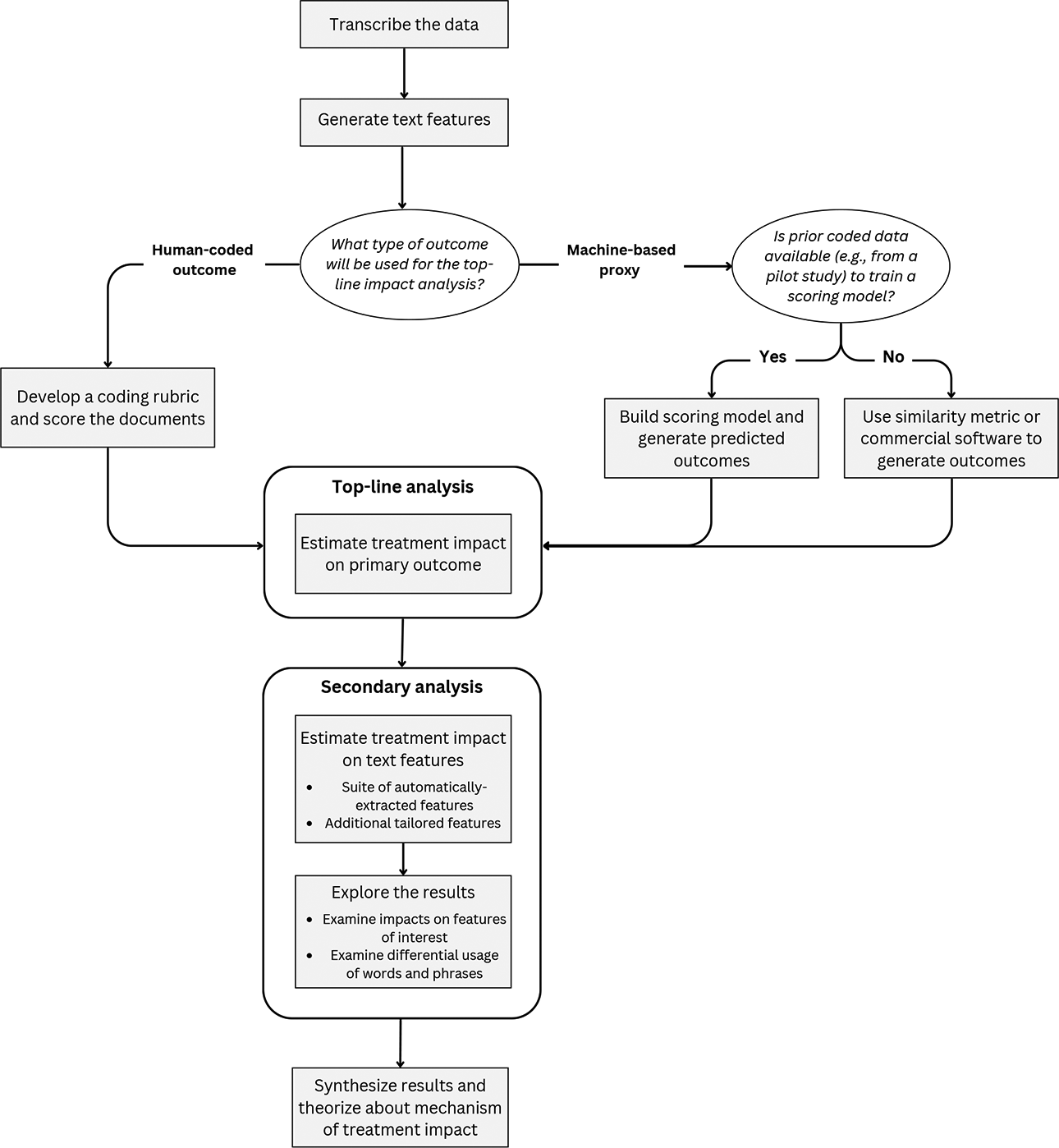
Proposed workflow for combining human and automated scoring methods in an impact analysis with text-based outcomes.
Generating Auxiliary Outcomes From Text
As a first step for unpacking treatment impact on aspects of the text that may not have been directly assessed in the human coding process, we generate a rich set of numerical features that capture different descriptive characteristics of the text. We build these features from the raw text itself using a mix of simple statistical procedures (i.e., counting frequencies of words) and off-the-shelf software packages that generate the sets of features designed to capture different aspects of text. Given the “unstructured” nature of text, there is essentially no limit to the number of features possible. In general, we are most interested in features that are easy to interpret; for example, measures of complexity in vocabulary usage or the tone of writing might be of interest for assessing a treatment aimed to improve academic writing quality. In the following paragraphs, we describe several common tools that can be used to generate a wide array of possible features that span a range of aspects one might be interested in. Many of the implementing packages named below are called via our
Simple summary measures
The simplest summary measures of text are based on term frequencies, which count the total number of times a given word or special character appears in a text. Once tabulated, these counts can then be aggregated to calculate univariate summaries of text such as lexical diversity. For example, the type–token ratio, defined as the number of unique words in a text (i.e., types) divided by the overall number of words (i.e., tokens), reflects the breadth of vocabulary used in a given document and can provide an indication of text cohesion (Dowell et al., 2016). In the same manner, one can also calculate the term frequencies for a set of predetermined words and phrases. For example, if part of an intervention focused on encouraging the use of more scientific language, we might identify a set of words targeted by the intervention itself and count the rates of appearance of these words. Counts for these key words could be used as standalone features, or aggregated to cumulative usage rates. Simple word counts can also be used to identify common rhetorical relations used in writing. For instance, previous research in the field of discourse analysis suggests that words such as “perhaps” and “possibly” are common cues used by writers to express a belief while developing an argument (Burstein et al., 1998). Tools for computing term frequencies and simple text summaries for collections of documents are available in most modern computing programs; see, for example, the Natural Language Toolkit (Bird et al., 2009) in Python and the
Natural language processing
NLP describes a class of tools based on algorithmically recognizing linguistic patterns within text (see Allen, 1995; Clark et al., 2013; Martin & Jurafsky, 2009, for general references). Standard NLP tool kits can be used to extract an array of features that measure both the syntactic and lexical characteristics of text. Basic techniques in this domain can segment texts by sentences or paragraphs, allowing for the calculation of measures such as average sentence length. Other common NLP techniques extract part-of-speech categories (e.g., nouns, verbs, adjectives), sentence structures (e.g., verb phrases, clauses), and named entities (Benjamin, 2012; Collins-Thompson, 2014). The ratios of syntactic structure types per sentence are also commonly computed as measures of syntactic variety (Burstein et al., 1998).
In addition, there are a number of canonical metrics that have been developed for automatic evaluation of text with respect to constructs such as reading grade level and discourse cohesion, many of which can be easily computed using freely available NLP tools such as Coh-Metrix (Graesser et al., 2004) and the Tool for the Automatic Analysis of Text Cohesion (TAACO; Crossley et al., 2016a, 2019). For instance, formulas such as the Flesch Reading Ease Score (Flesch, 1948) and the Flesch-Kincaid Readability Score (Kincaid et al., 1975) provide an index for readability and comprehension difficulty based on the word and sentence lengths found in a text. Similar statistical devices have been developed for cohesion, which measures the presence or absence of explicit cues used to establish connections between ideas expressed in a text, and coherence, which represents the sense of meaning and organization derived by the reader (McNamara et al., 2014).
Validated dictionaries
Researchers have also developed more complex dictionaries with collections of terms and phrases that are believed to be indicative of certain psychological processes and affective states reflected in writing. For example, Linguistic Inquiry Word Count (LIWC; Pennebaker et al., 2001)—a popular and commercially available tool for performing sentiment analysis—measures the percentage of words within a given text that reflect different emotions, thinking styles, and social concerns. The output generated by LIWC includes indices for several syntactic and grammatical attributes (i.e., rates of pronoun or punctuation use, as discussed above) as well as an array of psychological dimensions (e.g., anger, insight, power) and four high-level summary variables measuring analytical thinking, clout, authenticity, and emotional tone (Pennebaker et al., 2015). LIWC has been validated in the psychological literature (e.g., Tausczik & Pennebaker, 2010) and has been widely applied in education research (Robinson et al., 2013; Sell & Farreras, 2017). More broadly, LIWC has been used for the analysis of classical literature, personal narratives, press conferences, and transcripts of everyday conversations (Pennebaker & Graybeal, 2001).
Model-based representations
In addition to features that are directly measurable from the text, one might be interested in evaluating latent constructs captured in language data. For instance, statistical topic models such as the latent Dirichlet allocation (Blei et al., 2003) and the structural topic model (Roberts et al., 2014) are frequently used to represent documents as a mixture of K latent topics, denoted
Similar features can be calculated using neural network embeddings, such as Word2Vec (Mikolov et al., 2013), which have been found to be useful in machine translation (e.g., Branting et al., 2019). These embeddings allow for projecting each document, using a function trained on alternate bodies of text, into a dense lower dimensional space. The set of coordinates of the documents in this space can then be used as features, with one feature per dimension; this collapses variable-length pieces of texts to a canonical, quantitative form (Mikolov et al., 2013), just as with topic modeling. Because these embeddings implicitly contain representations of word similarity, this approach can be especially appealing for short excerpts of text such as single sentences or paragraphs, as related words will end up with similar representations. Interpreting what these features signify can be more difficult than with a topic model, however.
There are some complications in using features derived from model-based representations such as these within the context of a randomized experiment. For example, generated models fit to the text itself can vary depending on the impact of treatment on that text. Then, in the topic-modeling case, if the treatment itself alters the set of topics identified in the topic model, describing the impact of treatment becomes more difficult (see Egami et al., 2022, for further discussion). More broadly, interpreting impacts on generated features can be more difficult than more directly measured quantities. That being said, these tools offer a rich suite of additional features one might consider.
Estimating Treatment Impacts Across a Suite of Text Features
Given a feature set derived from machine measures of text, we can then estimate treatment impacts on each of these features using standard inferential tools (e.g., regression, t tests, or randomization tests). Estimating impacts for all generated features has the distinct advantage that it requires no a priori knowledge of which aspects of the text may be sensitive to treatment; however, simultaneously comparing treatment and control groups across a large number of text-based outcomes opens the door to a massive multiple testing problem. To correct for multiple comparisons, we employ the Benjamini–Hochberg (BH; Benjamini & Hochberg, 1995) procedure for controlling the false discovery rate (FDR), which is the expected proportion of false identifications among a set of findings deemed statistically significant. Specifically, after all hypothesis tests of interest have been performed, we apply the BH procedure to the resulting set of p values to adjust for the number of “significant” results. This screened list constitutes aspects of the text significantly impacted by treatment, including features that may not have initially been considered in the human coding process. The BH procedure ensures that, in expectation, no more than a prespecified proportion of these identified features are spurious results.
We prefer the BH approach over more classical, conservative methods such as the Bonferroni correction because FDR approaches are scalable; the BH’s performance remains strong as the number of tests grows (Glickman et al., 2014). With text, we do not expect the treatment to have significant effects on all of our generated features. We also expect that groups of related features would all be impacted, to some degree, by the treatment. We therefore seek methods that can distinguish positive findings in a context, where the expectation is that many hypotheses may well be null; the FDR method is well-suited for this aim. Finally, the FDR method can also flexibly accommodate collections of hypothesis tests that are believed to be correlated, which will usually be the case with summary measures of text.
Discovering Differential Use of Words and Phrases
To better contextualize the ways in which a treatment impact could manifest the text, we can also look for systematic differences in the use of key terms and phrases. As previously discussed, the words people use contain powerful signals of both what and how they think about a particular topic (Pennebaker et al., 2014). In experimental contexts, a natural question therefore asks, “do the words used by individuals in the treatment group differ systematically from those used in the control group?” For this more exploratory question, we use concise comparative summarization (CCS; Jia et al., 2014), a sparse regularized regression method, as implemented by the textreg R package (Miratrix & Ackerman, 2016). CCS regresses a treatment indicator on the dynamically generated set of all words and phrases found across a collection of documents and identifies those words and phrases that are most predictive of treatment. These identified words and phrases are then taken as a summary of what separates the two groups of documents.
CCS is a version of the LASSO (Tibshirani, 1996), a sparse regularized linear modeling approach, with a particular normalization of the features (a feature here being any possible word or phrase). The regularization means it “costs” to use any given feature, and thus, only those features particularly associated with treatment will be preserved. The sparseness ensures that only a small subset of the many thousand possible candidate phrases are ultimately selected. Sparseness makes the output tractable for human interpretation. Indeed, both Jia et al. (2014) and Miratrix and Ackerman (2016) found CCS to be an effective strategy for identifying terms and phrases that (1) were interpretable by human readers and (2) meaningfully differentiated between groups of documents targeted for comparison. CCS is also, at root, a predictive model: Recent work by Kuang (2017) found CCS outperformed several other methods in terms of predictive accuracy and stability of the identified predictive text features when applied to political texts.
In the context of an impact analysis, there are two notable concerns with using sparse regression to identify words and phrases that differentiate between treatment groups. First, text is highly correlated: Words and phrases tend to appear together. This means that while a selected set of phrases might meaningfully divide the treatment and control corpora, others may be nearly as effective. From a human interpretation point of view, either set could be potentially useful in understanding how one set of documents is different from the other. Second, ML methods usually have a variety of tuning parameters and design decisions that one needs to set and make as a precursor to model fitting. Especially with text data, where features are highly correlated, even subtle changes to these settings can result in different final sets of identified phrases.
On the other hand, some of the tuning parameters offer an interesting opportunity for investigation. In particular, CCS has a parameter that controls the relative regularization cost of different words and phrases as a function of their overall frequency in the corpus. Specifying different values of this parameter therefore allows us to explore a range of textual summaries, beginning with prioritizing commonly used words and ending with prioritizing very specific snippets of text. We can then, as a sensitivity check, count the number of times each phrase is selected across a suite of differently tuned models. Phrases that consistently appear are taken as the more robust findings.
Application to the Case Study
For each essay in our case study, we generate a host of features that all might capture different aspects of how the intervention may have impacted the students. We first generated a variety of common text statistics, such as essay length, average word length, and so forth. We then, using the
We also generated word counts for two researcher specified lists of “concept words” identified by the initial research team as target vocabulary terms of the intervention (one list of vocabulary actively taught in the intervention and one list of vocabulary implicitly taught). We calculated rates of word use for each of these lists, so we can include treatment impacts on these rates as a separate secondary analysis.
For each of the four-grade level (Grades 1 and 2) by domain (science and social studies) groups, we follow the impact model used in the original, top-line result (described fully in Supplementary Appendix A). In particular, for each of the generated text-based outcomes, we fit a separate linear regression model with cluster robust standard errors of the outcome onto treatment and a pre-test score. As we are analyzing within grade, we have a full cluster randomized trial for each of our four evaluations, so do not include school fixed effects. For each group, we then adjust the full set of findings using the FDR correction to identify the set of textual features that have been most prominently impacted by treatment. We can then compare the patterns of impacts across the grades to examine consistency of findings.
Finally, we used CCS to regress the treatment indicator onto the set of all words and phrases to determine which words and phrases appear more (or less) often in the treated students writing than the control. To get a rich range of features, we refit CCS under different specifications of the various tuning parameters, harvesting the phrases from each. For each model, we selected the regularization parameter using a permutation approach following Miratrix and Ackerman (2016), accounting for the school-level clustering of treatment by permuting at the school level. The resulting selected phrases in each group provide additional context about the ways in which treatment is impacting what students write.
The Promise and Perils of Automation Without Human Coding
In some cases (e.g., if resources are tight), we may wonder what conclusions might be reached if relying solely on the machine-generated features for impact analysis without any human coding effort. We explore two methods for proxying the top-line result in this spirit. Our first way of assessing top-line results is to calculate how similar each essay is to a gold standard exemplar and then estimate impact of treatment on these similarity scores. The second approach for an automated top-line impact analysis we investigated is to train a model that directly predicts our human-coded result on human-coded pilot data and then use this model to predict scores for all documents in the main data.
Importantly, due to the randomized treatment assignment, either of these methods provide a valid estimate of impact; in other words, if there was a systematic difference between treatment and control on any sort of predicted scores, that would be evidence that the treatment caused change. What would not be guaranteed, however, is whether the scores generated using automated methods would be in alignment with the original conceptual construct. They could be distorted. Thus, while the impact itself would be valid, the interpretation of what the impact signifies could be more difficult.
To help diagnose whether this may have happened, our proposed pipeline for exploring impacts across the range of automatically generated features used for prediction, can help contextualize a found impact or lack thereof. Also, our fit model allows us to see to what degree the collection of features discussed above can predict human judgment (and thus replicate our gold-standard human-coded results) in our context. We can compare the overlap of features used in the ML model and features impacted by treatment, for example. More broadly, it is of substantive interest to know to what degree different numerical measures, which are straightforward to measure but likely be more difficult than hand-coded constructs to interpret, are related to careful coding and qualitative assessment.
We next give more details of these two approaches in the following subsections.
Assessing Impact on Textual Similarity
Our first approach for a machine coded top-line measure for impact analysis is based on comparing the “informational value” of a collection of documents. The idea is to measure how different one document is from one or more reference documents. For example, if our target outcome is, in effect, a measure of essay quality, we can compare each student essay to a range of “gold standard” essays, scoring how related each text is to this set. The more similar a given document is to a document known to be of high quality, the more we might believe the text in question is also high quality. While any individual assessment based on this approach would, of course, be missing a lot, we can compare the average document-level similarity scores across treatment and control groups to assess whether there was an overall impact of the treatment. In general, while clearly inferior to actual human coding, perhaps this rough proxy measure, when coupled with the subsequent steps, could still prove informative, at least when viewed in aggregate.
Following Mozer et al. (2020), we define the “descriptive similarity” of two text documents using the cosine similarity metric, which measures the cosine of the angle between their corresponding term frequency vectors. 3 This metric has been widely used for text matching in computer science and has been shown to be highly predictive of human judgments about the descriptive similarity between texts (Mozer et al., 2020; Salton et al., 1975). Using this measure, we can calculate, for each document in a corpus, the cosine distance between that document, represented as a vector of word counts, and the corresponding “gold-standard” reference text. A similarity score equal to 1 indicates that the document in question uses exactly the same words as the source text while a similarity of 0 means the two texts have no overlap at all.
Predicting Outcomes Using Prior Data
A direct strategy for generating a machine measure of text that can serve as a proxy outcome is to use human-coded pilot data to train a predictive model based on our set of automatically extracted features. This model can then be applied to the target sample to generate predicted outcomes and compute estimated impacts, treating the predicted values as a top-line result. Impacts on these proxy outcomes could serve as a way of cheaply assessing whether the data show any signal of a treatment impact before undertaking a full human-coding effort.
Under this approach, the ML model trained on the pilot data is simply a “black box” component used to predict outcomes. We could alternatively use off-the-shelf essay grading tools such as e-rater (Attali & Burstein, 2006) or the Intelligent Essay Assessor (Foltz et al., 1999). As long as the method for machine scoring is established without reference to the target data, we are protected from any concerns of bias as the scoring is independent of the randomization. Of course, if our machine-generated outcome has no connection to human meaning, then a found impact may be difficult to interpret. For example, simply taking the length of essays in our case study as our measure of “quality” could result in a found impact, but it would not inform us as to whether the impact was meaningful in terms of the real goals of the intervention.
The usefulness of this approach will depend on how well we are able to train a predictive model to mimic human judgment using the prior data. Automated scoring methods require thorough training and validation, and even then, there may be areas of misalignment compared to what would be achieved via full human coding. In the present case study, for example, automated methods may not fully capture the richness and complexity of student writing, particularly when it comes to aspects like creativity or argumentation quality. Thus, just as with any proxy outcome, impact estimates based on machine-generated scores may lead to incorrect inferences about the treatment effect. If, for example, treatment impacts creativity, and we do not pick up creativity in our predictive model, then we could miss an impact entirely.
Despite the risks, automated methods offer a rapid, cost-effective means of assessment. They also promote consistency in scoring, eliminating the potential for human bias or rater fatigue. This may be particularly advantageous in large-scale evaluations involving large quantities of text, especially when the outcome of interest is fairly simple (i.e., can be reasonably predicted from machine measures of text). On the other hand, the risks may outweigh the benefits in smaller studies or studies with highly technical or complex outcomes, as well as in contexts where the stakes of the assessment are high.
Application to the Case Study
We conduct impact analyses using both similarity scores and predicted scores for the present case study. To compute similarity scores, we use the source texts coupled with each of the four writing prompts (one for each grade and subject combination). In particular, we test the hypothesis that students exposed to the content literacy intervention would structure their argumentative writing essays in a manner that more closely resembled the structure and vocabulary of the source material (i.e., the passage the student was asked about in the writing prompt) by calculating the cosine similarity between each essay and this source text (rather than a “gold standard” essay). These similarity scores provide an objective and holistic measure of students’ writing, in terms of content and syntactic structure, which we then use as a stand-alone outcome for impact analysis. It should be noted, however, that any realized impacts on this outcome—or on any outcome defined by comparisons across documents—is context-specific. While a higher similarity score in the case study suggests a “better” essay, it is a relative measure of writing and is only meaningful for comparing essays generated in the same context.
To generate the predicted quality scores that are used as a proxy measure for holistic writing quality in our case study, we applied a predictive model trained on pilot data collected in a prior study of the same content literacy intervention (Kim et al., 2021a). Our training data used essay texts from a sample of
To predict these human-coded scores, our feature set consisted of 247 machine measures of text including simple text summaries (e.g., word count), nominal measures of sentiment calculated using LIWC (e.g., use of “cognitive” words), and others derived from natural language representations that have been trained on separate corpora (e.g., GloVe word vectors; Pennington et al., 2014). We then fit over 20 candidate ML models using the
These candidate models were finally aggregated into a single ensemble learner—a predictive model formed by a weighted combination of multiple submodels (Zhang & Ma, 2012)—using the
Using the approach described above, our final model achieved an average out-of-sample prediction accuracy. 5 Notably, as our predictive model is fit on a separate data set, the predictions for our primary study are simply summary measures of the text just as any other.
For both of our similarity scores and predicted quality scores, we estimate impacts using our same regression approach as we did for the human-coded scores. Because these scores are a summary measure of the text, and the summarization is independent of treatment—in fact, in both cases, the scoring function can be specified at baseline—any found impact on these scores is rigorous, randomized trial evidence of the treatment impacting writing; the clear interpretation of what this signifies is what would potentially be lost without human coding.
Importantly, our proxy measures are quite different in character. The similarity scores could be taken as a secondary outcome with its own interpretation of how much the vocabulary used in the children’s text has been shifted toward the gold standard text. The predicted score, by contrast, is most directly interpretable as an attempt to directly reproduce what a human scorer would do.
Empirical Analysis and Results
We demonstrate our proposed analytic pipeline by first presenting a set of empirical results as a case study; we will then reflect on different methodological choices researchers might make in their own contexts in our discussion and conclusion. In particular, we first demonstrate theorizing about how the intervention achieved its top-line result by looking at how it impacted several aspects of students’ writing, including students’ underlying psychological states, through a series of auxiliary analyses using machine measures of the essay texts. We then show two ways of examining students’ use of vocabulary, with an initial investigation of differences in the use of specific terms and phrases between treatment arms and then by exploring differences in the lexicon more broadly. We finally show how one might synthesize across these different types of findings to gain a deeper understanding of how the intervention impacts first- and second-grade students’ approach to writing and domain knowledge in science and social studies.
Impacts on Psycholinguistic Properties
To assess the impacts of the intervention on the psycholinguistic properties of students’ writing, we analyzed each of our four grade by subject groups separately. For each of the 117 text-based outcome measures, we first collected the point estimates and corresponding 95% marginal confidence intervals for the standardized differences in means between treatment and control groups. For the ease of the reader, we present results for only a subset of the original features tested. Figure 2 shows the impact estimates for each of the four groups with respect to 10 common text statistics, including total word count, readability score, and four summary measures of higher level thinking generated using LIWC. Figure 3 shows the estimated effects for the set of other auxiliary outcome measures that were found to have significant treatment impacts, after the FDR adjustment, in at least one of the four groups, so as to aid comparison of the pattern of results across subjects and grade levels.
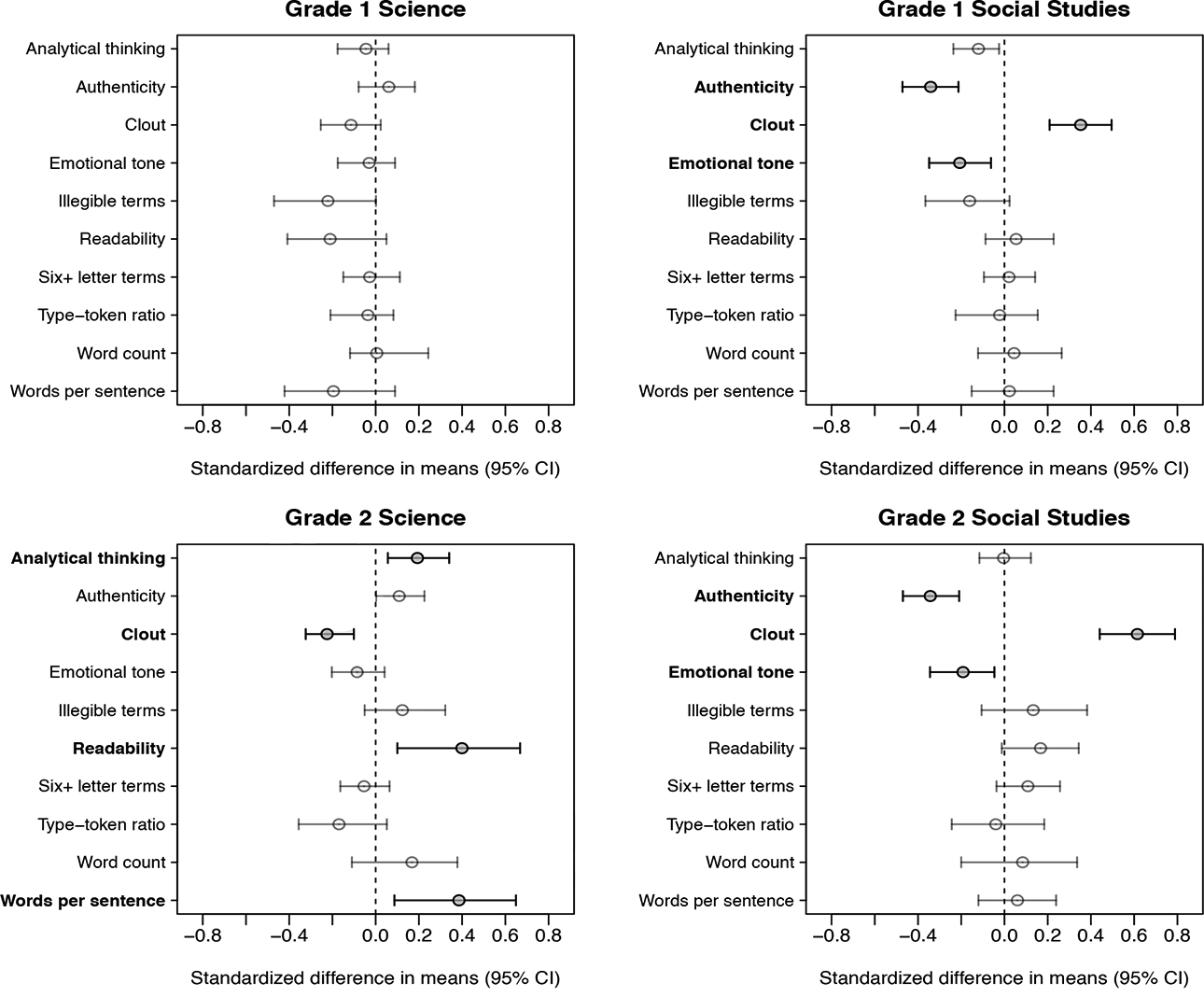
Standardized differences in means for 10 text-based outcomes, grouped by grade and subject. Bold feature names indicate statistical significance at the
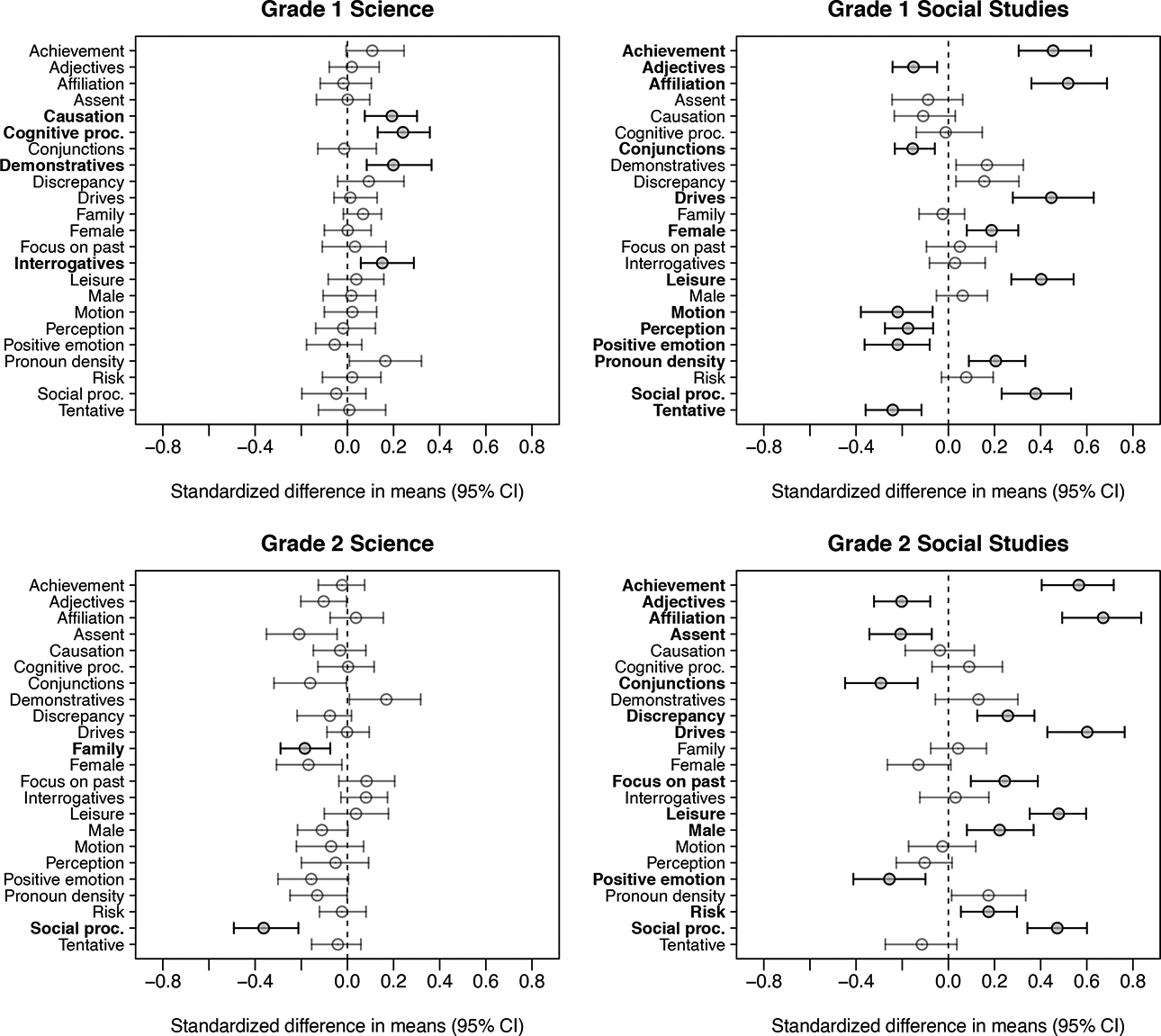
Standardized differences in means for features found to be significant in at least one of the four grade by subject groups. Bold feature names indicate statistical significance at the
These findings uncover several important potential mechanisms as to how the intervention was effective for improving students’ writing abilities in each domain. In the second grade, for instance, we see that treatment group tends to score higher on the dimension of analytical thinking and lower on the dimension of clout compared to the control group. Comparisons in this domain also reveal a number of significant differences between treatment and control groups with respect to students’ underlying psychological states. For example, we find that first graders in the treatment group scored significantly higher on the LIWC dimension measuring cognitive processes compared to those in control. We see evidence of treatment impacts on different psychological dimensions in the second grade, with the treatment group scoring significantly lower on the indices for social processes and family dynamics compared to the control group.
Impacts on various structural and psychological aspects of students’ writing are even more pronounced in the social studies domain, particularly for the set of features included in our post hoc comparisons. Across both grade levels, the treatment group scores significantly higher on the dimension for clout, suggesting that students who received the classroom intervention are writing from perspective of higher expertise and with more confidence, on average, than students who received typical instruction. Treated students also write with significantly lower levels of authenticity and emotional tone than students in control, which indicates a more formal and distanced form of discourse. In addition, we find significant differences between treatment and control groups at both grade levels on a number of dimensions related to students’ drives, needs, and motives. We also see that, among treated students, first graders use significantly more female references and second graders use significantly more male references compared to first and second graders assigned to control. Given that the essay prompts for each grade level asked students to make an argument in favor of one of two historical—Amelia Earhart or Sally Ride for first graders and Henry Ford or Leonardo DaVinci for second graders—this finding might suggest that the intervention is promoting a more structured writing style and a greater attention to detail than typical instruction.
Differential Use of Words and Phrases
We have two investigations of word use. The first is an impact analysis comparing the rates of use for predetermined sets of words deemed relevant to the intervention. The second is a discovery process identifying words and phrases used differently in each treatment arm.
Table 1 summarizes the total number of occurrences of specifically taught and untaught “concept words” within each subject and grade level. For each group, there were seven taught words (e.g., adaptation, survive) that treatment students directly and explicitly learned in the unit lessons and five untaught words (e.g., camouflage, unique) that were not explicitly taught during the lessons but were incidentally encountered through reading, listening, and discussion activities. As a sensitivity check, we examine both total number of occurrences and proportion of essays with at least one occurrence for both types of words. First, we see very different patterns of results across our four groups in terms of baseline usage of words. For example, 16% of the Grade 1 social studies students were using the untaught words, whereas none (0%) of the Grade 2 social studies students were using those words. This is likely due to the different word lists consisting of more or less common words. In terms of impacts, we see positive impacts on all word lists that had substantial baseline prevalence. For example, Grade 1 social studies saw a near doubling, from 16% to 32%, on the proportion of first graders in the treatment group that used at least one untaught concept word in their written responses. (The taught words were more rarely used, but we still see a modest estimated increase, from 1% to 3%.) Among second graders, we see a similar, albeit smaller, difference between students’ use of taught concept words.
Use of Taught and Untaught Concept Words in Treatment and Control, Grouped by Grade and Subject
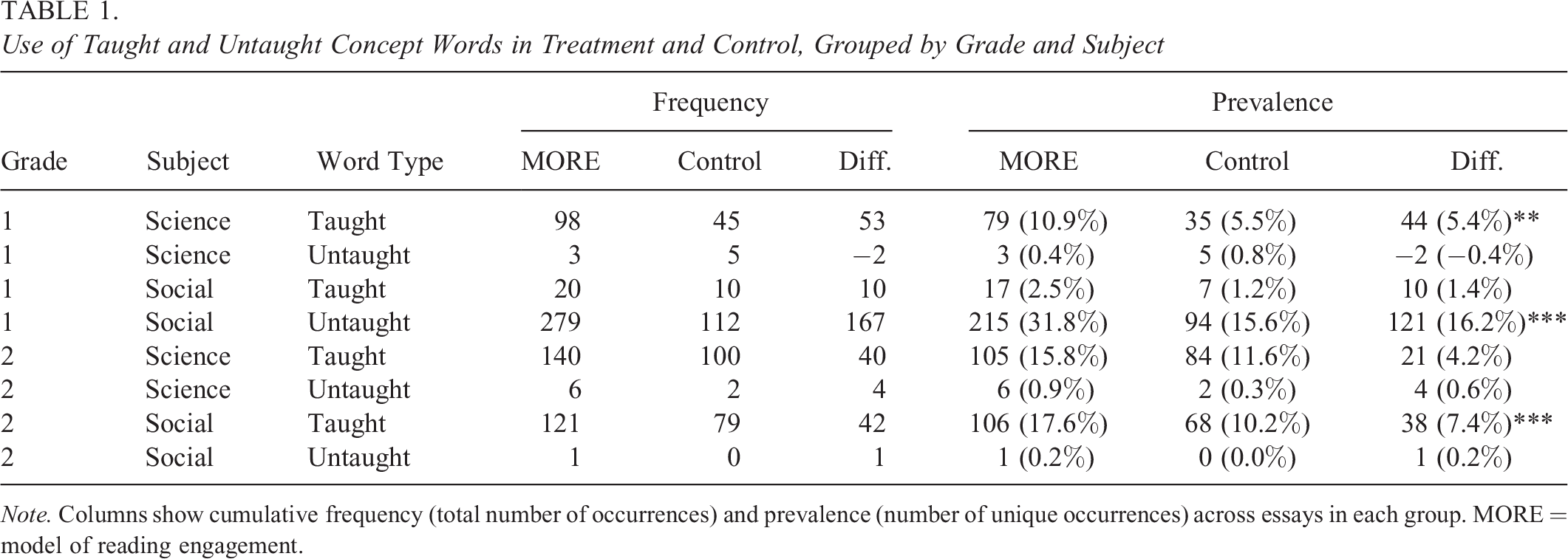
Note. Columns show cumulative frequency (total number of occurrences) and prevalence (number of unique occurrences) across essays in each group. MORE = model of reading engagement.
We next turn to asking what words and phrases, more broadly, the treated students used. For each subject and grade level, the terms and phrases identified via CCS as distinguishing between treatment and control text, across all possible phrases, are presented in Figure 4. Our main finding here concerns the elevated use of the terms “should” and “I think” by students in the treatment group compared to the phrase “my opinion,” which appears more commonly in the control group. These differences, consistent across both subjects and grade level, might suggest that treated students approached the argumentative writing task with a greater sense of agency than students in the control group. In social studies writing, we also see an elevated use of “celebrate,” indicating a tighter attention to the essay prompt.
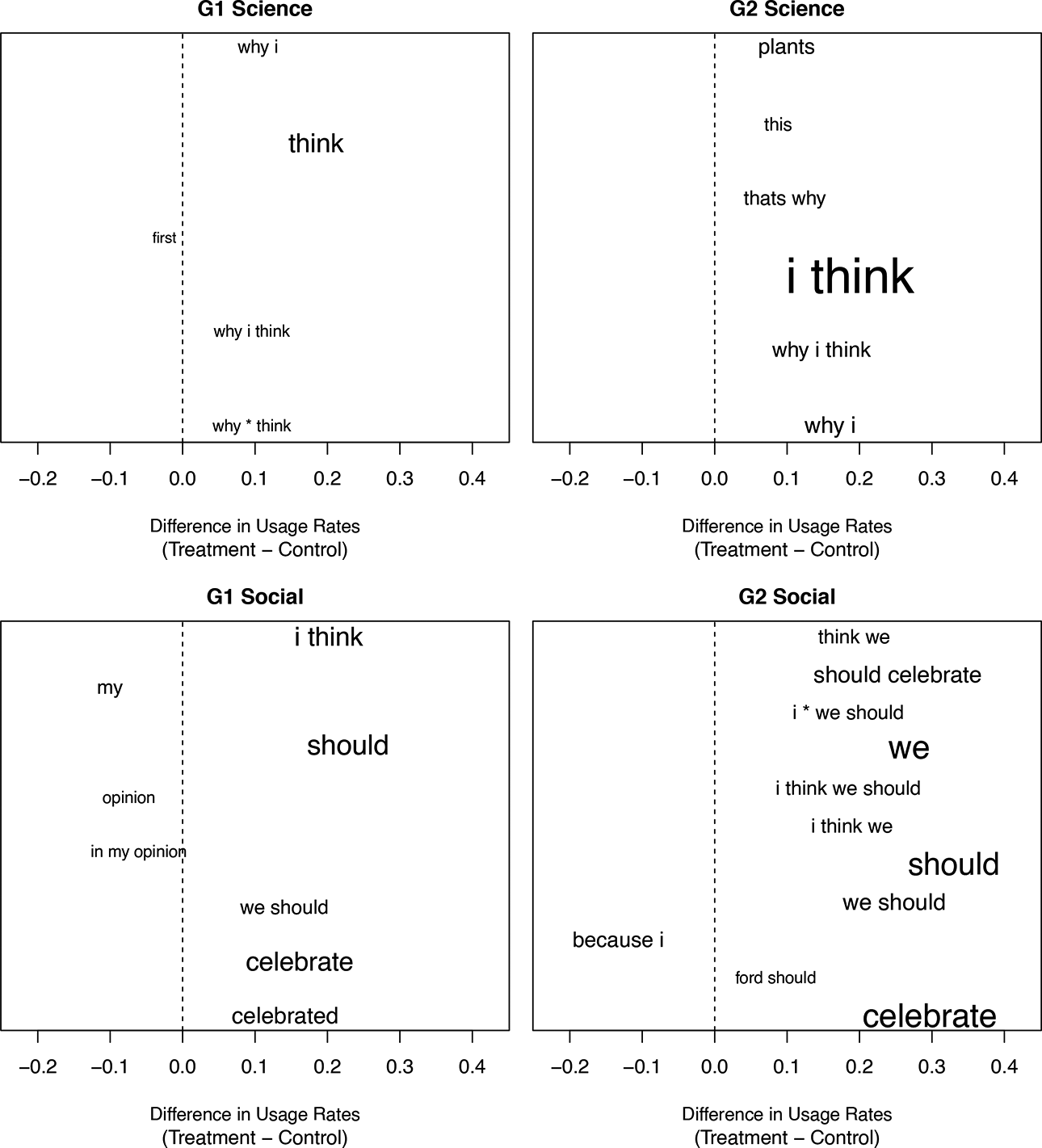
Terms and phrases identified as most predictive of assignment to treatment or control within each subject and grade level. Larger terms indicate greater cumulative frequency and terms that appear farther to the right indicate greater prevalence in the treatment group.
Impacts on Descriptive Similarity
Figure 5 shows, for each subject and grade level, the distribution of descriptive similarity scores calculated between each essay and its corresponding “gold-standard” reference text. We see positive shifts toward the gold-standard reference texts in both subjects and grade levels, with significant differences for all but first-grade science. The corresponding effect estimates on average descriptive similarity, controlling for students’ pretest scores, are presented in Table 2 (discussed in the following). Overall, these findings seem to support the hypothesis that the classroom intervention leads students to compose their arguments in a more structured manner that includes incorporating one or more pieces of evidence to support their claims. We see corresponding location shifts in the distributions of similarity scores for both subjects and grade levels. Further, the distributions of similarity scores in treatment and control groups appear similar in terms of shape for each of the four groups; thus, the location shift is suggestive of a consistent improvement in writing among students who received treatment.
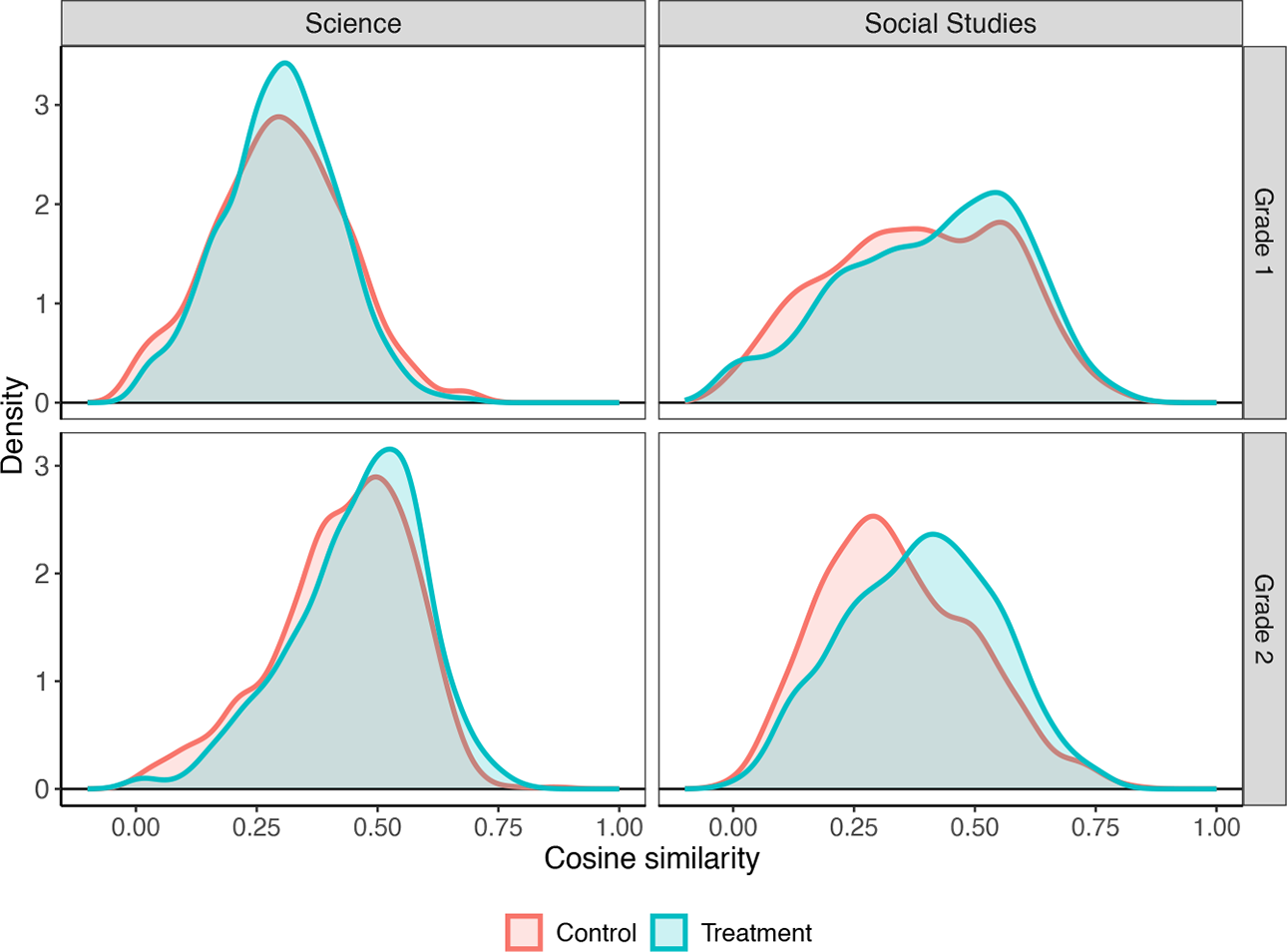
Kernel density estimates for the distribution of similarity scores in treatment and control for each subject and grade level. Higher values of cosine similarity suggest a higher degree of overlap with the source text.
Impacts on Proxy Measures of Overall Writing Quality
We finally turn to assessing how results from a machine-coded top-line impact analysis would compare to those of a human coding effort. Table 2 summarizes the estimated treatment impacts on the measures of essay quality generated from each of these approaches. We estimate impacts for these four groups with two models, one for science and one for social studies, that each include a grade by treatment interaction term. Our first proxy is machine-coded similarity scores calculated as the average descriptive similarity between each essay and its corresponding “gold-standard” reference text in each subject. Our second proxy is predicted quality scores for each essay calculated by applying predictive ensemble of machine learners trained on a sample of human-coded writing samples collected in a separate study by Kim et al. (2021a).
Estimated Effects (in Effect Size Units) of Grade Level, Pretest Scores (MAP/RIT), and Receipt of MORE Intervention Compared to Typical Instruction on Average Human-Coded Quality Scores (Left), Average Descriptive Similarity Scores (Center), and Average Machine Learning (ML) Predicted Quality Scores (Right) for Each Grade Level and Subject
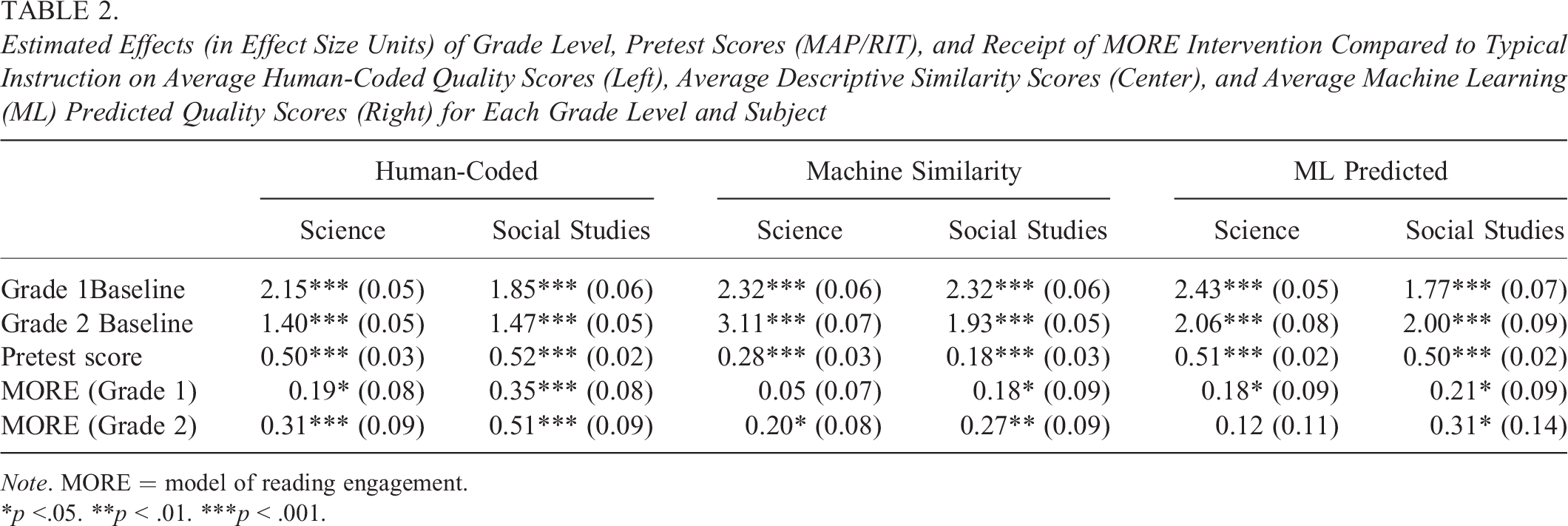
Note. MORE = model of reading engagement.
*p <.05. **p < .01. ***p < .001.
Both proxy measures estimate positive impacts of the MORE intervention across both subjects; most of these impacts are significant. For first-grade science, the ML-predicted impact estimate of 0.18 is very close to the human-coded impact of 0.19, which is sensible given that the data used to fit the proxy model came from a pilot study that focused only on this domain and grade. By contrast, the similarity scores fared the worst for this area, with an estimated impact of only 0.05. For the other three groups, the effect sizes of both proxy estimates are generally lower in magnitude than the human-coded impact estimates, although they all agree in sign.
Overall, the pattern of results suggests that machine coding can be used to demonstrate impacts on measures related to a target measure of interest. On the other hand, treating an impact on a machine measure with some skepticism seems warranted. The machine measures were only loosely correlated with human-scored outcomes, with correlations within the four groups ranging from 0.37 to 0.51. In the case of second-grade science, the lack of alignment completely erased the impact estimate, underscoring how a poorly calibrated automatic scoring model can fail to capture a true impact. The prior analysis of individual features would be protective here: We saw movement on many measures for the social science outcome, suggesting that our failure to achieve a top-line impact is due to misalignment in the proxy measure, not the treatment itself. Given the full set of these findings, perhaps there are middle roads one might take here, such as assessing initial impacts using a proxy measure before committing to a full human coding effort. The impact on the similarity score can be interpreted beyond it being a proxy; it shows that one of the ways the text was changed was by moving the pattern of word usage toward the reference text.
Summary
To our knowledge, this study represents one of the first attempts to apply machine-based text analytic and data mining tools to enrich an experimental assessment on young children’s argumentative writing outcomes. In general, the answers to our research questions underscore the idea that machine-based scoring and analytic tools should supplement rather than supplant human-coded writing scores. Overall, we have argued that these methods go beyond the question, “did the intervention work?” to address “how did it work?”
For RQ1, we find clear evidence of qualitative, rather than quantitative, shifts in writing. That is, we see consistent treatment impacts on young children’s underlying psychological states rather than on the technical aspects of their writing (e.g., word count and readability). For RQ2, we find suggestive evidence that treated students were likely to use vocabulary words that were directly taught by teachers in Grade 1 science and Grade 2 social studies. For RQ3, we see descriptive similarity scores that are higher for treatment than control, suggesting that treated students moved toward the word choice in “gold-standard” reference texts.
Our ML tools generated new findings that highlight several intervention mechanisms driving improvement in the first and second-graders’ writing outcomes. By focusing on a single topic over several days, students acquired the deep knowledge of the target vocabulary and concepts and developed greater expertise in argument discourse structures (e.g., making a claim, using textual evidence and vocabulary to support claims). Theoretically, words often reveal inner psychological states of students (Pennebaker & King, 1999), and our results indicate that treated students were more likely than control students to write social studies essays with greater authority, social restraint, and caution, which are the key features of academic writing. Additionally, students in the treatment group demonstrated a more analytical writing style in second-grade science. Their essays contained more words indicating formal and logical thinking, which are crucial for success in academic contexts. Treated students also produced essays that included more of the directly taught vocabulary words and mirrored argument discourse features found in the gold standard texts. In many ways, these qualitative shifts in argumentative writing paint a more comprehensive and fine-grained picture of how students were thinking and writing like emerging scientists.
We also find that top-line treatment impacts estimated using supervised ML models can align with results based on human coding for grades and domains where prior data are available, but that the size of estimated impacts can be attenuated if the model is not well tuned to the given context. These results also highlight the importance of having good training data to improve machine-based predictions. In particular, in our case, we had trained our predictive algorithm on only first-grade writing data (the only available pilot data) and it appears as if differences in the writing across our considered domains made these predictions less aligned to the human-coded quality scores in the other domains considered. The full analysis on all the individual features can help diagnose these potential alignment failures, as it does with the social science outcome in our empirical example.
Overall, while the fully automated approach in our case produced findings that aligned with the human-coded results, it is important to recognize that this may not translate to every context. A machine-based prediction as a proxy outcome is not a one-size-fits-all solution; the success of this approach will vary depending on the specific research design and characteristics of the data at hand. Furthermore, we expect generating a suitable machine-predicted proxy outcome for human-coded quality scores will typically require access to coded data from a pilot study of the same, or closely related, intervention; this is a condition that may not be feasible in some settings. Models built for one specific case may not readily generalize for automated scoring tasks outside the context of that case. That being said, future work on how well large language models and autoscoring programs can serve should certainly be done here.
Discussion
In this article, we presented a workflow and analytical template for using automated scoring methods to augment a traditional impact analysis in evaluations that use text as an outcome. Through our case study, we demonstrated that examining a variety of text-based features generated using automated methods can indeed uncover important potential mechanisms as to why the treatment was effective. We also gauged the extent to which the results from an impact analysis using a proxy outcome, taken in isolation, can replicate the gold-standard findings based on careful human coding. Overall, our empirical results support the claim that machine-based text analysis tools should be used to supplement rather than supplant human scoring efforts in experimental assessments of writing. Importantly, while our specific case focused on an intervention aimed to improve the first- and second-graders argumentative writing ability, our workflow and template is broadly useful for applied researchers seeking to analyze impacts on textual data from classroom observations (e.g., Liu & Cohen, 2021) or mixed-methods studies that collect quantitative outcomes and qualitative interview data (e.g., Grissmer, 2016; Kling et al., 2005). Unfortunately, researchers have yet to fully capitalize on human and automated scoring methods in order to enrich experimental findings that, to date, have largely focused on easy-to-measure quantitative outcomes. Thus, our proposed analytic arc is designed to provide broadly relevant practical guidance for education researchers seeking to understand effects on textual outcomes. Relying exclusively on human scoring, by contrast, is a lost opportunity.
We implemented all analyses with our newly developed R package,
We close with an outline of the proposed analytic arc we used in this work, along with some final practical guidance that we acquired in our own efforts. We hope this will help researchers interested in leveraging both human and machine-based scoring methods in their own evaluations.
The steps we took in our analysis are as follows:
Transcribe the data. Machine-based tools are not (easily) possible without a digital representation of text. This can be done in house or with the usual transcription services. OCR scanning, etc. could also work here; because we are looking for general trends, some errors would not necessarily be debilitating.
Develop a well-defined outcome and rubric. A treatment has goals, and those goals should manifest in specific outcomes according to the theory of action of the intervention. A clear sense of this via a rubric will keep the overall analysis focused.
Manually score the data and conduct the top-line analysis. The human-scored outcome gives our primary result that tells us whether the treatment worked. The analyses that follow are intended to expand on this top-line result.
Generate a host of text features ranging from the simple (word count, average word length) to the complex (lexile score, sentiment, etc.). Have a fairly open policy; include any feature one is curious about.
Generate additional tailored features. Two examples we use in our case study are the occurrences of certain context words of interest and similarity scores to reference texts. Many others are possible. Estimate the impact of treatment on all generated features, and correct to control the false discovery rate. This allows us to explore large numbers of features and encourages discovery.
Explore the results. For example, we created visualizations of all features found to be moved by treatment.
Examine impacts on features initially identified to be of interest. Some text features may be considered important enough that they, regardless of significance, should be examined. In our case study, for example, we looked at the frequency of context words.
Examine differential usage of words and phrases. As a separate step, compare the treated text to the control to see how words and phrases are used differently. This can provide further insight into how the text has been changed by treatment.
Theorize about how the treatment may have worked by looking at the constellation of results. This theory building may align with the initial theory of action, or not; in either case, this can shine light on treatment mechanism. Findings should be verified by future studies.
If interested in using ML to proxy a human score, then adjust the above as follows: Skip step 3. For Step 5, decide on proxy measures for the identified outcomes found in Step 2. This will depend on available resources. For example, given pilot data, one could directly train an ML model
6
to predict the scores that would be generated in a standard human coding effort. Absent that, a similarity score, or automated essay scoring system, could provide usable scores. If no significant impact is found on the proxy outcome, then stop. Otherwise, add a final analytical step after Step 9, where you assess, given your full set of analyses, the extent to which the proxy outcome appears to be capturing the intended construct. Consider verifying found results with a human-coding effort at this point; this also allows an opportunity to code for more specific, complex aspects of text to answer questions that arose in the first-pass analysis.
These arcs can hopefully serve as a template for making one’s own plan given one’s own context. These steps and tools are flexible and modular. Which pieces to include, and the order to do them in, is easily adjusted. For example, one might explore estimated impacts on machine-generated outcomes before human coding to help refine the human coding process.
We next provide a few key take-away points and lessons learned regarding impact analysis with text-based outcomes.
Consider a broad range of outcomes
Experimental assessments of text are often focused on a single endpoint that has been carefully defined and measured through a process of human scoring. However, as demonstrated in our case study, there are many different ways in which an intervention could lead to meaningful changes in text. A primary advantage of machine augmentation is that researchers can easily consider a broad range of secondary outcome measures. This should be taken advantage of.
Customize to your context
Look for opportunities to customize the outcomes to suit the needs of a particular analysis. For example, identify a list of words or phrases believed to be related to the intervention under investigation, and use appearance rates as an outcome of interest.
Plan to include automated methods
When planning a large-scale assessment of text, researchers should think about the nature of the text they plan to capture (e.g., narrative or expository writing, dialogue) and carefully consider what aspects of the text can and cannot be readily evaluated using automated methods. Given the time and resources required for human scoring, human scoring efforts should ideally be reserved for measuring constructs that (1) cannot be readily extracted from text and (2) cannot be easily predicted from other machine measures of text.
Pay attention to null results
To better contextualize the results of an impact analysis that examines both human and machine-generated text outcomes, it is also important to consider those features that did not show significant treatment impacts. In our case study, for example, the finding that treatment did not lead to significant differences in word count (i.e., the total length of students’ essays) strengthens the claim that the intervention worked by teaching students to write better rather than simply leading them to writing more.
ML supplements, not supplants, human coding
In our case study, we found that carefully chosen machine-generated proxy outcomes can provide a cheap and easy substitute for human-coded outcomes when evaluating impacts on holistic measures such as writing quality, but that this does have a cost. While our proxy impacts were generally positive and significant, as our primary outcome was, they did not fully replicate the human-coded analysis, but the lower coding burden could reduce barriers for using text as an outcome, which we believe is a good thing. Overall, the greatest advantage we found from using machine-generated outcomes was in enriching the interpretation of the human-scored, top-line result.
Supplemental Material
Supplemental Material, sj-pdf-1-jeb-10.3102_10769986231207886 - Combining Human and Automated Scoring Methods in Experimental Assessments of Writing: A Case Study Tutorial
Supplemental Material, sj-pdf-1-jeb-10.3102_10769986231207886 for Combining Human and Automated Scoring Methods in Experimental Assessments of Writing: A Case Study Tutorial by Reagan Mozer, Luke Miratrix, Jackie Eunjung Relyea and James S. Kim in Journal of Educational and Behavioral Statistics
Footnotes
Authors’ Note
The data and all replication materials for this study are publicly available and can be accessed at: github.com/reaganmozer/reads-replication
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: In this study, Reagan Mozer and Luke Miratrix were partially supported by the Institute of Education Sciences, U.S. Department of Education, through Grant (R305D220032) to Harvard University and Bentley University.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.