
Abstract
Time is pervasive of the human way of approaching reality, so that it has been widely studied in many research areas, including AI and relational Temporal Databases (TDB). While temporally imprecise information has been widely studied by the AI community, only few approaches have faced temporal indeterminacy (in particular, “don’t know exactly when” indeterminacy) in TDBs. Indeed, as we will show in this paper, the treatment of time in general, and of temporal indeterminacy in particular, involves the introduction of implicit forms of data representation in TDBs. As a consequence, we propose a new AI-style methodology to cope with temporal indeterminacy in TDBs. Specifically, we show that typical AI notions and techniques, such as making explicit the semantics of the representation formalism, and adopting symbolic manipulation techniques based on such a semantics, can be fruitfully exploited in the development of a “principled” treatment of indeterminate time in relational databases.
Introduction
Time is pervasive of reality, and plays a fundamental role in many intelligent tasks, so that it has been widely investigated by the AI community, which, from its early years, has developed many different methodologies for temporal representation and temporal reasoning. Starting from the middle 80’s, also the scientific DB community has started to recognize that time has a special status with respect to the other data, so that its treatment within a relational database context requires dedicated techniques [20,21]. Such a consideration has led to the development of many different approaches to cope with time in the area of temporal relational databases (TDB in the following; see, e.g., [16,27]). Just as an example, the 1998 cumulative bibliography about TDBs refers more than 2000 papers [27]. Such approaches pointed out a quite wide range of solutions, proposing, e.g., different data models, and algebraic operations to query them. However, TDB approaches have developed quite completely in an independent way with respect to AI methodologies. This is probably due to the fact that, to the best of our knowledge, no TDB approach has explicitly taken into account the fact that, while adding time to a relational DB, one adds We formally define and extend the snapshot semantics for temporal data [20] to cope also with temporal indeterminacy, We propose a 1-Normal-Form We analyse the We face the task of defining the relational algebraic operators (which perform
Result (iv) enforces the core message of our approach: in TDBs, the representational model contains implicit (temporal) information. Thus, AI techniques could/should be used to analyse its semantics, and to devise algebraic operators that perform symbolic manipulation on the representational model, consistently with the devised semantics. In other words, in this paper we propose the first (to the best of our knowledge) AI approach in which an AI methodology is developed to be applied to the relational DB context, to cope with time and temporal indeterminacy.
The paper is organized as follows. In Section 2, we briefly overview the related work, focusing on the TDB approaches to temporal indeterminacy. In Section 3, we informally introduce our AI-style methodology to cope with temporal indeterminacy in TDBs, motivating it. In Section 4, we start with the technical contributions, proposing a “functional” (data and query) semantics for determinate time in TDB. In Section 5, we extend such a semantics to cover temporal indeterminacy. In Section 6, we propose a compact representation (in First Normal Form – 1NF for short) for an important class of temporally indeterminate data, and define temporal algebraic operators to query it, consistently with the semantics of the representation. In Section 7, we provide experimental results, showing that our treatment of temporal indeterminacy only adds a negligible overhead to the “standard” TSQL2 treatment of determinate temporal data. Finally, Section 8 contains conclusions and future work. The Appendix briefly presents the “consensus” BCDM semantics for determinate time, elaborated by the TDB community [15].
TDB approaches to valid time temporal indeterminacy
Many different approaches have been devoted to the treatment of time in TDBs. One of the first milestones was the distinction between the time when facts are inserted/deleted into/from the DB (termed transaction time), and the time when such facts occurred in the modelled mini-world (termed valid time) (consider, e.g., [22]). In the following, we only consider the latter. Despite their variety, until now most TDB approaches have focused on individual occurrences of facts, whose valid time is exactly known (i.e., with determinate time). However, as well known in the AI field, in many real-world cases the exact time of occurrence of facts is not known, and can only be approximated, so that temporal indeterminacy (i.e., “don’t know exactly when” indeterminacy [10]) has to be faced. Temporal indeterminacy is so important that “support for temporal indeterminacy” was already one of the eight explicit goals of the data types in TSQL2 [20], the milestone “consensus” approach devised by the TDB community. In effect, temporal indeterminacy in TDBs has various possible sources, including scale, dating techniques, future planning, unknown or imprecise event times, clock measurements (this list is not exhaustive, and is taken from TSQL2 book [20]). Due to the fact that temporal indeterminacy is pervasive in many application domains, since the 80’s AI a plethora of approaches has been devised to cope with it (just to mention few examples, consider the early surveys in [1,13,26]). However, in the area of relational databases, the number of approaches coping with temporal indeterminacy is more restricted (see e.g. the surveys in [10,15]) and current approaches have several limitations.
In the earliest TDB work on temporal indeterminacy, an indeterminate instant was modeled with a set of possible chronons [19]. Dutta [9] introduced a fuzzy set approach. Gadia et al. [14] proposed a model to support value and temporal incompleteness. In the TSQL2 “consensus” book [20], Chapter 18 presents a 1NF data model for temporal indeterminacy and an extension of SQL, while it does not provide a relational algebra. Dyreson and Snodgrass [11] and Dekhtyar et al. [7] have proposed probabilistic approaches coping with different forms of temporal indeterminacy. Dyreson and Snodgrass cope with valid-time indeterminacy by associating a period of indeterminacy with a tuple. A period of indeterminacy is a period between two indeterminate instants, each one consisting of a range of granules and of a probability distribution over it. However, in such an approach, no relational algebra is proposed to query temporally indeterminate data. Dekhtyar et al. introduce temporal probabilistic tuples to cope with a quite specific for of temporal indeterminacy, concerning instantaneous events only (i.e., with data such as “the tuple d is in relation r at some point of time in the interval
Towards an AI-style semantic-based methodology to cope with time in relational DBs
A premise is important, when starting a discussion about the semantics of temporal relational DBs. Indeed, seen from an AI perspective, a “traditional” non-temporal relational database is just an elicitation of all and only (given the closed-world assumption [18]) the facts that are true in the modeled mini-world. In such a sense, the semantics of a non-temporal DB is “trivial”, since the DB do not contain any implicit data/information. Since all the data are explicit, no “AI-style” reasoning mechanism is required, and (algebraic) query operators are enough to extract the relevant data from a DB. However, such an “easy” scenario drastically changes when time is introduced into DBs, by associating with each fact its valid time, i.e., the time when it holds/occurs. Roughly speaking, in such a case, eliciting explicitly all true facts would correspond
Of course, for space and time efficiency reasons, no TDB approach in the literature directly implements temporal databases making all data explicit: representational models are used to encode facts in a more compact and efficient form. Notably, this is a major departure from “traditional” DB concepts: a TDBs is not just an elicitation of all facts that holds in the modelled mini-world, but a a semantics for making explicit the intended meaning of the representational models must be devised. algebraic operators must operate on the (implicit) representation algebraic operators must provide an output expressed in the given representation (i.e., the representation formalism must be closed with respect to the algebraic operators)
algebraic operators must be correct with respect to the semantics of the representation
In such a context, the algebraic query operators cannot simply select and extract data (since some data are implicit). Making all data explicit before/while answering queries is certainly not a good option (for the sake of space and time efficiency of the approach). As a consequence,
In the following, we make the above discussion more concrete and formal. We start from the definition of a semantics for determinate time, and then we extend it to consider temporal indeterminacy.
Snapshot semantics for determinate time DBs: A “functional” perspective
In BCDM [20], a semantics for being extended to cope with temporal indeterminacy and specifying the semantics of temporal algebraic operators in terms of their non-temporal counterparts.
Data semantics
We first introduce the notion of tuple, relation, and database. We then move to the definition of time, and define the notion of (semantics of) a temporal database.
((non-temporal) Database, Relation, Tuple).
A (non-temporal) relational database
As in many TDB approaches, including TSQL2 [20], and in the BCDM “consensus” semantics [15], we assume that time is discrete and bounded.
(Temporal domain
).
We assume a limited precision for time, and call chronon (as in TSQL2 [20]) the basic time unit. The domain of chronons is totally ordered and isomorphic to a subset of the domain of natural numbers. The domain of valid times
In the (commonly agreed) snapshot semantics, a temporal database is a set of conventional (non-temporal) databases, one for each chronon of time. In this paper, we propose to specify such a concept formally through the introduction of functions, relating each time to the facts holding/occurring at that time.
(Temporal database (semantic notion)).
Given a relational schema
Analogously a Given a temporal database As a simple running example, let us consider a simple database John had high fever from 10 to 12 of 1/1/2018 Mary had moderate fever from 11 to 13 of 1/1/2018 The temporal database (semantic notion) modeling such a state of affairs is the following (for the sake of clarity and simplicity, we omit the chronons in In this example
Notably, Definition 3 above is a purely “semantic” definition. Other definitions of the snapshot semantics for TDBs, such as the one in BCDM, are more “operational” and are closer to actual representations/implementations (see the Appendix). Indeed, our “functional” definition is similar to the “relation-stamped representation” of abstract temporal databases in the work by Chomicki and Toman [5]. (Time slice).
(in the example, we assume that chronons are at the granularity of hours, and hour 1 represent the first hour of 1/1/2018).
The semantic of queries is commonly expressed by specifying in terms of relational algebraic operators. Codd designated as complete any query language that was as expressive as his set of five relational algebraic operators: relational union (∪), relational difference (−), selection (
(Relational algebraic operators on temporal databases (“semantic” notion)).
Denoting by
In Definition 5 above, we assume that
Of course, the above “purely semantic” definition of temporal relational algebraic operators is highly inefficient, since snapshot(s) of the underlying relation(s) at every single chronon (e.g., day, millisecond) are computed. As a consequence, more “operational” definitions of algebraic operators have been proposed in the literature. Notably, however, the “commonly agreed” BCDM definition of the semantics of algebraic operators (see Appendix) is consistent with Definition 5 above.
Snapshot semantics for temporal indeterminacy in TDB
In TDBs, the notion of temporal indeterminacy is usually paraphrased as “don’t know exactly when” indeterminacy (consider, e.g., the Encyclopedia survey in [10]): facts hold at times that are not exactly known. An example is reported in the following: As a simple running example, let us consider a simple database John had high fever at 10 and 11, and possibly at 12, or 13, or both. Mary had moderate fever at 12 and 13, and possibly at 11
(in the example, we assume that chronons are at the granularity of hours, and hour 1 represents the first hour of 1/1/2018).
Of course, we can still retain the definition of the temporal domain
(Indeterminate temporal database (semantic notion)).
Given a relational schema
Analogously, a temporally indeterminate relation
(cont).
The indeterminate temporal database
For the technical treatment that follows, it is useful to introduce the notion of alternative slice.
(Scenario slice).
Given an indeterminate temporal database
For example, considering Example 2 above,
Query semantics
Of course, for the algebraic query operators, we can still retain all the general requirements discussed so far for determinate time. However, we have to generalize the above approach, to consider the fact that a set of alternative (determinate) temporal databases (scenarios) are involved. Therefore, given two temporally indeterminate relations
(Relational algebraic operators on indeterminate temporal databases (“semantic” notion)).
Denoting by
(In Definition 8,
Indeed, indeterminacy intrinsically involves alternative possibilities, so that the approach usually followed in the TDB area (as well as, of course, in AI) is the introduction of modalities, to ask for possible (i.e., valid in at least one of the possible scenarios) or necessary (i.e., valid in all the possible scenarios) answers (see, e.g., [4]). With the introduction of the modalities (POSS – for possible – and NEC – for necessary), the semantics of algebraic query operators in the indeterminate (temporal) context can be still be easily expressed in terms of their Codd’s non-temporal counterparts, as shown in Definition 9 below.
(Relational algebraic operators on indeterminate temporal databases (“semantic” notion)).
Denoting by
(In Definition 9 above,
Roughly speaking, the above definition dictates that, to preserve the snapshot semantics in the indeterminate context, the evaluation of a binary temporal operator
Applying the corresponding Codd’s operator at each chronon, and considering each combinations
In the NEC modality (at each chronon), the intersection among the results of such an application in the different scenarios is performed, to grant that the facts hold in all the scenarios. In the POSS modality (at each chronon), union is used, since we want to report as output (at the given chronon) all the facts that hold in at least one scenario.
Notably, we regard Definition 9 above as one of the major results of this paper: until now, no approach in the TDB community has been able to clarify the semantics of temporal algebraic operators on indeterminate time in terms of their Codd’s counterparts.
But, obviously, this is query data and query
Possible “compact” approaches to temporal indeterminacy
Very different realizations of temporal relational databases for determinate time have been proposed in the literature. Actually, all of them (except few “pioneering” approaches) respect the “snapshot” semantics, and provide an efficient implementation for it. The large majority of such approaches enforce at least two key requirements to achieve efficiency:
Temporal algebraic operators directly manipulate the representation
The most frequently adopted representational model to cope with (valid) time in a compact and 1NF way is the At the representation level, a temporally indeterminate relational database In the temporally indeterminate context, the relation SYM (called the fact represented by the tuple
In the following, we show that a “rough” semantics like (sem1) above is not enough: it must be fully formalized (e.g., in terms of the sematic model proposed in Section 5 above) as a starting point for devising a “proper” representational model and algebra, following the methodological requirements M1–M4 above.
A first way of interpreting the “ambiguous” semantics (sem1) above is the following:
the fact represented by the tuple
In such a semantics, all the scenarios includes the chronons
(Semantics sem1′).
The semantics of a tuple
This is, probably, the most intuitive notion of temporal indeterminacy in TDBs: each tuple represents Given the temporally indeterminate relation Notably, if we assume the semantics (sem1′), the fact (f1)
John had high fever at 10 and 11, and possibly at 12, or 13, or both
Algebraic operators for indeterminate time (independent chronons semantics). Of course, the specification of the semantics if fundamental also for the definition of the algebraic operators. In particular, we must grant that such operators
Are correct with respect to the semantics, and Are closed with respect to the representational model Notably, it is possible to show that it is not possible to define correct algebraic operators closed with respect to the representational model also in case one admits the possibility that facts in the TDBs do not necessarily occur, i.e., imposing
cannot be represented in the representational model: as a matter of fact, in the semantics (sem1′) the tuple 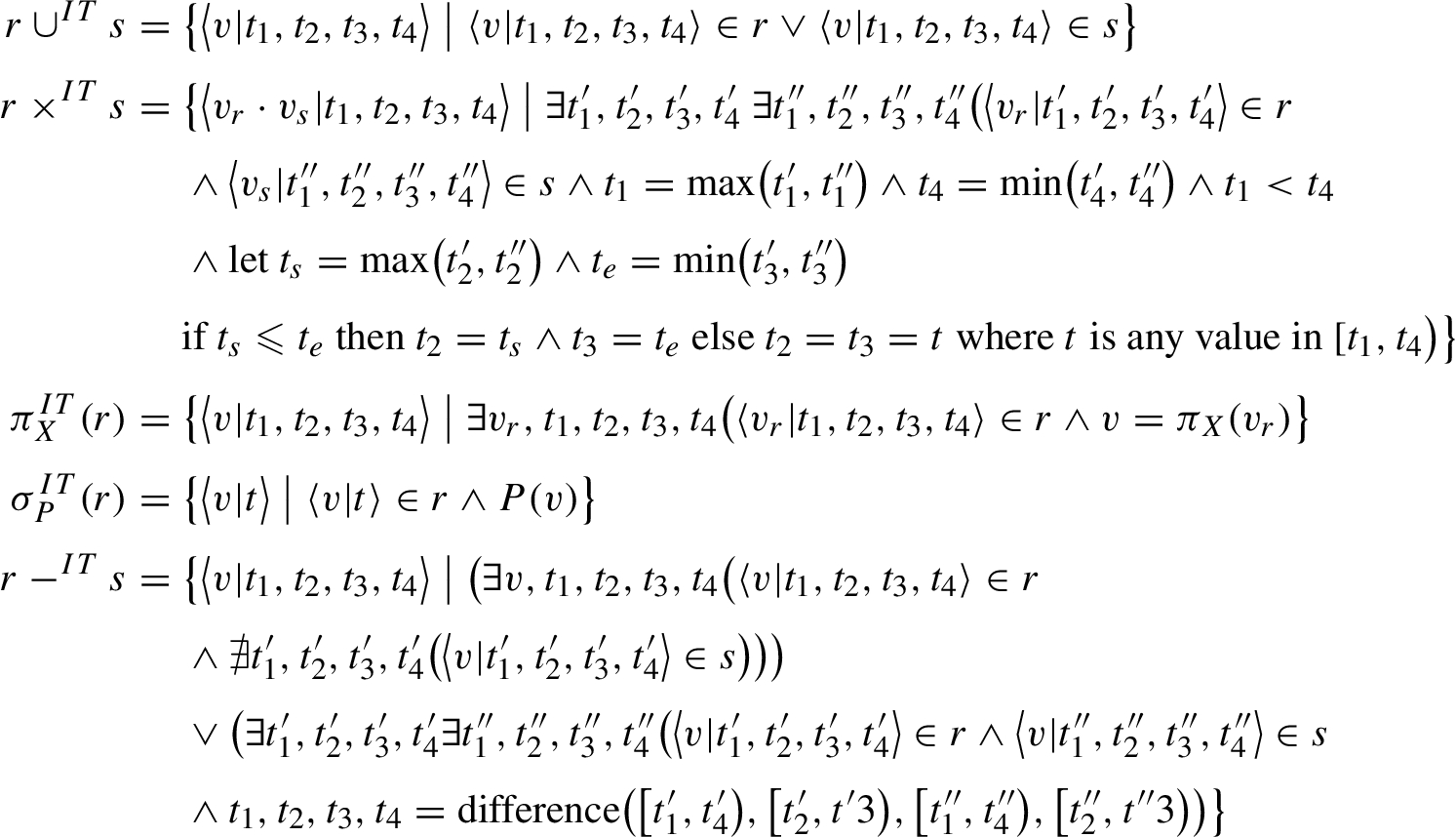
Notably, if we assume the semantics (sem1′) for the representational model in Definition 10, there is no way to satisfy both requirements (i) and (ii).2
Consider the difference between two relations
A different way of interpreting the “rough” semantics (sem1) above is the following:
the fact represented by the tuple
In such a semantics, each scenario includes the chronons
(Semantics sem1′′).
The semantics of a tuple
In such a semantics, there is no notion of single occurrence at all. One simply regards chronons independently of each other. In such a context, it looks natural to impose
Given the temporally indeterminate relation John had high fever at 10 and 11, and possibly at 12, or 13, or both
is represented in the representational model by the tuple
With such a semantics for the representational model, it is possible to define correct and closed algebraic operators as follows:
Let r and s denote relations of the proper sort and

The difference function accepts as parameters two time intervals for the minuend (
In such a context, the NEC and POSS operators can be defined as in Definition 14.
Let r denote an indeterminate time relation and
Roughly speaking, since the semantics of the representation is (sem1′′) above, the chronons in which a fact necessarily occurs/holds are the ones in
The algebraic operators in Definitions 13 and 14 are correct (with respect to the semantics defined so far) and are closed with respect to the representational model.
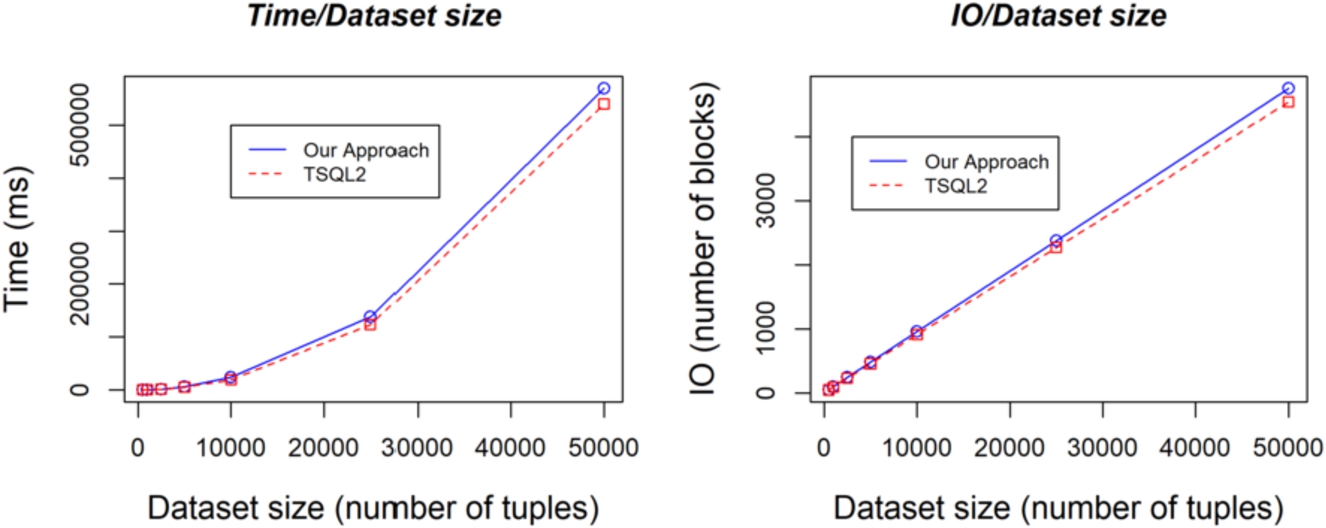
Cartesian product. Comparisons between our approach and TSQL2 as regards execution time (on the left) and I/O (on the right), considering datasets of different dimensions.
Let us consider, for example, the case of Cartesian Product. The closure of such an operation directly follows from its definition: the output is a set of tuples having as non-temporal values the concatenation of the non-temporal values being paired, and as temporal part a quadruple of values a tuple a tuple
(where
The proof in the other direction is similar, and is not reported for the sake of brevity. □
As discussed in Section 3, the treatment of temporal indeterminacy involves the management of implicit data in the treatment of query answering (algebraic operators), so that AI symbolic manipulation techniques can be used. Specifically, in Section 6.2, we have defined new algebraic operators for indeterminate time, and we have proven their correctness with respect to the underlying semantics. In this Section, we discuss some experimental evaluations, showing that, though significantly more expressive, our approach only adds a negligible overhead with respect to TSQL2, in which only determinate (i.e., exact) valid time is considered (notably, in TSQL2 book, Chapter 18, also temporal indeterminacy is considered; however, no extension of algebraic operators to cope with indeterminacy is proposed).
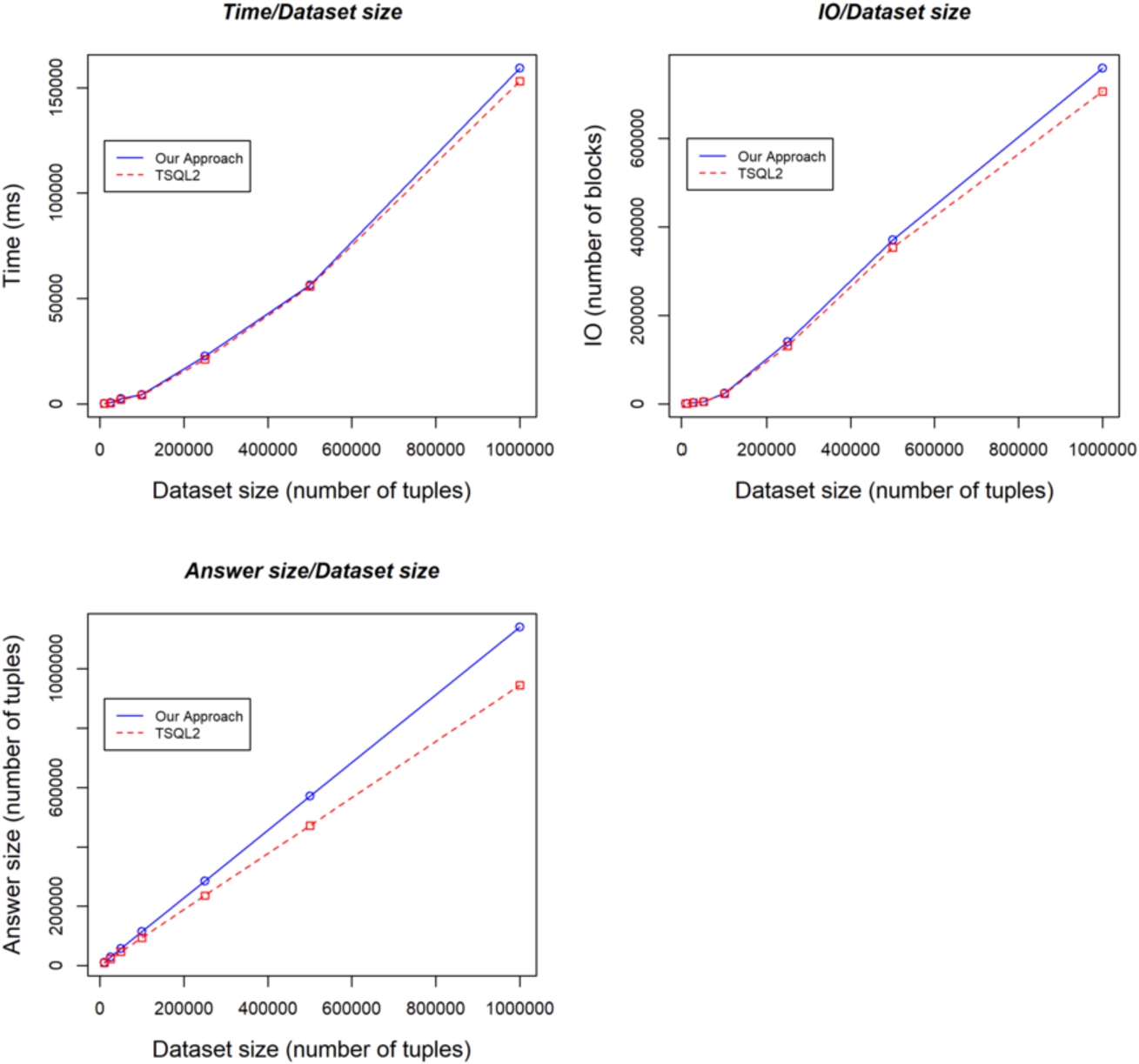
Difference. Comparisons between our approach and TSQL2 as regards execution time (top left figure), I/O (top right figure), and answer set (bottom left figure), considering datasets of different dimensions.
We have implemented the data model and algebra discussed in Section 6.2 and the TSQL2 model and algebra to cope with determinate time, using PL/pgSQL stored procedures and PostgreSQL. We have experimentally evaluated the performance of our temporal algebra. Experiments have been performed on an Intel Core i7-6700HQ CPU, 2.60 GHZ, 8 GB RAM, OS Windows 10, using PostgreSQL 10 DBMS with default settings (effective cache size 500 MB, 8 KB page size and 500 MB shared buffers).
We have generated datasets of different dimension, to test and compare the scalability of our approach, with respect to TSQL2. In particular, we have focused our experiments on the algebraic operators that manipulate the temporal attributes, i.e., Cartesian Product and difference. As regard Cartesian Product in our approach, we have generated two tables T2 and T2 (of increasing dimension: 500, 1000, 2500, 5000, 10000, 25000, and 50000 tuples each) such that 10% of the tuples of T1 intersects as regards the possible chronons and, among them, 50% intersects also as regards certain chronons. In TSQL2, the two tables T1’ (corresponding to T1) and T2’ (corresponding to T2) have been implemented considering only two temporal attributes (to model the start and the end of the valid time). They contain the same tuples as T1 and T2 as regard the non-temporal attributes, and have as valid time the possible valid time of the corresponding tuples in T1 and T2. Left part of Fig. 2 shows the execution times of Cartesian Product in our approach (blue and solid line) and in TSQL2 (red and dotted line), expressed in milliseconds. Right part of Fig. 2 shows the physical I/O (number of blocks). The answer set is not shown, since, obviously, it is the same for the two approaches. Notably, the I/O is slightly greater in our approach, due to the fact that our data model has two additional temporal attributes (to model both possible and certain time) with respect to TSQL2 (in which only determinate time is modeled). Such a fact also explains the slight overhead in execution time, which is also caused by the fact that the computation of intersection requires more operations in our approach (with respect to TSQL2).
As regard temporal difference, we have generated two tables T1 and T2 of increasing dimension (10000, 25000, 50000, 100000, 250000, 500000, 1000000 tuples) in such a way that 10% of the tuples in T1 have a value-equivalent counterpart (i.e., tuples with the same values for the non-temporal attributes) in T2. Among them, 20% temporally intersects as regards possible times, and 10% intersects also as regards certain time. As above, the tuples in the corresponding TSQL2 tables contain the same tuples as T1 and T2 as regard the non-temporal attributes, and have as valid time the possible valid time of the corresponding tuples in T1 and T2. Notably, the answer set of our approach is significantly greater than the one in TSQL2. This is a natural consequence of the different semantics of data. In TSQL2, only certain time can be considered, so that, e.g., the difference between a time interval t and a time interval t’ containing t is obviously empty. On the other hand, in case t and t’ are possible times, their difference is t. As an obvious consequence, the output in our approach can be larger. Given the larger answer set, and the additional memory needed to store four temporal attributes (instead than two, as in TSQL2), also the I/O (and the execution time) of our approach is higher than in TSQL2. Notably however, Fig. 3 clearly shows that the I/O and execution-time overhead of our approach is negligible.
To summarize, our experimental evaluations show that, while adding the possibility of modeling and querying indeterminate time, our AI-based approach only adds a negligible overhead to the “consensus” TSQL2 approach, in which only exact time is considered.
In this paper, we propose an innovative AI approach in which a semantic-based AI-style methodology is applied to the context of TDBs in order to cope with temporal indeterminacy. Specifically:
We have proposed a new “functional” semantic definition for indeterminate time in TDBs, which allows us to express the semantics of temporal algebraic operators in terms of their Codd’s counterparts (thus formally providing a “snapshot semantics” for indeterminate time TDBs). We have proposed a new AI-style methodology to the treatment of TDBs, using it to develop a semantically-grounded 1NF approach (data model plus algebra) to cope with “interval-based” temporal indeterminacy. We have experimentally shown that our AI-based approach only adds a negligible overhead to the “consensus” TSQL2 approach, while adding significant additional expressiveness (i.e., indeterminate time with respect to exact time).
Indeed, in this paper we have widely discussed the fact that, when introducing the temporal dimension, TDBs have to cope with implicit information, which has to be symbolically manipulated by algebraic operators to answer queries. As a consequence, we have proposed an innovative AI-based methodology to cope with time in relational DBs. We are confident that our methodology can be fruitfully applied to other types of temporal information in TDBs (e.g., “now-relative” data [2], implicit representation of periodically repeated data [23,24], temporal data with preferences [25]), and possibly of other forms of indeterminacy, thus leading to a new AI stream of research to cope with indeterminate/implicit data in relational DBs.
Footnotes
BCDM semantics
BCDM (Bitemporal Conceptual Data Model) [15] is a unifying data model, isolating the “core” semantics underlying many temporal relational approaches, including TSQL2. In BCDM, tuples are associated with valid time and transaction time [22]. For both domains, a limited precision is assumed (the chronon is the basic time unit). Both time domains are totally ordered and isomorphic to the subsets of the domain of natural numbers. The domain of valid times
Valid-time, transaction-time and atemporal tuples are special cases, in which either the transaction time, or the valid time, or both of them are absent. In the following, we restrict our attention to valid time (in fact, temporal indeterminacy cannot affect transaction time). In BCDM, in which each tuple is paired with all the chonons when it holds. In BCDM, temporal databases directly associate valid times with tuples, so that the semantics of Example 1 above would be modeled as follows:
Codd designated as complete any query language that was as expressive as his set of five relational algebraic operators: relational union (∪), relational difference (−), selection (
This definition can be motivated by a sequenced snapshot semantics [8]: results should be valid independently at each point of time. Such a property is formally proved by proving the reducibility property.
To prove reducibility, they first introduce the timeslice operators. For the sake of simplicity, here we consider valid time relations only, so that valid timeslice operator is introduced.
The valid timeslice operator, given a valid time BCDM relation and a time t, removes the temporal part of the tuple and retains only the tuples whose valid time contained t.