
Abstract
Reuse of elements from existing ontologies in the construction of new ontologies is a foundational principle in ontological design. It offers the benefits, among others, of consistency and interoperability between such knowledge structures as well as sharing resources. Reuse is widely found within important collections of established ontologies, such as BioPortal and the OBO Foundry. However, reuse comes with its own potential problems involving ontological commitment, granularity, and ambiguity. Guidelines are proposed to aid ontology developers and curators in their prospective reuse of content. These guidelines have been gleaned over years of practice in the ontology field. The guidelines are couched in experiential reports on designing and curating particular ontologies (e.g., EXACT and EXACT2) and using generally accepted approaches (e.g., MIREOT) in doing so. Various software tools to assist in ontology reuse are surveyed and discussed.
Keywords
Introduction
When one sets out to capture the knowledge in the domain of biology and biomedicine using an ontology, a natural question to ask is whether some of the content has been modeled before and can thus be reused in the present context. Invariably, the answer is yes. In fact, reuse is an important design principle in the ontology curation community. Ontology reuse is at the core of the OBO Foundry’s espoused foundational principles (OBO Foundry, 2022; Smith et al., 2007). It has also been proposed as one of the “ten commandments” of ontological engineering: “honor interoperability, so that your ontology has a long life and can be reused by others” (Jansen and Schulz, 2011). In the context of ontological engineering, reuse is considered a basic activity of the conceptual modeling phase (Kendall and McGuinness, 2019). We find support for reuse in the Web Ontology Language (OWL) via owl:imports axioms (OWL, 2022) and in the Protégé ontology editing software (Protégé, 2022; Noy et al., 2000). Additionally, top-level ontologies have been constructed with the express purpose of facilitating content reuse and alignment. An example is the Basic Formal Ontology (BFO; Grenon et al., 2004). Other “upper domain” ontologies, such as the Ontology for General Medical Sciences (OGMS, 2022) and BioTop (Beisswanger et al., 2008), have extended the BFO with more general domain knowledge that can also be reused by ontology authors.
In previous work, we have studied the kinds of reuse availed of in a large collection of ontologies housed in the BioPortal (2022). Specifically, in the paper of Ochs et al. (2017), we identified those ontologies that did indeed reuse content and investigated how and to what extent those ontologies utilized existing classes and properties to model new classes and properties. In further work (Halper et al., 2018), we examined the common kinds of modeling errors and inconsistencies that are likely to arise when reusing existing content. Examples include duplicated classes and properties as well as versioning problems.
Following up on the latter point, let us note that ontology reuse is not a panacea, and it is not as easy as it may first seem. An ontology author needs to be aware of potential issues that can affect the quality of their ontology. If reused content is not utilized correctly and/or not maintained properly, unintended erroneous concepts or properties may be introduced. And that leads us to the work presented in this paper. We wish to promote some guidelines that should help the prospective ontology author in content reuse. Since we realize that it is difficult to internalize abstract guidelines, we couch these guidelines in case studies of ontology reuse and enumerate what to look out for in order to avoid problems. The first study is in the context of the construction of the EXACT ontology (Soldatova et al., 2008) and its successor EXACT2 (Soldatova et al., 2014). The second involves general ontology construction employing OWL imports and the “Minimum Information to Reference External Ontology Terms” (MIREOT) technique (Courtot et al., 2011). Some of the issues discussed revolve around ontological commitment (Schulz and Cornet, 2009; Gruber, 1993; Kendall and McGuinness, 2019), granularity (Kumar et al., 2004), and ambiguity (Nirenburg and Raskin, 2001). We also survey some software tools that can aid an ontology author in the construction of an ontology benefiting from reuse. The advantages and disadvantages of the tools are discussed.
The remainder of this paper is organized as follows. In the next section, we review background information pertaining to biomedical ontology structure and reuse. Sections 3 and 4 constitute the results of this work. In particular, Section 3 contains the proposed guidelines for reuse along with experiential reports of ontology reuse that highlight the guidelines. Section 4 covers software tools that can facilitate such reuse tasks. Discussions and conclusions follow.
Background
Ontology structure and existing repositories
The exact definition of what an ontology constitutes has been an ongoing discussion for many years (Guarino et al., 2009). Ontologies can range across the spectrum from informal structures to highly formal representations specified in various logical languages (Guarino et al., 2009; Bodenreider and Stevens, 2006). In general, an ontology is a structure for capturing the knowledge of some domain of interest, such as biomedicine. It is often used in support of other applications to enable standardization and interoperability. A review of the utilization of various ontologies in the biomedical domain can be found in the paper of Rubin et al. (2008).
In this paper, we take a computer-science perspective and view ontologies toward the more formal end of the spectrum (Guarino et al., 2009; Bodenreider and Stevens, 2006). In particular, an ontology is defined using a language such as OWL or the OBO format. From a structural perspective, an ontology comprises a network of concepts organized in a hierarchy of IS-A relationships. If concept
The BioPortal is a site that houses a collection of over 1000 ontologies (BioPortal, 2022). These can serve as a good source of material for instances of reuse. The OBO Foundry also maintains a large collection of ontologies (OBO Foundry, 2022). The majority of ontologies appearing in the BioPortal are available in either OWL or OBO format. Other ontologies can be found through the Open Ontology Repository (OOR) Initiative (2022), as well as Ontobee (Xiang et al., 2011) and the EBI Ontology Lookup Service (EBI OLS; Jupp et al., 2015). Additionally, AberOWL consists of a collection of ontologies, allowing for ontology-focused access to biological data (AberOWL, 2022).
Ontology reuse
Abstract ontologies and patterns
Ontology researchers and developers have realized for some time that elements of reuse are important in ontology design and are key for successful ontology utilization and interoperability. Reuse promotes alignment of and consistency between ontologies and obviously eliminates duplication of work. The OBO Foundry has a stated principle of “commitment to collaboration” emphasizing this point (OBO Foundry, 2022). In a discussion of the conceptual modeling phase of ontology engineering, it has been stated that “we never start from scratch” (Kendall and McGuinness, 2019). In that context, the reuse is often focused on metadata, provenance, and pedigree.
To facilitate this reuse, we find a variety of ontologies focused more on abstract, foundational components of ontology content than on domain-specific knowledge. These include foundational ontologies (also called top-level ontologies or upper ontologies) and upper domain ontologies (also called top-level domain ontologies or top-domain ontologies).
A foundational ontology comprises very high-level categories and generic relationships that can be commonly used as the bases in other domain-specific ontologies (Keet, 2011; Khan and Keet, 2012). Such ontologies often define abstract concepts such as continuants and occurrents and seek to capture concepts that underlie natural languages and human discourse. Examples include the Suggested Upper Merged Ontology (SUMO; Niles and Pease, 2001), the Basic Formal Ontology (BFO; Grenon et al., 2004), the Descriptive Ontology for Linguistic and Cognitive Engineering (DOLCE; Gangemi et al., 2002), and the General Formal Ontology (GFO; Herre, 2010). In a study from the year 2015 (Ochs et al., 2017), we found that 77 out of 355 (= 21.7%) ontologies in BioPortal included at least part of the BFO in their content. According to the OBO Foundry, BFO is the upper ontology upon which OBO Foundry ontologies are built, and many OBO Foundry ontologies were among the 355 ontologies that were analyzed.
An upper domain ontology serves a similar purpose to a foundational ontology but focuses its attention on abstract concepts for a specific domain of interest, such as biomedicine. In the paper of Beisswanger et al. (2008), it was suggested that there is a need for a mediating layer between foundational ontology concepts and those comprising domain-specific knowledge. This is the role proposed for upper domain ontologies. Examples include OGMS, BioTop, and the General Formal Ontology for Biology (GFO-Bio; Hoehndorf et al., 2008).
Content reuse from upper domain ontologies like the OGMS, and domain-specific ontologies like the Gene Ontology (GO; Gene Ontology Consortium, 2022) and Chemical Entities of Biological Interest (ChEBI; 2022), is also fairly common. In recent efforts to quickly create COVID-19 ontologies, e.g., the Ontology of Coronavirus Infectious Disease (CIDO; He et al., 2020), curators employed reuse to accelerate the process. Reuse is so extensive in CIDO that out of its 7,834 concepts, only 774 are original. The rest are reused from 20 ontologies, including ChEBI, the Human Phenotype Ontology (HPO; Groza et al., 2015), GO, National Drug File – Reference Terminology (NDF-RT; Carter et al., 2006), and the Drug Ontology (DrON; Hogan et al., 2017). Studies have been conducted to determine the prevalence of ontology reuse. We find an analysis of term reuse and an accompanying analysis of error patterns in the work of Kamdar et al. (2017). A review of the orthogonality of the OBO Library ontologies can be found in the paper of Ghazvinian et al. (2011). In the work of Ochs et al. (2017), an investigation into the utilization of reused content in a sample of 355 BioPortal ontologies was carried out.
Ontology design patterns (ODPs) are “documented descriptions of proven solutions to typical problems of ontological modeling” (Zagorulko and Borovikova, 2020). Content ODPs, also known as knowledge patterns, typically model aspects of complex ontologies that frequently occur (Hitzler et al., 2016). Reusing the design pattern of ontologies in a similar domain improves consistency and alignment of ontologies. ODPs offer designers best practices and solutions that have been tried and tested by other ontology authors in the domain, thereby saving time and effort in the development process. When ontology authors reuse ontology content, it is important to take note of the commitments being made by the ODPs as well as the content and be aware of conflicts when different ontologies implementing different ODPs are reused at the same time.
In addition to direct ontology reuse, establishment and maintenance of mappings between ontologies has been employed. For example, mappings between life-science ontologies have been dealt with in the work of Groß et al. (2013).
Reuse approaches
An author of a new ontology O can reuse content from an existing source ontology, say, S in a couple of different ways. The different approaches have consequences in dealing with the periodic updates (e.g., error corrections and content additions) to S. An ontology author may choose to include content using the owl:imports mechanism defined in OWL syntax and implemented in the OWL API. This approach allows for the inclusion of the entire content of S into O “on the fly.” As such, updates to S will appear in O without any intervention on the part of O’s author. However, there may be unexpected consequences downstream, especially after classification.
On the other hand, O’s author may choose to reuse a fixed version of S’s content. This may be either S’s complete content or a selected subset extracted using, e.g., the MIREOT approach (Courtot et al., 2011). Reusing a fixed version of S’s content provides the author of O with greater control over when reused content is updated. But it comes at the expense of making the integration of changes to S into O more labor intensive.
Related work
As noted, reuse is accepted as a critical aspect of ontology development. Previous work has sought to facilitate the reuse process. The work of Keet and Grütter (2021) addresses the issue of resolving conflicts arising due to reuse (such as among imported concepts and relationships). Automated resolution strategies, that keep the human in the decision loop, are presented in explanatory ways. We see this work as complementary to ours. Our proposed guidelines seek to avoid the introduction of conflicts in the first place. But resolving the inevitable conflict that gets by helps assure the quality of the target ontology.
A software tool called ONSET has been developed to assist in the selection of an appropriate foundational ontology for a specific ontology development effort (Khan and Keet, 2012). This complements our guidelines with recommendations for choosing the best foundational ontology, if desired by an ontology developer. In contrast, we are not proposing criteria to distinguish the quality of different foundational ontologies.
The NeOn methodology defines a set of nine scenarios for building ontologies and ontology networks (Suárez-Figueroa et al., 2012,2015; Suárez-Figueroa, 2010). Scenario 3 of NeOn, “reusing ontological resources,” is most closely aligned with our aims, with Scenario 5, “reusing and merging ontological resources,” being related as well. Scenario 3 defines a sequence of activities, such as ontology search and ontology selection, to be carried out by the ontology practitioner toward successful reuse. To supplement the workflow, a “filling card” and assessment table are provided. Again, we see our own guidelines as complements to the NeOn approach, which has some wider goals in dealing with reengineering and the utilization of non-ontology resources. We are strictly focused on reusing existing ontologies.
As noted, ontology design patterns capture best practices for dealing with ontology modeling problems (Ontology Design Patterns . org, 2021; Gangemi and Presutti, 2009; Hitzler et al., 2016). In particular, reengineering ontology design patterns are sets of transformation rules that can be applied to a source model in order to produce a new ontology. In this approach, the source could be an ontology or even a non-ontological entity such as a data-model pattern, a UML specification, or some kind of linguistic structure. Our approach is to provide guidance based on past practice rather than transformation rules. However, we could see more formal rules emerging from the utilization of our guidelines and informing design patterns.
Reuse guidelines and experiences
Reuse guidelines
How does one go about initially selecting which ontology, or even which part of an ontology, to reuse? It certainly depends on the ontology design approach being applied. If a top-level ontology, such as BFO, or a top-domain ontology, such as OGMS, is being used, it often provides options within its ecosystem (i.e., among the ontologies that use the framework), making alignment easier. For example, the Infectious Disease Ontology (IDO; Cowell and Smith, 2010) is a sub-domain ontology that is based on OGMS and provides a broad framework for representing infectious diseases. Furthermore, its extensions, such as the Brucellosis Ontology (Lin et al., 2011), the Virus Infectious Disease Ontology (VIDO; 2022), the COVID-19 Infectious Disease Ontology (IDO-COVID-19; 2022), and the Malaria Ontology (Topalis et al., 2013), provide coverage of some specific areas. The same is true of the Sleep Domain Ontology (SDO; Arabandi et al., 2010). Top-level ontologies are often a good place to start when developing a new ontology, and they promote a modular way of building an ontology. Yet another option is to use an existing ontology with a broad coverage of biomedicine, such as SNOMED CT (SNOMED International, 2022),1
SNOMED CT is available free of charge in SNOMED International member countries. (See
The first aspect for selecting an ontology for reuse that comes to mind is certainly coverage, i.e., does the reused ontology provide good coverage of the domain of interest? (See, e.g., the paper of Kendall and McGuinness (2019).) For example, the Foundational Model of Anatomy (FMA; Rosse and Mejino, 2003) provides a broad and deep coverage of the anatomy domain, and SNOMED CT offers a broad and deep coverage of the clinical medicine domain. The Malaria Ontology, on the other hand, presents a deep coverage of malaria; however, it is a narrow ontology as it only covers malaria.
Another issue is the quality of the source ontology. Metrics derived from an ontology, or explicitly provided by its curators, can give a summary of the general quality and structure of an ontology. For example, the number of concepts defined in an ontology indicates the level of domain coverage. Ontology repositories, such as BioPortal, present basic metrics to users when viewing an ontology. And additional metrics, e.g., the number of concepts with textual definitions or the number of ontologies that reuse the ontology, could be used to guide users toward ontologies with higher quality content. As an example, when reviewing the SDO in BioPortal, one can glean these metrics: classes: 1382; properties: 100; depth: 19; maximum and average number of children: 48 and 2, respectively; and the number of classes without a definition: 611.
In previous work (Ochs et al., 2013; He et al., 2013b,a), we carried out quality-assurance studies of ontologies, e.g., SDO, the Cancer Chemoprevention Ontology (CanCO; 2022), and the Ontology for Drug Discovery Investigations (DDI; Qi et al., 2010), that were designed employing reuse. We demonstrated a number of cases of the migration of irrelevant concepts, which were not necessary for the new, target ontology. We also illustrated examples of duplicate concepts and duplicate properties, resulting from reuse.
How one reuses the content of an ontology depends on application and modeling need. If there is a need to cover anatomy in detail, then one should reuse a large portion of the FMA. However, if the need is limited to, say, anatomy of the feet, then importing the FMA in its entirety is really not necessary. Just importing a subhierarchy of the FMA will suffice. Therefore, depending on the situation, one could import an entire ontology, or a fragment thereof, or just individual classes. Related to this issue is the modularization of the source ontology, i.e., the ease with which the desired content can be separated from material that is not of interest (Kendall and McGuinness, 2019). In recent years, several ontology modularization techniques have emerged. An extensive review of these techniques can be found in the paper of Le Clair et al. (2022). Reusing a module of an ontology is one approach that allows ontology authors to limit the number of reused concepts while ensuring sufficient coverage based on their needs.
Let us note that a major issue that may arise in ontology reuse is increased difficulty in managing ontological commitments. In general, ontological commitment refers to the “precise agreement about the objects and relations [in the domain of interest that are] being denoted by the terms and concepts [in the ontology]” (Schulz and Cornet, 2009). Ontological commitment is a commitment to a certain theory or discourse that describes or explains the domain of interest. We would ask, “what entities or kinds of entity exist according to a given theory or discourse, and thus are among its ontological commitments?”2
See footnote 2.
As with all ontologies, a top-level ontology reflects a certain theory. For example, BFO, which is reused in over 200 domain ontologies, is based on realism. Consequently, those domain ontologies inherited ontological commitment to realism. While that may well be suited for biomedical ontologies describing biological and chemical entities, it may not be so for other ontologies, i.e., those that include abstract entities.
Importing an existing ontology (even partially) – and especially an upper-level ontology – to an ontology that is under development forces its developers to make ontological commitments about the structure, granularity, and the refinement of representations of the domain of interest. Imports from different ontologies may lead to difficulties in managing potentially inconsistent ontological commitments and logical entailments. Moreover, if some ontological commitments are no longer suitable for the intended applications, then that may require a fundamental redesign of the ontology.
In the following, we explore these issues from the perspective and experience of building the EXACT ontology (and its successor EXACT2) and from the use of OWL Imports and the MIREOT methodologies. Before moving on to those discussions, we enumerate the set of nine ontology reuse guidelines that we are proposing. Their relevance will be elucidated in the following. Let us again note that one of our overall aims in this work is to introduce our guidelines proposal and invite more people in the ontology community to expand on the work. We would like to see this as an ongoing effort.
Check the ontological commitments of the candidate ontology for reuse and compare them to the ontological commitments of the curated ontology before carrying out the reuse.
Consider all attributes of a reused concept, not only its name or label.
Reuse only ontology entities that come with textual definitions.
Check other concepts in the same IS-A subhierarchy where a reused concept is placed to ensure that there is no conflict created by ontological commitments of the sibling or hierarchically related classes.
Preserve the integrity of the taxonomy of the curated ontology consisting of all the hierarchical relationships in the ontology.
Check the ontological commitments of all superclasses (e.g., by axioms) in the source ontology of the entity being chosen for reuse.
Use software tools to automate some of the reuse tasks.
Obtain the proper licensing before reusing ontology content.
Reuse content only from actively maintained ontologies.
Let us comment on the last three guidelines here. Guideline 7 recommends the use of software tools, some of which are surveyed in Section 4. An important issue raised in the work of Kendall and McGuinness (2019) is licensing, listed here as Guideline 8. It is certainly mandatory to obtain the proper permission in order to reuse any ontology content, and the author of a new ontology must remember to do so before embarking on any reuse activities.
Another significant complication, addressed by Guideline 9, is that hundreds of potential reuse ontologies in BioPortal have not been updated in several years (if ever), based on the metrics provided by the site. Many of these ontologies are no longer maintained and had potentially reused old versions of source ontologies that are themselves long out of date. This leads to, for example, twelve versions of OBO REL/RO/BFO properties appearing throughout BioPortal’s ontologies (Ochs et al., 2017). This situation can impact ontology authors who decide to reuse the contents of these “dormant” ontologies (using, e.g., the BioPortal reuse plug-in for Protégé). Alternatively, the problem could be avoided by adding to reuse tools and ODEs a capability of prioritizing recently updated ontologies, based on their recorded update time-stamps, when searching for a concept to be reused. In this manner, the concept in the updated source ontology will be selected before some concept in a dormant ontology. This reinforces Guideline 7.
Let illustrate some of the commitment issues associated with reuse on the example of the ontology EXACT (EXperimental ACTions) that was focused on the representation of functional genomics experiments run within the Robot Scientist project (Soldatova et al., 2008). EXACT employed the SUMO (Niles and Pease, 2001) as a top-level ontology to ensure interoperability with other software used in the project. Consequently, EXACT had the following top-level classes: Abstract entity, Object, Process, Proposition, Quality, Role. The set of these top-level classes reflects the ontological commitment about the structure and features of the chosen area of knowledge. For example, ontology developers often choose not to consider logical abstractions pertinent to the domain they model, and consequently the resulting ontology does not include abstract entities. In the case of EXACT, the representation of such abstract entities as Truth value and False value ware essential for the representation of pre- and post-conditions of experimental actions.
The developers of EXACT soon realized that other areas of biology may benefit from formal representation of experimental actions and their properties. Hence, “EXACT2” was designed to capture the full semantics of biomedical protocols required for their reproducibility (Soldatova et al., 2014). It reused BFO, Information Artifact Ontology (IAO; Ceusters, 2012), Phenotypic Quality Ontology (PATO; 2022), and Ontology of Biomedical Investigation (OBI; Bandrowski et al., 2016) classes to improve interoperability with other biomedical ontologies. And it reused ChEBI (Chemical Entities of Biological Interest (ChEBI), 2022) for the representation of biochemical entities, as well as the Eagle-I Research Resource Ontology (ERO; Torniai et al., 2011) for the representation of equipment employed in experiments. These reused ontologies have different commitments compared with the SUMO ontological commitments, and consequently the structure of EXACT2 differs significantly from that of EXACT (following Guideline 1).
BFO is based on the philosophy of reality that does not allow for the inclusion of abstract entities (due to the requirement that each ontological class must have instances in reality). Therefore, such classes as True value and False value were removed from EXACT2. As the result, EXACT2 does not support the representation of pre- and post-conditions of experimental actions. That was the necessary compromise between the level of expressivity and interoperability with biomedical ontologies reusing BFO. Hence, the class SUMO: Object has been replaced with the class OBI: material entity, the class SUMO: Proposition has been replaced with the class IAO: information content entity, and the class SUMO: Process has been replaced with the class OBI: planned process (definition: a process that realizes a plan which is the concretization of a plan specification) (Guideline 3).
The OBI: planned process branch has been carefully assessed, and several planned processes were imported or explicitly mapped to EXACT2 experimental actions (Guideline 4). However, from the perspective of the intended application – the reproducibility – the representation of processes in OBI lacks some essential information, because the intended applications of OBI are different (Guideline 2). For example, OBI has the following property for the class process: achieves planned objective (target: material maintenance objective), and realizes (target: concretizes some plan specification). Consequently, storage as a subclass of the class OBI: planned process inherits all its properties (Guideline 6).
Based on our analysis of the protocols (Soldatova et al., 2014), the specification of objective and plan are not essential for the reproducibility, while (storage) temperature, and period (of storage) are essential; but these latter elements are not captured by OBI. Some biochemical entities must be stored at (or below)

Example OBI and EXACT2 representations (unlabeled, solid arrows are IS-A relationships).
To overcome such limitations imposed by the commitment to OBI, EXACT2 introduces two types of descriptors of experimental actions: compulsory and optional. EXACT2: goal (that corresponds to OBI: objective) is represented as an optional descriptor, while material entity (which is being stored), storage temperature, and period are represented as EXACT2: compulsory descriptor. EXACT2 representations not only explicitly capture what information is essential for reproducibility and what is not, they are also more intuitive than those of OBI (see Fig. 1).
EXACT2 is being increasingly used to support automated experimentation, where all experimental information has to be encoded explicitly and in great detail (Williams et al., 2015). EXACT is being reengineered again to provide better support for such an application and to ensure interoperability with relevant areas. EXACT is being aligned with the Core Ontology about Robotics and Automation (CORA) proposed by an IEEE working group (Prestes et al., 2013). One of the extensions of CORA is the task ontology, and it aims to formally define principles for the representation of plans (including experimental plans), e.g., goal, task, subtask, constraint, evaluation, action, and capability. The developers of EXACT are participating in the development of the task ontology (Balakirsky et al., 2017).
Interestingly, CORA is based on SUMO. Consequently, the new version of EXACT for automated experimentation will have ontological commitments that are similar to the original EXACT.
The following experiences are based on reuse of ontology content by two main methodologies: OWL import and MIREOT. The latter is mostly based on two different implementations of MIREOT.
Picking ontology entities by textual definitions, not just by names/labels
A very common mistake is to pick entities from ontologies (classes, object properties, etc.) based on their name or label alone (see Guideline 2). This is a problem that applies not only to ontology reuse, but also to the use of controlled vocabularies and ontologies more generally. The term name or label can be very evocative, and it quite often turns out to be ambiguous upon closer inspection. A good example is the term “cell.” In biology and biomedicine, most people will immediately think about the smallest independently reproducing unit of life, while it is obvious that “cell” can have a multitude of meanings besides this, e.g., for cellular phone.
The same problem frequently occurs in reusing classes or other entities from ontologies as the following example shows: in a student exercise, students are asked to represent the fact that a trauma medical director is part of a trauma center. The students are provided with a basic ontology called the Ontology of Organizational Structures of Trauma Centers and Trauma Systems (OOSTT; 2021) and are asked to use Ontobee (2022), a browser for ontology terms, to discover entities from ontologies for reuse. OOSTT provides the representation of trauma medical director role and of trauma center. Medical director can be created as an anonymous class of Homo sapiens bearing a role trauma medical director using the object property bearer of from the Relation Ontology (Smith et al., 2005).
The most challenging part of the assignment was to find the proper relationship to connect a human being bearing a medical director role to a trauma center. One student picked the object property relation has member (from the Semanticscience Integrated Ontology (Dumontier et al., 2014)). But has member is defined as a mereological relationship between a collection and an item. It is obvious that this does not properly represent the relationship between an organization and a person being a part of that organization in the sense of filling a role therein. This becomes even more obvious looking at the definition of organization, one of the superclasses of trauma center (Guideline 5). An organization is an “entity that can bear roles, has members, and has a set of organization rules. Members of organizations are either organizations themselves or individual people. Members can bear specific organization member roles that are determined in the organization rules. The organization rules also determine how decisions are made on behalf of the organization by the organization members.” The third sentence of this definition makes it sufficiently clear that membership in an organization goes beyond a merely mereological relationship. Hence, picking that relationship was not the best option. A better option would have been to pick the relationship is member of organization from OBI, the same ontology from which organization came.
This demonstrates that in reusing entities from ontologies, we should not rely on the names or labels of entities, but we need to consult their textual definitions (Guideline 3). This also stresses how important it is for ontology developers to provide a textual definition for the entities that they represent. The best practice is to enter the definitions the moment the entities are added to the ontology to prevent later insecurity regarding what the entity was intended to represent.
This leads to the question about what to do with classes that do not come with definitions. In a July 2022 search using the “search ontology class” feature of BioPortal with the string “cell” (exact match), the returned results were matches in 77 ontologies. Of these matches, 29 (= 37.6%) did not have a definition (e.g., GO includes a textual definition, but SNOMED CT does not). Per SNOMED CT’s documentation,4
But why should we be bothered by this? Certainly, when we say “cell,” especially in the biomedical domain, the definition is clear. Reviewing all of the definitions of “cell” in the BioPortal search results demonstrates how important definitions are. The GO defines cell as: “The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope” (Gene Ontology Consortium, 2022). Many of the classes retrieved are defined in a similar way, and we may assume that the definitions provided are co-extensive. But there are examples of definitions that show that based on the term alone, we might have made faulty assumptions on what the class is intended to represent. In the Mosquito Gross Anatomy Ontology, the class named “cell” represents a part of the wing anatomy of mosquitoes and is defined as: “an area of wing membrane delimited by veins or by veins and the wing margin; named after the vein immediately anterior to it or after the posterior element if the vein is formed by the ‘fusion’ of two vein branches” (Mosquito Gross Anatomy Ontology, 2022). The VIVO-Integrated Semantic Framework uses a class called “cell” as a subclass of “Telephone Type” defined as: “also called mobile telephone” (VIVO-Integrated Semantic Framework, 2022). These definitions show that ontology developers looking for reuse of terms should not make assumptions based on entity names, but that they need to check the definitions to ensure the intended meaning of the term in question is as expected. Due to this, it is not recommendable to reuse ontology entities that do not come with any definition (Guideline 3).
This fairly common problem is related to the problem using names (see Guideline 2) since it also relies on picking a term based on its name or label. This mistake can easily happen, especially when using roles that have abbreviated labels. Two examples of this are metabolite from ChEBI and active ingredient from DrON (Drug Ontology, 2022). Ontology developers aiming for reuse sometimes pick these terms as parents for classes representing metabolites or active ingredients (e.g., 2,3-dihydrodipicolinate and acetaminophen, respectively). However, looking at the textual definition of active ingredient reveals that this would be a mistake: “a role of a scattered molecular aggregate that is part of a drug product that is realized by (1) administration of the drug to an organism followed by (2) some change in the structure or functioning of some part of the organism” (Guideline 3). So, we are dealing with a role of a portion of a chemical substance here. The portion of acetaminophen in a capsule of 500 mg Tylenol is a bearer of an active ingredient role. This portion’s role active ingredient is an instance of active ingredient; the portion is not. While in DrON such issues were clarified by the definition, ontology developers striving for reuse face an additional hurdle. Looking up the definition of metabolite, we find: “any intermediate or product resulting from metabolism. The term ‘metabolite’ subsumes the classes commonly known as primary and secondary metabolites” (Drug Ontology, 2022). Based on this, it seems we might safely reuse the class to represent individual portions of 2,3-dihydrodipicolinate. However, looking further into the matter, the ChEBI specification also includes in an axiom that “metabolite” is a “biochemical role.” This shows that our assumption based on the name and the textual definition is not correct and that the taxonomic relationship prevents us from using metabolite as the superclass of 2,3-dihydrodipicolinate or as a type for portions thereof (Guideline 5).
Confirming ontological commitments based on textual definitions in the taxonomy
Neglecting ontological commitments based on textual definitions is another reuse problem that frequently arises. It might, in fact, not be due to reuse per se, but by developers trying to re-model the structure of external information models or surveys in their own new ontologies. Suppose that a developer needs to model current patients and previous patients of a hospital. They find that patients are represented using patient roles, e.g., in OBI. The ontology developer assumes that previous patient ought to be a role, too. Nothing in the definition of the superclass role deters one from such a plan, as it reads: “b is a role means: b is a realizable entity and b exists because there is some single bearer that is in some special physical, social, or institutional set of circumstances in which this bearer does not have to be, and b is not such that, if it ceases to exist, then the physical makeup of the bearer is thereby changed” (Smith et al., 2005).
However, when reusing entities from ontologies, it is vitally important to check other entities on the same branch of the taxonomy to ensure that there is no conflict created by ontological commitment of superclasses (Guideline 4). In our example, the conflict would arise immediately at the next superclass to role, namely, realizable entity. The latter in OBI is defined as: “to say that b is a realizable entity is to say that b is a specifically dependent continuant that inheres in some independent continuant which is not a spatial region and is of a type, instances of which are realized in processes of a correlated type.” This definition clearly demonstrates that all roles are realized by a process. There are no processes that would be realized by a previous patient role. Not participating in treatment or not meeting a research nurse are clearly not processes; they are absences, and they cannot be used as grounding for the realization of a role.
Another example that would raise an ontological commitment challenge in reusing OBI is when the author needs to model a person who declines to sign an informed consent for a clinical trial. Based on the Realizable entity class in OBI, there is no action that would realize a “declined informed consent” role; hence, representing a person as a role in this instance would be an error. For developers focusing on reuse, the important guidance here is to check the ontological commitments of all superclasses (Guideline 6). This, of course, assumes that the taxonomy that the developer plans to reuse is in itself consistent and correct.
Confirming ontological commitments based on axioms in the taxonomy
Sometimes, it is not only the textual definition that conflicts with the reuse, but also an axiom on a class, either through a necessary and sufficient axiom or through a necessary axiom. These cases are particularly important since they can easily lead to inconsistencies of the ontology, once the development progresses and more and more axioms are added. An example of this came up in the development of an ontological representation for the divorce process based on the ontology of document acts (d-acts; 2022) and the Ontology of Medically Related Social Entities (OMRSE; 2022). Given that we wanted to represent the actual divorce (the process that legally annuls the marriage) and the agreement of the spouses to get a divorce, how would we do that? The former is clearly a document act in most legal systems. For example, in the d-acts, we find: “a social act creating, revoking or transferring a socio-legal generically dependent continuant or a role by validating (signing, stamping, publishing) a document.” In the divorce, the mutually dependent roles of the spouses are revoked.
We might now think that the mutual agreement of the two spouses to get a divorce is a declaration, as it exists in OMRSE. However, consulting the textual definition should already deter us from that idea: “a social act that brings about, transfers or revokes a socio-legal generically dependent continuant or brings about or revokes a role. Declarations do not depend on words spoken or written, but sometimes are merely actions, for instance the signing of a document.” But more importantly, there is a necessary and sufficient axiom on this class that postulates that each member of this class has to revoke a social or legal entity, transfer it, or create it. However, none of that happens when two spouses declare their willingness to get a divorce. Hence, that act should not be a member of that class. This demonstrates how important it is to check the ontological commitments created by axioms on superclasses that are being chosen (Guideline 6). Under no circumstances should these be neglected.
Reuse checklist; “G1” is “Guideline 1,” etc.
Reuse checklist; “G1” is “Guideline 1,” etc.
To complete our survey of the guidelines for the reuse process, we provide in Table 1 a reuse checklist for the benefit of the ontology author. The table is organized as a series of ten yes/no questions, with accompanying actions based on the answers. The checklist questions are generally related to the overall reuse process; however, some questions are more relevant to specific guidelines. In the table, we have mapped the questions to their most significant guideline(s). For example, the ontology author is asked (Question 4; Guidelines 2, 3, and 7): do you use automated tools to identify and import suitable classes? If yes, the author should check the definitions of the imported classes to ensure that they have the intended semantics. If not, the author is encouraged to employ reuse tools.
Software tools
Finding suitable ontologies for reuse and effectively reusing them is not easy, and will probably be time consuming, especially for novice ontology developers. In the work of Butt (2015), it was shown that the reuse challenges may deter developers. Therefore, it is important to select the right software tools for the right reuse tasks (Guideline 7). In the following sections, we discuss features of popular reuse tools to (a) support searching for relevant ontologies, and (b) import terms from the reused ontology into the new ontology.
Ontology search tools
The first task for an ontology developer, who is considering reusing already existing resources, is to identify if such suitable ontologies exist. Ontology libraries and repositories provide a convenient platform for ontology developers to publish their vocabulary of terms in an easily accessible format. The popular ontology repositories have built-in tools that allow the user to search for terms which they intend to reuse. These platforms also offer sophisticated functionalities such as visualization, querying, analysis, and mapping of terminologies. Another innovative functionality is the recommender system that takes a text description of a project or ontology and uses keyword matching to recommend ontologies the user should consider reusing. This is very useful in narrowing down the number of ontologies to explore, which can otherwise be overwhelming. There are additional services such as REST APIs and SPARQL endpoints that allow developers to easily integrate the resources from the ontology repositories into application programs. Some of the popular ontology repositories that offer the preceding features include the BioPortal (Whetzel et al., 2011), Ontobee, Linked Open Vocabularies (LOV; Vandenbussche et al., 2017), and the EBI OLS.
The BioPortal and the EBI OLS enable users to search for terms in ontologies from the biomedical domain. Although these libraries contain a large number of ontologies, the tools are restricted in being domain-dependent. The LOV and Ontobee work similarly to BioPortal and EBI OLS but have the advantage of being domain independent. LOV also has ontologies developed in languages other than English.
There are some tools that are designed to search through multiple ontology libraries and extract relevant information such as the IRIs (Internationalized Resource Identifiers), term labels, and definitions for reuse. An example of such a tool is the OntoMaton, a Google Spreadsheet widget that allows users to search for terms within ontologies (Maguire et al., 2013). OntoMaton was initially developed to find terms from the BioPortal but was later extended to search through the LOV and the EBI OLS. Figure 2 shows the user interface of the OntoMaton tool.

OntoMaton ontology search tool in Google spreadsheet.
There are several efforts towards ontology search tools which have either become obsolete or are not yet available to the public. For example, TONES Ontology Repository (Horridge, 2015) provides a general domain-independent search tool, but it appears to be deprecated. MapOnto (An et al., 2006) is also no longer maintained, while CORE (Fernández et al., 2006) and WebCORE (Cantador et al., 2020) seem to be stuck in the research phase.
Most ontology development environments (ODEs) have the capability of importing and thus reusing ontologies. Protégé is one of the most popular ontology development tools (Noy et al., 2000; Singh and Anand, 2013). It supports a direct import of an ontology from a specified file or a location on the web. A user can import an entire ontology or reuse selected terms from the ontology. Protégé’s import from a web location feature has the advantage of reusing the most up-to-date version of an ontology. Figure 3 shows the direct import feature of Protégé with the available import options.
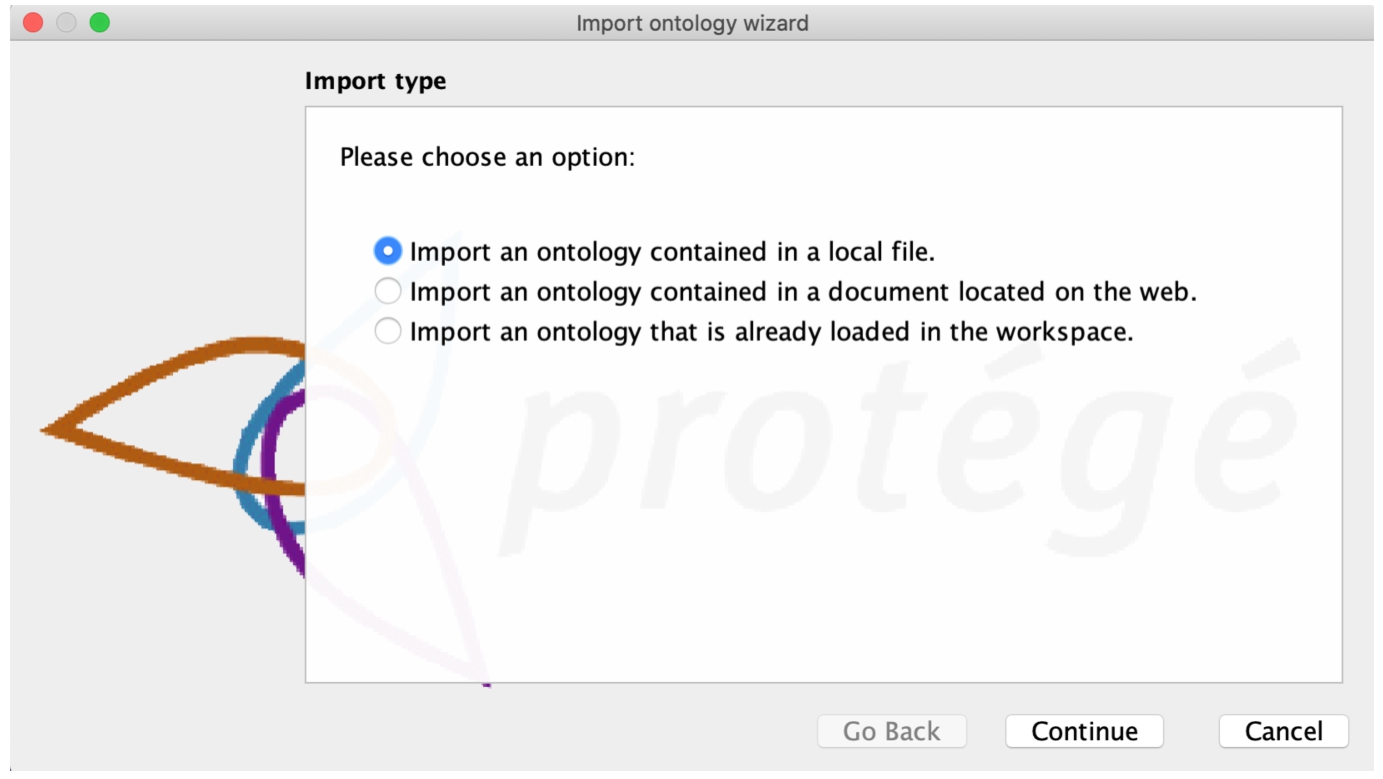
Protégé direct ontology import wizard.
Protégé also has a range of plug-ins to support reuse, one of which is the MIREOT plug-in (Hanna et al., 2012). This plug-in offers the convenience of searching for terms and directly importing the relevant ones within the same ODE. This tool allows the user to search through a list of available ontologies or from an external ontology. Figure 4 shows the MIREOT plugin for Protégé with the available features.
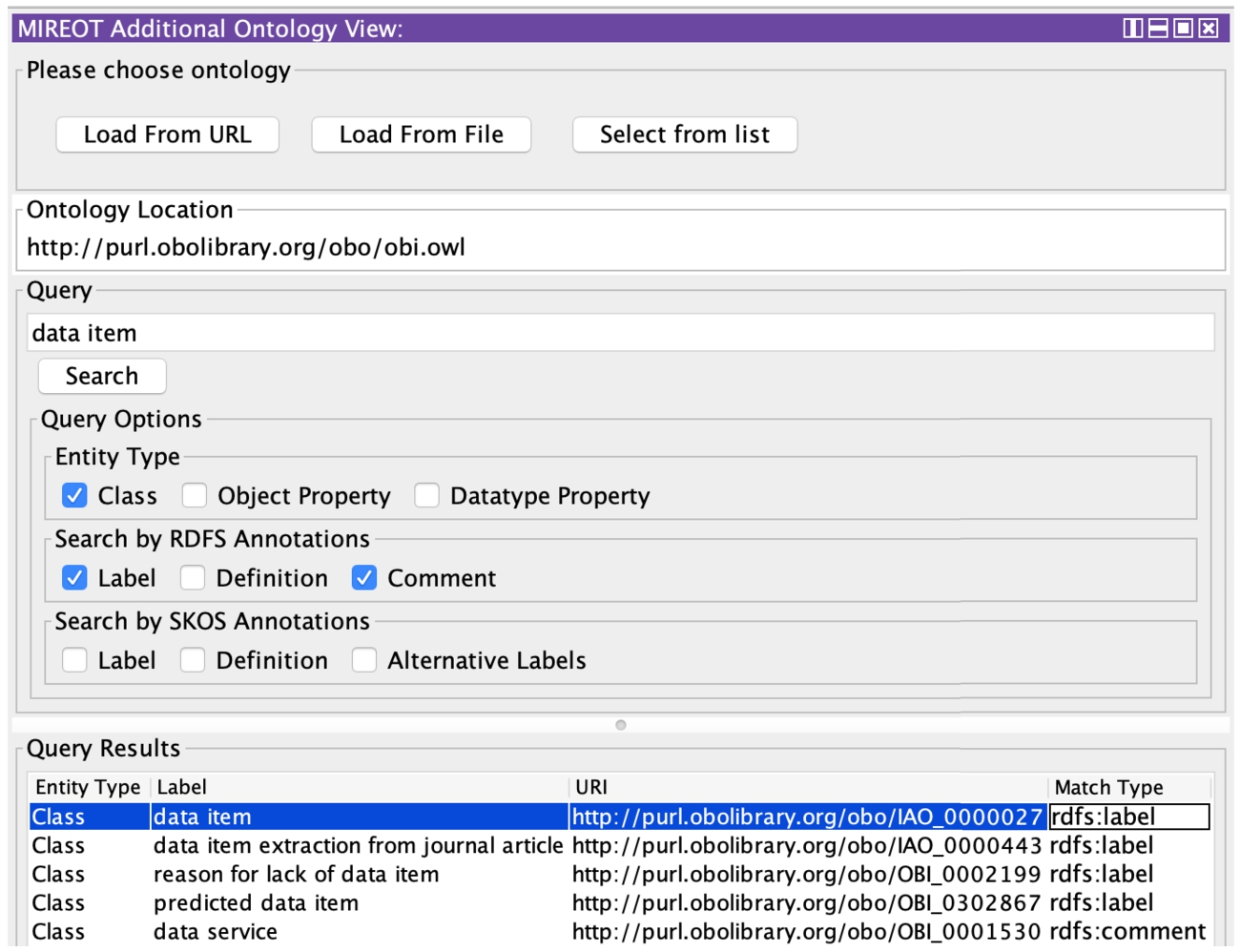
MIREOT plugin for Protégé.
Protégé has built-in reasoners, such as HermiT (Glimm et al., 2014), that check for logical consistency (Question 7 of the reuse checklist). HermiT also identifies subsumption relationships between classes which can help the ontology author identify inferred classes and check that they align with the hierarchical structure of the curated ontology (Guideline 5).
Ontofox is another popular tool for reusing ontology terms (Xiang et al., 2010). This is a web-based tool that creates a file and stores only the selected terms the developer wishes to reuse from a particular ontology. This file can then be imported, for example, using Protégé’s direct import feature. Ontofox has the advantage of following the full MIREOT guidelines for reusing ontology terms (Xiang et al., 2010). Ontofox contains a database of ontologies and the tool has a feature that allows the user to provide the source of any external ontology and extract terms for reuse. Ontofox is helpful in promoting modularization by allowing the author to extract and reuse a fragment of or specific terms from an ontology based on their needs.
There are other ODEs with reuse features and plug-ins. For example, WebODE supports reuse and the merging of ontologies (Hanna et al., 2012). OntoEdit has plug-ins for importing and exporting ontologies in different formats (Sure et al., 2002).
Another reuse tool is ROBOT, which is available as either a Java library or a command-line tool to automate workflows during ontology development (Jackson et al., 2019). ROBOT is an open-source library built by packaging some useful, low-level OWL API functionalities into high-level functionalities for working with OBO ontologies (Jackson et al., 2019). ROBOT was built to support OBO Foundry ontology development according to best practices, as specified in the OBO Foundry principles (OBO Foundry, 2022; Smith et al., 2007). Among the various features of ROBOT, there are the “extract,” “remove,” and “filter” commands to create subsets of ontologies as import modules. The import modules from several reused ontologies can then be combined into one import file or into the main ontology using ROBOT’s “merge” command. It is worth mentioning that ROBOT offers a wide range of capabilities besides the reuse commands to support functions such as reasoning, querying, and reporting. In addition, ROBOT supports template driven term generation using Dead Simple OWL Design Patterns (DOS-DPs; Osumi-Sutherland et al., 2017), which fosters reusability of those newly created terms by other ontologies.
Table 2 gives a summary of the ontology reuse tools in this section highlighting the core features of each tool and the current status of each tool.
Summary of reuse software tools highlighting the tools’ core features that support reuse, and the current usage status
The reuse of ontology content is a foundational design pattern of ontologies. With more and more ontologies being created and deployed in important biomedical applications, it is critical that reuse be done correctly so as to avoid erroneous content and accompanying deleterious effects on the applications. For this purpose, we outlined a set of reuse guidelines to help ontology authors, especially novice authors. Since those guidelines are abstract, we brought use cases to illustrate what happens when the guidelines are not followed. In this way, we have surveyed some of the problematic outcomes associated with reuse and offered suggestions for avoiding them.
For example, regarding Guideline 1 (focusing on ontological commitments), we note that different ontologies can be used for various applications that may imply different ontological commitments. Such commitments can be enforced by the reused ontologies. Changes in ontological commitments may lead to a significant redesign of the conceptual framework of the supporting ontology and to a re-evaluation of which ontologies are suitable for reuse. As we discussed, the EXACT ontology was initially designed for the representation of automated experiments, and it adhered to the SUMO commitments. Then, EXACT was redesigned for a wider application, namely, the representation of biomedical experimental procedures to ensure their reproducibility. As a part of the redesign process, the suitability of SUMO as a top-level ontology was re-evaluated. It was decided that BFO was a more suitable top-level ontology for the intended application. The change of the top-level ontology (and as a result, ontological commitments) led to substantial structural changes in EXACT. The redesign of an ontology is certainly a complex and expensive process, and it is prone to errors and hard to automate. Therefore, ontology developers need to take into consideration such possible complications when reusing other ontologies, and Guideline 1 captures an important aspect of this.
We believe it is important for those venturing into the creation of a new ontology based on existing ontologies to familiarize themselves with the guidelines presented herein before starting. This way errors in the reuse of ontologies may be prevented a priori. Furthermore, we observe that many creators of ontologies are typically committed to one model of ontologies and are not familiar with other models. Thus, we made a choice to illustrate the guidelines according to different models and perspectives at the expense of some repetition of cases, e.g., confirming commitments based on definitions and not just names. This allows the prospective ontology developer to see the implications of following the guidelines in the context of different models.
Let us note that while ontology search tools can help promote reuse, they can also lead to violations of Guideline 2. This is due to the fact that such search tools match keywords to ontology term labels. The user must then manually check if the terms in the search results indeed have the intended semantics. Unfortunately, this is not always the case, as different ontologies may use the same term with different contexts or meanings, as discussed above. For example, in the Schema.org, the label ‘Place’ is a class of entities that have a fixed physical extension, while in the Event Ontology ‘place’ is the property that relates an event to a spatial object. Another common problem is that different ontologies may use different synonyms for the same term, and a search tool could fail to find some of the synonyms. Using the same example, the location of an event and the event can be related with either the property ‘place’ from Event Ontology or ‘location’ from Schema.org. However, if the user searches for the term ‘location’ in Event Ontology, it cannot return the result of ‘place’ even though they mean the same thing, and vice versa for searching in Schema.org.
The BioPortal does slightly better in this regard as it uses the Lexical OWL Ontology Matcher (LOOM) to show mappings between classes in different ontologies. LOOM is an ontology alignment tool that takes two OWL ontologies and identifies corresponding concepts by comparing the preferred names and synonyms of the concepts using an approximate matching technique (Ghazvinian et al., 2009). The technique used in LOOM allows matching of concepts despite slight misspellings as well as the use of synonyms, which is helpful in answering Question 8 of the reuse checklist to avoid duplication of terms.
It is important to bear in mind that ontology editing software, such as Protégé or similar tools, may not enforce adherence to guidelines and best-practices recommendations for ontology reuse, e.g., those provided by the OBO Foundry. The OBO Foundry requires that every term in an OBO Foundry ontology have a textual definition. Most ontologies create an annotation value that uses the IAO definition annotation. One of the OBO Foundry’s recommendations for ontology reuse is: “if an individual term is reused without change to the definition, the original term IRI should be used. If the definition of a term (either text or logical) is changed, the original term IRI should not be reused” (Smith et al., 2007).
The first part of this recommendation is typically what is implemented in tools for reuse of individual terms, such as Ontofox (Xiang et al., 2010) and the MIREOT-based Protégé plugin (Hanna et al., 2012). However, if a developer makes changes in the textual definition of a term from an external ontology, then it is important to ensure that the IRI is changed as well. This is crucial since, otherwise, entities that do not belong in the class a term refers to could end up being elements of that class. For example, let us assume that someone wants to reuse the term “journal article” from the IAO to support a network of annotating medical journal papers. The IAO term is defined as: “A report that is published in a journal.”5
Thus, ontology reuse tasks are adequately supported by suitable tools and ODEs. However, it is important to be cognizant of their limitations. It would be beneficial to ontology developers if tools could include additional monitoring features that helped ensure adherence to recommendations and guidelines.
Overall, the problems ontology developers are facing regarding ontology reuse, and associated problems that arise from it, can be taken as a call for increased and improved education in knowledge representation, semantic web technologies, and ontologies. This is especially important since many ontologies are created by professionals in various disciplines where such ontology creation is required for the support of their applications. Given the existing necessity to semantically integrate data in data-intensive fields such as biomedical research and clinical care, knowledge representation and reasoning basics warrant a prominent place in curricula for students aiming to work in data science within those fields.
Let us point out that we did not run any controlled experiments creating ontologies with the use of our guidelines. The guidelines were gleaned from the many years of experience of the authors in ontology creation and curation. We do expect to be able to examine the quality of future ontologies formulated with an eye toward the reuse guidelines to assess their impact. Moreover, as mentioned, we see our set of guidelines as a starting point. We do hope that the set will be augmented and refined by the ontology community in an ongoing effort. As alluded to, a good way to aid in this would be to have the guidelines incorporated into some of the tools we have surveyed or additional software to be designed in the future. Let us mention that experiments in teaching good biomedical ontology design to novices have been carried out (Boeker et al., 2012).
It will be noted that in the scientific community there has been a push to make scholarly data, particularly data gathered in the context of publicly funded research projects, more easily accessible via automated means. A set of “FAIR” (“Findability, Accessibility, Interoperability, and Reusability”) principles has been proposed toward this end (Wilkinson et al., 2016). While the focus of FAIR may be on underlying data, it does include a knowledge component. And, in this respect, ontologies can play a key role by standardizing scientific domain knowledge. Moreover, our guidelines for ontology reusability play right into this. It is critical that different ontologies maintain consistency of their constituent knowledge to allow for consistent interpretation of disparate data sets. Our guidelines seek to promote this consistent knowledge. The process of ontology reusability also implies an element of interoperability. Lastly, the ontology community at large has sought to address the issues of findability and accessibility via the establishment of various ontology repositories, discussed in this paper.
And finally, let us mention something about the authors’ ontology experiences and development efforts. Author LNS has created EXACT (Soldatova et al., 2008) and was involved in the development of EXPO (Generic Ontology of Experiments; Soldatova and King, 2006), OBI (Bandrowski et al., 2016), OntoDM (Ontology for Data Mining; Panov et al., 2008), OntoDT (Ontology of Data Types; Panov et al., 2015), Exposé (Machine Learning Experiments; Vanschoren and Soldatova, 2010), and DDI, among others. Author FSM has worked on the development of OCL-SOP (Maikore et al., 2017), NDDO (Kostovska et al., 2019), an ontology to describe relationships between behaviors as part of the TURBBO project (Tools for Understanding Relationships Between Behaviours using Ontology (TURBBO), 2022), and an ontology for child abuse injuries (Ontology for ELEctronic tool for Clinicians, Trainers and Researchers In Child Abuse, 2022).
Author MB is the main curator or co-main curator of nine ontologies and has contributed to multiple others. The ontologies he has created or co-created are: Ontology of Biobanking (Brochhausen et al., 2016), Proper Name Ontology (2022), d-acts (2022), OOSTT, Drug-drug Interaction and Drug-Drug Interaction Evidence Ontology (DIDEO; Brochhausen et al., 2014), Apollo-SV (Hogan et al., 2016), ACGT Master Ontology (Brochhausen et al., 2011), OMRSE, and the Ontologized MIABIS (OMIABIS; Brochhausen et al., 2013).
Authors MH, CO, and YP have been involved in the analysis and application of ontology reuse efforts. They have developed a number of ontology summarization methodologies, including a variety of abstraction networks. Among other applications, these techniques have been brought to bear in quality-assurance efforts of ontologies, many of which have been created with reuse paradigms. Some of the ontologies analyzed are SNOMED CT, the National Cancer Institute thesaurus (NCIt; Sioutos et al., 2007), ChEBI, ERO, the Uber Anatomy Ontology (Uberon; Mungall et al., 2012), GO, SDO, the Ontology of Clinical Research (OCRe; Sim et al., 2014), DDI, and CanCO.
Ontologies have become critical to biomedicine and health care information processing enterprises. Given the fact that ontology reuse is widely employed – and encouraged – by the ontology community, when curators seek to formulate new ontologies, it is necessary to provide them guidance to avoid common mistakes and promote quality and consistency of the new products. Toward that end, we have presented a collection of guidelines to be followed by ontology authors as they work on their new ontologies. These guidelines have been gleaned from years of experience working on various ontologies. We presented experiential reports about the EXACT and EXACT2 ontologies, as well as work using MIREOT to illustrate these abstract guidelines in actual settings. We also surveyed some software tools available to the prospective author looking to employ reuse of existing ontology content. Overall, adherence to the suggested guidelines should lead to the curation of ontologies of better quality and enhanced interoperability. Furthermore, we suggest that ontology authors who follow these guidelines will save significant time and effort, which would otherwise be necessary for quality-assurance regimens focusing on errors arising due to improper reuse of ontologies.
Footnotes
Acknowledgements
Research reported in this publication by author MB was partially supported by the National Institute of General Medical Sciences of the National Institutes of Health under award number R01GM111324. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.