
Abstract
Knowledge graphs have been introduced into recommender systems due to the rich connectivity information. Many knowledge-aware recommendation methods use graph neural networks (GNNs) to capture the high-order structural and semantic information of knowledge graphs. However, previous GNN-based methods have the following limitations: (1) they fail to make full use of the neighborhood information of entities and (2) they ignore the importance of user interaction sequences on reflecting user preferences. As such, these models are insufficient for generating accurate representations of users and items. In this study, we propose a
Introduction
Users are inundated with many choices in the age of information explosion. To tackle the problem of information overload, electronic retailers and content providers apply recommender systems to help users find items of interest. A recommender system is an information filtering system, which can mine users’ interests and match them with the most appropriate items. Due to the importance in practice, recommender systems have been playing an increasingly important role in modern society.
One of the most prevalent recommendation techniques is collaborative filtering (CF) [1–3], which models user preferences based on user similarity or item similarity from the interaction data. Although CF-based methods have many prominent characteristics such as generality and implementation simplicity, they suffer from the cold start problem and perform poorly in sparse scenarios where users have a few interactions with items. To alleviate these problems, many works attempt to incorporate side information into the learning process [4], such as user profiles [5], item attributes [6], etc. Nevertheless, these methods assume that relations among items are independent and overlook the connectivity between them.
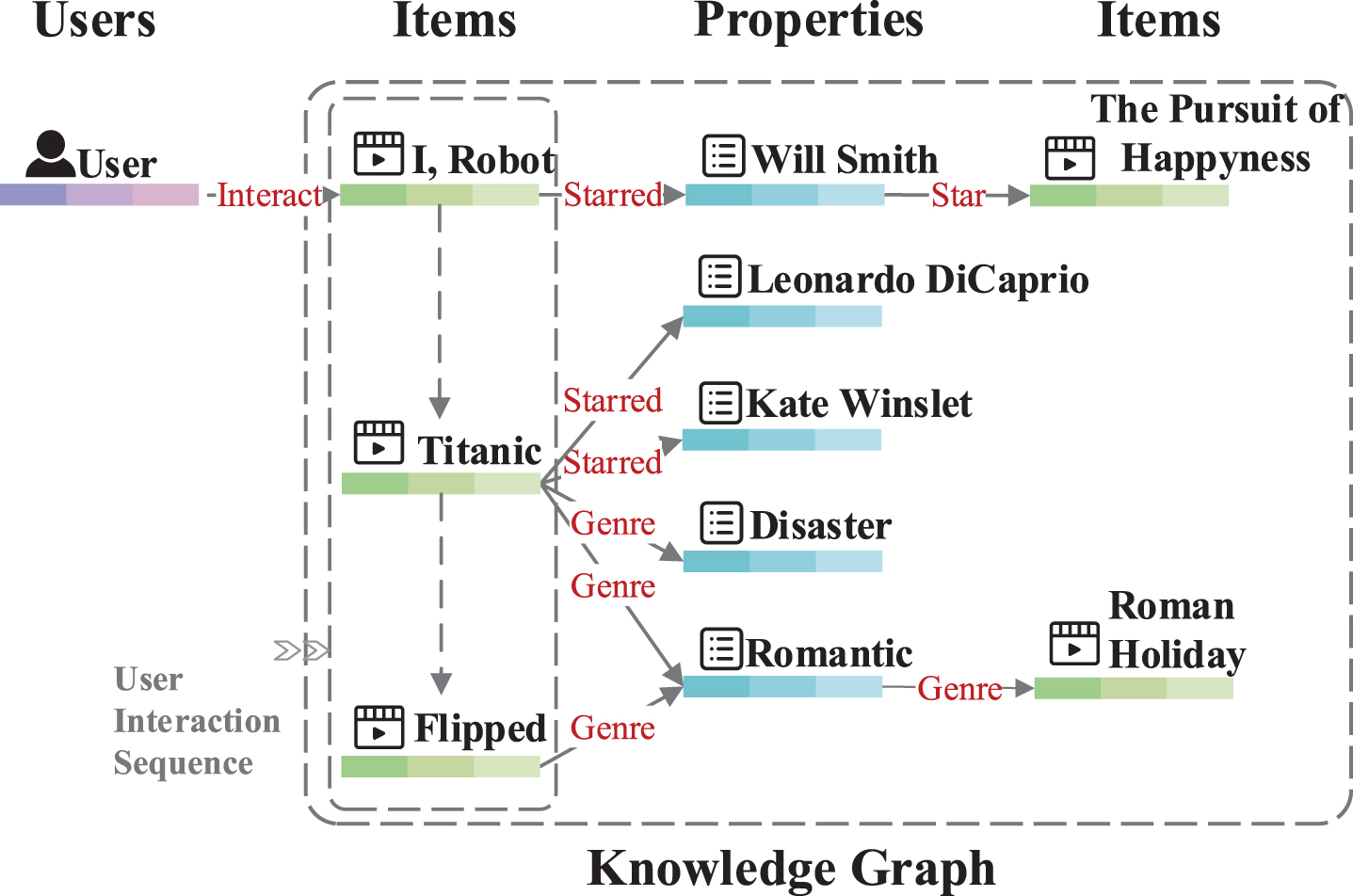
An example of KG-aware recommender system. The dashed line denotes that the user interacts with the item, while the solid line denotes that the item has the property in the knowledge graph.
Based on the above observations, a few recent studies propose to incorporate knowledge graphs (KGs) [7–9] into recommendation. A KG is a directed graph, where nodes correspond to entities and edges correspond to relations between entities. The information of entities and relations is usually organized in the form of triplets (h, r, t), which represents the fact that head entity h has a relation r with tail entity t. For example, the triplet (Will Smith, Star, The Pursuit of Happyness) means that Will Smith stars in the movie The Pursuit of Happyness. KG associates items with their attributes via various relations, which has shown great potential to improve the accuracy of recommender systems. Taking movie recommendation as an example (Fig. 1), a user interacts with I Robot, and The Pursuit of Happyness share the same actor Will Smith with I Robot. Therefore, we can reason that the user may also be interested in the movie The Pursuit of Happyness. Such rich semantic relatedness among items is helpful for reasoning about unseen user-item interactions. Meanwhile, KG also compensates for the data sparsity due to the integration of side information.
There have been several knowledge-aware recommendation methods. (1) Embedding-based methods [7, 10] leverage knowledge graph embedding (KGE) methods, such as TransE [11] and TransD [12], to map entities and relations to low-rank representations. These methods only consider one-hop relations between entities rather than multi-hop relation paths, resulting in a lack of reasoning ability and interpretability. (2) Path-based methods [13–15] introduce meta-paths to match the similarity of the items or users. By exploring the connectivity information of users and items in KGs, these methods can better provide the ability of interpretability for recommendation. However, commonly-used path-based methods rely heavily on manually designed meta-paths, which leads to the inability to reason on unseen connectivity patterns.
Considering the limitations of existing methods, several methods take inspiration from the development of graph neural networks (GNNs) [16] for recommendation. GNN-based methods [17, 18] can leverage both the semantic representations used in embedding-based methods and the semantic connectivity information used in path-based methods, and have proven to be one of the best performing architectures for various graph learning tasks. The key idea of GNN is to update a target node representation by recursively aggregating the information from its multi-hop neighbors. Since different neighbor nodes contribute unequally to the central node, it is necessary to discriminate the importance of neighbor nodes carefully. However, most GNN-based methods either treat the neighbors of each entity equally or roughly discriminate the importance of neighbors, leading to a failure to fully utilize neighborhood information.
Moreover, existing GNN-based methods completely neglect the importance of user interaction sequences on reflecting user preferences. For instance, as shown in Fig. 1, a user interacts with the movie I Robot, Titanic, and Flipped. Without considering the user interaction sequence, we can recommend the movie The Pursuit of Happyness to the user since it has the same leading actor as I Robot. However, once we take the user interaction sequence into account, we can infer that the user prefers romantic movies as most of the movies the user interacts with belong to romantic movies. Therefore, the movie Roman Holiday is a more suitable recommendation item than The Pursuit of Happyness.
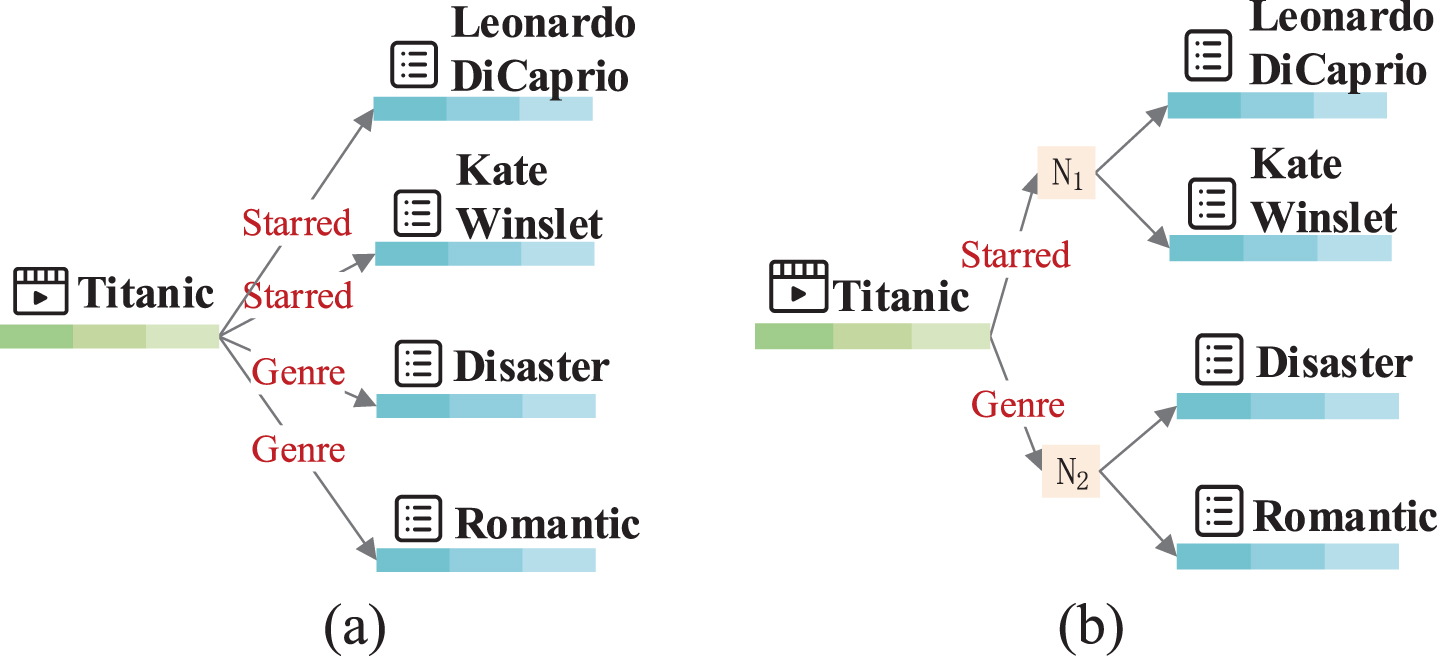
(a) The entity Titanic and its neighbors. (b) The hierarchical structure of Titanic’s neighbors. N1 denotes the set of neighbor entities under relation Starred. N2 denotes the set of neighbor entities under relation Genre.
In this paper, we propose a knowledge-aware hierarchical attention network based on GNN, dubbed KHAN. Our design objective is to take full advantage of the local neighborhood information of each entity to obtain better entity representations and incorporate user interaction sequences to capture user preferences more accurately. The core of KHAN is an item encoder and a user encoder. In the item encoder, we design a hierarchical attention network, which can generate item (entity) representations by aggregating neighborhood information of items. More specifically, we first treat the connections between a central entity and its neighbors as a hierarchical structure [19]. A central entity connects to different relations and each relation links the central entity to one or more neighbor entities. For instance, we select Titanic and its neighbors from Fig. 1 as Fig. 2(a), and Fig. 2(b) can be viewed as the hierarchical structure of neighbors. Next, based on the above hierarchical structure, we elaborately devise a hierarchical attention mechanism to discriminate the importance of different neighbors. The hierarchical attention consists of user-relation attention and user-entity attention. Wherein, user-relation attention represents the importance of relations to users while user-entity attention characterizes the importance of different neighbor entities under each relation. Then the user-relation attention and the user-entity attention are combined as the final scores of neighbors when aggregating neighborhood information. In the user encoder, we employ a self-attention mechanism to capture the relatedness of user interaction sequences to fully extract user interests. The learned user representations are then combined with user representations used in the item encoder through a gating mechanism to generate the final user representations. We conduct extensive experiments on two datasets to verify the effectiveness of our model.
To sum up, the contributions of this paper are as follows: We highlight the importance of taking full advantage of neighborhood information for enhancing the recommendation task and propose an end-to-end model KHAN, which aggregates neighborhood information of each entity via a hierarchical attention network. We consider the importance of user interaction sequences and design a new user encoder to learn more accurate user representations from user interaction sequences. Experimental results on real-world datasets demonstrate that KHAN significantly outperforms state-of-the-art KG-based methods for recommendation.
The rest of this paper is organized as follows. The related works are reviewed in Section 2. Section 3 presents the problem formulation. In Section 4, we describe our proposed model KHAN in detail. Thereafter, we provide an extensive evaluation of our model in Section 5 to demonstrate its effectiveness. Finally, Section 6 concludes the paper.
In this section, we briefly review KG-based recommender systems, which can be roughly divided into three classes: embedding-based methods, path-based methods, and unified methods.
Embedding-based methods exploit the structured information of KG to learn low-rank embeddings of entities and relations, such as TransE [11], TransD [12], TransR [20], etc. For example, DKN [7] fused the knowledge-level representations of entities learned via TransD and word-level representations of titles learned with CNN to model news for news recommendation. Instead of explicitly leveraging high-order information, these methods only take into account the direct relations between entities. Therefore, embedding-based methods lack reasoning ability and interpretability, and are not very suitable for recommendation.
In the meantime, path-based methods were proposed. Path-based methods take advantage of the connectivity patterns of entities to match the similarity between users and items. To get the paths between selected nodes, they define meta-path patterns [14, 15] or automatically select the most salient paths [13]. For example, MCRec [14] considered the mutual effect between the meta-paths and the involved user-item pair in an interaction, and employed an attention mechanism to mutually improve the representations for meta-path based context, users, and items. KARN [21] combined the users’ clicked history sequences and the path connectivity between users and items for recommendation. However, the methods of defining meta-path patterns require domain knowledge to define meta-path manually. They usually cannot capture all connectivity patterns, which leads to suboptimal recommendation results.
Recently, unified methods [17, 22–24] have become one of the most popular methods for recommendation. Unified methods are based on the idea of embedding propagation, which updates the target node representation guided by the connective structure in the KG. As one of the unified methods, GNN-based methods have received growing attention due to their excellence in integrating node information and topological structure. For example, KGAT [17] refined an entity embedding based on the embeddings of its neighbors and applies an attention mechanism to learn the weight of each neighbor on the user-item knowledge graph. Nevertheless, the method ignores the correlation between the target user behavior and the item in the embedding learning process. KGCN [18] proposed to use scores relying on the connecting relation and specific user to weight neighbors on the item knowledge graph. As a result, the users’ personalized interests in relations can be characterized. However, the method does not consider the fact that users’ interests in different entities (items) are various even under the same relation. More recently, KGIN [25] explored the hidden user intent by modeling each intent as an attentive combination of KG relations. Different from all these methods, in this work, we treat the connections between a central entity and its neighbors as a hierarchical structure and design a hierarchical attention mechanism, including user-relation attention and user-entity attention, to refine the aggregation process of neighborhood information. The methods of organizing information into hierarchies have been verified to yield better results. For example, RGHAT [19] proposed a hierarchical mechanism to utilize the neighborhood information of entities and successfully applied it to the task of knowledge graph completion. The difference between RGHAT and our work is that RGHAT takes the semantic relevance of head and tail entities as the main factor to determine the attention scores of triplets, while our work mainly focuses on the users’ interest in triplets. By introducing users’ interests into triplets, an item can adaptively learn different representations when facing different users. Therefore, RGHAT is more suitable for knowledge graph completion while our work is more suitable for recommendation. In addition, existing GNN-based methods fail to consider the importance of user interaction sequences on reflecting user preferences. In our work, this problem is also effectively addressed.
Problem formulation
In the study of knowledge-aware recommendation scenario, we have user set
Therefore, we can formulate the recommendation task as follows: given a user u, a candidate item v, the interaction sequence S (u) of user u and KG
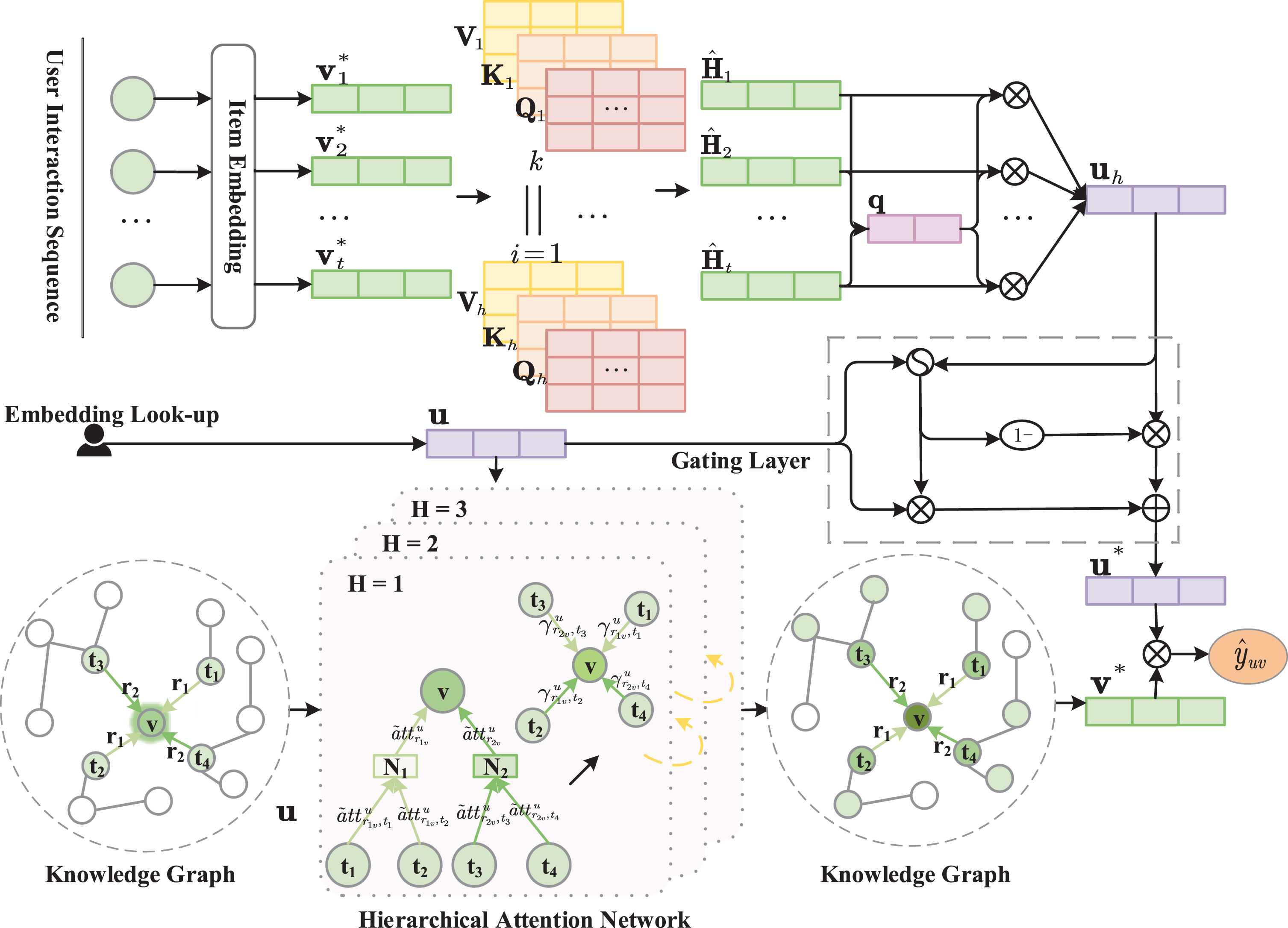
The overall architecture of the KHAN model. The symbols ⊕ and ⊗ denote the element-wise addition and multiplication, respectively.
In this section, we present the proposed KHAN model. As is illustrated in Fig. 3, the model framework consists of two components, i.e., item encoder and user encoder. Specifically, the item encoder regards the neighborhood of an entity in KG as a hierarchical structure and designs a hierarchical attention network accordingly. Then the neighbors of central entity are weighted by hierarchical attention scores and further form the neighborhood representation. Finally, to get the final entity representation, the neighborhood representation is aggregated to the central entity. The user encoder employs multi-head self-attention to draw global dependencies of user interaction sequences and further learns user representations. The learned user representations are then combined with user representations introduced in the item encoder through a gating mechanism to generate the final user representations.
Item encoder
The item encoder aims to learn item representations based on the idea of the GNN for recommendation. Following the general process of GNN, we design two components for the item encoder: hierarchical attention-based information propagation and information aggregation.
Hierarchical attention-based information propagation
The information propagation operation tries to model information propagated from neighbors for the central entity. Given a central entity v, a common way to obtain the neighborhood representation of v is to compute the linear combination of v’ tail entity. The process is given as:
To learn the weight γ t more accurately, we design a hierarchical attention mechanism, which consists of user-relation attention and user-entity attention. The hierarchical attention architecture is inspired by RGHAT [19], where the goal is to learn a better representation for the target node by making full use of the neighborhood information for enhancing the knowledge graph completion task.
Combining user-relation attention with user-entity attention, we can get the final attention score
In RGHAT, attention scores are also calculated for triplets. However, the focus of our model and RGHAT is different when calculating attention scores. RGHAT determines the attention scores of triplets based on the semantic relevance of the triplets. If the semantic relevance of a triplet is strong, then the triplet can contribute more information to the central (head) entity. Such a strategy is reasonable for knowledge graph completion. However, for recommendation task, we argue that user preferences are the key factor in determining how much information is propagated to the central entity by a triplet. For example, there is a movie Titanic, a triplet (Titanic, Starred, Leonardo DiCaprio), and two users u1 and u2. We want to predict whether to recommend the movie Titanic to the user u1 and u2. Assuming that by calculation we find that the user u1 is highly interested in Leonardo DiCaprio while user u2 is not concerned about the leading actor, then we can infer that Leonardo DiCaprio is more important for u1 compared to u2. Accordingly, for u1, we should increase the amount of information propagated from the above triplet to the central entity, while for u2, we can appropriately reduce the information passed to the central entity. In this way, we can learn different representations for movie Titanic adapted to u1 and u2, hence improving the accuracy of the recommendation. To demonstrate that our method is more suitable for recommender systems, we compare the performance of RGHAT and our model in the experiments section.
Unlike previous approaches described in Equation (3) that simply use the linear combination of v’s tail entity as the final neighborhood representation, we aggregate Con (u, r
v
, t) obtained from the above calculation as the neighborhood representation. Con (u, r
v
, t) combines the information of relation r, tail entity v
t
, and user u. It is a natural way to aggregate the representations of both relations and tail entities as neighborhood representation. We incorporate user representation into neighborhood representation to tackle the problem that the item knowledge graph cannot capture collaborative signal due to the lack of user-item interaction information. By modeling user information into the entity representation, we can close the spatial distance of the entities preferred by similar users. The neighborhood representation of v is computed as follows:
Having obtained the neighborhood representation of v as
Finally, to mine user interest in a deeper way, we further stack multiple propagation layers to aggregate information from multi-hop neighbors.
In the previous steps, to learn user-personalized item representation, we introduce user representation
To get the final user representation
After obtaining user representation
We employ a uniform negative sampling strategy to learn the parameters of our model. For each item that a user interacts with, we randomly sample an item that is not selected by this user. The loss function of the KHAN model is defined as follows:
In this section, we perform extensive experiments on real-world datasets to evaluate the proposed KHAN model.
Dataset description
To verify the effectiveness of KHAN in different scenarios, we conduct experiments on two benchmark datasets: MovieLens-20M and Dianping-Food. The two datasets have been extended by [27]. We use the extended datasets to perform experiments and, to ensure the objectivity of the results, they are identical to the datasets used by [27].
Statistical details of the datasets
Statistical details of the datasets
The statistical details of the two datasets are presented in Table
Baselines
To evaluate the effectiveness of our approach, we compare it with the following baselines. SVD and LibFM are KG-free methods, and the rest of the models are KG-aware methods. SVD [28] transforms both items and users to the same latent factor space using inner product to model user-item interactions. LibFM [29] is a factorization model, which considers second-order feature combination. We concatenate user id, item id as input. CKE [10] integrates text, image, and structure information of KG for recommendation, which employs TransR to learn structural knowledge, guiding the representation learning of items. PER [30] is a path-based method, which extracts meta-path based features to represent the connectivity between users and items. KGAT [17] constructs a new heterogeneous graph by combining user-item interactions and KG, and then uses attention-based propagation to generate user and item representations on it. KGCN [18] is an approach based on GNN, which combines neighborhood information with bias to learn item representations on KG. KGNN-LS [27] is an improvement over KGCN, which introduces label smoothness assumption to regularize the model. RGHAT [19] is a method designed for knowledge graph completion, which mainly consists of an encoder and a decoder. The encoder is used to learn the entity representation based on the KG. In this paper, we use the encoder of RGHAT for recommendation. KGIN [25] is a state-of-the-art GNN-based method. It considers user intents and models them as an attentive combination of KG relations.
Evaluation metrics
For each dataset, we divide it into three parts: training set (60%), validation set (20%), and test set (20%). To demonstrate the effectiveness of KHAN in different scenarios, we evaluate our model in click-through rate (CTR) prediction and top-K recommendation: (1) In CTR prediction, we use the trained model to predict user-item matching scores in the test set. If user-item matching score
Parameter settings
For fair comparison, we do not use any pretrained parameters, but learn all models from scratch. We use Tensorflow in the experiment, and optimized all models with Adam optimizer. Grid search is used to find out the best settings of hyper-parameters. The dimension of embeddings D is tuned in {4, 8, 16, 32, 64}, the number of neighbors N for each entity is searched amongst {2, 4, 8, 16, 32}, the number of propagation layers L is tuned amongst {1, 2, 3, 4}, the number of self-attention heads K is searched in {2, 4, 8}, the L2 regularization weight λ is searched amongst {10-8, 10-7, 10-6, 10-5, 10-4}, and the learning rate η is tuned in {10-5, 2 × 10-5, ⋯ , 2 × 10-2, 10-1}. We also set the maximal length of the user interaction sequence T for users and determine its value by calculating the median of the user interaction sequence length across all users. The hyper-parameter setting of our model is given in Table 2, which is mainly determined by optimizing Recall@10 on the validation set. Moreover, we repeat the whole experimental process five times and report the average values as results to keep the reliability of the model.
Hyper-parameter settings of KHAN. D is the dimension of embeddings; N is the number of neighbors fcor each entity; H is the number of propagation layers; T denotes the maximal length of user interaction sequence; K is the number of self-attention heads; λ is L2 regularization weight; η is learning rate.
Hyper-parameter settings of KHAN. D is the dimension of embeddings; N is the number of neighbors fcor each entity; H is the number of propagation layers; T denotes the maximal length of user interaction sequence; K is the number of self-attention heads; λ is L2 regularization weight; η is learning rate.
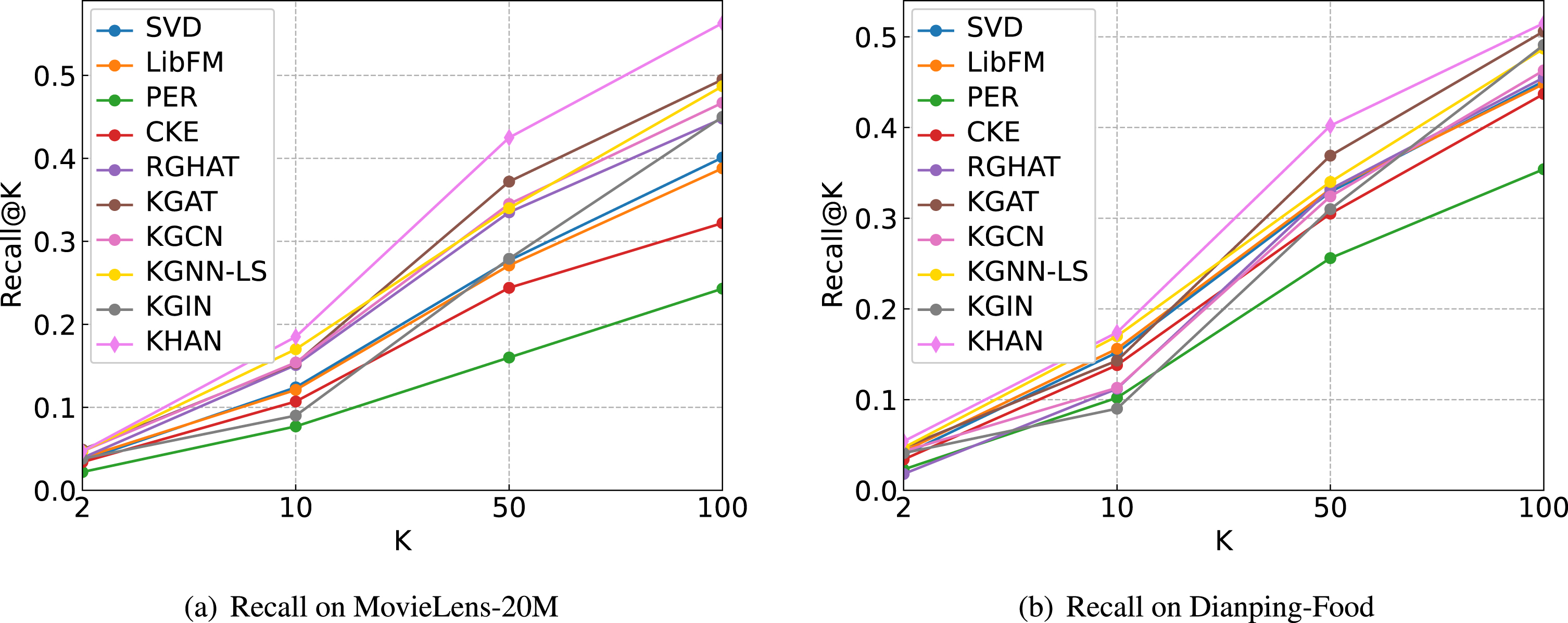
The performance of different methods in top-K recommendation.
The performance of different methods in CTR prediction. “RI” denotes the average relative improvements of KHAN over the corresponding baseline.
The performance comparison results are shown in and Fig. 4 and Table 3. From Fig. 4 and Table 3, we have the following findings: PER has the worst performance on both datasets. It is mainly because PER relies heavily on the predefined meta-paths, and defining optimal meta-paths is difficult. CKE performs poorly compared to other baselines, which is probably because CKE cannot fully utilize the KG through TransR regularization. Knowledge-free methods (i.e., SVD and LibFM) outperform PER and CKE baselines but are weaker than KGCN and KGNN-LS methods, which indicates the importance of making full use of the KG. RGHAT is slightly worse than KGCN and KGNN-LS, which shows that it is necessary to learn different representations for items when facing different users. Compared with KGCN, the performance of KGNN-LS is significantly improved by introducing LS regularization, which indicates the LS part helps learn the edge weights in KG and has better generalization ability. KGAT performs better on Dianping-Food compared to most of the baselines. One possible reason is that there are a large number of user-item interactions in Dianping-Food, and KGAT better captures the similarity of user interaction behavior by introducing user-item interaction information into knowledge graph. KGIN shows strong performance compared with other baselines. This is mainly because KGIN preserves the semantics of long-range connectivity using relation dependencies. Note that we also incorporate information of relations in KHAN model. Our model consistently achieves the best performance on both datasets, which proves the effectiveness of our model. KHAN not only learns more effective item representations by a hierarchical attention network, but also captures user preferences more accurately by combining user representations introduced in item encoder and user representations based on user interaction sequences in a unified framework.
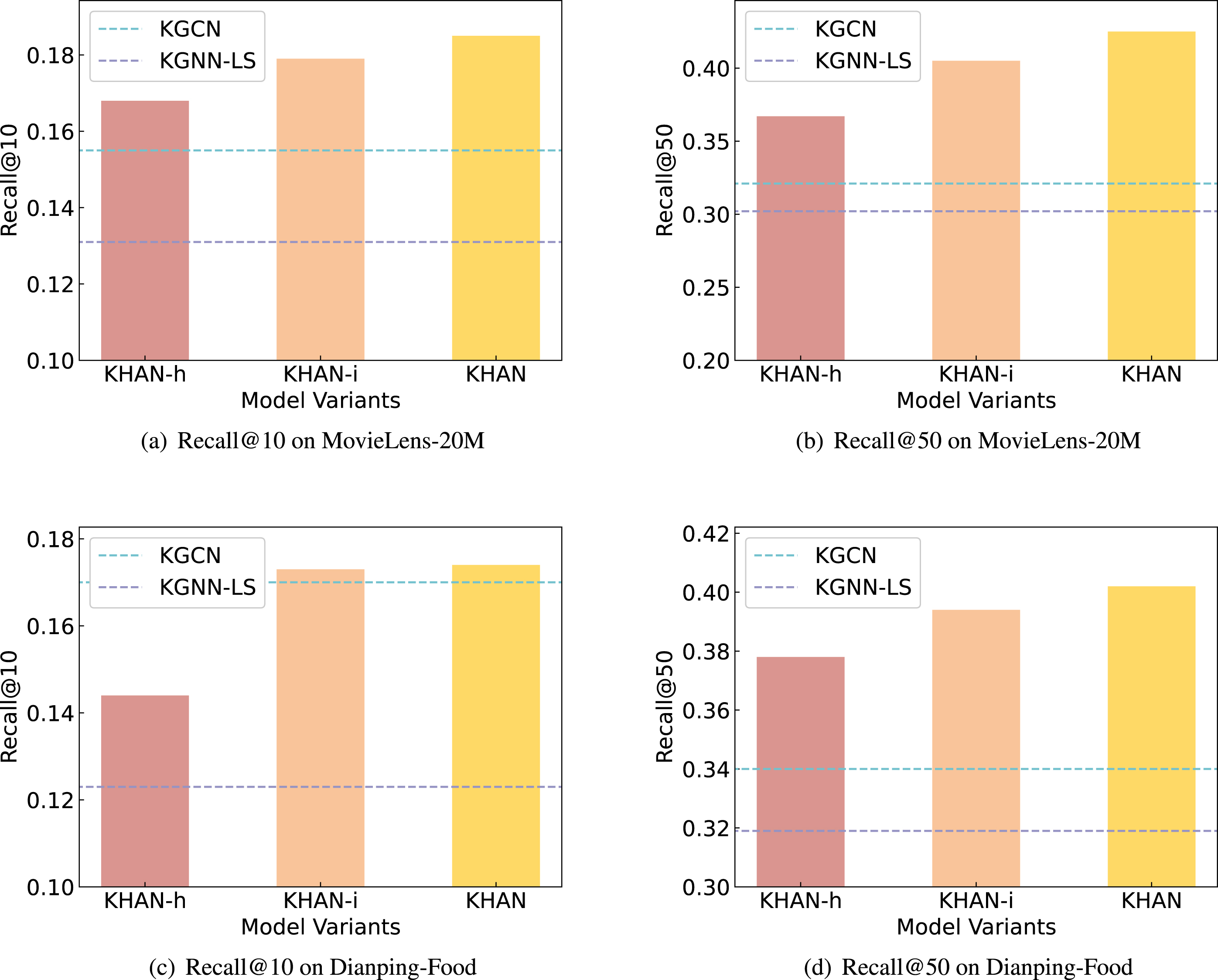
The performance of variants of KHAN methods. The best performing methods, KGCN and KGNN-LS, are also added as baselines, which are denoted as two dashed lines, respectively.
In this section, to demonstrate the effectiveness of item encoder and user encoder, we consider the following two variants: KHAN-h, in this model, we do not consider user interests based on user interaction sequences. Specifically, we use the user representation KHAN-i, the variant model simply employs the embedding of the item ID as item representation without learning from KG.
Figure 5 illustrates the results of KHAN-h, KHAN-i, and KHAN in terms of Recall@10 and Recall@50. We also add KGCN and KGNN-LS as baselines, where KGCN only distinguishes user-relation attention, and KGNN-LS performs best w.r.t Recall@10 compared with other baselines. According to Fig. 5, we have the following findings: KHAN outperforms KHAN-h and KHAN-i on both datasets, which validates that the user encoder and the item encoder are both beneficial for recommendation. KHAN-i performs better than KHAN-h on both datasets. One possible reason is that user interaction sequences can better reflect user interests and excessive reliance on KG may introduce noise to user preferences. Even without considering user interests based on user interaction sequences, KHAN-h still outperforms KGCN and KGCN-LS in most cases, which indicates the effectiveness of the hierarchical attention network. Note that KGNN-LS performs better than KHAN-h in Recall@10 on Dianping-Food, indicating that mitigating overfitting is also a significant part to be considered in the use of KG.
Results in data sparsity
One major motivation to exploit KG in recommender systems is to alleviate the sparsity issue. In order to investigate whether exploiting connectivity information of KG is helpful to alleviate this issue, we conduct experiments in cold-start scenarios where user-item interactions are sparse. With the validation and test set being kept fixed, we reduce the size of the training set from r = 100% to r = 20%. Figure 6 shows the results w.r.t. AUC on MovieLens-20M. From the results, we have the following observations:
When the training set is reduced from 100% to 20%, the performance of methods using only user-item interactions decreases significantly compared with KG-based methods, indicating that the information learned from KG can compensate for the lack of use-item interactions. Our model consistently performs well compared with other KG-based methods, which validates that KHAN can effectively mitigate the data sparsity issue.
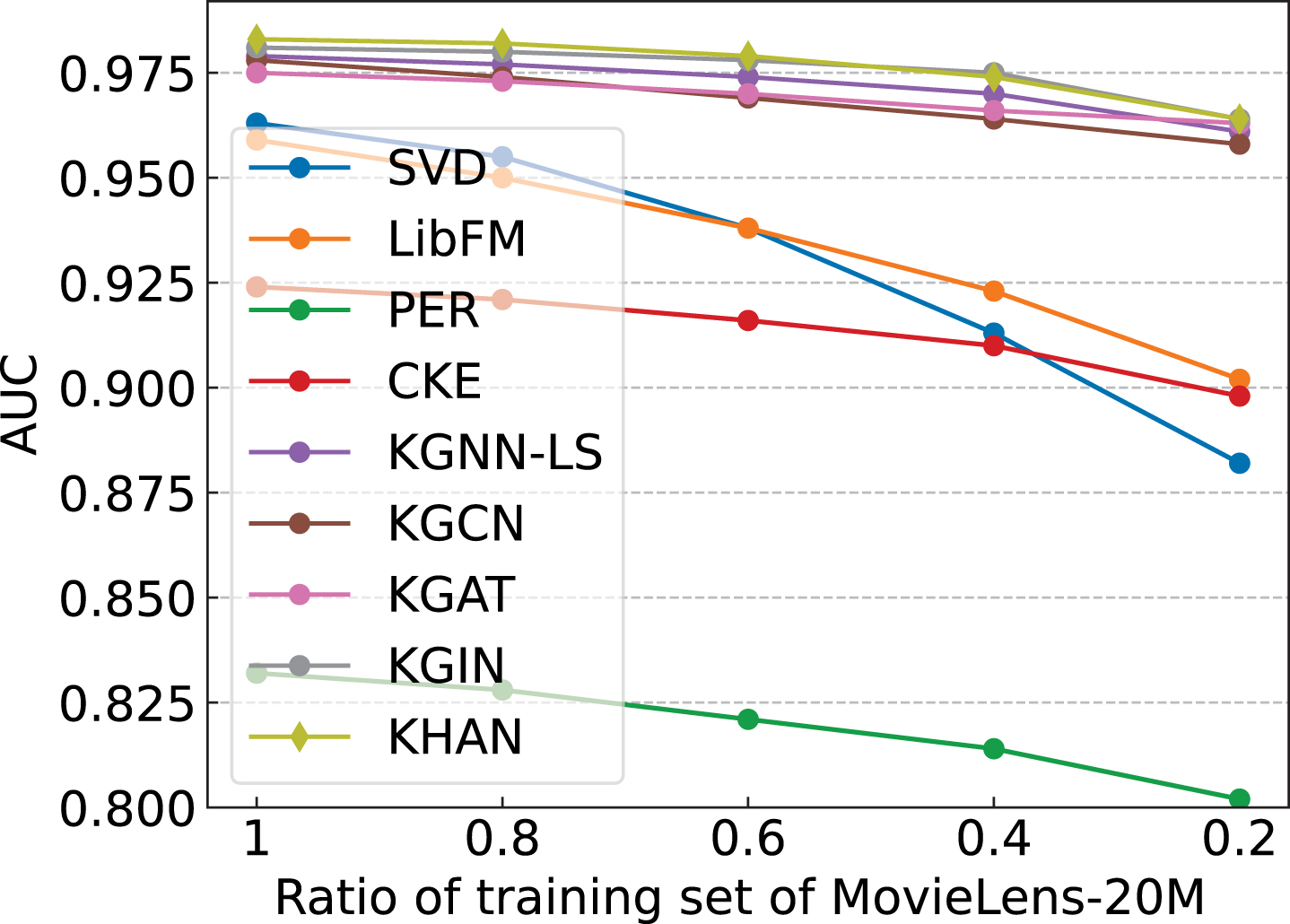
The performance of different methods w.r.t. the ratio of training set.
In this section, we attempt to understand how the hierarchical attention mechanism facilitates item representation learning. Towards this end, we randomly selected two users u73 and u205 from MovieLens-20M, and one item v548 that they both interact with. Figure 7 presents how the hierarchical attention mechanism distinguishes the contribution of neighboring entities to the central entity. There are two findings as follows: KHAN can explicitly distinguish the importance of different relations and different entities under the same relation to a user. As we can see, for user u73, he pays most attention to the movie director, and focuses secondly on the movie actor. For different movie actors, he also has different preferences. In addition, combining the attention values in the knowledge graph endows KHAN the ability of interpretability. For example, u73 chooses v548 because v548 matches his preference for a certain director. Jointly analyzing the hierarchical attention values of item v548 when facing user u73 and user u205, we find that the movie director contributes significantly to the item v548 for user u73, while the movie actor achieves a higher attention score for user u205. It verifies that KHAN can adaptively learn different representations for an item when facing different users.
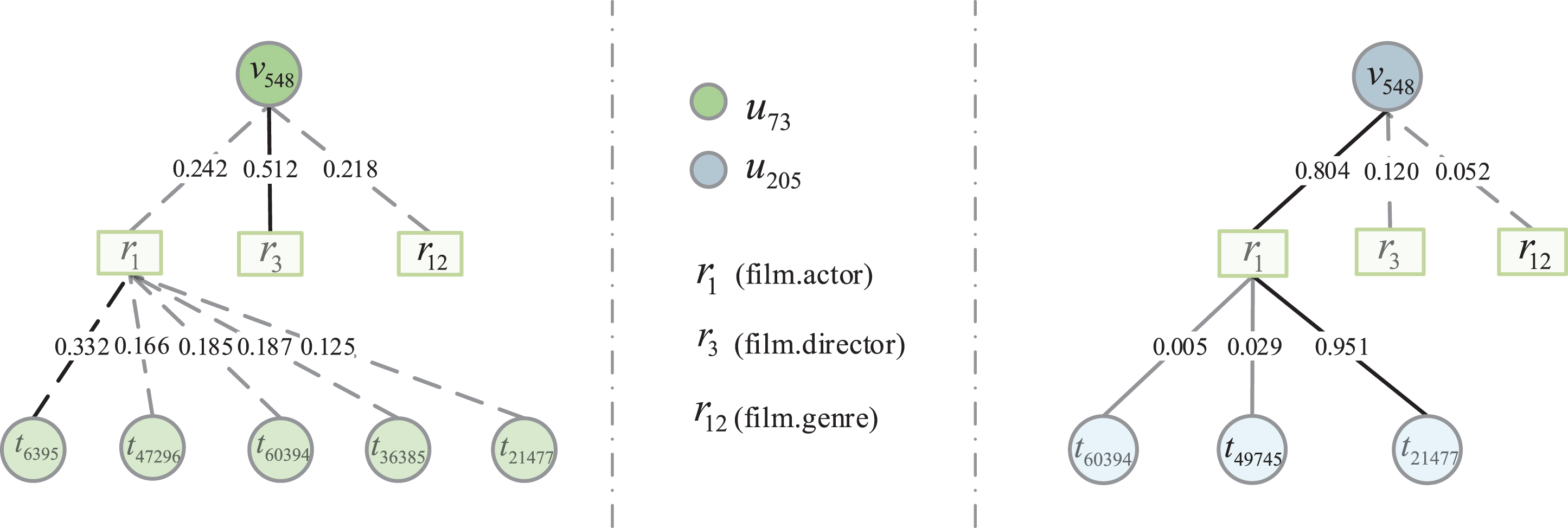
Hierarchical attention values of item i548 when facing user u73 and user u205. Relations connected to only one entity omit their entity since the entity weight is fixed to 1.
In this work, we have proposed a knowledge-aware hierarchical attention network KHAN for personalized recommendation, which is comprised of an item encoder and a use encoder. In the item encoder, to learn effective entity representations, we have designed a hierarchical attention network that makes full use of the local neighborhood information from surrounding an entity by carefully discriminating the importance of the neighbors. In the user encoder, we have learned user representations based on user interaction sequences and combined them with user representations introduced in the item encoder through a gating mechanism to capture complex user interests. We have conducted extensive experiments on real-world datasets. The results have shown that KHAN improves over the strongest baselines in terms of AUC and F1 by 0.51%, 0.75%,1.51% and 1.26% on MovieLens-20M and Dianping-Food, demonstrating the significant advantage and rationality of the proposed model.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under grant No.61872163 and 61806084, Jilin Province Key Scientific and Technological Research and Development Project under grant No.20210201131GX, and Jilin Provincial Education Department project under grant No.JJKH20190-160KJ.
https://grouplens.org/datasets/movielens/
https://www.dianping.com/