
Abstract
The multi-layer feature pyramid structure, represented by FPN, is widely used in object detection. However, due to the aliasing effect brought by up-sampling, the current feature pyramid structure still has defects, such as loss of high-level feature information and weakening of low-level small object features. In this paper, we propose FI-FPN to solve these problems, which is mainly composed of a multi-receptive field fusion (MRF) module, contextual information filtering (CIF) module, and efficient semantic information fusion (ESF) module. Particularly, MRF stacks dilated convolutional layers and max-pooling layers to obtain receptive fields of different scales, reducing the information loss of high-level features; CIF introduces a channel attention mechanism, and the channel attention weights are reassigned; ESF introduces channel concatenation instead of element-wise operation for bottom-up feature fusion and alleviating aliasing effects, facilitating efficient information flow. Experiments show that under the ResNet50 backbone, our method improves the performance of Faster RCNN and RetinaNet by 3.5 and 4.6 mAP, respectively. Our method has competitive performance compared to other advanced methods.
Introduction
Object detection is a fundamental task in the field of computer vision and is widely applied in various domains, such as autonomous driving [5], face mask detection [35], unmanned aerial vehicle (UAV) scene analysis [37], and robot vision [34]. In recent years, with the rapid development of deep convolutional network model architectures for extracting image features [14] and advancing object recognition, detectors based on deep convolutional networks have brought higher accuracy to this essential task. This significant improvement also introduces new challenges, including the imbalance of feature levels [8] and inconsistent object sizes [36]. Feature Pyramid Network (FPN) [18] is a representative network structure proposed to address these issues.
FPN extracts multi-layer feature maps of different sizes and dimensions from different feature extraction stages of the backbone model designed for image classification and connects them horizontally into a pyramid network structure. FPN incorporates top-down connections between adjacent levels for incorporating rich semantic features at higher levels into the low-level feature maps to generate feature representations that combine high resolution and strong semantics. Although the FPN structure is simple and effective, there is still room for optimization and improvement. Some existing methods such as NAS-FPN [9], Aug-FPN [12], and Bi-FPN [32] can improve the detection accuracy of object detection methods using FPN structure to some extent at the expense of speed and training duration. However, there are still some problems: 1. Loss of the information in the highest-level feature maps. 2. Weak features of small objects in low-level feature maps. 3. Insufficient feature fusion at each level.
1. Loss of the information in the highest-level feature maps. In the FPN structure, the features of different stages in the backbone network are used, and the
2. Weak features of small objects in low-level feature maps. In the FPN structure, the low-level feature map retains detailed information about the image, and the detection of low-level features is more advantageous for objects that occupy a small image area. High-level feature maps have rich semantic information, so for detecting objects with complex shapes and complex features, the high-level features are more effective. However, due to the direct fusion of high-level features into low-level features in the FPN structure, the high-level features with rich semantics occupy the main prominence in the shallow features used to detect small objects, weakening the small object features and thus hindering the detection of small objects [17].
3. Insufficient feature fusion at each level [21]: The feature fusion among each level is the key content of FPN structure improvement in recent years, such as PA-FPN [22], NAS-FPN [9], Bi-FPN [32], etc. proposed to densely connect the feature maps between various layers and then stack multiple network structures, although this way increases the final accuracy, but introduces a large number of parameters and slows down the inference speed of the network.
In response to the above problems, we designed a new feature pyramid network structure named FI-FPN in our work and proposed three modules to optimize the existing problems of the FPN structure. First, we propose the multi-receptive field fusion (MRF) module for addressing the information loss of the top-level feature map. Before the feature pyramid structure, the highest-level features are obtained by stacking dilated convolution and standard convolution to obtain a larger receptive field, covering objects of various sizes. The max-pooling layer is used simultaneously to extract features of different scales, and the features at each stage of the extraction process are concatenated for efficient use of the highest-level features. Second, we proposed the contextual information filtering (CIF) module, which uses two branches for different contextual information extraction and combines the channel attention mechanism [15] to enhance the feature extraction process. Finally, aiming at the problem of insufficient feature fusion of each layer in FPN and the problem of aliasing effect [11], we propose the efficient semantic information fusion module (ESF). This module introduces a new branch that fuses the features of each layer of the feature pyramid by progressive splicing and fusion from low-level to high-level, and maintains the detection performance of the object detector for small objects by subtracting high-level features from low-level features.

The visualization of our object detection method is compared with that of the same backbone. Green bounding boxes represent the results of FPN, while blue bounding boxes represent the results of FI-FPN.
We evaluated our model on the MS COCO dataset [20] by replacing the FPN structure in RetinaNet [19] and Faster R-CNN [29] with FI-FPN. Our method achieved an improvement of 4.6 points and 3.5 points in Average Precision (AP) on ResNet50 as the backbone, respectively, outperforming other advanced FPN-based detectors. As shown in Fig. 1, the improvements from our method can be visualized when using the same backbone network. It is evident that our method can locate the bounding box more accurately and demonstrates better performance for small objects.
CNN-based object detector
After R-CNN [10] introduced CNN into the field of object detection, it opened the first two-stage object detection algorithm based on deep learning, which greatly improved the effect of object detection tasks. The current mainstream CNN-based object detectors are generally divided into two-stage object detectors and one-stage object detectors; they identify and localize objects by learning scale-sensitive features [17].
In the two-stage detector, SPPNet [25] proposed the Spatial Pyramid Pooling (SPP) strategy to solve the repeated operation problem in R-CNN, which converts any input into a fixed-length output through the pooling operation, thereby avoiding Repeated computation of convolutional features. Faster RCNN proposed a Region Proposal Network (RPN) instead of pre-handled proposals to generate candidate regions and uses nine shapes of anchor boxes as initial predictions and then performs regression adjustment on the anchor boxes, which greatly improved the performance of the two-stage object detector, almost all the two-stage detectors after Faster RCNN are based on it. Based on Faster RCNN, R-FCN [6] removes each branch’s fully connected layer of independent computation and designs an architecture that shares computation on the entire image to reduce workload and improve detection accuracy. Mask RCNN [13] introduced RoIAlign instead of RoIPooling based on Faster RCNN to obtain a better localization effect and added a mask branch for instance segmentation.
On the other hand, the one-stage object detector uses a unified network to directly regress and analyze the location and category information of the object and output the results directly to identify and localize the object. YOLO [26] predicted the classification confidence and bounding box on a single feature map, divided the input image into
Multi-level features
For object detection tasks, solving the key problem of the semantic difference between multi-scale features [16] is crucial. FCN [24] and U-Net [30] used skip connections to fuse information from lower layers. FPN used horizontally connected multi-level features and a top-down structure to enhance the detection of objects of various scales, greatly improving the detection effect. PANet [22] was the first to propose a bottom-up path augmentation FPN model, which used accurate low-level localization signals to enhance the entire feature hierarchy, thereby shortening the information path between low-level and top-level features. Long-range feature correspondences are captured in a multi-scale feature pyramid. NAS-FPN introduced Neural Architecture Search [38](NAS) into the field of object detection. Through NAS, the best FPN architecture was obtained, and multi-layer stacking was performed, which greatly improved the model’s accuracy.
Bi-FPN introduced learnable weights to learn the importance of different input features and increased cross-layer links. Compared with the previous feature pyramid structures, it further strengthens the feature fusion between layers using bidirectional connections. Aug-FPN analyzed the various information losses generated by FPN in the fusion process and proposed a series of solutions. Nevertheless, existing methods are still insufficient for detecting objects of different scales and addressing the problem of information loss in necks.
Methodology
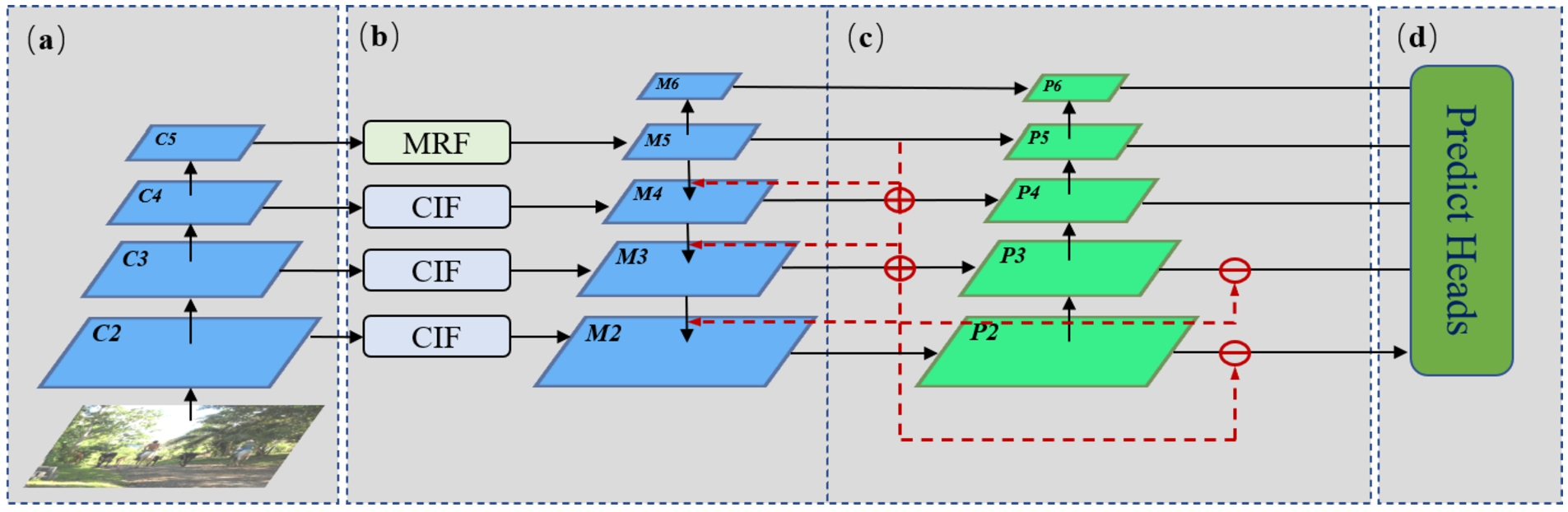
Overall pipeline of FI-FPN based detector. Among them, (a) is the backbone network, such as ResNet50, etc., (b) and (c) are the two main components of FI-FPN, where (c) is the ESF module, (d) is the predict head of the object detector. We will introduce the three modules of MRF, CIF and ESF in detail in the following.
In this section, we detail the proposed pyramid network FI-FPN for optimizing channel information loss and addressing the design flaws existing in the FPN structure. The usage conditions of FI-FPN are fundamentally similar to those of FPN. FI-FPN is a feature fusion technique that enables hierarchical feature fusion across different scales. For backbone networks that extract feature maps at multiple stages and scales (a characteristic possessed by most mainstream and well-performing backbone networks), FI-FPN can be combined with them to improve the performance of computer vision tasks such as object detection.
Its overall framework is shown in Fig. 2(b) and (c). The method shown in the figure takes the common Faster RCNN framework as an example, taking an image as input and outputting multi-scale features {C2, C3, C4, C5} from various feature extraction stages in a CNN backbone (e.g., ResNet50), which correspond to the feature maps with strides {4, 8, 16, 32} pixels in feature hierarchy concerning the input image. The highest C5 layer extracts its rich semantic information through the MRF module. The remaining layers use the CIF module to reduce the dimension and introduce channel attention. They then use the up-sampling and down-sampling operations to generate the feature pyramid {M2, M3, M4, M5, M6}. Finally, the aliasing effect reduction and dimensional bottom-up concatenation are performed through the ESF module to achieve bottom-up feature fusion. FI-FPN consists of three main components, which we will describe in detail below.

MRF module. Among them (a) shows the overall architecture of the module, (b) shows the details of the receptive field extraction(RFE) component,
In FPN, the network’s input is the output of different stages of the backbone network. For the general backbone network (VGG [31], ResNet, Darknet [27], Effcientnet), in the process of feature extraction, the length and width of the feature map gradually become smaller, and the number of channels gradually increases. Taking ResNet50 as an example, the number of output channels in each feature extraction stage is {256, 512, 1024, 2048}, and the high-level features are rich in semantic information after many calculations. In the previous work, a
In the work of YOLOF [4], the author only uses the features of the highest level and uses Dilated Encoder and Uniform Matching to obtain information on objects of different scales and successfully achieves results similar to the method of Multiple-in-Multiple-out, which shows that high-level features still have the potential to be exploited.
Inspired by this, we designed the MRF for the problem of information loss in the FPN. As shown in Fig. 3, we use the highest-level layer to reduce the dimension to a feature map with a higher dimension than other layers (512 dimensions are used in this experiment) and then input the receptive field extraction (RFE) component, as shown in Fig. 3(b). MRF gradually expands the receptive field of feature maps to cover more scales of objects by stacking dilated convolution [3] and max-pooling layers. And then, the feature maps of different receptive fields’ output at different stages are concatenated to fully integrate the detection capabilities of different receptive fields for objects of different scales. Finally, two feature selection layers
Based on the experience of dilated convolution parameter tuning [33], we designed dilated convolution sequences with stride {2, 5, 1, 2} (since the convolution layer with dilated rate 1 is equivalent to ordinary convolutional layer, we put {1, 2} two dilated convolutions in the same layer). Ablation experiments show that the MRF can more effectively retain high-level semantic information and improve the model’s accuracy.
In FPN, a
CIF module. Where

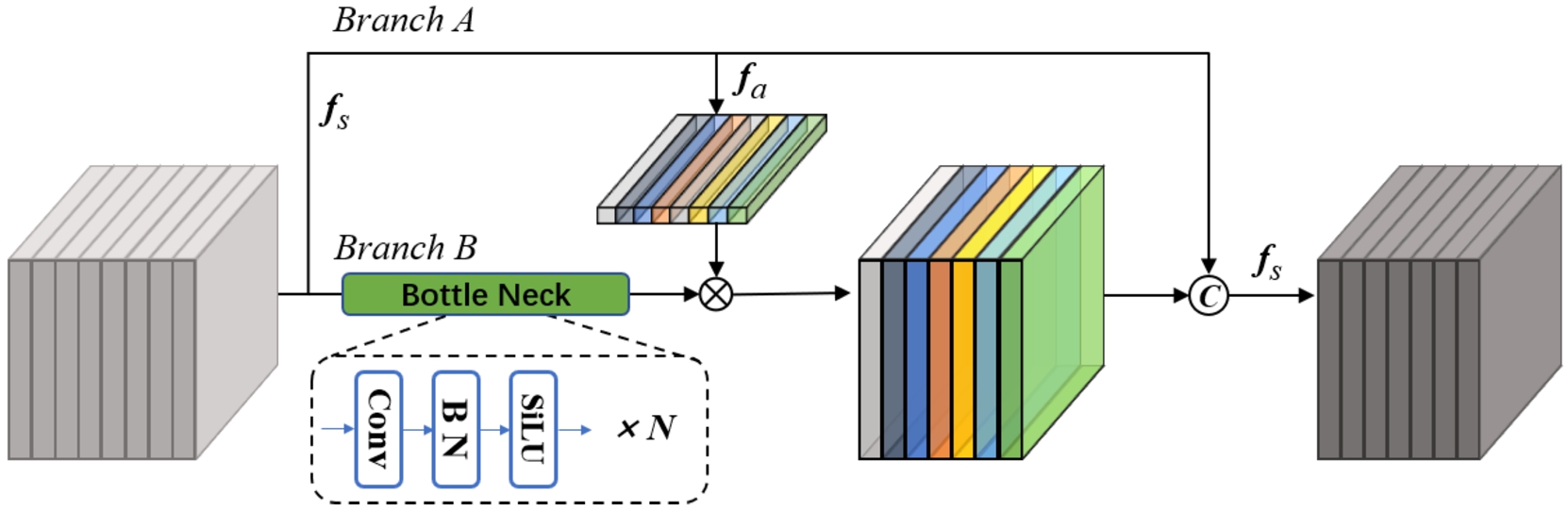
ESF module. The red line is a branch added for top-down feature fusion and low-level aliasing reduction. Where U is the up-sampling operation and S is the corresponding element subtraction.
After extracting the rich semantic information in the P5 layer and reducing their loss through the MRF module, the feature fusion from higher layers to lower layers is also an important part of the FPN. In FPN, the high-level features are directly added to the low-level features, and then the up-sampling operation is performed before the feature layer
Where i is the index of the pyramid level,
In our work, we use the method shown in Fig. 4 to extract features and then perform up-sampling operations, and the residual path can largely retain high-level information. The red line shows the flow path of high-level information in the model in Fig. 5. On the premise that the two branches obtain different semantic information, branch A retains more high-level raw information because only
Where σ is the sigmoid activation function,
The high-level feature map of the pyramid structure is rich in semantic information, and the low-level feature map is rich in detailed information. The key point in the previous pyramid structure design is how to better integrate the two factors. We propose the ESF, whose structure is shown in Fig. 5. The features of the high-level feature map are fused to the low-level feature map using multiple up-sampling. However, since the up-sampling process uses summation for feature fusion, it will cause aliasing effects in the low-level feature maps. We use an aliasing effect reduction module for the lowest two feature layers to mitigate the impact of aliasing effects on model localization information. Taking the implementation of FI-FPN on Faster RCNN as an example, the output of the P2 layer subtracts the aliasing information extracted from {M3, M4, M5} layers after up-sampling, and the output of the P3 layer subtracts the aliasing information extracted from {M4, M5} layers after up-sampling, to weaken the aliasing effect.
Inspired by PANet [22], we concatenate the feature maps of each level from the bottom to the top of the channel dimension last, which achieves feature fusion from the lower layer to the upper layer and enhance the model’s ability to detect objects of different sizes.
Experiments
Dataset and evaluation metrics
We perform our model on the MS COCO dataset benchmark. It contains 115k training images (train2017) and 5k validation images (val2017), and 20k unpublished labeled images (test-dev) for testing, with a total of 80 categories of object annotations. We train all models on train2017 and report the results of ablation experiments on val2017. Test-dev’s evaluation server gives the final result. All reported results follow the standard COCO-style average precision (AP) metric.
Implementation details
All our experiments are implemented based on MMDetection [2]. We train and validate the model on an NVIDIA Tesla V100 (32GB) GPU. All experiments use the default configuration of MMDetection, and the short side of the input image is adjusted to 800 pixels. No additional image augmentation is used, and 8 images are trained each time. In Table 1, 1× represents training for 12 epochs and decreasing the learning rate tenfold after the 8th and 11th epochs; 2× represents training for 24 epochs and decreasing the learning rate tenfold after the 16th and 22nd epochs; 50e represents training for 50 epochs and decreasing the learning rate tenfold after the 30th and 40th epochs.
We use RetinaNet and Faster RCNN as baselines for one-stage and two-stage detectors, with initial learning rates set to 0.01 and 0.005, respectively, and stochastic gradient descent (SGD) optimizer. All other hyperparameters in this paper follow the MMDetection default parameters if not otherwise specified.
Main results
Comparisons with state-of-the-art methods on COCO test-dev. Top: baseline for one-stage detectors and two-stage detectors; Middle: state-of-the-art FPN-based methods; Bottom: our implementations. ‘
’ indicates that the method uses additional data augmentation
Comparisons with state-of-the-art methods on COCO test-dev. Top: baseline for one-stage detectors and two-stage detectors; Middle: state-of-the-art FPN-based methods; Bottom: our implementations. ‘
To verify the effectiveness of our work, we evaluate the most popular one-stage and two-stage detectors with FI-FPN on the COCO test-dev set and compare them with other state-of-the-art FPN-based object detection methods on the COCO test-dev in Table 1.
In the one-stage object detection model, by replacing the FPN of the RetinaNet model with our FI-FPN, an improvement of 4.6 AP and 2.9 AP was achieved with ResNet50 and ResNet101 as the backbone network, respectively, and 40.9 AP and 42.0 AP were achieved without using additional data augmentation and without changing the loss function. In the typical two-stage model Faster RCNN, when ResNet50 and ResNet101 are used as backbone networks, it increases by 3.5 AP and 2.8 AP, from 37.4 AP and 39.4 AP to 40.9 AP and 42.2 AP, respectively.
The results of recent years’ state-of-the-art FPN-based methods for the same experimental settings in MMDetection are also presented in Table 1. The experiments demonstrate the improvement of our method compared to the state-of-the-art FPN-based method in different models.

Comparison of PR curves. IOU refers to the intersection-over-union. The results are reported based on the COCO val2017 dataset.

Example comparison of qualitative results. Replace the neck part of the object detection model. When FPN is the neck, the detection result is represented by a green bounding box; when Fi-FPN is the neck, the detection result is represented by a blue bounding box. Both methods are implemented in RetinaNet with ResNet50 as the backbone, and the training settings and training duration are the same.
Figure 6 compares the precision-recall (PR) curve after replacing the FPN structure with FI-FPN. Experiments show that FI-FPN can improve the precision while improving the recall rate at different IOUs, which helps the detection model detect more positive objects.
We also visualize the comparison of our FI-FPN and FPN performance in Fig. 7. It can be seen that the FPN will miss or incorrectly locate some objects that are too small or occluded, which may be caused by insufficient feature fusion or insufficient acquisition of receptive field information. FI-FPN can effectively optimize these problems and produce satisfactory results. These images are output by RetinaNet with FPN and RetinaNet with FI-FPN based on ResNet50 backbone with 1× training duration, respectively, marked in green and blue, with a threshold of 0.5. The input images are selected from the COCO val2017 dataset.
Validating the effects of each module component
To quickly and effectively validate the effects of each component and verify the performance of our method on various datasets, we use the PASCAL VOC [7] dataset and ResNet50 backbone network when validating the components of each submodule. The PASCAL VOC challenge is a world-class image classification and object detection competition, containing a total of 16k images. We select the training and validation sets from PASCAL VOC 2007 and PASCAL VOC 2012 as the training sets for this experiment. Since the annotations for the PASCAL VOC 2012 test set have not been released, we use the PASCAL VOC 2007 test set for this experiment. Apart from using the PASCAL VOC dataset, the experimental settings remain unchanged.
To validate the optimal configuration of each components in the MRF module, we add different improvement strategies based on the original FPN structure, and the experimental results are shown in Table 2, Conv refers to using an additional convolutional branch, Dila Conv refers to adding dilated convolution in that branch, Channel concat and Channel sum represent two feature map fusion methods. Based on the ablation study results in Table 2, we ultimately chose the combination of dilated convolution and Channel concat, which can effectively improve the model’s detection accuracy.
CIF and ESF modules are typically used in combination. To validate the optimal configuration of each components in these modules, we add different improvement strategies based on the original FPN structure, and the experimental results are shown in Table 3.
In Table 3, channel attention refers to using an additional channel attention branch, sub path refers to the path that reduces aliasing effects through feature map up-sampling, down-up path refers to the bottom-up feature fusion path. Based on the ablation study results in Table 3, we ultimately chose the combination of channel attention mechanism, sub path, and down-up path, which can effectively improve the model’s detection accuracy.
Ablation study results of different components in the MRF module on the VOC dataset
Ablation study results of different components in the MRF module on the VOC dataset
Ablation study results of different components in the CIF and ESF modules on the VOC dataset
Meanwhile, we also validate the impact of each module in FI-FPN on the COCO dataset. The ablation experiment is performed on the RetinaNet with ResNet50 as the backbone network, with input images reshaped to a resolution of
The effect of each component. From results reported at COCO val2017
The effect of each component. From results reported at COCO val2017
The experimental results show that the MRF module improves the mAP index by 1.5 AP based on FPN, which effectively improves the model’s ability to detect objects, which is in line with the original intention of the design. The combination of CIF and ESF modules can improve mAP by 1.7 AP, proving the advantages of combining the two modules. Finally, our method improves mAP by 2.4% overall.
We also measure the inference time of FI-FPN. The average inference time is calculated by sequentially inputting all images of COCO val-2017 into the model, and the size of the input images is unified as (800, 1333). We run the test on an NVIDIA Tesla V100 (32GB) GPU. RetinaNet with FPN can run at 16.5 fps; as a comparison, by replacing the neck part of RetinaNet with FI-FPN, the model can run at 15.3 fps. The 1.2 FPS reduction only decreases the inference speed, while the accuracy is increased by 4.6 mAP. The results demonstrate the inference speed advantage of our method.
Conclusion
In this paper, we proposed a new FI-FPN for object detection, which fixes the design flaws in FPN. To reduce the loss of high-level feature information, we proposed the MRF module, which uses dilated convolutions to obtain receptive fields at different scales. We also proposed the CIF module that uses a dual-branch and channel attention mechanism to redistribute channel attention weights to enhance features. Finally, we proposed the ESF module to optimize and fuse different levels of feature information. Experiments show that FI-FPN can improve the performance of mainstream object detection frameworks on the challenging MS COCO dataset.