
Abstract
The task of designing an ontology through reuse is difficult, and a major challenge in this effort is choosing between different ontologies that are candidates for reuse. To address this challenge, we introduce a notion of preference between ontologies and provide a definition that allows the developer to make a well-founded comparison across a set of ontologies, with respect to their semantic requirements. The preference between ontologies is based on an assessment of relative accuracy and precision, which are also defined here. These concepts formalize the underlying intuitions related to the different possible outcomes in the assessment of an ontology against a developer’s semantic requirements. We also present a procedure to demonstrate the viability of the definition of preference, resulting in a novel approach to the choice between ontologies for reuse; it is sufficiently well-defined such that it could provide the basis for tool support to assist in this task. By providing ontology developers with a means of effectively comparing different ontologies for reuse, this work addresses several of the key limitations for ontology reuse, as identified by the 2014 Ontology Summit Communiqué (Obrst et al., 2014, pp. 155–170).
Introduction
The inherent reusability and shareability of ontologies makes them particularly appropriate tools for Semantic Web applications. Apart from the usual development-related motivations, reuse is the key to supporting shareability between ontologies. When an ontology from one application is reused in another, shareability and interoperability between the applications results naturally, thereby eliminating the need for cross-application mappings and integration. Part of the case for ontologies is that they provide a method for knowledge representation that is shareable and reusable. Unfortunately, as recognized in the 2014 Ontology Summit Communiqué (Obrst et al., 2014), reuse is currently not a common means of ontology design. This lack of reuse presents a serious problem to the ontology community as it translates directly to a lack of demonstration these supposed benefits of ontologies.
In this paper we introduce a novel definition to formalize a notion of preference that may be used to inform the choice between different ontologies that are candidates for reuse. We illustrate its viability by way of a set of procedures that dictate how the definition may be implemented, resulting in a new approach to the comparison of ontologies. Given the difficult nature of choosing which ontology to use, it is not surprising to find that many of the limitations identified in the 2014 Ontology Summit Communiqué are in fact tied to this task. Consequently, by resolving challenges associated with the choice between ontologies this work addresses many of the key limitations of reuse identified by the summit.
In the Communiqué, the challenges identified during the Summit were consolidated into seven limitations for reuse. Of particular interest for this work are the following:
Ontology reuse sometimes fails because the developer misunderstands and attempts to reuse an ontology that is not suitable. This can sometimes result due to a mismatch between the meaning the developer perceives from the name of a concept, and its actual meaning resulting from the ontology’s axioms.
Simply finding the right ontology poses a challenge. The Communiqué discusses the need for useful metadata to assist in the identification of an ontology that matches the user’s requirements, beyond simply looking at traditional keyword search (semantic-oriented criteria such as provenance and competency questions, for example).
It’s possible for an ontology to be appropriate, while not directly reusable. In some cases an ontology may satisfy the requirements, if some issue(s) are corrected. For example, the ontology might be missing some semantics, a particular concept, or perhaps it is not formalized in the desired language. To better take advantage of existing ontologies, developers must be able to determine what parts of an ontology, or what modifications may be required to satisfy their requirements.
Due to the work required to find and understand existing ontologies, reuse may sometimes not be seen as a viable option. The Communiqué discusses that the barriers and bottlenecks apply to both reuse and traditional development, and note that reuse is a potential cost-saver. However, this is only true so long as it does not bring its own additional instances of these barriers and bottlenecks to the process.
We address the challenge of mismatches and misunderstandings by employing the already accepted and understood technique of competency questions (CQs) for requirements specification. We leverage CQs as a means of both identifying and assessing ontologies for reuse, such that the elimination of inappropriate ontologies is straightforward. The use of CQs here is also aligned with the best practices advised by the Communiqué.
Finding Mr. Right Ontology is a broad challenge including community-wide issues of metadata and infrastructure. While these are out of the scope of this work, we address this issue in part by identifying a rationally-motivated approach for the identification of ontologies for reuse, which describes how the search for ontologies may be reduced to a single criterion. We also discuss the range of different possible implementations of such an approach. Further, when given a set of ontologies, finding the ‘right’ one will be facilitated by the assessment of preference as defined here.
This work also accounts for the goldilocks problem of This Ontology Doesn’t Fit… described in the Communiqué. The approach to choosing between ontologies assumes that some changes may need to be made in order to reuse a particular ontology. The notion of preference provides a means of accounting for this through a formal assessment of which ontologies will be ‘easier’ to reuse. This also helps to mitigate the Just Do It Yourself issue. This approach to choosing an ontology reduces the amount of effort required to understand and assess preference between candidates. With this assistance in choosing between ontologies we can mitigate cases where the decision to design from scratch (“do it yourself”) is made simply to avoid the effort required to make an informed choice between the alternative ontologies.
Related work
The challenge of choosing between candidate ontologies is in itself, not novel. Much existing work has recognized the challenge of making a well-informed choice with a reasonable amount of effort, and attempted to design a solution. However, no work to date has been presented that addresses the challenge of assessing the candidates’ semantics. Whether implemented as a tool or presented as a guideline, the majority of existing work employs some sort of calculation over a set of subjectively-weighted criteria (Fernandez et al., 2006; Fernández-López et al., 2012; Lozano-Tello and Gómez-Pérez, 2004). While this may be a useful indication for some requirements, these approaches are too superficial to account for the candidates’ semantics. An ontology should not necessarily be preferred over another simply because it satisfies more requirements – such an assessment requires a deeper consideration. In contrast, the approach specified by Pinto and Martins (2001) gives the ontologies’ content a more thorough consideration. Unfortunately, this is labour-intensive, requiring considerable input from subject-matter experts and ontologists, and so it does not address the other half of the issue: the effort required for the comparison. Further, with a lack of formal definitions the methodology is not defined in sufficient detail to be easily reproduced.
On the subject of related work, it is worthwhile to note that the topic of ontology matching is conceptually related to this subject, as it also involves a comparison between ontologies. Whereas Euzenat et al. (2007) describes matching as being aimed at finding “correspondences between semantically related entities of ontologies”, this work is considerably different as we are attempting to compare candidate ontologies, with respect to some required semantics.
Scope
With respect to the entire ontology development process, this work is restricted to reuse, which we view as a specialization of axiom design. More specifically, this work focuses on supporting the task of choosing which ontology to reuse, with respect to the developer’s required semantics. Naturally, this problem also requires consideration of how these candidate ontologies are found; we term these tasks Choice and Search, respectively. In the following subsections we describe the informal intuitions of both tasks in order to more precisely define the scope of this work.
It is well accepted that design occurs after (possibly in a feedback loop with) the tasks of analysis and requirements specification. Consequently, aspects of analysis wherein the designer identifies the required signature and set of intended models for his/her conceptualization are outside of the scope of this work. However, it is important to clarify that the validity of this contribution does not depend on a complete set of intended models being known. While the definition of ontology preference is necessarily based upon a known (and shared) signature and set of intended models, whether or not (or to what degree) these models are known in practice is a matter for implementation. To this end, we devote an entire section to viability where we address this and other pragmatic concerns, such as assessment of preference between ontologies with varied signatures.
This work also makes several assumptions about the available infrastructure – primarily that the available ontologies are consistent and modular. While this may not be representative of the current state of practice, it is feasible and aligned with already recognized best practices. It is our hope that this work should serve as motivation for such infrastructure improvements, however in general the infrastructure itself is out of the scope of this work.
Search intuitions
Given a set of requirements, there may be a number of aspects that we would like to incorporate in our search against some repository(s). Consider the task of search independent of existing and proposed approaches: we have access to some collection (physical or otherwise) of ontologies; we also have access to the specification of requirements; we review these requirements and “keep them in mind” while sorting through the collection of ontologies, pulling out any that seem as though they might be related. This selection might be done based on a ontology’s title, some grouping that it is stored under, or perhaps a closer examination of its documentation or concepts.
This basic intuition behind the task of Search is also quite similar to that of using search engines on the web: given some criteria (e.g. keywords) the aim is to return a set of relevant results. With each ontology returned by the search process, a conjecture of relevance is implicitly being made. We might select a particular ontology for further consideration because we conjecture that (some of) its axioms could be used to satisfy (some of) the requirements. Naturally, the goal is not to return just any set of relevant ontologies – the familiar aims of high precision and recall apply here as well.
We consider the task of Search insofar as how it is structured and what the input and output should be. We do not aim to propose a single solution for Search, but to consider generically how the ontologies that are to be compared are found.
Choice intuitions
The task of choice is complex; it requires the consideration and assessment of a variety of objective and subjective requirements – criteria that often have interdependencies as well as individual, implicit and explicit priorities. Independent of any particular methodology, the task of choice can be described as follows: given some set of potentially relevant ontologies, the developer must choose which is the ‘best’ with respect to some explicit and/or implicit requirements. Owing to the aforementioned variety of potential requirements, the precise interpretation of what it means to be the ‘best’ is unclear. Intuitively though, in the context of reuse the ‘best’ choice is the one that requires the least effort in order to satisfy the developer’s requirements. While other requirements oriented to ontology qualities such as representation languages and evaluation results will certainly have an impact on the final choice of ontology, these factors are not in the scope of this work. This approach is restricted to consider only the semantic requirements. Therefore, while we cannot claim to provide a complete solution to the task of choice, this work does serve to provide a critical input to the decision-making process.
Background
Here we review the technical concepts that play a role in the definition and techniques that follow.
Competency questions as semantic requirements
The requirements for a semantically correct ontology may be defined using the relationship between the intended models for the ontology, and the actual models of its axiomatization (see Fig. 1). A theory is a set of first-order sentences closed under logical entailment. and within this paper, use the words ‘ontology’ and ‘theory’ interchangeably.1
Note that we do not claim an arbitrary theory to be the definition of an ontology. Indeed, an ontology is not just an arbitrary logical theory, but rather a particular logical theory aiming at characterising people’s assumptions about the nature and structure of a domain, and the intended meaning of terms used to talk about such domain. However, for the purposes of this paper, it is enough to assume that an ontology is a logical theory.
An axiomatization
In other words, an axiomatization is semantically correct if and only if it does not include any unintended models, and it does not omit any intended models.
Recall that a class of structures is elementary iff it is first-order axiomatizable, so with the above notion of correctness used in this paper, we are restricting our attention to applications in which the intended models of the ontologies are axiomatizable in first-order logic. We are not considering classes of intended structures such as connected graphs or the standard model of Peano Arithmetic, which are not first-order axiomatizable.
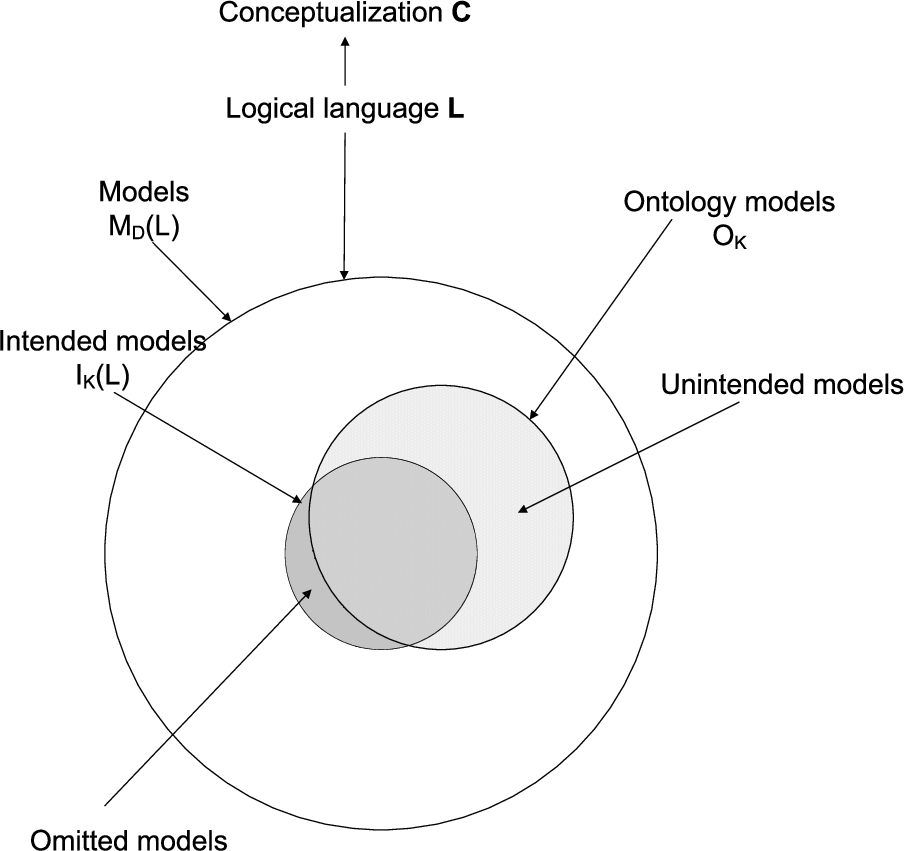
The relationship between intended models for an ontology and the models of the ontology’s axioms (from (Guarino, Oberle & Staab, 2009)).
Formally, the potential semantic errors that prevent an ontology from being semantically correct are defined as follows:
An error of superfluous models is present in the ontology
Following from Definition 2, we can define the class of superfluous models
In other words, a superfluous model of T is one which is not in the class of intended structures.
A second potential semantic error considers structures which are intended, yet which are not models of the ontology.
An error of model omission is present in the ontology
Following from Definition 4, we can define the class of omitted models
Competency questions (CQs) are a well-accepted means of requirements specification for ontologies (Grüninger and Fox, 1995, 1994; Uschold and Grüninger, 1996); they represent sentences that the ontology should be able to entail, thus they indirectly impose requirements on both the scope of an ontology’s concepts and its semantics. For example, when specifying the requirements for a time ontology, we might have a CQ such as: (CQ-1) ‘is there some time interval that contains a unique timepoint?’, or (CQ-2) ‘is there some timepoint that cannot be contained by any interval?’ If we were developing an ontology for a more general application, perhaps we might have something like: (CQ-3) ‘is there some process that can only occur at a single timepoint?’. Recent work interprets CQs more specifically as semantic requirements and provides a methodology for their evaluation with the use of an automated theorem prover in the process of ontology development (Katsumi and Grüninger, 2010). The evaluation of these entailment problems requires the CQs to be encoded in a chosen logical language and vocabulary, for example CQ-1 might become:
We adopt the concept of a hierarchy from the COLORE repository, where it is presented as a means of storing similar ontologies (Grüninger et al., 2012). Formally:
A hierarchy
The Root Theory,
We make reference to these COLORE-specific concepts in the procedures only because they are convenient for the presentation of this work. It is important to note that the contributions presented here are independent of any particular repository or other approach to the search for candidate ontologies. The hierarchy is utilized as a construct to provide a common basis for organizing and assessing the candidates in cases where the scope of the concepts in the CQs and the candidates are not completely in-line with one another. For instance, the scope of CQ-3 includes not only time but also the concept of an event, even though it was a requirement for a time ontology. It is therefore quite possible that in this case the candidates might include both time and event ontologies. The notion of a hierarchy provides a common context to allow for the collective consideration of candidates with varying scopes that may not precisely correspond to that of the CQs.
Essentially, in a signature translation we map the concepts (signature) from one theory into the language of another. This is closely aligned to the definition of an interpretation from a language into a theory as specified by Enderton (1972). The key difference in our notion of signature translations is that we do not require them to be complete (whereas the language interpretation by Enderton specifies a mapping on the whole language). For our purposes the mapping of even a single term in a language is of interest and thus a signature translation is defined as an extended notion of language interpretation. An interpretation π of the theory π assigns to ∀ a formula π assigns to each n-place relation symbol P a formula for any atomic sentence for any sentence for any sentences for any sentence For any sentence Given some theory,
Recall that the basic intuition of Search can be described as follows: given some specification of requirements, the developer is tasked with collecting a set of relevant candidate ontologies. There are two variables of this task that affect how it is performed:
the criteria employed in the collection process, and the source(s) being searched.
In other words, the two key aspects are where the developer looks and how they look. Once the requirements have been specified, the search criteria can be extracted and applied to retrieve a set of candidates in a completely objective manner.
Search criteria
Any theory that is selected as a candidate ontology by the search criteria essentially corresponds to one or more conjectures of relevance. For example, if I select a particular ontology,
If a theory is relevant, we should be able to describe the way in which its content corresponds (i.e. maps) to our requirements. In other words, if a theory is relevant, it must be interpreted by some subtheory of the semantic requirements; if not, then we can conclude that it is irrelevant with respect to the requirements we have specified. We can formally describe a conjecture of relevance as a translation definition(s) from the candidate’s own signature to the signature of
It follows that the criteria for Search may be formalized simply as the signature of
In order for an ontology to be a candidate it must have at least one conjectured mapping (translation definition) to the signature of the set of semantic requirements. The current approach to search does this implicitly; when searching through a repository for ontologies with some keyword (presumably an important concept in the ontology), the results are essentially a set of alternative ontologies with a single direct mapping to the keyword.
While keyword search in itself is straightforward, to use this technique for the retrieval of relevant ontologies with high precision and recall is extremely cumbersome to do well. In most cases it is not feasible to completely specify an accurate condition for relevance with a single term. Even in a specialized domain, there is the possibility for morphemes and synonyms to come into play. Often times there may be many relevant concepts as the requirements may cover several domains. To perform all necessary searches and aggregate the results requires considerable effort on the part of the developer. A procedure to perform this task would mean that it could be offloaded (potentially automated) in its entirety and thus completely removed from the workload of the developer.
Not only is such a procedure feasible, but there is a range of possible implementations – varying with respect to how the conjectures are identified. For each alternative, we could specify a different procedure, and for each such procedure we could prove its correctness and completeness (with respect to a given repository), relative to the specification of the conjecture type. However, as each candidate output by search is simply, by definition, a conjecture of a potentially relevant theory, it makes no sense to discuss the correctness or completeness of the output in the absolute sense. How then, do we know what these alternative means of conjecture specification are, and how can we decide which of these is best? Again, we emphasize that this is an implementation decision. It is a heuristic to be defined that has no bearing on any of the formal definitions or subsequent procedures we specify; it is a decision based on consideration of the trade-off between exhaustivity and efficiency in the search for candidates.
The following is an example of an implementation with a simple heuristic for generating candidates. For each ontology (

An example of candidate retrieval
Clearly this example procedure could result in the omission of potentially relevant candidates in some cases – however, there may also be scenarios in development via reuse when the desired signature is known and thus this would be sufficient. A more thorough approach to develop conjectures might look beyond basic matches to include synonyms and morphemes. We could even look at candidates outside of the context of our requirements and conjecture mappings simply based on term arity matches, (this might lead to reuse scenarios similar to the work presented by Grüninger and Katsumi (2012), where the same ontology is reused in a variety of domains).
Translation definitions need not be restricted to one-to-one term mapping. There are many different approaches that might be incorporated to identify possible sentences that might be used to define terms in the candidate’s signature. For example, while a candidate may not possess a relevant concept of mother explicitly in its theory, we may make the conjecture that the candidate’s concept of a woman who has a child is in fact relevant (equivalent) to the concept of mother. At the most thorough end of the spectrum, we find an approach with a procedure that may not terminate. In such an approach, for each term in
This second approach is clearly not a reasonable one; it illustrates that there is a balance that should be found between exhaustiveness and practicality. Yet we need not sacrifice rigour for efficiency; there are certainly opportunities to implement clever ways of generating good, thorough conjectures. For example, we could implement some type of learning from previous users’ translation definitions; we could leverage relationships between theories to make additional conjectures; we could apply a relatively basic conjecture generation approach with an option for user-override to allow for additional conjectures the user may want to test out.
There are countless approaches to conjecture generation that could be implemented in a procedure for search. While there is no single correct procedure, there will certainly be some methods that will be better than others, and perhaps some more appropriate in different contexts. What is important is that some effort is made to design a heuristic that will provide a useful, thorough set of candidates. While the recall of a procedure will be limited by certain feasibility considerations, it is high recall that will contribute to the objective of increased reuse benefits by minimizing the opportunity for the omission of candidates with the potential to facilitate these benefits. Finally, it is important to note that the possible conjecture criteria implementations are also dictated by the sources used. For example, to implement a procedure that retrieves additional conjectures based on mappings between ontologies would require the use of a source(s) that provides this information. Regardless of the approach taken to identify the candidate ontologies, modularity is a critical factor for the feasibility of the subsequent solutions. Given the size and breadth of scope of some ontologies it is crucial that the search return only the relevant modules, rather than the entire theory.
Choosing between ontologies
By allowing the developer to capture their desired scope of concepts and semantics, CQs play a vital role in ontology development. It follows that they should also be a key consideration when comparing candidate ontologies in the task of reuse. However, the application of CQ evaluation to assess preference between candidates is not straightforward. We cannot simply compare the number of CQs satisfied; for example, what if one candidate satisfies more requirements than some alternative, while in fact requiring more extensive modification to meet all of the requirements? Or, what if two candidates satisfy the same number, but different sets, of the CQs – should they be considered comparable? Clearly more knowledge is required in order to make an accurate assessment.
In the context of reuse, superfluous models correspond to a semantic error where some aspect of the candidate is weaker than required. Such models satisfy the candidate, but are not models of the requirements. Such models will prevent some aspect of the requirements from being satisfied (i.e. some competency questions will not be provable) and so the theory must be strengthened if the designer wishes to reuse it.
Omitted models on the other hand, indicate a semantic error where the theory is stronger than is required. These are intended models of the requirements that are not entailed by the candidate ontology. In such cases the candidate has consequences beyond what was specified in the requirements; the designer may therefore need to weaken the axioms so as to include the otherwise omitted models which they have deemed necessary.
Recall from Section 4.1 that at the core of the specification of semantic requirements is the relationship between the consequent of the entailment problem, and the models of the axiomatization. Building on our understanding of semantic requirements, we will formally define a notion of preference between candidate ontologies that will serve to inform our decision. Such a definition would allow for the production of unambiguous, verifiable results about the candidates. Most importantly, it would simplify the task of performing a thorough comparison, thereby reducing the investment required to obtain a deep understanding of how the candidates compare to each other, with respect to the desired ontology.
Preference defined
In general, any notion of preference between candidates should address the question of which ontology is the closest match to the requirements. The underlying motivation of this being that the closer a candidate is to the requirements, the less development work will be required to achieve the desired ontology via reuse. In the context of semantic requirements, the consideration of which semantic requirements are and are not satisfied provides an indication of the effort that will be required in each case to “bridge the gap” to obtain the desired ontology, should a particular candidate be chosen for reuse. We formalize the concept of preference as the comparative effort required between two candidates, relative to the set of semantic requirements.
The concept of preference is comprised of two complementary perspectives that capture the relative effort required to achieve the desired ontology: candidate accuracy and precision. Intuitively, an ontology that is more accurate or more precise with respect to the models of the desired ontology will be preferred over other candidates; its reuse will require less effort as there are fewer corrections to be made. Both of these perspectives are expressed (naturally) as orderings, and are based on the possible models of the candidates, and the identification of semantic errors, as described in the previous section. The orderings derived from these models represent a three-way relationship between theories – a comparison of two candidate theories, relative to the requirements.
The Accuracy Ordering captures the notion of required effort by extending the notion of semantic correctness discussed in the previous section; a candidate requires less effort if it is more correct than another, as fewer changes and corrections will need to be made in order to reuse it.
Candidate ontology
If one candidate has fewer omitted and fewer superfluous models than another, it is clearly the more accurate candidate. In cases where one candidate does not have both fewer superfluous and omitted models than another, they are incomparable in the Accuracy Ordering. This is a necessary limitation because there is no means of comparing a combination of omitted and superfluous models in general.
Candidate ontology
Candidate ontology
By the definition of omitted models,
Combining these cases give us
In this special case of accuracy, we will say that
Let
If
If
Since ⪯ is transitive, reflexive, and antisymmetric, it is a partial ordering. □
The Precision Ordering is motivated by the distinction between omitted and superfluous models – it addresses a special case in which candidates are not comparable in the Accuracy Ordering, but one should still be preferred over the other. Informally, this preference can be motivated by the observation that whether choosing an ontology for reuse or developing one from scratch, it is far easier to identify and address errors of omitted models than superfluous models. The omitted models are clearly present in the requirements theory, and the cause of their omission is unambiguously present in the theory itself. It is fairly straightforward then, to identify which axioms are causing the omission of certain models from the candidate theory (then, as part of design determine which axioms to change and how). The resolution for superfluous models on the other hand, is much less clear. Even once they are identified, the task of designing an axiom to eliminate them is more challenging as the possibilities and their implications may be complex and difficult to recognize. The Precision Ordering is defined as follows:
Candidate ontology
Let
If
Similarly,
Transitivity is trivially satisfied, since we cannot have both
This second ordering may be less intuitive than the first as it strictly prefers candidates with no superfluous models, regardless of the differences in omitted models. However, when this condition is satisfied, the relationship between the candidates’ omitted models is irrelevant to the preference between candidates. In contrast to superfluous models, omitted models affect only the completeness of a candidate with respect to the requirements. If we have no superfluous models, regardless of what models are omitted, we can say for certain that the models of the candidate are correct with respect to the requirements. On the other hand, any instance of superfluous models indicates that the candidate’s models are not correct with respect to the requirements and therefore less precise. Further, candidates without superfluous models can entail all of the CQs specified in the requirements. Assuming that the CQs do not completely characterise the desired ontology, such candidates may even be satisfactory as-is for the intended application. Thus any theory that is more precise than another will require less (possibly no) effort to reuse. So, in the context of the required effort for reuse, these more precise theories should be preferred over candidates that contain superfluous models.
Preference (
Candidate ontology
Earlier work by Staab et al. (2004) introduces similar assessments of coverage and precision, however in this case they are used to provide an indication of quality. These concepts are combined in the notion of accuracy presented in this work, whereas the notion of precision in this work is a specialized case of the precision described by Staab et al. (2004). It is important not to confuse the assessment and interpretation of these concepts with the orderings presented here. This earlier work presents a means of assessing quality, whereas the orderings defined here are meant to define a preference with respect to which ontology will be the easiest to reuse; it is not necessarily the case that an ontology with a higher quality will be the easiest to adapt to satisfy the designer’s requirements.
Note that we will never run the risk of having to resolve conflicting orderings to determine the Preference Ordering – if we prefer
If
Assume that there exist two theories,
Therefore, by definition we cannot also have
In other words, if we say that
Let
Since
Suppose
If
The second case (
The third case (
Finally, the fourth case (
Thus, the Preference relation ≪ is antisymmetric.
Now suppose
The definition of Preference allows us to formalize the fact that we prefer a more accurate and/or precise candidate as it will be less work to reuse. If we were to consider the problem of choosing between time ontologies, using examples CQ-1 and CQ-2 from the previous section to approximate the intended models, the definitions would indicate that we should prefer to reuse the theory of linear points2
Note that in practice the set of CQs would likely be much larger making for more interesting and complex results.
We now operationalize our notion of preference by introducing a set of procedures capable of producing the Preference Ordering for a given set of candidates and formalized CQs. These procedures implement a set of criteria that is provably complete and correct with respect to the definition of preference.
Assumptions
The procedures make the following assumptions:
The candidates share some common (the same or overlapping) signature with the CQs. We assume whatever mappings exist between the theories have already been applied. This is a reasonable assumption due to the fact that, should a candidate be relevant in any way, there must exist mappings between its terms and those of the CQs. In fact, the procedures described to aid in the task of Search in the previous section produce the necessary mappings via their conjectures of relevance. Even forgoing any implementation of such procedures, the mappings must be known (at least implicitly) in order for a theory to be identified as relevant. Once they are it is straightforward to apply them to achieve a common signature. While this could be incorporated into the procedures, it is replaced with this assumption for simplicity. The candidates are in the same logical language as the CQs. This is reasonable given that most search tools or sources of ontologies are language-specific. Further, if a particular language is necessary or desired, it is reasonable to assume that the CQs would be formalized in this language, and the selection of candidates would include only those in the appropriate language. All candidate ontologies are consistent and modularized. In the absence of such an assumption there are model builders that could be employed to test this and filter out inconsistent theories; a procedure was also presented by Grüninger et al. (2012) to decompose theories into modules which could be called in the case of non-modularized candidates. However, the inclusion of such procedures for every candidate would not be practical nor ideal, thus we view the modularization and consistency/verification of theories as supporting infrastructure requirements rather than necessary steps in the procedure.
The procedures
The following set of procedures are designed to obtain the Preference Ordering defined in the previous section.
The Preference Ordering is assigned between a pair of candidates if any of the following criteria holds:
If If If
Where
We adopt the concept of a hierarchy from Grüninger et al. (2012), where it is presented as a means of storing similar ontologies. Formally:
A hierarchy
The Root Theory,
We make reference to these COLORE-specific concepts in the procedures, strictly because they are convenient for the presentation of this work. It is important to note that the contributions presented here are independent of any particular repository or other approach to the search for candidate ontologies. The hierarchy is created as part of a procedure meant to provide a common basis for the candidates’ signatures in cases where the scope of the concepts in the CQs and the candidates are not completely in-line with one another. For instance, consider CQ-3 described in the example of time ontologies: its scope includes not only time but also the concept of an event. It is therefore quite possible that in this case the candidates might include both time and event ontologies. The notion of a hierarchy provides a common context to allow for the collective consideration of candidates with varying scopes that may not precisely correspond to that of the CQs (


The top-level procedure required to implement the criteria is specified below in Procedure 2. First, we consider the possible combinations between all candidates as additional candidates; this expanded set of candidates is then transferred into a common context (the Requirements’ Hierarchy,

Note that this specification of procedures is primarily intended to demonstrate the feasibility of the implementation of the Preference Ordering, and is not meant to be the most efficient approach. For example, the consideration of all possible combinations of candidates in Procedure 3 simply generates all (consistent) combinations of the candidates’ modules and adds these to the set of candidates to be considered.

The pseudocode for the sorting procedure is provided in Fig. 2; it is taken directly from its original presentation and adapted to determine partial ordering is on a set of theories by searching for the “weakest/strongest theory that entails/is entailed by e”, as opposed to the smallest/largest elements. The authors employ the concept of a chain, referring to a subset of mutually comparable elements from the ordering, in order to define and navigate the partial ordering more precisely.

The Poset-BinInsertionSort algorithm from Daskalakis et al. (2011) is adapted here to determine a partial ordering of theories based on entailment.
Given a set of theories,
and and Given some set of theories
we will have shown that Procedure 2
This follows from the definition of a power set. By definition, the power set of Given some set of theories
Lines 1–3 of Procedure 4 initialize the hierarchy
Lines 4–13 of Procedure 4 create the root theory
Lines 14–17 of Procedure 4 add
Therefore, the partially ordered set of theories, sorted on entailment (as per the algorithm from Daskalakis et al. (2011)) returned on line 18 is in fact a hierarchy
Since Given a hierarchy
The procedure considers each pair of theories,
From Lemma 1, two candidates are equally accurate if and only if they are logically equivalent. This addresses both the correctness and the completeness of the third criteria in the procedure. Thus the following theorem considers only the first two criteria, (1)
Suppose
For any two candidate ontologies
In the following, we first prove that if either condition (1) or (2) in Theorem 3 are met, then the preference ordering
In the second part of the proof, we show that for all ⇐
If If For all models If For all models Therefore, if Therefore by definition of the accuracy ordering we have If Since Therefore Since Therefore Therefore Assume that a Preference Ordering holds between two candidates, Assume For any two candidate theories, For any two candidate theories, This conflicts with our assumption that no criteria hold, as we have shown it is impossible to have Assume If
This conflicts with our assumption as we have shown that it is impossible to have
In the following, we identify and justify choices that were made in the design of the procedures to implement the definition of preference.
The use of hierarchies
The reader will likely have noticed that the transfer to a hierarchy structure in Procedure 4 is not necessary to determine the ordering, however there was sufficient motivation for its inclusion. The hierarchy structure provides useful means of storing the candidates in a common context after the translation and expansion of their signatures. It also offers a structured venue for storing and reusing results of these evaluations. Beyond this, the ordering of theories in the hierarchy may be leveraged to improve the efficiency of the Preference Ordering implementation, as certain cases of the Preference Ordering may be identified via the non-conservative extension ordering, thus eliminating the need to evaluate certain pairs against the entailment criteria.
The use of a hierarchy also offers potential benefits for other areas of reuse. The use of hierarchies supports the potential to leverage the notion of the similarity5
Informally, the similarity between a set of theories is the strongest theory that is entailed by all of the theories.
While the use of CQs as requirements is well-established, their role as approximating the required theory,
In the review of related work, we saw approaches that assigned weightings or priorities to the requirements. It follows from this perspective that requirements are often times not equally important, and thus our definition of preference is lacking this dimension. However, it is our position that in the context of semantic requirements, such approaches are flawed; given the nature of a CQ there should be nothing malleable about them. Although the decision of which interpretations should be models of the ontology may be subject to revision, at any point in time a model is either desired or it is not.
root theory definition
A reader familiar with the notion of a hierarchy as defined in COLORE will have noticed that the root theory used here differs from that which is defined in the COLORE literature Grüninger et al. (2012). This deviation was supported by pragmatic and philosophical factors; we discuss the alternative approaches, and the rationale behind this decision here.
Typically, the root theory represents the most basic ontological commitment in a given hierarchy (domain). In the context of COLORE, where hierarchies provide a tool to organize different theories, it makes sense to require that a hierarchy have a unique root theory. This acts as a kind of sorting mechanism as it requires that theories with varied basic commitments be stored in separate hierarchies.
For our purposes, we wanted to gather the candidate theories into a single hierarchy for comparison, but what would it mean to be the root theory of such a hierarchy? After all, a hierarchy of candidate theories is not necessarily a true hierarchy. It is a collection of candidate conjectures gathered via some heuristics and there is no guarantee that there is a meaningful, underlying commitment shared between them, in fact we expect this will often not be the case. The root theory was a necessary tool to expand the signature of the candidate theories (and semantic requirement theory) in a consistent manner, such that they could be considered in the same hierarchy. The concept of the root theory for this task was appealing in that, as the ‘weakest theory’ in the hierarchy it would be a benign addition to each of the theories in order to achieve the required vocabulary. However the meaning and attainability of a true root theory in a scenario of varied candidates with overlapping and possibly even disjoint signatures is unclear.
One potential means of discovering the root theory was to take an informed approach, requiring the identification and consideration of the root of each candidate. The idea would be to iteratively create a root theory for
Instead, we chose to derive the weakest possible root for
Implementation concerns
As mentioned, the procedure presented here is a bare-bones demonstration of feasibility. While in theory these procedures may be followed and even (semi-)automated to achieve the desired results, in their current state they would admittedly not make for a very pragmatic solution.
For instance, in Procedure 3, we provide for a consideration of potential candidate merges through the addition of all possible combinations of candidate modules. This is a brute force approach – although it will identify combinations of candidates that may be advantageous merges, it will also result in the consideration of many combinations which could easily be identified as useless. Consider the case where two candidates,


Identify semantics beneficial merges
A similar observation can be made with respect to the candidates’ semantics; if the combination of two theories does not result in a new candidate that is better with respect to the semantic requirements, then we have no cause to consider it as a potential merge. This could be accounted for with an approach similar to the previous suggestion, as outlined in Procedure 8. Alternatively, we might simply omit consideration of merges altogether unless prompted by the designer.
Beyond these suggestions, there is a great deal of room to improve upon the design of the procedures we have presented here. In general, while we recognize that the implementation’s efficiency is an important consideration, it is out of the scope of this work.
By leveraging the formal and objective nature of CQs we were able design a procedure capable of producing a useful comparison between candidate ontologies. We have provided an solution that successfully simplifies the evaluation and assessment of candidate ontologies with respect to the semantic requirements. The definition of preference described here addresses several of the limitations for reuse identified in the 2014 Ontology Summit Communiqué.
The ordering can be used to clearly identify and compare relative mismatches or misunderstandings (Mismatches and Misunderstandings) that might have occurred in candidate selection – a candidate that is considerably less preferred differs substantially from the required semantics. Where initial impressions may have indicated that some candidate should be chosen for reuse, the Preference Ordering allows the developer to either confirm or refute this without the difficulty of performing a detailed investigation of all of the alternatives.
We describe how CQs may be employed to select candidate ontologies, and further with the implementation of the Preference Ordering we illustrate how these CQs may again be used to sort through the candidates to find the most suitable ontology (Finding Mr. Right Ontology), with respect to the semantic requirements.
The problem of ontologies not ‘fitting’ the requirements (This Ontology Doesn’t Fit…) stems from the fact that the answer to the previous question of whether or not an existing ontology meets the requirements is not a simple yes or no. The Preference Ordering accounts for this and essentially compares the relative effort to fit each of the candidates to the semantic requirements.
Because this work simplifies these aspects of design by reuse, it also reduces the potential for the difficulties involved to prompt developers to simply to do-it-themselves (Just Do It Yourself).
The work presented here may be extended to address the recommendations in the Communiqué. The assumed infrastructure necessary to support these solutions may serve as input for the best practices for shareable and reusable content that the Communiqué recommends be adopted by the community. The procedures specified here are sufficiently well-defined such that they could provide the basis for tool support to address these limitations of reuse. This makes a substantial contribution to the Communiqué’s recommendation that tools should be developed to better support reuse, (among other aspects of development). Finally, this work has implications beyond design by reuse. An interesting direction of future work may be to consider how this notion of preference could be applied to assess the relative shareability between existing ontologies to determine, for example, which applications might work best together.