
Abstract
There are problems that standard square convolution kernel has insufficient representation ability and recurrent neural network usually ignores the importance of different elements within an input vector in sound event localization and detection. This paper proposes an element-wise attention gate-asymmetric convolutional recurrent neural network (EleAttG-ACRNN), to improve the performance of sound event localization and detection. First, a convolutional neural network with context gating and asymmetric squeeze excitation residual is constructed, where asymmetric convolution enhances the capability of the square convolution kernel; squeeze excitation can improve the interdependence between channels; context gating can weight the important features and suppress the irrelevant features. Next, in order to improve the expressiveness of the model, we integrate the element-wise attention gate into the bidirectional gated recurrent network, which is to highlight the importance of different elements within an input vector, and further learn the temporal context information. Evaluation results using the TAU Spatial Sound Events 2019-Ambisonic dataset show the effectiveness of the proposed method, and it improves SELD performance up to 0.05 in error rate, 1.7% in F-score, 0.7° in DOA error, and 4.5% in Frame recall compared to a CRNN method.
Keywords
Introduction
Sound event localization and detection (SELD) is to identify the temporal activities of each sound event, estimating their respective spatial positions trajectories when active, and further associating with textual labels with the sound events. It is a combined task of sound event detection (SED) and direction-of-arrival (DOA) estimation. Sound event localization and detection have been widely used in many fields such as robotics, smart cities, smart homes and industries, smart conferences, and biodiversity monitoring, and it has very broad application prospects and important research value.
Due to the emergence of more hard-labelled audio datasets, more and more methods based on deep neural network models have greatly improved the performance of SELD. Recently, deep neural networks have achieved good results in sound event detection [16], and they have been applied successfully to pure source localization [2,7,19], showing potential for joint modelling of the SELD task. Advanne et al. [1] present SELDnet, which is a convolutional recurrent neural network that can identify, locate and track multiple sound events at the same time, the results show that this method is generic and applicable to any array structure, robust to reverberation, and low signal-to-noise ratio scenarios. After that, most structures adopt the method of combining CNN and RNN. Kong et al. [14] proposed a sound event localization and detection method based on convolutional neural network, and by studying the CNN of layers 5, 9, and 13, it is found that the CNN of layer 9 is a better-performing model. Kapka et al. [12] use four CRNN SELDnet-like single output models into estimating the number of sound sources, estimating the direction of arrival of a single sound source, estimating the direction of arrival of the second source where the direction of the first one is known and a multi-label classification task, achieving a lower error rate than CRNN. Cao et al. [5] use two CRNNs for SED and DOA estimation, using log mel feature for sound event detection, using intensity vector and generalized cross-correlation features for localization, which can improve the performance of SED and DOA estimation, and is significantly better than CRNN. Ranjan et al. [20] combine the deep residual network with the recurrent neural network to estimate the classes and direction of sound events in the reverberant environments, which is a great improvement over the CRNN. Cordourier et al. [8] use the generalized cross-correlation with phase transformation algorithm to augment the magnitude and phase features at each frame, generalized cross-correlation can calculate the arrival time difference in the audio signal, compared with using phase and amplitude as the input feature, generalized cross-correlation with phase transformation CRNN has achieved good results. Ronchini et al. [21] use the convolutional recurrent neural network with the rectangular filter to identify important features related to tasks, and also uses data augmentation technology to increase the size of the training dataset, the system has better results than the CRNN model. Celsi et al. [6] use quaternions as input features, which are related to the sound intensity, and the sound intensity is related to the direction of arrival of the sound source, compared to existing methods, this method can improve the performance of sound event localization. Krause et al. [15] are based on arborescent convolutional recurrent neural networks designed to enable joint localization and detection of overlapping acoustic events, where the relationship between the phase and amplitude channels is utilized independently in the two branches and is connected before the recurrent layer. Nustede et al. [18] present contribution incorporates group delay features into the baseline system of DCASE 2019 task3, supplementing them with amplitude features. Group delay encoding may constitute a more robust feature for data-driven algorithms as it represents time delays of the signal’s spectral-band envelopes. Komatsu et al. [13] combine the learnable gated linear unit with convolutional neural network to extract useful features from the amplitude and phase, compared to the CRNN method, this method improves the performance of SELD. Guirguis et al. [10] use temporal convolutional network for sound event localization and detection, it uses dilated convolution to enlarge the receptive field, so that more input data is helpful for output, the proposed framework has achieved good results in four different datasets, and has good robustness to different types of noise and reverberation, improved the performance of sound event localization and detection model.
The above SELD methods based on deep neural network models have achieved good results. However, most models use standard square convolution kernel which can not extract abundant feature information. In addition, recurrent neural network (RNN) always ignores the importance of different elements within an input vector, resulting in the performance degradation of the SELD. In order to solve the above problems and further improve the performance of SELD, this paper proposes an EleAttG-ACRNN model, which is verified by the TAU Spatial Sound Events 2019-Ambisonic dataset. The experimental results show that the method proposed in this manuscript has certain advantages, and significantly improves the performance of sound event localization and detection. The main contributions of this manuscript are as follows:
An asymmetric convolutional block (ACB) is proposed to replace the standard convolutional layer. Through the asymmetric convolutional block, the weight of the kernel skeleton position can be increased, and the representational ability of the square convolutional kernel can be improved, allowing the network to extract rich features. Context Gating (CG) is proposed as the activation function. Context Gating can highlight the important information of time-frequency units by weighting important features. Reduce the interference of useless information. By adding Squeeze Excitation (SE) after convolution. SE can improve the interdependence between channels, allow the network to recalibrate features, and learn to use global information to selectively emphasize information features, enabling the model to extract more discriminative sound features. Integrating Element wise Attention Gate (EleAttG) into the Bidirectional Gated Recurrent Unit (BGRU) network can highlight the importance of different elements in the input vector, while suppressing the influence of unimportant elements, and obtaining the temporal correlation between frames.
Sound event localization and detection based on EleAttG-ACRNN model
EleAttG-ACRNN model structure
We propose the EleAttG-ACRNN model, which includes input, three CG-ResASECNN modules, two EleAttG-BGRU modules, FC and output. First, the phase and amplitude of the sound signal are input to the stacked three CG-ResASECNN modules for depth feature extraction. Then the output of CG-ResASECNN is sent to the EleAttG-BGRU module which can highlight the importance of different elements within an input vector and further learn the temporal context information. The output of EleAttG-BGRU is sent to the SED branch and the DOA branch, the SED branch outputs the classes of events in each time frame that through the sigmoid activation function, the DOA branch outputs the azimuth and elevation classified by the event in each time frame. As shown in Fig. 1.
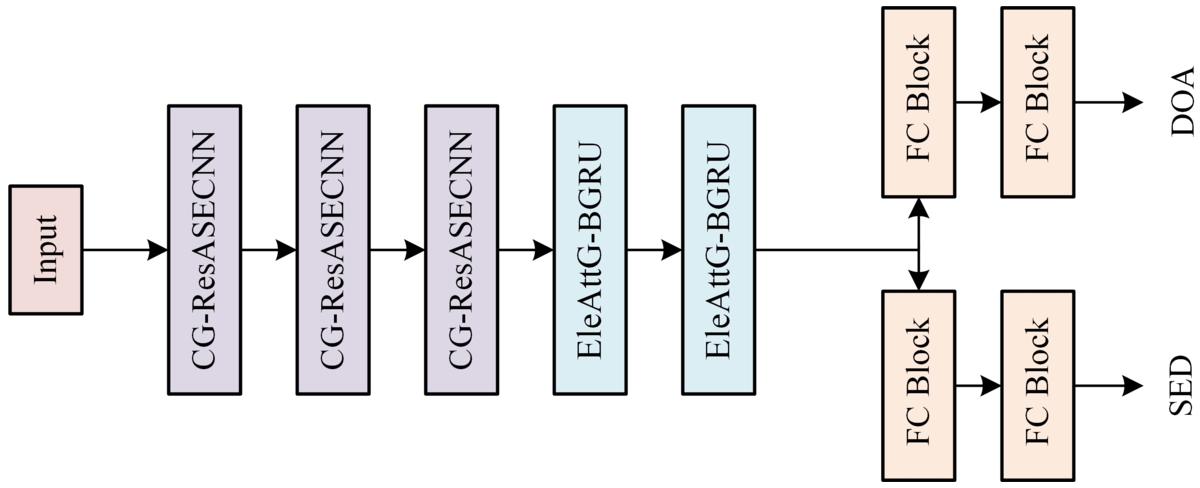
EleAttG-ACRNN network structure diagram.
Essentially, CNN performs a standard square convolution, but can not extract rich feature information. Therefore, this paper adopts the asymmetric convolution block (ACB) as the building block of CNN [9], it uses one-dimensional asymmetric convolution to improve the representation ability of the square convolution kernel and enrich the feature space. In order to extract effective information from amplitude and phase, this paper uses context gating (CG) as the activation function to weight the features. Then applies squeeze excitation (SE) to model interdependencies between channels and to strengthen the representational power of the CNN by improving the quality of spatial encodings throughout its feature hierarchy. The residual connection can accelerate the training speed, greatly alleviate the problem of gradient disappearance in the deep networks, and improve the model effect. It is shown in Fig. 2.
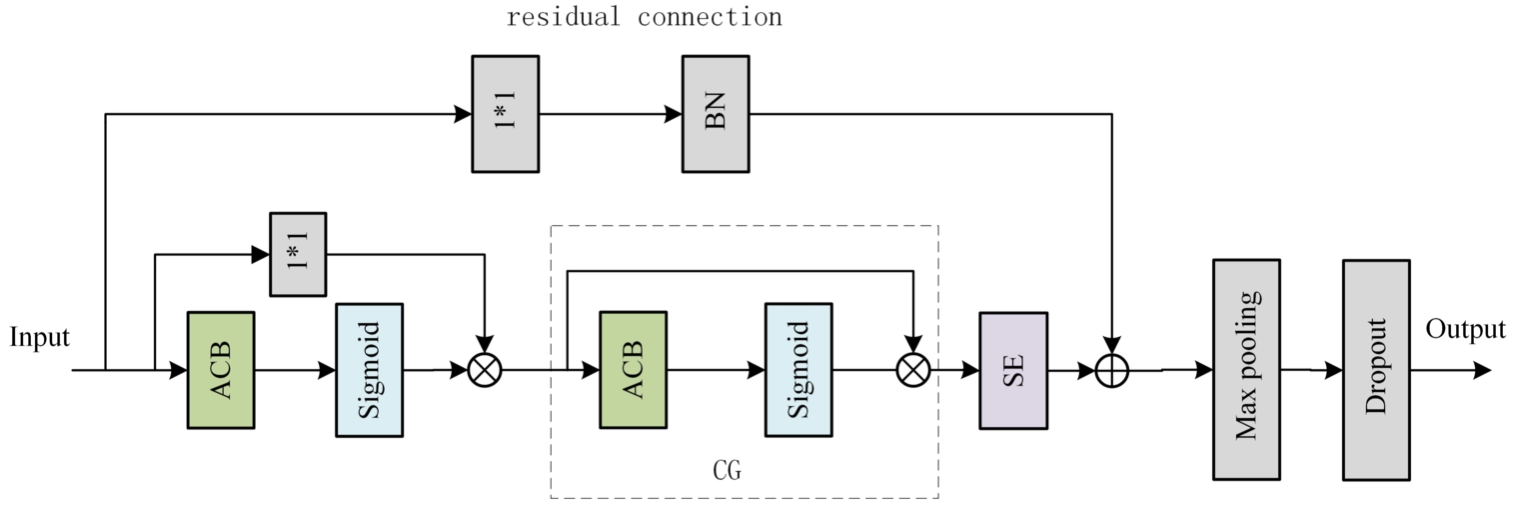
CG-ResASECNN network structure diagram.
A standard
By randomly setting the weights at different locations of the
In the network model of this paper, the ACB consists of three parallel layers with kernel sizes of
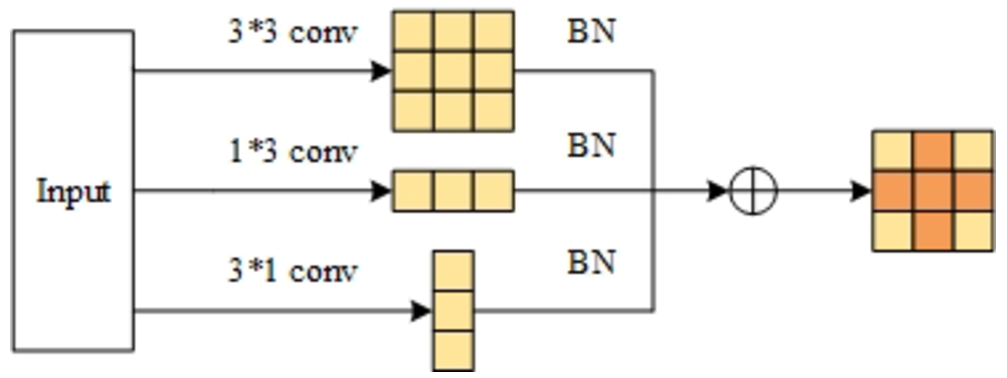
ACB structure diagram.
In the network structure of this paper, in order to make the model pay more attention to the important part of the audio features. Therefore, we use the learnable CG as an activation function to replace the conventional ReLU activation function in the CRNN model [17]. CG can capture the dependencies between features to recalibrate the different activation intensities of input features. The CG is connected to each CNN layer, and the output of each CNN layer is weighted that according to the importance of the input. The CG is computed as follows:
Compared to the gated linear unit, the CG weights the input vector X directly, rather than the linear transformation of X, so the CG only learns a set of weights and reduces the training parameters.
Squeeze excitation (SE)
SE improves the quality of the network representation by modelling the interdependencies between the channels of its convolutional features [11]. This mechanism allows the network to perform feature recalibration, in which it learns to use global information to selectively emphasize informative features and suppress less useful ones. It is shown in Fig. 4.

SE structure diagram.
For any given transformation
Recurrent neural networks (RNNs) are capable of modelling temporal dependencies of complex sequential data. In general, currently available structures of RNN tend to control the contributions of current and previous information. However, the exploration of different importance levels of different elements within an input vector is always ignored. Therefore, adding EleAttG to the RNN block, to empower the RNN neurons to have attentiveness capability [22]. For all neurons of an RNN block, the input and output of EleAttG are attention vectors of the same dimension, then the original input is modulated by the attention vector to strengthen the impact of important elements while suppressing the impact of unimportant elements.
For an RNN block, EleAttG is used to enhance the RNN neurons to have attentiveness capabilities. EleAttG is a vector
The neuron iterative expression of adding EleAttG to the BGRU is computed as follows:
The structure of EleAttG-BGRU is shown in Fig. 5.

EleAttG-BGRU structure diagram.
Data set
The experiment uses the TAU Spatial Sound Events 2019-Ambisonic dataset, which consists of a development and evaluation set [4]. The development set consists of 400 one-minute long recordings sampled at 48000Hz, divided into four cross-validation splits of 100 recordings each. The evaluation set consists of 100 one-minute recordings. The development and evaluation sets are synthesized using spatial room impulse response (IRs) collected from five indoor locations, which have 504 unique combinations of azimuth-elevation-distance. Furthermore, in order to synthesize the recordings, the collected IRs are convolved with the isolated sound events dataset from DCASE 2016 task 2. Finally, to create a realistic sound scene recording, natural ambient noise collected at the IR recording locations is added to the synthesized recordings, which makes the average SNR of the sound events is 30 dB. The number of azimuth and elevation angles of the sound source direction is 36 with 10° intervals from −180° to 180° and 9 with 10° intervals from −40° to 40°, respectively. The dataset contains 11 sound event classes, such as throat clearing, coughing, doorbell pressing, door pushing, door knocking, speaking, laughter, and flipping books, etc. In addition to the Ambisonic format data, this dataset also provides Microphone Array format data.
Measurement metrics
The SELD task is evaluated using individual metrics for SED and DOA estimation. For SED, we use the standard SED metrics, error rate (ER) and F-score (
ER measures the number of errors according to insertion errors
For DOA estimation, we use two frame-wise metrics: DOA error and Frame recall.
For a recording of length T time-frames, the
In order to account for time frames where the number of estimated and reference DOAs are unequal, we report the second metric Frame recall. The Frame recall is computed as follows:
Experimental setup
The experimental equipment in this manuscript uses the Inter(R) Xeon(R) Gold 5122 CPU@3.60GHz processor with a memory size of 64 GB. GPU model is NVIDIA Corporation GK210GL8, experiments run in GPU mode, the operating system environment is Ubuntu 16.04, the development integration environment is Anaconda, the development frameworks are Keras and Tensorflow, and the development language is Python.
During the training process, all models are trained for 100 epochs with the Adam optimizer and a batch size of 16. The learning rate is 0.0001. Early stopping is employed, where training is stopped if no improvements on validation split is observed for 20 epochs.
Experimental results and analysis
To evaluate the performance of the proposed EleAttG-ACRNN network, we conducted six sets of experiments. The first two sets of experiments are in search of the best hyperparameter ρ of SE on the development and evaluation set. The third and fourth sets of experiments are to verify the effectiveness of the proposed network. The last two sets of experiments are the comparison of the proposed EleAttG-ACRNN model with other network models.
Parmeter selection experiment
In order to study the squeeze-excitation residual blocks contribution, it is decided to carry out a grid search of different possible ratios. The network is made up of 3 blocks of 64 filters. The ratio (ρ) is the same for all blocks as it can be seen in Fig. 1. The experiment results can be seen in Table 1 and Fig. 6.
Experimental results of different parameters in the development set
Experimental results of different parameters in the development set

Experimental results of different parameters in the evaluation set.
Experimental results of ablation under the development set
For sound event localization and detection, lower ER and DOA error values and higher F1 and Frame recall values indicate a well-performing network model. The results of the evaluation set experiments are shown in Fig. 6, using both the SED evaluation metrics (i.e., F1 and ER) and the DOA estimation metrics (i.e., DOA error and Frame recall). We can conclude that when
To verify the effectiveness of the ResSE, ACB, CG and EleAttG proposed in this paper, six comparative models are designed to perform ablation experiments. Based on the CRNN model, we add ResSE, ACB, CG and EleAttG. The results are shown in Table 2 and Fig. 7. The following is a description of the specific models:
CRNN network, which contains only a simple three-layer CNN and a two-layer RNN.
ResSE-CRNN network, which adds ResSE to the CRNN network.
ACB-CRNN network, which adds ACB to the CRNN network.
CG-CRNN network, which adds CG to the CRNN network.
EleAttG-CRNN network, which adds EleAttG to the CRNN network.
EleAttG-ACRNN network, which adds all the above modules to the CRNN network.
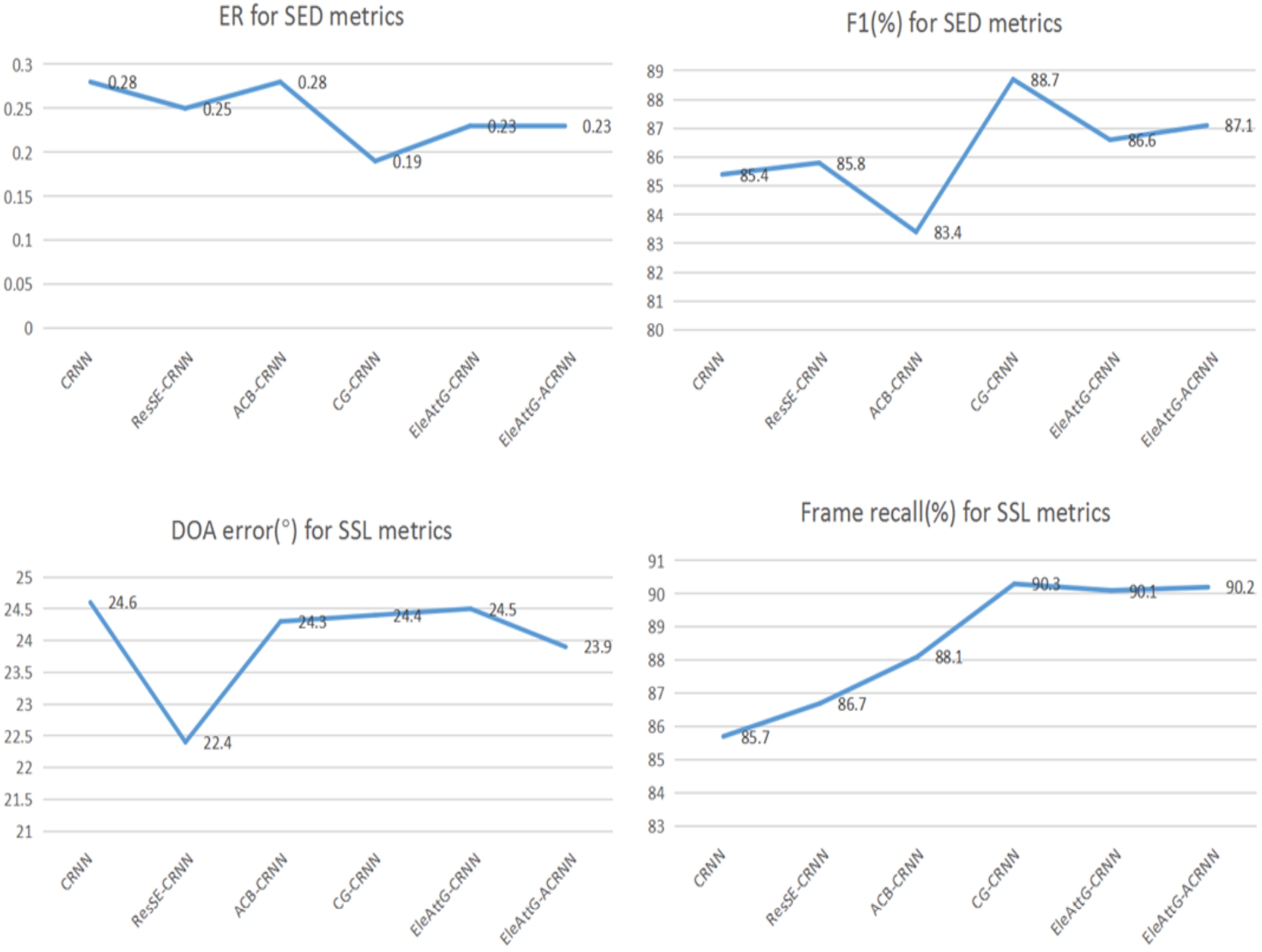
Experimental results of ablation under the evaluation set.
The results of the evaluation set experiments are shown in Fig. 7. We compared our proposed EleAttG-ACRNN network with the CRNN network, and the EleAttG-ACRNN network is superior in SED performance. The ER values are reduced by 0.03, 0.08, 0, 0.05 and 0.05 respectively, the F1 values are increased by 0.4, −2.0, 3.3, 1.2 and 1.7 respectively. For the DOA estimation, the proposed EleAttG-ACRNN network is superior in DOA estimation performance compared to CRNN. The DOA error values are reduced by 2.2, 0.3, 0.2, 0.1 and 0.7 respectively, the Frame recall values are increased by 1.0, 2.4, 4.6, 4.4 and 4.5 respectively. This indicates that our proposed EleAttG-ACRNN network is superior to CRNN in SED and DOA estimation performance.
Compare the results of the EleAttG-ACRNN model with other network models on the TAU Spatial Sound Events 2019-Ambisonic dataset. The results are shown in Table 3 and Fig. 8.
Experimental results of different models under the development set
Experimental results of different models under the development set
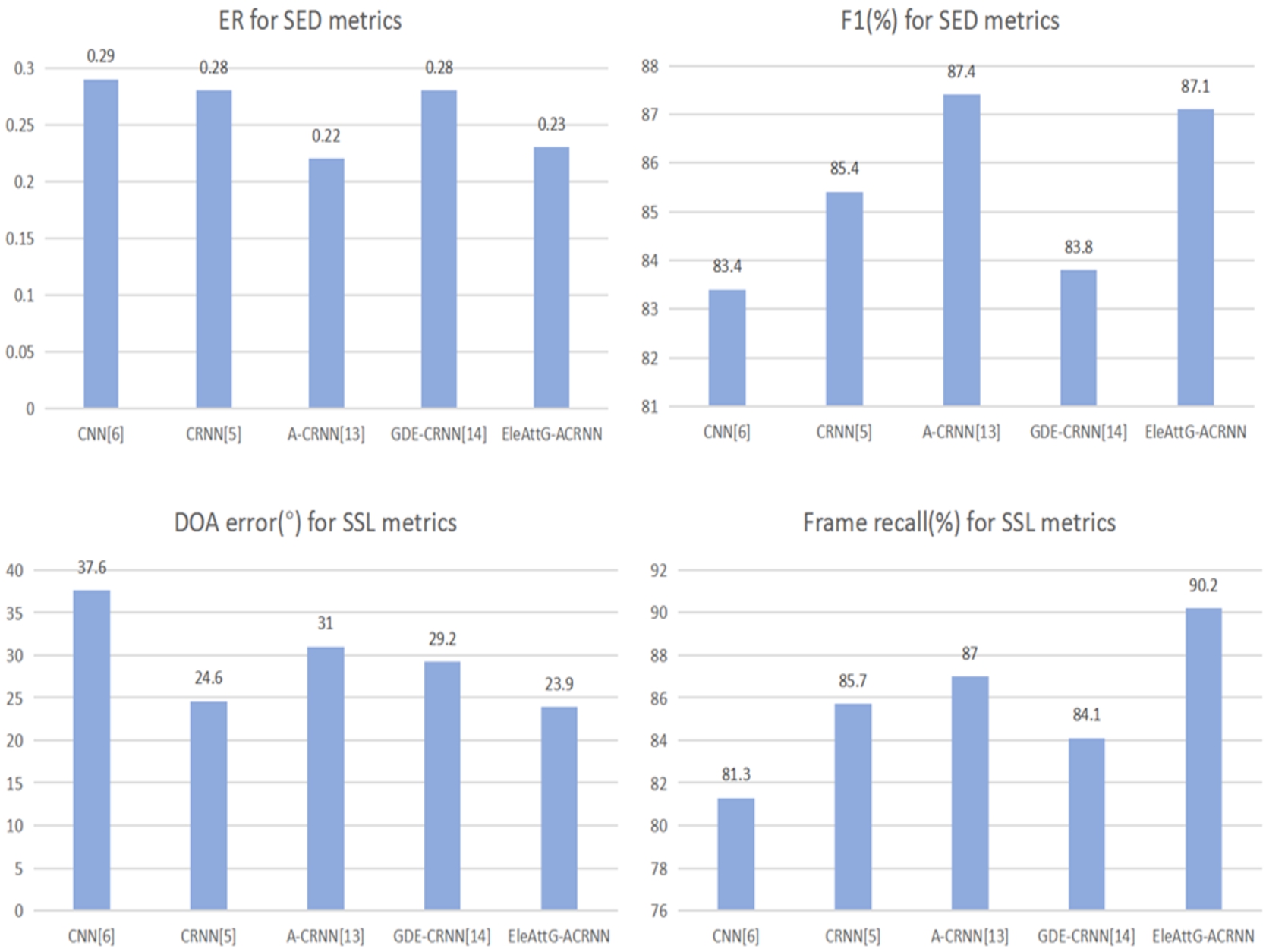
Experimental results of different models under the evaluation set.
The results of the evaluation set experiments are shown in Fig. 8. Compared to CNN, A-CRNN and GED-CRNN, the ER values of the EleAttG-ACRNN network are reduced by 0.06, 0.01 and 0.05 respectively, the F1 values are increased by 3.7, −0.3 and 3.3 respectively, which indicates that our proposed EleAttG-ACRNN network is superior in SED performance compared to other networks. For DOA estimation, the DOA error values of the EleAttG-ACRNN network are reduced by 13.7, 7.1 and 5.3 respectively, the Frame recall values are increased by 8.9, 3.2 and 6.1 respectively, which indicates that our proposed EleAttG-ACRNN network is superior in DOA estimation performance compared to other networks. So our proposed EleAttG-ACRNN network has some advantages over other networks on the same dataset.
This paper has proposed an EleAttG-ACRNN model for sound event localization and detection. Compared with CRNN, the EleAttG-ACRNN model improves the representation capability of the convolution and enriches the feature space. The EleAttG-ACRNN model weights the important features and suppresses the irrelevant features, and learns the features of space and channel independently, so that it can improve the interdependence between feature channels. The EleAttG-ACRNN model highlights the importance of different elements within an input vector and further learns the temporal context information. Evaluation results using the TAU Spatial Sound Events 2019-Ambisonic dataset show the effectiveness of the proposed network, and it improves SELD performance up to 0.05 in ER, 1.7% in F-score, 0.7° in DOA error, and 4.5% in Frame recall compared to a CRNN method. Therefore, the EleAttG-ACRNN network model proposed in this paper effectively improves the performance of sound event localization and detection.
Footnotes
Acknowledgements
This work was supported by National Natural Science Foundation of China (Grant No. 61902228), the Fundamental Research Funds for the Central Universities (Grant No. GK202105006, GK202103083).