
Abstract
Recommendation systems (RS) play a crucial role in assisting individuals in making suitable selections from an extensive array of products or services. This significantly mitigates the predicament of being overwhelmed by excessive information. RS finds powerful utility in online industries by vending products over the internet or furnishing online services. Given the potential for business expansion through their implementation, RS is relevant in such domains. This comprehensive review article overviews RS and its diverse variations and extensions. Specifically, this review provides a thorough comparative analysis for each method that encompasses many techniques employed in RS, encompassing content-based filtering, collaborative filtering, hybrid, and miscellaneous approaches. Notably, the article delves into the manifold applications of RS across various practical domains. Additionally, the assortment of evaluation metrics utilized across RS is explored. Finally, we conclude by encapsulating the distinct challenges RS encounters, which enhance their precision and dependability.
Introduction
In the rapidly evolving landscape of the digital era, the exponential growth of digital content on the internet, coupled with its vast and diverse user base, has given rise to a formidable challenge known as information overload. Fueled by the sheer volume and variety of online information, this phenomenon poses a significant obstacle to users attempting to promptly access desired content [26]. The repercussions of this challenge have led to a pressing need for innovative solutions, and recommendation systems (RS) have emerged as a crucial response to the ever-expanding realm of information overload [69, 53]. The recommendation systems field has evolved significantly since its nascent collaborative filtering (CF) exploration in the mid-1990s [2]. Over the past decade, there has been a surge in research efforts, both academia and industry, aimed at devising novel RS methods to enhance user experience and mitigate the effects of information overload. The interplay between technological advancements and the increasing global population of Internet users has intensified the demand for effective recommendation systems.
Recent innovations in social network platforms, combined with the seamless convenience of online commerce, have transformed user interactions and streamlined tasks into simple mouse clicks. This evolution has unlocked a multitude of choices for users worldwide, leading to a rapid proliferation of online content and services. However, the abundance of options often presents users with a daunting dilemma of choices, necessitating assistance in navigating through their preferences. The concept of personalized RS has gained widespread acceptance among users seeking assistance in exploring, organizing, categorizing, refining, and distributing online content [36, 40]. Recommendation systems are algorithmic constructs designed to propose relevant item lists based on either item similarity or user profile attributes. The term “pertinent items” encompasses a wide array of content, including movies, TV shows, reading material, product purchases, and other offerings, depending on the industry sector [56]. For RS to be effective, they must engage in adaptable interaction with users, aiming to understand their characteristics and preferences to provide tailored suggestions [56]. A prominent example of a platform successfully implementing personalized RS is Amazon, which employs a sophisticated recommendation model utilizing diverse methodologies to enhance user engagement and satisfaction [34, 4].
In the pursuit of advancing recommendation systems, various methods have been proposed and explored, including content-based [5, 3], collaborative filtering [15, 23, 16, 51, 59, 66, 42], and hybrid recommendation systems [27, 65, 25, 13, 14, 52, 61, 54, 67, 68, 33]. These approaches span different industrial and academic domains, reflecting users’ diverse needs and preferences in various contexts.
While multiple surveys have explored the principles, methodologies, evaluations, and algorithms of recommendation systems [57, 45], there exists a notable gap in examining RS from the perspective of datasets and practical implementation. This survey seeks to address this gap by emphasizing the datasets, evaluation techniques, and application domains utilized. As the inaugural attempt to scrutinize RS research through the lens of datasets, our effort aims to comprehensively address challenges inherent to all recommendation systems and propose potential remedies. The survey spans various RS approaches, including content-based, collaborative filtering, session-based, sequential, and other diverse categories, providing a comprehensive landscape overview.
Classification of recommendation systems
Content-based recommendation systems
Content-based Recommender Systems (RS) propose items to users by leveraging their data directly or indirectly. The concept of content-based RS is illustrated in Fig. 1. These systems analyze previously rated documents or descriptions to construct a comprehensive user profile that encapsulates their historical rating patterns [43, 63]. This user profile becomes the cornerstone of the recommendation process, aiding in identifying items that align with the user’s preferences. The application of content-based RS extends across diverse domains, prominently featuring in Information Retrieval systems (IR) and the realm of artificial intelligence [53].
The foundational mechanism of content-based strategies centers around key concepts such as term frequency (TF), inverse document frequency (IDF), and the cosine similarity matrix. These analytical tools play a pivotal role in evaluating the significance of various types of content, including documents, articles, news items, movies, and more [69]. In this approach, a user’s preferred or purchased item is the catalyst. The system meticulously dissects the selected item’s contents, categories, and attributes to discern its unique traits. Subsequently, armed with this insightful analysis, the system identifies other items within its database that share similar characteristics. The recommendation is then based on these similarity scores, presenting the user with suggestions that closely align with their preferences and past choices [1].
The comparison between various content-based approaches
The comparison between various content-based approaches
The principle of content-based recommendation systems.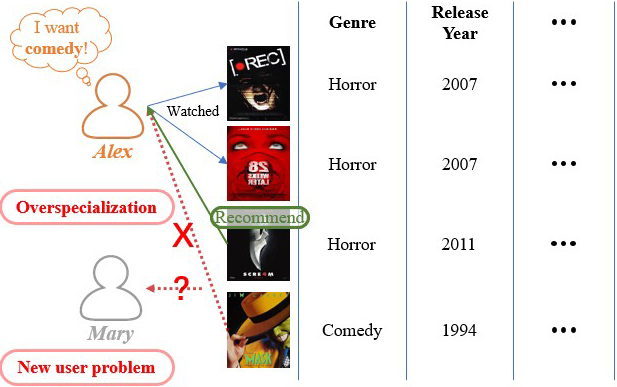
The comparative landscape of research in content-based approaches is encapsulated in Table 1. This table offers a comprehensive overview, highlighting the distinctions and nuances across various studies in content-based recommender systems. The comparative analysis aims to shed light on the diverse methodologies employed, providing researchers and practitioners with valuable insights into the evolution and efficacy of content-based recommendation strategies.
Collaborative Filtering (CF) is a pivotal and widely adopted approach in various industries, playing a crucial role in platforms such as Amazon, Flipkart, and Netflix to elevate product promotion and boost sales [18]. Figure 2 shows the principle of the process of CF-based RS. The roots of CF can be traced back to its initial application by developers at Xerox in document retrieval systems, with Google’s Page Rank Algorithm serving as an illustrative example of CF applied to document retrieval. Within Recommender Systems (RS), CF techniques pivot on the rich history of user interactions and items, relying on a comprehensive record of these interactions as input. Predictions for users are crafted based on their past item ratings [2].
The principle of collaborative filtering-based recommendation systems.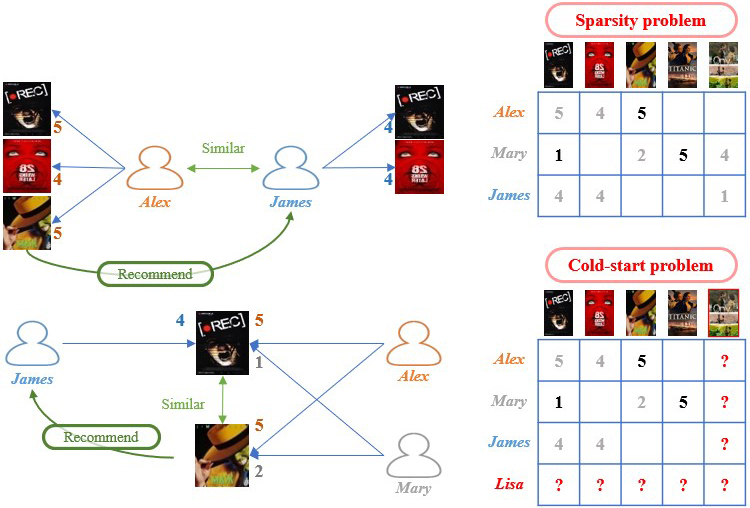
Two distinct categories of recommendation algorithms emerge within CF: memory-based and model-based methods [50]. Memory-based algorithms, characterized by their simplicity and lack of model-building requirements, depend on the correlations between items (item-based) or users (user-based). These algorithms effectively furnish recommendations using distance measurements such as nearest neighbor (k-nearest neighbor) [44]. In contrast, model-based algorithms leverage prediction models based on the user’s preference matrix (rating matrix) to generate recommendations [39]. Techniques like matrix factorization, Bayesian networks, genetic algorithms, clustering, singular value decomposition (SVD), and deep learning fall under model-based approaches.
Despite its efficacy, CF grapples with challenges like data sparsity, the cold-start problem, and scalability. To address scalability, Zhao et al. [71] devised a user-based CF technique tailored for the MapReduce framework, implemented on the widely-used Hadoop cloud computing platform. This innovative design aims to surmount scalability issues and enhance computational speed.
With the expanding use of Recommender Systems on the internet, a need arises to evaluate CF methods and establish measures to assess recommendation quality and user trust. Bobadilla et al. [6] introduced a framework prioritizing the evaluation of user recommendation novelty and trust in neighbors. Their work presents an equation formalizing and unifying the CF process and its evaluation, constructing the framework using four graphs: quality of predictions, recommendations, novelty, and trust. Addressing the data sparsity challenge inherent in CF algorithms, active learning algorithms emerge as effective solutions. Bobadilla et al. [24] introduced Bayesian Nonnegative Matrix Factorization (BNMF) techniques and an original clustering algorithm, enhancing CF-based recommendation system performance. This technique demonstrates high prediction accuracy and swift execution times, offering flexibility and accuracy to enhance overall system performance. As evidenced by these advancements, the constant evolution and innovation in CF methodologies underscore the dynamic nature of collaborative filtering within Recommender Systems.
Numerous challenges plague RS, such as the cold-start issues, where providing recommendations for new items is challenging due to the need for rating history. Other problems, the data sparsity and the scalability, also afflict RS, resulting in subpar quality and unsuitable suggestions. While the content-based aims to recommend cold-start items, their recommendations’ accuracy is generally lower compared to CF approaches. Conversely, CF-based systems provide better recommendations but must improve in addressing the cold-start problem and data sparsity problems. In the end, each of these techniques boasts weaknesses and strengths.
The hybrid recommendation systems.
A strategic hybrid approach has emerged in response to the intricacies inherent in recommendation systems (RS), amalgamating diverse forms of information derived from individual RS techniques. This integration alleviates the complexities of singular methodologies, ultimately refining recommendation outcomes [19, 60]. A prime illustration of the efficacy of hybrid RS can be observed in Netflix’s operations. The streaming platform adeptly tailors its suggestions by analyzing users’ viewing and browsing behaviors through collaborative filtering (CF). Additionally, it refines recommendations by proposing films that align with highly-rated selections made by the user [66]. This hybrid model enables Netflix to offer personalized and diverse content suggestions, enhancing the overall user experience. Robin Burke’s seminal survey on hybrid recommendation techniques identifies seven distinct categories, shedding light on the versatile strategies employed in hybrid RS [8]:
Weighted: This technique combines scores or points from different recommendation methodologies to produce a unified and comprehensive recommendation. A balanced and optimized recommendation is derived by assigning weights based on the relevance or effectiveness of each approach. Switching: In switching, the RS dynamically alternates among various recommendation techniques based on specific scenarios or user interactions. This adaptive approach ensures that the system deploys the most relevant recommendation strategy at any moment. Mixed: The mixed approach presents recommendations from diverse sources, allowing users to benefit from a broad spectrum of suggestions. This strategy promotes diversity and widens the range of choices available to users. Feature Combination: Feature combination involves merging features derived from different data sources and feeding them into a single recommendation algorithm. This collaborative use of features enhances the system’s ability to capture nuanced user preferences. Cascade: In cascade recommendations, one recommendation builds upon the suggestions provided by another. This sequential approach refines suggestions over multiple stages, offering users increasingly tailored and relevant content options. Feature augmentation: This approach leverages the output from one recommendation technique as an input feature for another. The RS gains a more comprehensive understanding of user preferences by augmenting the system with additional features derived from different methodologies. Meta-level: Meta-level recommendations involve applying certain recommendation techniques to create a model that serves as input for another method. This metamodeling strategy enables the RS to leverage the strengths of different techniques synergistically, enhancing overall recommendation performance.
Adopting hybrid RS, exemplified by platforms like Netflix,1
https://www.netflix.com.
The comparison between various hybrid approaches
Table 2 compares authors’ efforts across five papers, utilizing Hybrid-based RS on multiple datasets. The lower MAE values correspond to the better model regarding the accuracy of the recommendations. In this table, it becomes evident that the hybrid RS proposed in [62] showcases the lowest MAE value and most minimal processing time. In contrast, the experiment deployed in [17] used the FilmTrust dataset, yielding the highest MAE value, which means lower accuracy for the RS. Further, when comparing two methods introduced in [32] for a movie recommendation system, the alternative hybrid model outperforms the switching hybrid recommendation model in terms of accuracy. Among the experiments detailed in [30], the one conducted on the Last.fm dataset records the lowest MAE value. However, it’s noteworthy that this MAE value, while minimal, still exceeds the accuracy achieved by the model proposed in [10].
This section describes various recommendation methods beyond conventional collaborative filtering and content-based approaches. Each method showcased here offers unique insights and addresses specific challenges in tailoring recommendations to user preferences. We explore various methodologies, from knowledge-based recommendation systems that leverage domain expertise to cross-domain systems broadening their recommendation scope and context-aware systems that adapt to users’ changing preferences to demographic filtering that taps into user profiles.
The knowledge-based recommendation systems.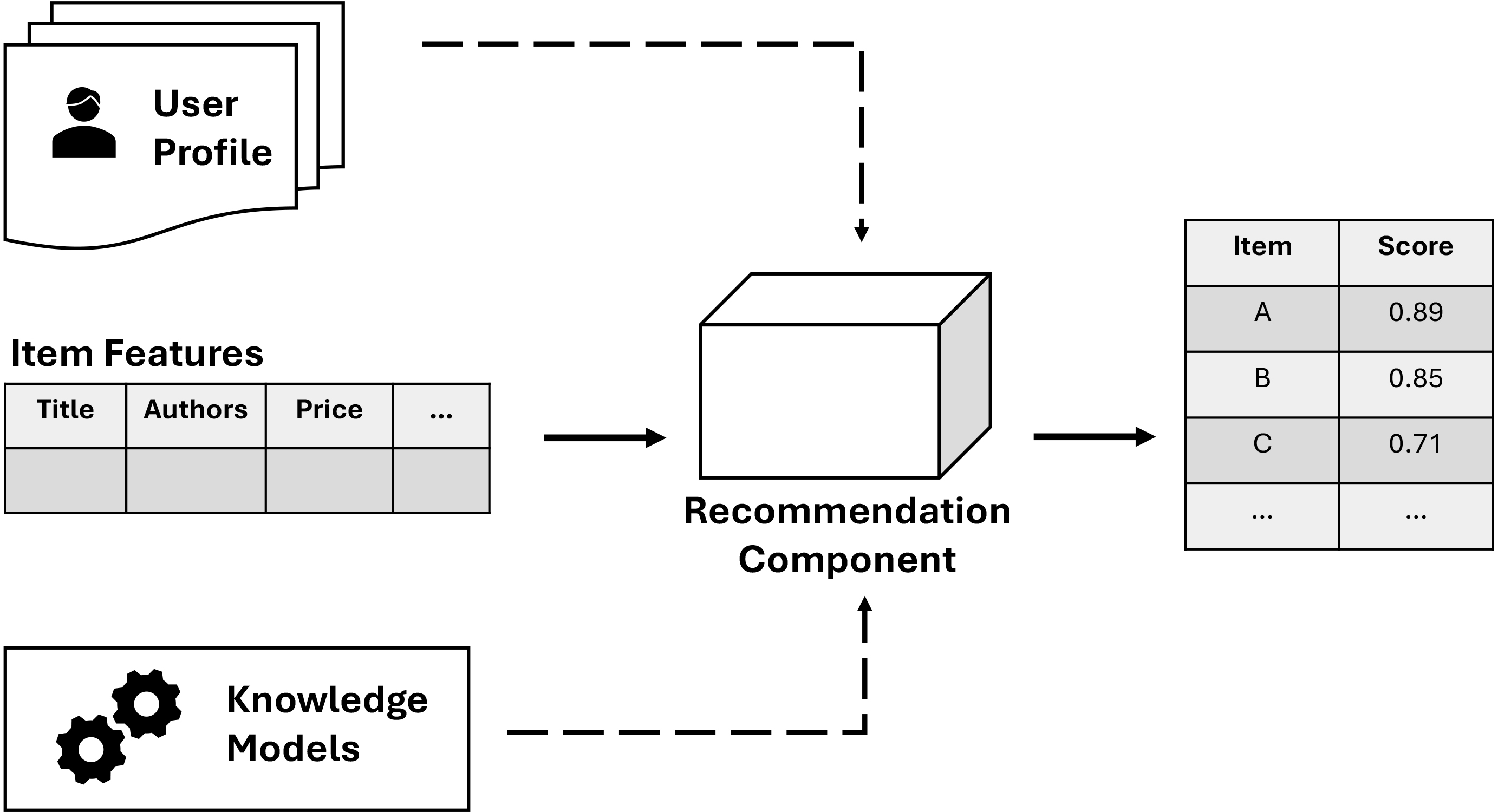
Knowledge-based Recommendation Systems represent a sophisticated approach to tailoring recommendations using user and item information. These systems go beyond traditional collaborative filtering and content-based methods, focusing on assessing the similarity between user profiles and item data to identify the most suitable items for users. The recommendation component of Knowledge-based Recommendation Systems is illustrated in Fig. 4. Unlike other methods, knowledge-based systems overcome cold-start issues by relying on domain knowledge rather than solely dependent on user ratings [2]. This reliance on domain knowledge becomes particularly beneficial in specialized contexts such as e-learning, where personalized recommendations leveraging ontology for knowledge representation are recommended [7]. Educators, too, can harness the potential of knowledge-based recommendation systems for teaching and learning activities facilitated by ontological modeling [38]. However, a notable drawback of these systems is their reliance on knowledge engineering skills, which can be challenging to acquire and implement effectively [8].
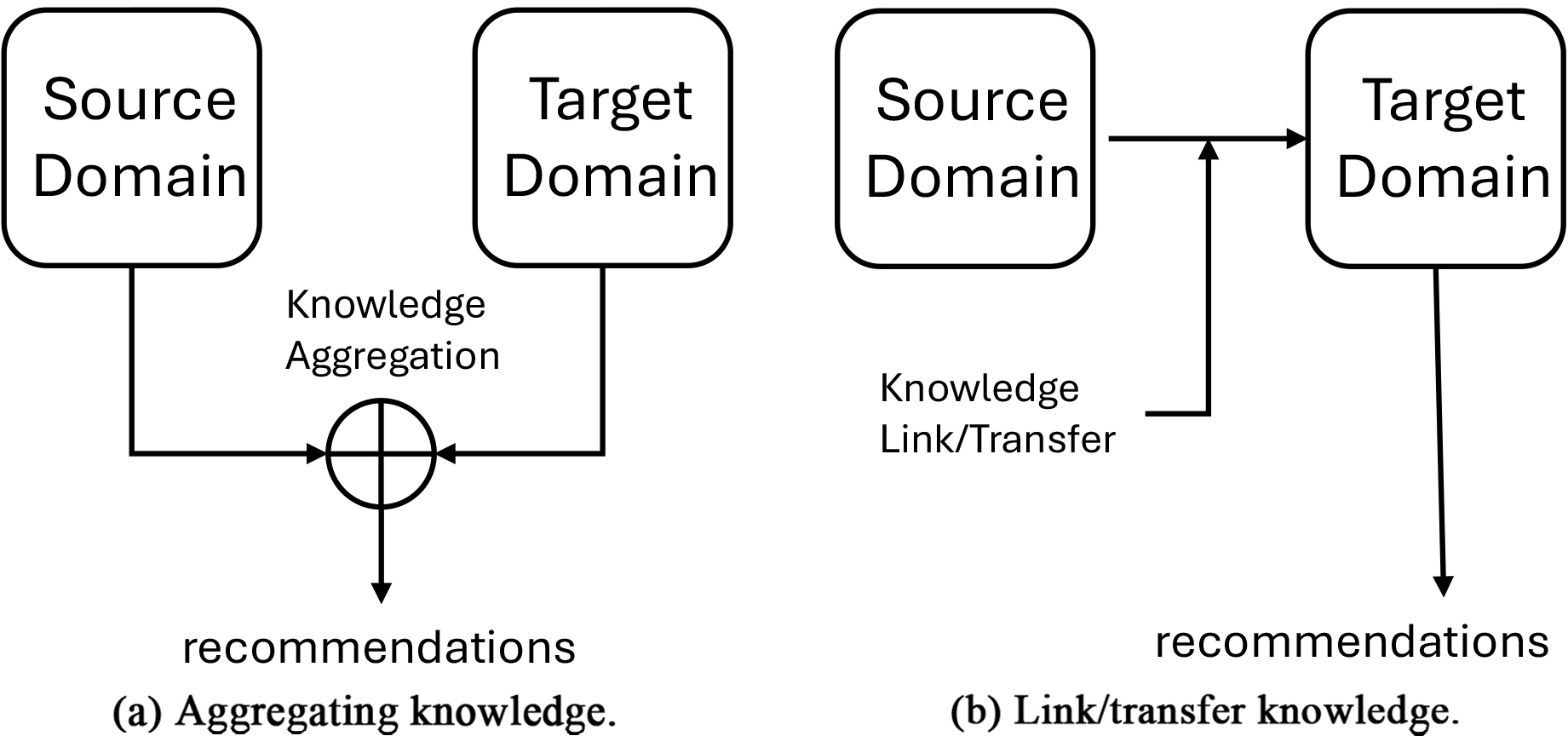
Cross-Domain Recommendation Systems (CDRS) offer a departure from the conventional recommendation systems that typically focus on specific domains for recommendations based on user ratings [28]. CDRS widens its scope by suggesting items across different domains, drawing on data from a separate source domain to enhance recommendations in a target domain. Figure 5 provides the progress of knowledge in CDRS that consist of two categories, Fig. 5a show aggregating knowledge from source and target domain while Fig. 5b denotes link/transfer knowledge from source to target domain for recommendation tasks. This innovative approach effectively addresses the common cold-start problem in target domains that lack sufficient user data by leveraging ratings from the source domain [41]. CDRS also excels in recommending bundles of related items from multiple domains, emphasizing the importance of assessing user rating similarities across domains to identify desirable item bundles [11]. For instance, if a user frequently purchases books in the fantasy genre, a CDRS could leverage data from the user’s movie preferences in a source domain to recommend fantasy movies in a target domain.
Progress of knowledge in cross-domain recommendation systems.
Context-Aware Recommendation Systems (CARS) take personalization to the next level by tailoring recommendations to users’ specific contexts, recognizing that item preferences can change in different situations. CARS relies exclusively on user contextual information to provide highly relevant recommendations. Integrating contextual data into the recommendation process ensures the benefits of suggesting items that align with the user’s current situation. In a large-scale CARS system proposed in [58], cold-start issues are effectively addressed through an adaptive clustering algorithm. CARS applications span various domains, including movies and music. For instance, a music streaming service implementing CARS might consider the user’s current location, time of day, and recent listening history to recommend upbeat and energetic music during a workout while suggesting calm and soothing tracks during the evening. A study in [47] compared different contextual modeling CARS methods, revealing three key factors influencing their effectiveness: the recommendation task type, context granularity, and dataset type. Demographic Filtering is another distinct approach that generates recommendations based on a user’s demographic profile, including nationality, age, and gender. Unlike collaborative and content-based methods, demographic filtering doesn’t rely on user ratings, addressing the cold-start problem effectively. However, acquiring user demographic data can be challenging, as many users hesitate to share such information online. In [48], a demographic approach is used to recommend restaurants by combining user demographic data and ratings. User information is collected from home pages, and text classification categorizes preferences. Although the performance of this approach may not be optimal, integration with other data sources could enhance results. Therefore, demographic recommendations are often integrated into hybrid approaches, capitalizing on their advantages to provide accurate and well-rounded recommendations. For example, a hybrid recommendation system might combine demographic and collaborative filtering to offer personalized movie recommendations, considering demographic information and user preferences inferred from collaborative filtering.
These diverse recommendation approaches illustrate the flexibility and applicability of recommendation systems in various domains. Each approach comes with its strengths and challenges, and the choice of a specific method or a combination of methods depends on the characteristics of the user base, the available data, and the specific goals of the recommendation system.
The evaluation of recommendation processes and methods has become increasingly pivotal in Recommender Systems (RS) research since its inception [23]. To effectively gauge the performance and efficacy of recommendation techniques, including algorithms, methods, and models, the RS domain relies on a set of indicators and measurement standards metrics [20]. The choice of evaluation metrics is often contingent upon the specific characteristics of the dataset and the tasks that the RS is designed to fulfill. Among the most commonly utilized evaluation metrics are:
Is a widely employed evaluation metric that quantifies the discrepancy between user values and those the system recommends. Smaller MAE values indicate more accurate predictions made by the recommendation process. The MAE is calculated as follows.
Root mean square error (RMSE) is a statistical accuracy metric emphasizing more significant absolute errors [26]. It is more sensitive to deviations or inadequate predictions. RMSE never drops below the MAE value. Lower RMSE values signify more accurate recommendation outcomes. The computation is as follows.
Precision gauges the ratio of relevant recommended items to the overall recommended items. Its calculation is as follows.
Recall measures the fraction of pertinent items in the list of recommended items. The formula for the recall is
F-measure offers a consolidated metric combining precision and recall. Its calculation is as follows.
The choice of evaluation metrics depends on the nature of the recommendation task and the system’s goals. For example, in e-commerce scenarios, precision and recall may be more critical, as accurately recommending relevant products is paramount. In contrast, in movie recommendation systems, user satisfaction is a key metric, user feedback, and subjective evaluations become crucial components of the evaluation process.
Diverse datasets have been employed in recommendation system research, ranging from movie ratings and e-commerce transactions to user behavior on social media platforms. Each dataset brings challenges and nuances, reflecting its specific domain characteristics. MovieLens [21], a widely used dataset in RS research, contains user ratings for movies, enabling researchers to develop and evaluate collaborative filtering and content-based recommendation algorithms. The statistical details of the latest MovieLen dataset are shown in Table 3. E-commerce datasets, on the other hand, capture user purchase history, providing valuable insights for building recommendation systems in the retail sector.
Statistical details of the MovieLens 25M Dataset
Statistical details of the MovieLens 25M Dataset
The Amazon review datasets
The Movielens dataset, for instance, is a classic example widely used for collaborative filtering experiments. It consists of movie user ratings, allowing researchers to explore and develop recommendation algorithms based on user preferences and behaviors. The dataset’s structure includes user IDs, movie IDs, ratings, and timestamps, offering a rich source of information for training and evaluating recommendation models.
Similarly, e-commerce datasets,2
https://cseweb.ucsd.edu/ jmcauley/datasets.html.
Social media platforms also contribute to the landscape of recommendation system datasets. Platforms like Twitter [55] and Facebook generate vast amounts of user-generated content, including tweets, posts, and interactions. Analyzing user behavior on these platforms provides insights into users’ preferences, interests, and social connections, which can be leveraged to enhance personalized recommendations.
Expanding upon the multifaceted nature of Recommender Systems (RS) and the datasets they engage with, it is crucial to recognize these systems’ pivotal role in shaping user experiences and facilitating decision-making processes. The five main categories dominating recommendation system development – movies, books, food, music, and purchased products or services – underscore the pervasive influence of RS in various domains. This influence extends beyond conventional realms, as a subset of RS ventures into unconventional datasets, exploring diverse avenues to enhance recommendation strategies and cater to broader user preferences.
In the dynamic landscape of e-commerce platforms, RS has become indispensable. As the number of consumers and the variety of merchandise grow, the need for efficient and personalized recommendation mechanisms becomes paramount. RS aids users in navigating through an overwhelming array of choices, offering tailored suggestions that align with their preferences and contribute to a more satisfying shopping experience. The significance of RS is further magnified in the context of social networks, where platforms like Facebook, Instagram, and Twitter employ people-centric recommendations. Leveraging user characteristics to foster connectivity and communication, RS enhances the overall user engagement on these platforms.
The evolution of the internet from a network of interconnected documents to a web of linked data has opened new avenues for RS. Publicly available databases, such as Linked Open Data (LOD) datasets, serve as valuable resources for constructing practical recommendation systems [12]. The application of content-based approaches to web-stored information, exemplified in film recommendations, showcases the adaptability of RS to diverse data sources.
In the expansive realm of the mobile music market, RS addresses the challenges posed by vast music libraries containing numerous tracks. Users often encounter frustration while navigating extensive lists, prompting a growing demand for more efficient recommendations aligned with individual preferences. This underscores the need for RS to evolve and innovate in tandem with emerging trends and user expectations.
Turning the focus to Music Recommendations, the cold-start problem remains challenging for Collaborative Filtering (CF) approaches, particularly with new or less popular tracks where user data is insufficient. Addressing this challenge, a study documented in [31] introduces a latent factor model that integrates Deep Convolutional Neural Networks (DeepCNN) to predict latent factors based on music audio. This sophisticated model represents a significant advancement over traditional approaches, such as the bag-of-words representation of audio signals. The study’s findings highlight the superior performance of the DeepCNN-integrated model, showcasing the potential of cutting-edge technologies to enhance the accuracy and personalization of music recommendations.
Challenges and directions for future works
Addressing RS challenges involves several strategies. To combat the cold-start problem, using a user’s IP address provides valuable contextual information, such as location and time, for recommending items based on similar user locations and purchasing times. Maintaining an updated dataset is essential, ensuring users have access to the latest trends and removing outdated items for higher recommendation quality through a cut-off date filter. Dealing with information overload due to mixed-domain datasets can lead to performance degradation; constructing a recommendation system with domain-specific functional components enhances accuracy and tailors recommendations more precisely. Besides, enhancing RS accuracy is achievable through deep learning methods, which excel at handling dimensionality reduction in large datasets, extracting latent features for improved recommendations. Sparsity issues arise from the abundance of users and items in RS, which can be partially alleviated with clustering techniques. Additionally, natural language processing methods help resolve problems related to synonyms and abbreviations, enhancing recommendation precision. Numerous researchers have conducted extensive studies to address these RS challenges. The following section details the challenges RS encountered and explores various solutions offered by researchers to address these challenges. Specifically, the subsequent issues faced by RS are examined below:
Cold start problem
The Cold Start Problem represents a formidable challenge in collaborative filtering (CF) systems, particularly when confronted with the introduction of new users or novel items [70]. This predicament manifests across three distinct scenarios, each presenting unique challenges:
New User Access: When a new user enters the system, CF models encounter a scarcity of historical interaction data to generate accurate recommendations. This lack of user-specific information hampers the system’s ability to understand and predict the preferences of the new user. New Item Introduction: The Cold Start Problem arises when a platform introduces new items into its catalog. Since these items lack a history of user interactions, CF algorithms struggle to assess their relevance to users, leading to potential inaccuracies in recommendations. Creation of a New Community Group: Establishing a new community group within a system presents another instance of the Cold Start Problem. When users form or join a new group, the collaborative filtering approach encounters challenges in predicting preferences and building accurate recommendations for the group.
A viable solution to these challenges involves adopting a hybrid approach combining content-based and CF techniques. This hybrid model leverages additional information, such as product descriptions, features, and user profiles, to enhance recommendation quality in the face of the Cold Start Problem.
For example, consider a scenario where a new user signs up for a movie streaming service. Traditional CF models might struggle initially to provide accurate movie recommendations due to the absence of the user’s viewing history. However, by integrating content-based techniques, the system can analyze the features and descriptions of movies to understand the genre preferences or themes that might align with the user’s interests. This hybrid approach ensures the system can generate relevant and personalized recommendations for the new user without historical interaction data.
Similarly, when introducing new items to an e-commerce platform, the hybrid model can consider product descriptions, attributes, and user profiles to make informed suggestions. By combining the collaborative insights derived from user-item interactions with the inherent characteristics of items, the system overcomes the limitations imposed by the Cold Start Problem. It delivers more accurate recommendations for both new and existing items.
In essence, the hybrid approach acts as a strategic alliance, merging the strengths of content-based and CF techniques to create a more resilient and adaptable recommendation system. By addressing the intricacies of the Cold Start Problem through this comprehensive strategy, recommendation systems can offer improved accuracy and relevance, ensuring a seamless user experience even in scenarios characterized by new users, new items, or the creation of new community groups.
The issue of data sparsity in recommendation systems arises from sparse user-item interaction matrices, where users have not rated all available objects. This sparsity can impede efficient computational learning and compromise the accuracy of recommendations. Mitigating data sparsity is crucial for enhancing the performance of recommendation systems. One effective strategy involves applying dimensionality reduction techniques, as highlighted in the study [2].
Dimensionality reduction techniques play a pivotal role in alleviating data sparsity by addressing the inherent challenges posed by incomplete user ratings [46]. By reducing unnecessary dimensions in the user-item interaction matrix, these techniques help distill meaningful patterns and relationships from the data. Essentially, they trim down the complexity of the matrix by eliminating irrelevant information or noise associated with products that lack substantial user ratings.
For example, consider a movie recommendation system where users have not rated every available film. The user-item interaction matrix for this system would be sparse, making it challenging to accurately predict user preferences. By applying dimensionality reduction techniques, the system can identify and retain the most relevant features, such as genres, themes, or user characteristics, while discarding less informative dimensions. This streamlined representation allows recommendation algorithms to work with a more condensed and informative user rating matrix, improving computational efficiency and recommendation accuracy.
In the broader context of e-commerce or content platforms, where users may not interact with or rate all available products, dimensionality reduction becomes a valuable tool. By eliminating redundant or less informative product features, these techniques enhance the system’s ability to discern meaningful patterns from the sparse data, ultimately contributing to more accurate and personalized recommendations.
In recap, tackling data sparsity through dimensionality reduction techniques is critical in optimizing recommendation systems. By refining the user-item interaction matrix and focusing on the most relevant dimensions, these techniques enhance computational efficiency and contribute to the overall effectiveness of recommendation algorithms, ensuring users receive personalized and meaningful suggestions even in sparse data scenarios.
Scalability
The scalability challenge in recommender systems becomes particularly pronounced when dealing with extensive user bases and vast catalogs of products, where the computational intensity of generating and evaluating recommendations can be overwhelming [35]. A notable example of a platform addressing scalability challenges is Amazon, which employs a strategic approach to enhance the efficiency and effectiveness of its recommendation system.
To tackle the scalability issue, Amazon utilizes a combination of collaborative filtering (CF) and a topic diversification algorithm. Collaborative filtering, a widely adopted recommendation technique, analyzes user-item interactions to identify patterns and similarities, providing personalized recommendations based on user preferences. However, as the user and product databases grow exponentially, the computational demands of CF increase significantly.
In response, Amazon incorporates a topic diversification algorithm into its recommendation system. This algorithm introduces complexity by diversifying the recommended items based on thematic or topical relevance. Doing so ensures that recommendations are personalized and exhibit a certain degree of variety, catering to users’ diverse interests.
For instance, consider a user who frequently purchases books in the science fiction genre on Amazon. While collaborative filtering might recommend additional science fiction titles based on user preferences, the topic diversification algorithm ensures that the recommendations include books from related genres, providing a more well-rounded and diverse set of suggestions.
Integrating topic diversification alongside CF is a strategic solution to the scalability challenge. It allows Amazon to efficiently handle the computational complexities associated with millions of users and products while enhancing the quality and diversity of recommendations. This approach mitigates scalability issues and contributes to a more engaging and satisfying user experience by presenting various relevant suggestions.
Grey sheep problem
The Grey Sheep Problem poses a unique challenge in collaborative filtering Recommender Systems (CF RS), particularly when anomalous users or user groups defy neat categorization, falling outside the typical alignment with specific categories or exhibiting characteristics that match multiple types [72]. This anomaly complicates generating accurate recommendations, as traditional collaborative filtering methods may struggle to discern patterns or similarities for these users. Addressing the Grey Sheep Problem requires innovative solutions to ensure the accuracy and effectiveness of the recommendation system.
One notable strategy for mitigating the Grey Sheep Problem involves offline clustering methods, such as k-means. These methods help distinguish grey sheep users – those who deviate from conventional user patterns – from regular users. By clustering users based on their behavior, preferences, or interactions, the system can identify and treat anomalous patterns separately, ensuring more accurate and tailored recommendations for users in the grey sheep category.
Additionally, techniques like histogram intersection play a crucial role in refining the user-user similarity distribution, contributing to the resolution of the Grey Sheep Problem. Histogram intersection involves comparing the distribution of preferences or behaviors between users, providing a more nuanced understanding of their similarities. This method enables the system to capture subtle patterns and relationships that might be overlooked by traditional collaborative filtering approaches, enhancing the accuracy of recommendations, especially for users with diverse or anomalous preferences.
For instance, imagine a collaborative filtering system for a streaming platform. Traditional collaborative filtering might struggle with users who have eclectic tastes, enjoying content spanning multiple genres or categories. The Grey Sheep Problem arises when these users do not neatly fit into predefined categories. By applying offline clustering methods like
Footnotes
Acknowledgments
This research was supported by AIT Laboratory, FPT University, Danang Campus, Vietnam 2024.