
Abstract
A smart home inhabitant performs a unique pattern or sequence of tasks repeatedly. Thus, a machine learning approach will be required to build an intelligent network of home appliances, and the algorithm should respond quickly to execute the decision. This study proposes a decision tree-based machine learning approach for predicting the activities using different appliances such as state, locations and time. A noise filter is employed to remove unwanted data and generate task sequences, and dual state properties of a home appliance are utilized to extract episodes from the sequence. An incremental decision tree approach was taken to reduce execution time. The algorithm was tested using a well-known smart home dataset from MavLab. The experimental results showed that the algorithm successfully extracted 689 predictions and their location at 90% accuracy, and the total execution time was 94 s, which is less than that of existing methods. A hardware prototype was designed using Raspberry Pi 2 B to validate the proposed prediction system. The general-purpose input-output (GPIO) interfaces of Raspberry Pi 2 B were used to communicate with the prototype testbed and showed that the algorithm successfully predicted the next activities.
Introduction
The number of elderly people will increase from 605 million in 2012 to approximately 2 billion by 2050, and the proportion of the population aged 60 and more will increase to 22% from 11% [19]. Although older people’s skills and expertise are vital resources in our society, the primary challenge is providing seniors with “age-friendly” environments. Another important factor identified by the World Health Organization (WHO) is that at least 650 million people live with disabilities [16]. To facilitate personal comfort and confidence, these large numbers of older adults and people with disabilities prefer to remain in their premises than in an alienating environment at a healthcare facility. It would be better to convert their current living spaces into interactive intelligent environments that adapt to the inhabitants’ needs and assist them in their daily living [17]. Smart homes are an application of ubiquitous computing in which information about the home environment is perceived and processed to predict future user activities. Future homes are expected to be the centre of many integrated services, e.g., communication, medical, energy, utility, entertainment and security services. People spend a significant amount of time at their homes, which has attracted potential investors to promote integrating a wide variety of services into traditional homes. This process requires understanding human behaviour and practical algorithms to solve uncertainty problems in the home. Although smart home research began several decades ago, several issues that must be addressed persist, e.g., immature home intelligence due to inadequate algorithms, improper activity recognition methods and low prediction accuracy rates [2,4,5,14,18]. However, one of the significant features of a smart home is the prediction of inhabitant activities. It is more evident in smart healthcare where the elder or handicapped people take support from the smart home and repeatedly do a few of their daily activities.
Although the smart home requires networking and other equipment, the algorithm also plays a critical role, especially for the elderly. Such people perform a few tasks each day, and if the algorithm is sufficiently smart to observe patterns and predict subsequent activities, it would be more effective at handling emergencies. Smart premises will generate an alarm or send a signal if the predicted patterns do not match; thus, unintentional situations can be resolved promptly. Many researchers have emphasized such activity predictions and have worked continuously to develop algorithms that can quickly and accurately predict the next activity. For example, Alam et al. developed the sequence prediction via enhanced episode discovery (SPEED) algorithm, which uses human activity patterns for future state prediction of home appliances [2]. The algorithm introduces episodes, where an episode is defined as the period between the start and end of a particular task, and established an algorithm to predict the next activity. Compared to other algorithms, such as C4.5, incremental probabilistic action modelling (IPAM), LeZi Update, and Active LeZi, the SPEED algorithm demonstrates more accurate results [4,7,20]. Researchers also showed that using a machine learning approach in the prediction model shows better accuracy [15]. The SPEED algorithm defines completed tasks as an episode and constructs a decision tree for prediction.
However, human activity patterns are generally affected by other components, such as location and time agents [1]. Marufuzzaman et al. used the SPEED algorithm concept and introduced a time agent for better efficiency [10]. The researcher also uses location agents in the SPEED algorithm and validation in an experimental home, too [12]. However, researchers who have focused on location for prediction primarily considered the inhabitant’s location and did not consider the tasks that occurred [3,8,9]. Therefore, to design an effective algorithm, several agents, such as time and location agents, must be considered. In other words, a multiagent-based intelligent system is required, and such a system will help represent human behaviours more clearly and will expect to improve the prediction accuracy. Very recently, Araf et al. showed that by introducing multiple agents, the algorithm could show better accuracy [6]. However, the algorithm does not show anything related to hardware implementation required for autonomous homes. To implement the algorithm, another major challenge is the execution time. Some researchers develop Agent-based hardware implementation, but the implementation cannot handle a large volume of data required to improve the accuracy of the machine learning algorithm [11]. An alternative solution can be using embedded hardware to implement the algorithm in real-time. Besides, implementing such an algorithm in an experimental home should have low execution time and not require on-site configuration of any kind.
In this research, the episode-based strategy was selected from the highly accurate SPEED algorithm and was modified to include multiple agents, such as time and location agents, to achieve better prediction accuracy and faster execution time. In this paper, the proposed algorithm is validated using a renowned smart home dataset, i.e., MavHome from MavLab [13]. Finally, a hardware prototype implementation is shown to support the algorithm for automation.
Research methodology
The fundamental problem related to inhabitant behavior is predicting the inhabitant’s next activity. This study modified the SPEED algorithm to improve accuracy and reduce processing time. The proposed algorithm considers all possible episodes and the time of occurrence and the location of appliances. The algorithm mainly depends on the number of episodes, i.e., the number of different smart homes. The overall process flow of the proposed algorithm is shown in Fig. 1.
In a home environment, the resident performs numerous tasks, and these tasks involve various information, such as the nature of the task, when the task is completed, and where the task is performed. If an algorithm considers all such task information, it can distinguish tasks and predict tasks more accurately. The proposed algorithm considers the time, location, and event of a task to construct an episode that represents a completed task. For example, consider a home with three rooms, where each room has a fan and a light. We know that an appliance has at least two states (i.e., ON and OFF). Therefore, Turn ON the light and after some time, Turn OFF that same light will be considered an Episode; i.e., the appliances’ activities in room 1 and room 3 are regarded as episodes. It is easy to see that, to predict the tasks of turning ON or OFF a light, we must know which room the target light belongs-to. Note that there may be other appliances in a home, such as coffee makers and televisions. The proposed algorithm considers the time, location and state for improving the effectiveness of the method. In contrast, the existing algorithm only finds the state of the given appliance.
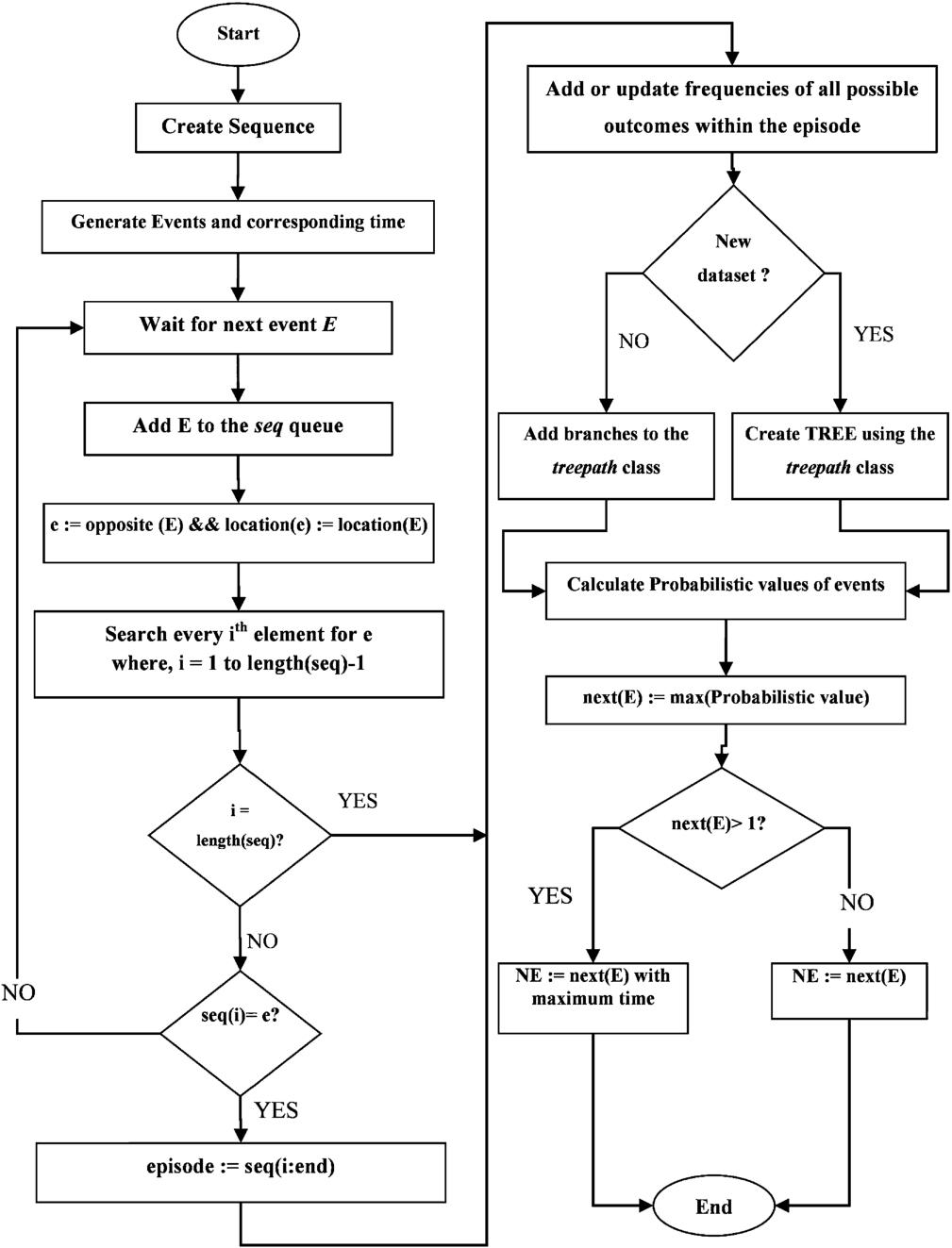
Process flow of the proposed algorithm.
Another major factor is that some appliances are repeatedly turned ON and OFF each day; thus, we consider that the most frequent events represent the most frequent activities. The algorithm must predict the next future activity using knowledge of all previous and current activities to realize a smart home. Here, suppose
Many data files that reflect the activities of an established smart home are available online. Such data files, which contain information about inhabitant actions at a given time, were used in this study. These periodic data sequences contain information about the characteristics of the inhabitants’ tasks and the appliances states during the time duration of those tasks. The proposed algorithm takes these periodical datasets and transforms them into sequences. First, a sequence filter method is used to discard redundant data and generate a sequence with unique events. This filter method was unavailable in previous SPEED; thus, it considers all the redundant data. After removing redundant data, the proposed algorithm follows the SPEED algorithm to create episodes. However, in this proposed algorithm, an episode is considered relative to both location and time. If an appliance is turned ON and then turned OFF after a specific time, this sequence can be viewed as a completed episode. Therefore, behavioural patterns are classified into distinct episodes. For example, user activities in room 1 may begin with turning the light ON and end with turning the same light OFF, and such a scenario is considered a complete episode. Another episode may occur with the same appliances, i.e., the light in room 2, which will be considered a sub-episode occurrence within an episode. To reduce processing time, this proposed algorithm always modifies raw data into a simplified format. Like the appliance are represented using alphabets, the states are represented in either small/capital form while the location is represented using the room number. Most importantly, the time is arranged in 1440 minutes per day format and is stored in a separate array; this defines how the tasks are represented as a string.
Note that sub-episodes may exist in an episode. In a smart home, patterns formed by daily living activities can be classified as episodes, where all episodes must contain a start-end point, duration and location. An episode is generated under the condition that an event and its opposite event are observed with a reasonable time and location. Note that it is impossible to initiate the same event again prior to ending the given previous event. These rules are used to reduce noise generated by unreliable sensors. Figure 2 shows the pseudocode of the sequence generation module.

Pseudocode for creating a sequence.
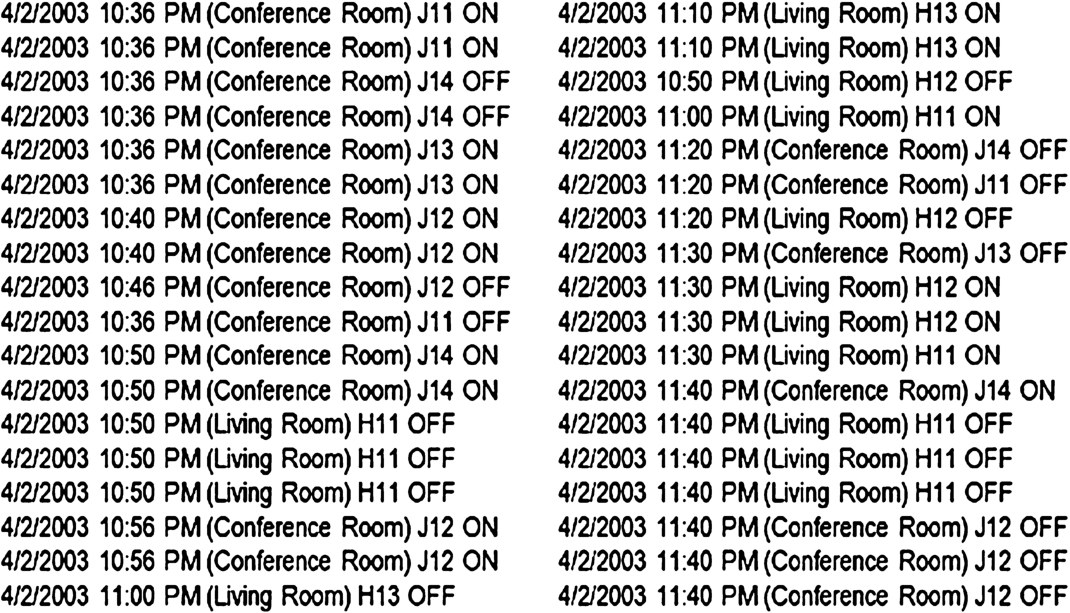
Sample data collected from MavHome dataset [13].
In this research, we considered the MAVHome dataset [13]. A chunk of that dataset is shown in Fig. 3. The sequence shown in Eq. (1) was extracted from that dataset using the pseudocode given in Fig. 2. We see that, the data needed for further processing is extracted from the original dataset, which is very much precise. In this format, the algorithm can process the data much faster. Note that storing time information is required to control the correctness of the further compromised sequence.
The length of the sequence is shrunk significantly using the pseudocode in Fig. 2. For example, the algorithm eliminates the superfluous occurrence of a second ON event for A, which occurs due to a refresh cycle. For a given appliance, the capital letters indicate ON events, and the corresponding lowercase letters indicate OFF events. The numbers that follow an event indicate the event’s location, the “@” symbol separates the time from the sequence’s location. The start and endpoint of event A are followed by a number, which indicates location A, and the four-digit number after @ indicates the corresponding time in the 1440-minute format. For example, 10:36 PM is represented by
To differentiate the same event in a different location and minimize the required memory, events in different locations are assigned different letters after compressing the sequence. Depending on the location, the event’s ASCII value changes; thus, the symbol also changes. For example, consider the above sequence. Here, element

Pseudocode to compress a sequence.
According to the definition of an episode, numerous episodes with boundaries of opposite events and valid location and time can be found. A valid location means that the number followed by the end point of an episode is the same as the number followed by the start event. Note that the number following an episode should be a positive integer. Another practical implementation of this algorithm is to consider sub-episodes based on the task duration. Inner tasks can’t take longer than outer tasks. For example, a person turns the light ON, then turns the oven ON for a while, turns the oven OFF, and finally turns the light OFF while leaving the room. Therefore, the oven has sub-episodes, and the duration of this episode must be less than that of the light. These properties are utilized to extract episodes from the event history. Fig. 5 shows the pseudocode for generating episodes. The use of letters is only one way to represent a specific event. Other possibilities include using numbered variables, which would increase the number of presentable applications. However, for our purposes, English letters are sufficient to represent the target dataset.

Pseudocode to generate episodes.
The input to this proposed algorithm comprises a valid sequence of events and their locations and durations. Note that redundant data are filtered out before the algorithm is executed. After generating an episode, the algorithm is used as an incremental decision tree. The concept of taking all episodes is taken from Marufuzzaman et al. [10]. However, the proposed algorithm also considers location information. Finally, the algorithm generates all possible contexts and their occurrence frequencies. All open and incomplete events are stored in another array by the proposed algorithm, whereas the previous algorithm failed to detect episodes that are out of the window range. This significant modification increases prediction accuracy.
Storage values and all possible contexts with their occurrence frequencies using the proposed algorithm for the AdCBbaDgBiI sequence
After detecting an episode, the algorithm generates possible contexts, as shown in Table 1. As with the SPEED algorithm, the proposed algorithm also generates a
A decision tree (Fig. 6) was constructed using the data shown in Table 1, and a future state prediction is defined by analyzing the tree. Here, the partial matching (PPM) algorithm is used to predict events. The PPM algorithm measures the weighted probability of an episode and estimates an event’s probability by reducing the episode length. Rather than using a static tree, an incremental design approach is employed, which means that the tree is generated such that a new branch is added to the old tree instead of generating the whole tree if events are added in the previous sequence. Note that the tree grows when each new episode is processed. This incremental tree visualizes the proposed algorithm’s learning process. Each processed sequence and each processed episode quickly contribute to better prediction accuracy.
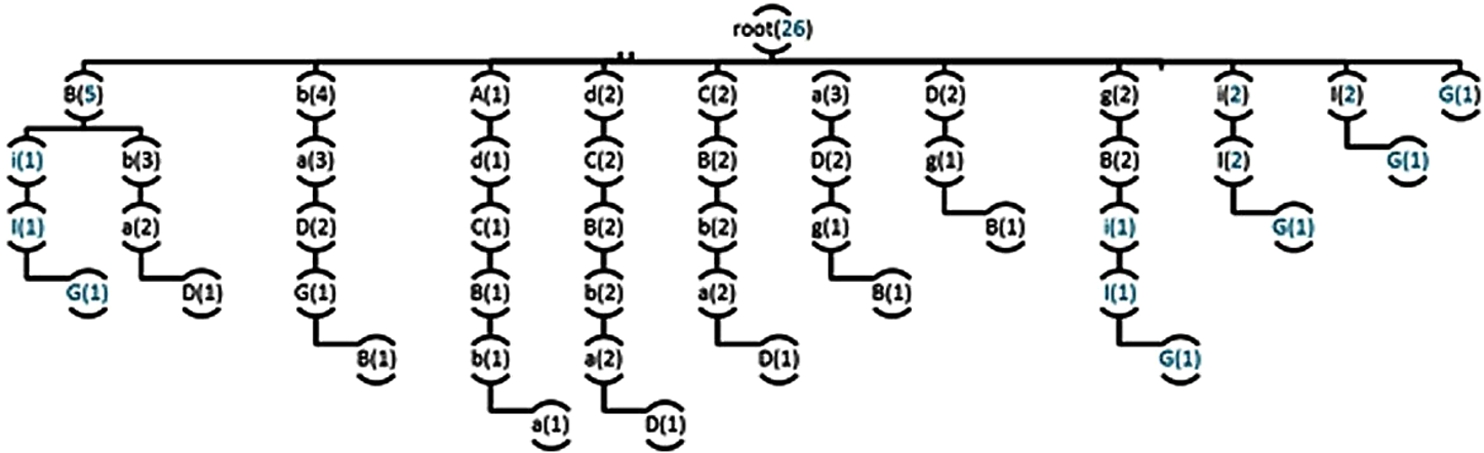
Tree formed by the algorithm after processing the AdCBbaDgBiI sequence.
The proposed system also implements the incremental tree approach, which means that the existing tree will be increased if new events are added to the old sequence and a new episode is generated. For example, if an event “G” is added to the previous sequence “AdCBbaDgBiI,” then the previous tree will extend its branches and leaves, as shown in Fig. 7.
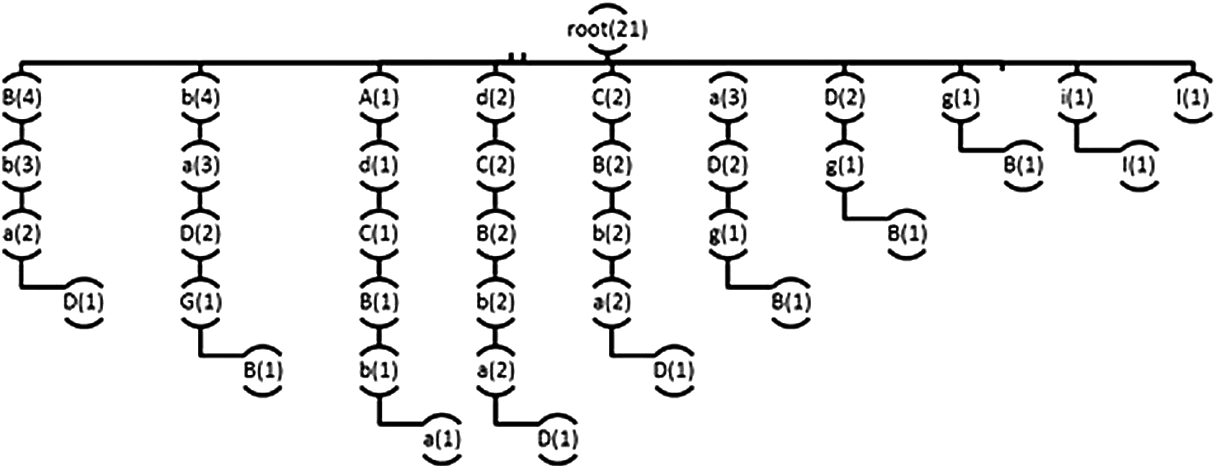
Incremental tree branches of the proposed algorithm after processing the new event “G”.
To calculate the probability of future events, assuming the previously considered sequence, i.e., AdCBbaDgBiIG and assumed that the current window state is AdC. The proposed algorithm follows the previous SPEED algorithms, i.e., it employs prediction via the PPM method. Thus, the probability of observing other symbols as the next event after AdC can be calculated, e.g., the probability of observing d is showing in Eq. (2).
After predicting the event, their corresponding location is stated. For example, if the next predicted event is A, then it is stated as “Event A in ROOM_1” whereas, if the next predicted event is G, then it is stated as “Event A in ROOM_ 2”. Therefore, the proposed system predicts the next event and predicts the location of that event. Compared to only considering event information, predicting a particular event with location information improves accuracy significantly. Besides, a location is predicted with events; therefore, it is easy to execute the decision.
The proposed algorithm can identify the next state after analyzing the dataset stored previously. The inhabitant’s behavior is a sequence of consecutive activities. The resident sequentially uses home appliances according to personal choice, environment, and situation demand. However, if we wanted to consider the overall algorithm representation in hardware, FPGA cannot afford such complex string operations. Therefore, the overall controller’s hardware prototype is built using Raspberry Pi 2 B in this research. The overall decision controller needs to detect ADL in real-time and produce the decision accordingly. Moreover, as mentioned earlier, the algorithm processed a considerable chunk of string data, which demands high processing power and huge memory. The processor also needs to capture data simultaneously from the appliances and execute the predicted state in real-time. As such, a processor with sufficient memory and data capturing port is needed. However, the platform also needs to be cheap to reduce the overall cost of the prototype. Considering all these constraints and requirements, the ‘Raspberry Pi 2 B’ board is used in this research.
In this research, a hardware prototype contains “store data” and “execute decision” features are implemented using Raspberry Pi 2 B. The GPIO interfaces are used, which are connected with a breadboard where three LED lights and two switches are attached. This research’s primary concentration is to develop the algorithm; therefore, prototype hardware was built that illustrates input with the low voltage switches and output with the LED lights. It is easily explicable that if we can manage to change the states of the LED light, then using a transistor, 5 V SPDT relay and diode, we can change the states of the appliances. Therefore, to simplify the prototype this research is used LED lights and Low Voltage switches. The prototype setup is shown in Fig. 8. The GPIO output of Raspberry Pi passes to the relay circuit and by using the relay switches; anyone can easily control any AC appliances. Most of the sensors are compatible with Raspberry Pi. So, if we can manage to sense the state of the switch’s same way, we can sense the sensor information too. As the research is built the prototype, therefore it shows the output using the LED lights and the input is considered as the low voltage switches.

Photograph of the hardware prototype.
The Raspberry Pi is connected through its GPIO interfaces with the Breadboard. Two 8-pin switches are used, one is to act as the input of the prototype and the other is to act as changing the mode (toggle IO MODE). Three registers are used in the circuitry for protecting the LEDs. At first, the IO MODE is toggled into input mode to store the data and it represents the appliances’ turn ON/OFF state. One user will turn ON/OFF the three LED’s, which are representing as three appliances. After some iteration, if the user wants to execute the decision, then the IO MODE switch needs to be toggled, i.e., input/output mode. The Raspberry Pi then acts as the decision agent, and sequentially shows the predicted states. According to the decision, the corresponding LED will turn ON or turn OFF. Python programming language is used for coding as it can manipulate the strings very efficiently and run the GPIO commands. A sample result after the hardware is executed is shown in Fig. 9.

Execution of the hardware controller.
The hardware prototype is generating a sequential prediction. After predicting the next event, it automatically appends that event into the previous sequence and based on that, it can again predict the next state. It is evident that instead of predicting just one event, predicting a sequence of events is useful. This feature will certainly make the hardware implementation more effective. Fig. 9 depicted the scenario where three LED is turning ON one after another based on their previous states.
The MavLab dataset was used to validate the proposed algorithm. This dataset was collected from a MavHome testbed at the University of Texas, Arlington [13]. More than 3000 sequential states were generated in one month. Here, we present the results obtained for each step of the proposed algorithm. The MavHome dataset contains 3015 data. To make it a sequence, each room is converted into a number, and the appliances are defined as one alphabet character. After filtering the raw dataset using the create_sequence() function, the algorithm generates noise filters, which contain the time, location, and event information. This function successfully generates a string with 4823 characters. After processing the string, the input sequence required for the algorithm is generated. Here, the event symbol changed according to its location, and 689 events were generated. Note that the information for a single event has one symbol, one location number, the ‘@’ symbol as a separator, and a 4-digit number representing time in the 1440-minute format. Therefore, seven characters are required to build information for a single event. Thus, from the 4823 characters,
The “gen_tree()” function generates the tree using the “treepath” class. The 211 episodes help build the tree. First, the algorithm generates all possible outcomes of the episodes. Here, 2113 possible outcomes are created from the episodes, and the treepath class then generates the tree’s branches using those possible outcomes. Note that 487724 elements are stored in the given tree. Using the PPM algorithm, the probability of occurrence of each node in the tree is calculated. After analyzing the MavHome dataset, the proposed algorithm produced the next state as “f”, i.e., the ”
A colossal dataset is required to validate the effectiveness and efficiency of an algorithm. In this study, we used the MavHome testbed dataset to evaluate performance. Compared to other algorithms, as mentioned earlier, the existing SPEED algorithm demonstrates the highest accuracy. Therefore, we compared the performance of the proposed algorithm to that of the existing SPEED algorithm. Note that both algorithms were evaluated and compared using the same dataset.
After prediction, a
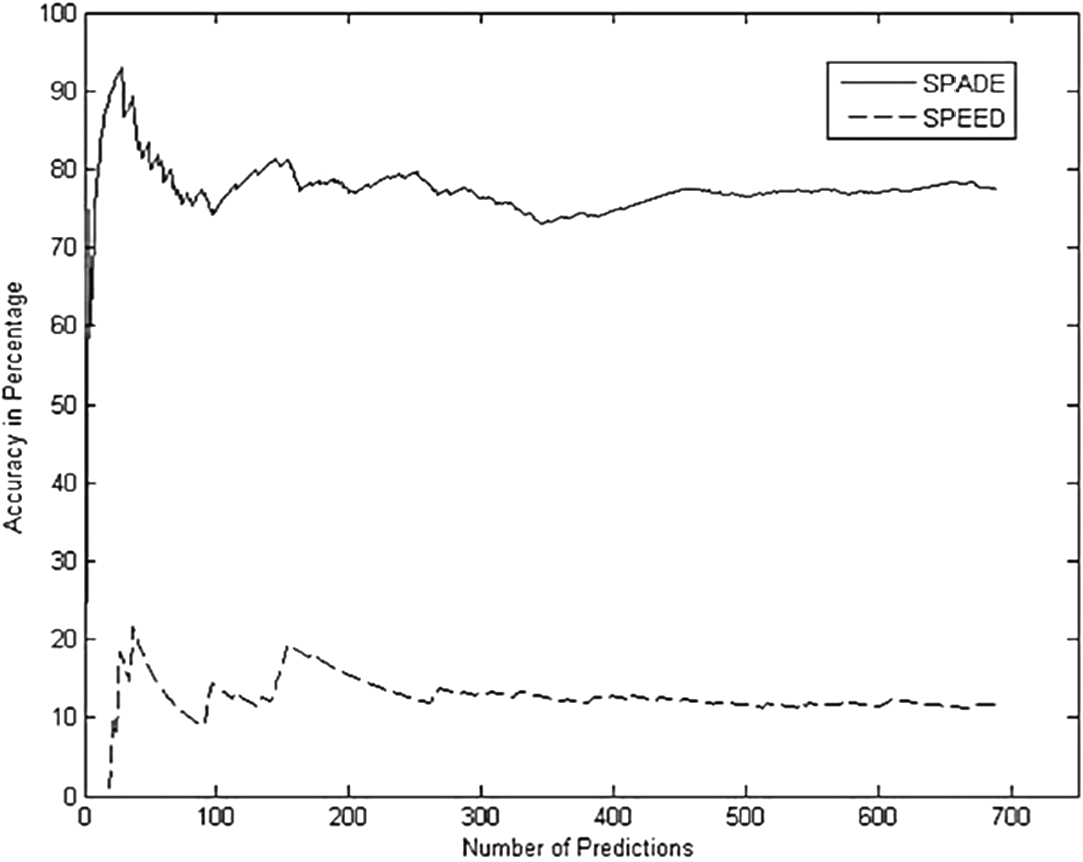
Accuracy comparisons between the SPEED and the proposed algorithms using MavHome data.
The proposed algorithm filters useful information out of any dataset. In contrast, the existing SPEED algorithm cannot detect invalid or redundant sequences. Therefore, these filtered sequences were used with the SPEED algorithm to obtain comparable results. After filtering, the redundant data (689 unique data) were considered for accurate measurement. Fig. 10 shows compare the performance of the algorithms when tested using the filtered MavHome data. As can be seen, this algorithm’s accuracy is initially similar to that of the SPEED algorithm; however, as more events occurred, the accuracy changes. As shown, the proposed algorithm’s prediction accuracy is always greater than that of the SPEED algorithm. In addition, the results demonstrate that the convergence rate is faster than that of the previous algorithm.
The proposed algorithm demonstrates better accuracy and execution time than the existing SPEED algorithm, which, in terms of accuracy, outperforms the Active LeZi, IPAM, LeZi update, and C4.5 algorithms [2]. Our results indicate that the proposed algorithm outperforms the SPEED. Moreover, by implementing the decision agent (decision-based on the probability), the algorithm can detect the next state with location information. After completing the probabilistic calculation, the SPEED algorithm predicts the next probable event but not the event’s location. It is expected that considering only the appliance state is insufficient to predict probable future activities. The prediction of the next probable event is more accurate if location information is considered. Thus, using a location agent and converting the sequence according to the location information yields more accurate results than the existing SPEED algorithm.
The algorithms’ execution time was measured using the MATLAB® Profiler application, which measures the total execution time of each function. The results are shown in Table 2.
Execution times of the SPEED and the proposed algorithms
Table 2 shows that the proposed algorithm’s execution time is significantly less than that of the existing SPEED algorithm. The proposed algorithm executes much faster as the size of the dataset increases. To test this phenomenon, the portion of the dataset is executed with MATLAB Profiler application two different numbers of data. First, it was run using 236 activities. Then, the same dataset was run using 479 activities. The results are shown in Table 3. As can be seen, with the proposed algorithm, the second execution time is nearly the same as the previous execution time. In contrast, with the existing algorithm, the difference between execution times is quite large.
Execution time comparison relative to changes in the same dataset
The proposed algorithm implements an incremental tree approach; therefore, the execution time of the second run was nearly the same as that of the first run (
According to the results, in terms of accuracy, the proposed algorithm outperforms the SPEED algorithm because the algorithm considers all episodes, whereas the SPEED algorithm only considers episodes in a limited window range. In this method, the event with the longest duration is considered the predicted event if two or more events have equal probabilistic values, which is impossible with the existing SPEED algorithm. Also, the proposed algorithm considers the latest opposite state of an appliance while building an episode. For example, if a light is turned ON at 5 PM and turned OFF at 5:05 PM, the episode is completed in both algorithms. However, if the same light is turned ON again at 5:10 PM and then turned OFF at 5:30 PM, the previous SPEED algorithm considers that latest scenario as the opposite state of the light at 5 PM; thus, it constructs only a single episode. However, the last event is not the opposite state of the 5 PM event. Instead, it completes the episode that started at 5:10 PM. In the proposed algorithm, these two episodes are differentiated. It is also expected that considering location information results in higher accuracy because an inhabitant does not demonstrate the same behaviours in different rooms. Assume there are two rooms, where each room has more than one common appliance. Thus, detecting only events will yield lower accuracy than also considering location information. The accuracy of the proposed algorithm is better than that of the SPEED algorithm. Episode isolation criterion of the proposed algorithm can be considered a robust data classification method that can effectively cluster unique smart home data patterns. Moreover, modifying the episode generation leads to a faster convergence rate and overall increased prediction accuracy. Since smart home data demonstrate a natural temporal pattern, it is essential to predict future states’ time components effectively. Even though the existing SPEED algorithm takes the same approach as the proposed algorithm to reach a decision, the differences in which the results are obtained significantly affect the outcomes. First, the proposed algorithm emphasizes the detection of false events in the input sequence. Second, the algorithm considers both appliances’ location and time information. Despite the increased focus on false event detection, the latter processing becomes increasingly quicker with fewer episodes in the decision tree. Finally, the proposed algorithm improves the most time-consuming component of this method, i.e., tree generation. Generating a tree takes a lot more time than increasing the number of branches and leaves of a given tree. The proposed algorithm employs this strategy to reduce execution time. Besides, each smart home inhabitant’s dataset will be updated continuously; therefore, each time the dataset is amended, the algorithm will store new possible outcomes in its branches and leaves. As demonstrated by our results, this feature reduces the execution time for large datasets. It is expected that even greater optimization can be obtained with a long-term testing environment when plotting several decision trees according to the weekend, weekday, and seasonal activities, as discussed previously. The algorithm code contains fewer loops compared with the SPEED algorithm, which also improves its execution time. In addition, the code stores different values in matrices and arrays for future utilization. Therefore, the required information is filtered from previously extracted information, and the complete input dataset is searched only once. Most importantly, the sequential prediction of the proposed algorithm provides real-time solutions for future intelligent environments.
This paper has proposed an algorithm, which can successfully identify significant episodes of smart home inhabitant activities. In contrast, the existing SPEED algorithm fails to detect episodes that are beyond a given window range. An effective algorithm should detect all existing sequences and utilize all agents to realize effective prediction. Such an algorithm should also only consider the latest opposite event as a match for the current event. Other matches lead to false episode detection, resulting in incorrect information, leading to false predictions. The proposed algorithm solves these two problems. In this study, the proposed algorithm’s accuracy was compared to that of the existing SPEED algorithm using the MavHome dataset. The results demonstrate that the proposed algorithm achieves more significant than 90% accuracy. In contrast, with the same dataset, the exiting SPEED algorithm obtained only 30% accuracy. Previously, it was demonstrated that the SPEED algorithm outperformed other recent algorithms. Therefore, the proposed algorithm provides better accuracy than recently published methods. The new algorithm yields better accuracy and results in faster execution time than the existing SPEED algorithm. The results demonstrate that using a dataset with more than 3000 elements, the proposed algorithm’s processing time was only 94 s. In contrast, with the same dataset, the execution time of the SPEED algorithm was 28000 s. Note that this positive difference in execution time increases with increasing dataset size. In this study, a sequence algorithm was designed to predict the next event. Furthermore, the algorithm is not limited only to the use of appliances but can be extended further for different tasks. In the future, inhabitant behaviours defined by two states can also be represented. Examples of such human actions include being in a room or not and being asleep or awake. Moreover, the variable assigned to certain events can also be altered according to the time of day or the calendar date. Another essential feature that can be adopted by this algorithm is multiple people working simultaneously. Thus, in the future, we plan to consider including additional parameters in the proposed algorithm.
Footnotes
Acknowledgements
The authors would like to thank Universiti Tenaga Nasional and Universiti Kebangsaan Malaysia for supporting the research works.