
Abstract
Fruit detection and segmentation is an essential operation of orchard yield estimation, the result of yield estimation directly depends on the speed and accuracy of detection and segmentation. In this work, we propose an effective method based on Mask R-CNN to detect and segment apples under complex environment of orchard. Firstly, the squeeze-and-excitation block is introduced into the ResNet-50 backbone, which can distribute the available computational resources to the most informative feature map in channel-wise. Secondly, the aspect ratio is introduced into the bounding box regression loss, which can promote the regression of bounding boxes by deforming the shape of bounding boxes to the apple boxes. Finally, we replace the NMS operation in Mask R-CNN by Soft-NMS, which can remove the redundant bounding boxes and obtain the correct detection results reasonably. The experimental result on the Minneapple dataset demonstrates that our method overperform several state-of-the-art on apple detection and segmentation.
Keywords
Introduction
Apples are grown on a large scale all over the world due to their delicious taste and rich nutrition. The most time-consuming and laborious task in apple orchards is harvesting [1]. Yield estimation is important for the efficient management of harvest operations in apple orchards, but traditional manual estimation is no longer suitable for industrial apple planting in orchards. Many machine learning algorithms have excellent capabilities for apple detection and segmentation and are widely used in apple orchards, these methods can make the yield estimation work with a small number of manual work but get higher precision. However, due to the complex background in the actual apple orchard, factors such as fluctuating illumination, dense fruit distribution, occlusion of fruits by branches and leaves, overlap fruits, camera angle and distance can have certain impacts on target detection, which cause difficulties and challenges in accurate identification of fruits [2].
At present, machine learning algorithms combined with computer vision [3–8] are still the dominant approaches for fruit detection and segmentation in orchards. Usually, these methods use a series of image pre-processing operations, such as color threshold segmentation, Circular Hough Transform (CHT), fruit edge detection, region growth, and watershed segmentation to extract the features of fruit from images. The extracted features, including color, texture, morphology, or combined multiple features, are put into machine learning models such as supporting vector machine (SVM), K-means clustering, and template matching for supervised or unsupervised learning. In [9], a series of processing operations were taken on citrus images: convert RGB image to HSV, thresholding, orange color detection noise removal, watershed segmentation, and counting. A correlation coefficient R2 of 0.93 was obtained between the citrus counting algorithm and counting performed through human observation. Zhuang et al. [10] used block-based local homomorphic filtering on citrus image to obtain an illumination-compensated image, an adaptive enhanced red and green chromatic map was then generated, Otsu algorithm, morphology operation, marker-controlled watershed segmentation, and convex hull operation methods were used in combination to locate potential citrus regions from the chromatic map. Local texture information was extracted from the potential regions using local binary patterns and fed to a histogram intersection kernel-based support vector machine to make the final decision. Gene-Mola et al. [11] proposed a fruit detection algorithm based on reflectance thresholding and SVM, and they reduced the fruit occlusions for LiDAR-based approaches from two different ways: applying forced air flow through an air-assisted sprayer and using multi-view sensing. Although the above methods can identify the fruit target from images, the identification accuracy decreases when the condition of the background changes. Furthermore, it is difficult to find an universal method that can detect and segment fruits from different growth stages, especially in complex environments.
Compared with the traditional methods, deep learning methods are widely used in image object detection because of their ability to automatic feature extraction, outstanding performance of learning, and strong adaptability to variances of the working scene. In recent years, The advantages of deep learning are obvious, compared with the algorithms based on handcrafted features such as color, shape, and texture [12]. Tian et al. [13] proposed an improved YOLO-V3 model and used the DenseNet to process feature layers with low-resolution for detecting apples during different growth stages in orchards with complex background. Mao et al. [8] proposed a cucumber detection method with a multi-path convolutional neural network (MPC NN), combined with color component selection and SVM. Sa et al. [14] used imagery obtained from two modalities: RGB and Near-Infrared (NIR) images to train the Faster R-CNN model, and explored early and late fusion methods for combining the multi-modal (RGB and NIR) information. Jia et al. [2] used Residual Network (ResNet) combined with DenseNet as a backbone network for Mask Region Convolutional Neural Network (Mask R-CNN), the input parameter is reduced and recognition speed is fast. Kang and Chen [15] proposed a multi-function network to perform the real-time detection and semantic segmentation of apples and branches in orchard environments by using the visual sensor, the atrous spatial pyramid pooling (ASPP) and the Gated feature pyramid network (FPN), which can enhance the feature extraction ability of the network, a light-weight backbone network based on the residual network architecture is developed to improve the real-time computation performance of the network. Yu et al. [1] proposed a visual localization method for strawberry picking, which was used with Mask R-CNN to generate mask images of ripe fruits, compared with four traditional methods, this method improved the universality and robustness of Mask R-CNN in a non-structural environment.
The methods mentioned above performed good results in fruit detection and segmentation. However, these general object detection and segmentation methods have no special improvement for features of fruits in complex background. Therefore, the performance of apple detection and segmentation methods can be considerably improved by a method designed for the features of apple in complex background.
In this paper, We propose an improved Mask R-CNN for apple detection and segmentation named SE-Mask R-CNN. Firstly, the detector network should pay more attention to the feature maps which contain more information of apple, so the squeeze-and-excitation block [16] is introduced into the ResNet-50 backbone to distribute the available computational resources to the most informative feature map in channel-wise. Secondly, we optimize the bounding box regression loss with aspect ratio to make the Mask R-CNN more suitable for apple detection and segmentation, which can assist the regression of bounding boxes by deforming the shape of bounding boxes to the apple in training stage. Finally, to improve the detection performance in complex background such as overlap and occlusion, we replace the traditional NMS in Mask R-CNN with Soft-NMS [17], which can remove the redundant bounding boxes and obtain the correct detection results reasonably.
The rest of this paper is organized as follows. Section 2 describes the SE-Mask R-CNN for apple detection and segmentation in detail. Section 3 introduces the model training and loss function of SE-Mask R-CNN. Section 4 reports the experimental evaluation and analysis of our method. Section 5 presents conclusions and future work.
Method
Mask R-CNN [18] is a simple but efficient image segmentation model, which performs object detection, and instance segmentation at the same time. Mask R-CNN combines Faster R-CNN [19] for object detection and FCN [20] for semantic segmentation. In this section, we introduce SE-Mask R-CNN from three parts, which respectively represent the three important operations of SE-Mask R-CNN, and we optimize parts of these to make the Mask R-CNN more suitable for apple detection and segmentation. The farmework of SE-Mask R-CNN is shown in Fig. 1.
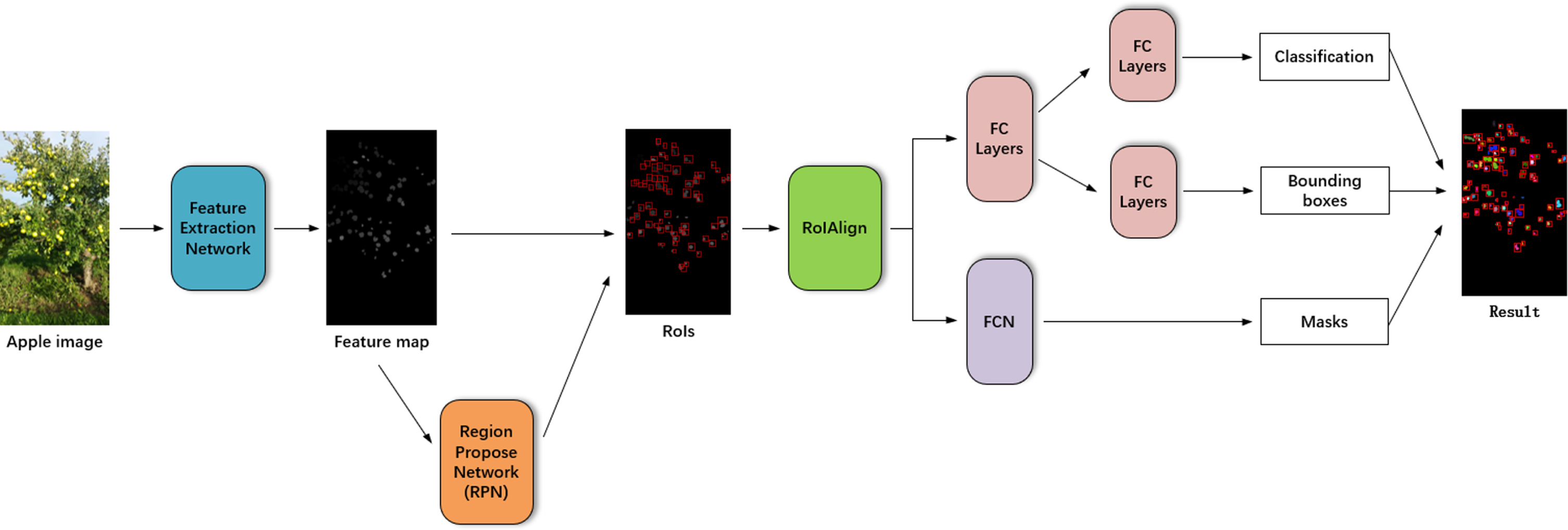
The framework of SE-Mask R-CNN.
The feature extraction network of SE-Mask R-CNN can be changed by different weight layers and depths. In general, a deeper feature extraction network may result in higher accuracy, but the speed of model training and testing will be descended, even when the network reaches a certain depth, the testing errors will increase because of over-fitting. ResNet can deal with this problem effectively by the residual structure which can learn the representation of residuals between inputs and outputs to accelerate the training and avoid over-fitting.
The feature maps extracted by ResNet are abundant, however, the following network should pay more attention on the feature maps which contain more information of apple. So it is necessary to assign more weight to the channels which contain more features of apple than others. The attention mechanism is generated to solve this problem, which can be interpreted as a method that can distribute the available computational resources unevenly, usually to the most informative components of a signal. Squeeze-and-excitation block (SE block) is a kind of channel-wise attention mechanism, so we introduce the SE block (Fig. 2) to the ResNet-50, feature maps generated by the Residual module of each layer is processed by SE block continuously, which can assign weights in each channel of feature maps, and give more weight to the feature maps which contain more information of apple.

The schema of the original Residual module (left) and the SE-ResNet module (right).
There are three steps in the SE block: squeeze, excitation, and scale (Fig. 3) [16]. Firstly, the feature maps U
C
are squeezed by global average pooling to generate channel-wise statistics. Then, the scale factor can be fully captured by a bottleneck with two fully-connected (FC) layers around the non-linearity, which describes the channel-wise dependencies. Finally, the output of the block is obtained by scaling the input feature maps U
C
with the scale factor S
C
, The output of the SE-block is defined as follows:

The structure of the squeeze-and-excitation block.
In this way, the post networks will pay more attention to the feature map which contain more information of apple than others, it is useful to improve the accuracy of apple detection and segmentation.
In the feature extraction network with multiple convolution layers, the high layers extract the low-resolution and semantically strong features, high-resolution and semantically weak features were extracted by the underlying layers. To better detect the apple in different scales, the Feature Pyramid Network (FPN) is introduced to the feature extraction network Fig. 4, which is developed for building high-level semantic feature maps at all scales. In the FPN architecture, the size of the top-level feature map is expanded to the same with the low-level feature maps by sampling, the number of channels of low-level feature map is changed by the 1x1 convolution, finally the top-level features are merged with the underlying features.
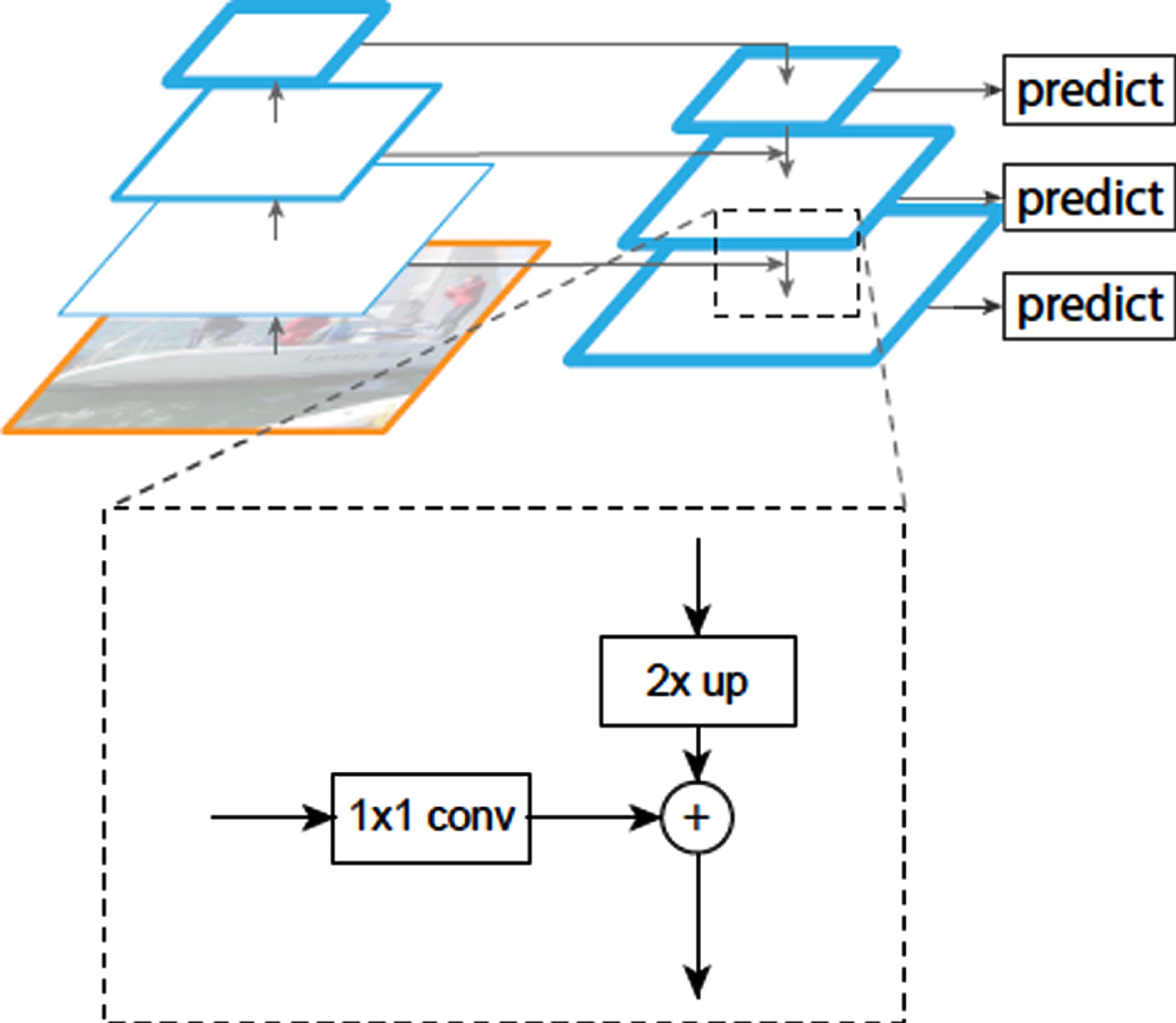
The structure of FPN. The top-level features are merged with the underlying features.
The feature maps generated by the feature extraction network are used as the input of the Region Propose Network (RPN) (Fig. 5), According to the size, scale and the shooting distance of apple image, there are five different area scales including 32 × 32, 64 × 64, 128 × 128, 256 × 256, 512 × 512, and three aspect ratios including 1:1, 1:2, 2:1 to be combined randomly to generate 15 kinds of anchor boxes for each corresponding pixel of the feature map, there are two tasks need to do for the anchors: On the one hand, the classification branch with SoftMax layer classify the anchor boxes, we assign a positive label to two kinds of anchors: (i) The anchor whose Intersection over Union (IoU) with a ground-truth box is the highest among all anchors whose IoU is not zero. (ii) an anchor that has an IoU overlap higher than 0.7 with any ground-truth box. On the other hand, the border regression branch is used to regress the coordinates of the anchor boxes. At the end of RPN, the proposal boxes are initially screened from the anchor boxes by the result of the two branches: 2 × 15 scores represent the probabilities of an object, 4 × 15 coordinates represent the offset distance from target boxes. The Regions of Interest (RoIs) are generated by mapping the proposal boxes to the feature maps extracted by the backbone.

The structure of the Region Propose Network (RPN).
Before the classification, bounding box regression, and instance segmentation, it is necessary to extract the corresponding features of each RoI from feature maps. In Faster R-CNN, this work is done by RoI Pooling, Firstly, the floating-number RoIs are mapped to the corresponding position of the feature maps. Secondly, The RoIs are subdivided into spatial bins. Finally, the feature values of each bin are aggregated by max pooling. However, there are two quantization operation performed in the first two steps, these operations may introduce misalignment between RoIs and the extracted feature [18], and have an negative effect on apple detection and segmentation. The RoI Align can solve this problem, which removes the quantization operation of RoI Pooling and uses bilinear interpolation operation to compute the position of RoIs in the feature maps.
In the last section of SE-Mask R-CNN, the target detection and instance segmentation result are generated by a multi-branch prediction network, which contains three prediction branches. Fully convolutional network (FCN) can segment the apple in pixel-level accurately, It is an end-to-end network including fully convolution and deconvolution to classify each pixel. The fully connected branch is used to classify the boxes in RoIs. The regression branch is used for the bounding boxes regression.
In the regression operation, the Non-maximum suppression (NMS) is used to remove the redundant bounding boxes. If there are two overlapping bounding boxes with different confidence scores, the bounding box with lower confidence score will be removed by NMS operation, despite the score of it, the detection result of overlapping apple will removed incorrectly in this way. So we introduce the Soft-NMS method to Mask R-CNN, which solve this problem by adding only one line of code based NMS, it decreases the score instead of removing the box with a lower score as in NMS, the higher the IoU factor, the more the decrease of the score, finally, the boxes whose score is lower than the threshold will be removed. The comparison of the results respectively generated by NMS and Soft-NMS are shown as Fig. 6.

The comparison of the results respectively generated by NMS and Soft-NMS. Apple detected by regression branch (left), NMS(middle), and Soft-NMS(right)
Transfer learning
Transfer learning means to transfer the trained model parameters to the new model, which can promote the new model training and make up the lack of training data, because most of the basic features extracted from images such as edge, shape are related, so through the transfer learning, we can share the pre-trained parameters with the new model to speed up and optimize the learning efficiency of the model, without learning from scratch [21]. In this work, a pre-trained SE-Mask R-CNN based on the COCO dataset [22] is introduced, COCO dataset is a huge dataset with 118k images and 91 categories.
Loss function
The loss function of the SE-Mask R-CNN is consist of two major parts: the loss L RPN computed by classification and regression operation in RPN and the loss of the multi-branch predictive network LMul-Branch, so the total loss function can be described as follows:
In the training process of RPN, the classification loss is generated by the Softmax Layers to measure the probability of whether the anchor box contains apple or not. And the bounding box regression loss is generated by the regression operation which regress the anchors belong to the foreground. So the L RPN is described as follows:
The loss function LMul-Branch of the multi-branch prediction network consists of three parts: Classification loss L cls which is computed by the classification branch, regression bounding box loss L reg which is computed by the regression branch, and mask loss L Mask which is computed by FCN. So, the LMul-Branch is described as follows:
So, the ratio of aspect ratio can be calculated as follows:
The SE-Mask R-CNN proposed in this paper is performed under the deep learning development framework of PyTorch, with TITAN XP for GPU acceleration, Inter (R) Xeon (R) E5-2620 v4 CPU. The network initialization parameters are shown in Table 1.
Initialization parameters of SE-Mask R-CNN
Initialization parameters of SE-Mask R-CNN
Limited by the lack of time and effort, researchers usually focused on the small dataset with little difference. Sa et al.[14] used the images acquired in indoor complex environments, but the quantity of images is only 122. Bargoti built a dataset with roughly 1000 images to train and test an apple detection network, but the image size is too small to learn from the feature map by the multiple convolution layers of Mask R-CNN [23]. To verify the stability and reliability of the proposed SE-Mask R-CNN, we conduct experiments on the Minneapple dataset [24]. Minneapple dataset contains 1000 apple images of resolution 1280 x 720 pixels (670 in training sets and 330 in test sets), which were taken either from the sunny or shady side of the tree row in the complex background (Fig. 7), and spread out the data acquisition over multiple days to ensure the varied illumination conditions. In addition, the focus of the image are not on the fruit but the whole fruit tree, which is according with the actual condition.

The different complex conditions of apple images in Minneapple dataset.
In this work, we use two kinds of evaluation metrics to evaluate the results of apple detection and segmentation respectively. Intersection over Union (IoU) is used to evaluate the result of apple detection, pixel accuracy is used to evaluate the result of apple segmentation. Moreover, we compute the class IoU and class pixel accuracy for apples. The formula is described as follows:
In this section, we compare the original Mask R-CNN with our proposed method. The experimental results are summarized in Table 2. The first row shows the performance of the original Mask R-CNN. The second row shows the performance of Mask R-CNN which uses the SE block combined with ResNet-50 as the feature extraction network. The third row shows the performance of Mask R-CNN with SE block and the aspect ratio to the bounding box regression loss. The fourth row shows the performance of our method.
Ablation Experiment of the SE-Mask R-CNN
Ablation Experiment of the SE-Mask R-CNN
As shown in Table 2, the performance of the Mask R-CNN & SE block is better than that of the original Mask R-CNN, the result demonstrates that the feature maps assigned with weights in channel-wise by SE block have high discrimination. The performance of Mask R-CNN & SE block & aspect ratio is better than that of Mask R-CNN & SE block, which proves that the optimized bounding box regression loss by aspect ratio is very effective in apple detection and segmentation, the aspect ratio can constraint the shape of the bounding box to make it similar to the shape of apple. The performance of our method is better than that of the Mask R-CNN & SE block & aspect ratio, which confirms that the Soft-NMS can remove the redundant bounding boxes and obtain the correct detection results more reasonably than NMS. So the Class Mean Accuracy of SE Mask R-CNN is higher than original Mask R-CNN. Besides, As shown in Fig. 8, the segmentation result of our method is better than the original Mask R-CNN under complex and dense environment.

The original image (left) and the segmentation result respectively generated by Mask R-CNN (middle) and SE-Mask R-CNN (right).
To further evaluate the performance of our method. We compare the performance between our method and the state-of-the-art. Semi-supervised GMM [25] is a semi-supervised clustering method based on Gaussian Mixture Models (GMM), which can be trained with few labels. User-supervised GMM [25] is the same model as in the semi-supervised GMM, this method used human supervision to create one model per tree row. U-Net [26] is a semantic segmentation network composed of a fully convolutional network, which consists of a contracting path and an expansive path, U-Net can generate great performance with very few training images, so it is suitable for the apple detection and segmentation while the dataset is not large. The experimental results are summarized in Table 3.
Comparison of the proposed method and Mask R-CNN
Comparison of the proposed method and Mask R-CNN
As the comparison shown in Table 3, the performance of our method is superior to terms of state-of-the-art. Our method extracts feature maps with SE-ResNet, which can distribute the available computational resources to the most informative feature map in channel-wise, so the Class IoU and Class Mean Accuracy of our method is superior to that of state-of-the-art. In addition, we introduce the aspect ratio to the bounding box regression loss, which can optimize the Mask R-CNN to be suitable for apple shape, and we replace the NMS by a robust Soft-NMS algorithm, which can remove the redundant bounding box reasonably. so the discriminating between each apple is more accurate than that of state-of-the-art.
In addition, we submit the segmentation result of our method to the Robotic Sensor Network Laboratories (RSN) MinneApple Fruit Segmentation Challenge 1 , and all terms of evaluation metrics are superior to other teams.
In this paper, we propose an effective apple detection and segmentation method named SE-Mask R-CNN. Firstly, in the feature extraction network, the SE block assigns weights in each channel of feature maps extracted by ResNet, which can distribute the available computational resources to the most informative feature map. Then, in the RPN, the proposals are detected by anchors, and the RoIs are generated by mapping the proposals on the feature maps. The bounding box regression loss with aspect ratio can deform the shape of apple. Finally, the detection and segmentation result is generated by the multi-branch prediction network. We replace the NMS by the Soft-NMS algrithm to remove the redundant bounding boxes robustly and reasonably. The experimental result on the Minneapple dataset demonstrates that our method can overperform several state-of-the-art on apple detection and segmentation.
Despite the considerable performance achieved by our method, there are still some room for improvement such as missed detection and over-segmentation, especially for the dense distribution of apples in images. In our future work, we will further explore the shape information of the apple to improve the performance.