
Abstract
Rapidly-exploring Random Trees (RRTs) are data structures and search algorithms designed to be used in continuous path planning problems. They are one of the most successful state-of-the-art techniques in motion planning, as they offer a great degree of flexibility and reliability. However, their use in other fields in which search is a commonly used approach has not been thoroughly analyzed. In this work we propose the use of RRTs as a search algorithm for automated planning. We analyze the advantages and disadvantages that this approach has over previously used search algorithms and the challenges of adapting RRTs for implicit and discrete search spaces.
Introduction
Currently most of the state-of-the-art planners are based on the heuristic forward search paradigm first employed by HSP [5]. While this represented a huge leap in performance compared to previous approaches, this kind of planners also suffers from some shortcomings. In particular, certain characteristics of the search space of planning problems hinder their performance. Large plateaus for h values, local minima in the search space and areas in which the heuristic function is misleading represent the main challenges for these planners. Furthermore, most successful planners use techniques that increase the greediness of the search process, which often exacerbates this problem. A couple of examples of these approaches are pruning techniques like helpful actions introduced by FF [23] and greedy search algorithms like Enforced Hill Climbing (EHC) used by FF and greedy best-first search used by HSP and Fast Downward [21].
Motion planning is an area closely related to automated planning. Problems in motion planning consist on finding a collision-free path that connects an initial configuration of geometric bodies to a final goal configuration. Some examples of motion planning problems are robotics [11,28], animated simulations [12], drug design [13] and manufacturing [15] to name a few. A broad range of techniques have been used in this area, although the current trend is to use algorithms that randomly sample the search space due to their reliability, simplicity and consistent behavior. Probabilistic Roadmaps (PRMs) [25] and Rapidly-exploring Random Trees (RRTs) [29] are the most representative techniques based on this approach.
Algorithms based on random sampling have two main uses: multi-query path planning, in which several problems with different initial and goal configurations must be solved in the same search space, and single-query path planning, in which there is only a single problem to be solved for a given search space. In the case of single-query path planning, RRT-connect [27], a variation of the traditional RRTs used in multi-query path planning, is one of the most widely used algorithms. RRT-connect builds a tree from the initial and the goal configurations by iteratively extending towards sampled points while trying to join the newly created branches with the goal or with a node belonging to the opposite tree. This keeps a nice balance between exploitation and exploration and it is often more reliable than previous methods like potential fields, which tend to get stuck in local minima.
Single-query motion planning and satisficing planning have many points in common. However, bringing techniques from one area to the other is not straightforward. The main difference between the two areas is the defining characteristics of the search space. In motion planning, the original search space of these problems is an Euclidean explicit continuous space, whereas in automated planning the search space is a multi-dimensional implicit discrete space composed of the states reachable from the initial state and the goal states. This has lead to both areas being developed without much interaction despite the potential benefits of an exchange of knowledge between the two communities.
In this work, we try to bridge the gap between the two areas by proposing the use of an RRT in automated planning. The motivation is that RRTs may be able to overcome some of the shortcomings that forward search planners have while keeping most of their good properties. This paper builds on previous work by the same authors [2], mainly extending the sampling methods and presenting a much more extensive experimentation; the major contributions of this paper are the following:
We describe how to implement a search algorithm for domain-independent planning based on RRTs.
We propose a general and efficient way of employing domain-independent reachability heuristics for their use as the distance estimator in the RRT.
We present a method based on constraint satisfaction to sample implicit search spaces at random.
We perform experimentation over a broad set of domains analyzing the impact of the different parameters that characterize the algorithm.
This document is organized as follows: first, some background and an analysis of previous works will be given; next, the advantages of using RRTs in automated planning will be presented as well as a description of how to overcome some problems regarding their implementation; later, some experimentation will be done to back up our claims; and, finally, some conclusions and future lines of research will be added.
Background
In this section we will present both automated planning and RRTs. Regarding RRTs, this includes both the original definition as a data structure and its subsequent evolution as a single-query search algorithm in motion planning.
Automated planning
A propositional formalization of a planning task is defined as a tuple
Finding a solution to a planning problem P consists of generating a sequence of actions
Rapidly-exploring random trees
RRTs [29] were proposed as both a sampling algorithm and a data structure designed to allow fast searches in high-dimensional spaces in motion planning. RRTs are progressively built towards unexplored regions of the space from an initial configuration. Configurations describe the position, orientation and velocity of the movable objects in motion planning and are equivalent to states in other search applications.
At start, the algorithm creates a tree containing the initial configuration. At every step, a random
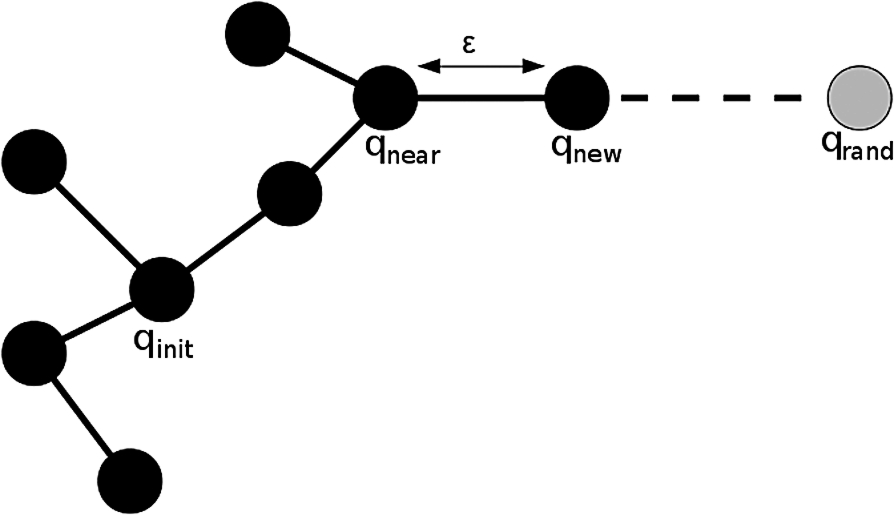
Extend phase of an RRT.

Description of the building process of an RRT
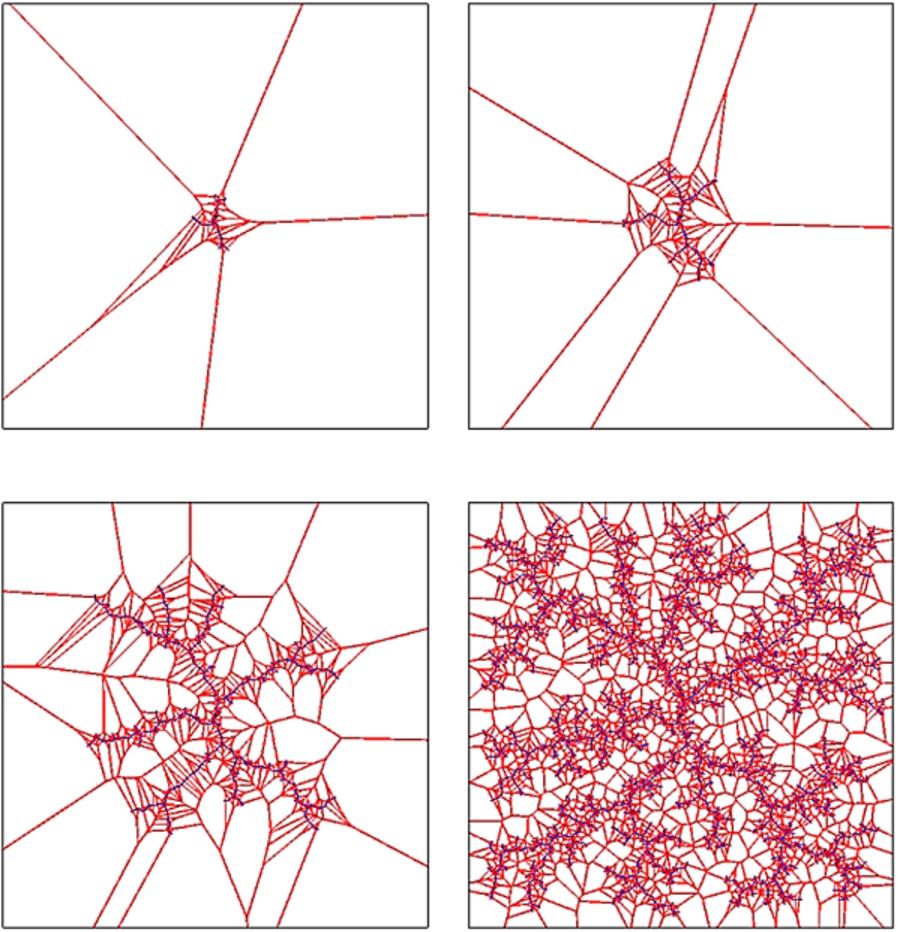
Voronoi diagram of an RRT. (Colors are visible in the online version of the article;
Once the RRT has been built, multiple queries can be issued. For each query, the nearest configurations (node) of the tree to both the initial and the goal configurations of the query are found. Then, the initial and final configurations are joined to the tree to those nearest configurations using the local planner and a path is retrieved by tracing back edges through the tree structure.
The key advantage of RRTs is that they are intrinsically biased towards regions with a low density of configurations in their building process. This can be explained by looking at the Voronoi diagram at every step of the building process. The Voronoi diagram is composed by Voronoi regions; Voronoi regions associated to a given node q of the tree are areas such that every point in the area is closer to q than to any other node

Progressive construction of an RRT.
After corroborating how successful RRTs were for multi-query motion planning problems, researchers in motion planning realized that using multi-query RRTs was often more efficient and robust than using specific single-query motion planning algorithms even for a single query. Motivated by this fact and aiming to develop a more suitable RRT-like algorithm for the single-query case, a variation for single-query problems called RRT-connect was proposed [27]. The modifications introduced were the following:
Two trees are grown at the same time by alternately expanding them. The initial configuration of the trees are the initial and the goal configuration, respectively.
The trees are expanded towards randomly sampled configurations with a probability p, and towards the nearest node of the opposite tree with a probability
The Expand phase is repeated several times until an obstacle is found. The resulting nodes from the local searches limited by ε are added to the tree. This is called the Connect phase.
Growing the trees from the initial and the goal configurations and towards the opposite tree gives the algorithm its characteristic single-query behavior. The Connect phase was added after empirically testing that the additional greediness that it introduced improved the performance in many cases. A common modification is also extending the tree towards the opposite tree after every
Previous work
Although RRTs have not been frequently used in areas other than motion planning, there is previous work in which they have been employed for problems relevant to automated planning. In particular, an adaptation of RRTs for discrete search spaces and a planning search algorithm similar to RRT-connect have been proposed.
RRTs in discrete search spaces
Despite RRTs being designed for continuous search spaces, researchers from other areas proposed their implementation for search problems in discrete search spaces [33]. The main motivation of this work was adapting the RRTs to grid worlds and similar classical search problems. Its authors analyzed the main challenges of adapting RRTs, in particular the need of defining an alternative measure of distance to find the nearest node of the tree to a sampled state and the issues related to adapting the local planner that must substitute the Expand phase of the traditional RRTs. The proposed alternative to the widely used Euclidean distance was an “ad-hoc” heuristic estimation of the cost of reaching the sampled state from a given node of the tree. As for the local planner, the limit ε that was used to limit the reach of the Expand phase was substituted by a limit on the number of nodes expanded by the local planner. In this case, once the limit ε was reached the node in the local search with the best heuristic estimate towards the sampled space was chosen, and either only that node or all the nodes on the path leading to it were added to the tree.
While the approach was successful for the proposed problems, there are two main problems that make it impossible to adapt it to automated planning in a straightforward way. First, the search spaces in the experimentation they performed are explicit, whereas in automated planning the search space is implicit. This adds an additional complexity to the sampling process that must be dealt with in some way. Second, the heuristics for both the distance estimation and the local planners were designed individually for every particular problem and thus are not useful in the more general case of automated planning.
RRT-plan
Directly related to automated planning, the planner RRT-plan [9] was proposed as a stochastic planning algorithm inspired by RRTs. In this case, the EHC search phase of FF [23], a deterministic propositional planner, was used as the local planner. The building process of the RRT was similar to the one proposed for discrete search spaces; that is, to impose a limit on the number of nodes as ε and add the expanded node closest to the sampled state to the tree. In this case, though, the tree was built only from the initial state due to the difficulty of performing regression in automated planning.
The key aspects in this work are two: the computation of the distance necessary to find the nearest node to the sampled or the goal state, and sampling in an implicit search space. In RRTs one of the most critical points is the computation of the nearest node in every Expand step, which may become prohibitively expensive as the size of the tree grows with the search. The most frequently used distance estimations in automated planning are the heuristics based on the reachability analysis in the relaxed problem employed by forward search planners, like the
Regarding sampling, RRT-plan does not sample the search state uniformly. Instead, it chooses a subset of propositions
Whereas RRT-plan effectively addresses the problem of sampling states in implicit search spaces, this kind of sampling limits most of the advantages RRTs have to offer. By choosing subsets of the goal set instead of sampling more uniformly the search space, the RRT does not tend to expand towards unexplored regions. Thus, it loses the implicit balance between exploration and exploitation during search that characterizes them. In fact, by choosing this method, RRT-plan actually benefits from random guesses over the order of the goals instead of exploiting the characteristics of RRTs. As a side note, this could actually be seen as a method similar to the goal agenda [26], albeit with random selection of subsets and the possibility in this case to recover from wrong orderings.
Advantages of RRTs in automated planning
As mentioned in the Introduction, during the last years there has been a big improvement in performance in the area of propositional planning. The most representative approach among those that contributed to this improvement is the use of forward heuristic search algorithms along with reachability heuristics and other associated techniques. However, heuristic search planners suffer from several problems that detract from their performance. These problems are related mainly to the characteristics of the search space that most common planning domains have. Search spaces in automated planning tend to have big plateaus in terms of the h value. The high number of transpositions and the high branching factor that are characteristic of many domains aggravate this fact. Heuristic search planners that use best-first search algorithms are particularly affected by this, as they consider total orders when generating new nodes and are mostly unable to detect symmetries and transpositions during search. It has been shown that techniques that increase the greediness of the search algorithm, like helpful actions from FF and look-ahead states from YAHSP [40], tend to partially alleviate these problems. However, even though reachability heuristics have proved to be relatively reliable for the most part, in some cases they can also be quite misguided. This increased greediness can be disadvantageous at times.
Figure 4 shows a typical example of a best-first search algorithm getting stuck in an h plateau due to inaccuracies in the heuristic. In this example, the Euclidean distance used as heuristic ignores the obstacles. Because of this, the search advances forward until the obstacle is found. Hence, the search algorithm must explore the whole striped area before it can continue advancing towards the goal. This highlights the imbalance between exploitation and exploration these approaches have. This problem has been previously studied, and several methods that tried to minimize its negative impact on search have been proposed [30,38]. However, this imbalance still remains as one of the main shortcomings of best-first search algorithms. To partially address this issue, we consider expanding nodes towards randomly sampled states so a more diverse exploration of the search space is done. In this example, a bias that would make the search advance towards
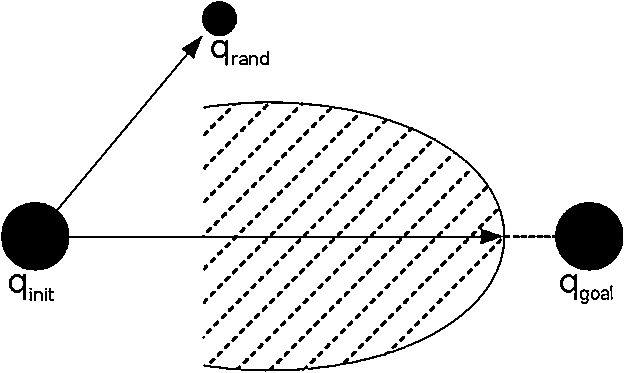
Simple example of a best-first search algorithm greedily exploring an h plateau due to the heuristic ignoring the obstacles. Advancing towards some randomly sampled state like
RRTs incrementally grow a tree towards both randomly sampled states and the goal. Therefore, they are less likely to suffer from the same problem as best-first search algorithms. The main advantages that they have over other algorithms in automated planning are the following:
They keep a better balance between exploration and exploitation during search.
Local searches minimize exploring plateaus, as the maximum size of the search is bounded.
They use considerably less memory, as only a relatively sparse tree must be kept in memory.
They can employ a broad range of techniques during local searches.
All in all, the alternation of random sampling and search towards the goal that single-query RRTs have is their most characterizing aspect. Thanks to this, they do not commit to a specific area of the search space and hence they tend to recover better than best-first search from falling into local minima. In terms of memory, the worst case is the same for best-first search algorithms and RRTs. However, RRTs must keep in memory only the tree and the nodes from the current local search. Trees are typically much sparser than the area explored by best-first algorithms, which makes them much more memory efficient on average. Memory is usually not a problem in satisficing planning because of the time needed for the heuristic computation, although in some instances it can be an important limiting factor.
Due to the differences in the search space, adapting RRTs from motion planning to automated planning is not trivial. In this work we propose an implementation partially based on RRTs for discrete search spaces and RRT-plan with some changes critical to their performance.
Sampling
The main reason why RRTs have not been considered for automated planning is the difficulty of properly sampling the search space. The difficulty arises from the fact that choosing propositions from S at random may lead to generating spurious states. Spurious states were initially defined as states that are not reachable from I [5], although other definitions exist [44]. In fact, there may be the case that a state reachable from I is unreachable from G in regression (such a state would be a dead end in progression), so a more general definition of spurious state is a state that cannot belong to any solution path of the problem. RRT-plan circumvented this by substituting uniform sampling with subsets of goal propositions. However, this negates some of the advantages that RRTs have, as explained before.
Checking whether a state is spurious or not is as hard as solving the problem itself [10], so an approximative approach must be used instead. Here we propose the use of state invariants as constraints to reduce the chances of obtaining a spurious state when uniformly sampling the search space. In particular, we propose the use of mutually exclusivity between propositions [5] (already employed by evolutionary planners like
Mutually exclusivity between propositions
First, we will define mutually exclusivity between propositions.
(Mutex).
A set of propositions
A common example of mutex is the location of an object in a transportation problem. For instance, in the Logistics domain, the propositions
The most common method to find mutexes is the
Another method for finding binary mutexes is the monotonicity analysis generally employed to generate a multi-valued formalization of the problem [22]. This monotonicity analysis ensures that the number of propositions true at the same time that belong to a set
In terms of efficiency, computing the monotonicity analysis is in most cases much more efficient that computing
Another advantage of
“exactly-1” invariant groups
Mutexes alone may not suffice to prune spurious states [1]. For instance, in the Floortile domain, cells can be either clear, painted or occupied by some robot. One can sample a state

Example of spurious sampled state in the Floortile domain. The second robot has no valid location, because all cells are either clear or occupied by another robot.
In order to avoid this, “exactly-1” invariant groups can be used.
An “exactly-1” invariant group is a set of propositions
By using “exactly-1” invariant groups one can infer an additional state invariant: if
Selecting propositions
Sampling a state using state invariants as constraints is analogous to solving a Constraint Satisfaction Problem (CSP). A CSP is formally defined as a triple
Solving a CSP is NP-complete. Actually, for some planning instances solving the CSP that represents the sampling process may be on average very time consuming if it is done naively. In our implementation we use forward checking [18] to improve the performance of the backtracking procedure needed for solving the CSP. The order of the variables (the order in which the “exactly-1” invariant groups are selected to be satisfied) is static, although it may vary between different sampling processes. “exactly-1” invariant groups with the highest cardinality are chosen first, with ties broken randomly every time a new state is sampled. Ordering of values of variables is chosen at random. This aims to reproduce the behavior of the degree (most constraining variable) heuristic [6] while trying to obtain sampled states as diverse as possible.
Ensuring the reachability of goals
Even after using state invariants, it may happen that the goal is not reachable from the sampled state. For example, a sampled state in the Sokoban domain may contain a configuration of blocks such that some block cannot be moved anymore. While this sampled state may not violate any state invariant, the sampled state is a dead end unless the unmovable blocks are at a goal location, since the original goal is not reachable. To address this problem, a regular reachability analysis can be done from the sampled state. If some proposition
Distance estimation
One of the most expensive steps in an RRT is finding the closest node to a sampled state. Besides, the usual distance estimation in automated planning, the heuristics derived from a reachability analysis, are also computationally costly. RRT-plan solved this by caching the cost of achieving a goal proposition from every node of the tree and using that information to compute
Tree construction
RRTs can be built in several ways. The combination of the Extend and Connect phases, the possibility of greedily advancing towards the goal with a probability
the tree is built from the initial state I only, as regression is overall not as efficient as progression in automated planning [1];
every node in the tree contains a state, a link to its parent, a plan that leads from its parent to the state, and the cached best supporters for every proposition
ε limits the number of expanded nodes in every local search (limiting the time is another possible stopping criterion, but we preferred to use the same implementation as RTT-plan);
there is a probability p of advancing towards a sampled state and a probability
a single node is added to the tree after every local search (instead of all the nodes along the solution path) to try to obtain a sparse yet representative enough tree;
when performing a local search, if a solution for the subproblem was not found, the last expanded node is added to the tree (be it when expanding towards a sampled state or the original goal G itself) to add to the tree the most promising node among those generated during the local search;
after adding a new node
No Connect phase is performed. This is because the Connect phase is probably counter-productive if it is done towards sampled states – sampled states may be completely irrelevant to the solution and the main benefit obtained from them is the additional bias towards exploration anyway – and partially overlaps with the expansions towards the goal with a probability
This configuration is the basis of the planner presented in this paper; we called this planner Randomly-exploring Planning Tree (RPT). Algorithm 2 describes the whole process.

Search process of RPT
The choice of the planner used in the local search is subject to some restrictions. First, after every Extend phase a new node to the tree is added even if a solution for the subproblem could not be found. This means that the local planner must be able to return an executable plan also when no solution was found, which rules out some planning paradigms like partial-order planners [43] and SAT-based planners [37]. Second, the tree is built forward, so the local planner must return a forward-executable plan. Again, backward search planners like HSPr [5] and FDr [1] cannot be used for this reason. Another important point is the preprocessing time. Since multiple local searches may be done, it is desirable that the time spent by the local planner prior to search is as short as possible. For example, the use of heuristics that require a relatively long preprocessing time and depend on either the initial state or the goals, like Pattern Databases [14], are discouraged.
In this work, the Fast Downward planning system [21] was used as the local planner. It was configured to use greedy best-first search with lazy evaluation as its search algorithm. The heuristic is the FF heuristic [23]. Preferred operators obtained from the FF heuristic were enabled.
Experimentation
In this section, we test the proposed approach against other state-of-the-art planners. The maximum available memory was set to 6 GB and the time limit was 1800 seconds, as in the last International Planning Competition (IPC-2011). The selected domains were all the domains from the deterministic track of the past IPCs. In the cases in which a domain appeared in more than one competition, we selected the instances from the hardest set. The criteria are the same as the ones used by Rintanen [37]. Additionally, we used the test problems from the learning track of the 2008 and 2011 IPCs for those domains that were not used in the deterministic track. The exception is the Sokoban domain; the definition of the domain and the structure of the problems are significantly different from the ones of the deterministic track, so we employed both versions. We call the version from the learning track Sokoban-learning. In this section, we will focus on the number of problems solved (also known as coverage), so all actions will be treated as if they had unit cost.
RPT was implemented on top of Fast Downward [21]. Since RRTs are stochastic algorithms, the experiments are repeated five times and the arithmetic mean and standard deviation are reported. The computation of
The planners we compare against are the local planner itself described in Section 5.4, that we call FD, and the first phase of the LAMA planner [36], the winner of the IPCs held in 2008 and 2011. We used the last revision from Fast Downward’s public repository for both planners.1
As of December 2013, revision 3288.
There are two critical parameters that affect the behavior of RPT in our implementation: the limit on the number of expanded nodes in the local search ε and the probability p of expanding towards a sampled state instead of towards the original goal G. In the experimentation we tried six different combinations resulting from combinations of ε and p. The values used for ε were
Additionally and for the sake of completeness, we compare the aforementioned configurations of RPT against a configuration with an artificially low ε of
Comparison between FD, LAMA and the different configurations of RPT
Comparison between FD, LAMA and the different configurations of RPT
Notes: Numbers in parentheses represent the total number of problems in the domain. Mean and standard deviation over 5 runs reported.
A more detailed comparison on a per domain basis shows that performance depends in a significant number of cases on the domain. For instance, RPT is notably better in Airport, Floortile, Sokoban-learning and Storage, whereas FD and LAMA are better in Barman and N-puzzle. The domains in which RPT performs better are often those in which there are dead ends undetectable by reachability heuristics, which cause FD and LAMA to explore big sterile plateaus. Note that Floortile, Sokoban-learning and Storage have a similar structure, as achieving the closest goal proposition first often leads to a dead end; in this case the additional exploration induced by the sampling method and the limit on the number of expanded nodes by the local search ε prove to be very beneficial.
Some domains in which RPT is outperformed by LAMA are domains in which state invariants do not suffice to avoid spurious states. Barman is the most notable example, because the current definition allows some unintended things to happen (such as a glass containing a drink and being clean at the same time), which reduces the number of mutexes found by invariant computation methods. Another very relevant case is Visitall, in which FD is able to solve only 3 problems, LAMA solves the whole set of problems and RPT is somewhere in the middle. The difference between FD and LAMA is explained by the heuristics they use: Visitall is a domain designed to induce plateaus when the FF heuristic is used, but it is otherwise easily solved with heuristics that employ additive schemes such as the goal-counting and the landmark-counting heuristics. However, this does not explain why RPT behaves like it does. An important fact is that sampling in Visitall is very problematic, as it is possible to sample a state in which a visited cell can be surrounded by not-visited cells, which is unreachable from I. However, RPT still solves more problems than FD, which shows that the possibility of recovering from exploring plateaus that RPT has compensates the added difficulty of sampling the search space adequately.
In a few domains RPT is also significantly helped by pruning spurious actions. Floortile, Matching-bw and Tidybot are such domains. In a modified version of FD that performs the same preprocessing as RPT, pruning spurious actions reduces the difference in coverage in these domains by a large margin even if state invariants are not exploited explicitly by FD during search.
In this work we experiment with the two parameters of RPT ε and p to analyze their impact. Higher values of ε mean that the local searches are larger, whereas p determines the balance between exploration and exploitation. Prior to the experimentation we expected to have very different results depending on the parameters of RPT; however, Table 1 shows that in reality the differences are not that big. Although different configurations of RPT have different coverage, their overall behavior compared to FD and LAMA is consistent. Also, there is no overall winner configuration, with different values of ε and p being more appropriate in some domains than in others.
The exception to this phenomenon is the Barman domain. As mentioned before, sampling in this domain is more complicated due to the frequent generation of spurious states. Because of this, larger values of ε and smaller values of p are preferable, since they reduce the sampling tendency of RPT and allow reproducing a behavior closer to FDs and LAMAs.
The lower coverage of the configuration with
Tree size
Number of tree edges that the solution with the highest number of tree edges in that domain has
Number of tree edges that the solution with the highest number of tree edges in that domain has
As expected, the size of the tree appears to be inversely proportional to ε. The version with
Another relevant fact is that many problems are solved with a single extension even with
As described in Section 5.1.3, sampling a state in an implicit search space requires solving a CSP. This CSP tends to be very small and the time spent solving it is on average negligible. Some exceptional cases occur though, when sampling a state takes a considerable amount of time. In the first run, in two problems of Airport, two problems of Tidybot and in the whole set of Barman problems sampling requires more than one second. In particular, for the first four cases it requires 699.55 s (problem 46 of Airport), 21.88 s (problem 47 of Airport), 152.53 s (problem 19 of Tidybot) and 301.75 s (problem 20 of Tidybot). In the Barman domain times range from 0.8 s to not being able to sample a state under the time limit of 1800 seconds. However, in all these cases the problem is not the time required to solve the CSP, but rather that G is unreachable from the sampled states – which is detected by the reachability analysis from the sampled state. For example, in problem 46 of Airport more than 18,000 states had to be sampled before a state from which G could be reached was found, which explains the long time spent sampling.
To ascertain that the heuristics proposed to solve the CSP are indeed necessary, we did some informal experimentation without them. After disabling forward checking and using a random ordering of the “exactly-1” invariant groups, in some domains solving the CSP was just not possible. For example, in many instances of Sokoban the backtracking algorithm was not able to sample a random state under the time limit of 1800 seconds. Such cases tend to occur in domains in which there are “exactly-1” invariant groups highly constrained by mutexes and other “exactly-1” invariant groups.
Finally, the relatively worse performance of the goals configuration, which implements RRT-plan’s sampling method, shows that random trees benefit more from random sampling than from choosing subsets of goals, even if the latter overcomes most problems derived from sampling in implicit search spaces. Again, there are exceptions to this, which means that RPT may benefit from switching from one method to the other randomly or when sampling by solving a CSP is not feasible.
Other measurements
Although memory is usually not a bottleneck in satisficing planning, it is interesting to test whether the claims about the efficiency in terms of memory of RPT are true. In the experimentation we measured the memory necessary to store the tree and the auxiliary structures that allow a faster computation of the heuristic from the nodes of the tree. In all the problems, the amount of memory is smaller than the memory necessary to ground the problem and to compute
Regarding quality, the plans returned by RPT were consistently longer than the ones returned by FD and LAMA whenever more than one edge was needed to trace back the solution in RPT. Such is the case in both versions of Sokoban, in Visitall and in N-puzzle. For example, and using the quality score from the last IPC, RPT_10k_0.5’s quality score in the first run is 8 points lower than FD’s in Sokoban and very similar in Sokoban-learning despite it being able to solve 6 problems more in the latter domain. This was to be expected though, as the added exploration and the uniform sampling often cause RPT to take detours on its way to a goal state. The same case was observed with time. Besides, the preprocessing made by RPT can in some cases be longer than the time spent by FD and LAMA during search, which further skews the time score in favor of the latter.
Related work
Stochastic search has also been employed by other planners. A prominent example is LPG [17], a planner inspired by random walk search algorithms. LPG searches in the space of plans employing a structure known as the action graph, choosing neighbor graphs based on a parametrized heuristic function. The main relation between LPG and RPT is that LPG tries to balance exploration and exploitation by performing random restarts. These restarts help LPG to avoid exploring plateaus and local minima.
Random exploration has also been proposed in the context of forward-chaining planning. This includes the use of Monte Carlo Random Walks to select a promising action sequence [34], local search combined with random walks [42] and the triggering of random walks when the planner detects that it has fallen into a heuristic plateau [31,41].
Lastly, inspired by real-time versions of RRTs [8], an RRT-like algorithm that stochastically interleaves search and plan reuse [39] has been proposed in [7]. In this case, the increased exploration comes from employing information from past plans instead of from sampled states. This includes reusing both plans and goals from previous searches.
Conclusions and future work
In this paper, we have analyzed how to adapt RRTs for their use in automated planning. Previous work has been studied and the challenges that the implementation of RRTs in contexts other than motion planning posed have been presented. In the experimentation we have shown that this approach has much potential, being able to outperform the state of the art. Besides, we have identified the major flaws of this approach, which may allow to obtain better results in the future.
The main challenge of the use of RRTs in automated planning, the design of an algorithm able to sample an implicit search space randomly, has been thoroughly studied. This novel problem has been tackled by exploiting state invariants of the problem extensively and formulating it as a CSP. The results show that, in domains in which current methods can find most relevant invariants, sampling is both efficient and useful.
Another of the drawbacks of RRTs, the estimation of the closest node, has also been analyzed. In this case we have generalized the cost-caching scheme previously proposed by the authors of RRT-plan. Here we employ a more general definition of caching of reachability heuristics, inspired by recent work on regression in automated planning.
We have also examined the characteristics of the local planners that can be used along with RPT. We identified their requirements and defined the limit ε of the local search in terms of state-space planning.
In the experimental evaluation we have run tests over a broad set of benchmarks. We focused on both overall and per domain coverage, with an special emphasis on the defining features of the domains that may affect the performance of RPT in comparison with other state-of-the-art planners. Other measures have been presented, including some specific to RRT-like algorithms like tree size and sampling performance.
After this analysis, several lines of research remain open. First, some approaches like growing two trees at the same time in a bidirectional manner and the implementation of a proper Connect phase are still unexplored. Additionally, given how the time to compute reachability heuristics per node varies greatly depending on the problem in automated planning, using a time limit as ε may be an interesting approach. Besides, an anytime version of RPT that gradually covers the search space improving the quality of the best solution found so far may prove useful for setting in which both coverage and quality matters, as in the IPC.
In terms of sampling, several improvements are left as future work. First, using landmarks [24] to bias the sampling process could yield more representative sampled states, allowing a faster convergence towards a solution. This in fact could be seen as an intermediate step between sampling subsets of goals and our sampling method, as goals are landmarks themselves. Another interesting possibility is biasing how propositions are chosen using the distance to I and to G in a delete-free formulation of the problem, or learning on the fly which sampled propositions could not be easily reached in previous iterations of the tree construction.
From a planning perspective, techniques like caching the heuristic value of explored states to avoid recomputation when they are expanded several times [35] may prove interesting for this kind of algorithms. Another interesting possibility is the usage of portfolios of search algorithms or portfolios of heuristics combined with RRTs in order to compensate the flaws of both best-first search algorithms and RRTs.
As a last remark, another possible future line of research includes adapting this algorithm for a dynamic setting in which interleaving of planning and execution is necessary. This approach looks promising for domains in which exogenous events and partial information may force the planner to replan in numerous occasions.
Footnotes
Acknowledgements
This work has been partially supported by a FPI grant from the Spanish government associated to the MICINN project TIN2008-06701-C03-03, and it has also been supported by the project TIN2011-27652-C03-02.
The fourth author was partially funded by the Office of Naval Research under grant number N00014-09-1-1031. The views and conclusions contained in this document are those of the authors only.