
Abstract
We demonstrate how machine learning based recommender systems can be effectively employed by market makers to filter the information embedded in Requests for Quote (RFQs) to identify the set of clients most likely to be interested in a given bond, or, conversely, the set of bonds that are most likely to be of interest to a given client. We consider several approaches known in the literature and ultimately suggest the so-called latent factor collaborative filtering as the best choice. We also suggest a scalable optimization procedure that allows the training of the system with a limited computational cost, making collaborative filtering practical in an industrial environment.
Introduction
In the corporate bond business, market makers need to handle large amounts of requests from clients, typically in the form of electronic inquiries - or Requests for Quote (RFQs) - and enter positions, assuming outright issuer risk. In some cases, those positions need to be closed quickly in order to minimize the associated market risk and balance sheet costs. When a position needs to be closed out, sales teams contact clients who may be interested in taking over that position. However, since it is generally possible to contact only a very small fraction of the dealer’s clients, it is of paramount importance for salespeople to be intimately familiar with the clients’ trading preferences.
This is particularly challenging because, at any given time, most of the market activity is concentrated on a small number of bonds while trading on the majority of the inventory happens fairly infrequently. This is known as the long-tail problem. In this situation an effective recommender systems (RS), that is an algorithm able to identify the small population of clients that are most likely to be interested in a given bond, could bring substantial value to the dealer and, by virtue of providing a better service, to its clients.
Similar problems are not uncommon in many other industries. A common challenge of e-Commerce websites is helping customers sort through a large variety of offered products to easily find the ones they are most interested in. Music and video streaming services, like Netflix or Spotify, are equipped with algorithms which aim at personalized recommendations to their users to improve their experience. One of the tools commonly employed for these tasks are RS (Goldberg et al., 1992; Linden et al., 2003).
In this paper, we investigate the application to corporate bond trading of RS based on machine-learning techniques able to use the information embedded in RFQs. Two main categories of models are described: content-based filtering and collaborative filtering, along with approaches to training and testing that we trialed on example data. We also suggest a few practical optimizations that are essential for reducing the time necessary to train the algorithms at a level that makes their usage viable in an industrial setting.
Bond recommender systems
Broadly speaking, RS fall into two categories, content-based and collaborative filtering, differing in their interactions with users, the agents we would like to make recommendations to, and items, the set of objects we need to recommend. Content-based filtering (CBF) methods (Lops et al., 2011) create profiles for users and items in order to characterize their nature and then try to match the user-item pairs using metrics based on the similarity between profiles. In the context of the bond market making business, each bond can be characterized by a set economic features and each client can be characterized by the features of the bonds they have been historically interested in. Collaborative filtering (CF) (Goldberg et al., 1992), instead, only employs past user behavior in order to detect users with similar preferences over items. For example, in the specific context, by knowing what bonds clients have historically inquired, one can infer the interdependencies among clients and bonds and thus find potential associations for new client-bonds pairs.
Content-based filtering
In general, CBF models assume that clients are looking for bonds with certain economic characteristics or features. For example, some clients are more likely to trade long-dated bonds within certain industries. Based on this idea, the profile of the clients can be represented by the features of previously traded bonds. If bond i has similar features to those traded by client u, then it makes sense to recommend bond i to client u. This can be formalized as follows.
Each bond is characterized by a set of categorical features (e.g.
Region, Industry, Coupon Type) and numerical features (e.g. Maturity,
Yield, Credit Rating). We indicate with
Similarly, we indicate with
A simple way to use such data to make recommendations is to compute the
predicted preference of client u for bond
i,
By differentiation, the set of weights minimizing Equation (1) reads:
Contrary to CBF, collaborative filtering (CF) can be performed using only the information contained in the so-called user-item observations matrix (Hu et al., 2008). The entries in this matrix can be either user ratings for explicit feedback data or built from the preference and indicator matrices, Equations (14) and (15), for implicit data. Given the observed entries in such a matrix, different methods can be used to compute the missing ones.
Neighborhood models
The most common approach to CF is based on Neighborhood models (Hastie et al., 2009), which usually have two forms: user-oriented and item-oriented. User-oriented Neighborhood CF (U-NCF) models try to estimate the unknown preference of a client for a bond given the preferences of similar clients. Conversely, item-oriented Neighborhood CF (I-NCF) models use the information about a client’s preference for similar bonds.
Given the user-item observation matrix p ui in Equation (14) for all client-bond pairs, the similarity between two bonds i and j can be computed as the following ‘cosine’ similarity:
After computing the pairwise similarity s uv or s ij for all clients and bonds, the missing preference of client u over bond i can be decided by finding either the top k most similar clients or most similar bonds. For example, denoting the set of the top k most similar bonds to bond i by S k (i), the preference for client u over all bonds is:
The basic idea underlying latent factor models is the factorization of the client-bond observation matrix, p ui , into a product of smaller matrices, which can be interpreted as the latent features for clients and bonds respectively, as depicted in Fig. 1. Following (Hu et al., 2008), this can be formulated as the following (non-convex) optimization problem
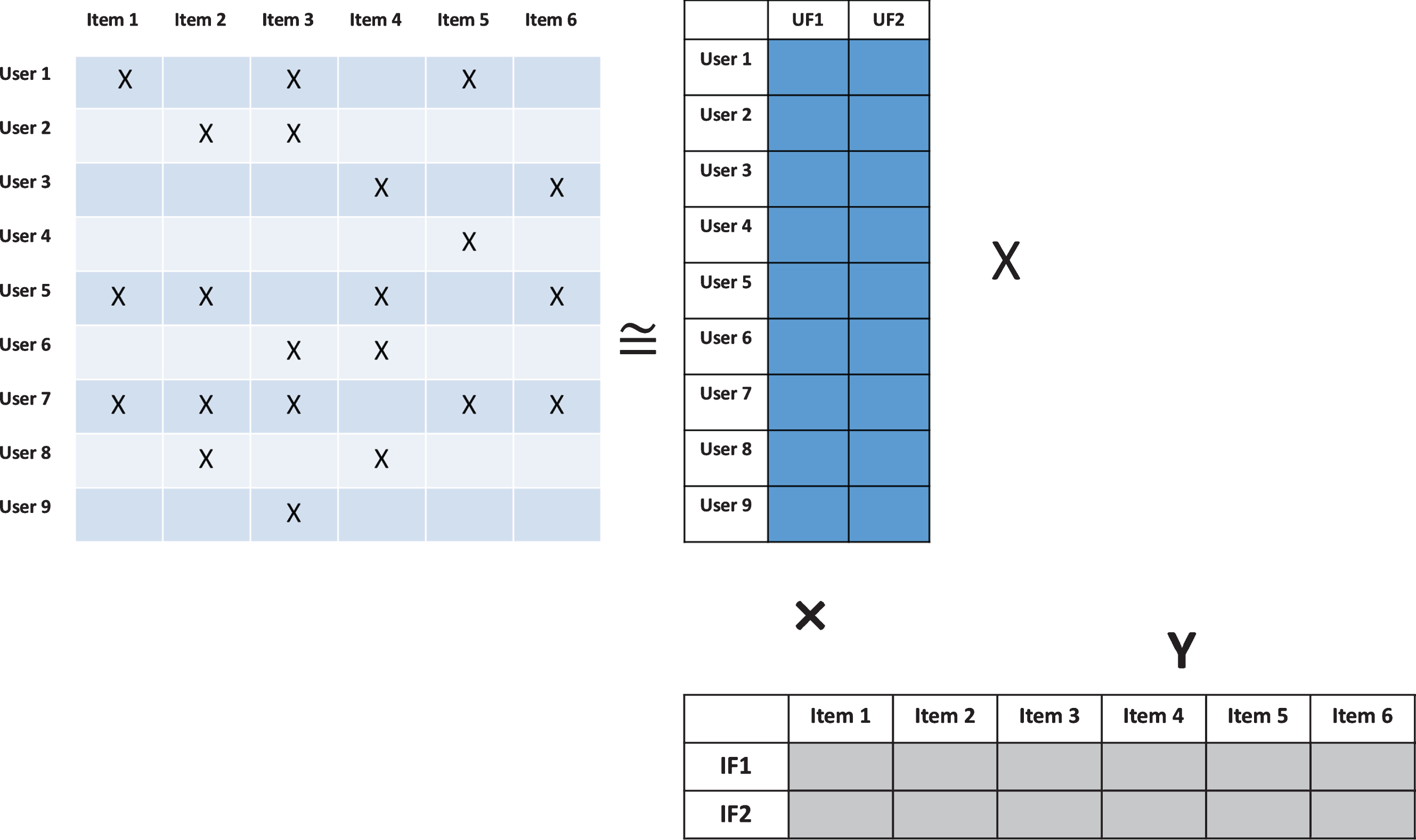
Illustration of matrix factorization for CF.

Example of ROC curve in red and AUC in grey. While the plot has been generated with simulated data, the results are indicative of the performance that can be expected from recommender systems in practice.
A common approach to this optimization is the so-called Alternating-Least-Squares (ALS)
(Hu et al., 2008), where the optimal
user-factors are computed assuming that the item-factors are fixed and vice-versa until
convergence. In this case:
The Latent Factor CF is significantly more computationally demanding than the other
methods. As a result, to make the approach practical, it is important to optimize the
computation of Eqs. (14) and (15). Firstly, one can avoid the matrix
inversion and compute the solution of the linear systems by means of the Conjugate
Gradient method (Hastie et al., 2009). This
lowers the computational complexity per client or user (when using a standard matrix
inversion) from
Testing
A proportion of the RFQ data must be reserved for testing performance, we refer to this as the validation data set. For each item (user) the recommender system gives a list of users (items) ordered by preference, with the most highly recommended at the top. We step though this list of users (items) and check whether it is present in the validation data set. If so we label it as a correct recommendation. Starting from the top of this list, the false positive (FPR) and true positive rate (TPR) are calculated for each item (user). The TPR is the proportion of correct recommendations so far in the ordered list of users (items) relative to the total number of correct recommendations. Similarly, the FPR is the proportion of incorrect recommendations relative to the total number of incorrect recommendations. Plotting the TPR on the y-axis versus the FPR on the x-axis gives a curve that is referred to as the receiver operating characteristic (ROC) curve. The ROC curve starts at (0,0) and, after going through the entire list of users (items) in order, ends at (1,1). Each correct recommendation increases the TPR while the FPR remains constant, similarly each incorrect recommendation increases the FPR while the TPR remains constant. Calculating the area under this curve gives the Area Under ROC Curve (AUC) score (Hastie et al., 2009), which is shown in grey in Fig. 1. We use this metric to compare the performance of our models. An area of 1 represents a perfect performance and an area of 0.5 is equivalent to a random guess.
Hyperparameter optimization
Before performing the evaluation, the model ‘hyperparameters’ must be decided. These are α and λ reg in Equation (14) for the CBF; the number of ‘nearest neighbors’ k in Eqs. (14) and (15) for the Neighborhood CF; and α, λ reg and the number of latent factors K in Equation (14) for the Latent Factor CF. A simple grid-based optimization approach with AUC as metrics and standard k-fold cross-validation (Hastie et al., 2009) can be used for this. For example one could use 80% of the data for training the model for each combination of hyperparameters, 10% for validation (namely choosing the set of hyper-parameters providing the largest AUC on the validation test), and 10% for the actual back-testing. Similarly, for the Latent Factor CF a 3-D grid search can be performed for the three hyperparameters α, λ reg and K. For the Neighborhood CF, only the number of neighbors k needs to be chosen.
Our testing in a practical setting has shown that the collaborative filtering techniques perform best in terms of AUC score on corporate bond data. In particular, the Latent Factor collaborative filter gives the best performance.
Conclusions
We investigated the recommendation problem in the corporate bond sales and trading business based on RFQ data. We outlined two sets of approaches that can be used: content-based filtering, which identifies similarities between bonds based on their features; and collaborative filtering which identifies similarities based on user preferences. Based on the examples we considered we found that the collaborative filtering techniques performs best in terms of AUC score. In particular, the Latent Factor collaborative filter gave the best performance.
An advantage of collaborative filtering (in addition to improved performance), which makes it well suited for the large variety of products available in the financial industry, is that it does not require the expert knowledge of product features required in content-based filtering. In other words, products other than bonds can easily be incorporated into the same user-item observation matrix.
While the latent factor collaborative filter is the most computationally intensive approach, we suggested computational optimizations that reduce the computational time required to training to a few minutes, thus making the approach practical in an industrial environment.
Footnotes
Acknowledgments
We are grateful to Jodie Humphreys for initial work on this topic; Fengrui Shi for his help with the implementation; and Toby Falk for reviewing the article. The views and opinions expressed in this article are those of the authors and do not represent the views of their employers. Analysis and examples discussed are based only on publicly available information.