
Abstract
Technological innovations in Internet of Things (IoT) have resulted in smart agricultural solutions such as a remotely monitored Aquaponics system and a wireless sensor network (WSN) of such systems (nodes). IoT enables continuous sensing of temperature and pH data at each node of the WSN, which is periodically transmitted to a remote fusion centre. In this regard, the data matrices acquired at the fusion centre often suffer from data vacancies and missing data problems, owing to typical wireless multipath fading environment, sensor malfunctions and node failures. This paper explores the applicability of different matrix completion approaches for missing data reconstruction. Specifically, the performance of baseline predictor, correlation based approaches such as baseline predictor with temporal model, k-nearest neighbors (kNN) and low rank based approaches such as Sparsity Regularized Singular Value Decomposition (SRSVD) and Augmented Lagrangian Sparsity Regularized Matrix Factorization (ALSRMF) have been explored. Reliable temperature and pH data for 19 independent acquisition hours with 60 samples per hour are acquired at the fusion centre via Ultra High Frequency (UHF) transmission at 470 MHz and suitable pre-processing. Simulating different data integrity scenarios, the reconstruction error plots from each of these matrix completion approaches is extracted. A hybrid of kNN and baseline predictor with temporal model rendered a Mean Absolute Percentage Error (MAPE) of 1.75% for temperature and 0.86% for pH, at 0.5 data integrity. Further, with ALSRMF, which exploits the low rank constraint, the error reduced to 1.25% for temperature and 0.7% for pH, thus substantiating a promising approach for Aquaponics system data reconstruction.
Keywords
Introduction
The burgeoning developments in Internet of Things (IoT), Machine to Machine (M2M) communications and Wireless Sensor Networks (WSNs) have been welcomed in a variety of applications such as smart agricultural solutions [3,8], health care systems [1], intelligent transportation services and many more. A WSN comprises of several nodes which continuously monitor a desired geographical region for physical quantities such as carbon dioxide, temperature, radiation etc., that are wirelessly transmitted to a remote server or a fusion centre [11]. Huge amounts of such stored historical data, play a crucial role in predicting and providing useful inferences and aid in decision making.
A smart WSN based agricultural solution, which is decorous and serene choice for a smart city scenario, is a remotely and continuously monitored network of Aquaponics systems or gardens [18], geographically spread over a commercial complex or a residential community. IoT enables each Aquaponics system (node) to continuously sense the system health parameters such as temperature and pH. These data values are periodically transmitted to the fusion centre, which processes and stores the received data. For efficient spectrum utilization, the wireless communication link between the nodes and the fusion centre can be established as a cognitive link on any underutilized Ultra High Frequency (UHF) band such as the TV band [13].
Aquaponics are smart food production systems, where plants and aquatic life form an eco-friendly environment. More specifically, the system comprises a grow bed for plants and a fish tank. Through the circulating waters, the fish waste reaches the grow bed, where beneficial bacteria convert ammonia into nitrites and in turn to nitrates, which are absorbed by the plants [10]. The oxygenated water recirculates to the fish tank, forming a symbiotic environment. These systems reduce water wastage and are very much suited in arid areas with water scarcity. In addition to small scale gardening, these systems can also be deployed in large scale farming [21]. Solutions offering remote health monitoring of such systems save a lot of man hours, and are deemed to be opportune in a smart city lifestyle. Such smart systems encourage more and more families to install such gardens, further ensuring a greener urban environment.
We consider an Aquaponics WSN with one node and a fusion centre, where periodical wireless data transmission happens from the node to the fusion centre. Accompanied by sensor malfunctions, power interruptions and system failures, multipath fading of the wireless link can result in severe data losses [1]. Hence the time series data collected at the fusion centre can have irregular vacancies or missing values. With the emergence and vast growth of compressive sensing theoretical concepts and applications [14], many research works started addressing acquisition or collection of few data points rather than all to reduce the storage problems. It is interesting to note that missing values may also arise if the node adopts a random transmission policy for resource saving, where the node is active or asleep with a pre-selected transmit probability [26].
The focus of this work is to interpret/estimate the missing data values using suitable reconstruction approaches and study their performance. This necessitates the availability/acquisition of actual and error-free data at the fusion centre. Such reliable temperature and pH data are acquired at the fusion centre transmitted from the node via UHF wireless link at 470 MHz, using the system described in [17]. The data is acquired for 19 independent acquisition hours with 60 samples per hour, collected in a span of 8 days distributed over summer and winter seasons. Deliberately, each data value is received multiple times at the fusion centre and then pre-processed suitably to avoid data loss. These reliably acquired temperature and pH data are arranged as two different 19 × 60 matrices, which form the actual data. On these data matrices, random missing data values are simulated corresponding to different data integrity values. For instance, to simulate a 0.4 data integrity, 60% of the values are uniformly removed from the data matrices. Different retrieval approaches are employed to estimate the missing data values, some of which are discussed in the following section. Each retrieval approach is assessed using the reconstruction error versus data integrity plots.
The rest of the paper is organized as follows. Section 2 addresses and discusses the related works from the available literature. Section 3 presents the details of the data matrices collected from the Aquaponics system, and the various matrix completion approaches considered. Section 4 presents the results and corresponding discussions, and the paper subsequently ends in Section 5.
Related work
Missing values in the acquired data matrices make them incomplete, thus giving rise to the problem of matrix completion. This problem is well-explored in recommender systems, which are the systems or websites that suggest different things to the users by monitoring a variety of factors [6]. These systems basically predict or interpret the missing values in a matrix. For instance, reconstructing items versus user preference data, matrix completion approaches can help in predicting user preferences and thus aid in developing item recommendations for each user [16]. Similarly, movies can be suggested to users as in a Netflix recommender system. Different users rate the movies differently and sometimes the users do not rate at all. These missing ratings in a user – movie matrix can be interpreted from available ratings via baseline predictors [12], where prediction of missing values is casted as an overdetermined system of equations. On the contrary, another approach known as baseline approximation, formulates missing value estimation as a minimization problem with regularization, which is iteratively solved using alternate least squares method. This approach is applied to reconstruct internet traffic matrices [20].
The k-nearest neighbor (kNN) is a memory-based matrix completion approach which predicts the missing values by identifying k most similar rows or columns, extracted via similarity measures such as Pearson correlation coefficient [2]. kNN is also employed for matrix completion in an indoor localization problem, for estimating unknown received signal strength [23]. Further, it is used for predicting drug associated disease indications [27] and also for traffic data matrix reconstruction [4]. It is interesting to note that kNN is a local interpolation approach and is suitable only when the data integrity is high [9].
A neighborhood based interpolation approach is used to estimate ratings in a user-item rating data matrix, where multi-kernel function is combined with the similarity measure to provide more accurate weights [5]. A multi-Gaussian model, exploiting the maximum a posterior estimation via spectral clustering has been employed for traffic matrix reconstruction [28], where most similar rows are first clustered, based on the eigenvalues calculated from the affinity matrix. A principal component analysis (PCA) based matrix completion approach, further extended to a two phase recovery scheme is developed for the recovery of corrupted and lossy sensor data [25], obtained from 196 weather sensors in Zhu Zhou, China.
Unlike the above, there is another class of matrix completion approaches which assume that the required matrix has a low rank structure and hence proceed by solving a rank minimization or nuclear norm minimization, while also incorporating matrix factorization. In this context, some of the works available in the literature are discussed as follows. Considering the missing data scenario as a compressively sensed data scenario, an orthogonal rank-1 matching pursuit, which is a sparse recovery approach is devised for matrix completion [19]. This approach which has rank as the only tunable parameter is tested on large scale movie dataset. As most of the real world data sets may not hold the necessary conditions assumed by compressive sensing algorithms [24], approaches based on matrix factorization and SVD such as the Sparsity Regularized Singular Value Decomposition (SRSVD) approach are devised incorporating nuclear norm minimization. The SRSVD is applied for internet traffic matrix reconstruction [20], where regularization acts as a tradeoff between exact fit of the measurement data and the low rank nature of the data matrix. An alternating least squares (ALS) method is used to solve the minimization problem, where each of the regularized factored matrices is alternatively estimated by fixing the other in each iteration. Note that ALS is only one possible solution method. Hence, instead of ALS, the same minimization problem is solved using matrix inversion and genetic approaches [15]. Further, to render a faster convergence, stochastic gradient can also be used alongside the ALS solution method [7].
The rank minimization of SRSVD does not assume any similarity constraints or special properties of the data matrix during optimization. By accounting such spatial and temporal properties, another approach named the Sparsity Regularized Matrix Factorization (SRMF) is formulated as a constrained optimization problem [20]. In addition to regularization on the factored matrices as in SRSVD, this approach includes the effect of similarities in the optimization, via spatial and temporal constraint matrices. Similar to the SRSVD case, this constrained optimization problem can be solved using the ALS method [20]. Note that the constraint matrices can be chosen a prior by mining the dependencies among the data elements or any structures present in the data elements due to factors like time or geographical distances. Replacing the ALS solution of the SRMF approach by an augmented Lagrangian based solution method, the Augmented Lagrangian Sparsity Regularized Matrix Factorization (ALSRMF) approach has been developed for road traffic matrix reconstruction [22], which rendered better performance than the SRMF approach.
Owing to the fact that success of a matrix completion approach depends on the application at hand, in this work we propose to investigate the suitability of various matrix completion approaches for Aquaponics data matrix completion. Hybrid approaches, which are a combination of the neighborhood models and the low rank approaches can also be suited for matrix completion. Hence, this paper studies the reconstruction performance of different matrix completion approaches based on neighborhood models and also the low rank optimization approaches for Aquaponics data matrix completion.
Data matrices and matrix completion approaches
In the following sections, bold faced lower case letters indicate vectors, bold faced capital letters indicate matrices, and lower case normal letters are used for scalar quantities.
Data matrices
Consider the Aquaponics WSN with one node and a fusion centre. The node senses the temperature and pH data every minute and transmits to the fusion centre, where they get stored. Data is collected for a total of 19 independent acquisition hours, each comprising 60 samples, resulting in 19 different temperature and pH time series datasets. These data are arranged as two matrices (temperature and pH) of size 19 × 60. A practical missing value scenario is depicted in Fig. 1, where A1 to A4 indicate the acquisition hours and S1 to S5 indicate the time series samples in each acquisition hour.
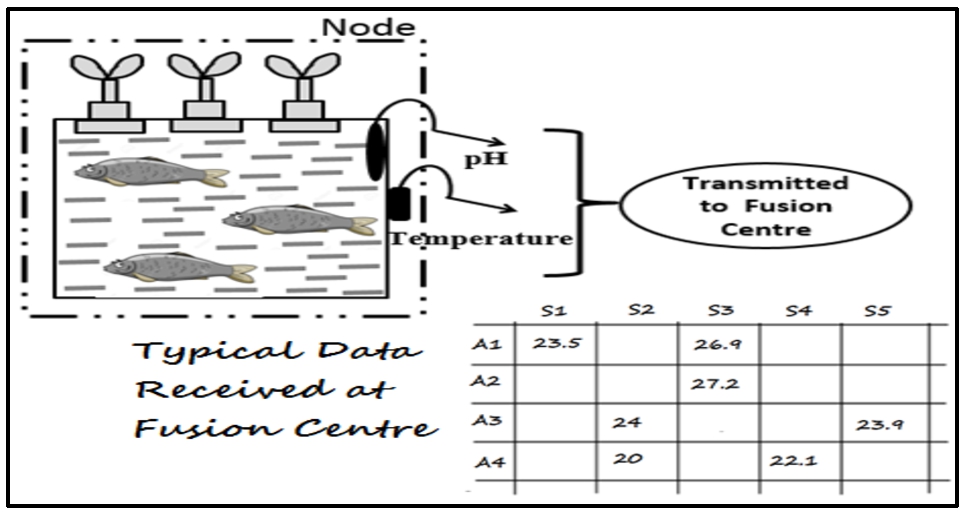
Typical data matrix from aquaponics system.
To be able to investigate the performance of different matrix completion approaches, first the actual data is acquired by sending and receiving each data value multiple times. At the fusion centre, the multiple received entries are preprocessed to obtain the single data value, as in [17]. Further, accounting for data corruption due to practical sensor noises [9], the data values in each acquisition hour are passed through a moving average filter, to suppress the noise via averaging. The resultant data is shown in Fig. 2 for temperature and pH respectively. From Fig. 2, note that the temperature time series of acquisition hours 16, 18 possess certain similarities, while those of acquisition hours 1, 4 and 7 are also having similarities. Similarly, the pH time series of acquisition hours 4, 7, 14, 16 and 18 appears to have significant amount of correlations. Correlations among the days and among the time samples are computed using Pearson correlation coefficients and corresponding Cumulative Distribution Function (CDF) plots are shown in Fig. 3. Plots related to temperature data show that around 20% of the days have more than 40% correlation and all the time samples exhibit more than 50% correlation. Plots related to pH data show that around 20% of the days have more than 25% correlation, while 70% of the time samples exhibit more than 50% correlation. Thus both the temperature and pH time series data possess significant correlations, providing scope for retrieving missing values via different neighborhood and low rank based matrix completion approaches, which incorporate similarity measures or constraints as discussed in Section 2.
In this regard, temperature/pH data matrix is represented as
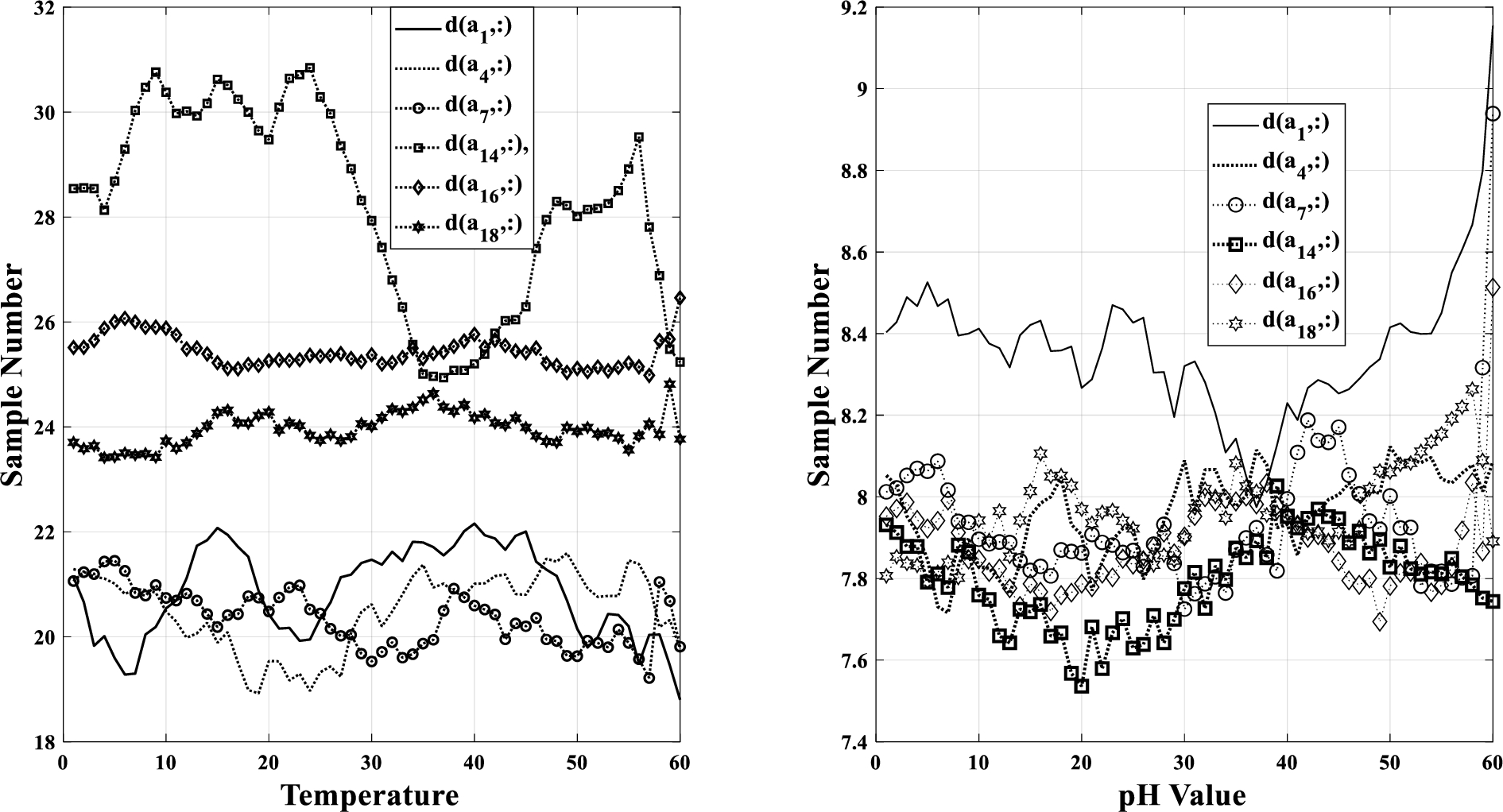
Temperature and pH time series of few acquisition hours.
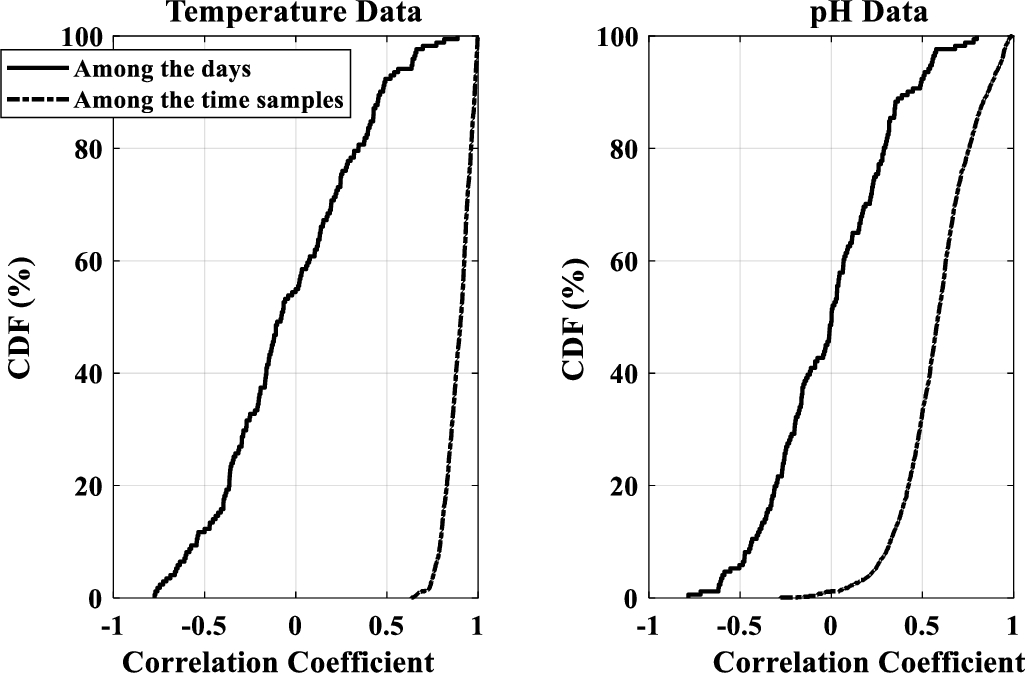
CDF of Pearson correlation coefficients.
In this approach, each available data value
Accordingly, observe that a total of (
In (4), the known vector
The baseline predictor with temporal model accounts for similarities among the columns or rows or both, in addition to the fixed row and column biases. Accordingly, each available data value
Similarities between any two columns, say,
The predictions of innovations are then calculated as
Adding back the fixed row, column and matrix biases to all such innovations estimates in (8), corresponding unknown values of
kNN approach
This neighborhood approach first assumes the number of neighbors, k. Consider the unavailable data value
Note that as data integrity reduces, the number of computations increases in a kNN approach. As the data integrity reduces, similarity coefficient
SRSVD approach
Low rank approaches assume
SRSVD using ALS solution method
SRSVD using ALS solution method
The optimization in (12) does not include any constraints that reflect the row/column interdependencies among the data elements in
Consider the auxiliaries
Subsequently, using the ADMM via augmented Lagrangian solution method, the unconstrained optimization becomes
Steps of ALSRMF approach
Steps of ALSRMF approach
On the acquired temperature and pH data matrices of size 19 × 60, random missing data values are simulated corresponding to data integrity values from 0.2 to 0.9 indicating 20 % to 90% data intact respectively. The missing values are estimated using Baseline, Baseline with correlation, kNN, SRSVD and ALSRMF approaches. Further, a hybrid of kNN and baseline predictor with temporal model, where reconstructed matrix from Baseline with temporal approach forms the initial matrix for kNN is also used to estimate the missing values. For different data integrity values, reconstruction error of each approach is obtained using Root Mean Square Error (RMSE), Normalized Mean Absolute Error (NMAE) and Mean Absolute Percentage Error (MAPE) defined as
For the temperature data matrix completion, the plots of RMSE, NMAE and MAPE versus data integrity are shown in Fig. 4, Fig. 5 and Fig. 6 respectively. Observe that, as data integrity increases, the errors (17) to (19) decrease. Note that in these figures Baseline with corr indicates the Baseline approach with temporal correlation considerations and the Hybrid indicates the hybrid of kNN and baseline predictor with temporal model.
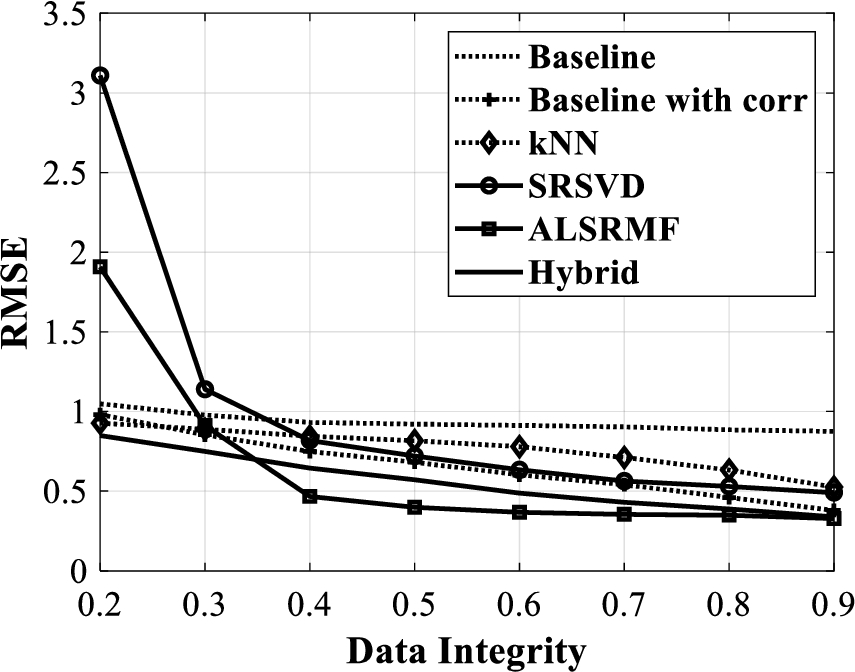
RMSE versus data integrity for temperature data.
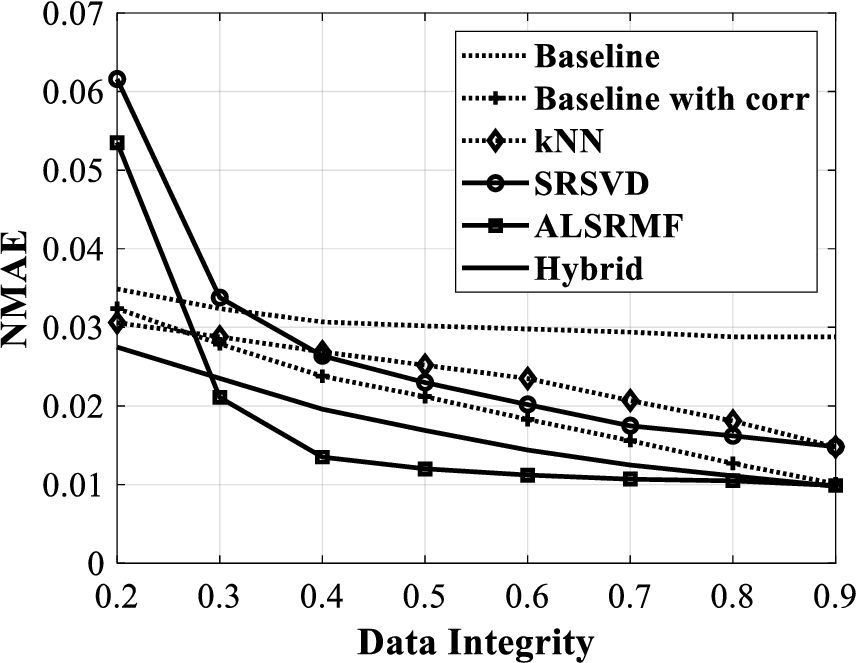
NMAE versus data integrity for temperature data.
The kNN approach is used with
From Fig. 4 to Fig. 6, it can be observed that the baseline with correlation approach performs better than the baseline and kNN approaches. Further the hybrid approach outperforms the baseline with correlation approach, while the SRSVD approach could not perform better than the baseline with correlation approach. Also, for a data integrity greater than 0.35, the ALSRMF approach outperforms the all the other approaches considered here and for a data integrity less than 0.35, the hybrid approach turns out to be a better choice. Note that when 50% of the data is lost, both the ALSRMF and the hybrid approach rendered less than 2% MAPE, with only 1.25% MAPE from the ALSRMF. Further, when 90% data is intact, both these approaches render highly close values of RMSE, NMAE and MAPE.
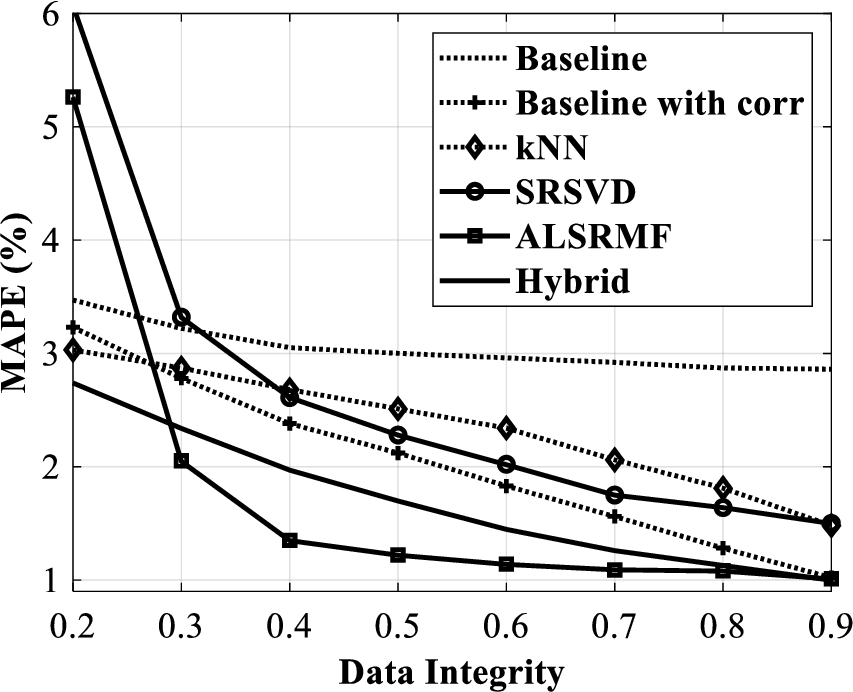
MAPE versus data integrity for temperature data.
Proceeding with similar studies on pH matrix, the results of RMSE, NMAE and MAPE for different values of data integrity are shown in Fig. 7, Fig. 8 and Fig. 9 respectively. In this case of pH matrix completion, the tuned parameters of ALSRMF approach are
From the figures Fig. 7 to Fig. 9, it can be understood that the Baseline with correlation approach outperforms the Baseline, kNN and the SRSVD approaches. Further, the hybrid approach outperforms all these approaches. Note that for a data integrity more than 0.25, the ALSRMF approach outperforms all the other approaches considered here. For a data integrity less than 0.3, the hybrid baseline with kNN approach performs better than all the others considered. Note that at a 50% loss of data, both ALSRMF and the hybrid approach render less than 1% MAPE, with only 0.7% MAPE from the ALSRMF approach.
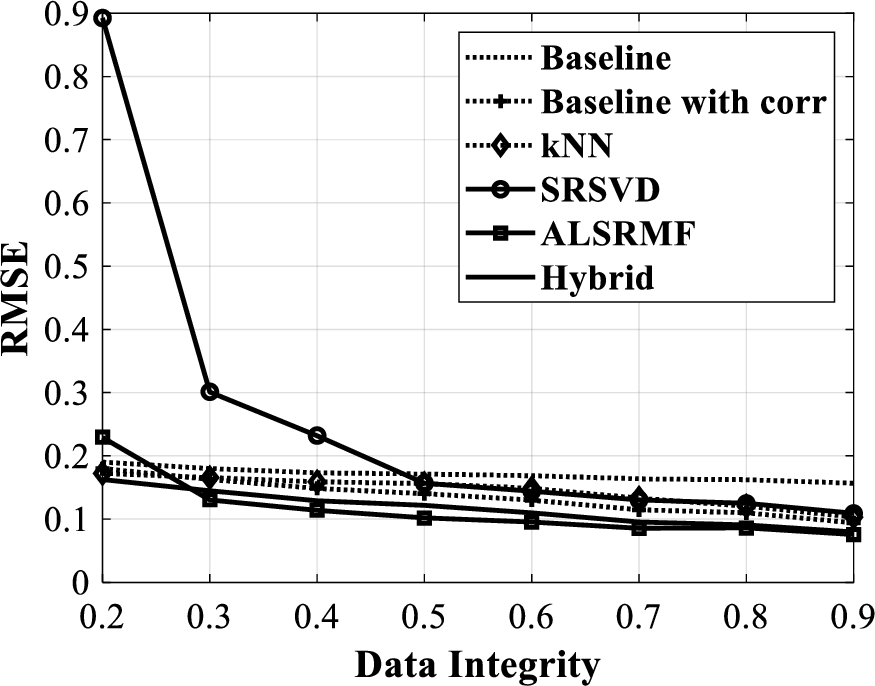
RMSE versus data integrity for pH data.
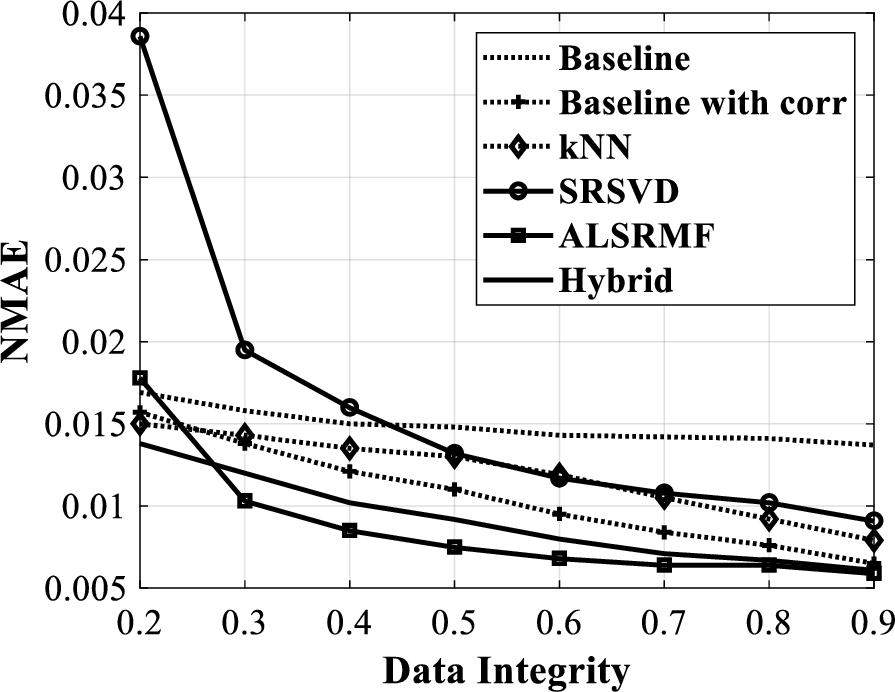
NMAE versus data integrity for pH data.
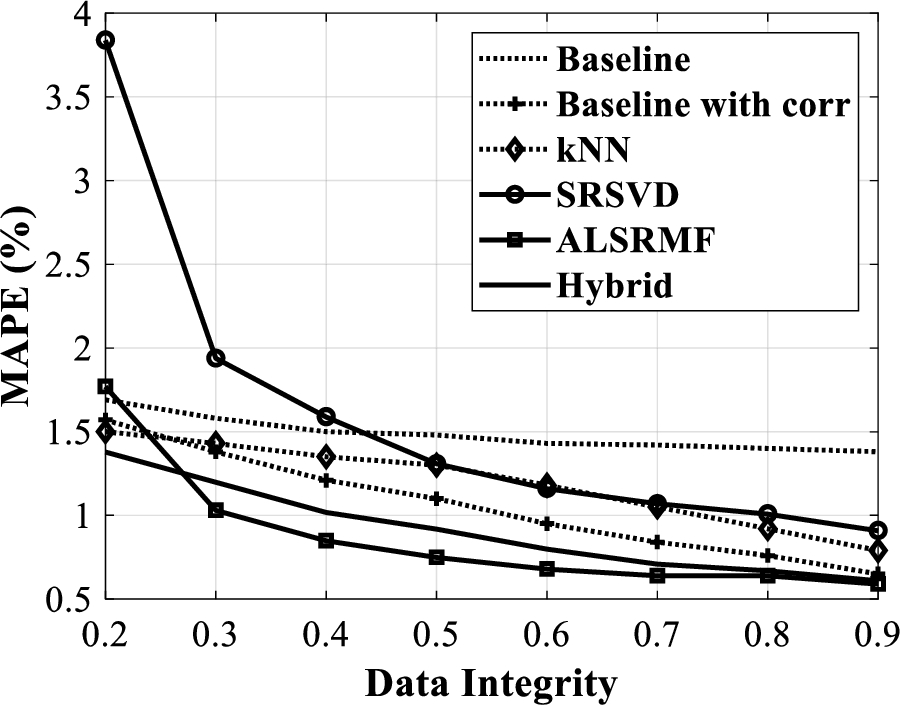
MAPE versus data integrity for pH data.
From the results of temperature and pH data shown in Fig. 4 to Fig. 9, it can be observed that the performance improvements obtained from ALSRMF for temperature data are much better than the improvements obtained for pH data. For instance, when data integrity changes from 0.3 to 0.4, the MAPE changes from 2 % to 1.25 % for temperature data, but from 1% to only 0.75% in the pH data case. This can be attributed to the fact that temperature data entries are relatively more correlated than the pH data entries, as discussed in Section 3.1. It can be interpreted that better the correlations among the data, better is the performance of the ALSRMF approach, thus making it an efficient matrix completion approach for Aquaponics data.
Data collected at the fusion centre of a WSN, transmitted by an Aquaponics sensor node is considered in this work. Specifically, two 19 × 60 data matrices of temperature and pH collected for 19 independent acquisition hours with 60 samples per hour are considered. Practically, these matrices tend to be incomplete, owing to missing data problems experienced by the fusion centre. Hence, data reconstruction using matrix completion is investigated via baseline predictor with and without temporal model, kNN, SRSVD, a hybrid of kNN and baseline with temporal model and ALSRMF approaches. The SRSVD and the ALSRMF are the iterative approaches based on low rank optimization, and so depend on the correlations among the data entries. Simulating different data integrity scenarios on both temperature and pH data matrices, reconstruction error is obtained in terms of NMAE, RMSE and MAPE for all these approaches. The results of reconstruction error versus data integrity plots demonstrate that the hybrid baseline with kNN approach performs better when data integrity is less than 0.3, and the ALSRMF approach performs better than the hybrid approach when data integrity is greater than 0.3. Thus the hybrid baseline with kNN and the ALSRMF approaches can be effectively employed for matrix completion. Development of the WSN with multiple nodes and a fusion centre, acquiring spatio-temporal data matrices, for subsequent investigations on matrix completion approaches via mining inter correlations among pH and temperature data, forms the scope of this work. Further, in addition to pH and temperature, data from multiple sensors that monitor the health of Aquaponics system can be explored for obtaining the inter correlations, that help in data reconstruction.
Conflict of interest
The authors have no conflict of interest to report.
Footnotes
Appendix
Solving for
Simplifying further, by retaining only the terms comprising
Applying vector differentiation principles, it further reduces to
Rearranging and solving for
Solving for