
Abstract
This article introduces a new methodology dedicated to classify the evolutions of urban blocks extracted from spatio-temporal topographic databases where an urban block is defined as the smallest area that is surrounded by communication network (roads, railways, …). To achieve that, an ascendant hierarchical clustering is applied to sequences of urban block states (i.e., sequences of class labels to which the block belongs to at each date). The principal originality of this approach is to use a distance measure based on DTW (Dynamic Time Warping) which is able to apprehend temporal behaviors (mainly time lags in dates corresponding to a change of state) and which takes into account the semantic proximity between the different kinds of urban blocks. Several experiments have been carried out on areas in the city of Strasbourg (France). First results are relevant and highlight realistic urban dynamics.
Introduction
Analysis of changes in urban and suburban areas over time allows estimating the nature of underlying natural and anthropic processes and to anticipate possible implications in terms of management of natural resources and territories (landscape). Urban sprawl is a universal, although unevenly distributed phenomenon. Its terms are different depending on the area and the period considered. The analysis of the distribution of urban areas at the European level shows that urbanization is taking place intensively in some areas, even though population may decrease or increase slowly. Monitoring urban sprawl and its consequences remains a major challenge for urban planning and management [9,10,12].
Urban fabric characterization is very useful in planning, modeling and simulation and it is an important precondition to better understand the urbanisation process of cities [19]. Nowadays, the availability of historical cartographic databases enables digital change monitoring and analysis of urban fabric characteristics thus replacing visual inspection and interpretation of city plans and maps. These vector databases are analyzed in order to improve the knowledge on specific objects such as buildings and to identify evolution characteristics at different meso-geographical levels (e.g., city or urban block). Some urban studies coming from urban geography research have focused on urban fabric characterization often based on morphometric indicators [3,7,8,19,24]. Few of them are focused on the analysis of their evolutions.
A process to analyse urban block evolutions could consist in classifying automatically urban blocks at each time point according to a predefined classification and then in learning evolutions from these monodate classifications. Unfortunately, from our knowledge, there is not taxonomy of urban block evolution classes which can be used to define the classes which can be considered and to define associated reference data (e.g., ground truth, training samples). As one cannot assume that such reference data are going to be available, methods that are able to process such evolutions in an unsupervised way are needed.
In this context, this paper focuses on the clustering of urban block evolutions extracted from topographic database. The extraction of relevant clusters aims to help the expert in three parts: firstly, for inducing a semantic meaning for them according to his/her expertise domain; secondly for studying each kind of evolution according to characteristics of urban blocks involved in the evolution and, thirdly for identifying representative evolutions (for example, evolutions near to the centres and/or the borders of the clusters) which can be used in supervised algorithm.
Section 2 introduces a global process for clusterize the urban block evolutions based on the use of DTW (Dynamic Time Warping). Section 3 presents the topographic database used and the way to construct the urban block state sequences while Section 4 introduces an adaptation of the DTW to symbolic data and details the similarity matrix used to define the similarities between the different states (i.e., classes) of urban blocks. Experiments carried out on several databases are presented in Section 5. Section 6 concludes this paper and proposes further work.
A global process to clusterize urban block evolutions
Clustering is a well-known family of methods which are able to process in an unsupervised way. This family is made up of well-known algorithms like the
In the case of numerical values, the values can be used to evaluate the similarity between the objects to compare.
This paper introduces a global process for clusterize the urban block evolutions based on the use of DTW (Dynamic Time Warping) to address the first three issues and on a linearization of the evolutions into urban block state sequences to address the fourth one. The proposed global process consists in four steps (Fig. 1):

Overview of the proposed process.
The area is selectionned by the expert from existing spatio-temporal topographic vector databases, one by year (cf. Section 3). Then, for each date, the urban blocks are built using communication network and are characterized by morphological attributes, by the spatial distribution of buildings and by the open space within a block (cf. Section 3.1).
All the urban blocks are classified using classification model given by the expert (cf. Section 3.1).
A graph of urban block evolution is built. That consists in linking urban blocks from two successive dates which overlap. Then this graph is linearized: a new sequence is built for each path from a block in the first date to a block in the last date. (cf. Section 3.3).
All these sequences are clusterized using DTW (cf. Section 4.3) based on a similarity matrix (cf. Section 4.6) and the Ascendant Hierarchical Clustering Algorithm (cf. Section 4.7).
Note that this global process is implanted in the

The FoDoMuST plateform with three interfaces (
Spatio-temporal topographic vector database
In this study, the geographic objects contained within the topographic databases (BDTOPO®IGN) produced by the French National Institute of Geography (IGN) are used as benchmark data. A such topographic database is, for a given date, a vector 3D description (structured objects) elements of the territory and its infrastructure, at meter accuracy, exploitable at scales ranging from 1:5000 to 1:50,000. Historic databases are then created for four test areas with the following six different dates: 1956, 1966, 1976, 1989, 2002 and 2008. These four zones are chosen because they have been subject to a variety of typical urbanisation processes. For example, the area presented in this paper (Fig. 3(a), (b), (c)) corresponds to a typical expansion phenomenon called peri-urbanisation phenomenon. It is also subject to natural constraints (rise of ground water) in the centre. This area is localized in the North of Strasbourg3
GSP coordinates: ⟨longitude: 7.739455223462405 ; longitude: 48.61865888192552; altitude: 0⟩.
The proposed typology of urban blocks (Table 1) is compatible with existing land-cover/use nomenclature (e.g., Corine Land Cover). It is adapted to map the territory at the scale of 1:10,000.
For each date independently, the urban blocks are built automatically using communication objects (road, railways and hydrographic networks) available in the topographic database. For each date, the set of blocks totally covers the study area (without holes or overlap). All the urban blocks are then labelled automatically by a supervised classification process which was only based on the morphological attributes and, the spatial distribution of buildings and the open space within a block. All the details about the method used to label the urban blocks are given in [16,24].

Three maps corresponding to the studied area. (a) 1976. (b) 1976 (Classified). (c) 1989. (d) 1989 (Classified). (e) 2002. (f) 2002 (Classified).
Figure 4 gives an example of PMML4
The Predictive Model Markup Language (PMML) is an XML-based language to define statistical and data mining models. More information about PMML can be found at
The aim of the work presented in this paper is to classify evolutions of urban blocks i.e., to classify their sequences of states. Each of these states corresponds to the class to which the block belongs at the considered date (see Section 3.2).
However, several changes can appear over an area, like the building (resp. the removal) of a road. By assumption, roads/railways/… form the boundaries of urban blocks (as urban blocks are surrounded by communication ways) and therefore building (resp. the removal) of a road/railways/... can split (resp. merge) urban blocks.
For instance, in Fig. 5, where
In the sequel of the paper, as only the labels of class are taken into account in the classification process, the notation used to describe sequence is simplified into
Urban blocks classes
Urban blocks classes
When studying the evolution of urban areas over time, the core of the process generally consists of comparing data in order to estimate (dis)similarity. The distance provides an estimation of this similarity.
When the data is temporal, the choice of the distance is crucial since it completely defines the way of tackling the temporality of the data. This dissimilarity measure must exploit the temporal distortions and compare shifted or distorted evolution profiles. It must be able to deal with sequences whose time sampling is irregular.
In this paper, we define and propose to use such a similarity measure which is a mix between the Edit-distance (also known as Levenshtein distance) [17] and Dynamic Time Warping (DTW), based on the Edit-distance and introduced in [27,28].

An example of PMML file.

Graph of urban block evolutions (5 dates).
In order to present the similarity measure used in this work, let us first define these two measures. Throughout this section, let
Levenshtein distance
The Levenshtein or edit distance [17] formalises the notion of distance between two character strings, by focusing on transforming (or editing) one string into the other by a series of edit operations on individual characters. This distance requires a similarity matrix between letters to know which characters are close to each other and which are not. The permitted edit operations are the insertion, deletion and replacement of a character. The cost of the transformation from one string to another can be recursively computed by:
The overall similarity is given by
Dynamic time warping
Dynamic Time Warping (DTW) is based on the Levenshtein distance and was introduced in [27,28], with applications in speech recognition. It is probably the most commonly used measure to quantify the dissimilarity between numerical sequences [1,2,6,22,23,26,29]. It finds the optimal alignment (or coupling) between two sequences of numerical values, and captures flexible similarities by aligning the coordinates inside both sequences. The cost of the optimal alignment can be recursively computed by:
Figure 6(a) shows such optimal alignements of three sequences. From this figure, one can notice that:
A and B are less similar than B and C even if lengths of A and B are equal and that of C is smaller. The cost to align In the subsequence if DTW aligns two states of same class from two sequences
In other words, on the one hand, DTW can deal with sequences having different lengths and so deal with missing data. In our case, databases covered by our method (and used in our experiments) have normally not missing data. Reader interested by this aspect, can find an example dealing with such data in [22]. On the other hand, it gives a chronological view of the phenomena rather than a chronometrical one. In the case of urban evolution, this property is very interesting. For instance, densification of a urban block is often composed of different keysteps: individual houses demolition, vegetation clearance, removal of soil, building construction, development of green spaces, …which can correspond to the sequence of states: C3 > C9 > C5 > C2 (Table 1) regardless (1) the date of transformation starting and (2) duration of each state. Figure 6(a) shows two such sequences B and C. These two sequences represent the same urbanization process. For the DTW measure they are very similar while the Euclidean measure, where the missing states in sequence C are supposed identical to the last one in the sequence, gives a value equals to 8 (Fig. 6(b)).

Distance between three sequences calculated using DTW and Euclidean distance. (a) Using DTW. (b) Using Euclidean distance (the missing states in sequence C are supposed identical to the last one in the sequence).
However, a direct implementation of this recursive definition leads to an algorithm that has exponential cost in time. Fortunately, the fact that the overall problem exhibits overlapping sub-problems allows for the memorization of partial results in a matrix, which makes the minimal-weight coupling computation a process that costs
DTW is mostly used in order to align sequences of numerical values, with
In [4], studies are conducted to compare different (dis)similarity measures. In particular, elastic measures as DTW and edit-based measures are compared to classical L-norms and longest common subsequence. Based on their experiments, the authors conclude that the accuracy of elastic measures converges with that of Euclidean distance as the size of the training set increases. On small data sets, elastic measures can be significantly more accurate than Euclidean distance and other lock-step measures, e.g.,
The use of DTW as a similarity measure in clustering technique [23] is relatively classical now. For instance, [14] proposes a density-based clustering using DTW to analyse climate change. Reference [22] shows benefits to using such similarity measure in satellite image time series analysis. In [30], DTW is applied to extract and represent the dynamic mobility patterns in different urban areas. More recently, [11] proposes some alternatives to fuzzy clustering methods to time series analysis based on the DTW distance and on the fuzzy C-means algorithm. Reference [18] presents a time-weighted version of the dynamic time warping method for land-use and land-cover classification using remote sensing image time series. It modifies the DTW method to include a temporal weight that accounts for seasonality of land-cover types. As one can notice, the main uses of DTW are in remote sensing image analysis domain and more rarely for the analysis of topographic databases as in our case.
The proposed similarity measure
In this work, we propose to combine these two ways of computing a similarity measure between two sequences of characters. As the objective is to compare evolutions of urban fabrics over time, all the states of evolution are used. As such, an adaptation of the Levenshtein distance is used in which no skips are permitted and which is close to DTW. Furthermore, DTW was adapted to sequences of symbols (instead of numerical values) and as the Euclidean distance cannot be applied in this setting, the states were compared using as

Symbolic Dynamic Time Warping
A distance of 1 means that classes are close in terms of composition and that the probability to confuse them is very high. A high distance means that classes have no similarity. For example, the similarity between
In order to evaluate the quality of the matrix, we have calculated the Euclidean distance between all classes based on attributes on buildings of each block (size, shape, elongation, number of buildings per block, etc.). It appears that the proposed semantic distance is close to the Euclidean distance. Nevertheless, some validations are still necessary but we assume that this study is out of the scope of this paper.
Ascendant hierarchical clustering
A lot of clustering algorithms exist [13]. Partitioning algorithms generates flat partitions of the data, i.e., sets of clusters (or groups). The clusters can be disjoints (hard clustering), can be overlapped (soft clustering) or be defined using degrees of membership (fuzzy clustering). Hierarchical algorithms produce hierarchies of clusters and present a lot of intrinsic advantages:
They do not require a pre-defined number of clusters: the user can select the “right” number of cluster by pruning the hierarchy manually or using (semi-) automatic methods; They can work directly with a similarity matrix which can be pre-processed (offline). As they does not need the data themselves in the clustering process (inline), the memory requirements are reduced. It is also especially interesting in case of information are private or not accessible (medical data, banking data, …); They do not require averaging method to calculate centers of cluster (as in the well-known K-means algorithm).
For the user, a representation of such hierarchy by a dendrogram seems more natural than flat representation and, then, simplify the understanding of the results. Nevertheless, one of the main drawbacks lies in the choice of cutting the tree. Indeed, as introduced in [13], (1) clustering algorithms find clusters, even if there are no natural clusters in the data and (2) each algorithm, implicitly or explicitly, imposes a structure on the data: if the match is “good”, algorithm is successful. Thus, without any examples, ground truth, model or typology of urban block evolutions, it is very difficult to quantify quality of clustering. Only qualitative quality can be evaluated. The only way to do that, is then to use knowledge of the expert and his/her ability to cut the tree so that the clusters are meaningful to him/her.
The Ascendant Hierarchical Clustering (AHC) performs clustering in four steps:
Begin with groups containing only one basic instance (i.e., N groups of one sequence where N is the number of constructed sequences at the previous step).
Compute (or update) the similarity (or the distance) between every group pair in a triangular matrix
Merge the two closest groups5
If there are more than two groups, two are randomly chosen among them.
If there are more groups than desired (generally, one group), go to step 2.
This algorithm hierarchically builds clusters of sequences while minimizing their intra-group variance. The linkage criterion determines the similarity (or the distance) between two clusters
In the case of time series analysis using SDTW, it is defined by:
By construction, the obtained hierarchy is a binary tree of clusters. It is usually modeled as a simple binary tree or as a dendrogram. In the case of the simple tree, there is no information about the distance between the two children of a node while in a dendrogram, the length of a branch is related to this distance. In our case, even if we calculate (and present to the expert) the dendogram, these distances are not used to evaluate evolutions associated with each cluster. In fact, we do not report the numerical values on all the figures.

No equal sequences having a DTW value equals zero and the associated average sequence.
Remark: DTW is not a distance because
But, we have never encounter in our experiences cases where DTW fails to build such a hierarchy. Nevertheless, this theoretical aspect should be studied but that it is out of the scope of this paper.
Thus, although in general leaves contain only one sequence, we decide to group, in a preprocessing step, all the sequences having a DTW value equals to zero into a leaf. Then, each of these leaves is summarized by the average sequence, i.e., the unique sequence (1) having a DTW value equals zero with all the sequences belonging to the leaves and (2) presenting the minimal length. Figure 7 (in the bottom) shows a such average sequence. One can notice that this sequence only provides a chronology of the states through which the sequences are passed through (see Section 4.3). It does not present necessary the same length than the initial sequences.
Finally, the ascendant hierarchical clustering starts from theses leaves: on all the figures, we report only the average sequences as leaves.
For readability purpose, we index the two childrens of a node by
Figure 8 shows the top of the cluster hierarchy obtained on our dataset with the ratio of objects in each cluster.

The top of the cluster hierarchy. The value associated with a branch corresponds of the percentage of sequences in the subclass.
To assess the relevance of our method for the analysis (i.e., the identification) of the principal blocks evolutions, several experiments have been carried out on an area in the city of Strasbourg (France) representing a surface of around 15 km2. Figure 3 shows three dates out the five ones. The number of urban blocks increases from less than 50 in 1956, to 74 in 1976, 105 en 1989, 130 in 2002 and finally around 140 in 2008.
The experiments consisted of applying the Ascendant Hierarchical Clustering algorithm on the urban block sequences using the proposed SDTW and the similarity matrix described in Table 2. The obtained hierarchy is pruned by an expert (see Section 4.7) according to the thematic evolution classes he/she looks for. Figure 8 depicts the top of the obtained hierarchy while Fig. 9(a) and (b) focuse on the two sub-clusters from
Dissimilarity matrix between urban block classes
Dissimilarity matrix between urban block classes
Figure 10 (resp. Fig. 11) illustrates the maps corresponding to the cluster
Note that the colours have been randomly chosen and thus do not represent semantics information.
Moreover, the first (resp. second) child is coloured in dark (resp. in light). For instance, in Fig. 10, sub-cluster
In the same way, Fig. 12 illustrates the map corresponding to the cluster

Decomposition of the cluster

Maps corresponding to the cluster
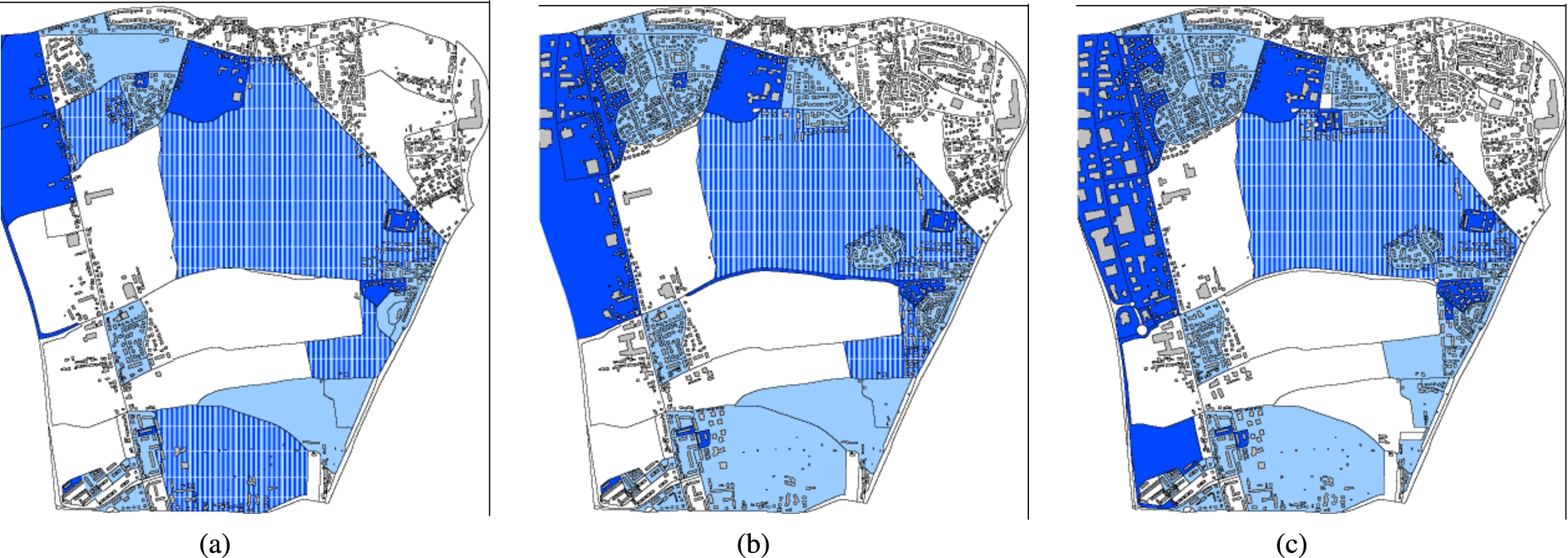
Maps corresponding to the cluster

Maps corresponding to the cluster
Several distinctive evolutions can be extracted from the clustering of urban blocks evolutions. Thus, cluster In Fig. 10(a)–(c) the evolution corresponds to the transformation of “low density mixing/urban fabric and area” ( In Fig. 11(a)–(b), the evolution corresponds to the transformation of areas with no or few buildings ( In Fig. 12 one can see blocks with low evolution, mainly roads and non-buildable areas shaded with green. The big block on the left appears in green in 1986 because it is the “father” of the small block corresponding to the roads on the left (2002 and 2008). The hatched dark and light blue block in the South (Fig. 11(a)) has been split between 1976 and 1989 into a block belonging to In these figures, one can see a very small urban block (localized at the far north, in the middle of the area). This block belongs to
According to theses observations, it is assumed that two-thirds of the
This article has presented a new methodology dedicated to extracting the evolution of urban blocks from spatio-temporal topographic databases. The principal originality of this approach is to use a distance measure (SDTW) which is able to apprehend temporal behaviours (mainly time lags in dates corresponding to a change of state) and which takes into account the semantic proximity between the different kinds of urban blocks. To validate this approach, an ascendant hierarchical clustering has been applied to sequences of block states (i.e., class labels) using SDTW. The class labels associated to the blocks on each date have been pre-calculated by applying a supervised algorithm to the database corresponding to the specific date. The results of the experiment have been studied by an expert and seem to correspond to the reality. This validates the relevance of the proposed methodology. Nevertheless, some additional experiments should be conducted to precisely quantify and identify the evolution patterns of one or more periods.
This work opens up several perspectives and different research directions. From a methodological point of view, we plan to study more formally (1) the definition of the blocks and of the sequences and (2) the quality of blocks and sequences built in order to evaluate their influences on the results. We also plan to compare this approach with K-means-based methods and to use the DTW Barycentric Averaging (DBA) [23] to do that.
Furthermore, it could be relevant to integrate an approach that enables the user to build the similarity matrix. Indeed, by asking the user for different constraint examples between the data (e.g., must-link or cannot-link constraints), semi-supervised clustering approaches could be used to learn/estimate the different values of the matrix.
From an applicative point of view, this methodology could be used for supervised classification (using the K-Nearest Neighbour algorithm for example). Although to define examples seems a difficult and time-consuming task that would require better theoretical definitions of the types of evolution.
Footnotes
Acknowledgements
The authors would like to thank the French National Research Agency (ANR) for having supported the GeOpensim (ANR-08-RAN52-Geopensim) and COCLICO (ANR-12-MN001-COCLICO) projects.