
Abstract
Graph Neural Networks (GNNs) are powerful tools in graph application areas. However, recent studies indicate that GNNs are vulnerable to adversarial attacks, which can lead GNNs to easily make wrong predictions for downstream tasks. A number of works aim to solve this problem but what criteria we should follow to clean the perturbed graph is still a challenge. In this paper, we propose GSP-GNN, a general framework to defend against massive poisoning attacks that can perturb graphs. The vital principle of GSP-GNN is to explore the similarity property to mitigate negative effects on graphs. Specifically, this method prunes adversarial edges by the similarity of node feature and graph structure to eliminate adversarial perturbations. In order to stabilize and enhance GNNs training process, previous layer information is adopted in case a large number of edges are pruned in one layer. Extensive experiments on three real-world graphs demonstrate that GSP-GNN achieves significantly better performance compared with the representative baselines and has favorable generalization ability simultaneously.
Introduction
Graph is a ubiquitous form in a variety of applications such as social networks [9,25], bioscience [4,20], finance [19], knowledge graph [21], traffic networks [1], etc. With the aim to learn effective representations of graphs and get great performance of downstream works, Graph Neural Networks (GNNs) are designed to put into practice and witnessed fabulous success in representation learning of graphs [14,23,30]. The main principle of GNNs is the neural message passing mechanism, which can propagate neural information along graph edges. Optimizing this mechanism helps GNNs to generate useful representations on downstream tasks [27].
Although promising performances have been achieved in various tasks, recent studies have shown that GNNs are susceptible to adversarial attacks [10,16,26]. In other words, the performance of GNNs can be decreased via attackers’ deliberately designed small perturbations. The lack of robustness of GNN models can lead to severe consequences. For example, in a credit score system, fraudsters can evade detection by exploiting massive transactions with high-credit users as the model usually assumes clients associated with high-credit customers are trustworthy. Hence, developing robust GNN models to defend against adversarial attacks is a crucial issue. The majority of existing adversarial attacks on graph data damage the graph topology by adding a few edges to contaminate the neighborhoods of nodes while models are training simultaneously. This type of attacks are called poisoning attacks [32]. Therefore, we aim to defend against poisoning adversarial attacks on graph in this work.
One method to design an effective defense algorithm is to clean the perturbed graph by removing the adversarial edges [17,24]. The challenge from this perspective is what criteria we should follow to clean the perturbed graph. It is well known that real world graphs often share certain properties. Similarity property is one of these properties, which is of significance to graphs. For instance, in a citation network, two connected publications often share similar topics [12]. But adversarial attacks can damage this property easily. Figure 1 and Table 1 demonstrate the attribute change in graphs via perturbations. Specifically, we apply the state-of-the-art graph poisoning attack, nettack [32], to perturb the graph data and visualize the properties change before and after nettack on Cora, Cora_ml and Citeseer. Figure 1 illustrates that adversarial edges tend to connect nodes with low node feature similarity. We also observe that nodes with low structure are mostly connected because most nodes connected with adversarial attacks have no common neighbors, as shown in Table 1. It is easy to observe that adversarial perturbations are mainly concentrated on node-pairs with low graph similarity property. Thus, graph similarity property has the potential to serve as the effective tool to clean the perturbed data.
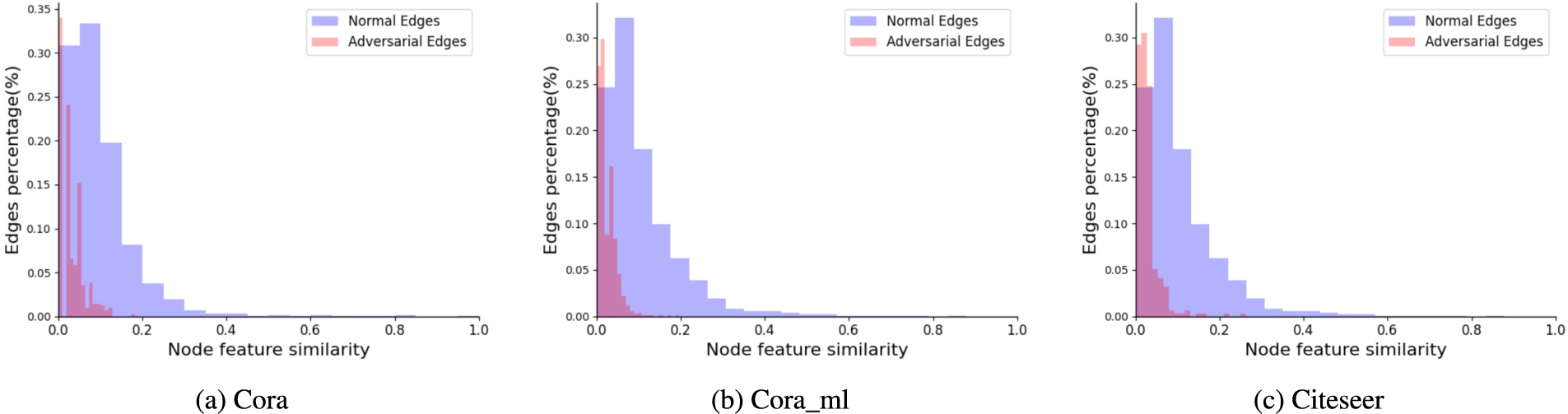
Nodes similarity change by adversarial edges.
The proportion of structural similarity of node pairs connected by adversarial edges
In this paper, we aim to exploit graph similarity property to design robust graph neural networks. In essence, we are faced with two challenges: (1) how to learn clean graph structure from poisoned graph data guided by similarity property; and (2) how to stabilize GNN training process while a large amount of edges being pruned. To solve these two challenges, we propose a general framework, Graph Similarity Property GNN (GSP-GNN), which can defend against adversarial attacks and get a clean and robust graph structure from a perturbed graph. The method mitigates negative effects by pruning adversarial edges via the similarity of node feature and graph structure. It can also stabilize and enhance GNNs training process via previous layer information in case a large number of edges are pruned in one layer. Extensive experiments on a variety of real-world graphs demonstrate that our proposed model can defend against different types of adversarial attacks and outperforms the state-of-the-art defense methods.
The rest of the paper is organized as follows: In Section 2, we review some of the related work. In Section 3, we introduce notations and formally define the problem. We explain our proposed framework in Section 4 and report our experimental results in Section 5. Finally, we conclude the work and introduce future work in Section 6.
In this chapter, we briefly describe related work on adversarial attacks and defense for graph data.
Adversarial attacks for GNNs
In recent years, it has been proved that deep neural networks (DNNs) are susceptible to adversarial attacks [3,28]. As the extension of DNNs to graphs, there is no doubt that GNNs inherit this vulnerability [8]. In general, based on the attacker’s goal, adversarial attacks on graphs can be divided into poisoning attack that perturbs the graph in training-time and evasion attack that perturbs the graph in testing-time [5]. GSP-GNN is designed to defend against poisoning attacks in this paper. Moreover, there are two types of poisoning attack: targeted attack and non-targeted attack [15]. Targeted attack investigates how the prediction of an individual target node changes under perturbations. For example, nettack [32] injects perturbations on graph to attack the targeted nodes, which leads GNNs to make wrong prediction. Bojcheshki et al. [2] derive adversarial perturbations that poison the graph structure and node embeddings. Non-targeted attack can degrades the overall performance of the trained model. To perturb the graph globally, metattack [33] is designed to use meta-gradient to generates global perturbations.
Defense for GNNs
As extensive works have suggested the vulnerability of GNNs, plenty of algorithms have been designed to promote the robustness of GNN models. But this research has just started recently. RGCN [31] is designed to absorb the effects of poisoned changes via modeling Gaussian distributions as hidden layers, which can escalate the robustness of GCN. According to nettack results, Entezari et al. [7] propose GCNSVD that preprocess the graph with its low-rank approximations, which drops noisy information through an SVD decomposition. Zhang et al. [29] propose GNNGuard to detect and quantify the relationship between the graph structure and node features, and exploit it to mitigate negative effects of the poisoning attack. Pro-GNN [11], a jointly learning framework, can simultaneously learn a structural graph and a robust GNN model from the poisoned graph. Wu et al. [22] have found that attackers tend to connect to nodes with different features, by which they propose to remove links between dissimilar nodes as a defense. PA-GNN [17] leverages a penalized aggregation mechanism to restrict the negative impact of perturbed edges.
However, the current methods lack generalization ability, which reduces the practicability of these algorithms. Different from the aforementioned defense methods, GSP-GNN eliminates the negative effects on graphs via similarity property and can also achieve practicability simultaneously.
Problem statement
Before introducing the problem, we first introduce some preliminaries to aid in understanding the problem.
Let
We mainly focus on Graph Convolutional Network (GCN) [12] in this work. For GCN, initially,
Given a graph
With the aforementioned notations and definitions, the problem we aim to study can be stated as follows:
Given
The proposed method
The overall architecture
The architecture of GSP-GNN is shown in Fig. 2. The method is composed of two components: graph similarity property and stability of training. As a number of poisoning attacks often lead to adding fake edges between nodes that have different similarity [10,22], GSP-GNN first measures graph similarity of node feature and topology structure via Jaccard similarity and common neighbors, respectively, then computes the two metric values to remove the edges with lower values. Moreover, to ensure GNN training process in case many edges are pruned in one layer, the information of previous layer is used to update the current GNN layer training. In the following subsections, we will give the details of the proposed framework.
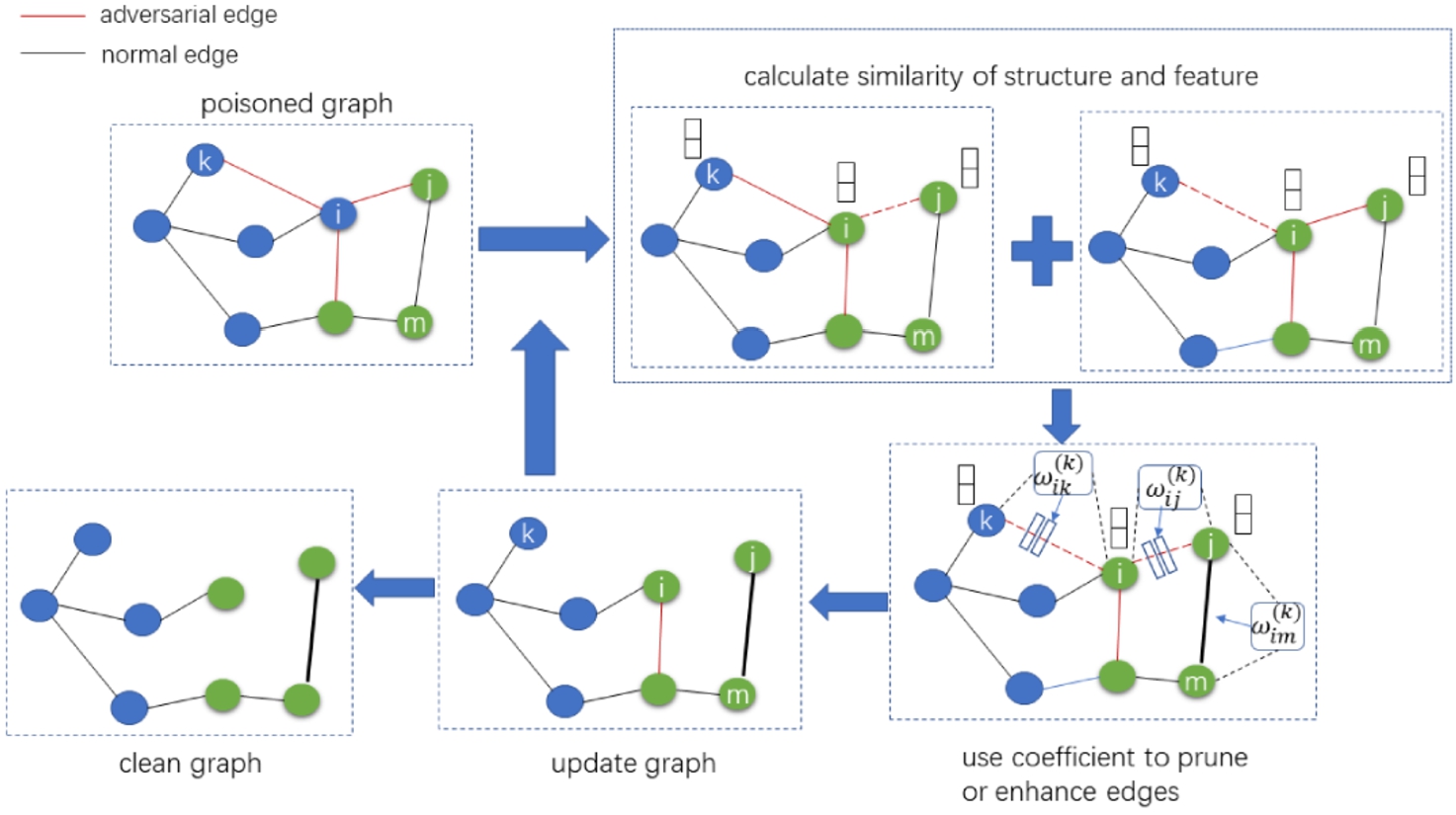
Overall framework of GSP-GNN. Our method firstly clean poisoned graph via similarity property, then use defense coefficient to further weaken negative effects, e.g.,
Utilizing graph structure property
It is evident that adversarial attacks can modify the structure of graphs to lower the performance of GNNs [34]. In order to remove the perturbed edges from the perturbed graph, we utilize the structure similarity attribute of the graph. Common Neighbor (CN) [6] is an excellent metric of this property because it is a classical algorithm in network topology to compute similarity. The core of this algorithm is that given two nodes, the similarity they own is proportional to the number of common neighbors. Hence, CN is often used to evaluate the structural similarity between node pairs. The structural similarity between node
Utilizing node feature property
According to recent works, poisoning attacks generally tend to attack the nodes with different features [29]. Therefore, node feature similarity can also be an effective tool for GNN to eliminate negative effects. Because the features of the datasets in this paper are bag-of-words, we use Jaccard similarity to denote the metric of feature similarity. To this end, the similarity of node
It is obvious that the value of the edges under adversarial attack can be small from Eq. (7). Thus, GSP-GNN adopt the metric to prune edges to reduce the bad effects of poisoned nodes in GNN. Specifically, the method calculates edge cutting score for
Then, based on the similarity analysis above, we define a function that indicates removing adversarial edges via two similarities where P, K are hyperparameters.
Note that our utilizing graph similarity property process is different from that of GCNJaccard [22] in two aspects: (1) Our method normalize node feature similarity as an importance weight, which represents the contribution of node
Stabilizing GNN training process
We can get a new graph through cutting node-pair edges meanwhile GNN is training. But this process may damage the stability of GNN if a huge amount of edges get pruned in a single GNN layer. To stabilize GNN, we use the information from the previous layer to update the next GNN layer. The stabilizing process is defined as follows:
Experiments
In this section, we mainly evaluate the performance of GSP-GNN against different adversarial attacks. To be specific, we aim to answer the following questions:
How does GSP-GNN perform compared to the state-of-the-art defense approaches under various adversarial attacks?
How is the generalization performance of GSP-GNN on other GNN models?
How do different components affect the performance of GSP-GNN?
How do the hyper parameters deployed in our work affect the defense performance?
Before presenting our experimental results and observations, we first introduce the experimental settings.
Experimental settings
Datasets
We validate our work on three publicly available datasets, i.e., Cora, Citeseer and Cora_ml according to [24,32]. We select the largest connected components of each graph in all experiments. The statistics of the datasets are shown in Table 2.
Statistics of the largest connected component of the datasets
Statistics of the largest connected component of the datasets
We compare our model with state-of-the-art GNNs and defense models to evaluate the effectiveness. The following methods are implemented by the Pytorch adversarial learning library DeepRobust [13]:
Parameters settings
We randomly split the dataset from each graph as: 10% training, 10% validation, and 80% test. For each experiment, we record the average performance of 20 runs. The hyperparameters of all the models are tuned based on the loss and accuracy on validation set. For GCN, GAT and GNNGuard, we adopt the default parameter setting in the original works. For RGCN, the number of hidden units is set from
Defense performance
In this subsection, with the aim to answer the first question, we evaluate our model on a node classification task against three types of attacks, i.e., non-targeted attack, targeted attack and random attack. For non-targeted attack and targeted attack introduced in Section 2.1, we adopt metattack and nettack, respectively.
We first use the attack method to poison the graph, then train GSP-GNN and baselines on the poisoned graph to evaluate the node classification accuracy achieved by these algorithms.
Node classification performance (Accuracy ± Std) under metattack
Node classification performance (Accuracy ± Std) under metattack
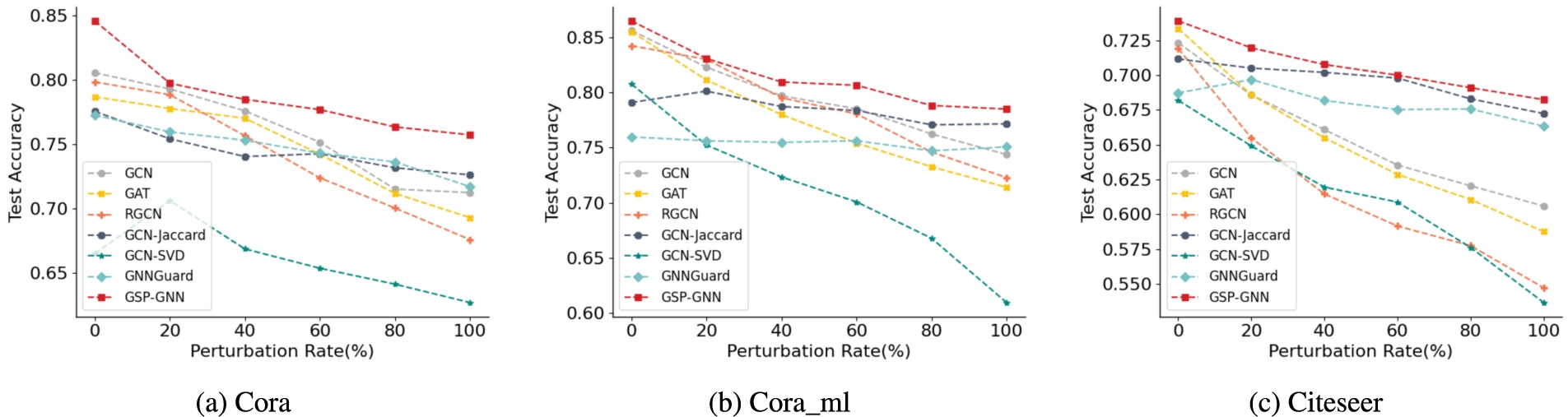
To evaluate the node classification performance of these different methods against non-targeted adversarial attack, we use metattack and keep all the default parameter settings in the authors’ original implementation. The perturbation rate is varied from 0 to 25% with a step size of 5%. All the experiments are conducted 20 times and the average accuracy with standard deviation are shown in Table 3. The best accuracy on node classification is highlighted in bold. From Table 3, several observations are derived as follows:
GSP-GNN consistently outperforms other methods under different perturbation rates. At 5% perturbation rate on the Cora dataset, our model only improves GCN by over 3%. However, at 25% perturbation rate on the three datasets, GCN performs poorly but our model improves it by nearly 26%, 9%, and 13%, respectively. In other words, the variation in our model’s performance is small, indicating that GSP-GNN is more stable when faced with adversarial attacks.
Although GCNJaccard also employs Jaccard similarity to get a clean graph, the performance of GCNJaccard drops rapidly, especially on Cora dataset. This is because the perturbed graph via simple preprocessing is not enough to recover the complex intrinsic graph structure from adversarial perturbations. The experimental results are also consistent with our discussion on comparison between GSP-GNN and GCNJaccard in Section 4.2.2. Moreover, the performance of GNNGuard is also worse than our model’s accuracy at each perturbation rate. The reason is that with the help of graph structure similarity, our model can outperform GNNGuard.
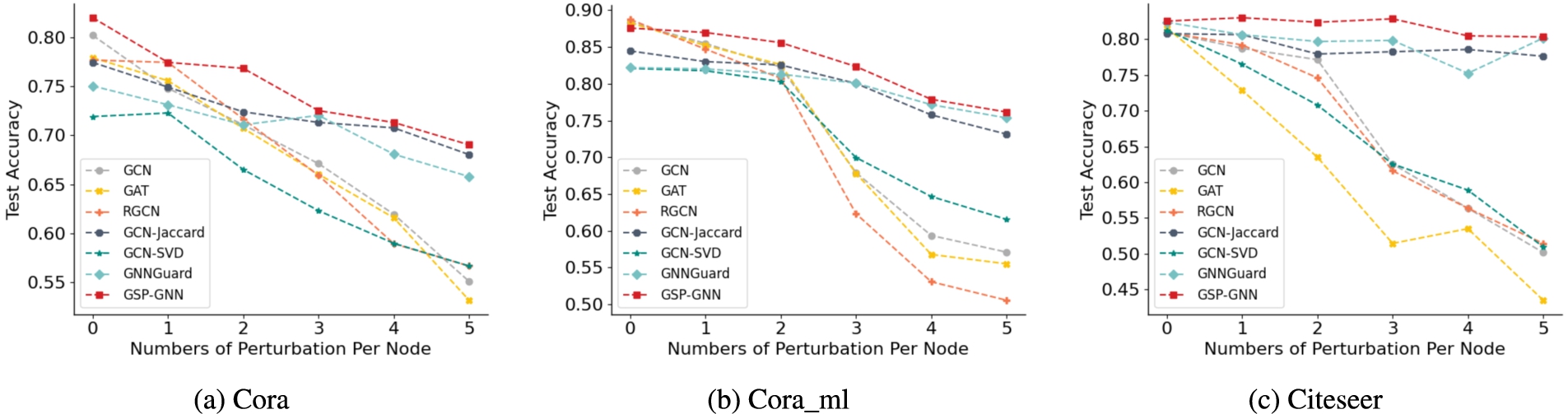
Results of different models under nettack.
In this experiment, we adopt nettack as the targeted-attack method and keep its default parameter settings in its original implementation. The perturbation number of each targeted node is set from 1 to 5 with a step size of 1. Nodes in the test set whose degree larger than 10 are set as target nodes. The node classification accuracy on target nodes is shown in Fig. 3. According to this figure, we can observe that as the number of perturbation raises, the performance of GSP-GNN is better than other methods on the attacked target nodes in most cases. For instance, on Cora_ml at 5 perturbation per targeted node, GSP-GNN improves vanilla GCN by 16% and also outperforms other defense baselines. This also shows that GSP-GNN can resist the targeted adversarial attack.
Results of different models under random attack.
The generalization ability results under metattack
We evaluate how GSP-GNN performs under different ratios of random noises from 0% to 100% with a step size of 20%. The results are reported in Fig. 4. The figure demonstrates that GSP-GNN outperforms all other baselines and successfully defends against random attack. Thus, with observations shown before, we can get a conclusion that GSP-GNN is able to defend various types of adversarial attacks.
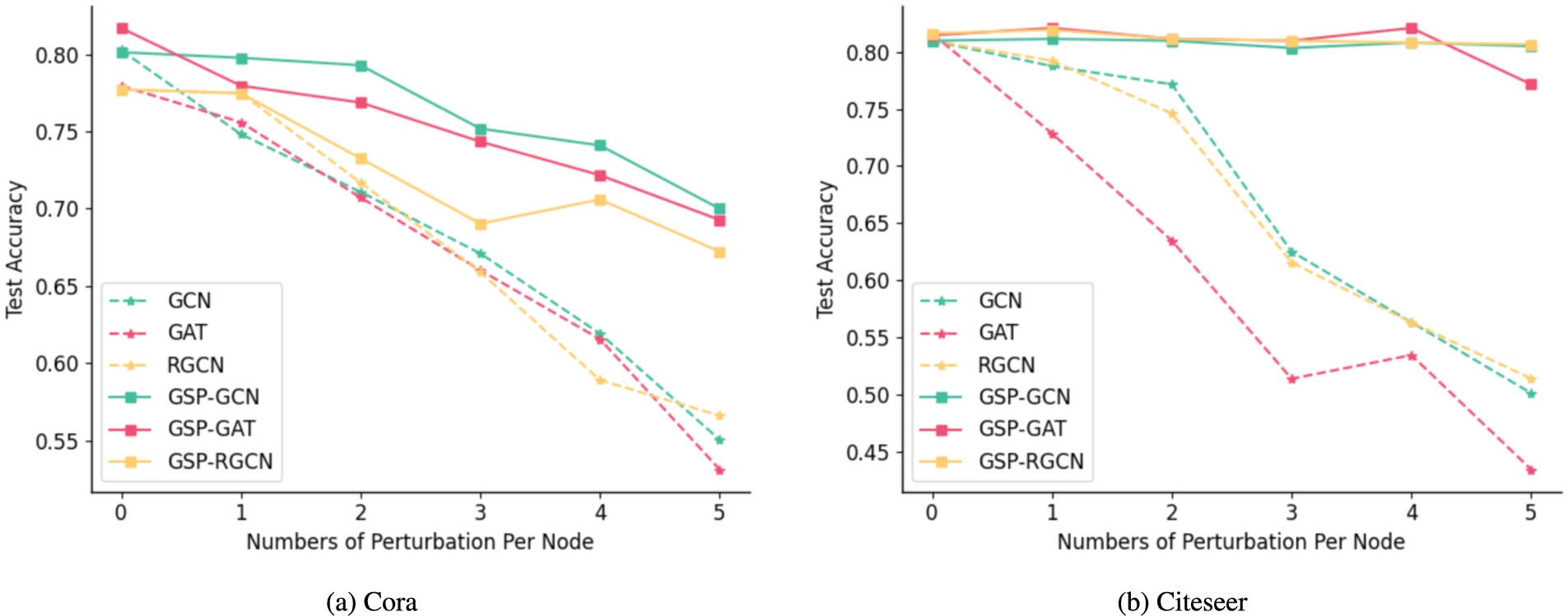
The generalization ability results under nettack.
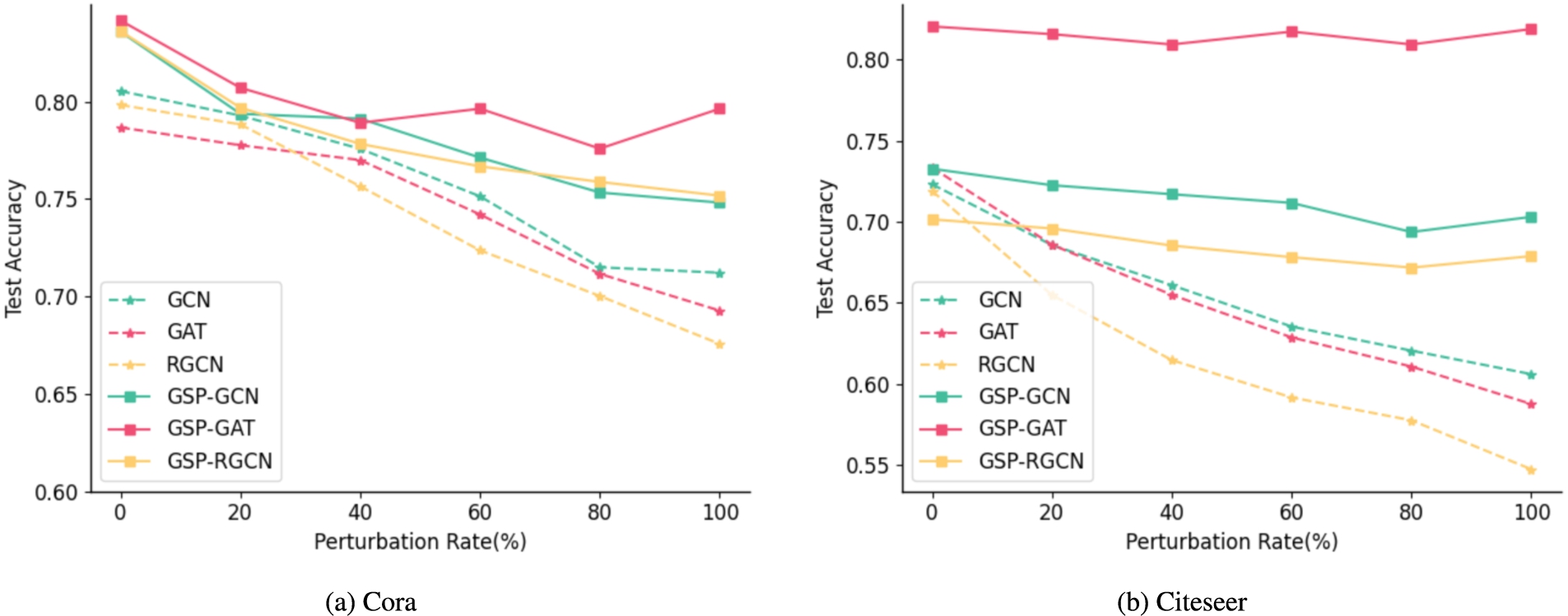
The generalization ability results under random attack.
In this subsection, we mainly discuss the generalization ability of GSP-GNN. To demonstrate that our proposed defense method is generic to other GNNs, we generalize our proposed method into GCN, GAT and RGCN, and test their node classification accuracy, respectively. We evaluate the experiments on Cora and Citeseer datasets under metattack, nettack and random attack settings. We name the new reconstructed GNN model as “GSP-model”. The results are shown in Table 4, Fig. 5 and Fig. 6. From the outcomes, the generalized model achieves better performances than the original models. For instance, on Citeseer dataset, GSP-GCN, GSP-GAT and GSP-RGCN all not only outperforming GCN, GAT and RGCN by a larger margin under netattack setting, respectively, but the former three models show better stability than the latter three methods simultaneously. A similar situation can be observed on Cora dataset under metattack. The reason is that our model can clean the negative effect via similarity of graph structure and node feature, stabilizing GNN with previous layer information while training. Thus, the classification accuracy of our new models on test datasets has gained remarkable improvement compared with the original models, which further demonstrates the generalization ability of our defense method.
Ablation study
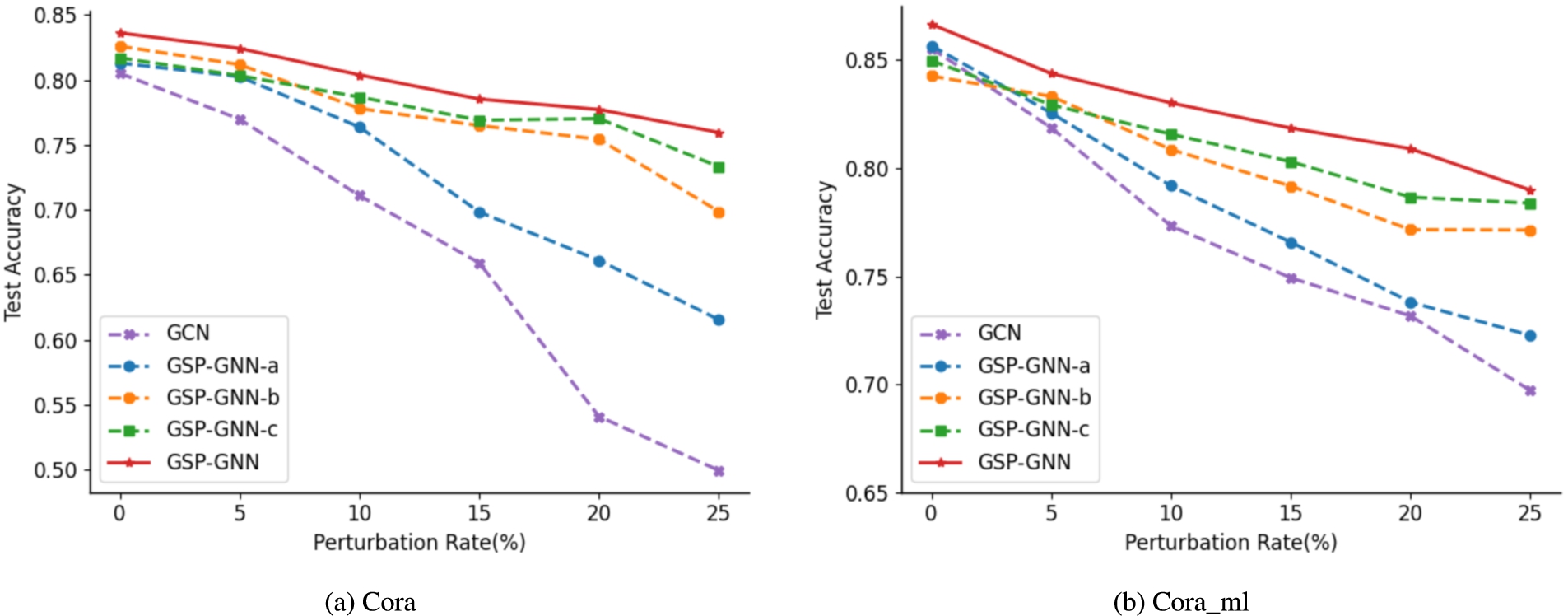
Classification performance of GSP-GNN variants.
To analyse what roles the different components in our model to defend against adversarial attacks, we conduct an ablation study and answer the third question in this subsection.
We create three model variants: GSP-GNN-a, GSP-GNN-b and GSP-GNN-c. GSP-GNN-a indicates the method only using previous layer information, GSP-GNN-b only uses pruning via similarity and GSP-GNN-c only uses jaccard similarity. For example, GSP-GNN-c denotes that we just calculate the similarity of node feature and control the effect of other components to zero simultaneously. We report results on Cora and Cora_ml under metattack and similar situations can be observed in other situations. The results are shown in Fig. 7. According to this figure, we can observe that GSP-GNN-a does not surpass too much than GCN under small perturbations. However, when the perturbation becomes large, this variant outperforms vanilla GCN especially on Cora dataset because GSP-GNN-a can exploit the previous layer information to stabilize model training and defense performance. Moreover, GSP-GNN-b and GSP-GNN-c perform much better than GCN. It should be noted that GSP-GNN-c outperforms all other variants except GSP-GNN, which suggests that it is of great significance to exploit node feature similar to reduce the impact of adversarial attacks. From the above observations, diverse components play different roles in defending adversarial attacks and these components can all enhance the performance of our model. Hence, GSP-GNN can outperform state-of-the-art baselines by incorporating these components consistently.
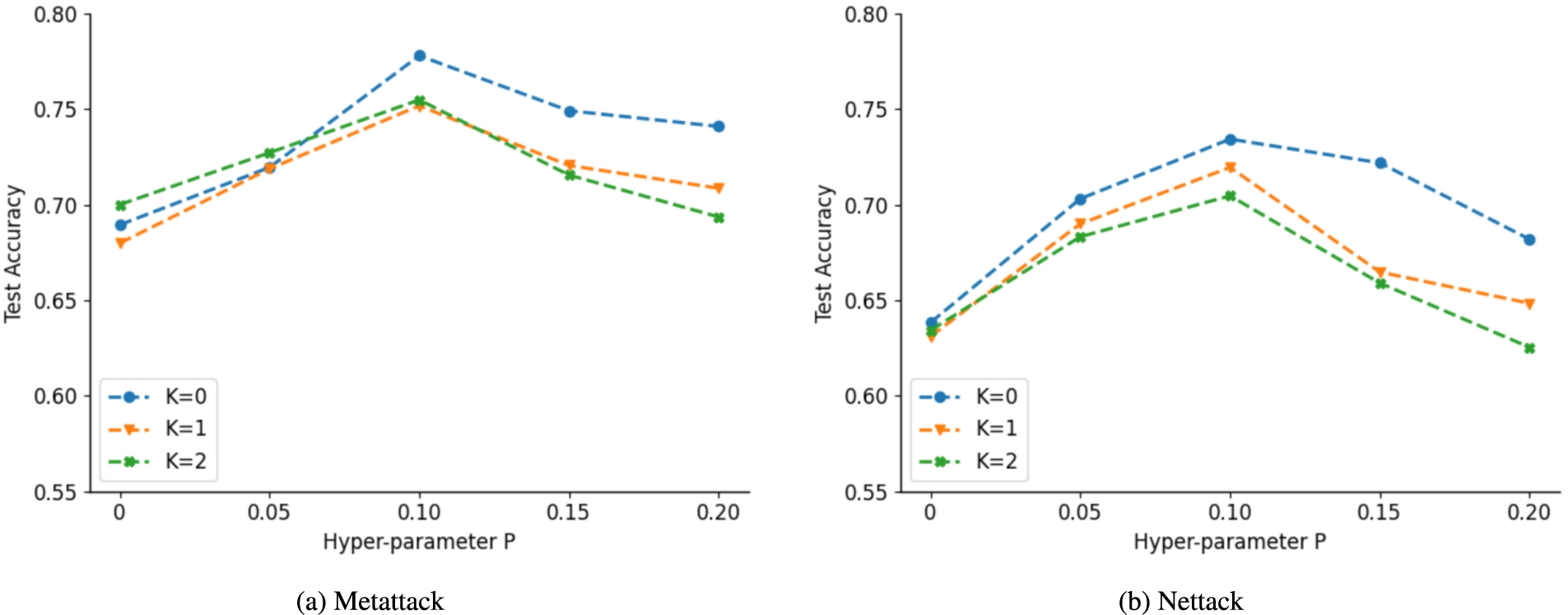
Results of parameter analysis on Cora dataset.
We analyse the sensitivity of hyper-parameters K and P for GSP-GNN to answer the fourth question, where K and P denote structure similarity threshold and node feature similarity threshold, respectively. In this experiment, we alter the values of K and P to see how they affect the performance of GSP-GNN. For detail, we vary K from 0 to 2 while P remains unchanged and vary P from 0 to 0.20 while K is constant. We only report the results on Cora dataset at 5 perturbations per targeted node by nettack and at 25% perturbation rate by metattack because similar conclusions can be made in other settings.
The performance change of GSP-GNN is illustrated in Fig. 8. As we can see if the appropriate values for these two hyper-parameters are chosen, the accuracy of our model can be boosted. More specifically, with the K value improving while the performance of GSP-GNN decreasing, this is because the graph structure becomes more sparse. In other words, if the value of K is higher, there is more possibility to prune normal and important edges in the graph. It is worth noting that appropriate value of P can also greatly increase the model’s performance but too large or too small value of P will hurt the performance. This experiment result is also identical with the observations in Table 1 and Fig. 1. Accordingly, small value of K and suitable P value can help improve our model’s performance.
Conclusion
In this paper, we first observe graph structure similarity and node feature similarity of three datasets attacked by representative attack – nettack, and find that adversarial perturbations are mainly concentrated on the node-pairs with low graph similarity property. Based on this observation, we introduce a novel defense approach, GSP-GNN. The proposed GSP-GNN employs the graph similarity property as an effective tool to prune adversarial edges. Meanwhile, it adopts the information of the previous layer to stabilize GNN so as to enhance the robustness of the model. A large number of experiments have been conducted on three real datasets to verify that GSP-GNN outperforms current defense algorithms under adversarial attacks. Moreover, we also show the proposed GSP-GNN is generic to other GNN models in node classification tasks through experiments. Inspired by the achievement of graph similarity property, we plan to explore more graph properties such as low-rank and sparse to further improve the robustness of GNNs.
Footnotes
Acknowledgements
This work is supported in part by the National Natural Science Foundation of China (61662079, 11761070, U1703262) and the Xinjiang Natural Science Foundation (2021D01C078).