
Abstract
Ensuring real-time performance while leveraging pedestrian detection is a crucial prerequisite for intelligent driving technology. The development of lightweight models with good detection accuracy is also crucial. This work proposes a novel method, the Attention Digital Filter with Anchor-Free Feature Pyramid Learning Model (ADFAFPLM), to meet these needs. The suggested method consists of combining two networks: one is a digital filter based on an attention network that eliminates noise and other picture distortions. The attention-based residual network digital filters are chosen for their enhanced filtering performance, adaptability, efficient learning through residual connections, noise suppression, interpretability, and generalization capabilities. Next, from the input crowded and occluded photos, the pedestrian is identified using an anchor-free feature pyramid network. The Eurocity person dataset was used to train the model, and it was also tested on other datasets like CityPersons, INRIA, PennFudan, and Eurocity. The investigation was expanded to include images in hazy, noisy, and occlusion environments, among other environmental conditions. The image resolutions were also considered for analysis and it was observed that with increasing image resolution, the mAP increases. Based on the ablation study, the ADF-AFPLM adopted YOLOv8n with batch size 16, and image size 640 is considered for efficient result with different testing datasets. The model achieved a mean average precision (mAP) of approx. 87% and shows its efficacy over state-of-art models.
Introduction
Object detection and identification are crucial in deep learning and machine vision, which advances in many image-based research areas. A subset of this, pedestrian detection, is gaining attention. Object recognition detects objects in images or videos and is valuable in safety surveillance and smart navigation [16]. Pedestrian identification has recently emerged as a research focus, referring to a particular use of the object identification issue. Object recognition is a machine vision method utilized to discover instances of objects in images or videos. It has a high application value in the fields of safety surveillance and smart navigation [20]. For example, Lidar, wireless sensor networks, and cameras cooperatively observe the surroundings in smart transportation, while mobile decision units are used for supervisory and decision-making operations [41]. Intra-class heterogeneity sometimes hampered pedestrian recognition since persons vary greatly in appearance and stance. Many approaches to resolving such issues are contributed by researchers [1]. However, when just using pedestrian characteristics, pedestrian detection approaches suffer a high false negative rate due to the presence of obstacles or background complexities. This means that there is need of more advanced recognition tools and techniques are required supplemented by a strong semantic comprehension of images [29]. The procedure of pedestrian identification is to forecast, find, and mark the location of a pedestrian to acquire data including the pedestrian’s location and activity [16]. Several recognition algorithms, meanwhile, are unable to recognize pedestrians adequately in real-time due to their randomized dispersion and dynamic properties. As a result, much effort is still expended each year to develop a cutting-edge approach. The sliding window patterns have traditionally been used to create the identification process, which depends on a lengthy scan of the image to locate the object locations. Throughout this analysis, characteristics for each window location were investigated and then evaluated by a classification model. Nevertheless, due to the complexities of feature analysis and the great amount of windows, this method is just impracticable. To reduce these complexities, it is required to use more refined visual features or characteristics. For this small regions are segregated that contain fewer regions of interest (RoI) [12–30]. In such specific applications, manual annotation is quite difficult. Therefore, machine learning and deep learning models transformed this need drastically with minimal manual interference [4, 42]. Among them, Convolutional Neural Network (CNN) results are the best. Several deep learning-based pedestrian identification approaches have been developed by researchers to enhance pedestrians’ identification performance [23]. Nevertheless, complicated sceneries, variations in pedestrian magnitude, object interference, and lighting variations all influence the precision of pedestrian trackers. The Histogram of Oriented Gradients (HOG) [32] is the most widely utilized approach to pedestrian identification. The directional gradient is employed in this approach to identify things in a picture. In the presence of occlusion or any obstructions, it is quite difficult to identify and recognize the objects. For these conventional approaches such as HOG feature extraction methods were used but these are time-consuming and are not compatible with real-time. Additionally, Wang et al. [48] presented a combined approach of HOG with local binary mode (LBP) to handle occlusion during object detection which is based on texture properties. As an advancement to this technique, Dollar et al. [15] merged the HOG and color characteristics to identify objects. Therefore, texture-oriented gradient characteristics resolve the pedestrian identification. To address the limitations of texture-oriented gradient features, researchers explored the region-based approach using deep learning algorithms [14, 39]. These strategies produce more precise and simpler outcomes. In recent times, pedestrian identification has demonstrated significant performances because of the quick development of CNN-based general object recognition [3]. In general, anchor-based and anchor-free pedestrian monitors on the CNN platform can be distinguished. Single-stage and two-stage detectors are two common layouts for anchor-based techniques [27, 38]. Usually two-stage pedestrian detection systems [9, 52] produce rough regional suggestions of pedestrian occurrences at the initial phase, and then at phase two, they improve the ideas by using certain area expertise that was learned in various methods [8]. Single-stage detection systems were demonstrated for quicker inference [25, 28]. But its accuracy was not enough, then two-stage trade-offs the inference speed and detecting precision as compared to single-stage. ALFNet [31] continuously grows anchor boxes with cascaded detecting heads while maintaining the single-stage layout to strike a balancing act between speed and precision. By incorporating occlusion-handling mechanisms while keeping the high speed of a single-stage identification architecture, the recommended PRNet and PRNet++ outperform these existing approaches [40]. Liu et al. [26] proposed an efficient data pre-processing strategy termed Attribute Preserving GAN (APGAN) implemented with background complexities. Dasgupta et al. [13] used RGB and infrared images to investigate an end-to-end multimodal fusion technique for pedestrian identification based on spatial-contextual features. It includes two fine-tuned ResNet50. The fused features are then passed through a graph attention network to combine these features. To overcome the difficulty of selecting RoI, algorithms like as YOLO and R-CNN were created [19]. However, the issue with R-CNN is that it requires a long duration of training and also results in poor performance. Then its weakness was addressed by Faster R-CNN (FRCNN) [49]. Then another best object detection model, YOLO, was introduced by Joseph Redmon et al. [33]. YOLO is a quicker object identification technique, processing 45 frames per second. The issue with YOLO is that it is limited by the spatial plane coordinate orientation of the algorithm, which prevents it from detecting tiny objects present in an image. Several modifications of YOLO were then introduced by researchers. Therefore, motivated by this, the paper used the YOLO model as a baseline for handling background complexities in pedestrian detection. Therefore, the major contributions of this paper are: In this paper, a novel contribution of pedestrian detection using advanced YOLO models (such as YOLOv8) is presented. In this paper, a hybrid approach is presented with the designing of the attention-based digital filter as an artifact removal to handle the background complexities caused due to noise present in images. Then, the anchor-free feature pyramid network is used for feature extraction and learning to detect the pedestrian among all other objects. The paper also presented the ablation study of baseline models such as Yolov8 versions and also investigated the performance with variations of batch size and image size. The model was also tested on different test image datasets.
The remaining sections of the paper are organized as: A brief overview of object detection of the YOLO model and its evolution is presented in section 2. Section 3 presented a discussion of the material and methods used to design the proposed model. The model architecture and training details are also presented in this section. Section 4 presents the result analysis that explains the experimental setup, ablation study, and comparison with state-of-art models. Section 5 has a discussion and section 6 presents a conclusion with future scope.
Object detection using YOLO
In 2016, a team of researchers such as Santosh Divvala, Ross Girshick, Ali Farhadi, and Joseph Redmon created the YOLO (You Only Look Once) model. The YOLO model can quickly and accurately identify items in both videos and images. Each object’s bounding box and class probability are predicted by a separate neural network in the YOLO model. Each cell in the model’s grid is responsible for making predictions about the class probabilities of the objects and bounding boxes contained within its portion of the input image. This model can interpret images rapidly and precisely since it is based on a convolutional neural network (CNN) [20]. The model employs a method called "anchor boxes" to enhance the precision of object detection, and it is trained on a huge dataset of labeled images. The YOLO model is quick, which is one of its key benefits.
Yolo model is comprised of 24 convolutional and 2 fully connected (FC) layers. To reduce the computational complexities of feature maps, some convolution layers instead utilize 1*1 reduction layers. It generates a shape tensor as the output of the last convolution layer (7, 7, 1024). After that, the tensor is squishy. Two fully connected layers are used to generate linear regression parameters (7 *7* 30), which are then reshaped to (7,7,30), or two boundary box predictions for each location. Each grid cell in YOLO is predicted to have numerous bounding boxes. We need only one of them to be the culprit to calculate the loss for the real positive. To do this, we look for the one that has the highest intersection over union (IoU) value with the real world. As a result of using this tactic, bounding boxes are becoming specialized in terms of forecasting. Size and aspect ratio predictions improve with each iteration. When determining a loss, YOLO takes into account the sum-squared error between the predictions and the reality. Here, classification loss l c , localization loss l l and confidence loss l c o combined called as loss function represented as:
Loss = l c + l l + l co (1)
l c = ∑c ϵ classes (P c - A c ) 2
Where P c = predicted class and A c is the actual class.
There are a number of versions of the YOLO Model developed to date as presented in Fig. 2. Starting with YOLOv1 in 2015, it set the stage for real-time object detection, achieving a mAP of 63.4% on the PASCAL VOC 2007 dataset [33]. However, it faced challenges with smaller images. The YOLOv2 version in 2016 addressed some limitations, incorporating batch normalization and anchor boxes, and enhanced performance to a mAP of 78.6% on VOC 2007 [34]. YOLOv3, released in 2018, integrated a feature pyramid network and a prediction module, boosting its mAP to 57.9% on the COCO dataset, with a focus on detecting smaller objects [35]. YOLOv4 in 2020 brought in several novel features such as the Mish activation, Mosaic data augmentation, etc. This model achieved mAP of 65.7% AP50 [5]. The same year, YOLOv5 was introduced, designed for greater efficiency and speed. YOLOv6 built upon YOLOv5, refining the design for industrial applicability [22]. In 2022, YOLOv7 was developed with Extended Efficient Layer Aggregation Network (E-ELAN) and combined architectures from its predecessors, offering better speed and accuracy [45]. The recent version of YOLO is YOLOv8 which uses the soft- Non-maximum Suppression that is applied for a soft threshold to the overlapping bounding boxes instead of discarding them outright [36]. The yolov8 achieved a mAP50- 95 of 0.685.
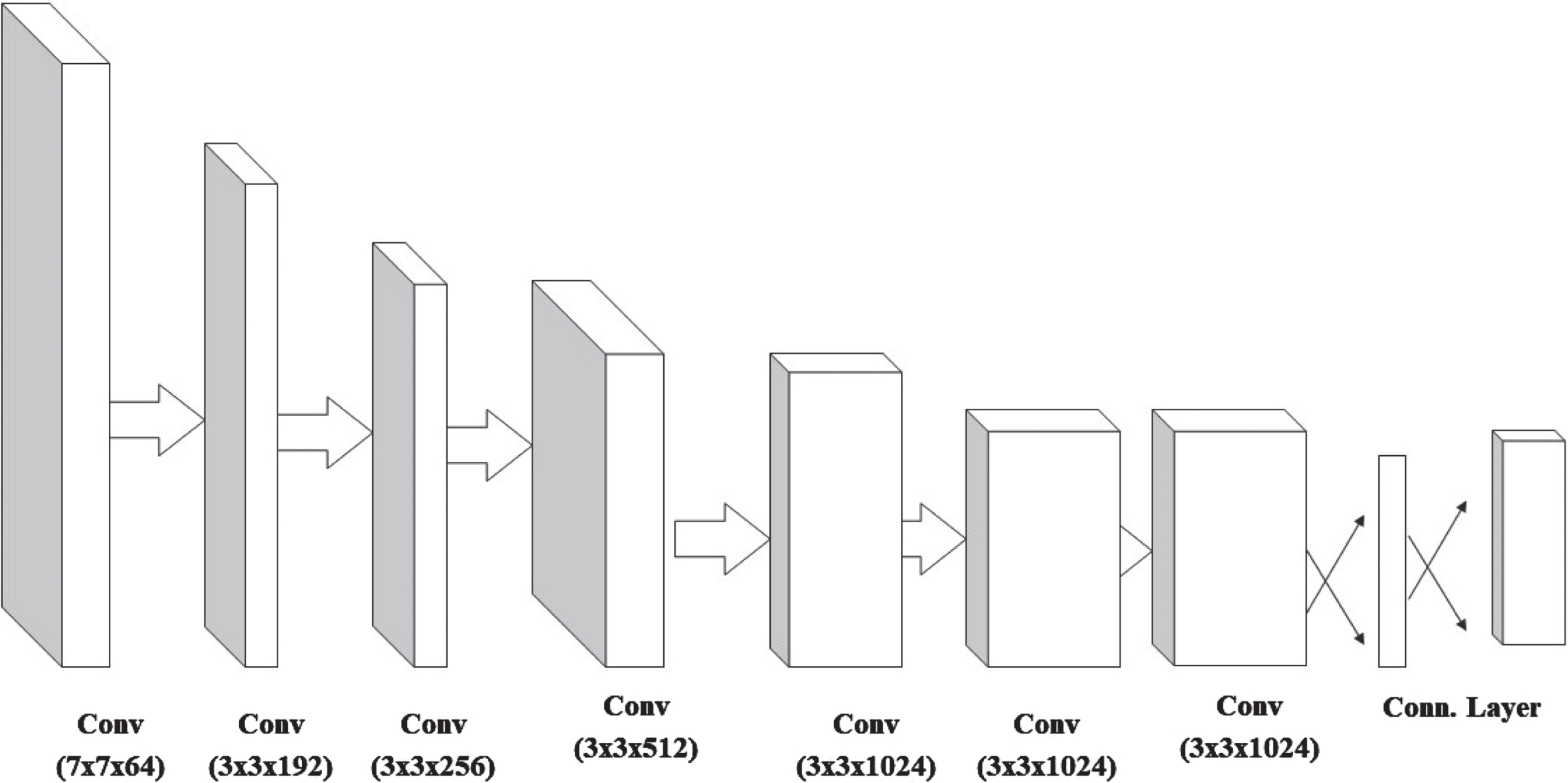
Architectural diagram of YOLO.

Evolution of YOLO models.
This section describes the methodology used with the architecture of the model used. Subsection 3.1 provides a detailed description of the network architecture. Subsection 3.2, presents the description of attention-based residual network digital filter, and section 3.3. presented the description of the pedestrian detection learning model and Section 3.4 shows the training details of the model.
Model layout
In this work, the hybrid model is proposed for the pedestrian detection model by combining attention-based residual network digital filter (ARNDF) and feature pyramid network such as the YoloV8 model. This hybrid approach is termed an Attention Digital Filter with an Anchor-Free Feature Pyramid Learning Model (ADF-AFPLM). The basic working step is presented in Fig. 3. The ARNDF is used to enhance the input image to clearly distinguish among objects present in the images. In this paper, attention-based residual network digital filters are adopted due to their enhanced filtering performance, adaptability, efficient learning through residual connections, noise suppression, interpretability, and generalization capabilities. After enhancement of image quality, the YoloV8 is used to extract features and perform learning for the identification of pedestrians among other objects present in the image.

Proposed pedestrian detection model.
It is not easy to distinguish among objects in an image due to low light exposure or some abnormalities in images. Therefore, pre-processing is required for a better segmentation process. In real-world applications, the environmental conditions are dynamic in nature and fail in exposing all pixels in more effective manner. Therefore, more exposure of the image is required to under-exposed pixels or regions in an image. Therefore, to enhance the image quality, an Attention-Residual model is used, motivated by [37, 47]. The architectural diagram is presented in Fig. 4. Once the attention-residual model estimates the noise in image I, it results in an artifact-removed image I d .
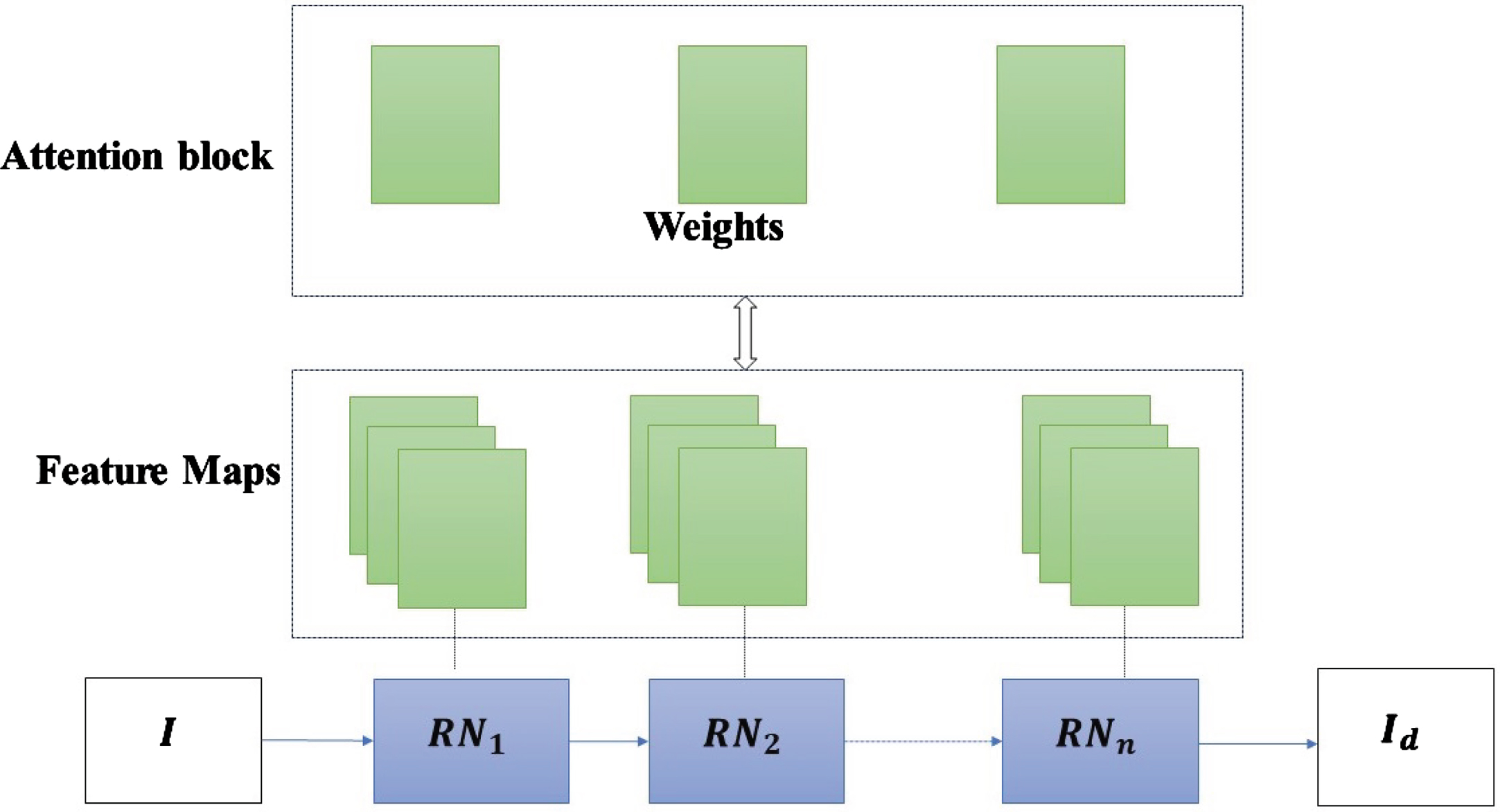
Attention-based residual network digital filter.
In Fig. 4, the attention block calculates the attention weight by grouping all feature maps extracted out of residual blocks. These feature maps are evaluated using the sigmoid function and summed up together in an attention block by using the softmax function. Therefore, attention weight is evaluated as:
Finally, after training the model properly, artifact removal is executed as:
In this paper, for the pedestrian detection learning model, a feature pyramid network is used as presented in Fig. 5. Anchor-free detection is an object detection approach where the model predicts the object’s center directly, without relying on predefined anchor boxes. Anchor boxes are predetermined boxes with specific sizes and shapes that are used in traditional object detection models to detect objects of various scales and aspect ratios. These anchor boxes are tiled across the image during detection. In anchor-free detection, the model outputs the probability and attributes for each tiled box, such as background information, intersection over union (IoU), and offsets. These outputs are then used to adjust the anchor boxes. The main advantage of anchor-free detection is its flexibility and efficiency. It eliminates the need for manually selecting anchor boxes, which can be challenging and may result in suboptimal performance in previous YOLO models. By directly predicting the object centers, anchor-free models can adapt better to objects of varying sizes and shapes, leading to improved detection accuracy. The feature pyramid model architecture is composed of a Backbone network, Head network, and detect network as presented in Fig. 5. The backbone uses the cross-stage partial (CSP) [46] to extract features in two layers: one is convolution and another is a concatenation layer. This will improve the learning and reduce the computational cost. The YOLOv8 [50] model is used as a baseline model that allows the model to extract more rich gradient information. The architecture of YOLOv8 is presented in Fig. 6. This model consists of a C2f module two conv layers and n Darknet network and are connected through split and concat layers. There is convModule also present that is composed of Conv-BN-SiLU layers. As compared to YOLOv5 [17], this module has less number of blocks at each stage which ultimately reduces the computational complexity.
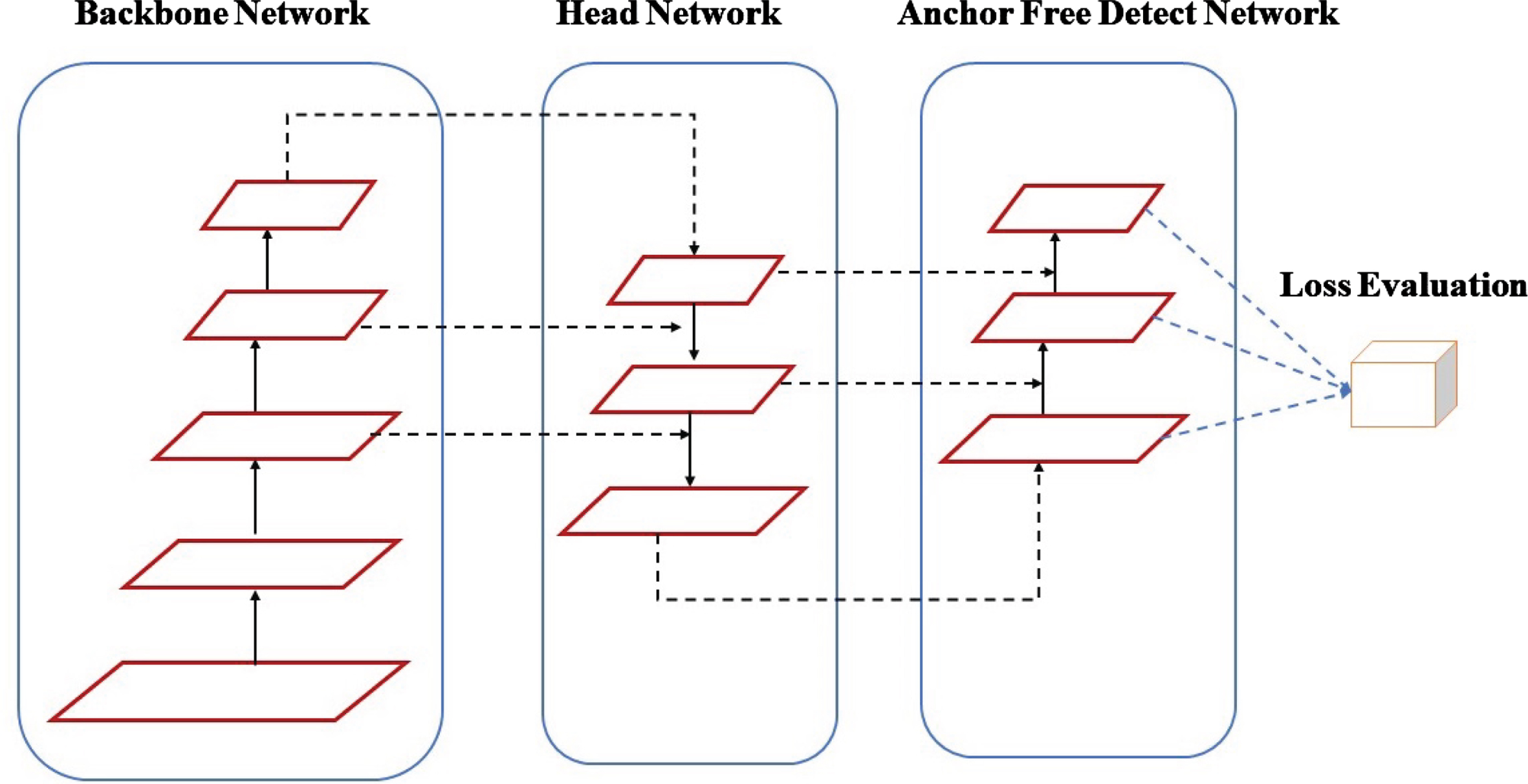
Architecture of pedestrian detection learning model.
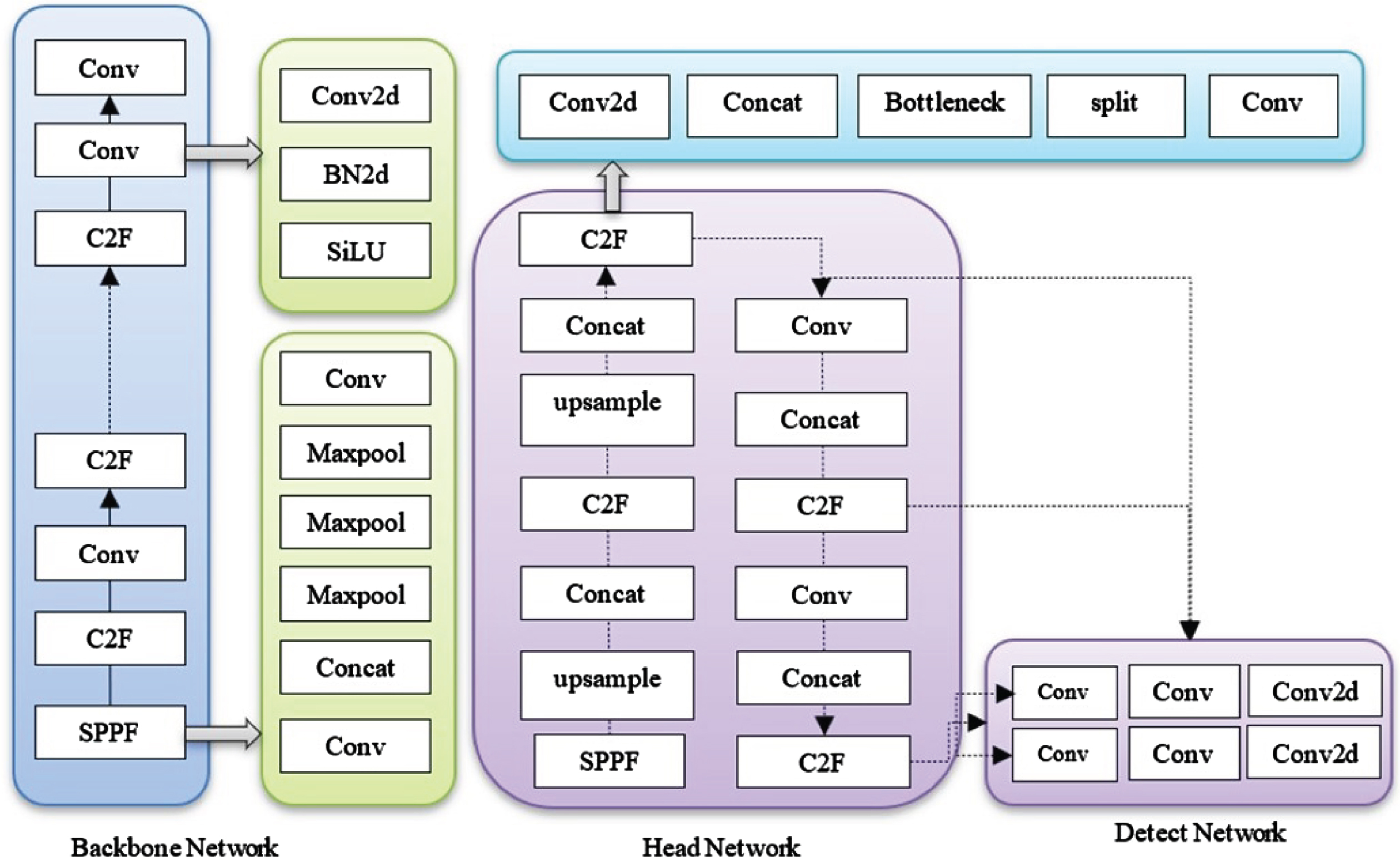
Architecture of YOLOv8 model.
Additionally, a spatial pyramid pooling fast (SPPF) layer is also added which improves the learning speed. The base of YOLOv8 is the Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) which reduces the learning complexity and improves the accuracy by combining features from the lower to the upper part of the pyramid. The feature information is preserved from lower layers which are passed to the upper layer of the network. The detect module performs the anchor-free operation which is used to identify the distance between the center of the object with the bounding box. Weighted score is used to classify the label of the person in the image according to the following equation:
The presented model is trained on google colab using python with backend implementation using TensorFlow. The total data set is split into two parts, with 70% dedicated to training and 30% dedicated to testing. Adam optimizer with a learning rate of 0.0001 is utilized for training. Training for all networks takes place on a Tesla P100-PCI-E GPU for a total of 100 iterations.
Input Inp i , images;
Output:
1. Initialization
2. I d = I n - Ar [R]
3. While loss reaches convergence do
4. For i max : Max epochs
5. Outi ← - - - - - - Yolov8 I d
6. Minimize (Loss fun ) = Loss n + Loss CIoU
7. End Return Out i
Result analysis
In this section, implementation details and result analysis are presented. The simulation model was implemented on the Tesla T4 GPU using TensorFlow. Section 4.1 describes the datasets used. Result analysis with variational parameters is presented in subsection 4.2, i.e., ablation study. Furthermore, in Section 4.3, a comparison of ADF-AFPLM is presented with other state-of-the-art approaches for pedestrian detection. The paper presented the result using the following parameters:
Mean average Precision (mAP): The mAP, is evaluated as:
Recall: It is a measure to find the ratio between true positive (TP) with total actual positive responses. It is evaluated as:
In this paper, the mixed dataset is prepared by collecting occluded images from CityPersons [53], PennFudan [42], INRIA [11], and Eurocity [7].
Ablation study
This section presents the validation of simulation experiments for the proposed model. This section provides a summary of the ablation study findings, with an emphasis on the execution of the prescribed work. The ablation research is used to demonstrate the benefits of each module used in the suggested approach. As a result, in this part, baseline models are compared to the proposed ADF-AFPLM. Comparison with baseline models: In this ablation study, we have compared four baseline models and proposed ADF-AFPLM. Baseline Model 1 (BM1): In baseline model BM1, ARNDF with the yolov8n model is used to detect a person. Baseline Model 2 (BM2): In baseline model BM2, ARNDF with the yolov8m model is used to detect a person. Baseline Model 3 (BM3): In baseline model BM3, ARNDF with the yolov8s model is used to detect a person. Baseline Model 4 (BM4): In baseline model BM4, ARNDF with YOLOv8l model is used to detect a person. The training performance of all models is presented from Fig. 7 to Fig. 10. Figure 7 presents the performance of BM1 for YOLOv8n as a baseline model. Similarly, BM2 model results are presented in Fig. 8, BM3 in Fig. 9, and BM4 in Fig. 10 respectively. Table 1 provides a performance comparison of all baseline models. From the result, the lowest value of loss (both Loss n and Loss CIOU ) are presented by BM3. However, BM1 achieved the highest mAP among other models. The table also presented the execution time analysis in which the BM3 achieved the lowest time as compared to others.
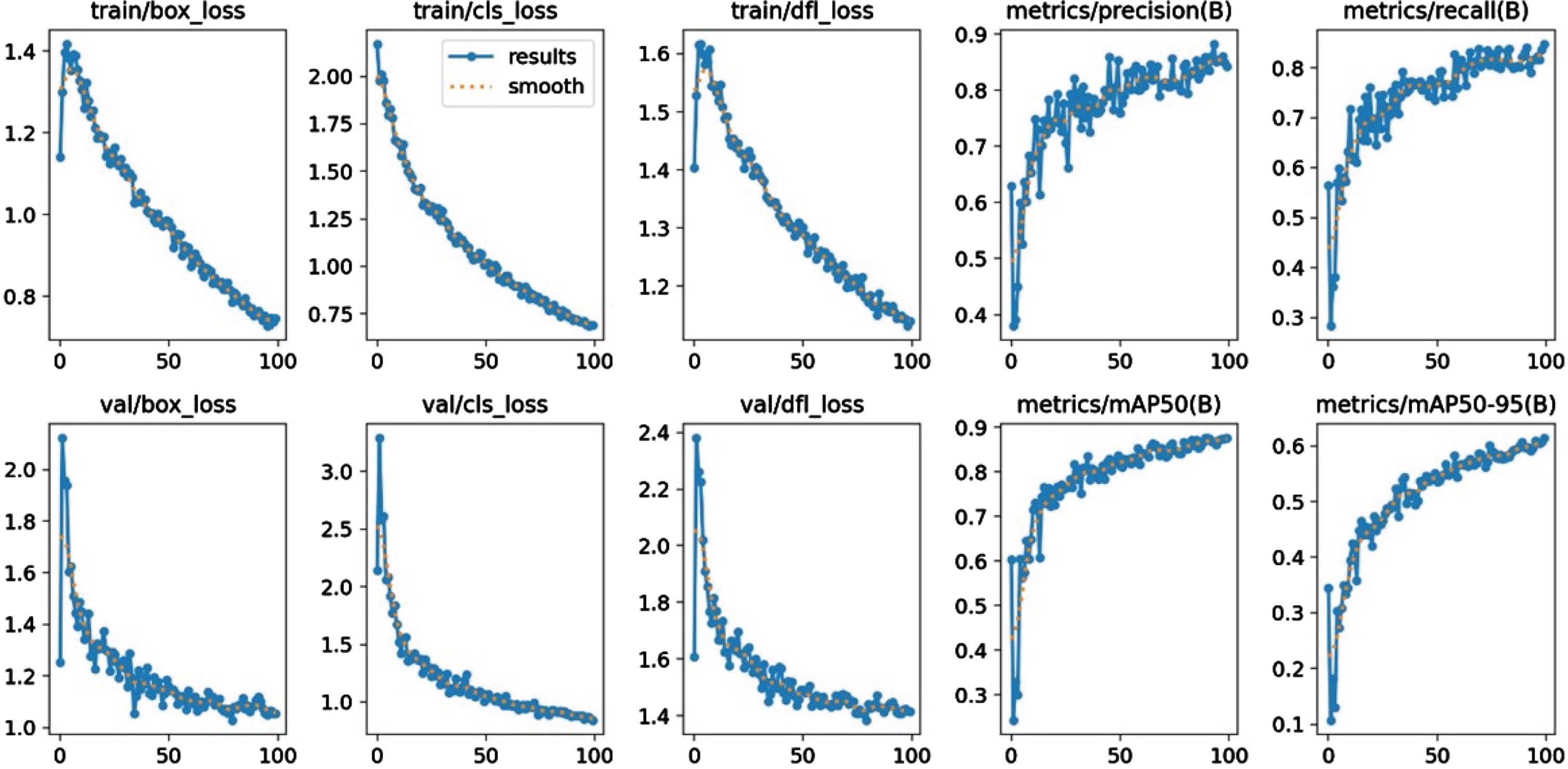
Training performance of BM1.
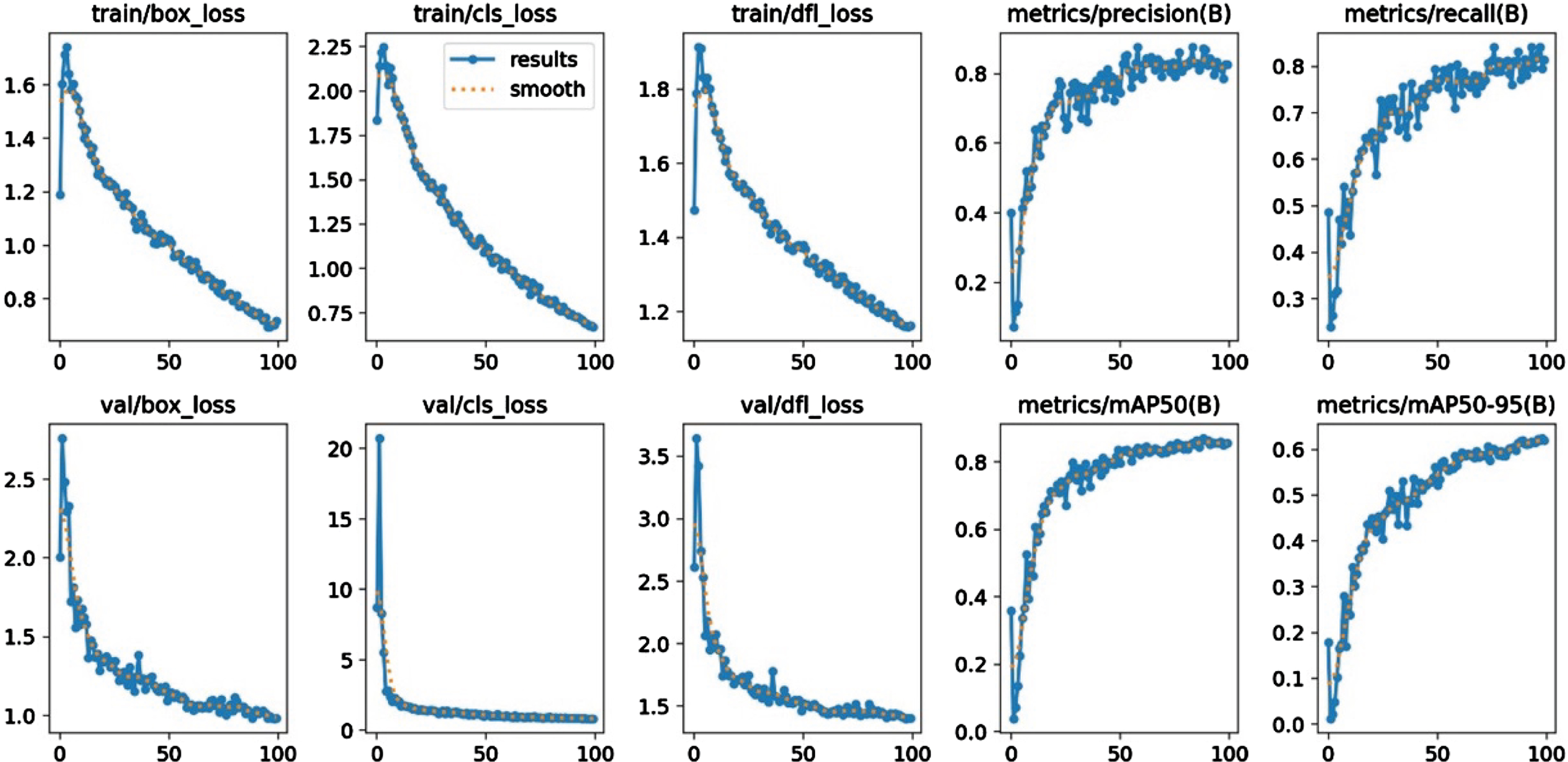
Training performance of BM2.
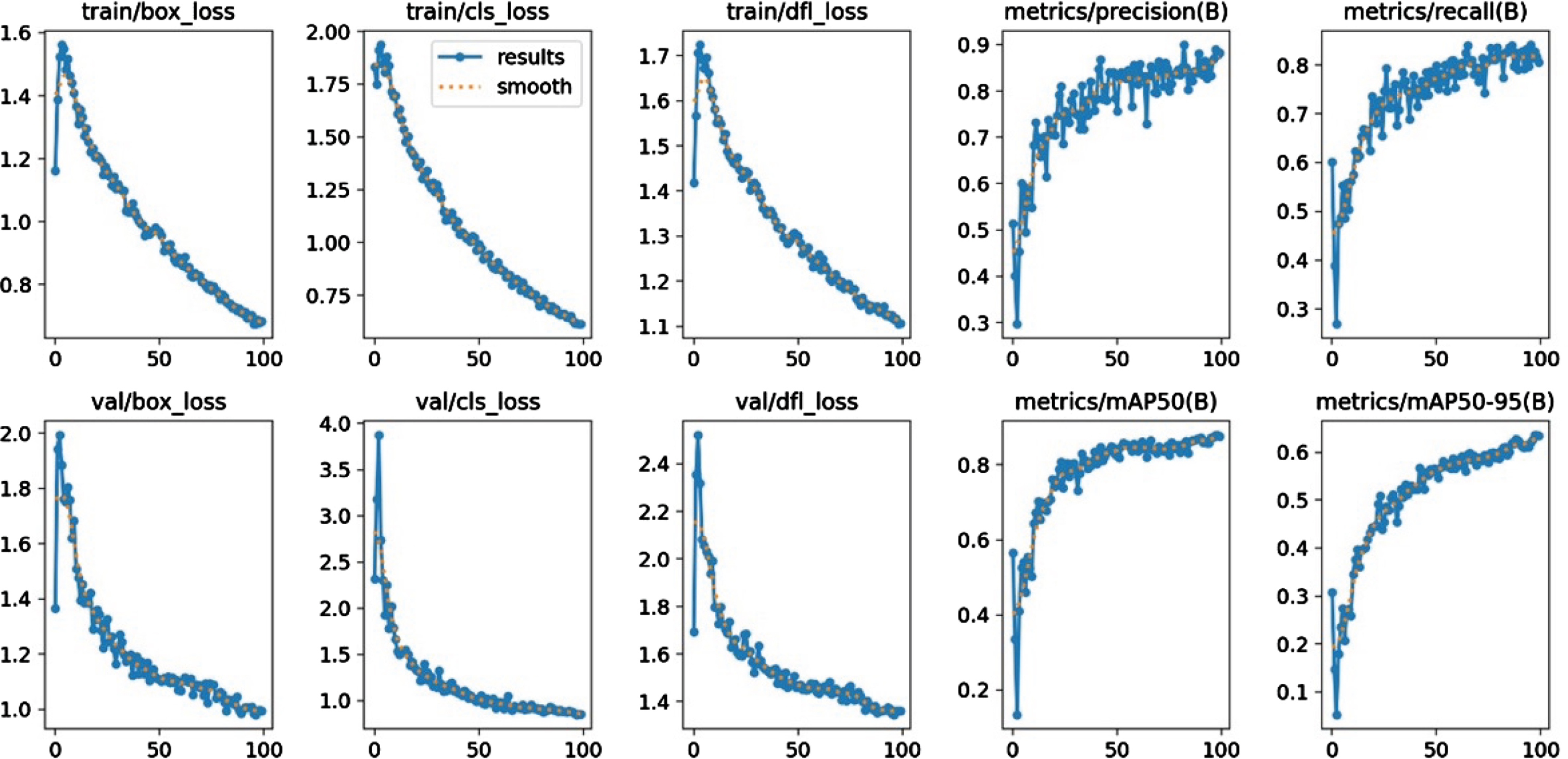
Training performance of BM3.

Training performance of BM4.
Performance comparison of baseline model
Table 2 presents the learning performance of ADF-AFPLM with varying batch sizes. A batch size equal to 16 achieves the lowest loss i.e., 0.63322 for Loss n and 0.70516 for Loss CIOU . Whereas, the highest precision was achieved by batch size equal to 16 i.e., 0.86877. But the highest recall was 0.84797 for batch equals to 8. Similarly, the highest mAP value is observed for the batch size of 8, with a mAP of 0.87641 and the lowest mAP value is observed for the batch size of 64, with a mAP of 0.79464. Based on these observations, it appears that the batch size of 8 performs well in terms of precision, recall, and mAP, while the batch size of 16 performs well in terms of loss. The batch size of 32 shows relatively lower performance in terms of loss, precision, and recall. The batch size of 64 shows lower performance in terms of loss and mAP. Therefore, it is recommended to use a lower batch size for more efficient learning of the model. The table also presented the execution time analysis in which batch size 64 achieved the lowest time as compared to others. Then below Fig. 11 to Fig. 14 present the learning precision-recall analysis of the ADF-AFPLM model with a variation of batch sizes. Figure 11 presents the precision-recall analysis with batch size 8. It was observed that for all class detection, the highest mAP was approx. 0.87. Whereas the batch size of learning was increased and presented in Fig. 12. In this analysis, the highest mAP was 0.867. The result of batch size 32 is presented in Fig. 13 and the highest mAP was 0.840 and finally in Fig. 14, result of batch size 64 is presented with highest mAP of 0.863.
Performance evaluation of ADF-AFPLM with variation of batch size
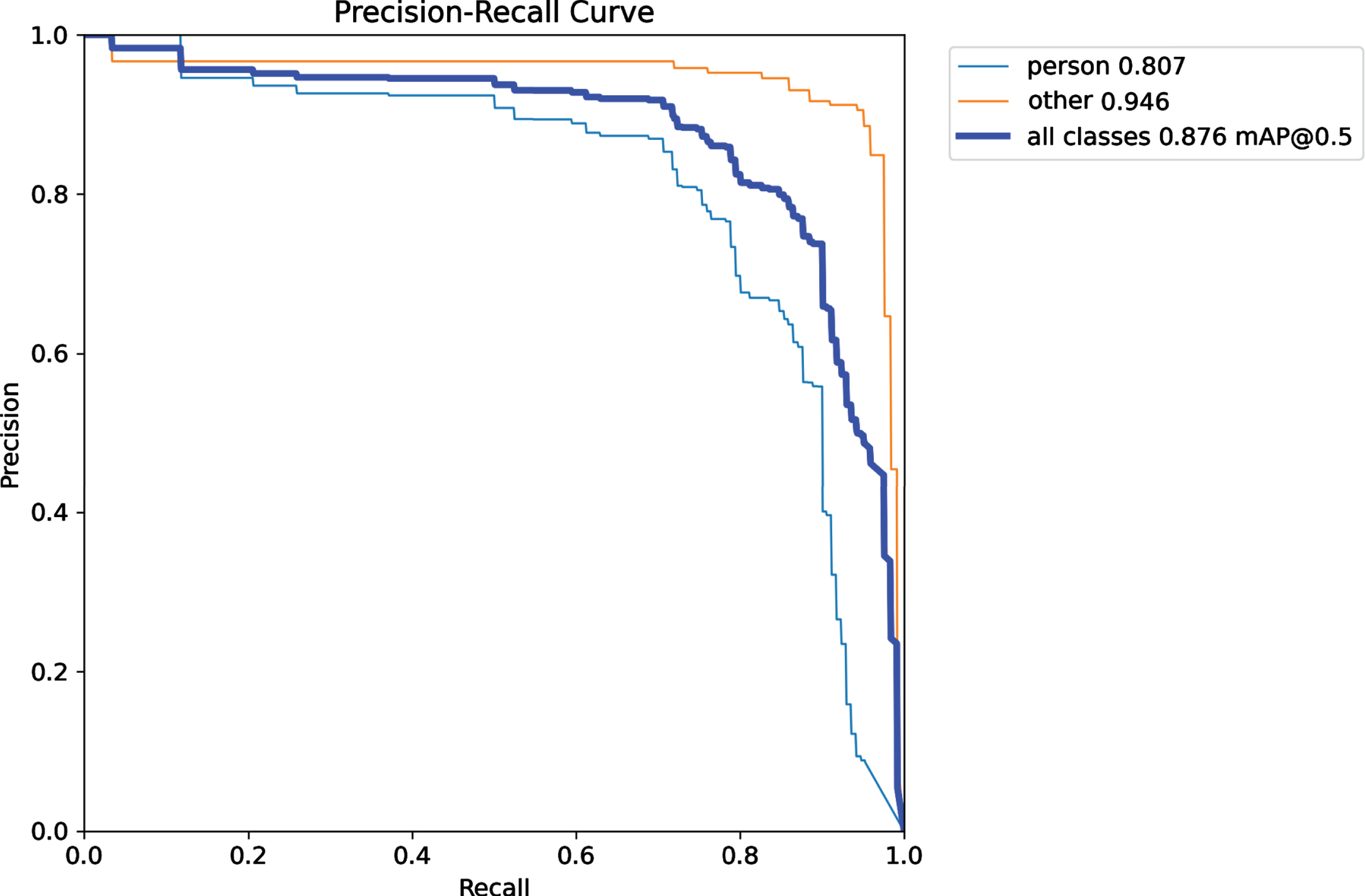
Precision-recall curve analysis of ADF-AFPLM with batch size = 8.
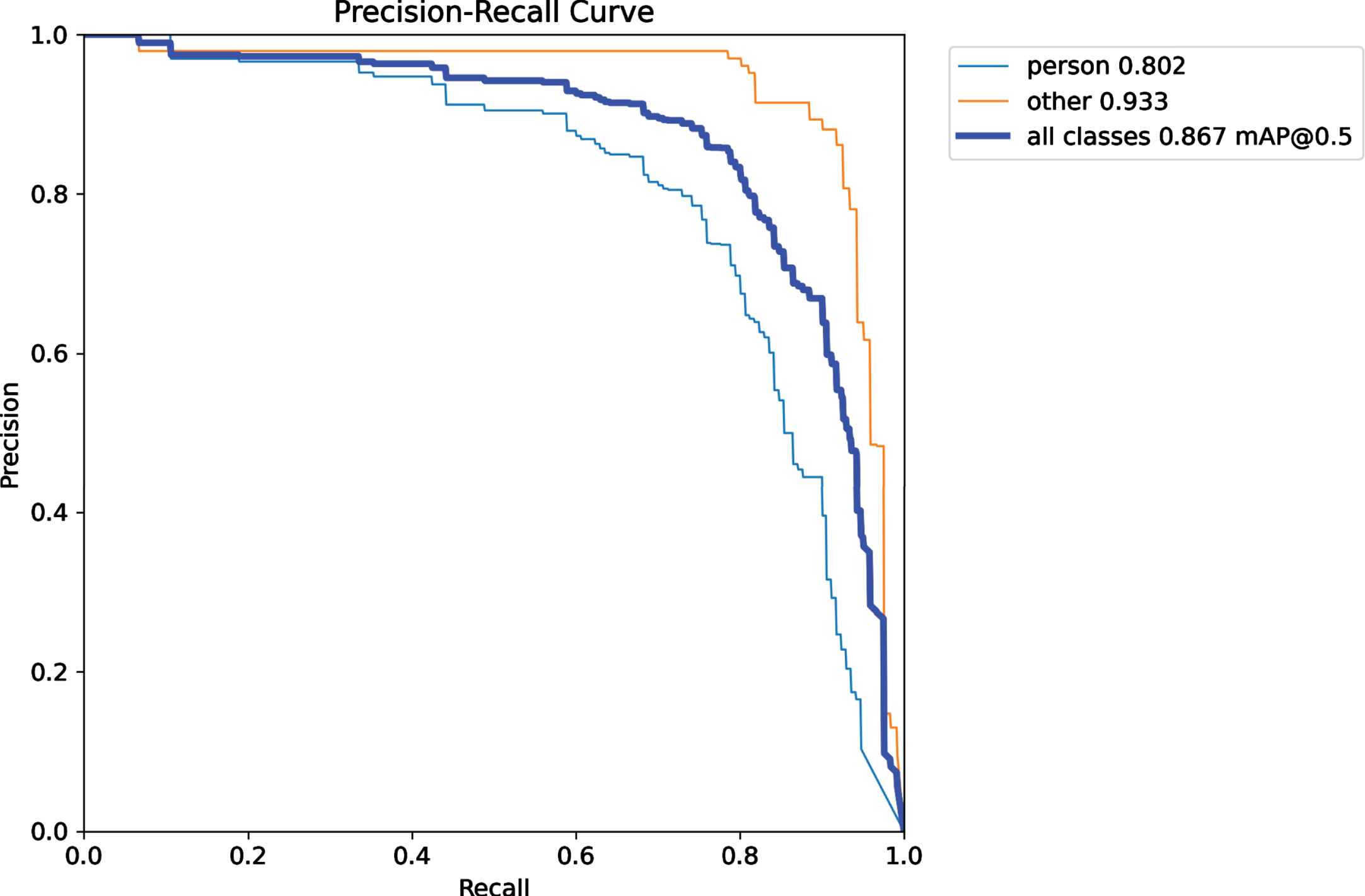
Precision-recall curve analysis of ADF-AFPLM with batch size = 16.
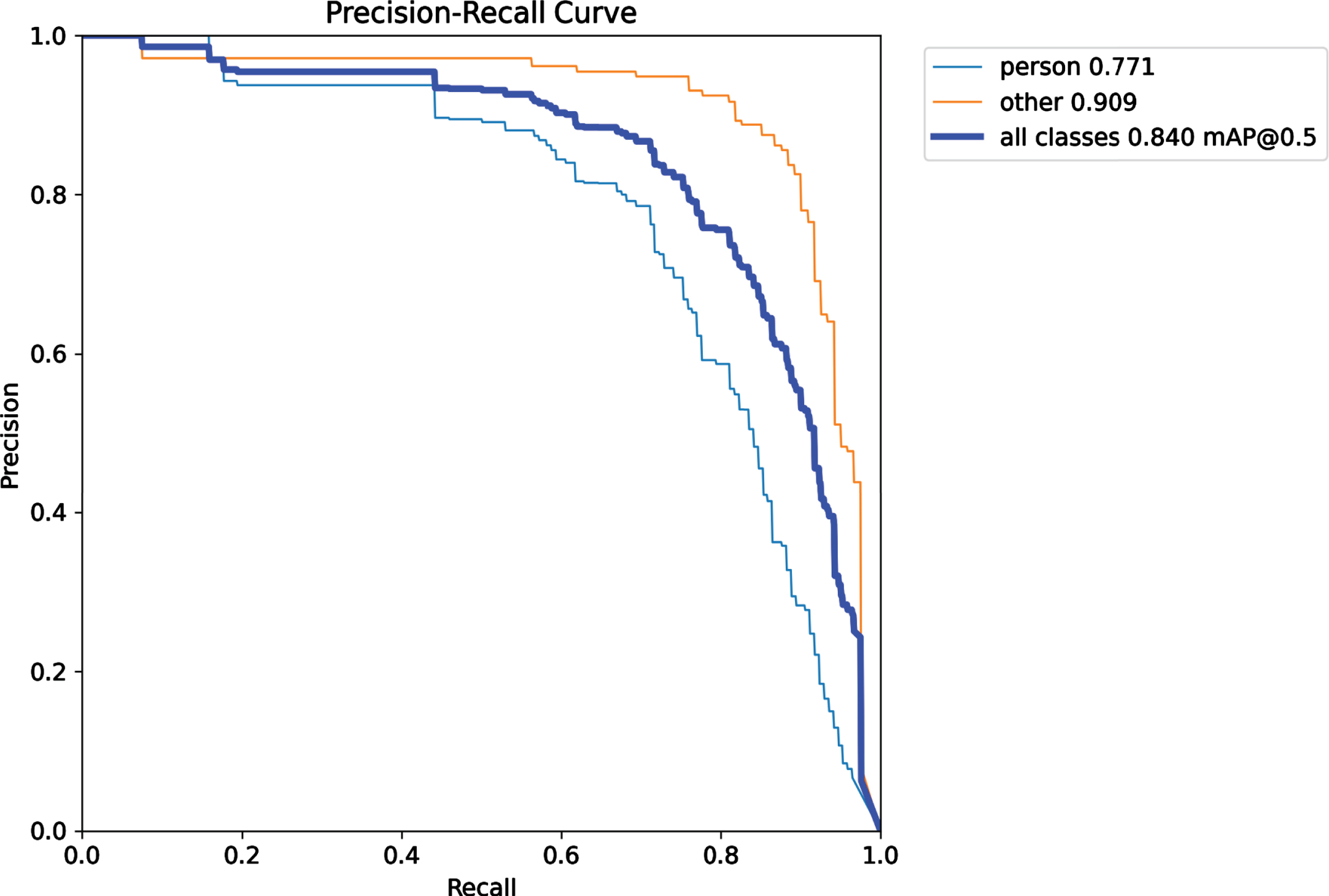
Precision-recall curve analysis of ADF-AFPLM with batch size = 32.
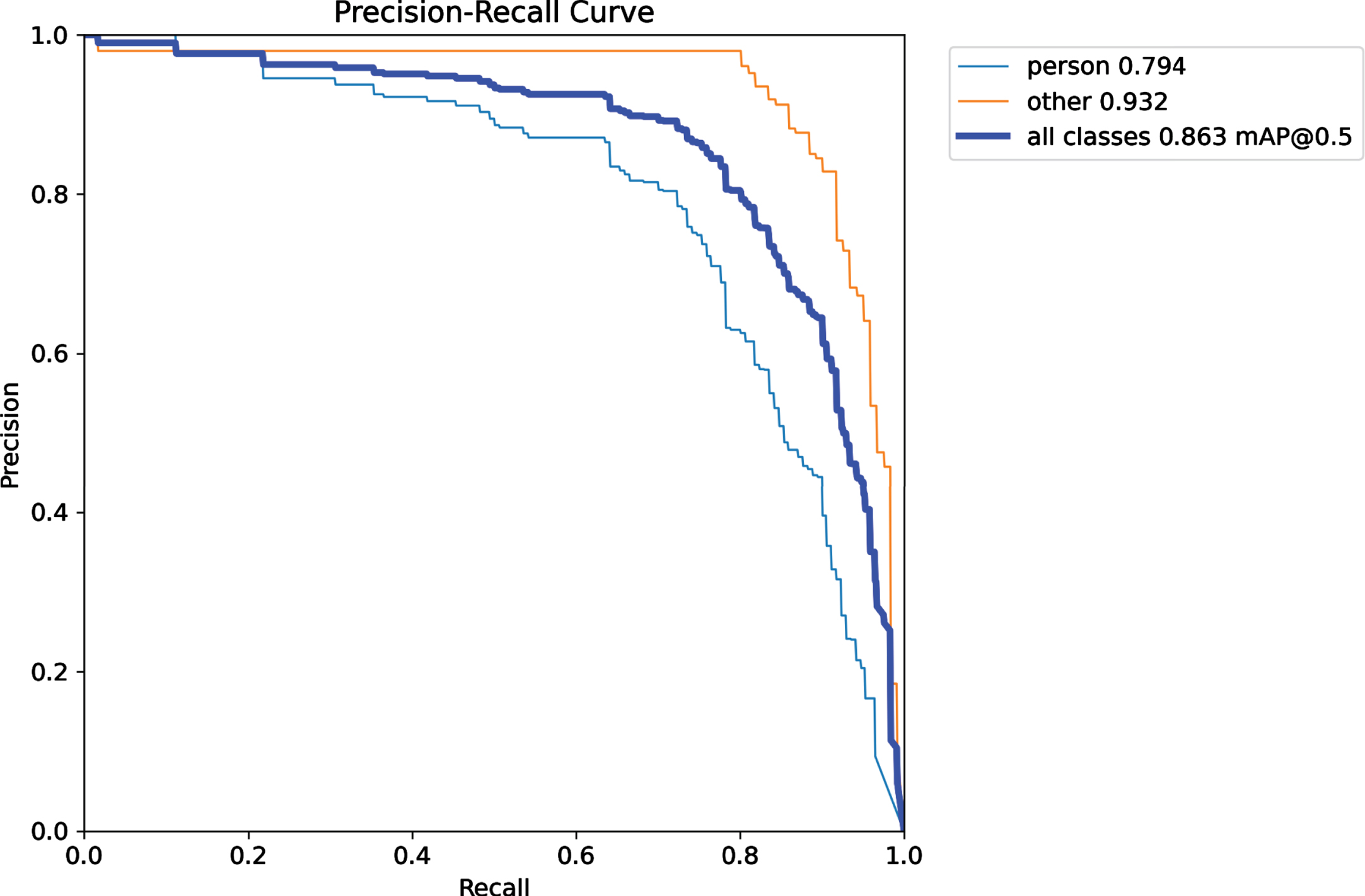
Precision-recall curve analysis of ADF-AFPLM with batch size = 64.
Table 3 presents the learning performance of ADF-AFPLM with varying image sizes. The lowest loss was achieved at an image size equal to 512 but the highest precision was achieved by image size equal to 256. Whereas the highest mAP was achieved at an image size equal to 640. The table also presented the execution time analysis in which the lower image size achieved the lowest time as compared to others. Figures 15 to 17 presents the precision-recall curve analysis of the ADF-AFPLM with varying image sizes. Figure 15 presents the precision-recall analysis with image size 256. It was observed that for all class detection, highest mAP was approx. 0.838. Whereas the image size of learning was increased upto 512 and presented in Fig. 16. In this analysis, the highest mAP was 0.855 and finally in Fig. 17, result of image size 640 is presented with highest mAP of 0.876. Similarly, table 4 presents the performance evaluation on different datasets. The model is trained on the Eurocity dataset and tested on other datasets such as CityPersons, PennFudan, and INRIA. The table also presented the execution time analysis in which PennFudan achieved the lowest time as compared to others.
Performance evaluation of ADF-AFPLM with variation of image size
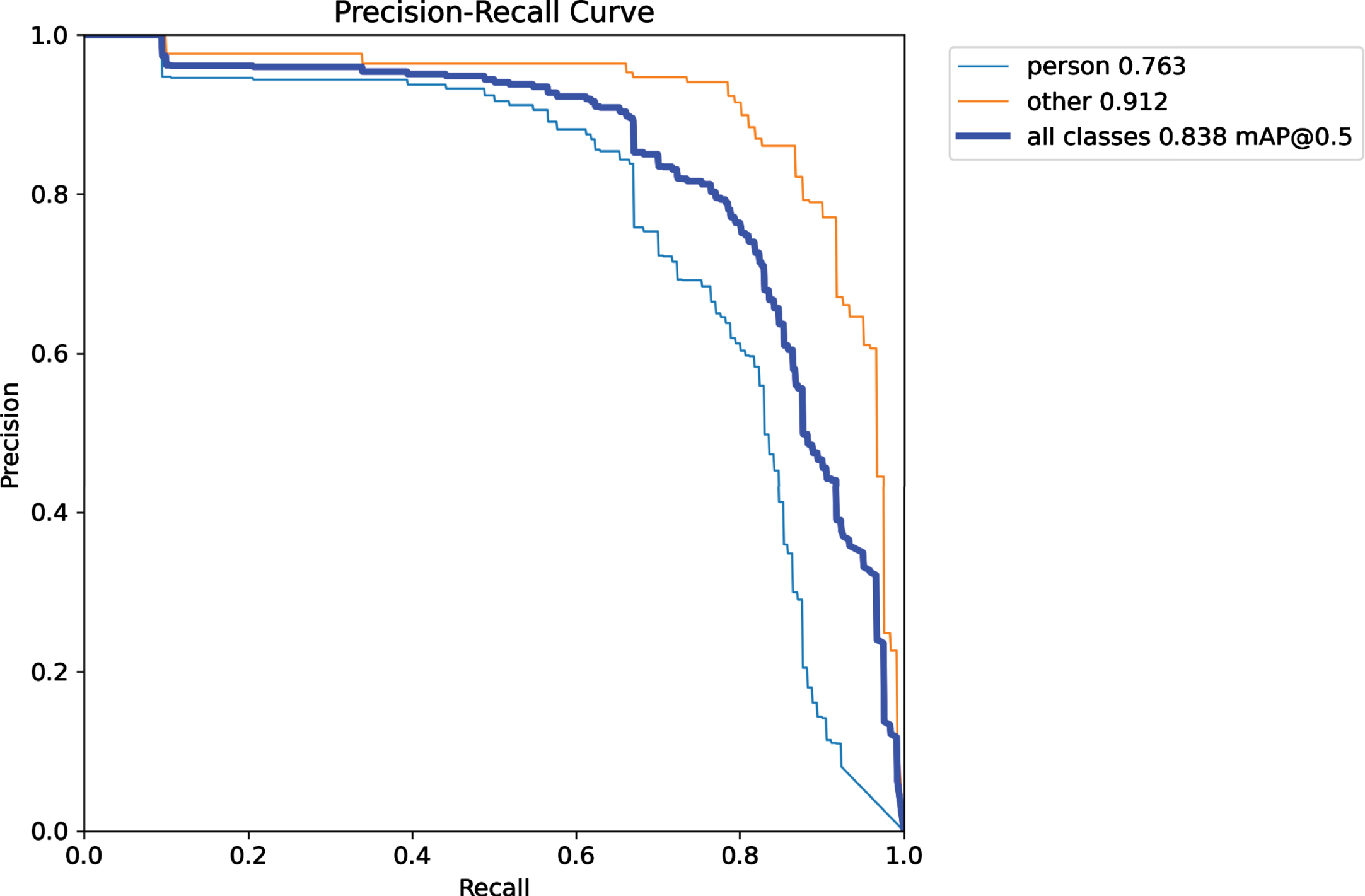
Precision recall curve analysis of ADF- AFPLM with image size = 256.
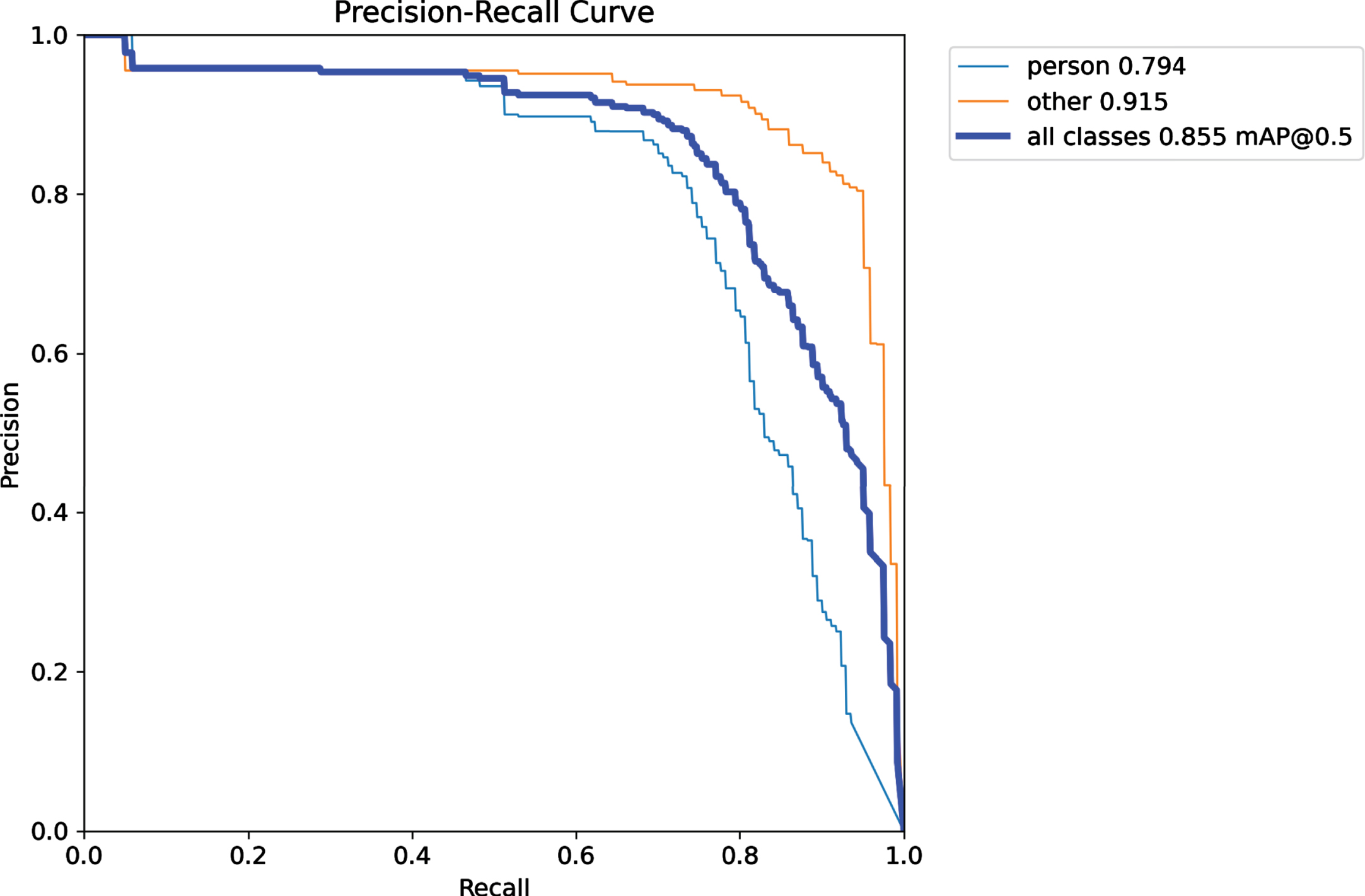
Precision recall curve analysis of ADF- AFPLM with image size = 512.
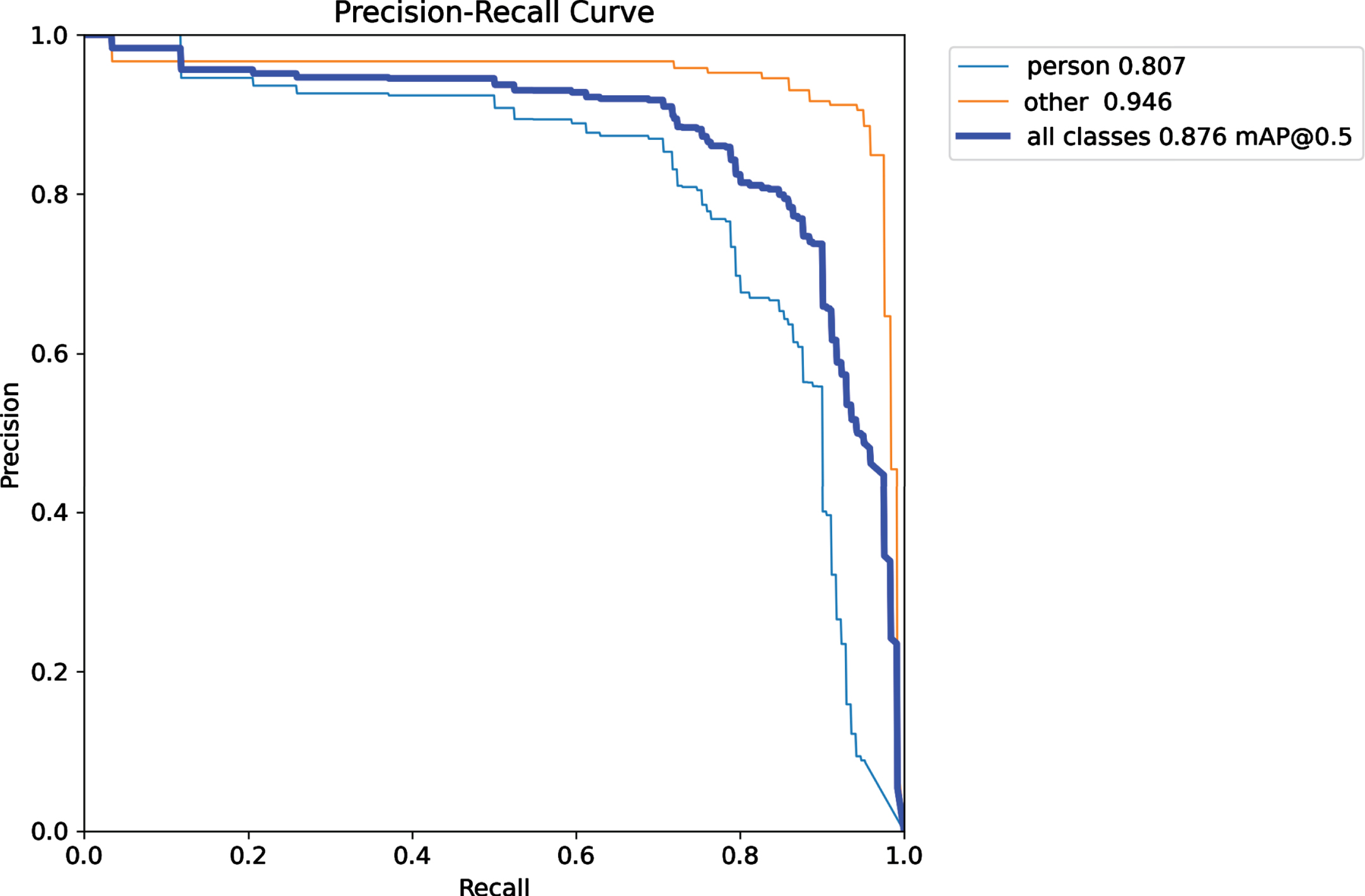
Precision recall curve analysis of ADF- AFPLM with image size = 640.
Performance evaluation of ADF-AFPLM on different datasets
Performance comparison of state-of-art models
Table 5 compares the performance of various state-of-the-art models in terms of precision, recall, F1 score, and mean Average Precision (mAP). For comparison, several state-of-art models are considered such as PRNet++ [40], I2V-MVPD [2], YOLOv3 [43], Improved YoloV4 [6], YOLOv4-HDPD [51], Improved YOLOV5 [18], SMG-Y [10], YOLO-ACN [21], RGBT [44], YOLO-CIR [54], and ADF-AFPLM (ours). I2V-MVPD [2] achieves a recall of 57.37%, an F1 score of 62%, and a mAP of 55%. Tumas et al. [43] presented YOLOv3 in perfect weather conditions and achieved a precision of 69%, a recall of 87%, an F1 score of 77%, and a mAP of 82%. However, it is still unknown what the performance is in adverse weather conditions such as hazy environments, night vision, etc. Then improved YOLOv4 version was presented by Boyuan and Muqing [6]. Improved YOLOv4 [6] achieves a recall of 80% and a mAP of 84%. The models are an advanced version of YOLOv4 but are not suitable for pedestrian detection under background complexities and have slow detection speeds. Hexiang, et al. [51] proposed YOLOv4-HDPD based on deep information fusion and achieved a recall of 65%, an F1 score of 69%, and a mAP of 75%. However, this model has an increased number of training parameters. However, the advanced algorithms for computer vision applications may suffer a number of challenges due to variations in posture, image scales, and occlusion. Hajari et al. [18] presented an Improved YOLOv5 model to mitigate these issues. The proposed method deals with partial occlusion circumstances and achieves 79% mAP. Chen et al. [10] presented a pedestrian detection network model with a background suppression module that will highlight the foreground features to identify objects. Moreover, Li et al. [21] presented a person detection network model from infrared images. The author worked on the loss function and the convolution module for optimal feature extraction. With the advancement of this, Vadidar et al. [44] used a fusion model based on infrared and visible images. To further refine these multi-spectral models, Zhou et al. [54] modified the YOLOv5 model to handle low-resolution images. But still, these algorithms have shown lower detection rates under occlusion and environmental complexities. Therefore, to handle occlusion, the proposed model presents the anchor-free detection model. Environmental complexities and background complexities can be handled by pre-processing networks which is an attention-based residual learning model. ADF-AFPLM (Ours) achieves a precision of 84.2%, a recall of 84.7%, an F1 score of 81%, and a mAP of 87%. In summary, based on the provided information, ADF-AFPLM (Ours) stands out as a high-performing model to address the occlusion challenges.
Discussion
In this paper, the Anchor-Free Feature Pyramid Learning Model is presented with an attention-based digital filter to detect persons in crowded and occluded images. The following major observations are concluded: BM3 (ARNDF with the YOLOv8n) had achieved the lowest loss and observed to be most efficient model in terms of this particular loss metric as compared to BM4 (ARNDF with YOLOv8l). Whereas BM1 and BM2 achieved moderate loss. Then precision was also good in BM3 but mAP of BM1 was better. But the execution time of BM3 was least as compared to others. Therefore, ADF-AFPLM adopted BM3 for further investigation. Then the result was analyzed with increasing learning batch size of image. In this least Loss
CIOU
was achieved by 16 batch size and precision was also highest. This indicates that batch size =16 is the optimal choice. The precision of batch size decreases with increasing batch size therefore, large batch size will adversely affect the efficiency of the model. The image resolutions were also considered for analysis and it was observed that with increasing image resolution, the mAP increases. Therefore, the final ADF-AFPLM had adopted YOLOv8n with batch size 16 and image size 640 is considered for efficient result with different testing datasets. As compared to state-of-art models the proposed ADF-AFPLM shows faster detection with better mAP.
Conclusion
The paper proposes a hybrid model for pedestrian detection by combining an attention-based residual network digital filter (ARNDF) with a feature pyramid network, specifically the latest YOLOv8 model. The attention-based residual network digital filters are chosen for their enhanced filtering performance, adaptability, efficient learning through residual connections, noise suppression, interpretability, and generalization capabilities. After enhancing the image quality, the Anchor-Free Feature Pyramid Learning Model (such as the YOLOv8 model) is utilized to extract features and learn to identify pedestrians among other objects in the image.
The main achievements of the study: Across various datasets, the model shows consistent performance, indicating its robustness and adaptability. Detection time is lower which shows the proposed model is light weight. The model achieved a mean average precision (mAP) of 87% and shows its efficacy over state-of-art models by approx. 2% more. The proposed model can efficiently handle environmental and background complexities and occlusion. The findings of this study provide valuable insights for researchers and practitioners in the field of computer vision and pedestrian detection.
Future research can further explore the application of ADF-AFPLM in real-world scenarios and investigate its performance in different environmental conditions and camera-related challenging situations.
Footnotes
Acknowledgment
The authors declare that there is no conflict of interest regarding the publication of this paper.