
Abstract
The paper studies the effects of new product rumors about the iPhone on the stock price of the Apple company. We scrape iPhone rumors from Macrumors.com, and obtain a dataset covering 1,264 articles containing 180 words on average between January 2002 and December 2015. Moreover, we construct a market-decided lexicon to transform qualitative information into quantitative data, and analyze what type of words and what information embedded in the rumors are apt to impact on Apple’s stock price. Unlike previous studies, we do not rely on the widely-adopted Harvard-IV-4 dictionary, as the coefficients of the words from the dictionary are neither significant nor consistent with their polarities, compared with our results. The paper obtains three main findings. First, the spread of rumors has a significant impact on the stock price. Second, positive words, rather than negative words, play an important role in affecting the stock price. Third, the stock price is highly sensitive to the words related to the appearance of the iPhone.
Introduction
As global outsourcing and production develop further, rumors about new products being planned or developed are more easily spread throughout industries and markets. Thanks to progress in communication technology, rumors spread to the public quickly. Consumers and investors are now less likely to be surprised when official announcements of new products take place owing to information leakage.
The literature contains relatively few studies on the topic of rumors about potential new products. The majority of these studies analyzed rumors concerning takeovers (Pound & Zeckhauser (1990) and Bettman et al. (2011)) and market efficiency (Tumarkin & Whitelaw (2001)). Among them, the most relevant research on the topic at hand concerned new product announcements and their effects on stock market returns (Chaney et al. (1991)). Other related studies paid attention to the impact of news on the stock market returns of the companies concerned. Particular emphasis was placed on topics such as stock splits, earnings announcements, mergers or takeovers, macroeconomic fundamentals, regulatory changes and bond ratings (Fama et al. (1969), Pinches & Singleton (1978), Eckbo (1983), Malatesta & Thompson (1985), Mikkelson & Partch (1986), Horsky & Swyngedouw (1987), Goh & Ederington (1993), McQueen & Roley (1993), Lane & Jacobson (1995), MacKinlay (1997), and Benbunan-Fich & Fich (2004), for example).
The information underneath rumors could be obtained and effciently analyzed when the knowledge of big data develops. Big data refers to a large volume of data that can be used for more accurate estimations and predictions. It is noteworthy that this type of data not only presents itself on a large scale but also permeates minute aspects of daily life, showing a variety of novel types. In addition to the supply of quantitative information, the underlying qualitative information plays a significant but typically neglected role in stock price prediction (Tetlock (2007)). By employing big data, many studies tended to focus on social media sources, such as Twitter (Bollen et al. (2011) and Sprenger et al. (2014)) and Sina Weibo (Bai et al. (2014) and Dong et al. (2015)), forums (Antweiler & Frank (2004) and Das & Chen (2007)) and search engines (Vosen & Schmidt (2011), Carrièere-Swallow & Labbée (2013), Varian (2014), and Smith (2016)). However, the content on these platforms tends to have character limits. Beyond the sources that previous research have tapped, big data can be obtained through other channels, such as articles and reports on websites. The rumor data used in the current chapter are crawled from a pool of such online articles.
A suitable case for applying big data in terms of qualitative information sourced from rumors is that of Apple’s iPhone. As a technology giant, Apple’s new product announcements have consistently attracted worldwide attention since the iPhone was introduced in 2007. The long queues outside Apple Stores demonstrate the significant degree of consumer interest. Such interest continues to build even when purchase restrictions are applied several months after products are launched. Prior to official announcements, rumors, such as what the next-generation iPhone might look like and what new features it might bring, circulate online in response to popular discussion.
Among Apple’s products, the iPhone has been a huge success and has become the main source of Apple’s revenue. It interests not only consumers but also investors. As Figure 1 shows, the revenue attributed to the iPhone, illustrated by the solid line, has increased considerably and has accounted for more than 50% of Apple’s total revenue since 2012 and over 70% in recent years. At the same time, the market capitalization of Apple has grown noticeably since the release of the first iPhone. Considering the importance of the iPhone in Apple’s total revenue, rumors related to the iPhone are assumed to be relevant to Apple’s stock returns. Moreover, Jung & Shiller (2005) proved that the stock market in the US was micro-efficient, indicating that the efficient market hypothesis was more applicable to individual stocks than to the overall stock market. This study thus intends to examine the relevance of iPhone rumors to the stock price of the Apple company through an in-depth study. We attempt to answer the following questions: (1) Are the rumors important enough to have an impact on Apple’s stock price? (2) If so, what types of words are more important to the market? (3) What information can be uncovered from the words that are apt to exert the influence?
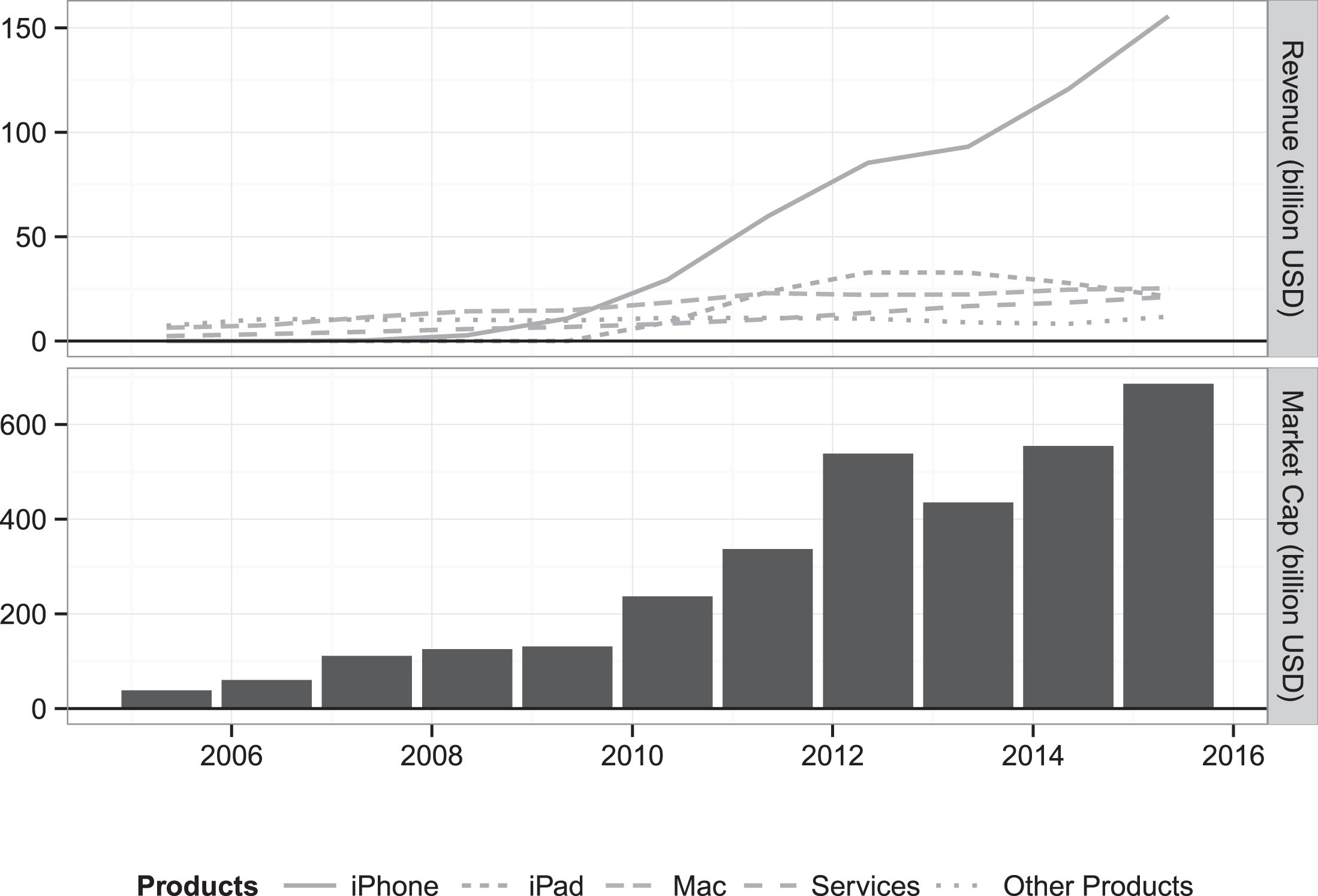
Apple’s Revenue and Market Capitalization.
In the study, the term “rumor” is defined as information that appears before Apple’s official announcement of each new generation of iPhones, regardless of whether it is true or not ex post. Such a definition differs from that of Blanchard et al. (2013), in which information or rumors were taken as “news” if they were proven to be true ex post or “noise” if they turned out to be false. Specifically, rumors from the production supply chain or commercial partners are chosen. Although Apple maintains strict confidentiality regarding new products, the public can still access new product information beforehand through rumors. These leakages are mainly from Apple’s supply chain, commercial partners and trademark or patent application documents. Some rumors, such as those concerning the specification of new products, can be exposed voluntarily by commercial partners since these partners are able to obtain detailed information through business and technological cooperation. These factors guarantee the rumors’ credibility and authenticity. Given this, this study uses the terms “rumor”, “leakage”, and “news” interchangeably.
The methodology of the current study is as follows. Firstly, an event study is employed to investigate whether the spread of rumors has effects on Apple’s returns in the stock market. In particular, we utilize the abnormal returns to measure and evaluate such impacts. The difference between rumor and non-rumor days is also investigated using the bootstrap method. After the influence of rumors on the stock price is confirmed, the rumors leading to the abnormal returns on these days are used to build a lexicon for further study. Secondly, to answer the question of which types of words are important to the market, sentiment analysis is adopted. Following Mao et al. (2014), a market-decided lexicon with two polarities (positive and negative) is constructed in four steps: processing text, selecting seed words, targeting expanded words, and identifying final words. Based on this lexicon, the different effects between positive and negative words on the next-day abnormal and stock returns are compared. At the same time, the performance of a widely accepted but fixed dictionary is examined. Finally, along with the relationship between this constructed lexicon and the fixed dictionary, the informational content and features of the positive and negative words in our lexicon are analyzed.
One of the major methodological challenges concerns how qualitative messages can be transformed into quantitative information. Owing to the improvement in sentiment analysis by Pang et al. (2002), Turney (2002), and Pang & Lee (2008), studies using embedded qualitative information expanded in the area of finance. Antweiler & Frank (2004) utilized the naive Bayes method to analyze a discussion on an online message board and found that messages were abundant in information and useful in predicting stock volatility. The authors split the data into “buy”, “sell”, and “hold” types and aggregated them into an indicator. Das & Chen (2007) a analyzed messages from Yahoo’s bulletin board and linked them to the stock market. By extracting and transforming the posted words into sentiment scores, the authors measured the opinions of small investors on the market status and its future, or specifically, the predictions of the investors on whether the market would be bullish or bearish. Combining firm earnings and stock returns, Tetlock et al. (2008) examined articles from the Dow Jones News Service and the Wall Street Journal, and found that underlying hard-to-quantify information existed in linguistic media content and that the proportion of negative words had a high degree of predictability. Luss & d’ Aspremont (2015) employed support vector machines and multiple kernel learning methods to test their forecasting abilities of price movements in financial assets. They found that the text performed better in predicting returns than the past return data did.
This paper studies the effects of rumors about the next-generation iPhone on Apple’s stock price and makes contributions to the literature in two ways. First, it examines the effects of the rumors of new products on the stock market. Previous studies on the impacts of rumors focused on important events of companies, such as earning announcements, stock splits, and takeovers; while studies on new products were confined to the announcement effects. The paper bridges the gap by collecting rumors on the next-generation products and examining the effects. Moreover, this paper emphasizes on exploring the qualitative information in rumors instead of simply counting the occurrence of the rumors. Due to different features of disciplines, we also construct a market-decided lexicon rather than employing any existing and general dictionary to transform the qualitative messages embedded in rumors into quantitative data.
Three conclusions are reached through the analysis of rumors. First, by analyzing the abnormal returns, we identify significant positive effects of the spread of rumors on the stock market. Second, on the basis of the abnormal returns, this study constructs a lexicon consisting of positive and negative words from rumors. Positive words, rather than negative words, are found to play an important role in the market in terms of prediction performance. This market-decided lexicon is confirmed to outperform the widely used Harvard-IV-4 dictionary. Third, the market is found to be most sensitive to the words that contain information related to the outward appearance of the iPhone rather than to the hardware configurations.
The rest of the study is structured as follows. The methodology and data description are introduced in Sections 2 and 3. In Section 4, the impacts of the spread of rumors on Apple’s abnormal returns are analyzed. The effects of words and the analysis of words to which the market is sensitive are also presented in Section 4. The last section concludes the results.
The abnormal return is employed to investigate and evaluate the effects of the spread of rumors. This is a widely used method in event studies to measure the degree of impact. The method for building a market-dependent lexicon proposed by Mao et al. (2014) is also briefly discussed in this part.
Abnormal return
The method has been widely adopted (Pound & Zeckhauser (1990), Chaney et al. (1991), Kiymaz (2001), and Lucca & Moench (2015)). As shown in Equation 1, the abnormal return AR
t
at time t depends on the difference between the actual and the expected returns (represented by R
t
and E (R
t
|X
t
), respectively), based on the conditioning information X
t
.
The term (R mt - R ft ) represents the excess return on the market, while the term SMB t indicates the performance difference between small and large stocks and is used to measure the size premium. HML t measures the spread of returns between high-value and growth stocks and captures the value effect. As defined by the authors, size of stocks is measured in terms of market equity; a high book-to-market ratio signifies high-value stocks and a low ratio suggests growth stocks. Similar to the market model, ε t is our focus and satisfies the two moment conditions above.
In this paper, we adopt the three-factor model in Equation 3 for our analysis. We also estimate a five-factor model (Fama & French (2015)). The model adds extra measures of profitability (the return spread between the most profitable firms and the least profitable ones) and investment (the return difference between firms investing conservatively and aggressively) to accommodate cross-sectional data better. However, we consider that this improvement is of trivial relevance to the current study, as our main concern is the excess return.
Based on this rationale, this paper uses the three-factor model to estimate abnormal returns (Tetlock et al. (2008)). The five-factor model and the market model are used for robustness check of the empirical results generated from the three-factor model.
Next, the parameters of the model are estimated. The timeline presented in Figure 2 shows three time ranges: before, during and after an event. The first grey area in the time between T1 and T2 is the estimation window, in which the coefficients in the models based on known returns can be estimated. The time interval between T3 and T4 is the event window, in which the coefficients obtained in the estimation window are employed to calculate the abnormal returns using the actual stock returns in this period. T = 0 indicates the exact day when the event happens. This paper uses a nine-day event window (including the event day and four days before and after the event day), as Kiymaz (2001) found that this window was more appropriate for studies related to rumors. Lastly, the interval shown in the last shaded area from T5 onwards indicates the post-event window. Specifically, since the three-factor model is used, the parameters

Timeline for Event Studies.
Another important term is the cumulative abnormal return (CAR), which is the aggregation of abnormal returns. If we assume that the time interval concerning the event window is between τ1 and τ2 and satisfies T3 ≤ τ1 ≤ τ2 ≤ T4, then the cumulative abnormal return from τ1 to τ2 is the sum of the abnormal returns within the periods, i.e.,
From previous studies on sentiment analysis, two approaches can be identified: the lexicon-based and the classifier-based approaches. The lexicon based sentiment analysis involves finding sentiment bearing words from a predefined sentiment word lexicon in a document to classify the polarity of the document. The sentiment analysis with a machine learning approach trains a classifier which is able to classify documents automatically in terms of sentiment. However, for the machine learning based sentiment analysis which needs manually labelled training data, selecting training sets among a number of news articles is time-consuming, and the results of the selection are often inconsistent among screeners.
For the lexicon-based approach, dictionaries such as the well-accepted General Inquirer Harvard-IV-4 (H-IV-4) and Loughran and McDonald Sentiment Word Lists are usually employed. Such word lists are widely used across various disciplines, including psychology and sociology. However, they were criticized for their loose application to fields in social science, in which the sentiment for the same word could be different or even antithetical. As Loughran & McDonald (2011) demonstrated, the domain was crucial for conducting sentiment analysis. The authors found that more than 70% of “negative words” in the commonly used H-IV-4 dictionary were misclassified as negative in the financial context. Therefore, this paper does not rely on any currently used dictionaries. Instead, following the method suggested by Mao et al. (2014), we construct a lexicon in this study. We let the stock market decide whether the words from rumors are positive or negative and compile them in a lexicon based on abnormal return.
With reference to the H-IV-4 dictionary and Tetlock et al. (2008), it can be presumed that only two word types exist: positive and negative. Building our lexicon involves four steps: processing text, selecting seed words, targeting expanded words, and identifying final words. In the first step, articles are collapsed into a matrix for further processing, and seed words, which are most sensitive to abnormal return, are selected. Based on the similarity to the seed words, other words from the matrix are chosen and added to the lexicon. In the last stage, words that are in Conflict with certain rules (as discussed below) are eliminated to ensure that the lexicon is consistent with the market’s reactions.
In terms of text processing, according to Das & Chen (2007), Tetlock (2007) and Tetlock et al. (2008), the construction of the lexicon in this paper is based on the content of news, instead of headlines as used by Chan (2003) and Mao et al. (2014). In this regard, the qualitative information contained in the articles needs to be collapsed into a document-term matrix (DTM) first before it is fully transformed into quantitative data. In this matrix, each row includes a rumor, while each column contains a word that is extracted from the data set 1 .
Furthermore, all the words in the rumors are transformed into their corresponding lower case before being collapsed into a DTM 2 . The bag-of-words scheme is adopted in the further processing of the matrix.
Contrary to the approach that focuses on whether words appear in the matrix or not, the scheme that we adopt counts the frequency of words’ occurrence instead. Methods applied in the area of natural language processing (NLP) are used here as well. To illustrate this point, a word is included in the matrix if it contains more than three letters (punctuation is excluded, except for intra-word hyphens) and if it appears in at least two documents. However, stop words (including articles and pronouns), which have a high frequency but are meaningless, are removed.
Beyond that, it is worth explaining that the method of stemming is not employed in this paper when rumors are collapsed into a DTM. Stemming indicates that words derived from the same root are considered to be the same and are transformed into the same form by affix removal. According to Liu (2007), current stemming algorithms could change the meaning of original words and link irrelevant terms. Because of this potential limitation, this method is not used. Additionally, since stop words have been eliminated, the weighting scheme applied in this paper to the matrix is based on the term frequency (TF) approach, which measures how often a term occurs in each rumor. Another popular weighting scheme is the term frequency-inverse document frequency (TF-IDF) method, which punishes the TF if the rumors contain many of the same terms. Although the TF-IDF method could fulfill the task as well, it would generate similar results while involving more complex work. Hence, the TF scheme is used.
Next, seed words are selected. Unlike Mao et al. (2014), who employed the raw stock returns, this paper uses the abnormal returns to represent the market reaction to the news. This is because abnormal returns are free from the influence related to market and industry volatility. In terms of specific procedures, the abnormal returns are normalized first. More precisely, they are centralized and divided by the standard deviation. Based on the assumption that positive (or negative) words are most likely to be found in the rumors that are associated with significant positive (or negative) abnormal returns, seed words are chosen from the extreme quantiles of the returns. Specifically, positive seed words are selected from rumors with the top 5% of abnormal returns, while negative seed words are chosen from the bottom 5%. (A change in these numbers, for instance, to 10%, would not have any obvious influence on the conclusion.) According to these criteria, the top 100 seed words with the highest TF are selected from the articles with extreme market responses. Following Mao et al. (2014), 30 words for each type of polarity are further picked out. The number of positive seed words and that of negative seed words should be the same. This assures that the judgments made in the next stages are free of bias. Moreover, the selected positive and negative seed words are assigned 1 and -1 as initial scores, respectively. This suggests that the words chosen in the next stage will have sentiment scores in the range of [-1, 1]. Additionally, the economic value (EV) proposed by Mao et al. (2014) is used to measure and verify the significance and the impact of the words in the lexicon on the stock market. It is shown in the following equation:
In the third stage, expanded words are targeted. More words are incorporated into the lexicon based on their similarity to the seed words. With reference to Mao et al. (2014), the word similarity is defined in Equation 5, where w
s
and w
o
refer to seed words and all the other words in the columns of the DTM, respectively.
Based on the results of word similarity, the semantic orientation (SO) for each of the other words can be calculated from Equation 6:
Specifically, the value of the SO for a word is the sum of the similarity coefficients between the word and all the seed words (including positive and negative ones). If the value is less than zero, the word is negative; if the value is greater than zero, the word is positive.
Finally, words that fail to satisfy certain conditions are removed. The most important condition is whether the SO is consistent with the effect of the word on the market. To achieve consistency, the EV is applied. If the direction of the SO of a word is opposite to that of the EV, the word is excluded. The significance of a word for the stock price is another condition. Therefore, only words with an EV that deviates from zero at the 10% level are included in the final set. In addition, words with an absolute EV value of less than 0.01 are excluded, since the number implies that the word has a minor and insignificant impact on the stock price. Lastly, as the TF weighting scheme is adopted, the upper limit of the word frequency applies to the final words as well. To eliminate noise, words with a frequency above the ninety-fifth percentile are excluded.
Qualitative data
The iPhone’s production is highly globalized: it is designed in the US, but its components are ordered internationally, assembled by millions of workers overseas, and tested by worldwide partners. Although non-disclosure agreements are signed as required, information leakage from links along the production chains still occur and are hard to avoid. Useful information on the next-generation iPhone can usually be extracted from such leakages. For instance, information about the production of the low-cost plastic iPhone 5C was available eight months before its release date, and information about the new rose gold color option for the iPhone 6S was leaked half a year before its official announcement. The following subsection describes the source and scope of the qualitative data used in the present study.
The qualitative data are generated using a web crawler written in Python from articles on the MacRumors.com website. By collecting and tracking the latest news, leakages and reports, the website has concentrated on rumors related to Apple’s products for over 16 years. Thanks to its success and impact in this field, it now has more than 865,000 registered users and 22 million posts in its forums. The website publishes or reposts new and detailed rumors promptly: it was one of the earliest websites to predict the change in the naming scheme for the iPhone 4S, and it was also the first website to publish articles disclosing the external appearance of an assembled iPhone 6.
In total, 25,414 articles are obtained from the Macrumors.com website published between January 2002 and December 2015. In addition to the iPhone, information on Apple’s major hardware and software products, such as the iMac desktop computer, MacBook laptop computer series and OS X operating system, is included. The original qualitative data set also contains important news on other IT companies, influential industry events and introductions to third-party accessories.
The data are further processed to ensure that the selected rumors focus on Apple and the iPhone. In addition, because rumors and unestablished facts are the concerns, articles that cover Apple’s launch events, annual reports, reportage of its patent fights with other enterprises, reports on user experiences and coverage of the iPhone’s market share are excluded. Moreover, round-up articles are omitted because they do not provide new information. Eventually, 1,264 rumors related to the iPhone covering the period from August 2002 to December 2015 are selected. The information in these rumors is provided by a range of sources, such as supply chain and commercial partners, including manufacturers, carriers, retailers and bureaus responsible for patent and trademark applications.
The final set of chosen rumors revolves around three main questions: (1) What would the new iPhone be like? (2) When would it be available? (3) Where can it be bought? The first question involves not only the officially designated name of the new iPhone but also its appearance, hardware configurations and features. These leakages may come directly from, for instance, assembly lines and source codes, or indirectly from new technologies announced by supply partners and patent application files prepared by Apple itself. The second question concerns when the next-generation iPhone would be released and when there would be sufficient supply. Among the leaked information in this category, the debut date of the new iPhone attracts the most attention from investors and consumers. The date can be inferred from its current production stage (such as whether it is undergoing testing or is in mass production) or from the actions taken by commercial partners. Pre-orders of the new iPhone and restrictions on vacation requests from Apple’s employees are other indicators. Additionally, because of limits on consumer orders, the question of when the new iPhone could be purchased receives wide attention. Thus, rumors about potential supply constraints are also of interest and are included. Lastly, the final question is specifically related to market expansion and is particularly pertinent in markets like the US and China. This includes issues such as the markets in which the new iPhone would be available and the new local carriers with which Apple would cooperate.
On average, each selected rumor contains 14.49 sentences and 180.34 words. Rumors are depicted in Figure 3 according to different time spans. The top left picture indicates that rumors are published more frequently on weekdays than at weekends, and that Thursday is the day with the most pieces of news. The top right figure presents a growing trend of iPhone rumors on a year-over-year basis. The bottom left chart shows that leakages occur intensively in the second and third quarters of the year. Denoting the release months of the new iPhone as zero and labeling the months leading to the product launch as negative numbers, the bottom right figure implies that the rumors leading up to a new product launch cycle can be divided into three groups chronologically. Half a year before each announcement, rumors start appearing, and they gradually increase in number in the first four months after the release of the first rumor. Finally, sudden growth is typically seen during the last two months and in the month when the new iPhone is released.
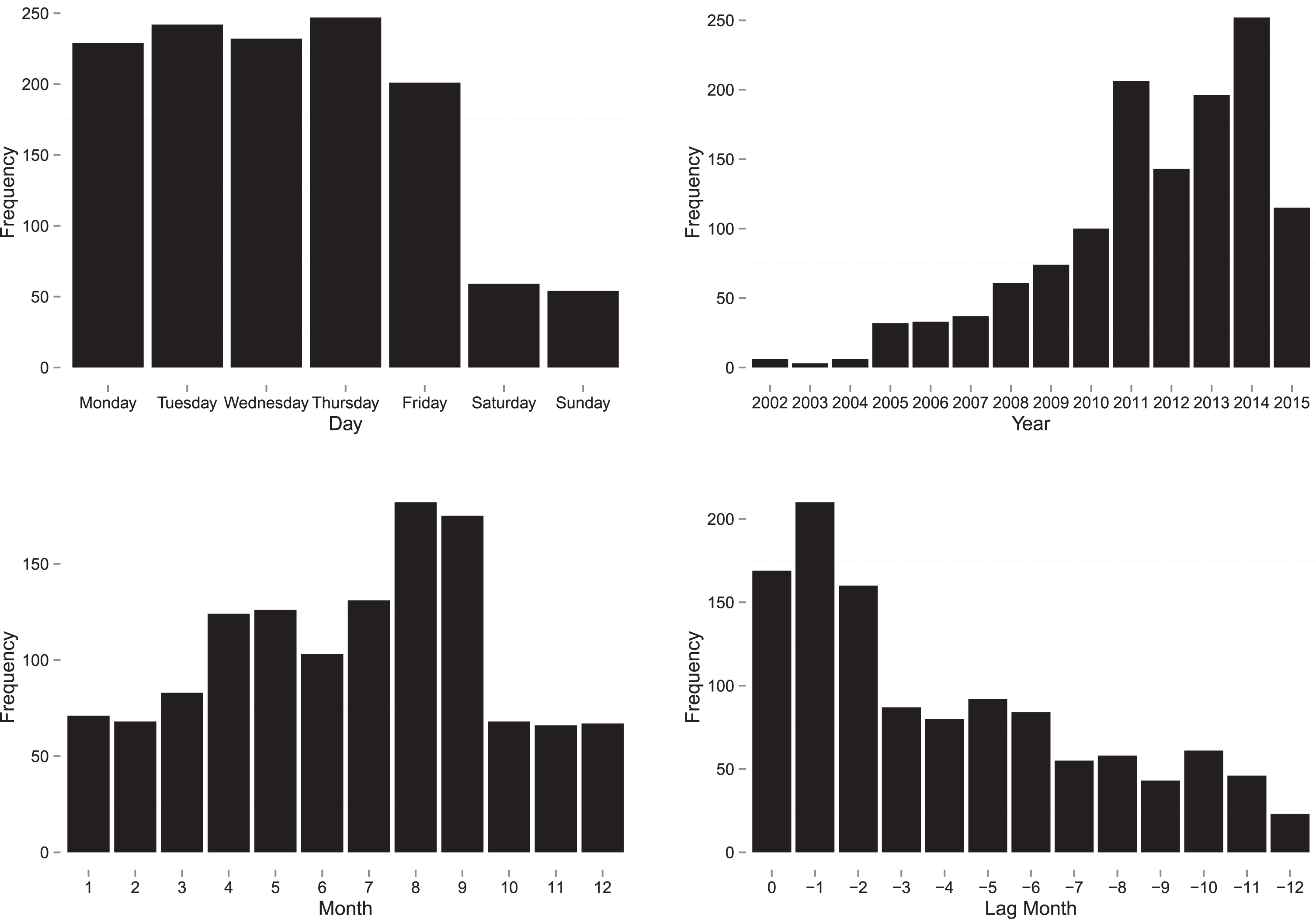
Rumor Data Description.
With reference to Tetlock et al. (2008), the estimation window is set at [-252, -31], i.e., starting from one calendar year to one and a half months before a rumor appears. Correspondingly, the time range of quantitative data is thus set from August 2001 to December 2015, and 3,627 observations for each variable are collected. However, the data on the abnormal returns will only be aligned with the qualitative data of the same date for further study. More specific procedures for the initial data processing are shown below.
Firstly, to ensure that there is sufficient time for the articles to be noticed fully, the rumors published before the last 30 minutes of each trading day are considered as occurring on the current day; otherwise, they are classified as articles released on the next day. Secondly, rumors are combined into one piece if multiple articles are posted on the same day. Lastly, leakages released at weekends are linked to the data of the next trading day. Given these adjustments, the occurrence dates of the rumors are decided. Applying the Fama-French three-factor model, we show the details of the abnormal returns on the days when rumors occur in Figure 4. The dashed horizontal line indicates the mean of AR. It is clear that the AR on rumor days is remarkable in both directions, although its average value is close to zero.
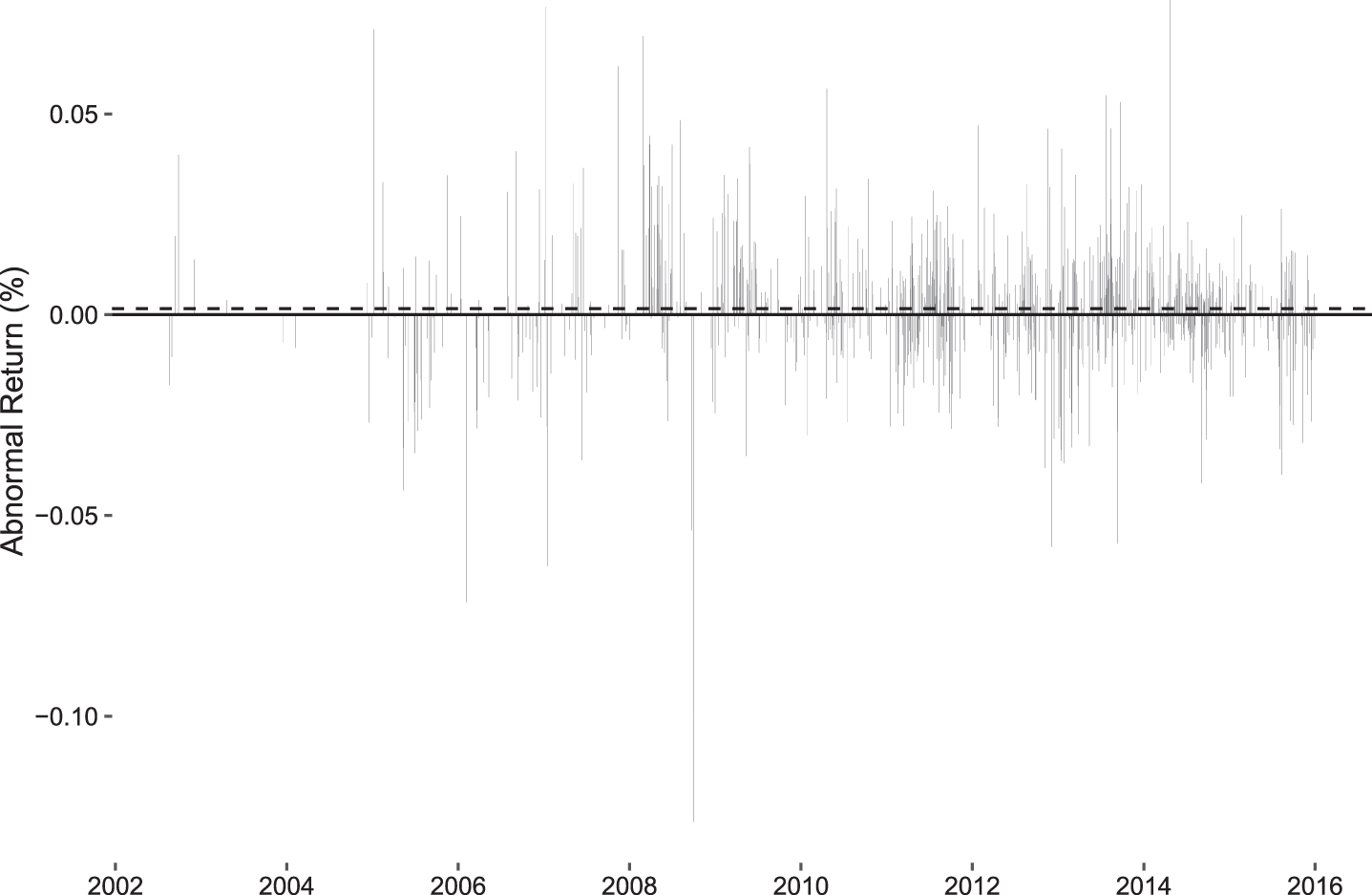
Abnormal Return on the Occurrence Days of Rumors.
Apart from Apple’s adjusted stock returns (R a ) and data for the three-factor model, the financial data set also contains the market value (ME), the book-to-market value (BM), the share turnover (ST), and the standardized unexpected earnings (SUE), with 963 observations for each variable. The data for the three-factor model include the excess returns on the market (R m - R f ), the performance spread between small stocks and big ones (SMB), and the performance spread between the growth and the value stocks(HML). The BM is calculated from the ME and the book value, and the book value is the difference between the total assets and the liabilities. The ST denotes the ratio of the number of shares traded to the number of outstanding shares. In addition, because of data limitations, the book value, ST and SUE are all updated quarterly. R a and data for the Fama-French three-factor model are collected from the Bloomberg database and Kenneth French’s website, respectively, whereas the remaining variables are obtained from Wharton Research Data Services (WRDS).
Additionally, with R a and the data from the three-factor model, the AR is estimated via Equation 4. FFCAR represents the fact that the CAR is derived from the Fama-French three-factor model. Based on Tetlock et al. (2008), FFCAR-30,-3, FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are employed to ensure that the full impact is estimated completely. The first variable indicates the abnormal returns accumulated from 30 days to 3 days prior to the event day, and the remaining ones show the abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31].
To provide further information, the data description for each financial series is provided in Table 1. It can be seen that the mean of AR and R a on non-rumor days is smaller than that on rumor days.
Descriptive Statistics on Quantitative Data
Note: This table reports the descriptive statistics for both rumors and non-rumors data. AR is the abnormal returns estimated via Equation 4. R a refers to Apple’s adjusted stock returns. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. FFCAR-30,-3 indicates the abnormal returns accumulated from 30 days to 3 days prior to the event day. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively.
In this section, the significance of the occurrence of rumors on Apple’s abnormal returns is verified. We also examine the specific impacts of the rumors from two perspectives: how the SO of the words in the rumors affects the stock returns and what information can be revealed by words to which the market is sensitive.
The impact of rumors on abnormal return
Based on the methods outlined in Subsection 2.1, the results of the event study show an obvious jump in the AR from one day ahead (t = -1) to the occurrence day (t = 0). Mathematically, it is a 0.158% increase, which is the largest rise in the event window, compared with the growth of 0.033% one day before. After the occurrence day, the growth rate of the AR for rumors drops. It only rises by 0.120% in total during the next three days.
Apart from the rumors, each announcement of the next-generation iPhone is included and serves the purpose of comparison. The pattern above is not observed on the day of Apple’s official iPhone announcement. The AR increases by an average of 0.068% on the announcement day, which is clearly smaller than that on the occurrence day of the rumor. This implies that the information of the announcement has already been revealed through the historical stock price, and thus no new information is released on the day of the product launch.
Before verifying the significance of the effects, distribution of AR is studied. Figure 5 shows the features of the AR for rumor and non-rumor days. The upper chart shows the relationship between the actual quantiles and the theoretical ones for the AR. The dark dashed line and light dotted line represent the theoretically expected normal distribution quantiles for rumor and non-rumor days, respectively.
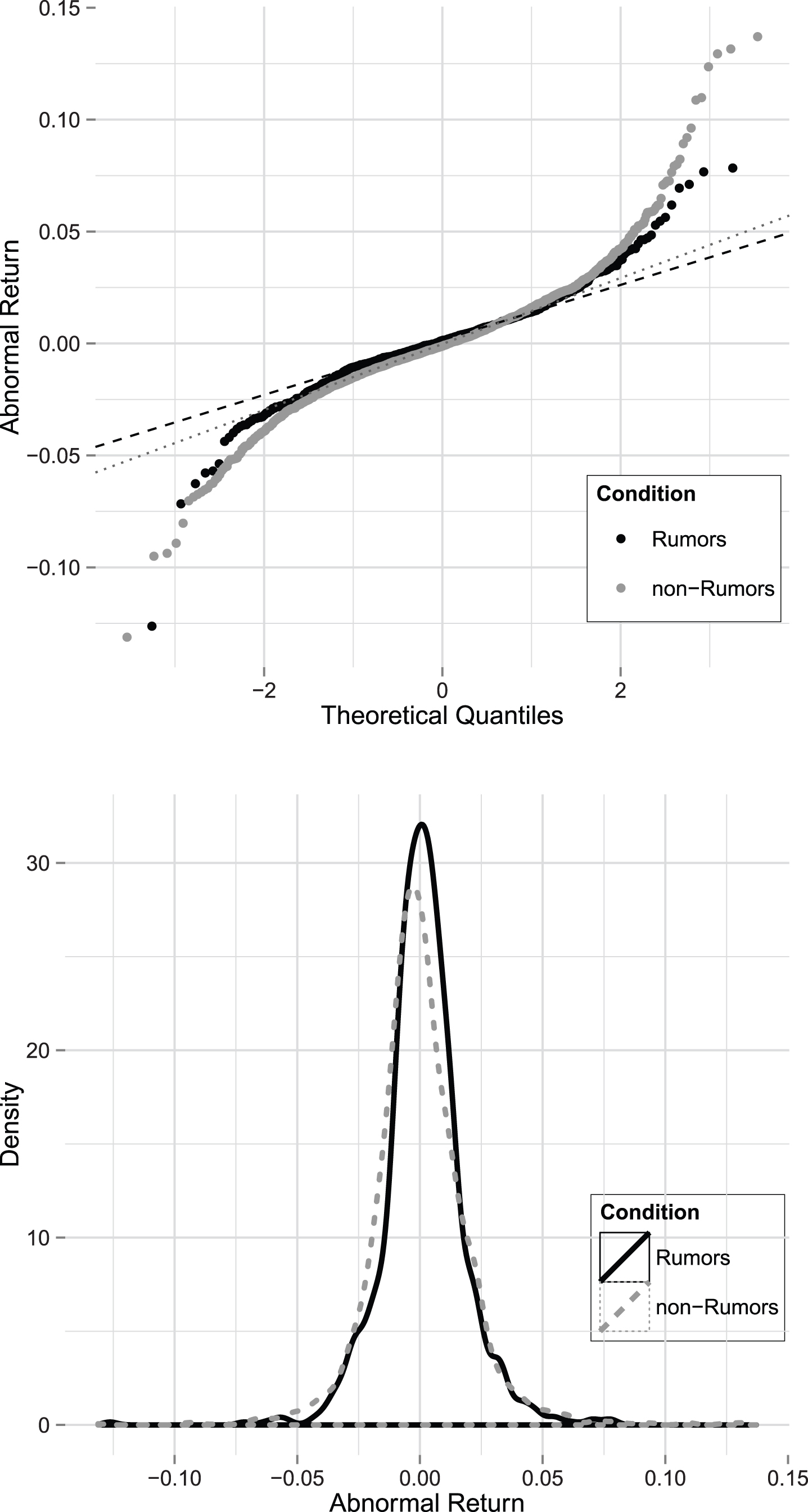
Features of Abnormal Return.
As Figure 5 indicates, the AR for rumor and non-rumor days are not normally distributed. The tails of AR under these two conditions are more dispersed than the corresponding expected normal distribution quantiles, while the middle parts conform well. This implies a fat-tailed feature, which means that there are more extreme values at both ends than theoretically expected —specifically, in low quantiles the values of the AR are more negative than the normal distribution suggests, and in high quantiles they are more positive. However, the AR on non-rumor days shows more extreme values than that on rumor days in both upper quantiles and lower quantiles. In addition, the values of the Shapiro ratio for rumor and non-rumor days are 0.939 and 0.93, respectively, also rejecting the hypothesis that the AR for rumor and non-rumor days follow a standard normal distribution at the 1% significance level.
The graph on the bottom depicts almost identical density of the AR on rumor and non-rumor days, and the AR is more clustered around the mean for occurrence days. Along with the kurtosis of the AR in Panels A and B of Table 1, the high peak feature of rumor and non-rumor days is clearly presented. Similarly, the AR for announcement days does not follow a standard normal distribution neither. Its Shapiro ratio is 0.792, rejecting the null hypothesis of normal distribution as well.
Given the non-normal distribution and based on Lucca & Moench (2015), we employ the bootstrap approach in a statistical significance test for the AR on the event day (day 0). Based on 10,000 replications, the lower bound of the 95% confidence interval is 0.04%, while the upper bound is 0.26%. The results support the conclusion that the AR is significant on the same day that rumors occur.
Furthermore, whether the AR on rumor days differs from the AR on non-rumor days is of importance. Considering that the AR on both rumor and non-rumor days do not follow the normal distribution, and given a 10,000 iteration bootstrap, the difference in means is 0.15%, which is significant at the 5% level. These results clearly show that the AR on the occurrence days of the rumor is significant and that the AR between rumor and non-rumor days is also significantly different. In addition, the tests are applied to the AR on iPhone announcement days, but the results indicate neither that the AR is significantly different from zero nor that the AR on release days differs from that on non-release days at the 5% significance level. According to the previous results, the impact of rumors on Apple’s abnormal returns can be verified. The lexicon is built on this basis, and further analysis is conducted based on the AR for the occurrence days of the rumor.
Based on the methods described in Subsection 2.2, 1,264 pieces of rumors are collapsed into a matrix with 6,433 columns, and over 6,000 words are initially extracted. Given the rumors’ association with the top and the bottom 5% AR, the corpus is further processed, and, correspondingly, positive and negative seed words are found. Specifically, the positive rumors include 102.73 words on average, whereas the negative ones contain 128.63 words. From the top 100 words, 30 seed words for each SO are identified according to TF.
As Table 2 shows, words that are commonly defined as “positive” are recognized by the market as positive seed words as well, including “advantage”, “agreement”, “faster”, “improve”, and “holiday". In addition, Apple’s intelligent assistant “Siri” appears in the list. The word “leaks” is also included, which implies that the market seems to welcome rumor leakages and sees them as a positive signal. This is also consistent with the result of the event study, which concludes that rumors can have statistically significant effects on the AR.
Selected Seed Words
Selected Seed Words
Note: The table reports the selected seed words, which are most sensitive to abnormal returns, for each type of polarity. Positive seed words are selected from rumors with the top 5% of abnormal returns, while negative seed words are chosen from the bottom 5%. Based on the similarity to the seed words, other words from the matrix are chosen and added to our lexicon.
Surprisingly, except for terms such as “costs” and “delays”, which are commonly labeled as negative, most negative seed words turn out to adhere closely to the technologies that the iPhone adopts. These include “TFT-LCD”, “backlight”, and “FinFET"(technologies in the screen), “LTE” (a communication standard) and “ARM Cortex” (a type of processor). The iPhone’s competitors and manufacturers are also included in the negative category, such as “Android” (Google’s rival operating system), “Qualcomm” and “Pegatron” (hardware firms involved in the iPhone’s design and manufacture). Based on a comparison between the two sides of the table, it is worth noticing that the term “difference” is positive, while “familiar” is negative. This suggests that the market desires distinct, novel products rather than similar ones with which the public is familiar.
Given these seed words, the average EV for positive seed words is 236.72 basis points, and it is -198.91 basis points for negative seed words. According to Mao et al. (2014), the 435.62 basis points difference between these values is significant and reflects the AR trends efficiently.
The degree of similarity between the seed words and the rest of the words in the DTM is then calculated. On this basis, similarity coefficients are assigned to each of the remaining 6,373 words before they are incorporated into the expanded word set. As Table 3 shows, the difference in the EV between the two polarities is notably narrowed, owing to the increasing number of words. After excluding the words with SO values that are opposite to their corresponding EV and the words with values of EV that are insignificant and unnoticeable, 314 words are obtained to form the final set. As a result of our control of the word number for both polarities in seed words selection, the positive words account for approximately 50.32% in the final set, which slightly exceeds the number of negative words. This pattern is consistent with that of Mao et al. (2014). Moreover, in terms of the impact on the AR, these two types of words differ from each other. According to Table 3, the average EV of all the positive words in the final set is 35.02, while that of negative terms is -48.81. Although the gap between positive and negative words in the final set is smaller than that in the seed word set, this difference is still shown to be significant.
Average EV of Lexicons
Note: This table reports the results of the economic value in seed words, expanded words and final words, respectively. The economic value is used to measure and verify the significance and the impact of the words in the lexicon on the stock market.
To verify the validity and the effectiveness of the final set of words, the evaluation method proposed by Mao et al. (2014) is used here:
The sentiment score (Senti j ) on a given day j is calculated through Equation 7, where SO (w i ) refers to the SO for word w i derived from Equation 6. f i represents the frequency of word w i , and N is the total number of the final words in the combined rumors on day j.
To assess the performance of the final words, all the rumors with different occurrence dates are randomly split into two sets, with a ratio of three to two. Hence, the first set includes 577 observations and the second set contains 386. Through this measurement, the sentiment scores for each rumor are calculated and divided into five quantiles. Based on the scores, the average AR for each group is obtained. Given the AR and the sentiment scores, a positive relationship is shown in Figure 6.
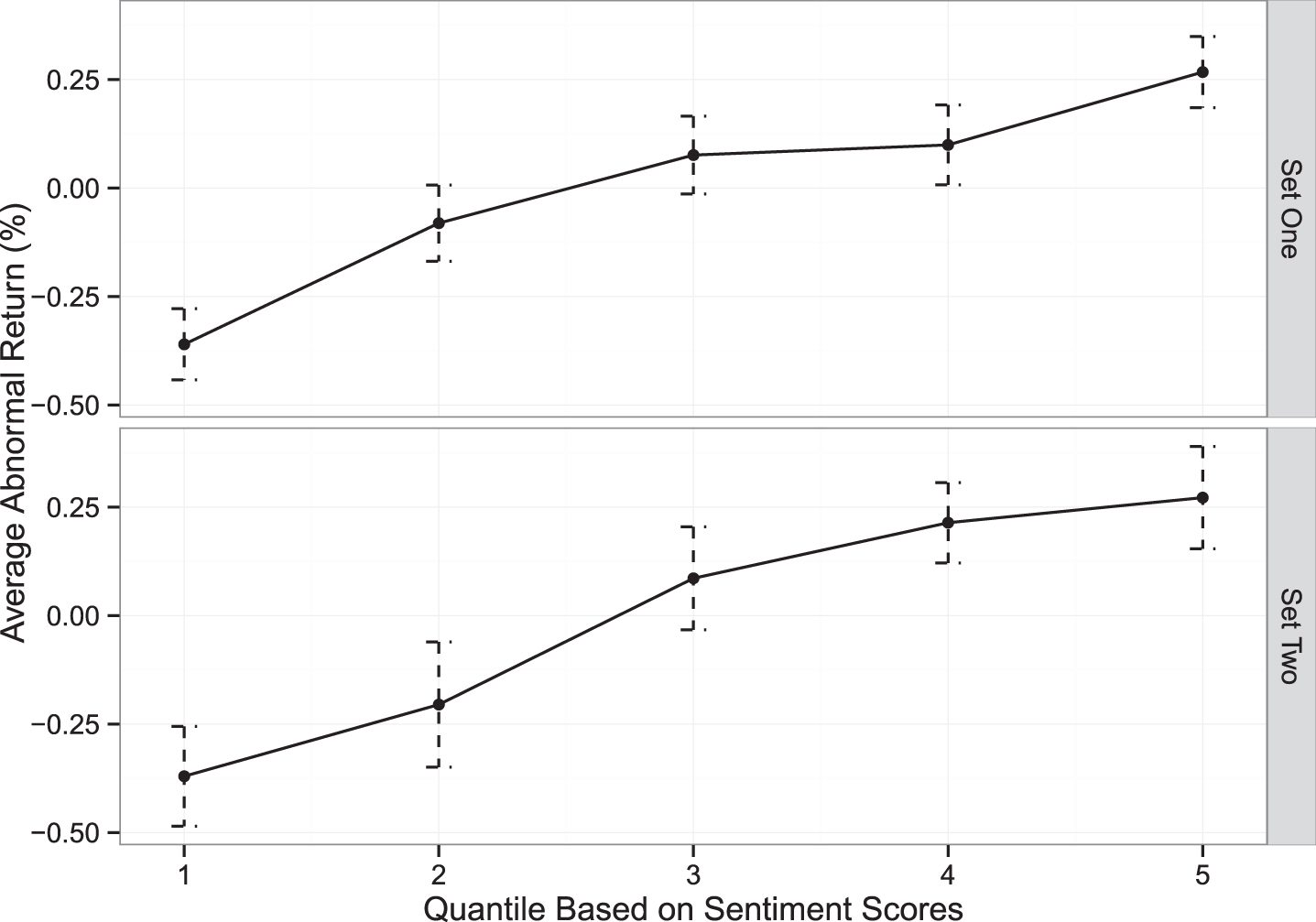
Evaluation of Final Word.
It is clear that the monotonically increasing patterns in both sets demonstrate that the final words are valid in measuring the AR, and that the qualitative information embedded in rumors reflects the preferences of the market. Considering this, the final words are used as the lexicon that we construct for the current study.
To transform these qualitative words into quantitative information, the positive and the negative words on a given day are counted and divided by the total number of words of the combined rumor. Following Tetlock et al. (2008), the resulting proportions are then transformed into standardized ratios by subtracting the mean and dividing by the standard deviation, and the standardized ratios for the positive and negative words are hereafter referred to as POS and NEG, respectively. The impacts of the qualitative information on the stock price are investigated using the H-IV-4 dictionary and our constructed lexicon. The results, with the next-day abnormal return and stock return being the dependent variables, are reported in Table 4 and Table 5.
Effects of Words on Abnormal Return in the Three-Factor Model
Note: This table reports the estimated effects of words on the next-day abnormal return in the three-factor model. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level.
Effects of Words on Stock Return in the Three-Factor Model
Note: This table reports the estimated effects of words on the next-day stock return in the three-factor model. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level.
In Table 4, the performance of factors on the AR is shown. Column one lists several control variables and serves as a benchmark model, which captures the effects of past returns and earnings, firm size, and trading volume. These variables are commonly adopted as Tetlock et al. (2008) suggested.
First of all, the standardized ratio is used, and the results are presented in columns two and three. It is obvious that the proportion of the positive words in our lexicon, or POS, is highly significant. It also implies that a one standard deviation increase results in a growth of 10.3 basis points in the next-day abnormal return. However, the proportion of the negative words is insignificant and small.
In addition to the standardized ratio, the widely used sentiment index
Other variables, such as the previous month’s returns, book-to-market ratio, and share turnover, are significant across these three models, whereas the past returns of two days ahead of the occurrence of rumors are significant in some models.
Meanwhile, the standardized ratios of the positive and negative words against the total number of words for the H-IV-4 dictionary are denoted by POS H and NEG H , respectively, and are listed in columns five to seven. Clearly, POS H is insignificant and displays values that are opposite to the expected direction. The influence of the words on returns is supposed to be in the same direction as their coefficients suggest. Although the coefficient of NEG H is slightly significant in column six, its value also displays a false leaning towards the negative polarity. Moreover, the coefficient of IDX H is tiny and insignificant.
Compared with the benchmark, there are improvements from 0.032 to 0.040 in the adjusted R2 in the models with positive words derived from our lexicon. The models with negative words from the H-IV-4 dictionary only improve the adjusted R2 marginally, from 0.032 to 0.034. The two models that involve negative words from the final set and positive words from the H-IV-4 dictionary perform slightly worse than the benchmark. This means that the negative words in the final set and the positive words in the H-IV-4 dictionary are redundant in the models.
Furthermore, the effects of other factors are evaluated. First, dummy variables are set for Apple’s products excluding the iPhone. Considering that the abnormal returns may be attributed to rumors about other products as well, the dummies serve as control variables. However, since Apple’s product line is large and covers a range of items from computers to watches, it is inevitable that news about other products will be reported on the same day as the release of iPhone rumors. Therefore, the dummy variables are adjusted to take a value of one if there is a rumor about a new product, excluding general updates to an existing product, and a value of zero if the rumor does not involve information on any new products.
In total, three dummy variables are used to represent Apple’s primary products. The dummy variable for the iPad includes not only the rumors of the first-generation iPad, which made its debut in 2010, but also those of the other two important models, the iPad mini and iPad Pro. The dummy for the MacBook coincides with both the MacBook Air, launched in 2008, and the ultra-thin MacBook, introduced in 2015. The higher-end MacBook Pro is not included because its first release in 2006 was earlier than the iPhone’s. Lastly, the Apple Watch, the latest of Apple’s products, is considered when the co-occurrence dummy is calculated. The number of pictures depicting a potential new iPhone model is also counted and added to the model. This additional variable’s function is to evaluate the credibility of the rumors. Generally, rumors published with photos, especially those concerning the parts of a product, provide visualized and catchy information and are thus more likely to be deemed authentic. The results are shown from columns eight to 12, and column eight is the benchmark for comparison. In terms of word sentiment, the results are similar to those listed in columns two to seven and indicate that POS plays an important role in affecting abnormal returns. Column nine states that POS is statistically significant at the 1% significance level.
The coefficient is economically significant as well. The estimated growth of abnormal returns is 4 × 0.093 = 0.372 standard deviations when POS increases from two standard deviations below the mean to two standard deviations above the mean. However, NEG in column ten is insignificant both statistically and economically, similar to what is shown in column three. By combining POS and NEG, the complete results can be obtained in column 11. The signs of the coefficients of POS and NEG are consistent with their polarities, respectively. POS is highly significant, while NEG is insignificant. However, column 12 indicates that POS H and NEG H are problematic because the signs of the coefficients are opposite to the polarities of words.
Apart from the sentiment, the coefficients of the control variables are worthy of note. Other Apple products, including the MacBook and the Apple Watch, contribute little to Apple’s abnormal returns. Even though the iPad seems to create some impact, it is only marginally significant. Furthermore, unlike Apple’s other products, the negative sign on the MacBook potentially demonstrates that the post-PC era is coming, given that smaller and more portable products, instead of laptops, are increasingly favored by the market. Moreover, including photos in rumors has a significant and positive impact on Apple’s abnormal returns across the models. This reflects the fact that leaked photos efficiently enhance the credibilities of rumors and thus affect expectations and abnormal returns.
Moreover, including POS improves the model performance. The adjusted R2 of 0.038 in the original benchmark increases to 0.045 and 0.044 in the models with POS only and in the one with both POS and NEG, respectively. Compared with the benchmark, the model with POS H and NEG H merely causes a marginal increase in the adjusted R2, from 0.038 to 0.041.
In addition to the influence on the abnormal returns, the impact of words from the rumors on Apple’s stock returns is investigated and presented in Table 5. From columns one to six, in which there are no control variables for other products and images, the main results are the same. The POS is significant at the 5% significance level. Every increase in its standard deviation causes a 7.8 basis points rise in stock returns. In contrast, the NEG is insignificant. Similar to the coefficients of POS H and NEG H in Table 4, the results indicate that the coefficients are insignificant, and that their signs are opposite to the polarities of words. This implies that the sentiment calculation, based on a fixed dictionary that neglects the characteristics of disciplines, can result in mistakes.
In contrast to the corresponding columns in Table 4, the cumulative abnormal returns do not affect the stock returns here. This reflects the difference in the dependent variables between the stock returns and the abnormal returns. In terms of the adjusted R2, adding POS to regression improves the model performance from 0.003 to 0.007, whereas the best performance of models with words from the H-IV-4 dictionary is only the same as that of the benchmark. After adding extra control variables, POS still plays a significant role, as the case of the abnormal returns suggests in Table 4. A one standard deviation increase in POS results in a growth of roughly seven basis points in the stock returns. However, NEG, POS H and NEG H have no impact on stock returns. Apart from the ratios of the words, the coefficients of the control variables are different from those in Table 4. Coefficients of all the other products, including the iPad, which is marginally significant in affecting the next-day abnormal return, are insignificant in influencing the stock returns. In addition, the sign of the MacBook coefficient remains negative. This implies that the market has changed its focus from computers to more portable electronic devices. Furthermore, as a symbol of the credibility of rumors, the coefficients corresponding to pictures in rumors turn out to be insignificant. In terms of performance, adding these control variables and POS improves the adjusted R2 from 0.004 in the benchmark to 0.008, whereas the models with the words from the H-IV-4 dictionary gain nothing relative to the benchmark. These results demonstrate that the words from our constructed lexicon outperform those from the H-IV-4 dictionary. Furthermore, the positive words in the lexicon perform better than the negative ones.
Given this conclusion, it can be seen that the comparison between our constructed lexicon and the H-IV-4 dictionary is of importance. The latter contains 4,206 word entries, including 1,915 positive words and 2,291 negative words. Table 6 shows the words that have the same polarity in both the H-IV-4 dictionary and our lexicon, as well as those that have opposite orientations.
Comparison between Words in the Final Set and in the H-IV-4 Dictionary
Note: This table shows the words that have the same polarity in both the H-IV-4 dictionary and our lexicon, as well as those that have opposite orientations.
In particular, the words in the top left and the bottom right corners have the same polarity in both dictionaries. In comparison, the top right and bottom left areas contain words of which the sentiments in the H-IV-4 dictionary are opposite to those in our lexicon. According to the previous regression results, the positive words, instead of the negative ones, from our lexicon play a significant role in affecting the next-day abnormal return and stock return. Therefore, the words in the right-hand column are less important than those in the left-hand one.
Moreover, the words in the constructed lexicon are investigated further to identify the specific information to which the market is sensitive. According to the SO values and frequency, words are further selected from the lexicon and displayed in Table 7. From the table, it is observed that words which describe the appearance of iPhone figure more prominently in the positive category of our lexicon. The words “colors”, “black”, and “gold” imply that the market focuses more on the colors of the new iPhone. Along with the colors, “appearance”, “thinner”, and “large screen” indicate that the iPhone’s outward appearance is more important to the market than its configurations and hardware components. This result implies that the iPhone is a product which represents the latest fashion; thus, only the features that differ remarkably from those of either other products or its previous models and the features that can be identified easily are attractive to the market. In the positive category, terms such as “early”, “image”, and “show” reflect expectations that the rumors about the new iPhone contain visual information. Additionally, the positive category of “developers” implies the importance of the iOS ecosystem to the iPhone, and the word “Jobs” suggests the notable influence of Steve Jobs.
Selected Final Words
Note: This table shows the selected positive and negative words from our lexicon.
In the negative category, the most negative word is “Samsung”, which is both Apple’s main supplier and strong competitor. Samsung supplies components to Apple, such as the iPhone’s screen and flash memory, but Samsung and Apple also compete in the global smartphone market. Moreover, some months are perceived as negative, for example “January” and “July"; however, “November” and “fall” are identified as positive words. This may be due to the release dates of the new iPhone, which are usually announced in the fall and become available to most of the world in November. These words should be considered positive if the next-generation iPhone is still released according to the schedule above. However, January and July tend to be the times of the year when the iPhone enters testing and mass production stages, and when problems and delays often occur. Other negative words are in line with those patterns found in seed words, namely, manufacturing partners and hardware components. They are classified as negative, perhaps because of the common association with potential problems that may delay the launch of the iPhone.
Based on the constructed lexicon, the five-factor model and the market model are employed to check the robustness of the results derived from the three-factor model. Tables 8 and 9 present the results for the five-factor model, while Tables 10 and 11 display the results from the market model. Since the Nasdaq index concentrates on the technology sector, to which Apple belongs and of which the industry features may present patterns that are different from the total stock market index, the Nasdaq index is adopted in the market model 3 .
Effects of Words on Abnormal Return in the Five-Factor Model
Effects of Words on Abnormal Return in the Five-Factor Model
Note: This table reports the estimated effects of words on the next-day abnormal return in the five-factor model for robustness check. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level. thereafter.
Effects of Words on Stock Return in the Five-Factor Model
Note: This table reports the estimated effects of words on the next-day stock return in the five-factor model for robustness check. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level. thereafter.
Effects of Words on Abnormal Return in the Market Model
Note: This table reports the estimated effects of words on the next-day abnormal return in the market model for robustness check. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level.
Effects of Words on Stock Return in the Market Model
Note: This table reports the estimated effects of words on the next-day stock return in the market model for robustness check. POS and NEG indicate the standardized ratios for the positive and negative words, respectively. IDX denotes the sentiment index derived from our lexicon. POS H , NEG H , and IDX H refer to the standardized ratios for the positive and negative words and the corresponding index derived from the H-IV-4 dictionary. FFCAR-30,-3 is the abnormal returns accumulated from 30 days to 3 days prior to the event day, while FFCAR-2,-2, FFCAR-1,-1 and FFCAR0,0 are abnormal returns on days -2, -1 and 0, respectively. FFAlpha-252,-31 represents the intercept in the event study regression with the estimation window [-252,-31]. ME, BM, ST, and SUE refer to the market value, the book-to-market value, the share turnover, and the standardized unexpected earnings, respectively. iPad, Macbook, and iWatch are the dummy variables and take a value of one if there is a rumor about a new product, excluding general updates to an existing product. Picture is the number of photos depicting a potential new iPhone model in a rumor. ***, **, * indicate significance at the 1%, 5%, and 10% level.
It is clear that POS is still highly significant at the 1% or 5% levels across these models. Consid ering all the control variables, if POS increases by one standard deviation, the next-day abnormal returns rise by 10.2 and 8.3 basis points for the five-factor model and the market model, respectively, whereas the next-day stock returns increase by 7.1 and 7.3 basis points. However, NEG is insignificant across the models. Furthermore, POS H and NEG H perform poorly, as suggested by the three-factor model, in which they are statistically insignificant and have coefficient signs opposite to the corresponding polarities.
In contrast to the results from the three-factor model and the market model, in which news concerning the iPad marginally affects Apple’s abnormal returns, the results of the five-factor model show that the effect is not robust. Although not reported in this paper, the coefficients of the market model using the S&P 500 index similarly suggest that the impact of the leakages concerning the iPad is insignificant.
However, regardless of which models are employed, the control variable for the number of leaked images in rumors is still remarkably significant in influencing Apple’s next-day abnormal returns. This demonstrates that the occurrence and the number of images in rumors play a key role in affecting the abnormal returns. An increase in the number of pictures shown in rumors would lead to growth of at least ten basis points in the abnormal returns. However, this pattern is not observed in the stock returns.
Moreover, the performance of the models with POS in terms of the adjusted R2 exceeds that of the models with POS and NEG in Tables 8 to 11. In addition, the performance on the next-day stock return of the market model outweighs that of other models in terms of the adjusted R2. This improvement may be attributed to the characteristics of the information technology industry included in the market model.
Robustness testing shows that, regardless of the different models employed, POS rather than NEG plays a significant role in affecting the next-day abnormal return and stock return. However, the ratio derived from the words in the H-IV-4 dictionary does not follow the same pattern. The analysis reveals that the H-IV-4 dictionary performs poorly because of its cross-disciplinary feature. Moreover, the number of images in rumors has a notable impact on the abnormal returns but not on the stock returns. Although the spread of the iPad rumors marginally affects Apple’s abnormal returns based on the three-factor model, the result is not supported by the five-factor model, and thus it is not robust.
Thanks to big data, information revealing itself in various formats and permeating daily life can be mined. The current paper, which uses big data by extracting rumors from the leading MacRumors.com website, aims to explore the effect of rumors on the market by focusing on the case of Apple’s iPhone. Data crawling via Python enables us to collect a large amount of qualitative information and transform such information into quantitative data. The final results show that qualitative information is valuable and cannot be neglected, which is in line with the findings of Tetlock (2007) and Tetlock et al. (2008). The paper contributes to the field by studying the effects of rumors of new products on the stock market, a topic that few previous studies discussed. Also, instead of relying on an existing dictionary as what was involved in the majority of previous studies, a market-decided lexicon is constructed to examine such effects of rumors.
Specifically, three main results are obtained. First, based on an event study, this paper verifies that the spread of rumors about the next-generation iPhone significantly influences Apple’s abnormal returns. The abnormal returns, which are also found to be significant on the occurrence days of rumors, are considerably different from those on non-rumor days, based on 10,000 bootstrap iterations. However, this pattern is not observed in official announcements: the bootstrap method indicates that the abnormal returns on the day when new products are released are neither significant nor substantially distinct from those on non-release days. This result demonstrates that the new information has already been received and absorbed by the market through previous leakages.
Second, the paper constructs a market-decided lexicon based on the rumors extracted from the website. In particular, the words extracted from the rumors are categorized into two polarities relative to the abnormal returns: positive words and negative words. It is found that the impacts of positive words on the next-day abnormal and stock returns, rather than those of negative words, are statistically and economically significant. This conclusion challenges the results in the literature, which has found the impacts of negative words to be more significant. We think the conclusion is justified in the sense that technology news belongs to a special domain, and that 70% of negative words are misclassified in the H-IV-4 dictionary (Loughran & McDonald (2011). In addition, it is found that our constructed lexicon outperforms the H-IV-4 dictionary.
Third, by examining the content of the positive and negative words from the constructed lexicon, we discover that positive words are primarily related to the outward appearance of iPhone. This is consistent with the iPhone’s image as a lifestyle product. In addition, the words related to competitors, suppliers, and hardware components are recognized as negative by the market. This result implies that the market responds more positively to outward appearances than to hardware configurations.
Footnotes
Acknowledgement
We would like to thank Joon Park, Aman Ulah, Jun Yu, Victoria Zinde-Walsh as participants of the 3rd Dongbei Econometrics Workshop held in Dongbei University of Economics and Finance for helpful comments. We would also like to thank Liugang Sheng, Chih Sheng Hsieh and Julan Du as seminar participants at the Chinese University of Hong Kong for constructive discussions and comments, and thank reviewers for their constructive suggestions. Any remaining errors are ours.
For instance, if there are two documents: (a) “I like rumors” and (b) “I hate rumors”, then the matrix would be:
The words shown in the paper are adjusted to their proper formats for the convenience of reading.
Although not reported here, the S&P 500 is employed and tested as the total market index as well; the coefficients change little and the conclusion remains the same.